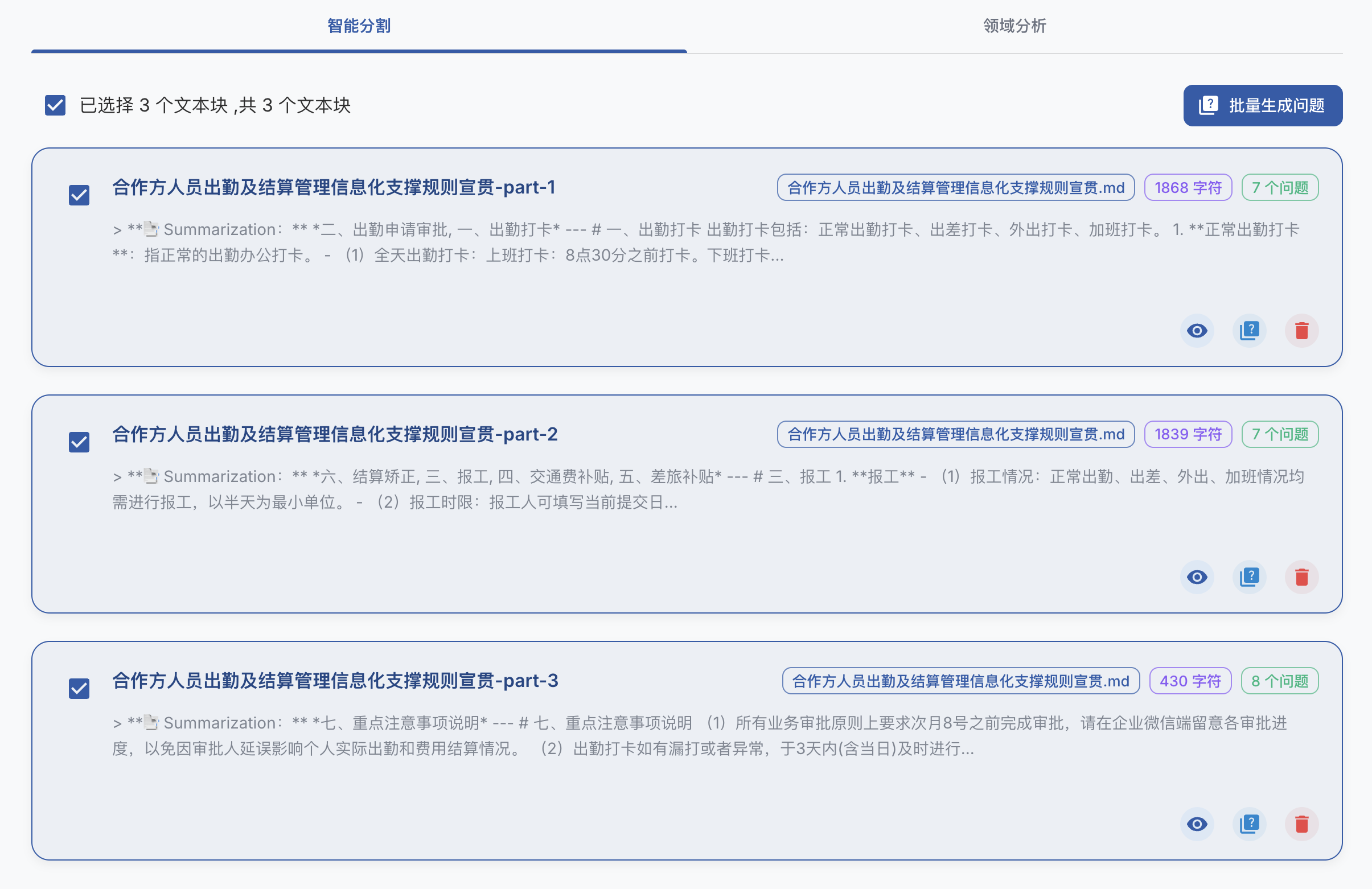
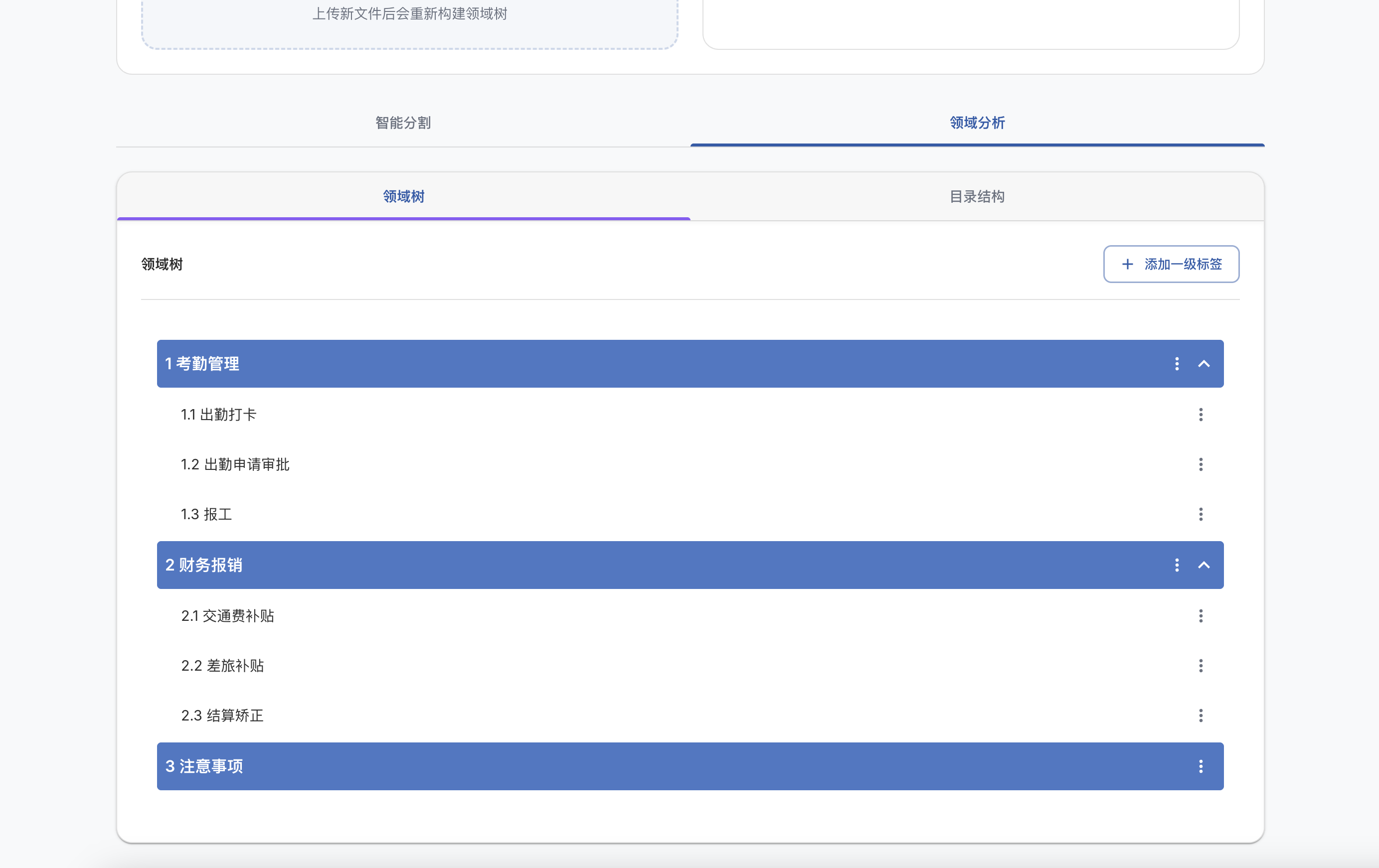
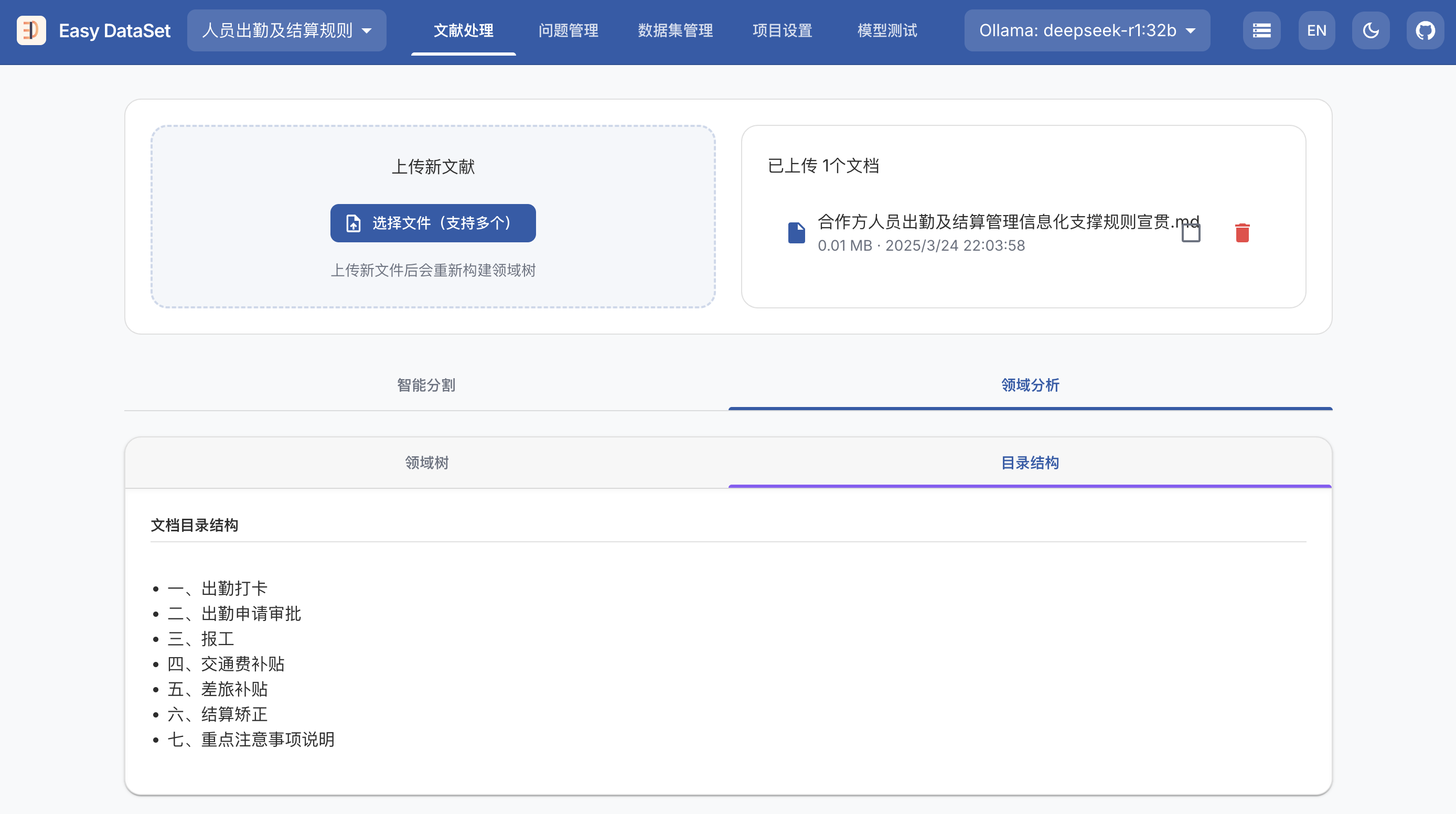
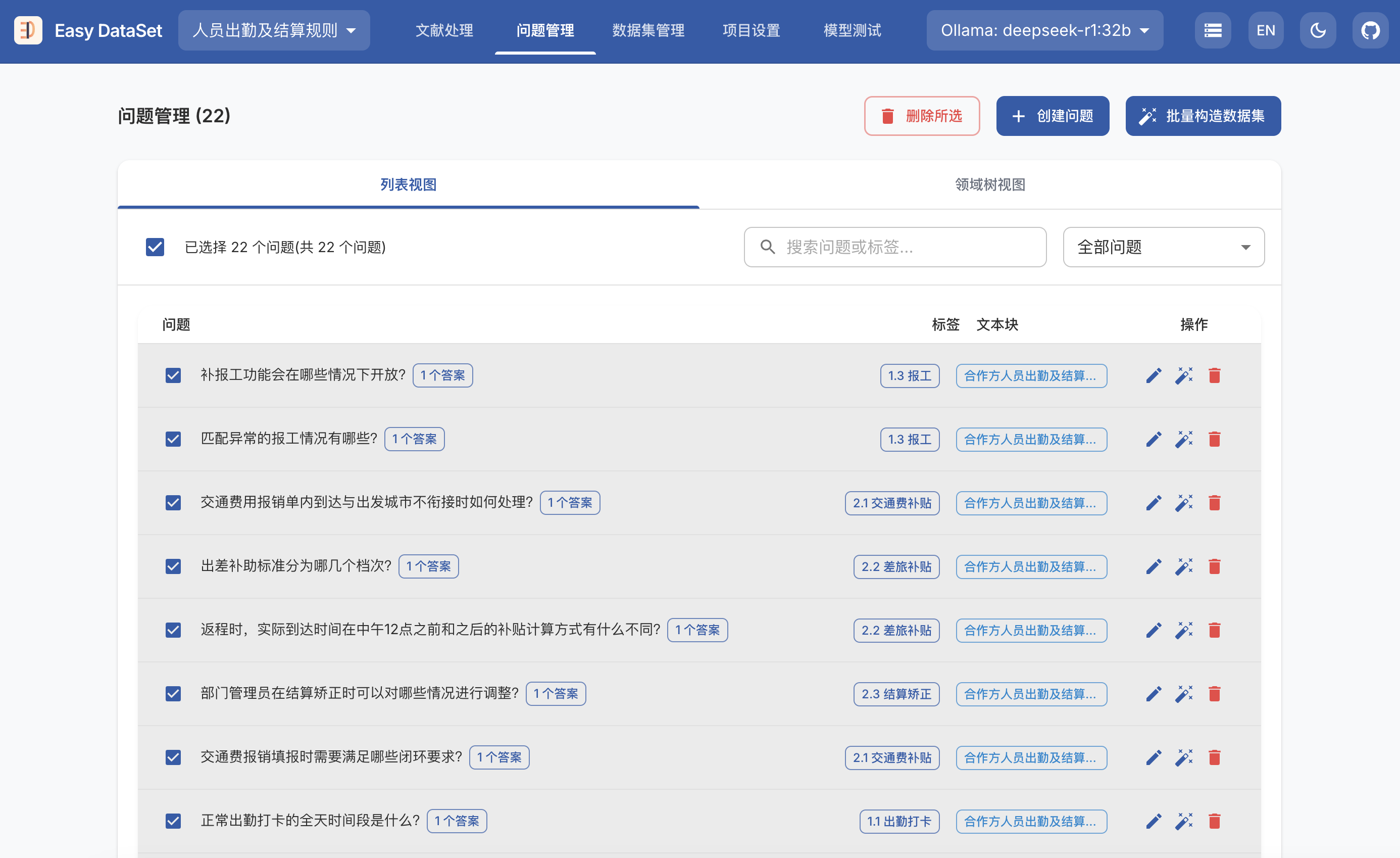
