模型上下文协议 (MCP) 全面解析:原理、应用与实现
这篇文章是使用 Google Gemini Deep Research 生成的。提示词:
研究 Model Context Protocol
1. 模型上下文协议 (MCP) 导论
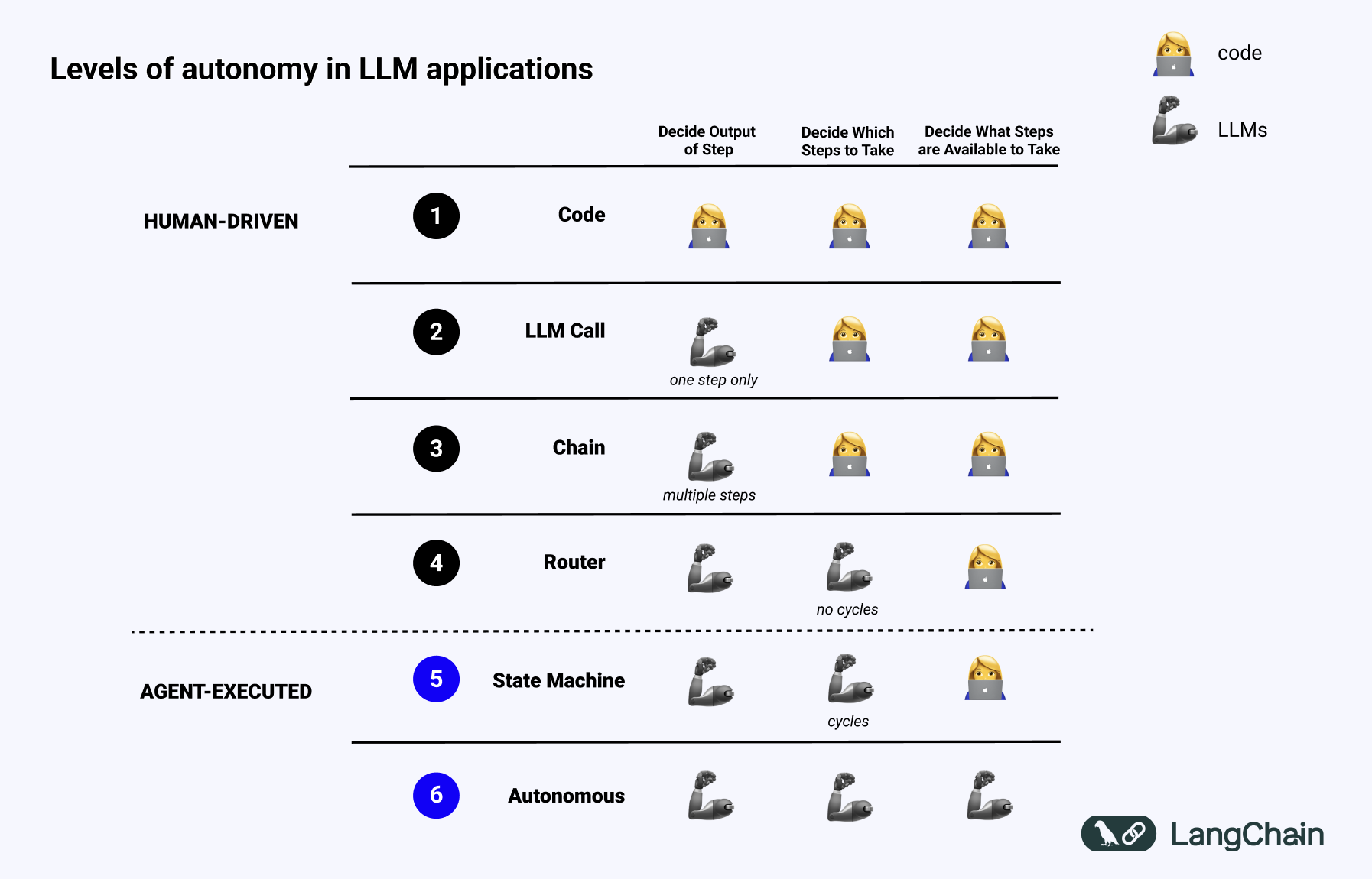
大型语言模型 (LLMs) 在理解和生成人类语言方面取得了显著的进步。然而,这些模型本质上是孤立的,它们的知识仅限于训练数据,并且缺乏与外部世界交互的能力 1。为了克服这些限制,将 LLMs 与外部数据源和工具集成变得至关重要 1。传统上,这种集成是通过为每个新的数据源或工具开发定制的连接器来实现的 1。这种方法导致了集成工作的重复,难以扩展,并且维护成本高昂,阻碍了上下文感知 AI 的广泛采用 1。
