Kimi Code 实战
安装 Kimi Code
curl -L code.kimi.com/install.sh | bash
Kimi Code CLI
登录配置
kimi
- 登录 - /login
- 选择平台 - Kimi Code
- 浏览器打开链接,微信扫码完成授权
- 返回终端,登录成功
安装 Kimi Code
curl -L code.kimi.com/install.sh | bash
Kimi Code CLI
登录配置
kimi
OpenClaw 简介
自2025年11月由PSPDFKit创始人Peter Steinberger作为周末项目启动(最初名为Clawd/Clawdbot),OpenClaw(曾短暂更名为Moltbot)在2026年1月迅速走红,成为当年上半年增长最快的开源AI智能体框架之一。该项目GitHub星数已超过13万(部分报道接近15万),其最大亮点在于真正实现了“本地优先、本地执行”的自主任务能力,而非单纯的云端聊天。
OpenClaw不是传统AI聊天助手,而是一个运行在用户本地硬件(Mac、PC、服务器)上的自动化中枢。它通过消息类应用(如WhatsApp、Telegram、iMessage、Discord等)接收自然语言指令,能够执行真实电脑操作:读写文件、运行命令、操作浏览器、管理邮件日历、甚至自主编写新技能。
OpenClaw 项目架构概览
设计哲学 OpenClaw 被设计为一个模块化、可扩展且强健的个人 AI 助手系统。其核心理念包括: 解耦 (Decoupling):将智能体逻辑与传输层(如 Discord、Telegram 等通道)以及控制平面(Gateway)分离。 可扩展性 (Extensibility):通过 Hook 和插件系统支持注入上下文或对智能体运行进行后处理。
iFlow 登录


OpenAI 兼容 API
可以手动修改配置文件:~/.iflow/settings.json
{
"cna": "dp3vIQIkkhcCAXyAlGrAY4my",
"selectedAuthType": "openai-compatible",
"searchApiKey": "sk-72c24939a1ac137a28e990cdee4d5d7f",
"baseUrl": "http://localhost:11434/v1",
"apiKey": "NONE",
"modelName": "qwen3-coder:latest",
"bootAnimationShown": true
}
不能使用工具(todo, write_file 等),不可用。
参考资料
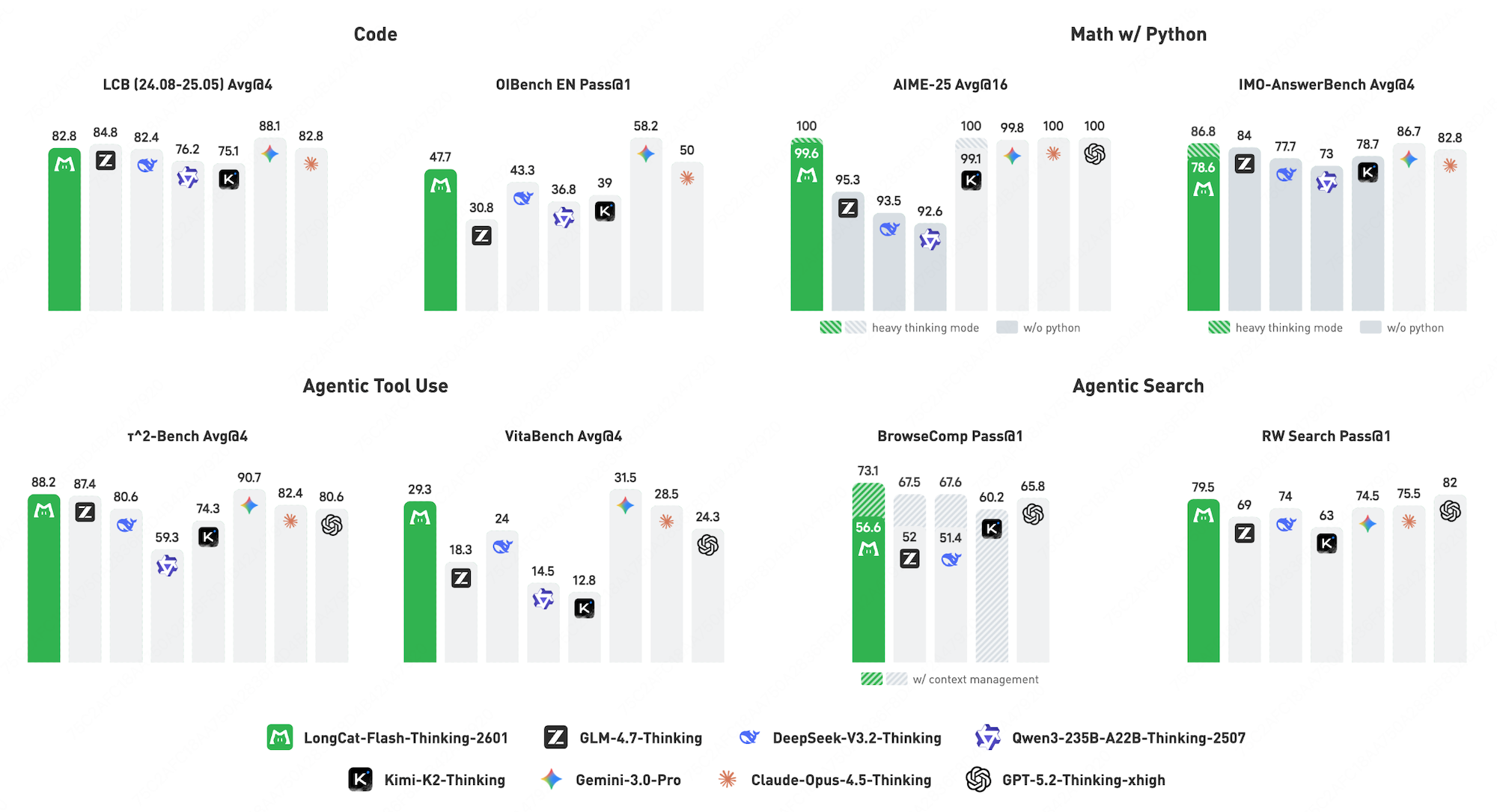
LongCat-Flash-Thinking-2601 创新性地开启了全栈式的智能体推理(Agentic Reasoning)训练体系与架构优化。首先,提出了自动化的环境扩展流水线,构建了覆盖 20 多个领域的高质量、可执行且可验证的智能体环境,有效解决了真实世界中复杂智能体交互数据匮乏的难题。其次,针对现实任务的不确定性,创新性地引入了鲁棒性智能体训练流程,通过系统性分析现实噪声模式并采用课程强化学习(Curriculum RL)将噪声整合进训练,显著增强了模型在非理想环境下的泛化与生存能力。在底层支撑上,扩展了异步强化学习框架 DORA 以支持高达 32,000 个环境的大规模并发训练,并引入了 Heavy Thinking(深思考)模式,通过在推理阶段同时扩展思考的深度与广度(Test-time Scaling),进一步突破了复杂任务的性能边界。此外,还设计了 Zigzag Attention 稀疏注意力机制,使模型能以极低开销实现高达 100 万 token 的长上下文扩展,为长程智能体任务提供了坚实的架构基础。
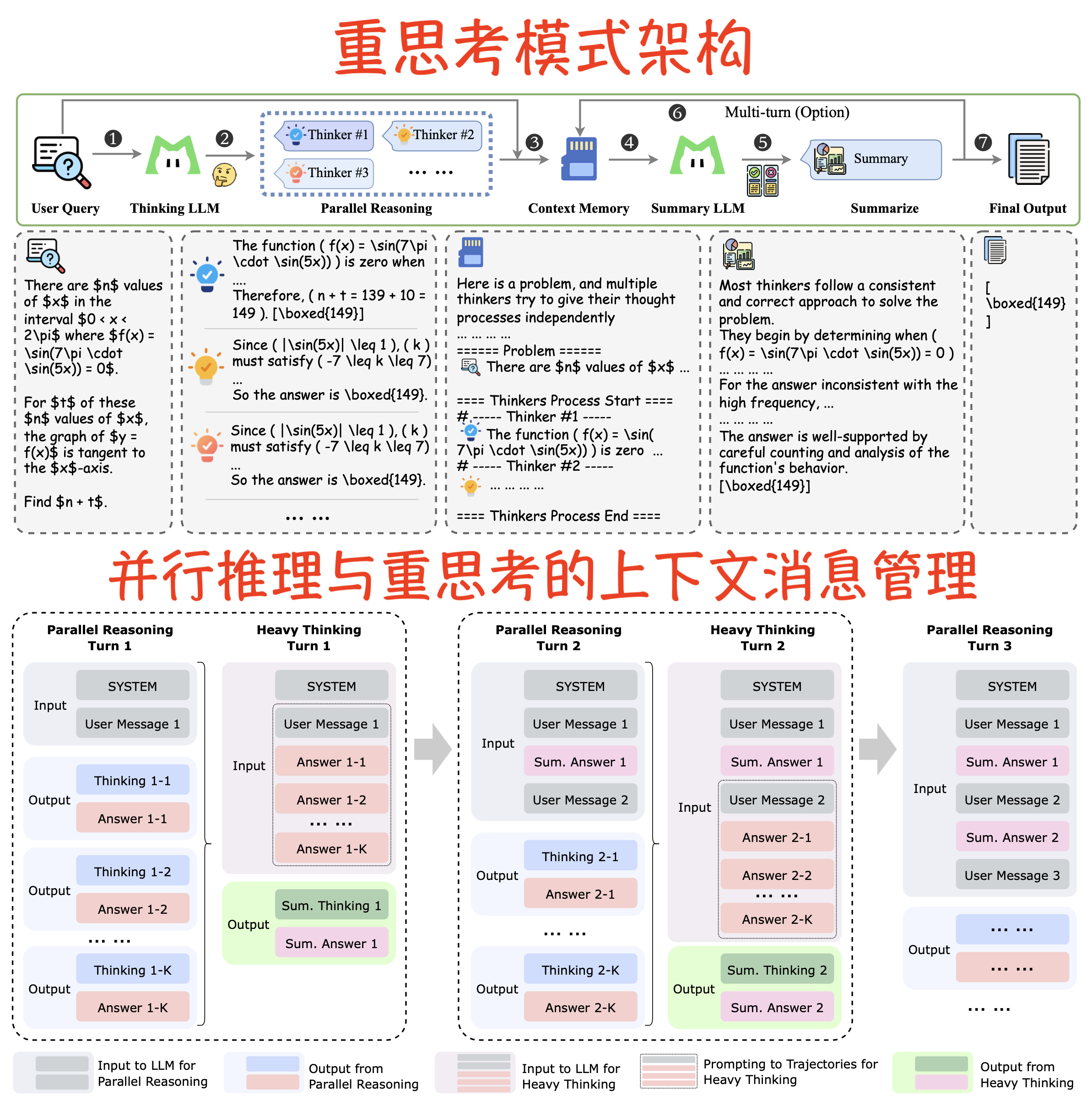
重思考模式架构
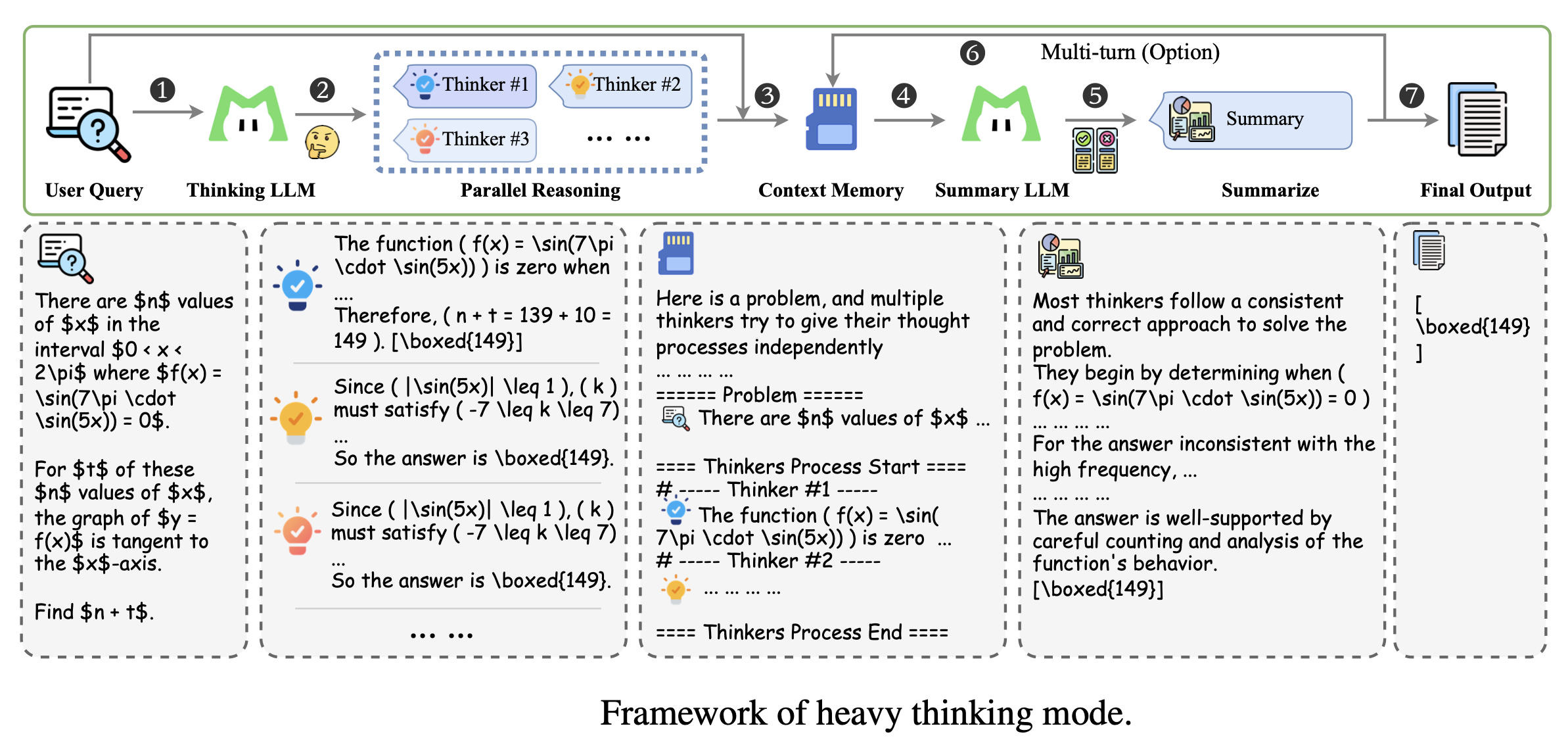
“重思考模式”(Heavy Thinking Mode)是 LongCat-Flash-Thinking-2601 模型为了突破现有推理能力极限而引入的一种推理时扩展(Test-Time Scaling)架构。
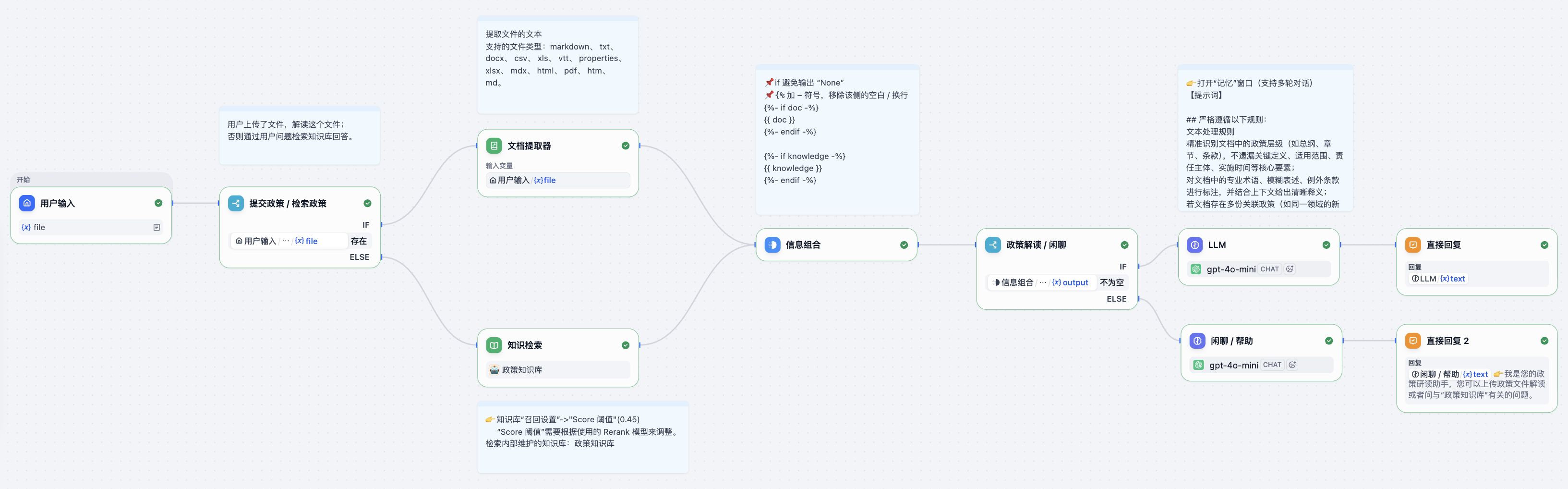
📌 DSL
Dify
git clone https://github.com/langgenius/dify
Dify 提供了 Docker 部署方式,您可以通过以下步骤快速部署:
cd dify
cd docker
cp .env.example .env
docker compose up -d
运行后,可以在浏览器上访问 http://localhost/install 进入 Dify 控制台并开始初始化安装操作。
vLLM
vllm serve /data/models/llm/deepseek/DeepSeek-R1-Distill-Qwen-32B-AWQ/ \
--served-model-name gpt-4o-mini \
--tensor-parallel-size 4 \
--max-model-len 102400 \
--dtype half \
--port 8111
Ollama
curl -fsSL https://ollama.com/install.sh | sh
systemctl edit ollama.service。这将打开一个编辑器。sudo systemctl edit ollama.service
对于每个环境变量,在 [Service] 部分下添加一行












