Kwai-Kolors 快手可图
Kolors:用于真实感文本到图像合成的扩散模型的有效训练
例子
小红帽和大灰狼在森林的小路上相遇

Kolors:用于真实感文本到图像合成的扩散模型的有效训练
例子
小红帽和大灰狼在森林的小路上相遇
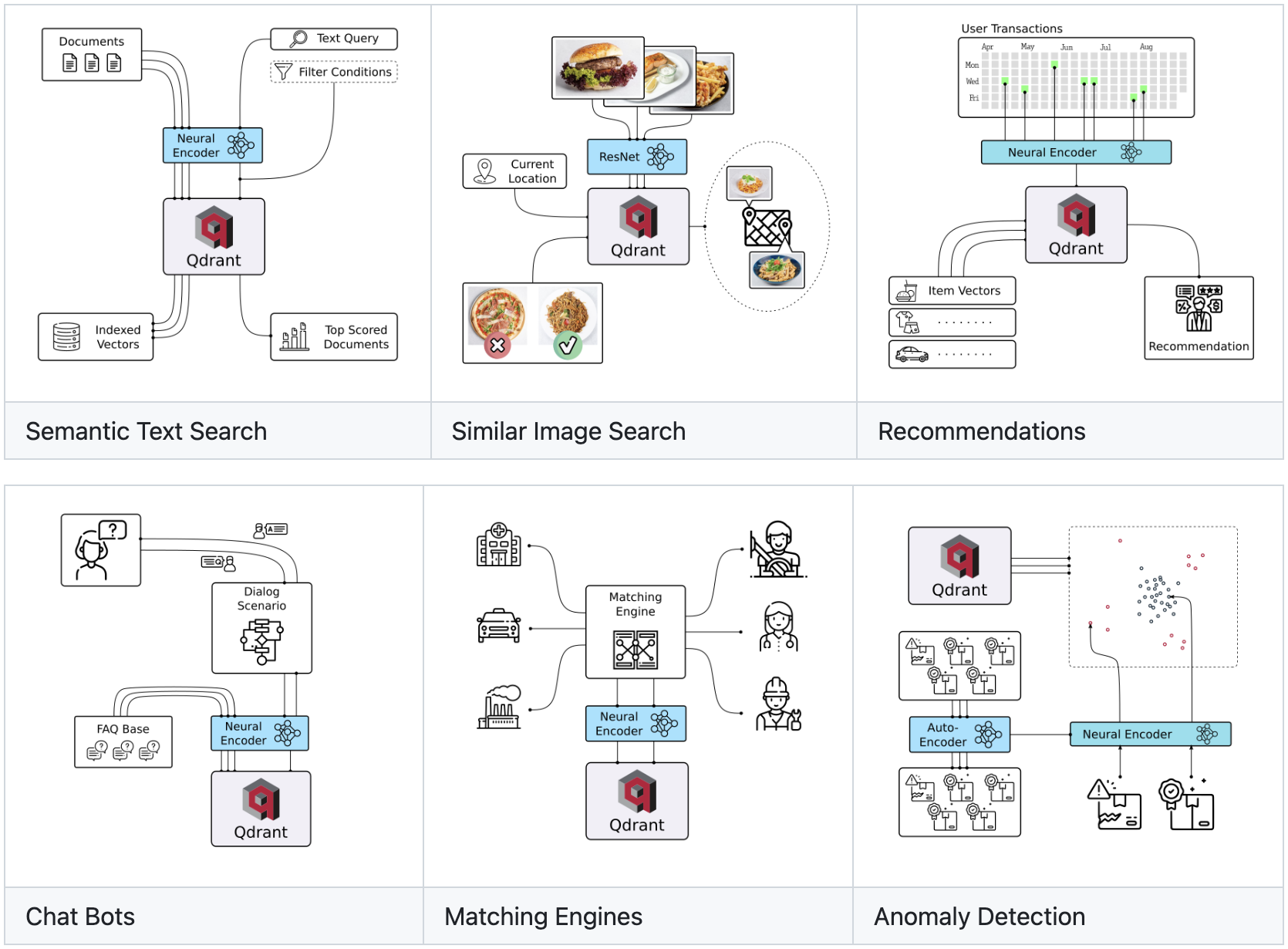
用于下一代人工智能应用的向量搜索引擎
Qdrant(读作:quadrant)是一个向量相似性搜索引擎和向量数据库。它提供了一个生产就绪的服务,具有方便的 API 来存储、搜索和管理点 - 具有附加有效载荷的向量。Qdrant 专为扩展的过滤支持量身定制。它对所有类型的神经网络或基于语义的匹配、分面搜索和其他应用非常有用。
解决方案
运行
Qdrant 镜像
docker pull qdrant/qdrant
启动 Qdrant 服务
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
Qdrant 现在可访问:
安装 Qdrant Client
pip install qdrant-client
代码示例
FastEmbed 是一个轻量级、快速的 Python 库,专为嵌入生成而构建。
安装
pip install -Uqq fastembed
支持的嵌入模型
import pandas as pd
from fastembed import TextEmbedding
supported_models = (
pd.DataFrame(TextEmbedding.list_supported_models())
.sort_values("size_in_GB")
.drop(columns=["sources", "model_file", "additional_files"])
.reset_index(drop=True)
)
print(supported_models)
使用检索增强来帮助您使用 LLM 为数据库生成准确的 SQL 查询。
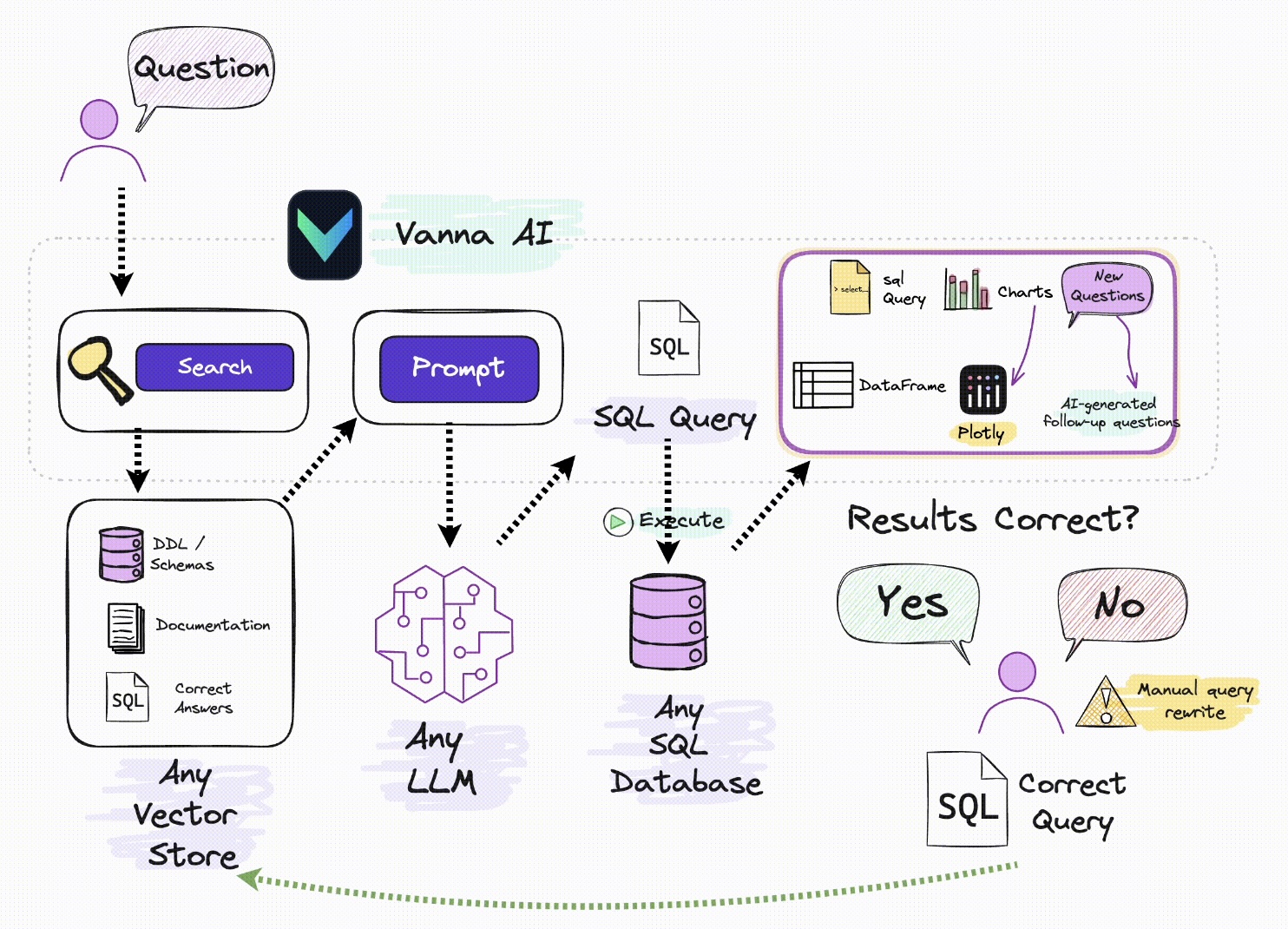
Vanna 的工作过程分为两个简单步骤 - 在您的数据上训练 RAG“模型”,然后提出问题,这些问题将返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。
