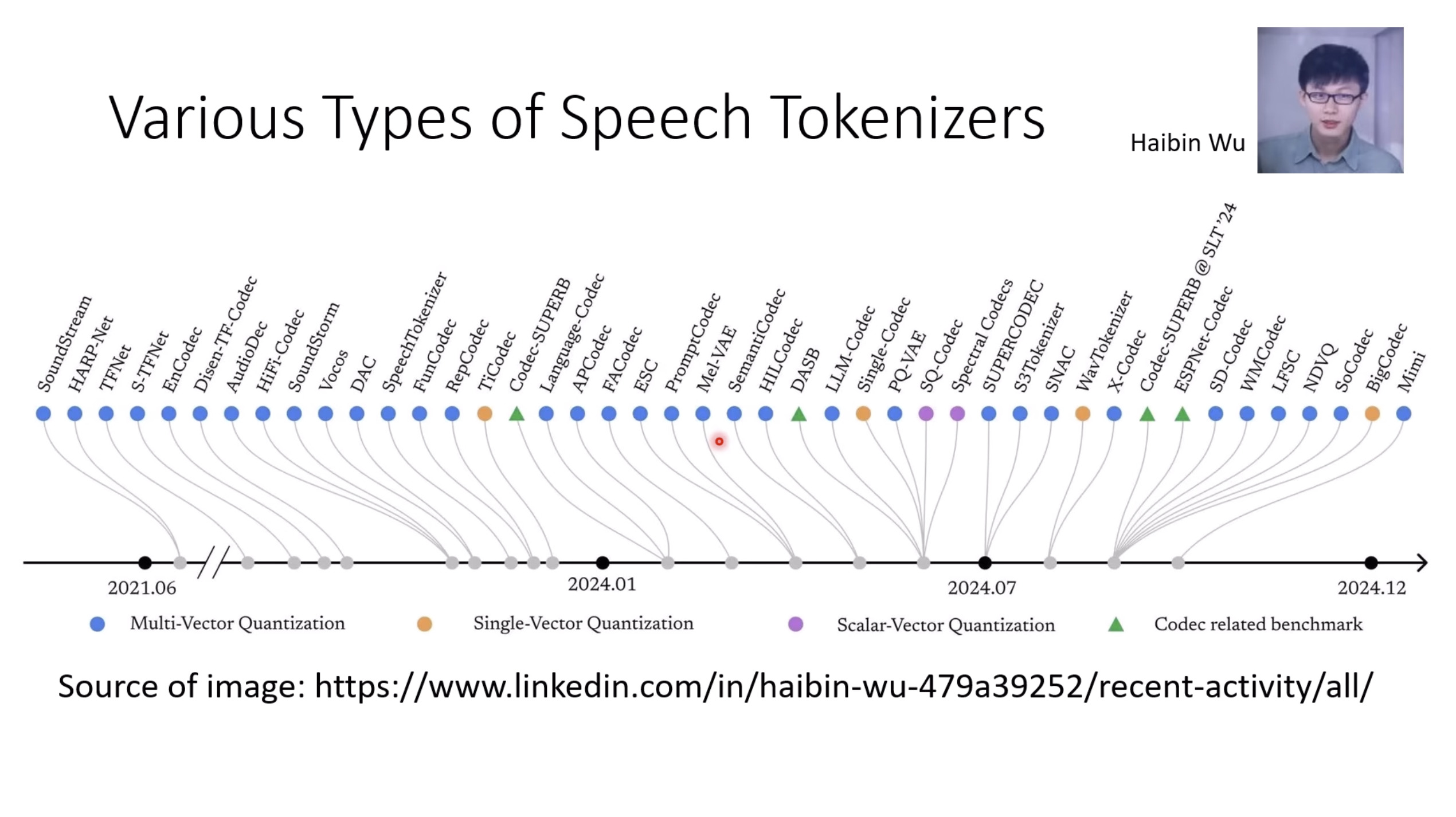
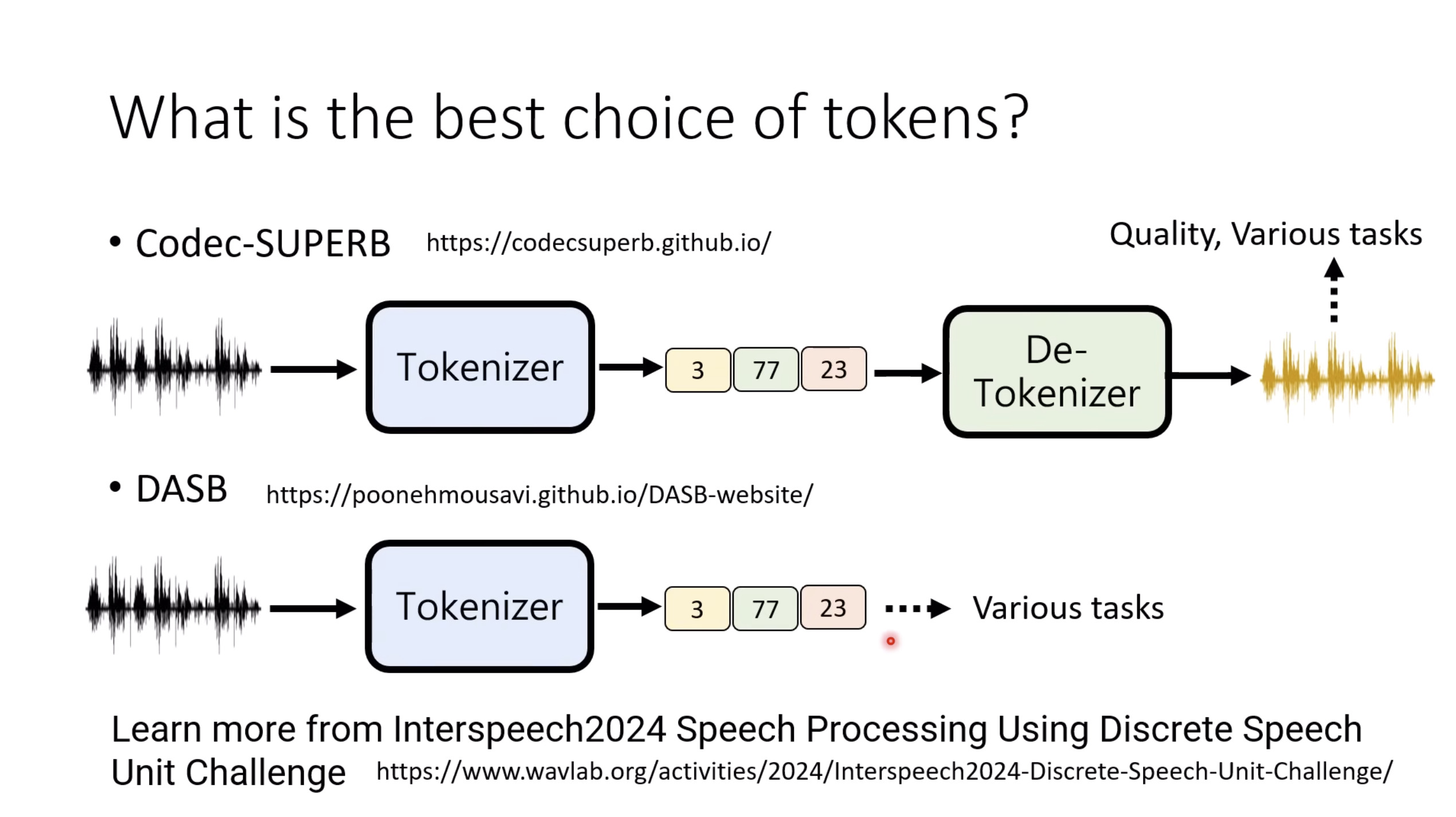
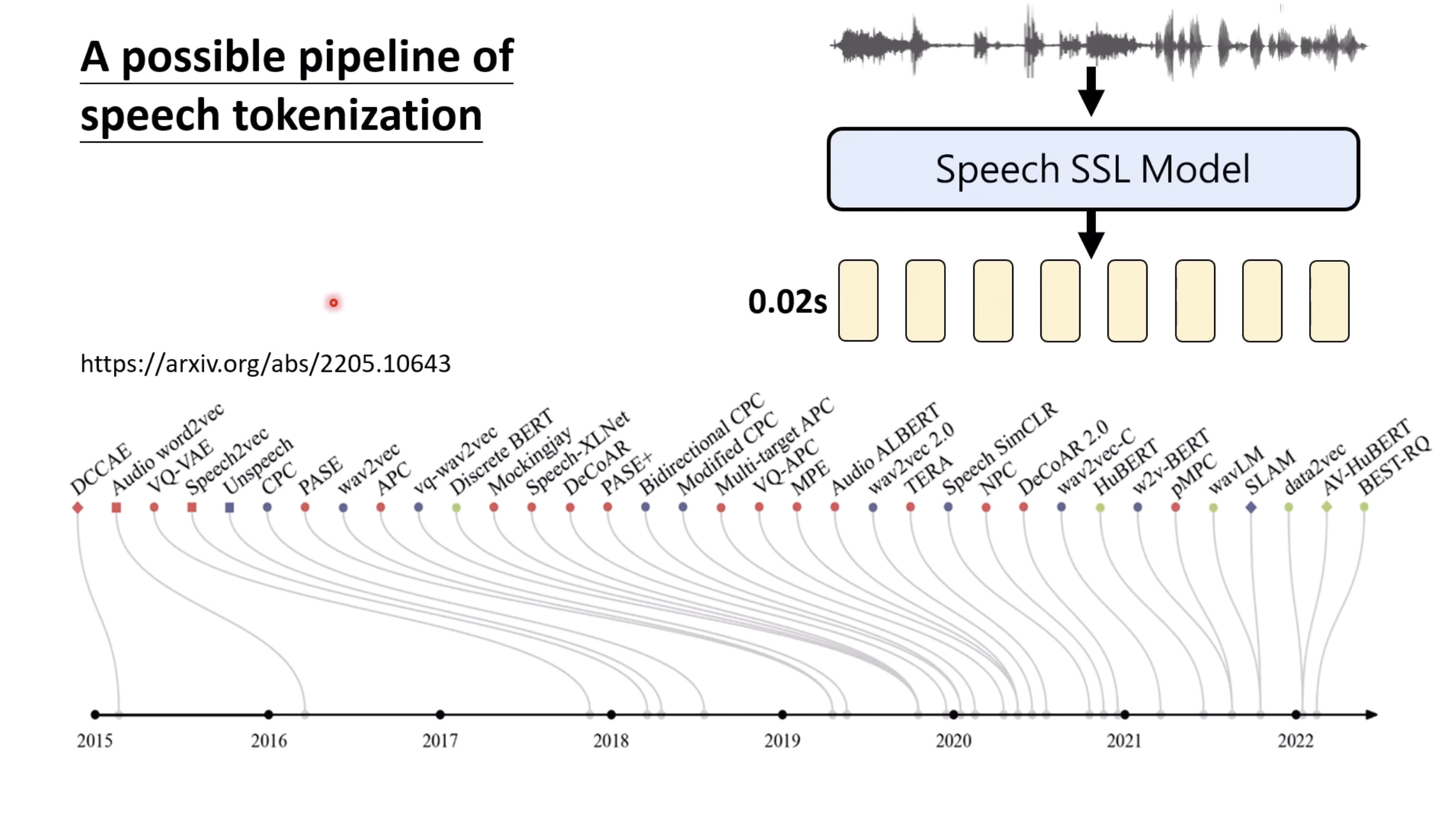
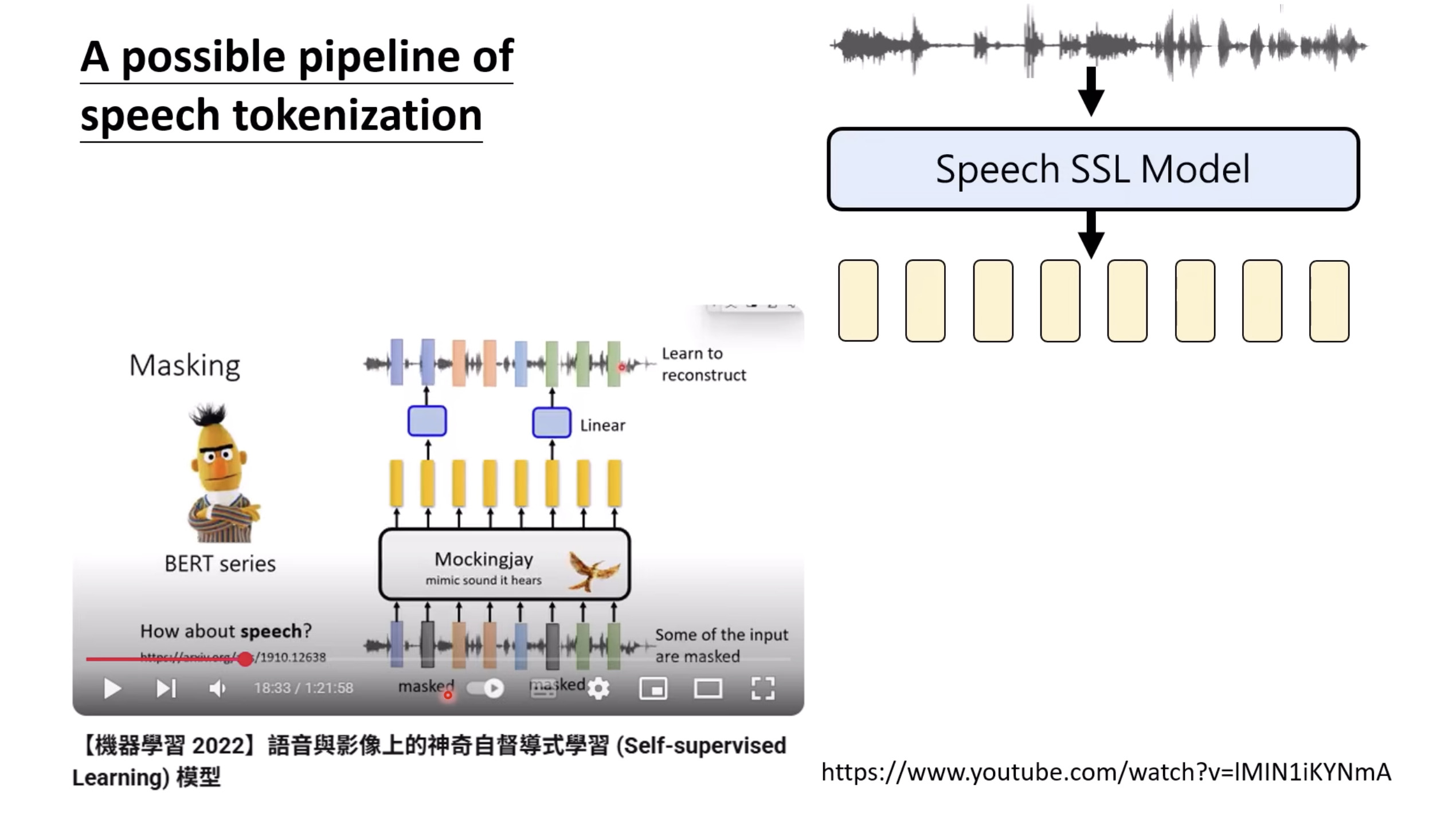
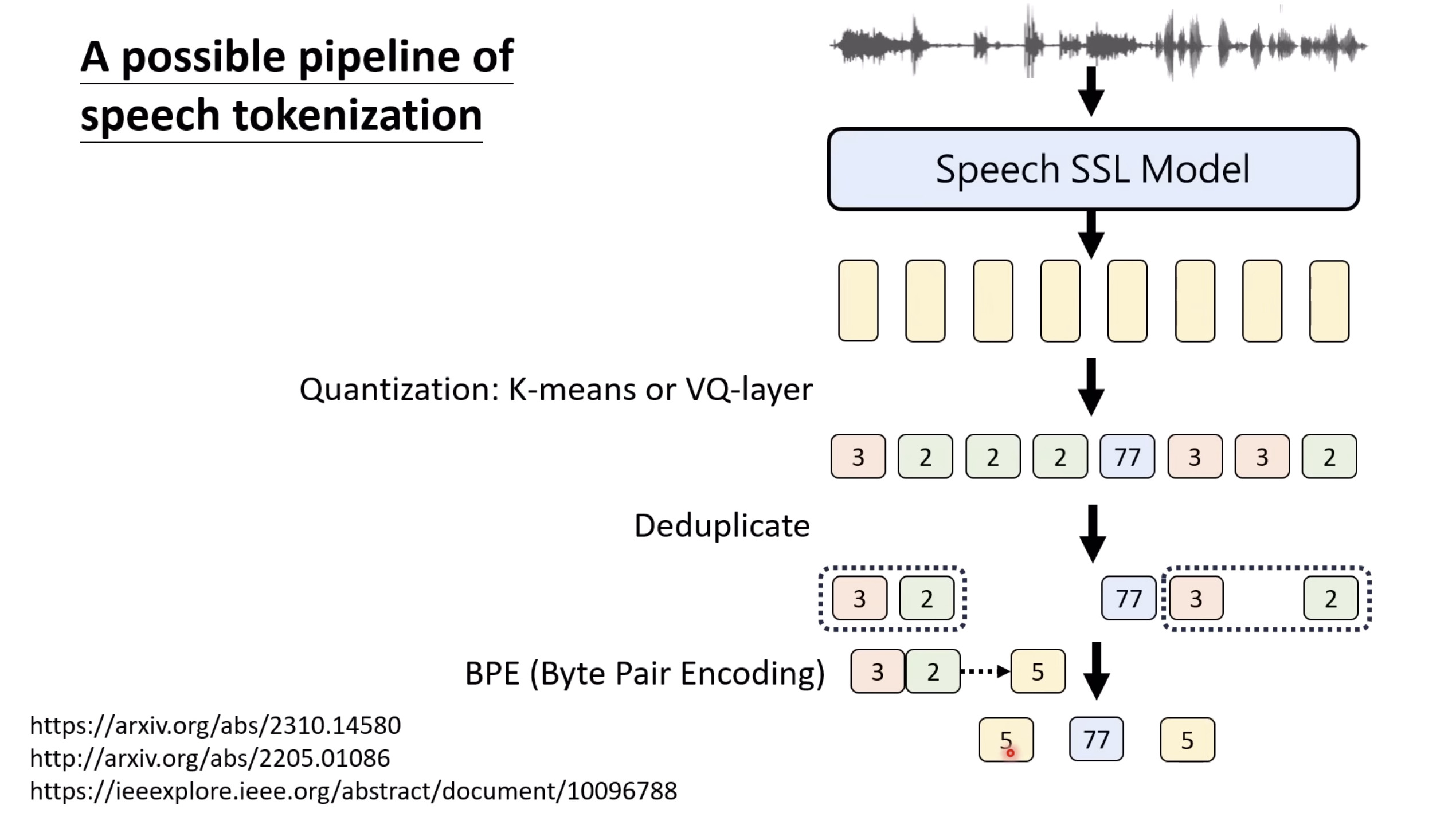
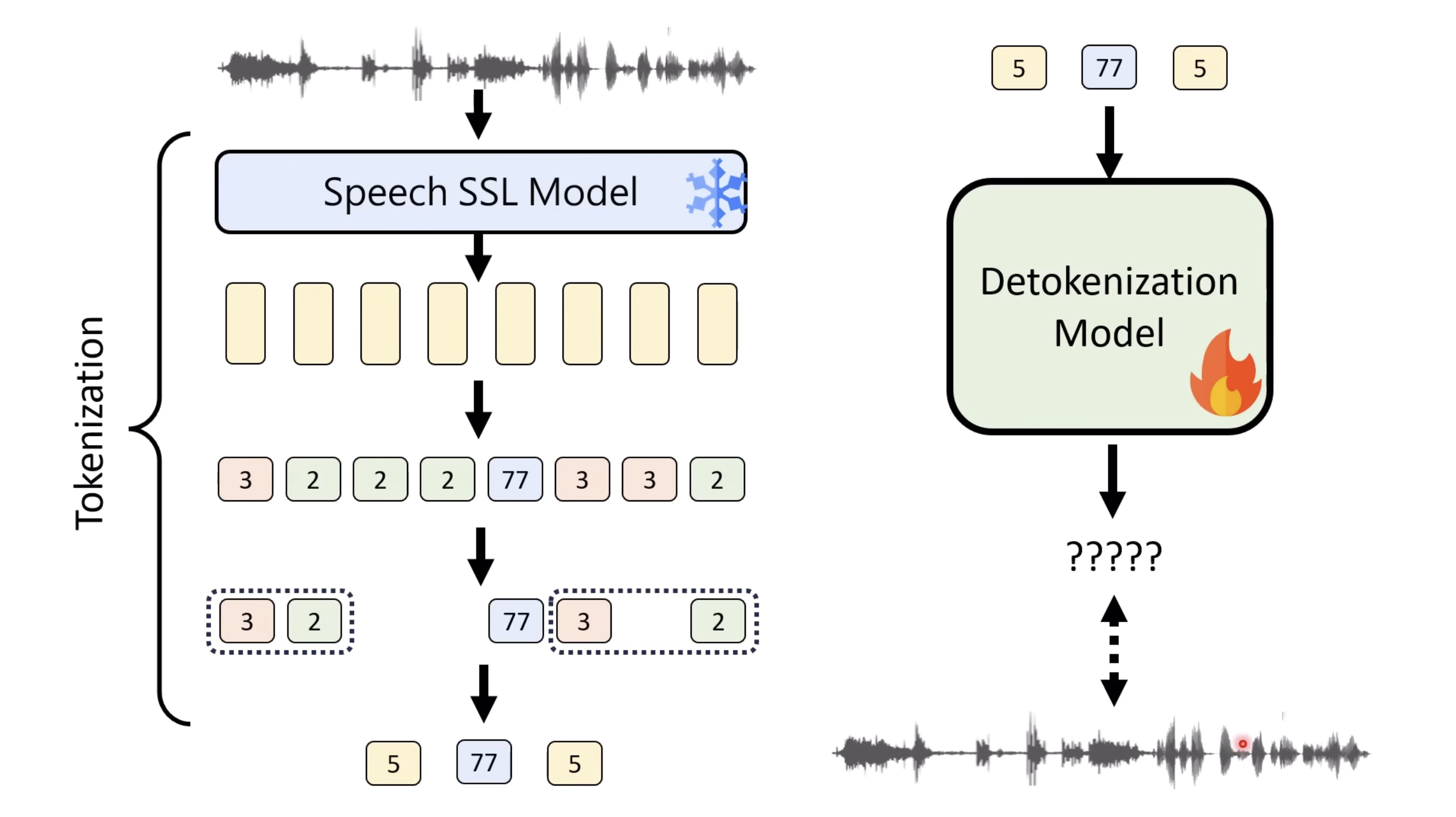
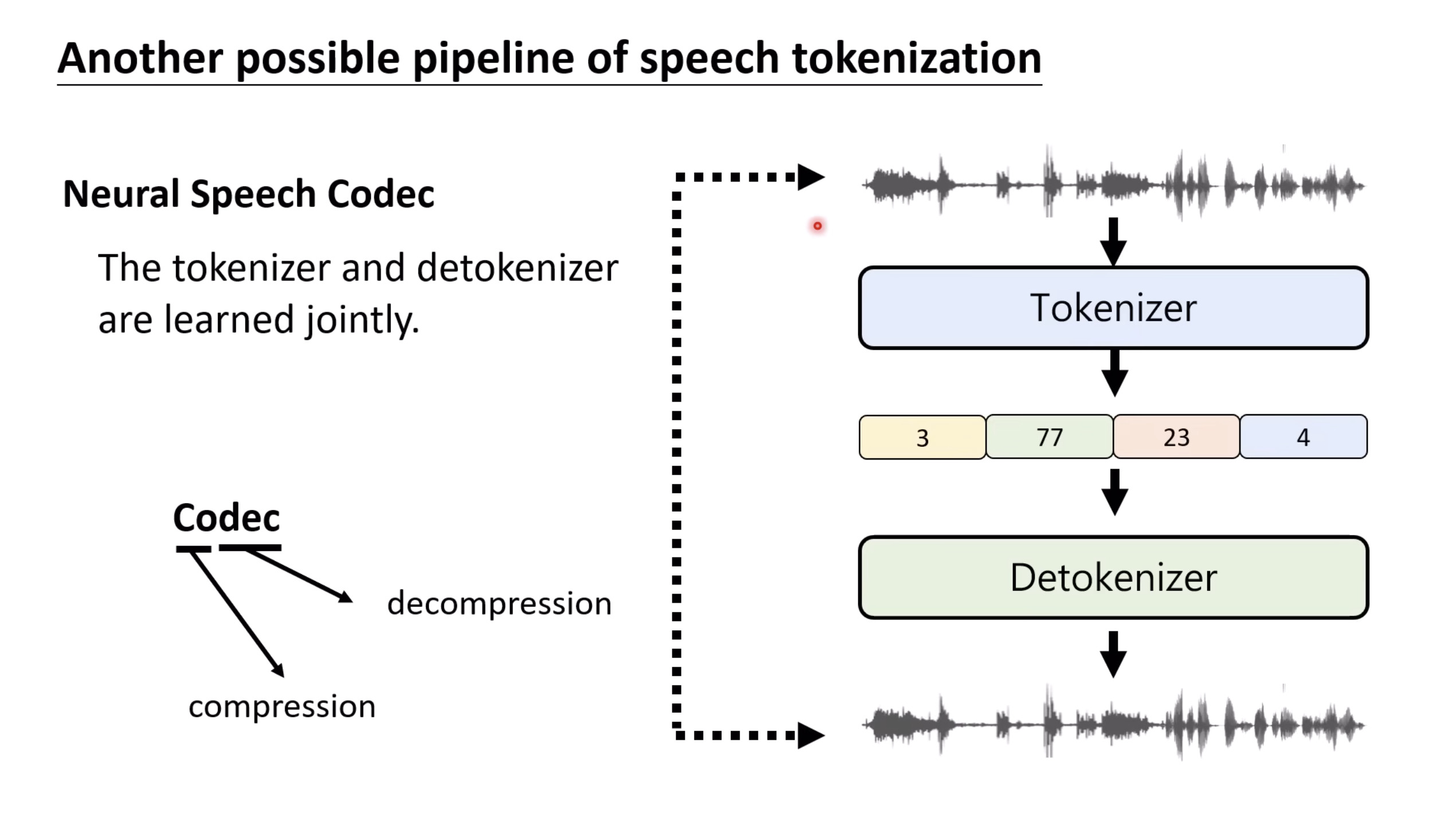
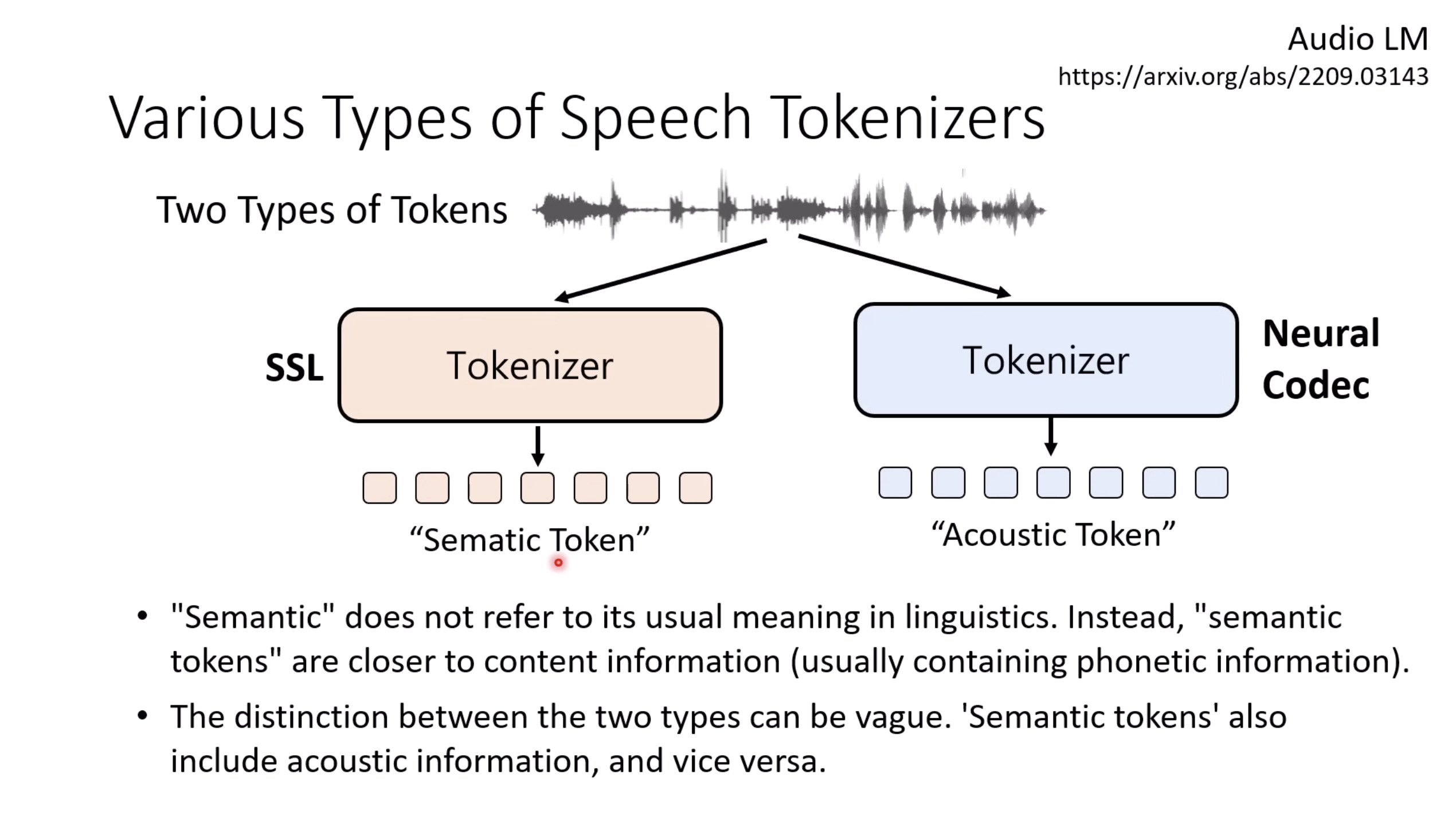
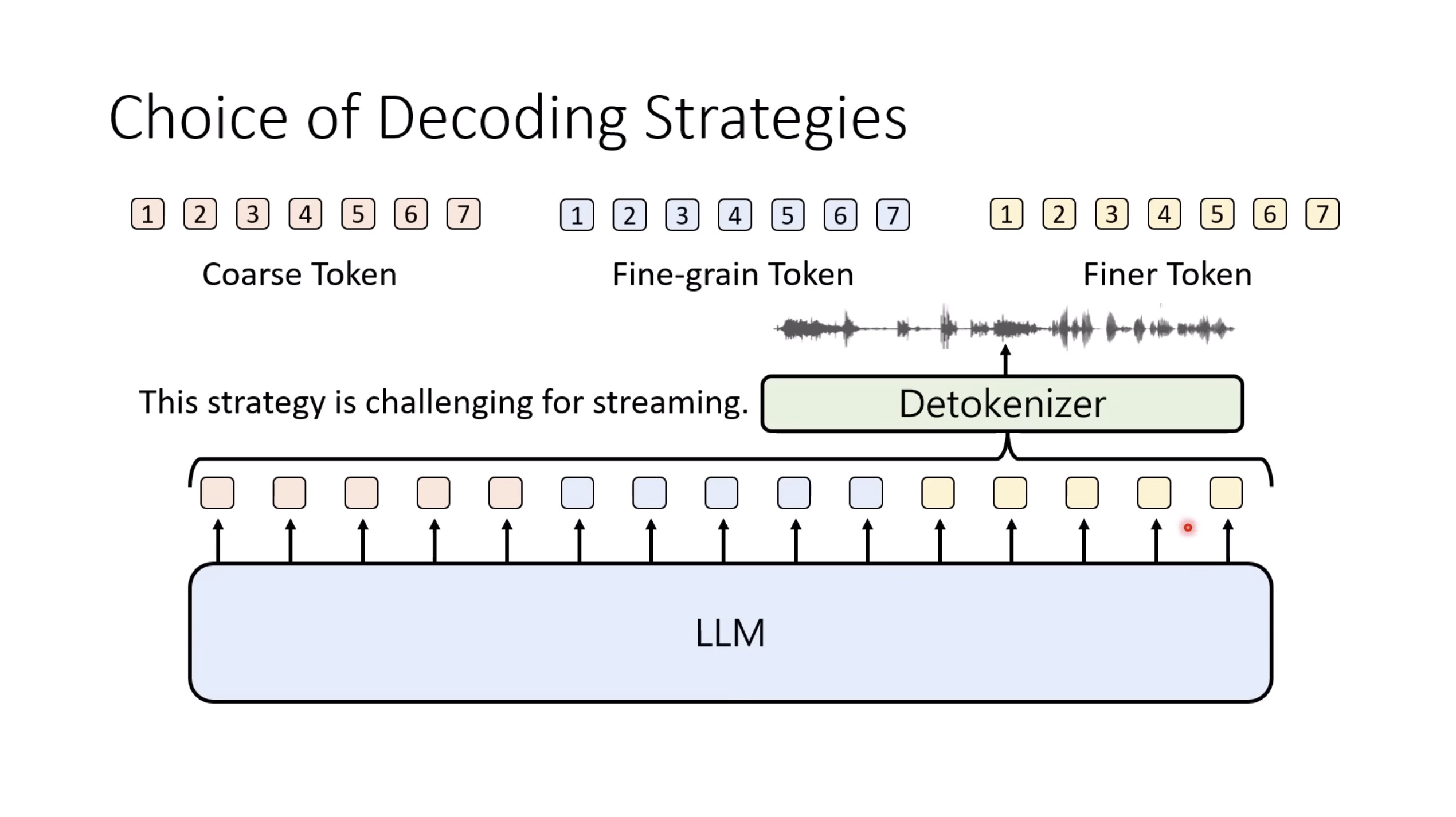
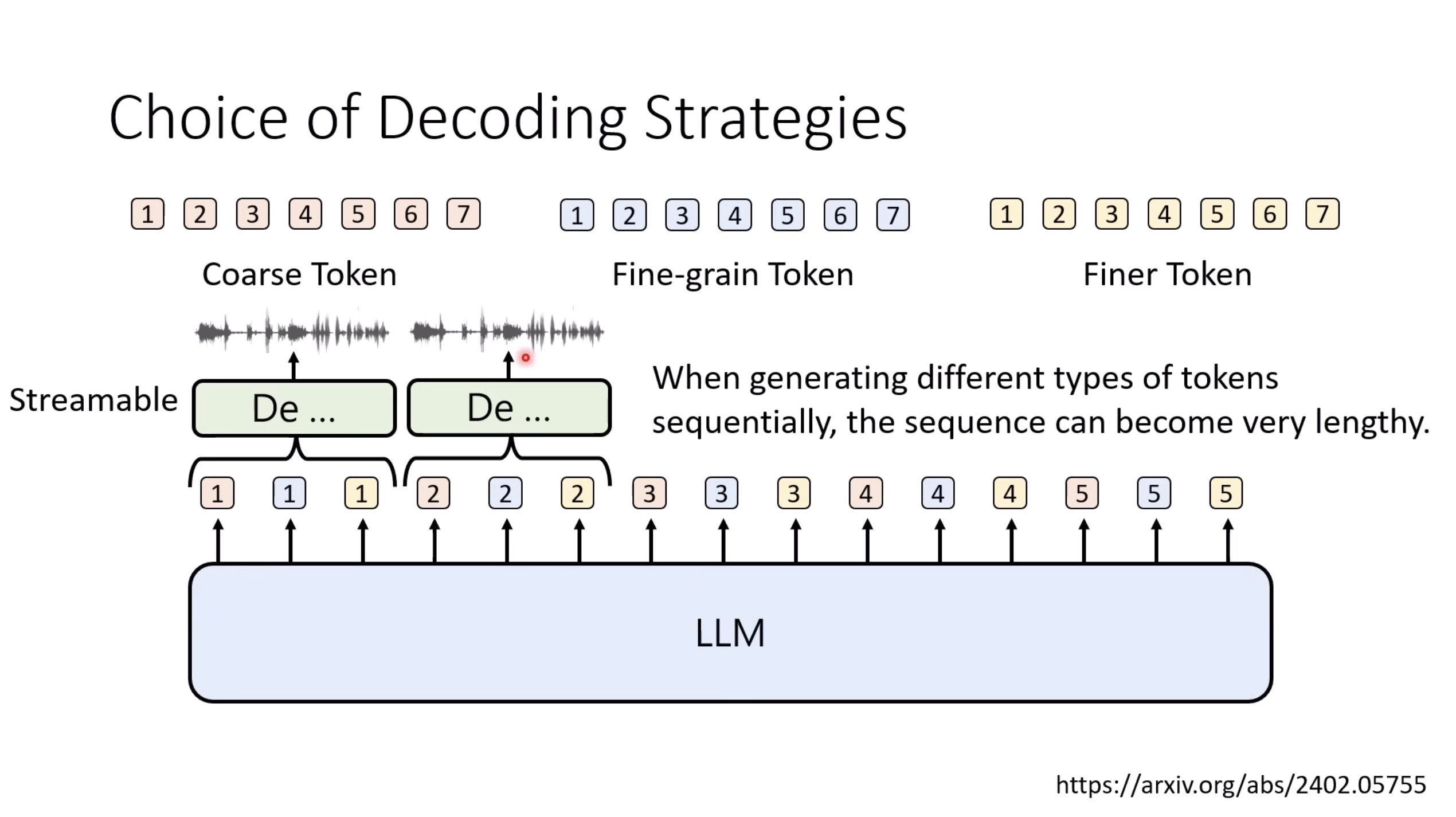
