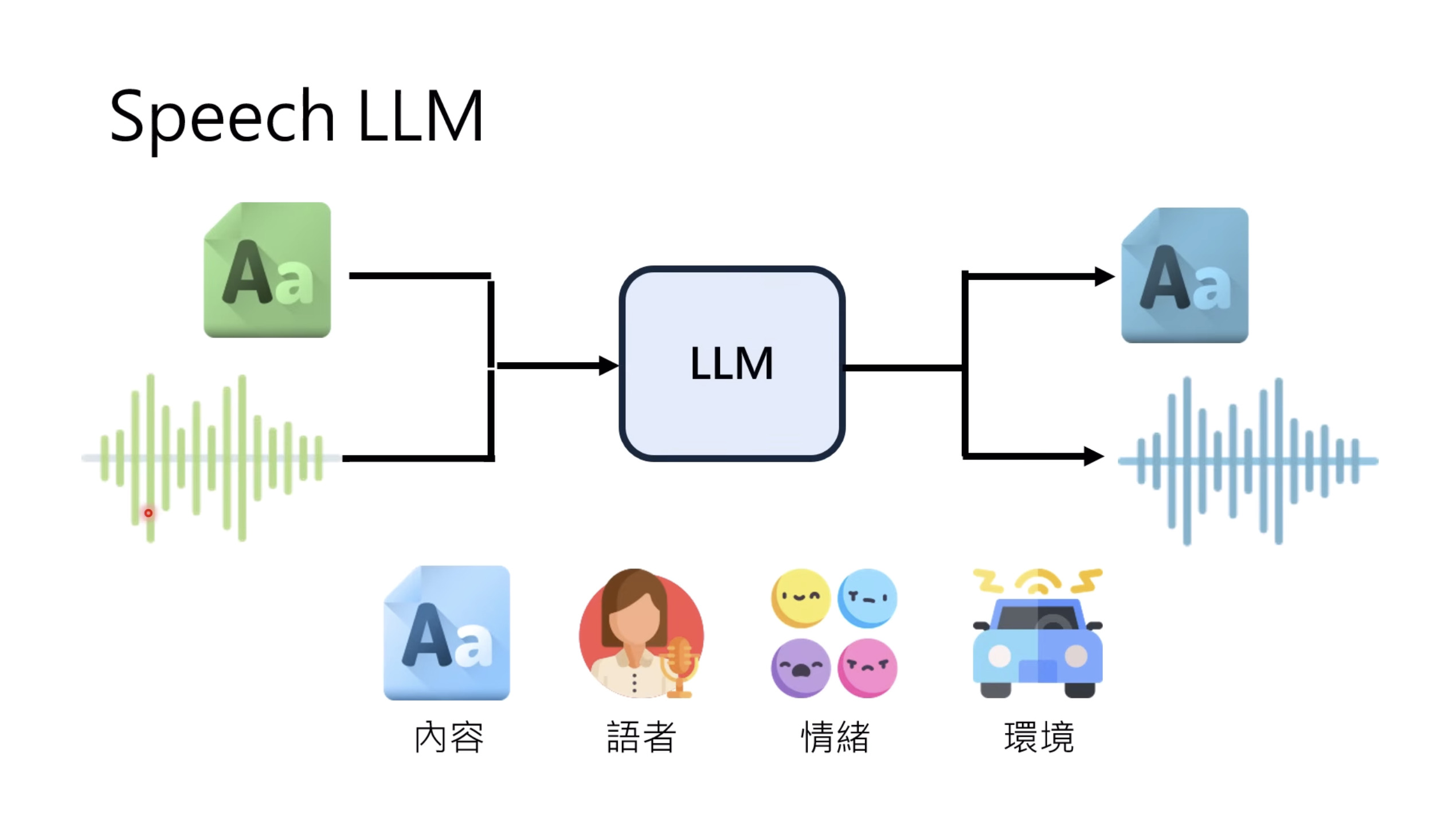
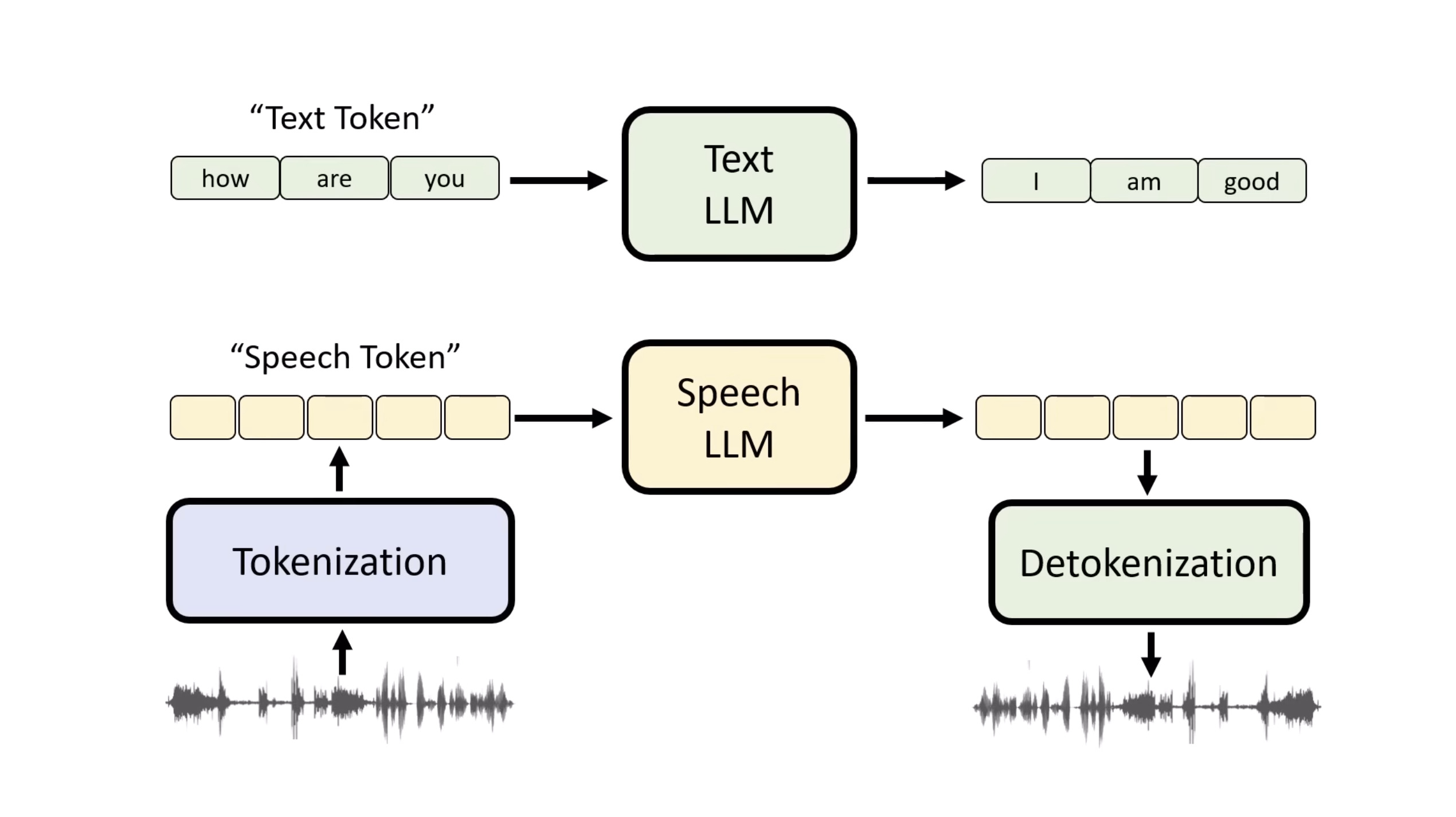
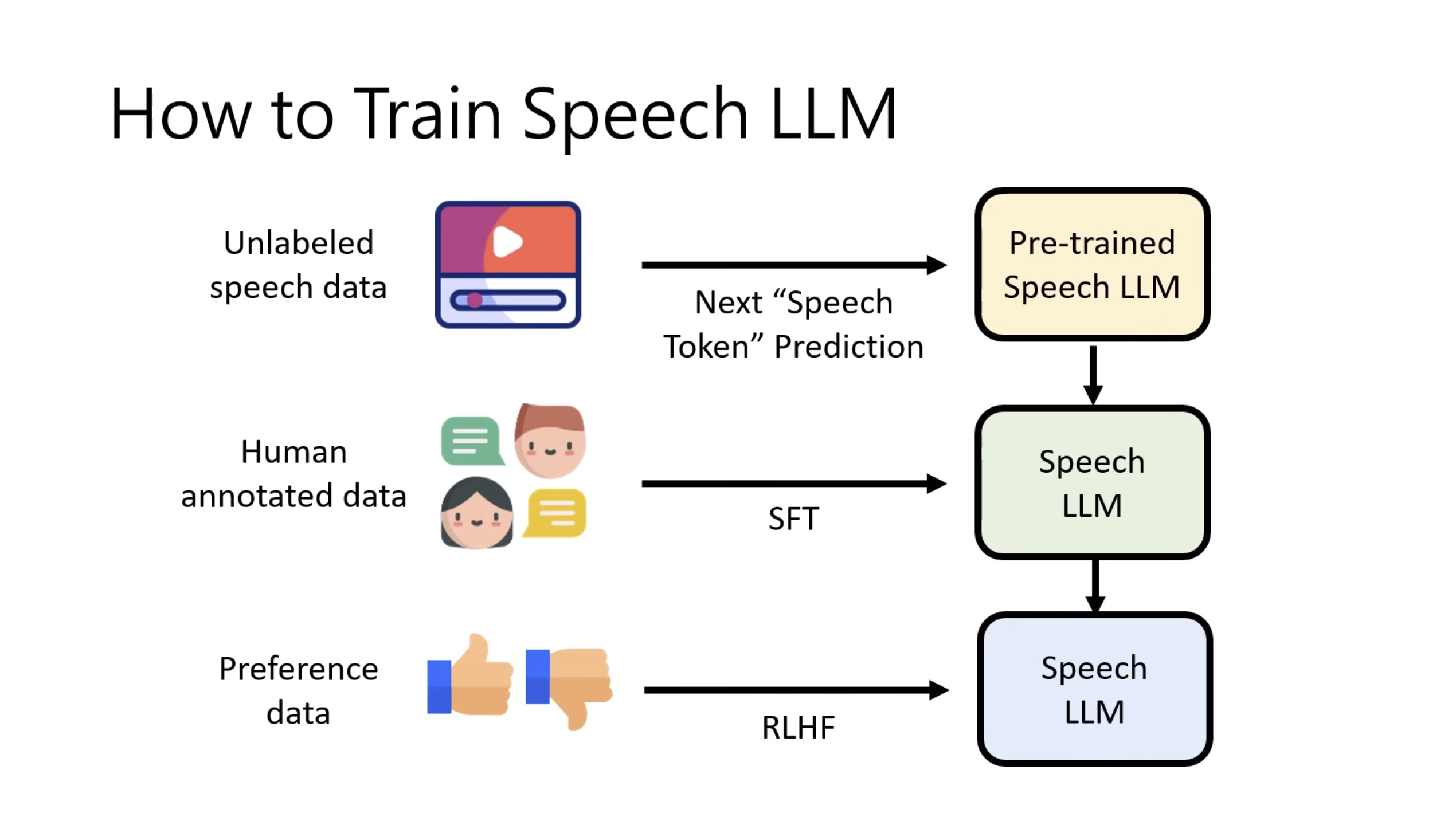
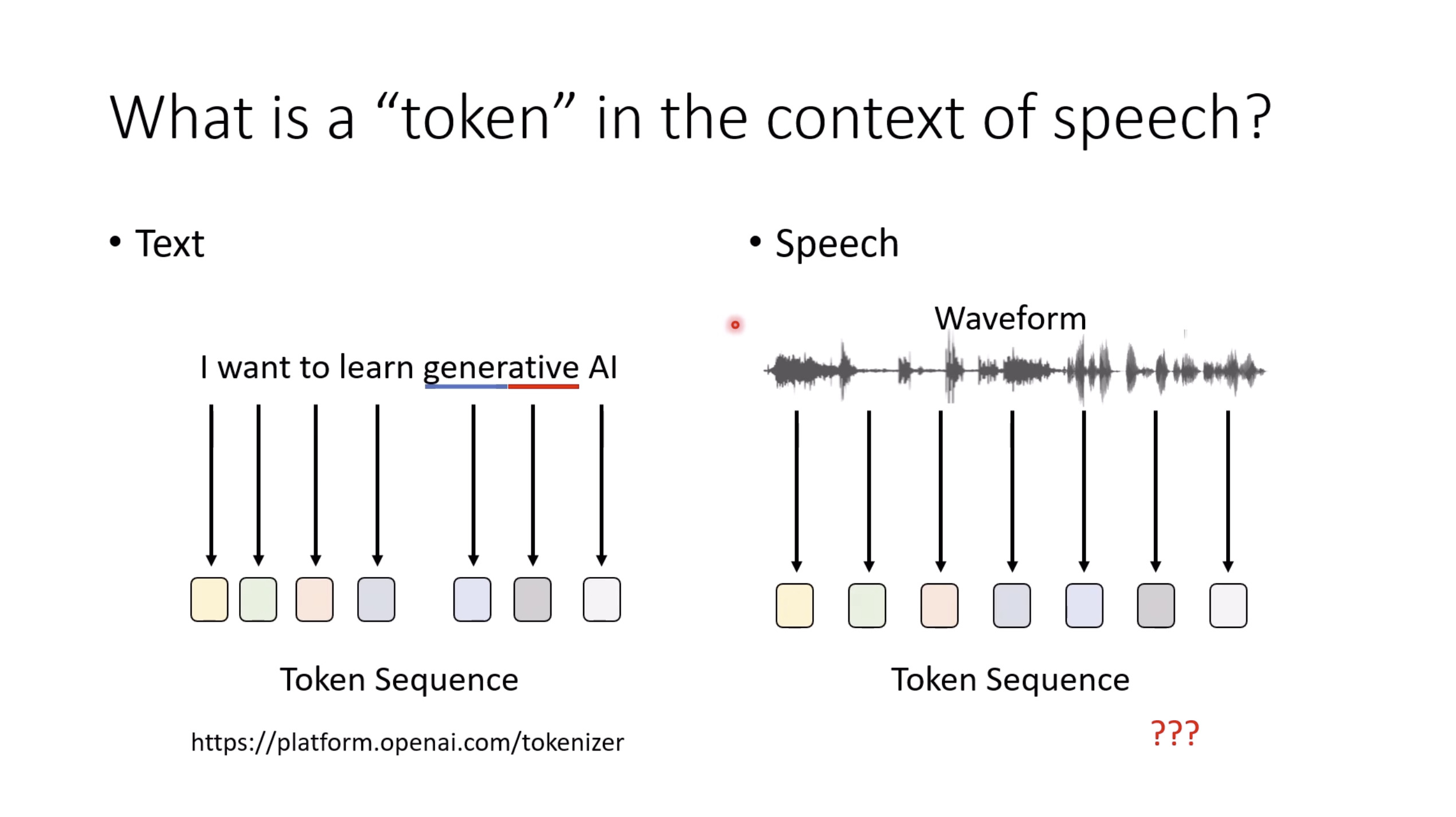
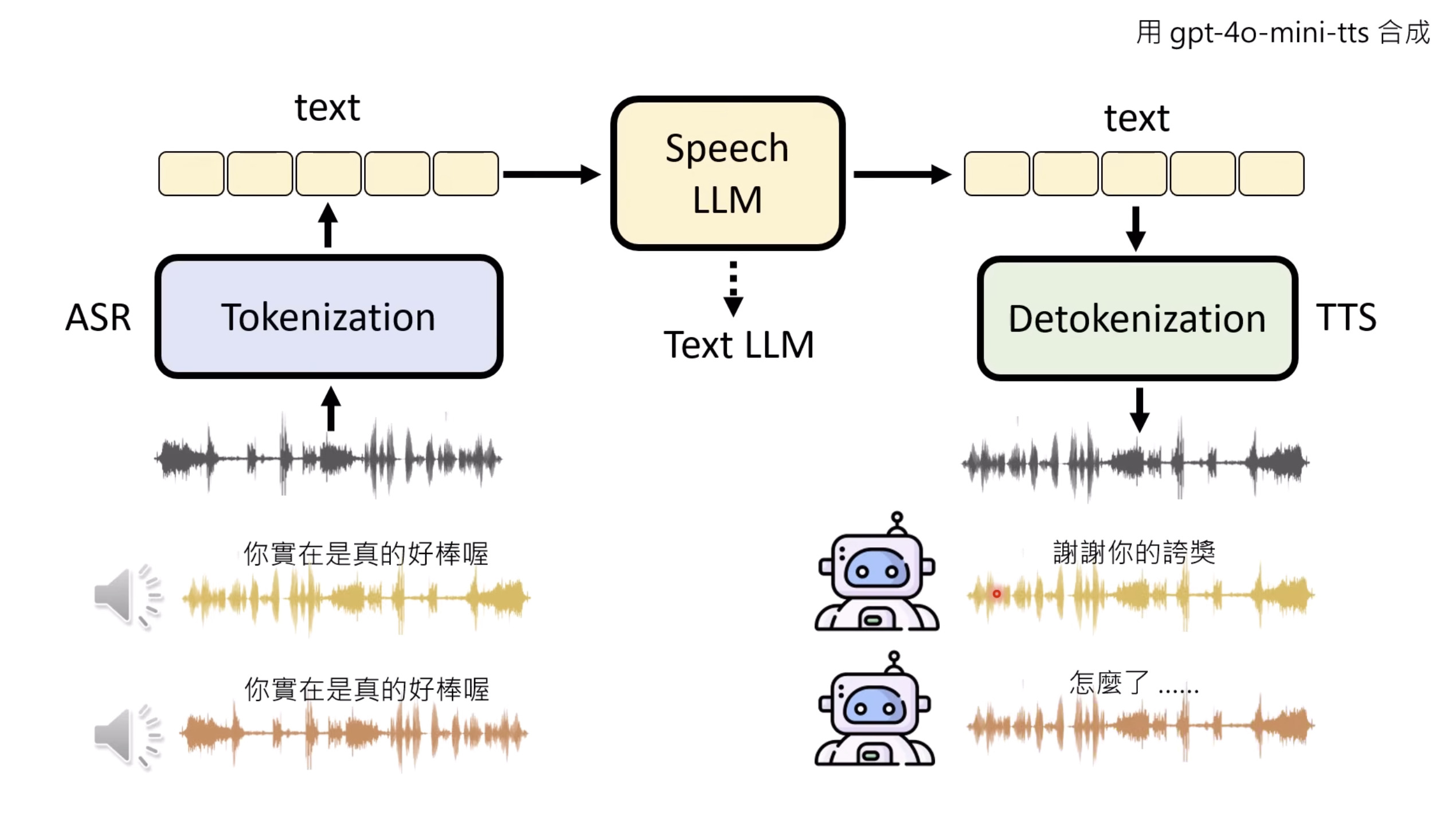
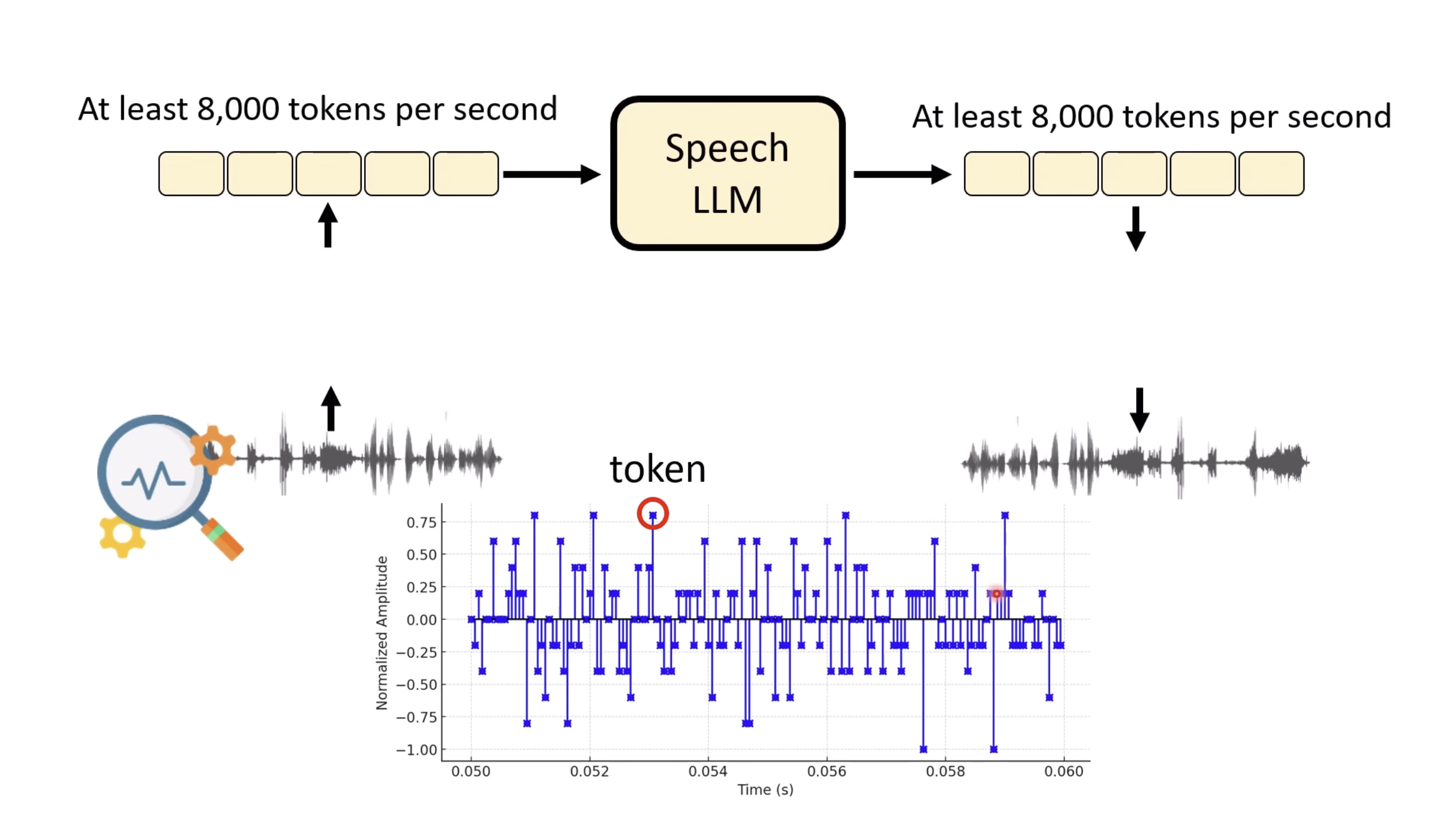
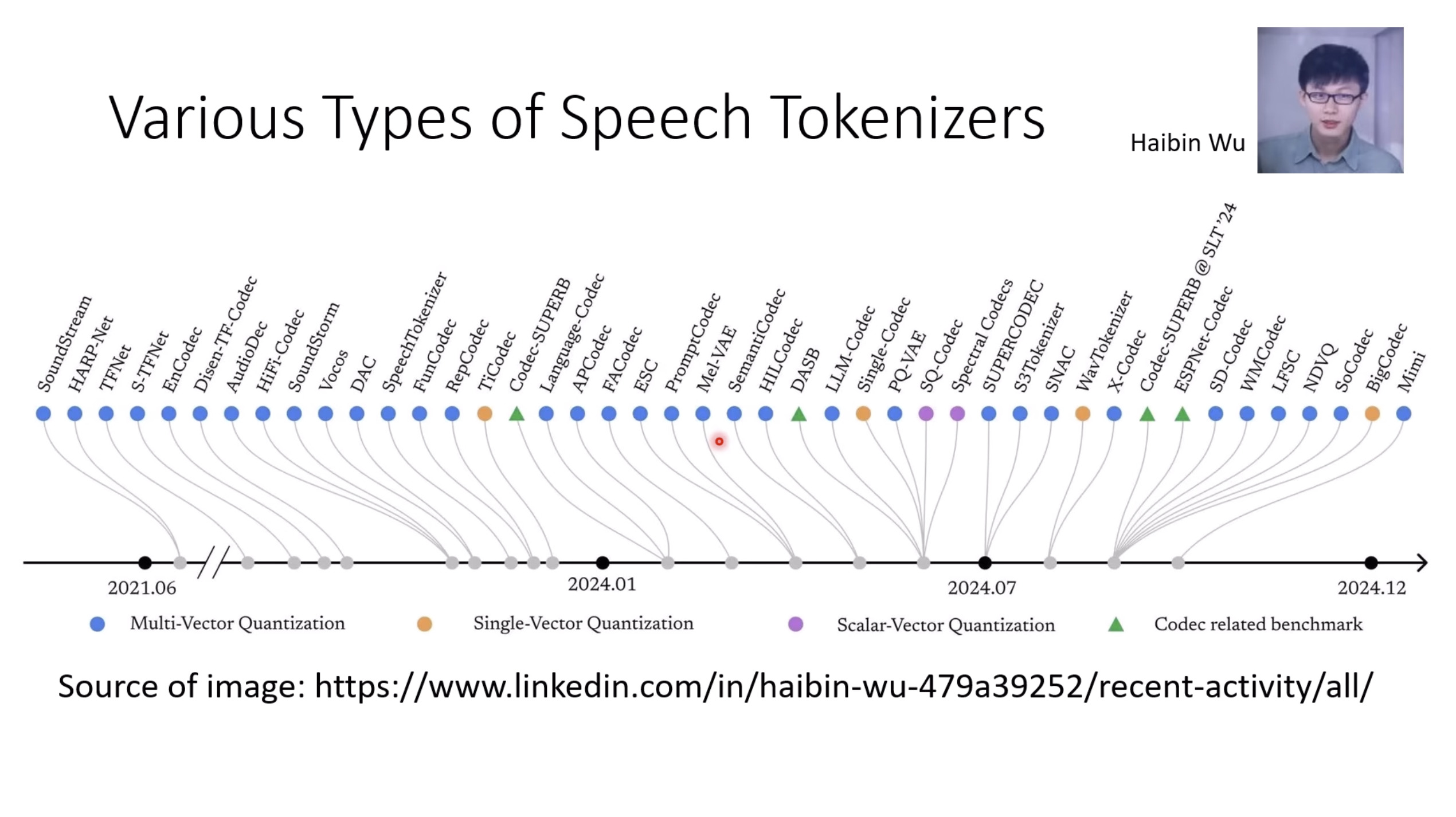
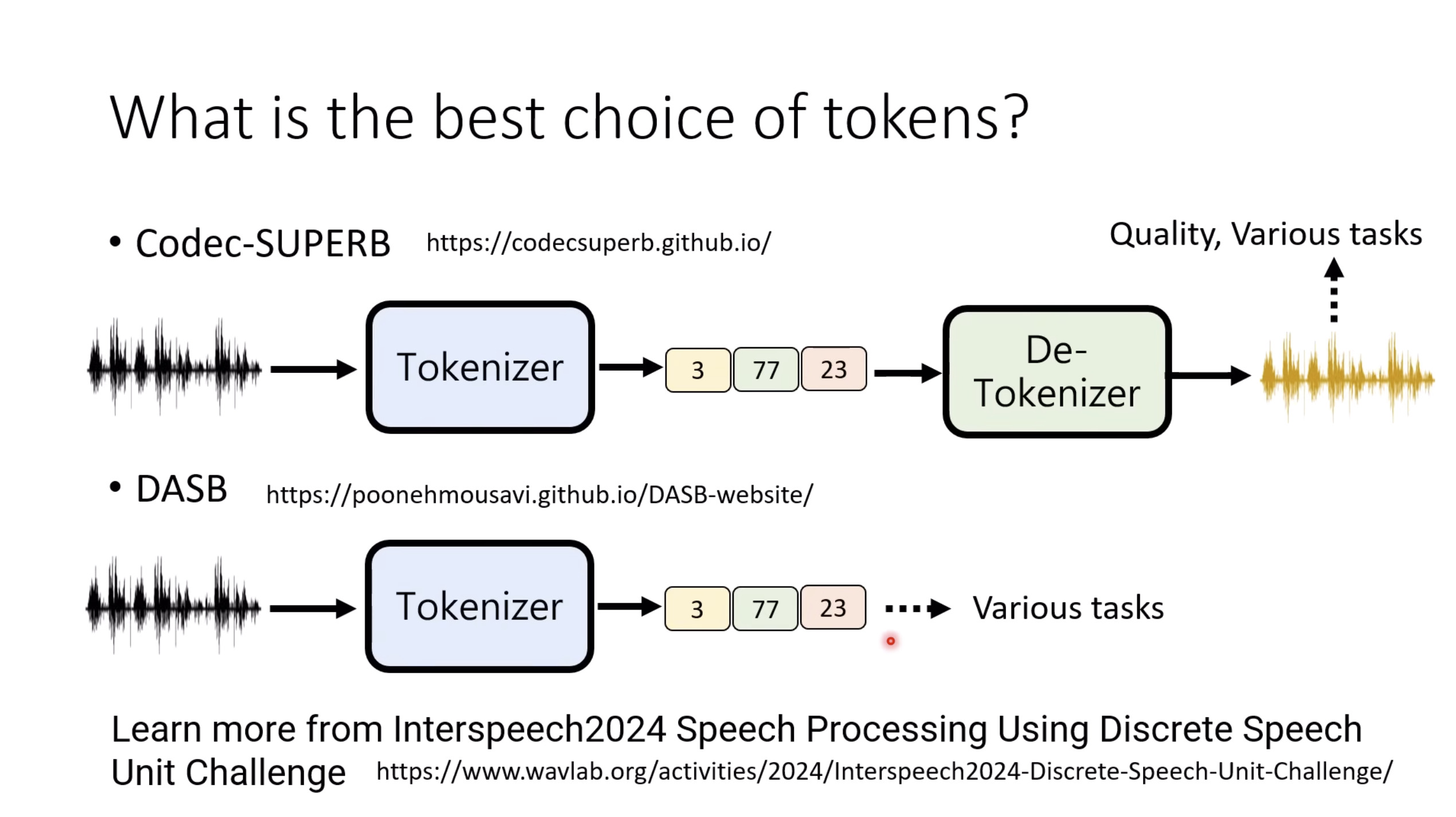
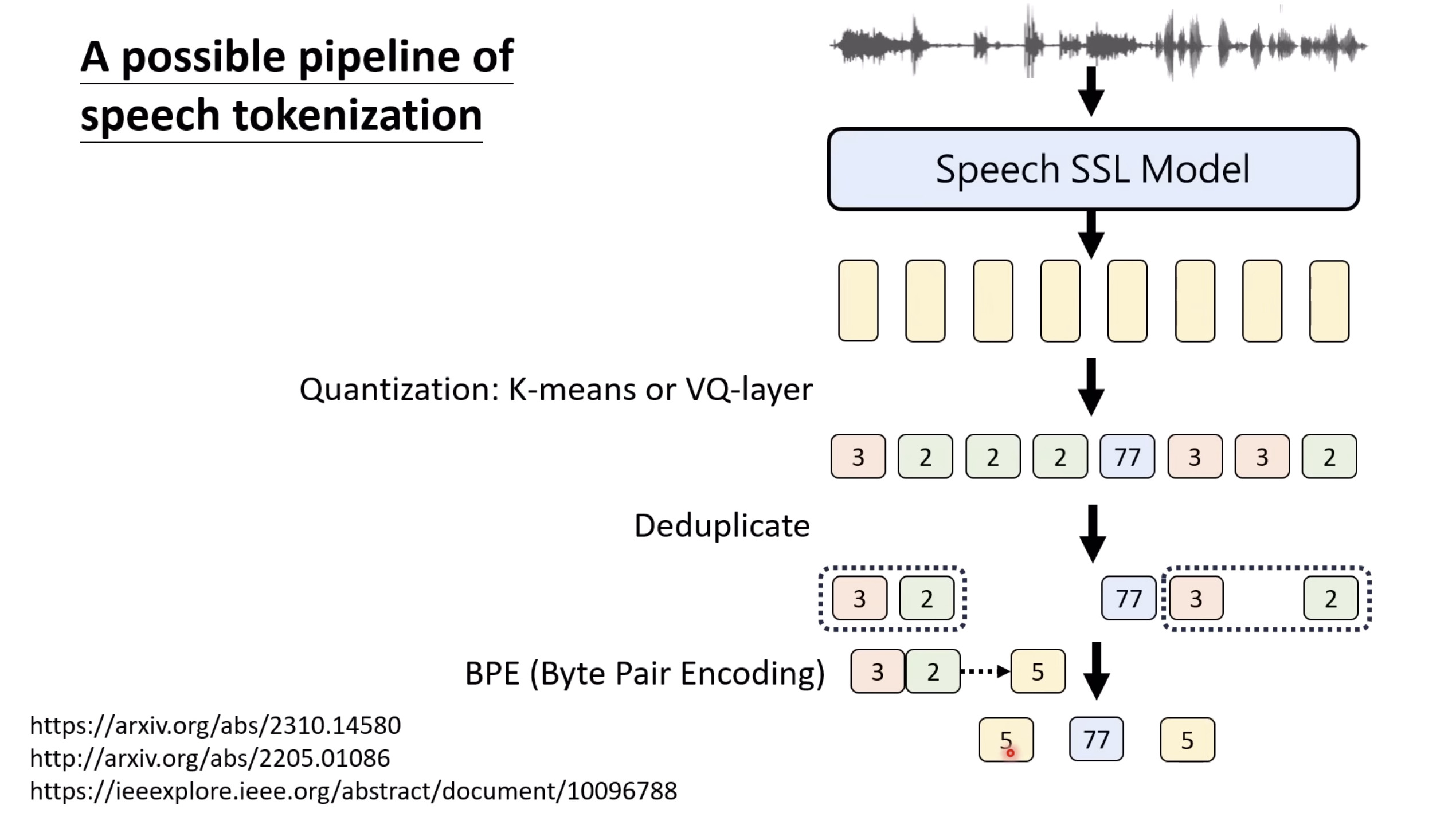
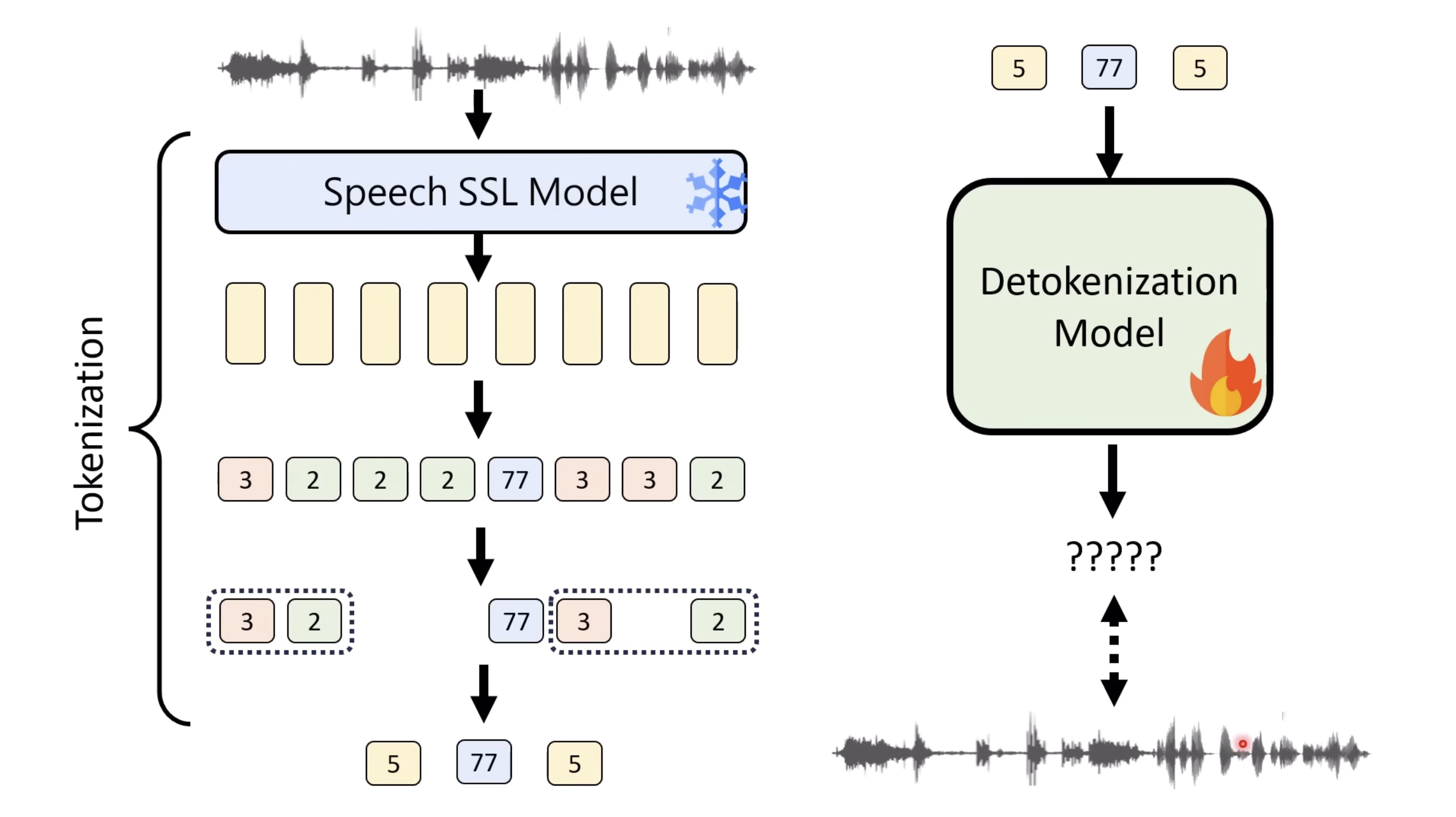
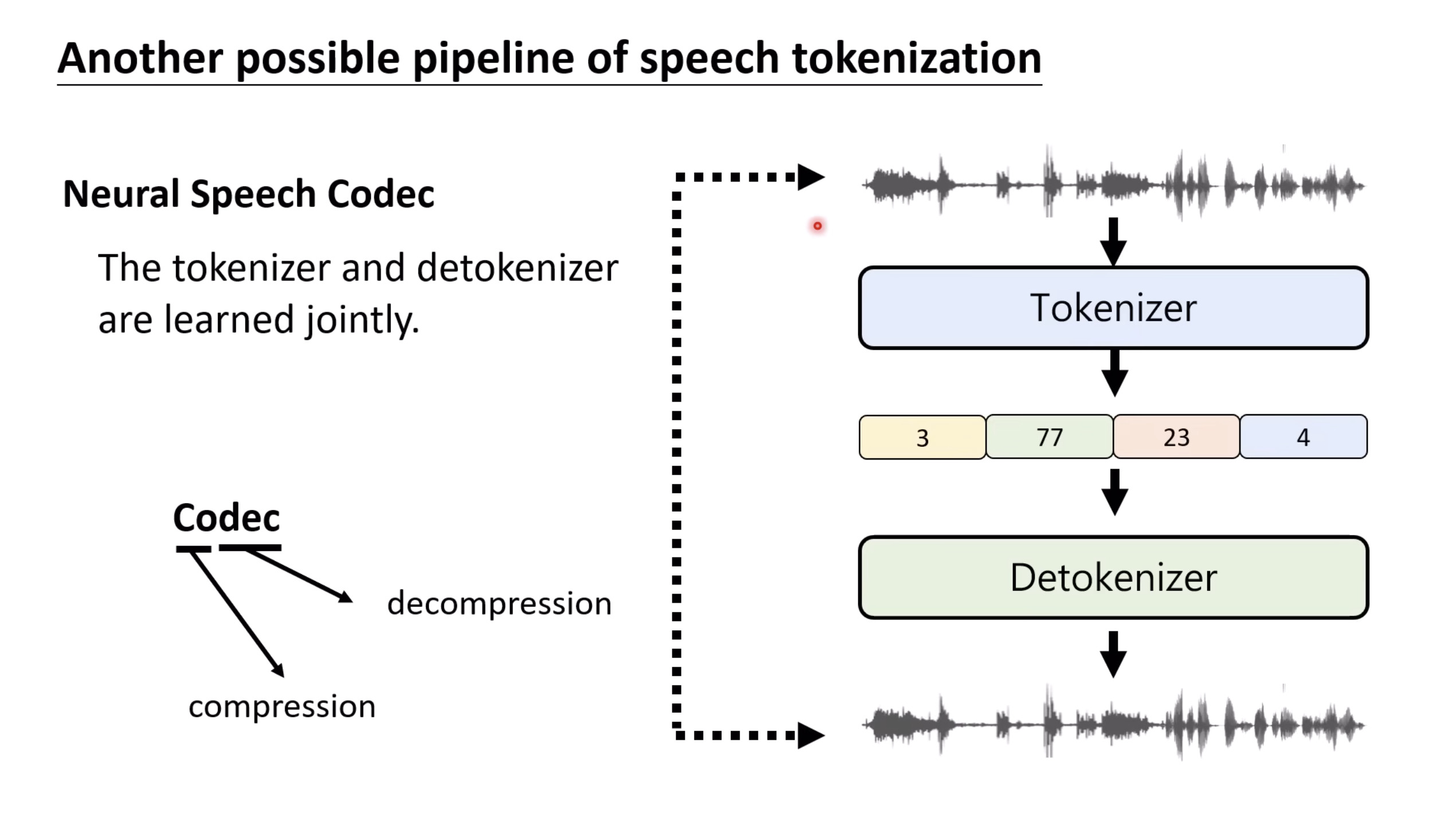
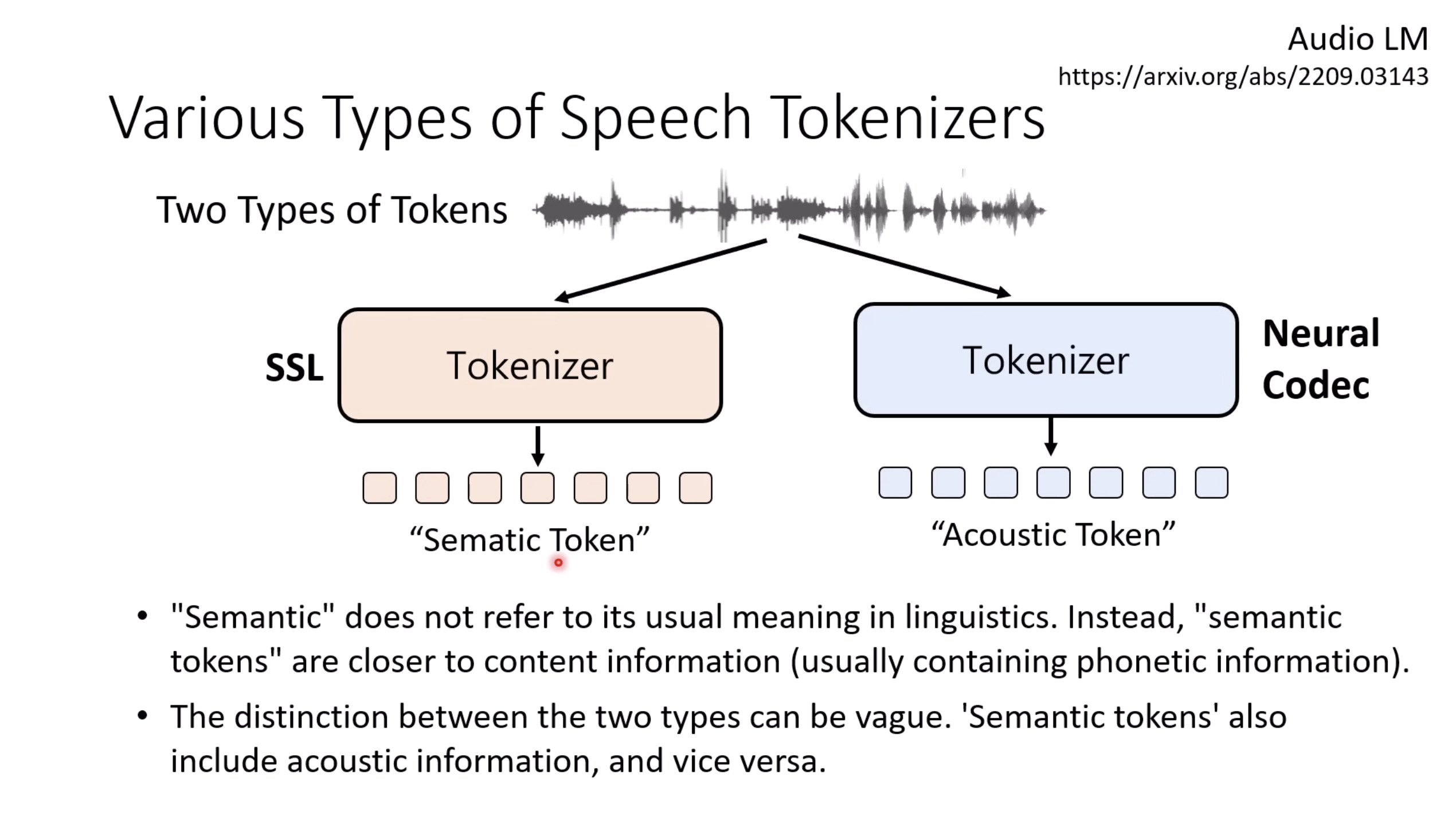
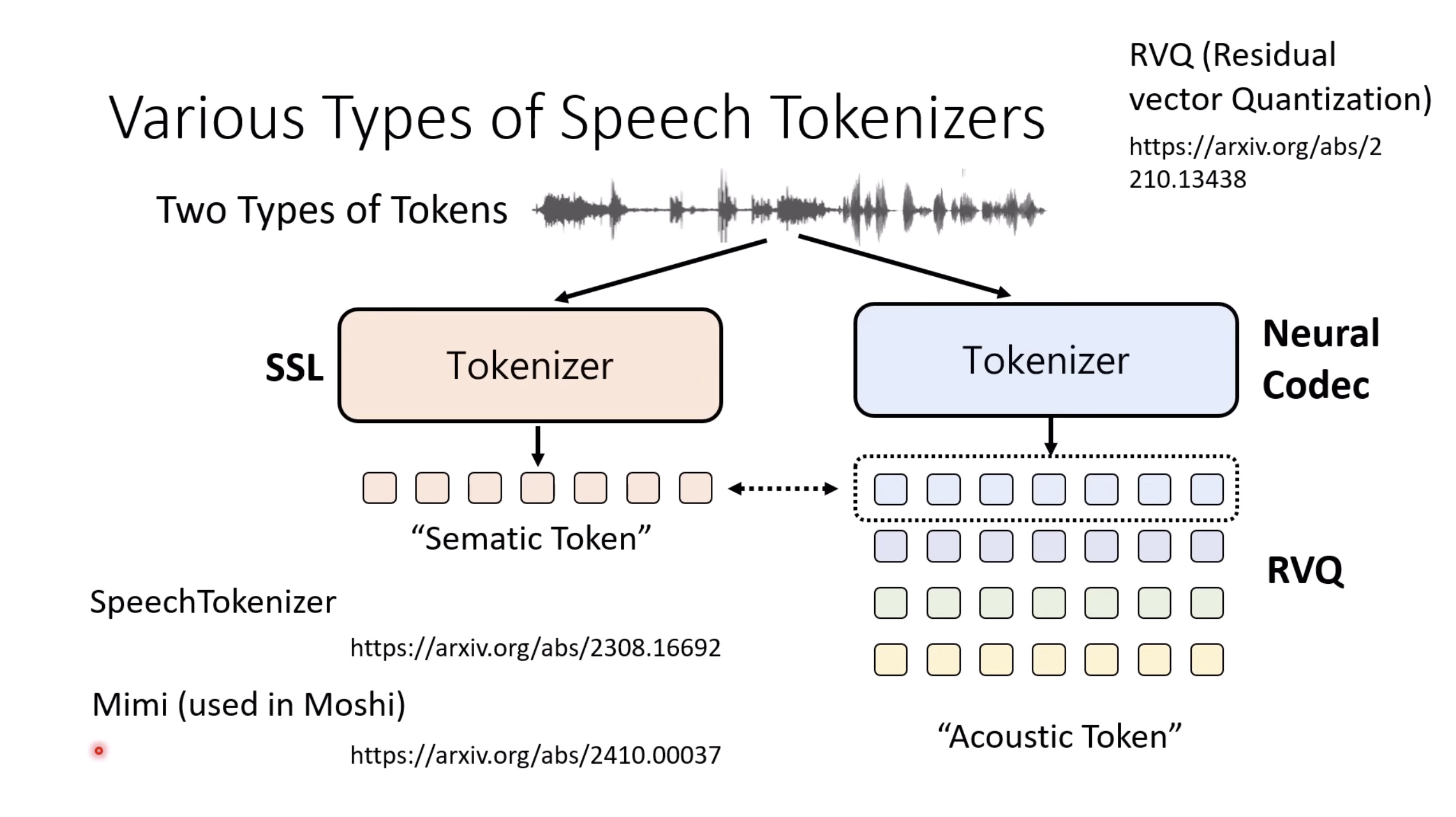
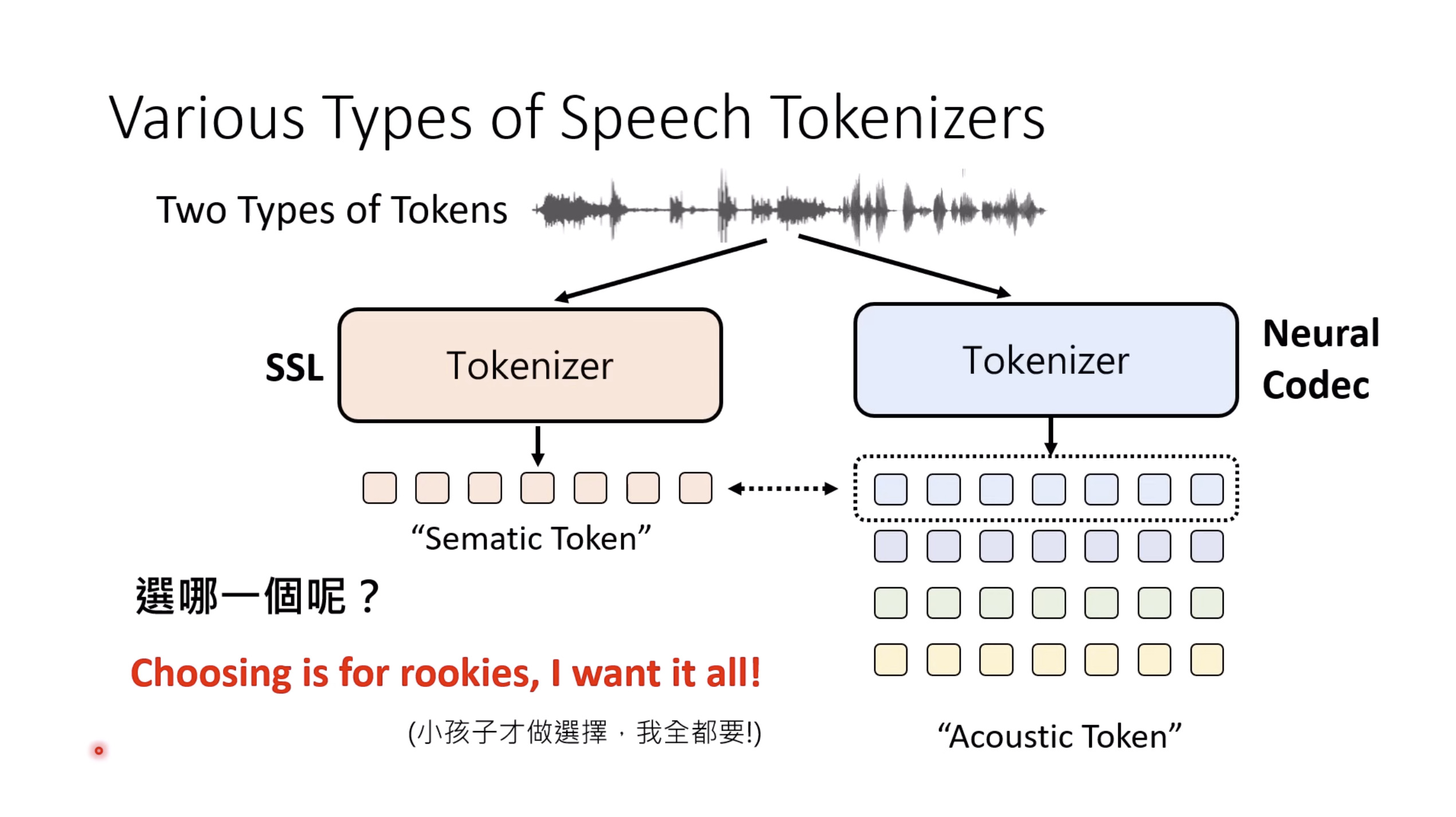