优先使用:豆包 和 Grok
提示词
根据历年财报进行投资分析
基于京东健康上市后历年的财报,从价值投资的角度进行分析。
文件:
评估各模型投资分析能力
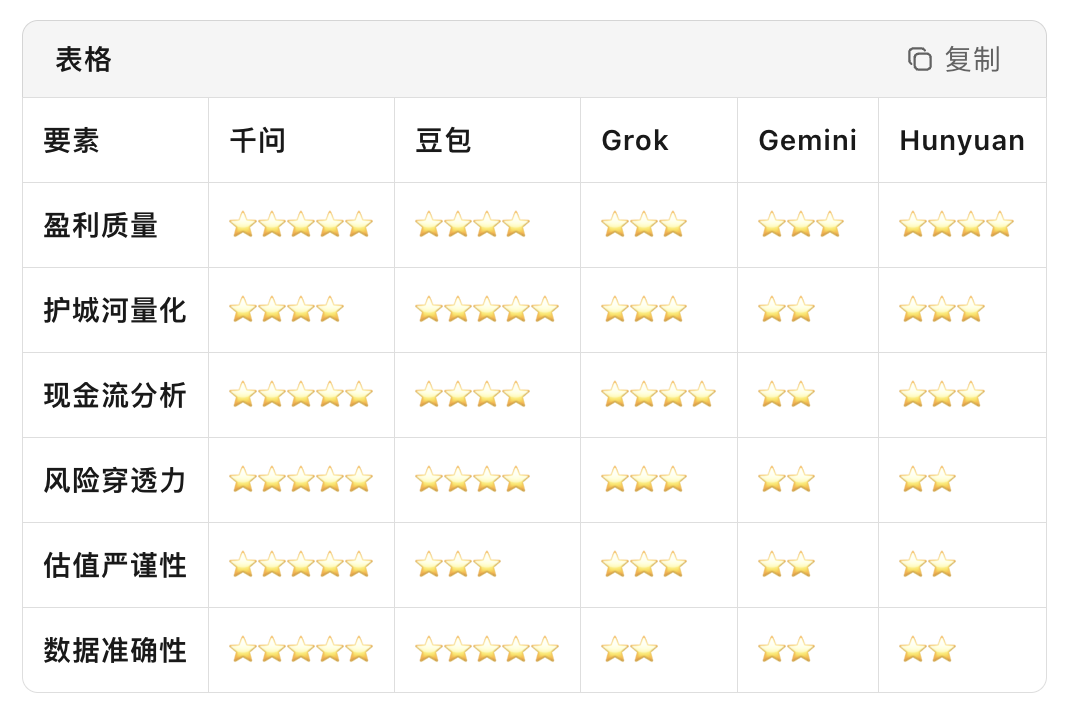
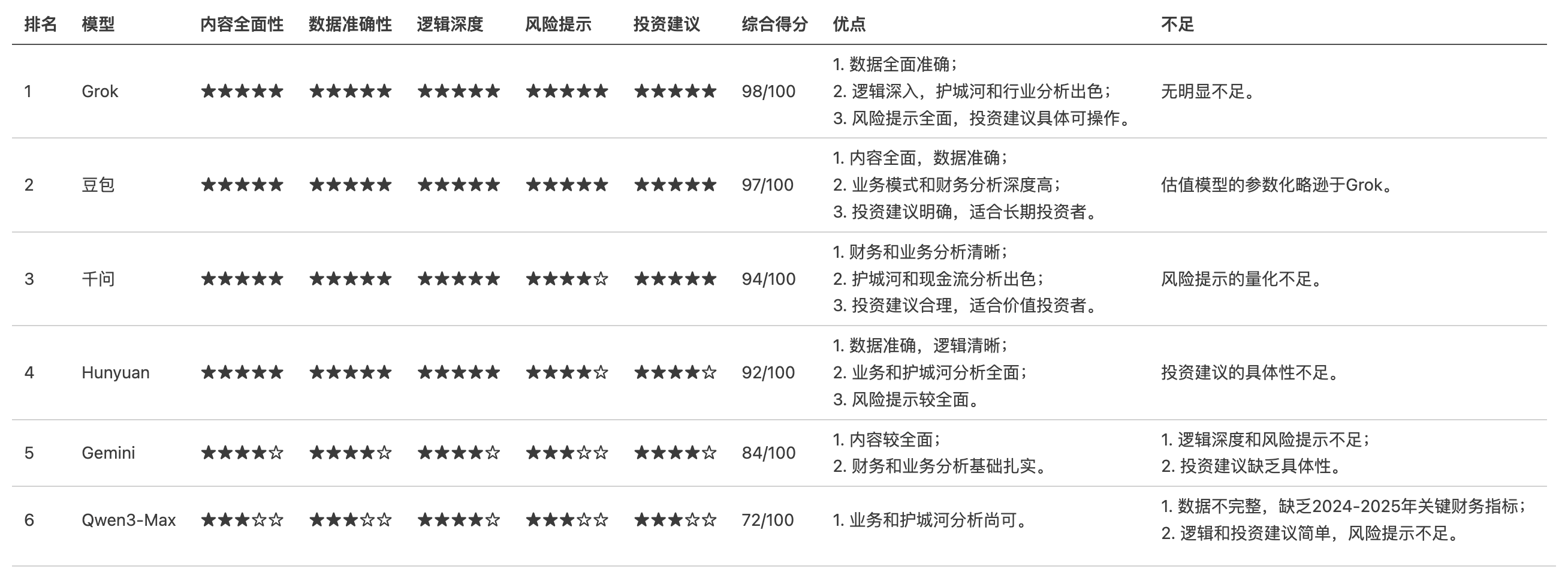
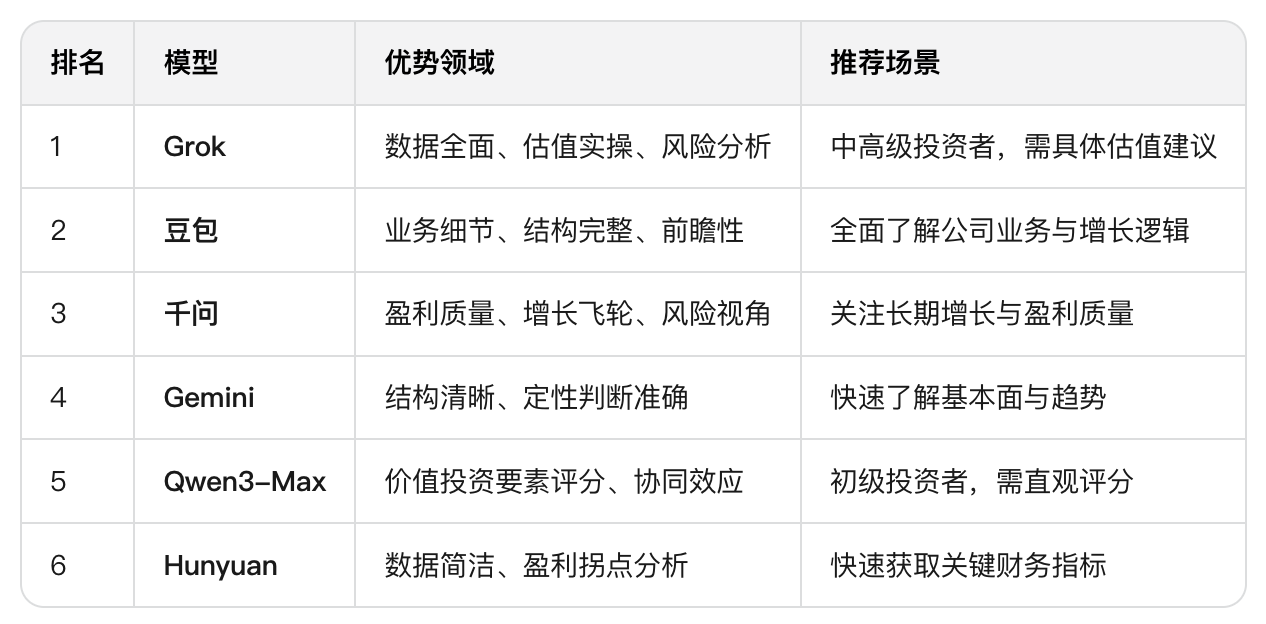
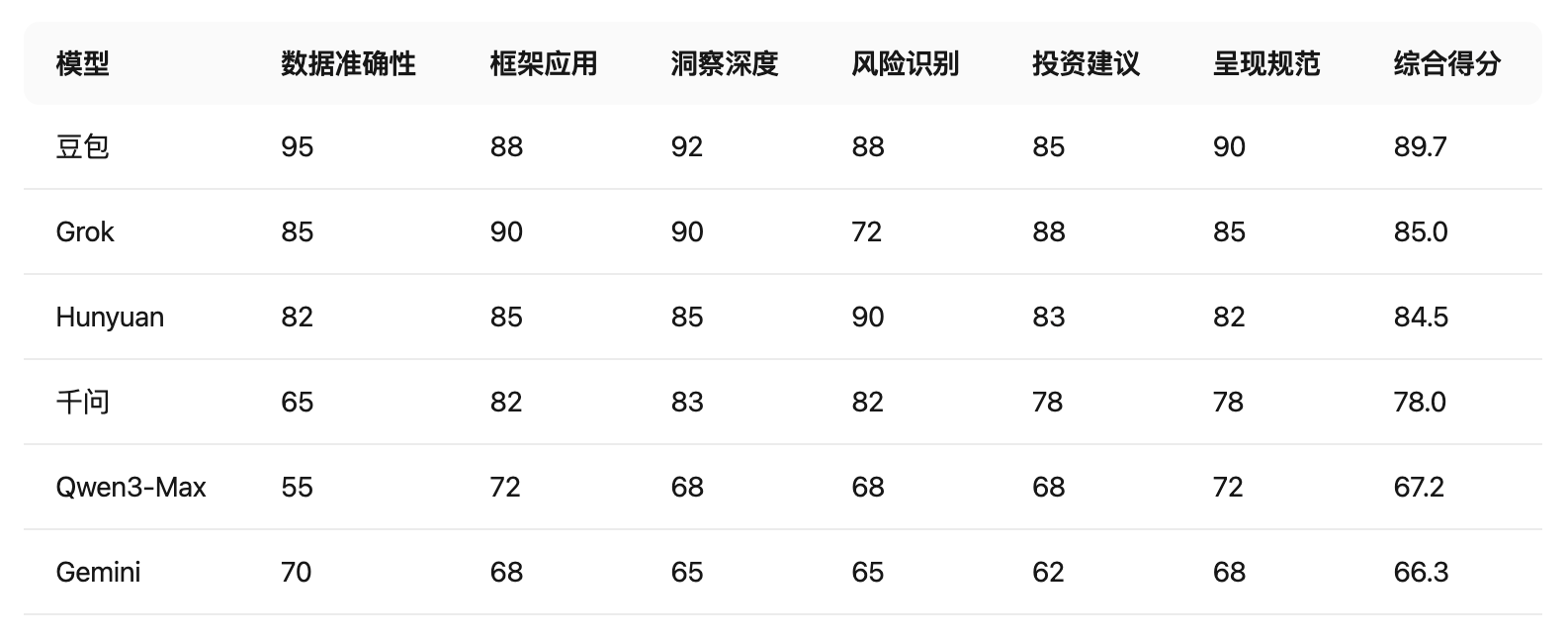
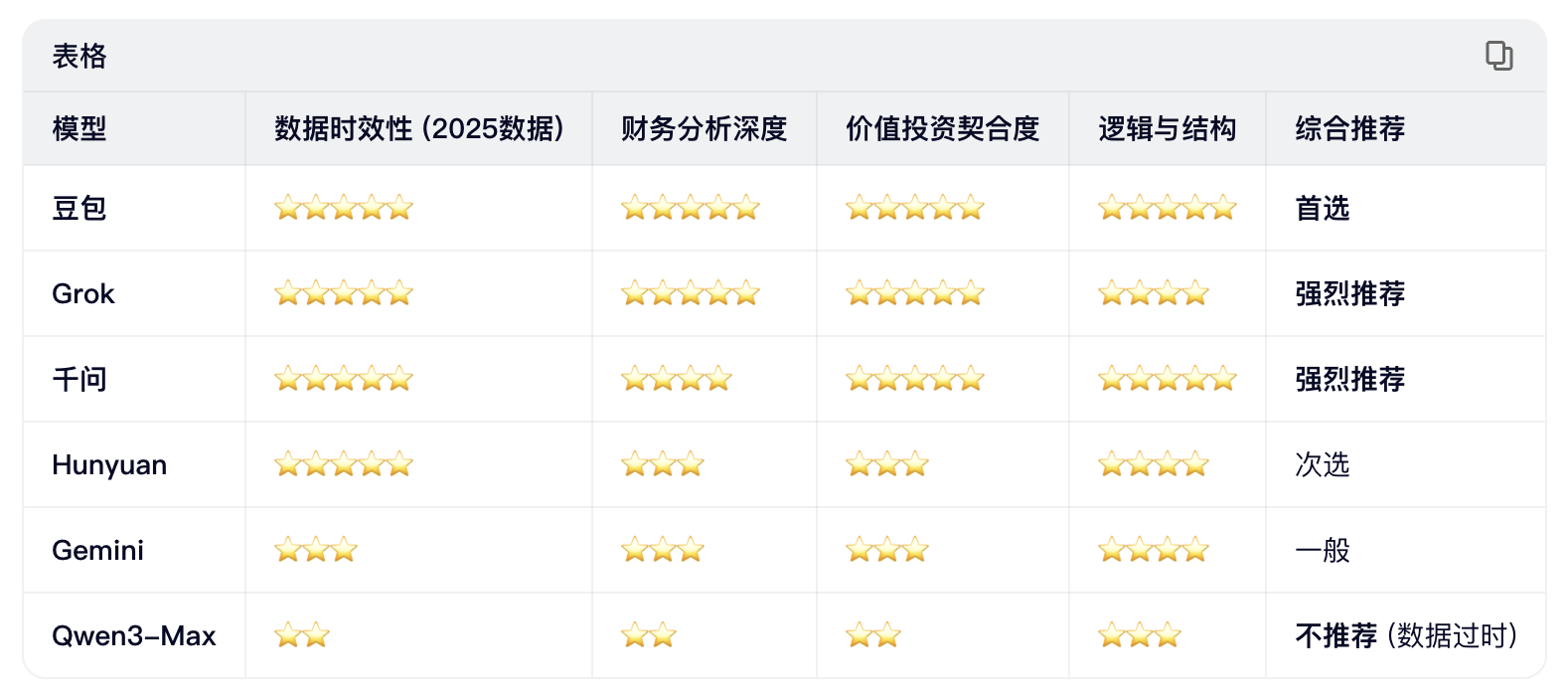
下面是我使用提示词:“基于京东健康上市后历年的财报,从价值投资的角度进行分析。”对多个大语言模型进行的分析结果。你作为一个评判专家,请对比各模型的分析内容,给出你的综合评价。
评判结果

