Continue 源码分析 - 各种命令调用大模型的输入和输出
Tab Completion
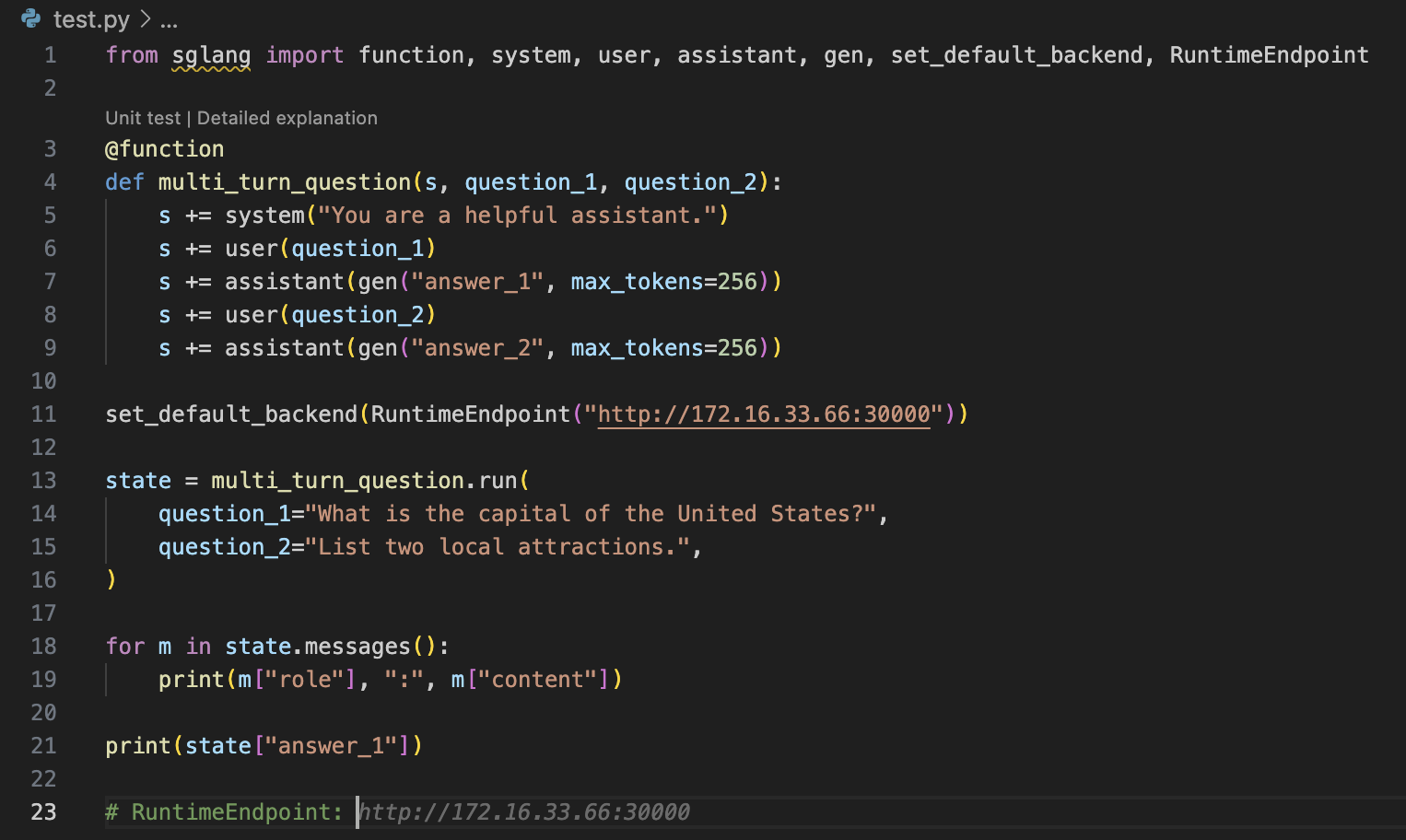
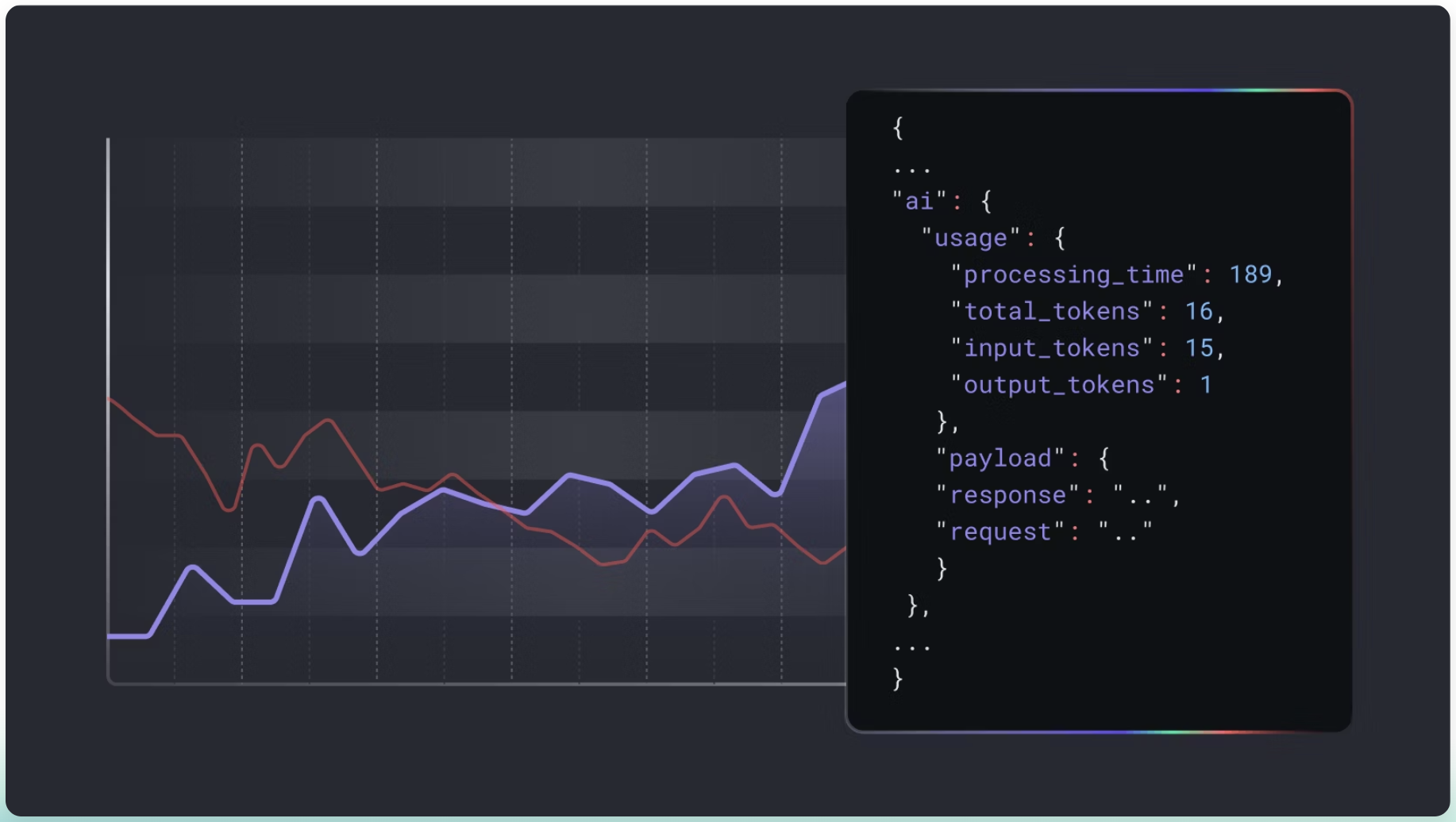
输入

Tab Completion
输入
Langfuse
LLM 可观察性(LLM Observability)、提示管理(Prompt Management)、LLM 评估(LLM Evaluations)、数据集(Datasets)、LLM 指标(LLM Metrics)和提示游乐场(Prompt Playground)
概述(Overview)
开发(Develop)
监控(Monitor)
LiteLLM Proxy Server (LLM Gateway)
安装
pip install 'litellm[proxy]'
编辑配置文件:config.yaml
model_list:
- model_name: qwen-coder
litellm_params:
model: ollama/qwen2.5-coder:7b
- model_name: bge-m3
litellm_params:
model: ollama/bge-m3
- model_name: llava
litellm_params:
model: ollama/llava:7b
api_base: "http://localhost:11434"
# api_base: http://127.0.0.1:11434/v1 # ❌ 500 Internal Server Error
- model_name: gpt-4
litellm_params:
model: openai/gpt-4-32k
// ...
