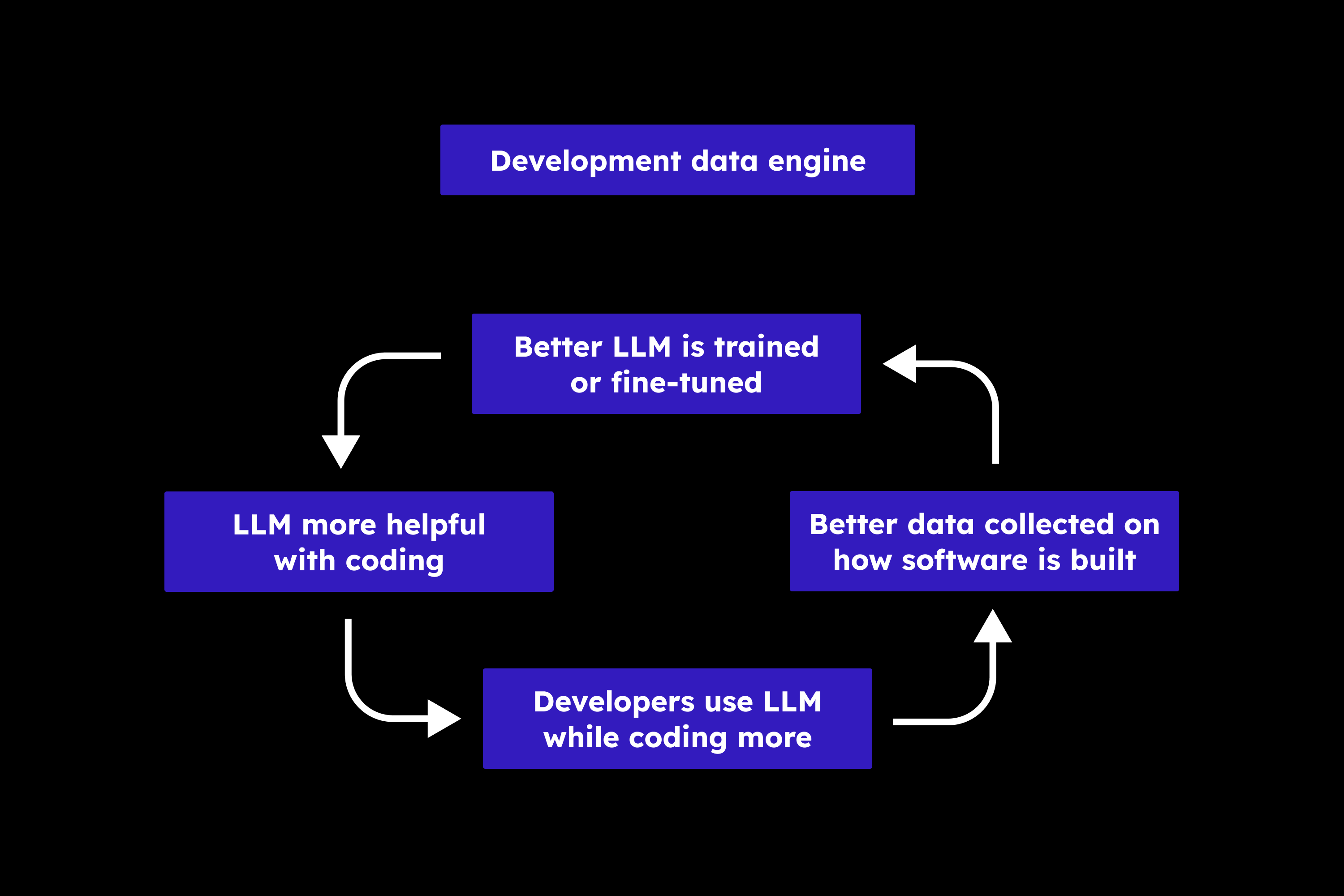
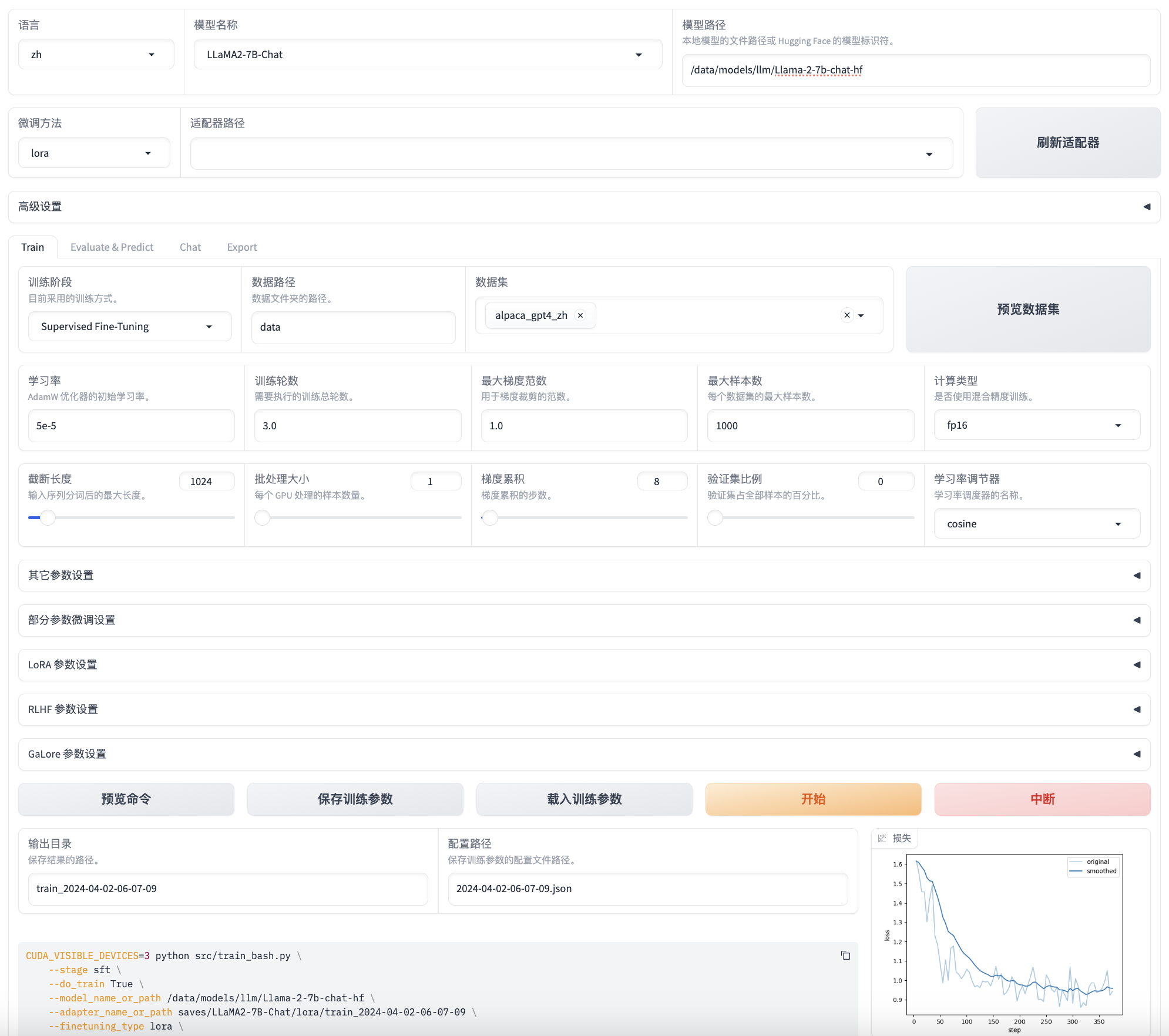
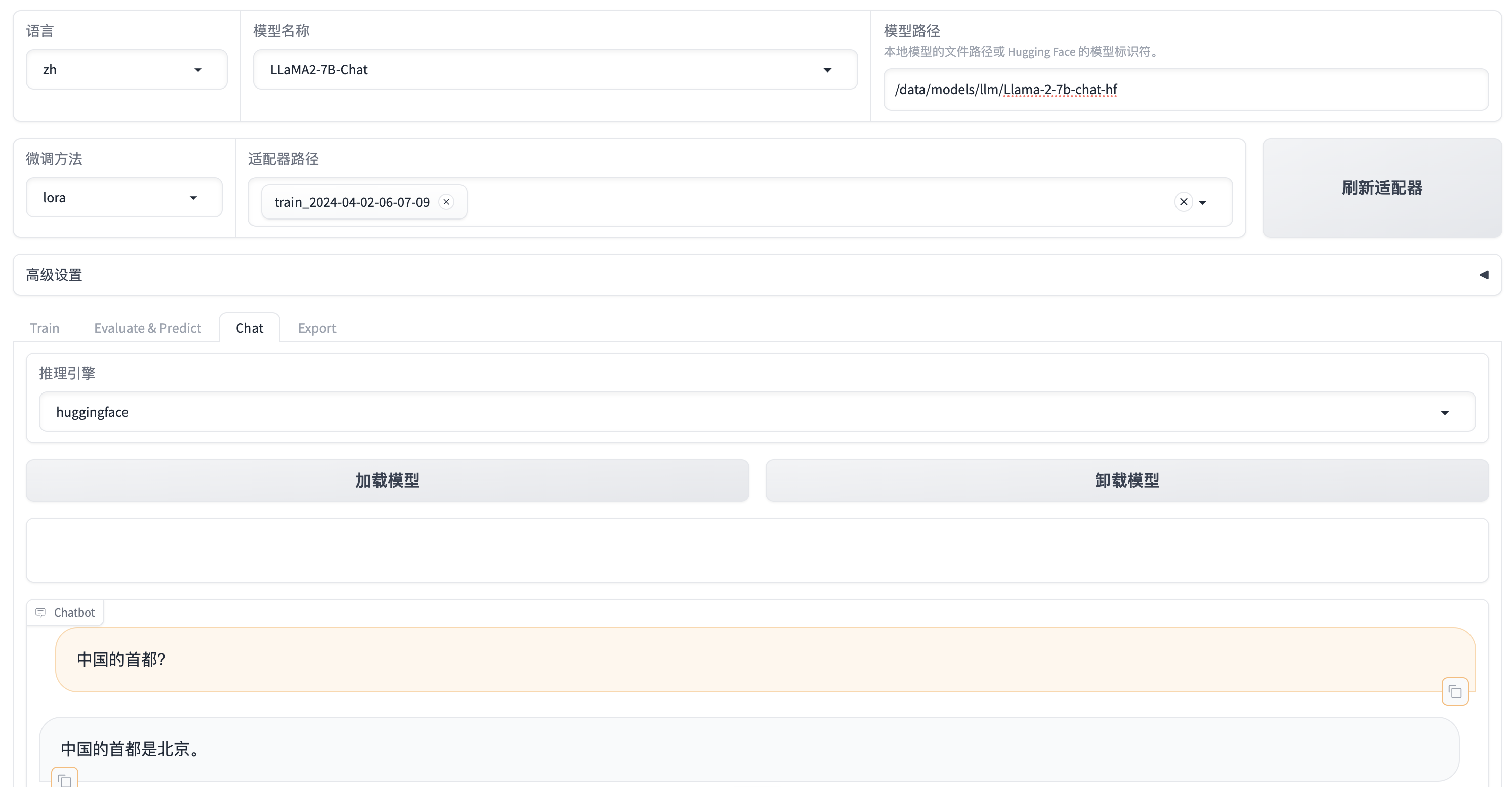
OpenAI Function Calling (OpenAI 函数调用)
import os
import openai
import json
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
# Example dummy function hard coded to return the same weather
# In production, this could be your backend API or an external API
def get_current_weather(location, unit="fahrenheit"):
"""Get the current weather in a given location"""
weather_info = {
"location": location,
"temperature": "72",
"unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)
# define a function
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
messages = [
{
"role": "user",
"content": "What's the weather like in Boston?"
}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
functions=functions
)
print(response)
{
"id": "chatcmpl-9CK2or9rtxzcsVgbfwWmIvqi36wF0",
"object": "chat.completion",
"created": 1712724014,
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "get_current_weather",
"arguments": "{\"location\":\"Boston\",\"unit\":\"celsius\"}"
}
},
"logprobs": null,
"finish_reason": "function_call"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 20,
"total_tokens": 102
},
"system_fingerprint": "fp_b28b39ffa8"
}