在 MLX 上使用 LoRA / QLoRA 微调 Text2SQL(六):使用 LoRA 基于 Deepseek-Coder-7B 微调
大模型 Deepseek-Coder-7B
数据集 WikiSQL
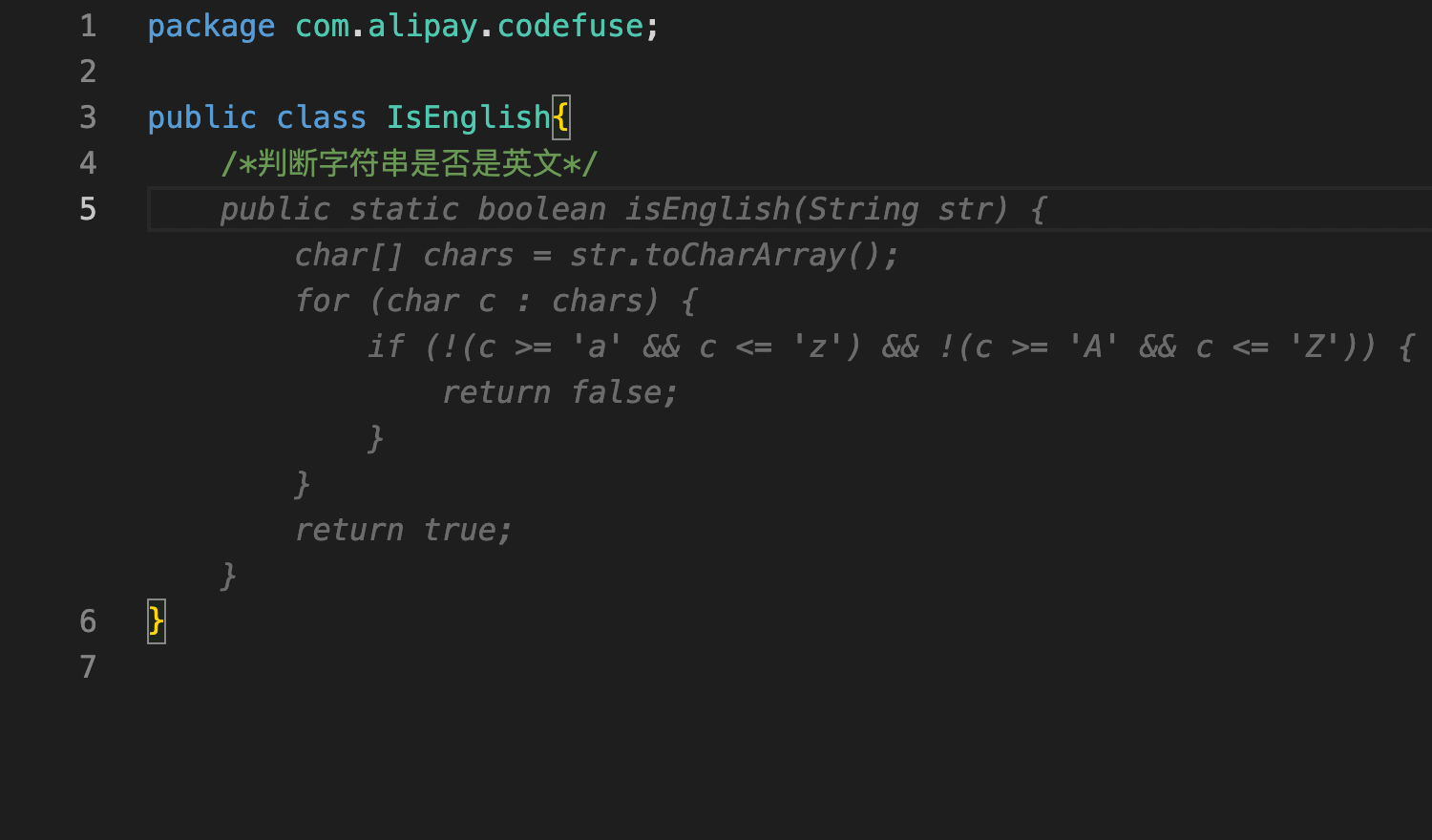
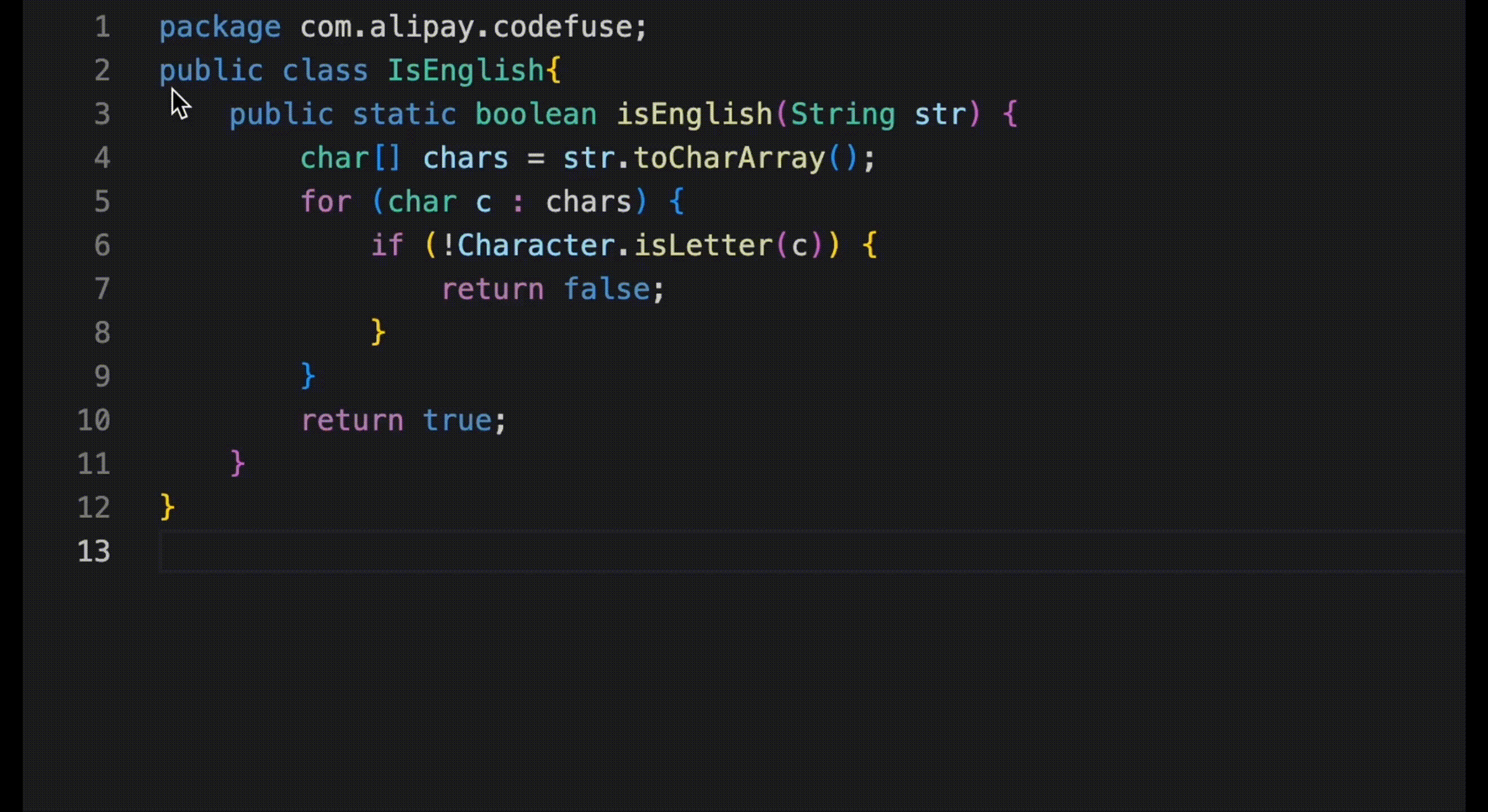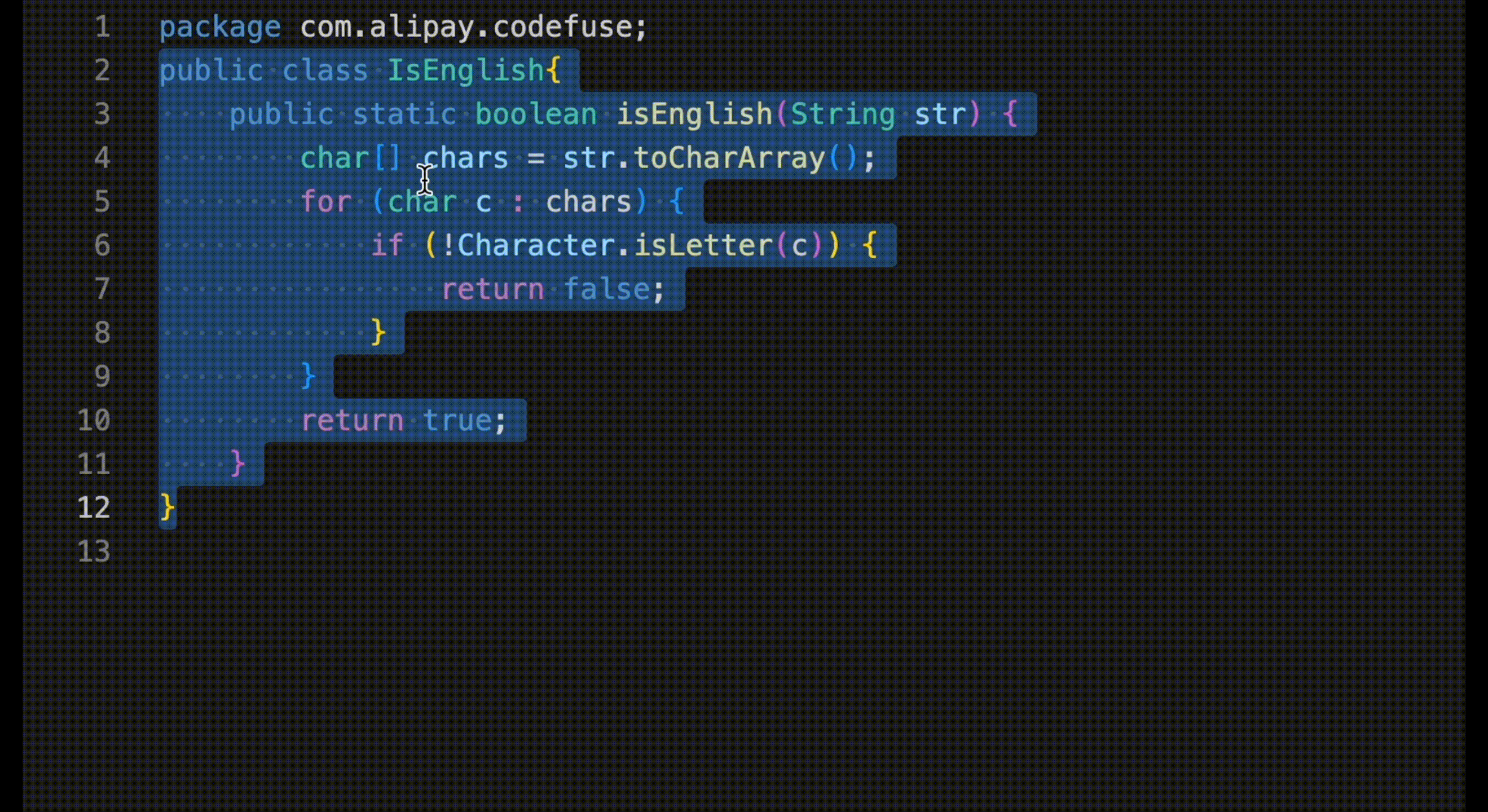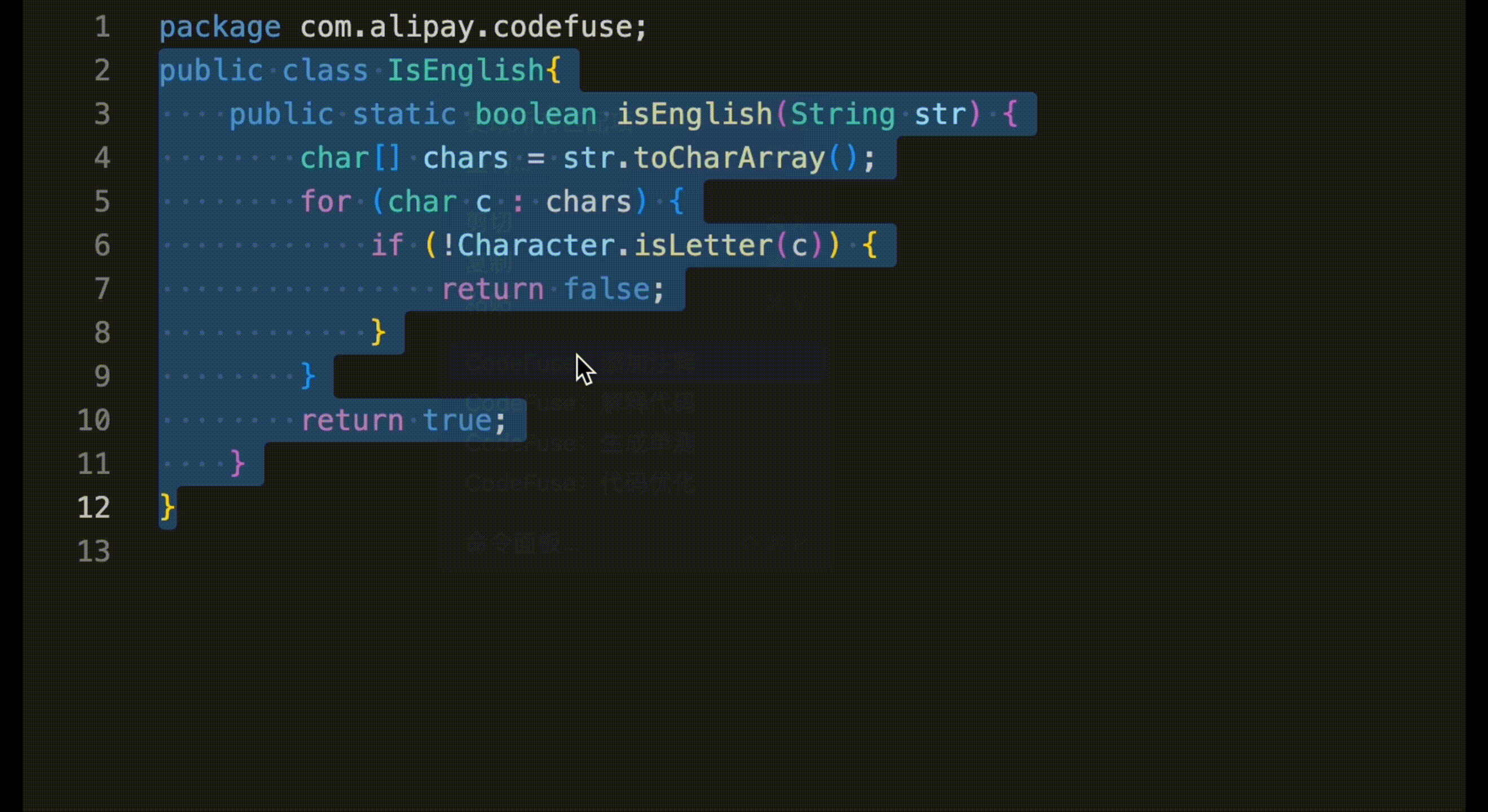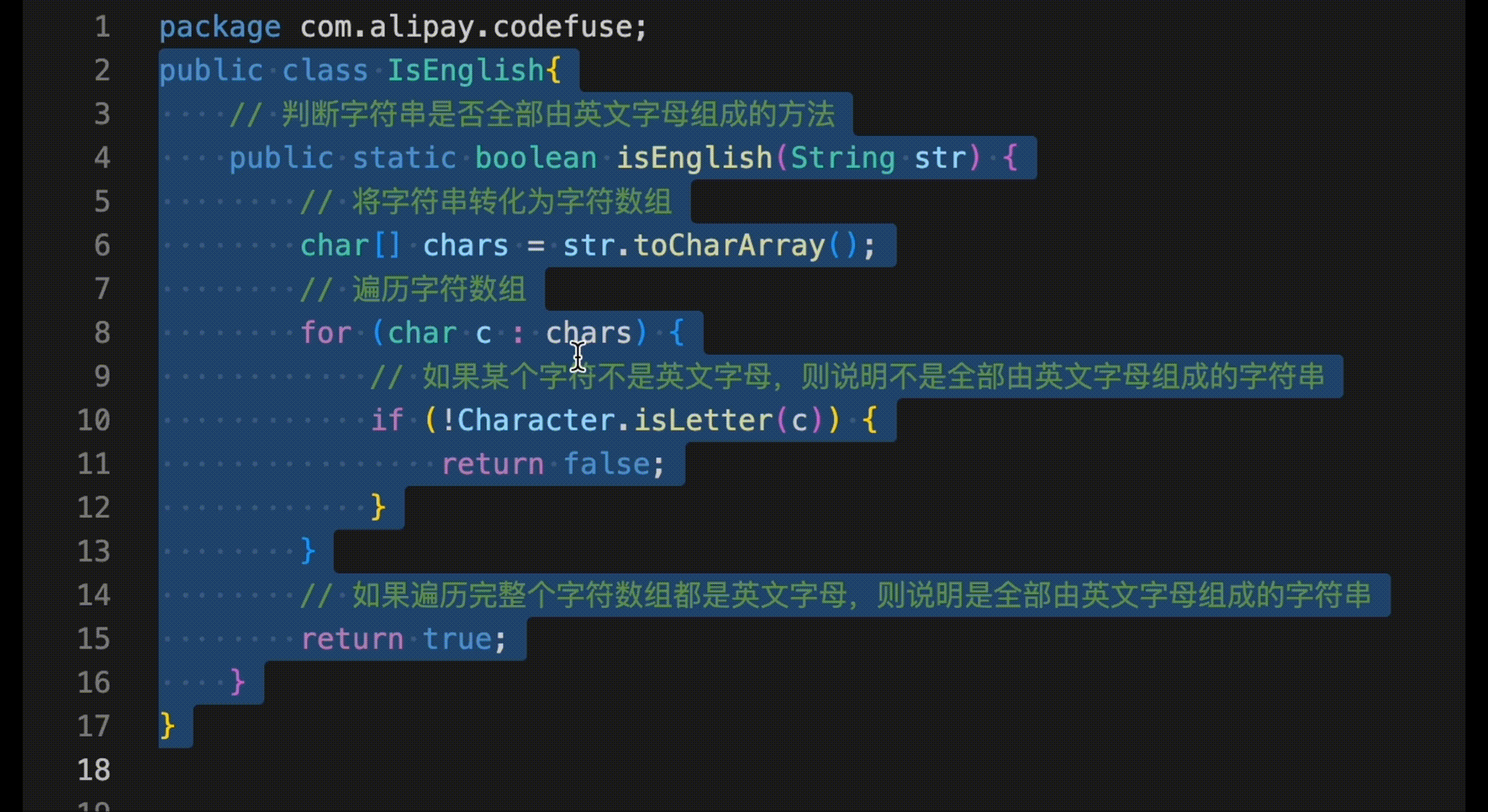
修改脚本 mlx-examples/lora/data/wikisql.py if name == "main": # ...... for dataset, name, size in datasets: with open(f"data/{name}.jsonl", "w") as fid: for e, t in zip(range(size), dataset): # deepseek-ai/deepseek-coder-7b-instruct-v1.5 # 去掉开头的 <|begin▁of▁sentence|>,因为 tokenizer 会自动添加 <|begin▁of▁sentence|> t = t[3:-4] + "<|end▁of▁sentence|>" json.dump({"text": t}, fid) fid.