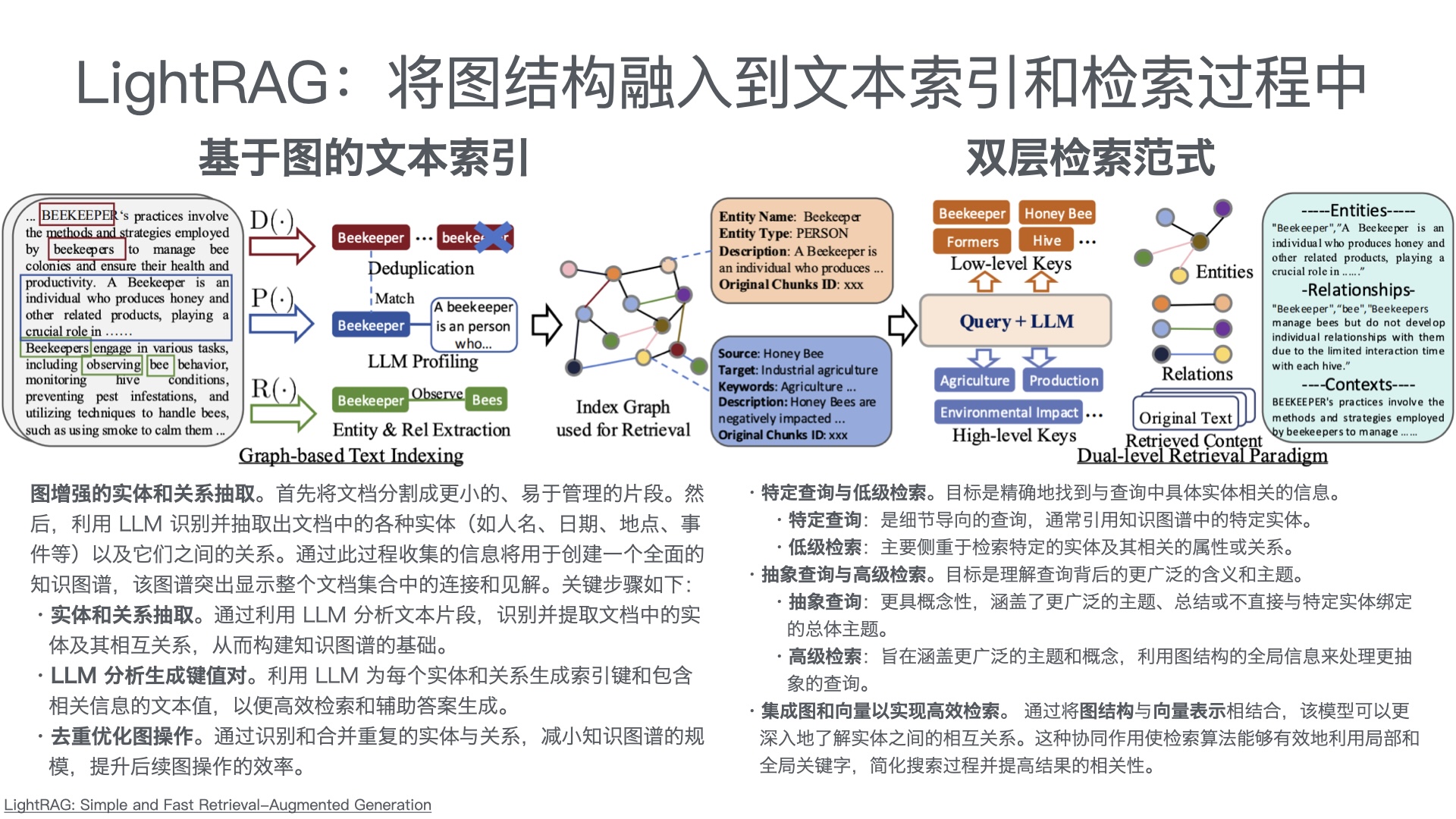
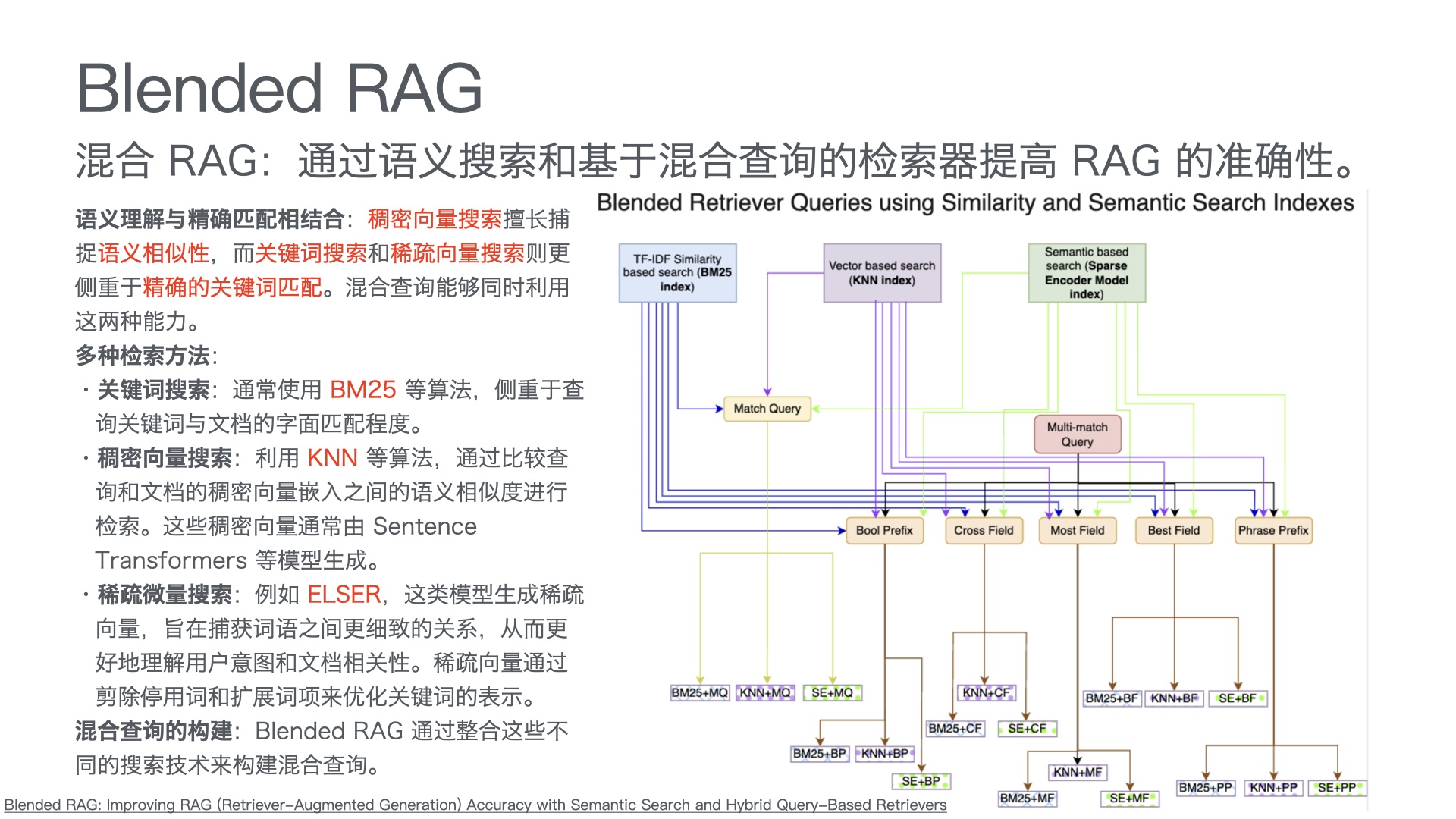
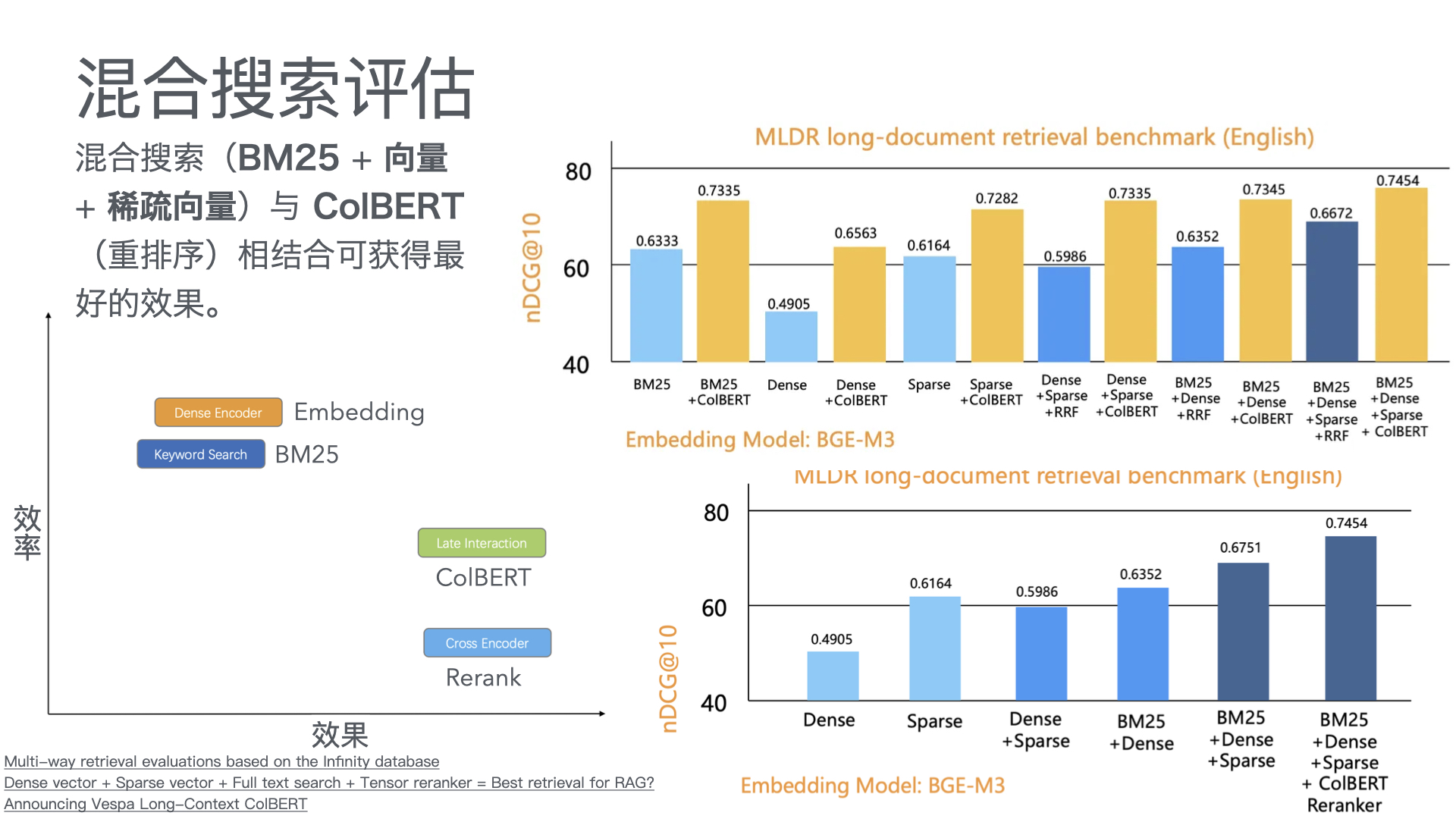
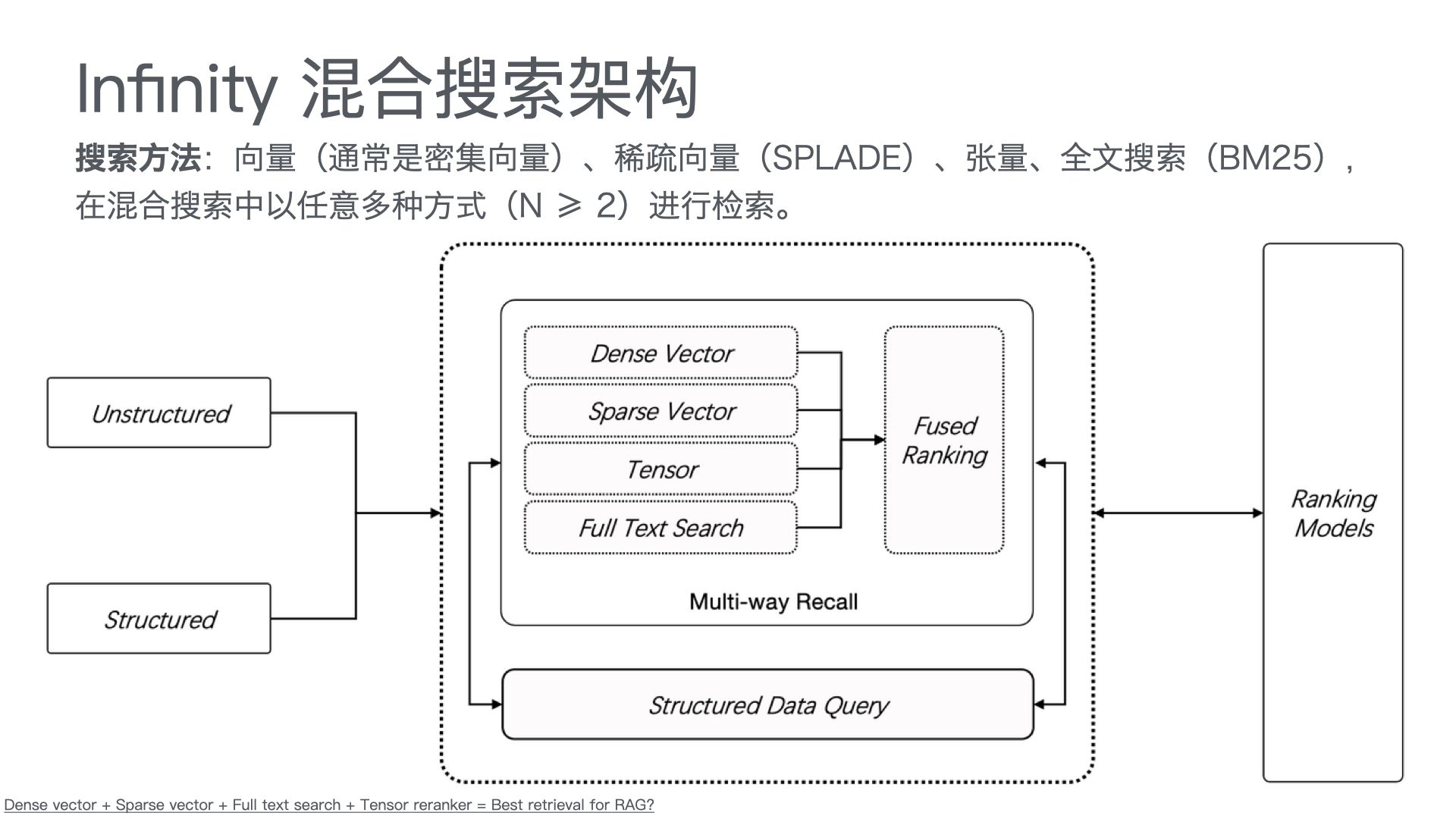