在您的数据上训练 RAG“模型”。这些方法将添加到参考语料库。
问问题。这将使用参考语料库生成可以在您的数据库上运行的 SQL 查询。
例子
与您的 SQL 数据库聊天 📊。通过 RAG 使用 LLM 实现准确的文本到 SQL 生成 🔄。
ChromaDB & Ollama from vanna.ollama import Ollama from vanna.chromadb import ChromaDB_VectorStore class MyVanna(ChromaDB_VectorStore, Ollama): def init(self, config=None): ChromaDB_VectorStore.init(self, config=config) Ollama.init(self, config=config) vn = MyVanna(config={'model': 'qwen2:7b'}) vn.
RAG 复杂场景下的工作流程
召回模式(选择数据集) → 混合检索(同时进行语义检索和关键词搜索) → 重排序(合并和归一化检索结果)
RAG 中构建知识库的解析方法
RAGFlow 是一款基于深度文档理解构建的开源 RAG 引擎,内置了丰富地文档解析方法,可以帮助用户快速构建知识库。
概述
Elmo 是您的 AI 网络副驾驶,可创建摘要、洞察和扩展知识。
免费且无需 GPT/OpenAI 帐户和多语言支持。
功能亮点:
✅ 总结网站:将网络内容转换为快速、简短的摘要。
✅ 总结 YouTube:通过视频快速洞察和导航。
✅ 总结 Google Docs:高效创建 Google Docs 的简洁摘要。
✅ 与 PDF 聊天:简化对大型文档的理解。
✅ 回答问题:从网页获得即时答案。
✅ 关键字探索:在浏览过程中无缝提取相关信息。
✅ 翻译:轻松将文本翻译成不同的语言。
✅ 改写段落:简化和澄清复杂的句子。
如何使用?
🔹 单击“添加到 Chrome”按钮并将其固定到工具栏。
🔹 单击图标或按 Cmd/Ctrl + Shift + E 激活 Elmo Chat。
🔹 Elmo Chat 将为您总结当前网页。
安装 PostgreSQL
下载
安装
Installation Directory: /Library/PostgreSQL/16
