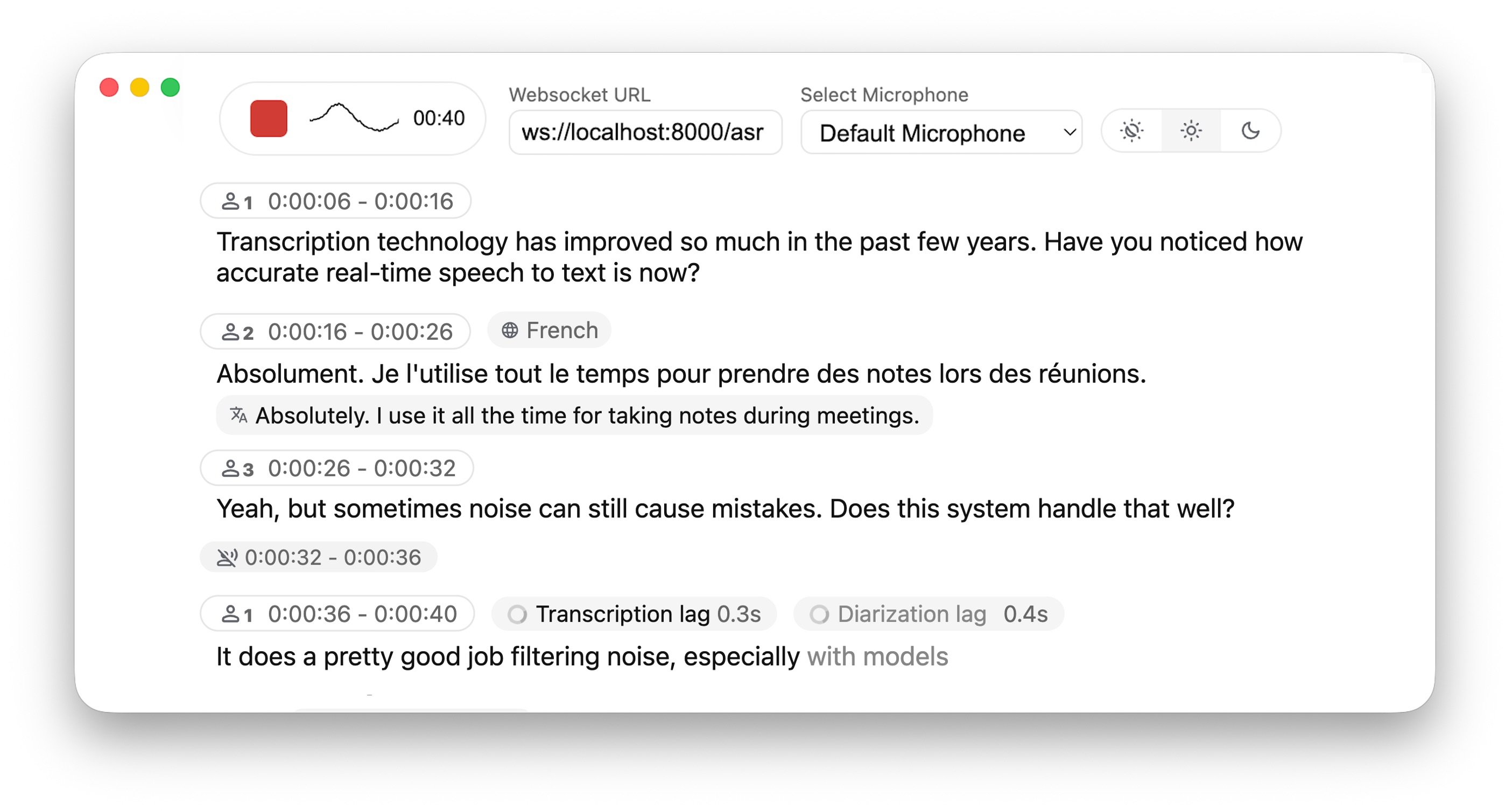
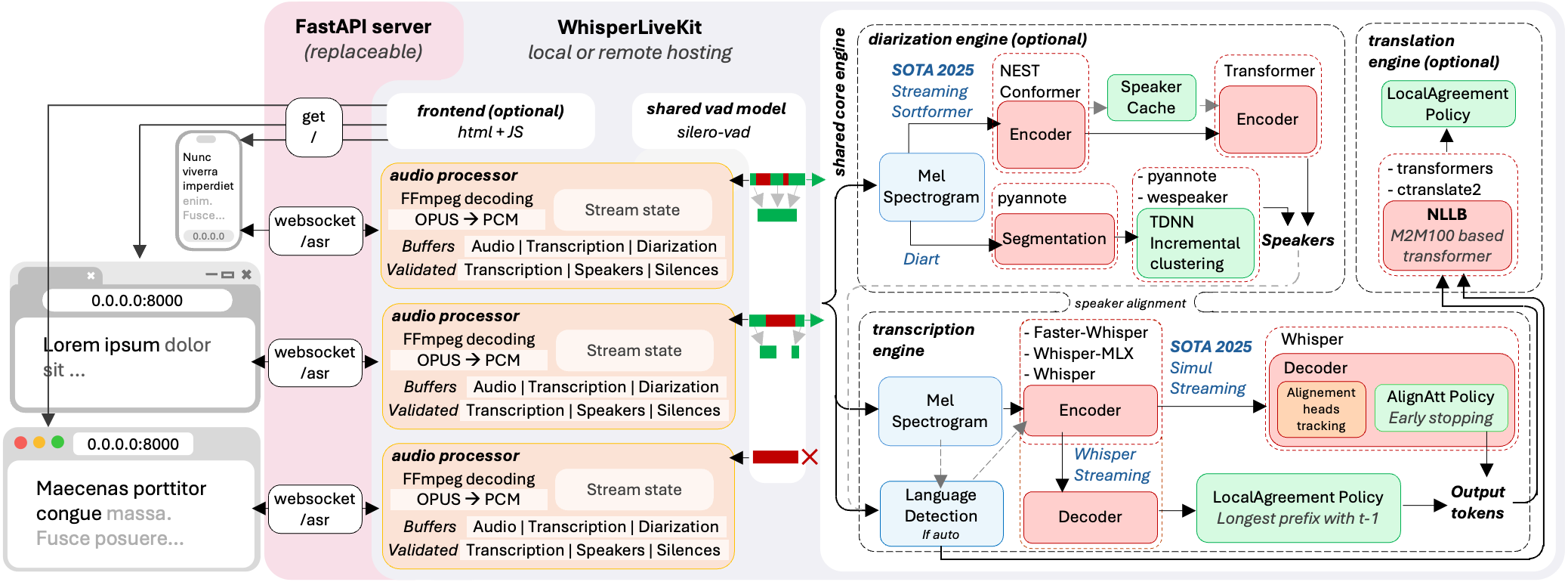
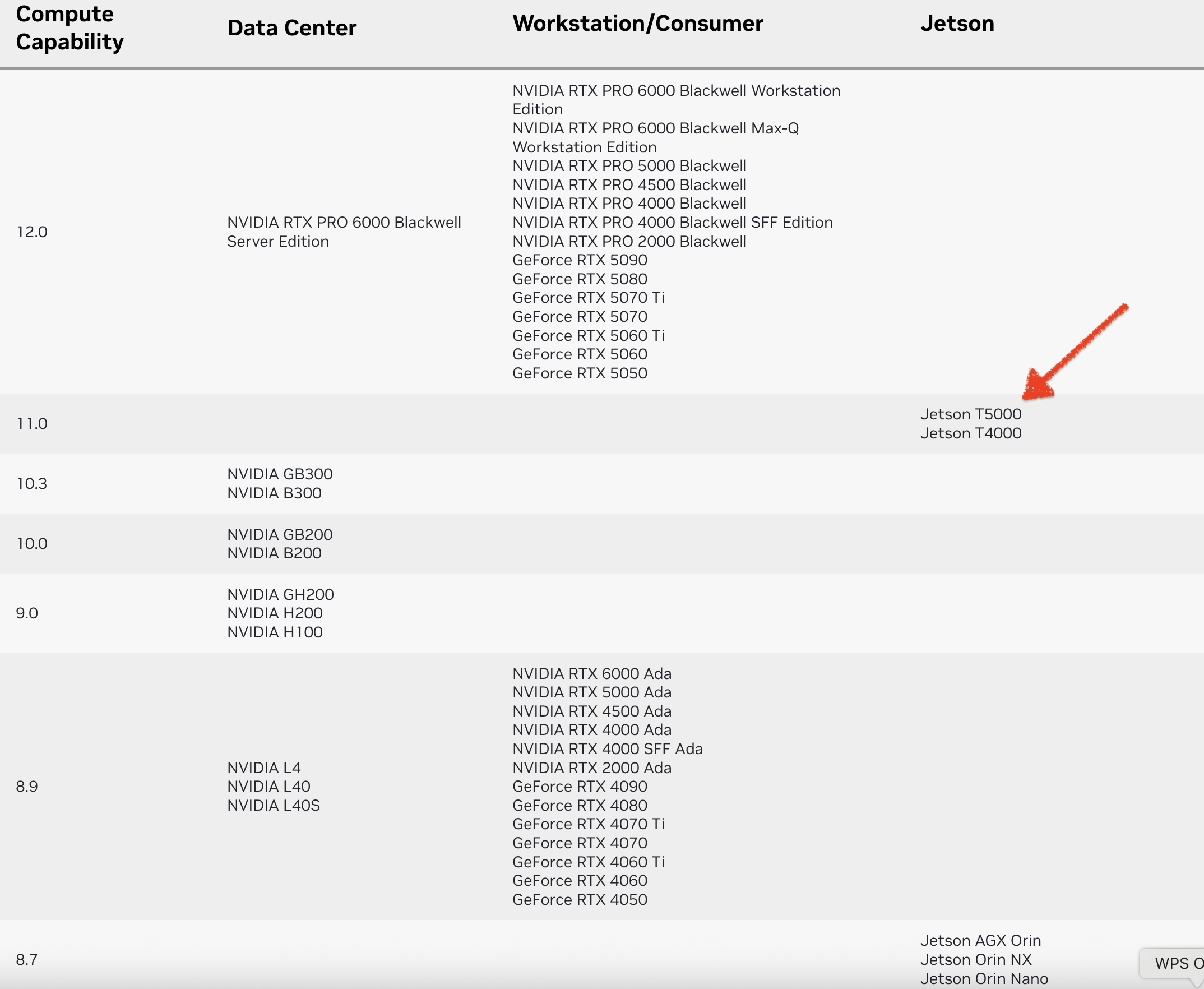
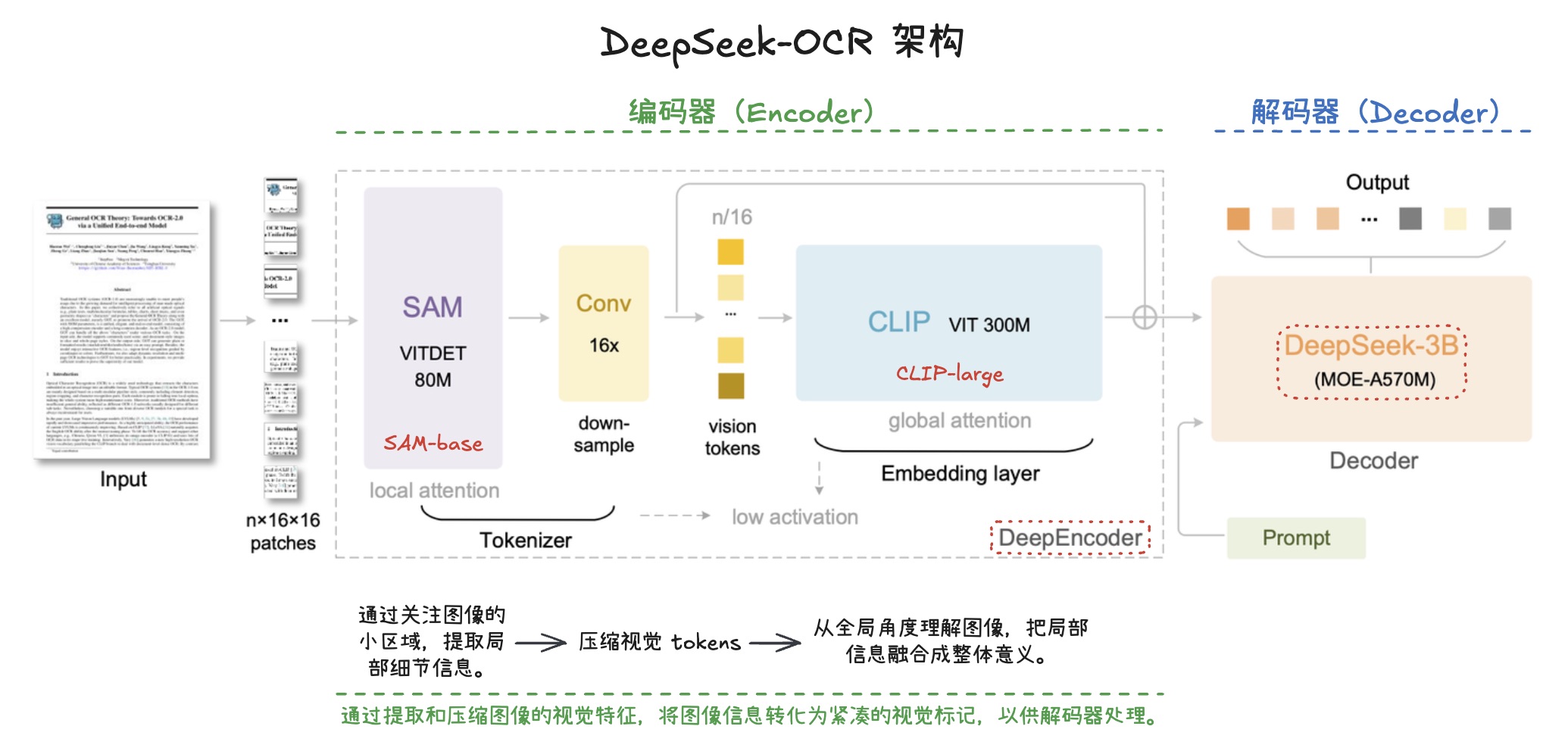