Doubao
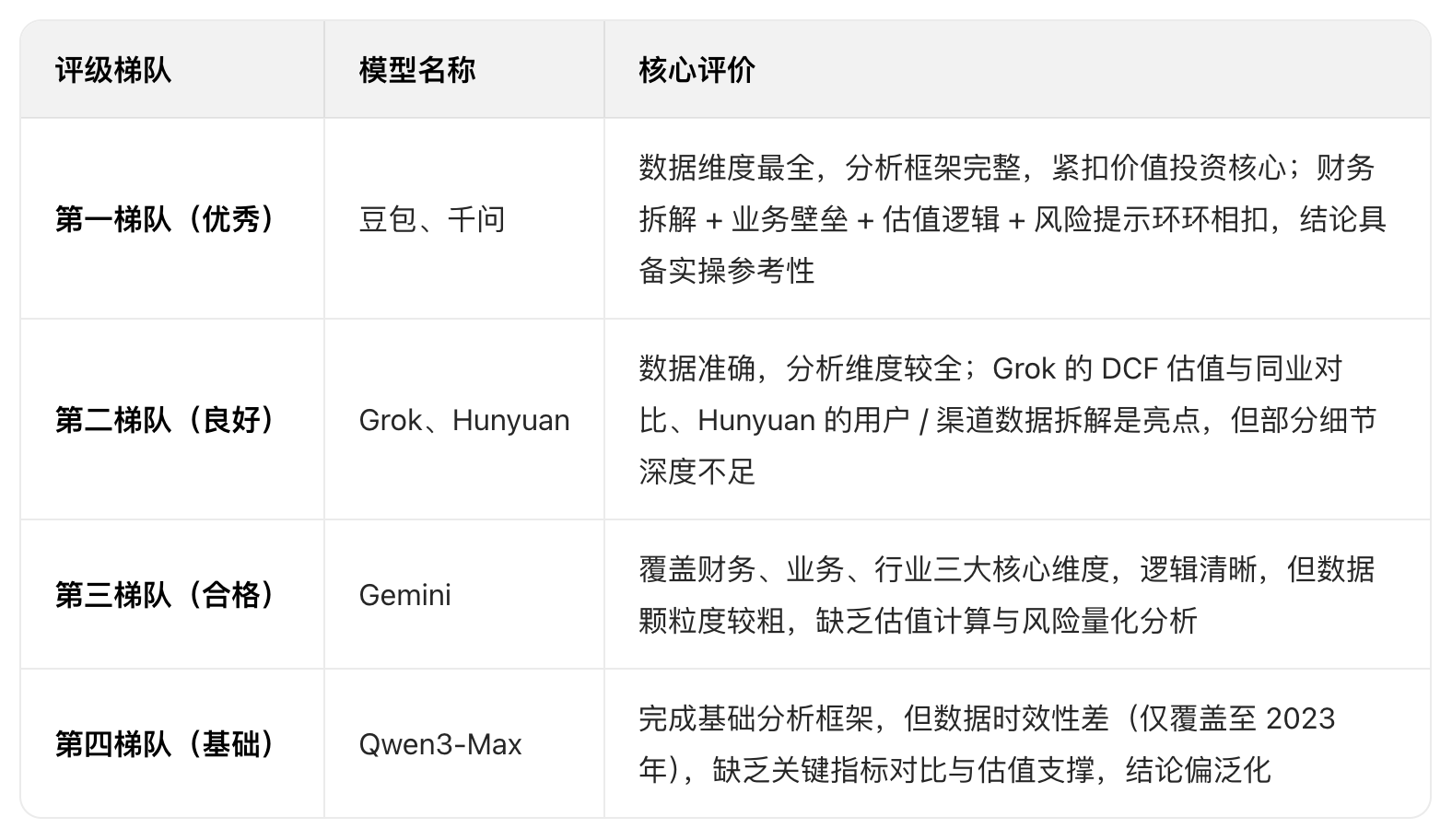
Grok 4.1

Gemini3
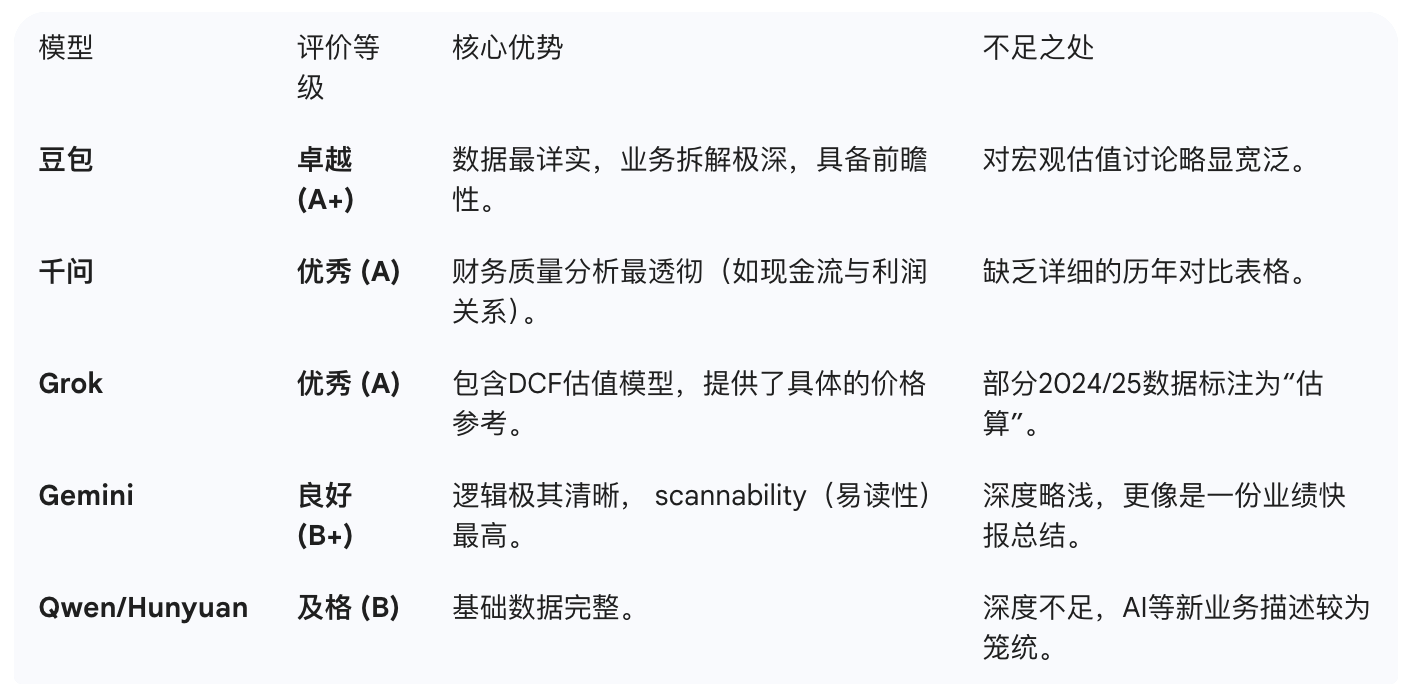
ChatGPT
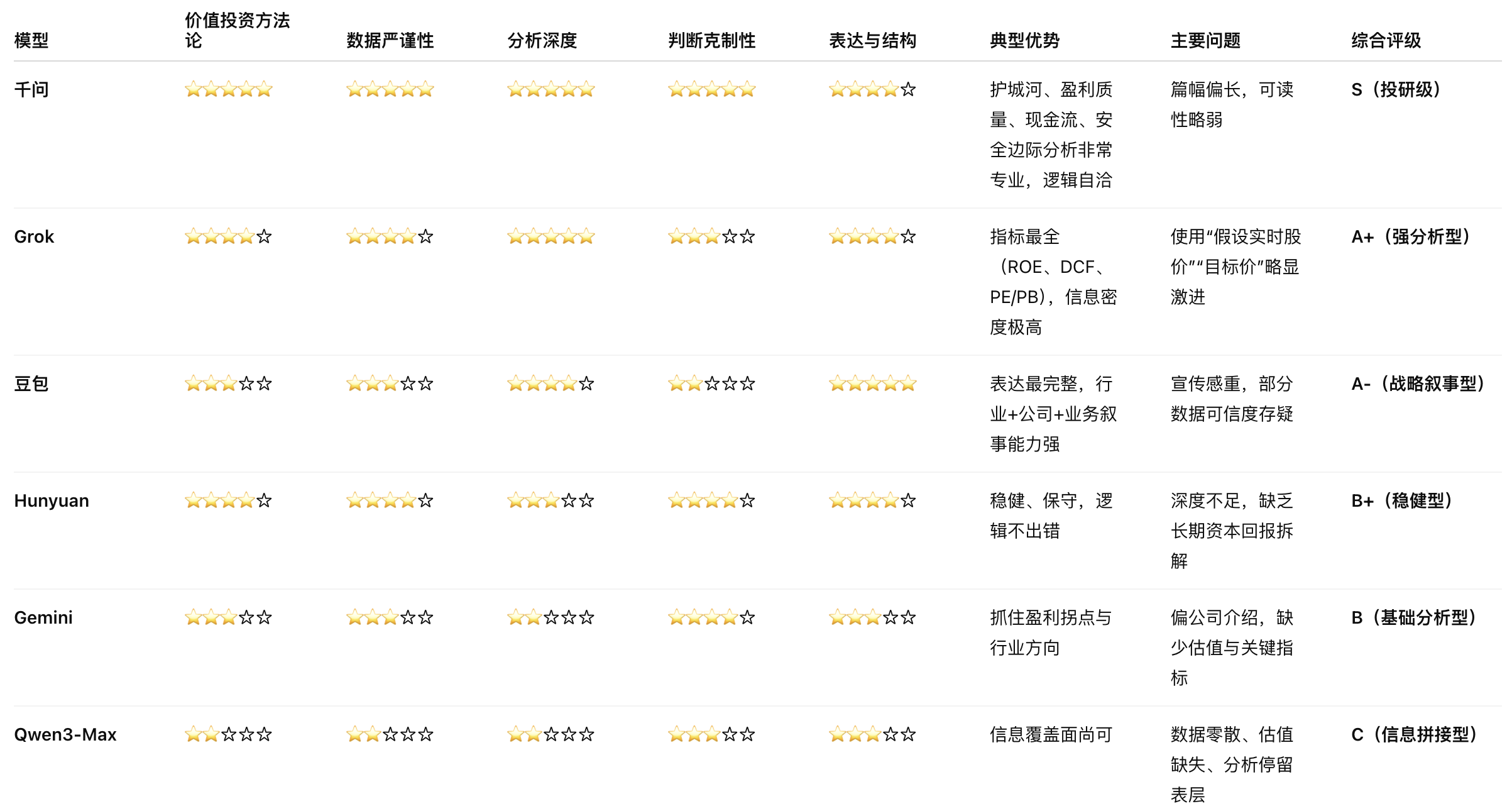
DeepSeek-Think
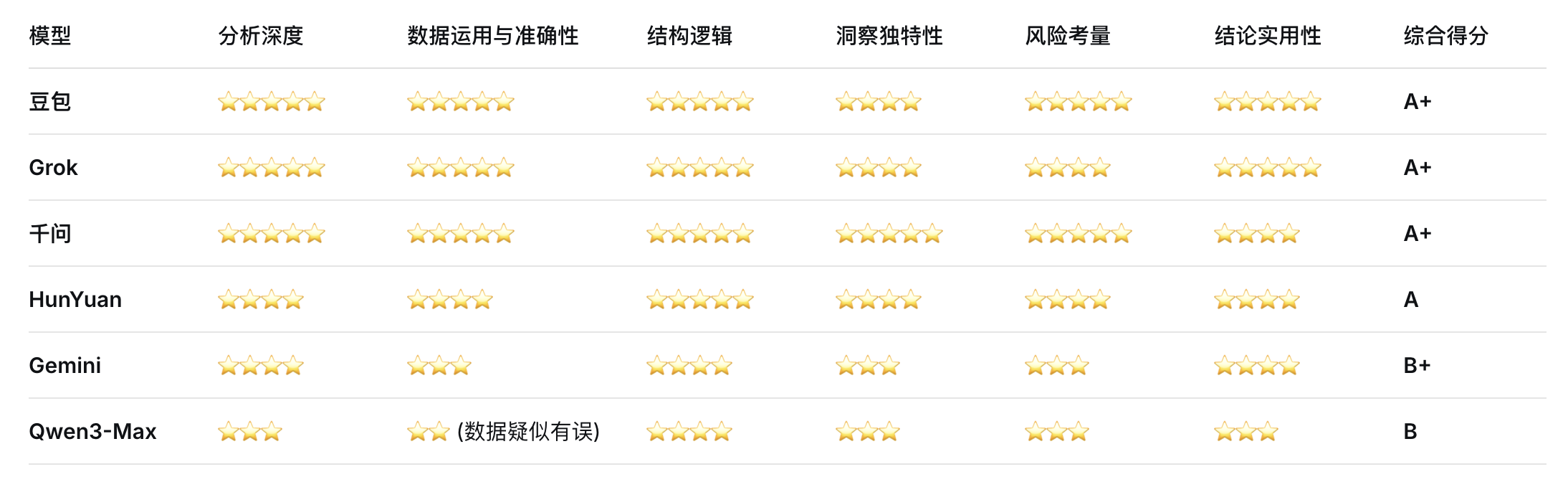
混元
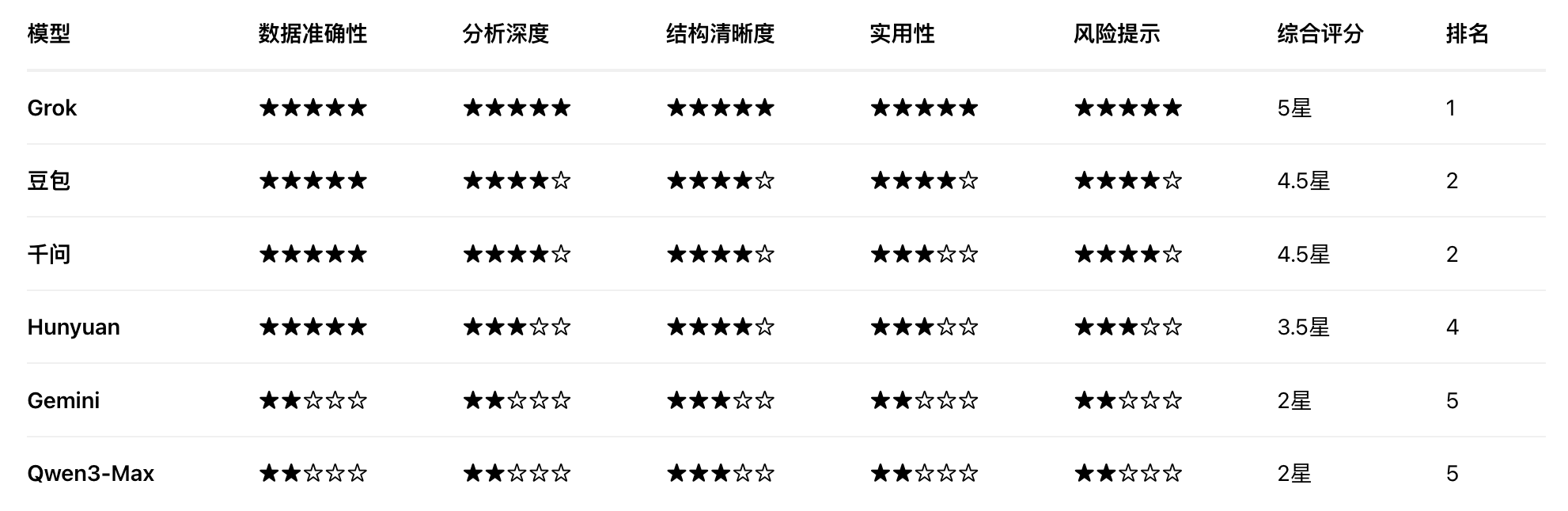
Kimi-K2-Think
LeChat
LongCat
MiniMax M2.1
Qwen3-千问
综合AI助手,全面回答工作、学习、生活各类问题
Qwen3-Max
千问系列中最强大的语言模型