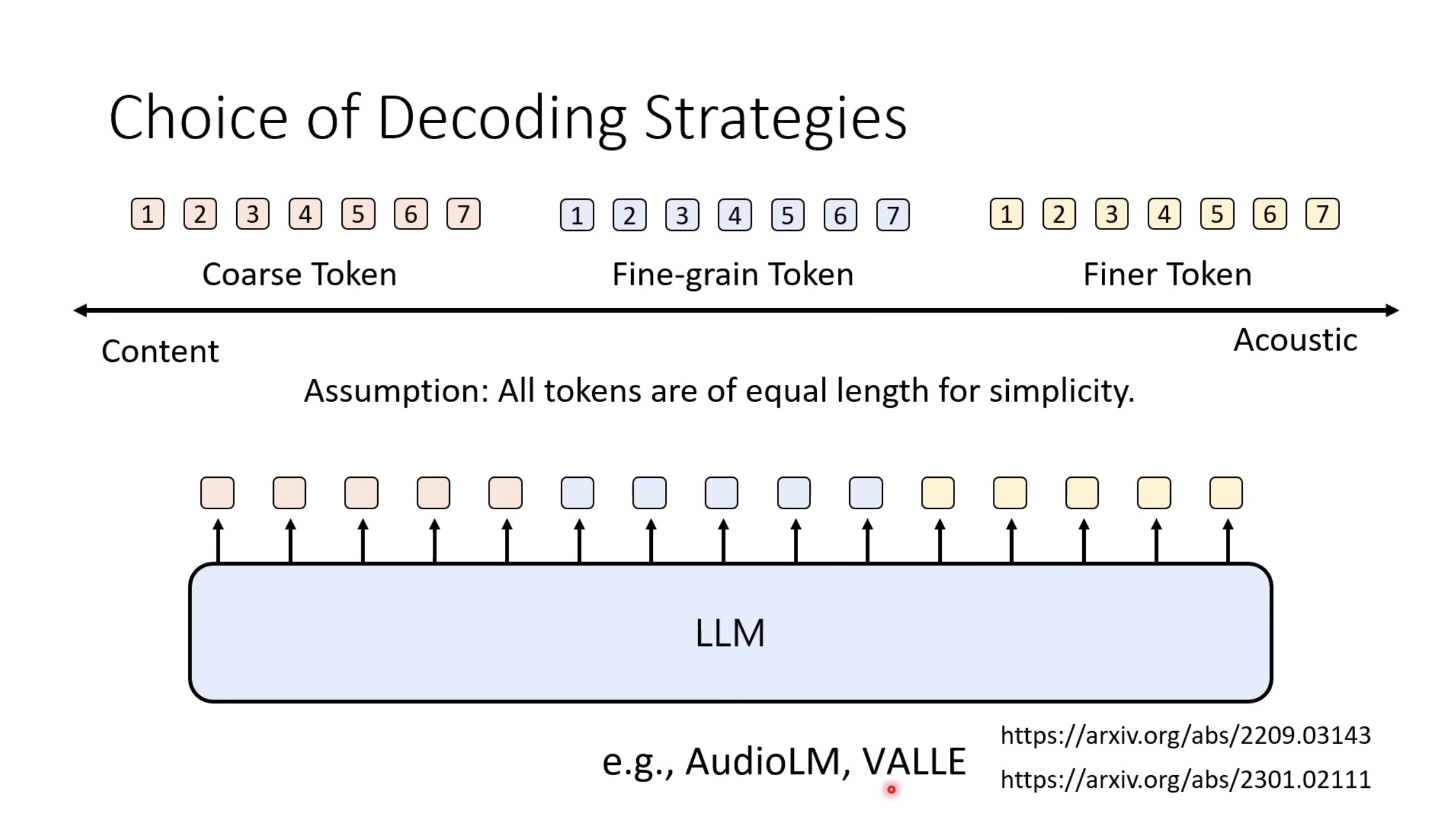
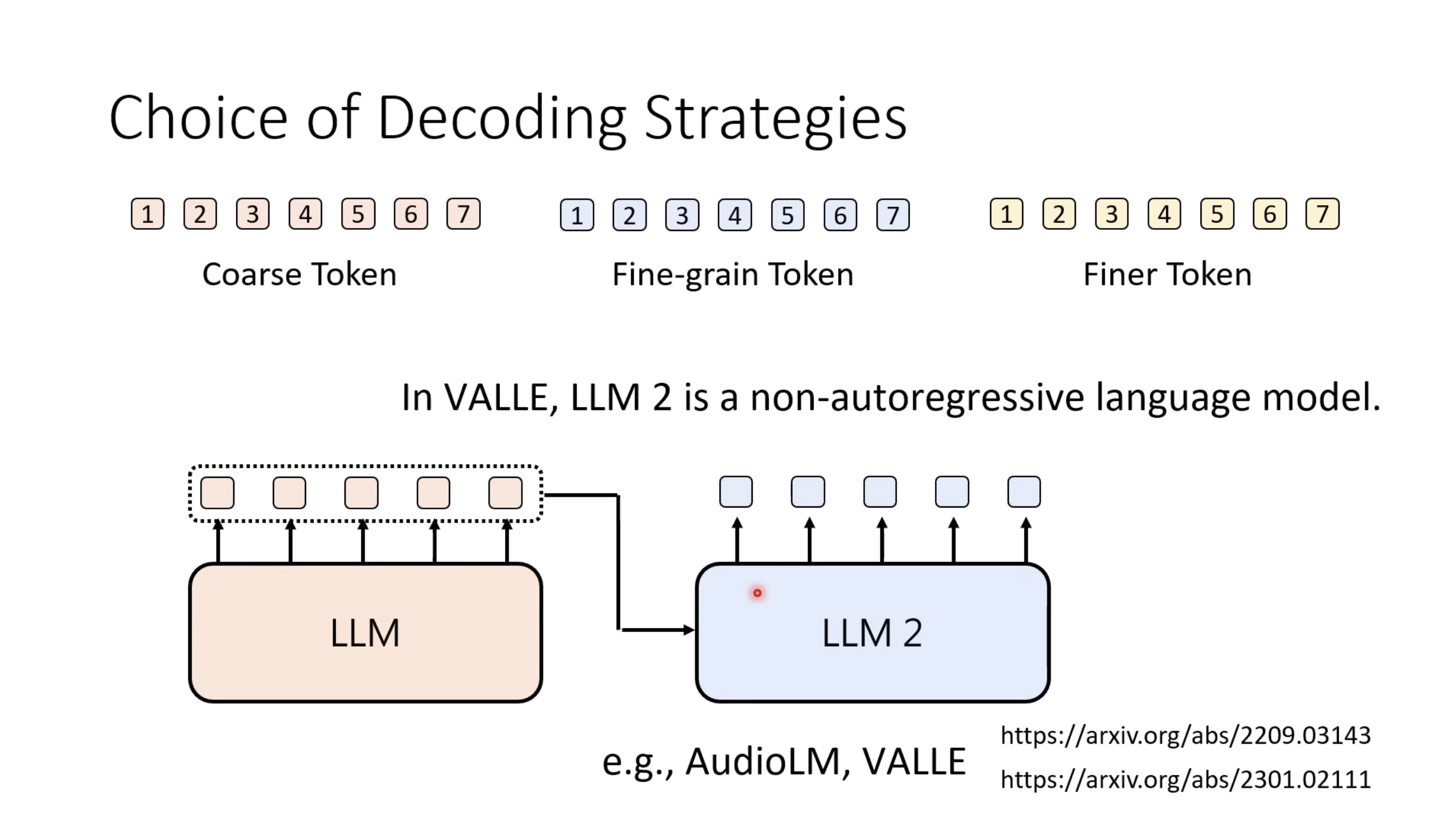
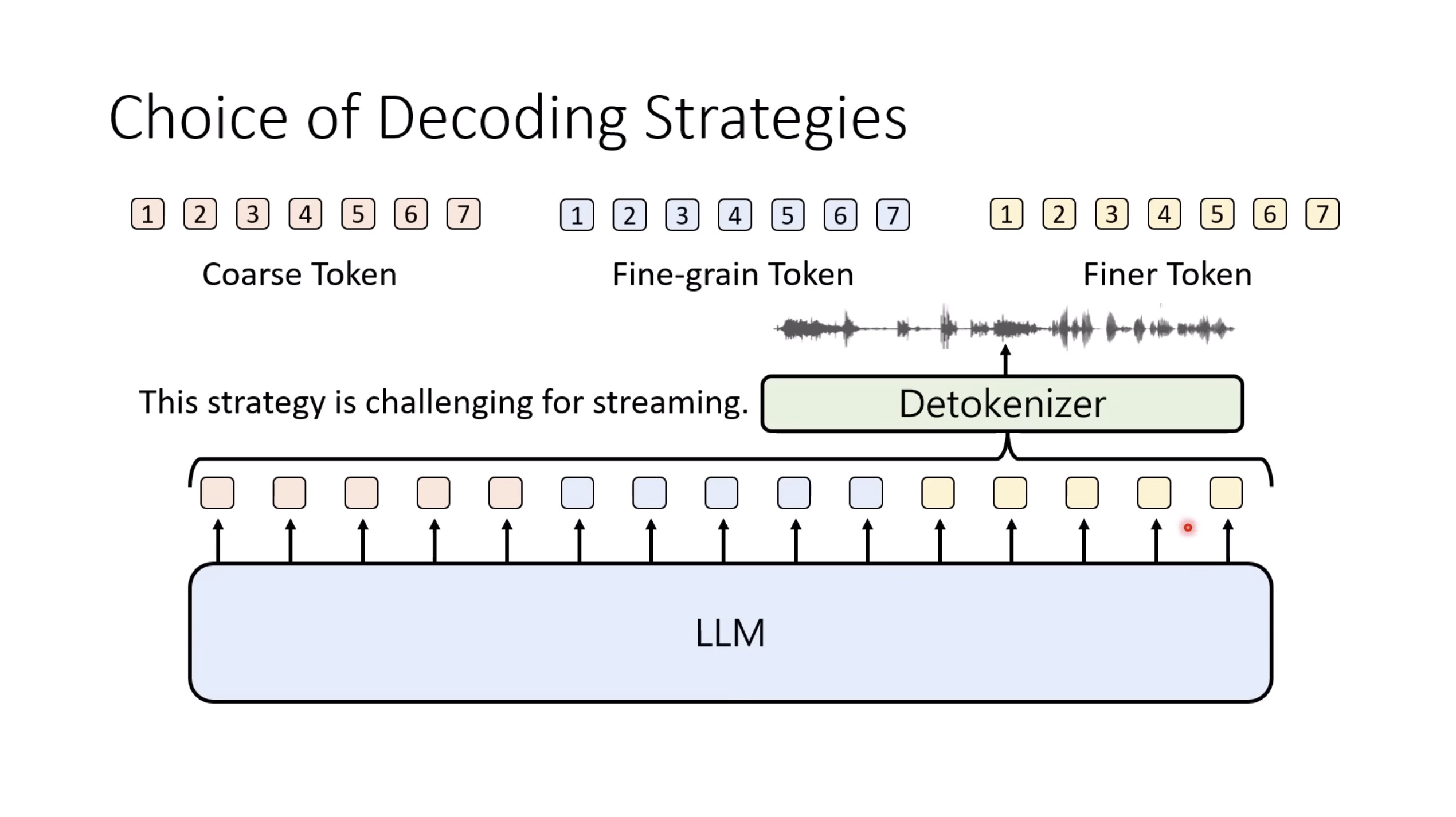
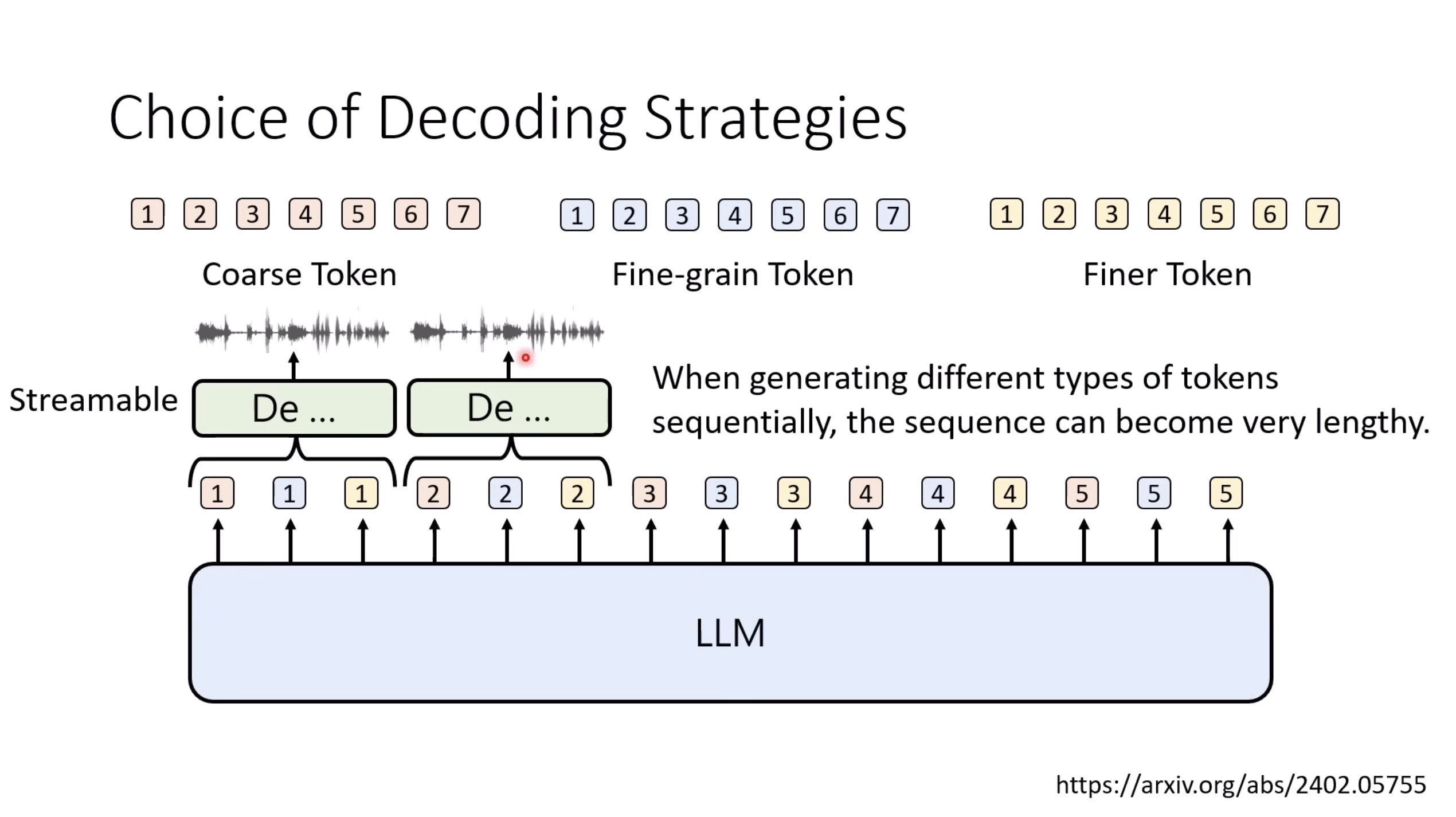
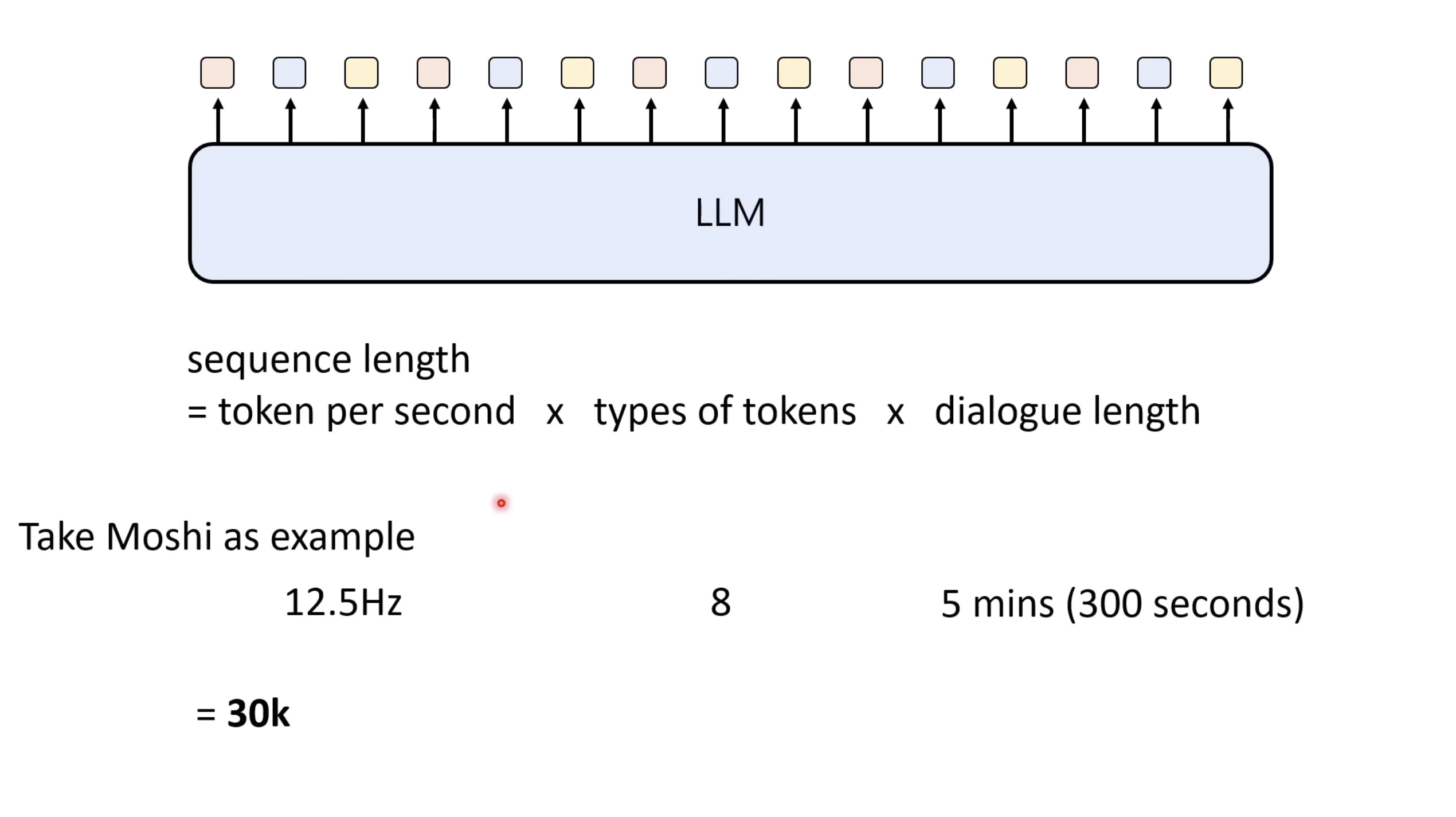
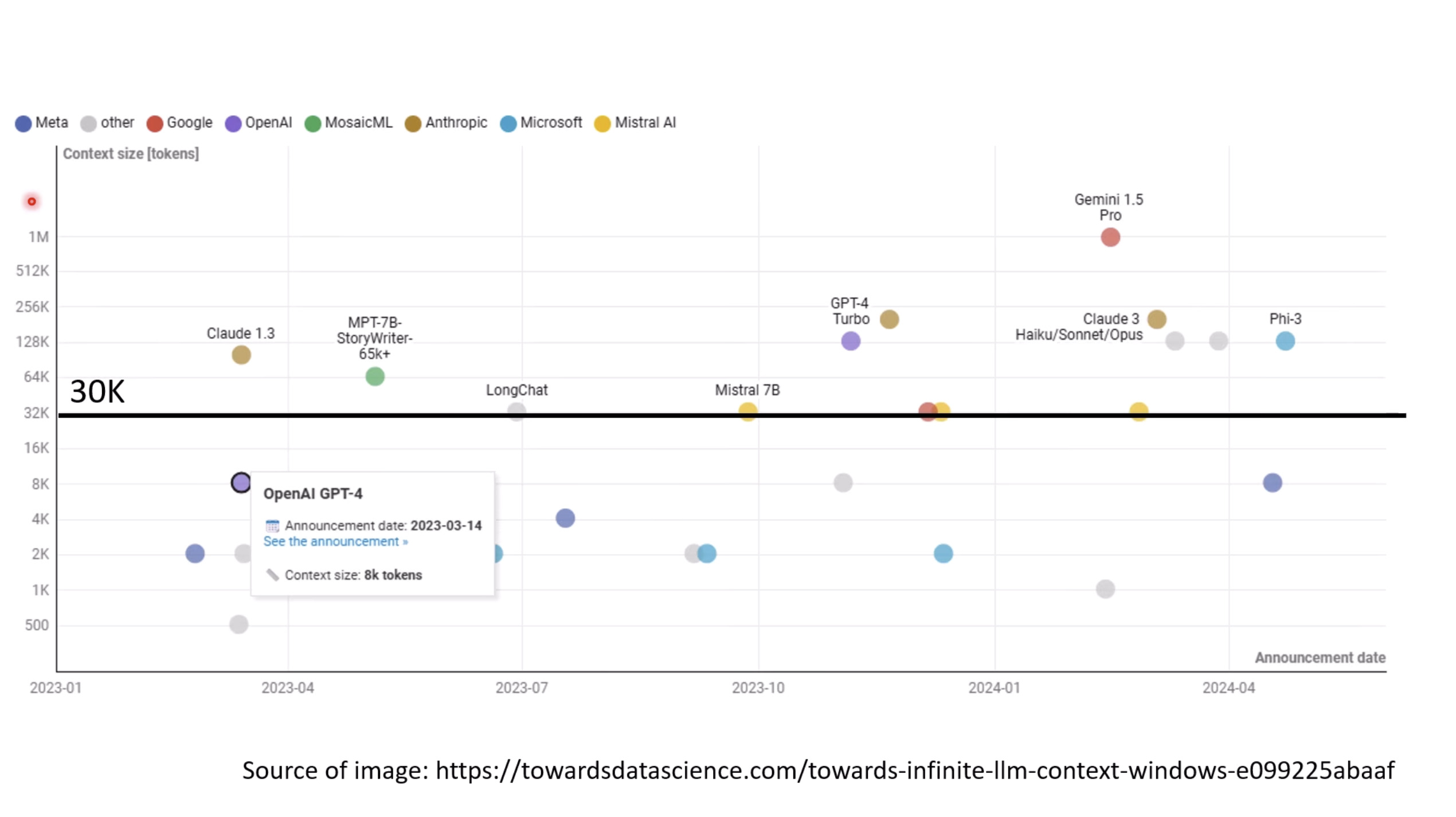
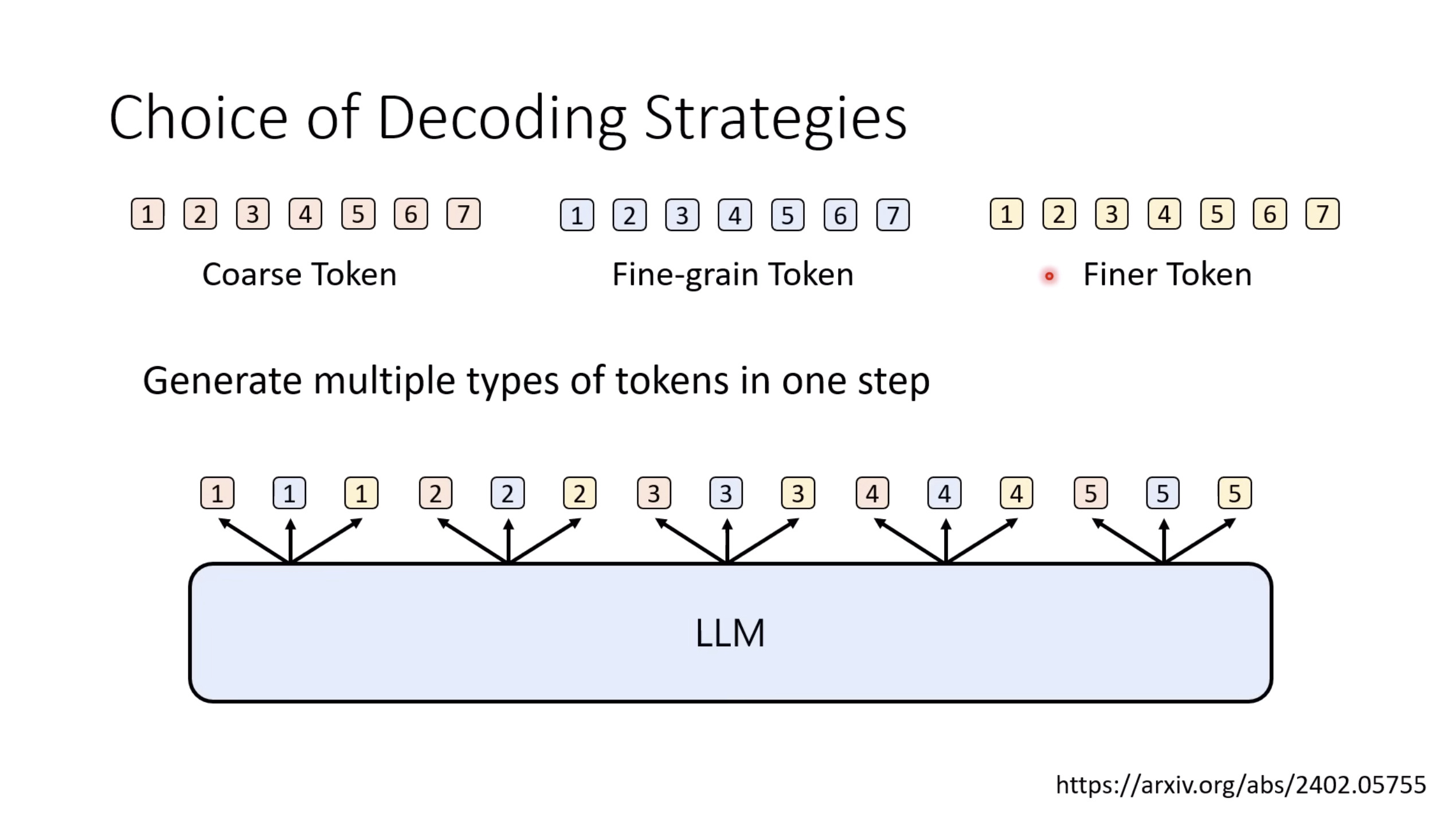
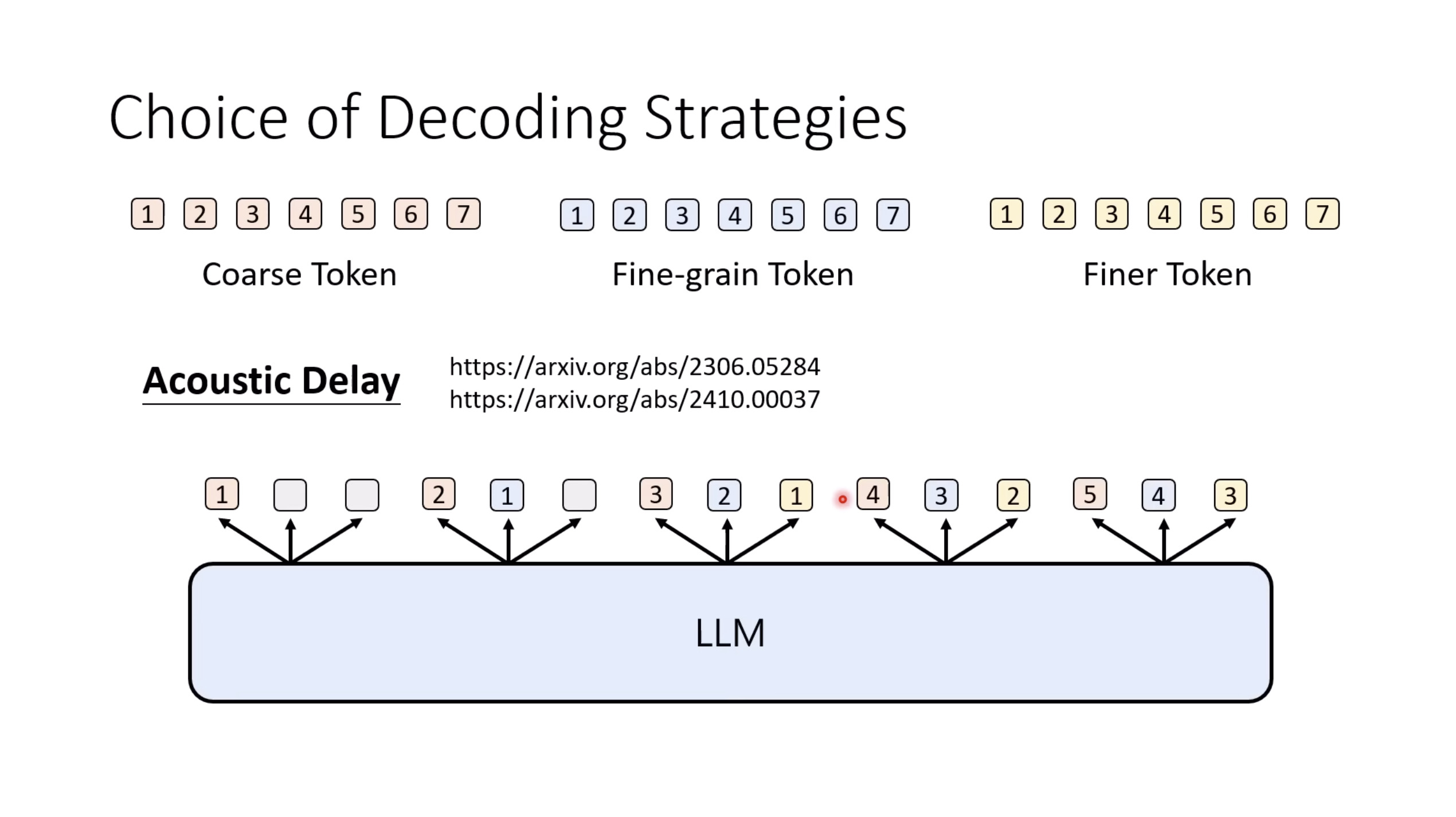
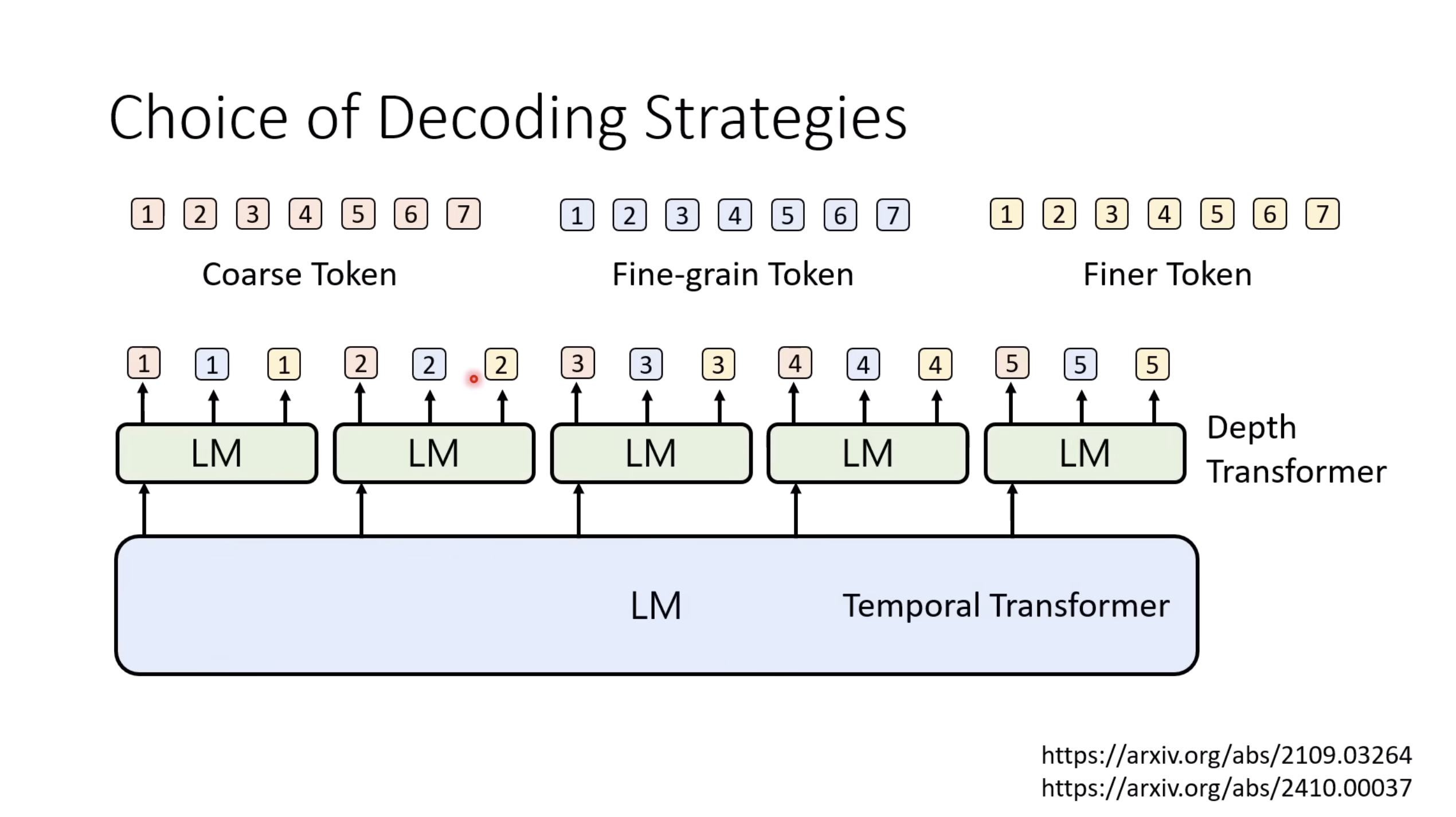
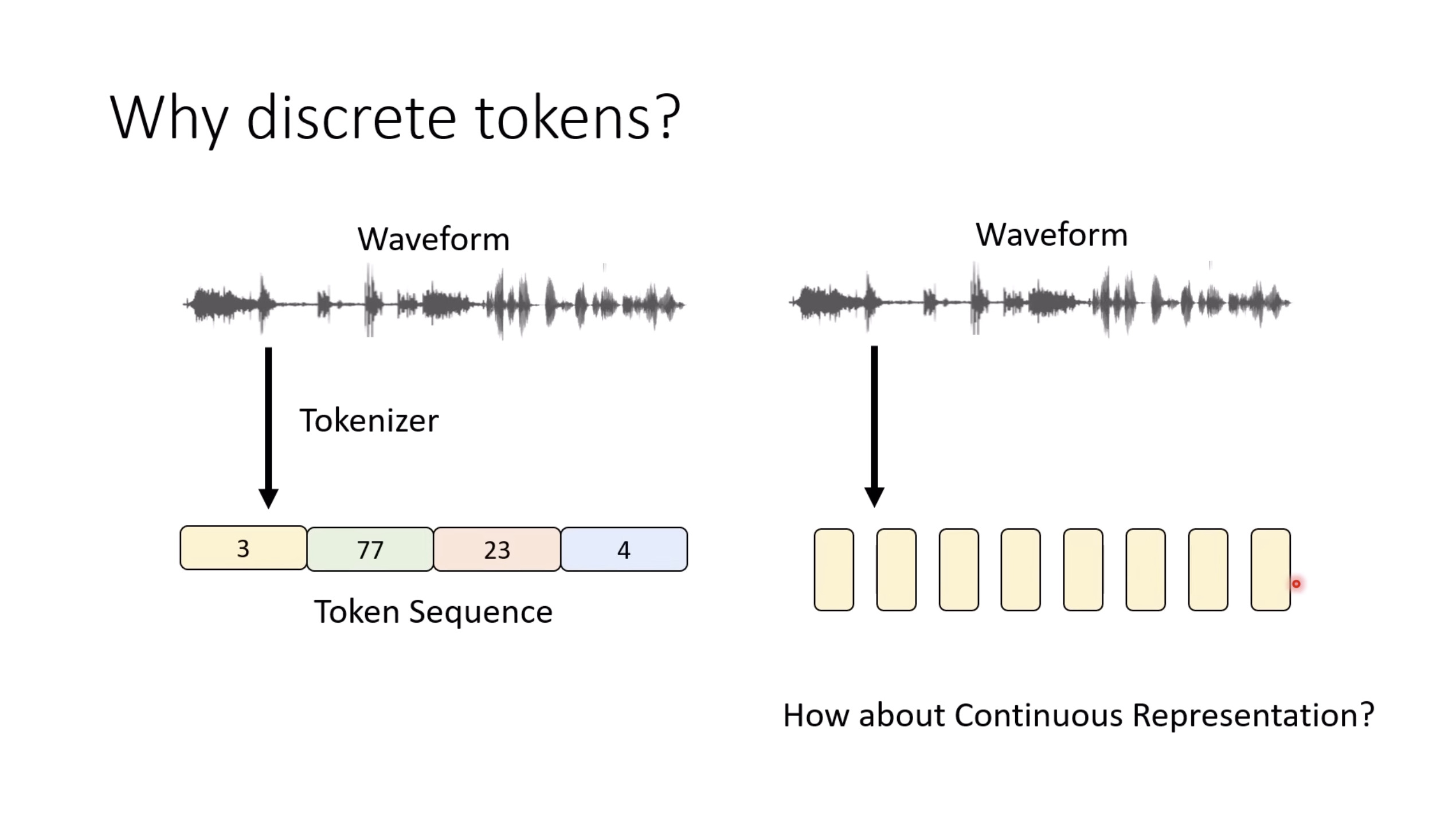
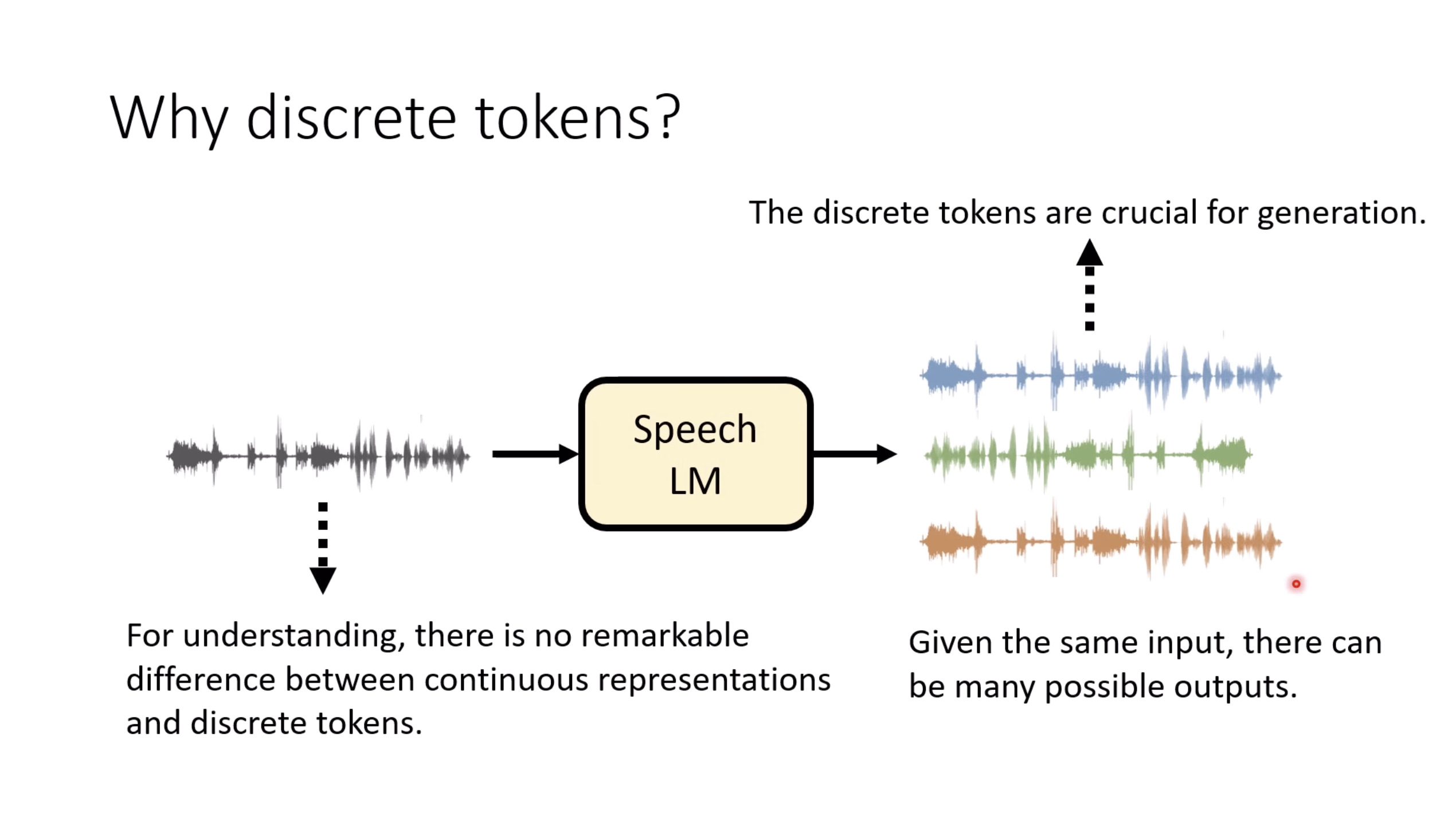
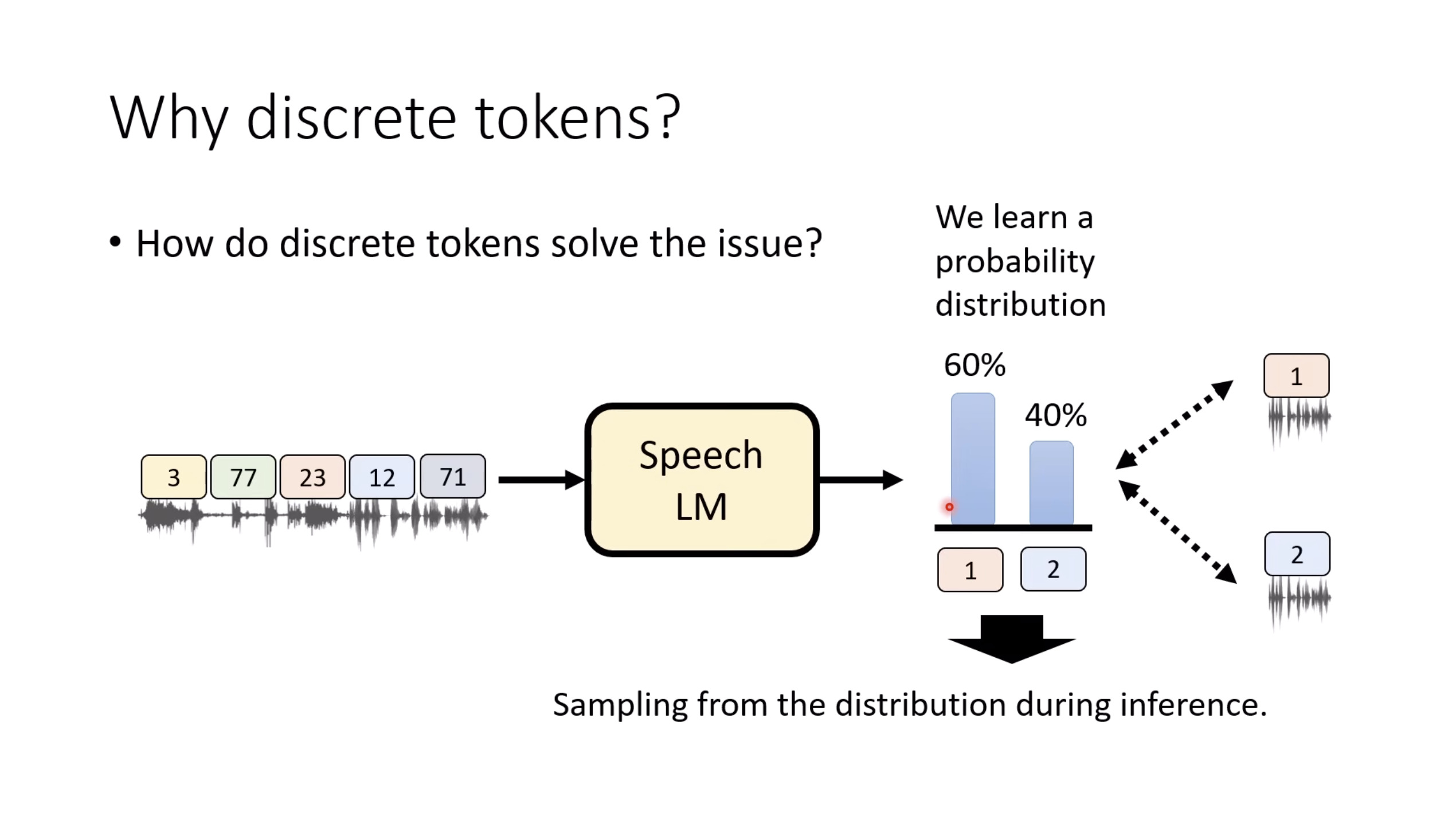
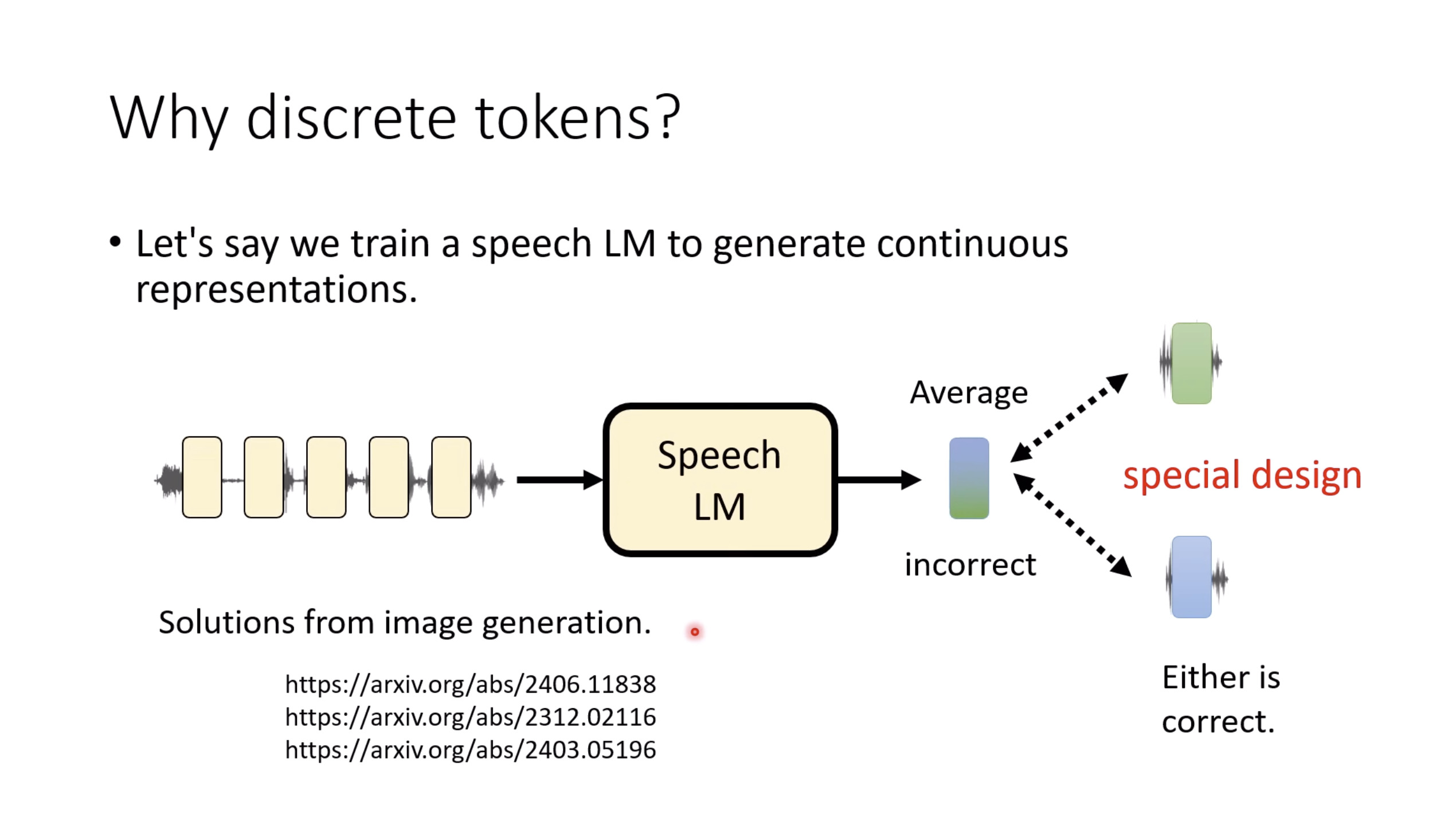
