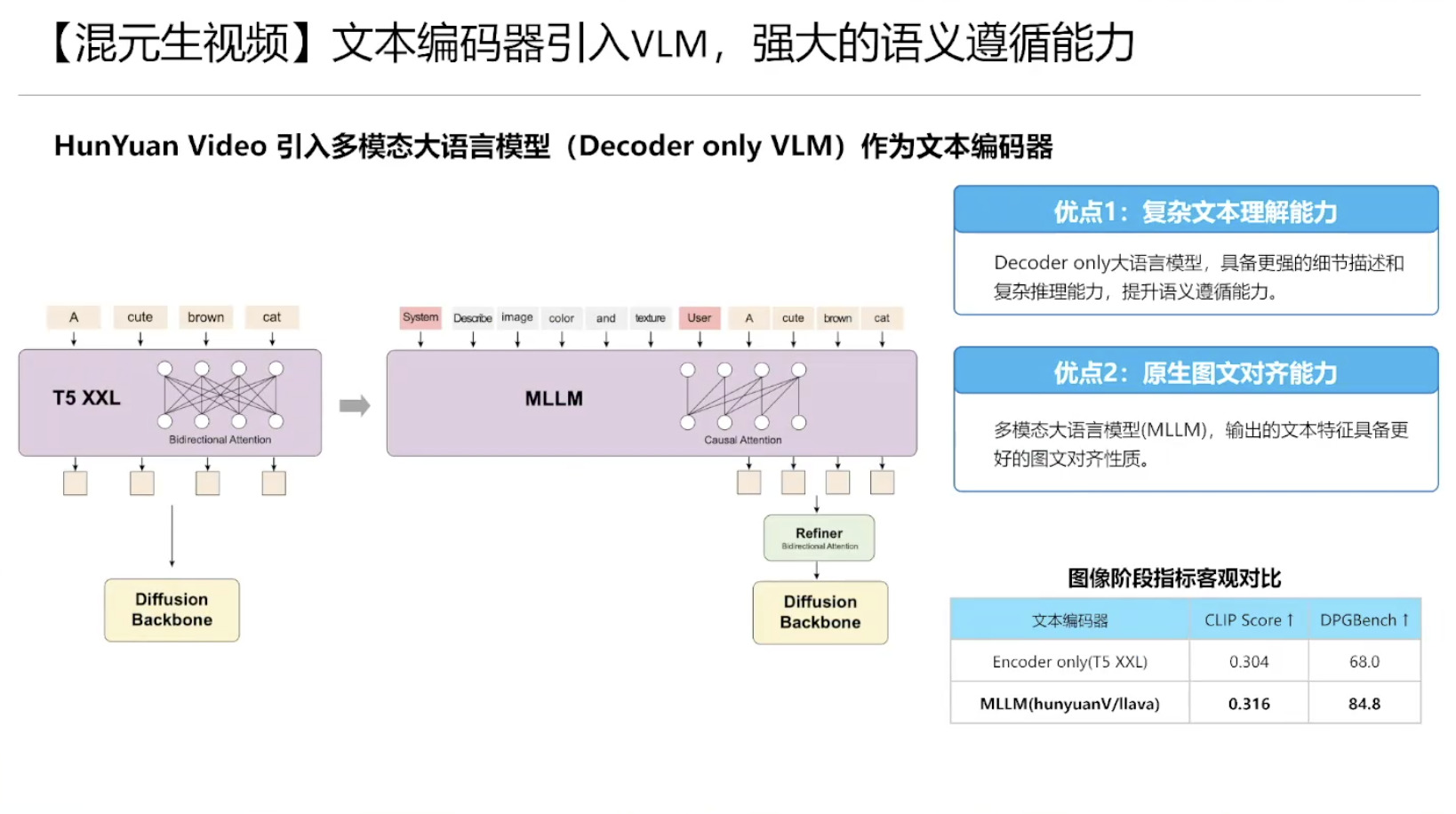
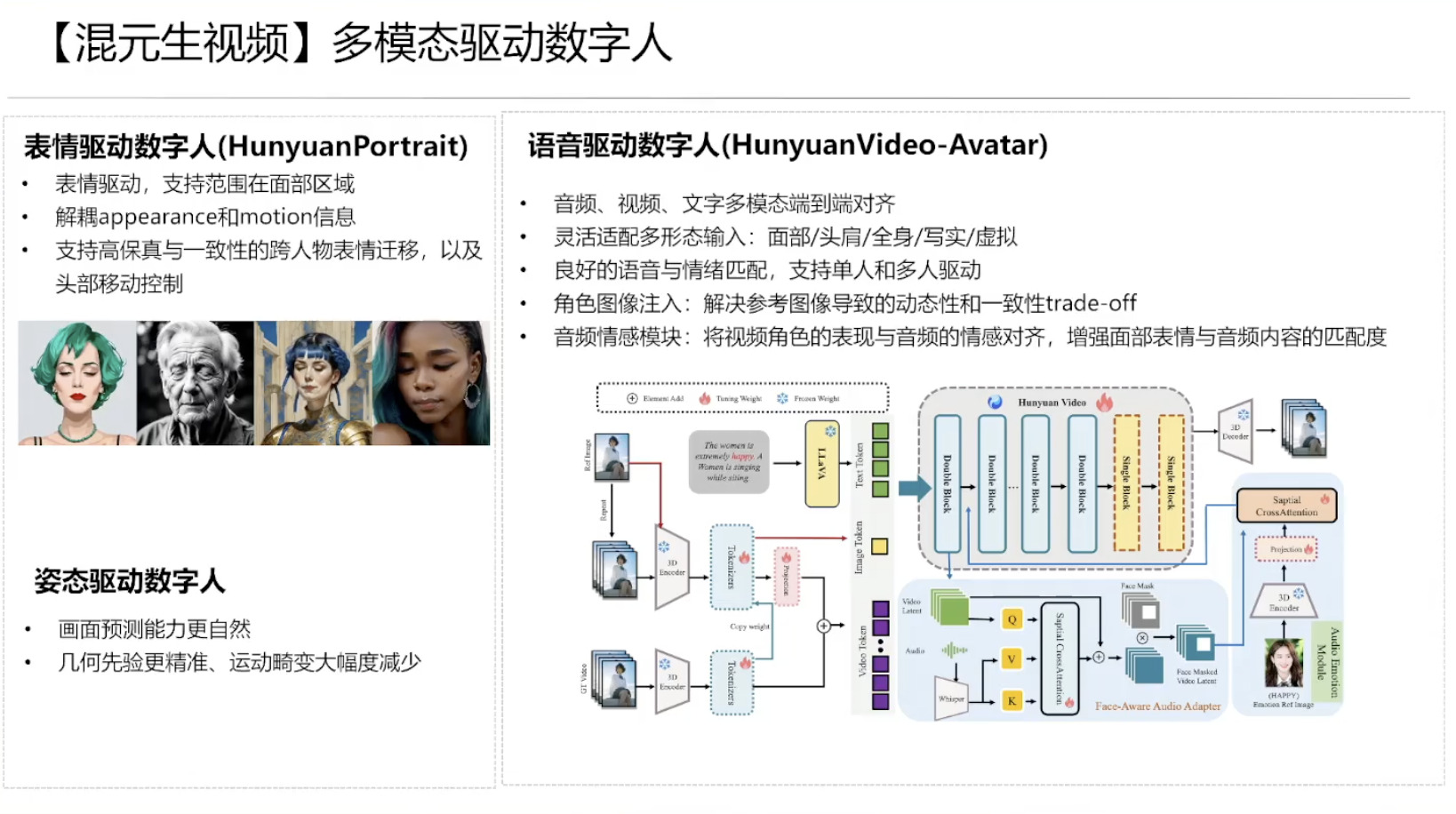
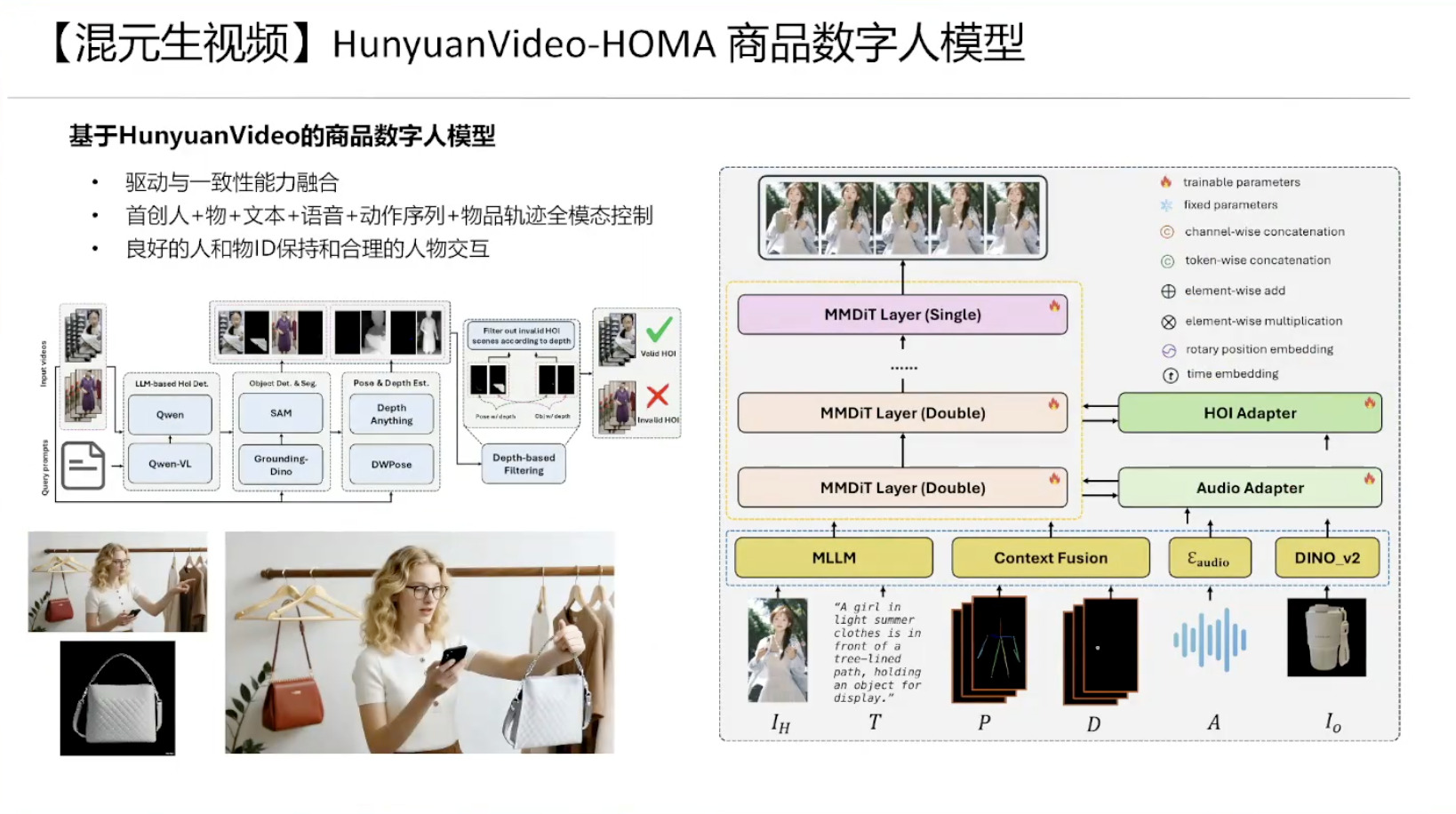