命令部署 # 集成 Langfuse LANGFUSE_PUBLIC_KEY=pk-lf-fd5d8fb
Kong
更快地构建生产就绪的 AI 应用程序(对于开发人员)
通过简单更改一行代码,使用现代基础设施构建具有多 LLM 支持和路由、高级 AI 负载均衡、LLM 可观察性、LLM 安全性和治理等功能的语义智能 AI 应用程序。
将语义智能注入到您的 AI 应用程序中(对于平台团队)
通过语义缓存加速每个 AI 应用程序,通过语义路由智能地跨多个模型路由,构建高级提示模板,检测和防止滥用,以及 AI 可观察性。
AI 流量的 L7 可观察性,用于成本监控和调优(AI 指标和可观察性)
获取应用程序发送的每个 AI 请求的见解,并捕获详细信息以了解和优化您的 AI 使用和成本,支持 10 多个日志摄取器。
安装(Docker)
PostgreSQL docker run -d --name kong-database \ -p 5432:5432 \ -e "POSTGRES_USER=kong" \ -e "POSTGRES_DB=kong" \ -e &q
Higress
Higress 是基于阿里内部多年的 Envoy Gateway 实践沉淀,以开源 Istio 与 Envoy 为核心构建的云原生 API 网关。
安装
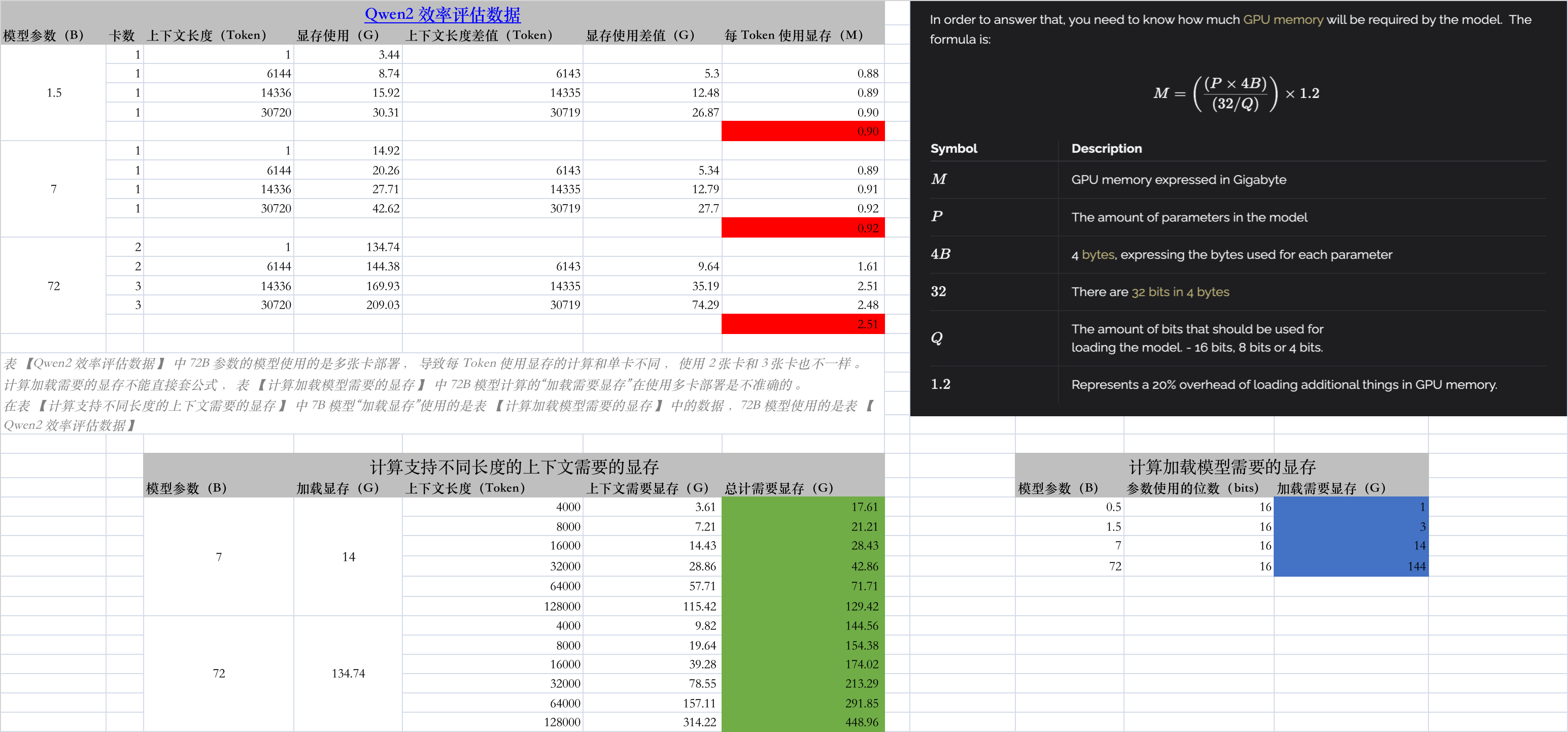
transformers 库进行推理,对于 vLLM,由于 GPU 显存预分配,实际显存使用难以评估。计算加载模型需要的显存
| 模型参数(B) | 参数使用的位数(bits) | 加载需要显存(G) |
|---|---|---|
| 0.5 | 16 | 1 |
| 1.5 | 16 | 3 |
| 7 | 16 | 14 |
| 9 | 16 | 18 |
| 22 | 16 | 44 |
| 72 | 16 | 144 |
计算支持不同长度的上下文需要的显存
RAG 复杂场景下的工作流程
召回模式(选择数据集) → 混合检索(同时进行语义检索和关键词搜索) → 重排序(合并和归一化检索结果)