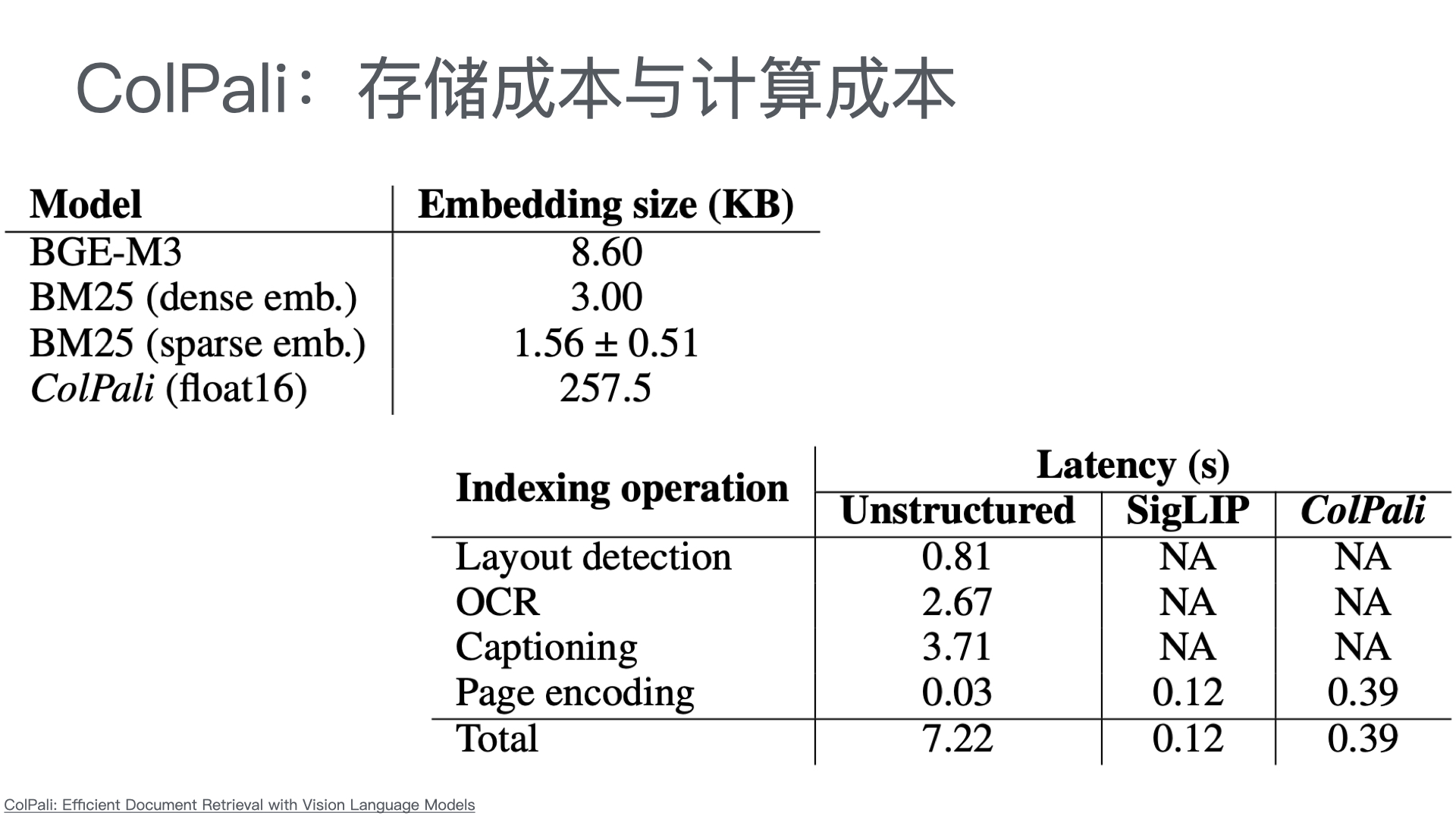
MCP Python SDK
概述
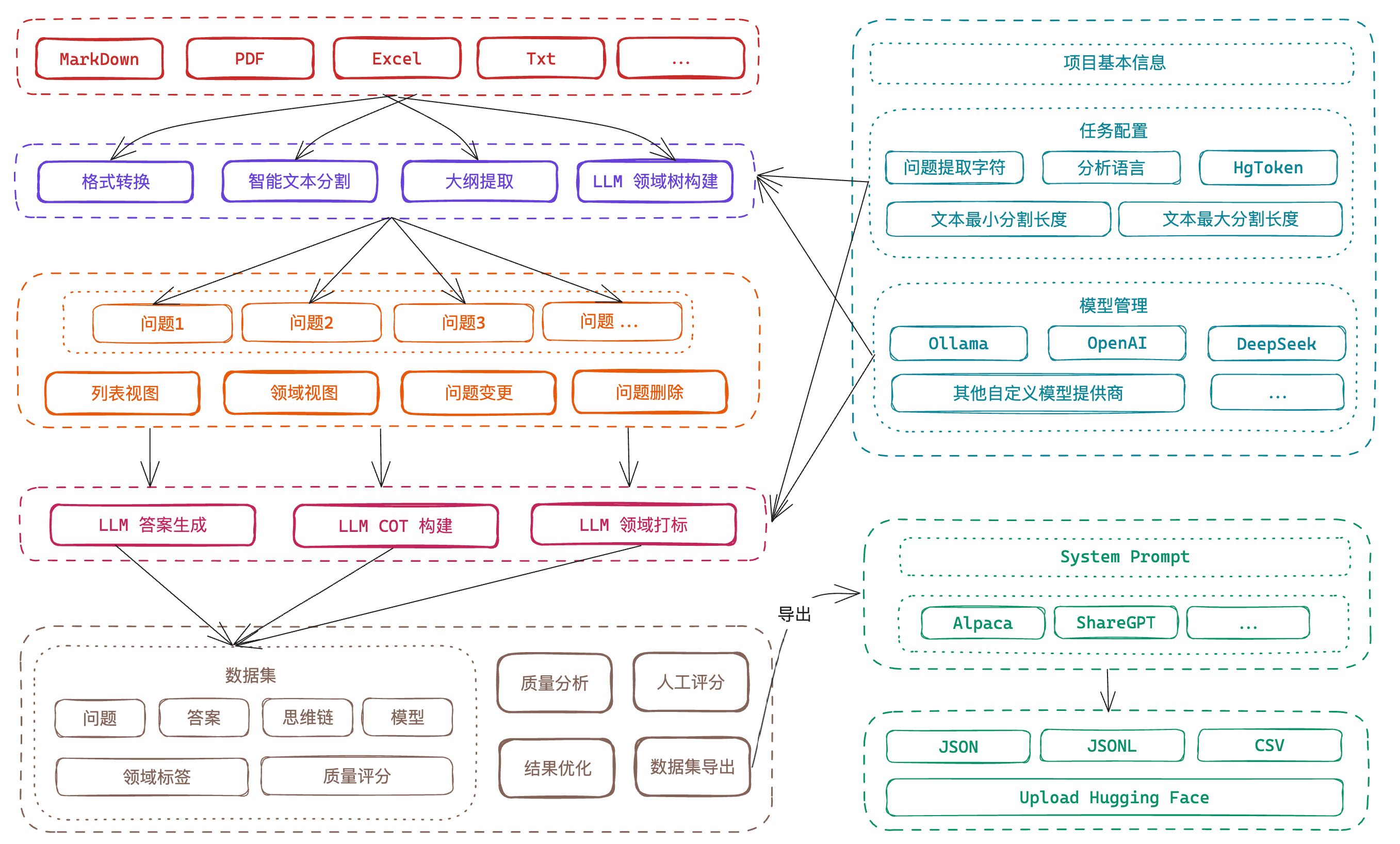
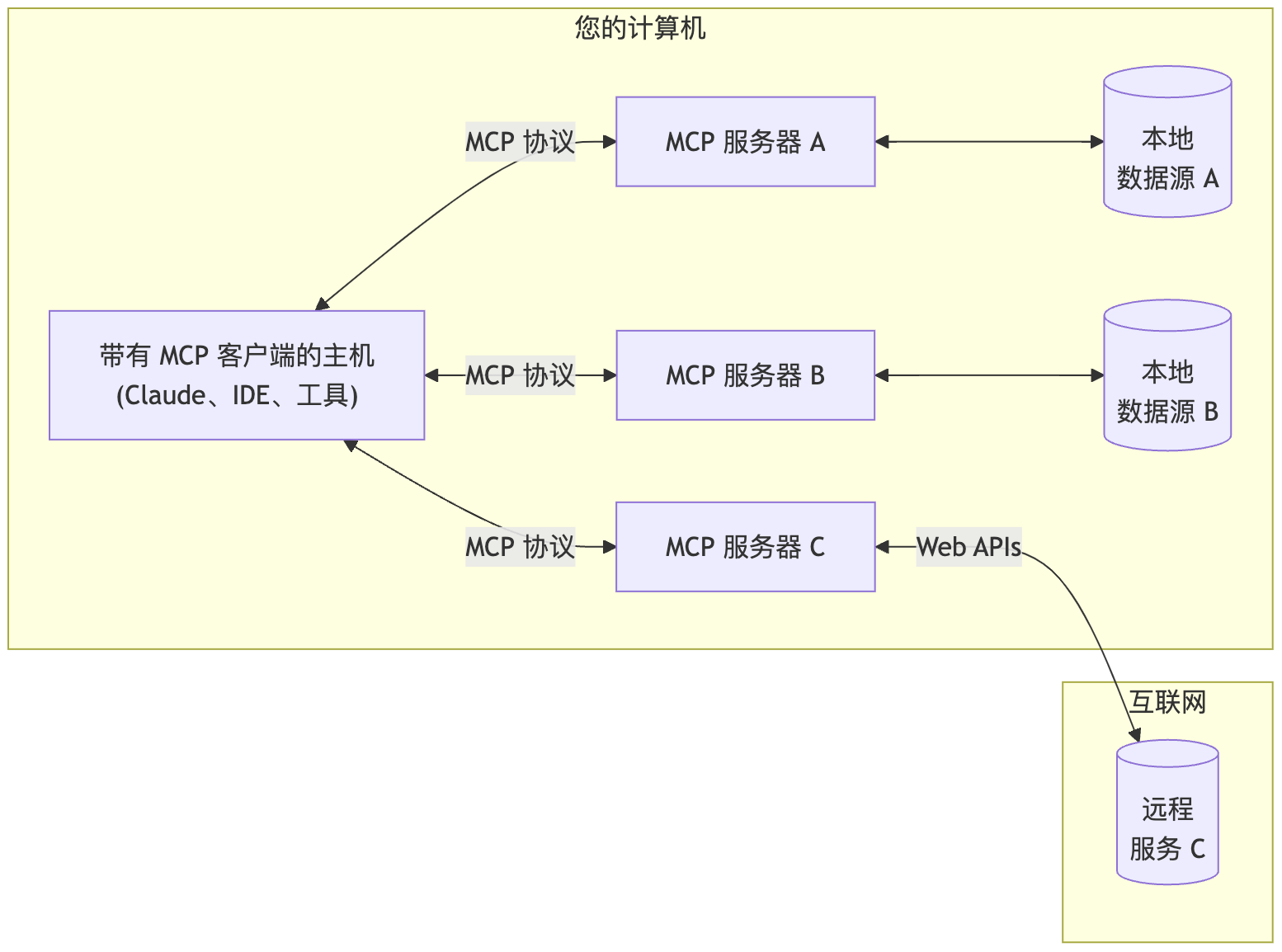
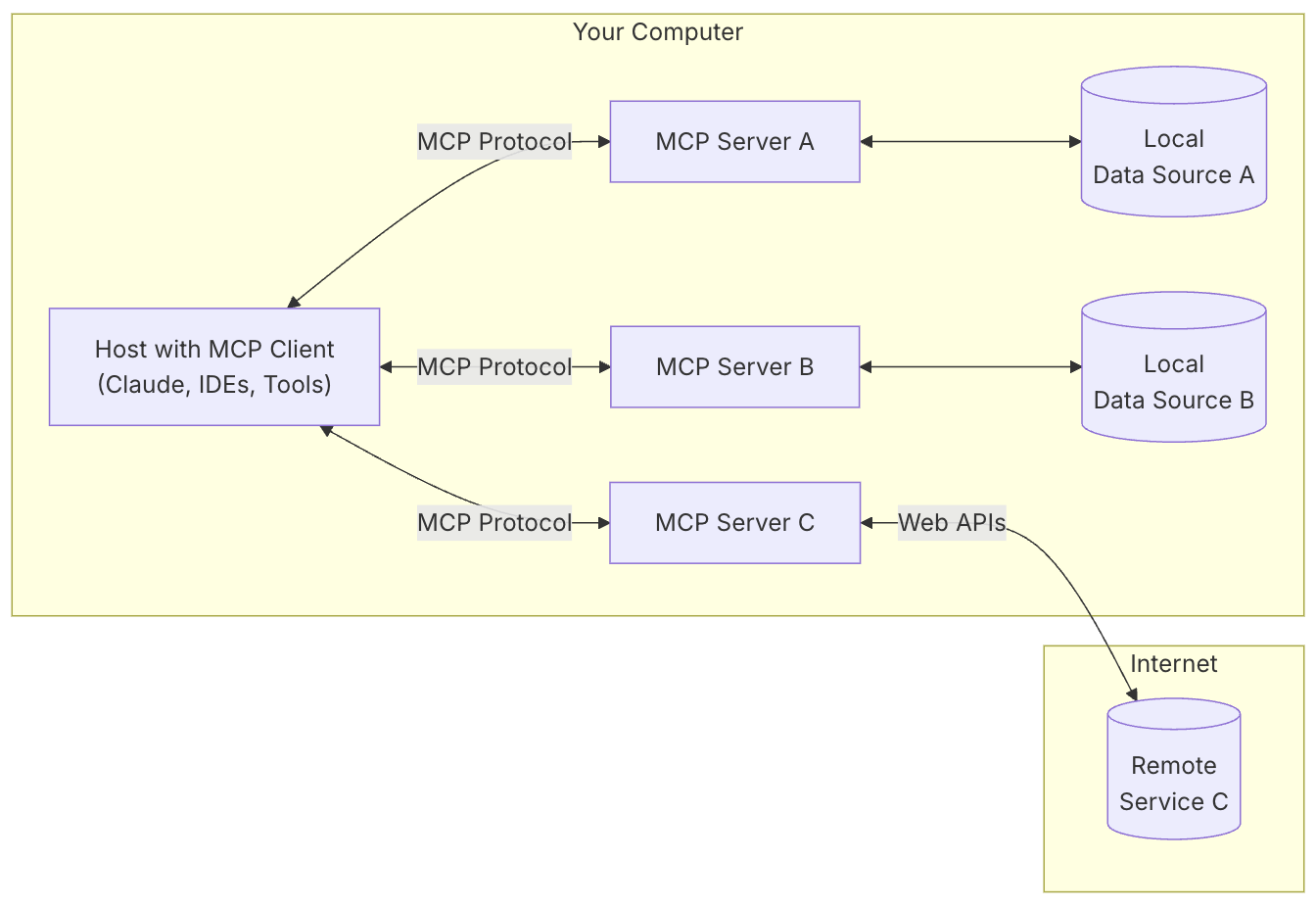