Server Installation Directory: /Library/PostgreSQL/16
Data Directory: /Library/PostgreSQL/16/data
Database Port: 5432
Database Superuser: postgres
Operating System Account: postgres
Database Service: postgresql-16
Command Line Tools Installation Directory: /Library/PostgreSQL/16
pgAdmin4 Installation Directory: /Library/PostgreSQL/16/pgAdmin 4
Stack Builder Installation Directory: /Library/PostgreSQL/16
Installation Log: /tmp/install-postgresql.log
使用默认设置安装即可。
Locale 我选择了 zh_CN,在创建数据库的时候遇到了错误:The
GLM-4V-9B
GLM-4V-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源多模态版本。 GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中均表现优异。
总结
相比 CogVLM2 能力还是不如。
文字识别
识别中文

提示词:输出图像中的文字
贵公司被认为中标人。中标价格为:307.6万元。 请贵公司在收到本中标通知书之日起30天内,携带所有签订合同所需的资料(包括但不限于法定代表人授权书、技术规范、技术图纸等),并按照招标文件和中标人的投标文件与项目单位订立书面合同。合同签订的安排由项目单位另行通知。 请贵公司收到本中标通知书后,签收并速回函确认。
确() 识别成全角识别手写英文

提示词:识别图像上的手写英文
I think student have many after-school classes is don't good for they. So I thing the student don't have after-school classes.