RAG 中构建知识库的解析方法
RAGFlow 是一款基于深度文档理解构建的开源 RAG 引擎,内置了丰富地文档解析方法,可以帮助用户快速构建知识库。
GLM-4V-9B
GLM-4V-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源多模态版本。 GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中均表现优异。
总结
相比 CogVLM2 能力还是不如。
文字识别
识别中文

提示词:输出图像中的文字
贵公司被认为中标人。中标价格为:307.6万元。 请贵公司在收到本中标通知书之日起30天内,携带所有签订合同所需的资料(包括但不限于法定代表人授权书、技术规范、技术图纸等),并按照招标文件和中标人的投标文件与项目单位订立书面合同。合同签订的安排由项目单位另行通知。 请贵公司收到本中标通知书后,签收并速回函确认。
确() 识别成全角识别手写英文

提示词:识别图像上的手写英文
I think student have many after-school classes is don't good for they. So I thing the student don't have after-school classes.
AutoGen
定义 Agent
from autogen import ConversableAgent
llm_config = {"model": "gpt-3.5-turbo"}
agent = ConversableAgent(
name="chatbot",
llm_config=llm_config,
human_input_mode="NEVER",
)
reply = agent.generate_reply(
messages=[{"content": "给我讲个笑话。", "role": "user"}]
)
print(reply)
// ...
