使用 Cline 从零开始构建自定义 MCP 服务器:综合指南
使用 Cline 从零开始构建自定义 MCP 服务器:综合指南
本指南提供了使用 Cline 的强大 AI 功能从零开始构建自定义 MCP (Model Context Protocol) 服务器的全面演示。示例将通过构建一个"GitHub 助手服务器"来说明这个过程。
理解 MCP 和 Cline 在构建服务器中的作用
什么是 MCP?
模型上下文协议(MCP)充当了像 Claude 这样的大型语言模型(LLMs)与外部工具和数据之间的桥梁。MCP 包含两个关键组件:
- MCP 主机: 这些是与 LLMs 集成的应用程序,如 Cline、Claude Desktop 等。
- MCP 服务器: 这些是专门设计用于通过 MCP 向 LLMs 公开数据或特定功能的小型程序。
当你有一个 MCP 兼容的聊天界面(如 Claude Desktop)时,这种设置很有用,因为它可以利用这些服务器来访问信息和执行操作。
为什么使用 Cline 创建 MCP 服务器?
Cline 通过利用其 AI 功能简化了构建和集成 MCP 服务器的过程:
- 理解自然语言指令: 你可以用自然的方式与 Cline 交流,使开发过程直观且用户友好。
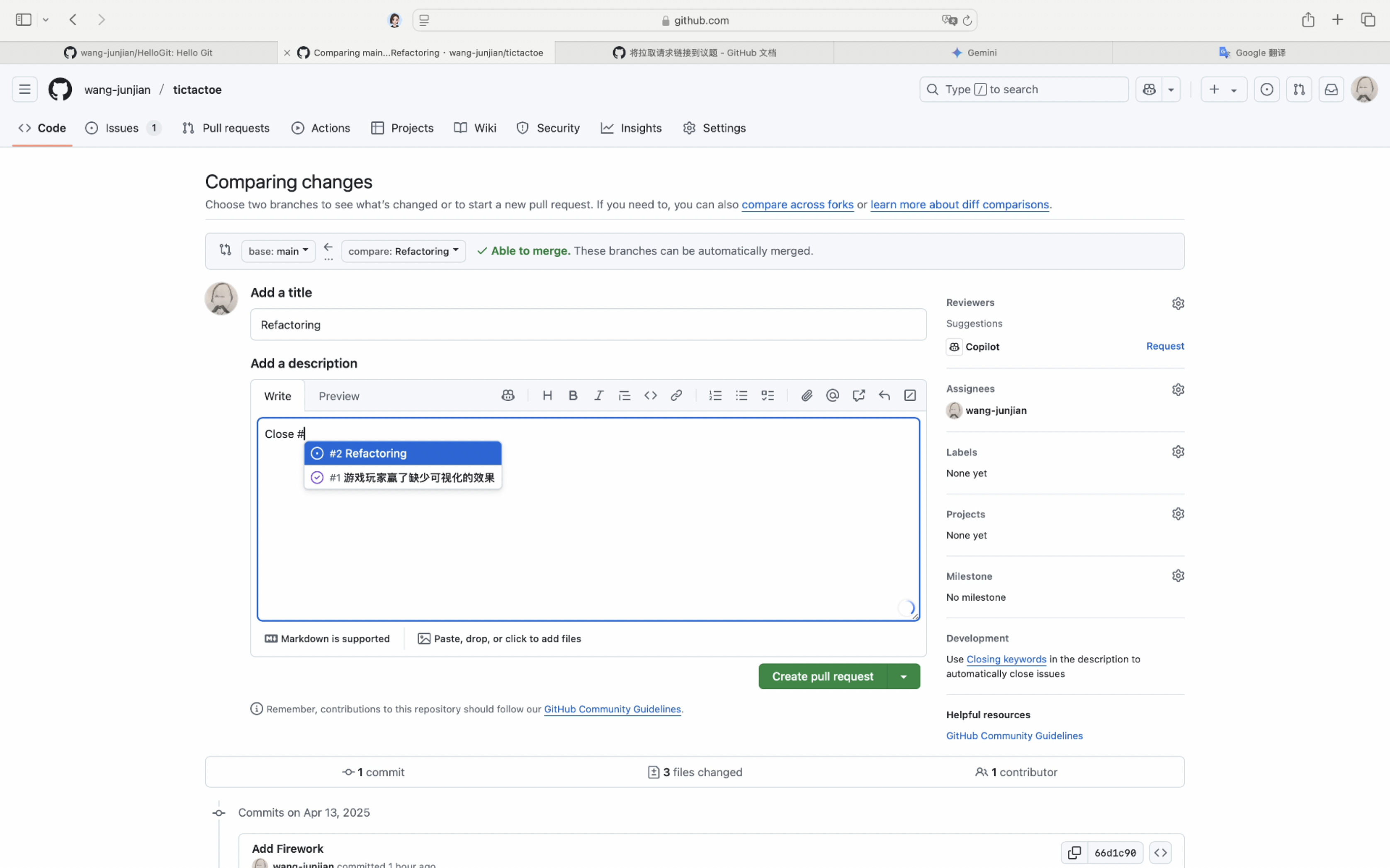