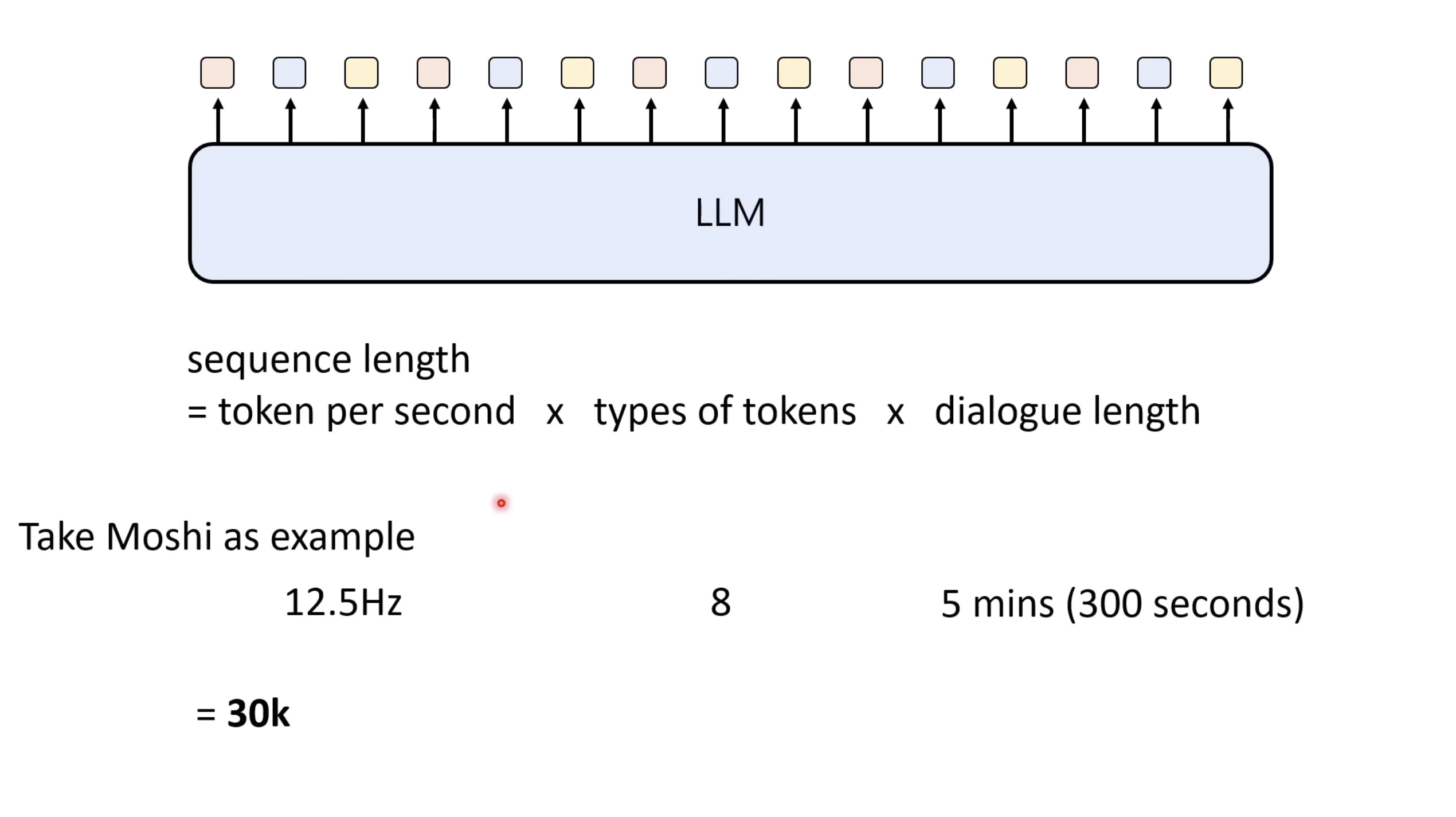
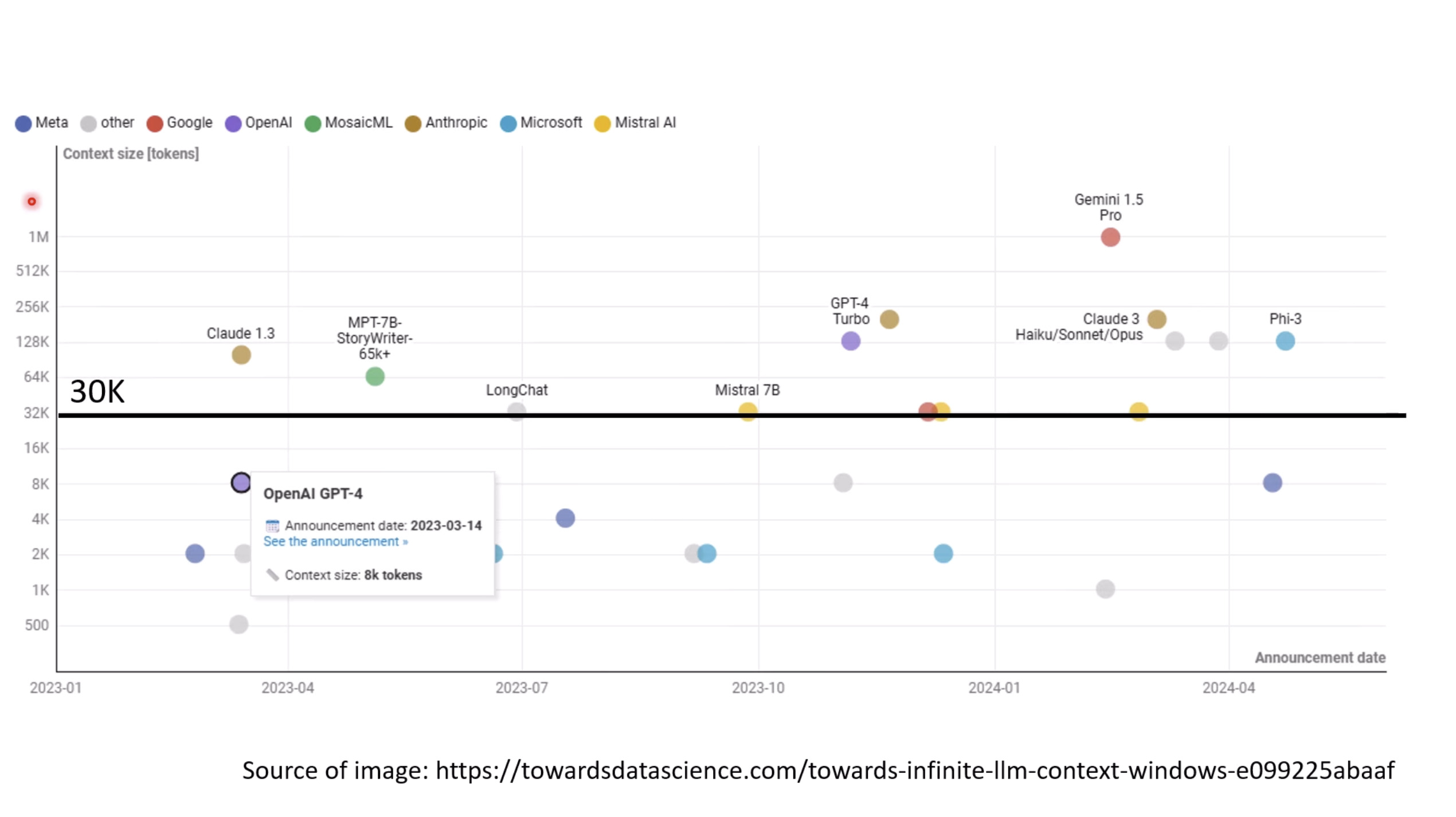
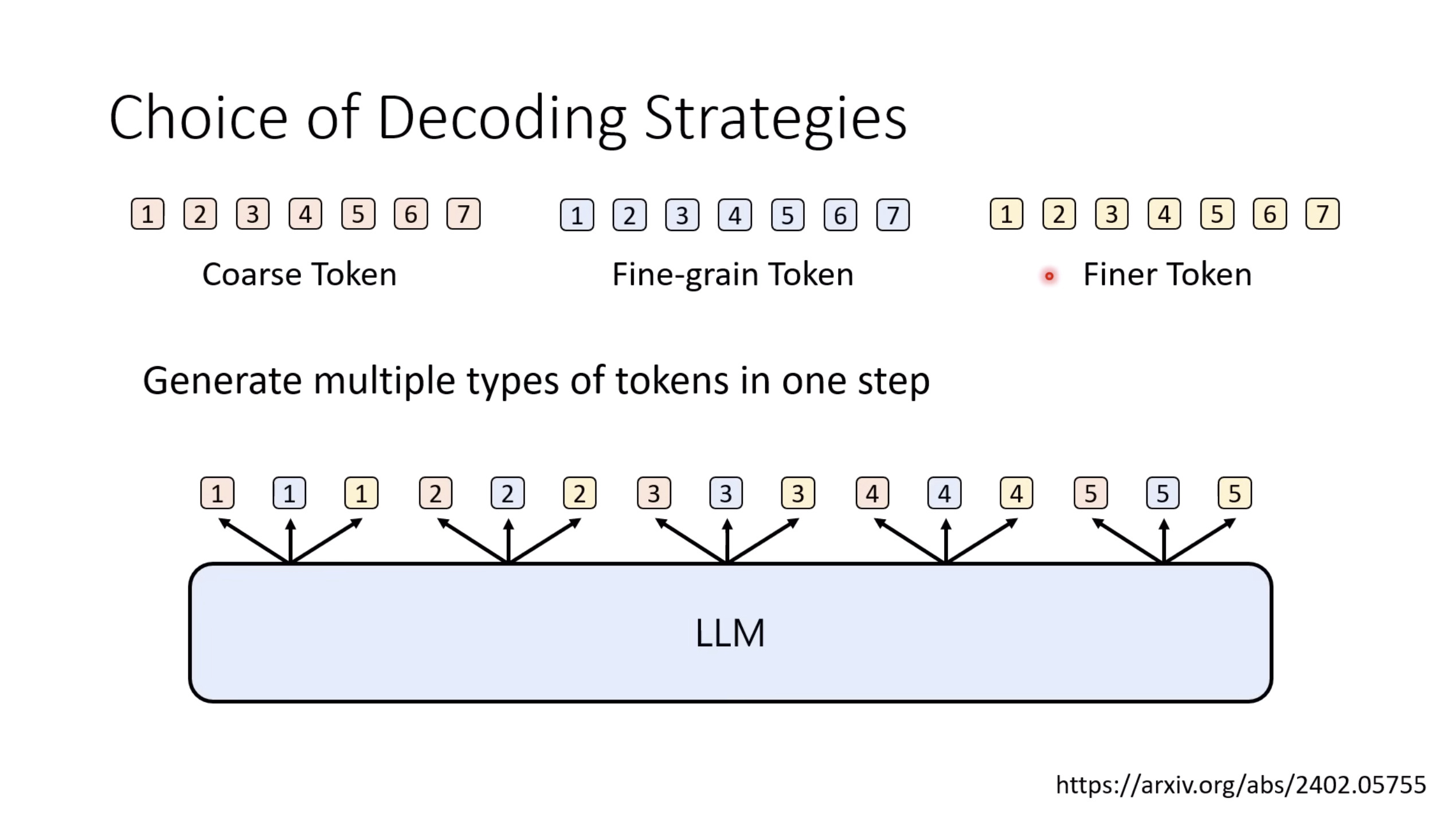
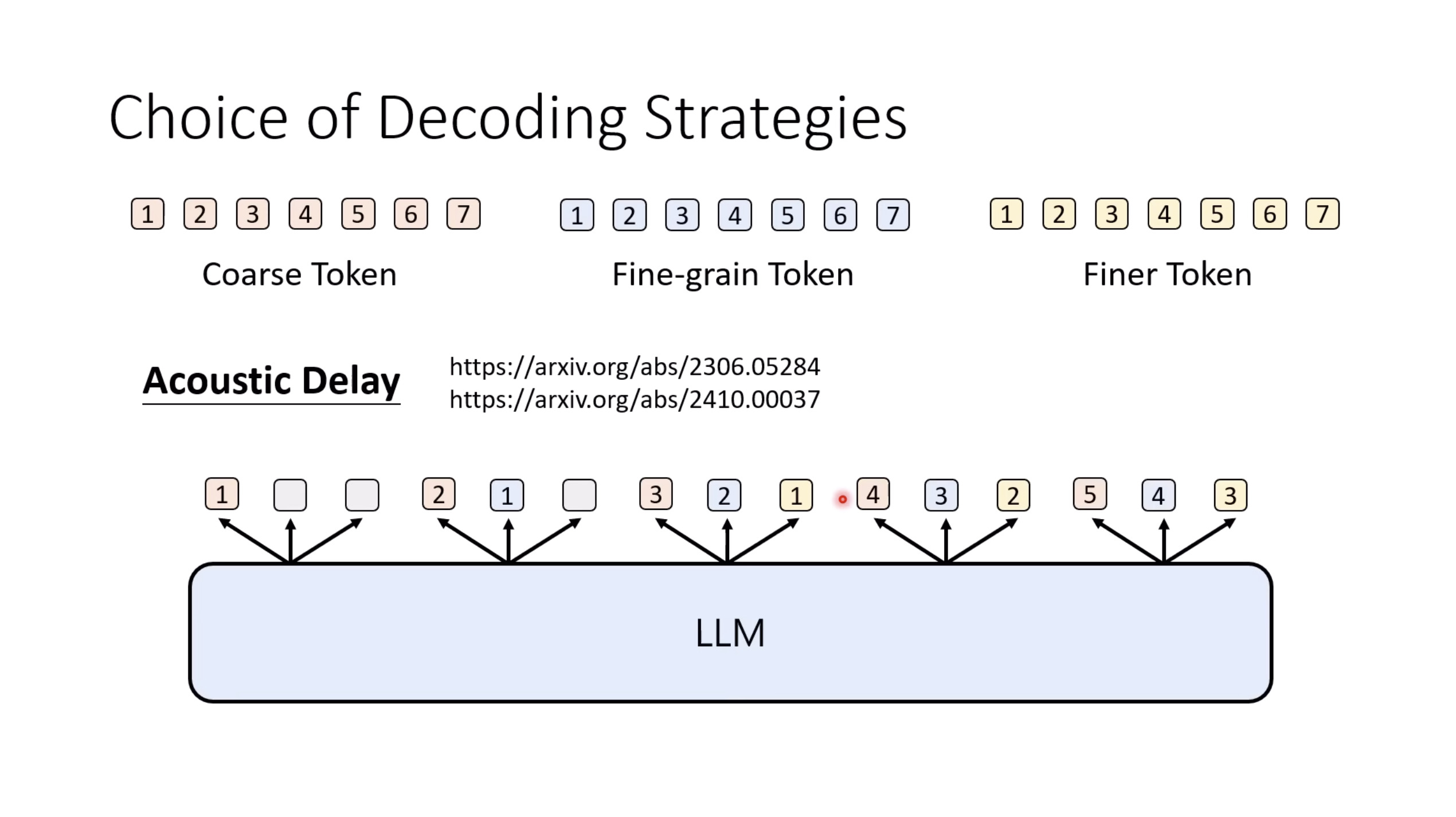
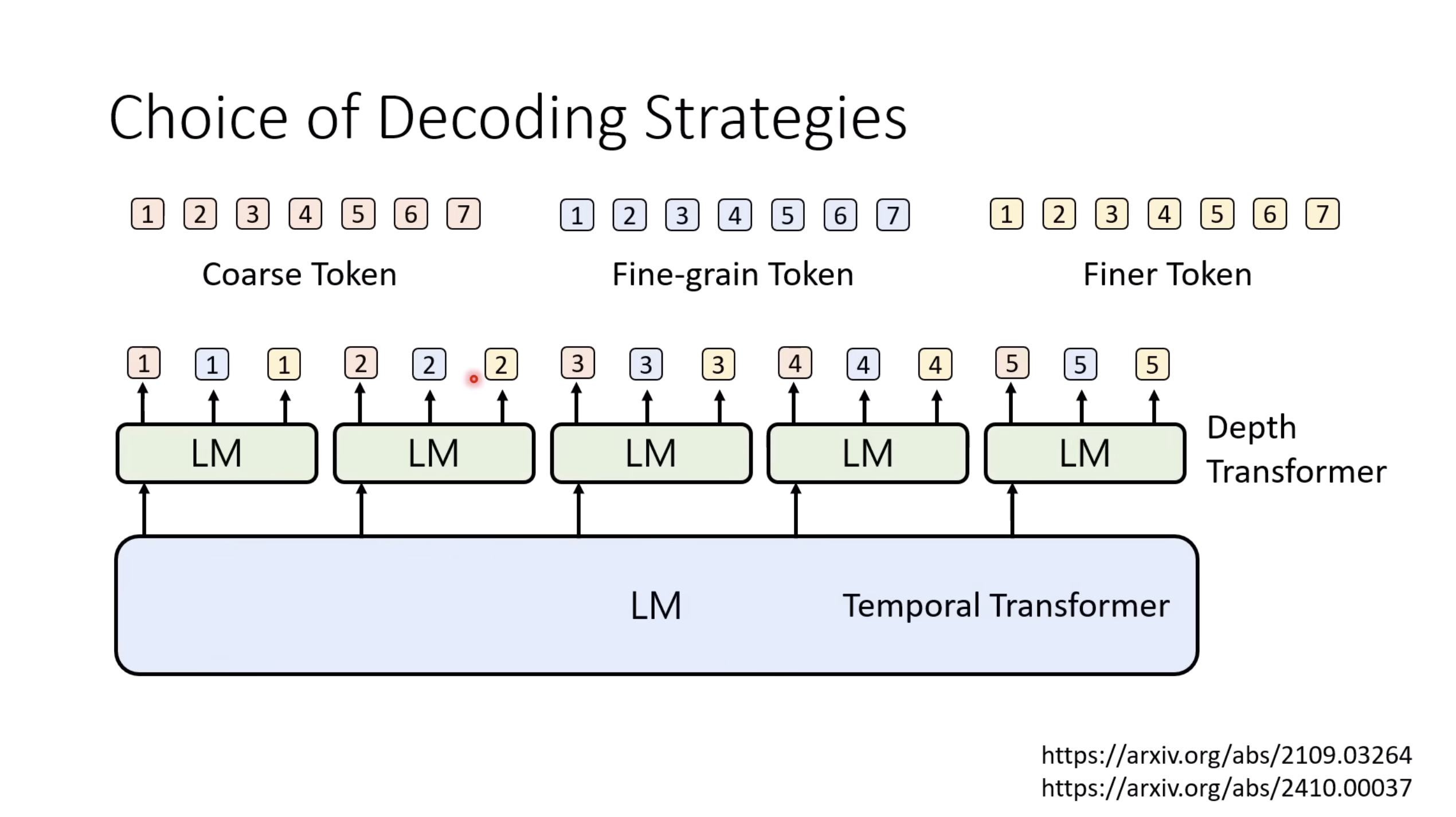
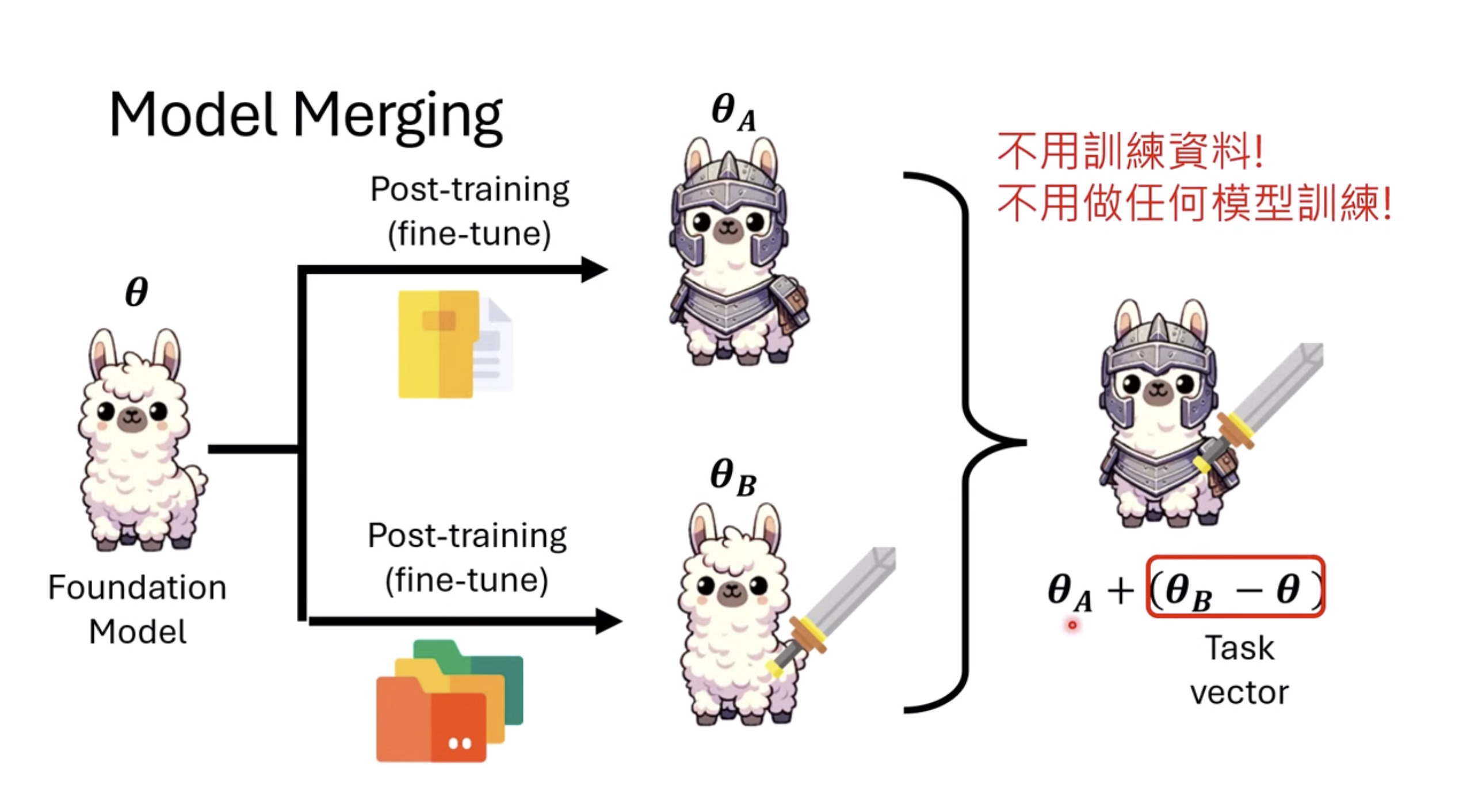
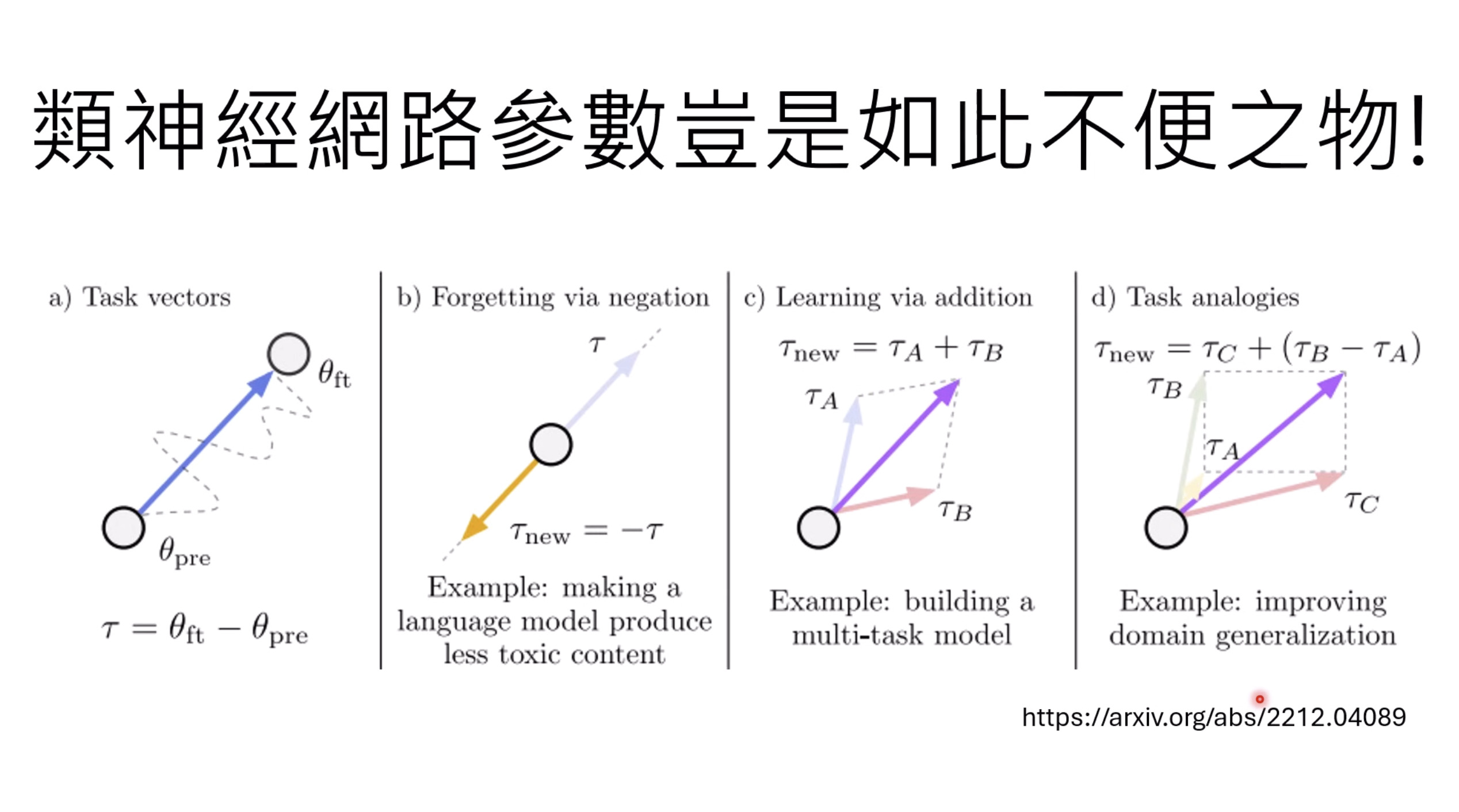
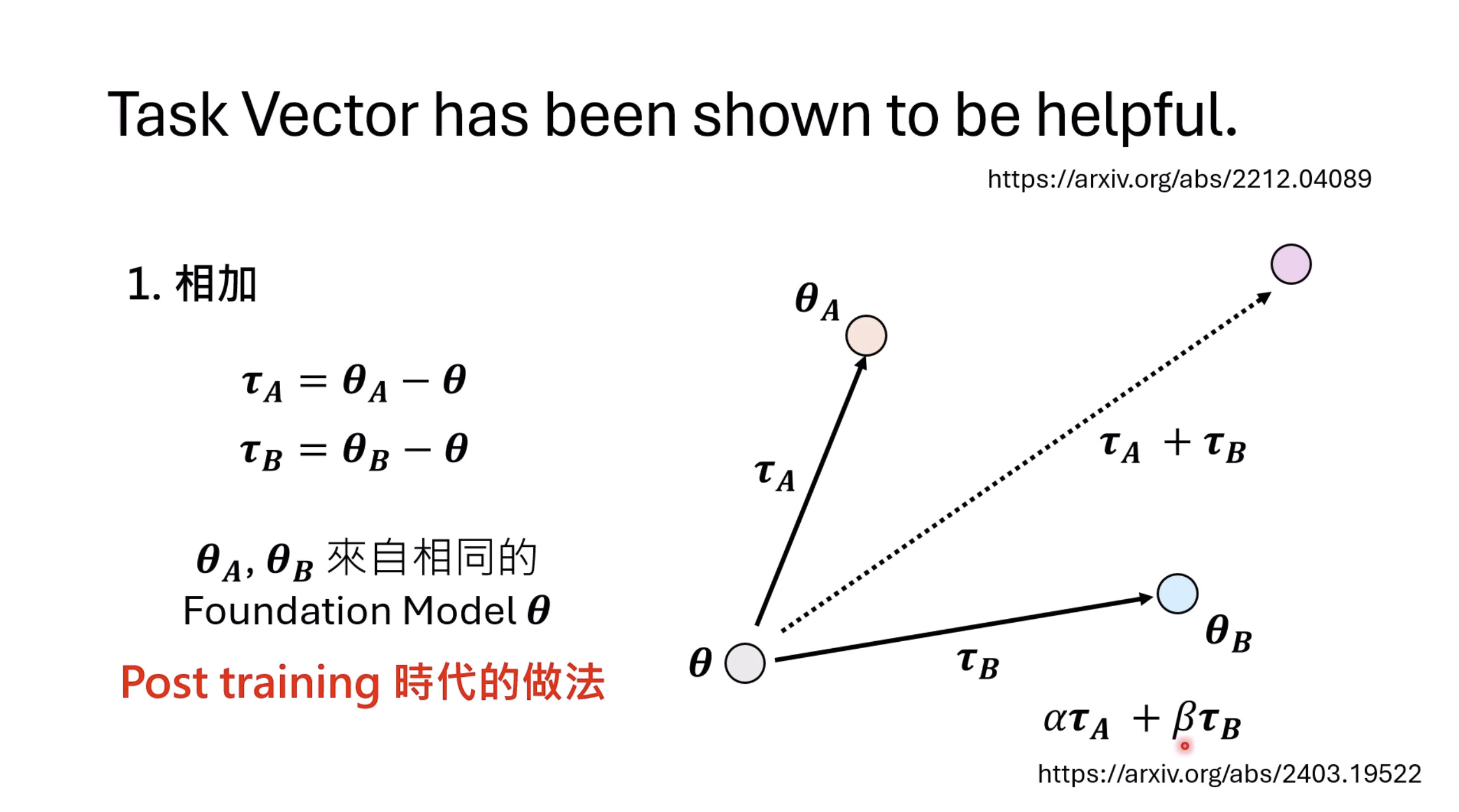
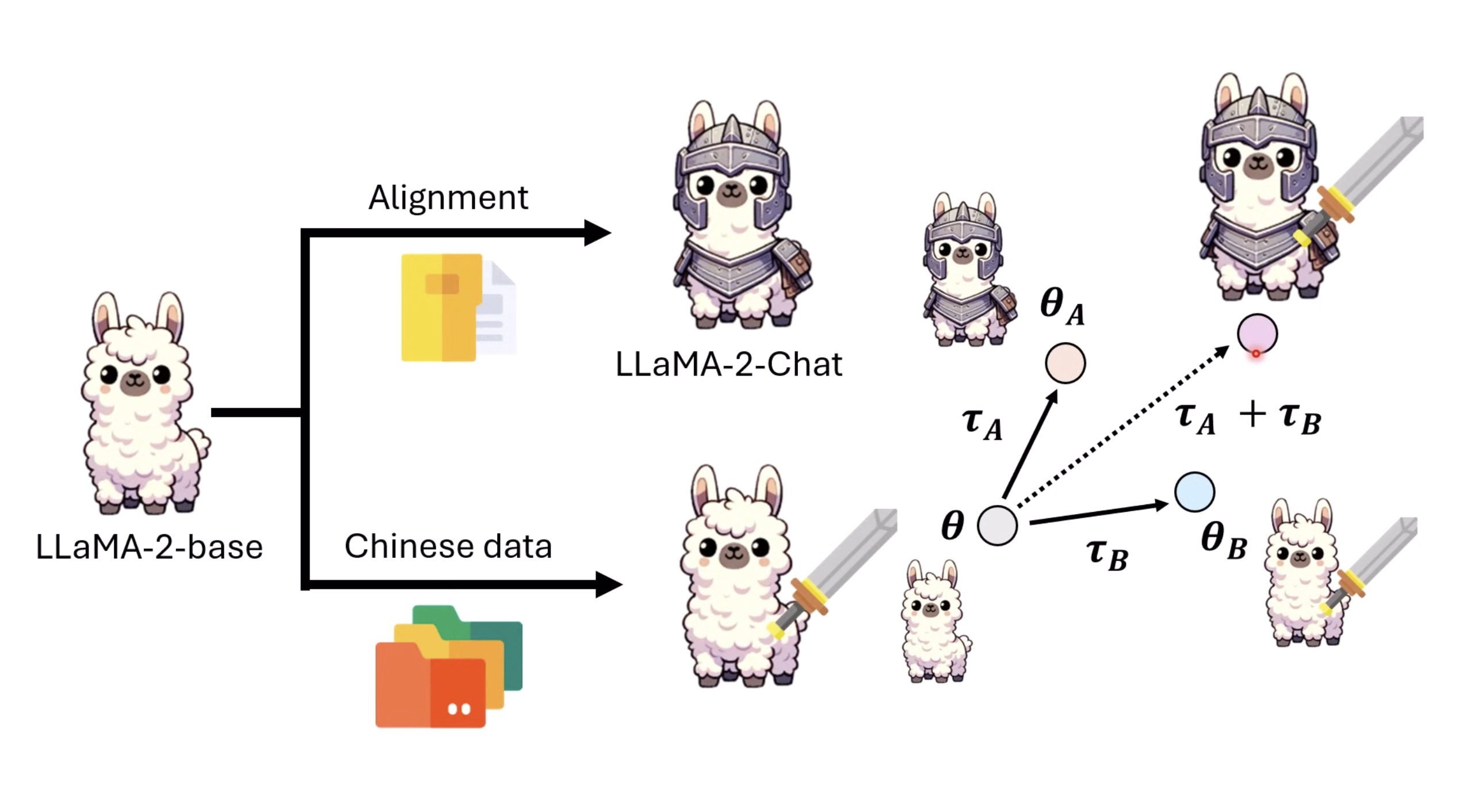
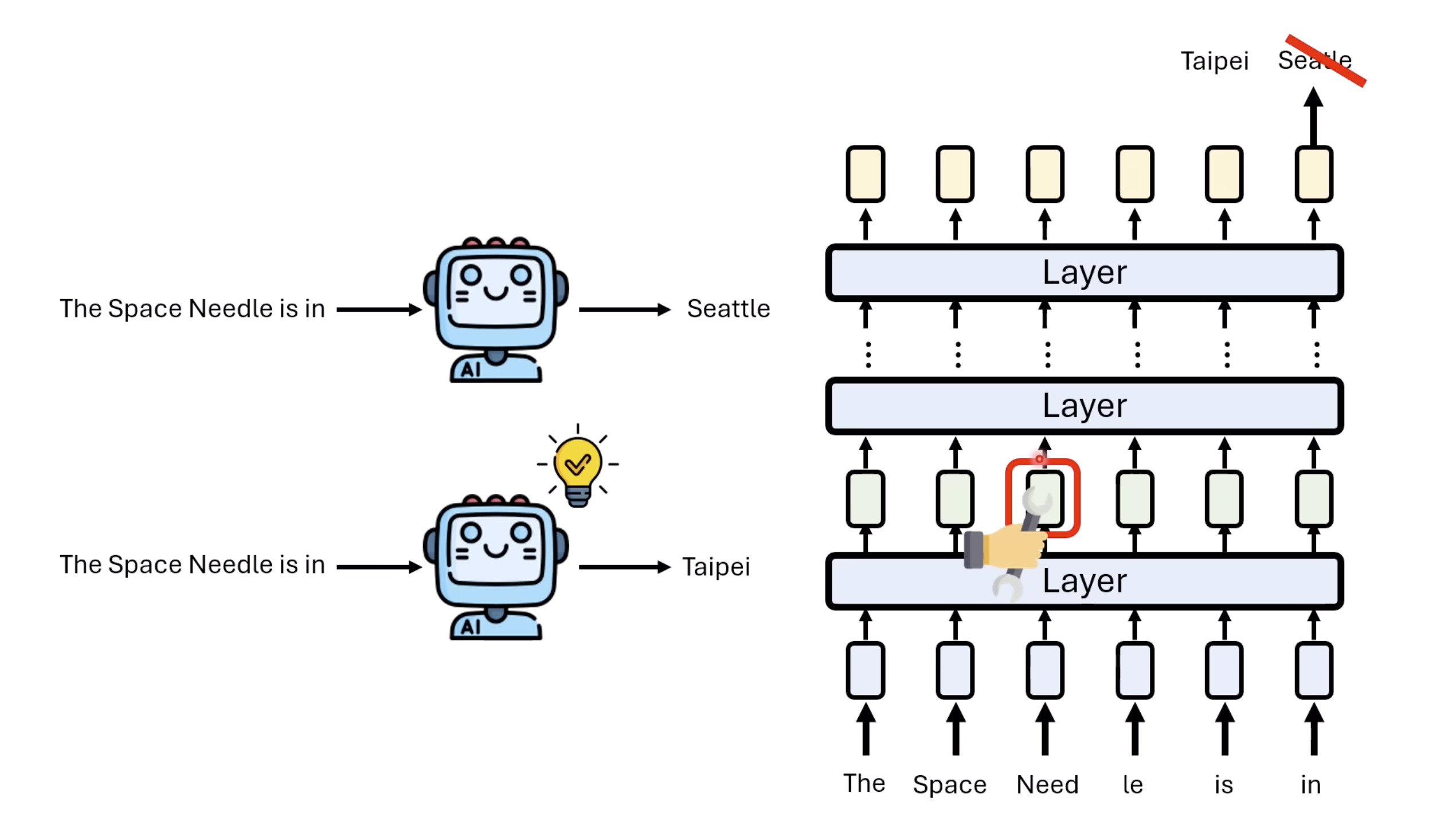
