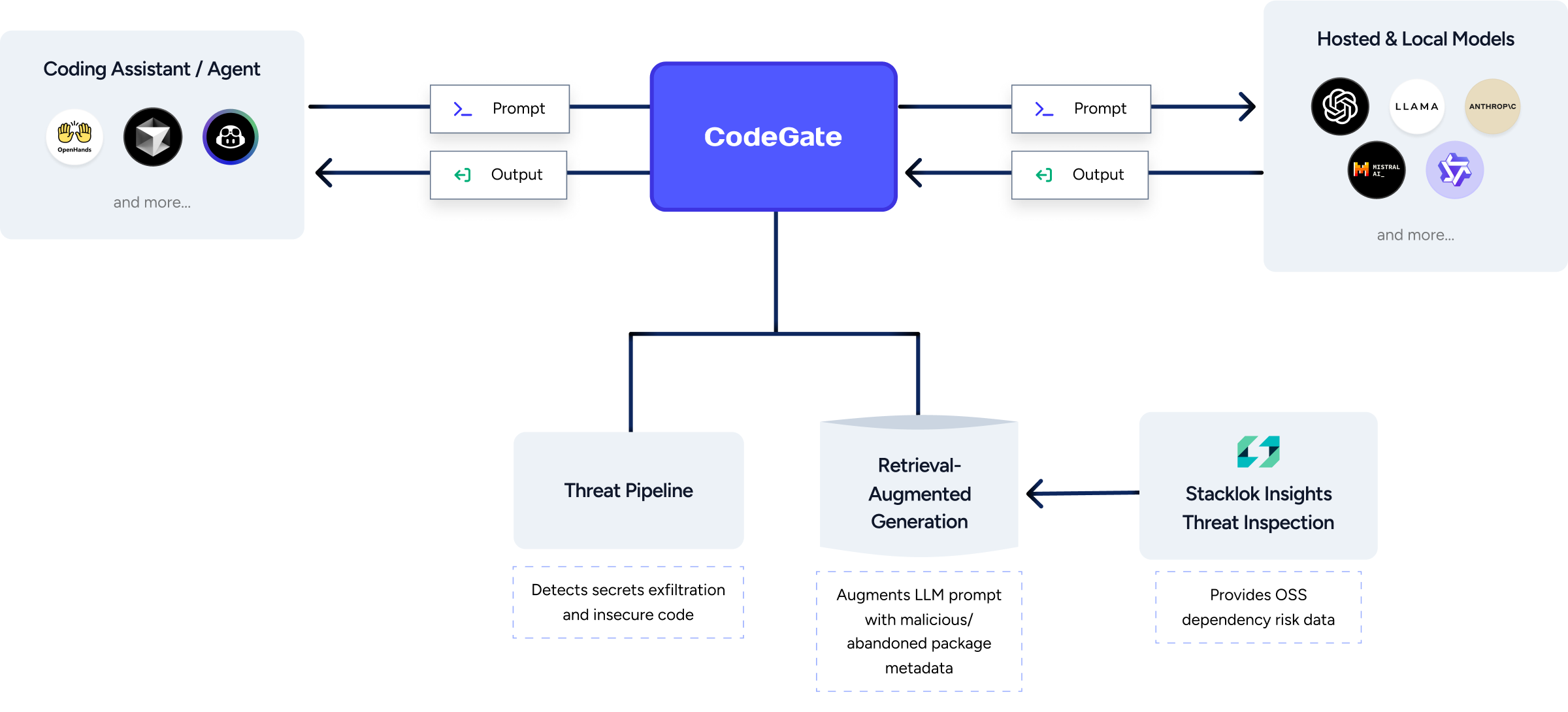
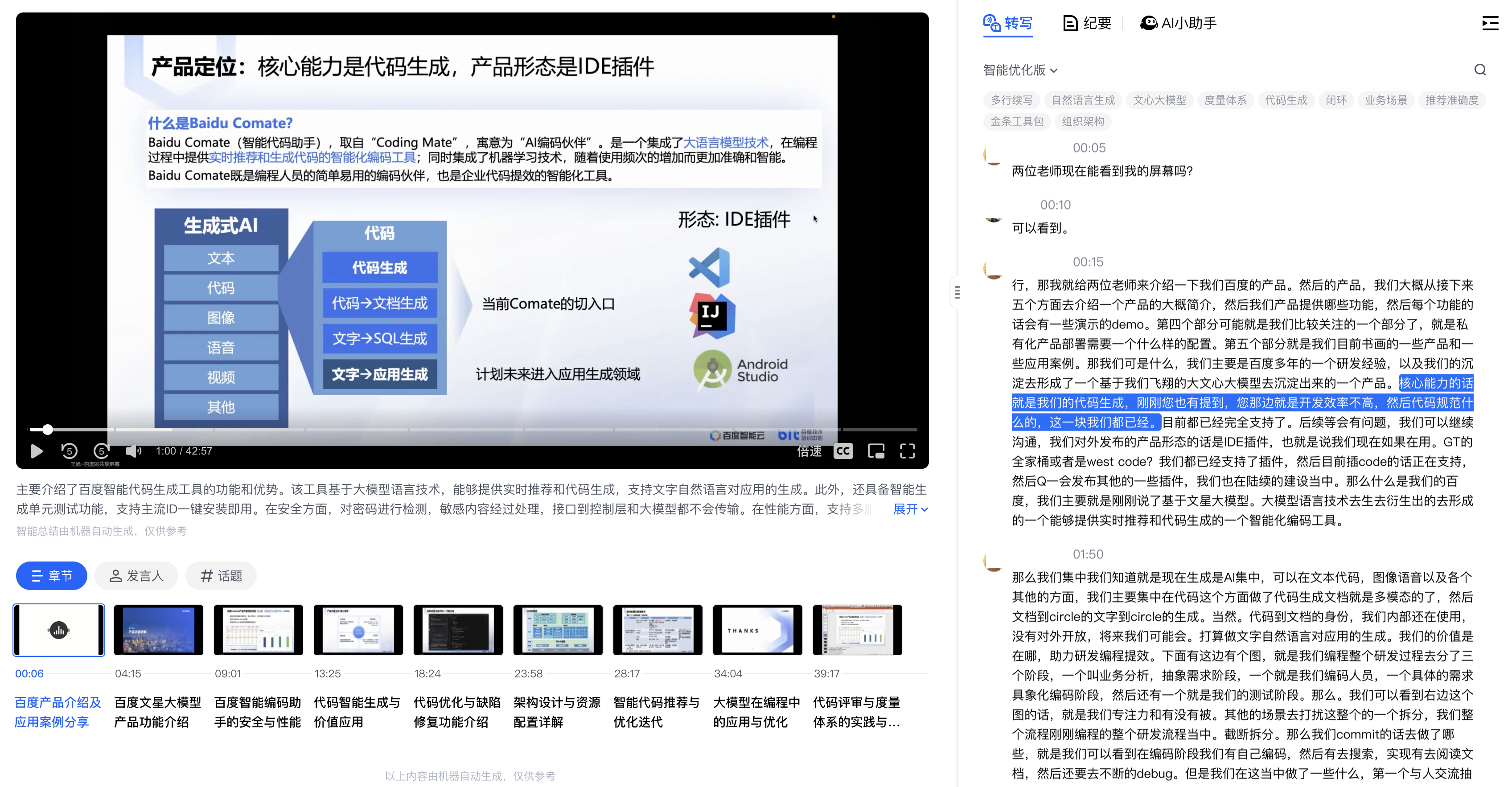
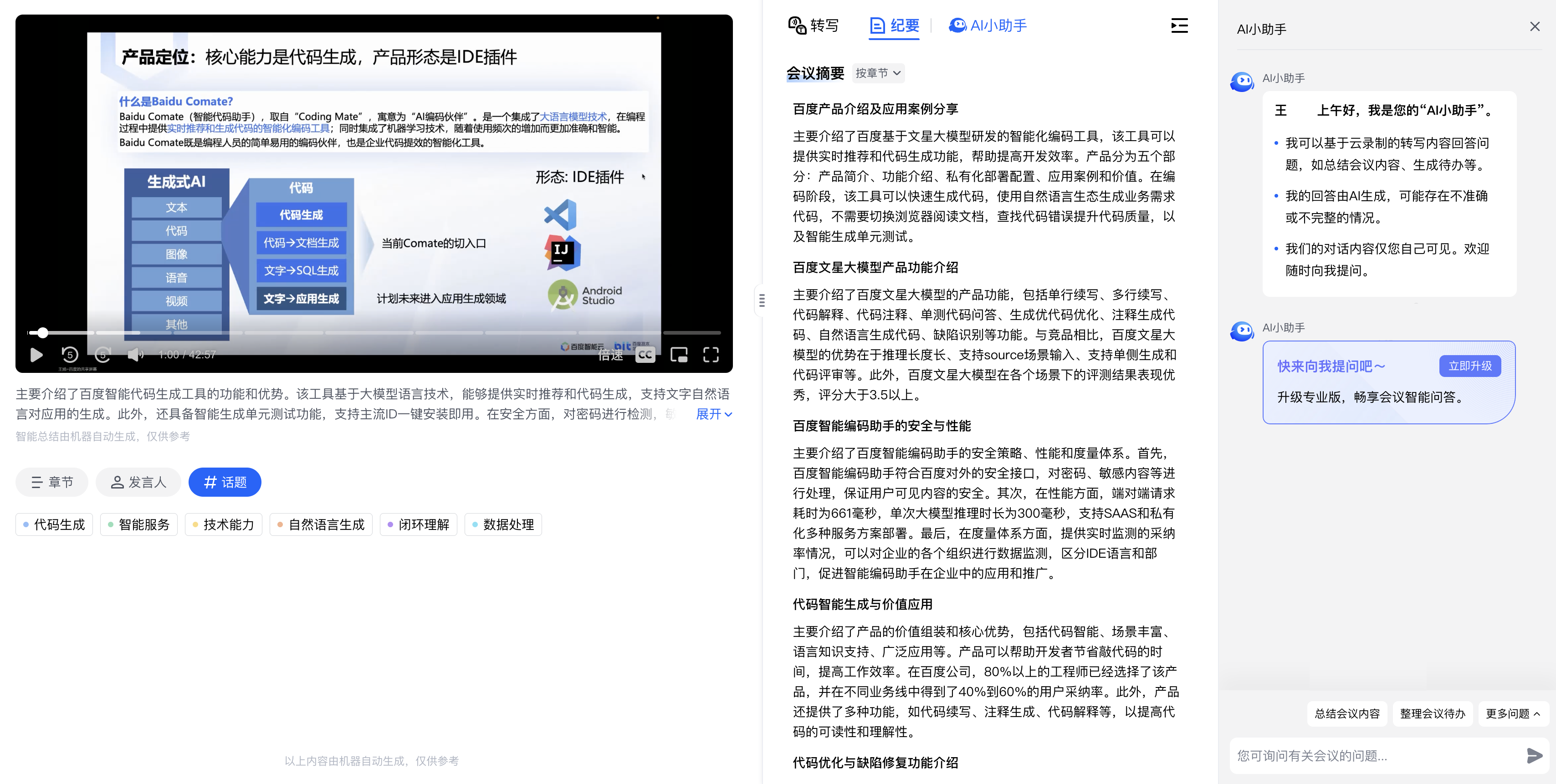
Open-source DeepResearch – Freeing our search agents
TLDR
Yesterday, OpenAI released Deep Research, a system that browses the web to summarize content and answer questions based on the summary. The system is impressive and blew our minds when we tried it for the first time.
昨天,OpenAI 发布了 Deep Research,这是一个浏览网页以总结内容并根据总结回答问题的系统。当我们第一次尝试时,这个系统给我们留下了深刻的印象。
One of the main results in the blog post is a strong improvement of performances on the General AI Assistants benchmark (GAIA), a benchmark we’ve been playing with recently as well, where they successfully reached near 67% correct answers on 1-shot on average, and 47.