使用 Prometheus Operator 在 Kubernetes 上部署 Prometheus 和 Grafana
监控组件
Prometheus 是一个开源系统监控和警报工具包。
架构图
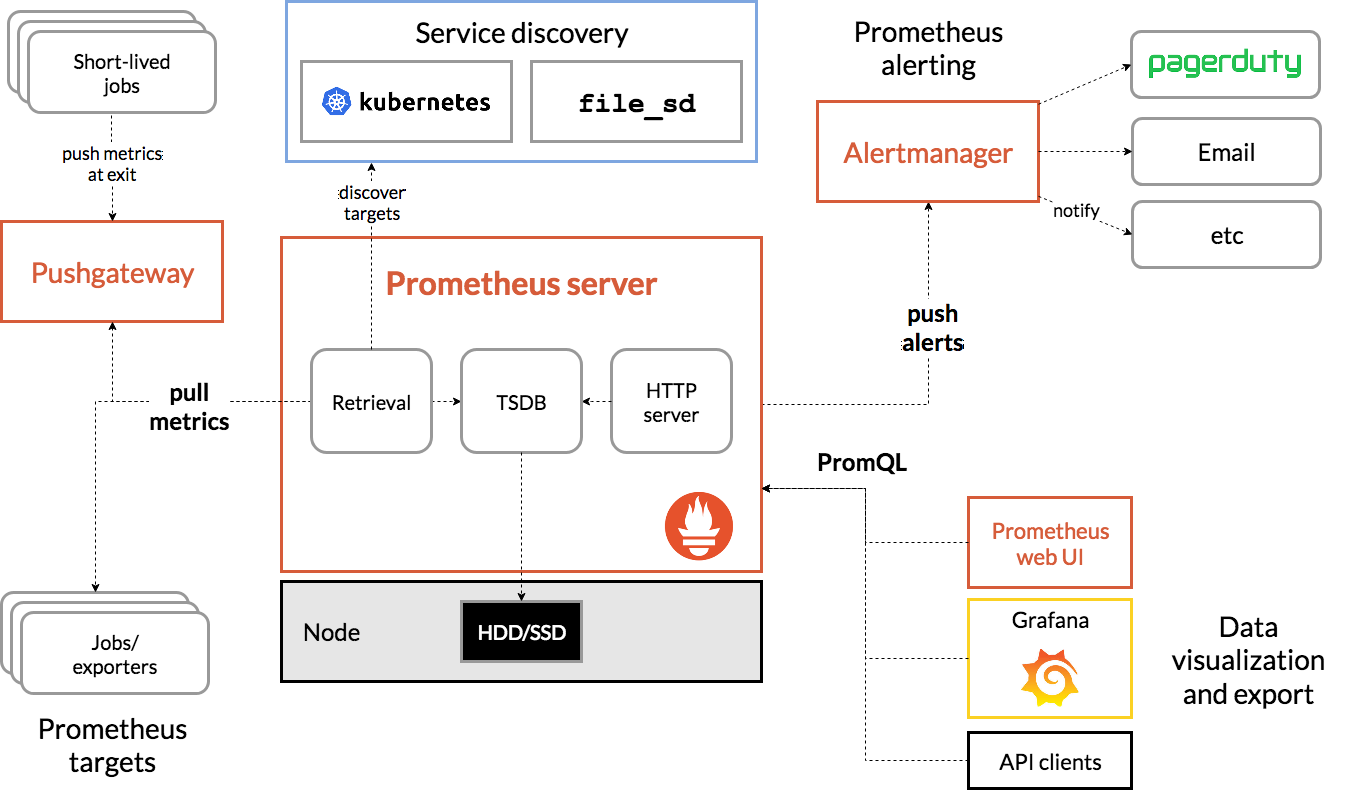
Grafana 用于对收集并存储在 Prometheus 数据库中的指标进行分析和交互式可视化。 您可以以 Prometheus 作为数据源,为 Kubernetes 集群创建自定义图表、图形和警报。
概述
Prometheus Operator 提供 Prometheus 及相关监控组件的 Kubernetes 原生部署和管理。 该项目的目的是简化和自动化 Kubernetes 集群基于 Prometheus 的监控堆栈的配置。