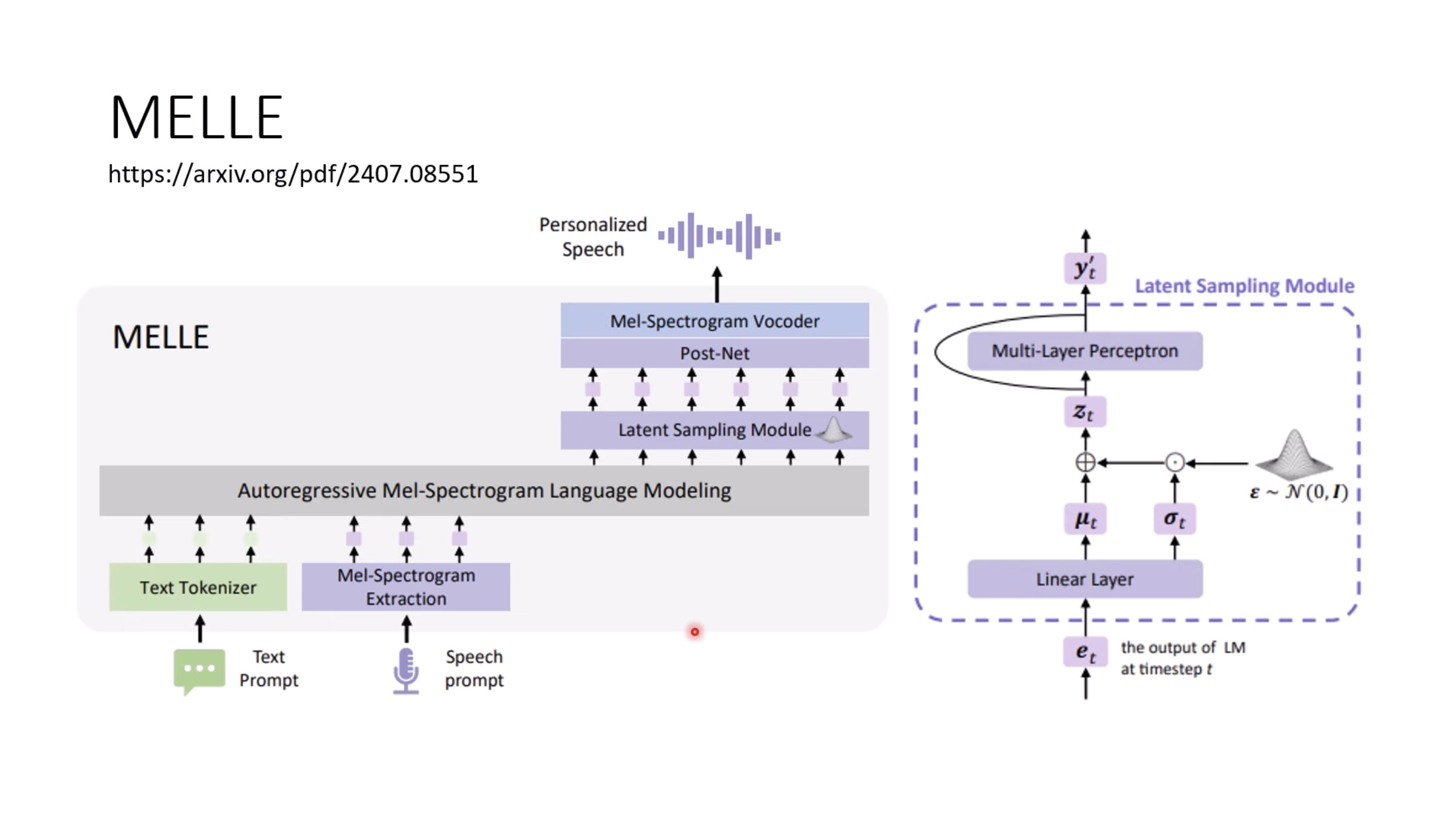
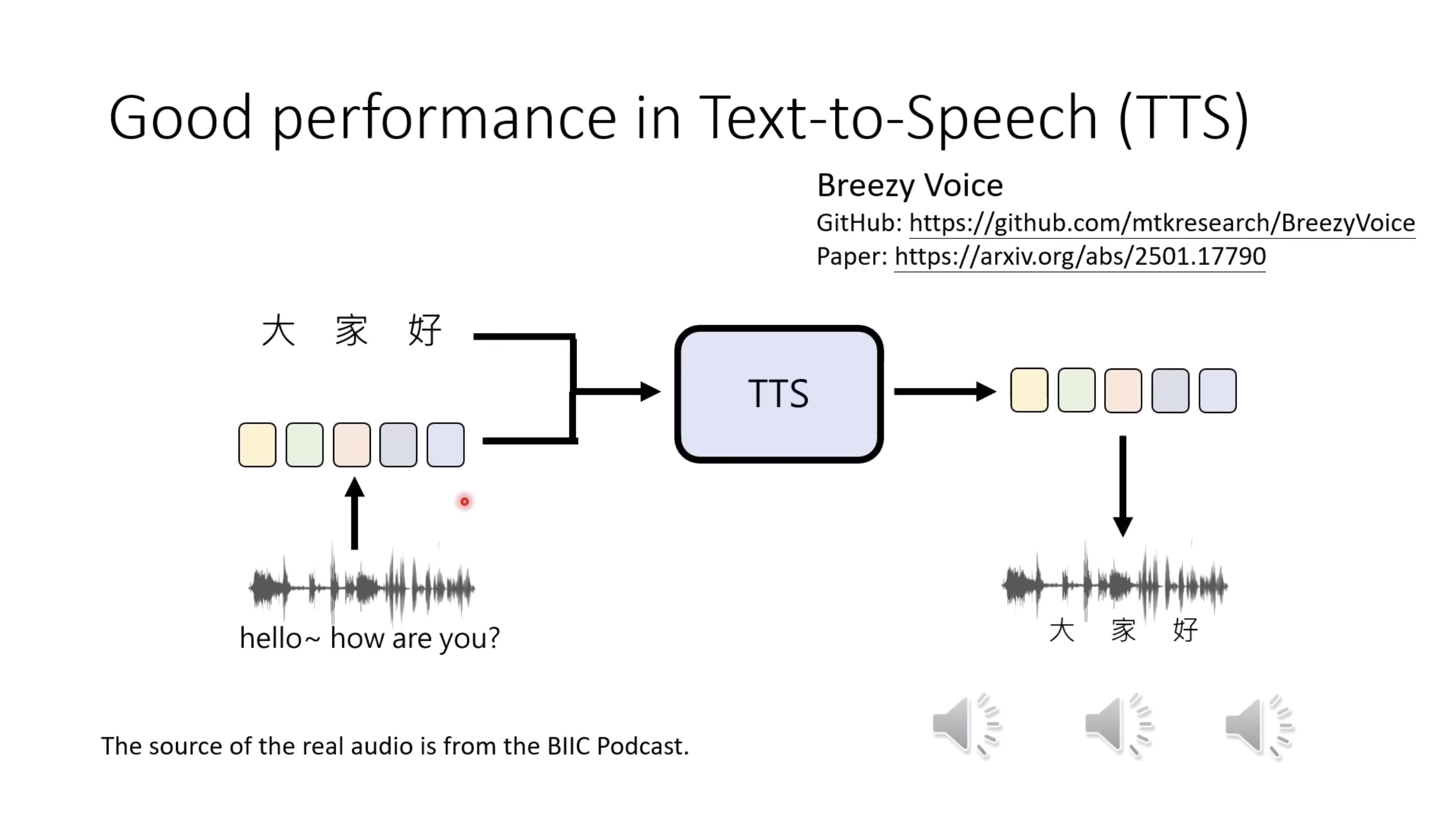
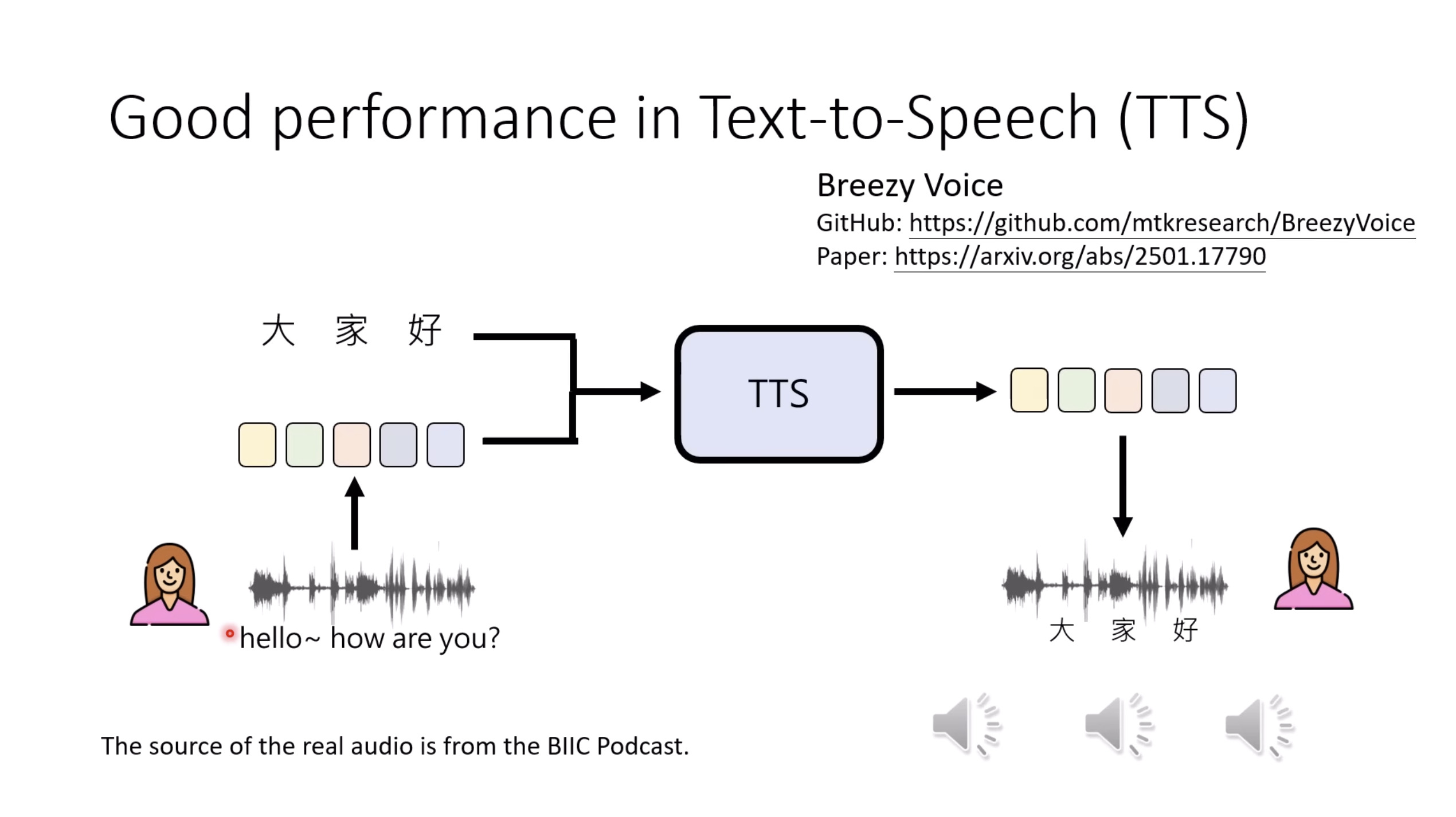
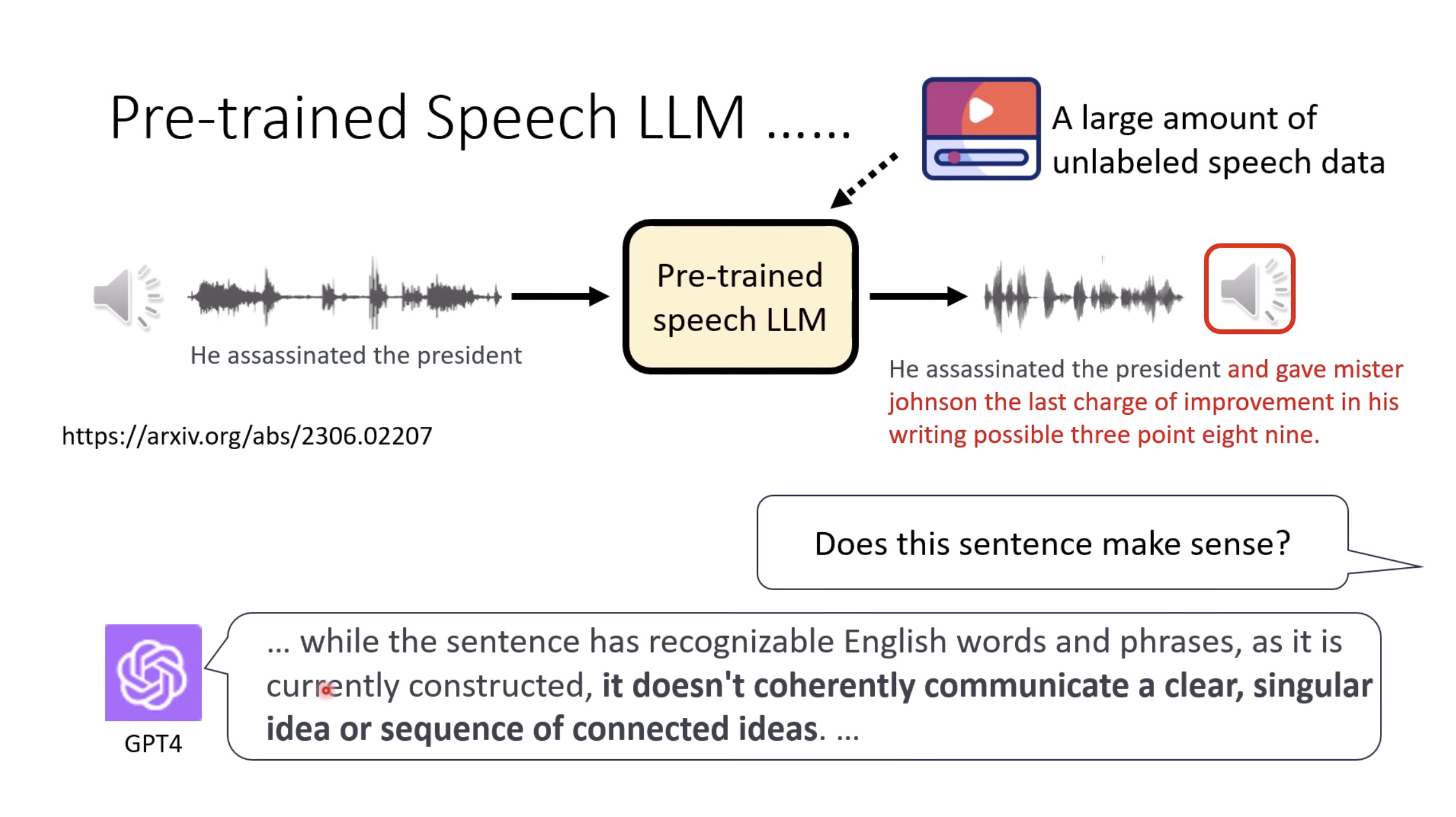
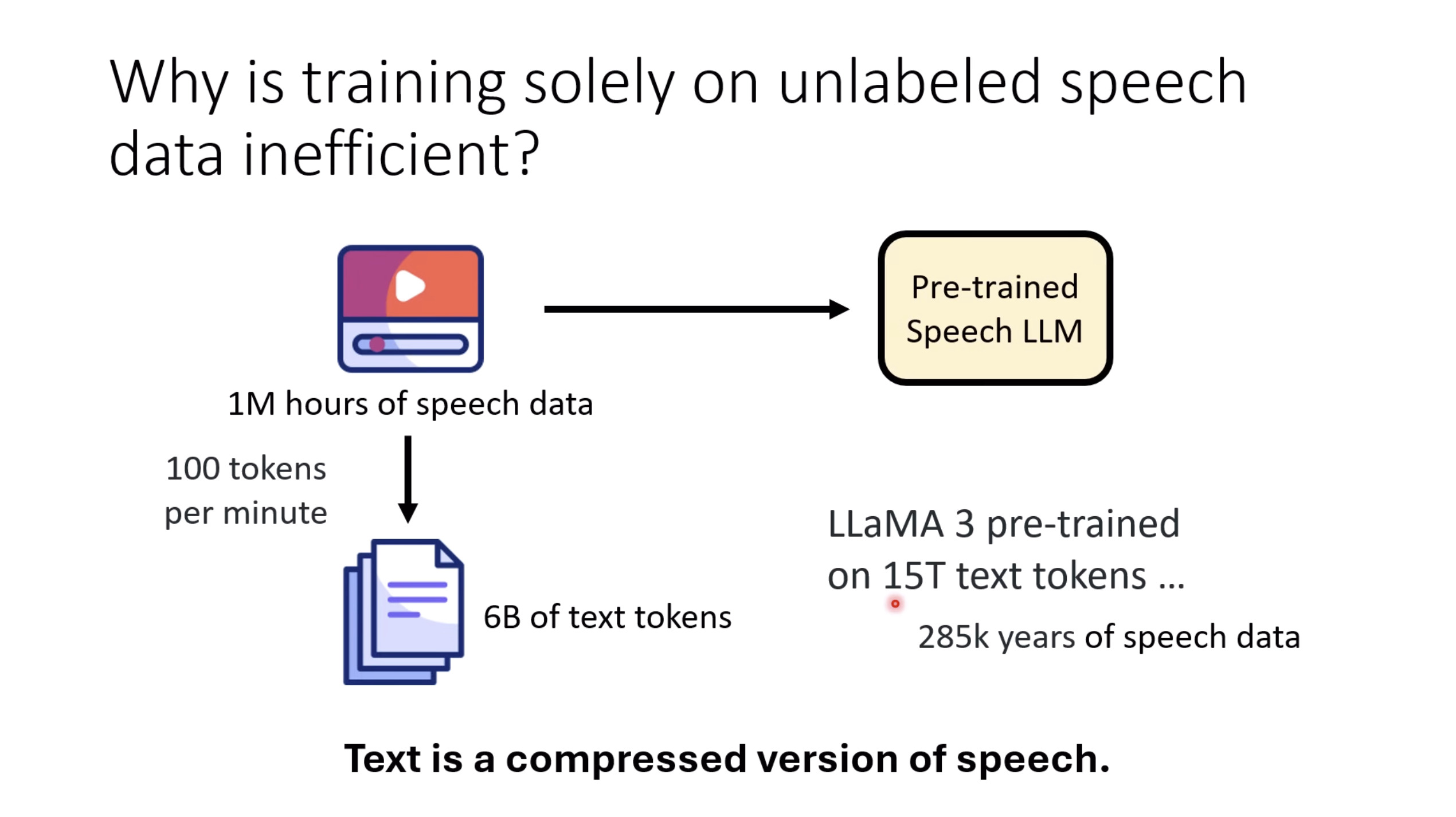
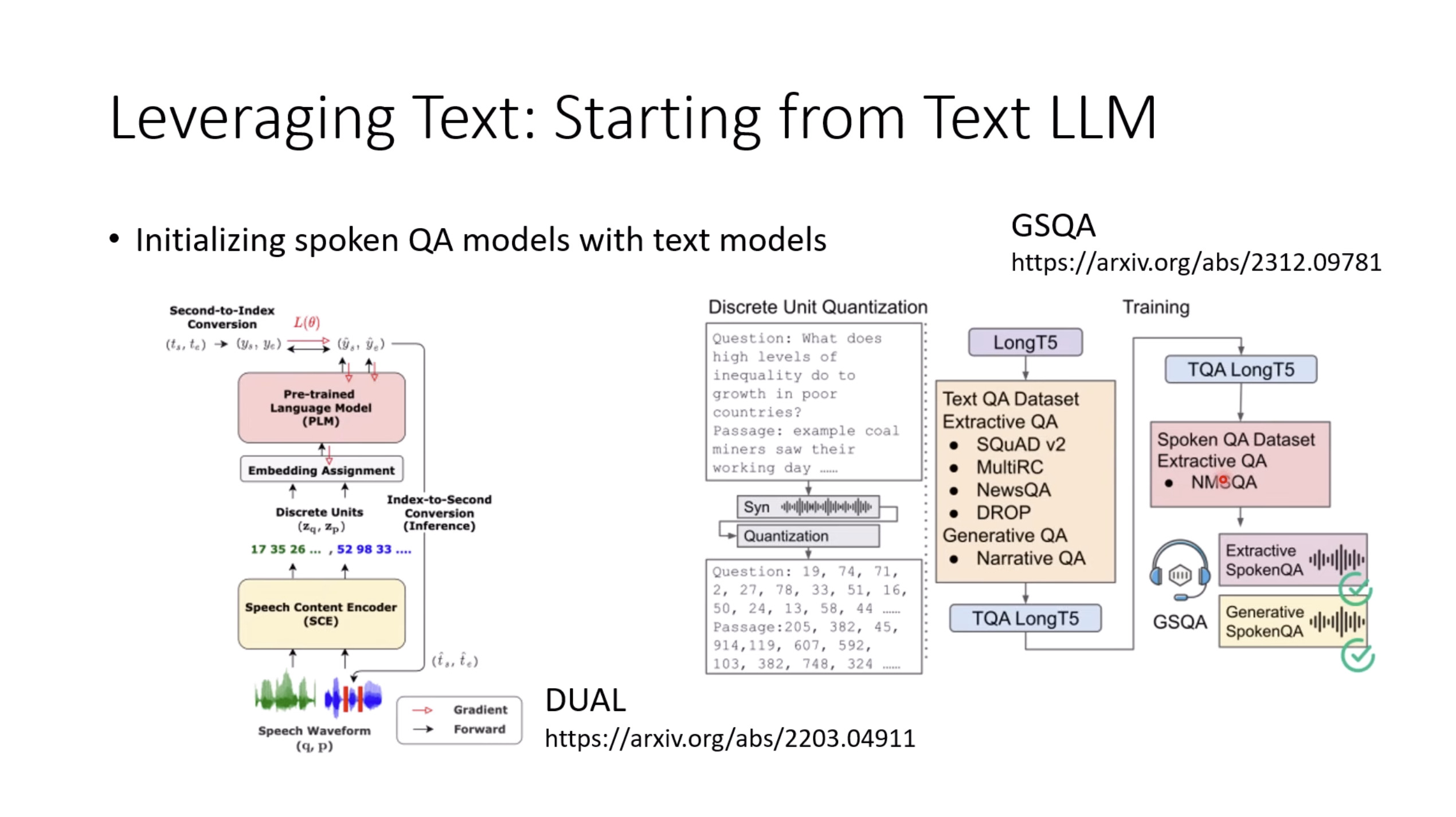
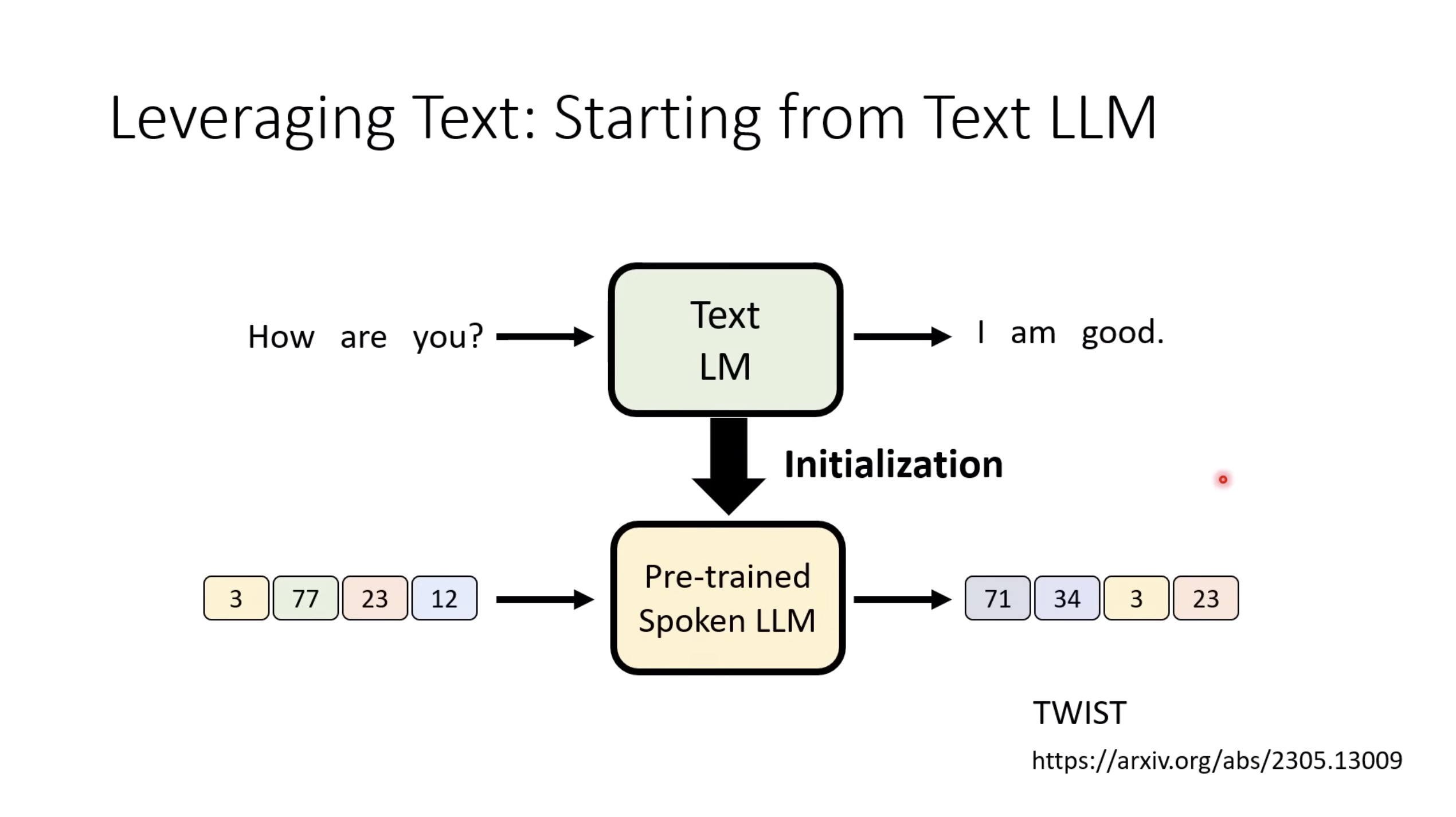
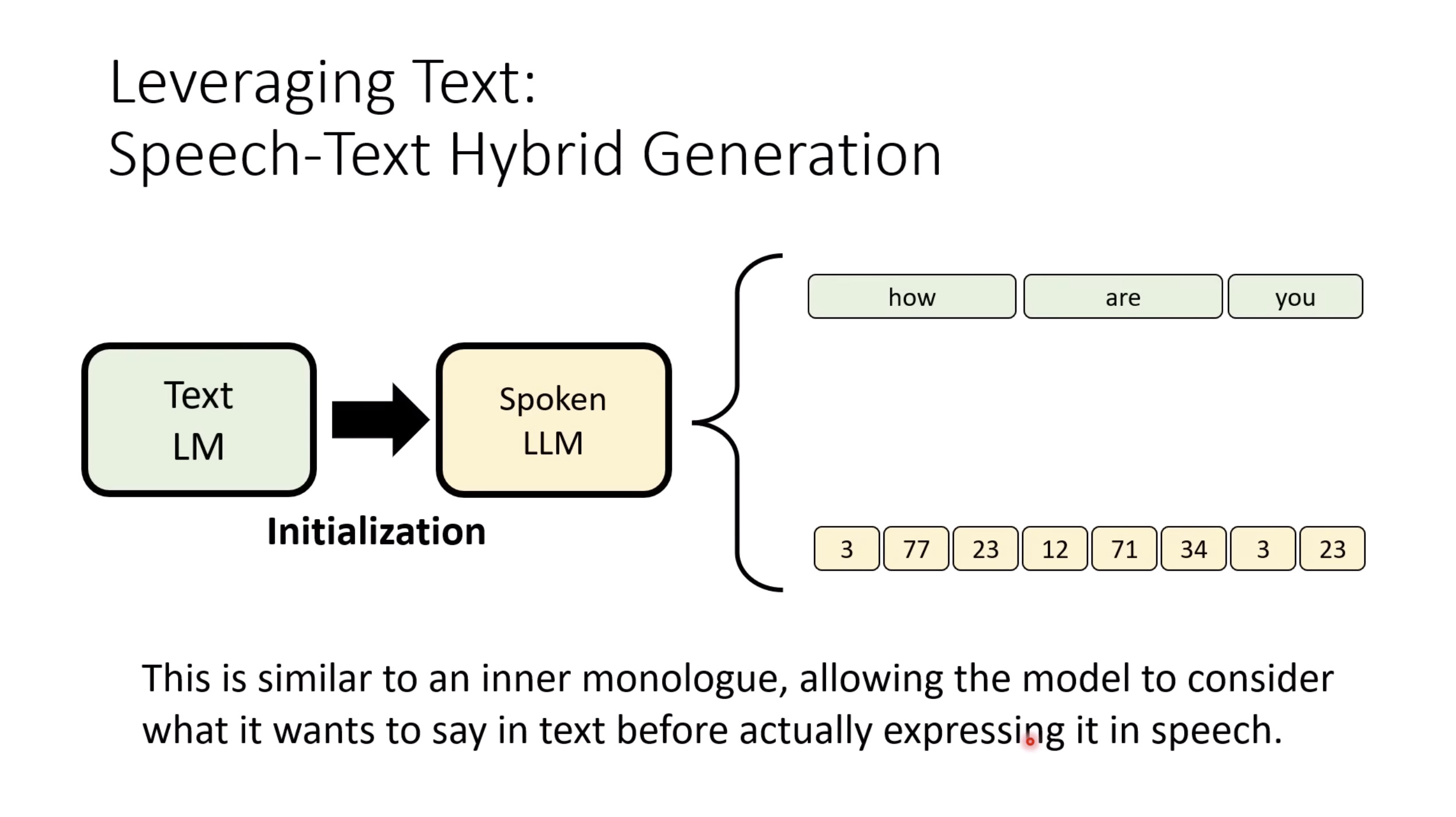
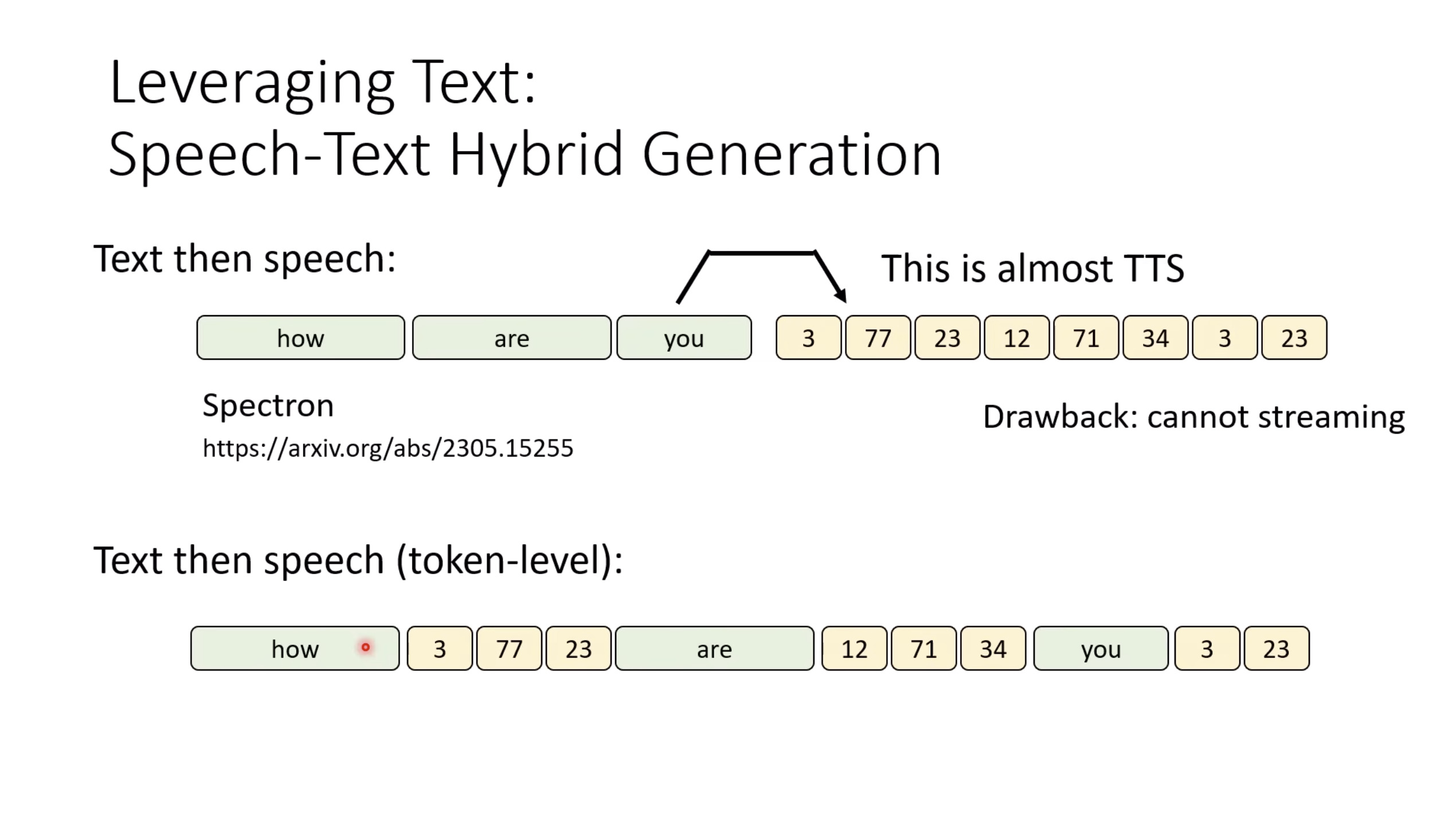
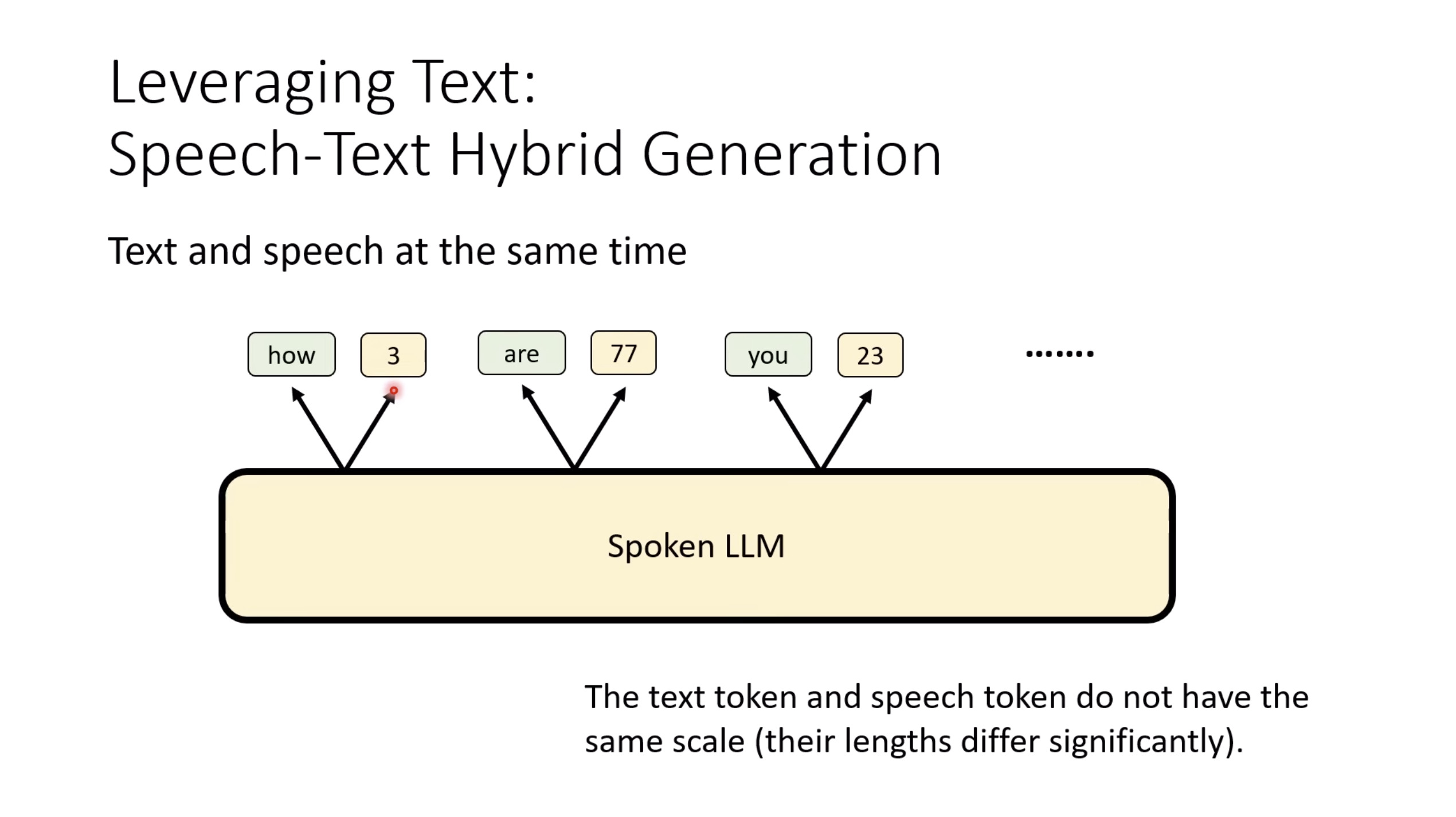
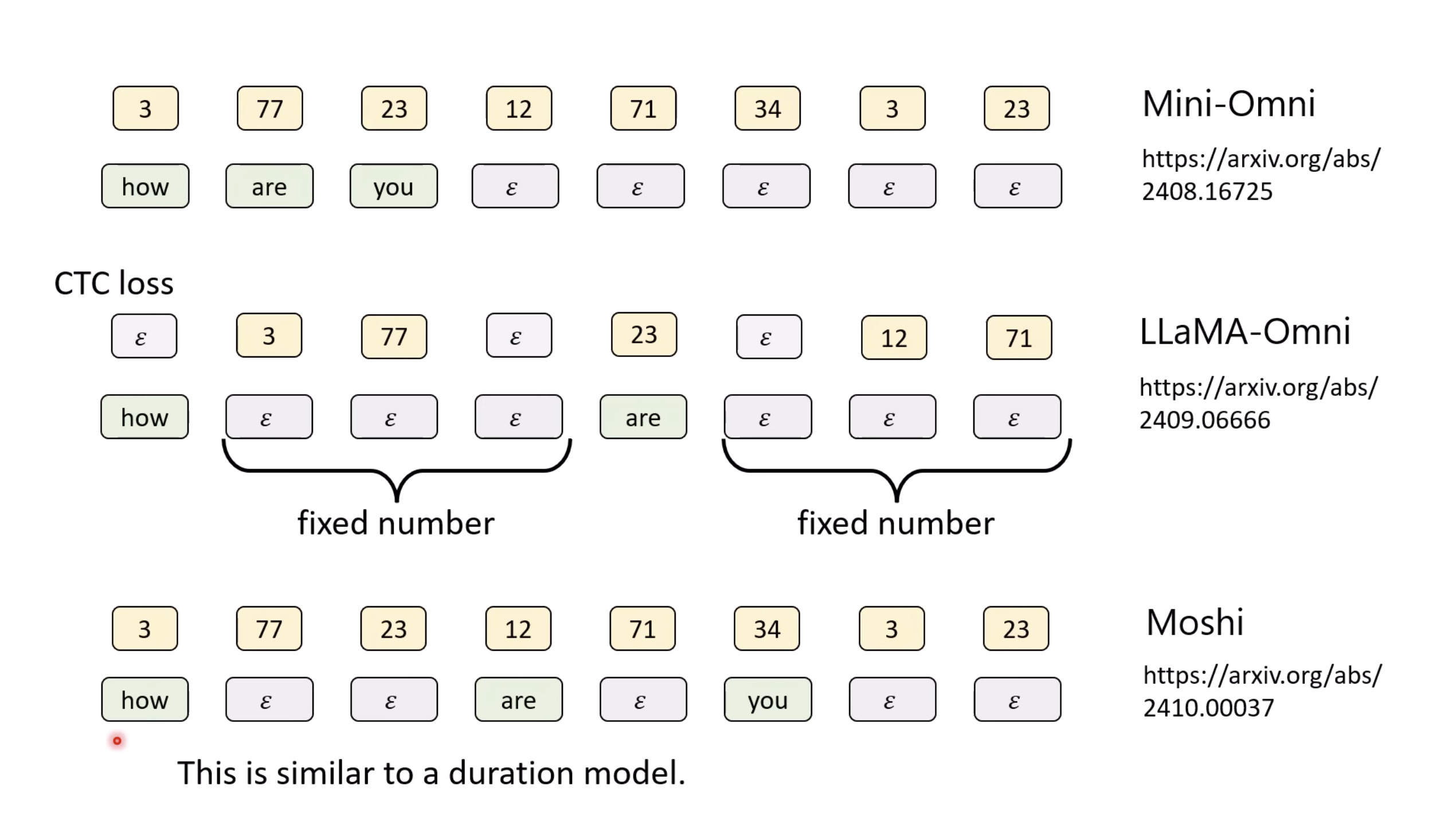
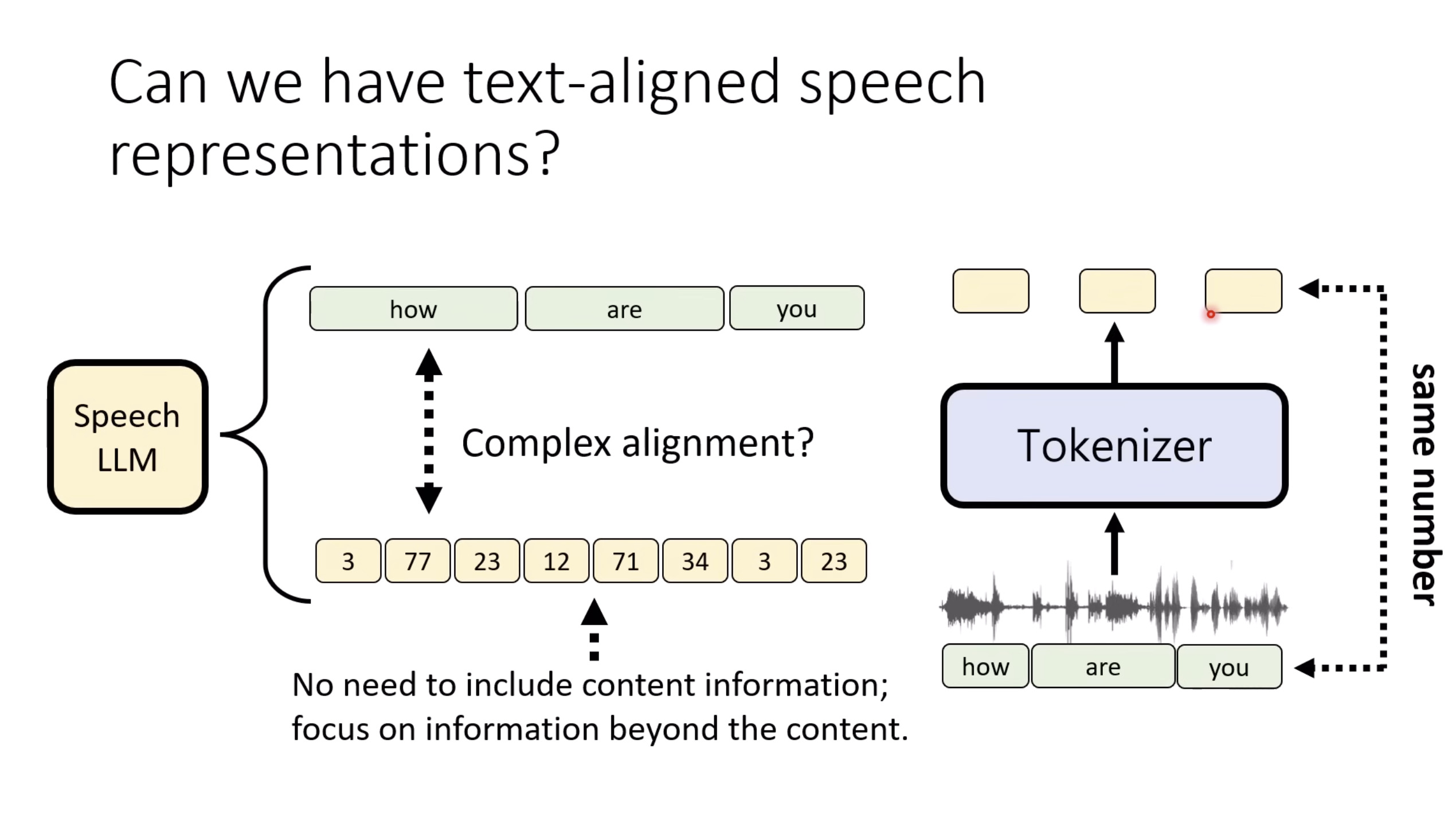
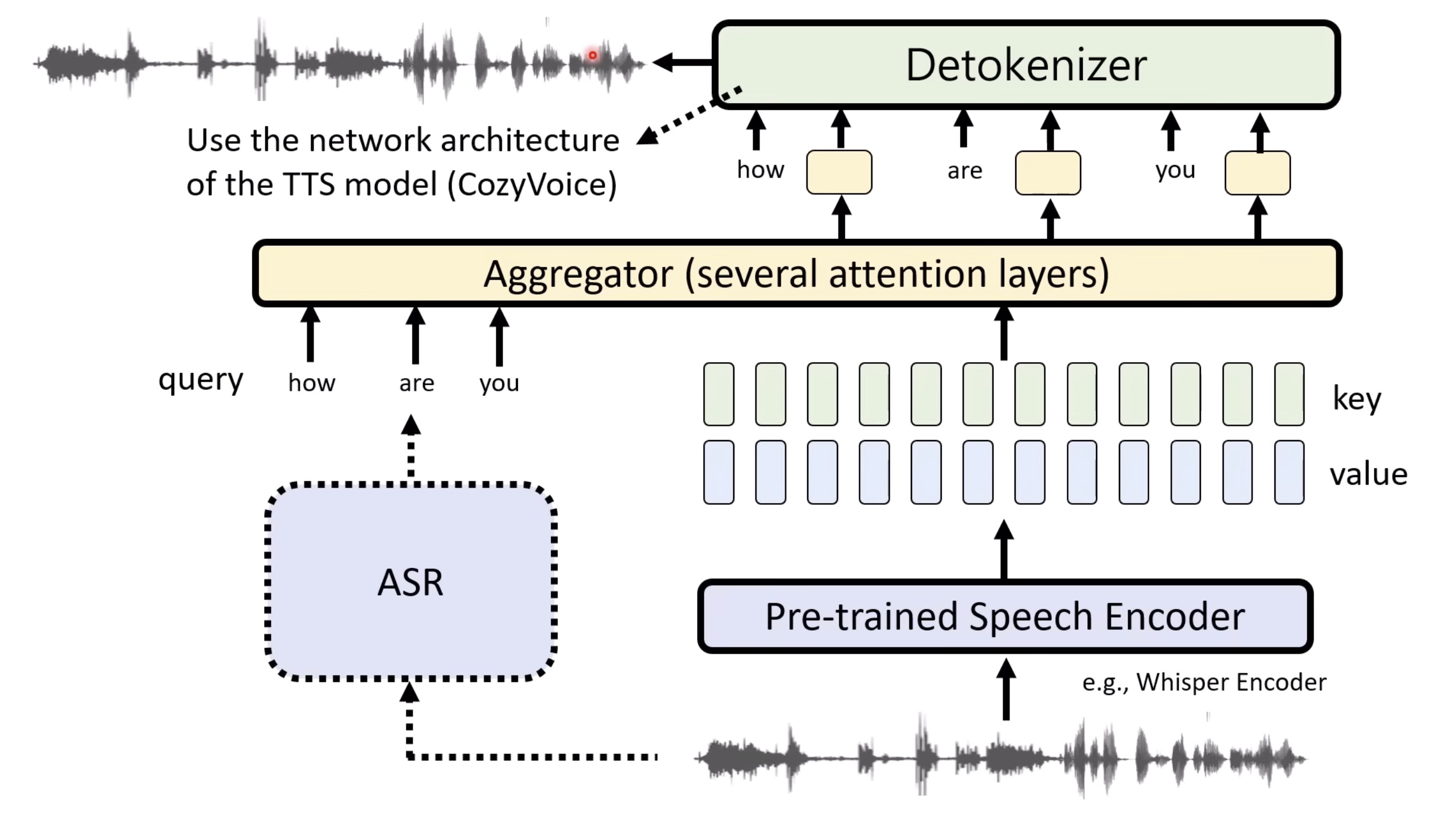
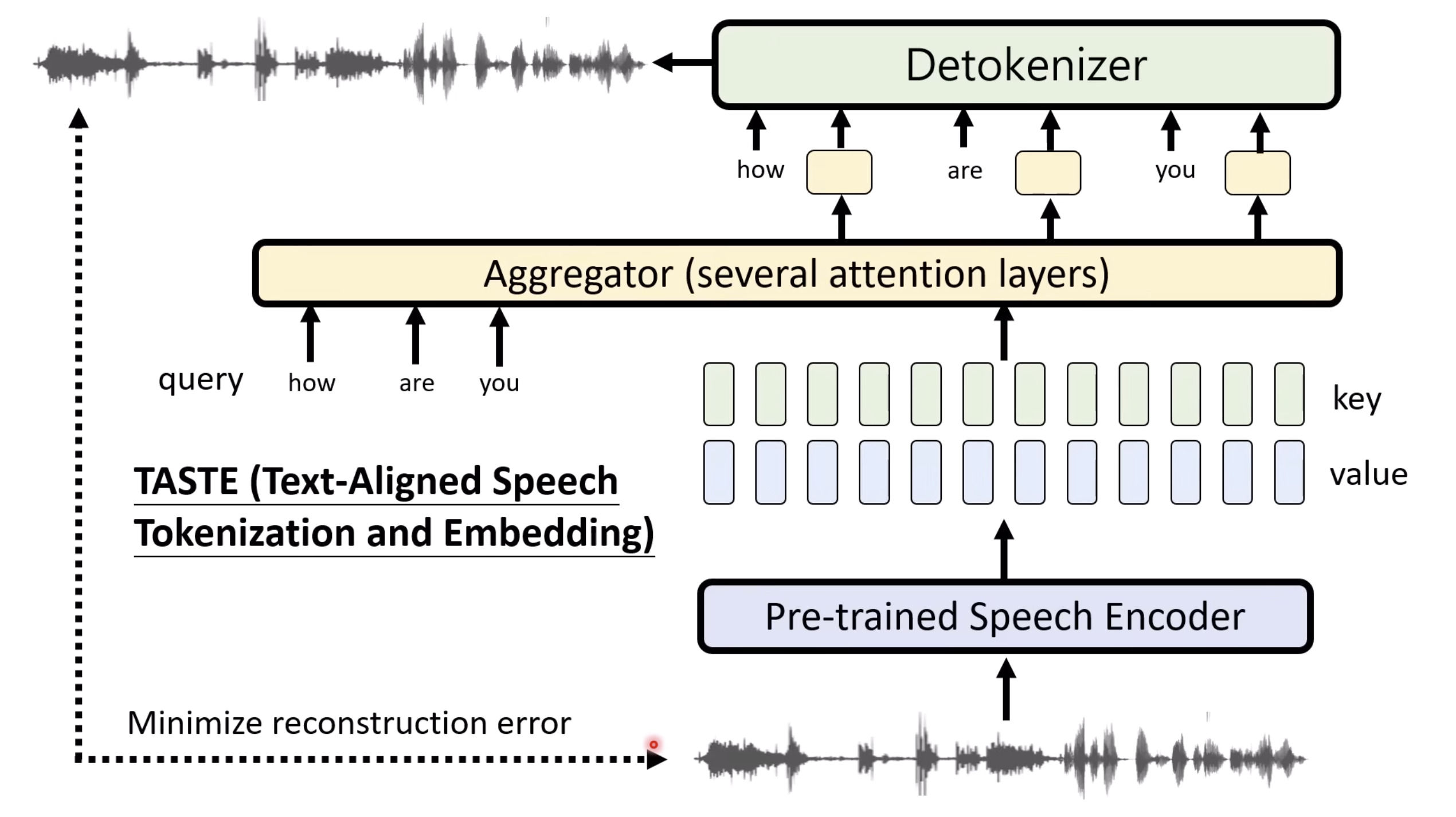