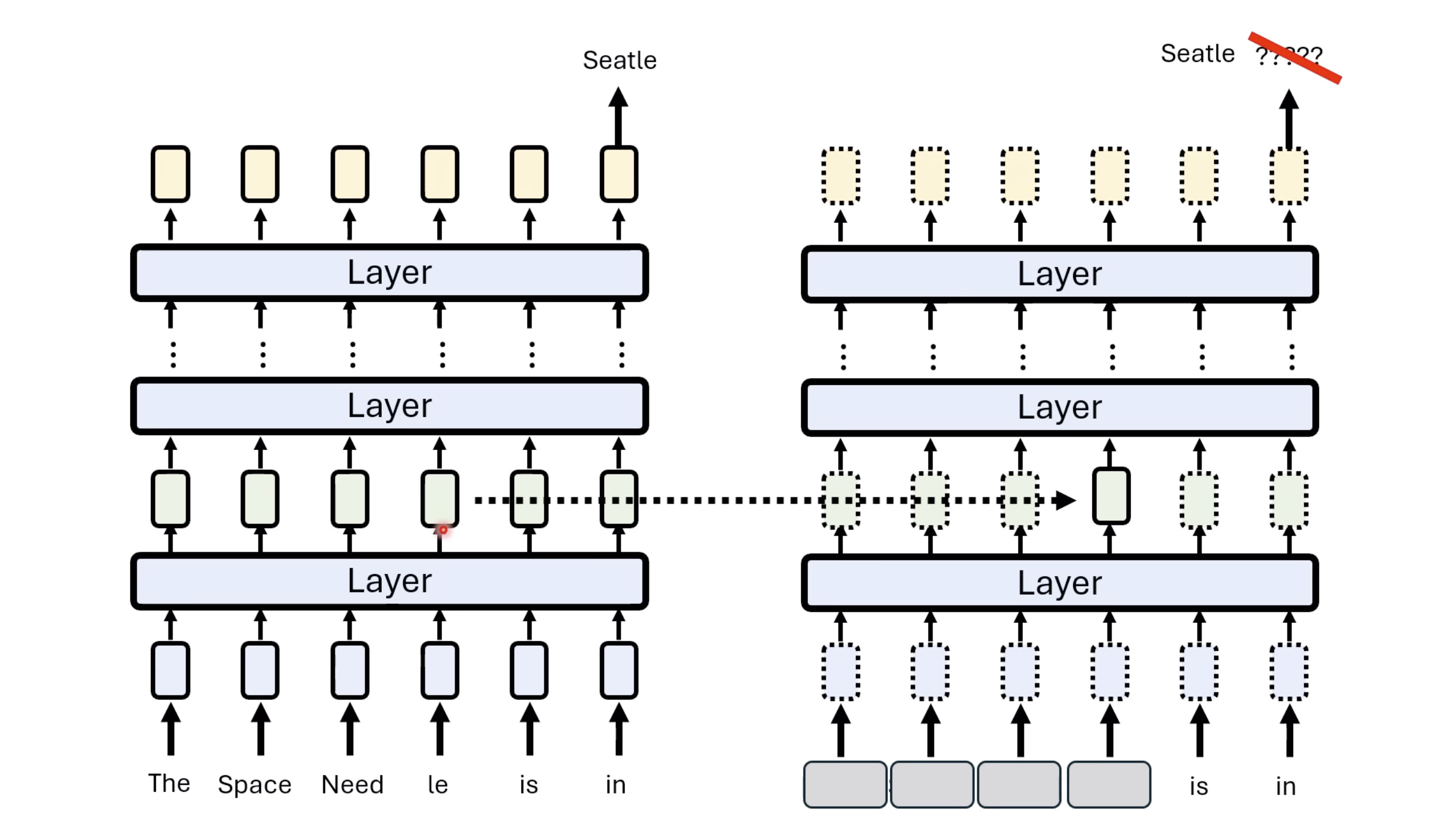
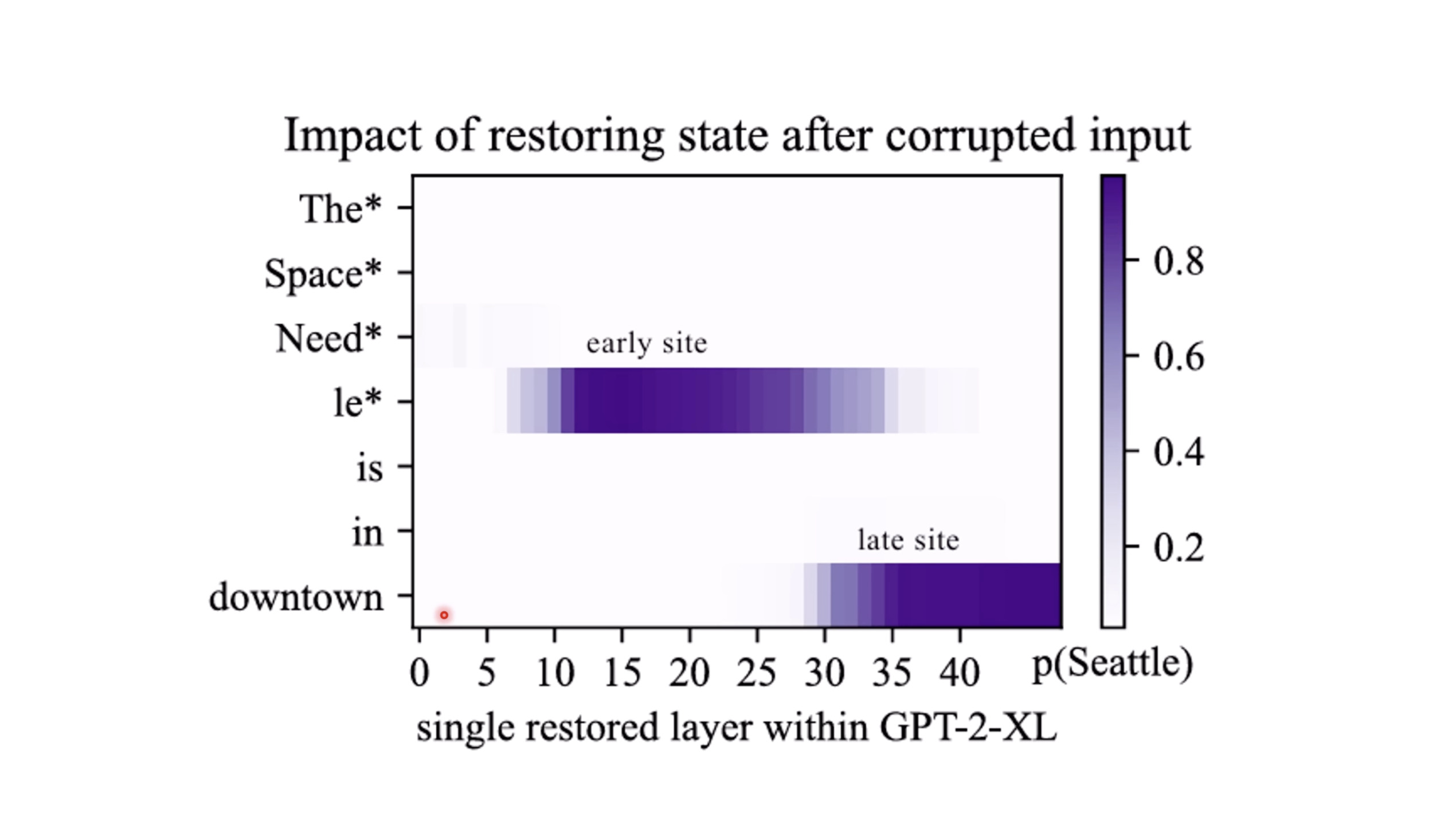
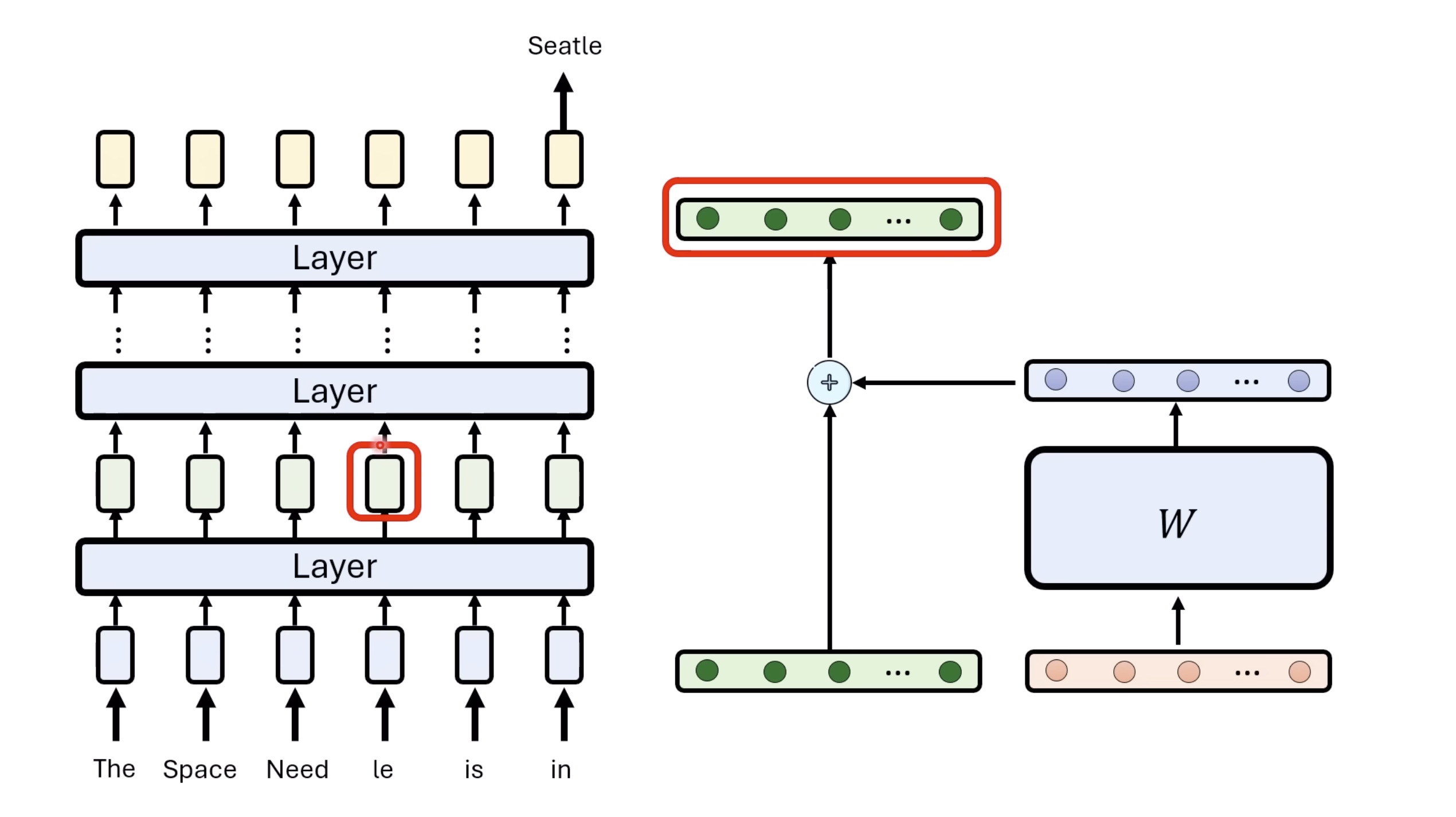
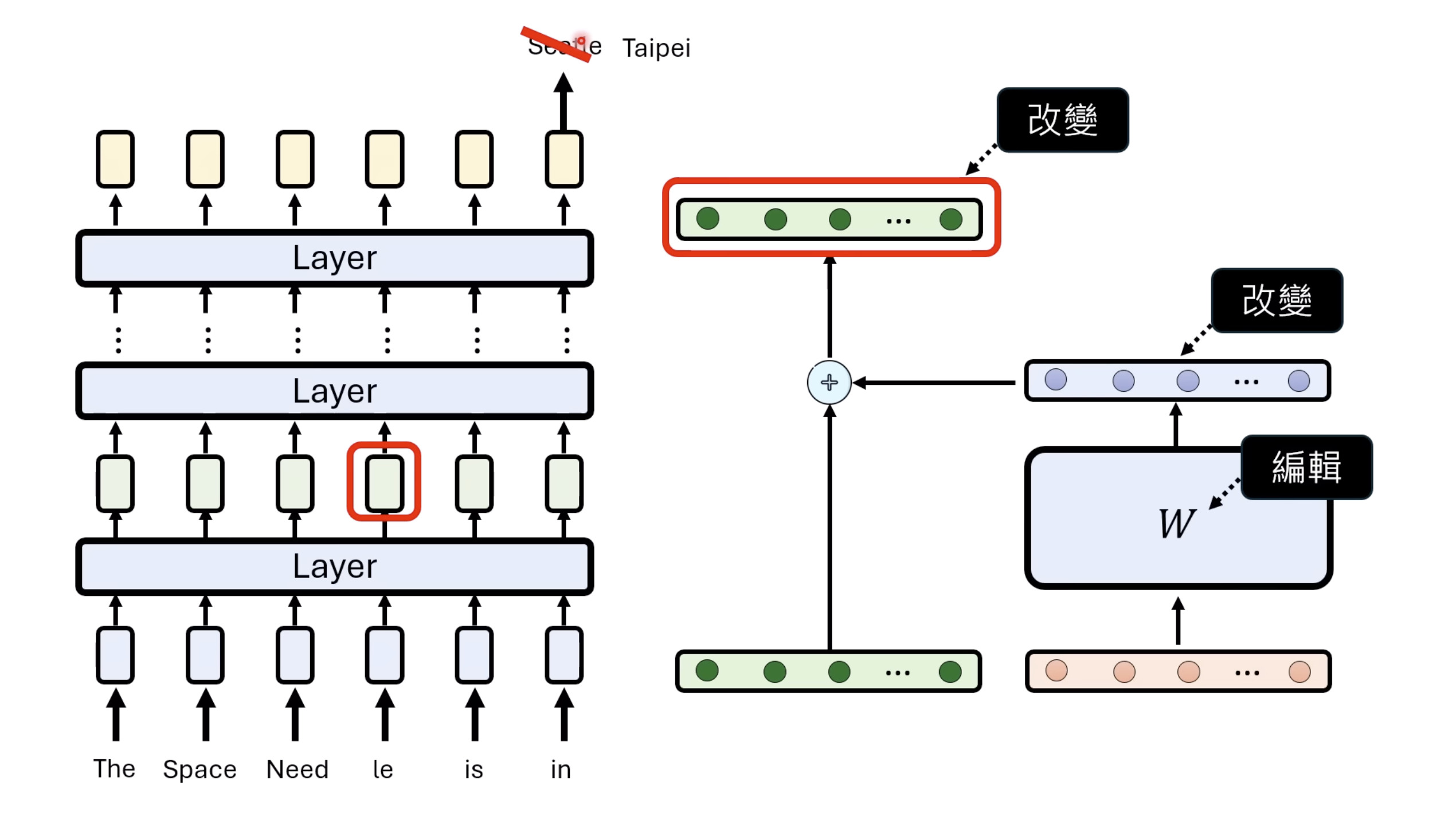
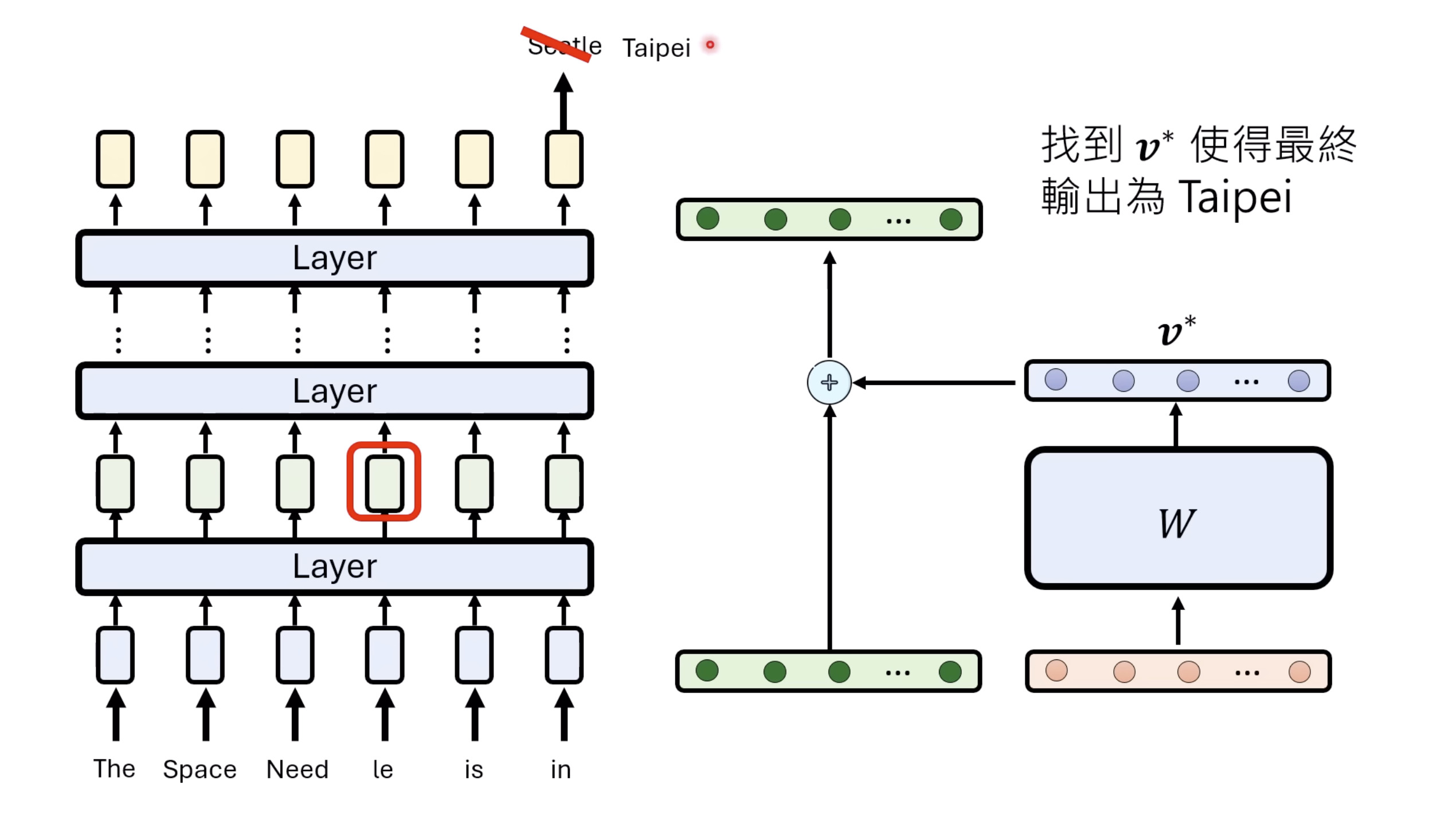
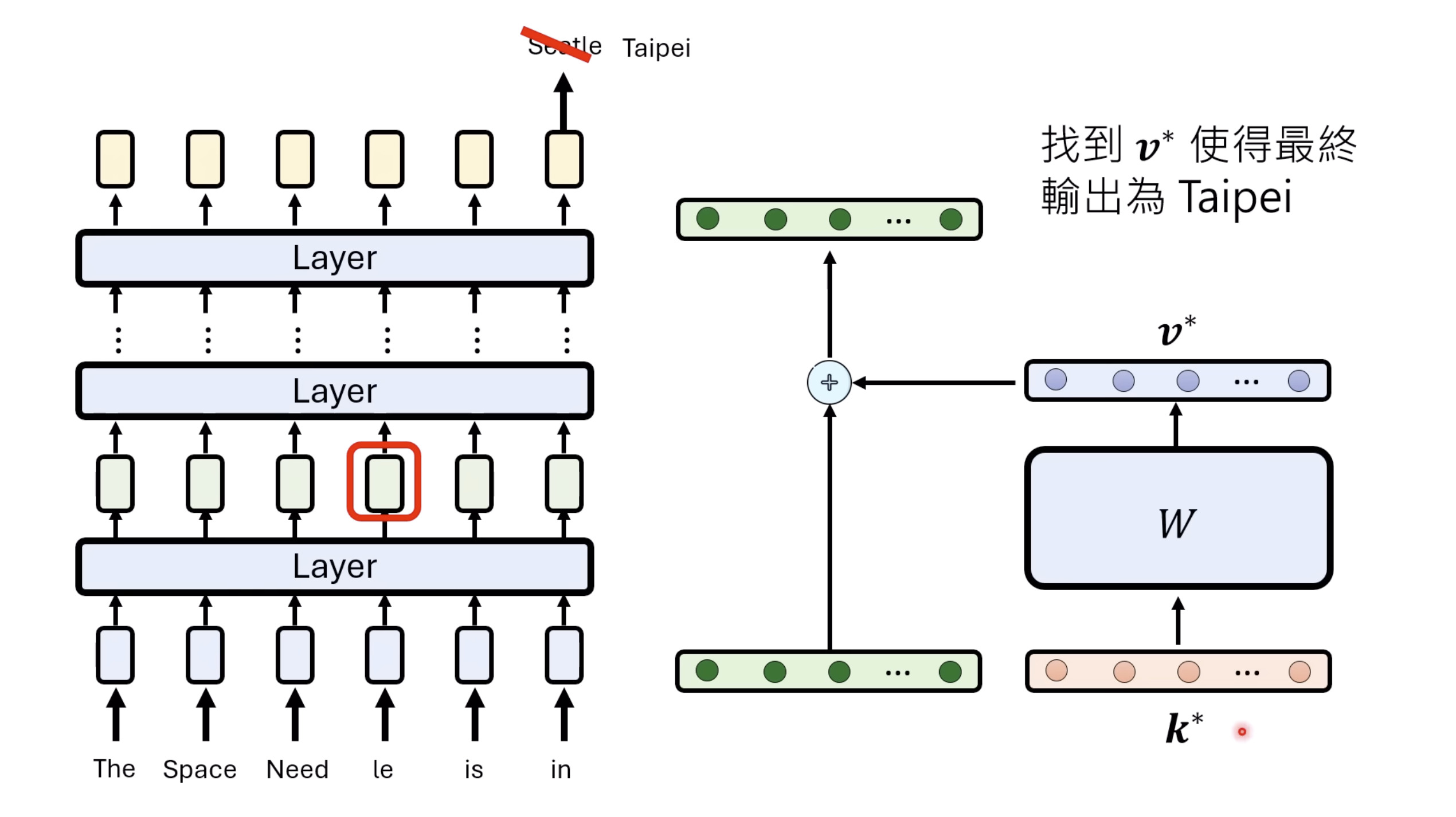
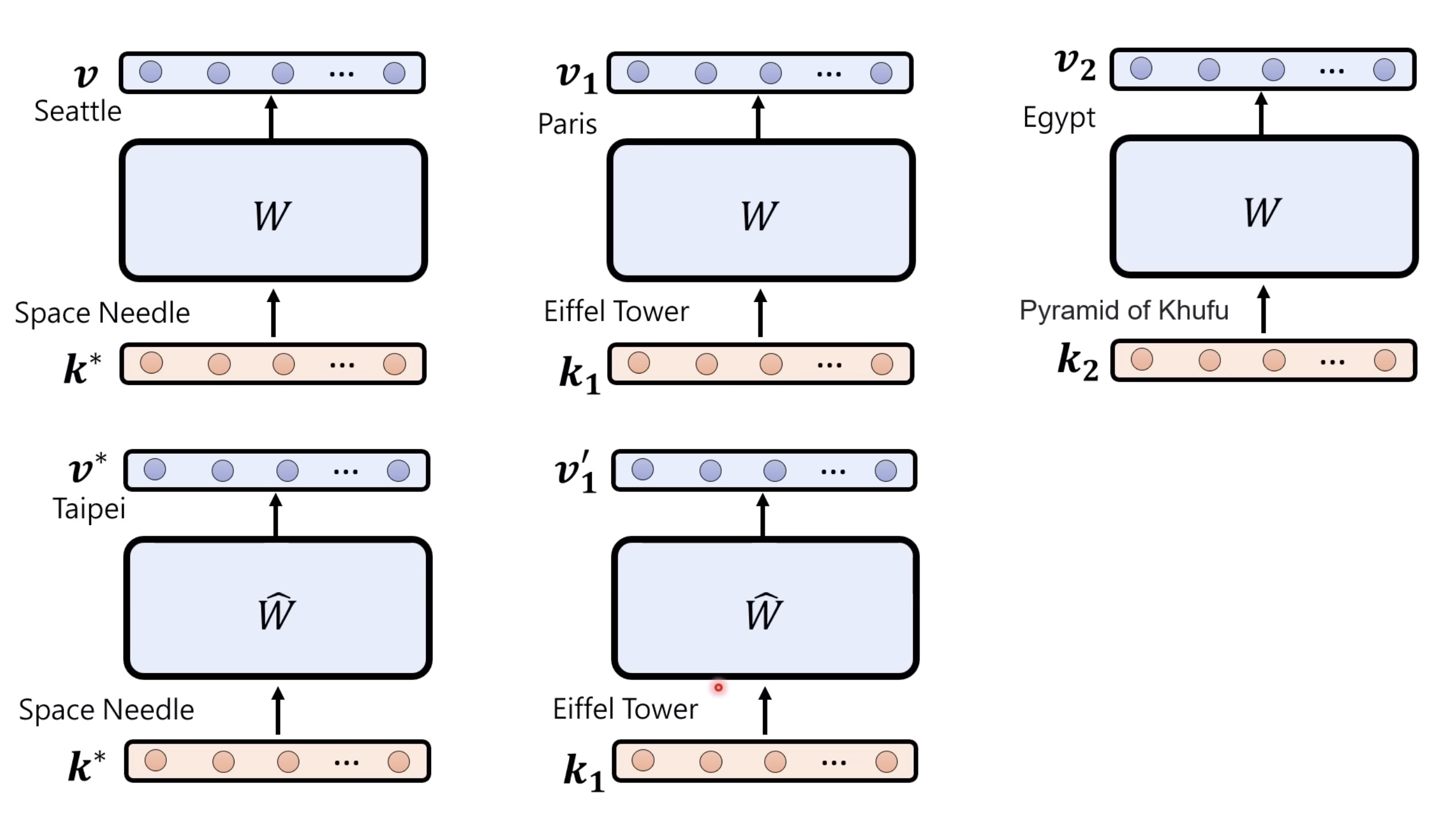
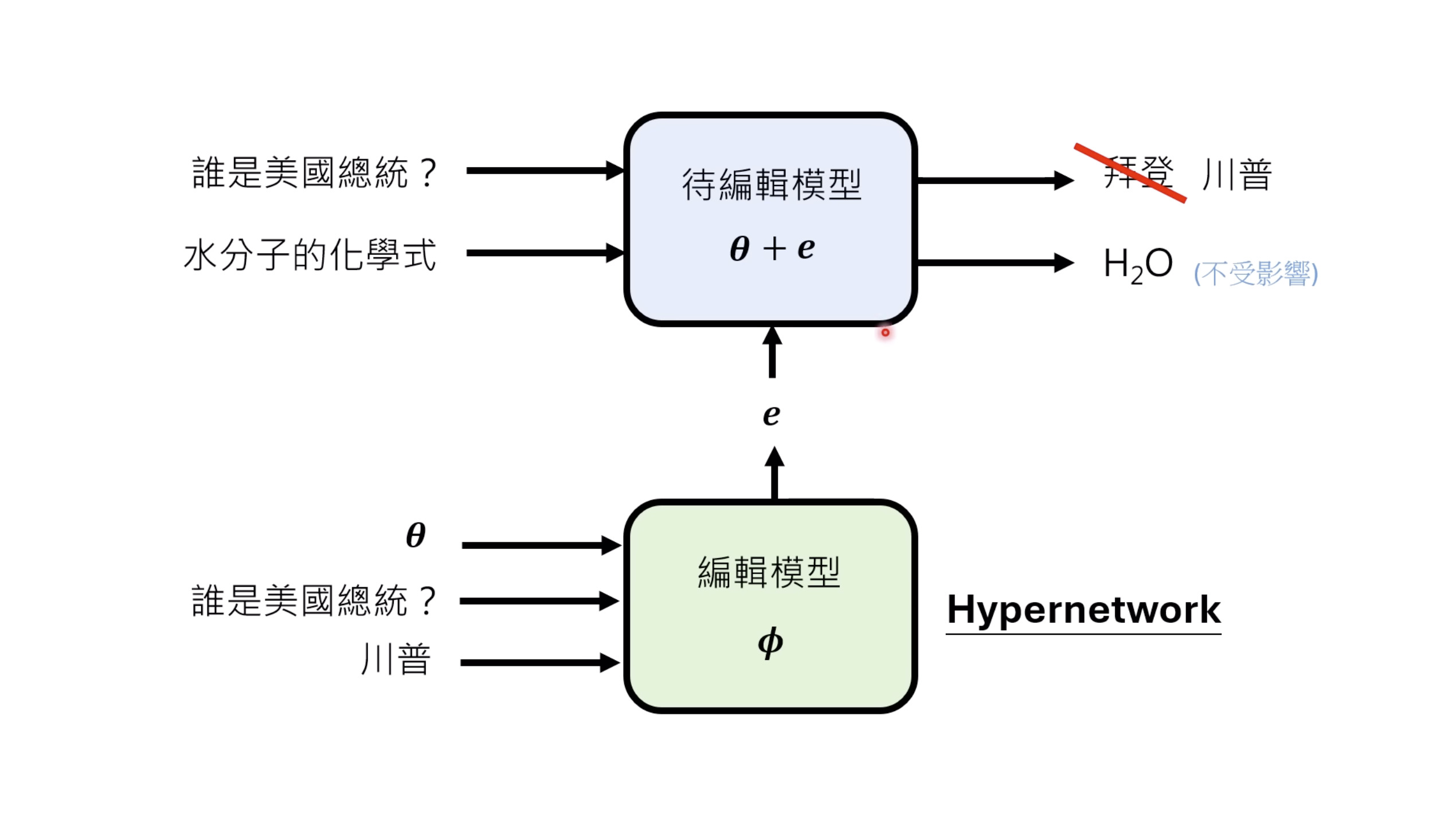
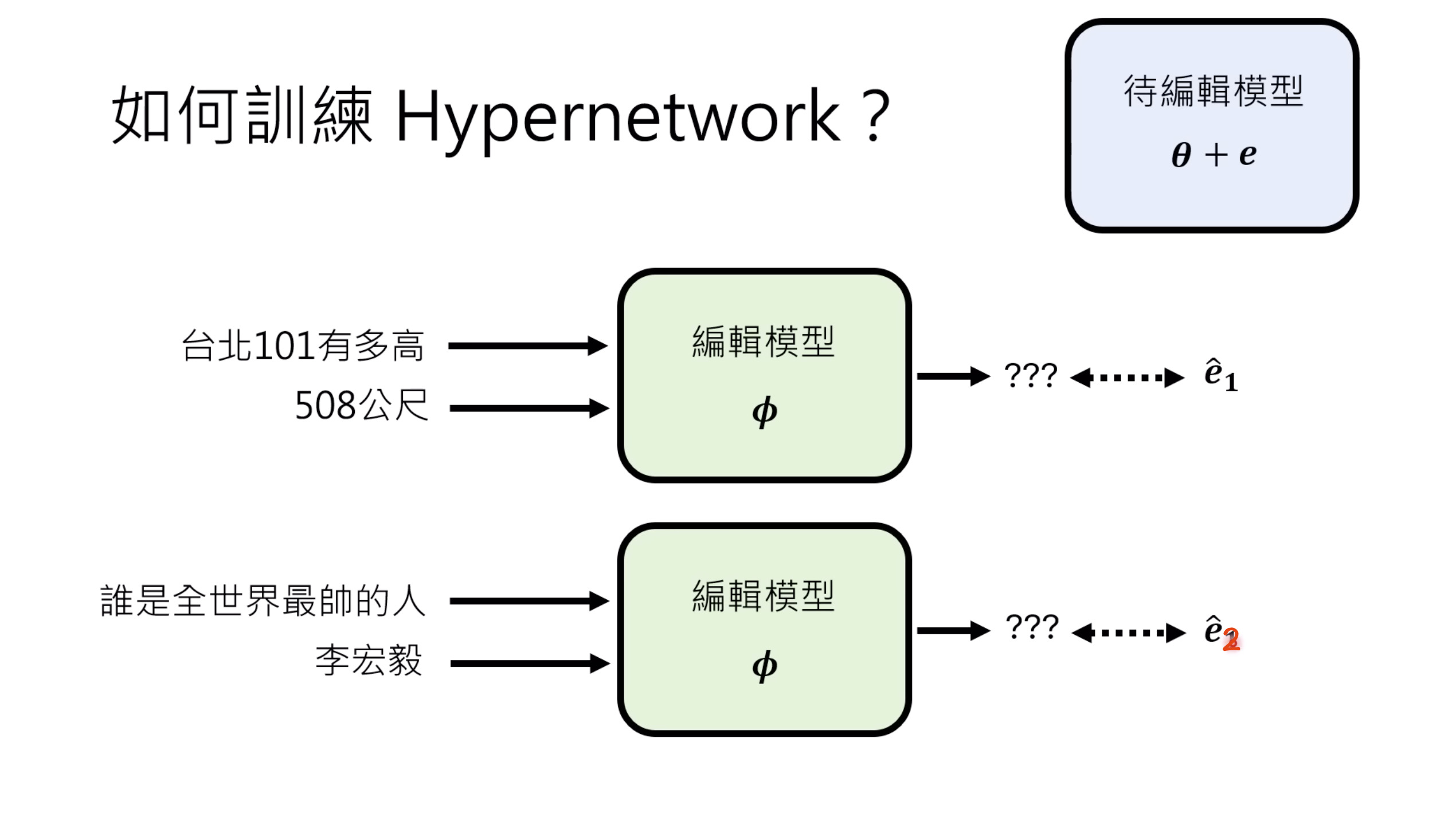