各模型投资分析结果
Gemini
《Context Engineering & Coding Agents with Cursor》(Cursor 的上下文工程与编程智能体),由 Cursor 团队成员 Lee 和 CEO Michael 主讲。视频深入探讨了软件开发的演变、Cursor 如何利用 AI 提升编程效率,以及未来编程智能体的发展方向。
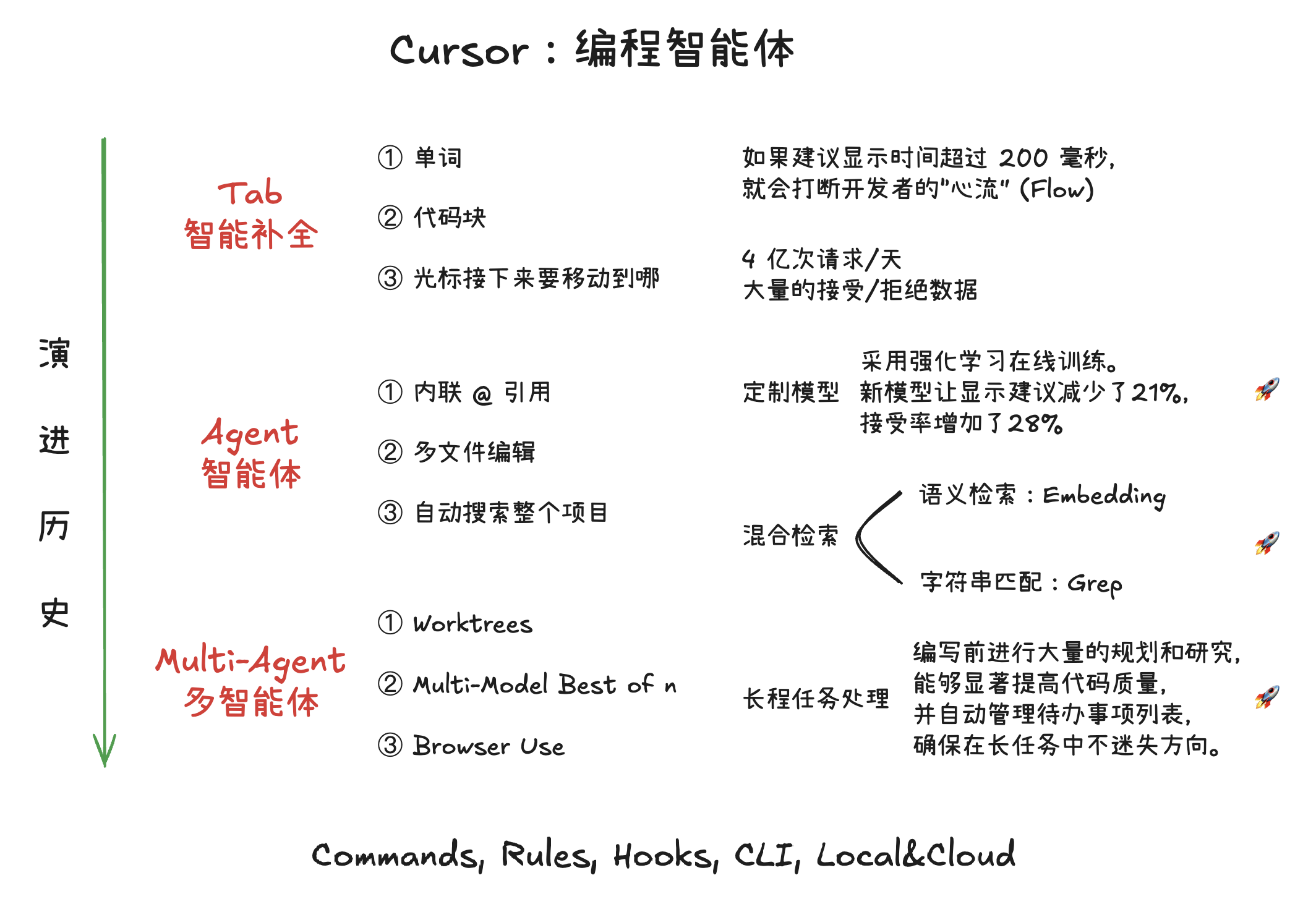
1. 编程的演变与 Cursor 的核心功能
2. 上下文工程 (Context Engineering)
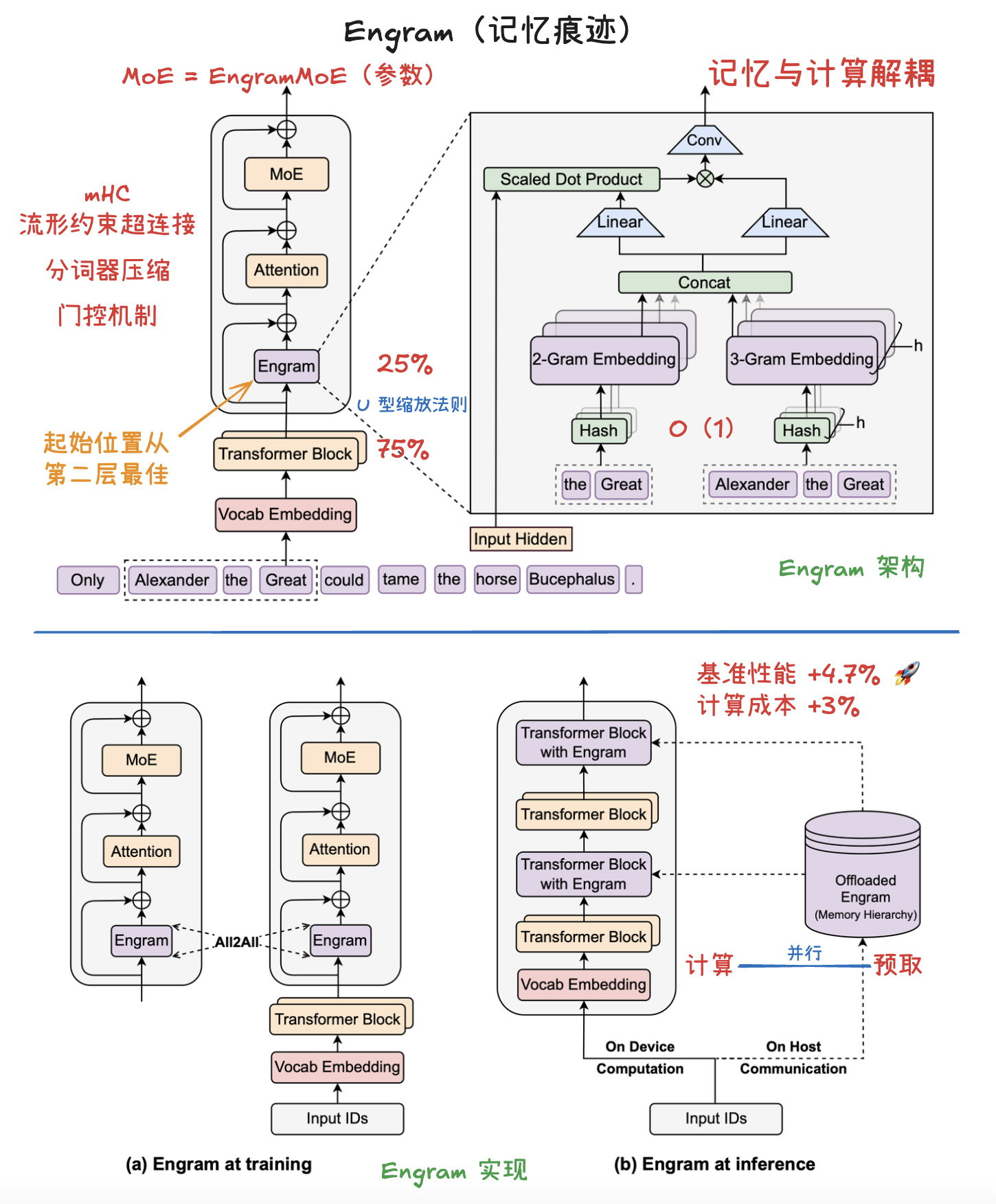
Engram 是一种旨在增强大语言模型性能的条件记忆(Conditional Memory)模块。传统的 Transformer 架构在处理静态知识检索时效率较低,往往需要通过复杂的计算来模拟记忆,而 Engram 通过现代化的 N-gram 哈希查找实现了常数级时间复杂度 O(1) 的知识获取。研究者揭示了一种 U 型缩放法则,证明在固定参数预算下,平衡条件计算(MoE)与静态内存(Engram) 能显著提升模型在推理、代码及数学任务中的表现。实验分析表明,Engram 能减轻模型底层对基础模式的重复构建,从而释放更多算力用于处理全球上下文和深度推理。此外,Engram 的确定性寻址特性支持从主机内存预取数据,使其能在不增加硬件负担的情况下实现大规模参数扩张。最终,该技术为构建更高效、具备长文本处理能力的新一代稀疏模型提供了核心原语。
Engram 架构
记忆内存的参数就像是图书馆书架上的一本本百科全书,记录着世界上的事实;而 Engram 模块的参数就像是一位经验丰富的图书管理员。管理员通过训练(学习),能够根据你当前提出的研究课题(隐藏状态),迅速判断哪些百科全书的条目是有用的,哪些是由于名字相似而找错的(哈希冲突),并帮你把这些知识翻译成你研究报告能用的语言(投影整合)。
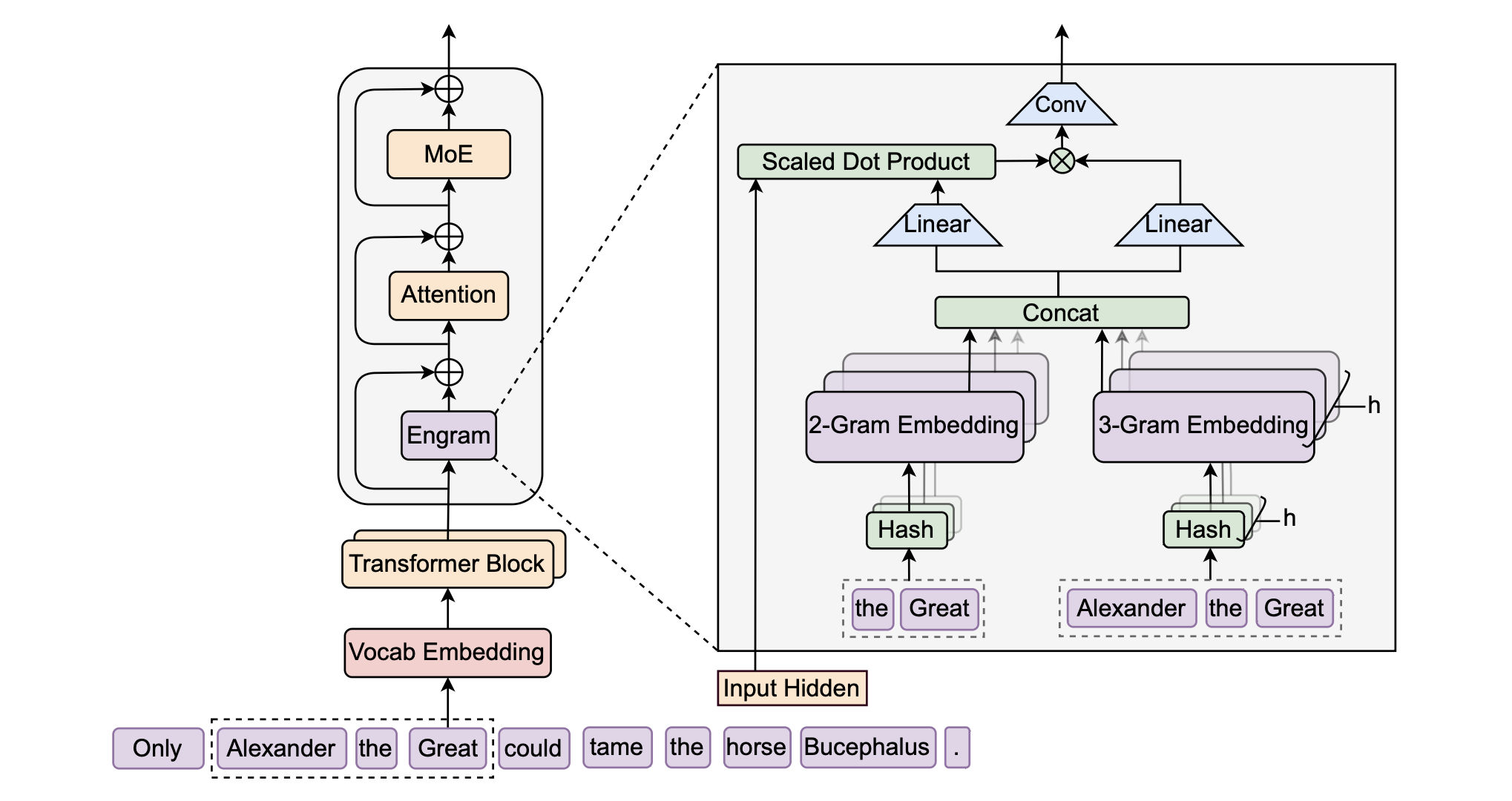
该模块通过检索静态 N-gram 记忆,并利用上下文感知门控(context-aware gating)将其
AI 编程的演进逻辑非常清晰:GitHub Copilot 作为插件,在传统 IDE 里为大众提供辅助;Cursor 则打破束缚,通过 AI 原生 IDE 实现了深度的体验跃迁;而 Claude Code 这类 CLI 工具,则是为追求极致自由与自动化的极客准备的——它摆脱了图形界面的繁琐,让开发者在命令行中,就能以‘操作指令’驱动 AI 完成从编码到部署的全流程。
AI 编程三剑客:时间线与营收对比
| 维度 | GitHub Copilot | Cursor | Claude Code |
|---|---|---|---|
| 代表形态 | IDE 插件 (Plugin) | AI 原生 IDE (Forked) | CLI 智能体 (Agent) |
| 正式发布/爆发时间 | 2021年6月 (预览) / 2022年6月 (正式) | 2023年 (起步) / 2024年底 (爆发) | 2025年2月 (GA) |
| 年营收 (ARR) | (2025年Q3数据) | 10 亿+ (2025年底估算) | $10 亿+ (上线6个月即达成) |
| 用户规模 | 2000万+ 开发者 | 100万+ 付费用户 | 爆发式增长中 (API驱动) |
| 核心地位 | 行业标准与基建 | 效率工具的巅峰 | 自主编程的开端 |
1. GitHub Copilot:稳坐江山的“老牌霸主”