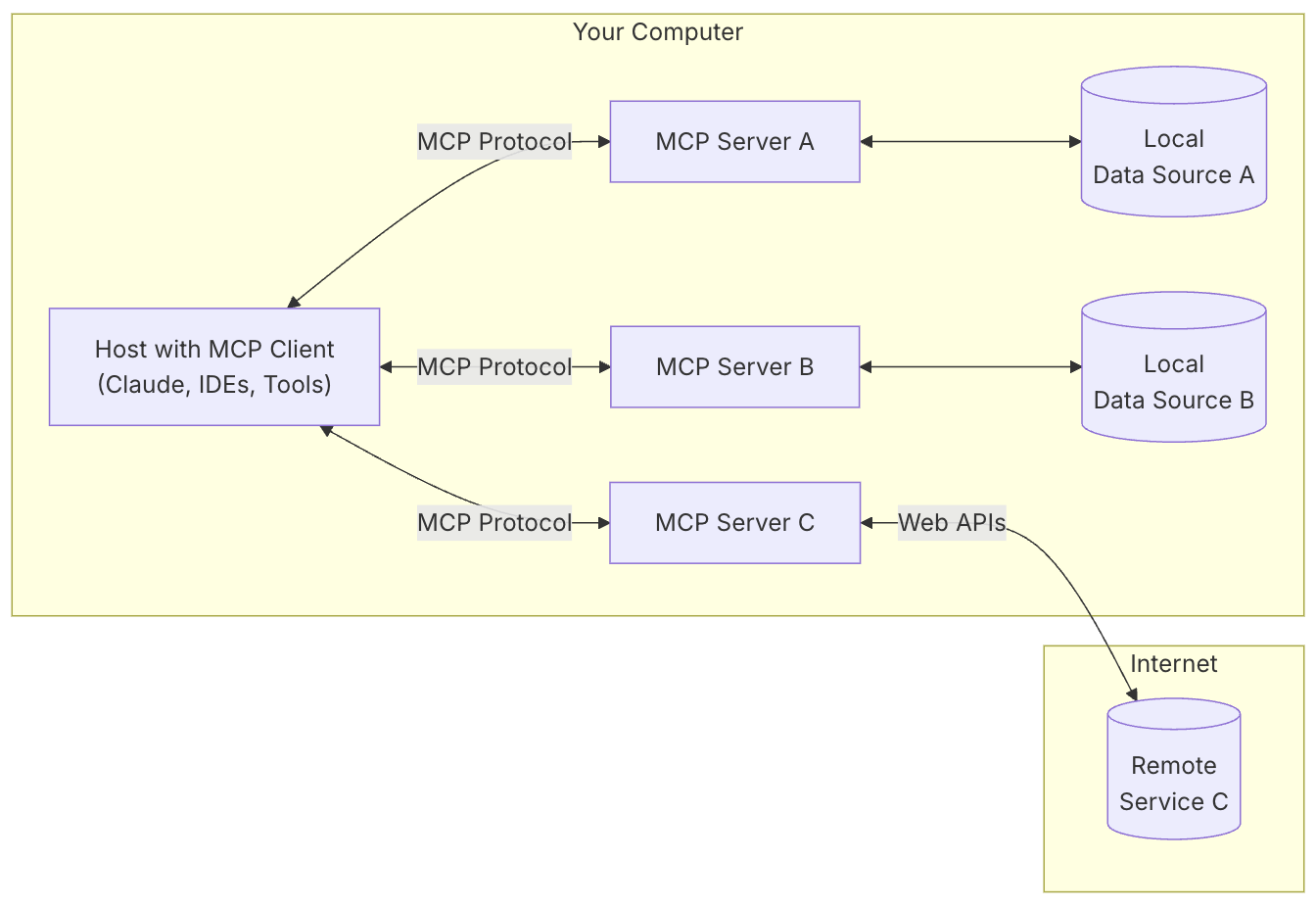
为了应对这一挑战,模型上下文协议 (MCP) 应运而生 1。MCP 是一种开放标准,旨在规范应用程序如何向 LLMs 提供上下文和工具 6。可以将 MCP 视为 AI 应用程序的通用连接器,类似于 USB-C 标准化了设备和外设之间的连接 6。通过提供一种标准化的方式将 AI 模型连接到各种数据源和工具,MCP 简化了集成,增强了互操作性,并促进了可扩展性 6。
本报告旨在对模型上下文协议 (MCP) 进行全面的解析,涵盖其基本原理、核心架构、通信机制、广泛的应用场景以及客户端和服务器端的创建方法。通过深入理解 MCP,开发者和组织可以更好地利用这一新兴标准,构建更智能、更具上下文感知能力的 AI 应用。