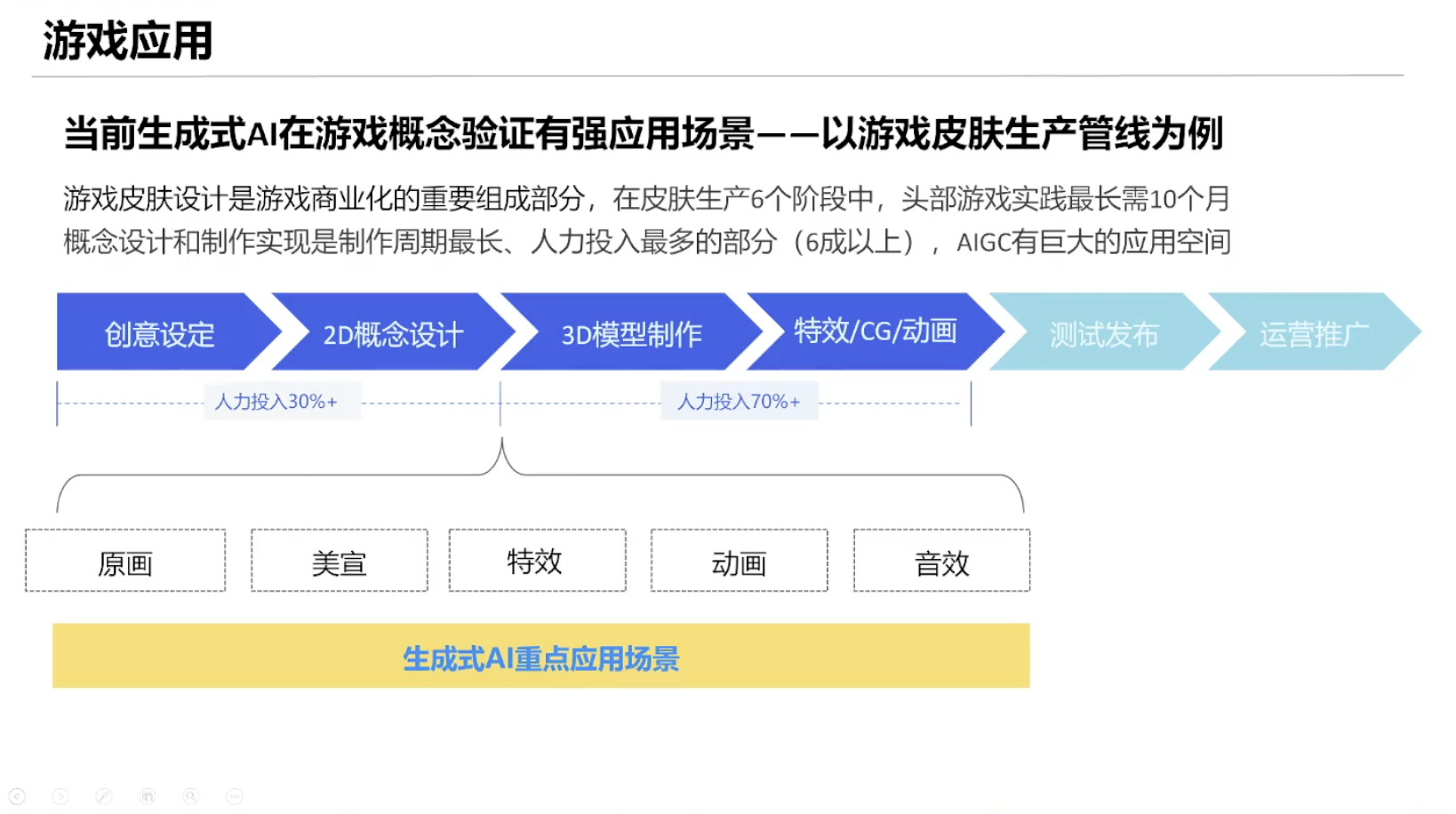
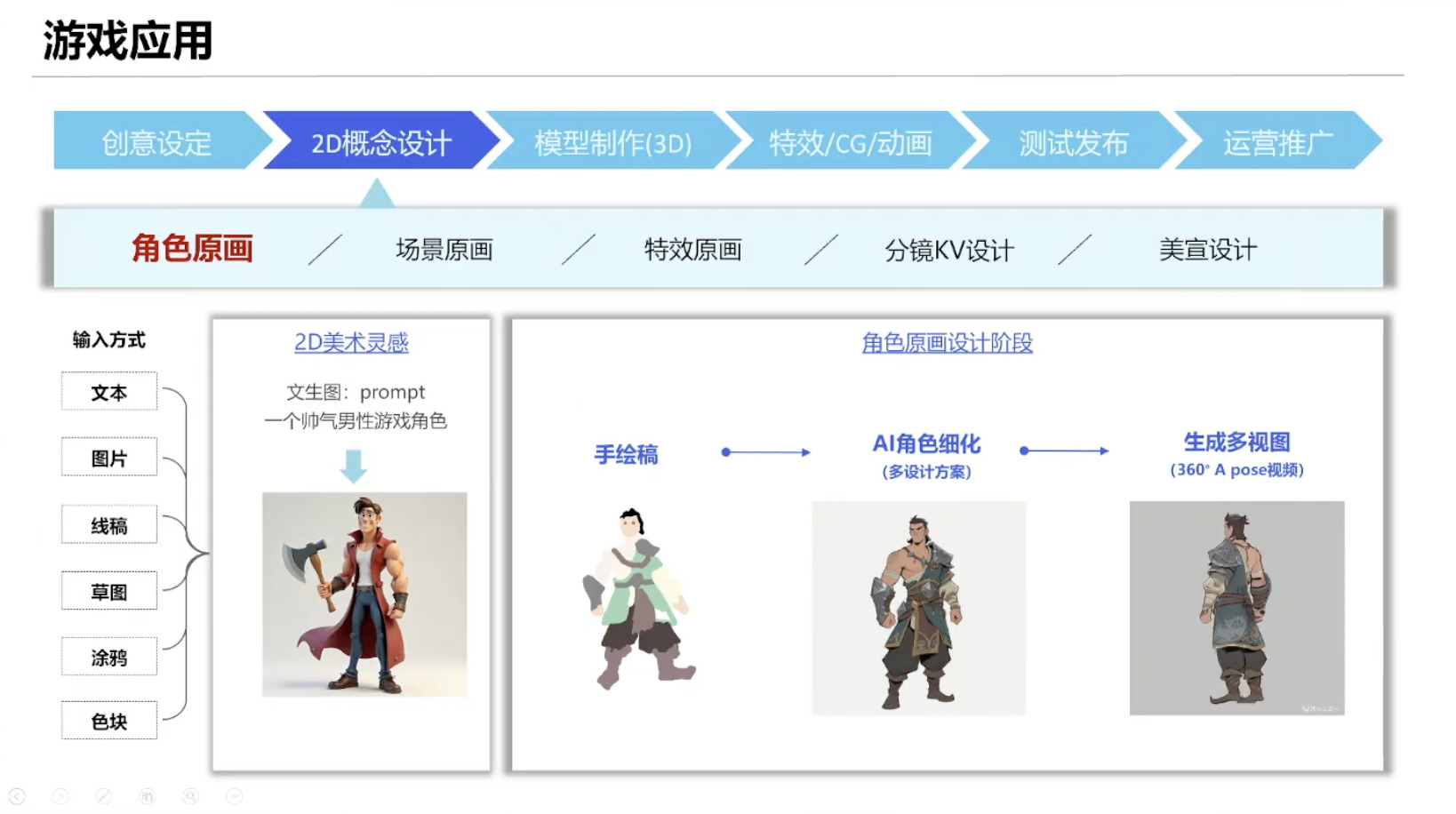
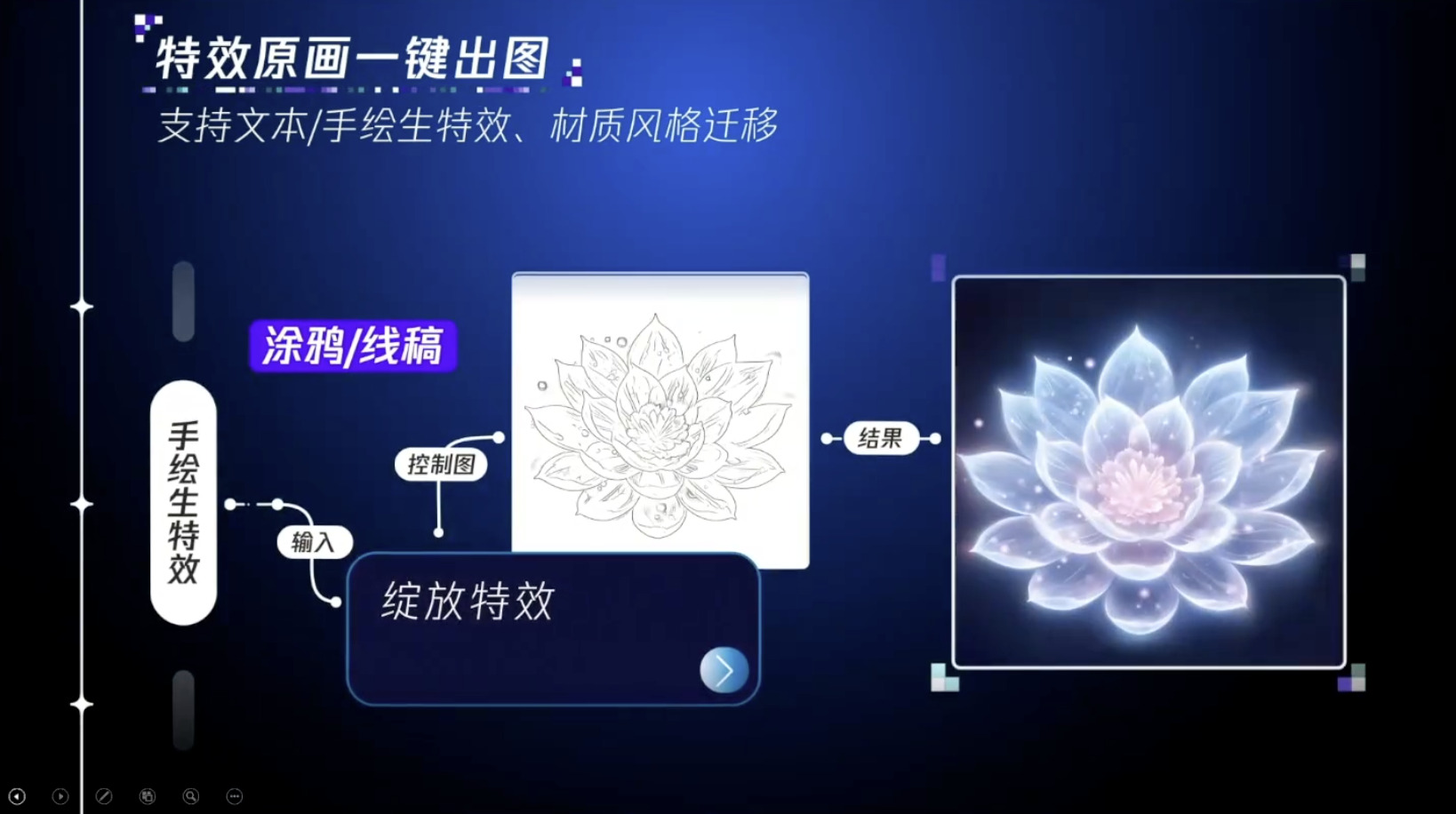