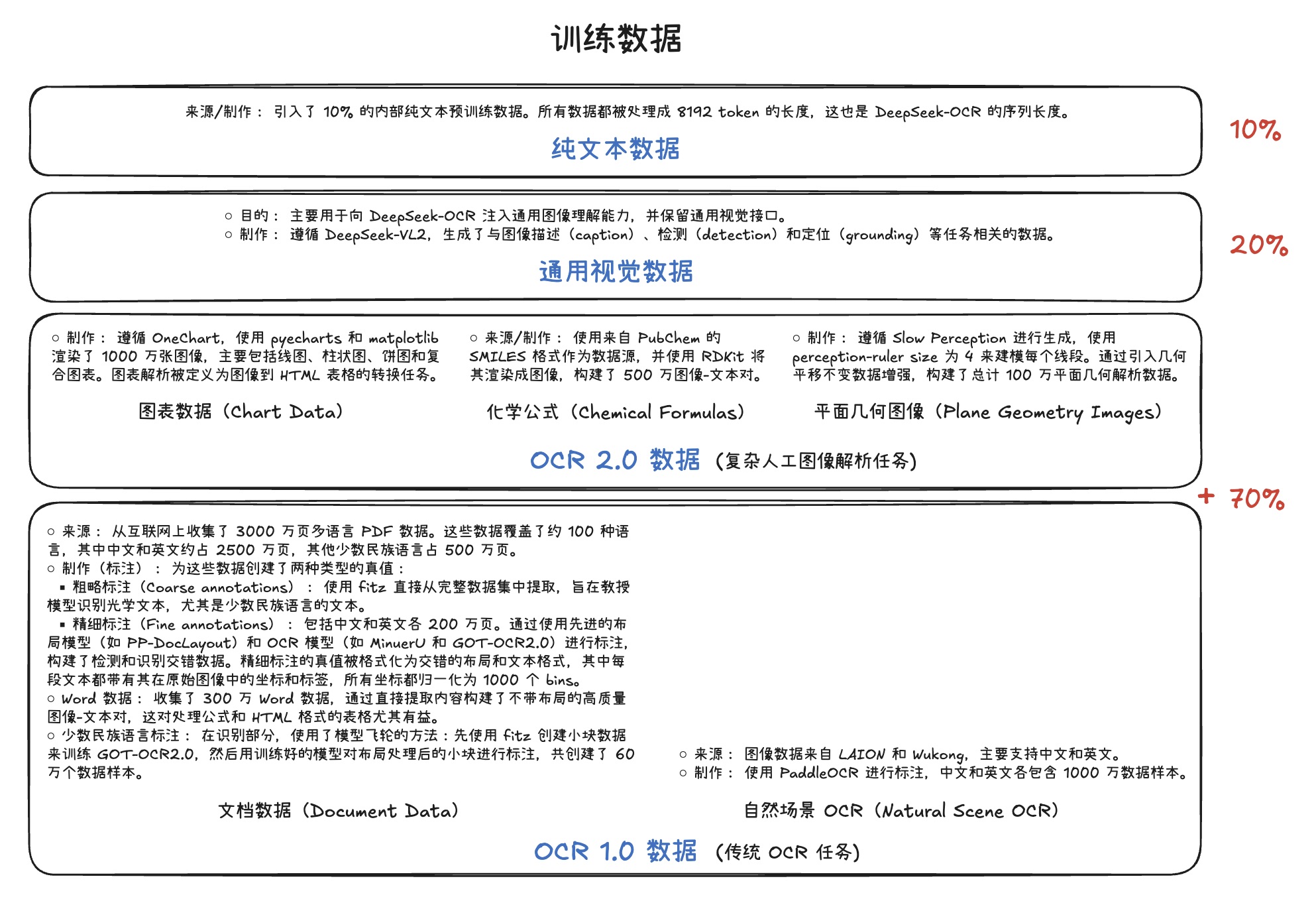
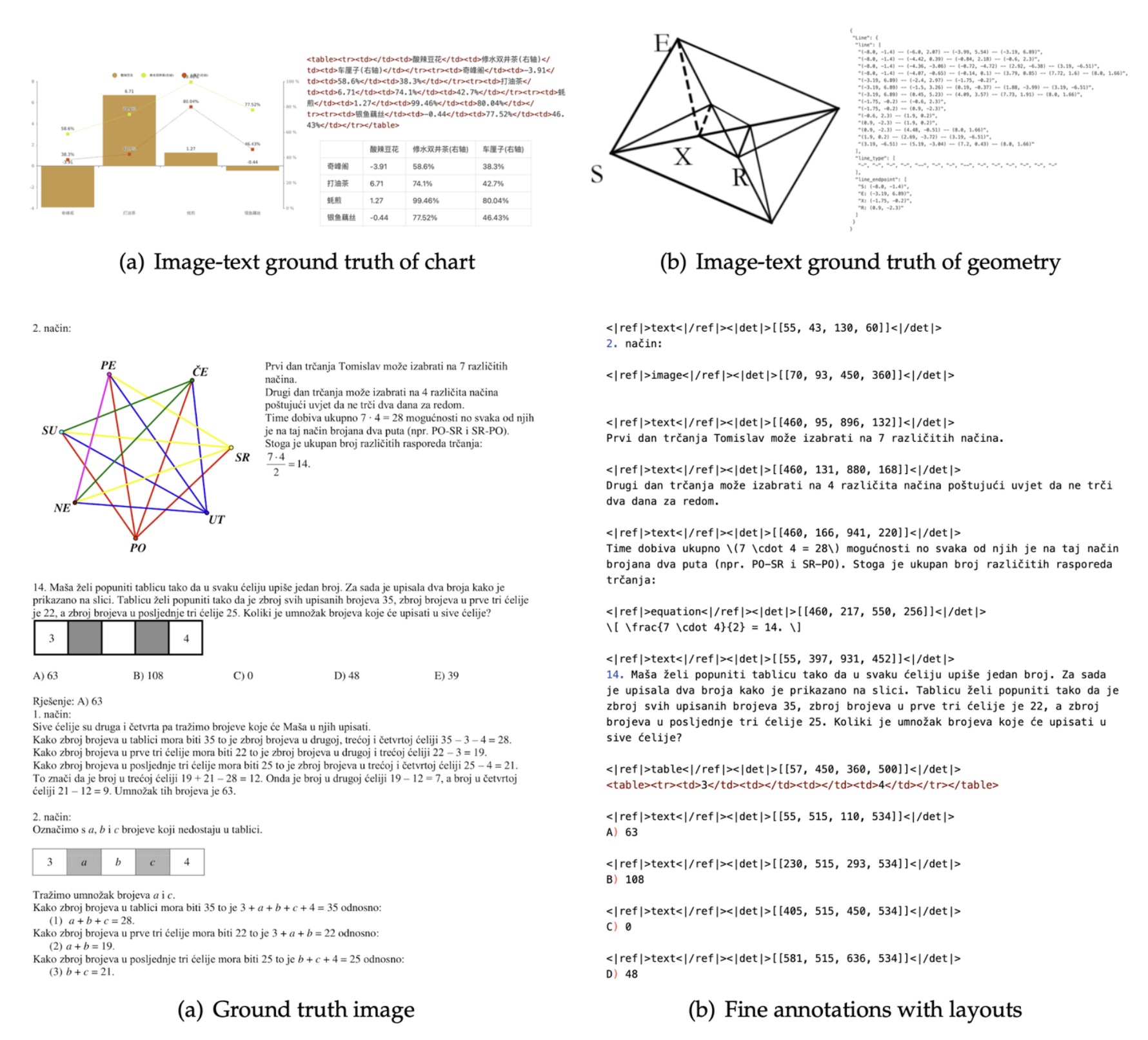
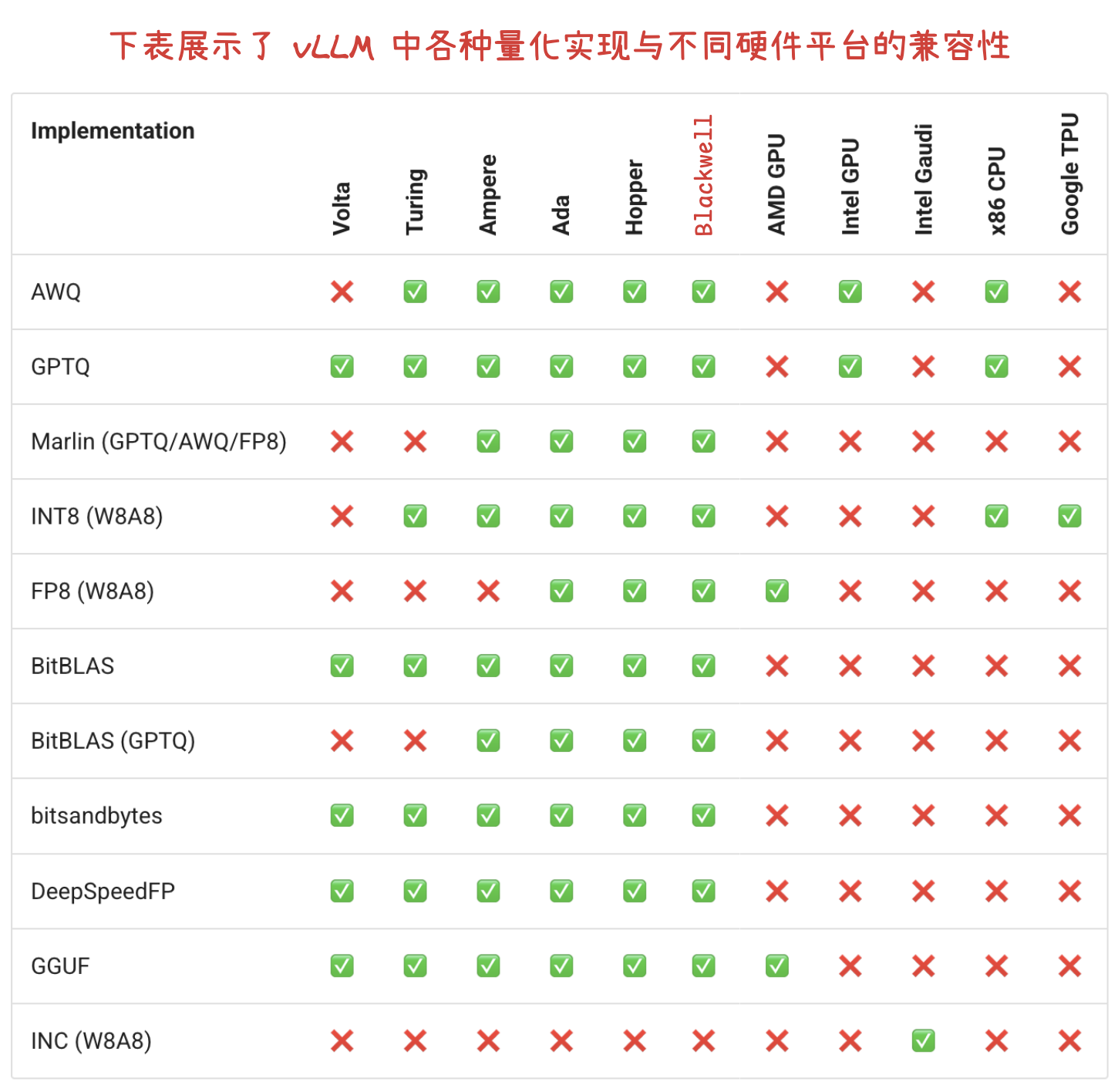
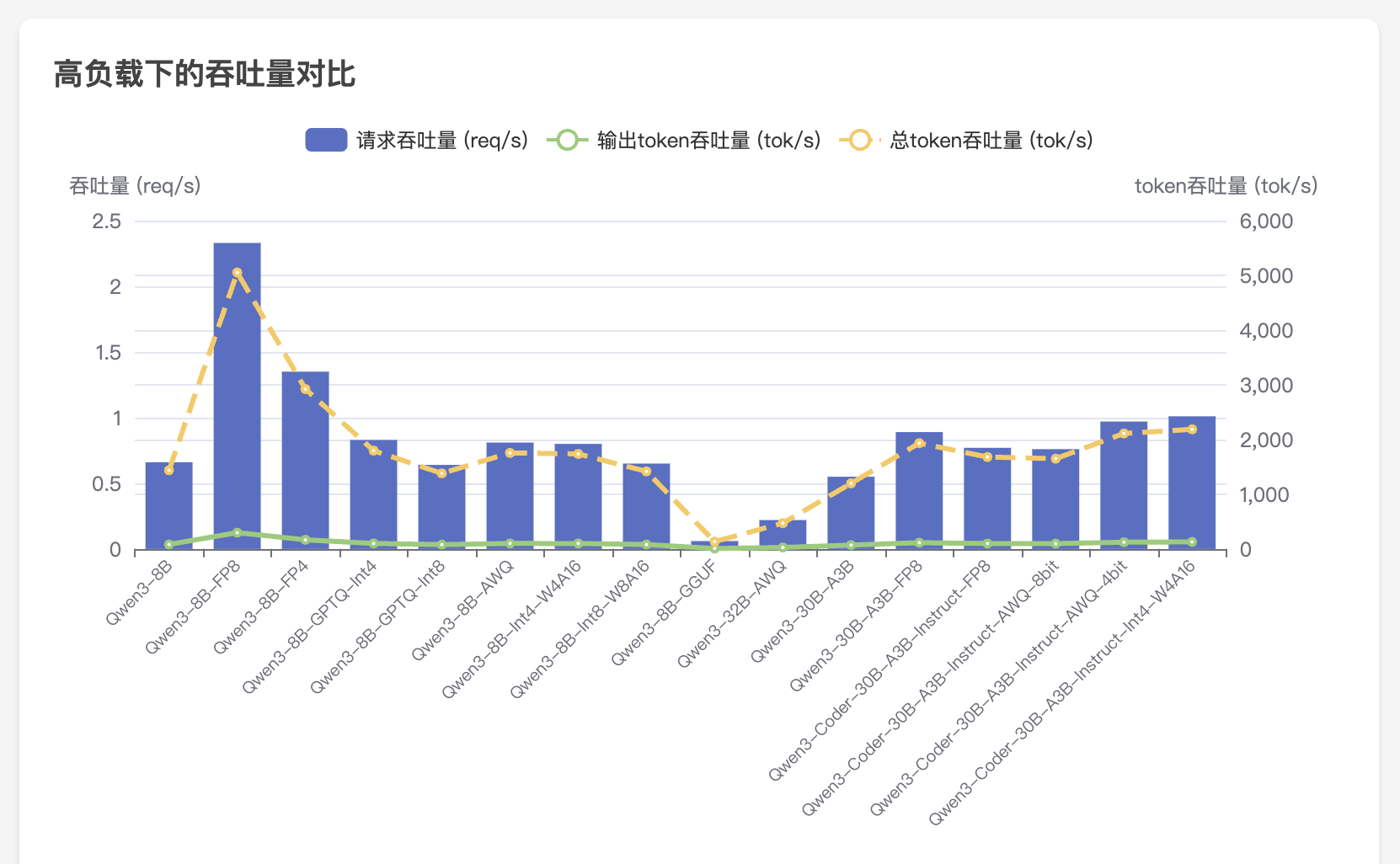