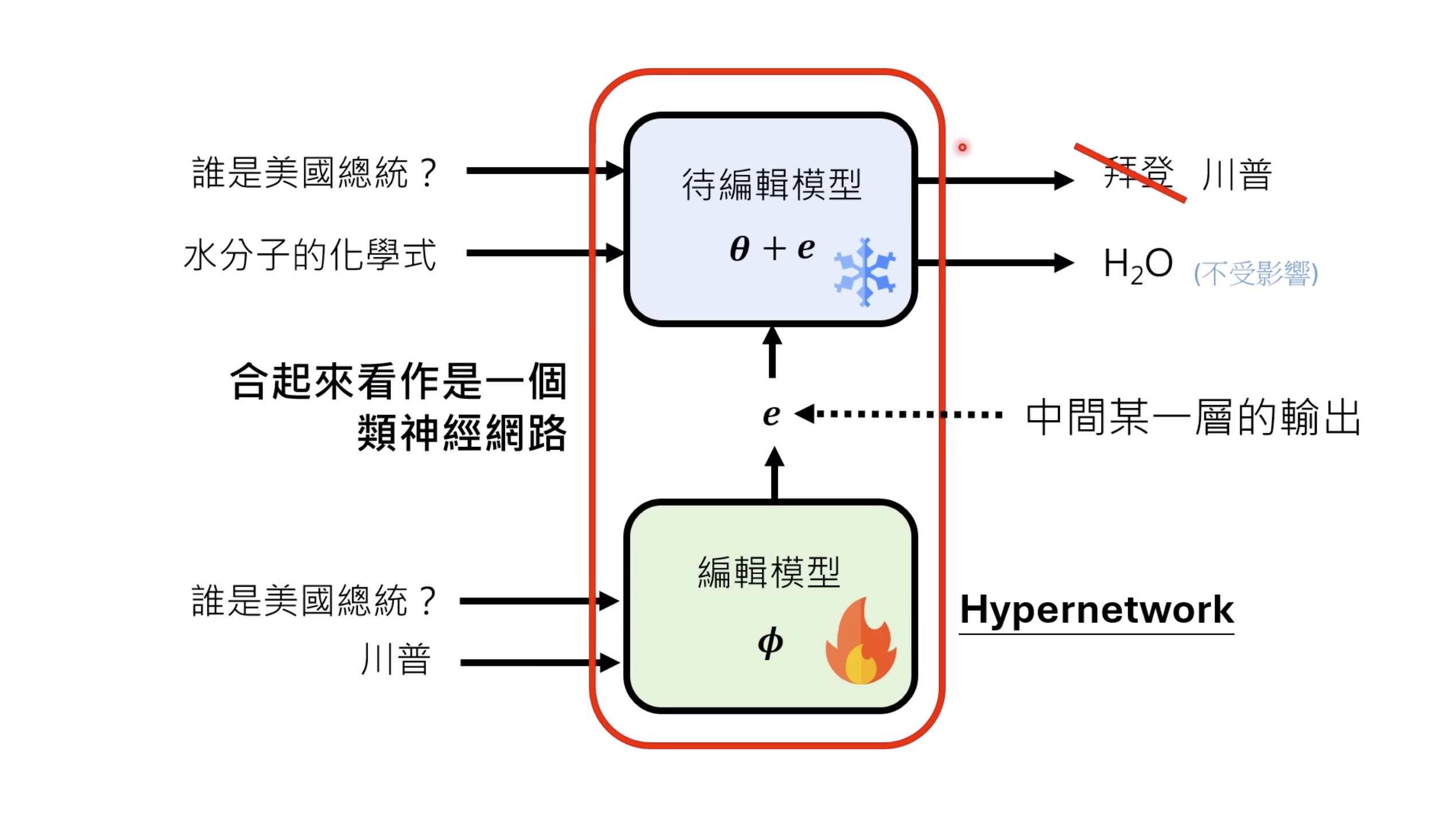
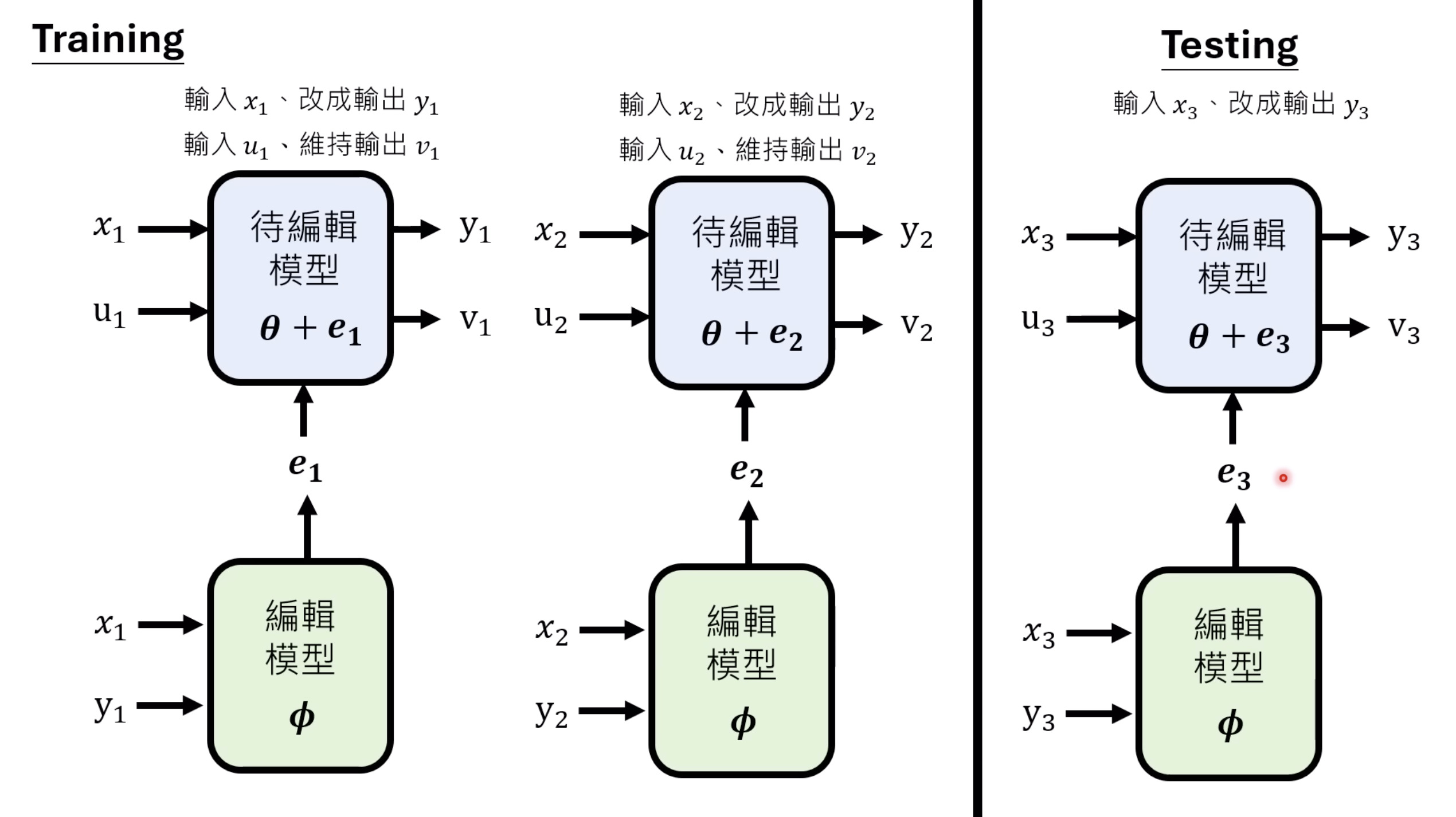
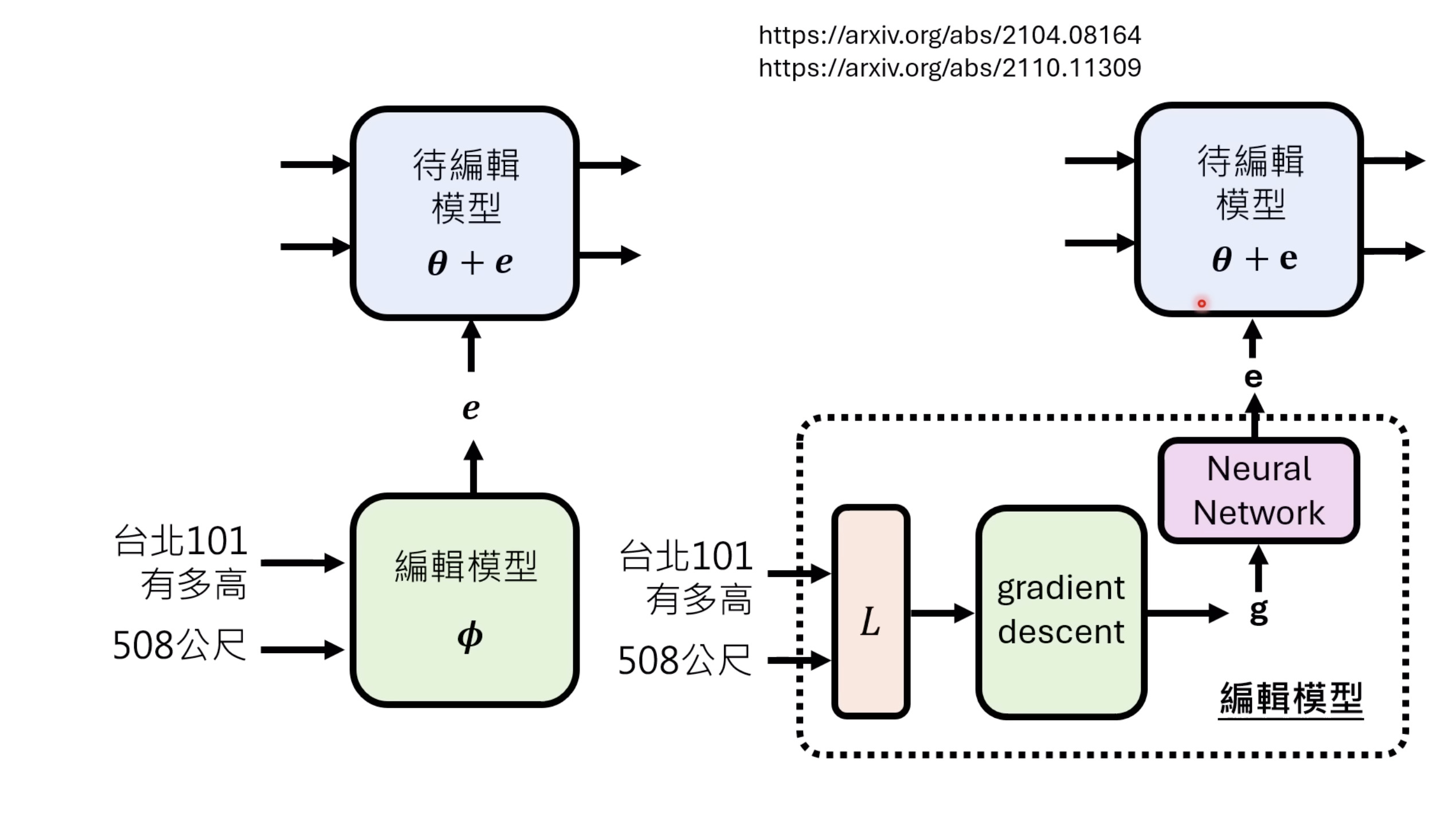
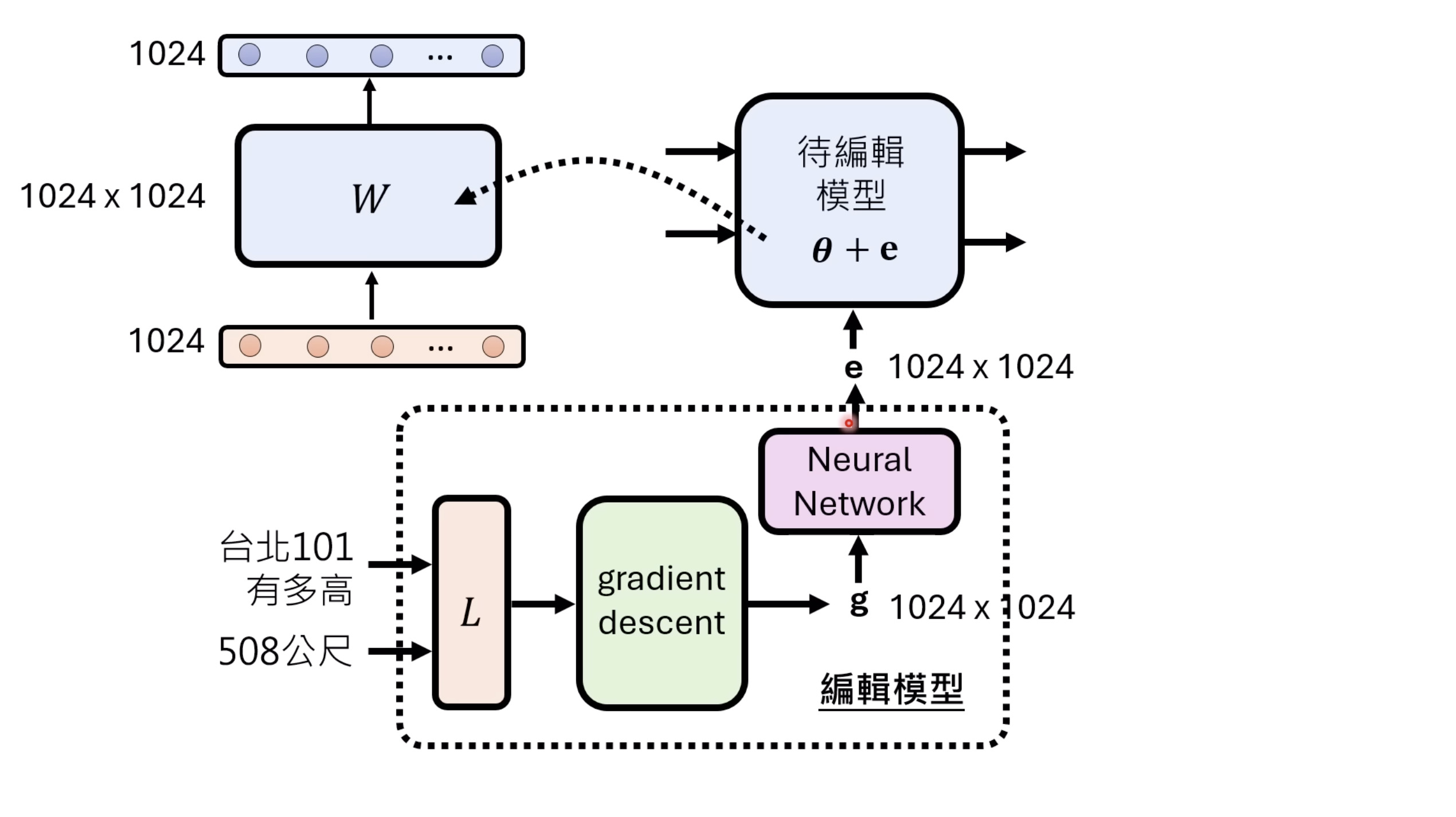
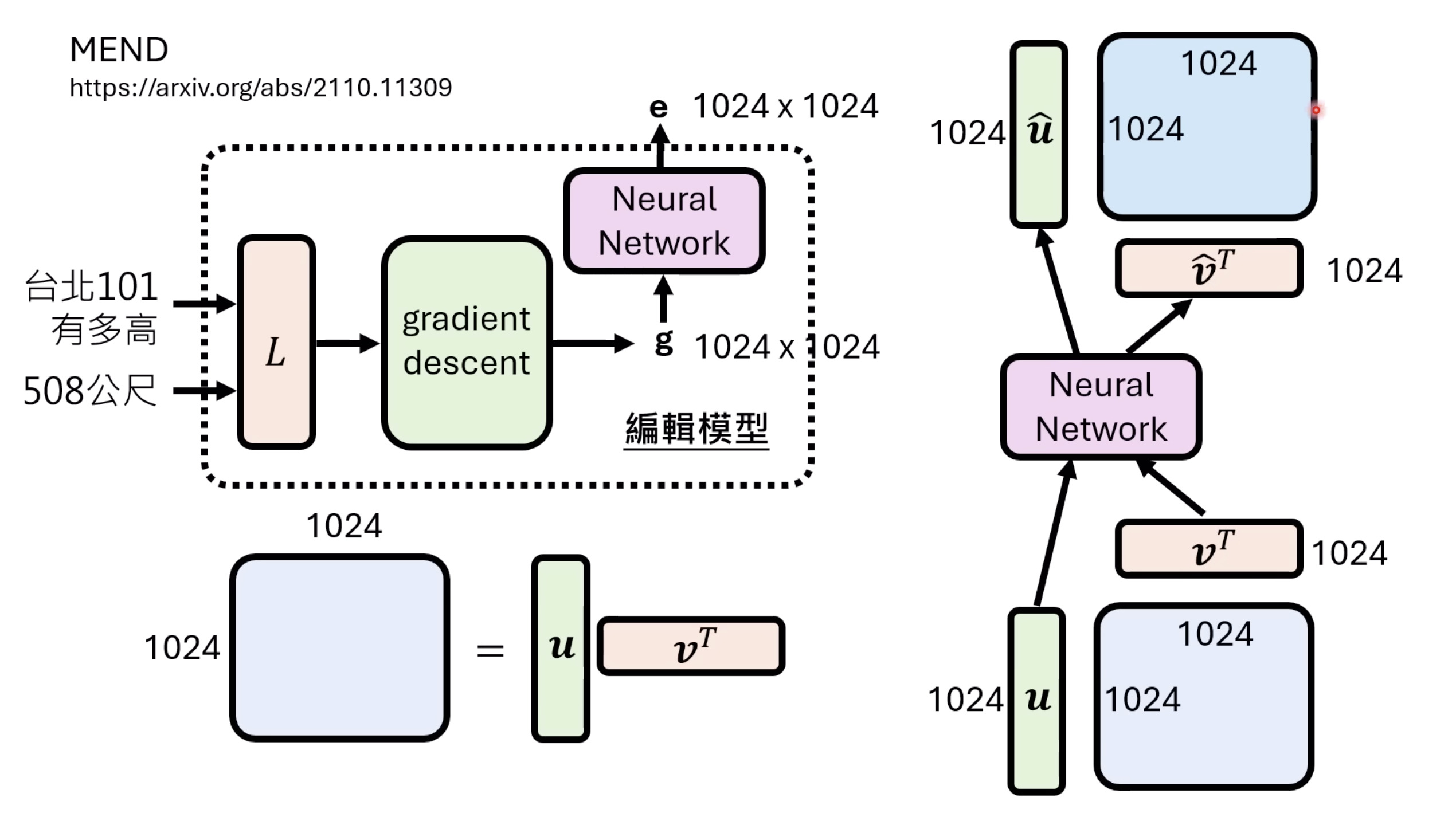
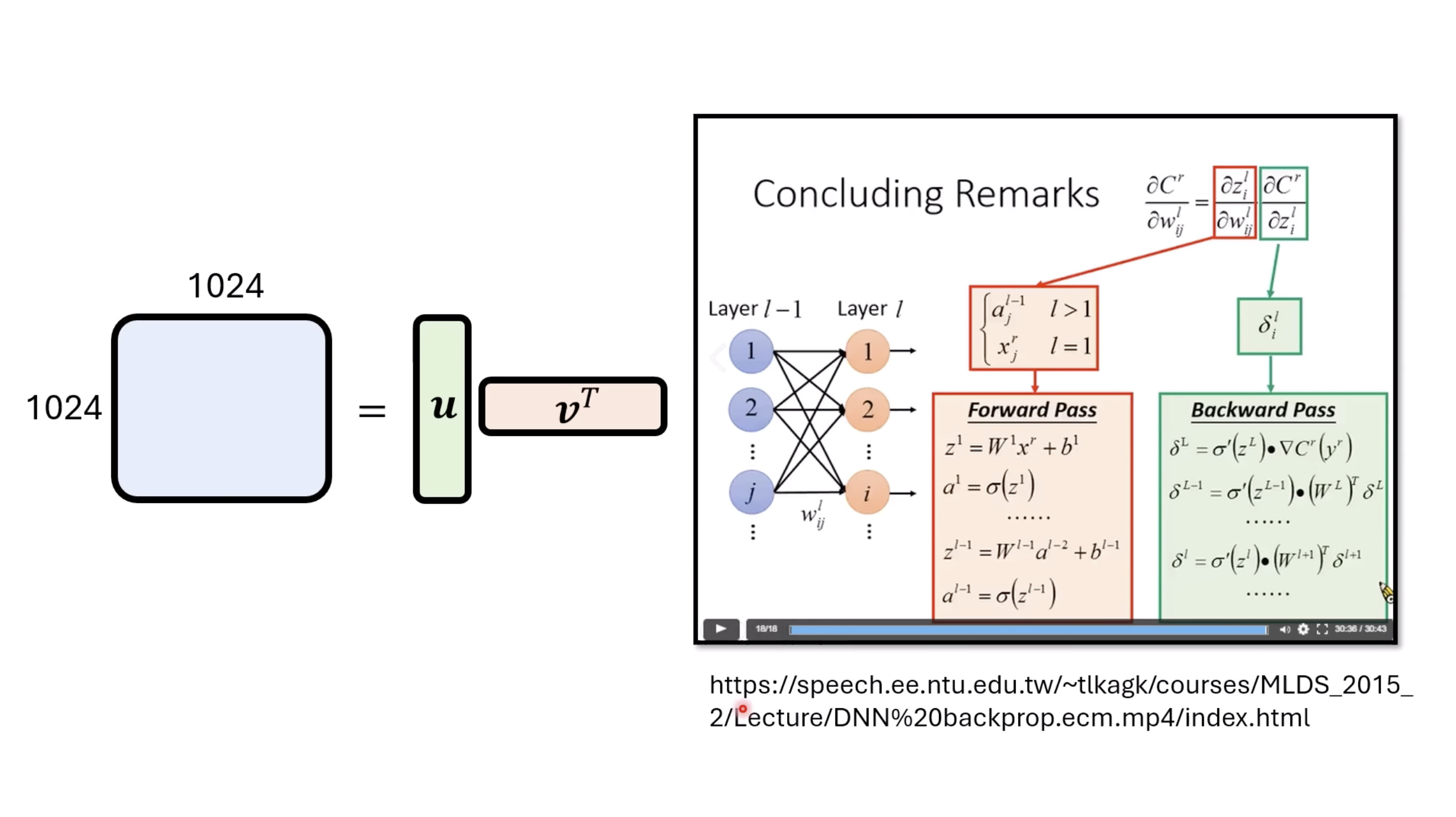
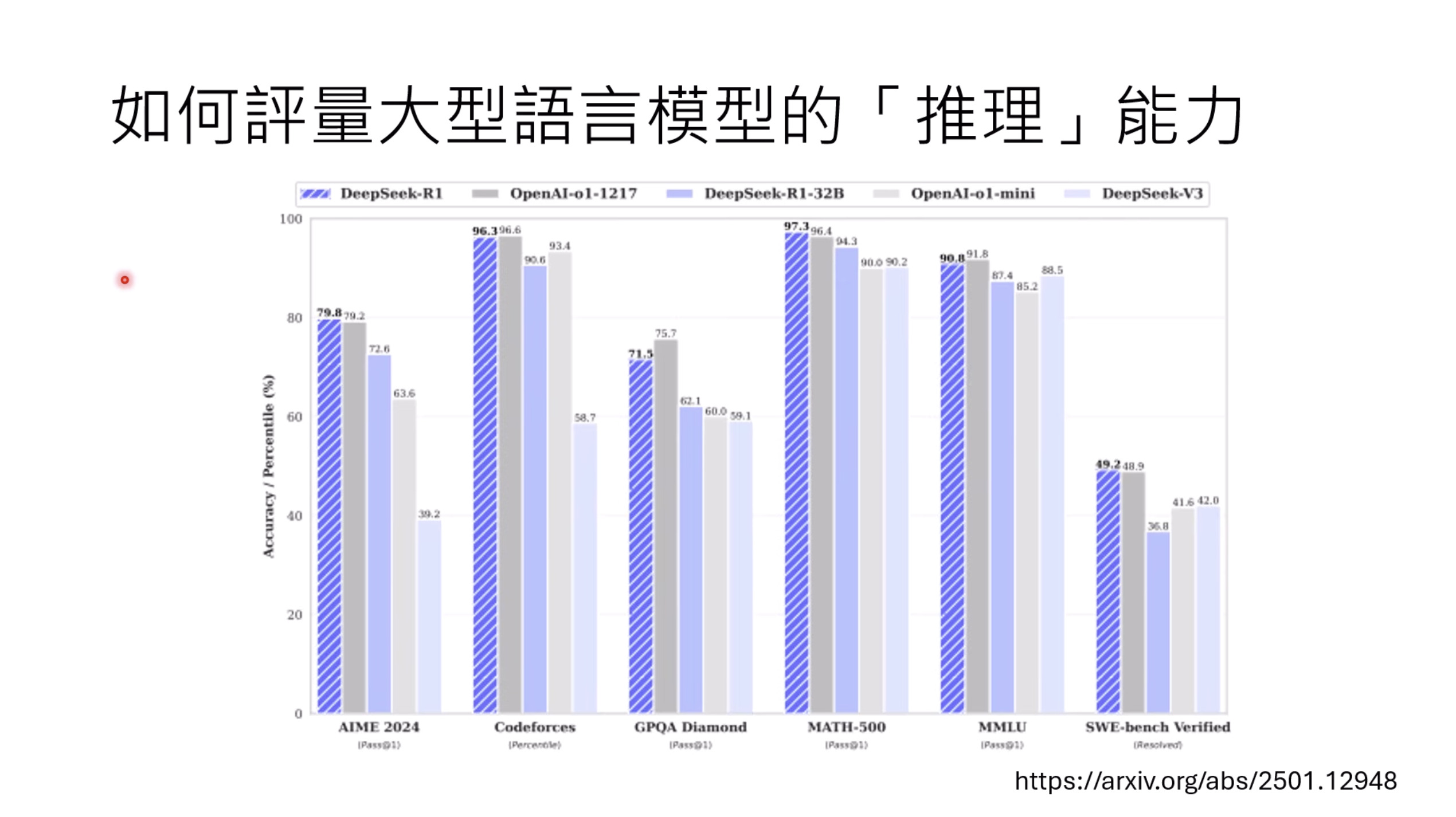
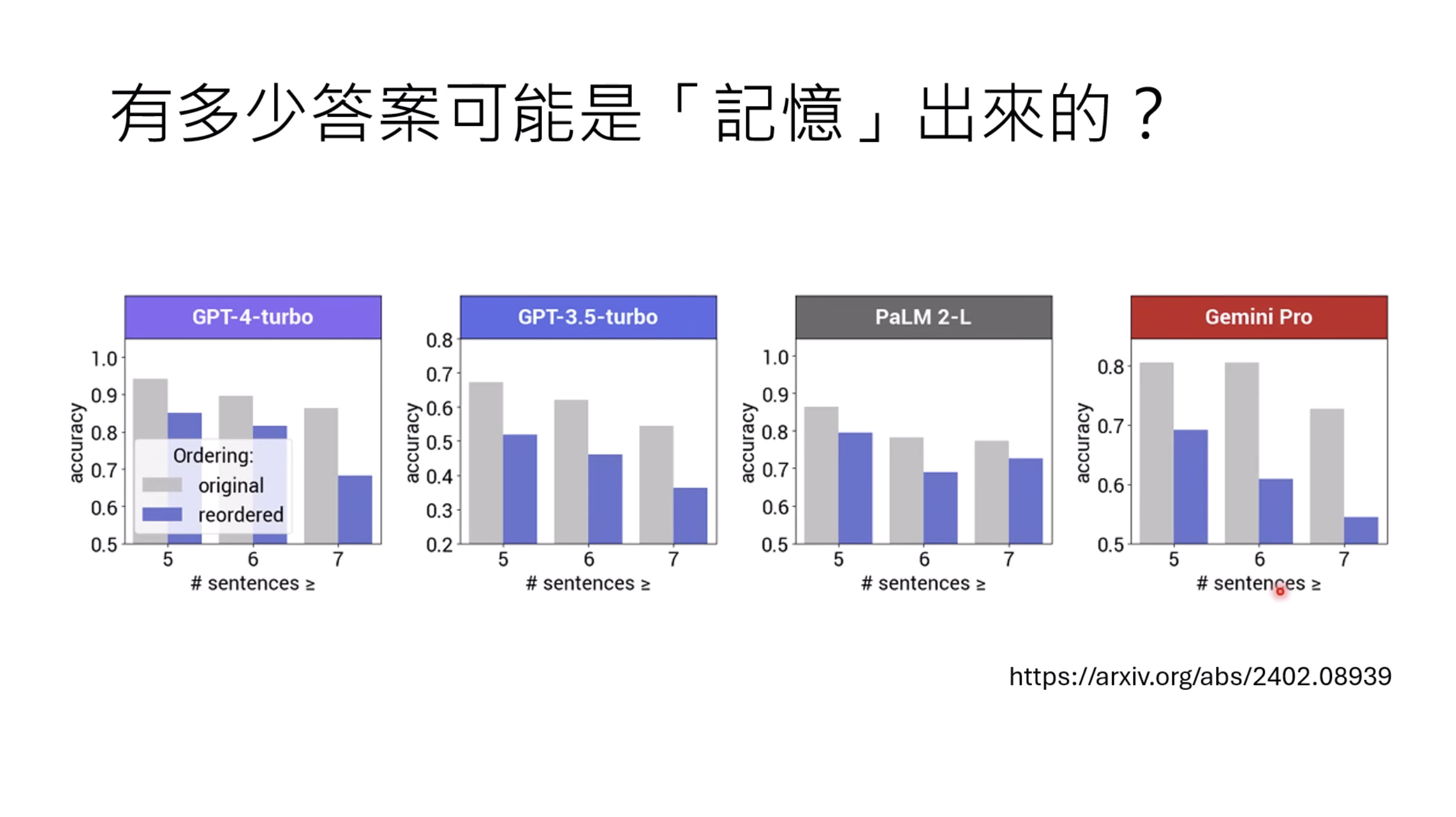
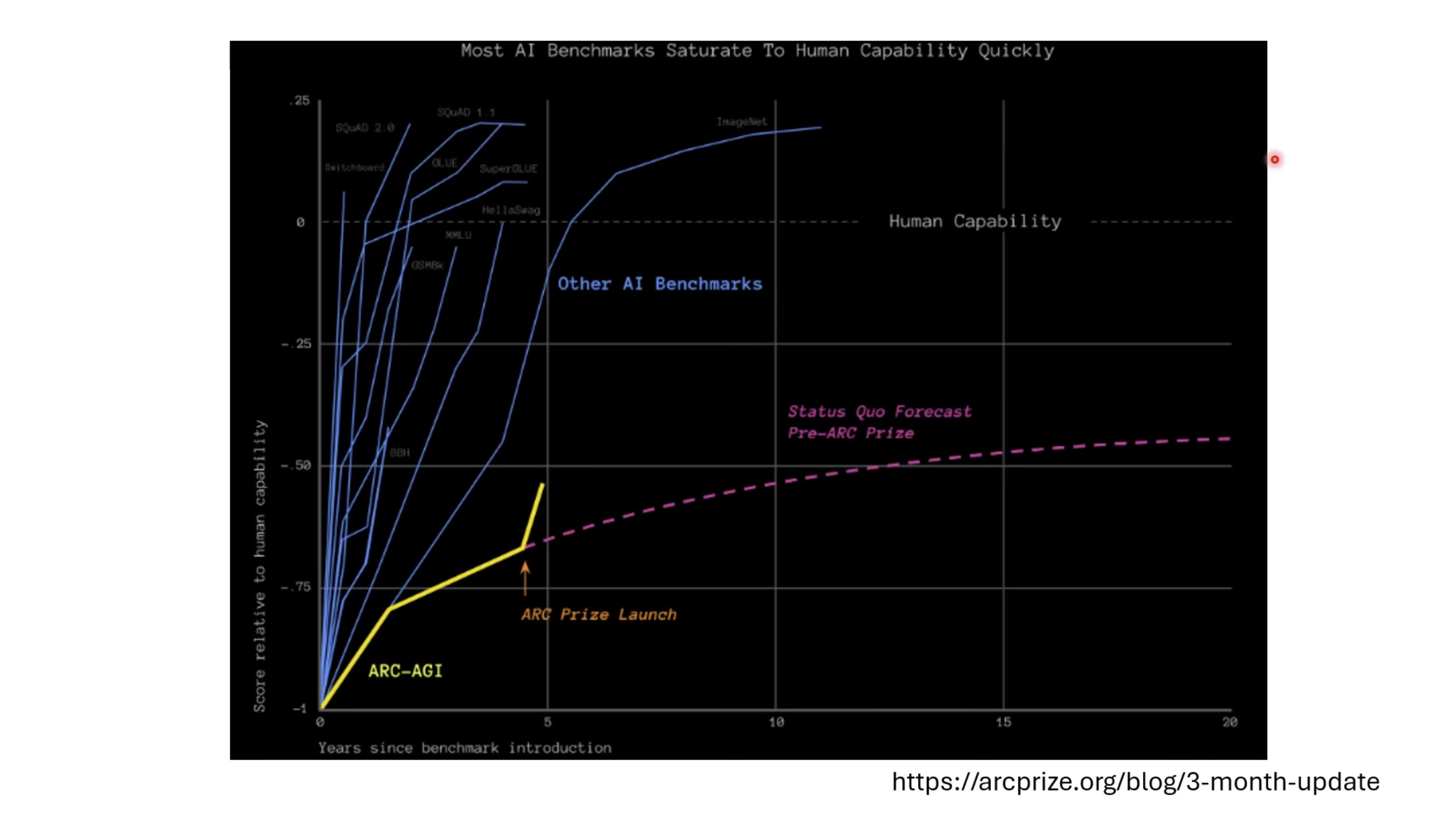
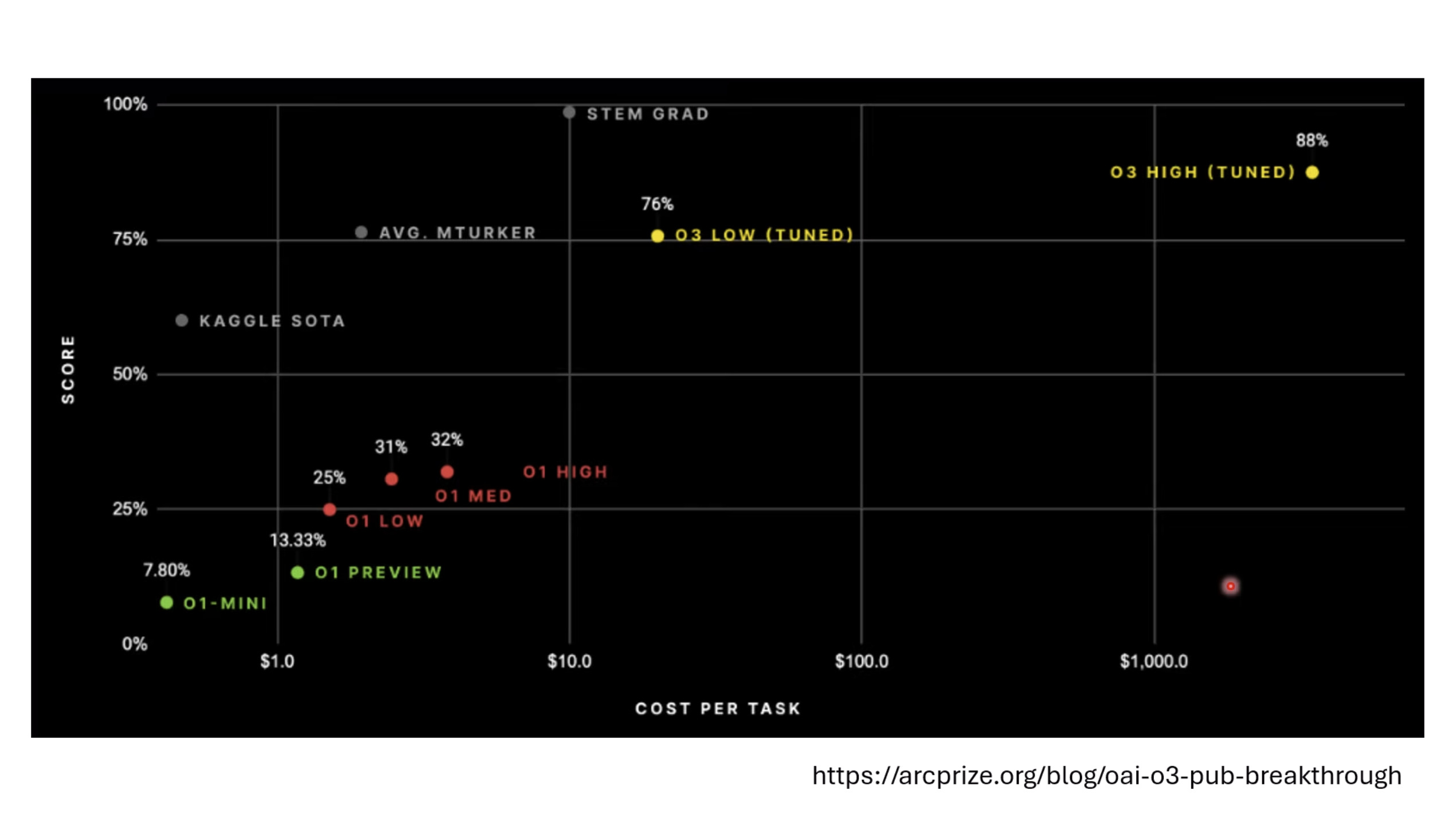