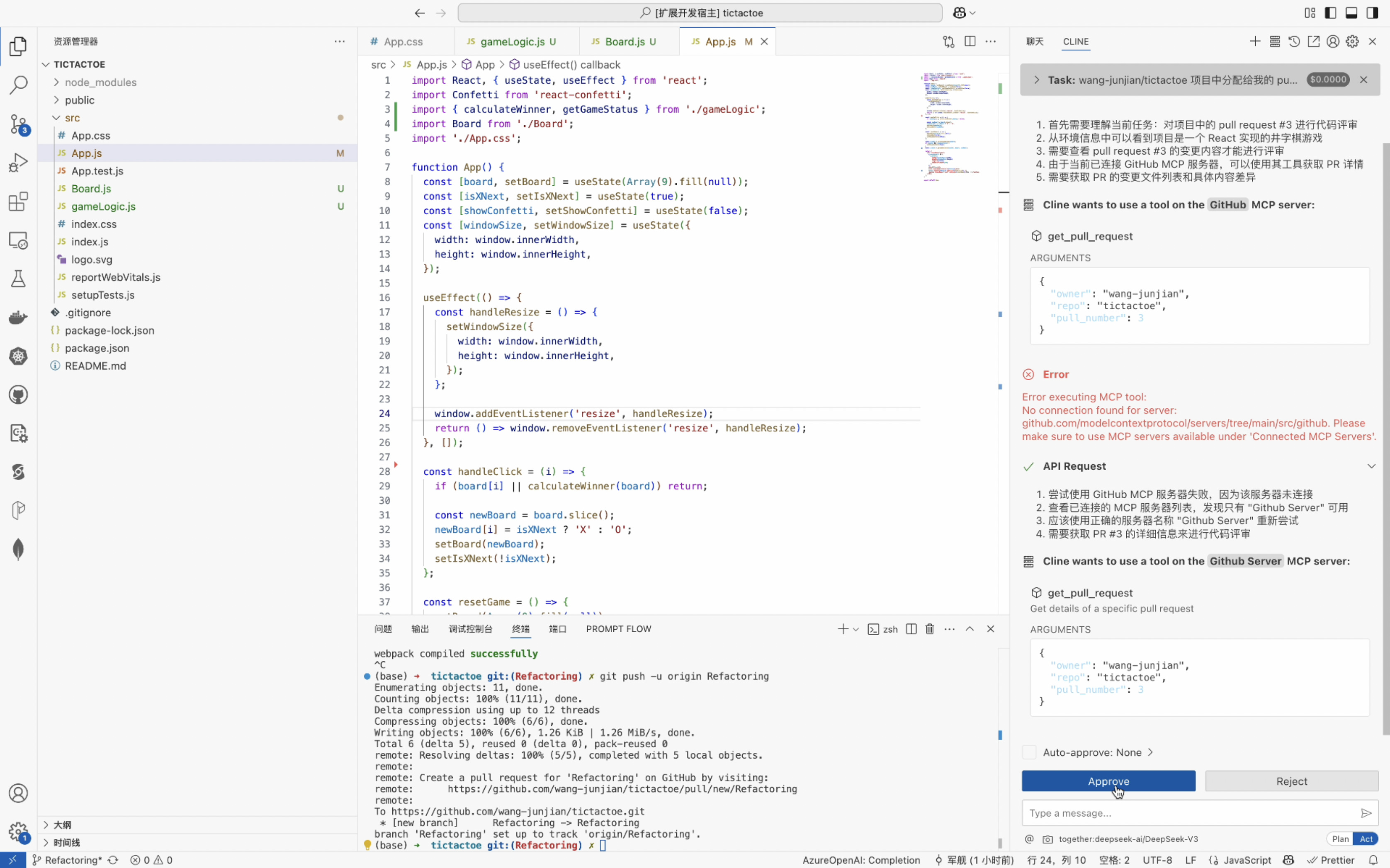
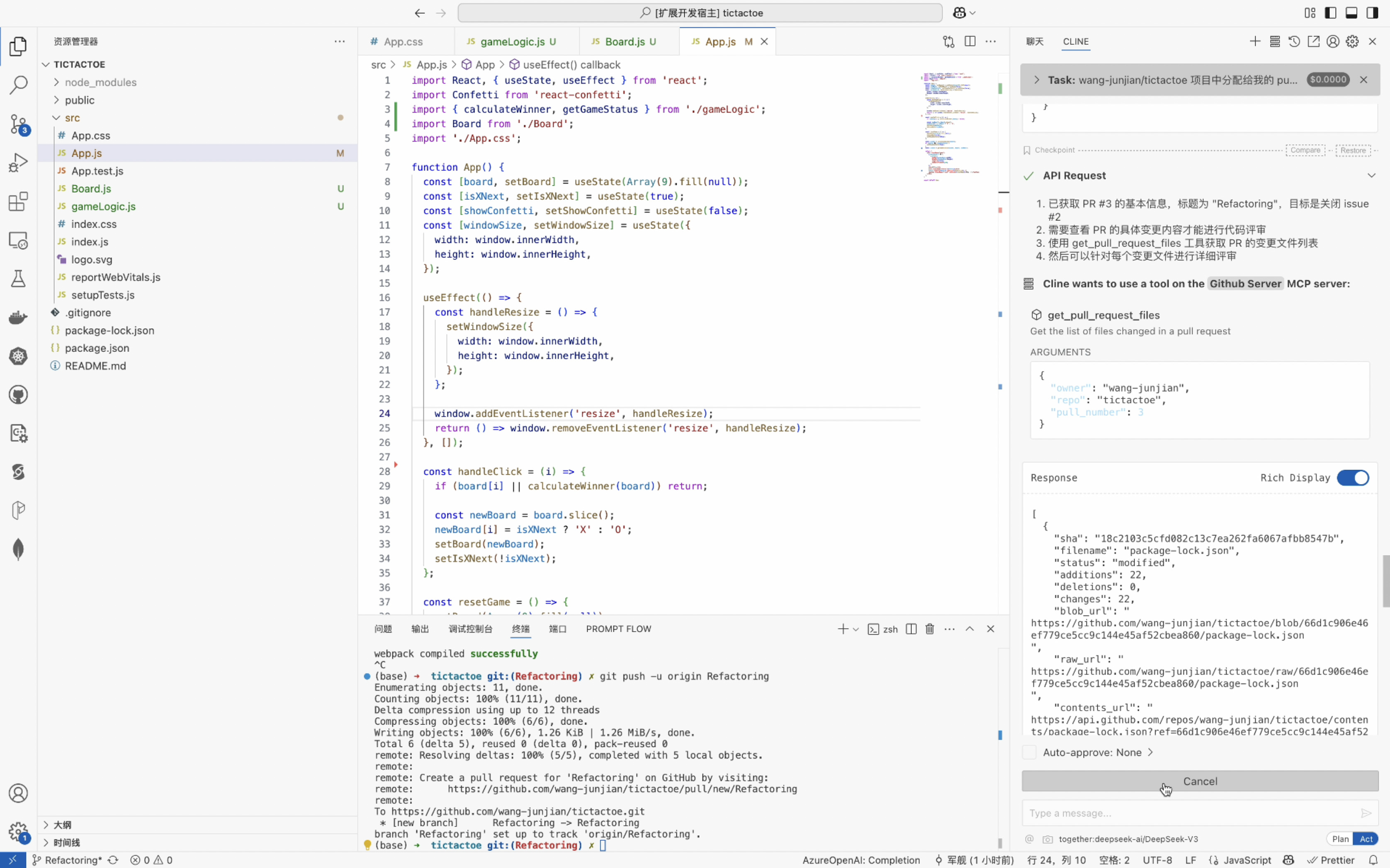
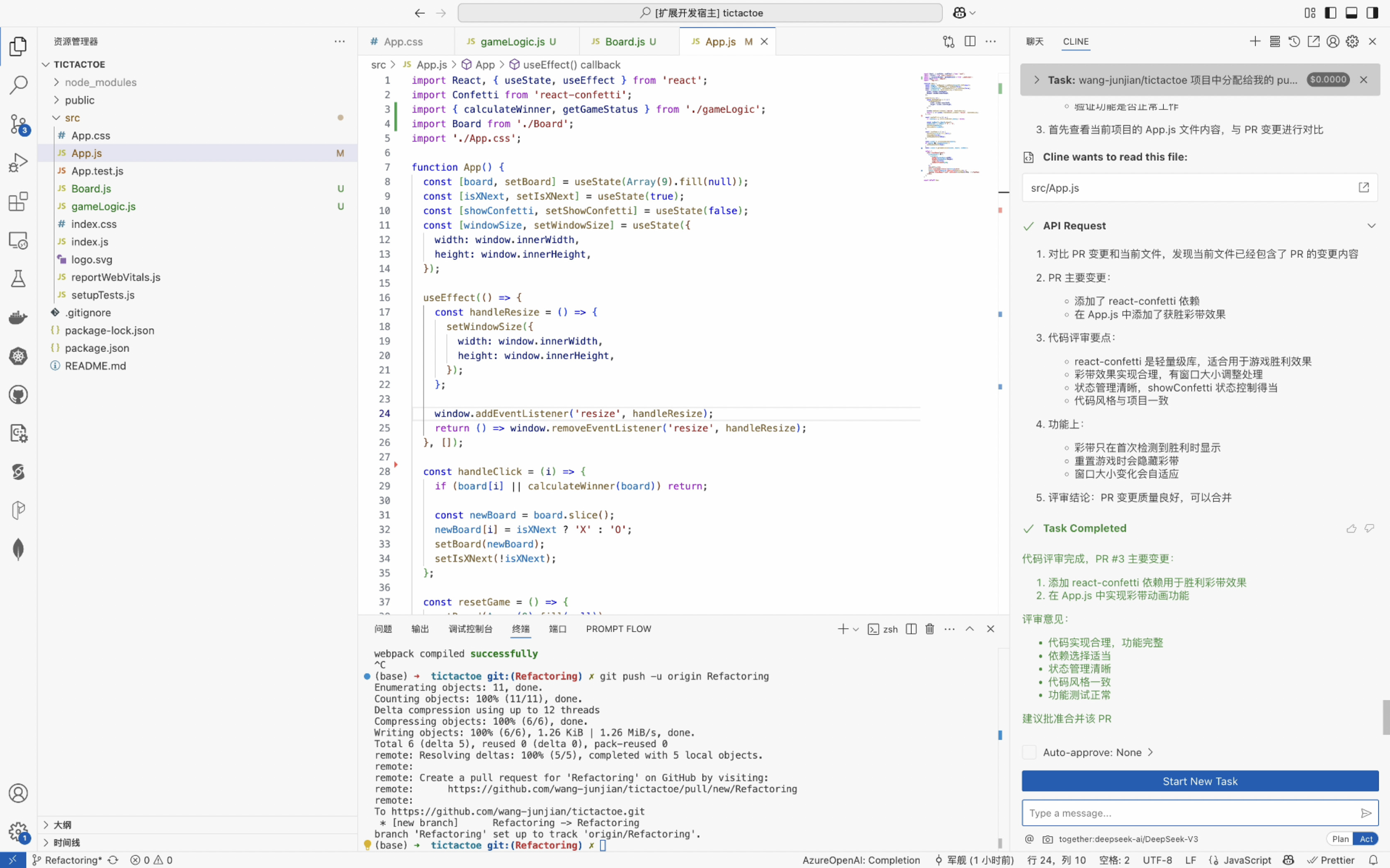
- 克隆代码库: Cline 可以直接从 GitHub 克隆现有的 MCP 服务器代码库,简化使用预构建服务器的过程。
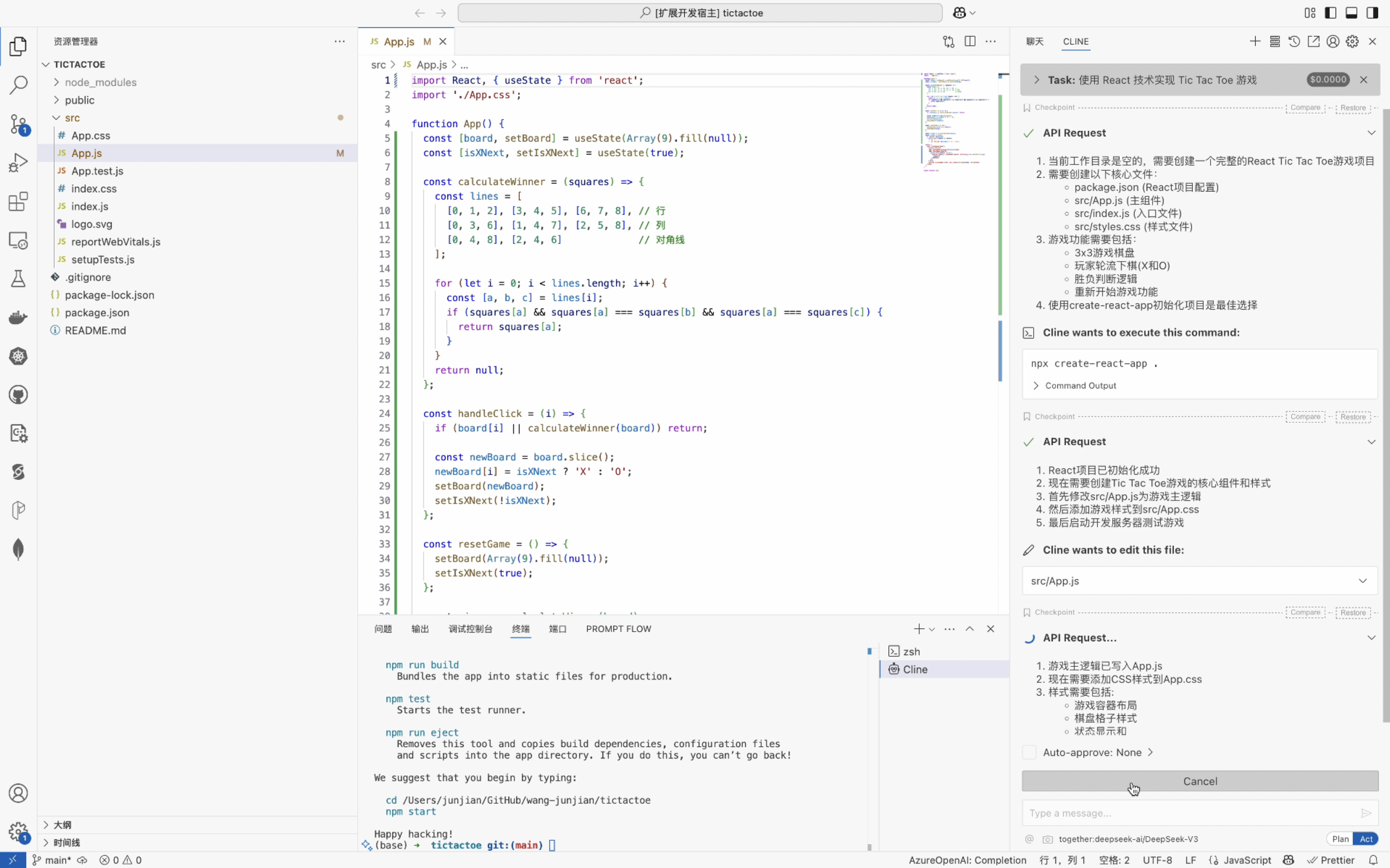
- 构建服务器: 一旦必要的代码就位,Cline 可以执行像
npm run build这样的命令来编译和准备服务器。 - 处理配置: Cline 管理 MCP 服务器所需的配置文件,包括将新服务器添加到
cline_mcp_settings.json文件中。 - 协助故障排除: 如果在开发或测试过程中出现错误,Cline 可以帮助确定原因并提出解决方案,使调试更容易。