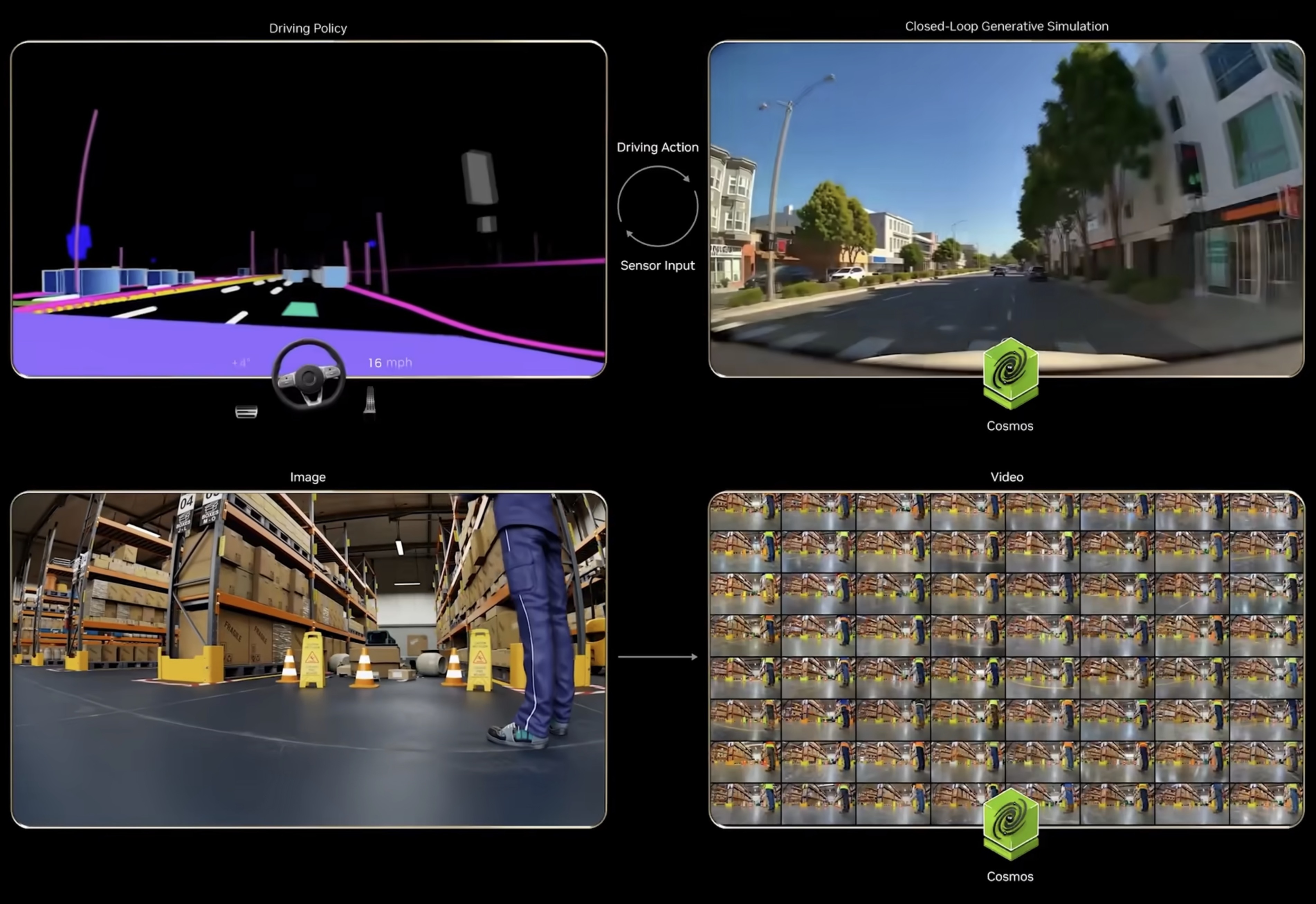
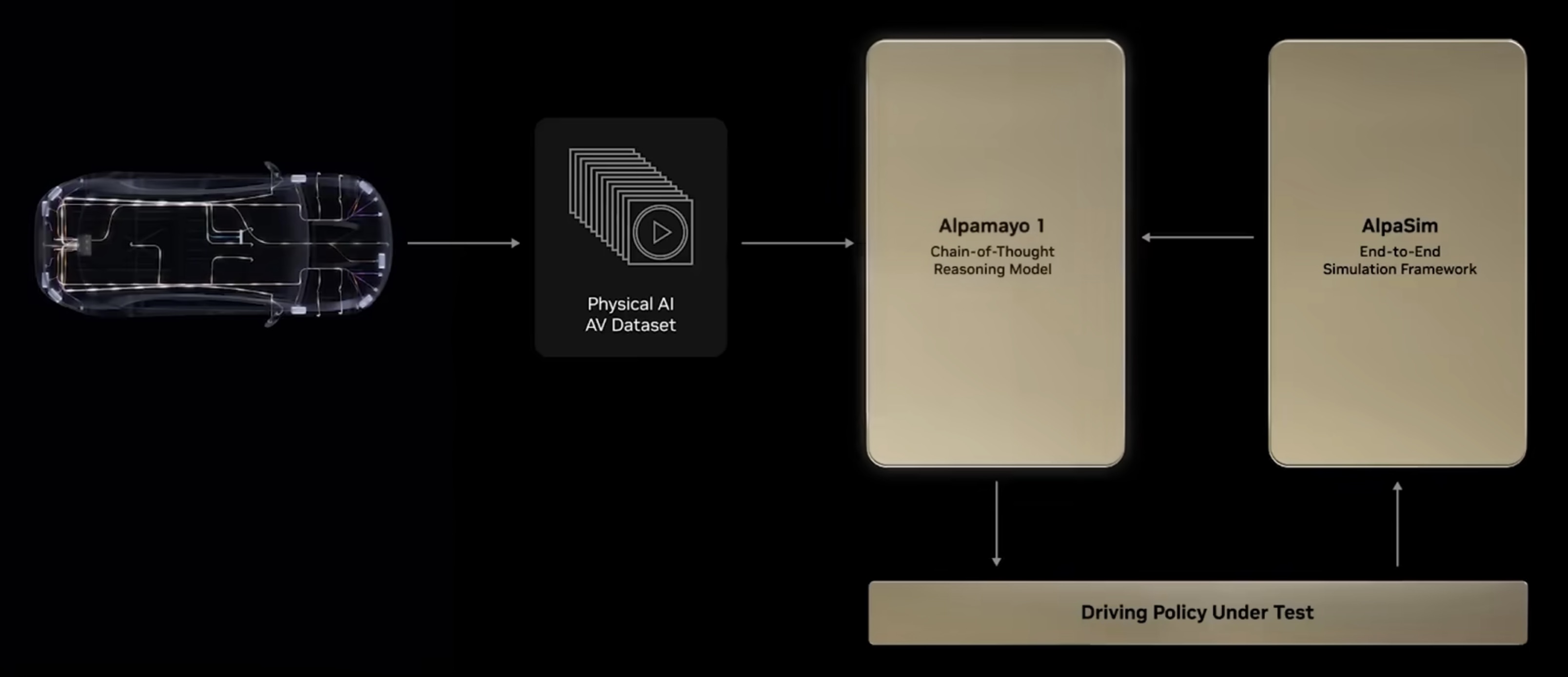
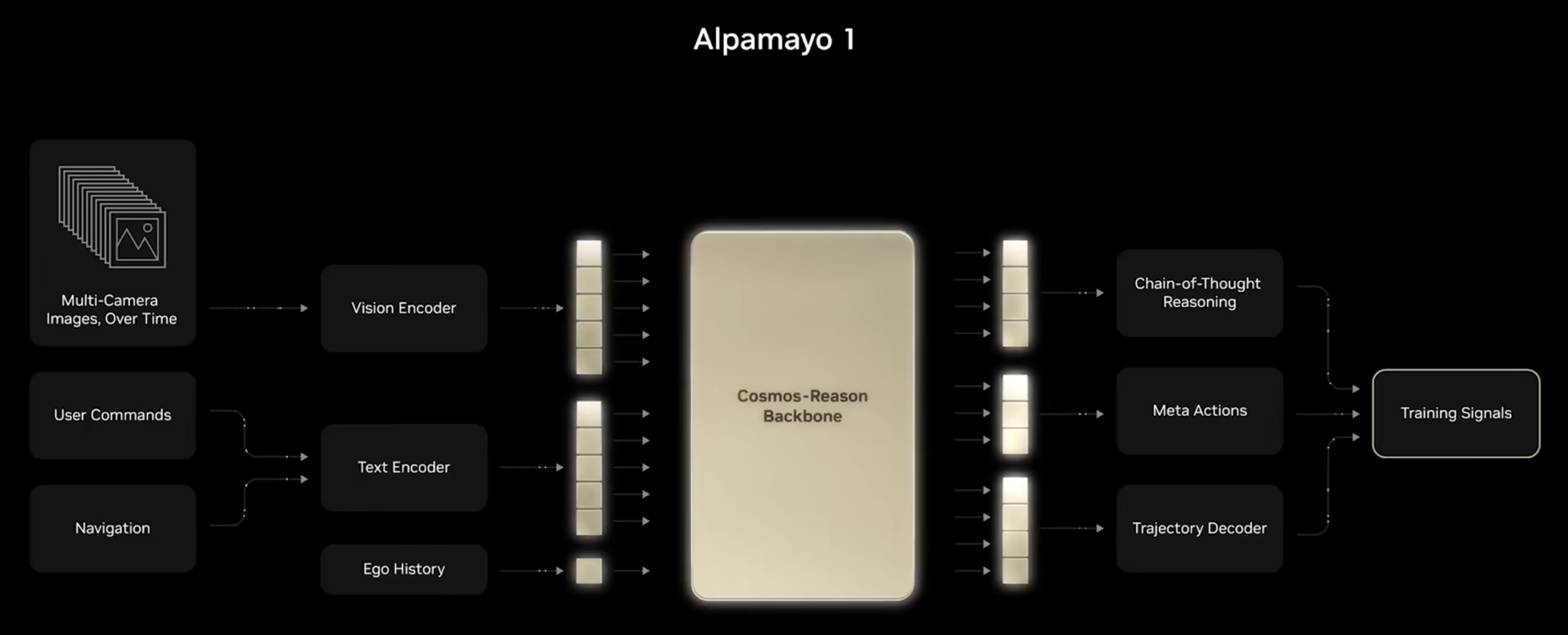
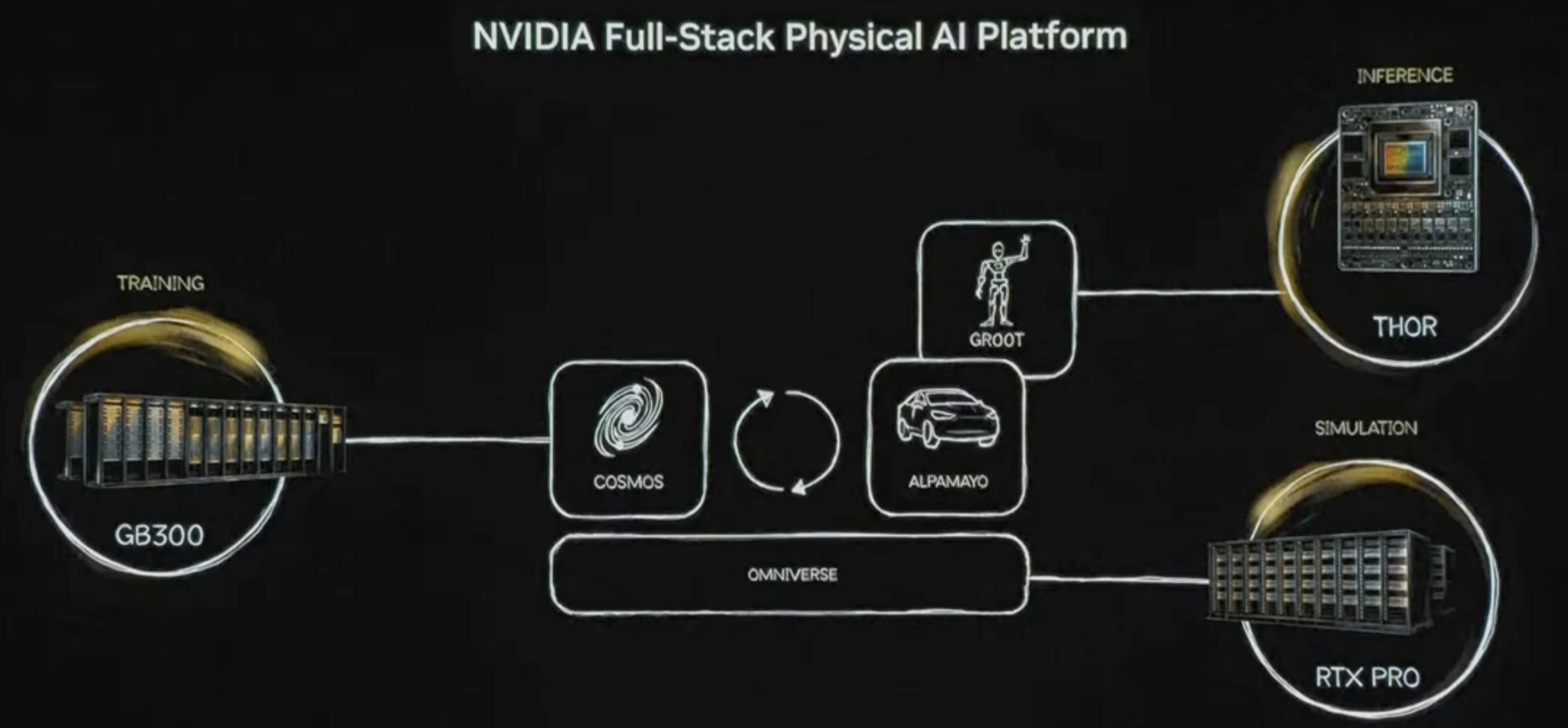
NVIDIA 正致力于打造全栈物理AI(Physical AI)平台,推动人工智能从数字领域向理解并交互物理世界跨越。该平台的核心由 Cosmos 世界模型、Omniverse 模拟环境以及针对机器人(GROOT)和自动驾驶(Alpamayo)的专属模型组成。
在硬件层面,NVIDIA 推出了突破性的 Vera Rubin 架构。其中,Rubin GPU 拥有 3360 亿个晶体管,其推理性能达到 Blackwell 的 5 倍;Vera CPU 则配备 88 个定制内核,显著提升了系统内存带宽。配合 BlueField-4 DPU 和 NVLink 6 技术,NVIDIA 构建了能够支持海量算力需求的 AI 基础设施。
基于边端电力设备的报文需要使用人工智能
这是一个非常前沿且具有实际意义的问题。简单直接的回答是:是的,在边端电力设备中引入人工智能(AI)处理报文,正在从“锦上添花”转变为“行业刚需”。
传统的电力报文处理主要依赖预设规则和阈值报警,但在复杂的现代电网环境下,这种方式已显露疲态。
以下是为什么边端电力设备报文需要 AI 的核心原因及应用场景:
1. 毫秒级的实时响应需求
电力系统的故障处理通常要求在 到 内做出反应。
2. 网络安全与入侵检测
电力报文(如 IEC 61850、DNP3)往往缺乏复杂的加密,容易受到恶意篡改或重放攻击。
3. 故障预测与健康管理 (PHM)
报文不仅是指令,还包含丰富的设备状态数据。
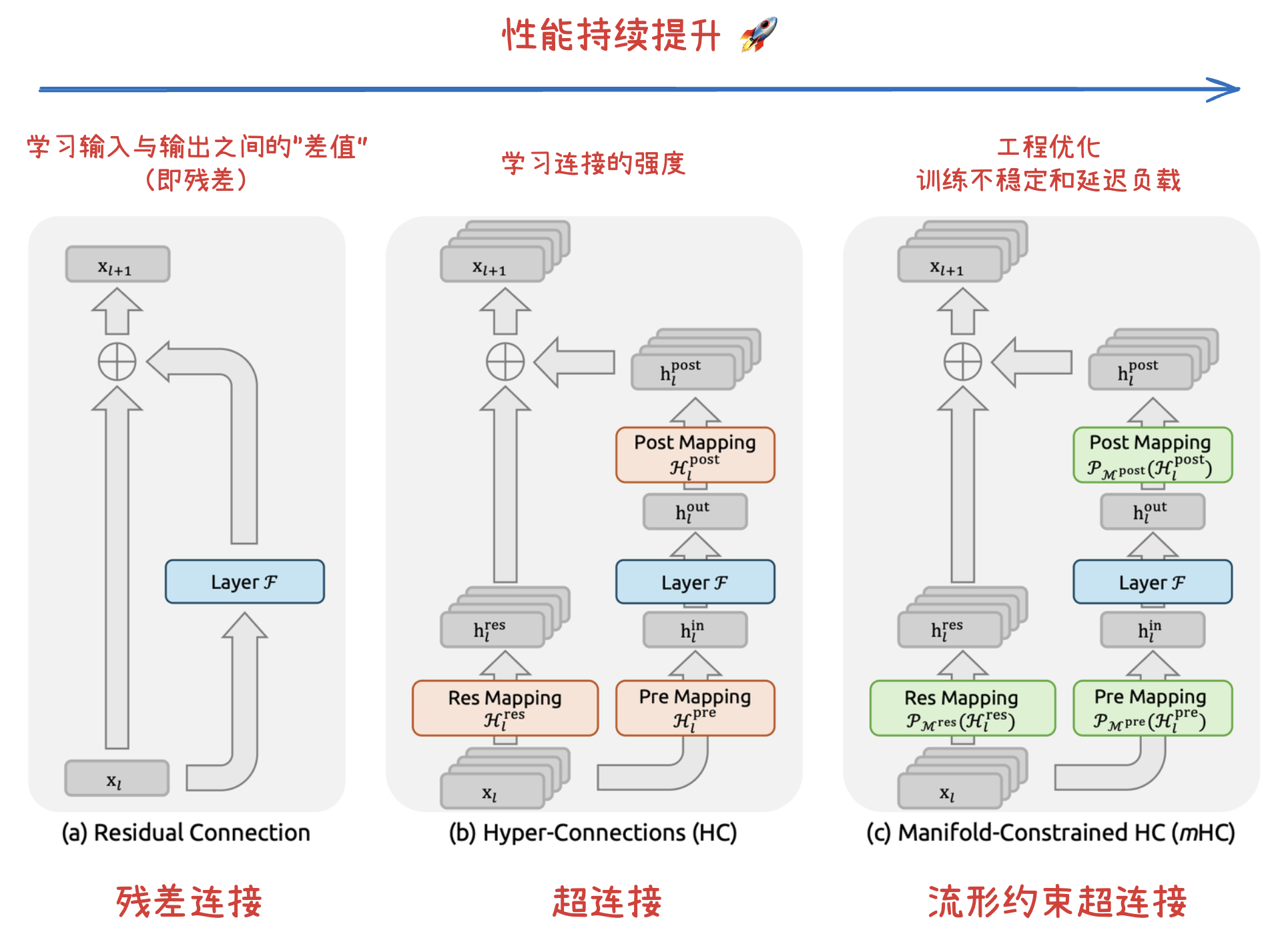
深度神经网络架构的演进,本质上是在寻找梯度稳定性与特征表达力的最优解:残差连接 通过恒等映射初步破解了深层网络的退化难题,但在缓解梯度消失与防止表征坍缩之间仍存在“跷跷板效应”;超连接(HC) 在此基础上打破了固定连接的束缚,通过引入可学习的深度连接与宽度连接,允许网络“自主学习最优连接强度”,显著提升了大模型训练的性能;流形约束超连接(mHC) 则通过将 HC 的连接矩阵投影至双随机流形,利用数学上的凸组合约束恢复了恒等映射的数值稳定性,并辅以算子融合、选择性重算和 DualPipe 通信重叠等工程优化,最终在大模型训练中实现了训练稳定性和显著降低延迟负载。
深度神经网络
梯度消失与梯度爆炸
在深度学习中,梯度消失(Vanishing Gradient) 和 梯度爆炸(Exploding Gradient) 是训练深层神经网络时经常遇到的两个核心障碍。
它们本质上是由于神经网络在反向传播过程中,梯度通过多层链式法则累积相乘导致的数值稳定性问题。
数学根源:链式法则的连乘效应
在反向传播时,我们需要计算损失函数对某一层权重的偏导数。根据链式法则,对于每一层,其梯度贡献项通常与激活函数的导数以及权重的数值有关。
NaN),模型剧烈震荡甚至崩溃。提示词(DeepSeek)
2026年新年来了,生成一张红色的飞马图像。以这个为基础写个生成图像的提示词
一只雄伟的飞马(天马)在绚烂的夜空中展翅翱翔,周围环绕着金色与橙红色的新年烟火,鬃毛与翅膀边缘散发柔和光芒,背景为深红色星空与闪烁的星光,风格融合奇幻艺术与节日喜庆,色彩以红色、金色为主,充满动态与希望感,4K高清,细节精致,史诗光影。
生成结果
ChatGPT