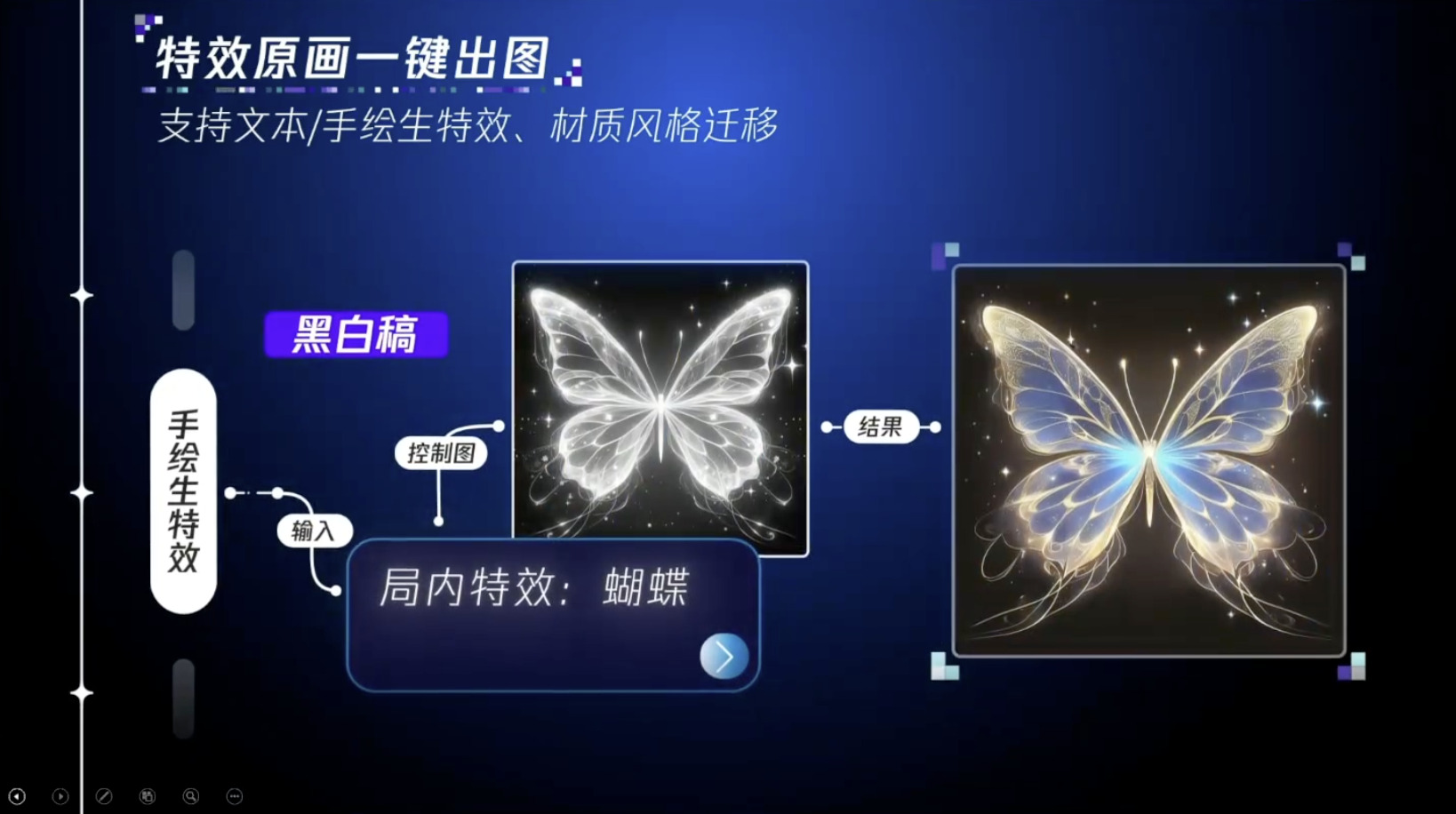
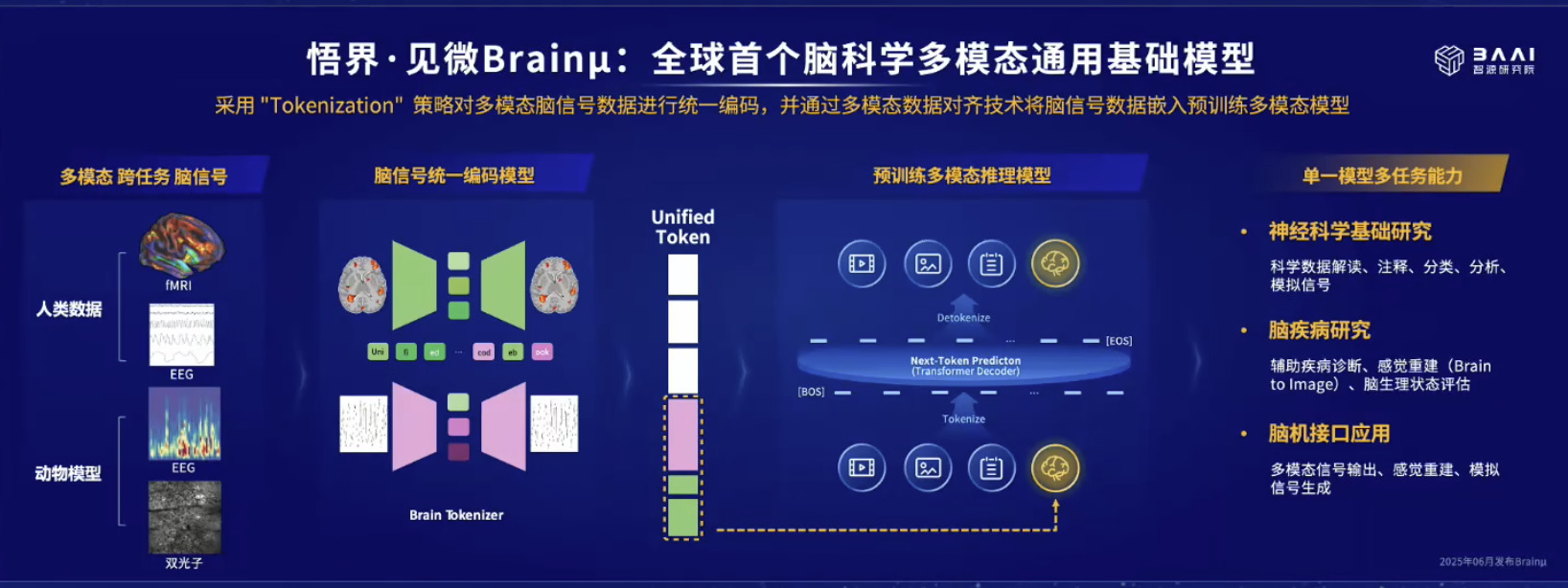
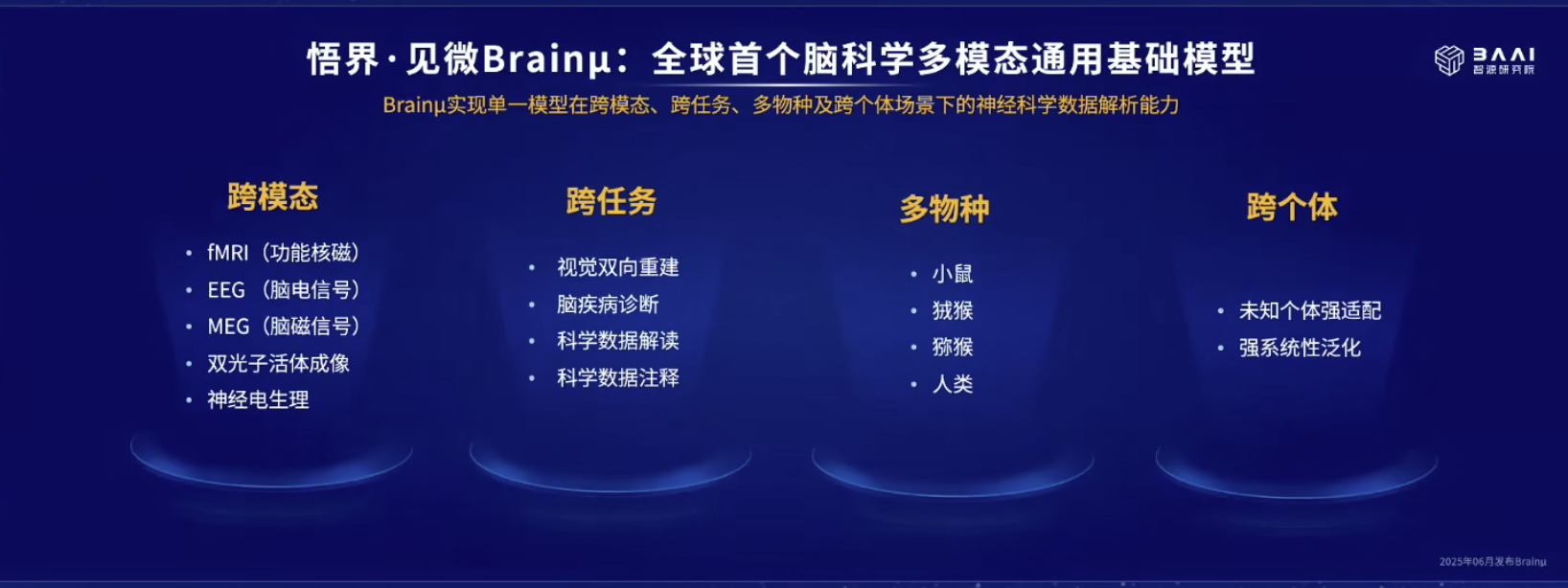