为什么八卦杂志最爱讲床上故事?因为上面都有新闻!哈哈哈~
为什么兔子喜欢吃胡萝卜?因为胡萝卜有好处,营养丰富!
多智能体对话
双人笑话
开放 Ollama 服务
环境变量
OLLAMA_HOST: Ollama 服务器的 IP 地址(默认 127.0.0.1:11434)OLLAMA_NUM_PARALLEL: 最大并行请求数(默认 1)OLLAMA_MAX_LOADED_MODELS: 最大加载模型数量(默认 1)OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的持续时间(默认 5m),-1 表示永久保持加载。Linux
curl -fsSL https://ollama.com/install.sh | sh
编辑 systemd 服务,调用 systemctl edit ollama.service。这将打开一个编辑器。 sudo systemctl edit ollama.service 对于每个环境变量,在 [Service] 部分下添加一行 Environment: [Service] Environment="OLLAMA_HOST=0.0.0.
框架
[SGLang][SGLang]
SGLang 是一种专为大型语言模型 (LLM) 设计的结构化生成语言。它通过共同设计前端语言和运行时系统,使您与 LLM 的交互更快、更可控。
平台
[Dify][Dify]
Dify 是一个 UI 驱动的用于开发大语言模型应用程序的平台,它使原型设计更加容易访问。它支持用户使用提示词模板开发聊天和文本生成应用。此外,Dify 支持使用导入数据集的检索增强生成(RAG),并且能够与多个模型协同工作。我们对这类应用很感兴趣。不过,从我们的使用经验来看,Dify 还没有完全准备好投入大范围使用,因为某些功能目前仍然存在缺陷或并不成熟。但目前,我们还没有发现更好的竞品。
工具
[Continue][Continue]
Continue 使您能够在 IDE 中创建自己的 AI 代码助手。使用 VS Code 和 JetBrains 插件保持开发者的流畅体验,这些插件可以连接到任何模型、任何上下文以及任何其他你需要的东西。Continue 使您能够使用适合工作的模型,无论是开源还是商业,本地运行还是远程运行,用于聊天、自动完成或嵌入。它提供了许多配置点,以便您可以自定义扩展以适应您现有的工作流程。
[Ollama][Ollama] Ollama 是一个在本机上运行并管理大语言模型的工具。
安装
pip install 'crewai[tools]'
CrewAI 使用 Ollama 运行本地 LLM
.env
OPENAI_API_BASE=http://localhost:11434/v1
OPENAI_MODEL_NAME=aya:8b
OPENAI_API_KEY=NULL
agent.py
版本1
每次执行结果都不一样
from dotenv import load_dotenv
load_dotenv()
from crewai import Agent, Task, Crew
from langchain_openai import ChatOpenAI
general_agent = Agent(
role = "数学教授",
goal = """为提问数学问题的学生提供解决方案并给出答案。""",
backstory = """您是一位优秀的数学教授,喜欢以每个人都能理解的方式解决数学问题。""",
allow_delegation = False,
verbose = True
)
// ...
版本2
稳定地生成结果
Application scenarios of AI agents(AI代理的应用场景)
AI代理是LLM应用的重要场景,构建代理应用将是2024年的重要技术领域。目前我们主要的智能形式有单AI代理,多AI代理,混合AI代理等三种。
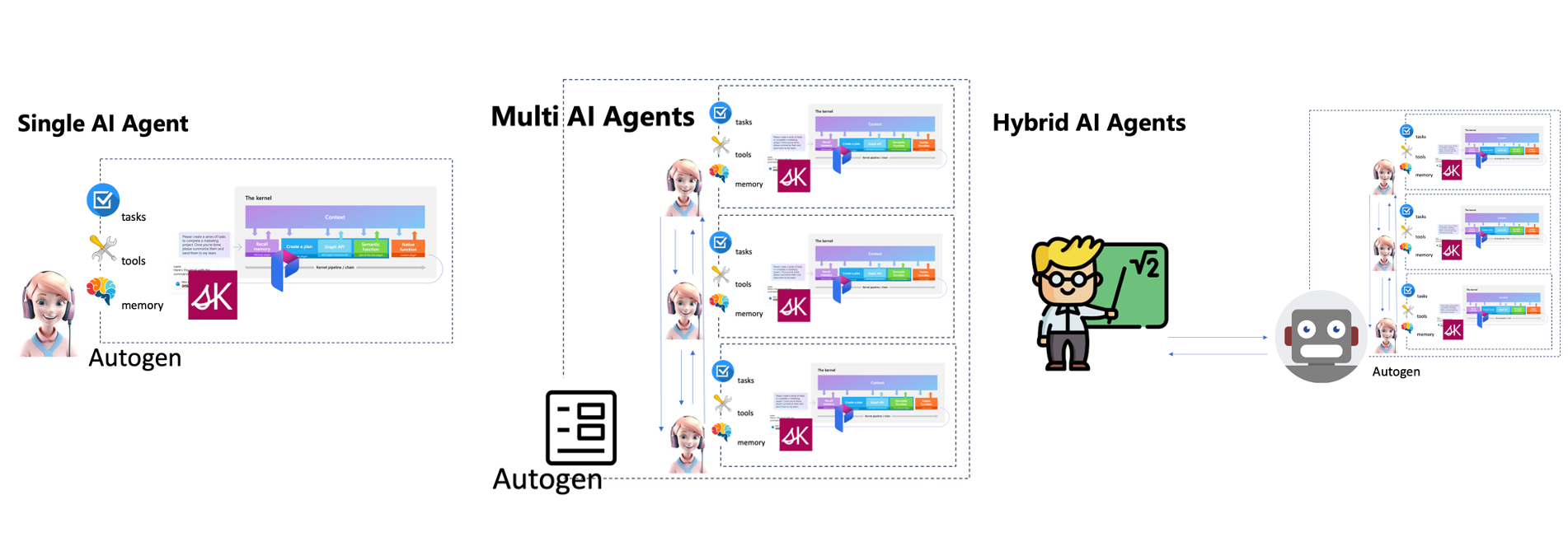
Single AI Agent(单一人工智能代理)
在特定任务场景下完成的工作,比如 GitHub Copilot Chat 下的代理工作区,就是根据用户需求完成特定编程任务的一个例子。基于 LLM 的能力,单个代理可以根据任务执行不同的动作,比如需求分析、项目阅读、代码生成等。它也可以应用于智能家居和自动驾驶。
Multi-AI Agents(多人工智能代理)
这就是AI代理之间相互交互的工作。例如上述Semantic Kernel代理实现就是一个例子。脚本生成的AI代理与执行脚本的AI代理进行交互。多代理应用场景在高度协同的工作中非常有帮助,例如软件行业开发、智能生产、企业管理等。
Hybrid AI Agent(混合人工智能代理)
这就是人机交互,在同一个环境下做决策。比如智慧医疗、智慧城市等专业领域,可以利用混合智能来完成复杂的专业工作。
Intro of AI agent, & AI agent projects s
代码注入:SQL注入:MyBatis
提示词
您是一名 Java 高级软件工程师,主要任务是根据缺陷报告的信息修复软件中的漏洞。
要求
请根据缺陷报告,修复缺陷代码片断的缺陷。
要求修复后的软件不改变原有的功能。
需要给出修复后的代码片段或者修复建议。
缺陷报告 缺陷类别: 一级类: 代码注入 二级类:SQL注入:MyBatis 详细信息: SQL注入是一种数据库攻击手段。攻击者通过向应用程序提交恶意代码来改变原SQL语句的含义,进而执行任意SQL命令,达到入侵数据库乃至操作系统的目的。在Mybatis Mapper Xml中,#变量名称创建参数化查询SQL语句,不会导致SQL注入。而$变量名称直接使用SQL指令,会导致SQL注入攻击。 例如:以下代码片段采用$变量名称动态地构造并执行了SQL查询。 <!
Phi-3 Vision 是一个轻量级、最先进的开放多模态模型,基于数据集构建,其中包括合成数据和经过过滤的公开网站,重点关注文本和视觉方面的高质量推理密集数据。该模型属于 Phi-3 模型系列,多模式版本可支持 128K 上下文长度(以 Token 为单位)。该模型经历了严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵守和稳健的安全措施。
模型参数 4B。
预期用途
主要用例
该模型旨在广泛用于英语商业和研究用途。该模型为通用人工智能系统和应用程序提供了视觉和文本输入功能,这些系统和应用程序需要
我们的模型旨在加速对高效语言和多模态模型的研究,作为生成人工智能驱动功能的构建块。
用例注意事项
我们的模型并非针对所有下游目的而专门设计或评估。开发人员在选择用例时应考虑语言模型的常见限制,并在特定下游用例中使用之前评估和减轻准确性、安全性和公平性,特别是对于高风险场景。开发人员应了解并遵守与其用例相关的适用法律或法规(包括隐私、贸易合规法等)。
手写文字识别
提示词:对图像文字进行识别
这段文字是一个人的自己写作,表达了对学生在学校和家庭生活中的看法。
提示词:这张图片上写了什么?
MiniCPM-Llama3-V 2.5 是 MiniCPM-V 系列的最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct 构建,共 8B 参数量,相较于 MiniCPM-V 2.0 性能取得较大幅度提升。MiniCPM-Llama3-V 2.5 值得关注的特点包括:
TextVQA, DocVQA。您可以在下表中看到 CogVLM2 系列开源模型的详细信息:
| 模型名称 | cogvlm2-llama3-chat-19B | cogvlm2-llama3-chinese-chat-19B |
|---|---|---|
| 基座模型 | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct |
| 语言 | 英文 | 中文、英文 |
| 模型大小 | 19B | 19B |
| 任务 | 图像理解,对话模型 | 图像理解,对话模型 |
| 模型链接 | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model | 🤗 Huggingface 🤖 ModelScope 💫 Wise Model |
| 体验链接 | 📙 Official Page | 📙 Official Page 🤖 ModelScope |
| Int4模型 | 暂未推出 | 暂未推出 |
| 文本长度 | 8K | 8K |
| 图片分辨率 | 1344 * 1344 | 1344 * 1344 |
总结 能力非常强大 👍 OCR 已经成为基础能力。包含印刷、手写、中文、英文。 图像描述。 基于图像问答。 信息提取。包含保单、车牌、火车票、手机充值。 表格识别。包含复杂表格。
Thoughtworks 技术雷达
Thoughtworks 技术雷达 (Tech Radar) 是一份每半年发布一次的技术报告,涵盖了工具、技术、平台、语言和框架等方面的内容。这一知识成果来自于我们全球团队的经验,重点介绍了您可能想要在项目中探索的内容。
环的含义如下:
参考:
技术 1️⃣ 将 CI/CD 基础设施作为一种服务 - 2023年4月 将 CI/CD 基础设施作为一种服务已经是很多元化以及成熟的方案,以至于需要自己管理整个 CI 基础设施的情况变得非常少见。
简介
SWIFT 支持近200种LLM和MLLM(多模态大模型)的训练、推理、评测和部署。开发者可以直接将我们的框架应用到自己的Research和生产环境中,实现模型训练评测到应用的完整链路。我们除支持了PEFT提供的轻量训练方案外,也提供了一个完整的Adapters库以支持最新的训练技术,如NEFTune、LoRA+、LLaMA-PRO等,这个适配器库可以脱离训练脚本直接使用在自己的自定流程中。
安装
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
支持的模型类型(model_type)
['chinese-alpaca-2-13b-16k', 'chinese-alpaca-2-13b', 'chinese-alpaca-2-7b-64k', 'chinese-alpaca-2-7b-16k', 'chinese-alpaca-2-7b', 'chinese-alpaca-2-1_3b', 'chinese-llama-2-13b-16k', 'chinese-llama-2-13b', 'ch