AutoGen
定义 Agent
from autogen import ConversableAgent
llm_config = {"model": "gpt-3.5-turbo"}
agent = ConversableAgent(
name="chatbot",
llm_config=llm_config,
human_input_mode="NEVER",
)
reply = agent.generate_reply(
messages=[{"content": "给我讲个笑话。", "role": "user"}]
)
print(reply)
// ...
为什么八卦杂志最爱讲床上故事?因为上面都有新闻!哈哈哈~
为什么兔子喜欢吃胡萝卜?因为胡萝卜有好处,营养丰富!
多智能体对话
双人笑话
Dify
介绍
Dify 是一款开源的大语言模型(LLM) 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。你可以基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活和安全的基础上,同时保持对数据的完全控制。
开发语言
| 语言 | 占比 |
|---|---|
| TypeScript | 49.9% |
| Python | 45.5% |
| MDX | 3.1% |
| CSS | 0.9% |
| JavaScript | 0.4% |
| SCSS | 0.2% |
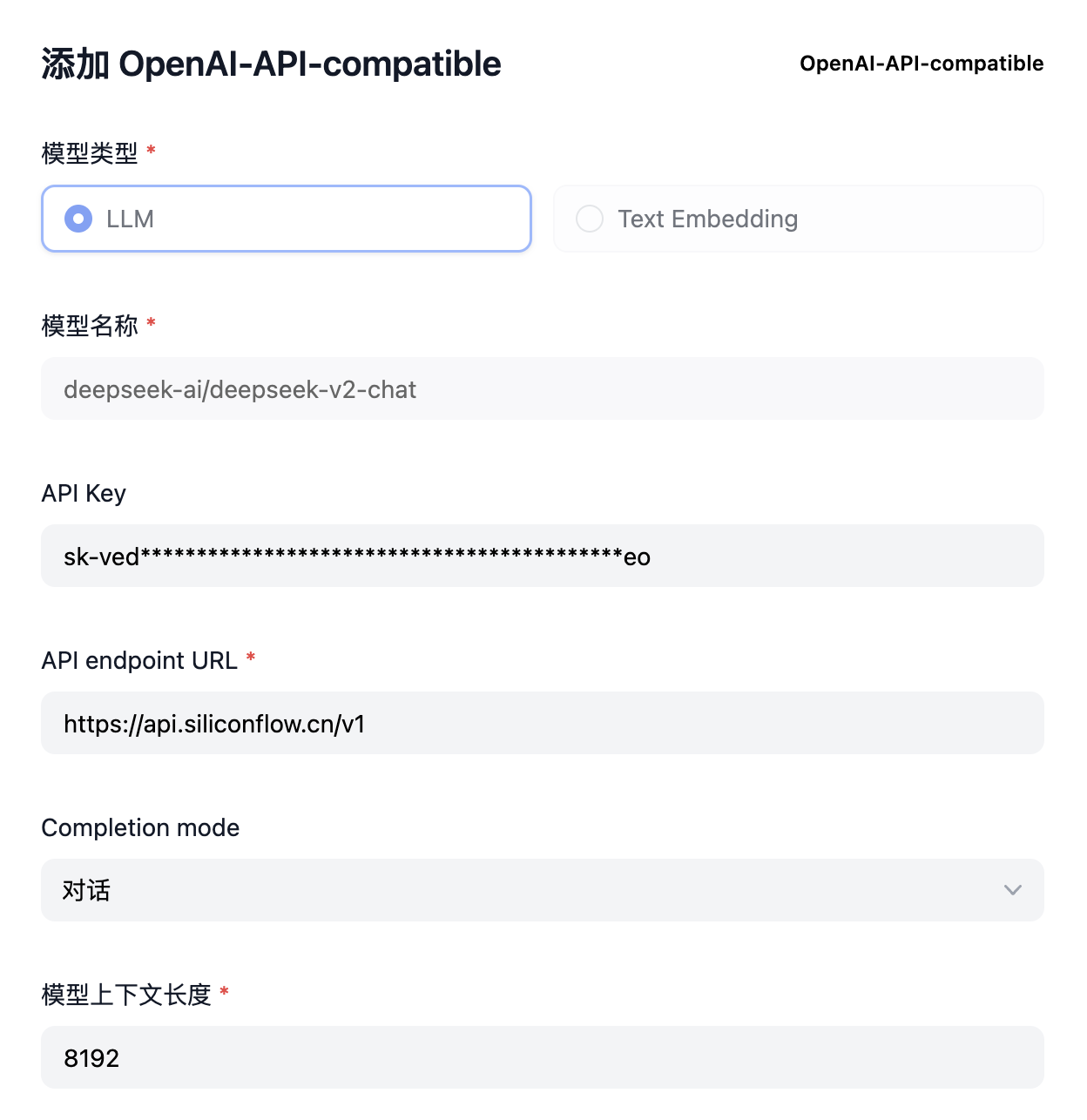
配置兼容 OpenAI API(SiliconFlow)
Continue
介绍
Continue 使您能够在 IDE 中创建自己的 AI 代码助手。使用 VS Code 和 JetBrains 插件保持开发者的流畅体验,这些插件可以连接到任何模型、任何上下文以及任何其他你需要的东西。
Continue 使您能够使用适合工作的模型,无论是开源还是商业,本地运行还是远程运行,用于聊天、自动完成或嵌入。它提供了许多配置点,以便您可以自定义扩展以适应您现有的工作流程。
开发语言
| 语言 | 占比 |
|---|---|
| TypeScript | 74.0% |
| Kotlin | 11.8% |
| Rust | 4.9% |
| CSS | 3.6% |
| Scheme | 2.5% |
| JavaScript | 2.4% |
| Other | 0.8% |
贡献(Contributing)
使用
开放 Ollama 服务
环境变量
OLLAMA_HOST: Ollama 服务器的 IP 地址(默认 127.0.0.1:11434)OLLAMA_NUM_PARALLEL: 最大并行请求数(默认 1)OLLAMA_MAX_LOADED_MODELS: 最大加载模型数量(默认 1)OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的持续时间(默认 5m),-1 表示永久保持加载。Linux