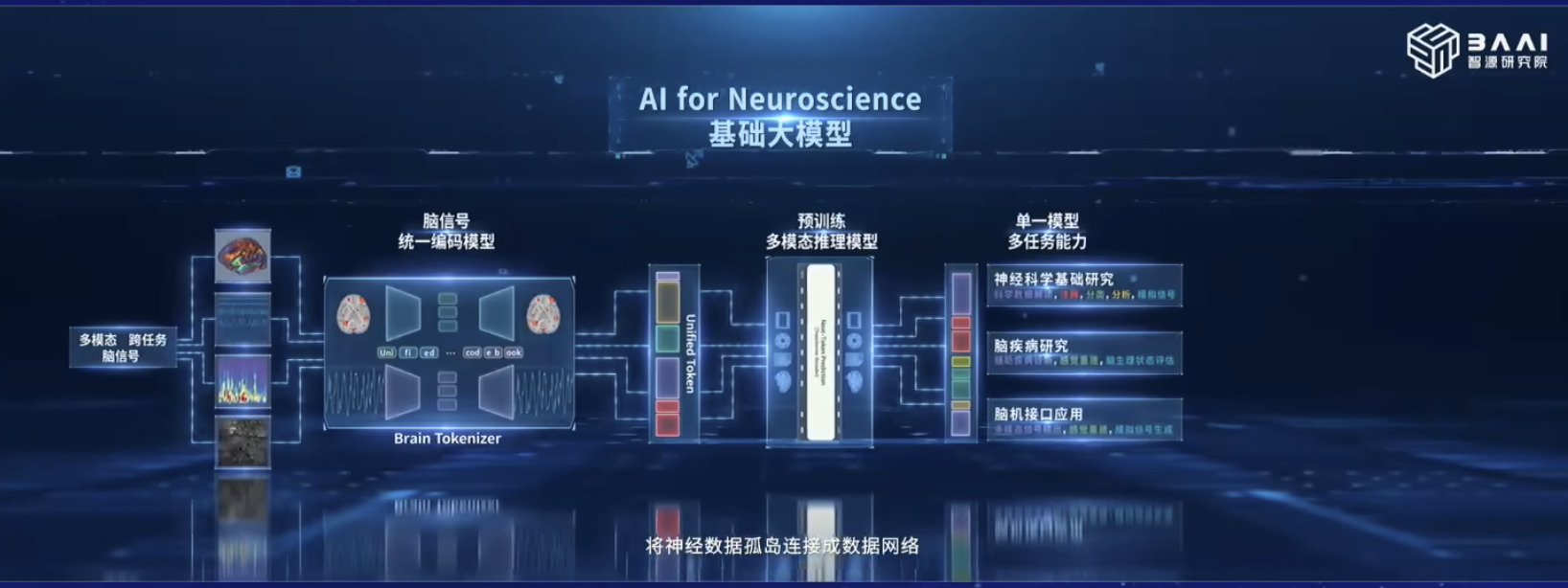
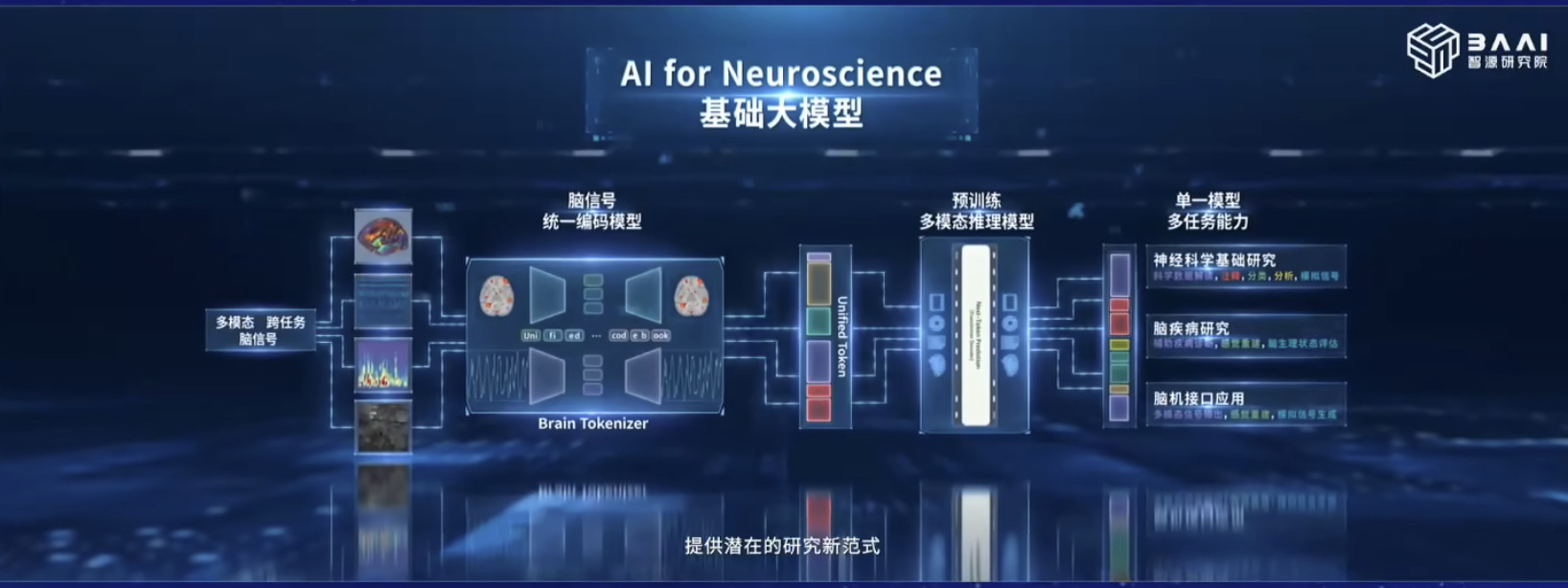
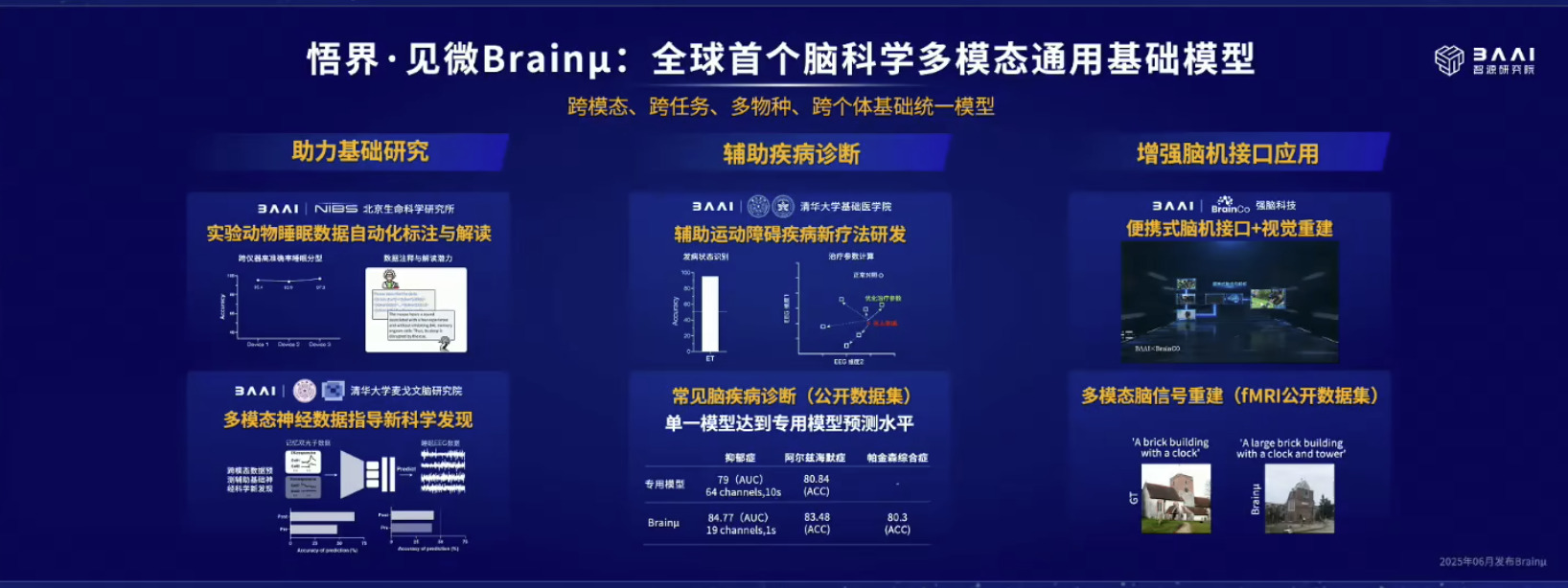