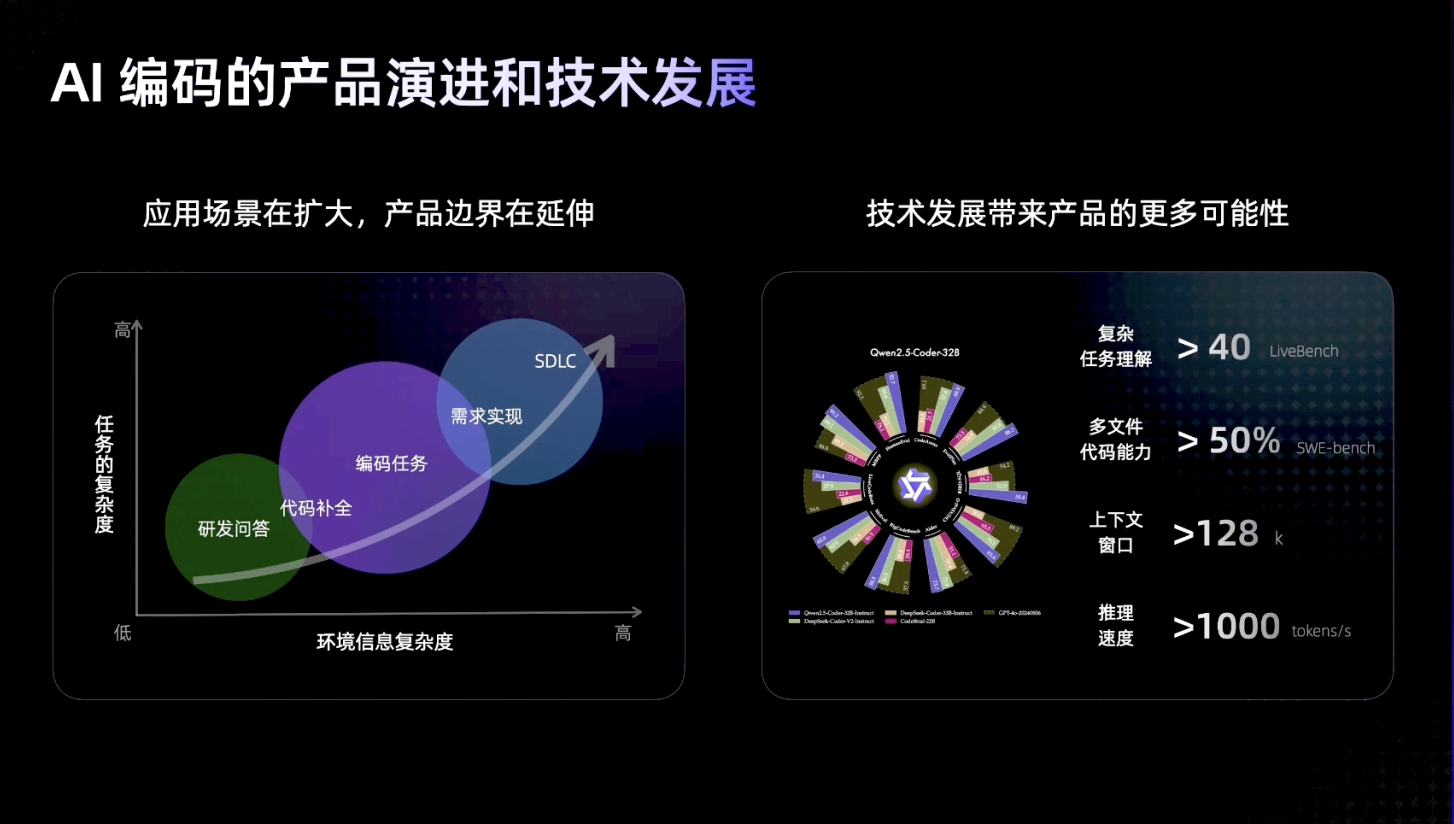
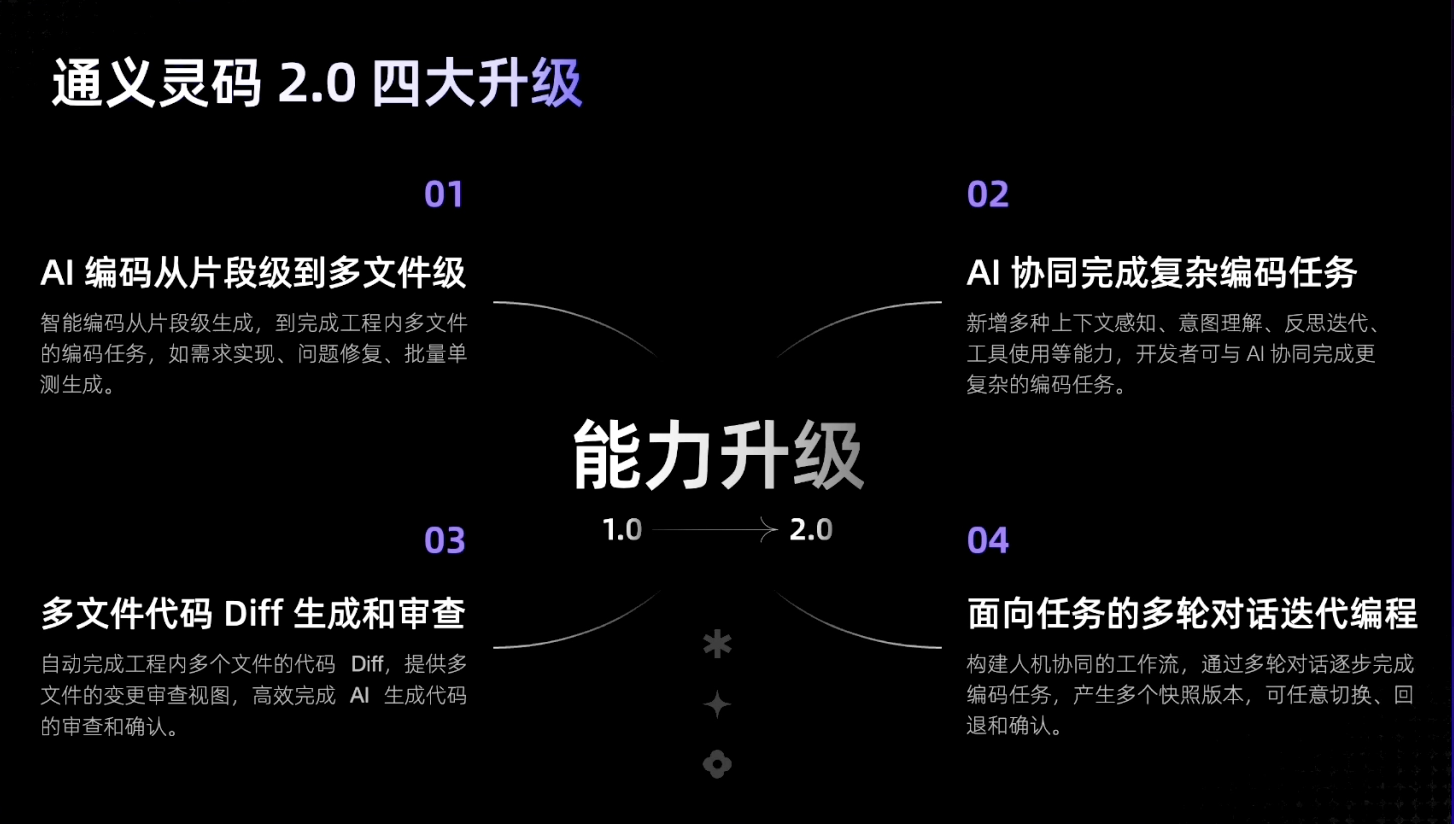
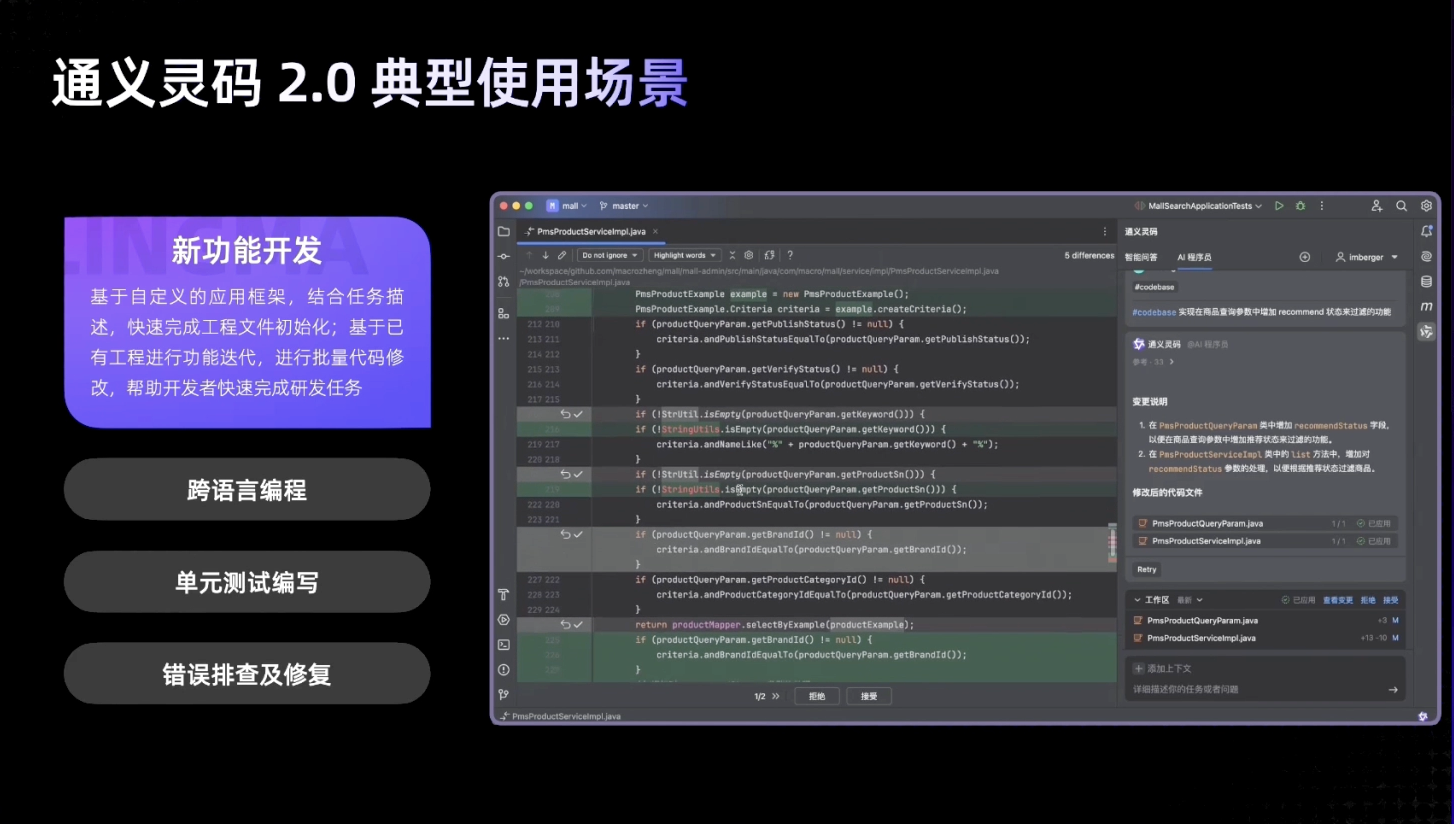
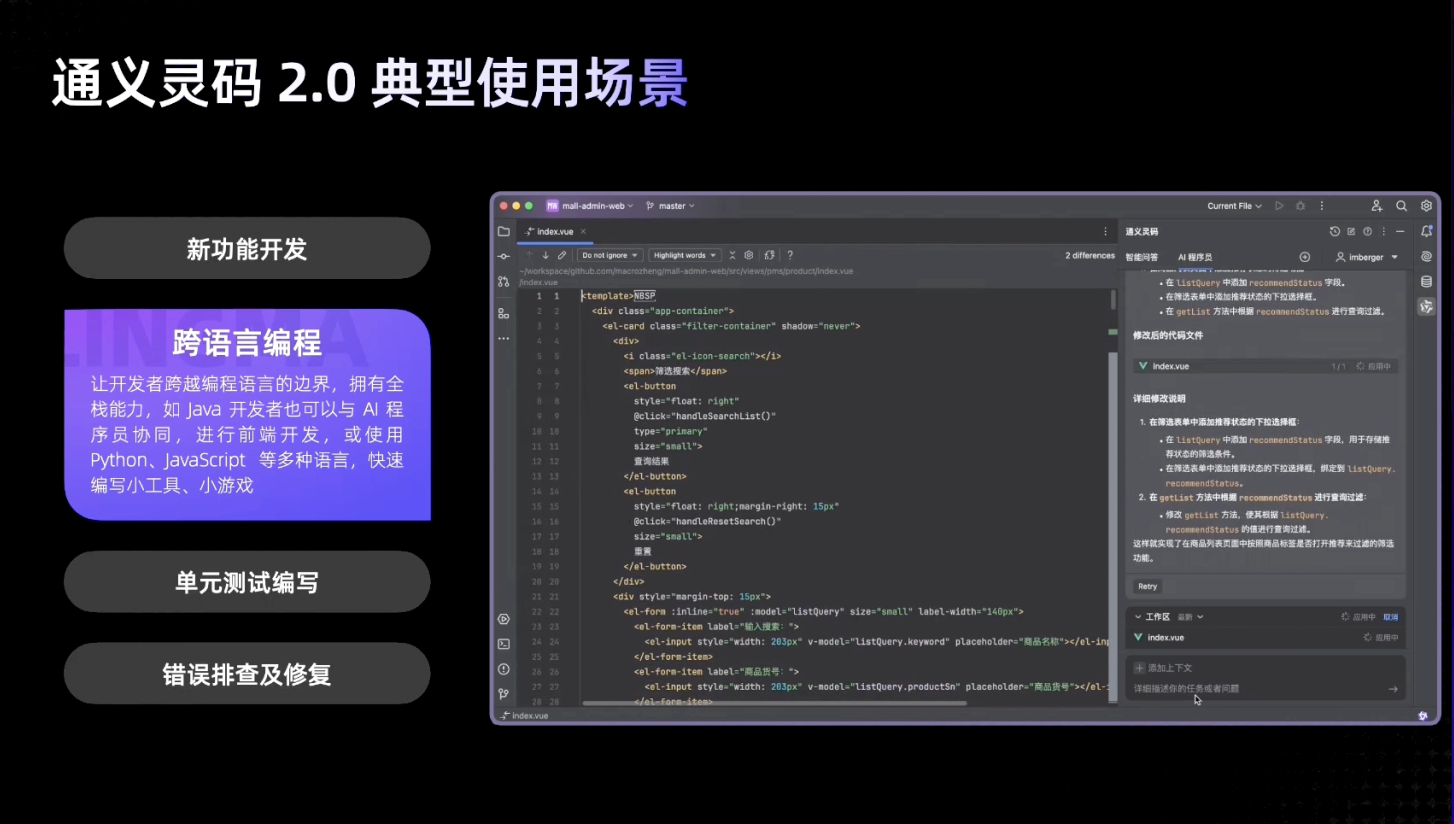