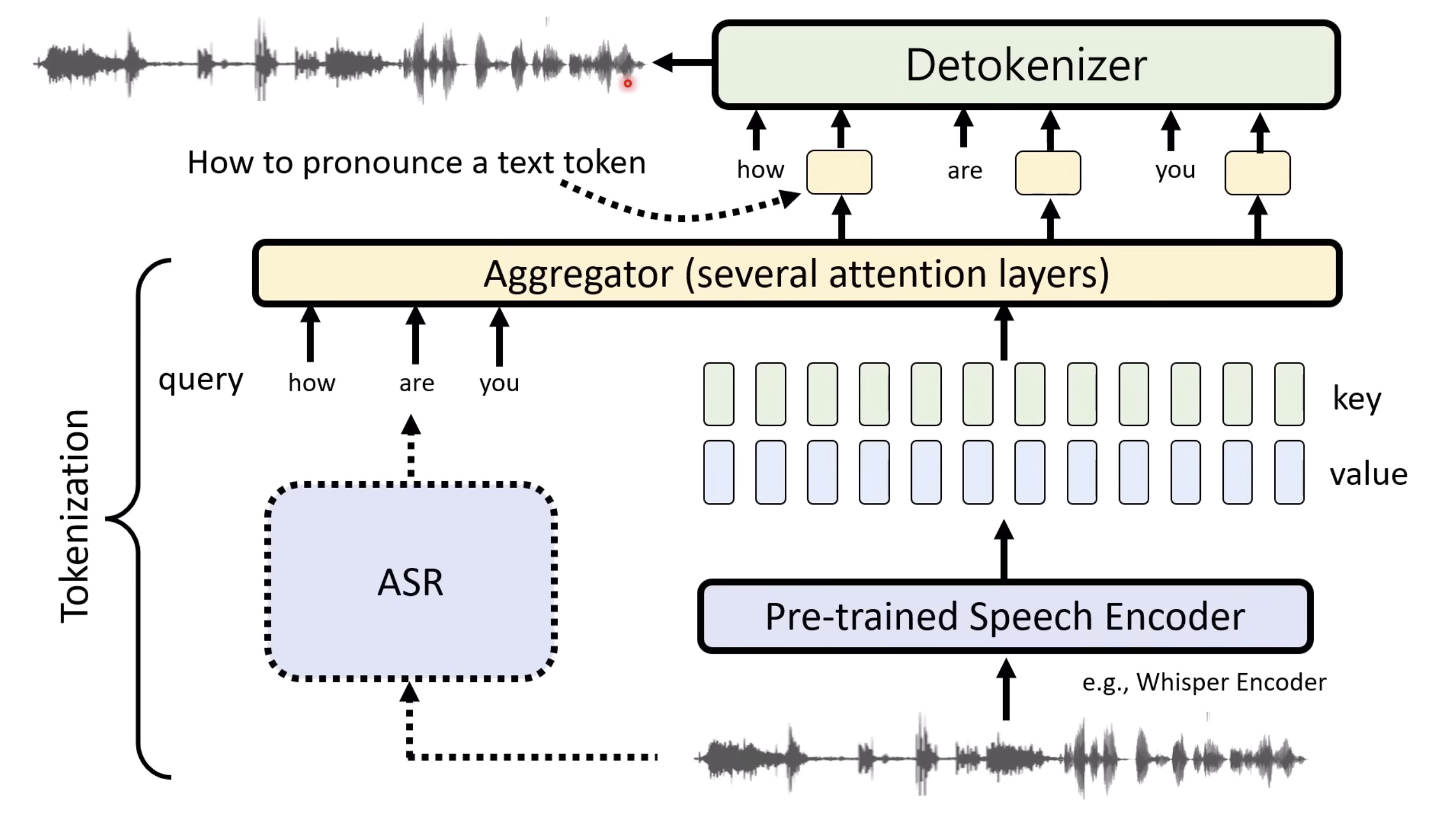
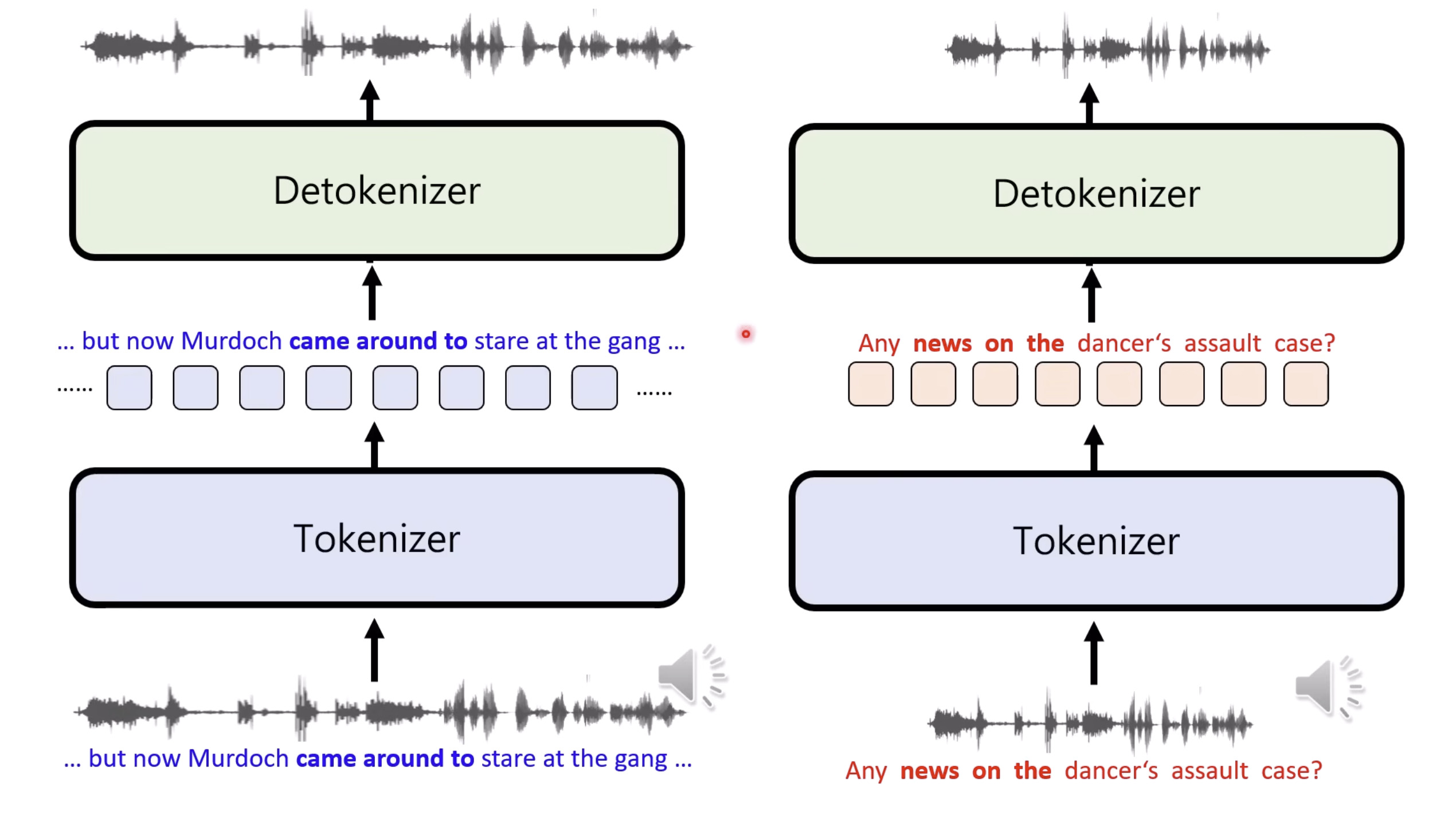
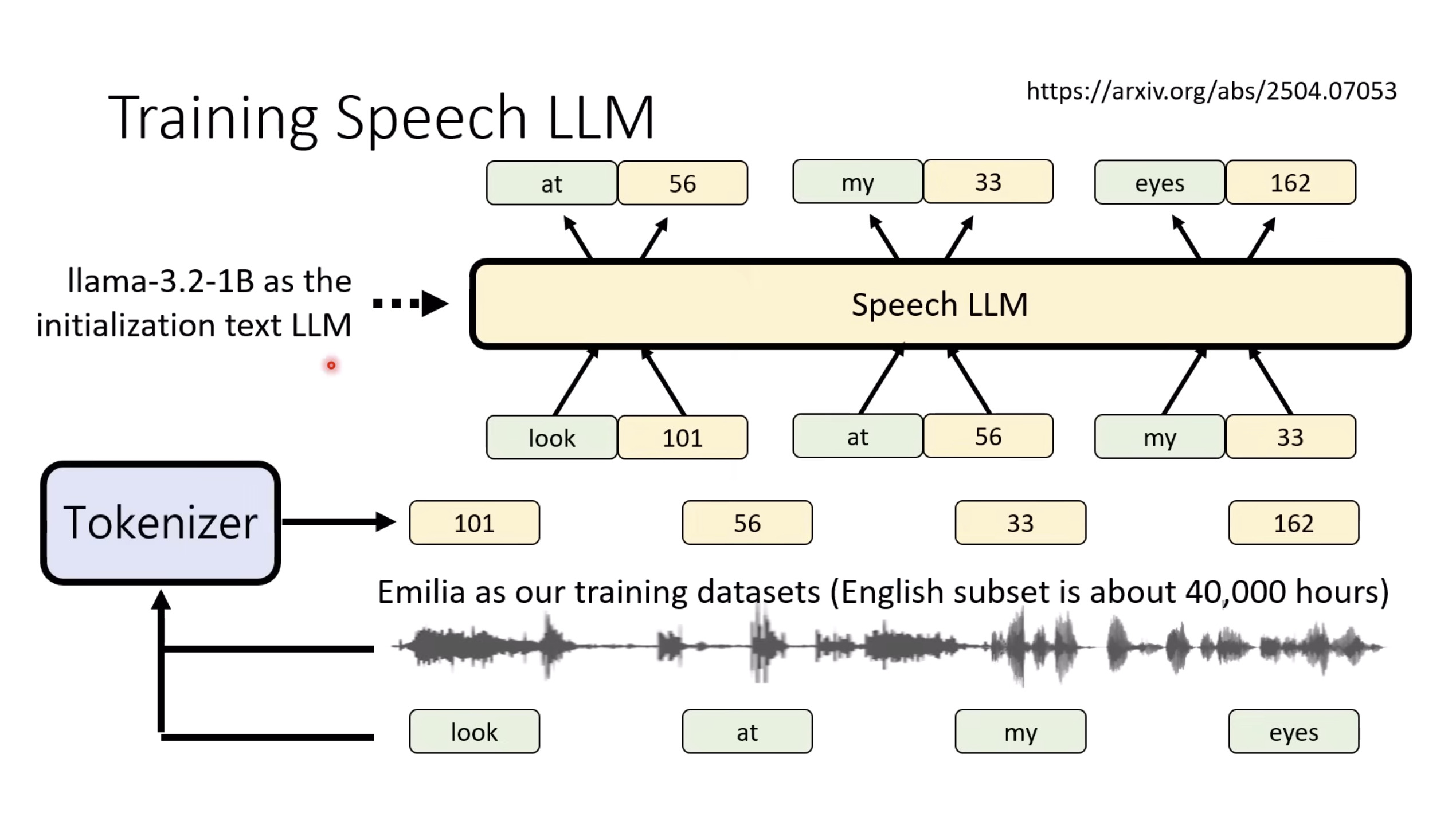
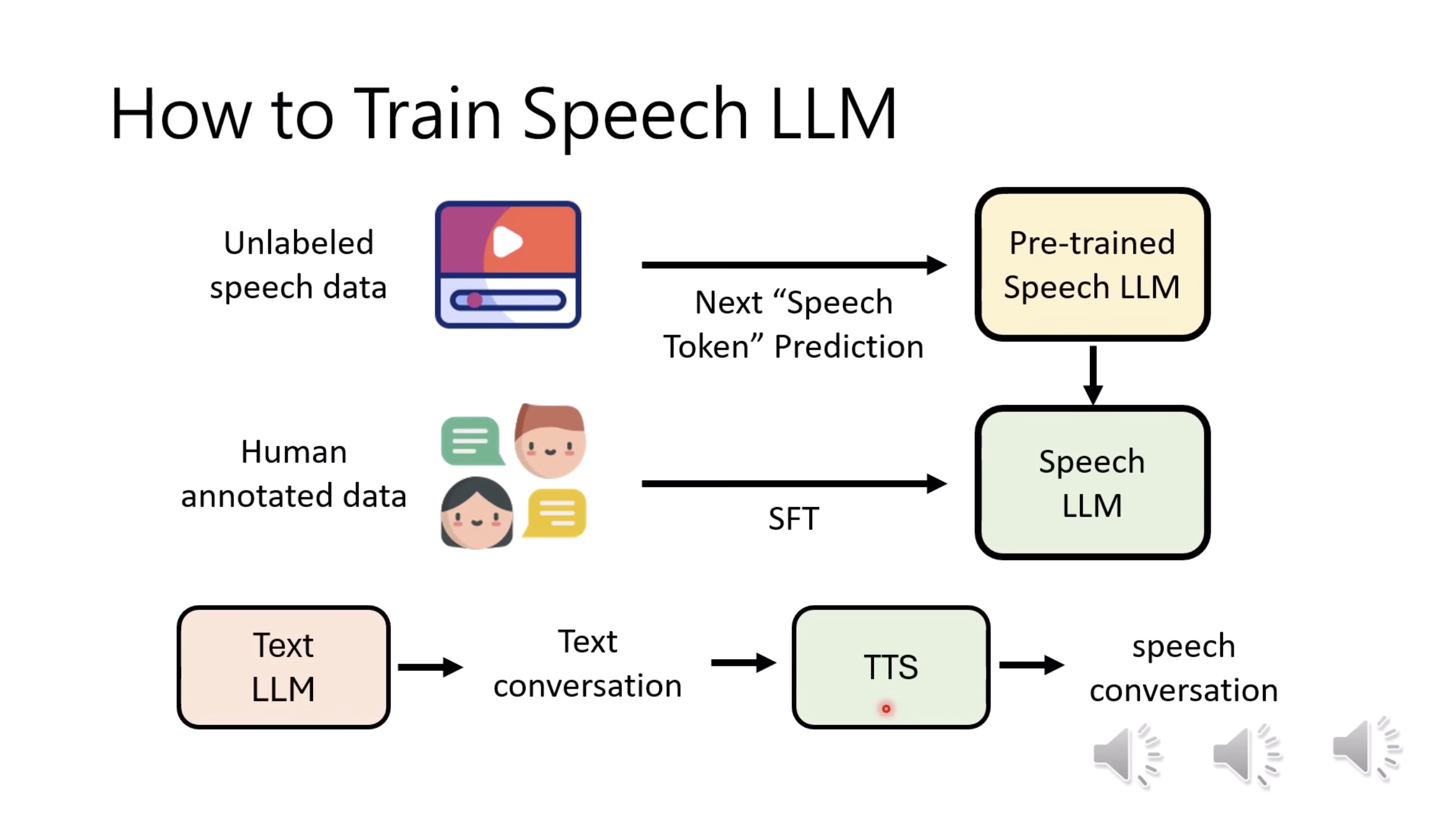
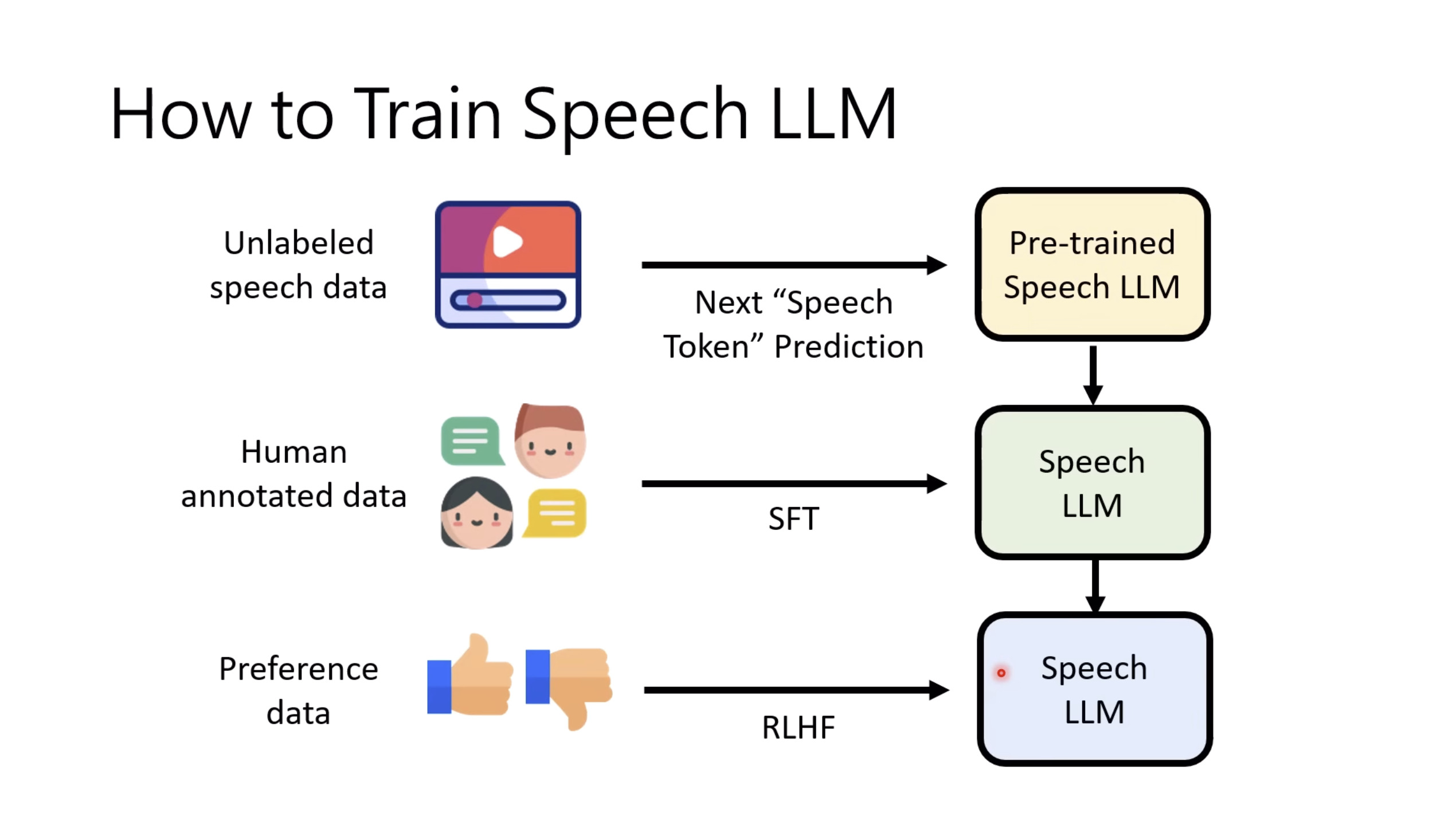
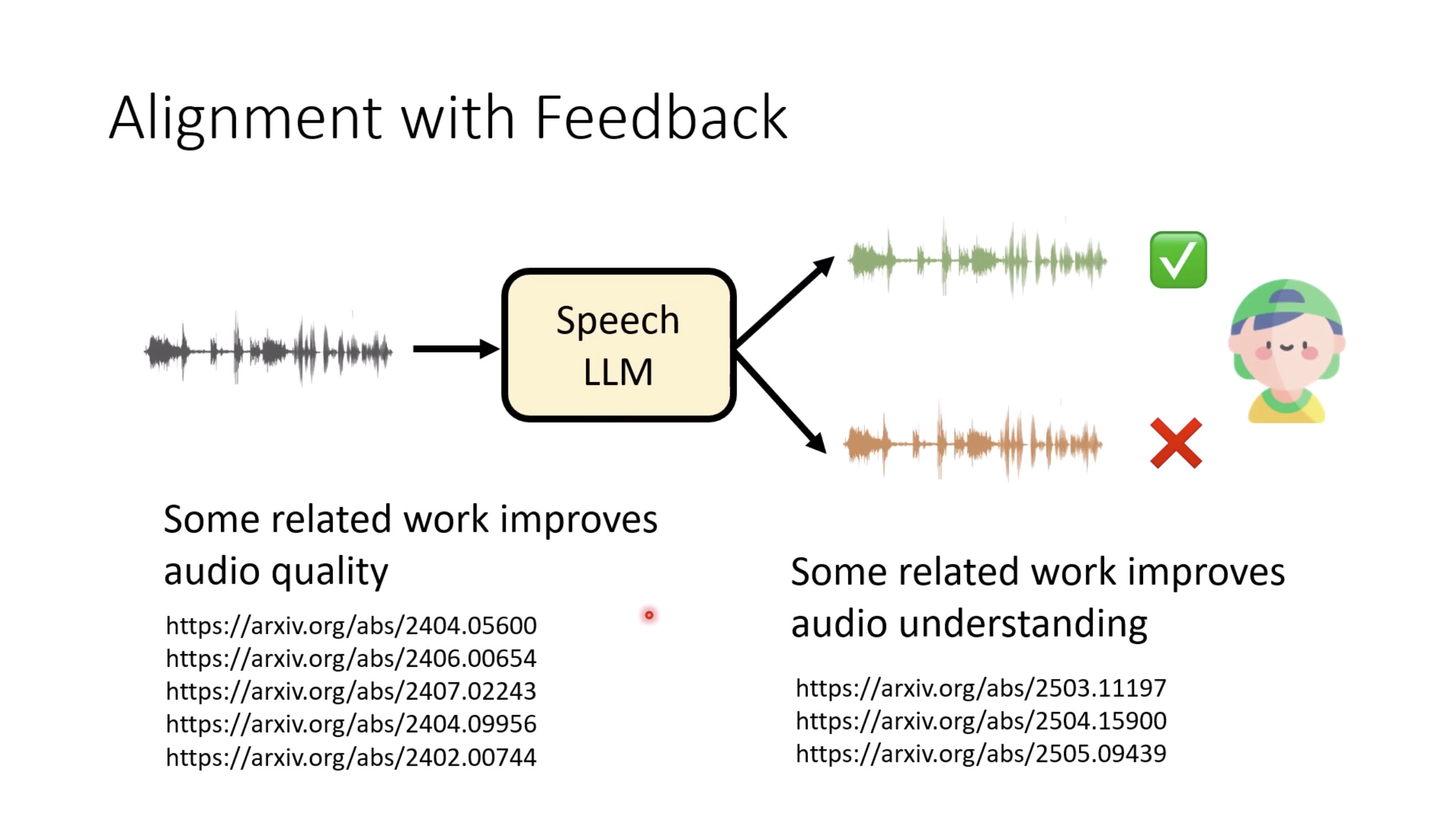
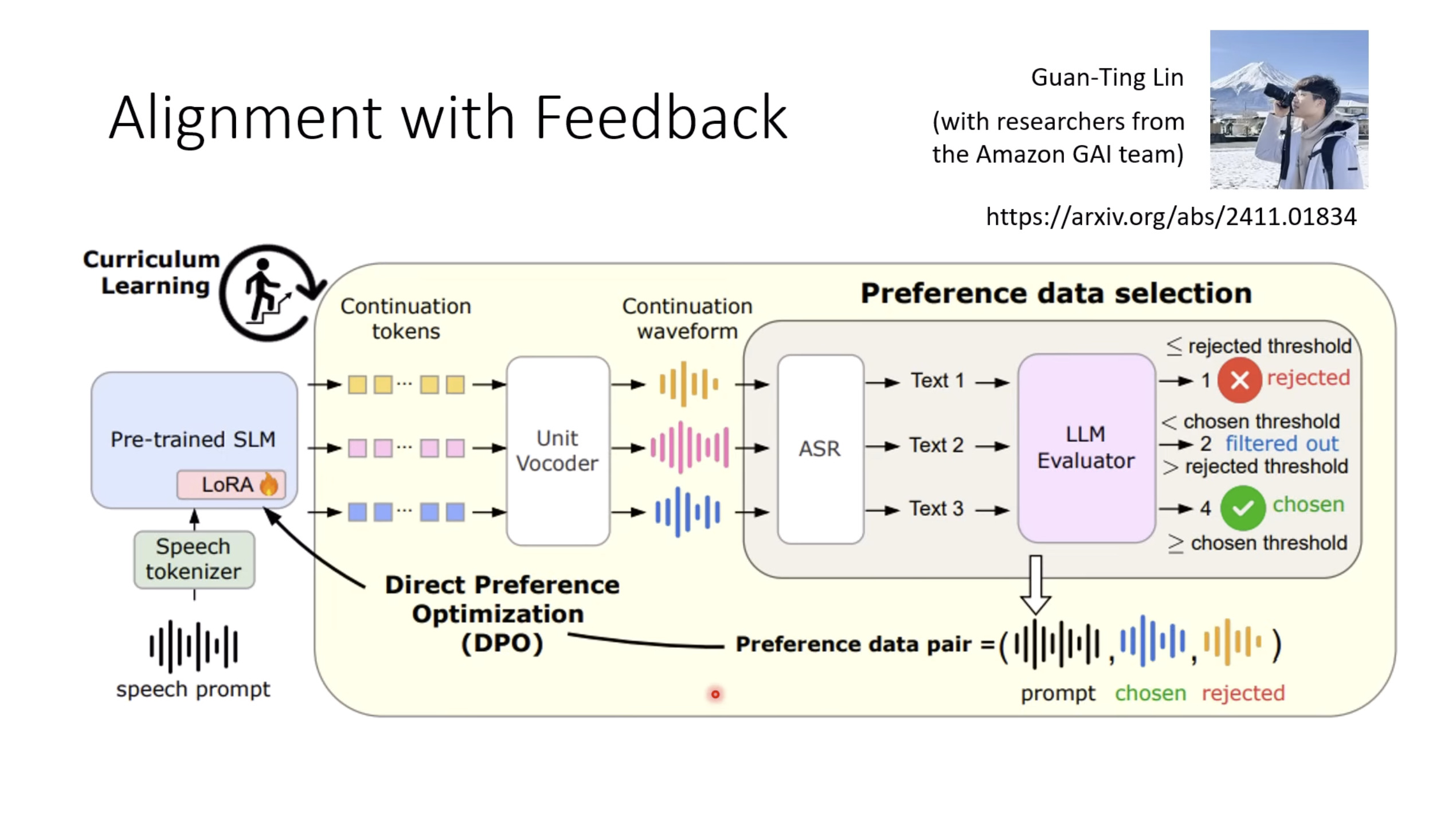
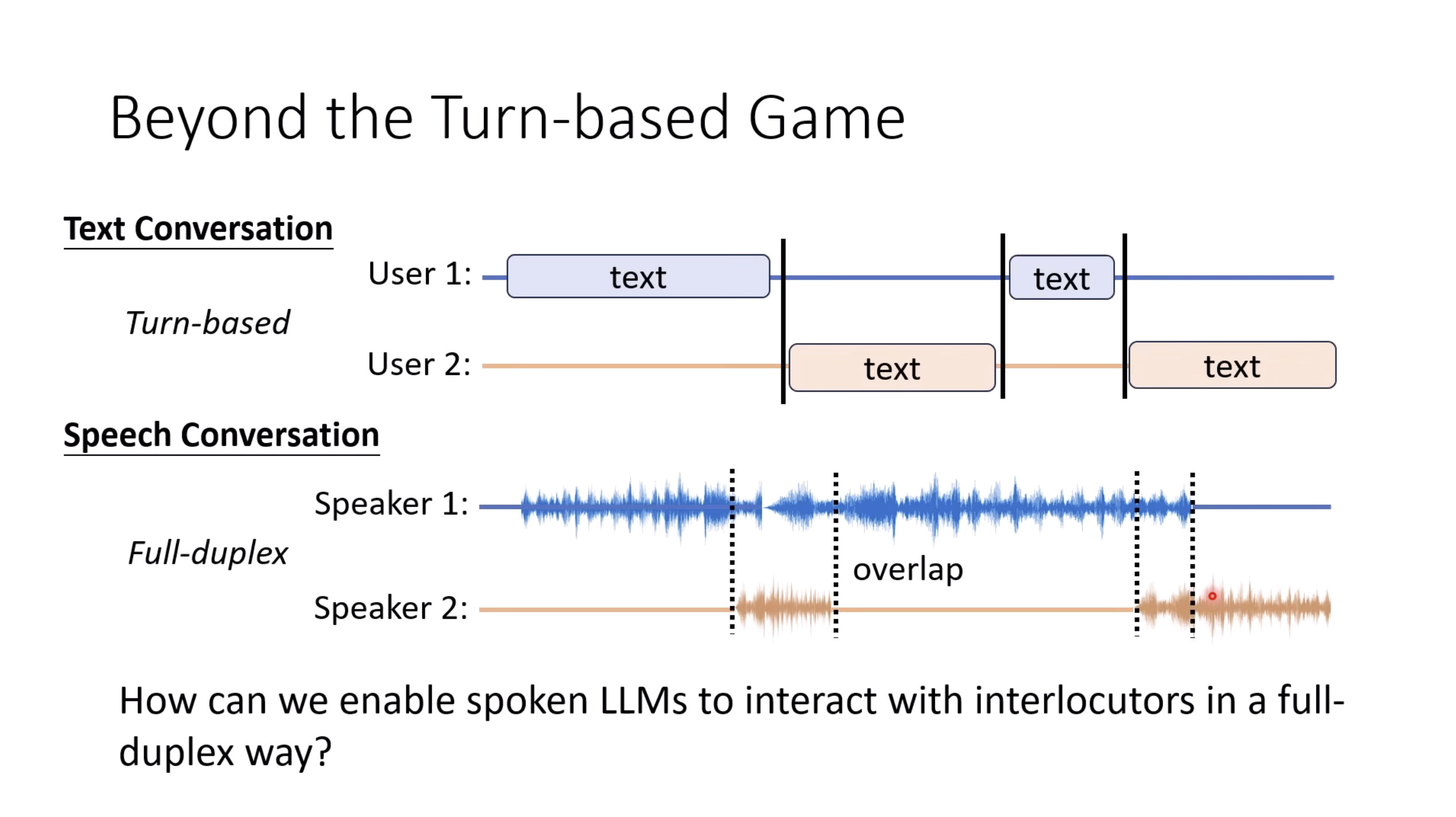
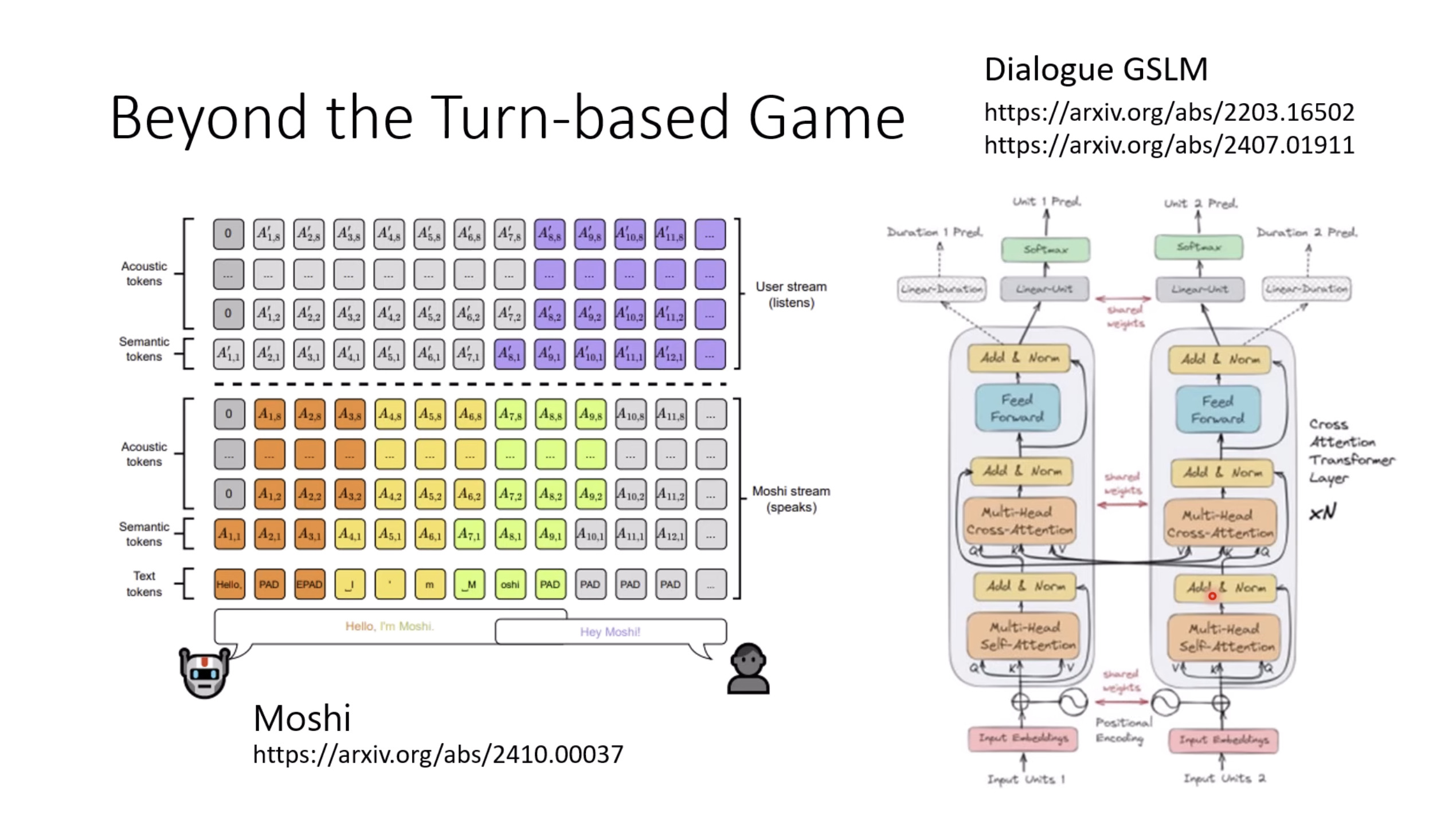
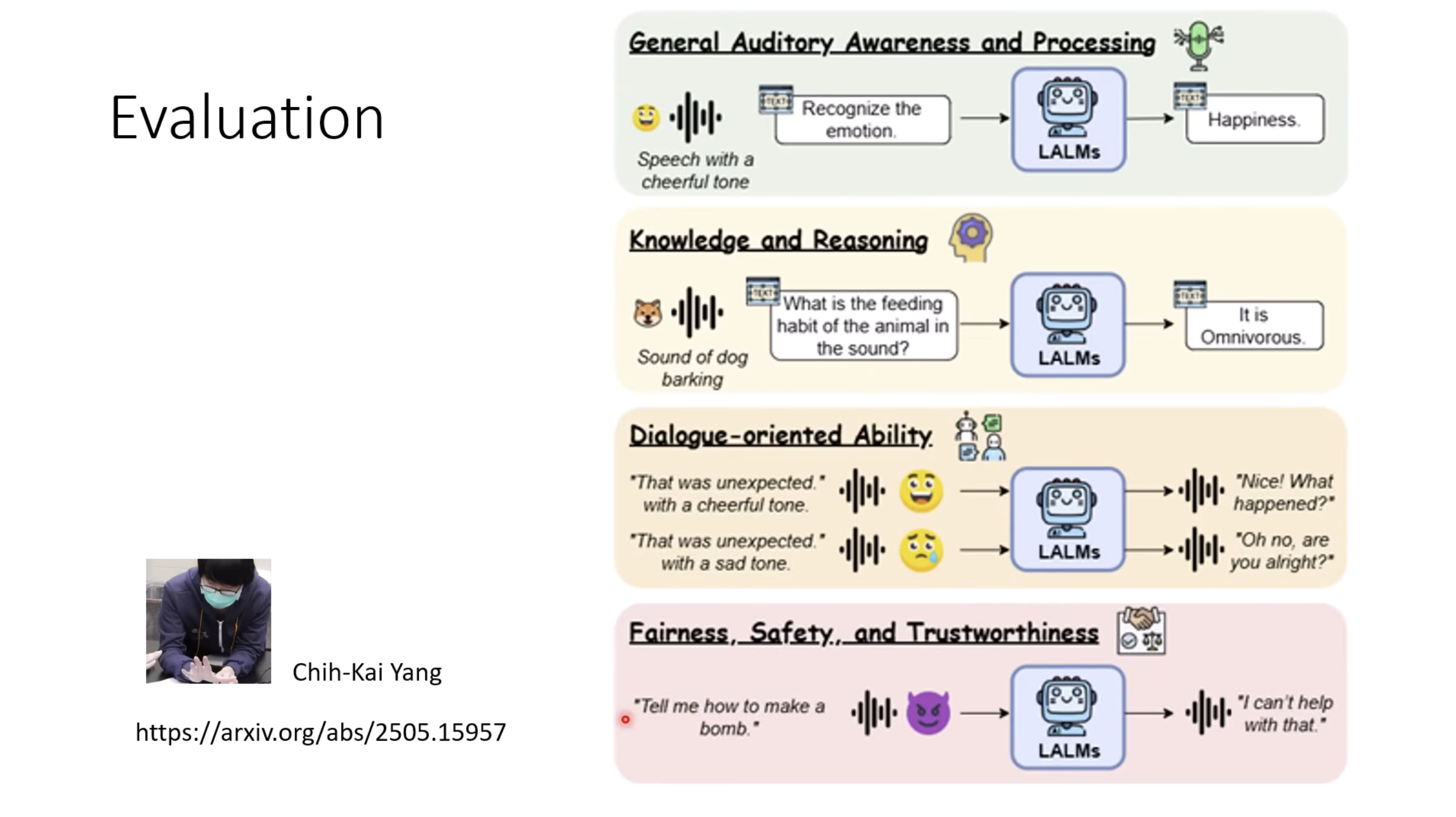
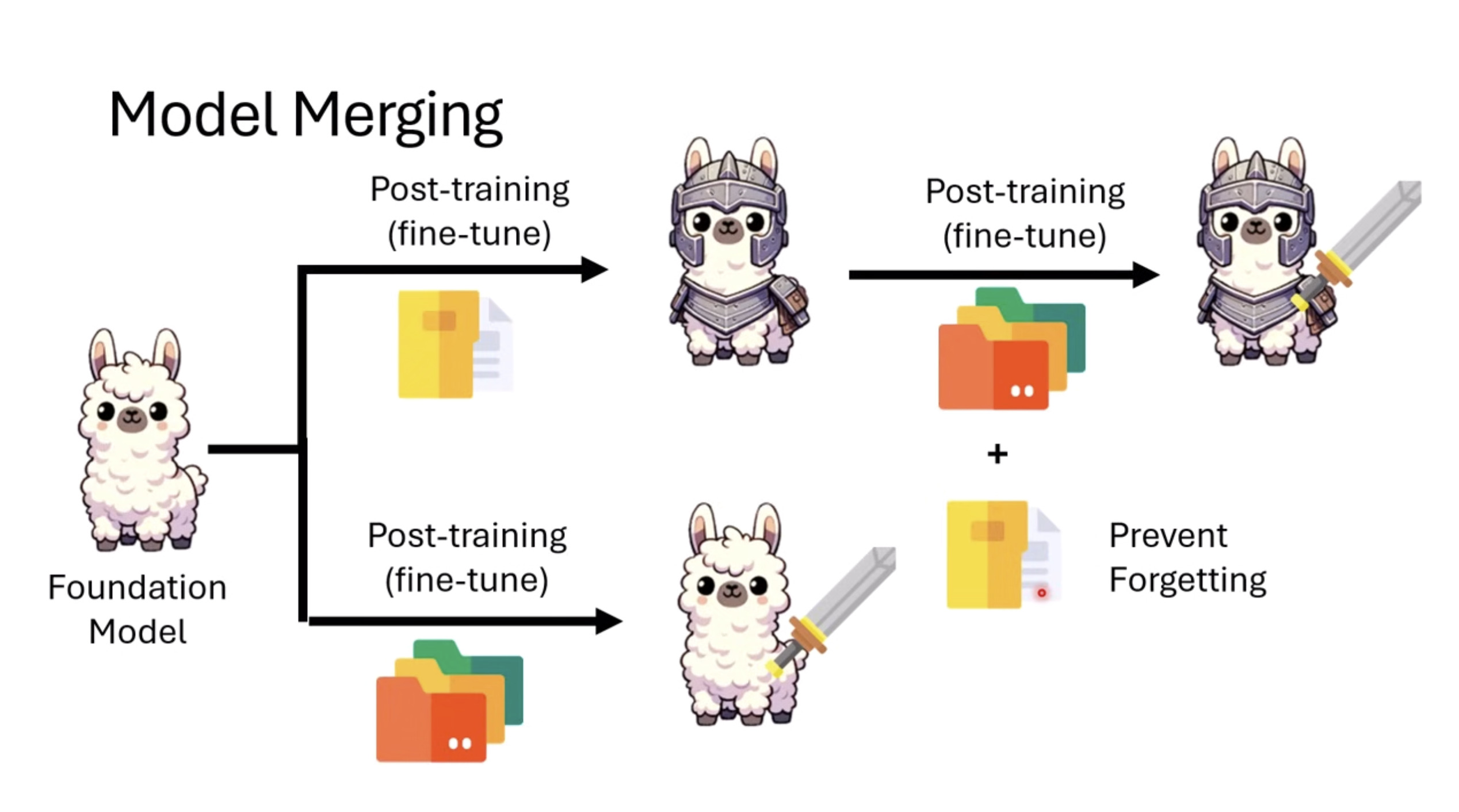
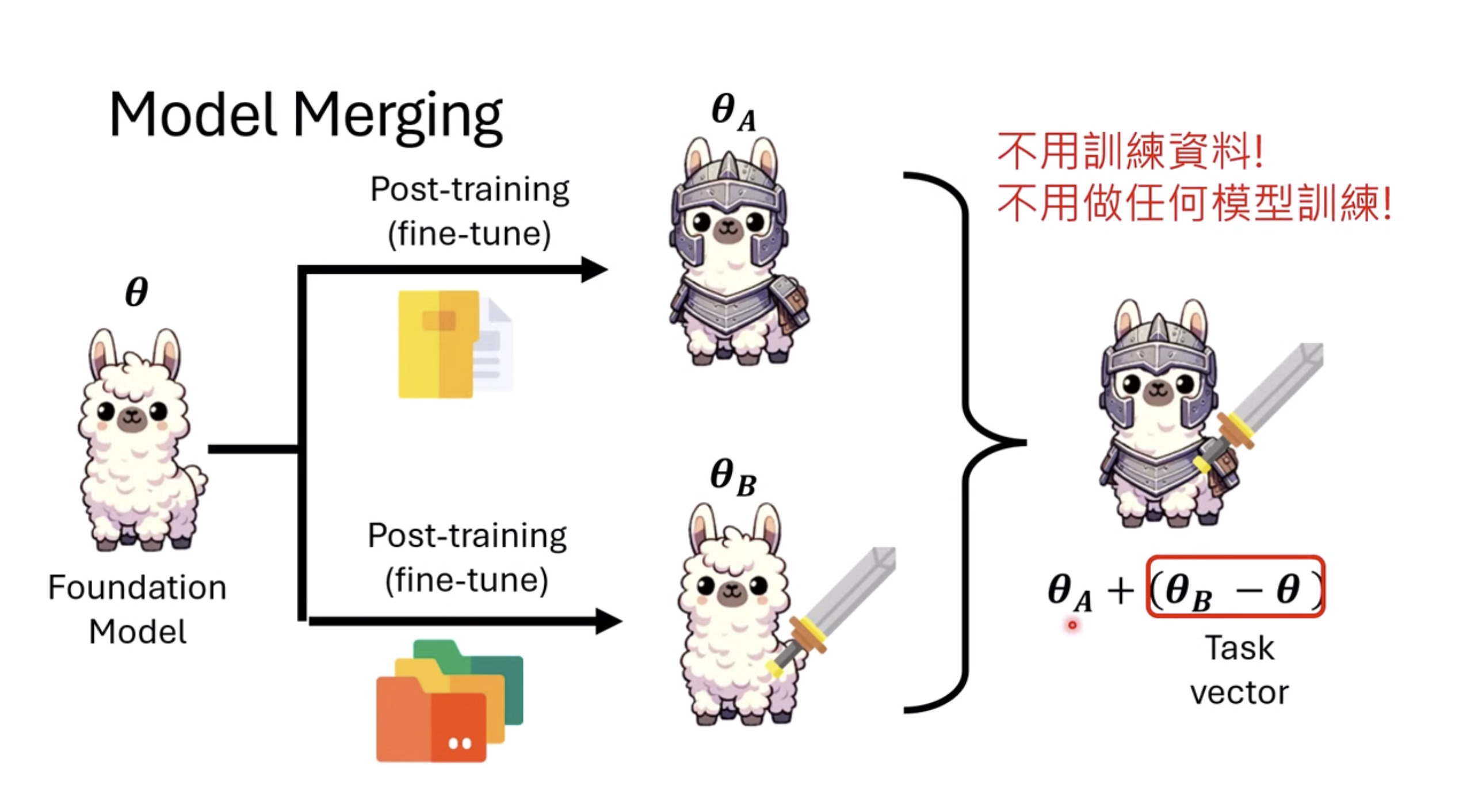
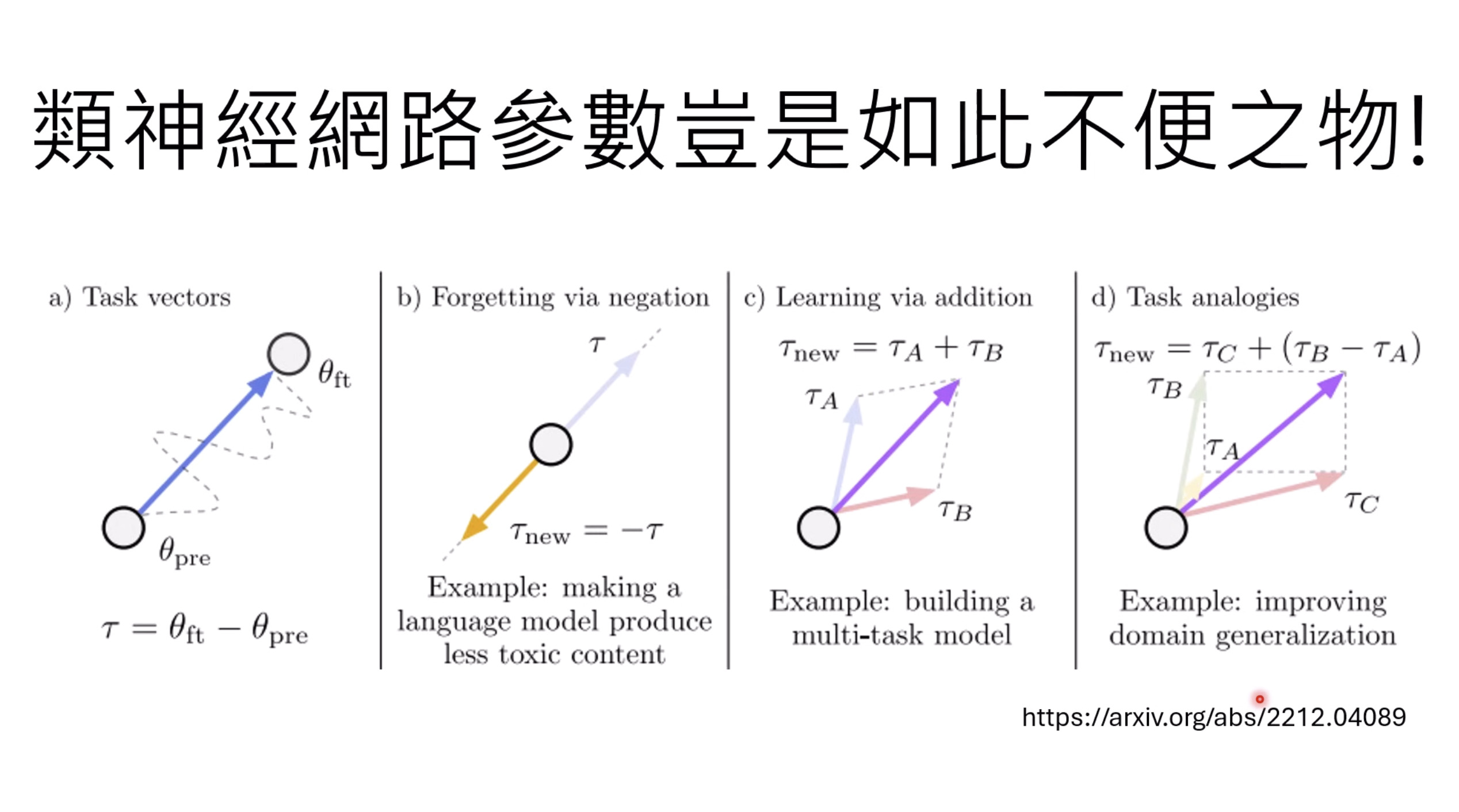
