Continue - It’s time to collect data on how you build software
是时候收集关于你们如何构建软件的数据了。
Development data engine (开发数据引擎)
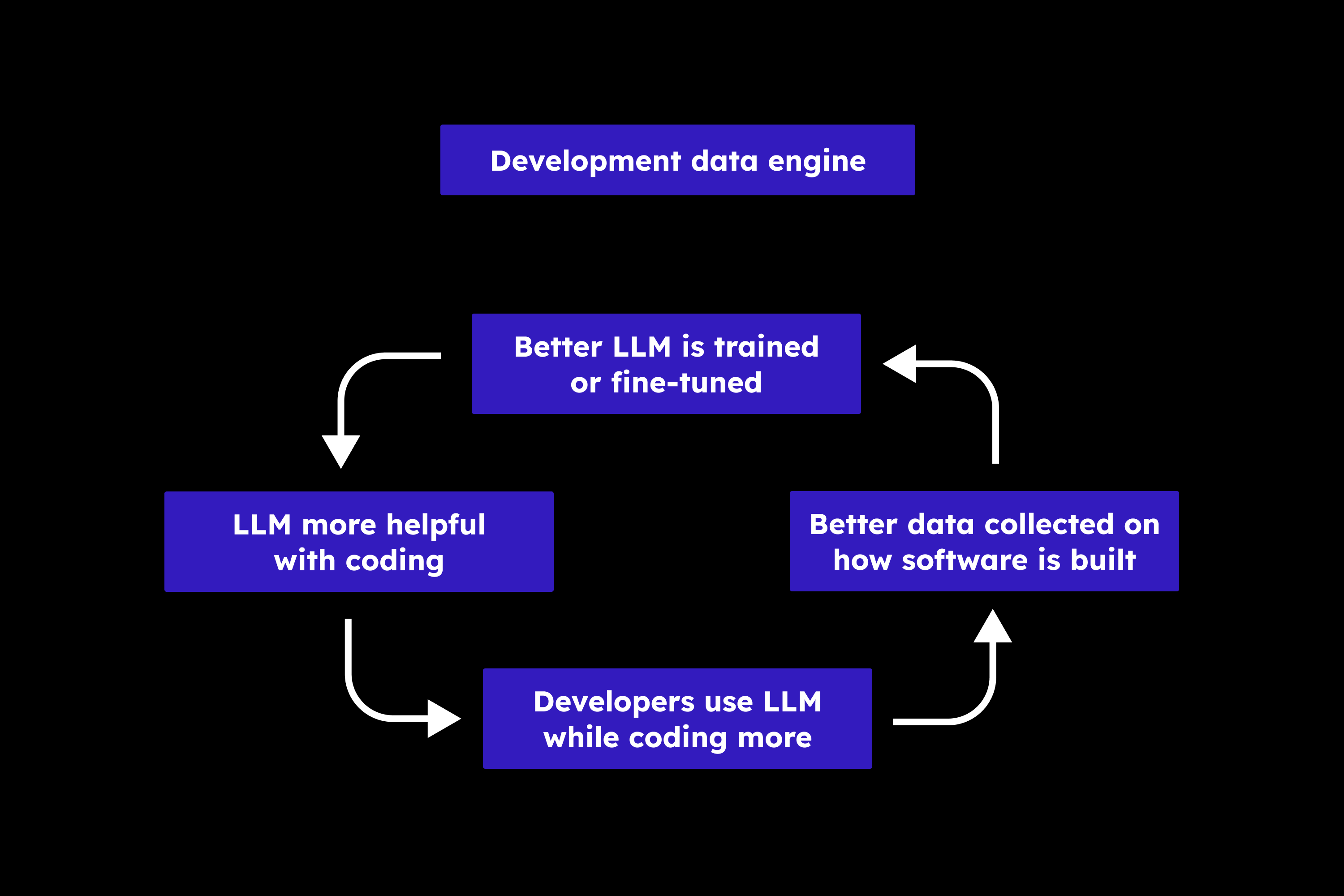
- LLM more helpful with coding (LLM在编码方面更有帮助)
- Developers use LLM while coding more (开发者在编码时更多地使用LLM)
- Better data collected on how software is built (收集到更好的关于软件构建方式的数据)
- Better LLM is trained or fine-tuned (训练或微调更好的LLM)
下一代开发者使用大型语言模型(LLMs)而不是谷歌搜索+ Stack Overflow。
随着时间的推移,开发者的偏好和使用的工具也在不断演进。当前一代的开发者正在用大型语言模型(LLMs)取代之前的Google和Stack Overflow,就像之前的一代人用Google和Stack Overflow取代了传统的参考手册一样。 在这个过渡期中,能够保留和吸引开发者的组织将会:
首先,理解他们的开发者如何使用LLMs,并通过收集开发数据——即他们组织构建软件的方式——来展示使用LLMs的投资回报率(ROI)。