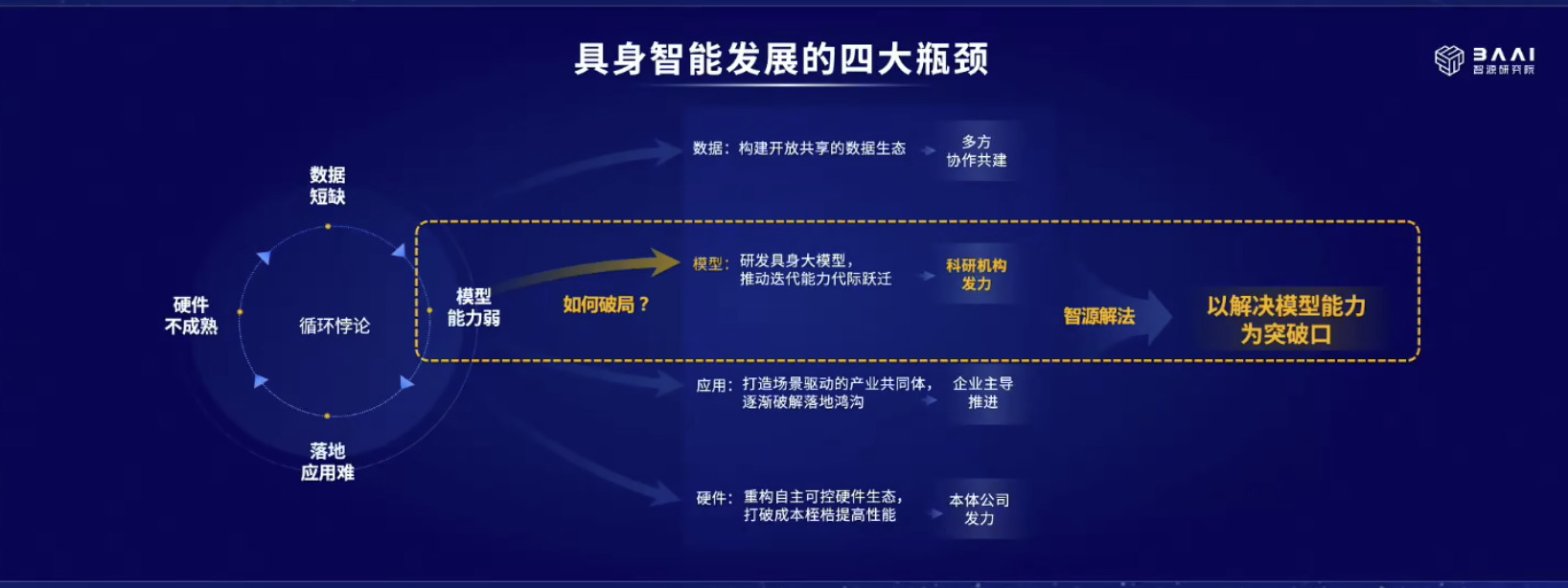
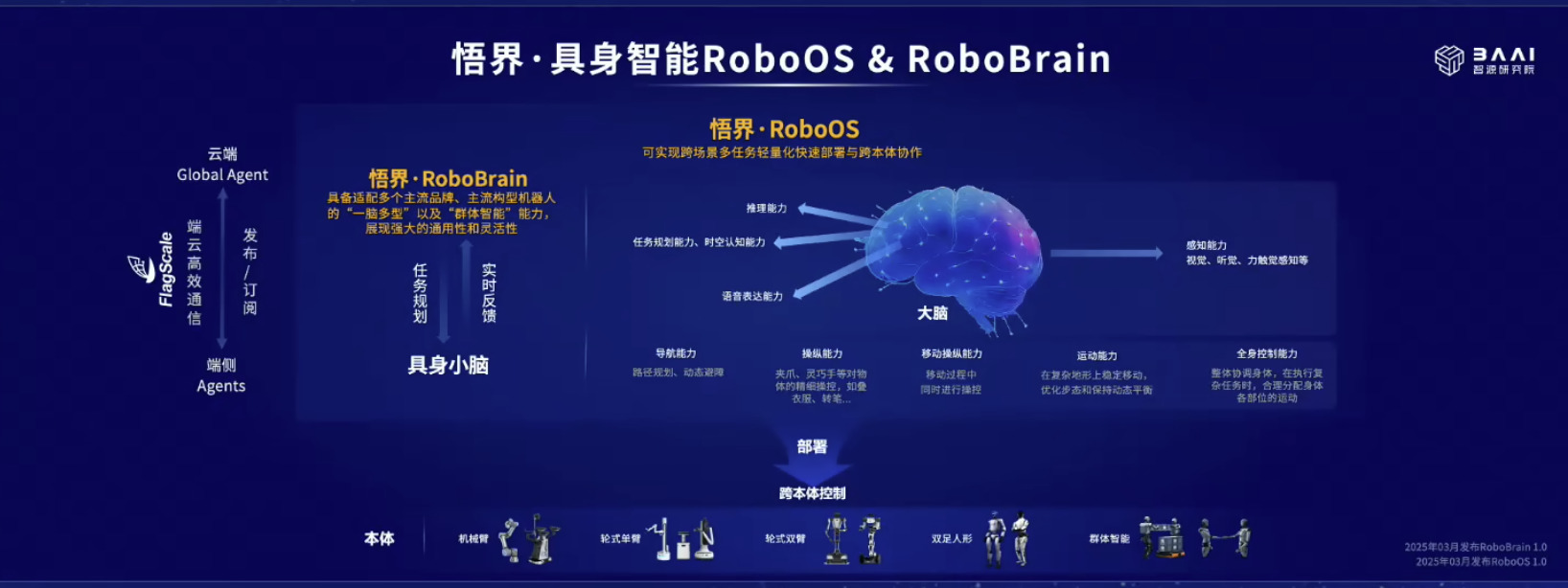
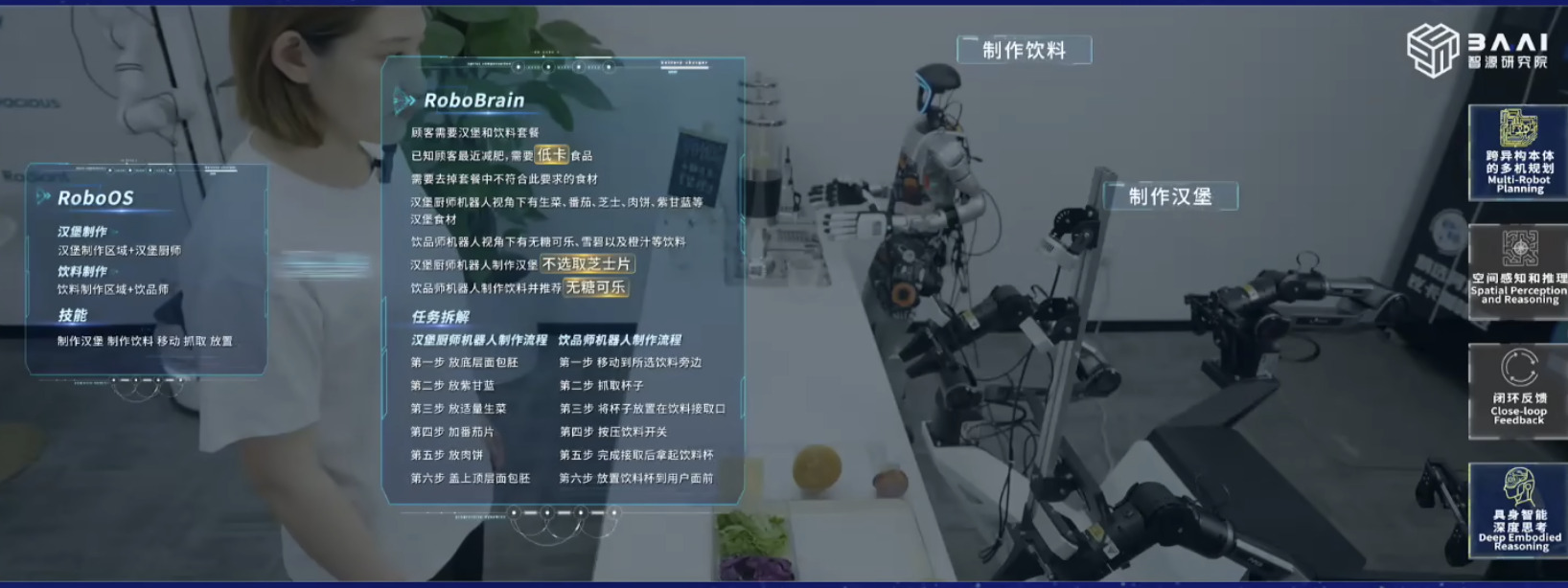