架构图
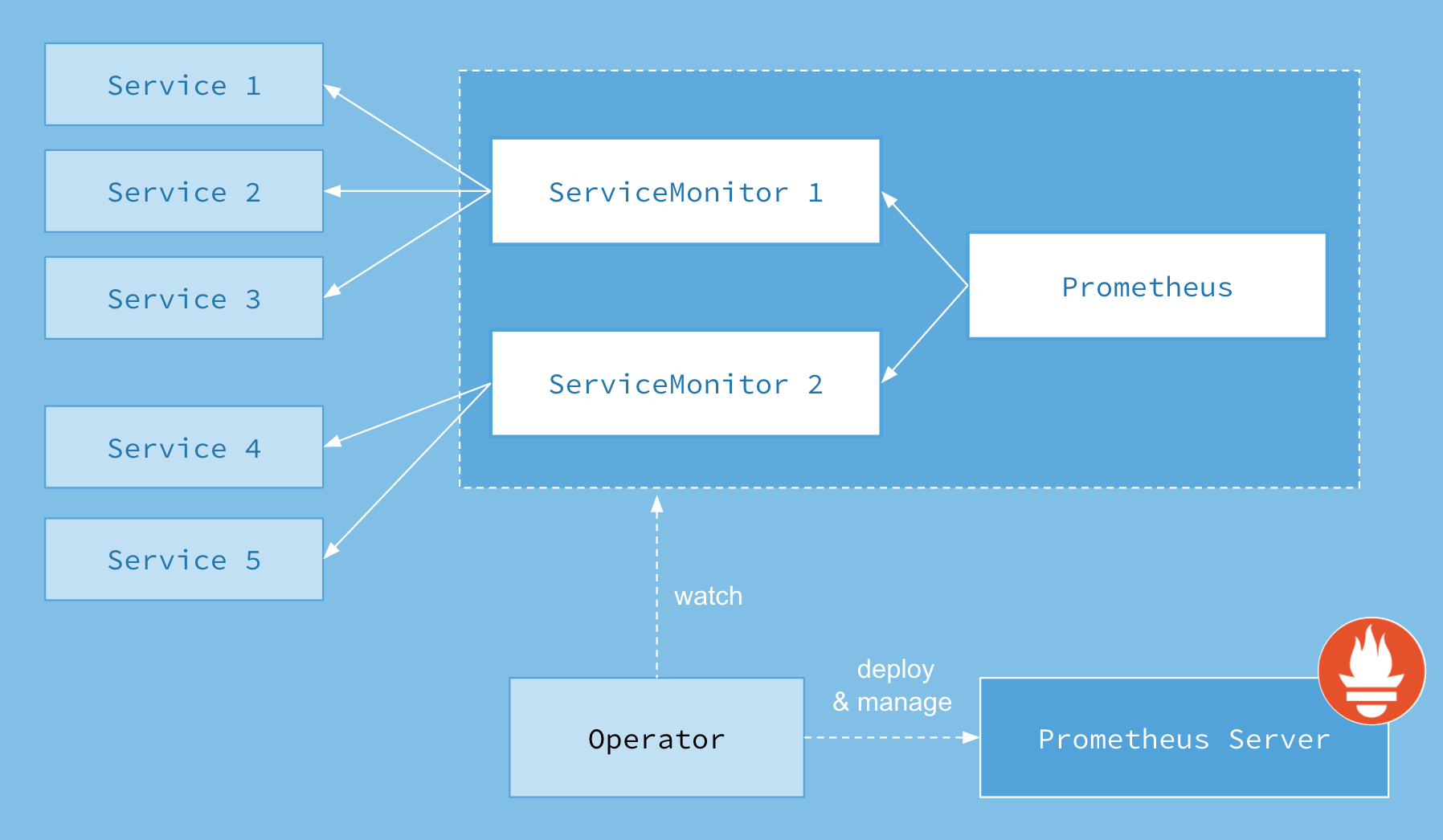
部署 Prometheus 和 Grafana Monitoring Stack
克隆 kube-prometheus 项目
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus/
创建 monitoring namespace, CustomResourceDefinitions 和 operator pod
创建 namespace 和 CustomResourceDefinitions