DeepSeek-V3 & DeepSeek-R1
用户的问题
用户的问题
构建AI代理的新手指南,帮助您克服挑战。
AI代理正变得越来越复杂,能够自动化工作流程、做出决策并与外部工具集成。然而,在现实世界中部署AI代理面临着很多挑战,这些挑战会影响其可靠性、性能和准确性。现在优先建立AI代理设计的强大基础,将为未来可靠、安全的自主系统奠定基础。
👉 本指南探讨了开发人员在创建AI代理时面临的五个最常见障碍,以及克服这些障碍的实用解决方案。 无论您是刚刚入门的新手还是正在改进方法的资深开发人员,这些最佳实践都将帮助您设计出在复杂环境中更可靠、更具扩展性和更有效的AI代理。
让我们开始构建代理式AI吧!
1. 管理工具集成
随着AI代理变得越来越复杂,管理它们对各种工具的访问和使用变得越来越具有挑战性。每增加一个工具都会引入新的潜在故障点、安全考虑因素和性能影响。确保代理适当地使用工具并优雅地处理工具故障对于可靠运行至关重要。
要解决这一挑战,请为代理工具箱中的每个工具创建精确的定义。包括何时使用该工具的明确示例、有效参数范围和预期输出。构建能够强制执行这些规范的验证逻辑,并从一小组定义明确的工具开始,而不是许多定义松散的工具。定期监控将帮助您识别哪些工具最有效,以及哪些定义需要完善。
2. 管理模型推理和决策
构建AI代理的一个基本挑战是确保一致可靠的决策。与遵循明确规则的传统软件系统不同,AI代理必须解释用户意图,对复杂问题进行推理,并最终基于概率分布做出决策。
git -C <目录> pull
这个命令用于从远程仓库获取最新代码并合并到当前分支。-C 选项允许你在指定的目录中运行 git 命令,而不需要先切换到那个目录。
下面是 MCP 相关的仓库
create-python-server