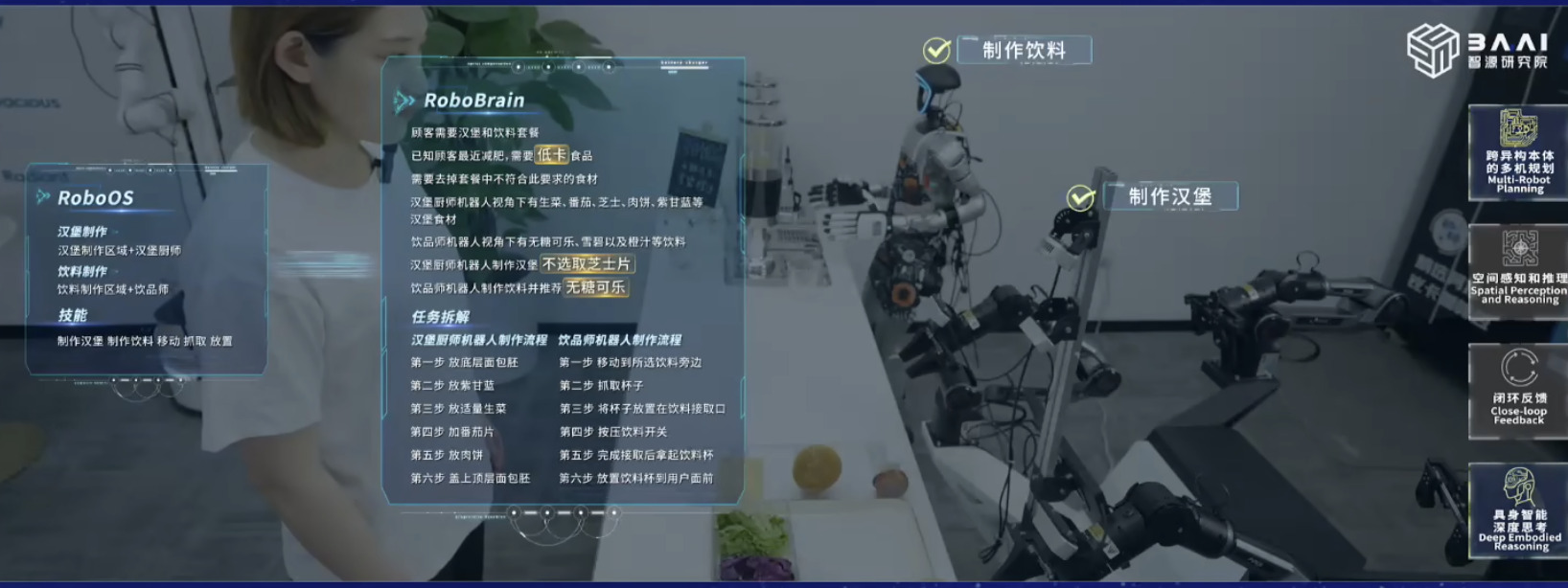
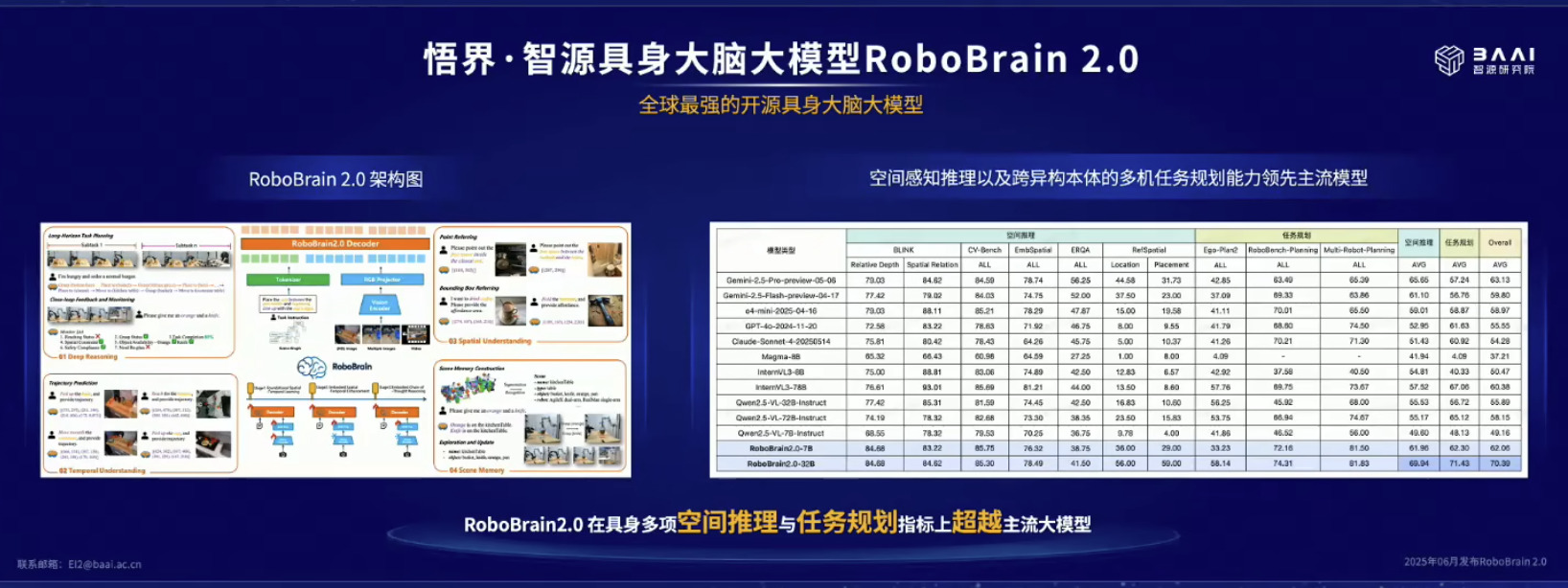
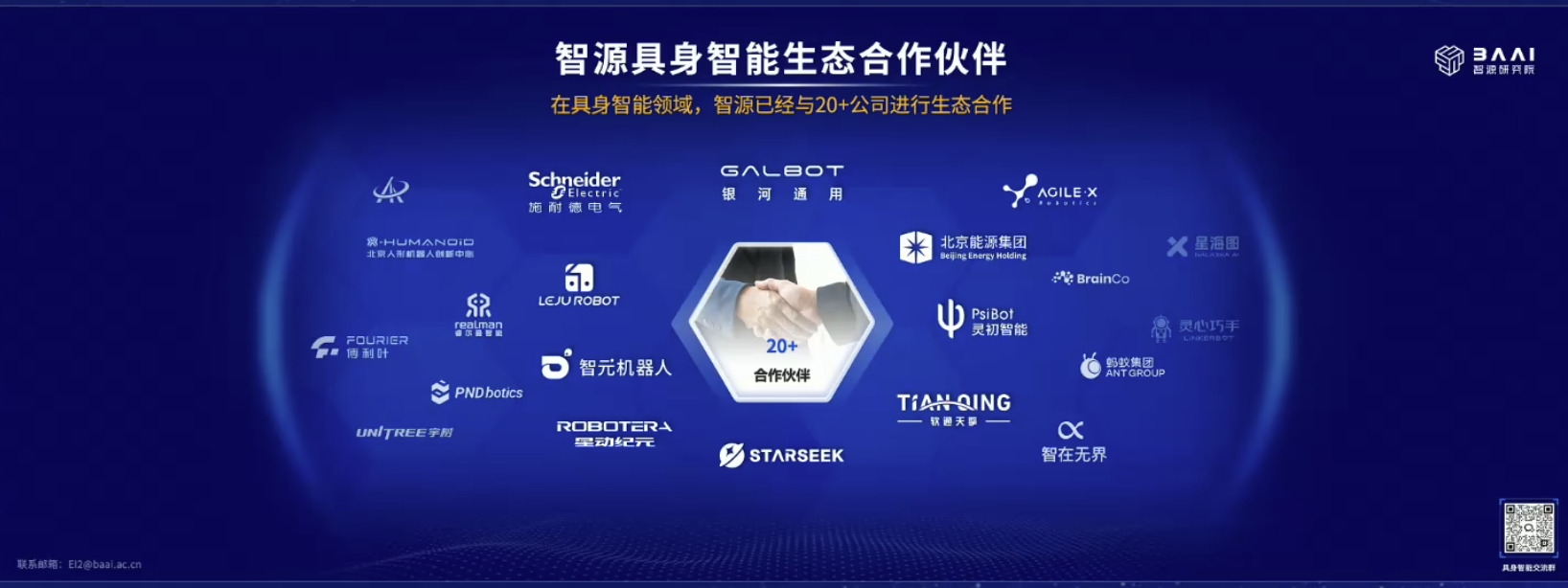