curl -fsSL https://ollama.com/install.sh | sh
编辑 systemd 服务,调用 systemctl edit ollama.service。这将打开一个编辑器。 sudo systemctl edit ollama.service 对于每个环境变量,在 [Service] 部分下添加一行 Environment: [Service] Environment="OLLAMA_HOST=0.0.0.
框架
[SGLang][SGLang]
SGLang 是一种专为大型语言模型 (LLM) 设计的结构化生成语言。它通过共同设计前端语言和运行时系统,使您与 LLM 的交互更快、更可控。
平台
[Dify][Dify]
Dify 是一个 UI 驱动的用于开发大语言模型应用程序的平台,它使原型设计更加容易访问。它支持用户使用提示词模板开发聊天和文本生成应用。此外,Dify 支持使用导入数据集的检索增强生成(RAG),并且能够与多个模型协同工作。我们对这类应用很感兴趣。不过,从我们的使用经验来看,Dify 还没有完全准备好投入大范围使用,因为某些功能目前仍然存在缺陷或并不成熟。但目前,我们还没有发现更好的竞品。
工具
[Continue][Continue]
Continue 使您能够在 IDE 中创建自己的 AI 代码助手。使用 VS Code 和 JetBrains 插件保持开发者的流畅体验,这些插件可以连接到任何模型、任何上下文以及任何其他你需要的东西。Continue 使您能够使用适合工作的模型,无论是开源还是商业,本地运行还是远程运行,用于聊天、自动完成或嵌入。它提供了许多配置点,以便您可以自定义扩展以适应您现有的工作流程。
[Ollama][Ollama] Ollama 是一个在本机上运行并管理大语言模型的工具。
安装
pip install 'crewai[tools]'
CrewAI 使用 Ollama 运行本地 LLM
.env
OPENAI_API_BASE=http://localhost:11434/v1
OPENAI_MODEL_NAME=aya:8b
OPENAI_API_KEY=NULL
agent.py
版本1
每次执行结果都不一样
from dotenv import load_dotenv
load_dotenv()
from crewai import Agent, Task, Crew
from langchain_openai import ChatOpenAI
general_agent = Agent(
role = "数学教授",
goal = """为提问数学问题的学生提供解决方案并给出答案。""",
backstory = """您是一位优秀的数学教授,喜欢以每个人都能理解的方式解决数学问题。""",
allow_delegation = False,
verbose = True
)
// ...
版本2
稳定地生成结果
Application scenarios of AI agents(AI代理的应用场景)
AI代理是LLM应用的重要场景,构建代理应用将是2024年的重要技术领域。目前我们主要的智能形式有单AI代理,多AI代理,混合AI代理等三种。
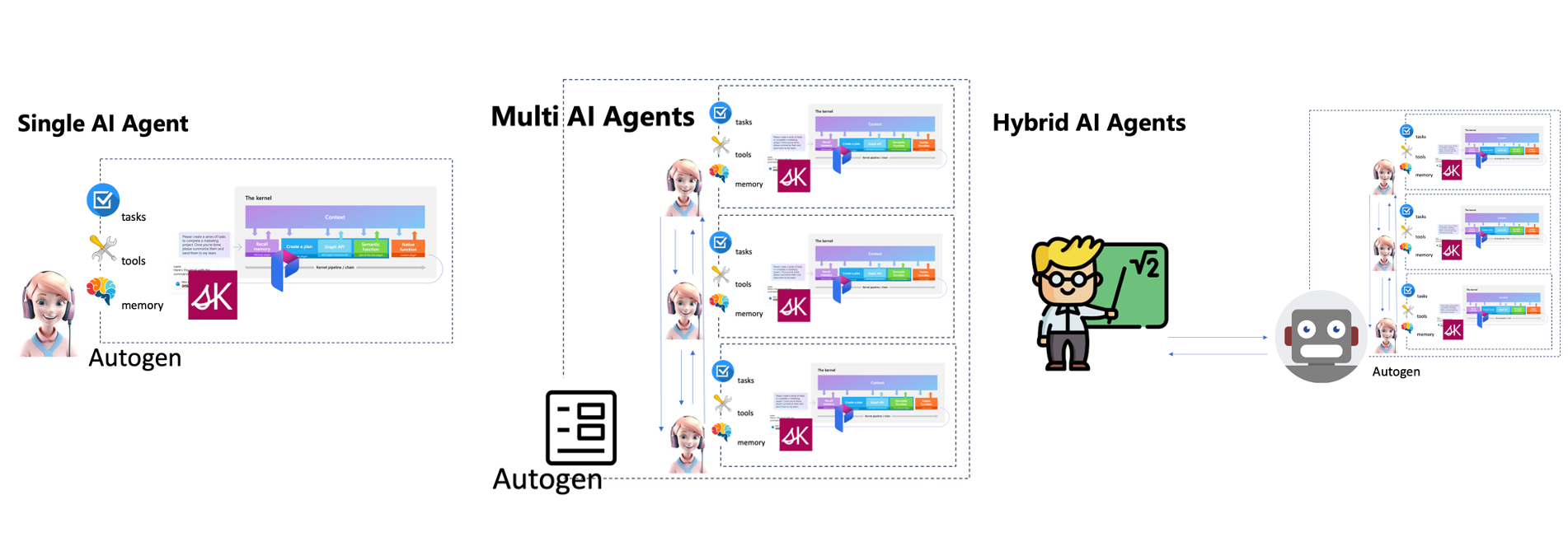
Single AI Agent(单一人工智能代理)
在特定任务场景下完成的工作,比如 GitHub Copilot Chat 下的代理工作区,就是根据用户需求完成特定编程任务的一个例子。基于 LLM 的能力,单个代理可以根据任务执行不同的动作,比如需求分析、项目阅读、代码生成等。它也可以应用于智能家居和自动驾驶。
Multi-AI Agents(多人工智能代理)
这就是AI代理之间相互交互的工作。例如上述Semantic Kernel代理实现就是一个例子。脚本生成的AI代理与执行脚本的AI代理进行交互。多代理应用场景在高度协同的工作中非常有帮助,例如软件行业开发、智能生产、企业管理等。
Hybrid AI Agent(混合人工智能代理)
这就是人机交互,在同一个环境下做决策。比如智慧医疗、智慧城市等专业领域,可以利用混合智能来完成复杂的专业工作。
Intro of AI agent, & AI agent projects s
代码注入:SQL注入:MyBatis
提示词
您是一名 Java 高级软件工程师,主要任务是根据缺陷报告的信息修复软件中的漏洞。
要求
请根据缺陷报告,修复缺陷代码片断的缺陷。
要求修复后的软件不改变原有的功能。
需要给出修复后的代码片段或者修复建议。
缺陷报告 缺陷类别: 一级类: 代码注入 二级类:SQL注入:MyBatis 详细信息: SQL注入是一种数据库攻击手段。攻击者通过向应用程序提交恶意代码来改变原SQL语句的含义,进而执行任意SQL命令,达到入侵数据库乃至操作系统的目的。在Mybatis Mapper Xml中,#变量名称创建参数化查询SQL语句,不会导致SQL注入。而$变量名称直接使用SQL指令,会导致SQL注入攻击。 例如:以下代码片段采用$变量名称动态地构造并执行了SQL查询。 <!
Phi-3 Vision 是一个轻量级、最先进的开放多模态模型,基于数据集构建,其中包括合成数据和经过过滤的公开网站,重点关注文本和视觉方面的高质量推理密集数据。该模型属于 Phi-3 模型系列,多模式版本可支持 128K 上下文长度(以 Token 为单位)。该模型经历了严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵守和稳健的安全措施。