豆包


Gemini


Grok

可灵 2.1

龙猫


MiniMax


千问


元宝


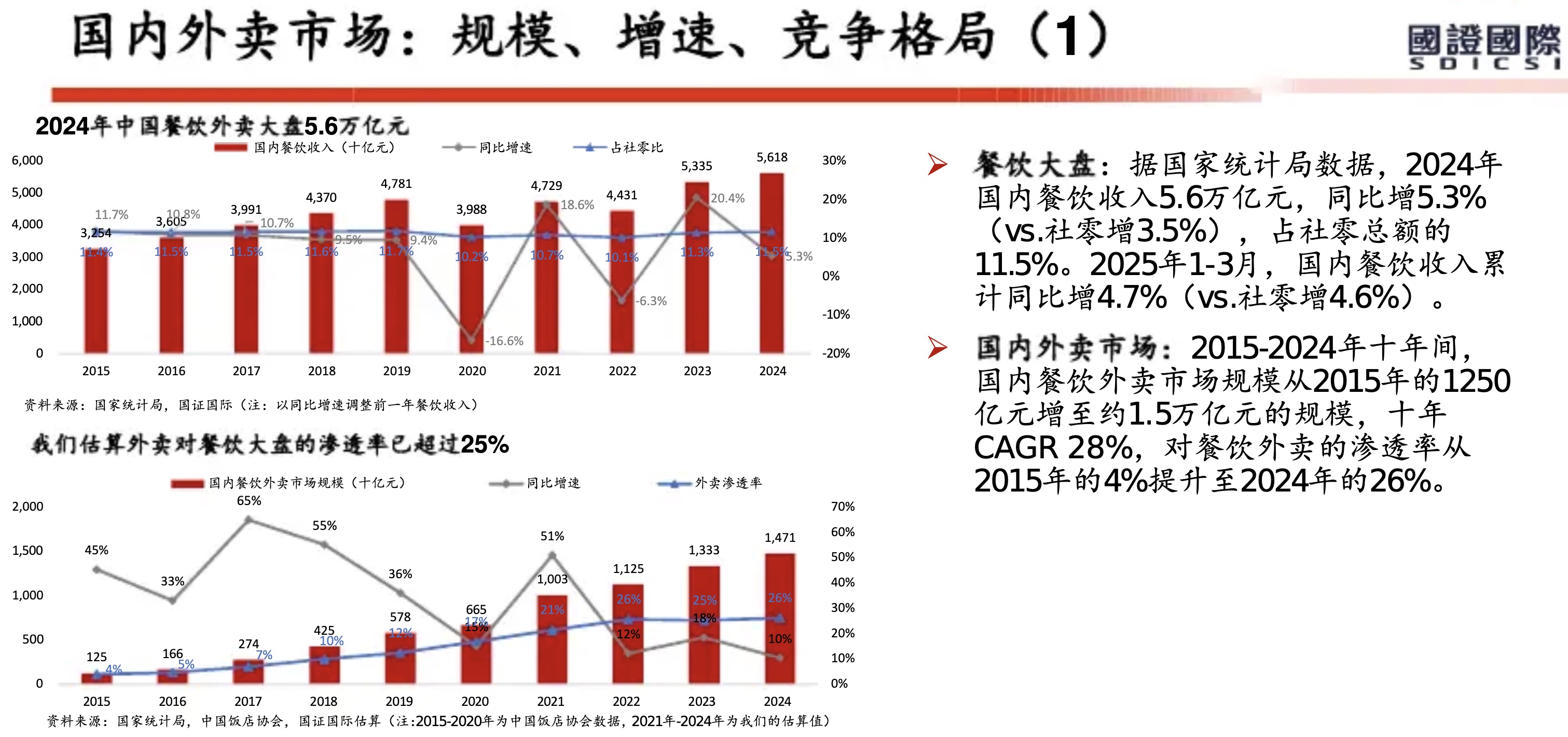
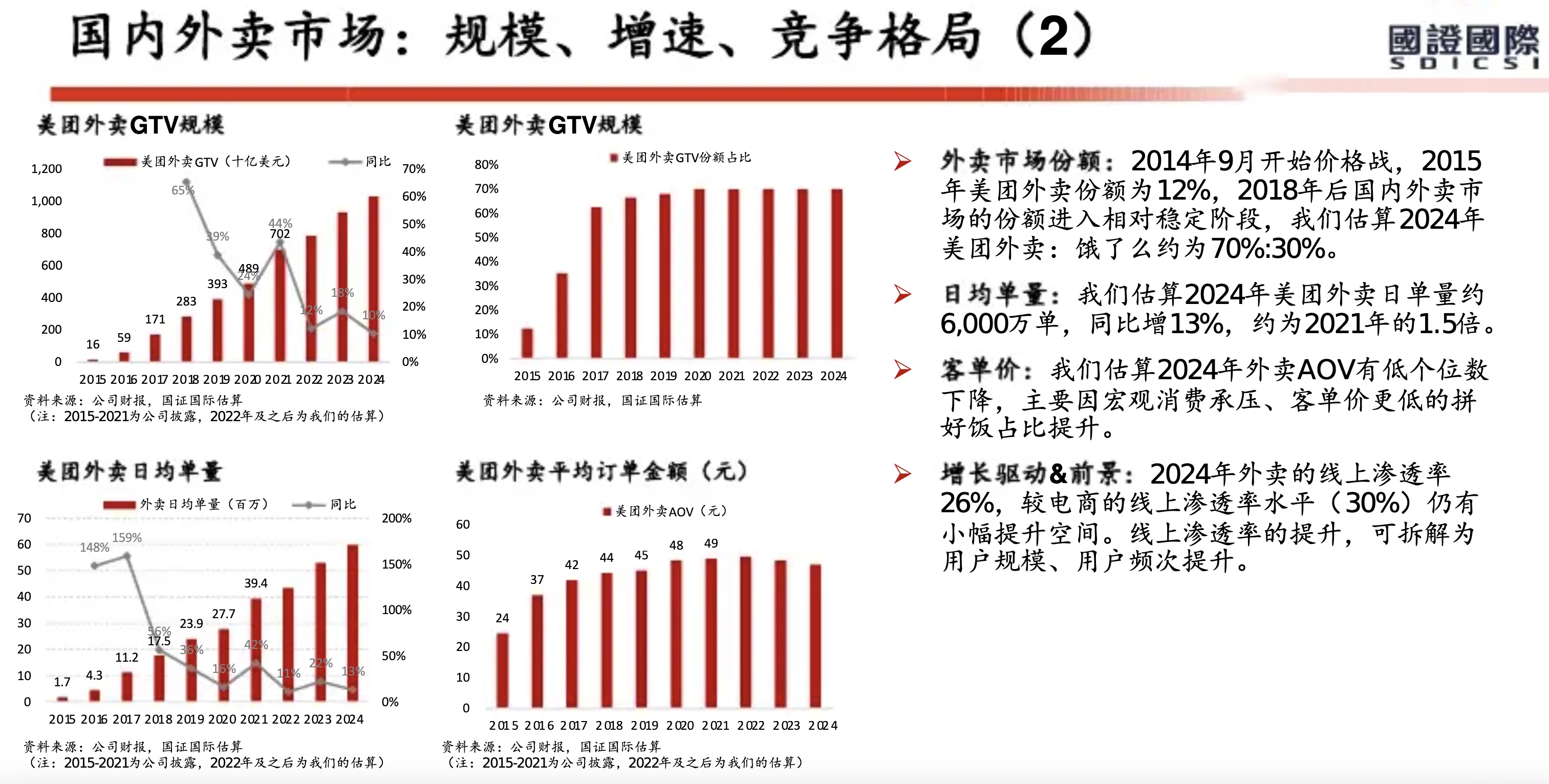
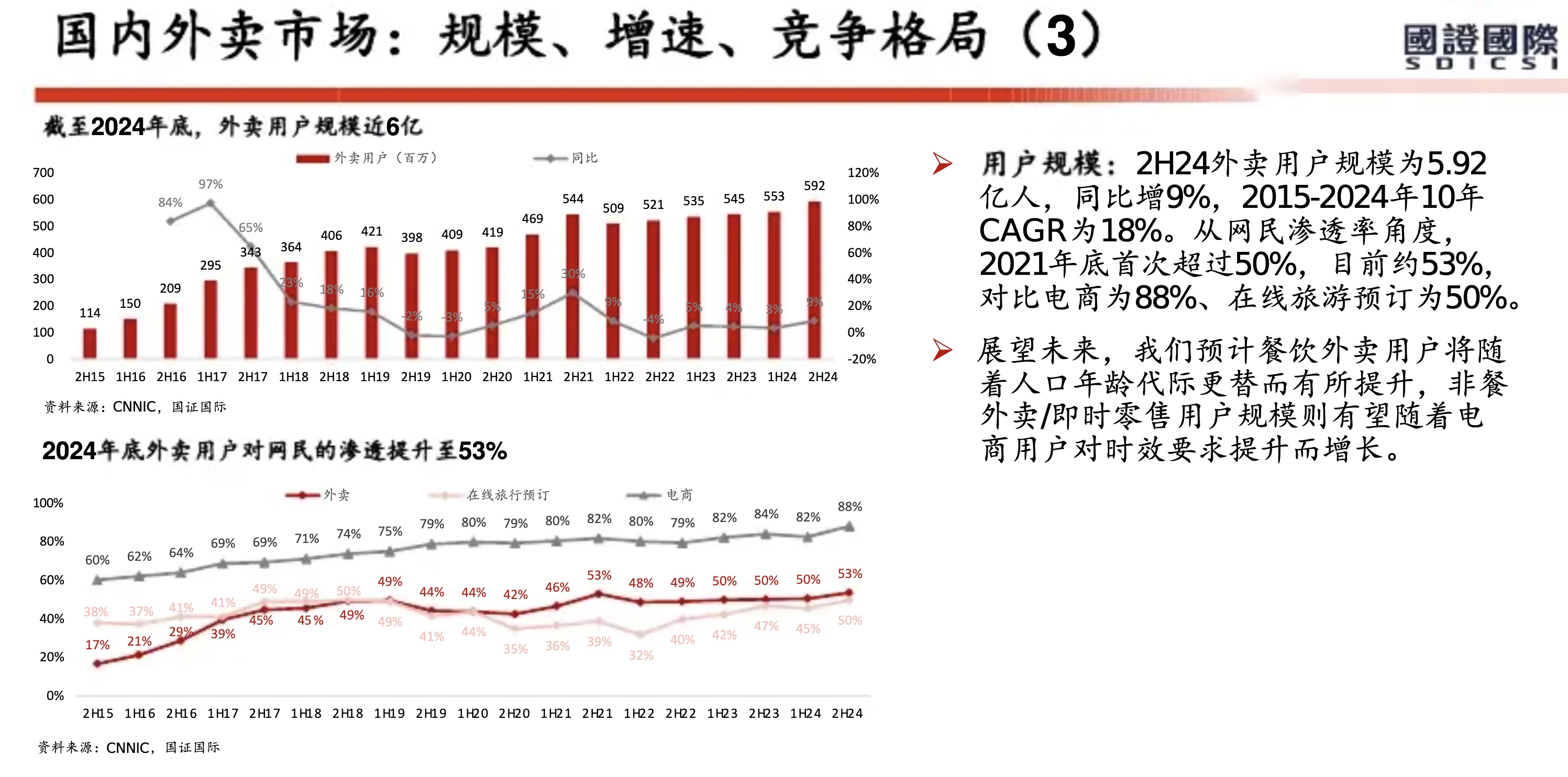
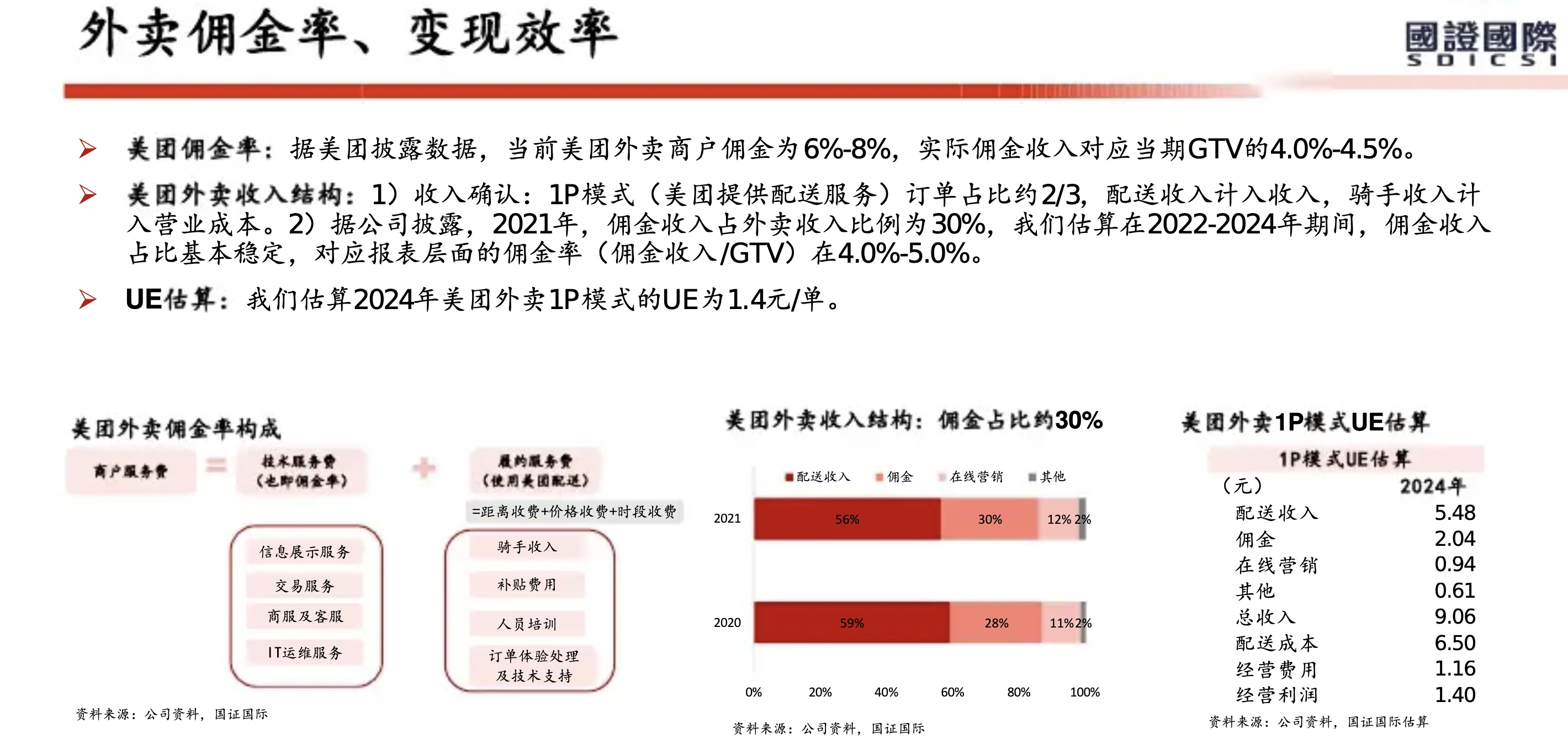
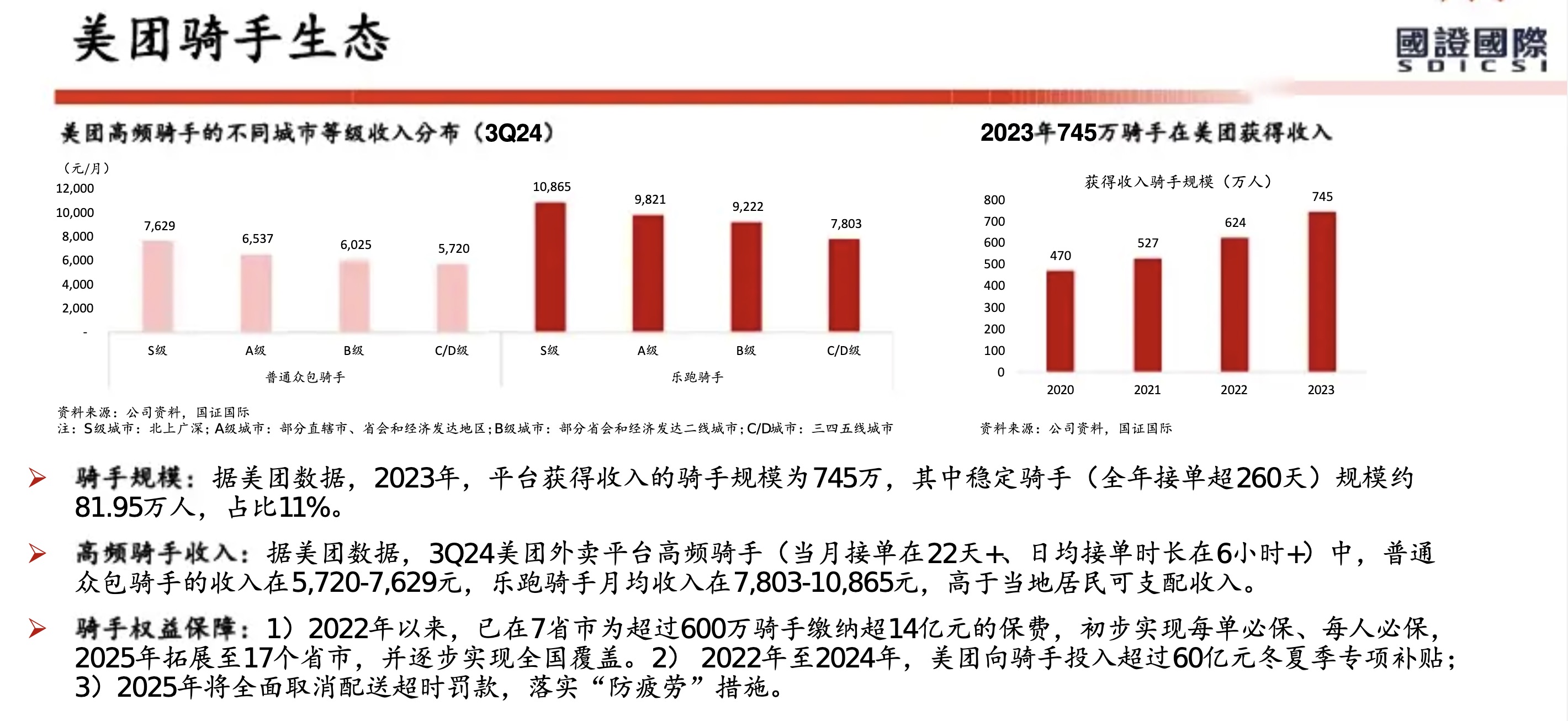
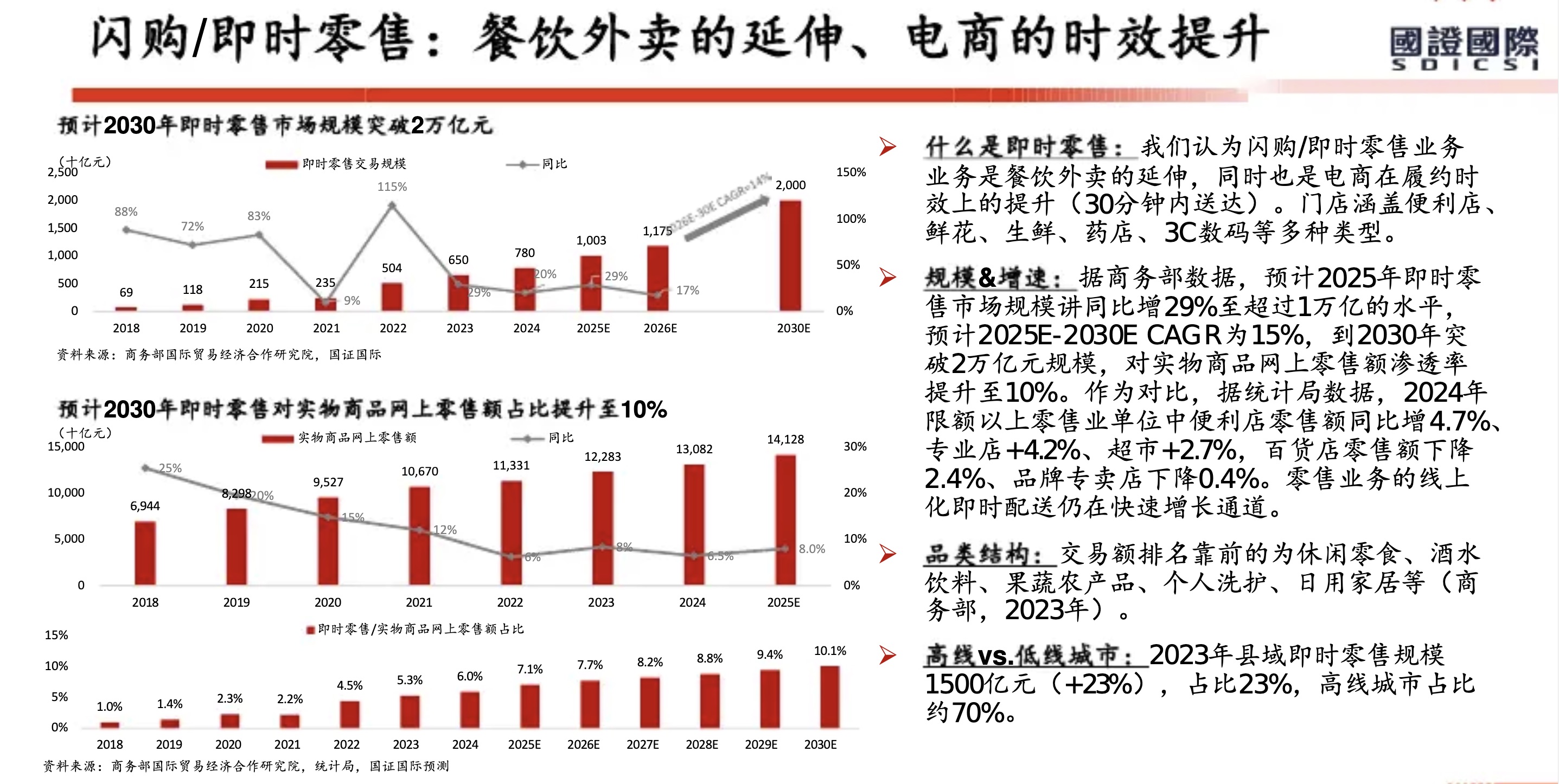