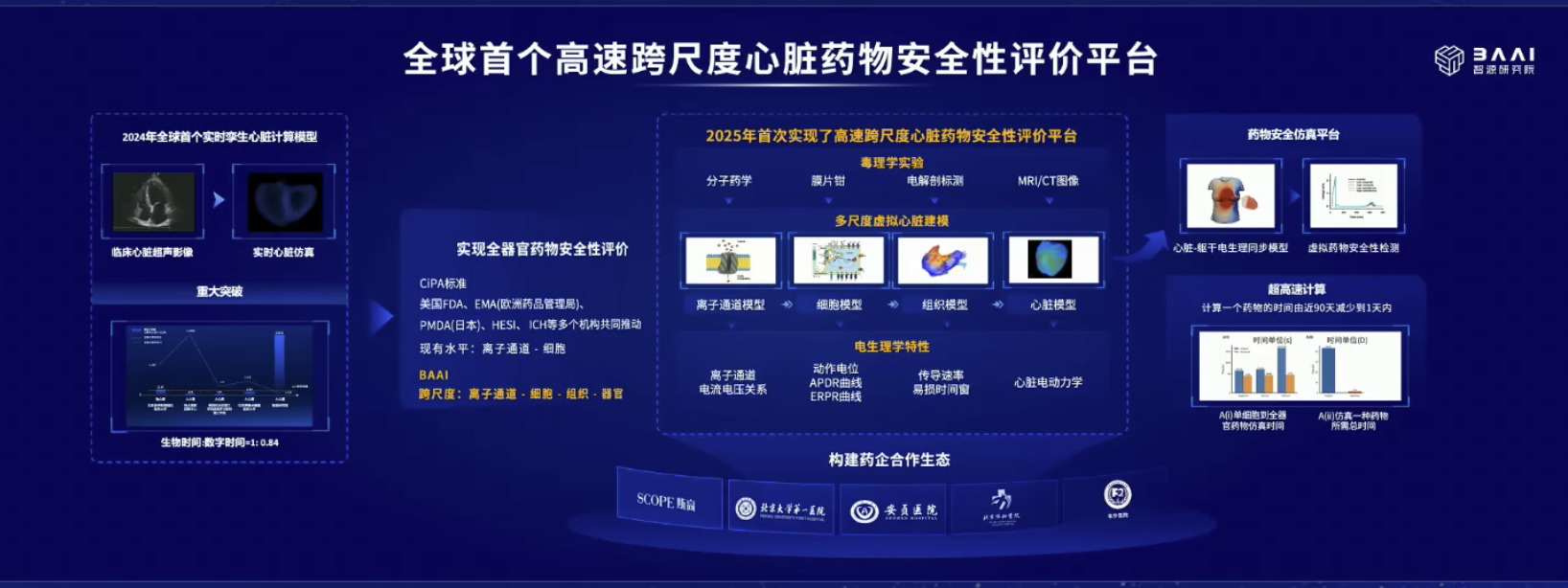
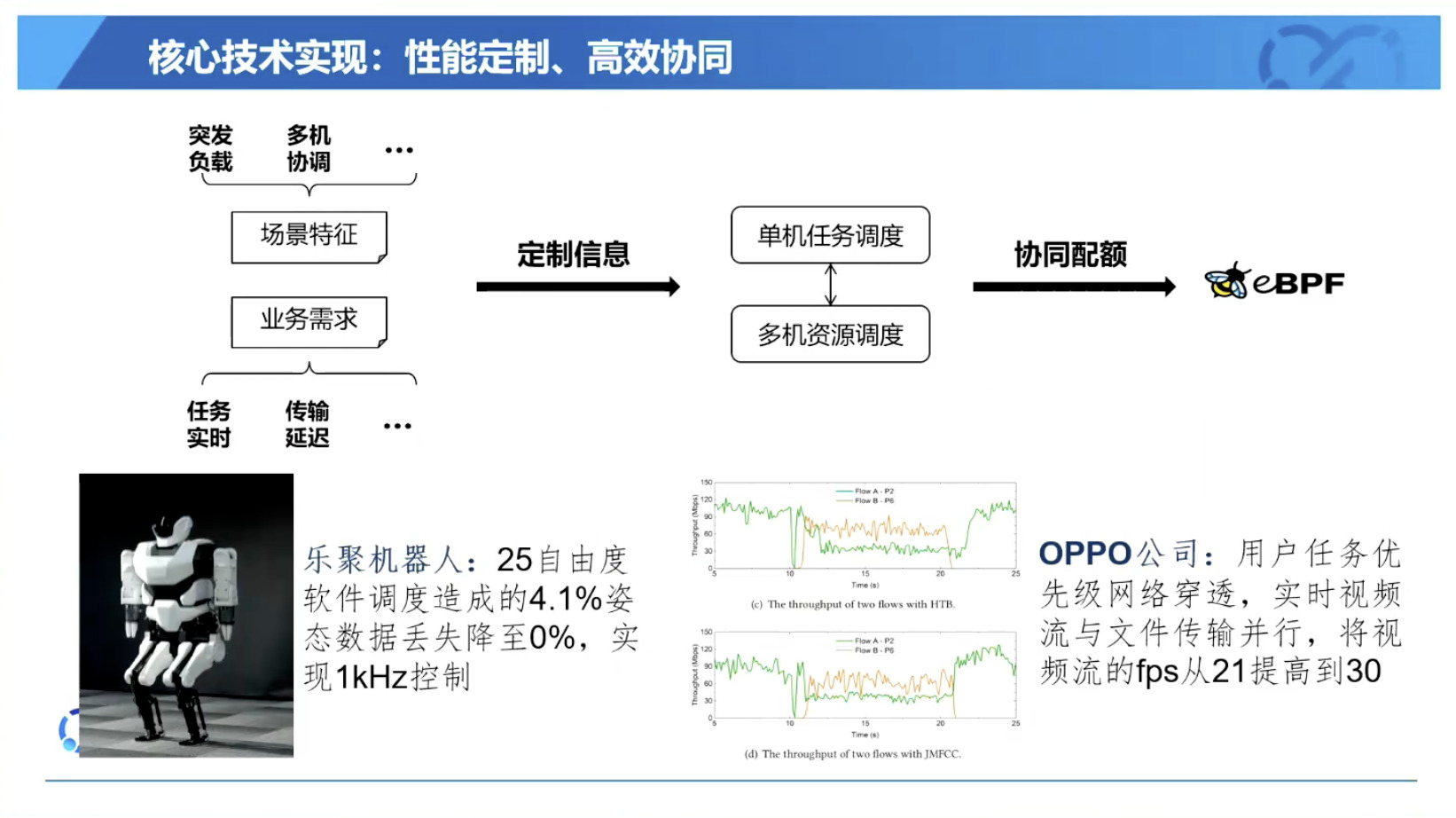
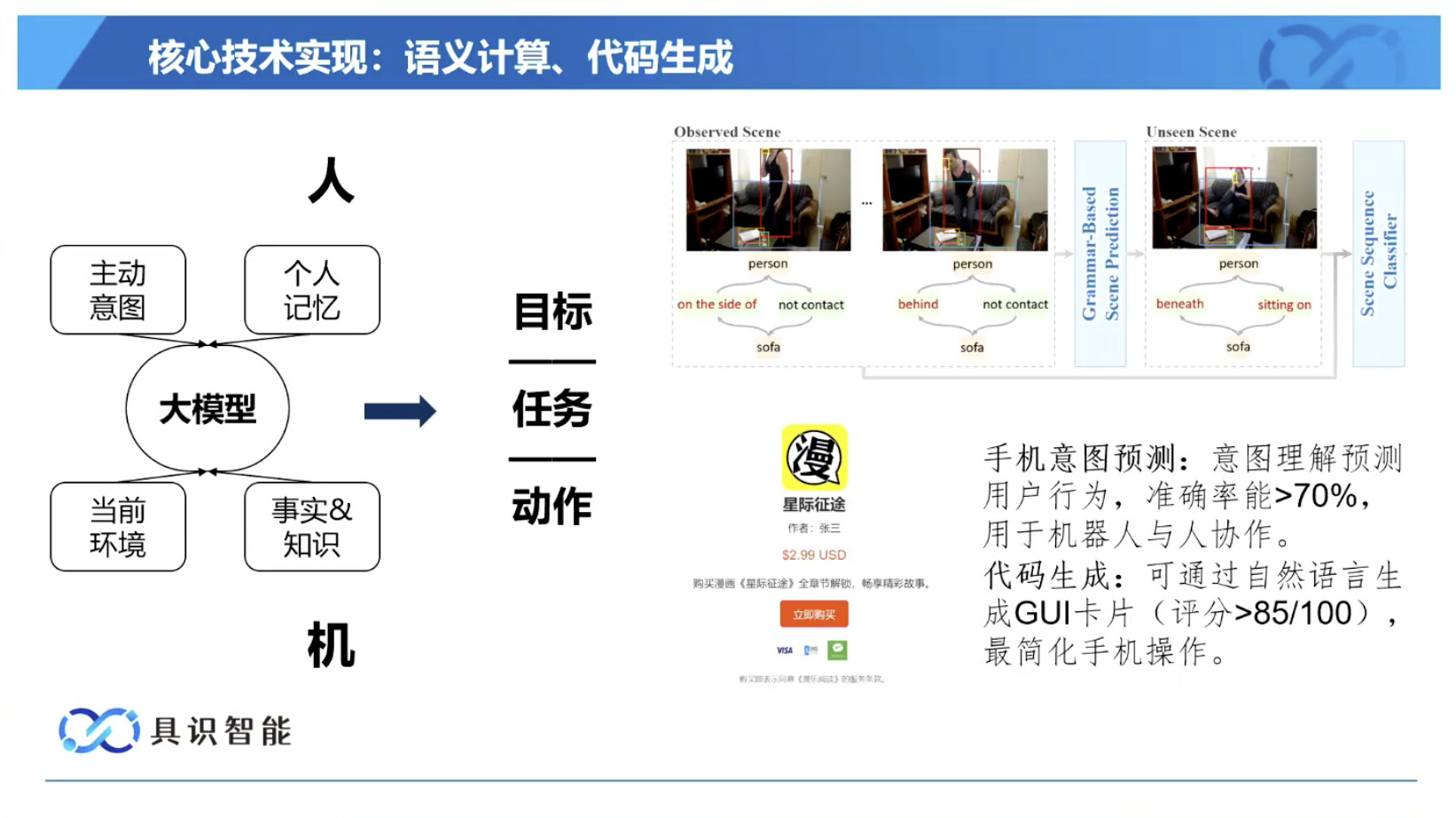