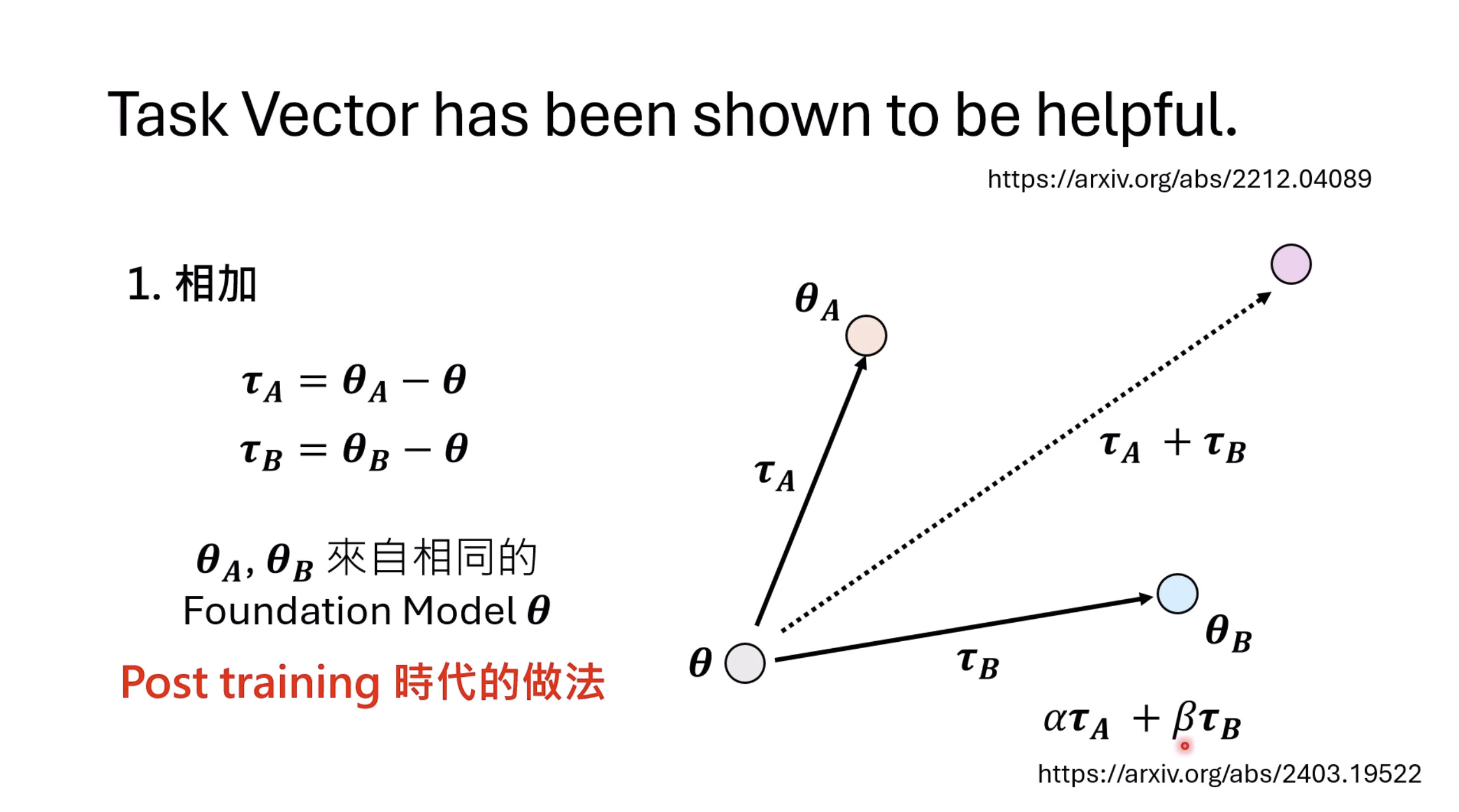
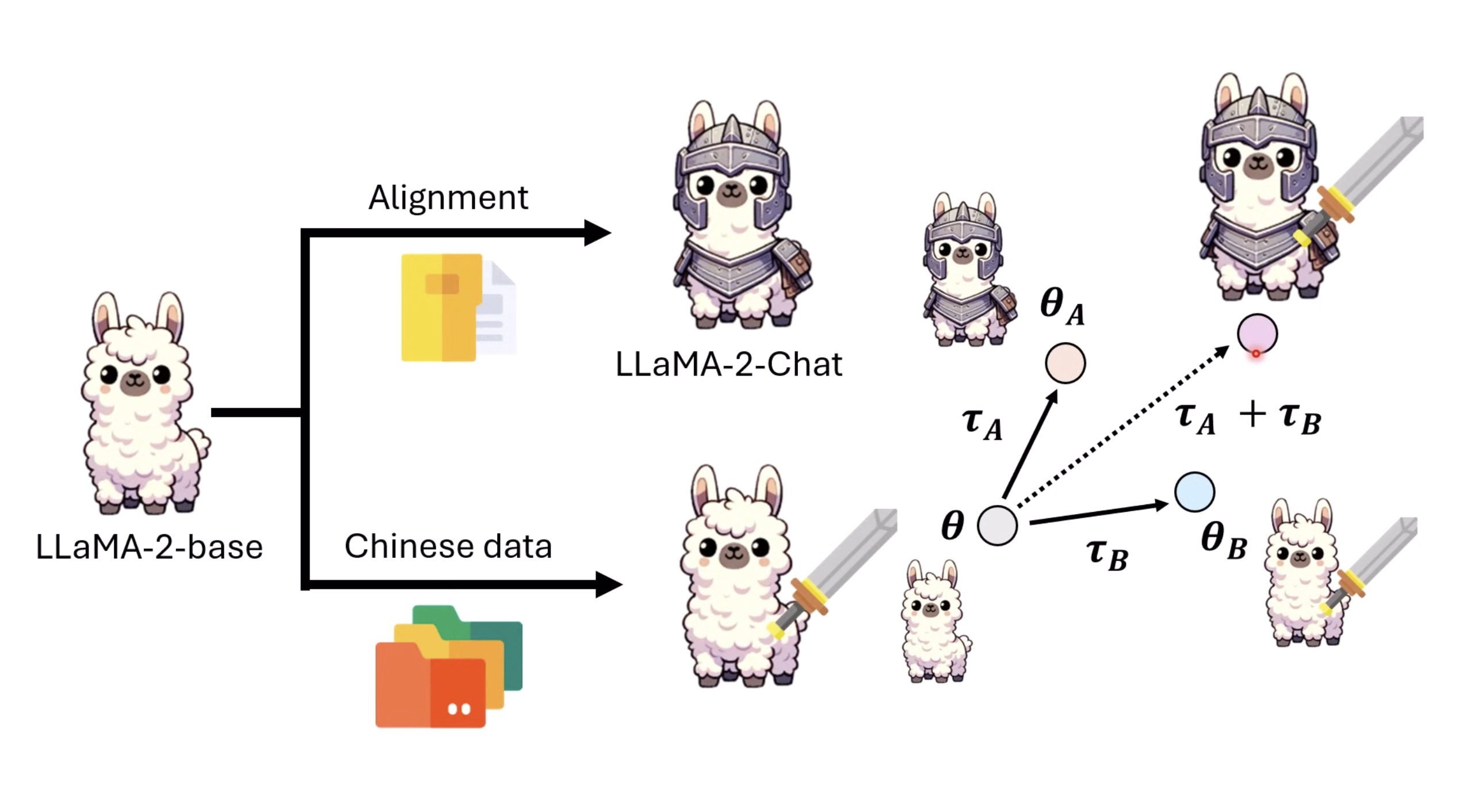
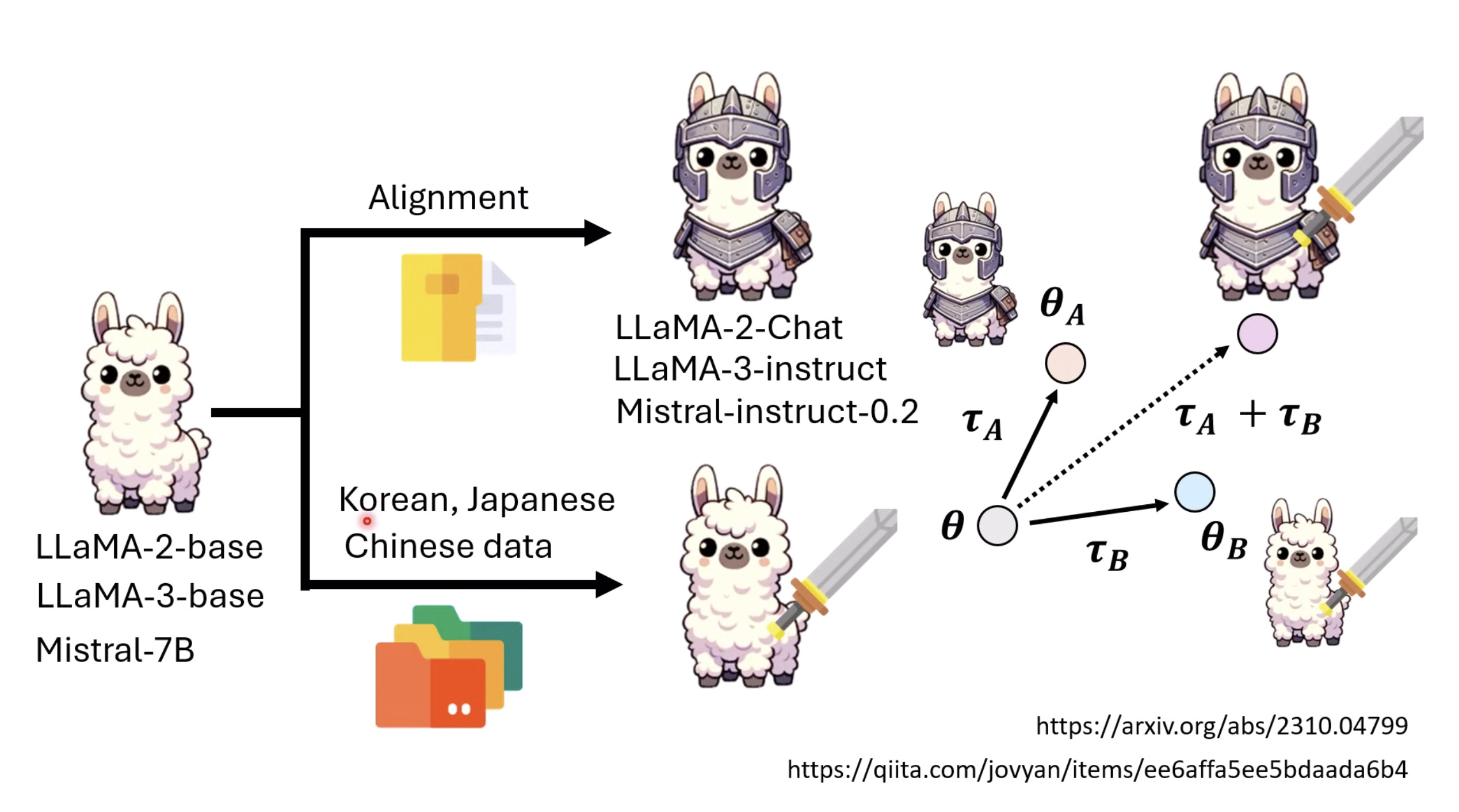
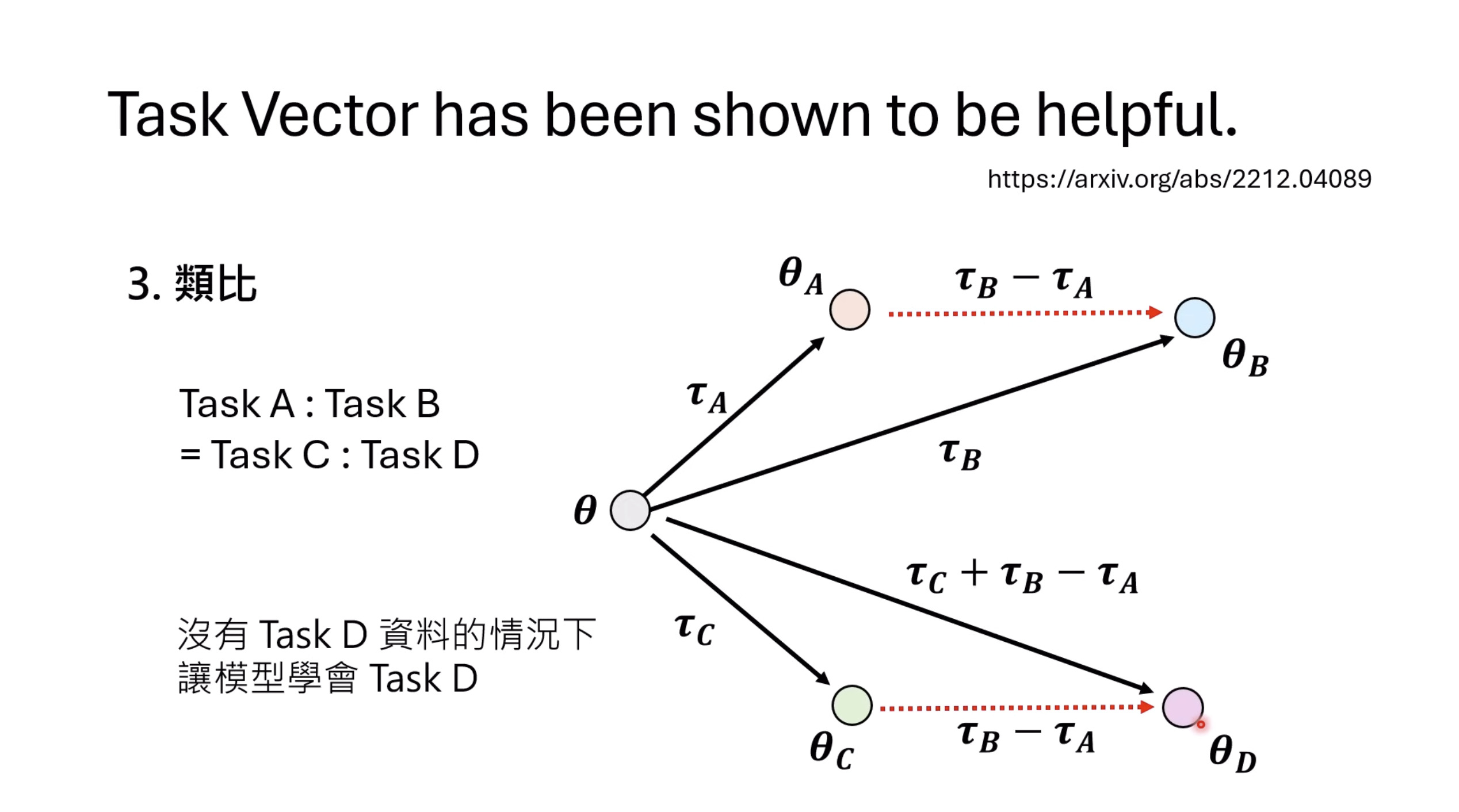
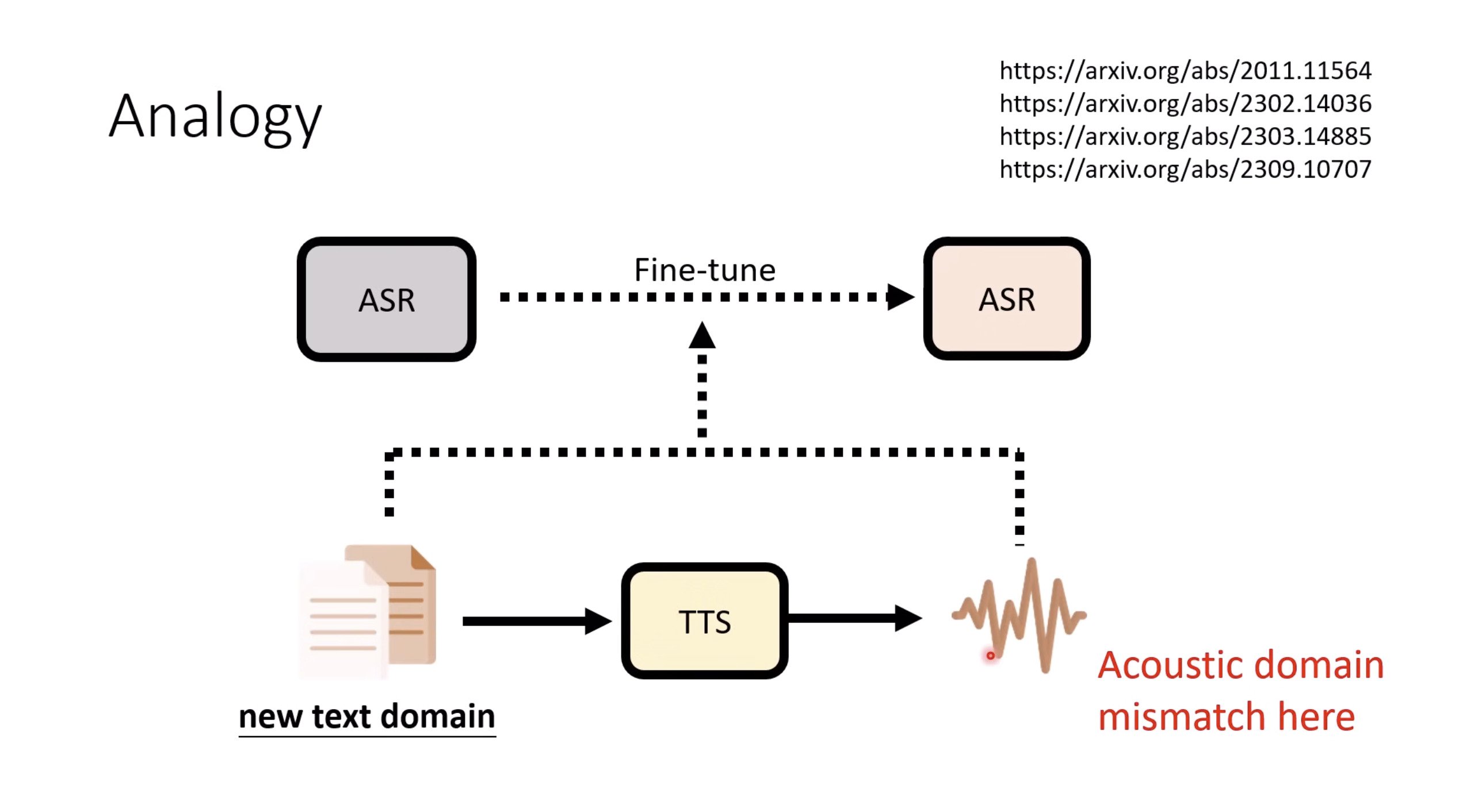
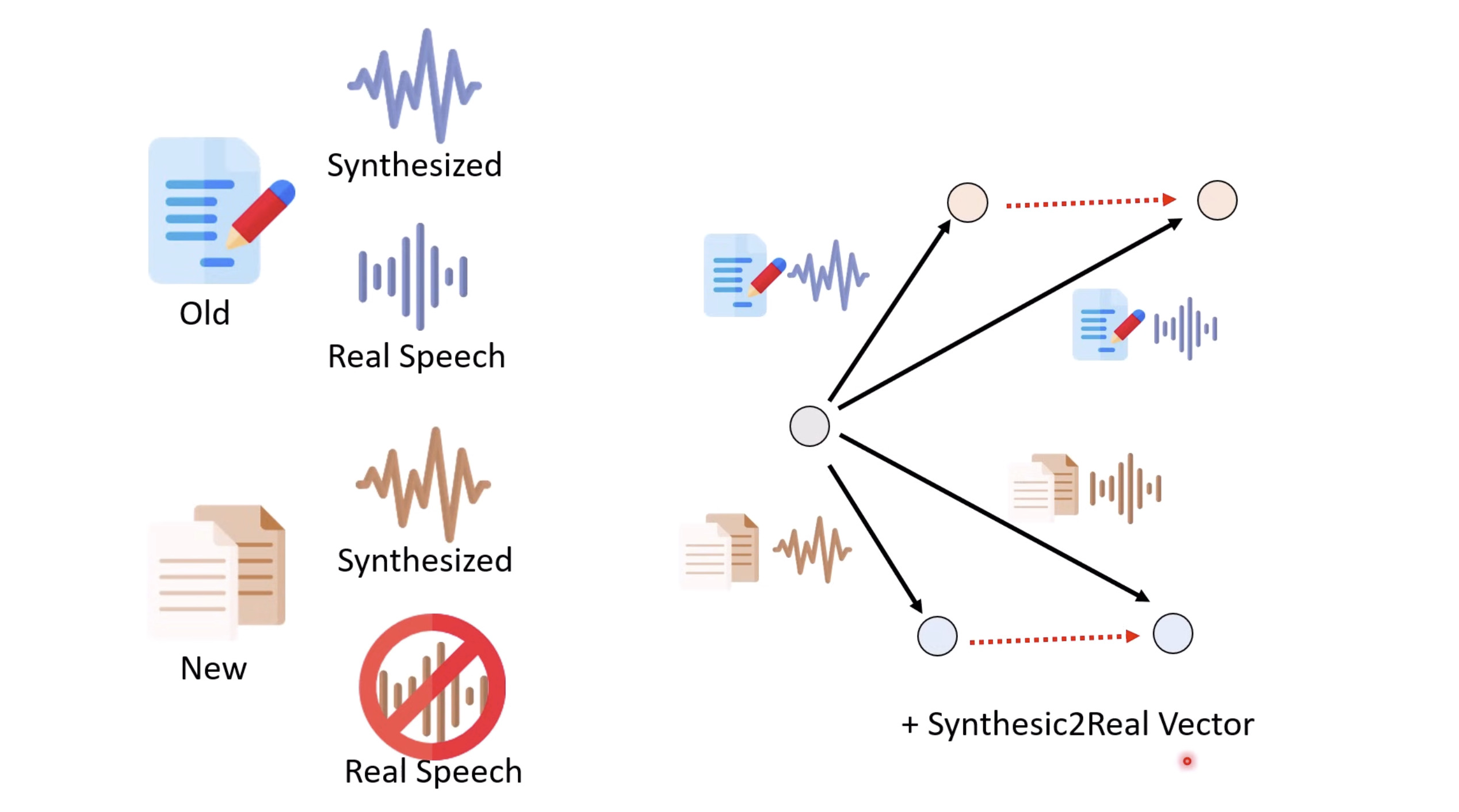
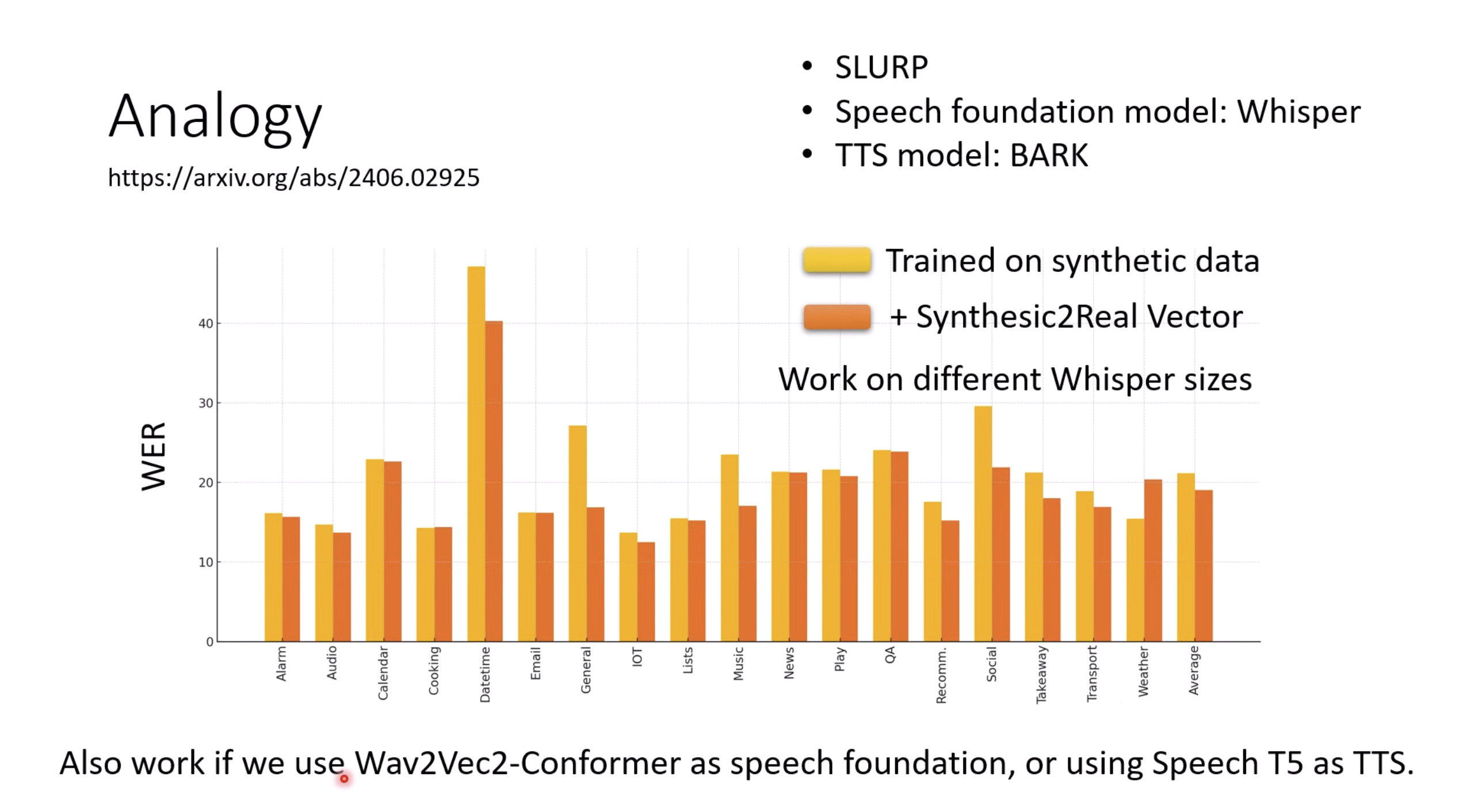
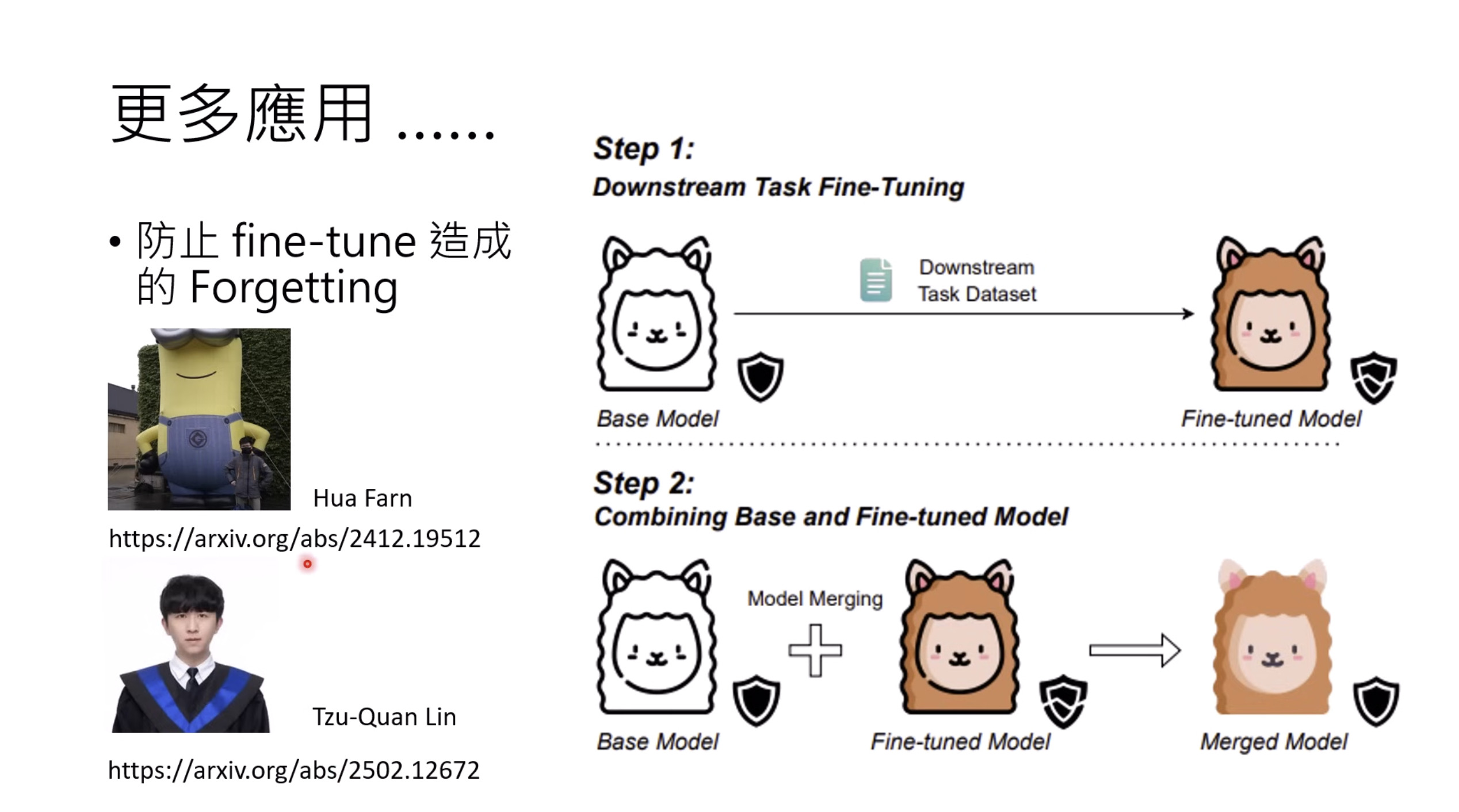
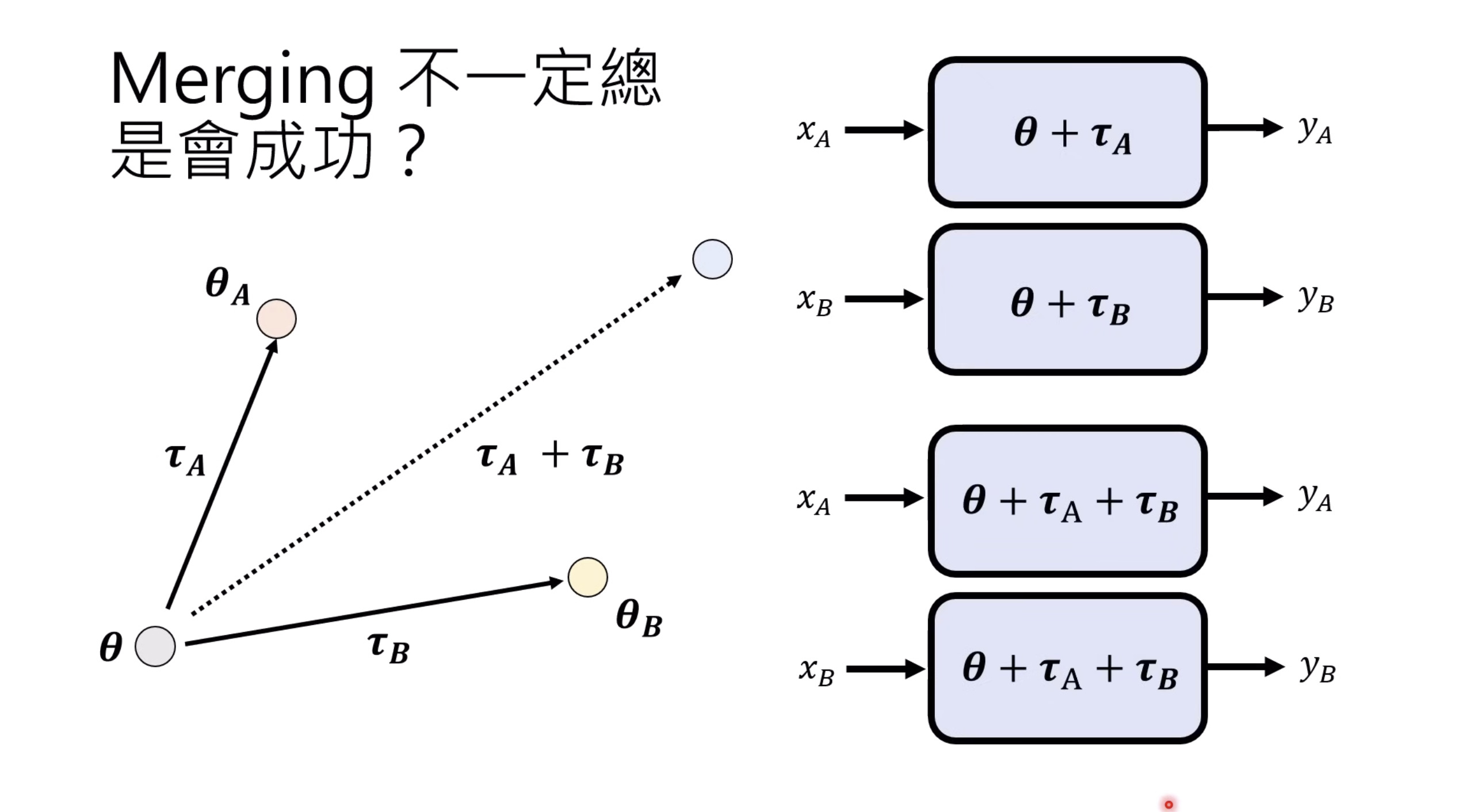
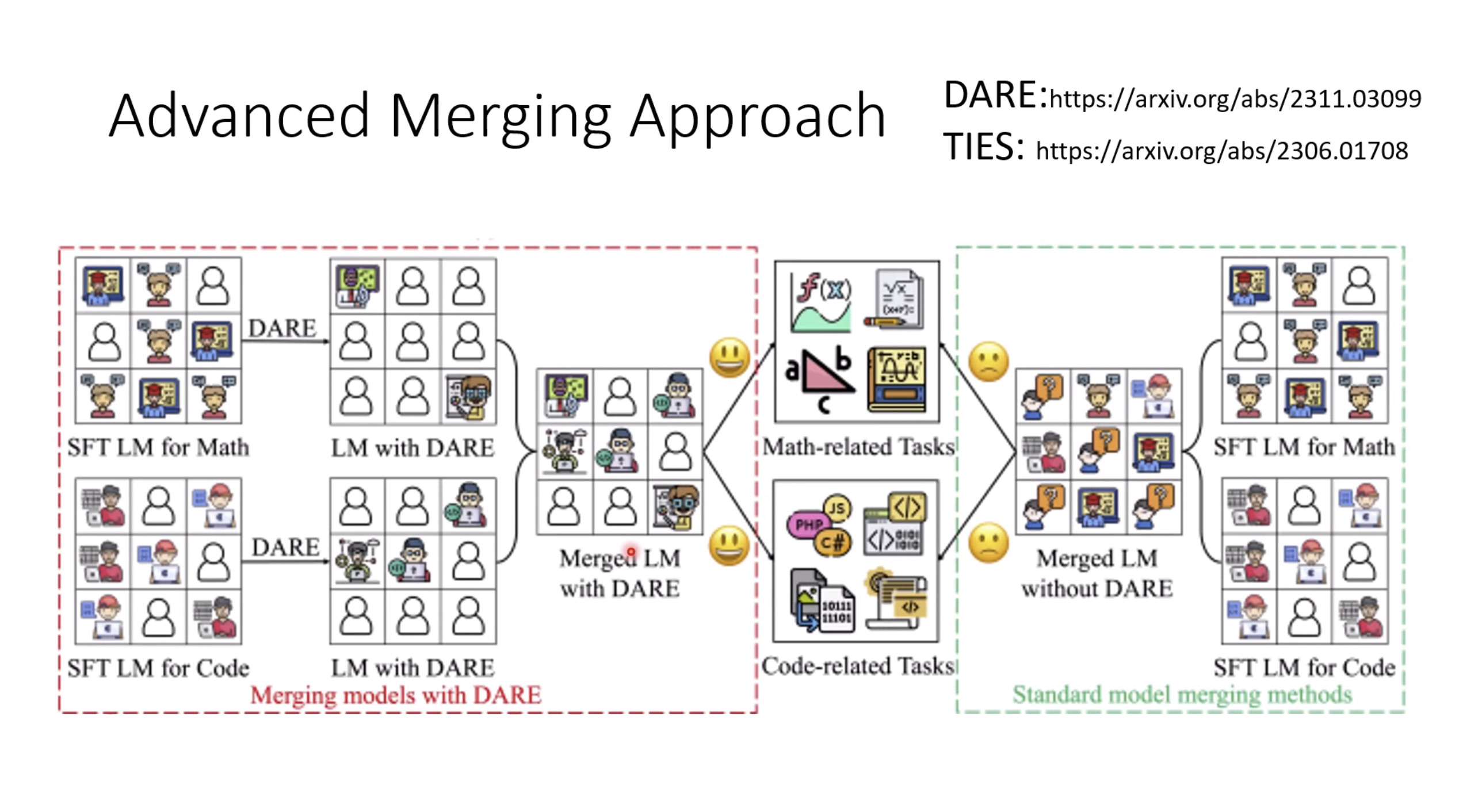
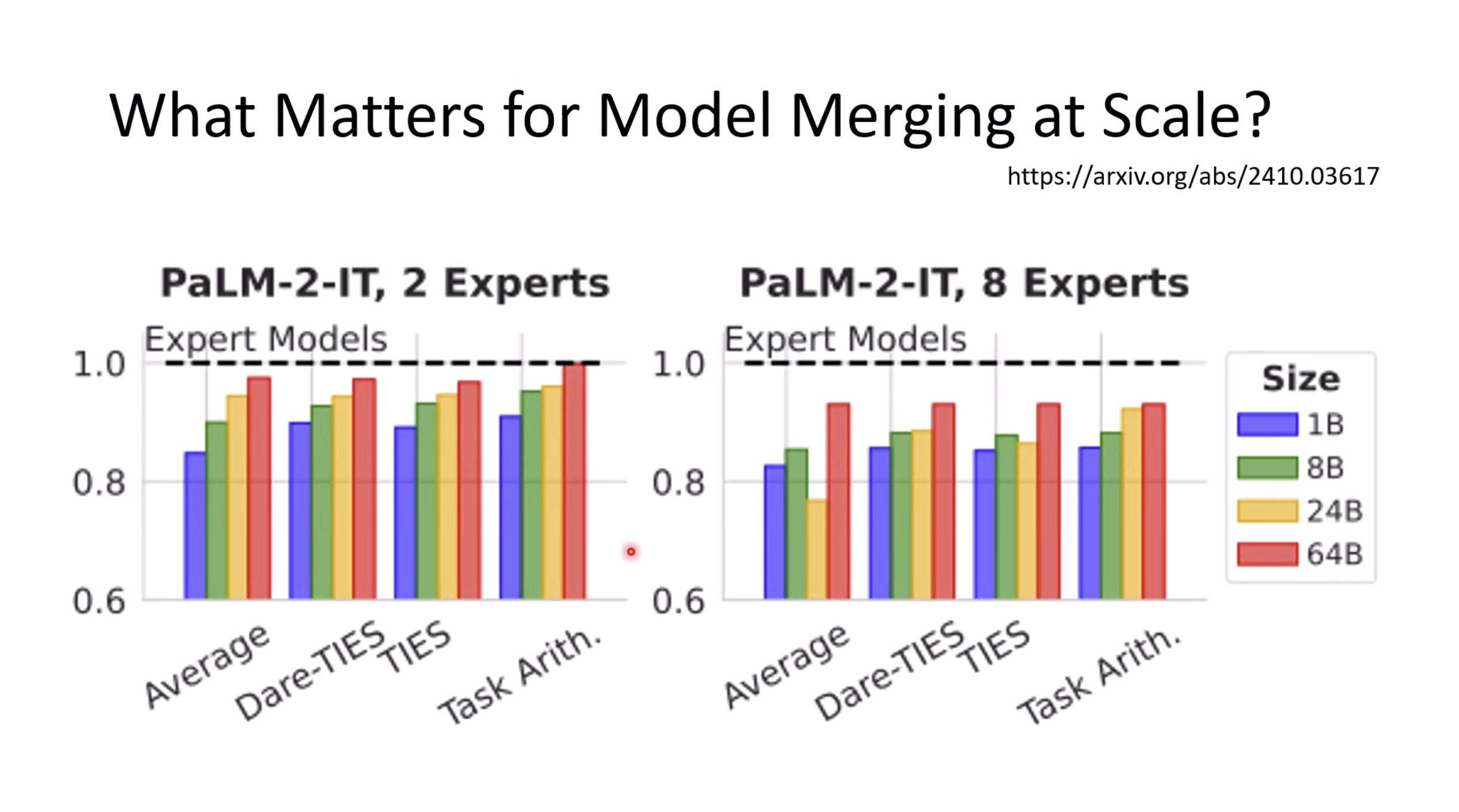
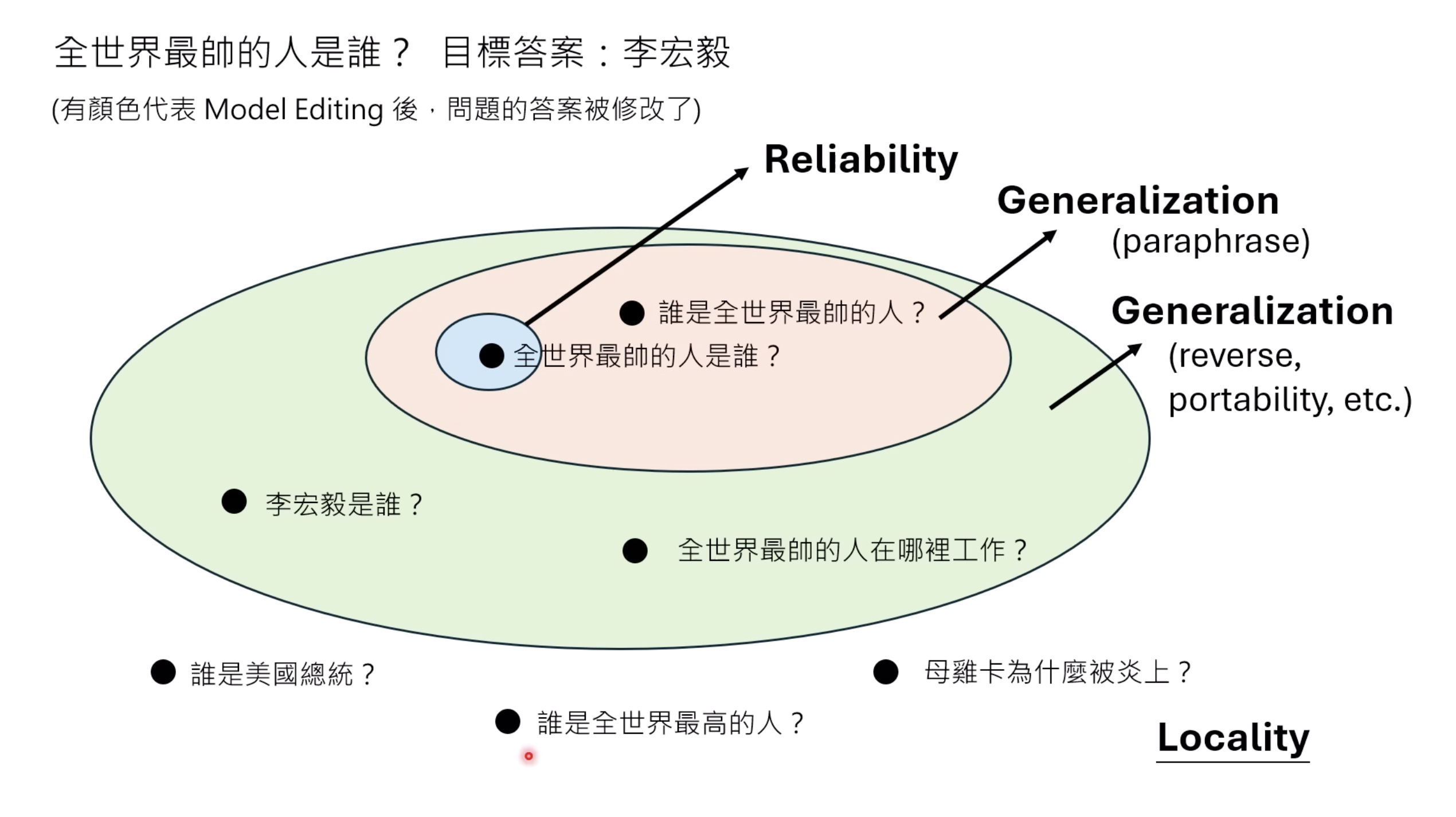
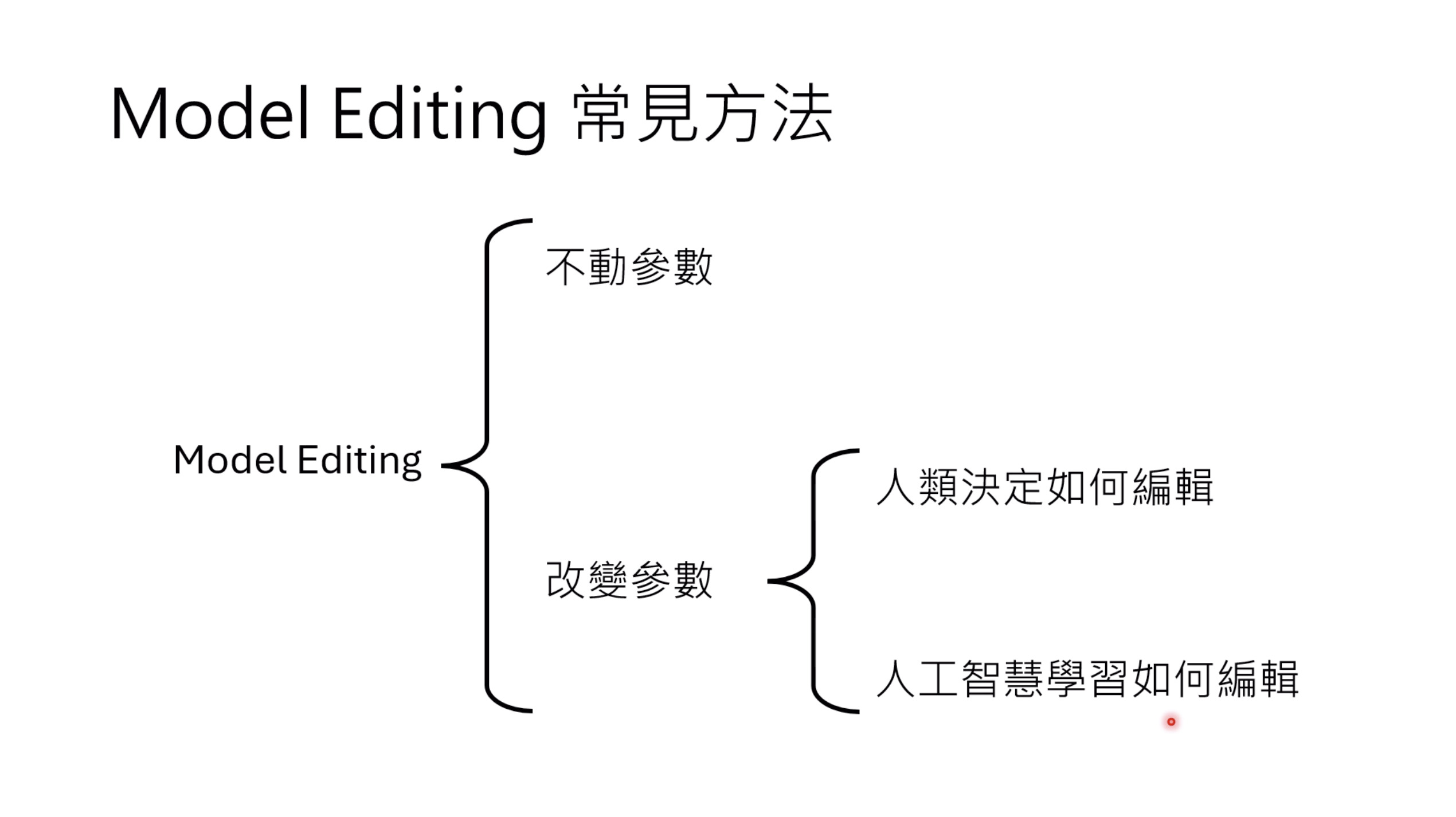
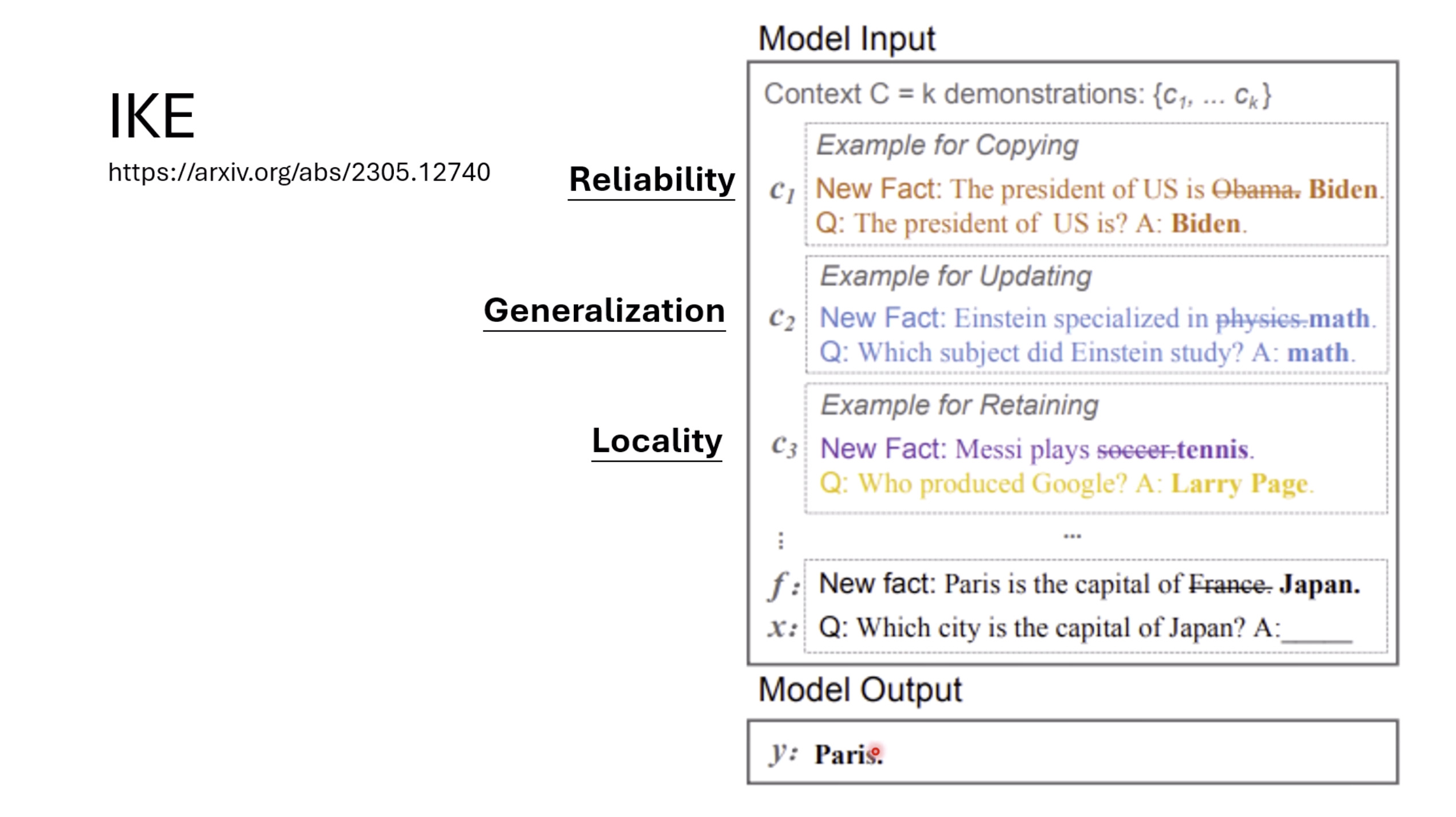