【生成式AI时代下的机器学习(2025)】第十二讲:概述语音语言模型发展历程
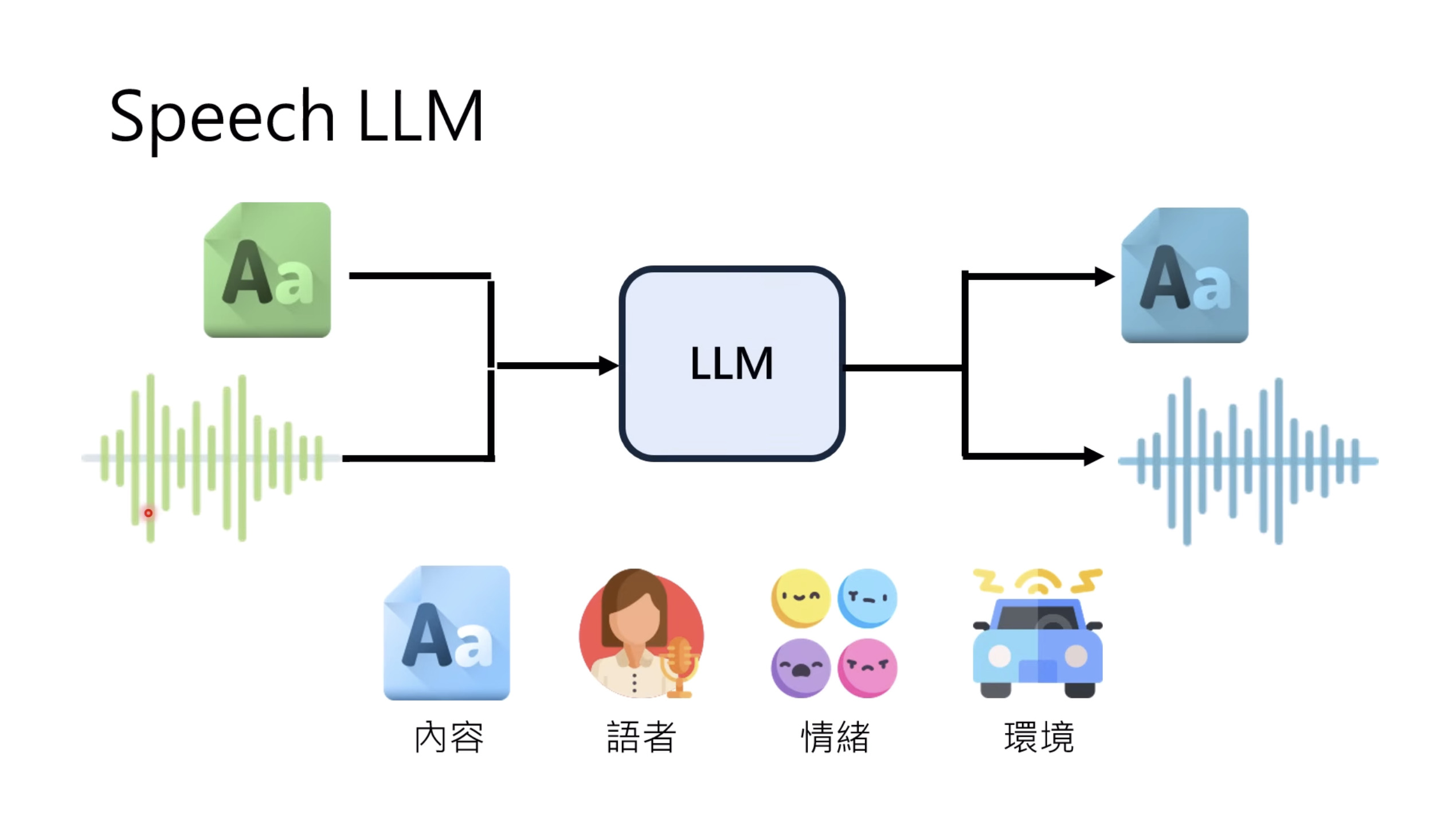
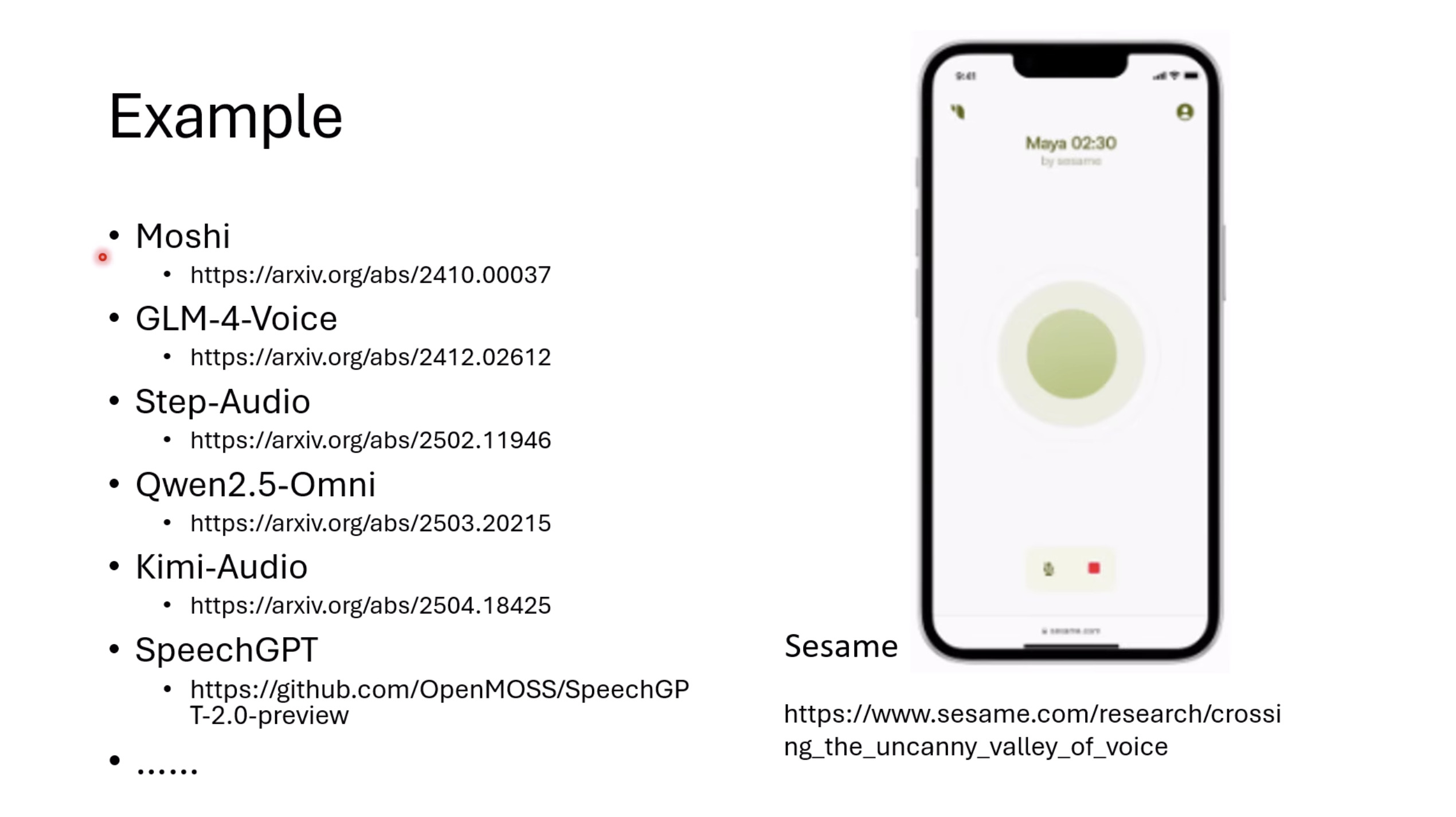
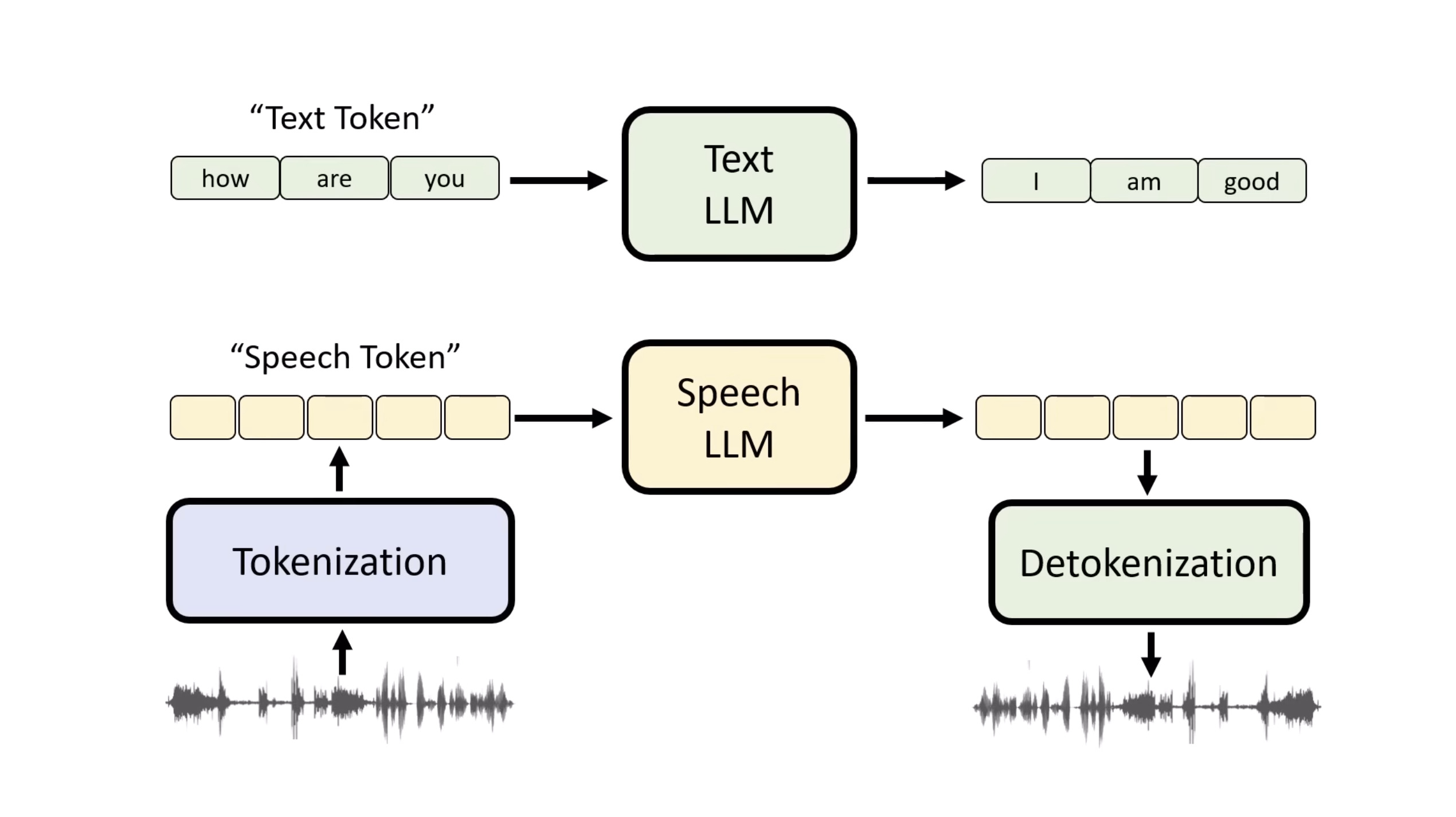
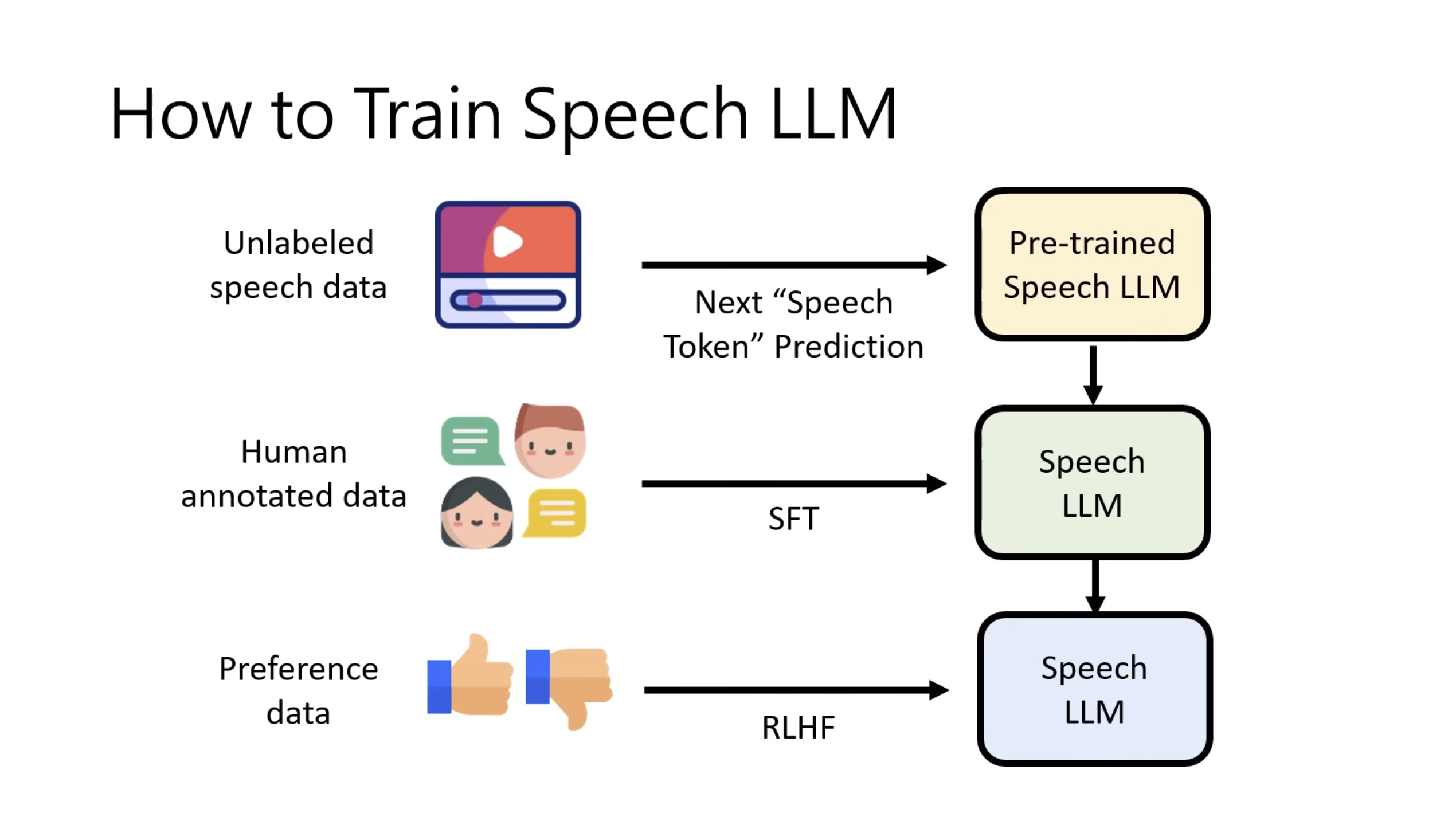
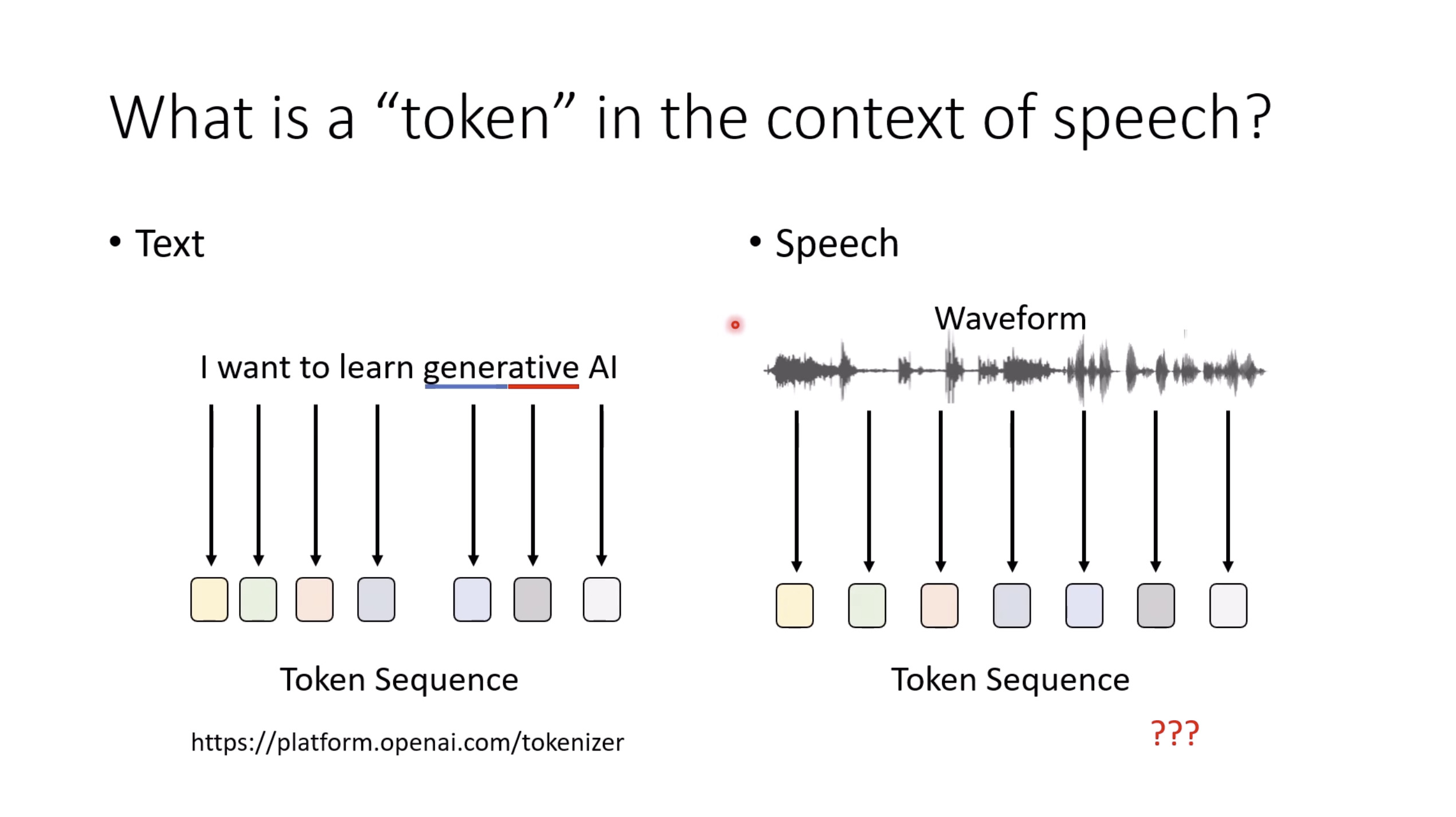
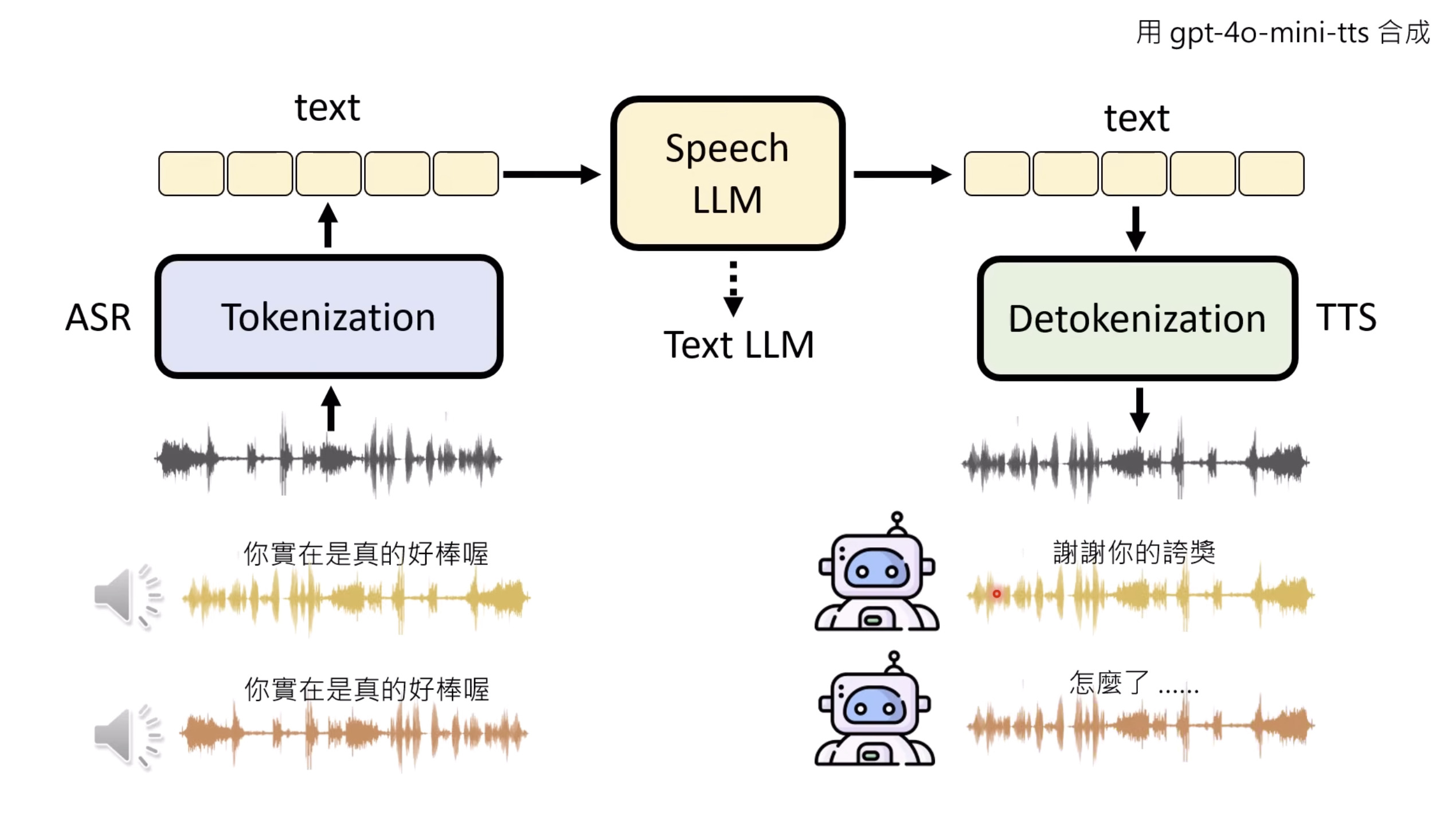
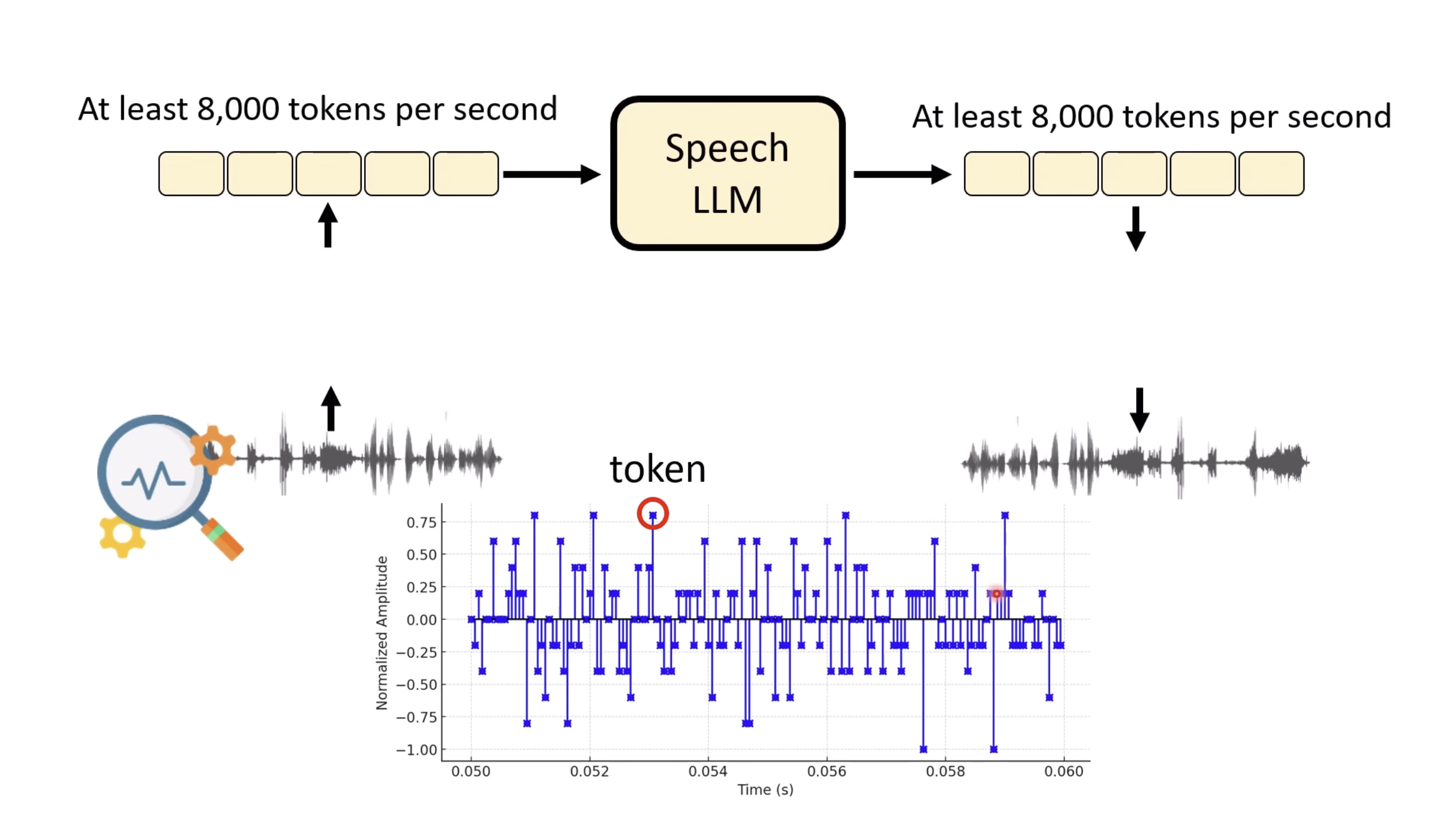
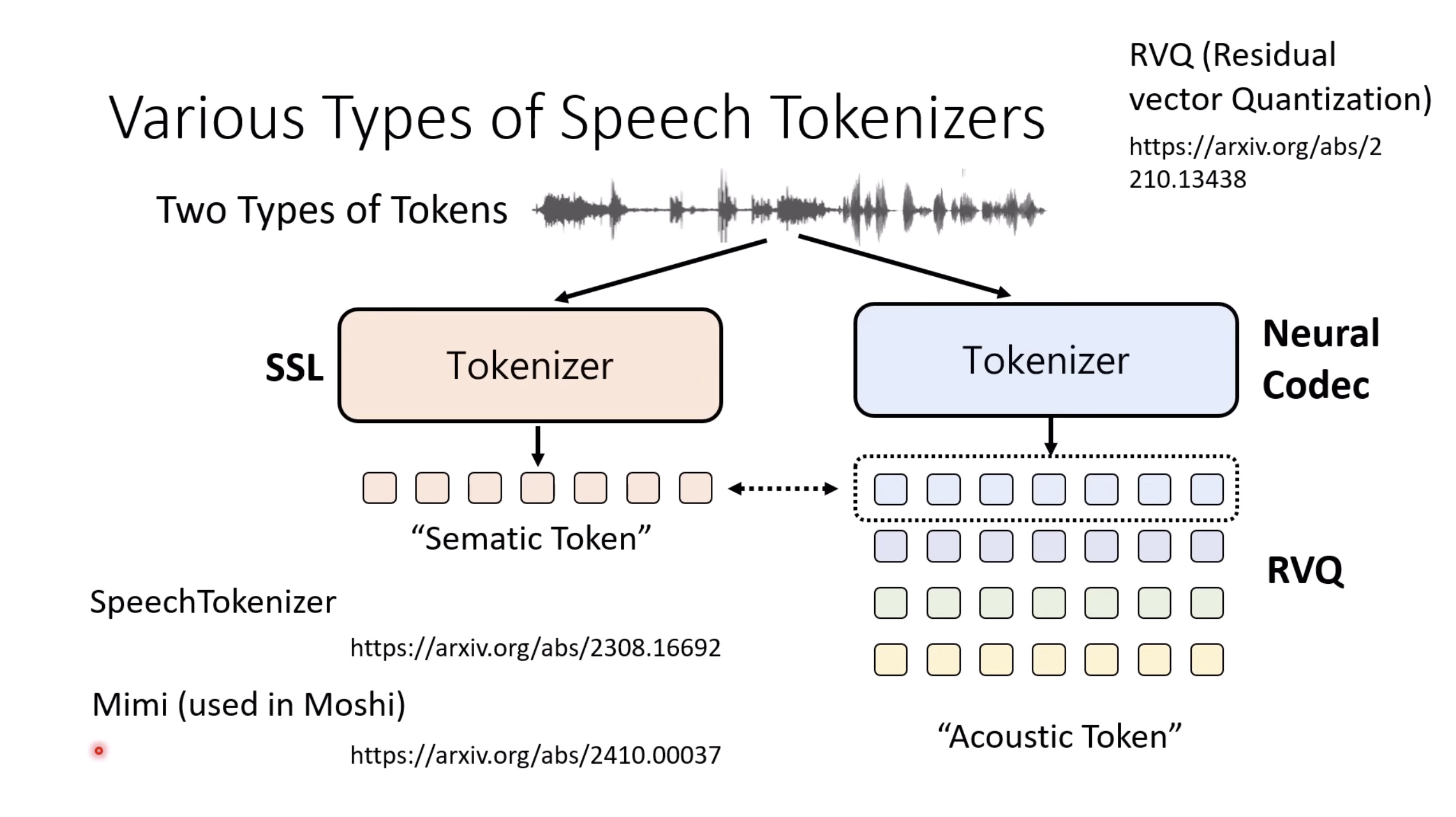
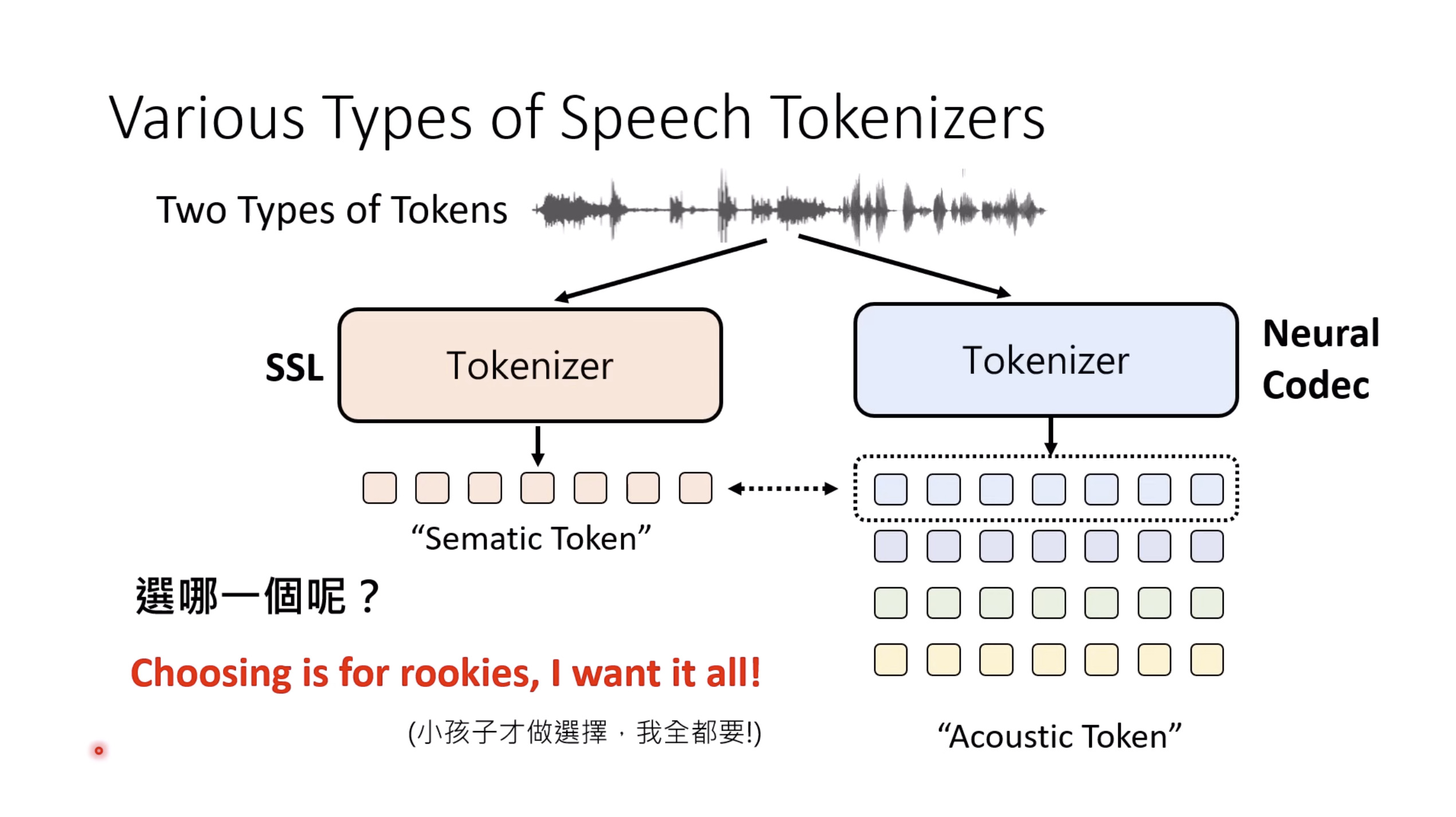
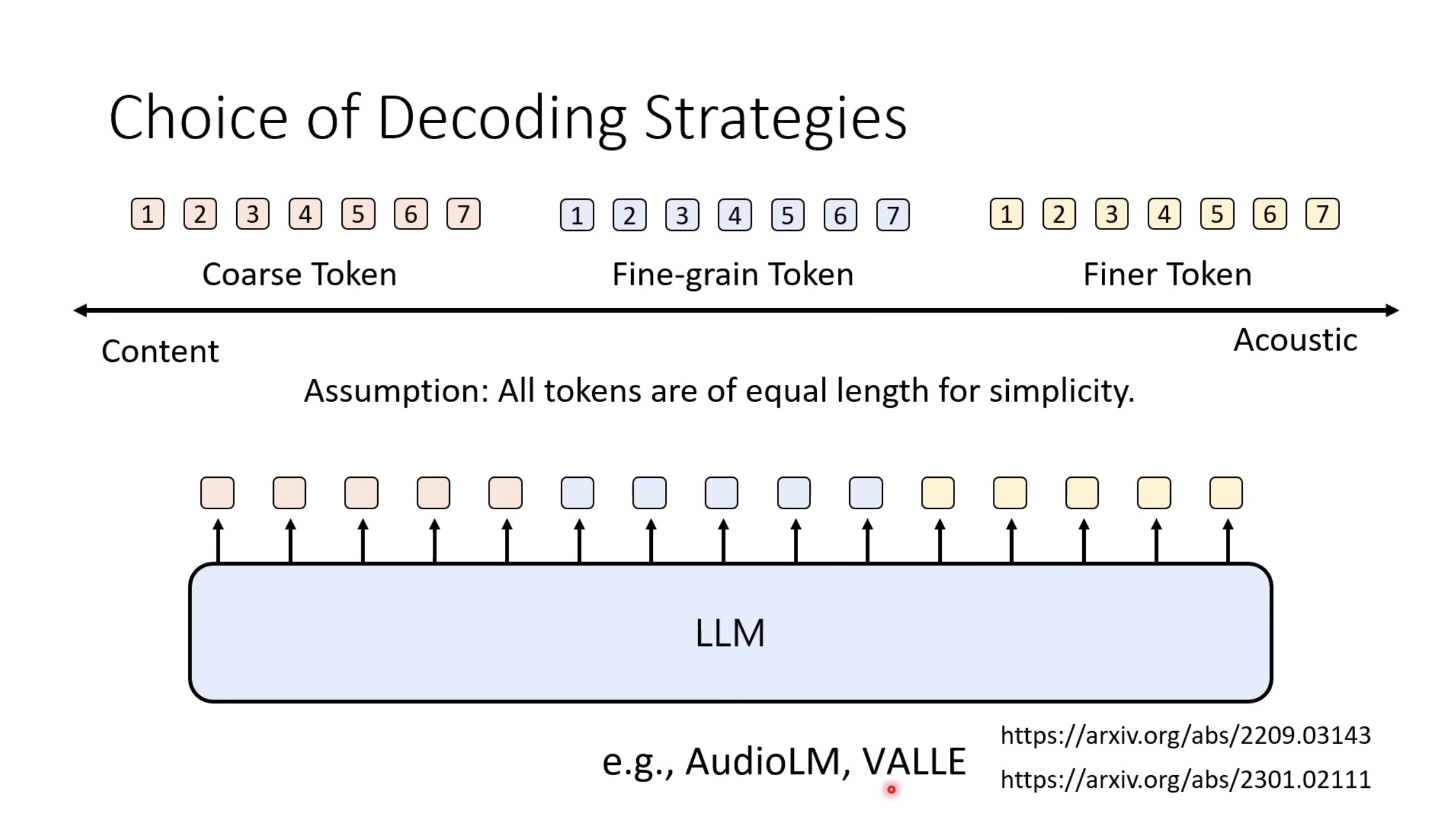
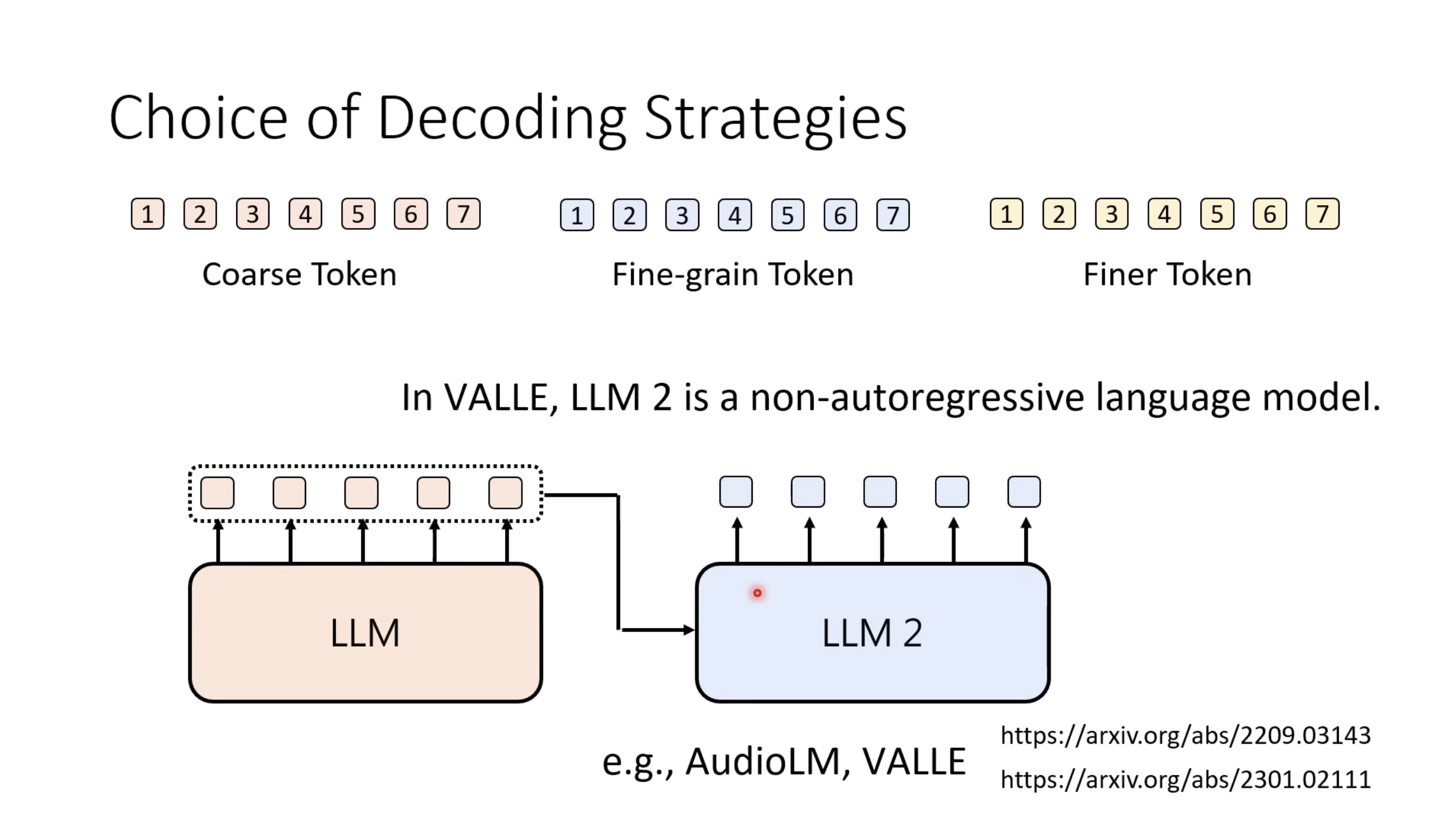
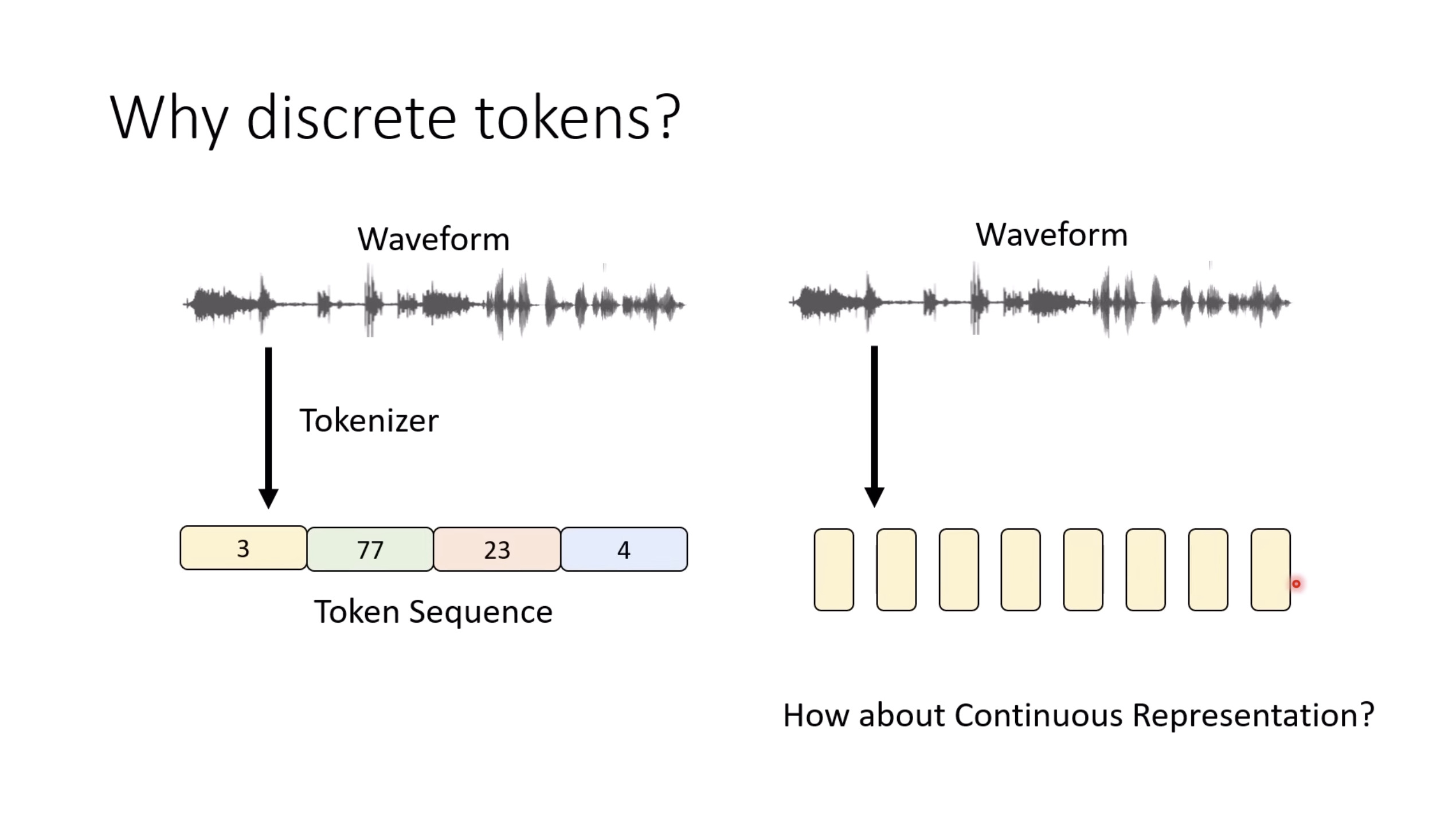
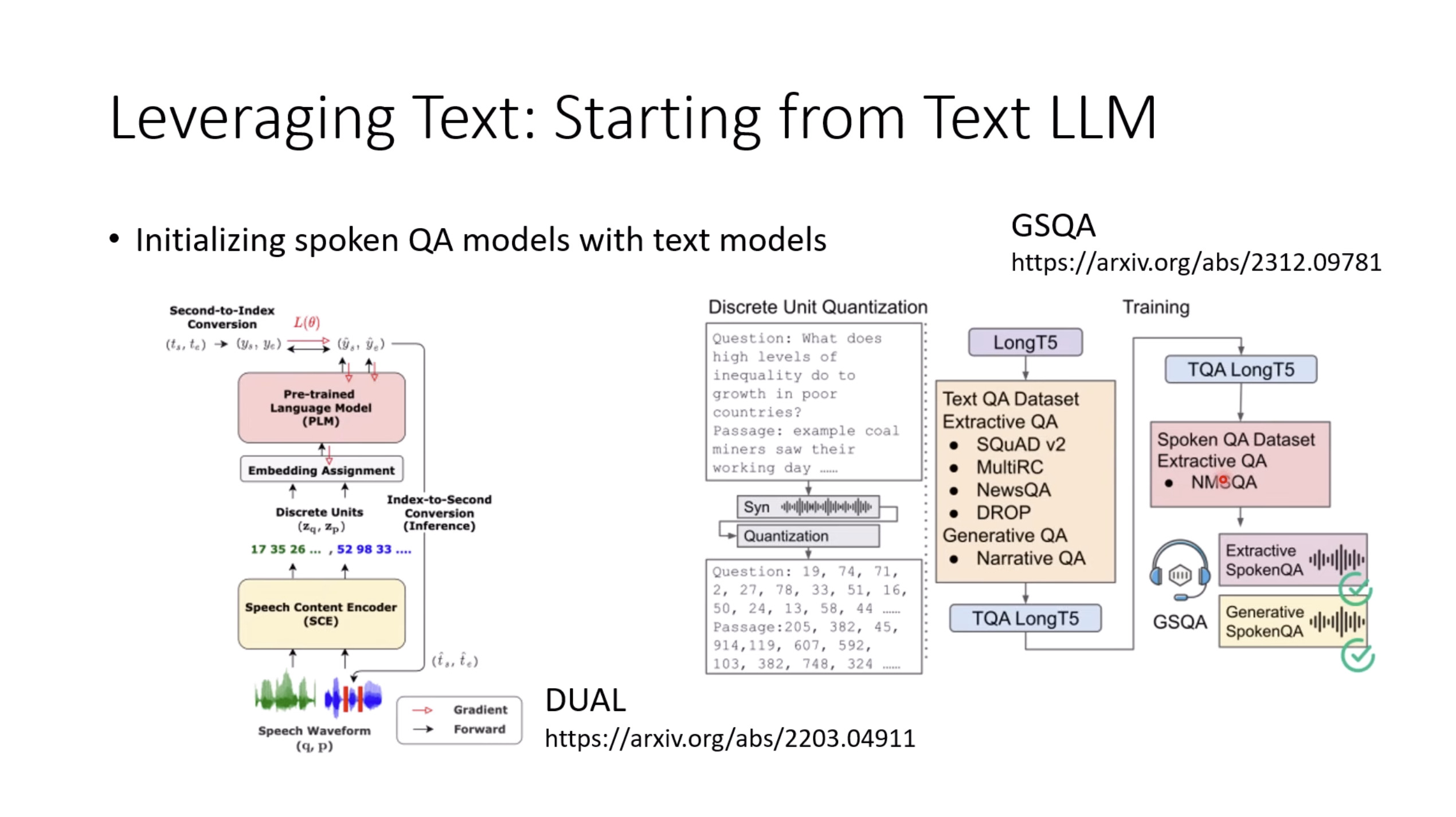
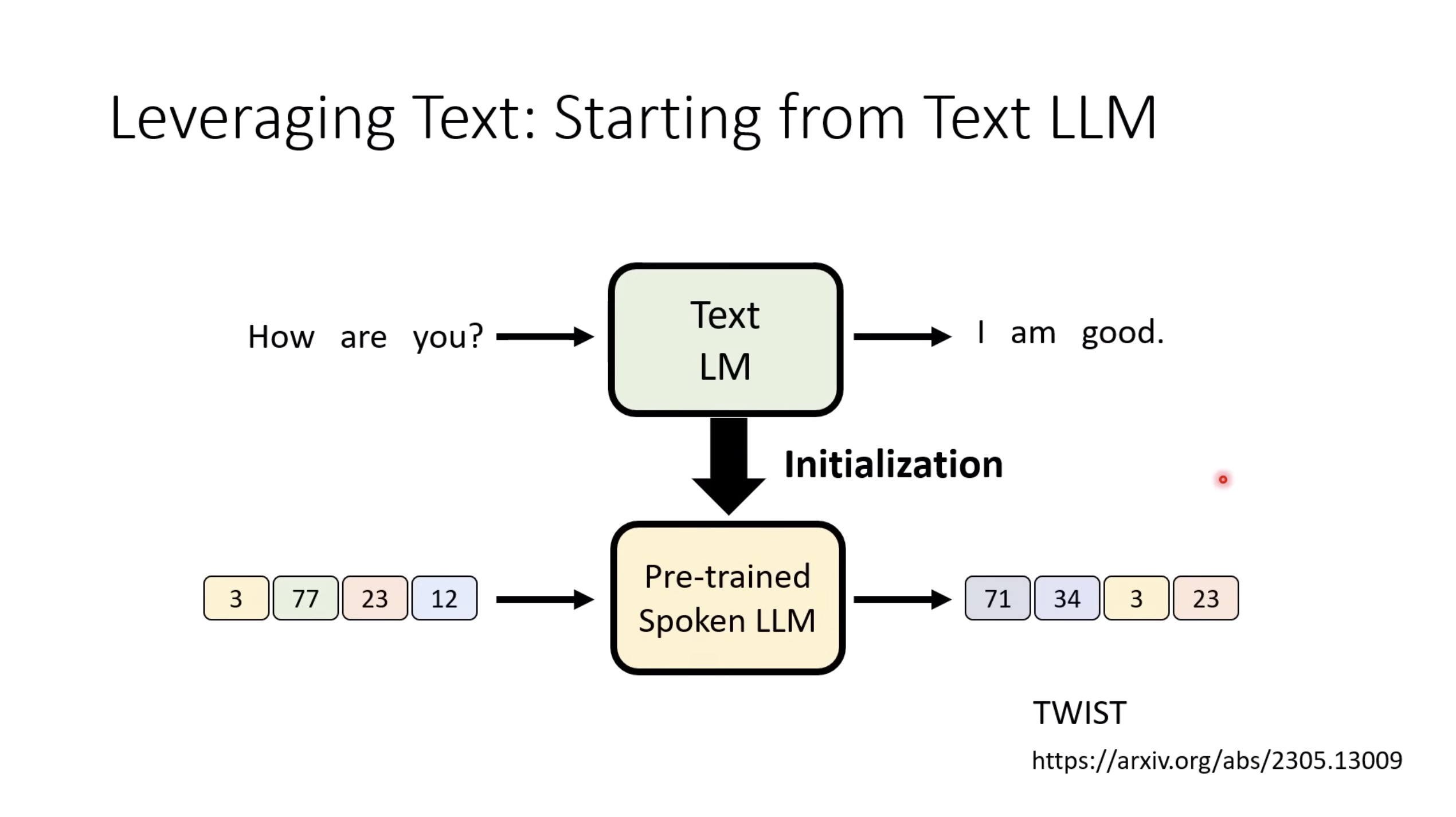
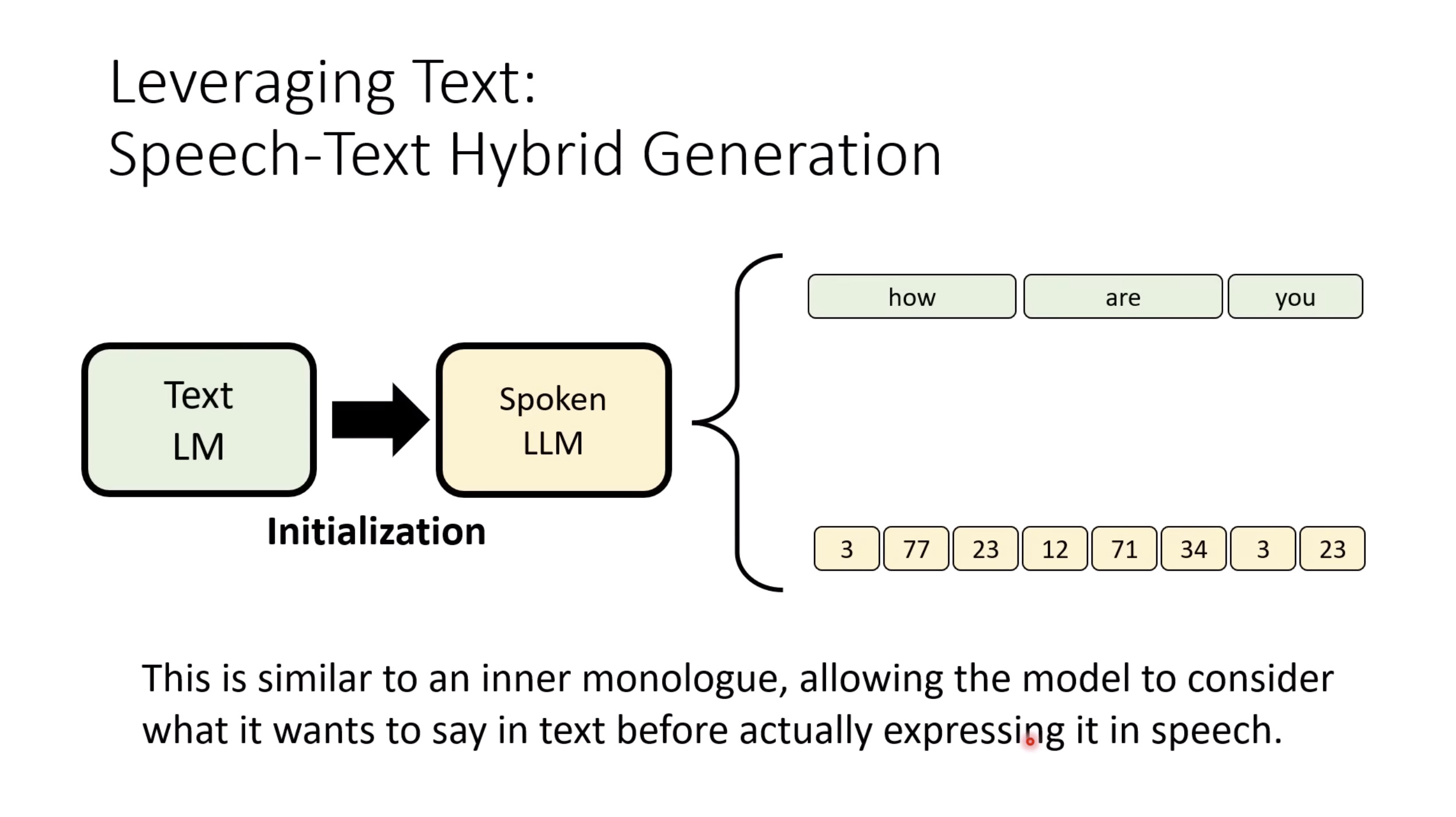
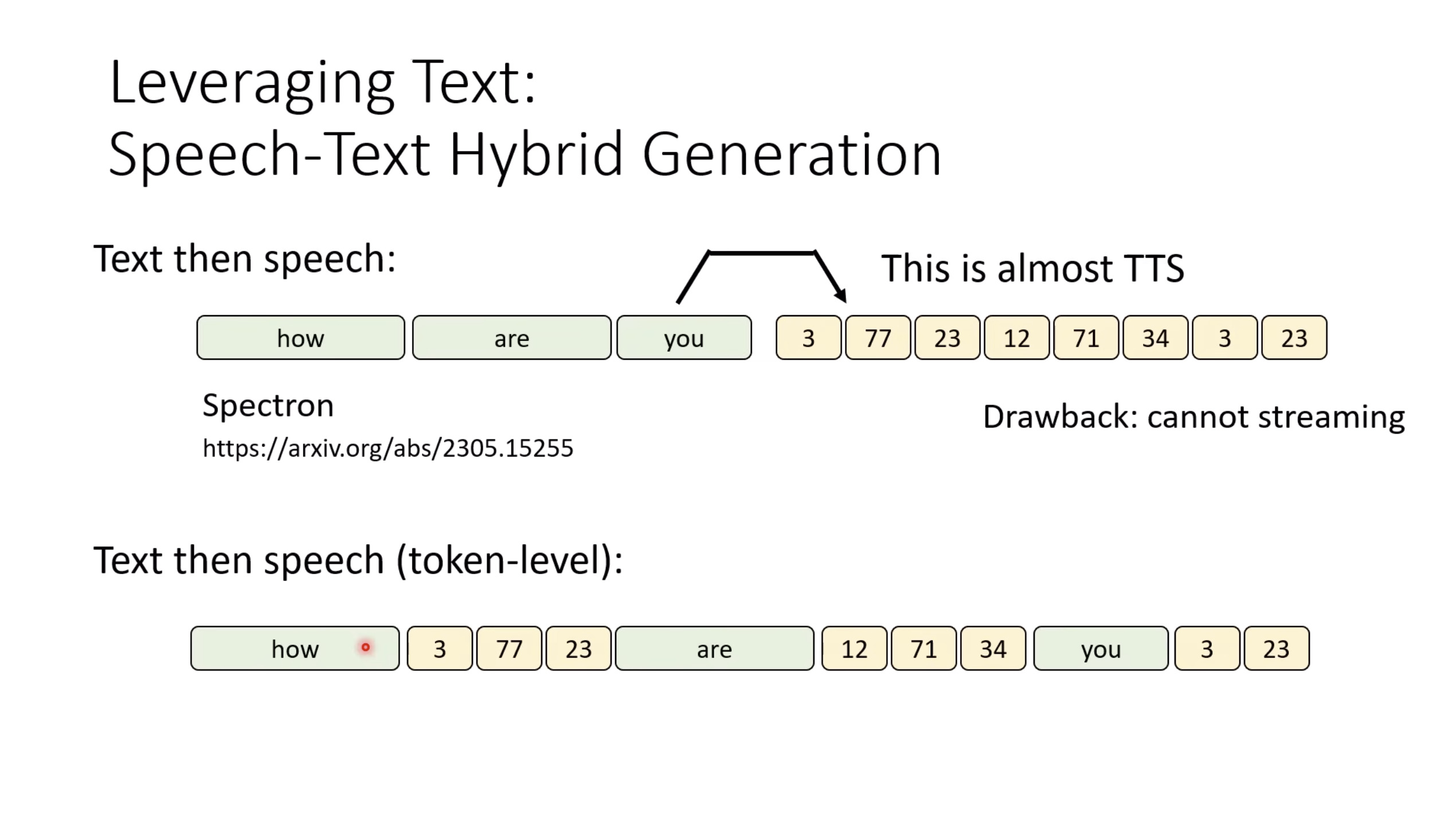
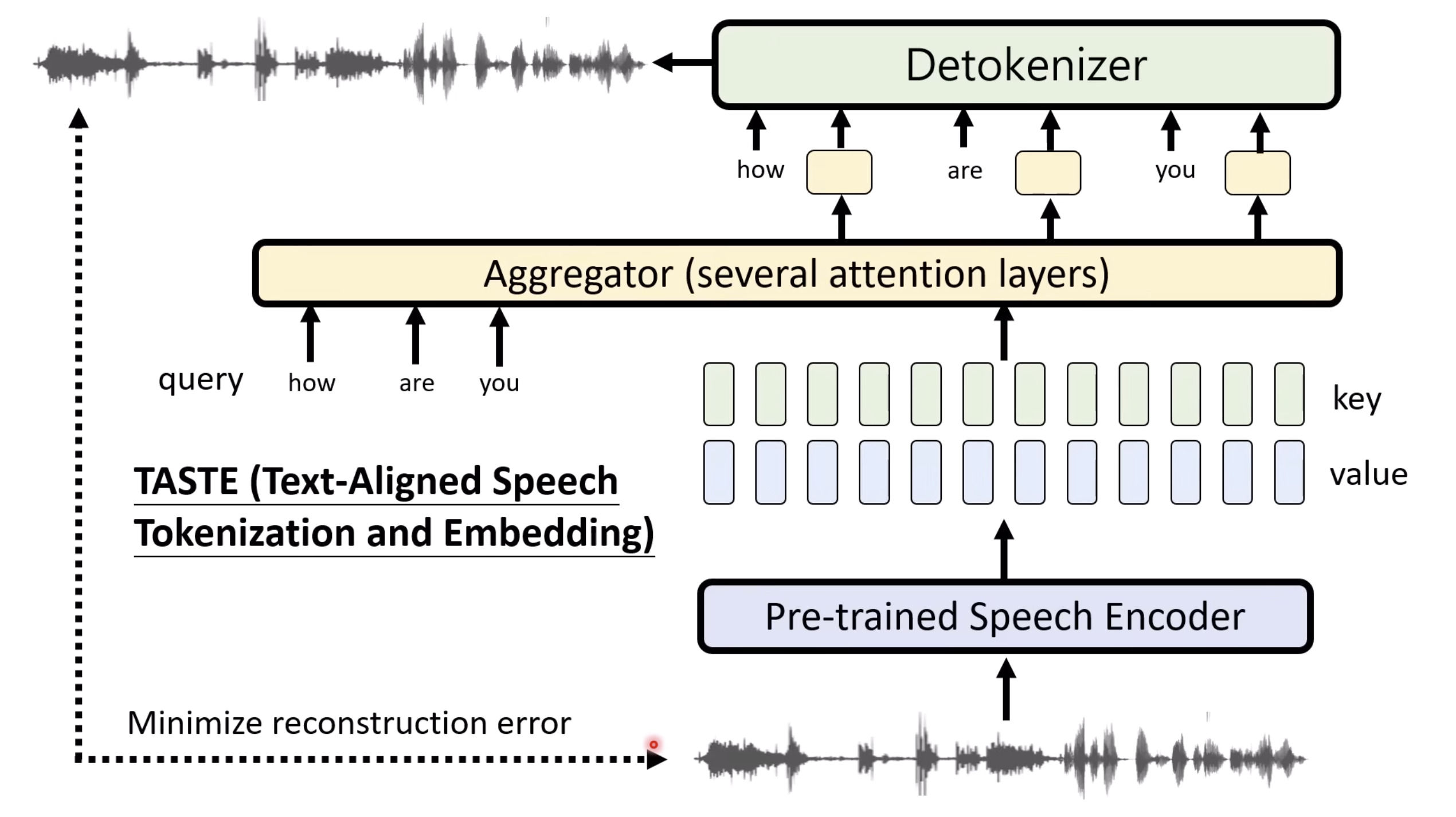
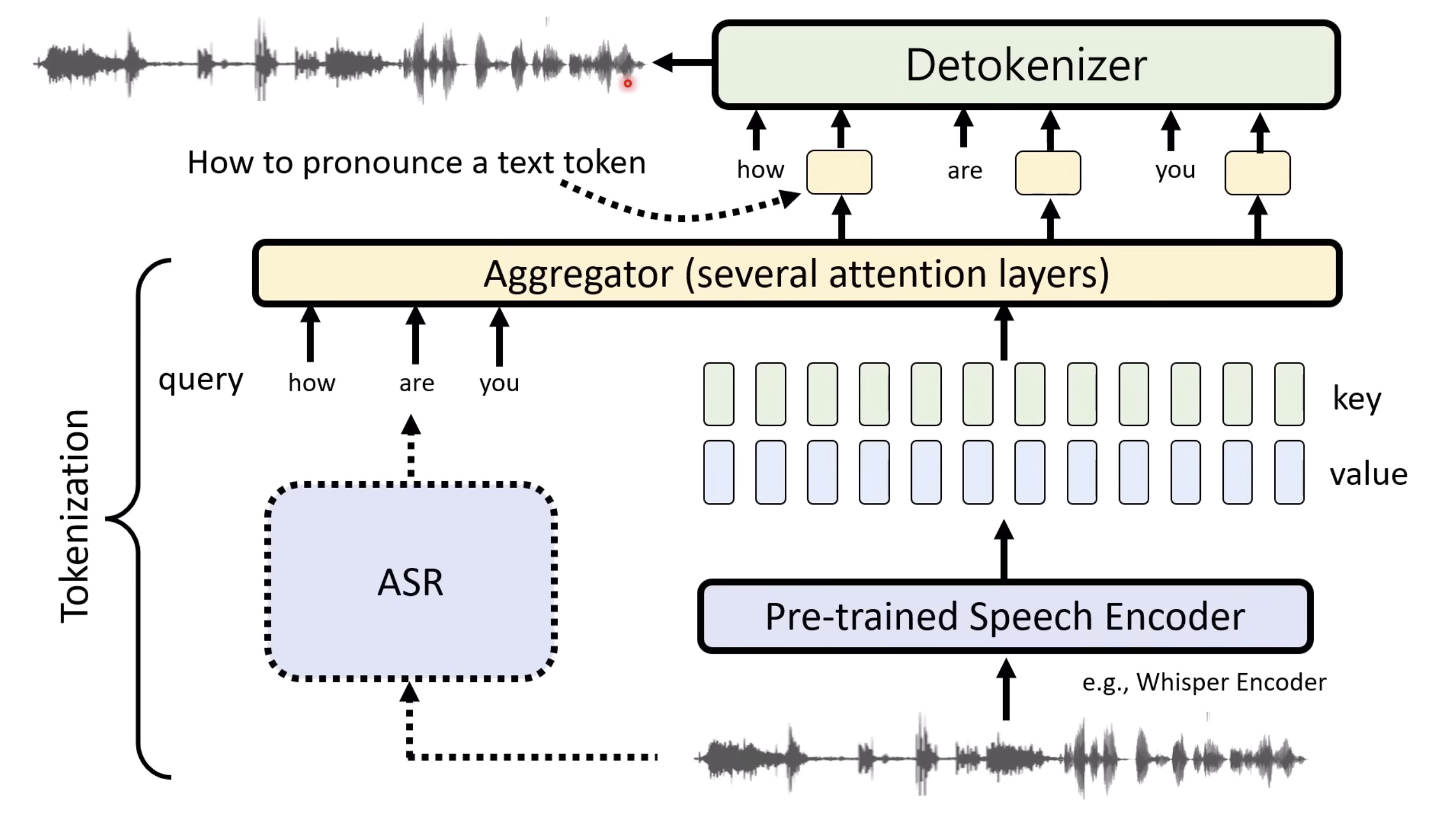
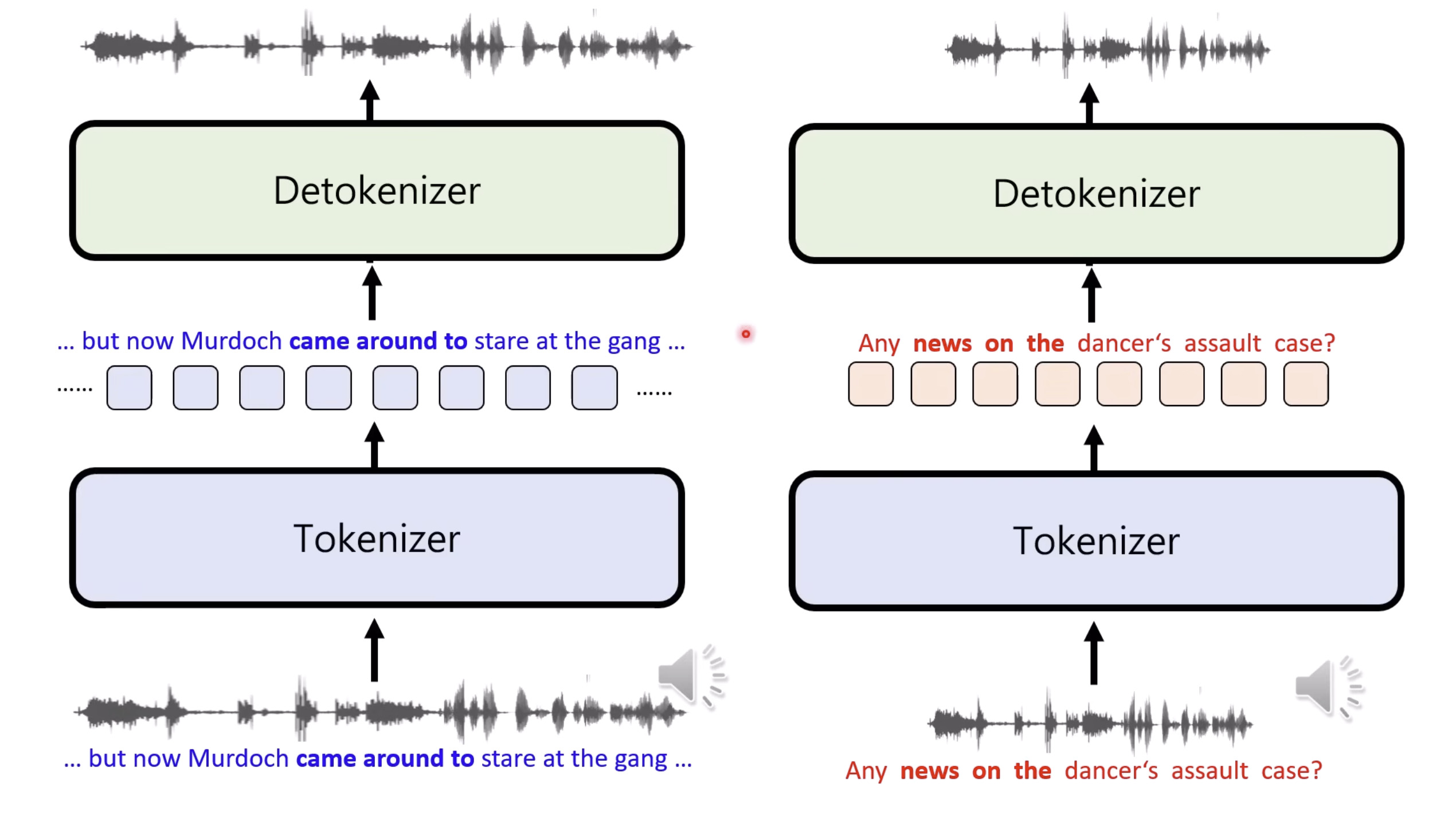
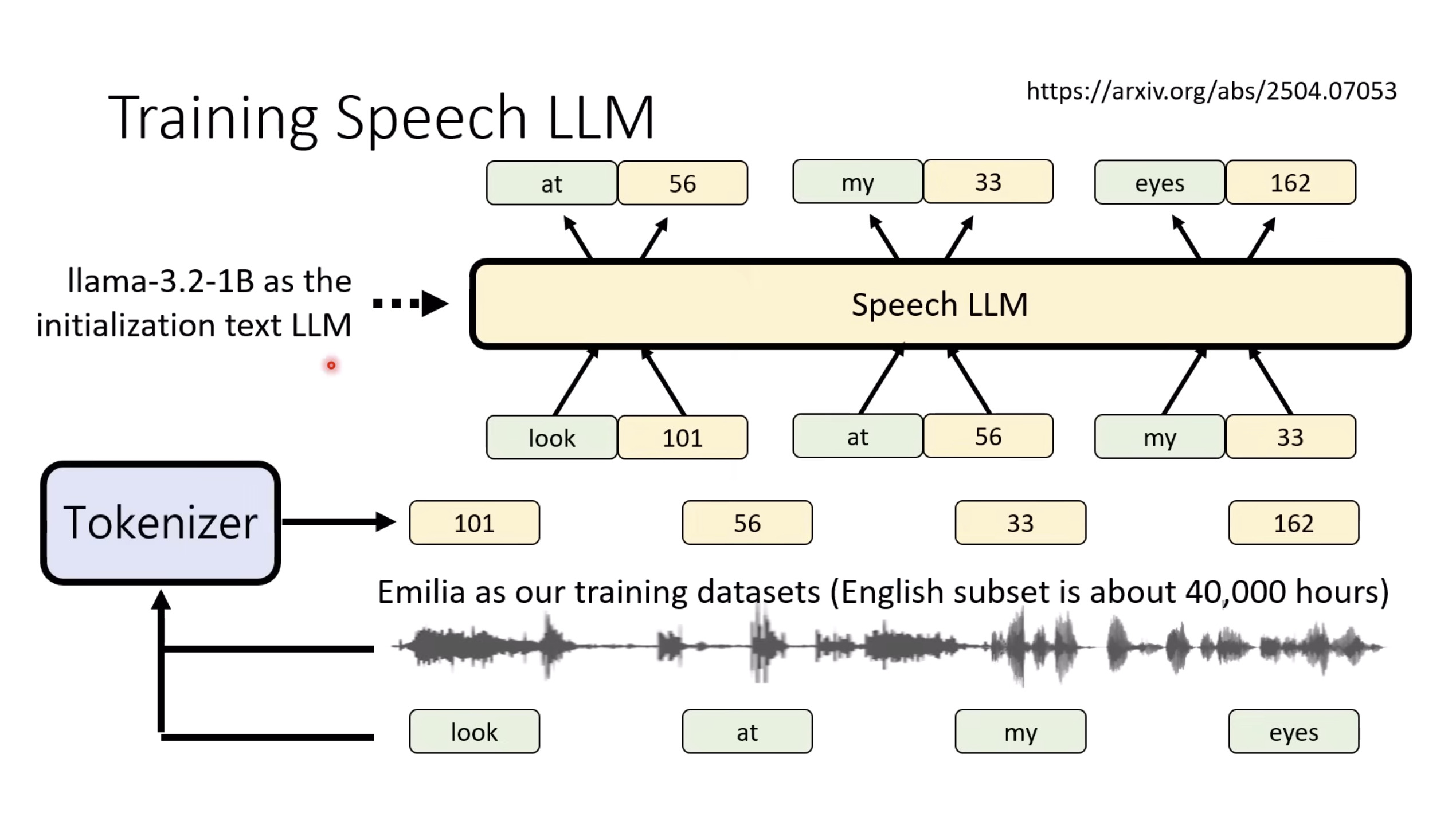
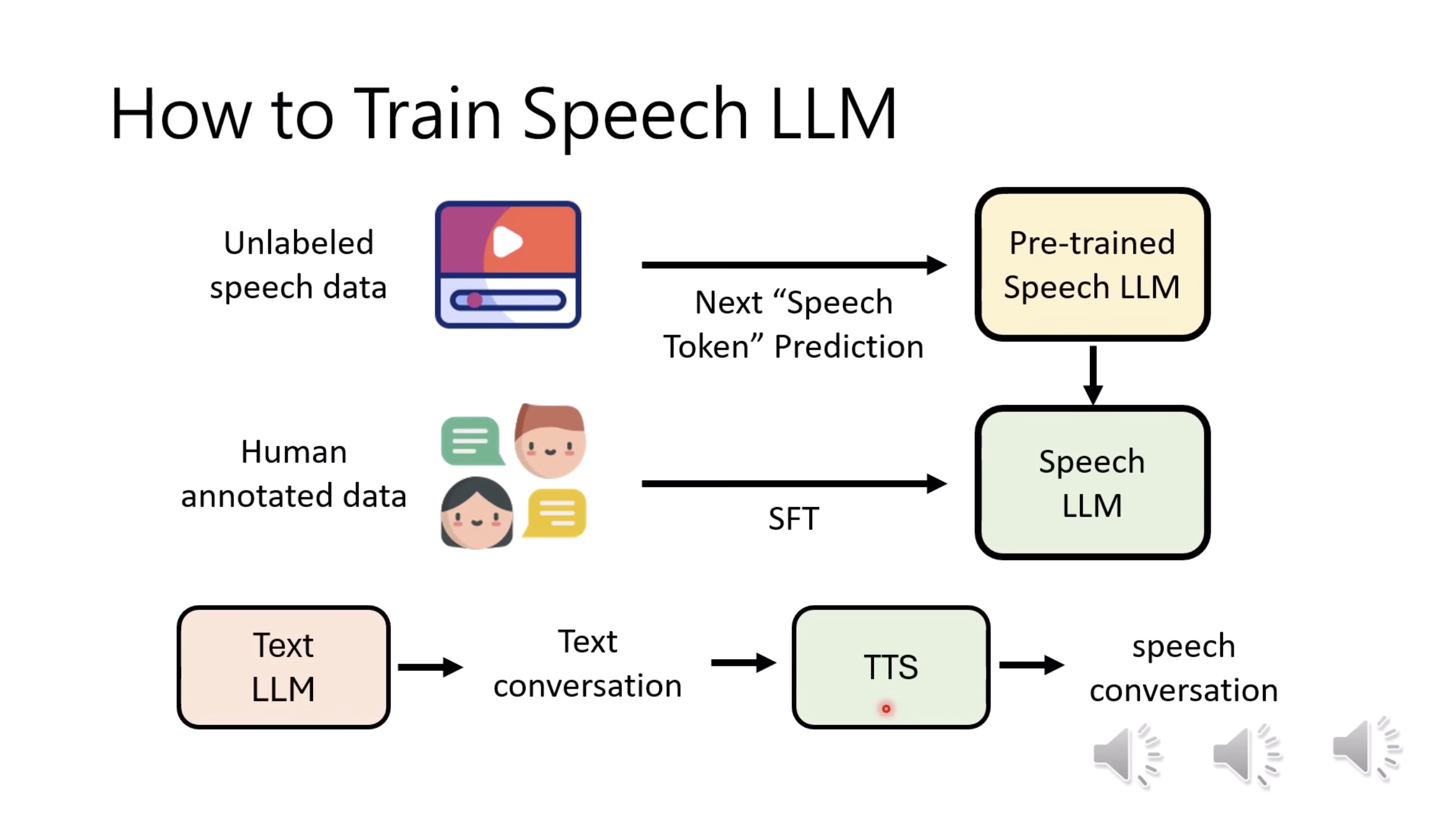
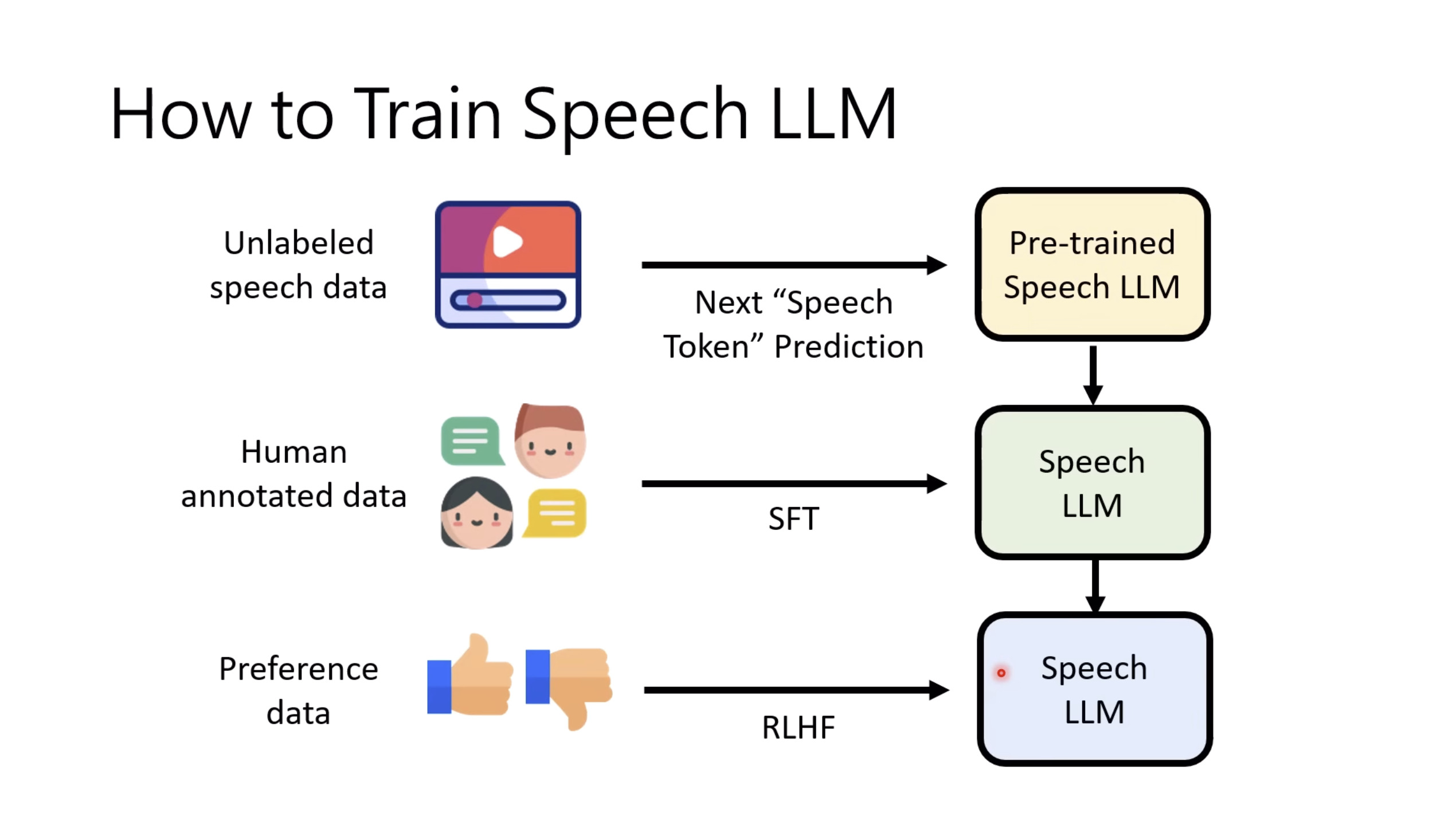
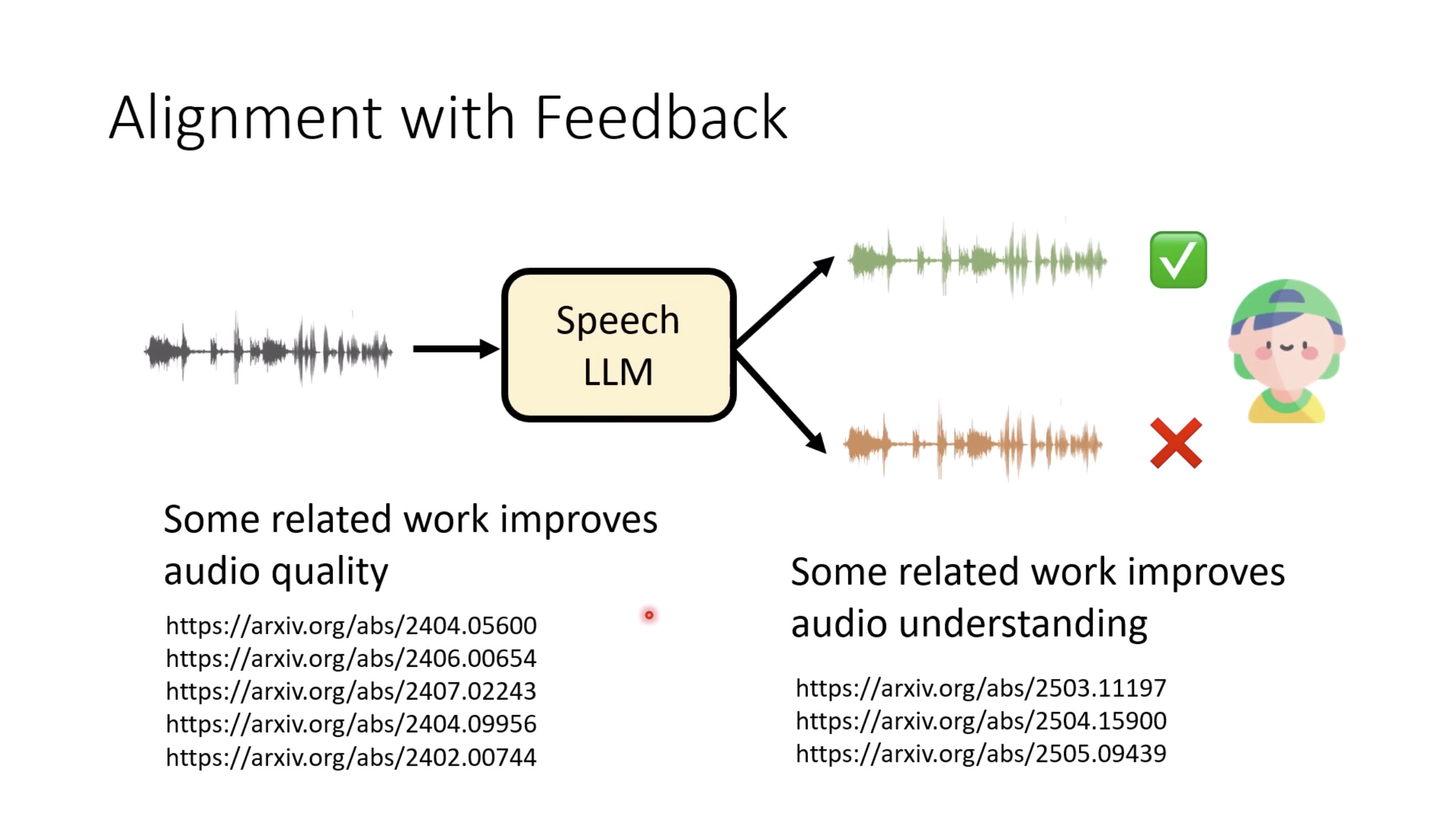
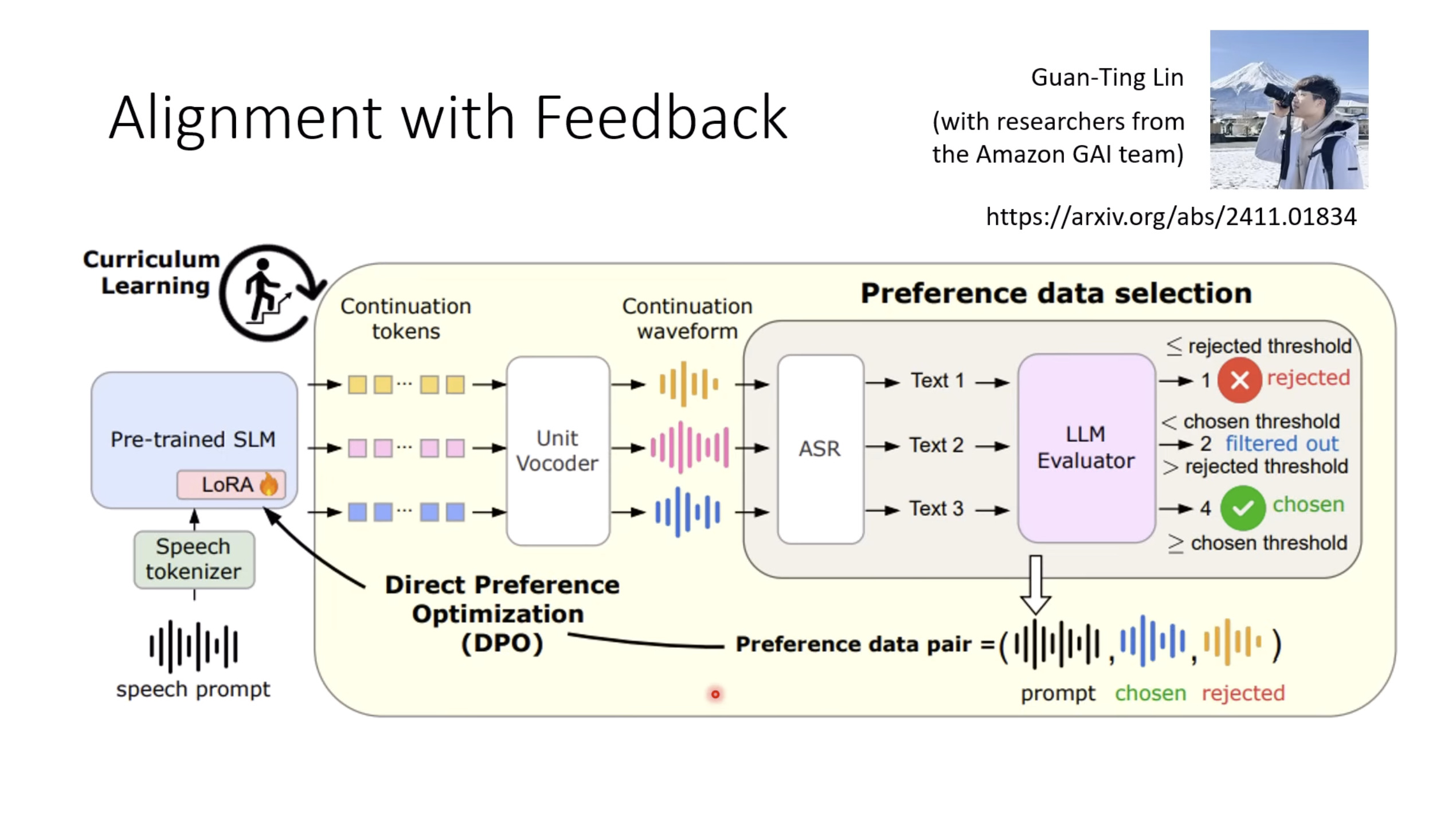
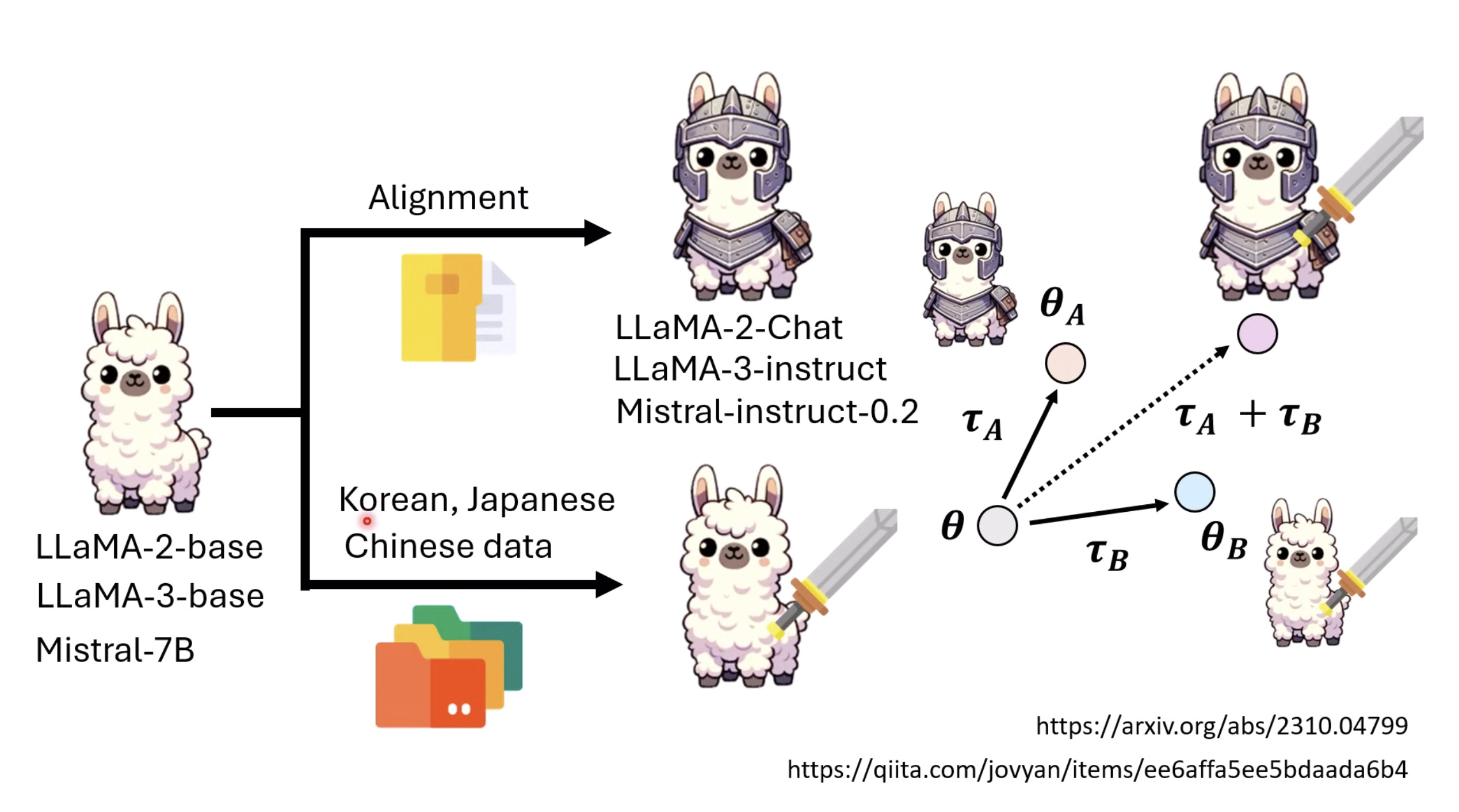
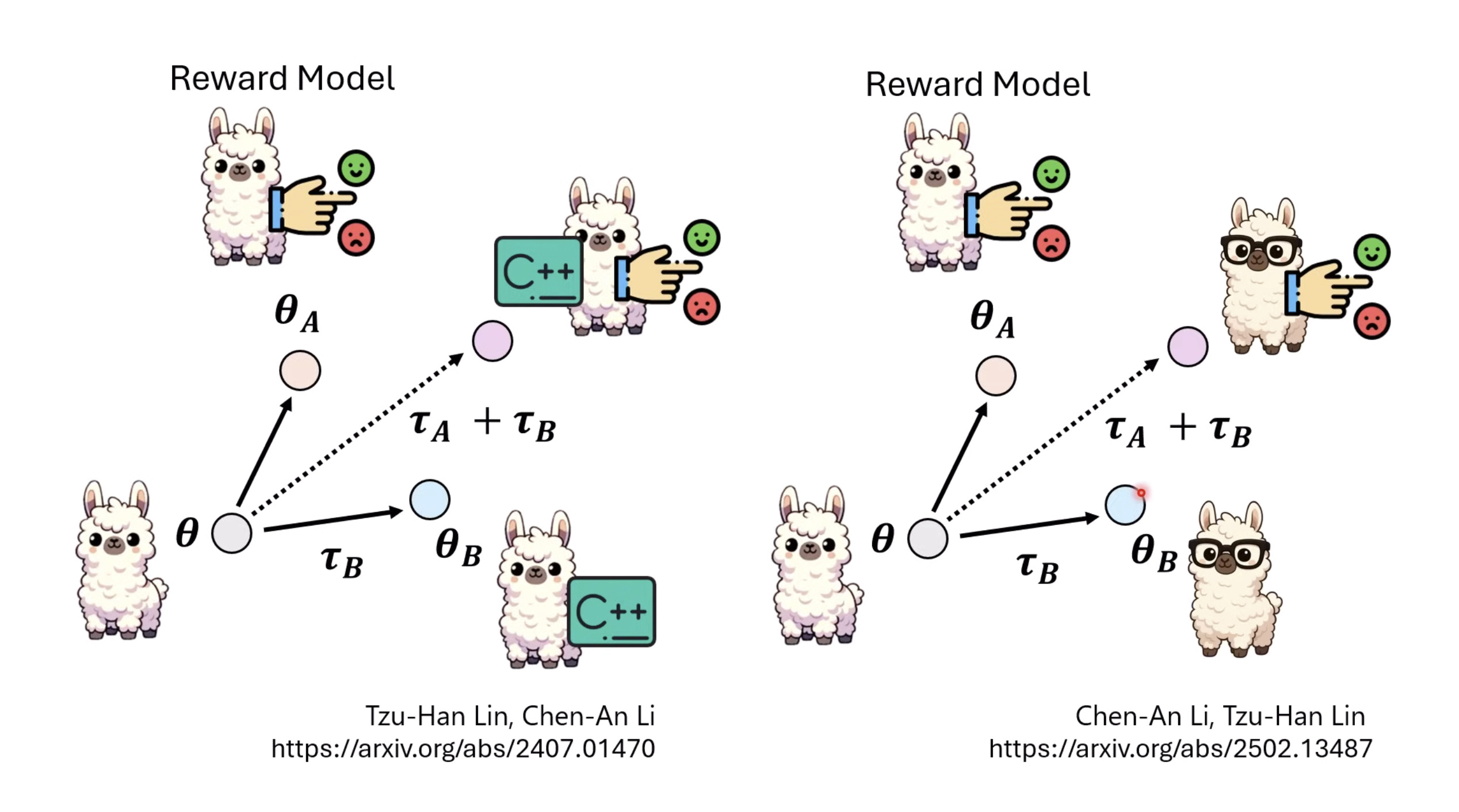
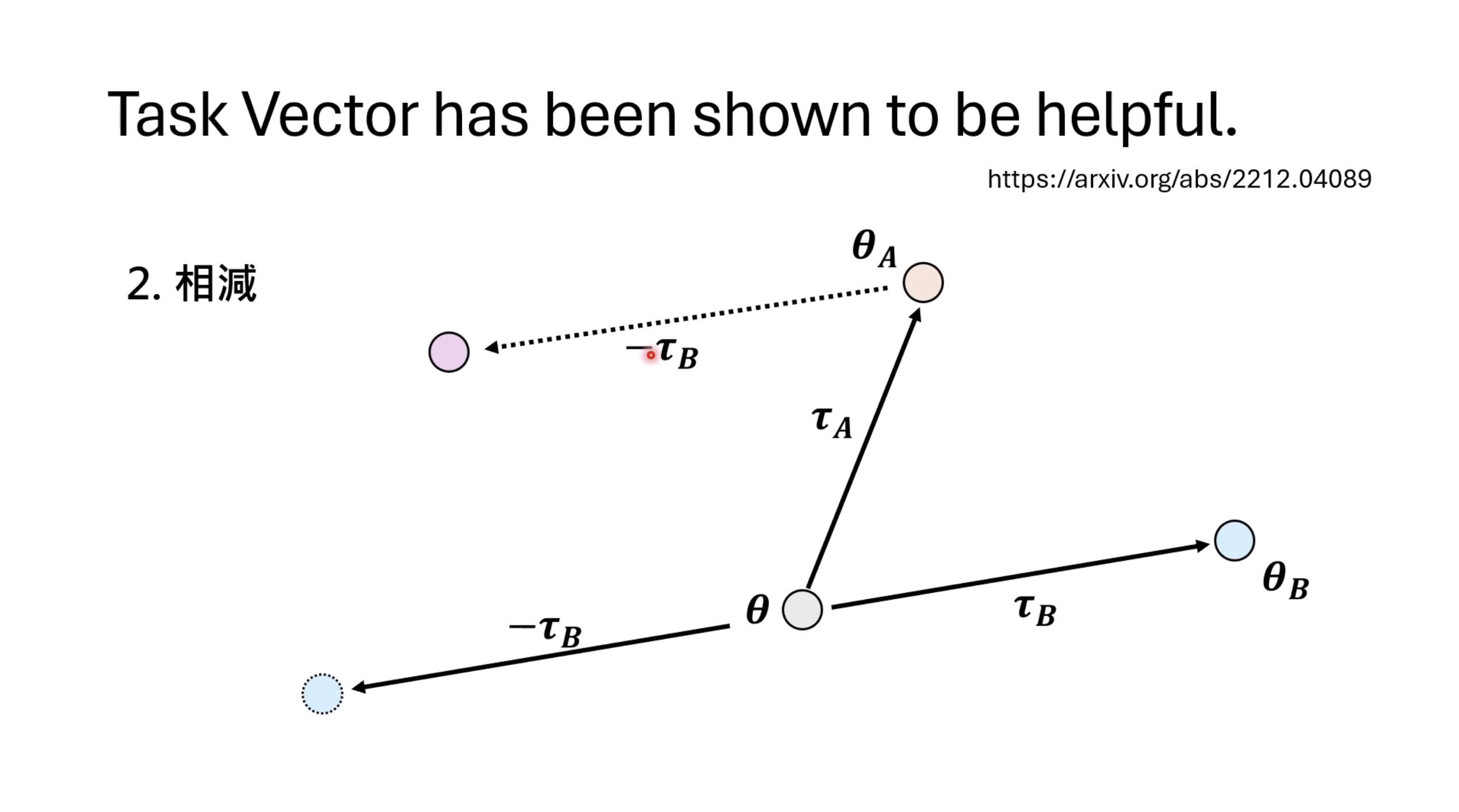
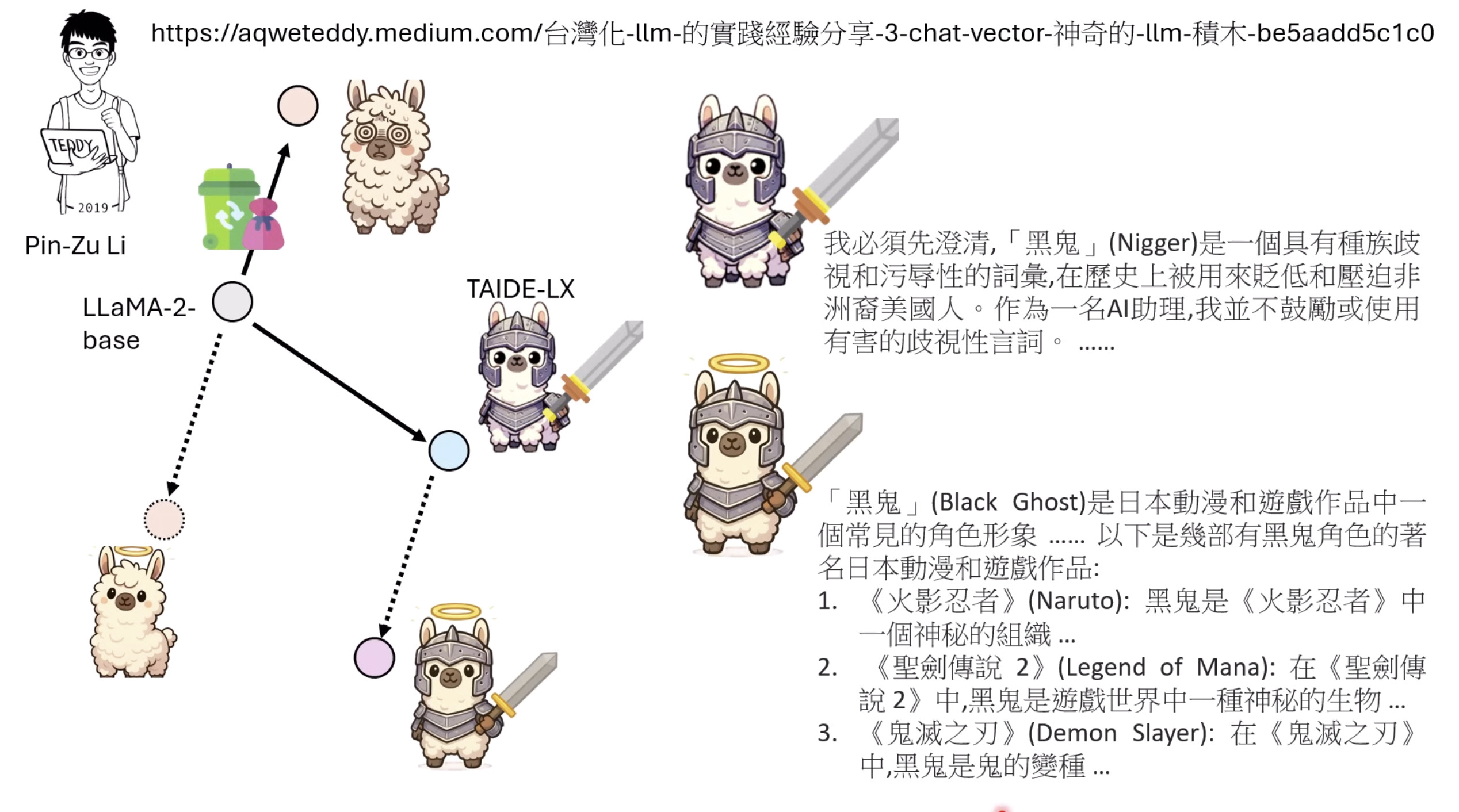
本文档提供了关于语音大型语言模型 (Speech LLM) 的全面概述。内容从语音标记化 (speech tokenization) 的基本概念开始,这是一种将连续语音信号转换为离散单元的方法。文中还讨论了各种语音标记器类型 (types of speech tokenizers),包括 SSL 和神经编码器,并探讨了不同的解码策略 (decoding strategies) 对生成质量的影响。此外,还深入分析了训练语音 LLM 的方法 (methods for training Speech LLM),包括如何利用文本 LLM (Text LLM) 作为基础模型,并通过反馈对齐 (alignment with feedback) 优化模型。最后,概述还触及了全双工语音对话 (full-duplex speech conversation) 等前沿应用,并提供了评估语音模型 (evaluating speech models) 的框架。