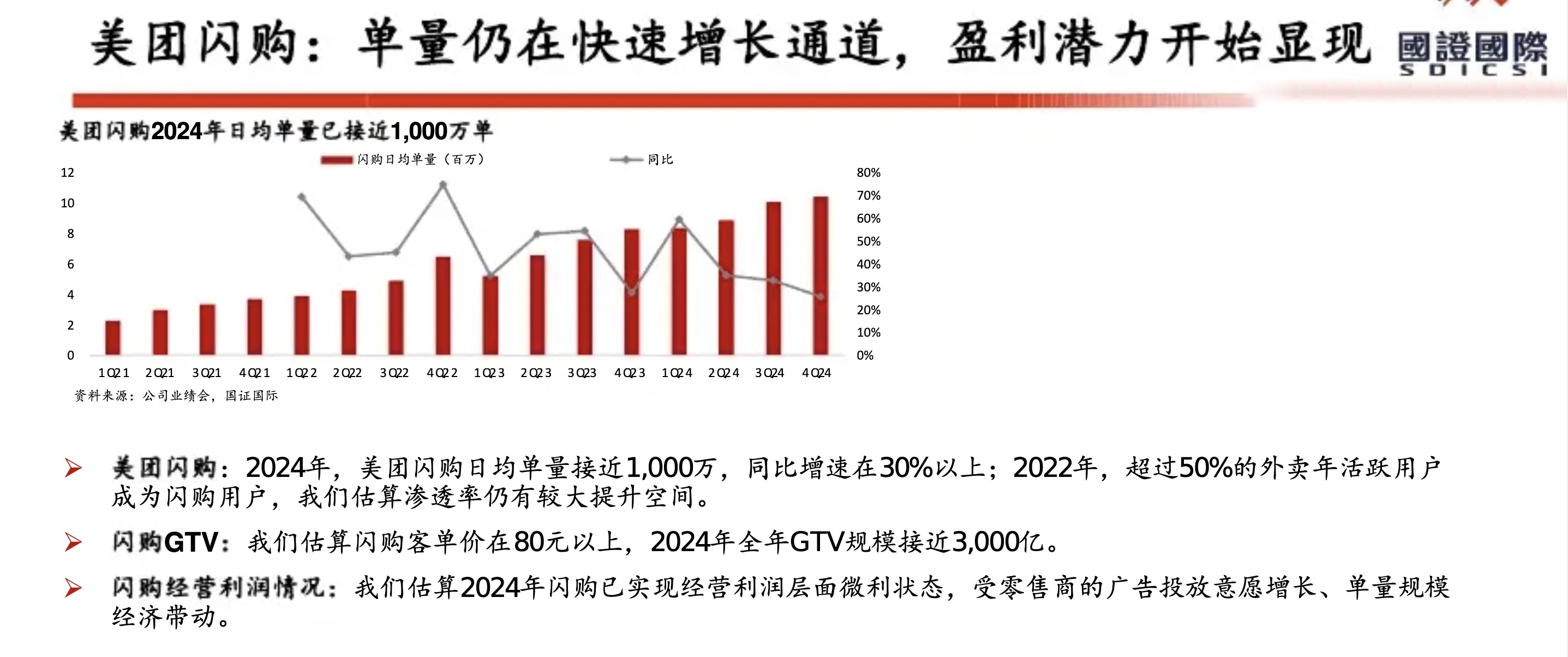
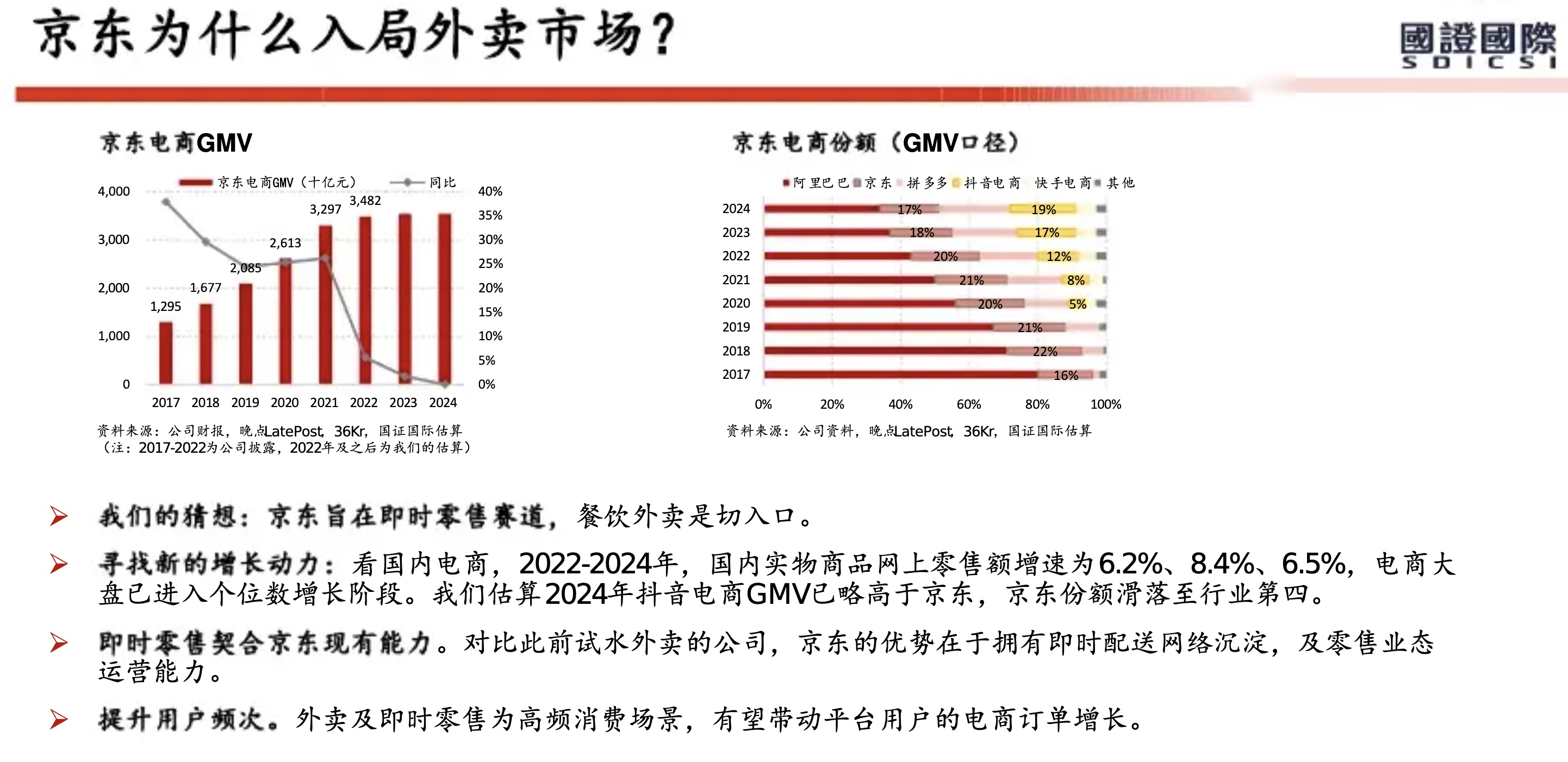
从美团历年财报(2018年至2025年上半年)来看,其核心能力已从早期的 “Food + Platform” 演进为 “零售+科技” 战略。在2025年上半年对“美团优选”进行战略转型并撤出亏损区域后,美团的护城河更加聚焦于高效率的即时履约网络和强大的零售生态体系。
以下是基于财报的美团核心能力与护城河分析:
1. 核心能力:全球领先的即时配送基础设施
2. 核心能力:高频带动低频的超级平台生态
京东健康核心数据成长 (2020年 - 2025年H1)