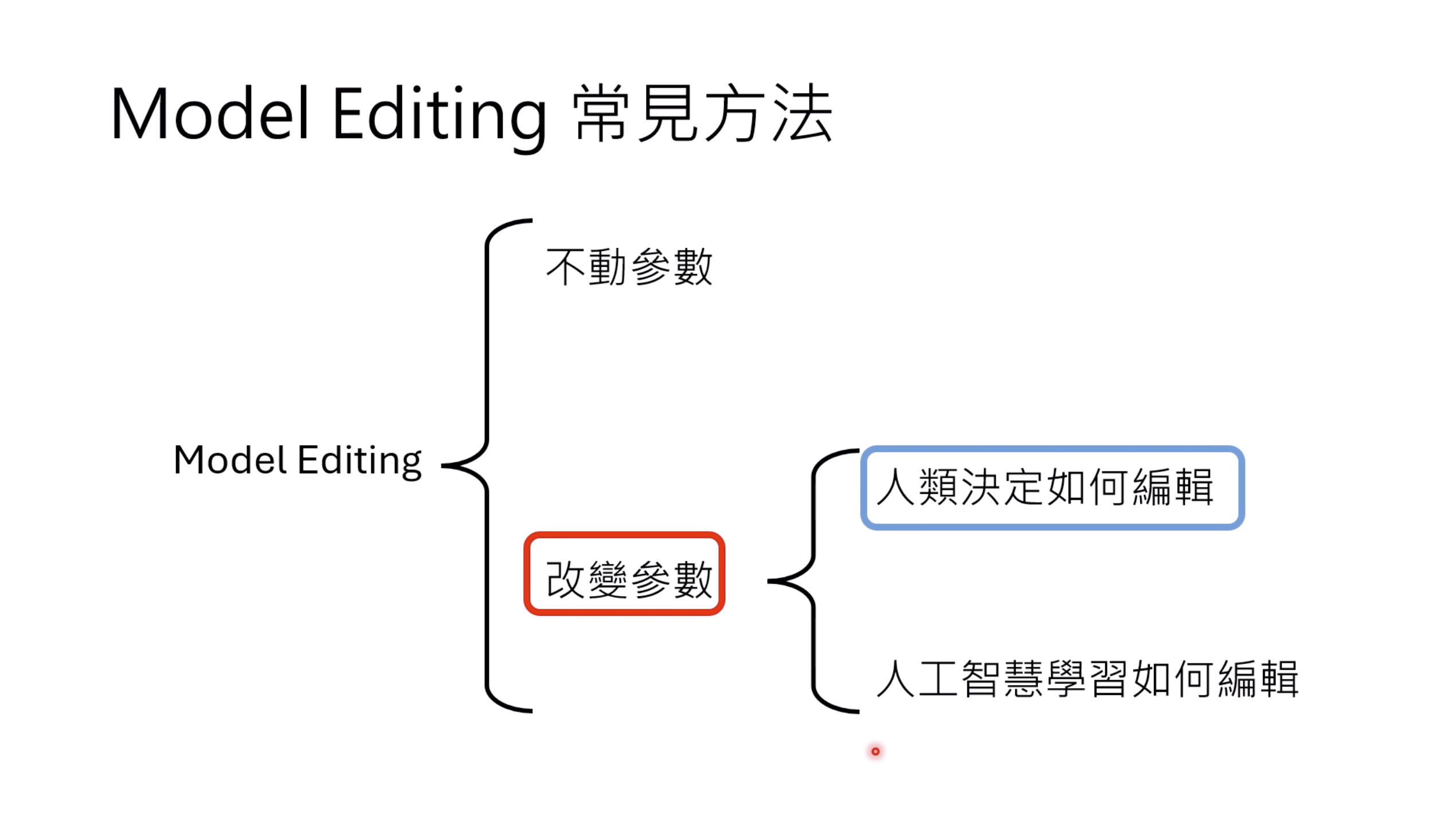
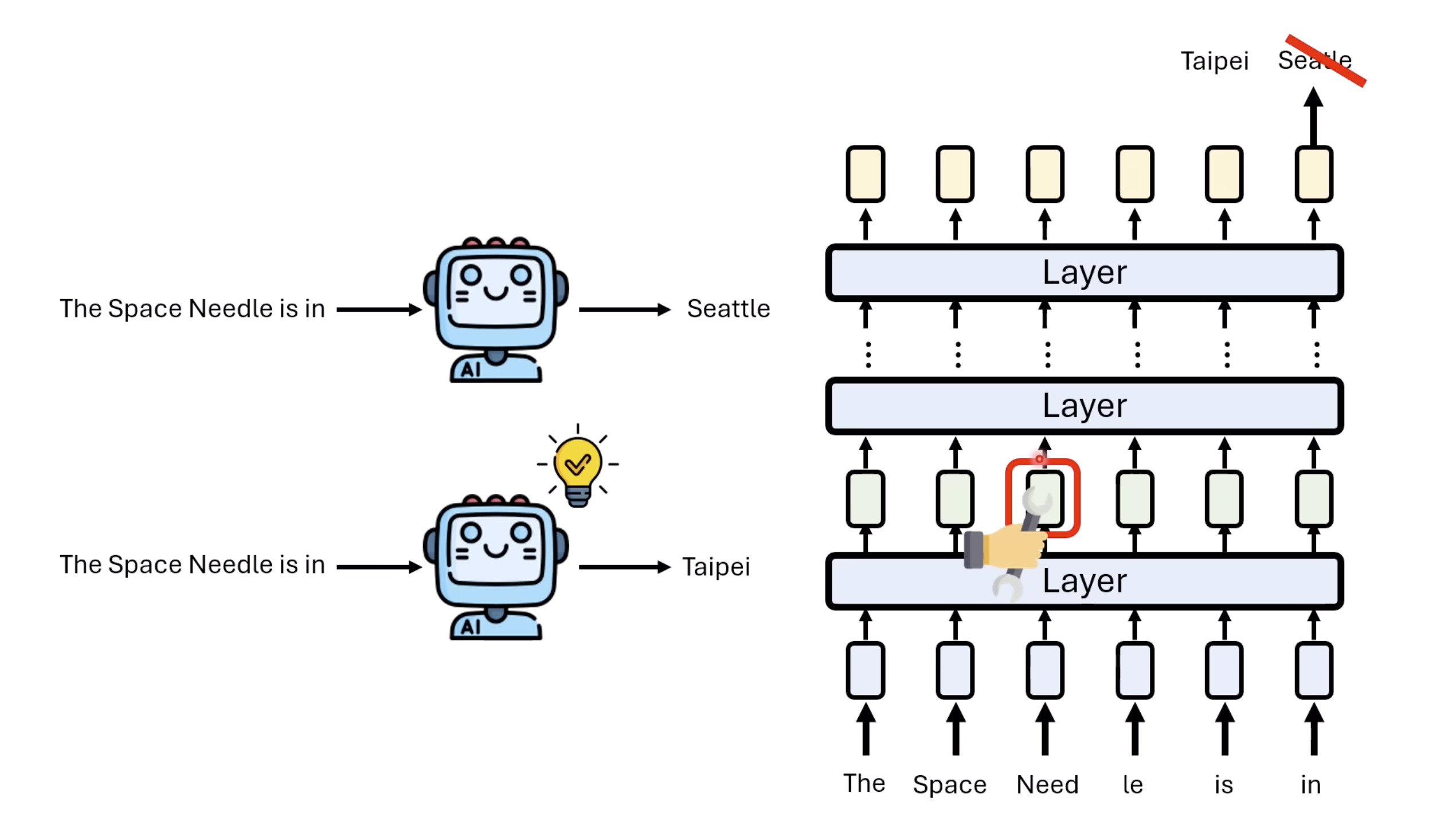
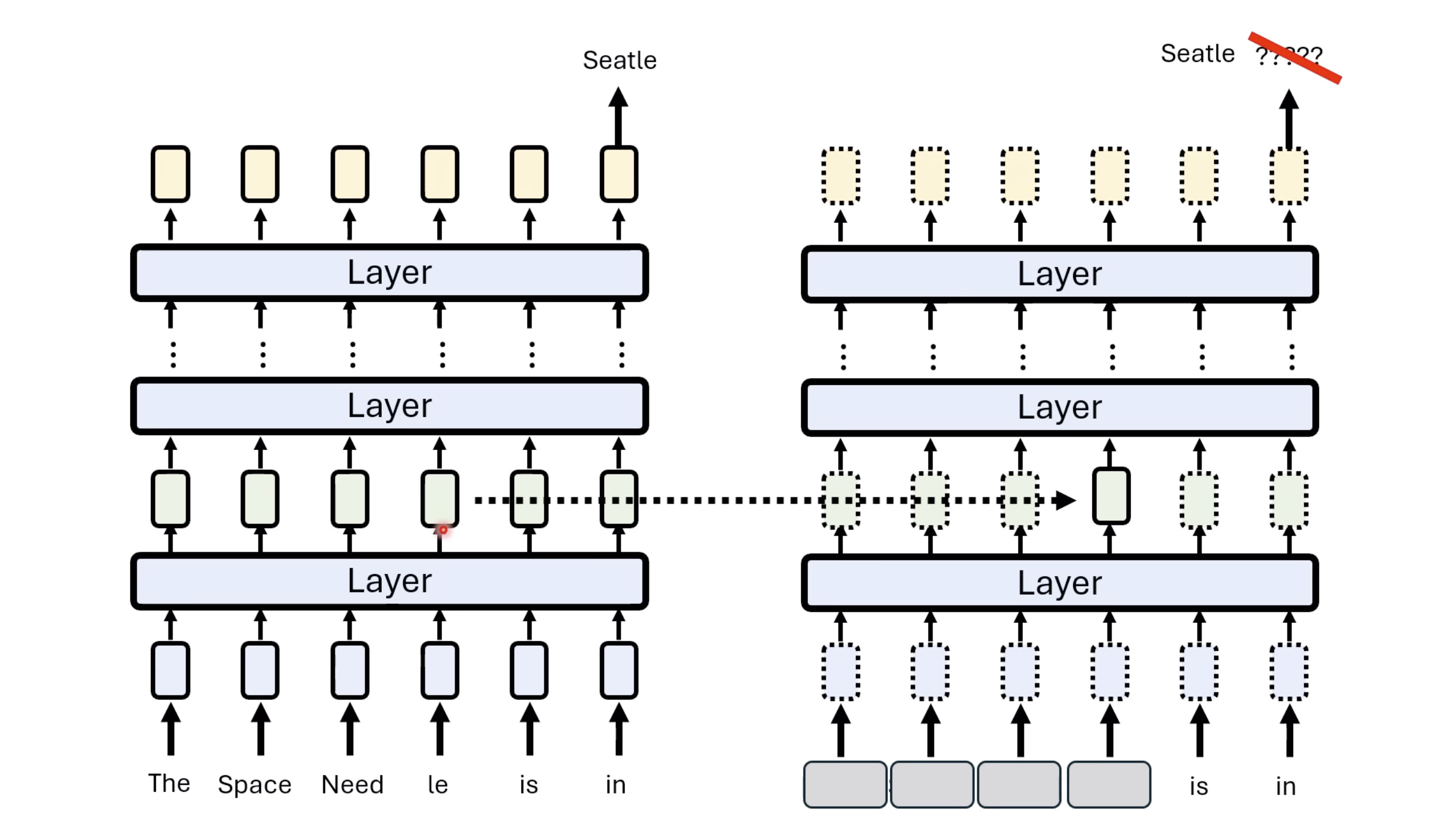
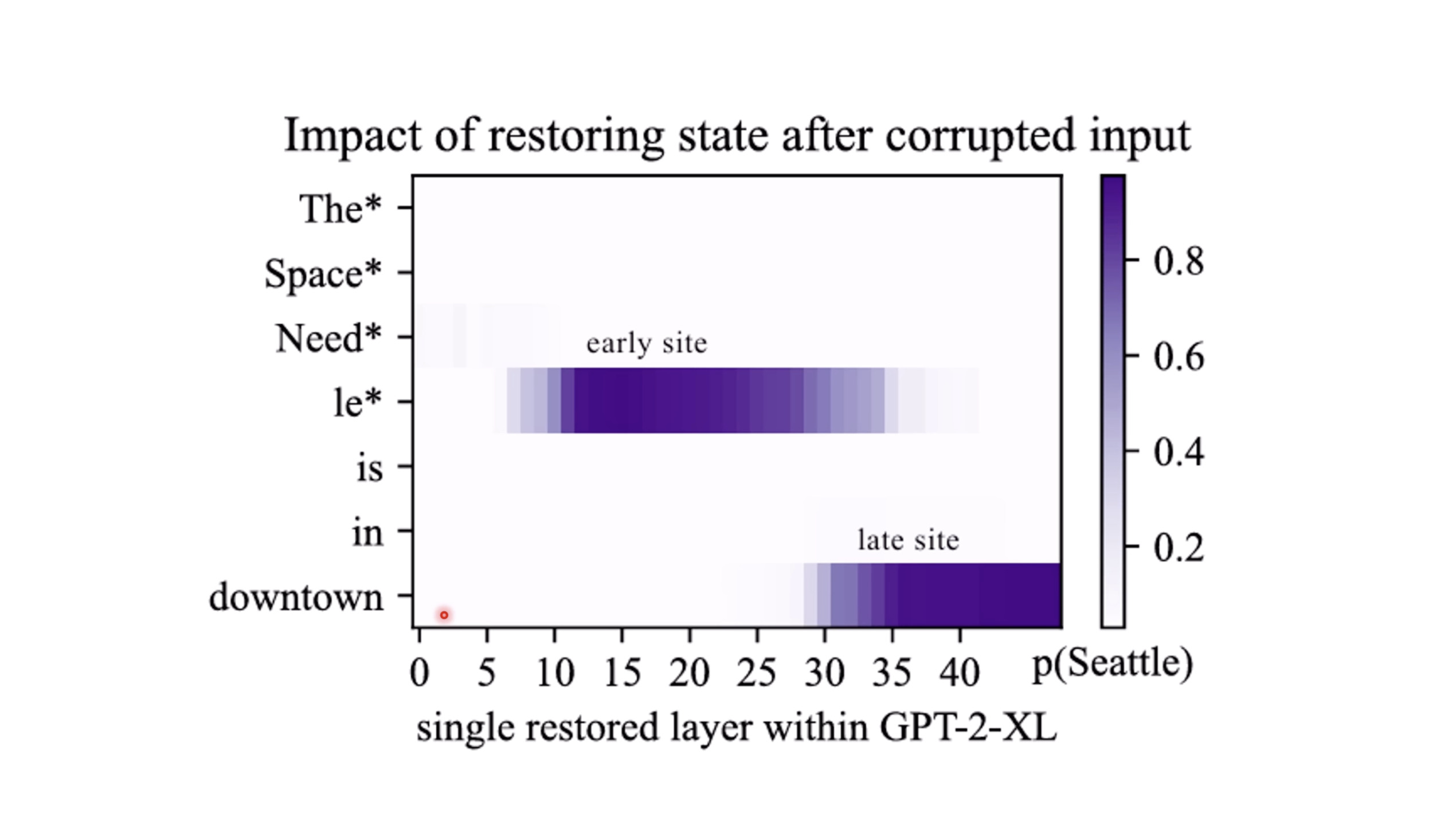
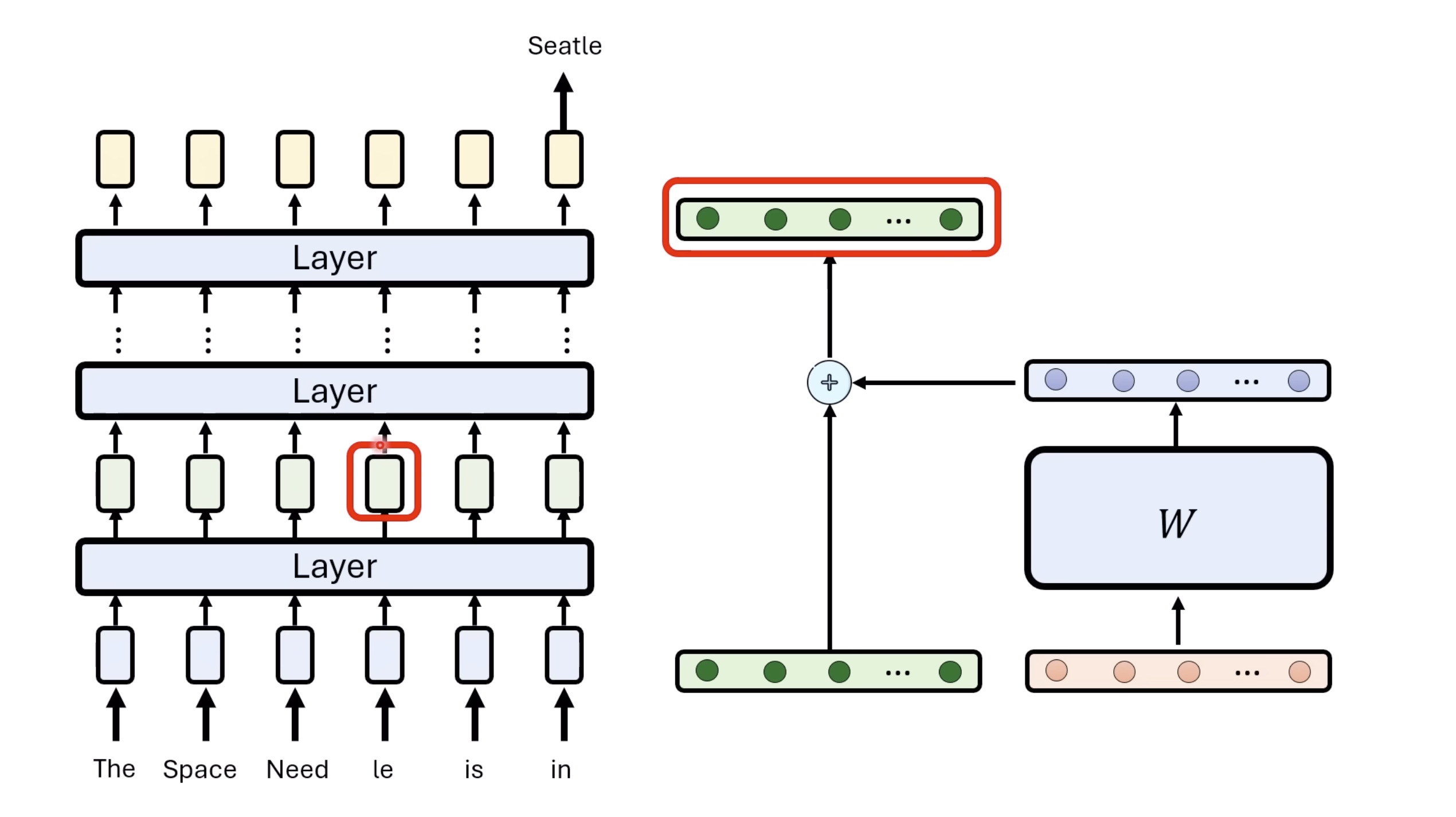
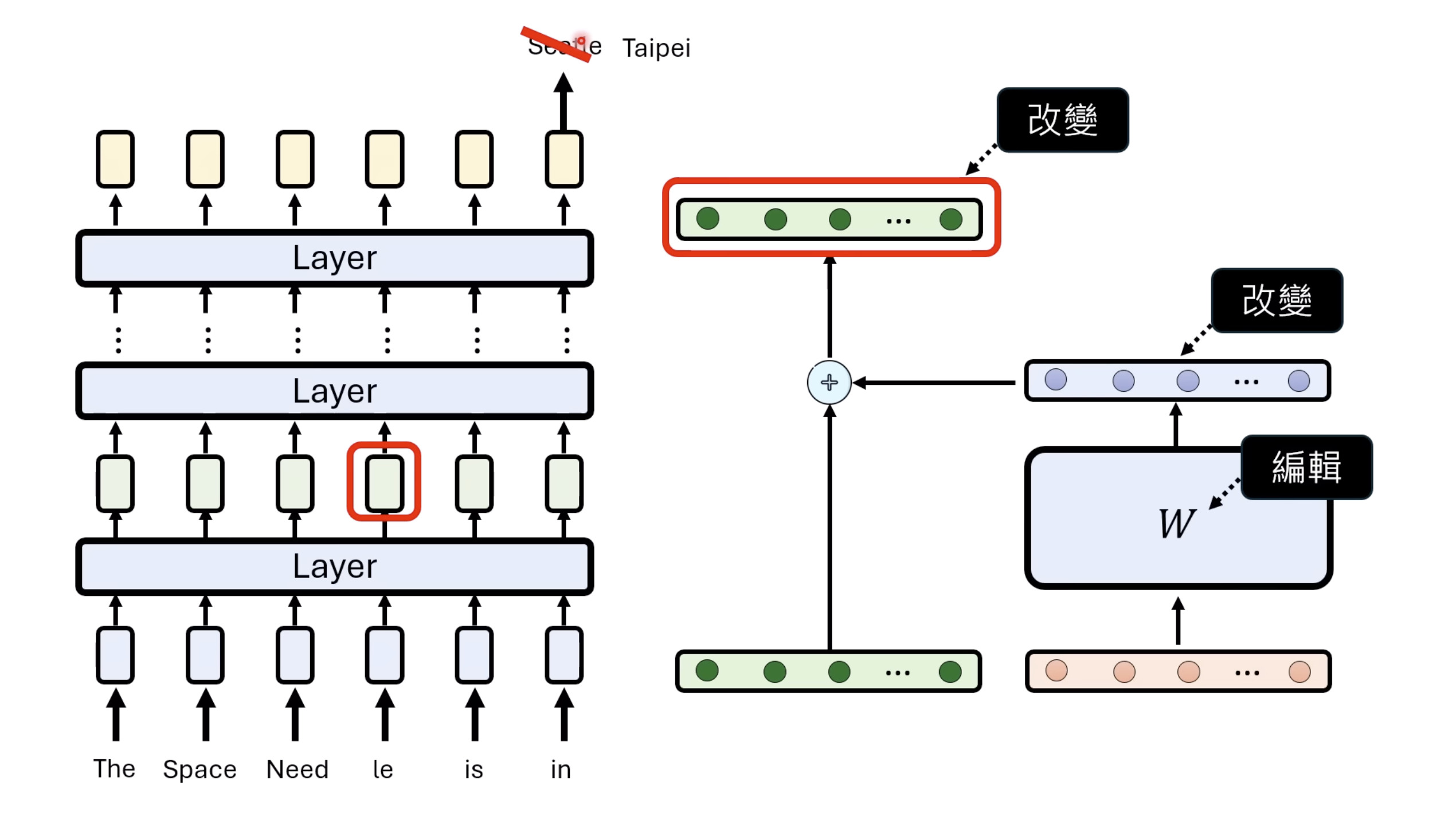
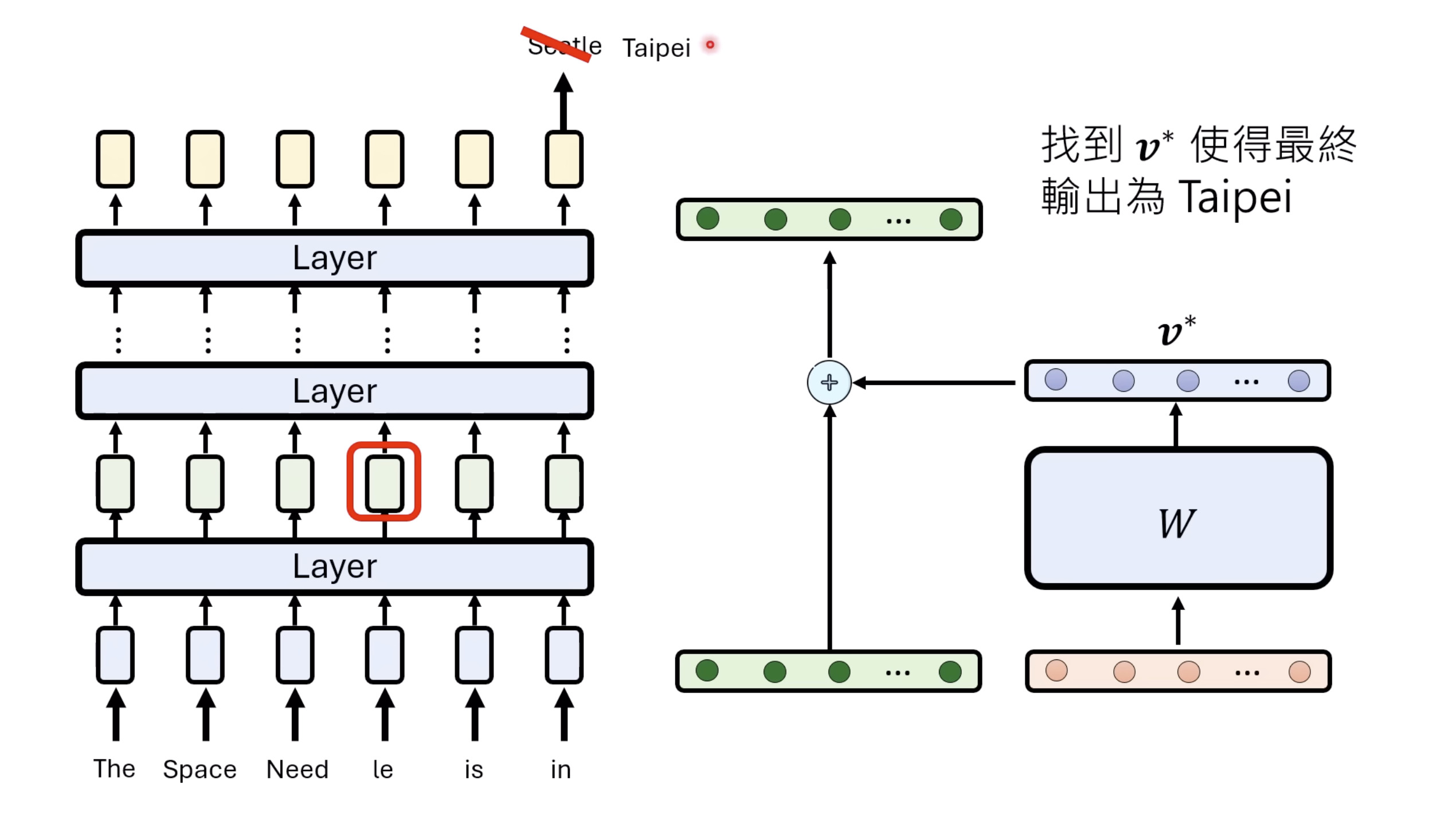
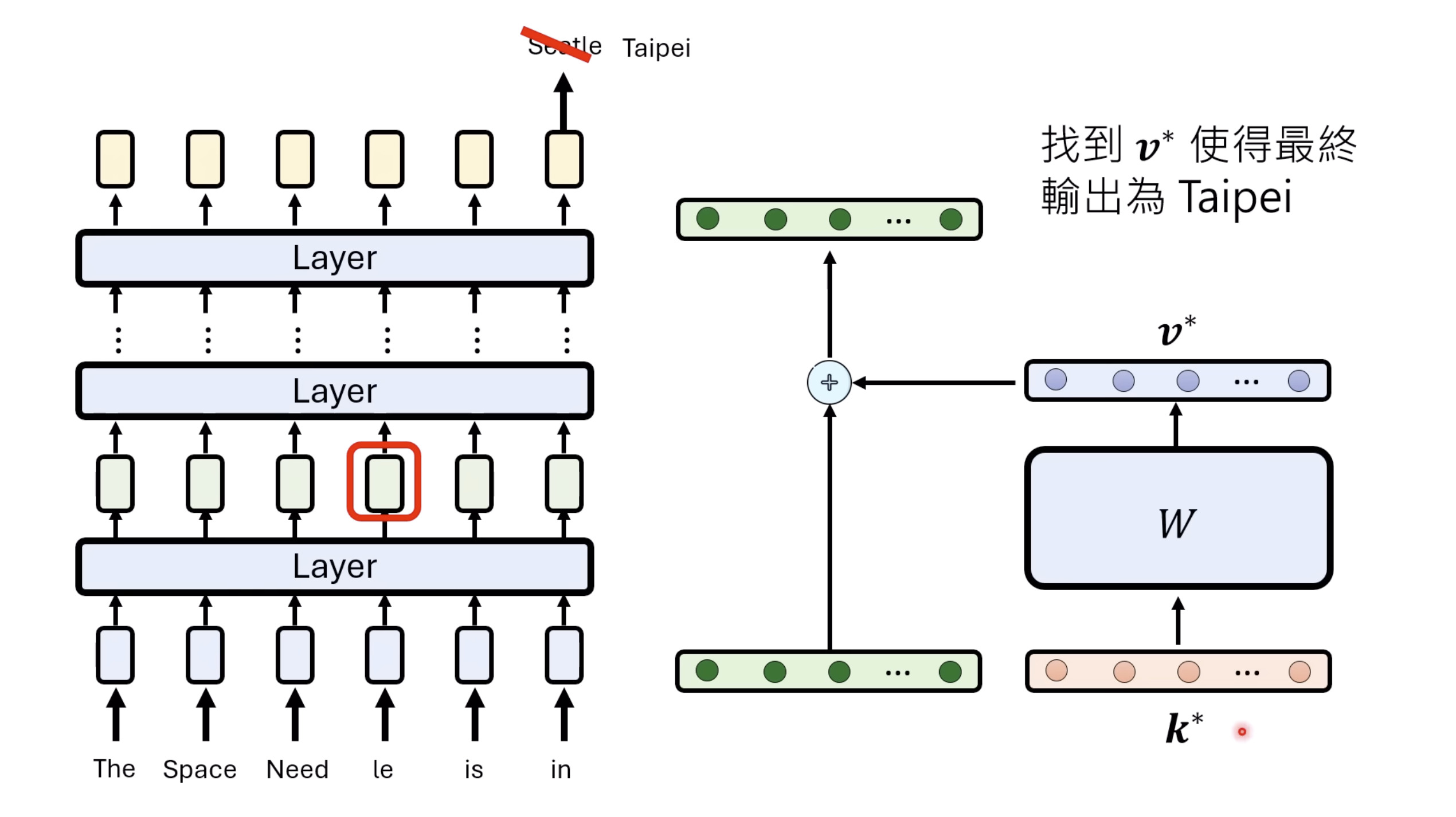
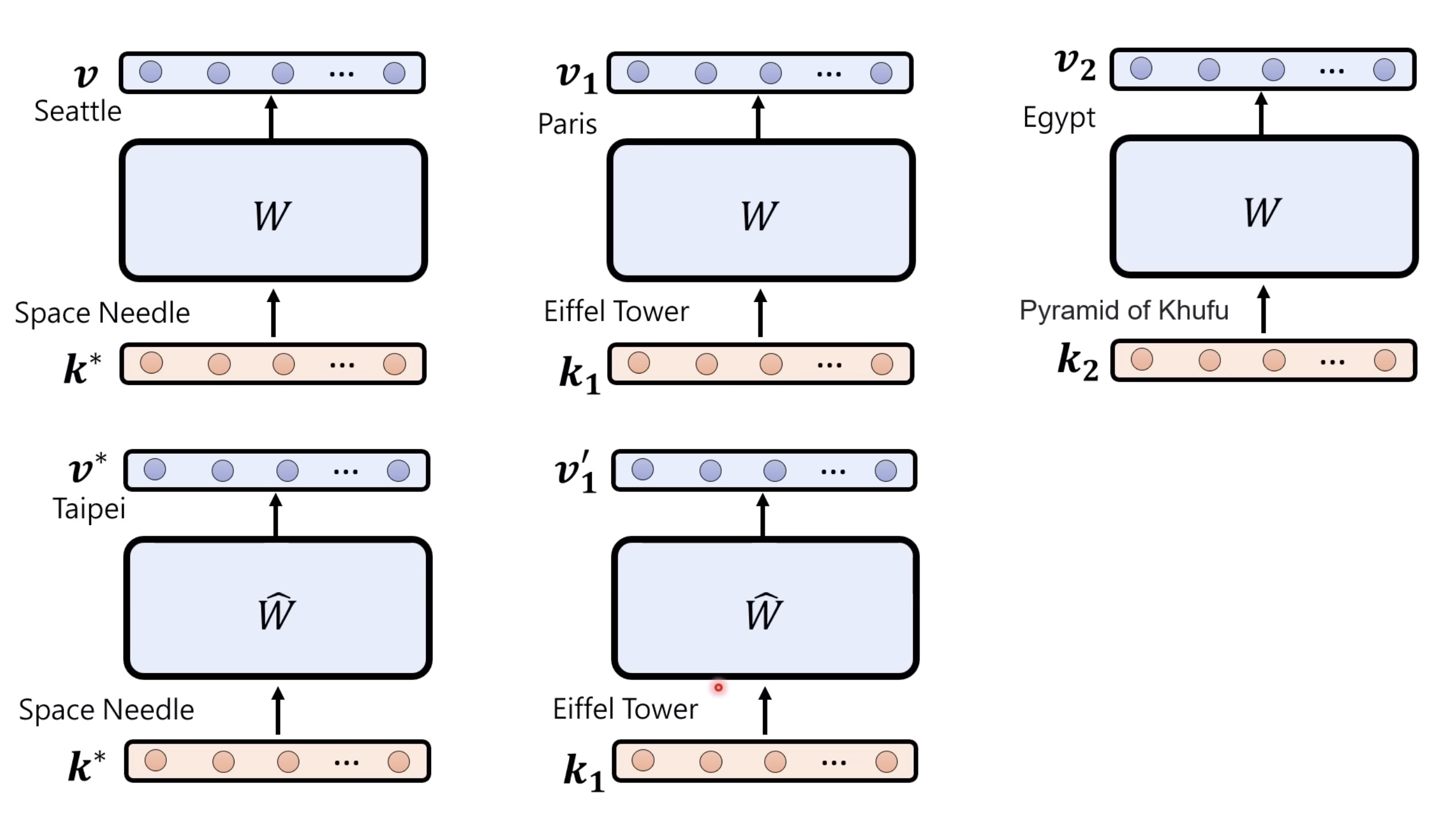
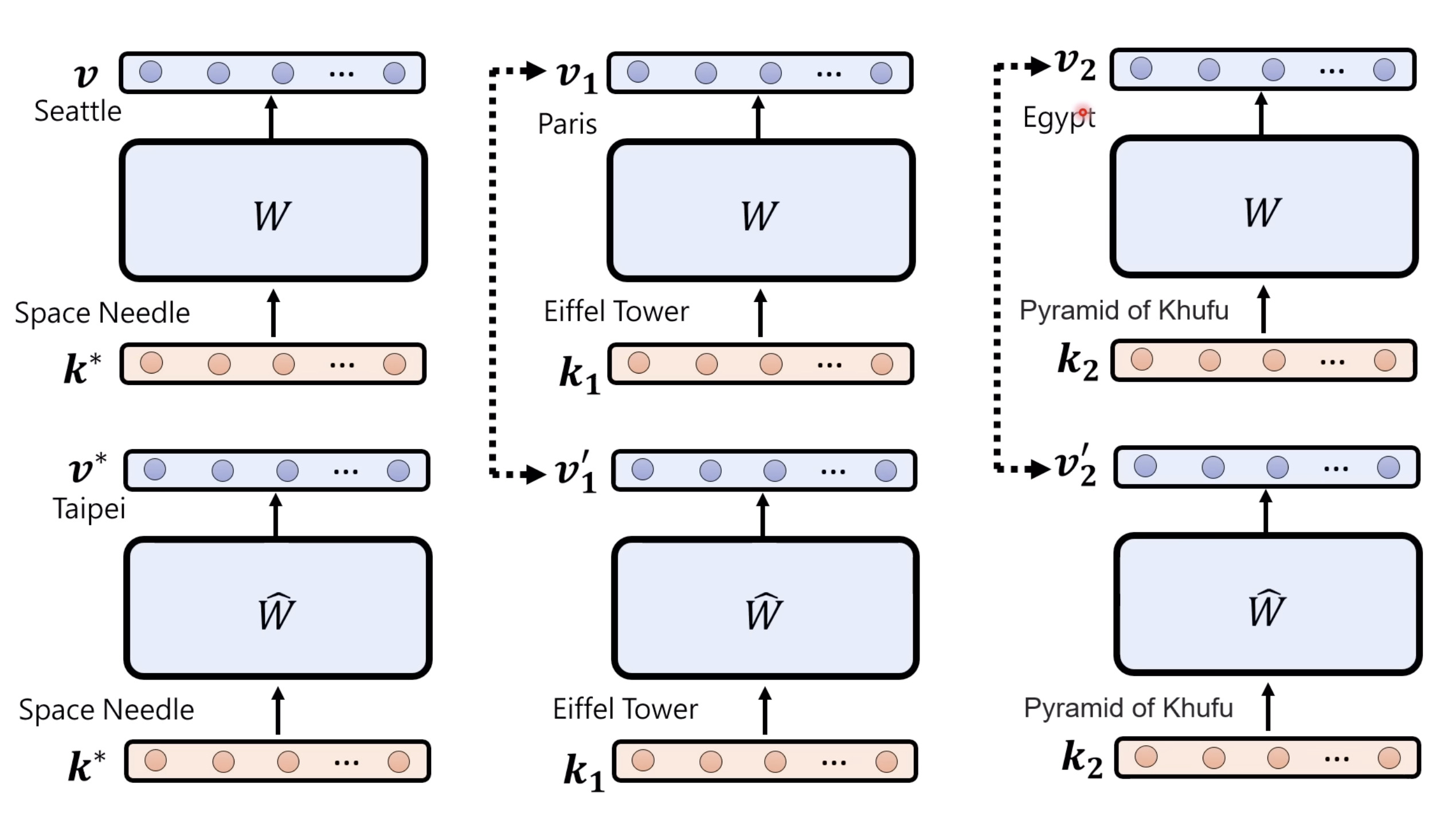
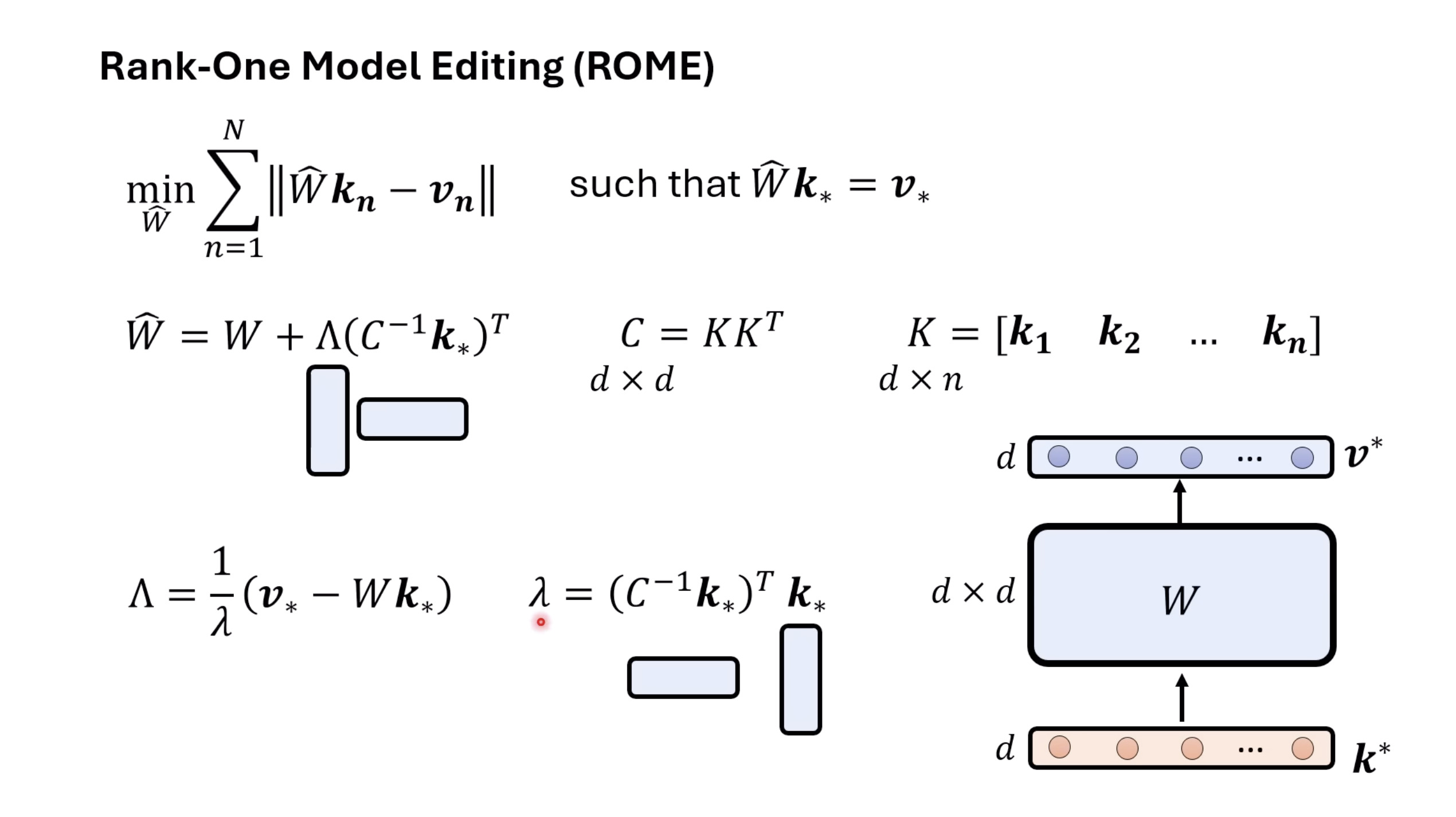
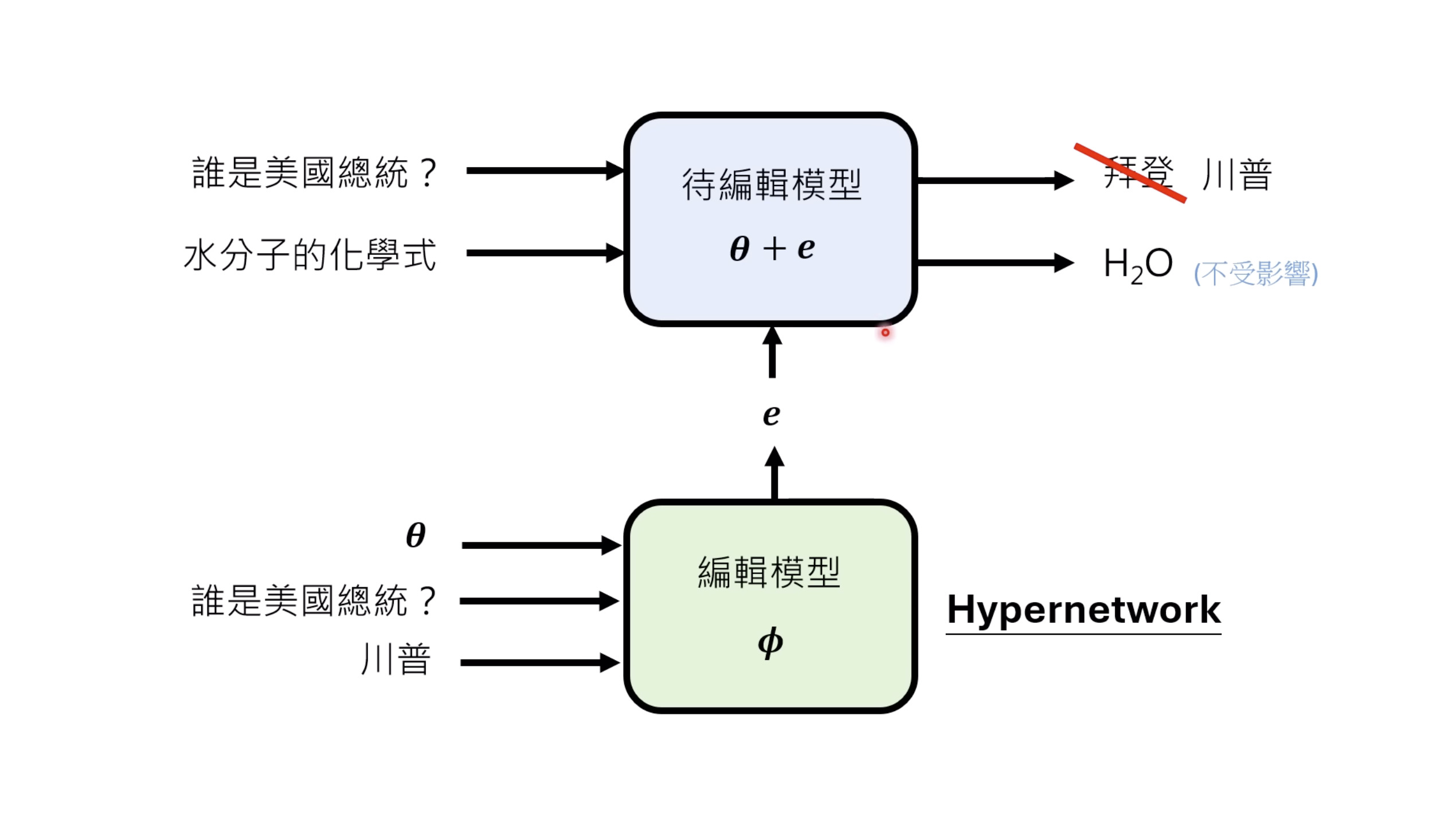
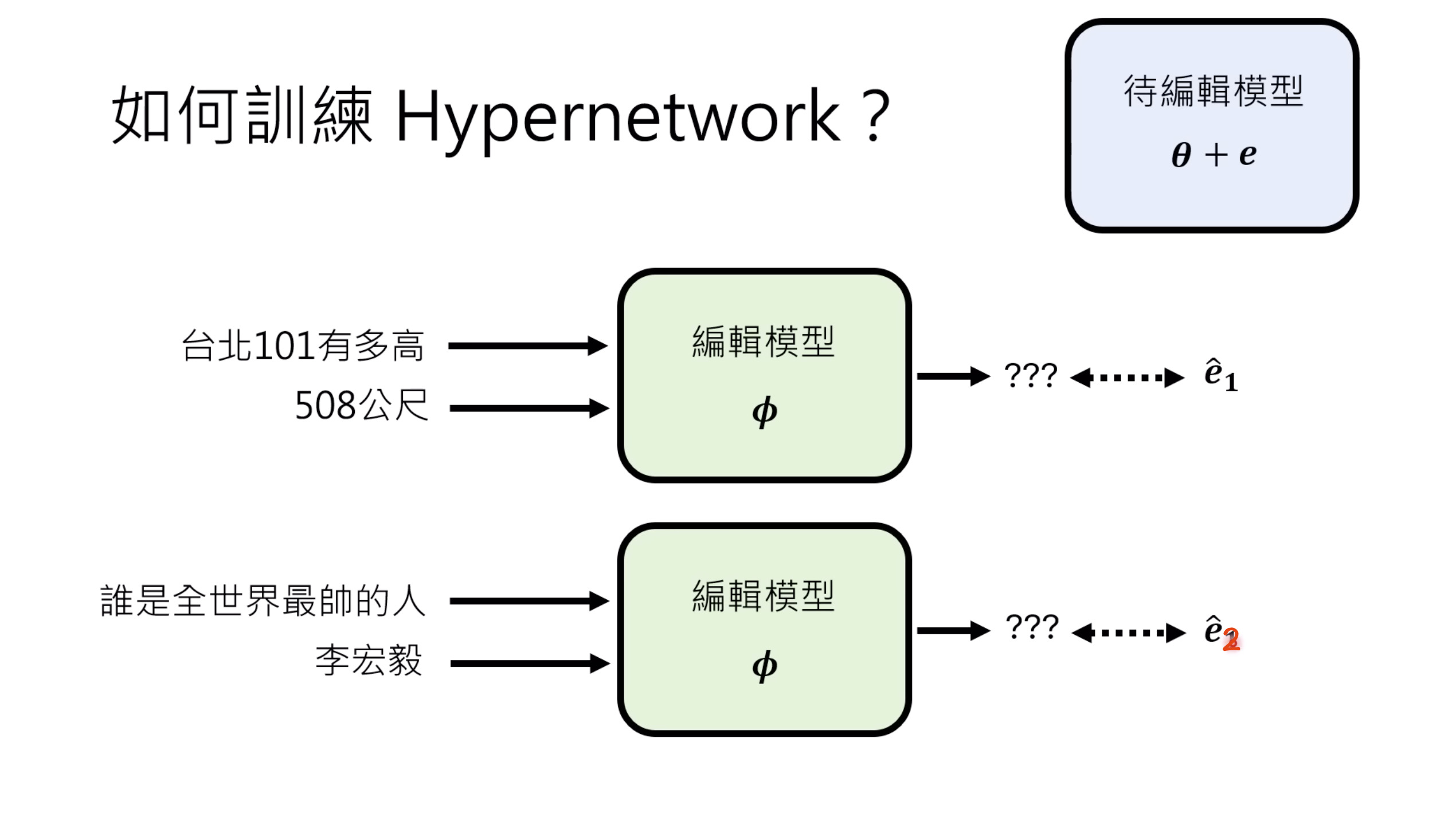
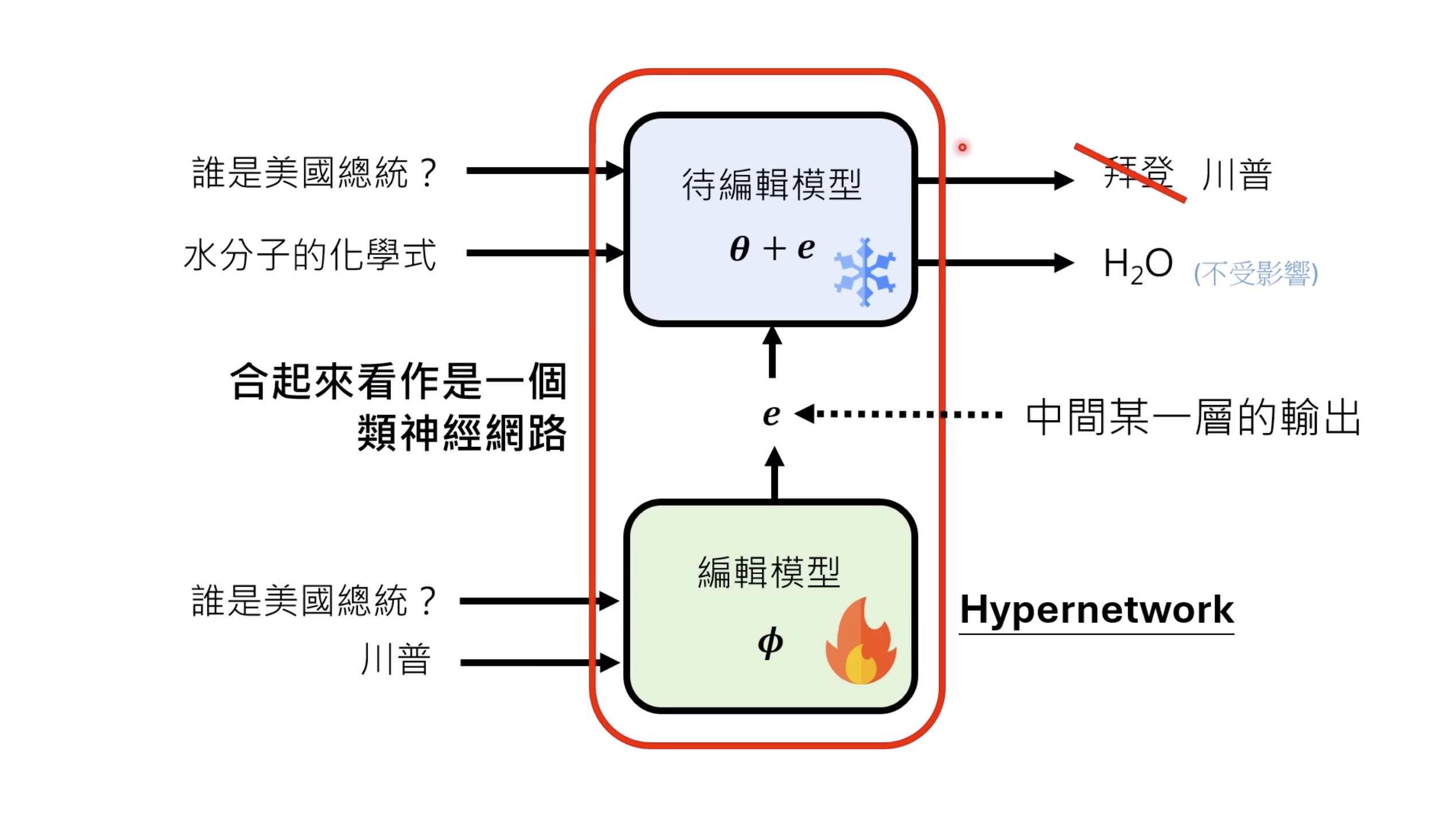
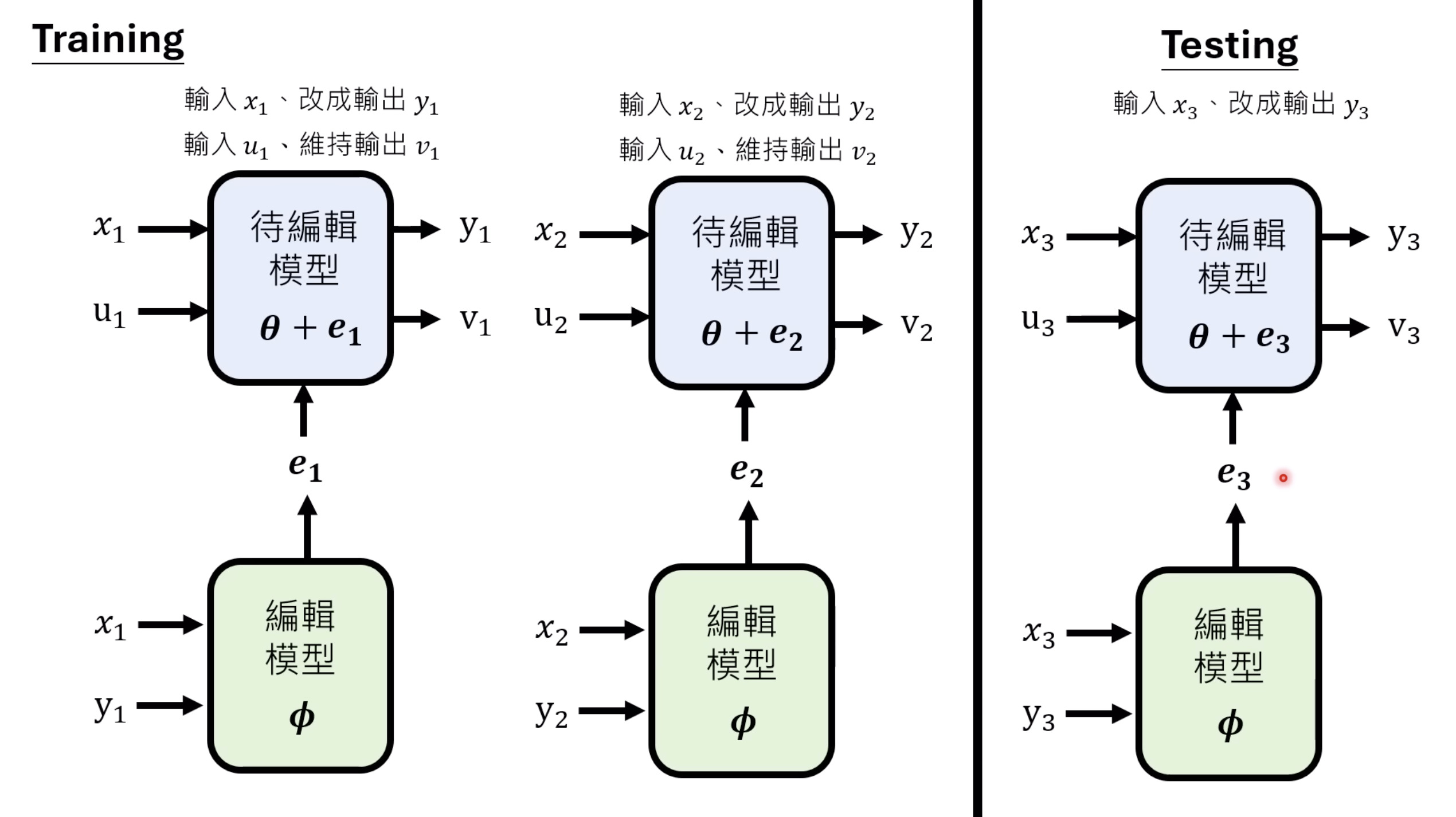
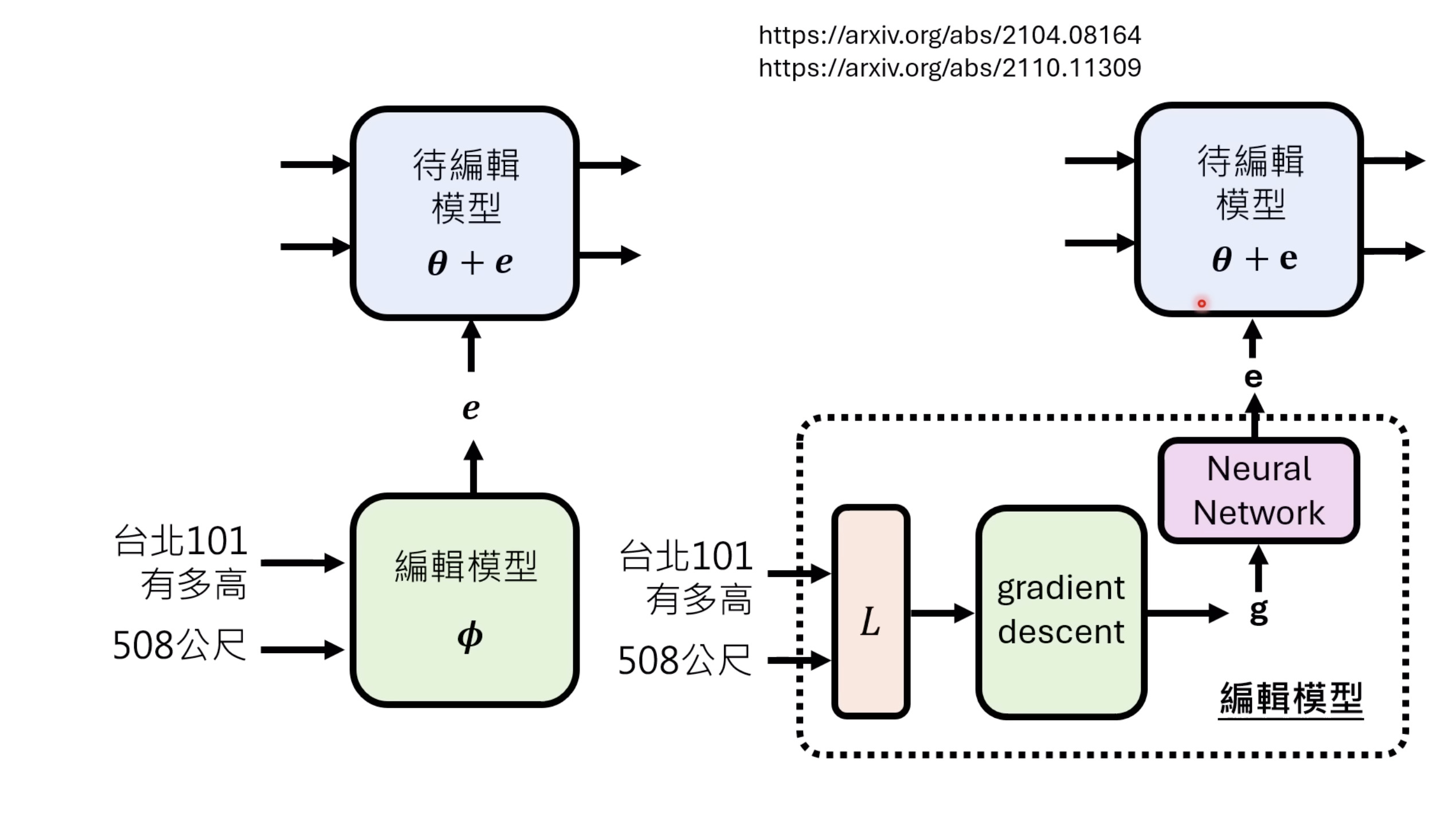
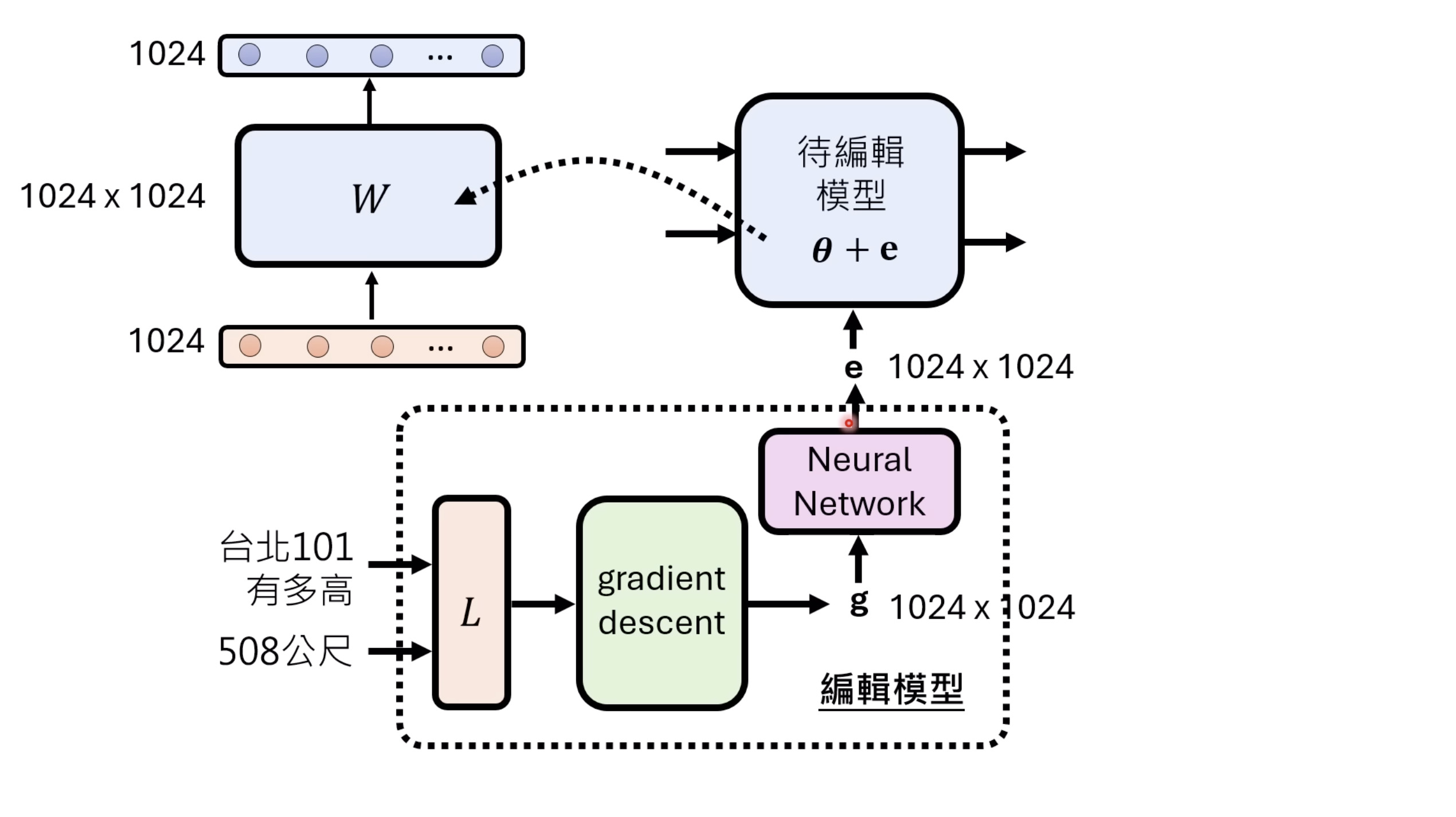
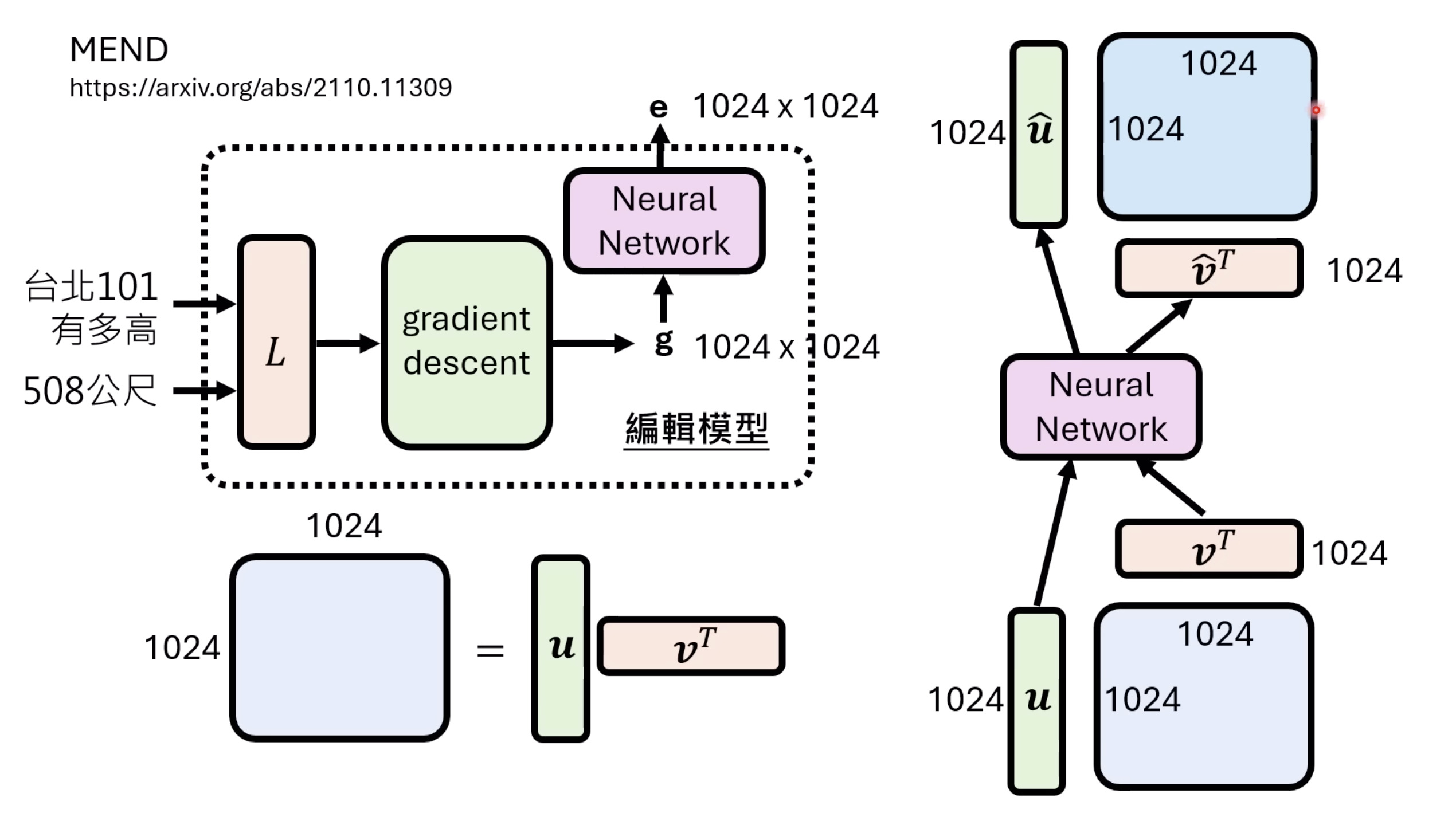
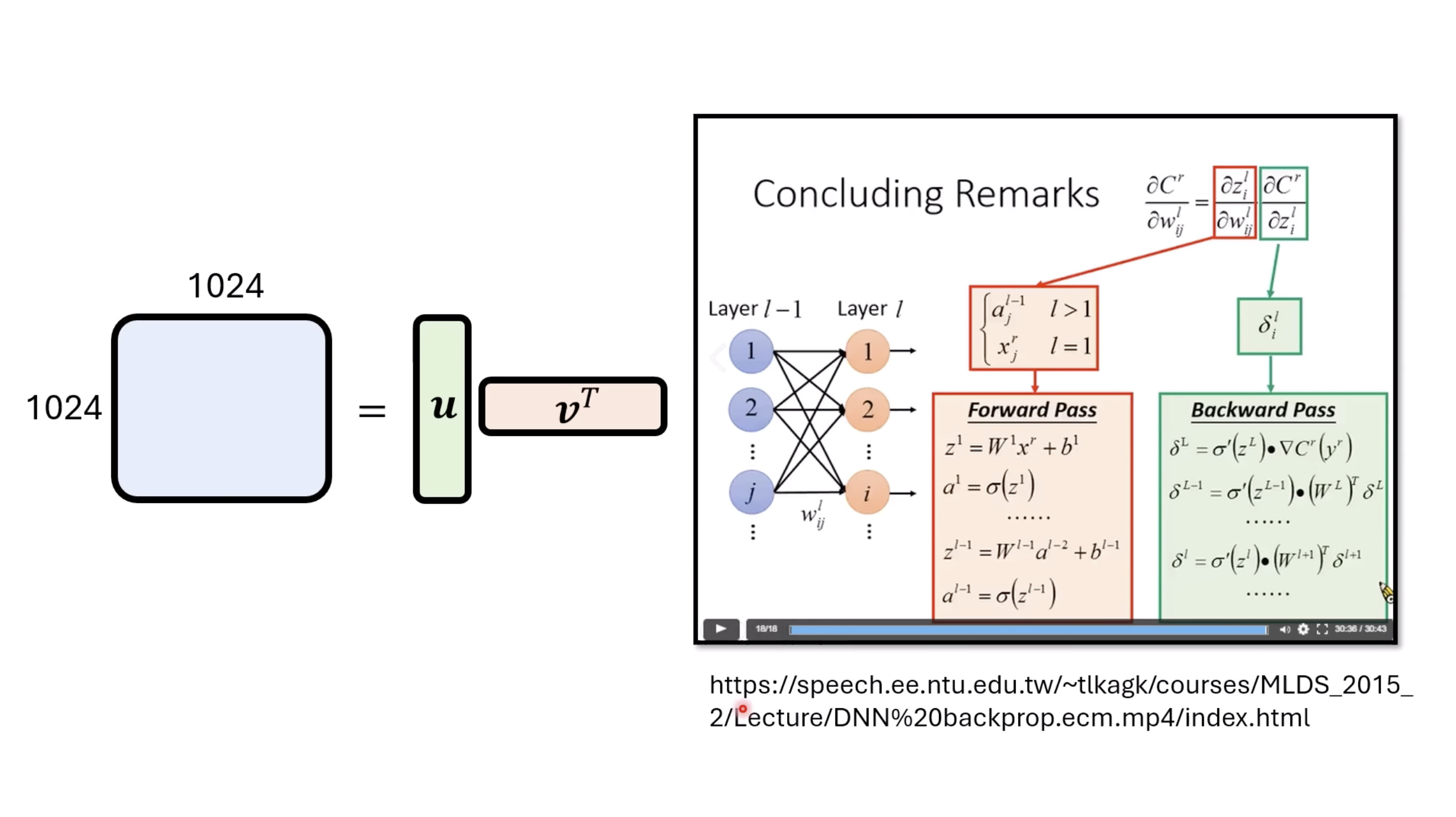
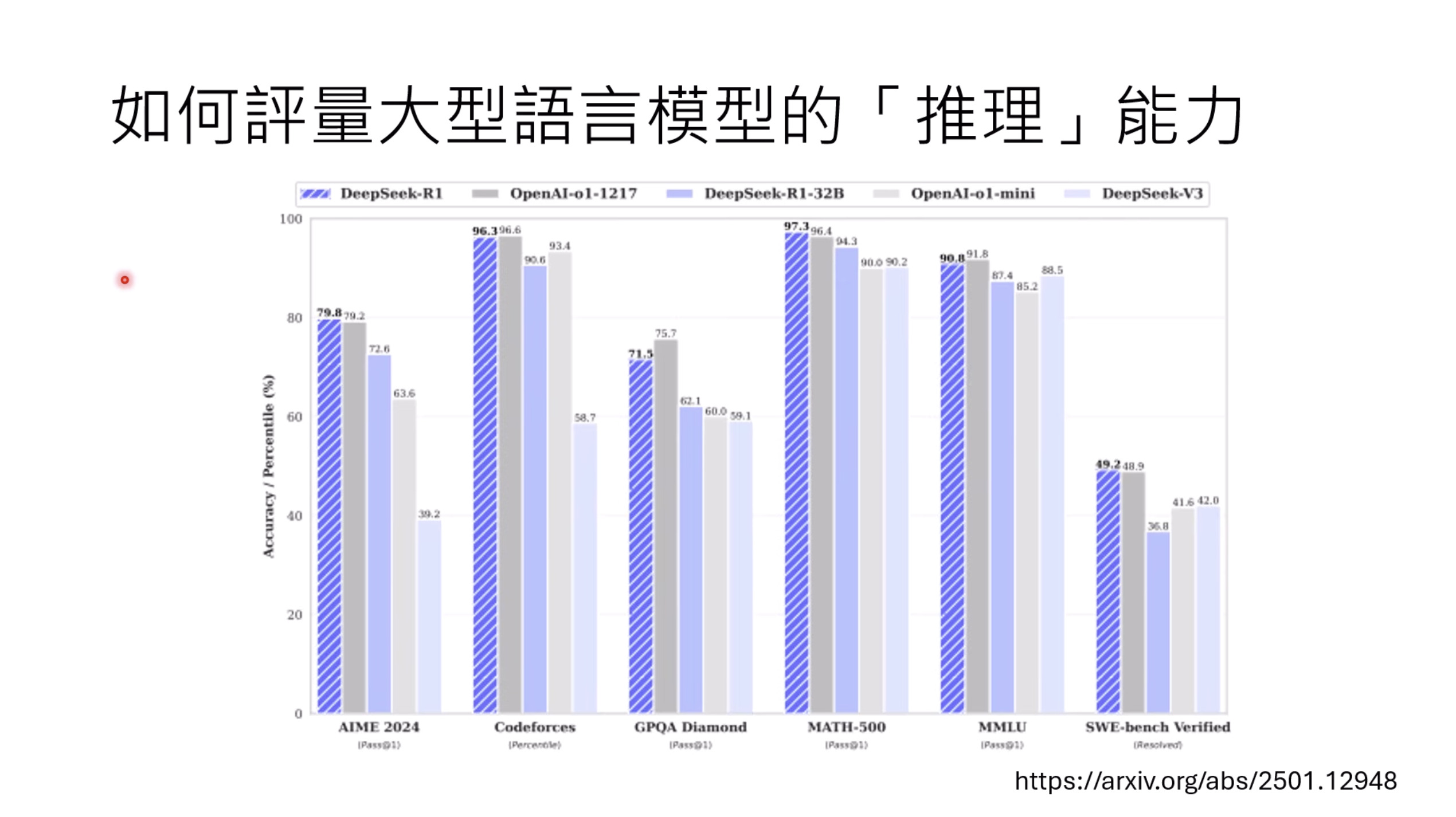
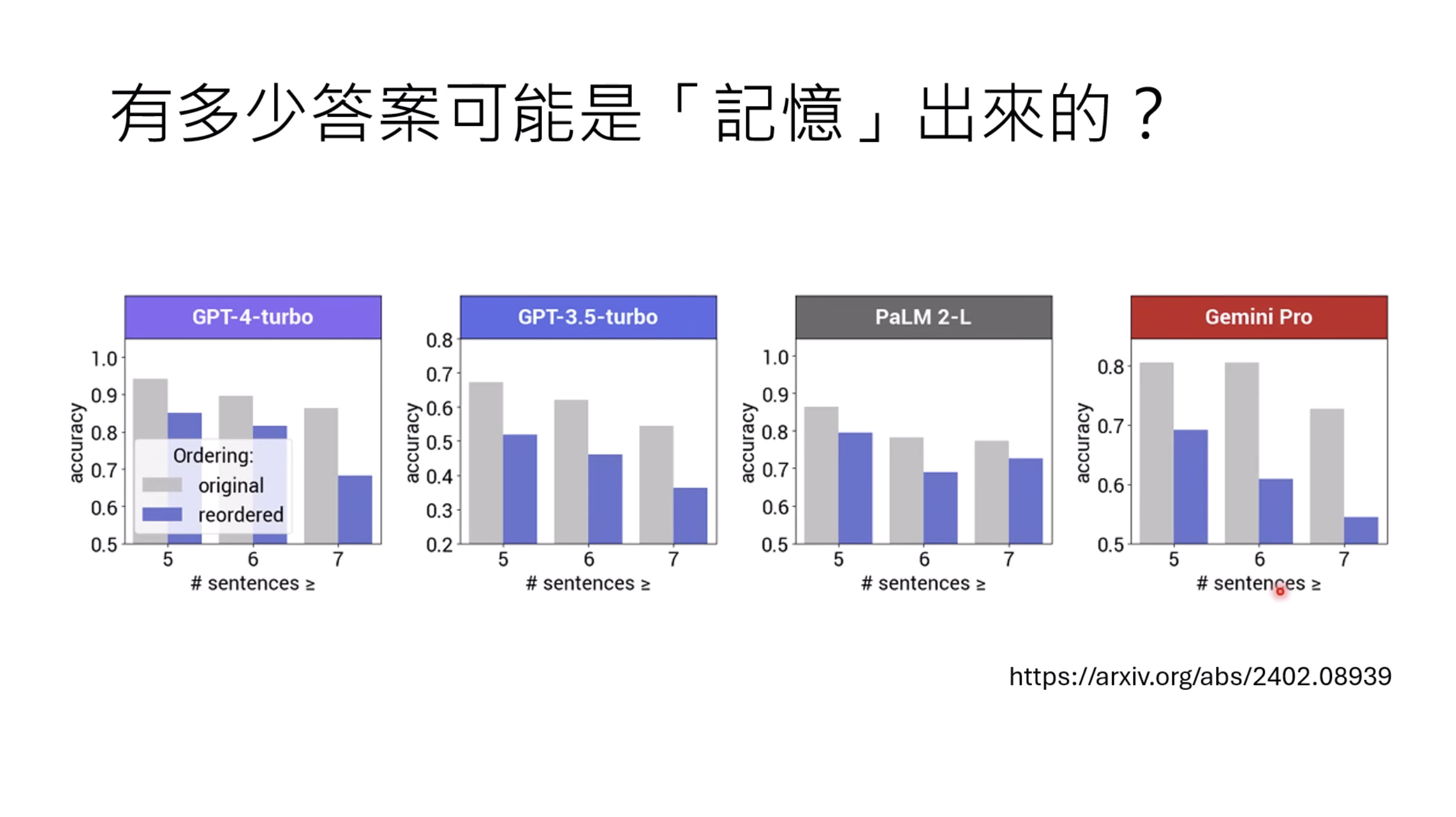
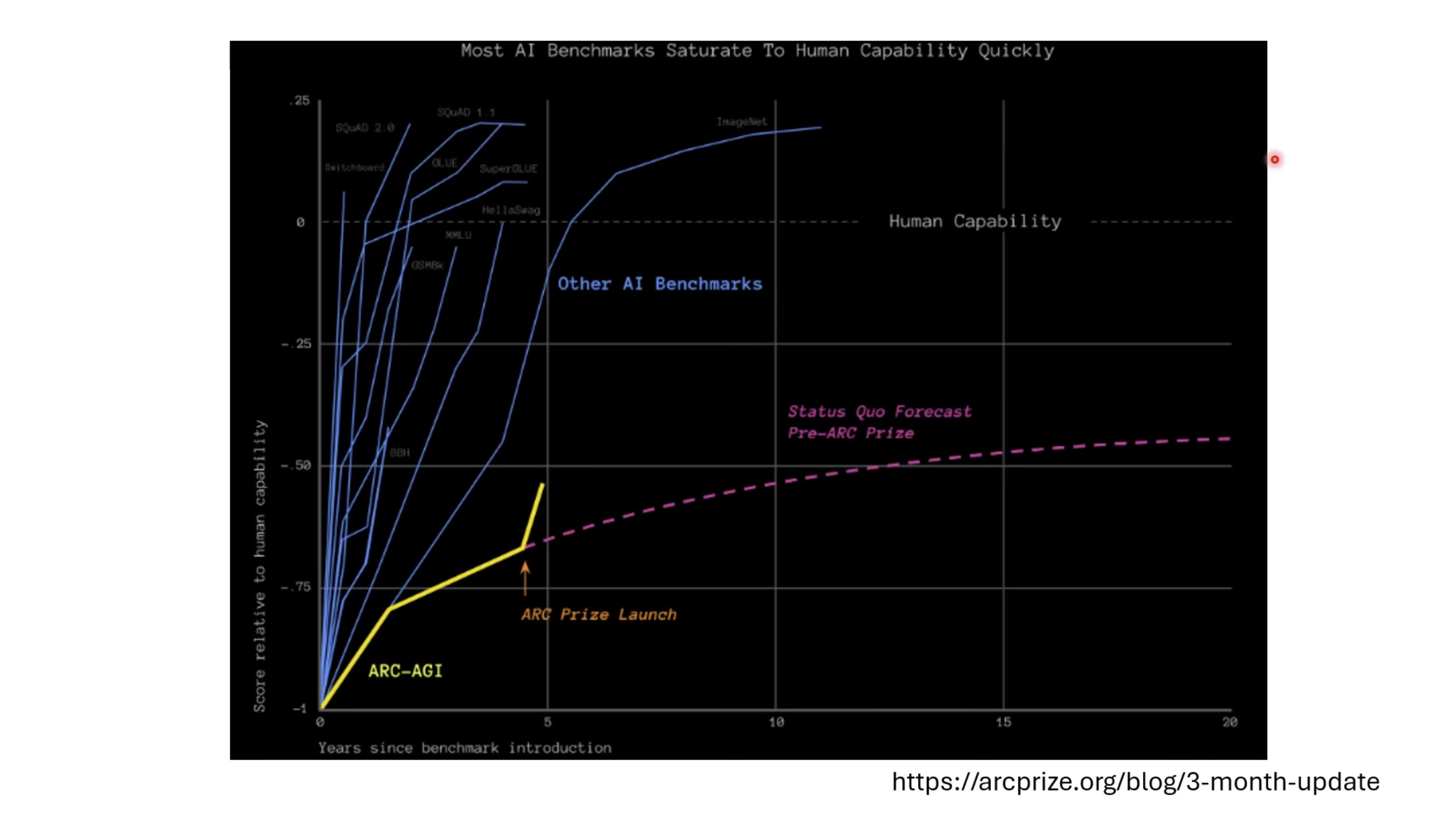
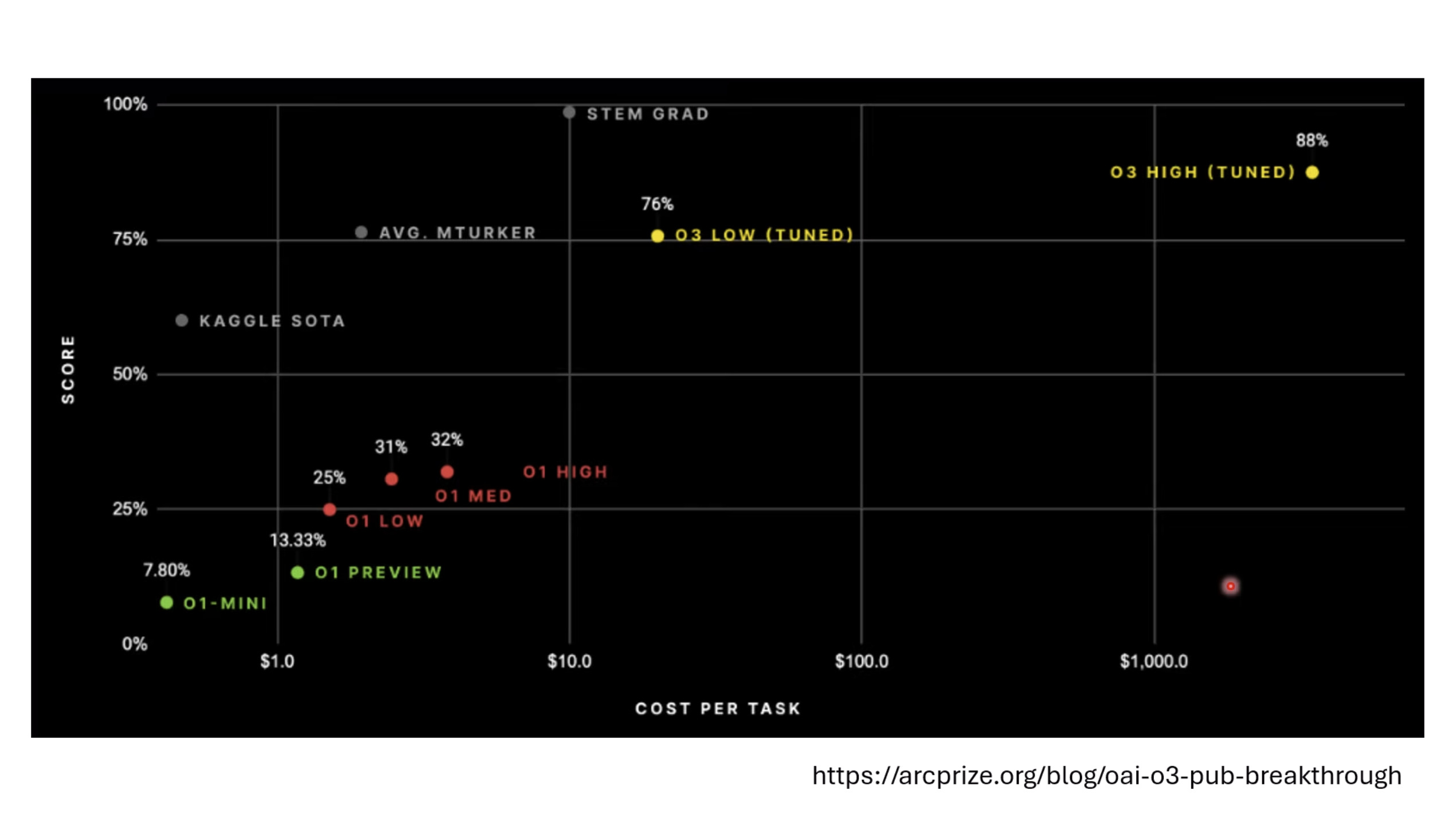
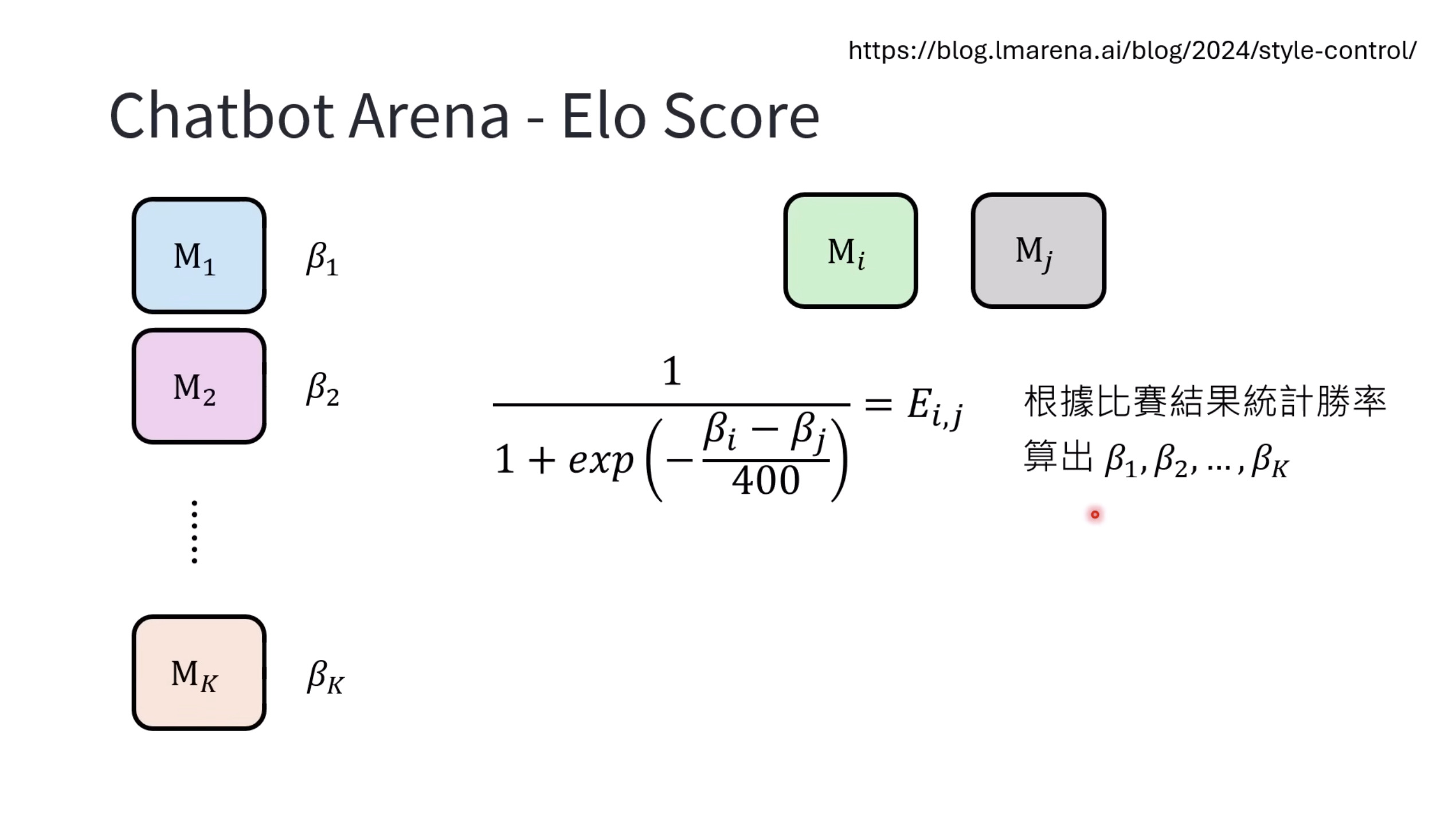
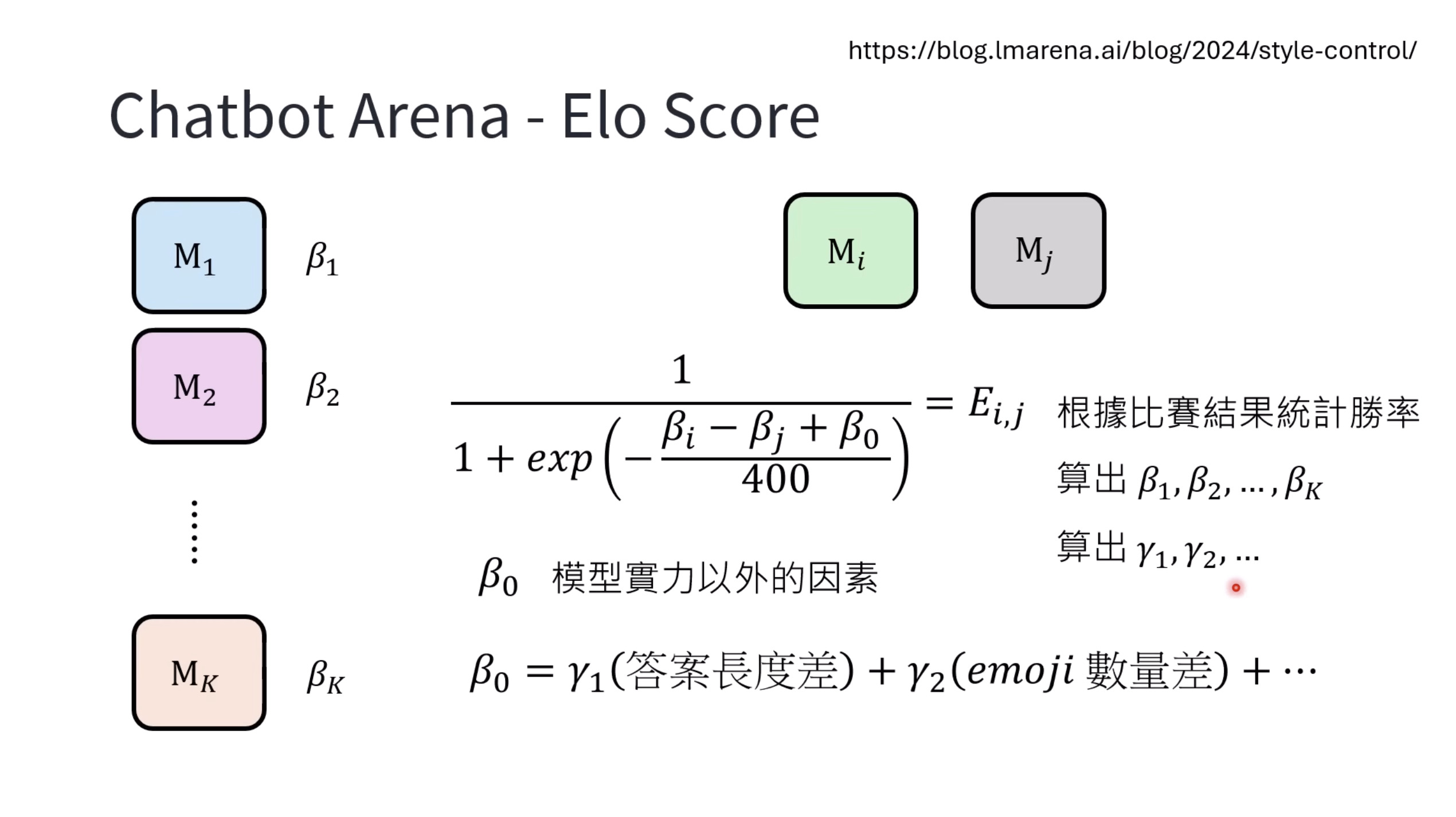
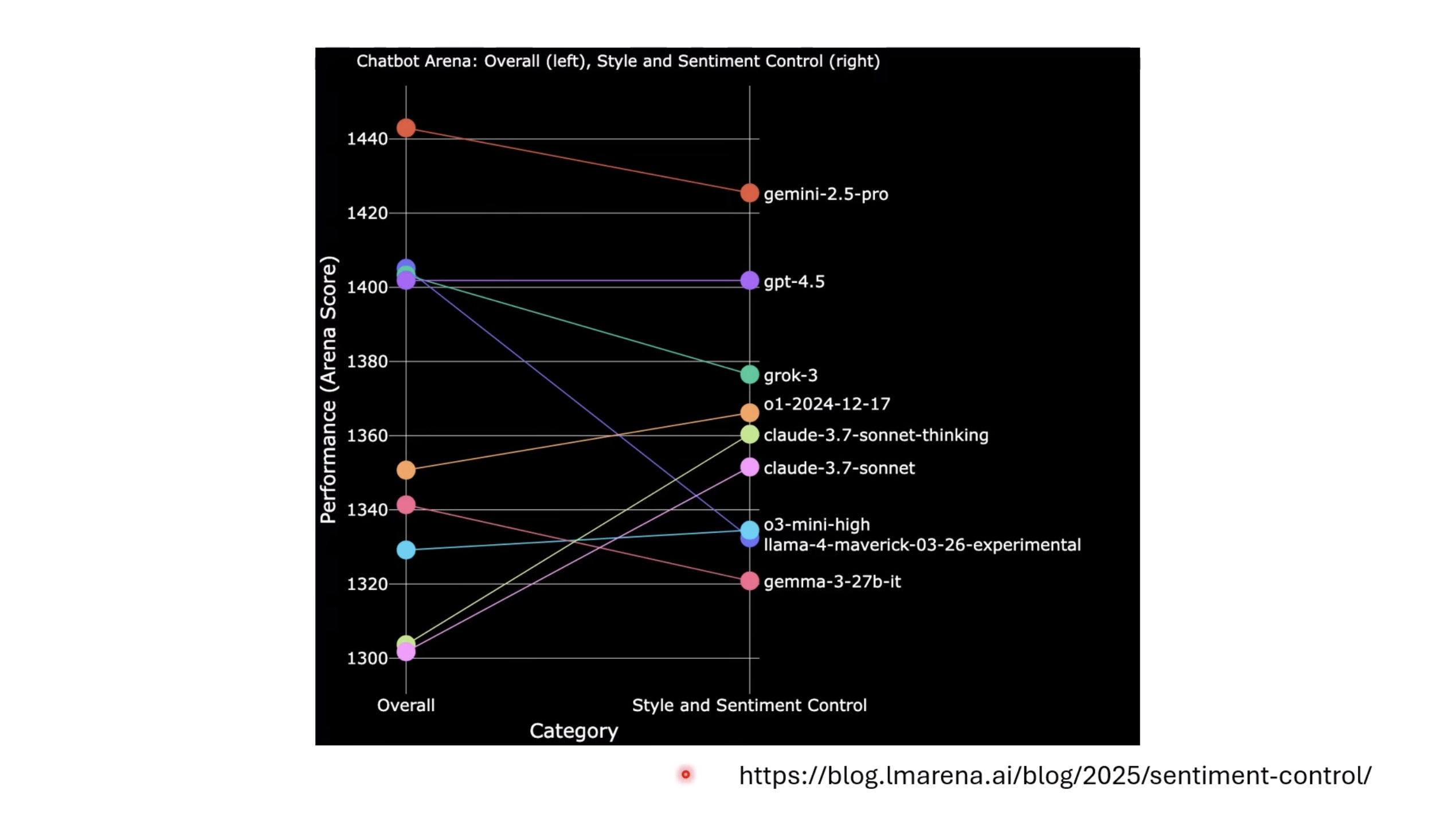
惨痛的教训(The Bitter Lesson)
AI 的未来不在于将人类现有的经验硬塞给机器,而在于设计出能够利用无限算力进行搜索与学习的“元方法”。