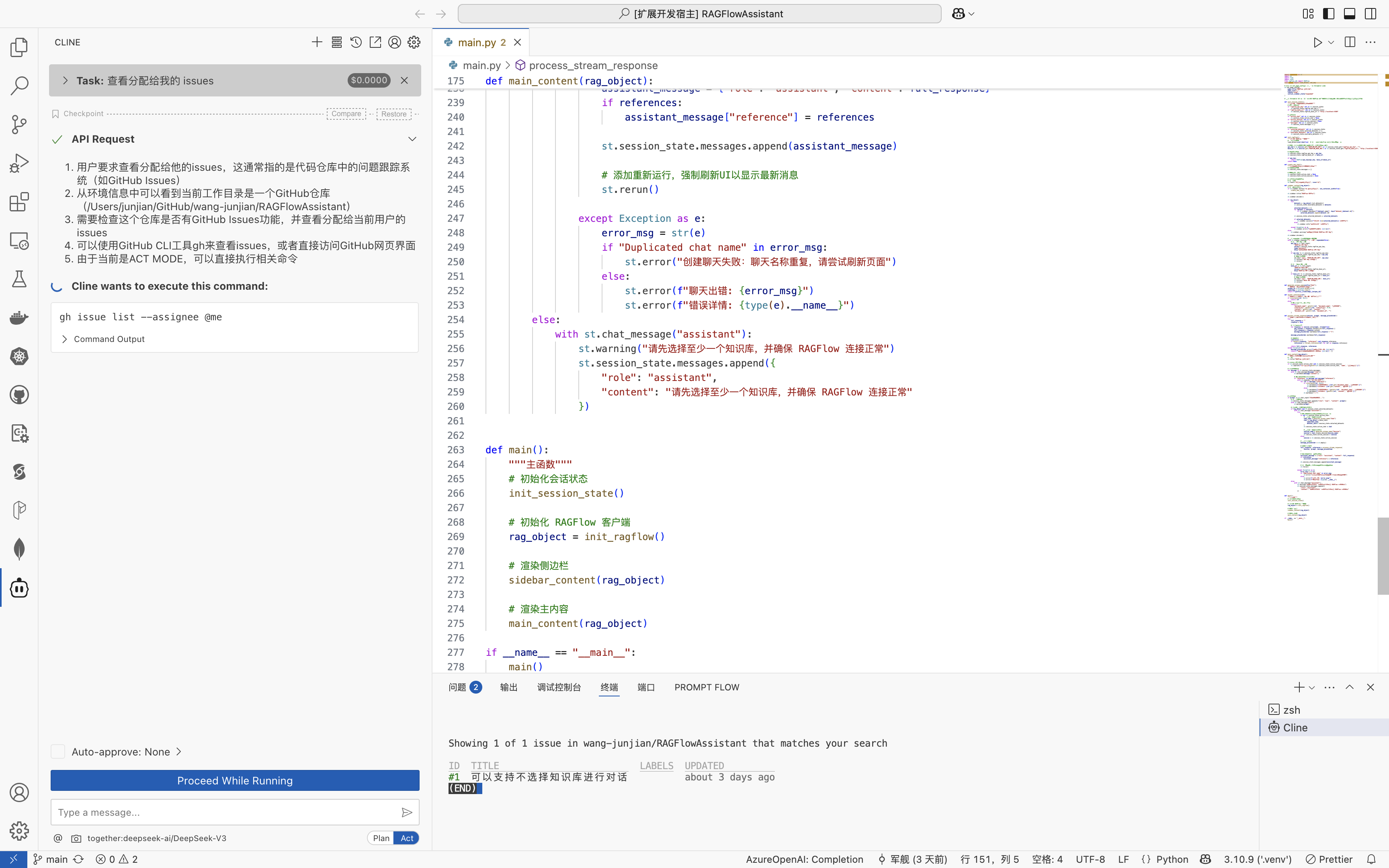
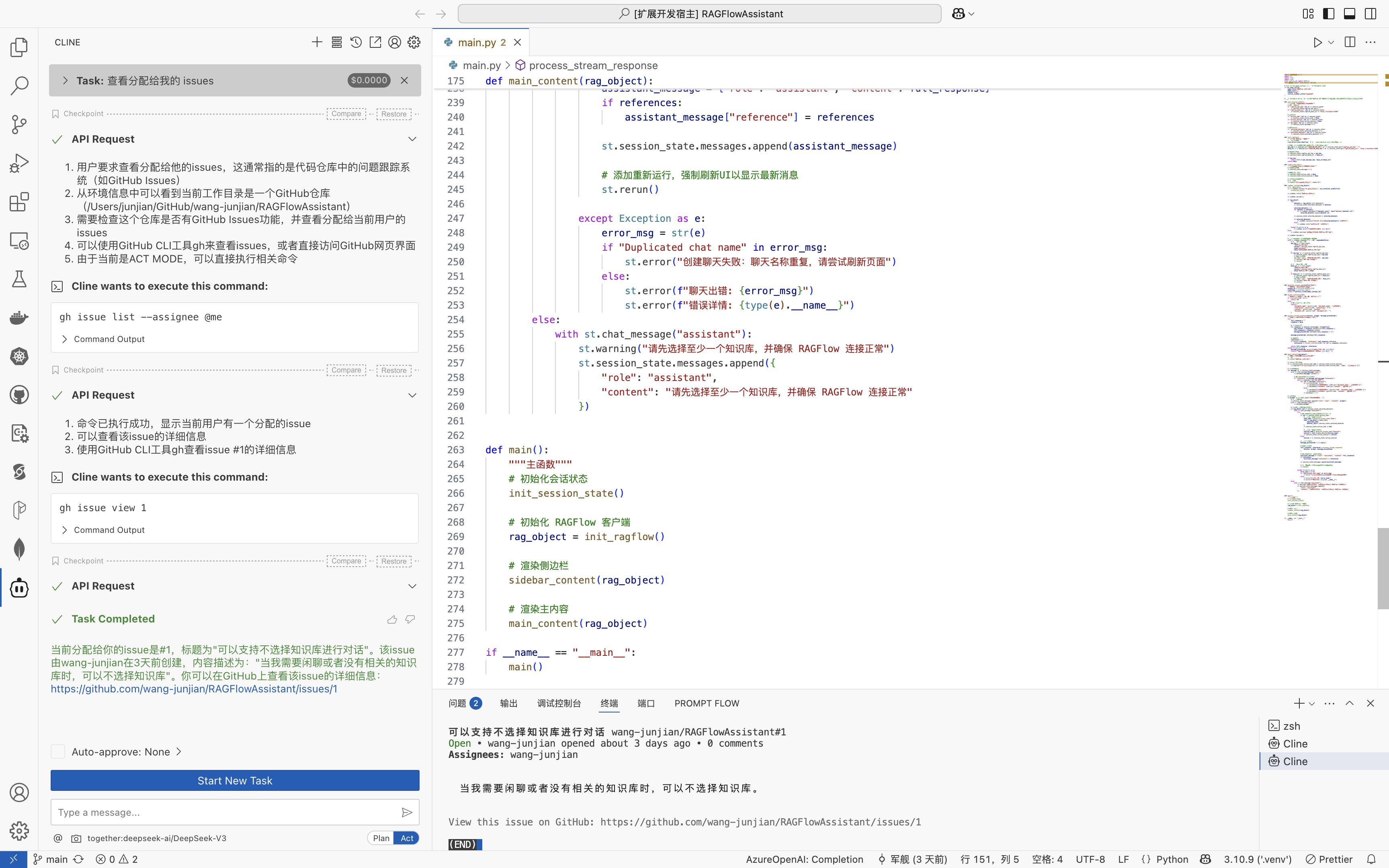
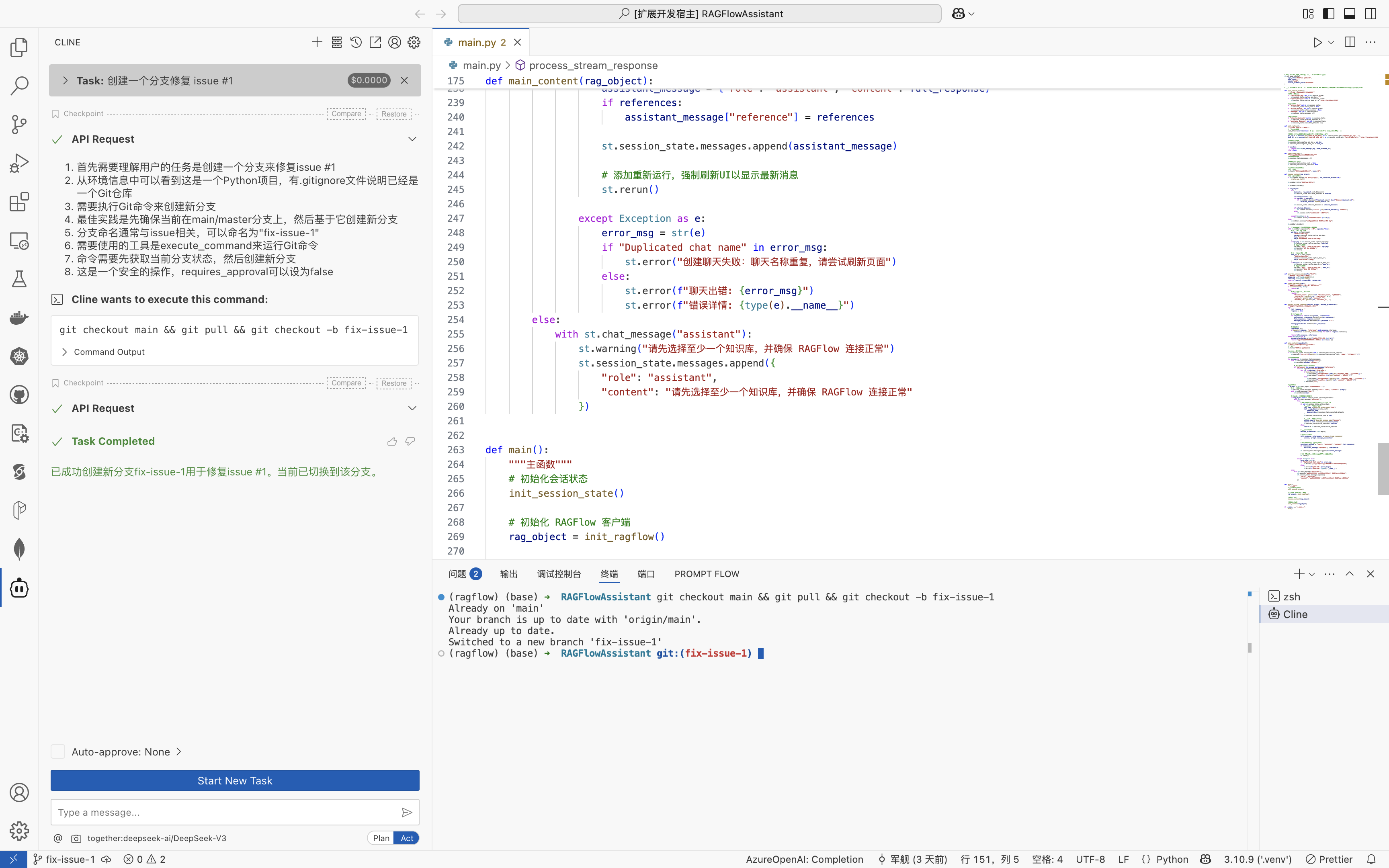
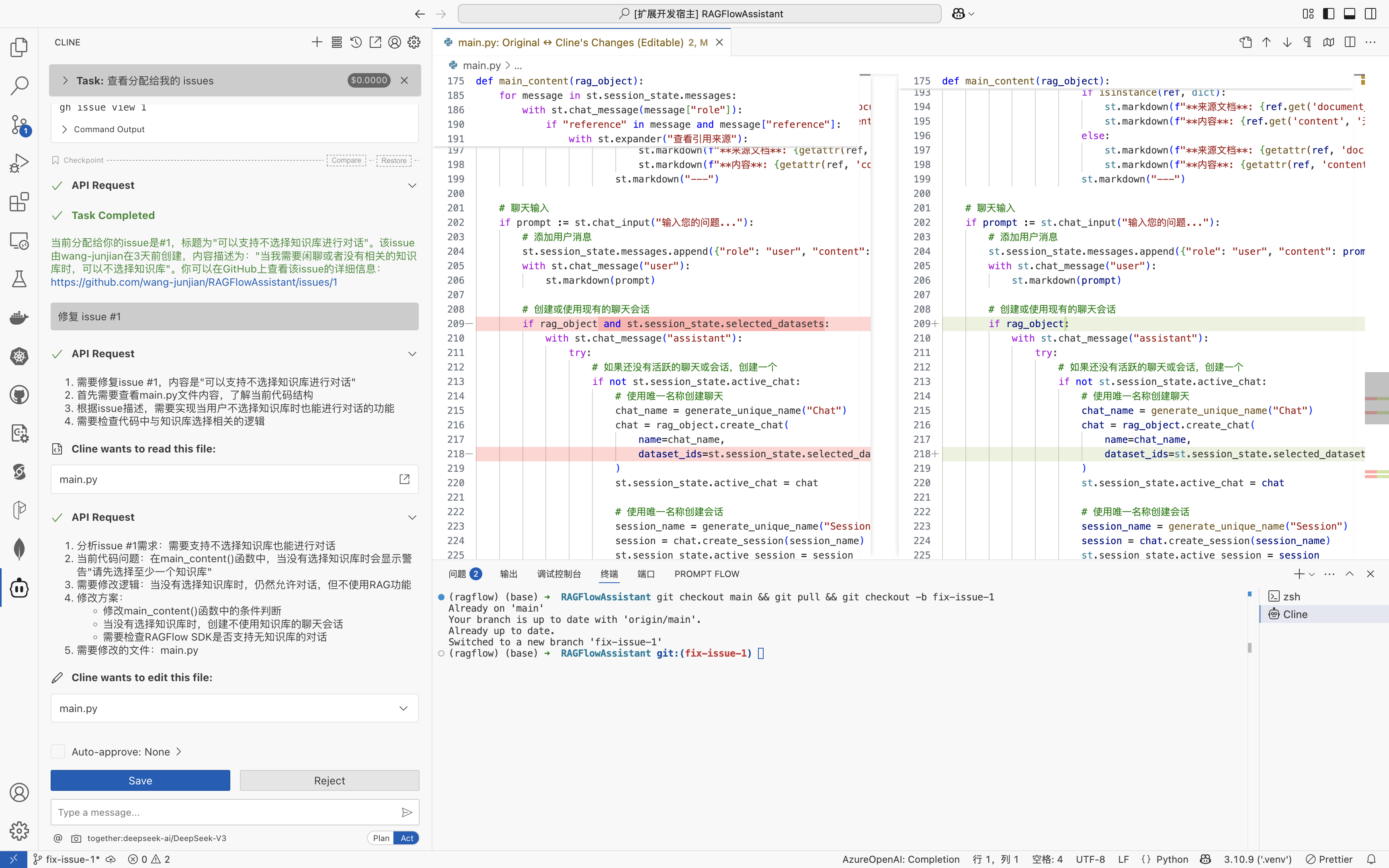