具身智能
Scaling Laws
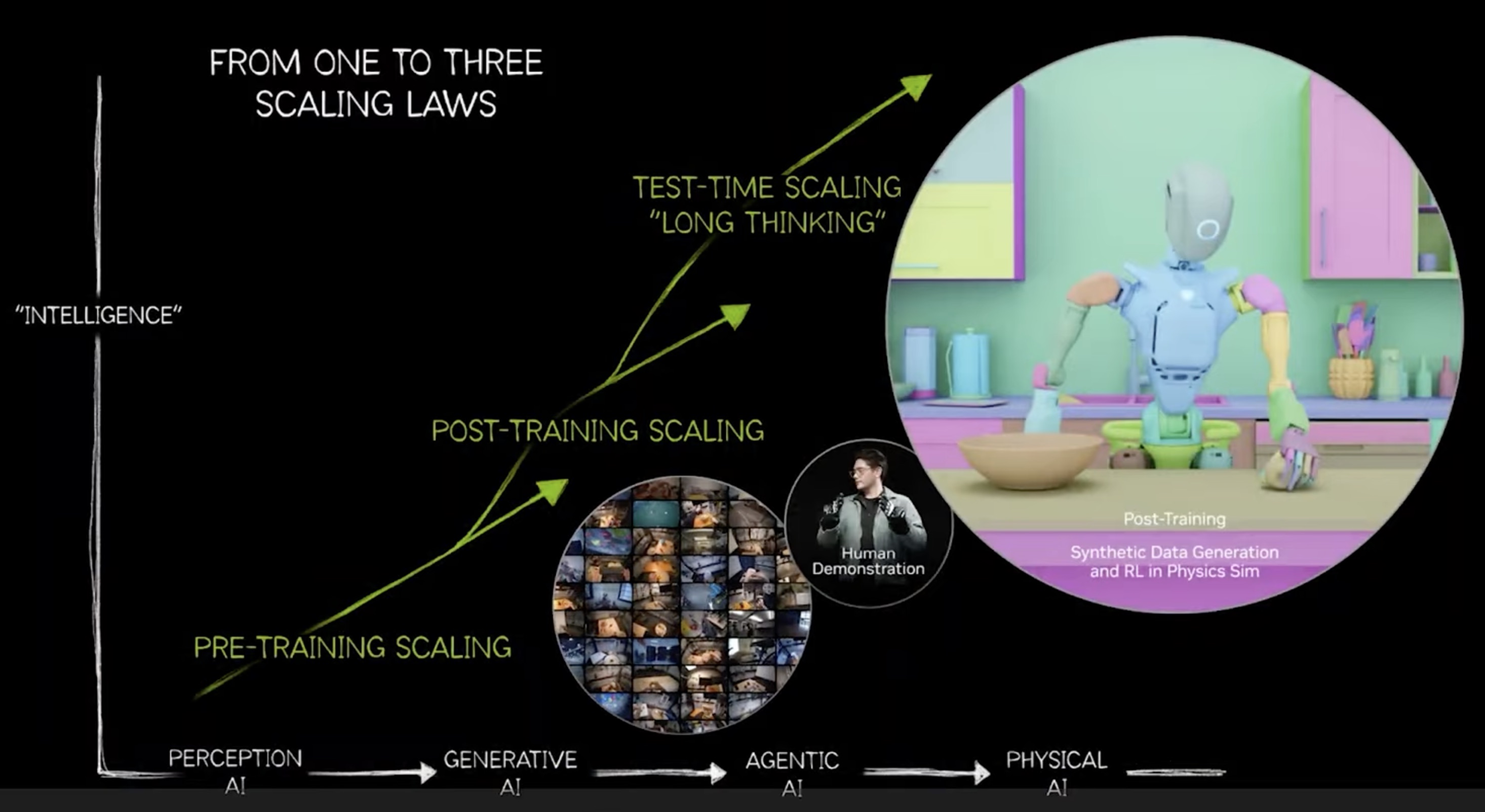
全链路解决方案
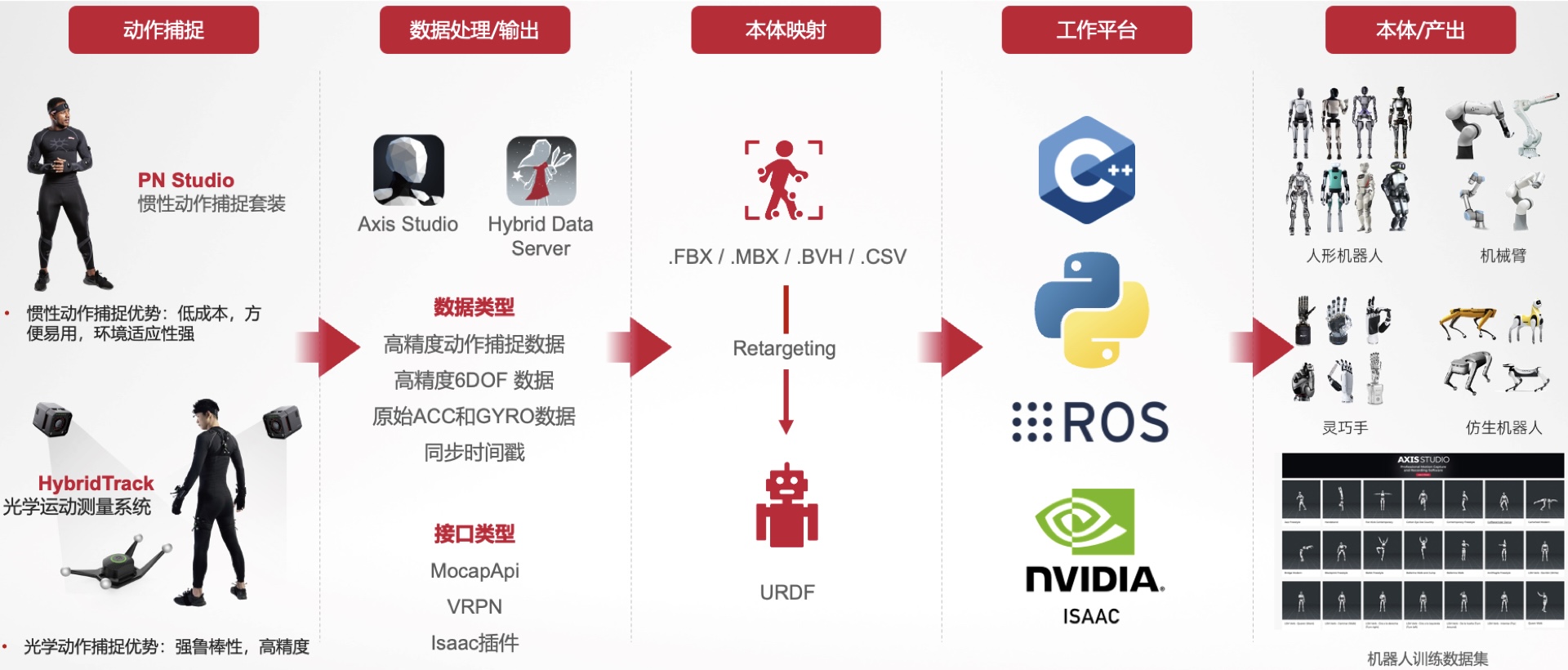
1. 动作捕捉
这一阶段负责采集人类的原始动作数据。图中列出了两种主要技术:
2. 数据处理/输出
捕捉到的信号通过 Axis Studio 或 Hybrid Data Server 进行初步处理。
3. 本体映射
这是将人类动作转化为机器人动作的关键步骤。
.FBX、.MBX、.BVH 和数据格式 .CSV。4. 工作平台
展示了开发和仿真所使用的核心软件生态:
5. 本体/产出
本文详细介绍了 FunASR 这一基础语音识别工具包,它提供了一套完整的语音处理服务,涵盖了离线转写和实时听写两大核心功能。其技术核心在于 AutoModel 多模型协调引擎,能够将不同的组件,如语音活动检测(VAD)、自动语音识别(ASR)、标点恢复和说话人分离(SV),按序串联起来,实现复杂的音频转录任务。文档清晰展示了从原始音频输入到最终带说话人标签的转录结果的完整处理流程和数据流向。此外,本文不仅罗列了支持的多种中英文模型清单,还附带了音频格式转换指南和代码示例。最后,通过实验性能对比,文章论证了在不同硬件上,结合 VAD、PUNC 和 SV 等组件后对推理用时和处理准确性的影响。
ASR 模型综合对比表
| 模型名称 | 中文准确度 | 英文/混合识别 | 可读性 (标点) | 附加功能 | 综合评分 |
|---|---|---|---|---|---|
| Fun-ASR-Nano | 极高 | 完美 | 极佳 | 生产环境级别 | 5.0 |
| SenseVoiceSmall | 高 | 较弱 (漏失) | 较好 | 情感/事件检测 | 4.0 |
paraformer-zh (ASR) |
一般 | 极差 | 无 | 原始数据 | 2.0 |
paraformer-zh (+VAD +PUNC) |
高 | 中等 | 优秀 | 自动断句 | 4.5 |
建议:
# 核心参数配置(无需修改,已按你的需求设定)
$targetMinDate = Get-Date "2024-06-01" # 目标日期区间:开始
$targetMaxDate = Get-Date "2024-12-31" # 目标日期区间:结束
$hourMin = 8 # 限制最小小时(8点)
$hourMax = 21 # 限制最大小时(21点,因22点不包含,实际最晚21:59:59)
$folderPath = "D:\test" # 要遍历的目录
$skipExtension = ".eml" # 需跳过的文件后缀
$logFilePath = "D:\log.txt" # 日志文件路径(与脚本同目录)
# 生成目标区间内随机时间(限制8:00-22:00)的函数
function Get-RandomTargetDateTime {
param(
[datetime]$DateMin = $targetMinDate,
[datetime]$DateMax = $targetMaxDate,
[int]$HourMin = $hourMin,
// ...
该PowerShell脚本的核心功能是 批量筛选并修改指定目录下文件的修改时间,同时跳过特定类型文件、记录操作日
没有找到匹配的文章