- The Bitter Lesson
- 里奇·萨顿(Rich Sutton)
- 2019年3月13日
回顾70年人工智能研究历程,最深刻的一条教训是:依托算力的通用方法,最终效果远超其他路径,且优势极其显著。究其根本,源于摩尔定律——或者更广义地说,单位计算成本持续呈指数级下降。绝大多数人工智能研究开展时,都默认智能体可使用的算力是恒定的(这种情况下,借助人类知识就成了提升性能为数不多的手段之一)。但只要研究周期稍长于普通科研项目,海量算力必然会成为现实。
研究者为追求短期见效的性能提升,往往试图融入自身对领域的人类认知;但从长远来看,真正起决定性作用的,只有对算力的充分利用。这两条路径本不必相互对立,现实中却常常冲突:投入在一方的时间,就无法用于另一方。研究者会在心理上执着于某一种研究思路;而依赖人类知识的方法,往往会让模型变得复杂,反而难以适配依托算力的通用优化路径。
人工智能研究者们屡屡迟来地领悟到这一惨痛教训,回顾其中几个典型案例,颇具启发意义。
在国际象棋领域,1997年击败世界冠军卡斯帕罗夫的算法,依靠的是大规模深度搜索。彼时,多数国际象棋计算机研究者对此倍感沮丧——他们此前一直钻研的,是融入人类对国际象棋特有棋局结构理解的方法。