Model Context Protocol 允许应用程序以标准化的方式为 LLM 提供上下文,将提供上下文的关注点与实际的 LLM 交互分离开来。这个 Python SDK 实现了完整的 MCP 规范,使您能够轻松地:
- 构建可连接到任何 MCP 服务器的 MCP 客户端
- 创建暴露资源、提示和工具的 MCP 服务器
- 使用标准传输方式如 stdio 和 SSE
- 处理所有 MCP 协议消息和生命周期事件
安装
将 MCP 添加到您的 Python 项目中
我们推荐使用 uv 来管理您的 Python 项目。在由 uv 管理的 Python 项目中,通过以下方式将 mcp 添加到依赖项:
uv add "mcp[cli]"
或者,对于使用 pip 管理依赖的项目:
pip install mcp
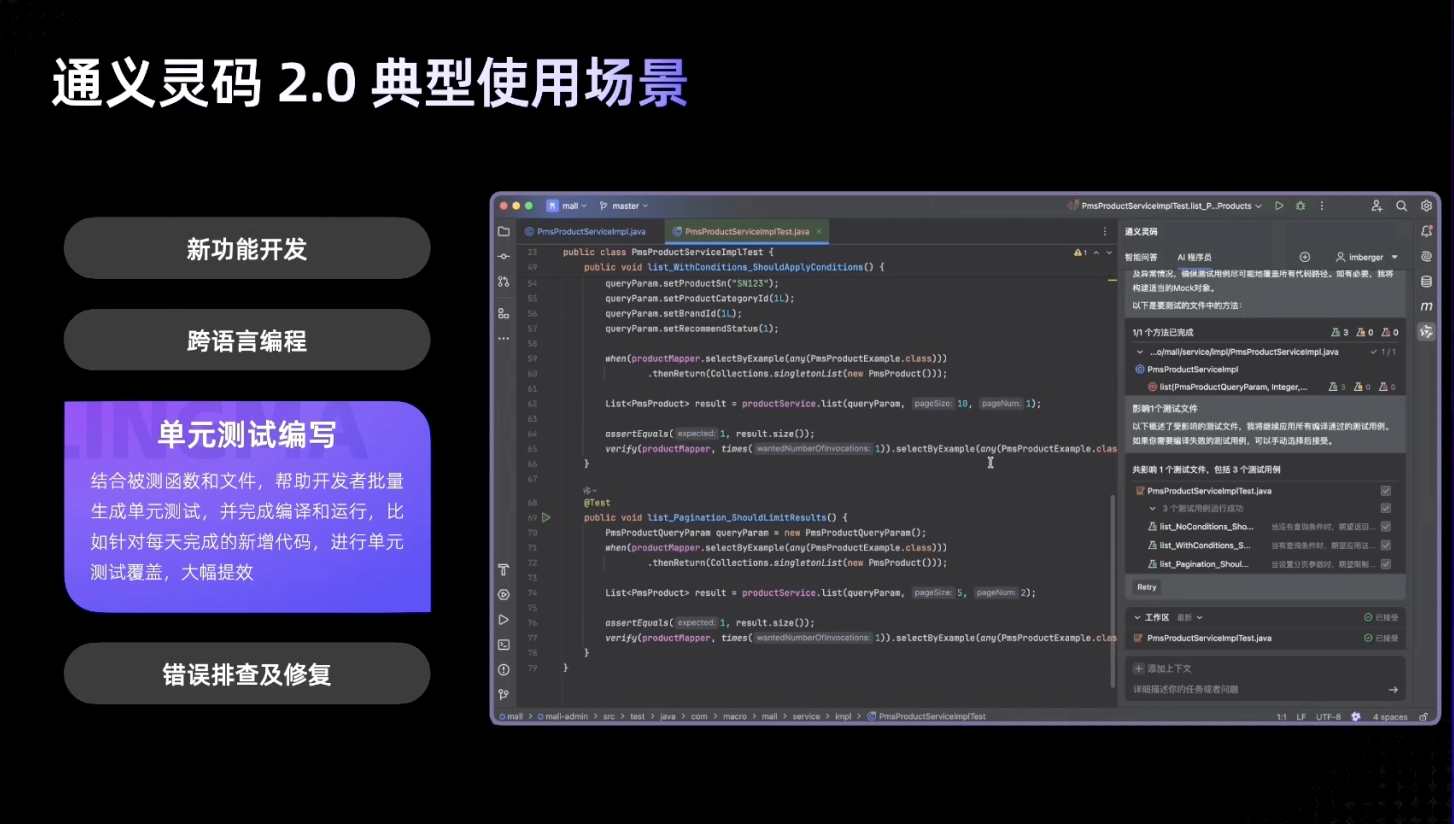
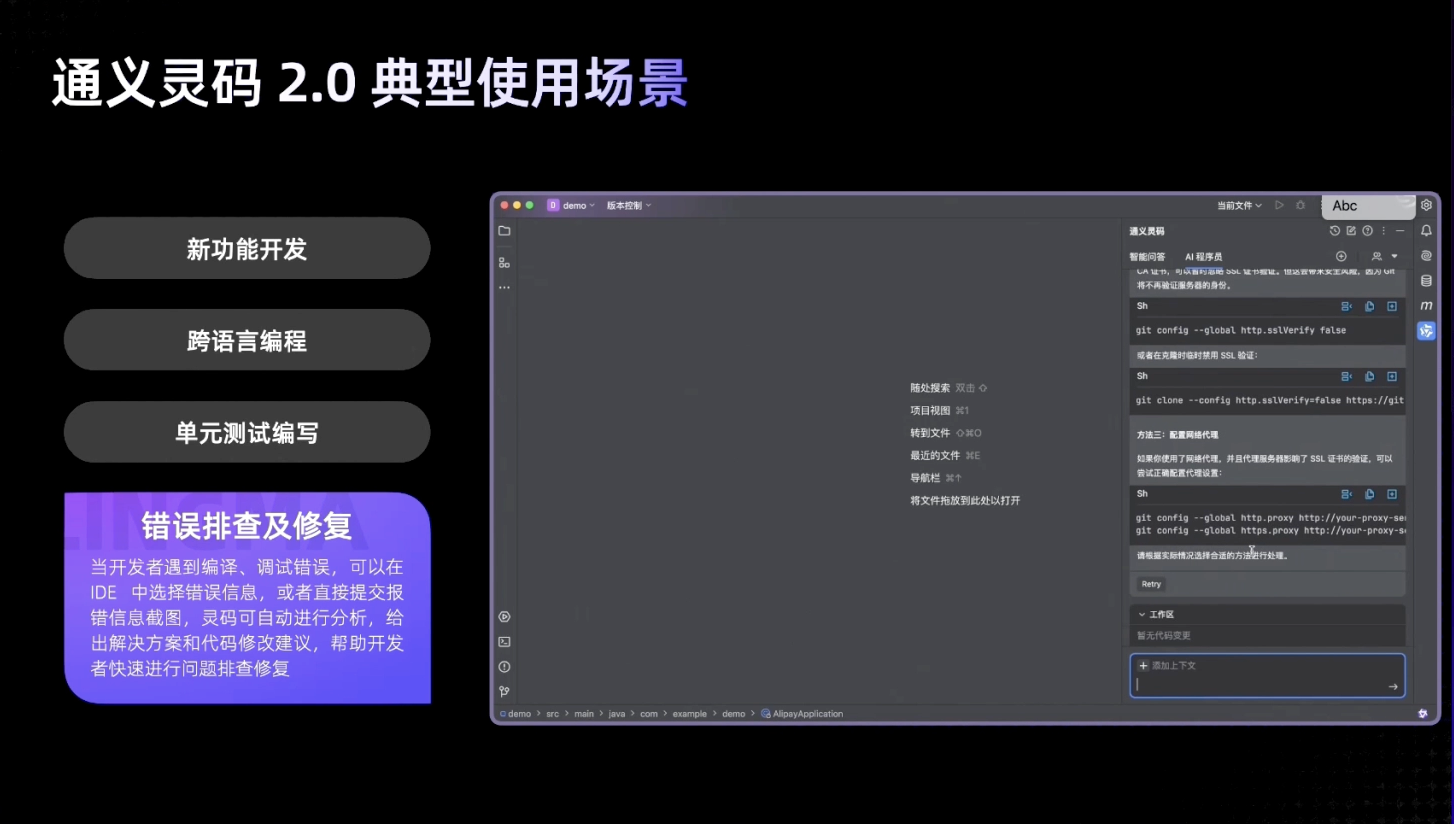
运行独立的 MCP 开发工具
要使用 uv 运行 mcp 命令:
uv run mcp
快速开始
让我们创建一个简单的 MCP 服务器,它暴露一个计算器工具和一些数据: