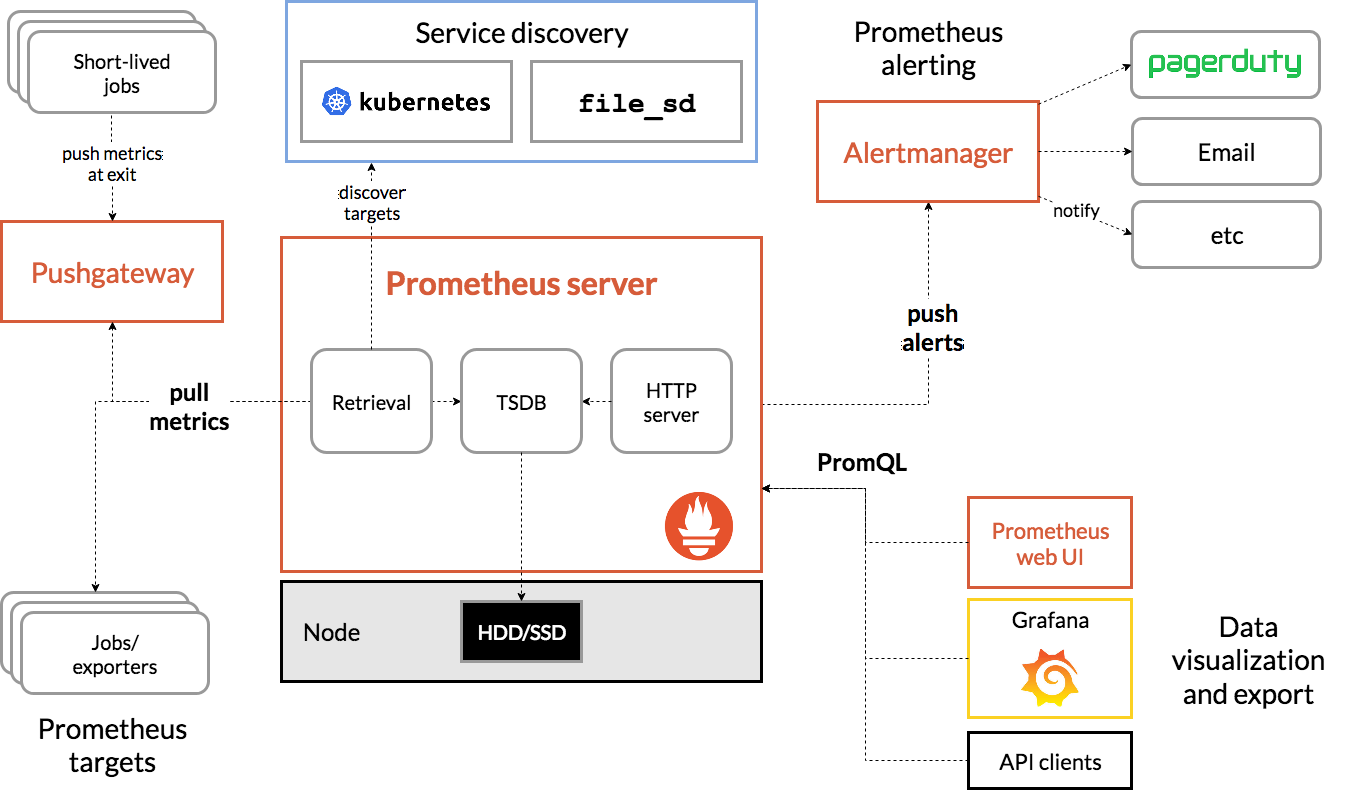
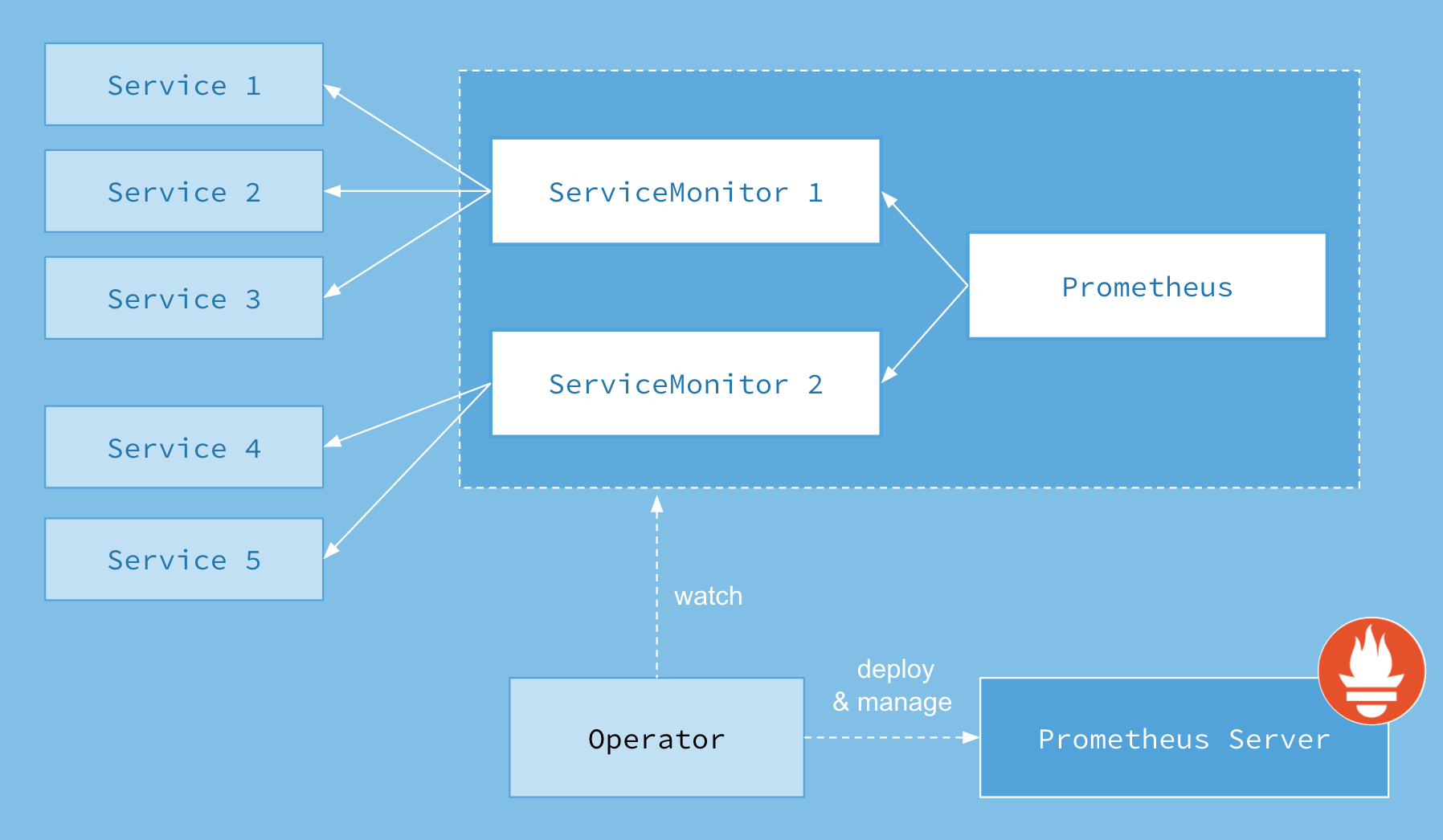
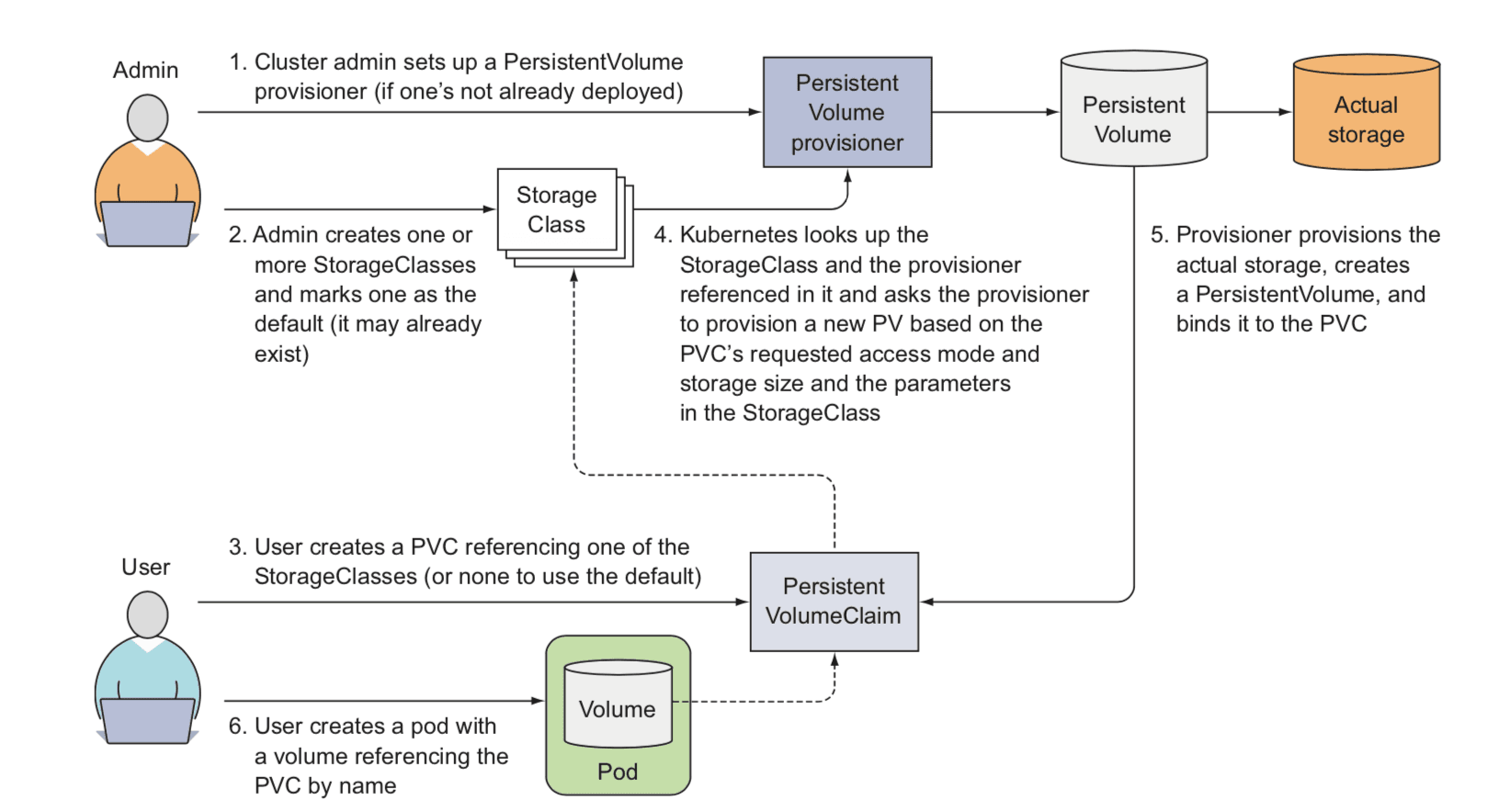
Velero: 备份和迁移 Kubernetes 资源和持久卷
Velero 是一款开源工具,用于安全备份和恢复、执行灾难恢复以及迁移 Kubernetes 集群资源和持久卷。
功能
- 灾难恢复 减少基础设施丢失、数据损坏和/或服务中断时的恢复时间。
- 数据迁移 通过轻松地将 Kubernetes 资源从一个集群迁移到另一个集群,实现集群可移植性。
- 数据保护 提供关键数据保护功能,例如计划备份、保留计划以及用于自定义操作的备份前或备份后挂钩。
与其他直接访问 Kubernetes etcd 数据库来执行备份和恢复的工具不同,Velero 使用 Kubernetes API 来捕获集群资源的状态并在必要时恢复它们。这种 API 驱动的方法具有许多关键优势:
- 备份可以捕获集群资源的子集,按命名空间、资源类型和/或标签选择器进行过滤,从而为备份和恢复的内容提供高度的灵活性。
- 托管 Kubernetes 产品的用户通常无权访问底层 etcd 数据库,因此无法直接备份/恢复它。
- 通过聚合 API 服务器公开的资源可以轻松备份和恢复,即使它们存储在单独的 etcd 数据库中也是如此。
此外,Velero 使您能够使用存储平台的本机快照功能或称为 Restic 的集成文件级备份工具来备份和恢复应用程序的持久数据及其 配置。
参考资料 Velero Kubernetes 備份,災難復原之 Velero 篇 使用