模型参数 4B。
预期用途
主要用例
该模型旨在广泛用于英语商业和研究用途。该模型为通用人工智能系统和应用程序提供了视觉和文本输入功能,这些系统和应用程序需要
我们的模型旨在加速对高效语言和多模态模型的研究,作为生成人工智能驱动功能的构建块。
用例注意事项
我们的模型并非针对所有下游目的而专门设计或评估。开发人员在选择用例时应考虑语言模型的常见限制,并在特定下游用例中使用之前评估和减轻准确性、安全性和公平性,特别是对于高风险场景。开发人员应了解并遵守与其用例相关的适用法律或法规(包括隐私、贸易合规法等)。
手写文字识别
提示词:对图像文字进行识别
这段文字是一个人的自己写作,表达了对学生在学校和家庭生活中的看法。
提示词:这张图片上写了什么?
MiniCPM-Llama3-V 2.5 是 MiniCPM-V 系列的最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct 构建,共 8B 参数量,相较于 MiniCPM-V 2.0 性能取得较大幅度提升。MiniCPM-Llama3-V 2.5 值得关注的特点包括:
TextVQA, DocVQA。您可以在下表中看到 CogVLM2 系列开源模型的详细信息:
| 模型名称 | cogvlm2-llama3-chat-19B | cogvlm2-llama3-chinese-chat-19B |
|---|---|---|
| 基座模型 | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct |
| 语言 | 英文 | 中文、英文 |
| 模型大小 | 19B | 19B |
| 任务 | 图像理解,对话模型 | 图像理解,对话模型 |
| 模型链接 | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model |
| 体验链接 | 📙 Official Page | 📙 Official Page 🤖 ModelScope |
| Int4模型 | 暂未推出 | 暂未推出 |
| 文本长度 | 8K | 8K |
| 图片分辨率 | 1344 * 1344 | 1344 * 1344 |
总结 能力非常强大 👍 OCR 已经成为基础能力。包含印刷、手写、中文、英文。 图像描述。 基于图像问答。 信息提取。包含保单、车牌、火车票、手机充值。 表格识别。包含复杂表格。
没有找到匹配的文章