未来 5 年公司智算需求预测
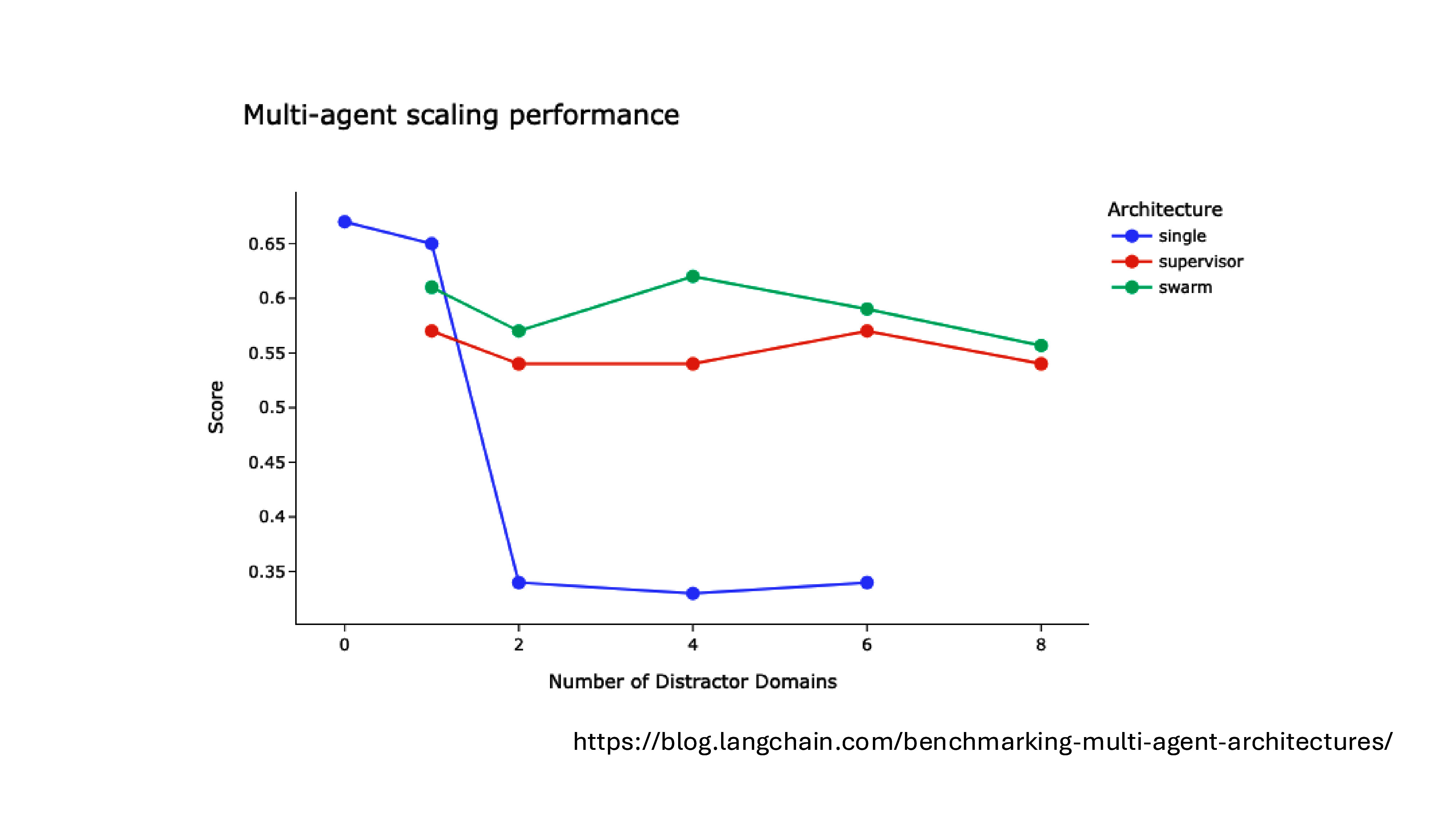
用半精度浮点数(FP16)计算能力评估服务器的智能计算能力,服务器算力=处理器芯片数x每时钟周期执行单精度浮点运算次数x处理器主频x处理器核数。
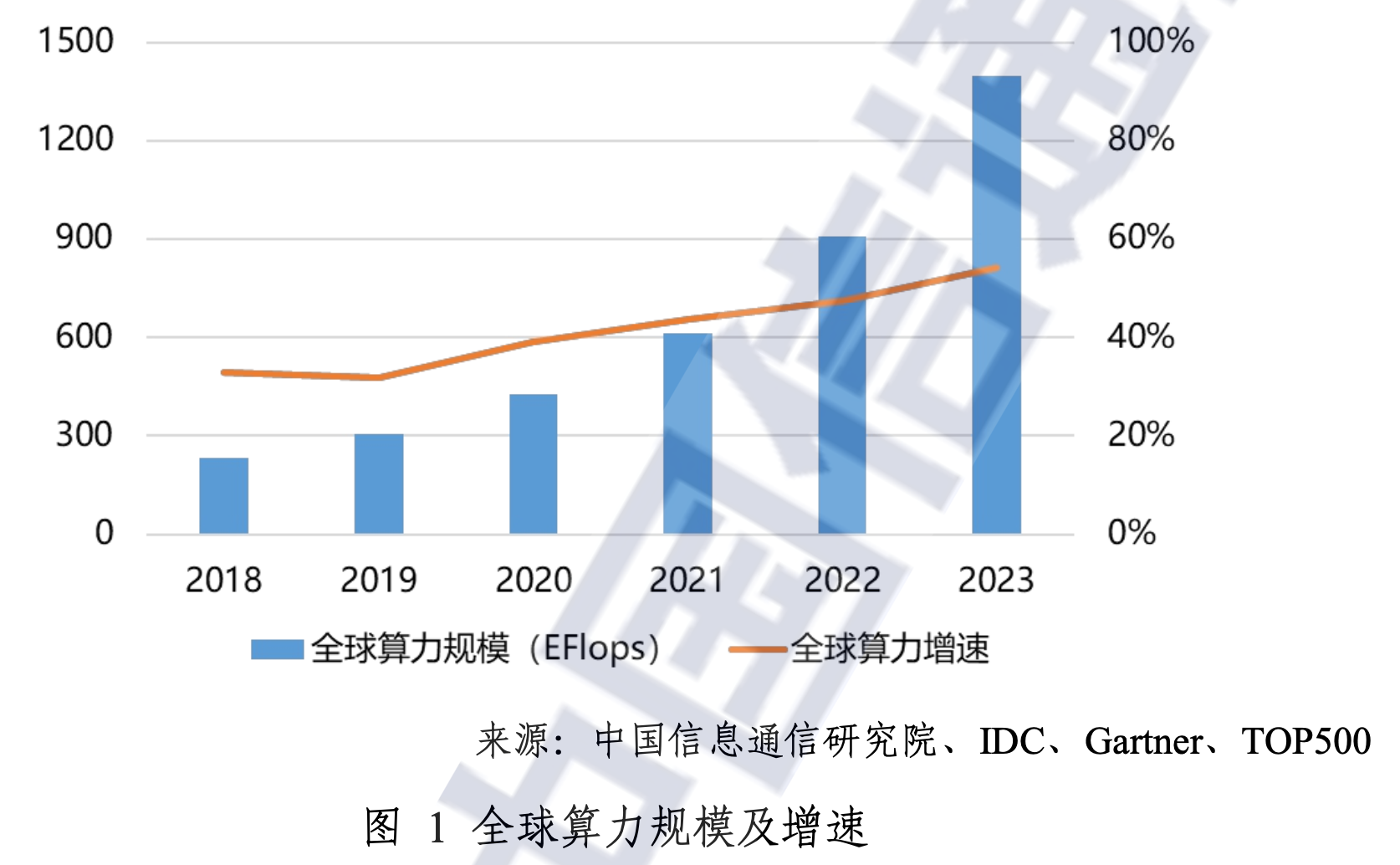
全球算力概览
中国算力概览
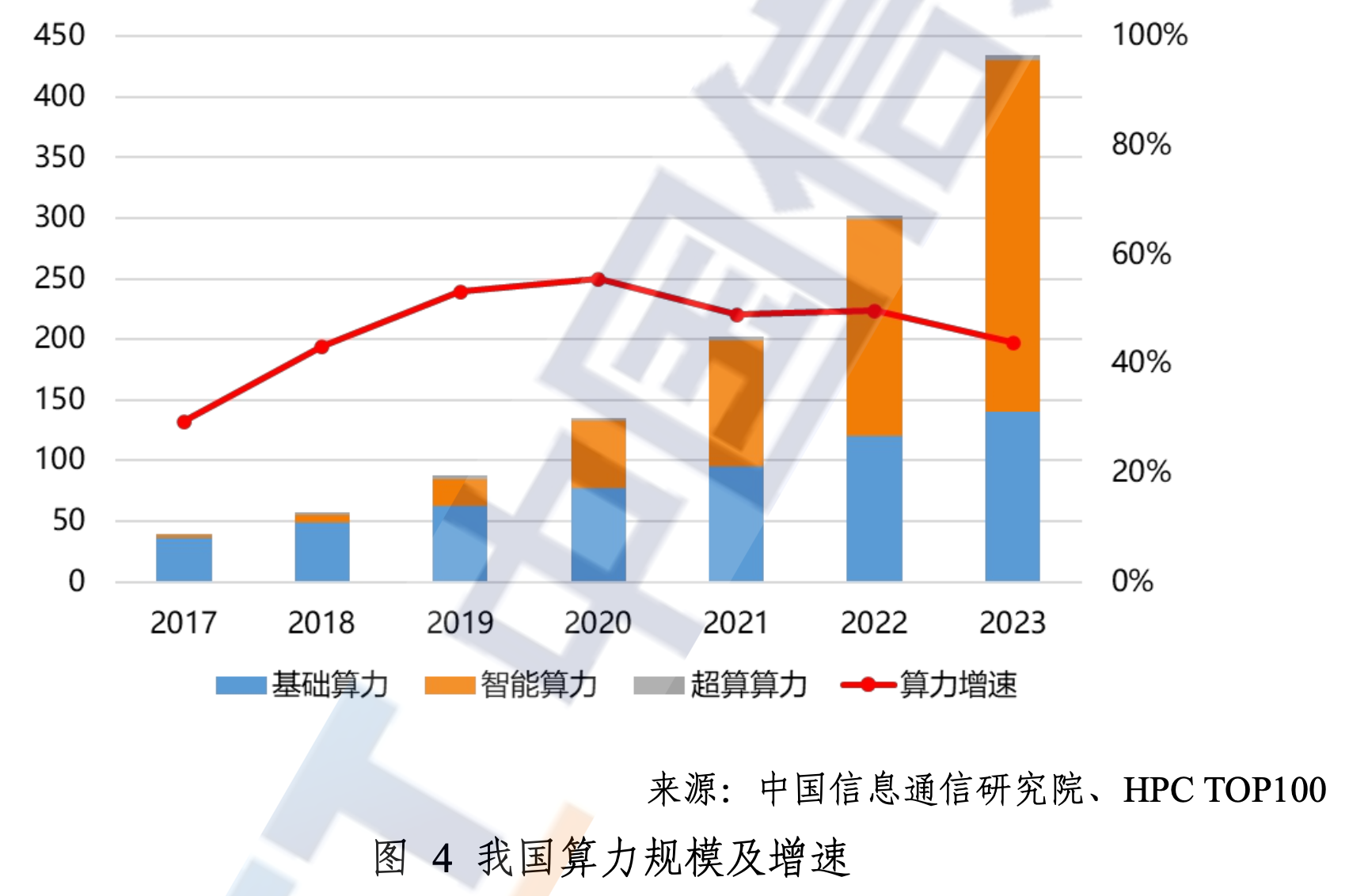
截至 2025 年 3 月底,我国智算规模达 748EFLOPS(FP16),近五年平均增速达 49%。
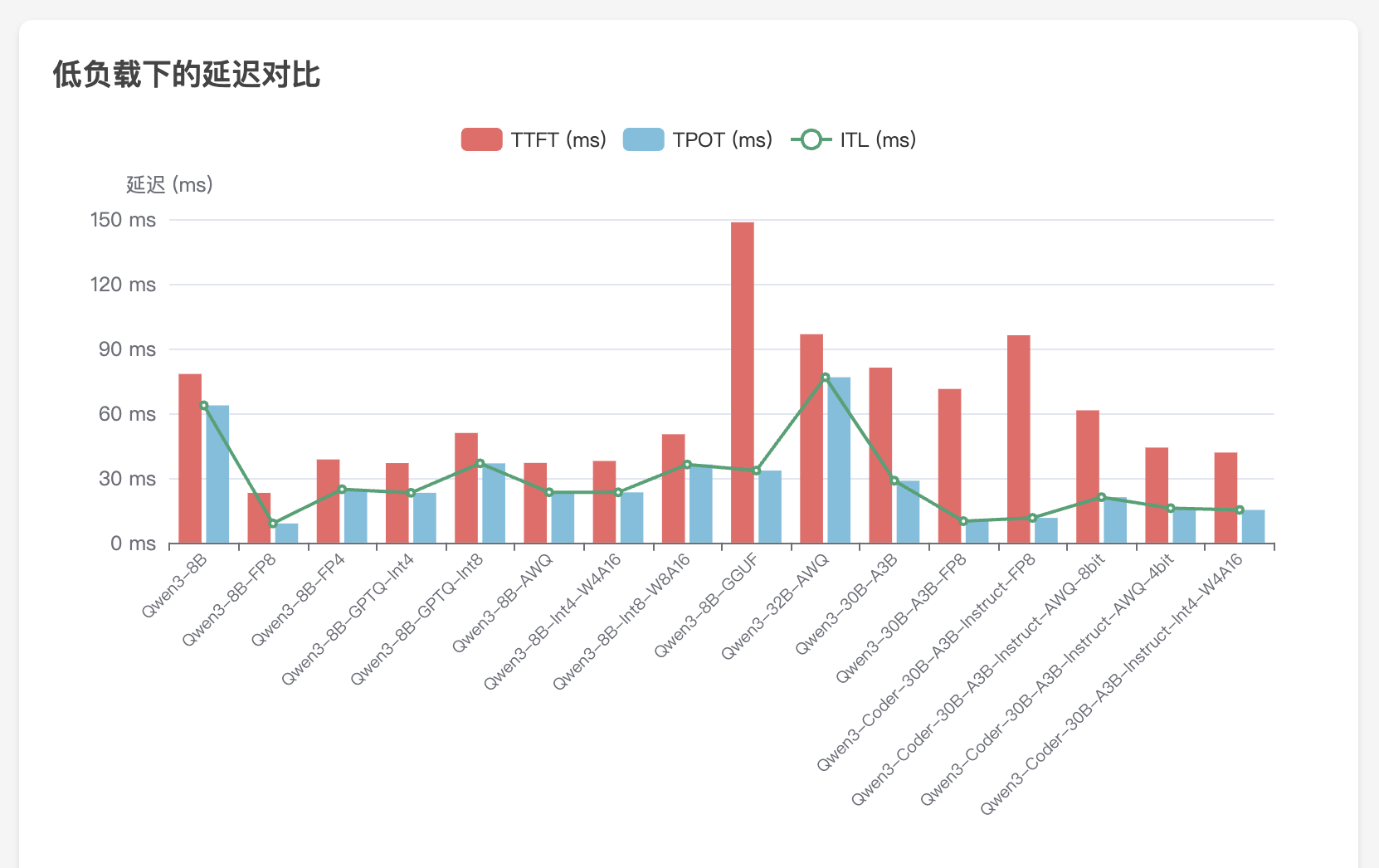
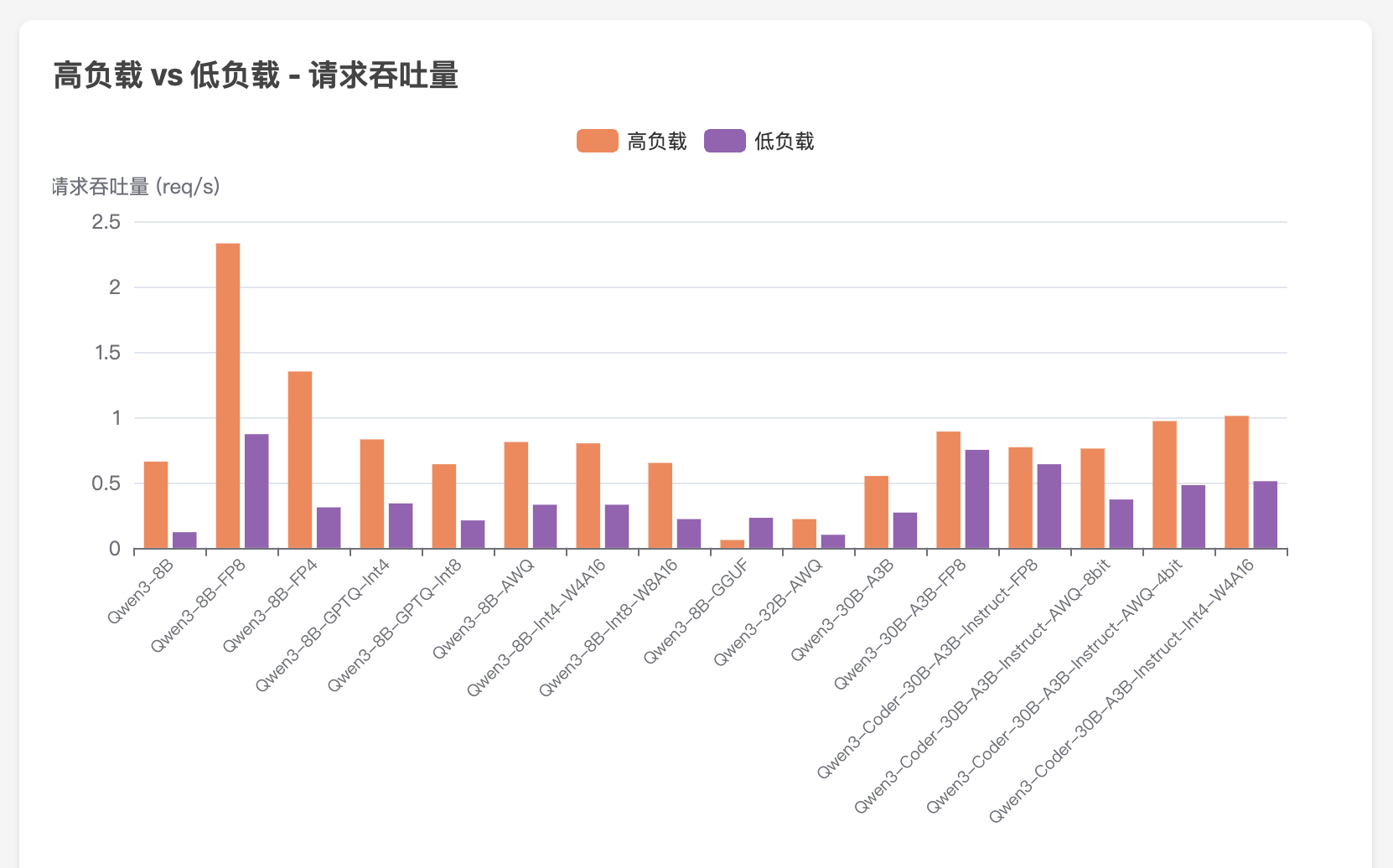
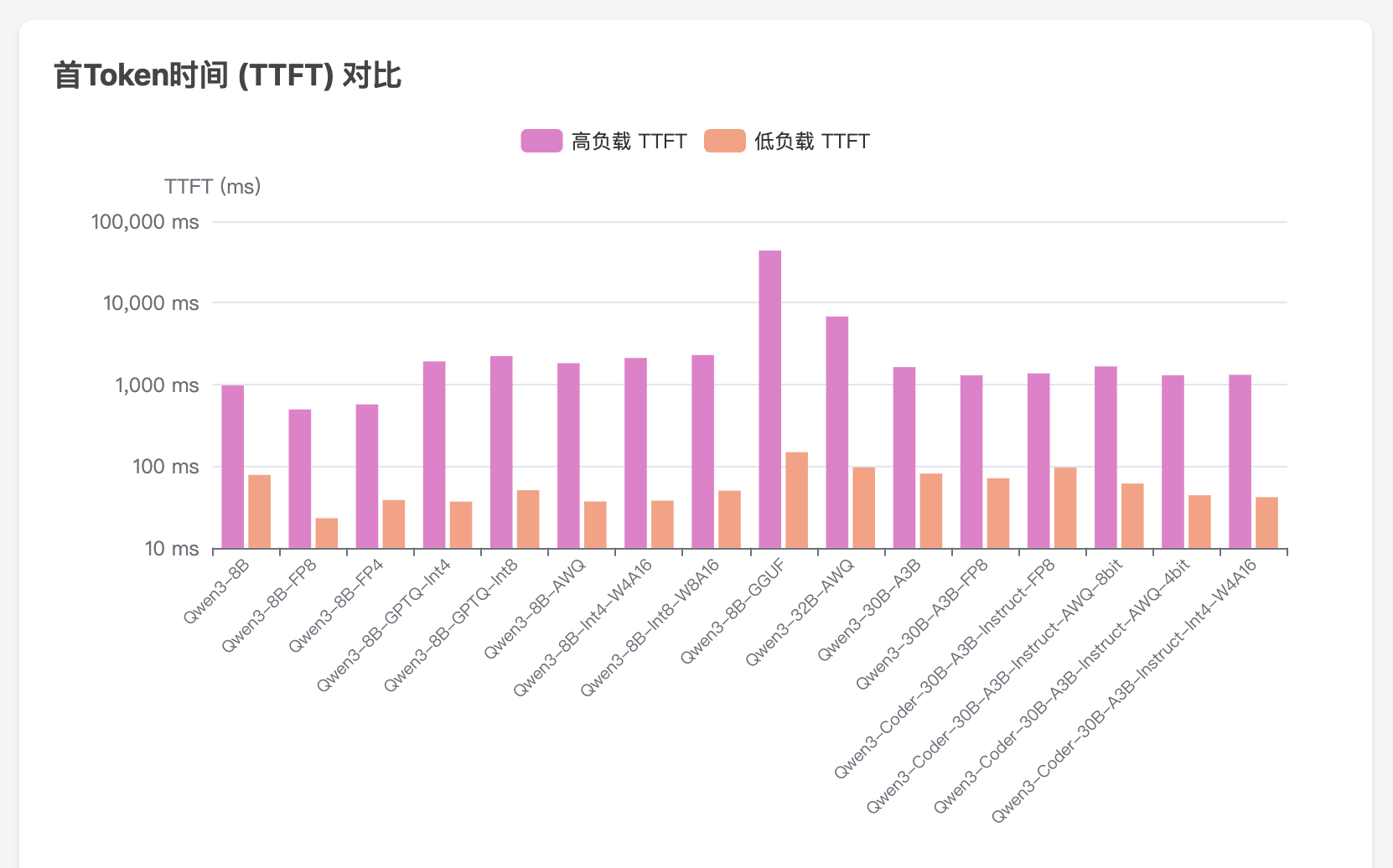
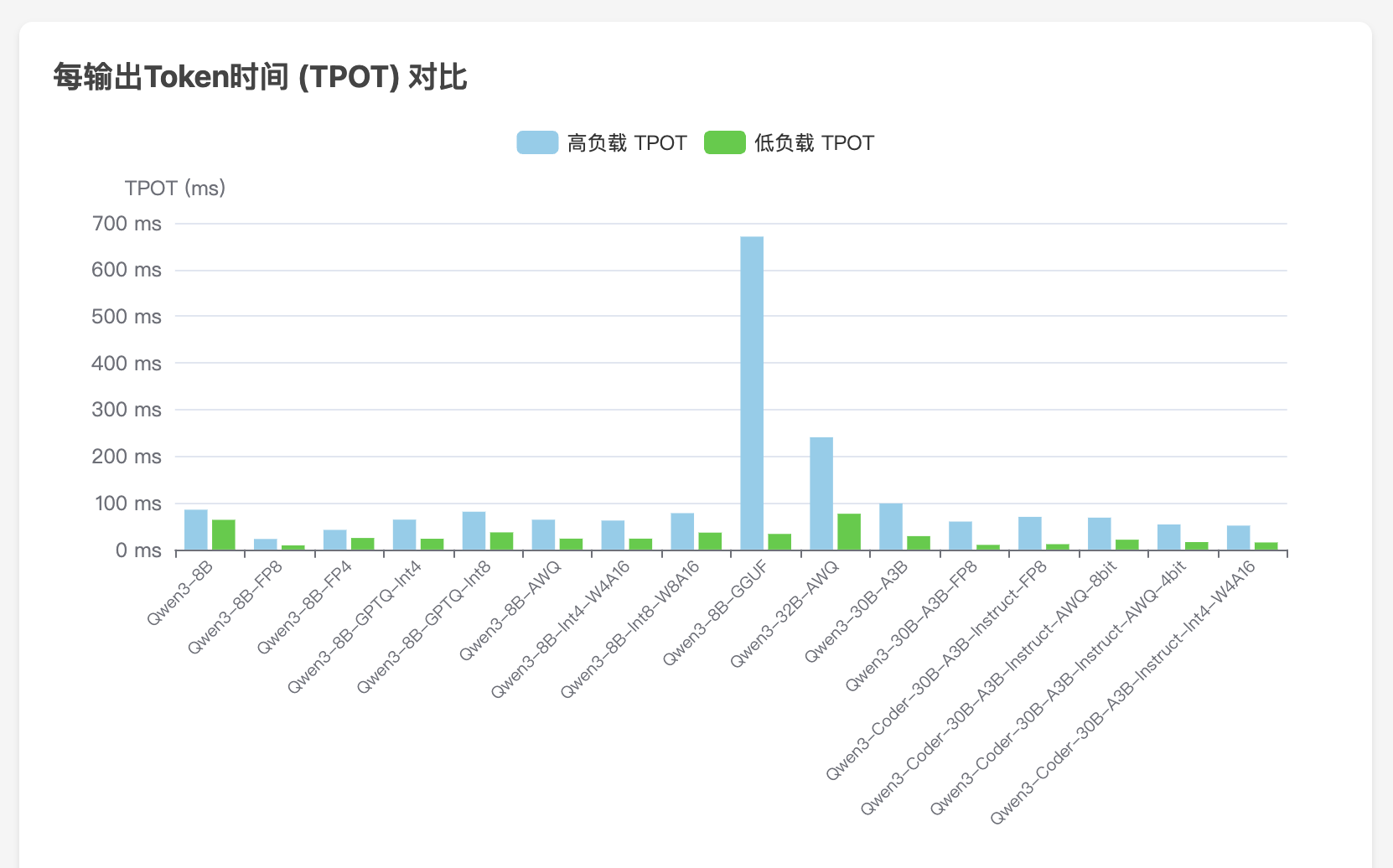
公司算力概览
昇腾 910B4 (32GB) 算力概览
| 配置级别 | 硬件描述 | FP16 峰值算力 | 备注 |
|---|---|---|---|
| 单卡 | 昇腾 910B4 (32GB) | 280 TFLOPS | 单卡 FP16 算力峰值 |
| 单机 | Atlas 800I A2 服务器 (8 x 910B4) | 2240 TFLOPS () | 服务器搭载 8 张 910B4 卡 |
| 集群 | 5 台 Atlas 800I A2 服务器 | 11.2 PFLOPS | 由 5 台服务器组成的集群 |
NVIDIA T4 (16GB) 算力概览
| 配置级别 | 硬件描述 | FP16 峰值算力 | 备注 |
|---|---|---|---|
| 单卡 | NVIDIA T4 | 65 TFLOPS | 使用混合精度 Tensor Cores |
| 单机 | 4 卡服务器 | 260 TFLOPS | 服务器搭载 4 张 T4 卡 |
| 集群 | 4 台 4 卡服务器 | 1.04 PFLOPS | 由 4 台服务器组成的集群 |
总算力