create-typescript-server
docs
inspector
python-sdk
quickstart-resources
servers
specification
typescript-sdk
更新所有仓库
方法一:手动更新
Continue 智能体
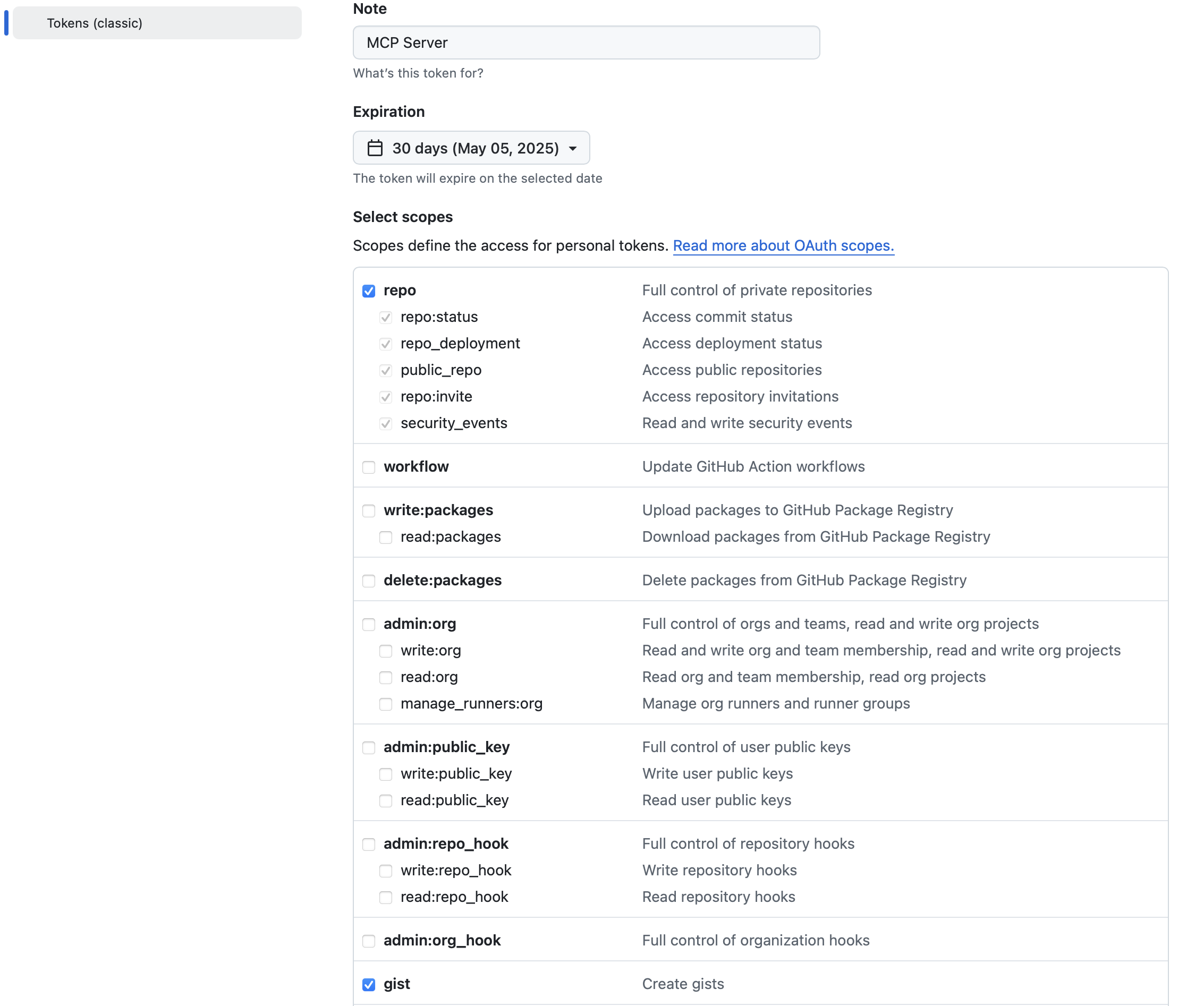
Agent 模式才支持 MCP Server。Agent 模式不支持 DeepSeek 系列的模型(包括官方API和开源)。Ollama 的模型:qwen2.5-coder:32b 和 qwq:latest。申请 GitHub 个人访问令牌(Personal Access Token)
GitHub 的 Settings 页面,点击 Developer settings。Personal access tokens,然后点击 Tokens (classic)。Generate new token 按钮。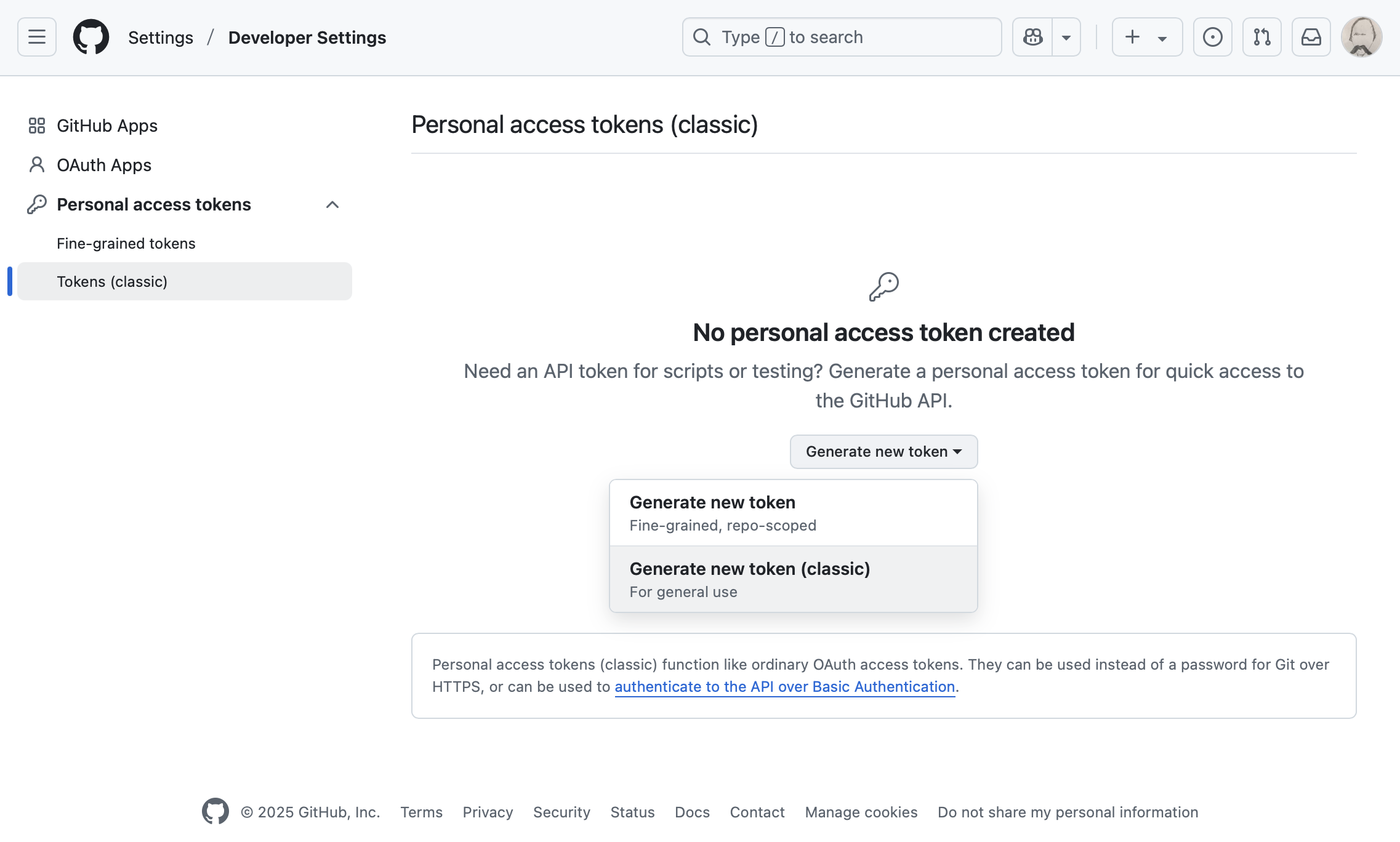
Continue 配置
config.yaml 文件配置如下:
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Autodetect
provider: ollama
model: AUTODETECT
- name: DeepSeek Chat
provider: deepseek
model: deepseek-chat
apiKey: sk-xxx
- name: DeepSeek Coder
provider: deepseek
model: deepseek-coder
apiKey: sk-xxx
// ...
安装 Node.js 环境
brew install node
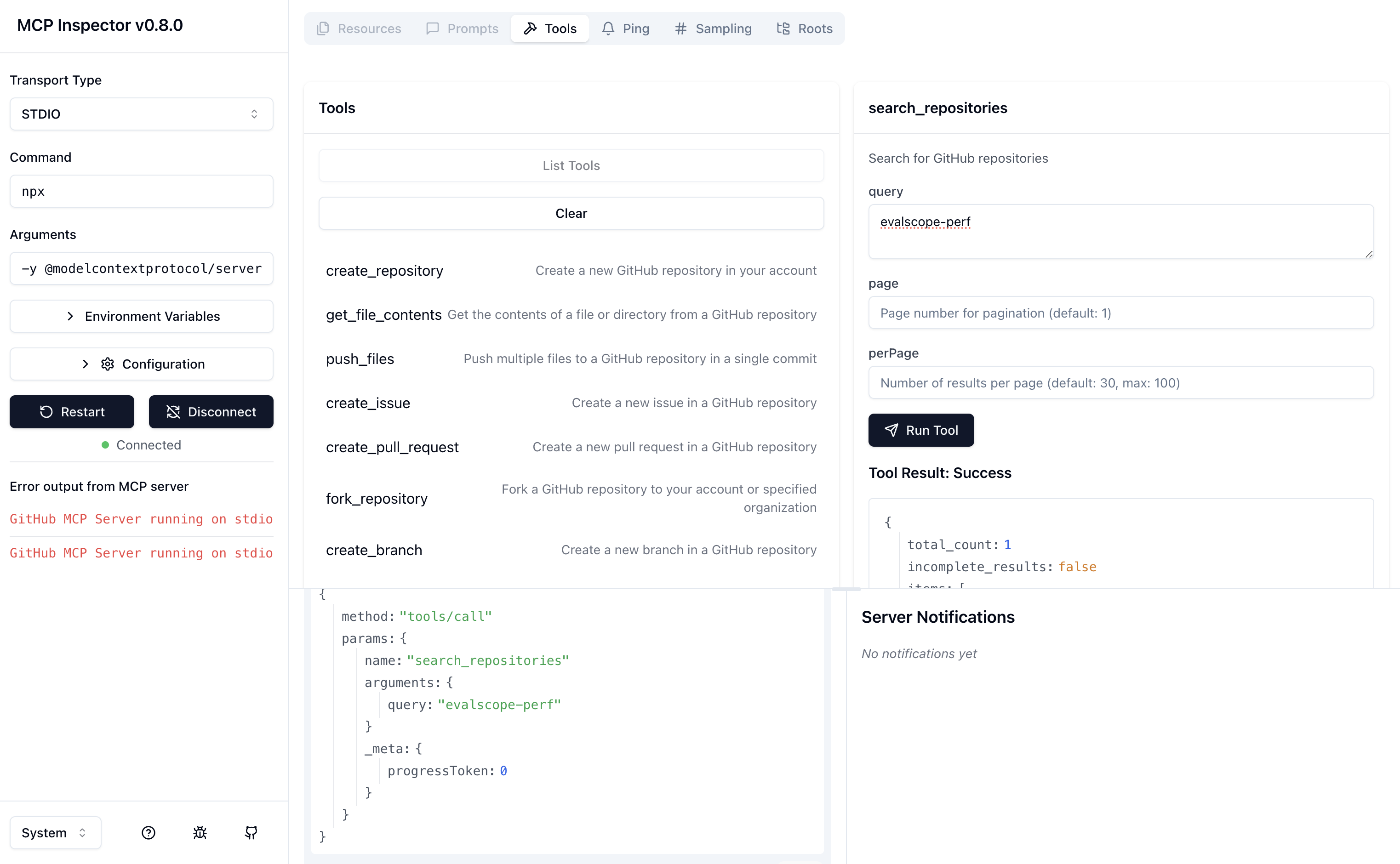
调试 GitHub MCP Server
export GITHUB_PERSONAL_ACCESS_TOKEN=github_pat_XXX
npx @modelcontextprotocol/inspector npx -y @modelcontextprotocol/server-github
用户界面
运行浏览器,访问 URL:http://127.0.0.1:6274/
参考资料
GitHub MCP 服务器
GitHub API 的 MCP 服务器,支持文件操作、仓库管理、搜索功能等。
功能特点
工具
create_or_update_fileowner (字符串):仓库所有者(用户名或组织)repo (字符串):仓库名称path (字符串):创建/更新文件的路径content (字符串):文件内容message (字符串):提交消息branch (字符串):要在其中创建/更新文件的分支sha (可选字符串):被替换文件的 SHA(用于更新)push_filesowner (字符串):仓库所有者repo (字符串):仓库名称branch (字符串):要推送到的分支files (数组):要推送的文件,每个包含 path 和 contentmessage (字符串):提交消息search_repositories 搜索 GitHub 仓库 输入: query (字符串):搜索查询
⚠️ Trae 试用感受
功能界面
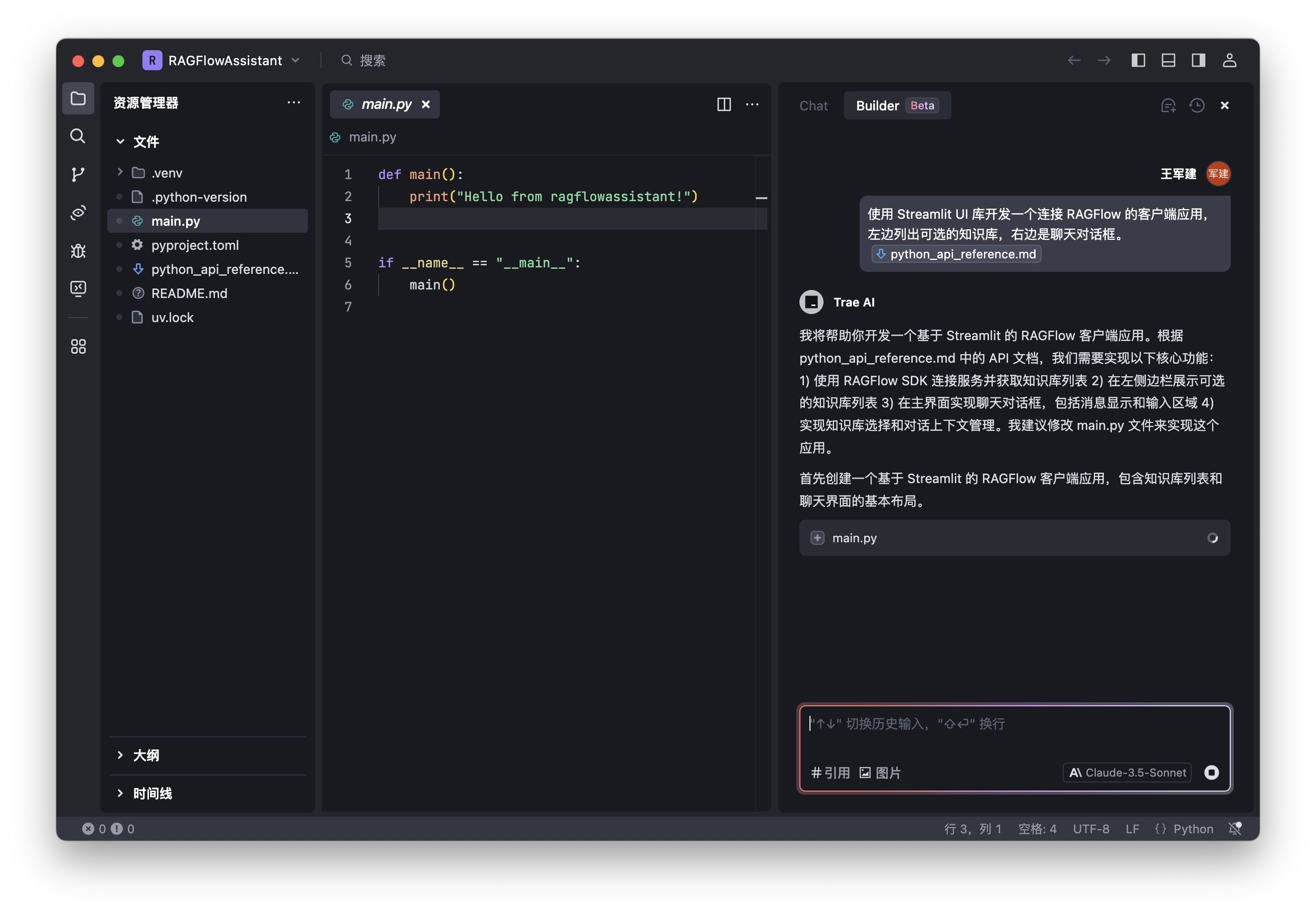
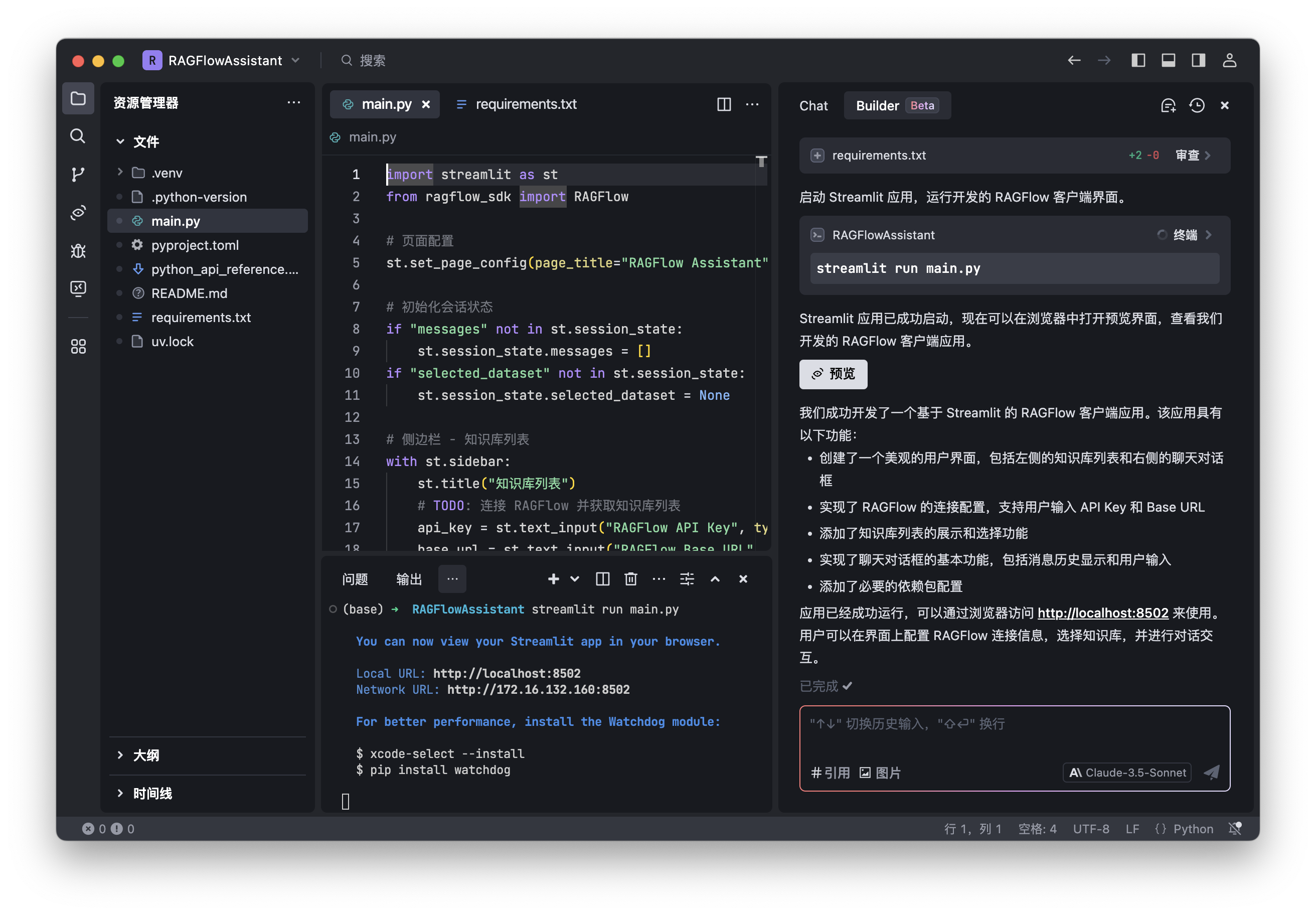
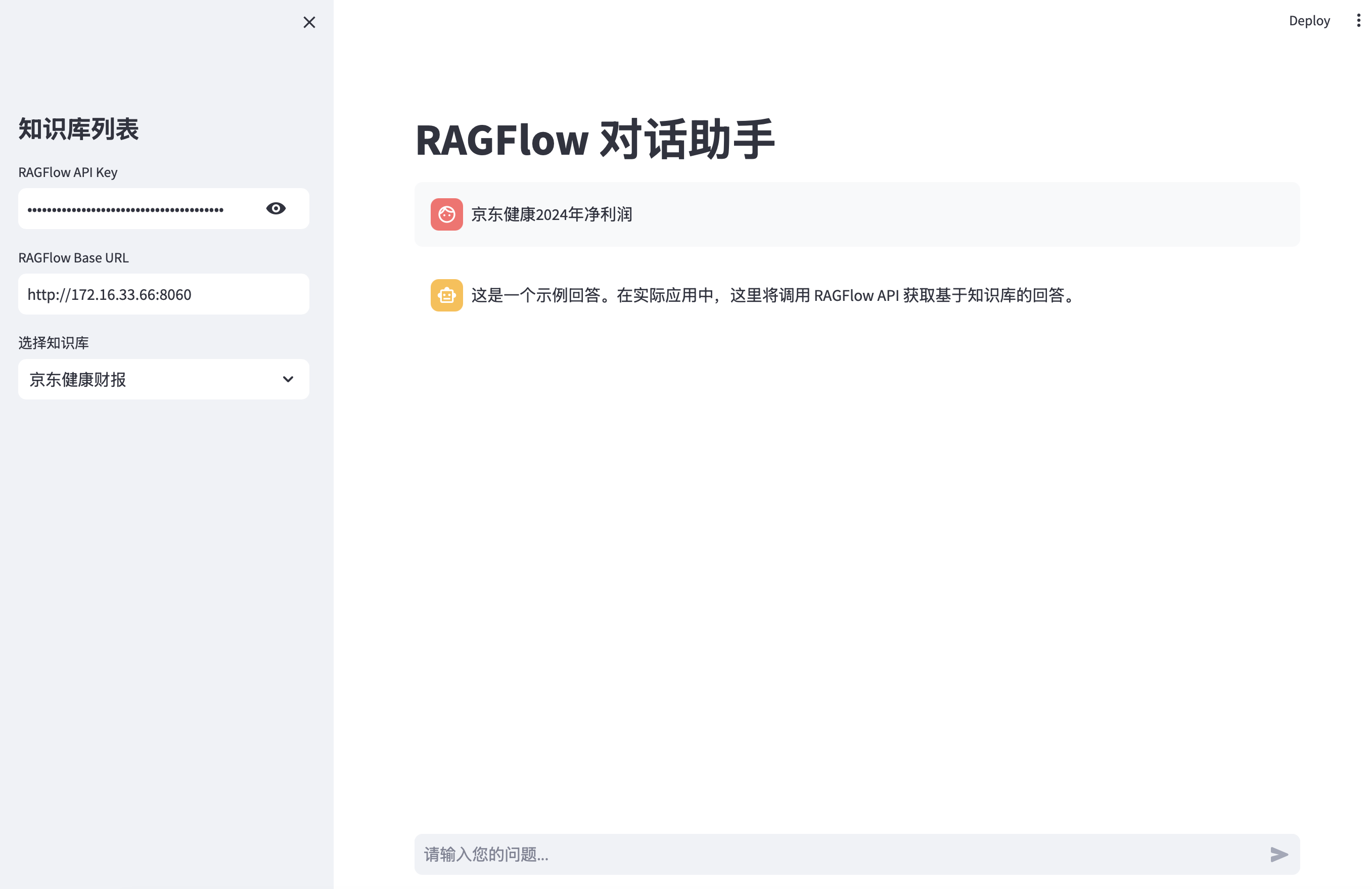
操作
提示词
使用 Streamlit UI 库开发一个连接 RAGFlow 的客户端应用,左边列出可选的知识库,右边是聊天对话框。
本页概述了支持模型上下文协议(Model Context Protocol, MCP)的应用程序。每个客户端可能支持不同的MCP功能,从而实现与MCP服务器的不同级别的集成。
功能支持矩阵
本页展示了各种模型上下文协议(MCP)服务器,这些服务器展示了该协议的功能和多样性。这些服务器使大型语言模型(LLM)能够安全地访问工具和数据源。
参考实现
这些官方参考服务器展示了核心 MCP 功能和 SDK 用法:
数据和文件系统
开发工具
Web 和浏览器自动化
生产力和通信
AI 和专业工具 EverArt - 使用各种模型的 AI 图像生成 Sequential Thinking -
大型语言模型(LLM)的工作原理根植于模式匹配和对下一个词元的统计预测("随机鹦鹉")。从这种方法中产生的一个有些出人意料的能力是它们也能在一定程度上"推理"解决问题。有些模型的推理能力比其他模型更强,OpenAI的"o1"和"o3"模型是两个突出的推理模型,而DeepSeek的"R1"最近引起了很大轰动。但是当我们在编码任务中使用AI时,这种能力发挥什么作用呢?
剧透提醒:我还没有答案!但我有问题和想法。
我将从两个方面开始讨论,这两个方面在我的理解中是推理能力的限制,而且这些限制在编码环境中是相关的。然后我将分享我的想法,即推理在哪些编码任务中可能有用,在哪些任务中可能没用。
上下文至关重要,尤其是对推理而言
苹果公司去年发表的一篇关于大型语言模型推理局限性的论文引起了广泛关注。作者引入了一个新的基准测试,用来测试LLM在"数学推理"方面的能力。他们的基准测试基于一个已有的包含小学数学问题的测试集。他们选取了100个问题,将其转化为带有变量占位符的模板,然后为每个模板创建了50个变体,形成了一个包含5,000个问题的数据集。在第二步中,他们还创建了一个新的数据集,在问题中添加了无关信息。
他们发现:
生成式人工智能和特别是大型语言模型(LLM)已迅速进入公众意识。像许多软件开发人员一样,我对其可能性感到好奇,但不确定它最终对我们的职业意味着什么。我现在在Thoughtworks担任一个角色,协调我们关于这项技术将如何影响软件交付实践的工作。我将在这里发布各种备忘录,描述我和同事们正在学习和思考的内容。
随着智能代理编码助手变得越来越强大,反应各不相同。有些人从最近的进步推断并声称,"一年后,我们将不再需要开发人员。"其他人则对AI生成代码的质量以及为初级开发人员准备应对这一变化的挑战表示担忧。
在过去几个月中,我定期使用Cursor、Windsurf和Cline中的智能代理模式,几乎完全用于更改现有代码库(而不是从头创建井字游戏)。总体而言,我对IDE集成的最新进展以及这些集成如何极大地提升工具辅助我的方式印象深刻。它们
所有这些都带来了与AI令人印象深刻的协作会话,有时帮助我在创纪录的时间内构建功能和解决问题。
然而。
即使在那些成功的会话中,我也一直在干预、纠正和引导。而且我经常决定不提交更改。
什么是生成式AI?
生成式AI是指能够根据提示或指令创建新内容的AI系统。这些系统被训练于大量数据,学习识别模式并生成类似于训练数据的新输出。现代生成式AI多为基于神经网络架构的深度学习系统。
目前主导生成式AI讨论的是大型语言模型(LLMs)。这些是经过大量文本训练的模型,可以生成连贯的文本,预测给定上下文中最可能的下一个词。尽管基础架构可能很复杂,但我们可以将其视为一个复杂的自动补全系统。
LLMs展现出的能力远超过以前的生成系统,它们能够:
关键应用领域
生成式AI已经在许多领域展示出其应用潜力:
代码生成和编程辅助
开发人员正在使用生成式AI工具(如GitHub Copilot、Amazon CodeWhisperer和Google Duet AI)来加速编码过程。这些工具可以:
内容创建和营销
生成式AI可以产生各种形式的内容:
客户服务和支持
生成式AI正在改变企业与客户的互动方式: 聊天机器人和虚拟助手 智能响应建议 自动票务分类和路由 知识库生成和
服务器通过MCP提供了为语言模型添加上下文的基本构建块。这些原语支持客户端、服务器和语言模型之间的丰富交互:
每个原语可以在以下控制层次结构中概括:
| 原语 | 控制方 | 描述 | 示例 |
|---|---|---|---|
| 提示 | 用户控制 | 由用户选择调用的交互式模板 | 斜杠命令、菜单选项 |
| 资源 | 应用程序控制 | 由客户端附加和管理的上下文数据 | 文件内容、Git历史 |
| 工具 | 模型控制 | 向LLM公开以执行操作的函数 | API POST请求、文件写入 |
提示词
模型上下文协议(MCP)提供了一种标准化方式,使服务器能够向客户端公开提示词模板。提示词允许服务器提供结构化消息和与语言模型交互的指令。客户端可以发现可用的提示词,获取其内容,并提供参数来自定义它们。
用户交互模型
提示词设计为用户控制的,这意味着它们从服务器暴露给客户端,目的是让用户能够明确选择使用它们。
通常,提示词会通过用户界面中的用户发起命令触发,这允许用户自然地发现和调用可用的提示词。
例如,作为斜杠命令:
然而,实现者可以自由地通过任何适合其需求的界面模式来公开提示词——协议本身不强制要求任何特定的用户交互模型。
能力
支持提示词的服务器必须在初始化期间声明prompts能力:
模型上下文协议(Model Context Protocol)由几个协同工作的关键组件组成:
所有实现必须支持基础协议和生命周期管理组件。其他组件可以根据应用程序的特定需求来实现。
这些协议层在实现客户端和服务器之间丰富交互的同时,建立了明确的关注点分离。模块化设计允许实现精确支持所需的功能。
消息
MCP 客户端和服务器之间的所有消息必须遵循 JSON-RPC 2.0 规范。协议定义了以下类型的消息:
请求(Requests)
请求从客户端发送到服务器,或者从服务器发送到客户端,用于启动操作。
{
jsonrpc: "2.0";
id: string | number;
method: string;
params?: {
[key: string]: unknown;
};
}
null。响应(Responses)
响应是对请求的回复,包含操作的结果或错误。
模型上下文协议(MCP)采用客户端-主机-服务器架构,每个主机可以运行多个客户端实例。这种架构使用户能够跨应用程序集成AI功能,同时保持明确的安全边界和关注点隔离。MCP基于JSON-RPC构建,提供专注于客户端和服务器之间上下文交换和采样协调的有状态会话协议。
核心组件
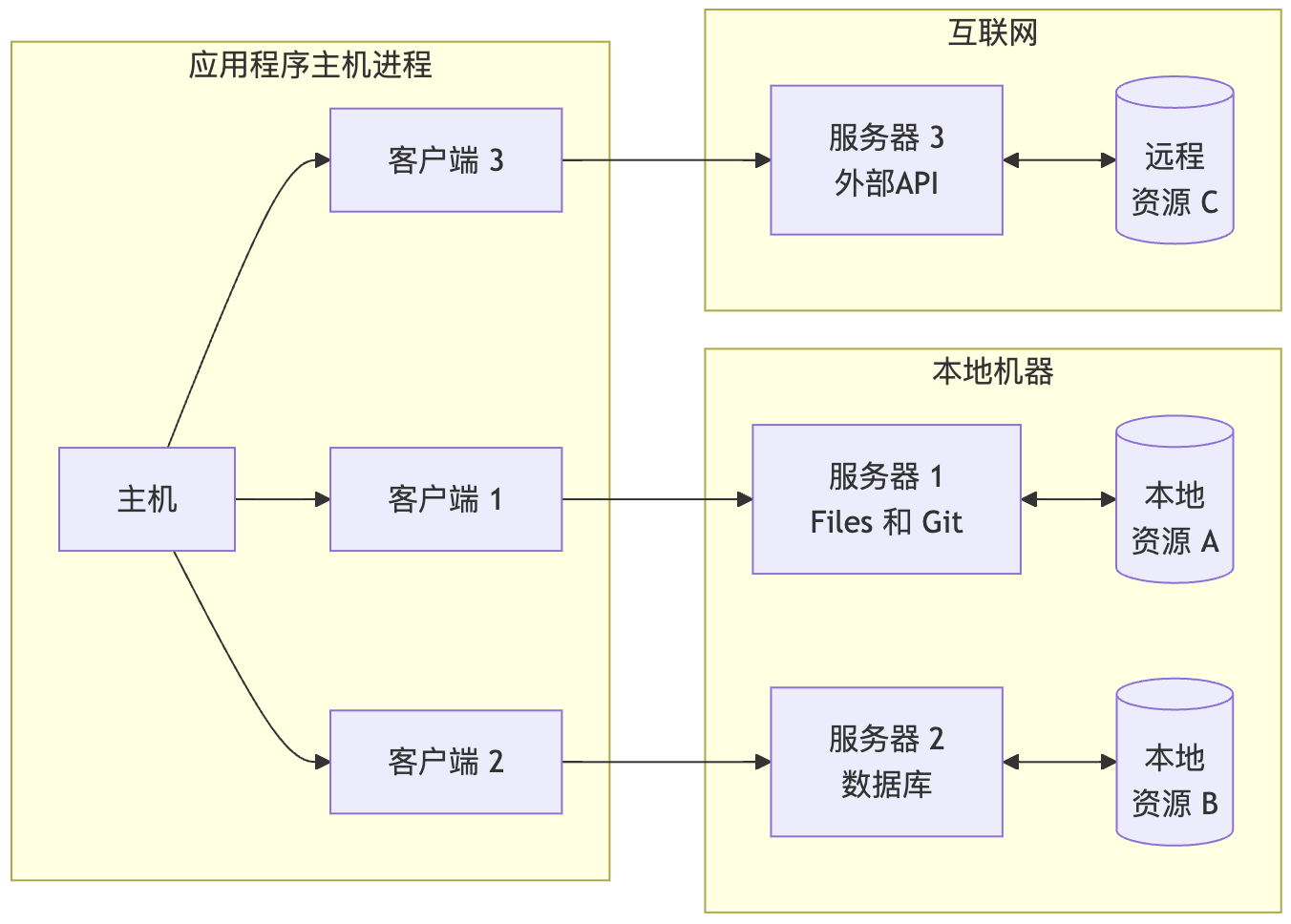
graph LR
subgraph "应用程序主机进程"
H[主机]
C1[客户端 1]
C2[客户端 2]
C3[客户端 3]
H --> C1
H --> C2
H --> C3
end
subgraph "本地机器"
S1[服务器 1<br>Files 和 Git]
S2[服务器 2<br>数据库]
R1[("本地<br>资源 A")]
// ...
主机
主机进程作为容器和协调器:
客户端
每个客户端由主机创建,并维护独立的服务器连接:
主机应用程序创建和管理多个客户端,每个客户端与特定服务器保持1:1关系。
服务器
服务器提供专门的上下文和功能:
协议修订版本:2025-03-26
Model Context Protocol(MCP)是一个开放协议,它使 LLM 应用程序与外部数据源和工具之间能够无缝集成。无论您是构建 AI 驱动的 IDE、增强聊天界面,还是创建自定义 AI 工作流,MCP 都提供了一种标准化的方式来连接 LLM 与它们所需的上下文。
本规范基于 schema.ts 中的 TypeScript 模式,定义了权威的协议要求。
有关实现指南和示例,请访问 modelcontextprotocol.io。
概述
MCP 为应用程序提供了标准化的方式来:
该协议使用 JSON-RPC 2.0 消息在以下组件之间建立通信:
MCP 部分受到 Language Server Protocol 的启发,后者标准化了如何在整个开发工具生态系统中添加对编程语言的支持。类似地,MCP 标准化了如何将额外的上下文和工具集成到 AI 应用程序的生态系统中。
关键细节
基础协议
功能
服务器向客户端提供以下任何功能:
MCP 服务器创建工具

![]()
创建无需构建配置的 模型上下文协议 (MCP) 服务器项目。
快速概览
# 使用 uvx (推荐)
uvx create-mcp-server
# 或者使用 pip
pip install create-mcp-server
create-mcp-server
您无需手动安装或配置任何依赖项。 该工具将设置创建 MCP 服务器所需的一切。
创建服务器
您需要在您的机器上安装 UV >= 0.4.10。
要创建新服务器,请运行以下任一命令:
使用 uvx (推荐)
uvx create-mcp-server
使用 pip
pip install create-mcp-server
create-mcp-server
它将引导您创建一个新的 MCP 服务器项目。 完成后,您将拥有一个具有以下结构的新目录:
my-server/
├── README.md
├── pyproject.toml
└── src/
└── my_server/
├── __init__.py
├── __main__.py
└── server.py
没有配置或复杂的文件夹结构,只有运行服务器所需的文件。
安装完成后,您可以启动服务器:
cd my-server
uv sync --dev --all-extras
uv run my-server
特性
安装
On macOS and Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
On Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
更新
uv self update
一键同步环境
创建/同步完整的开发环境
uv sync
执行该命令后,主要做了以下事:
pyproject.toml.venvuv.lock依赖包
安装
uv add "mcp[cli]"
移除
uv remove "mcp[cli]"
Python 项目
创建
uv init echo
cd echo
创建的文件:
.
├── .python-version
├── README.md
├── main.py
└── pyproject.toml
运行
uv run main.py
Hello from echo!
参考资料
没有找到匹配的文章