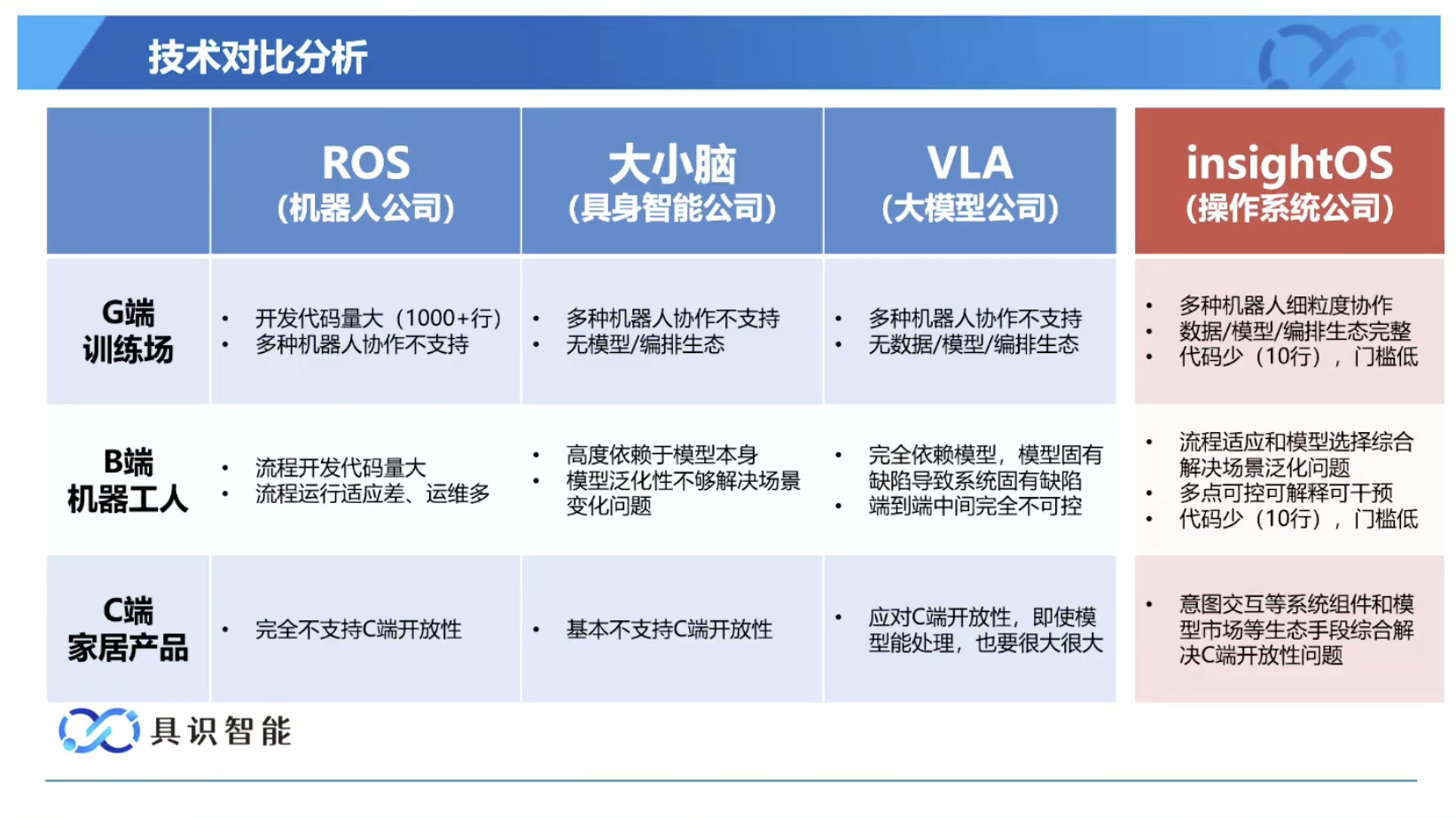
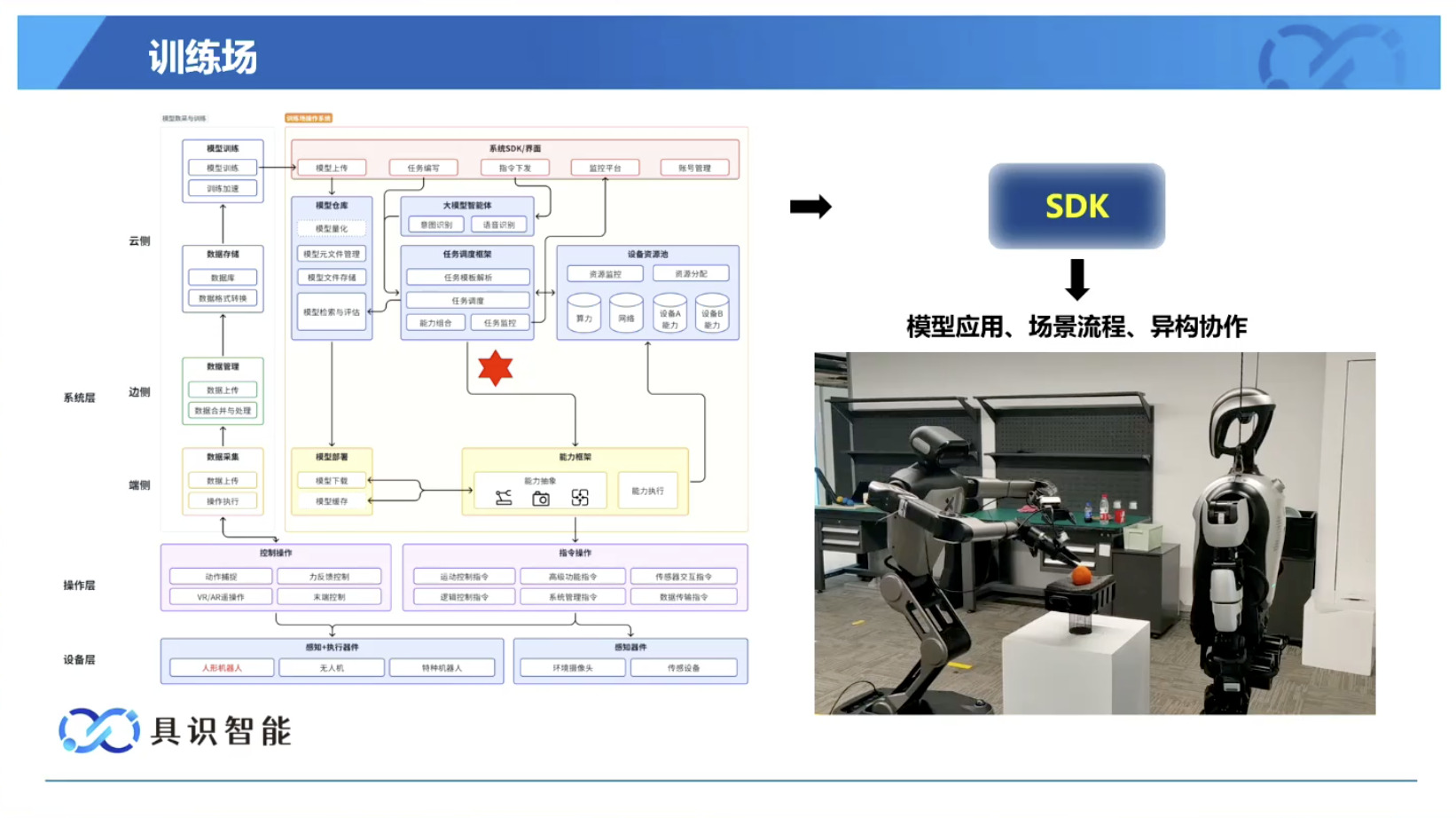
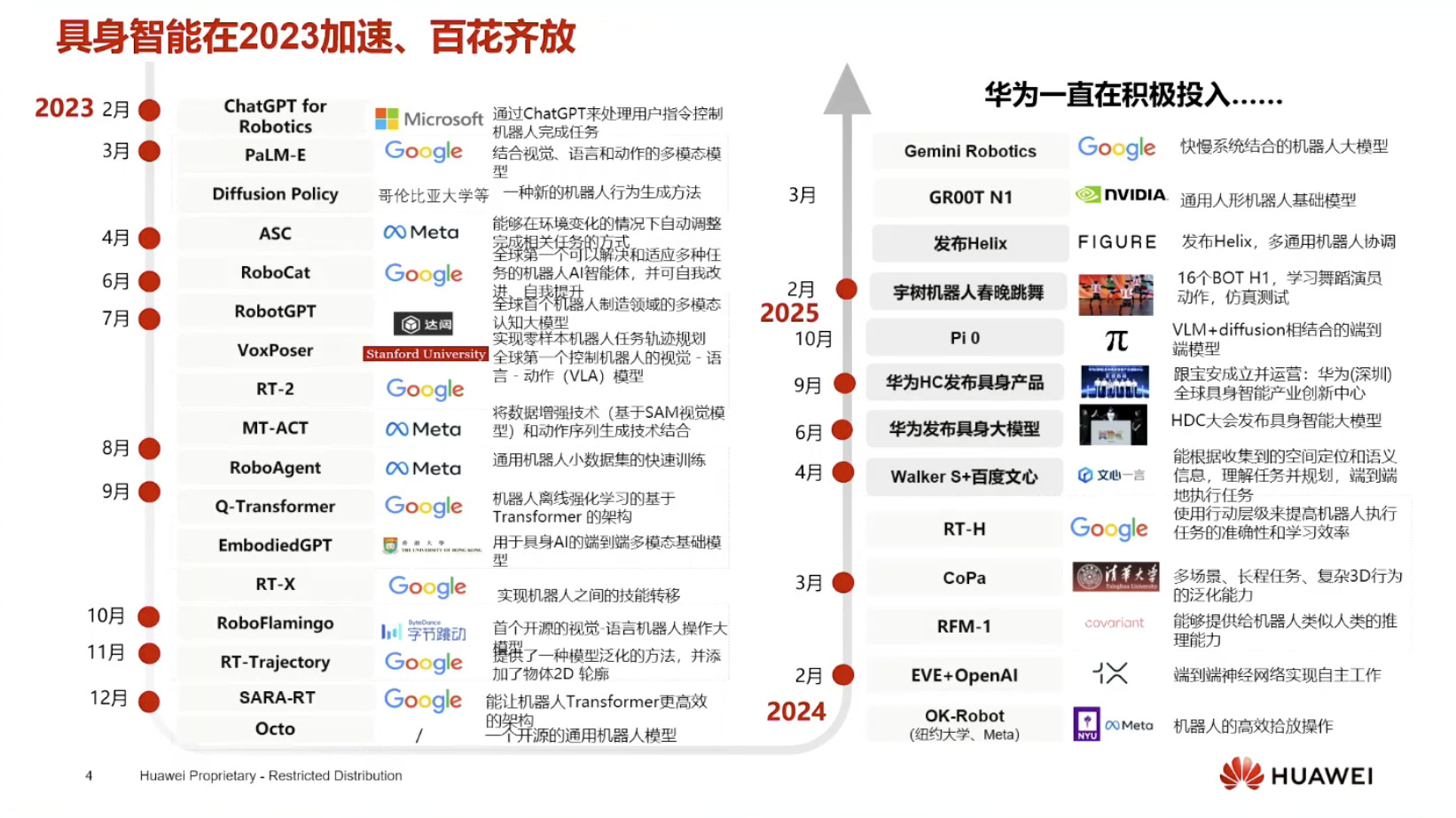
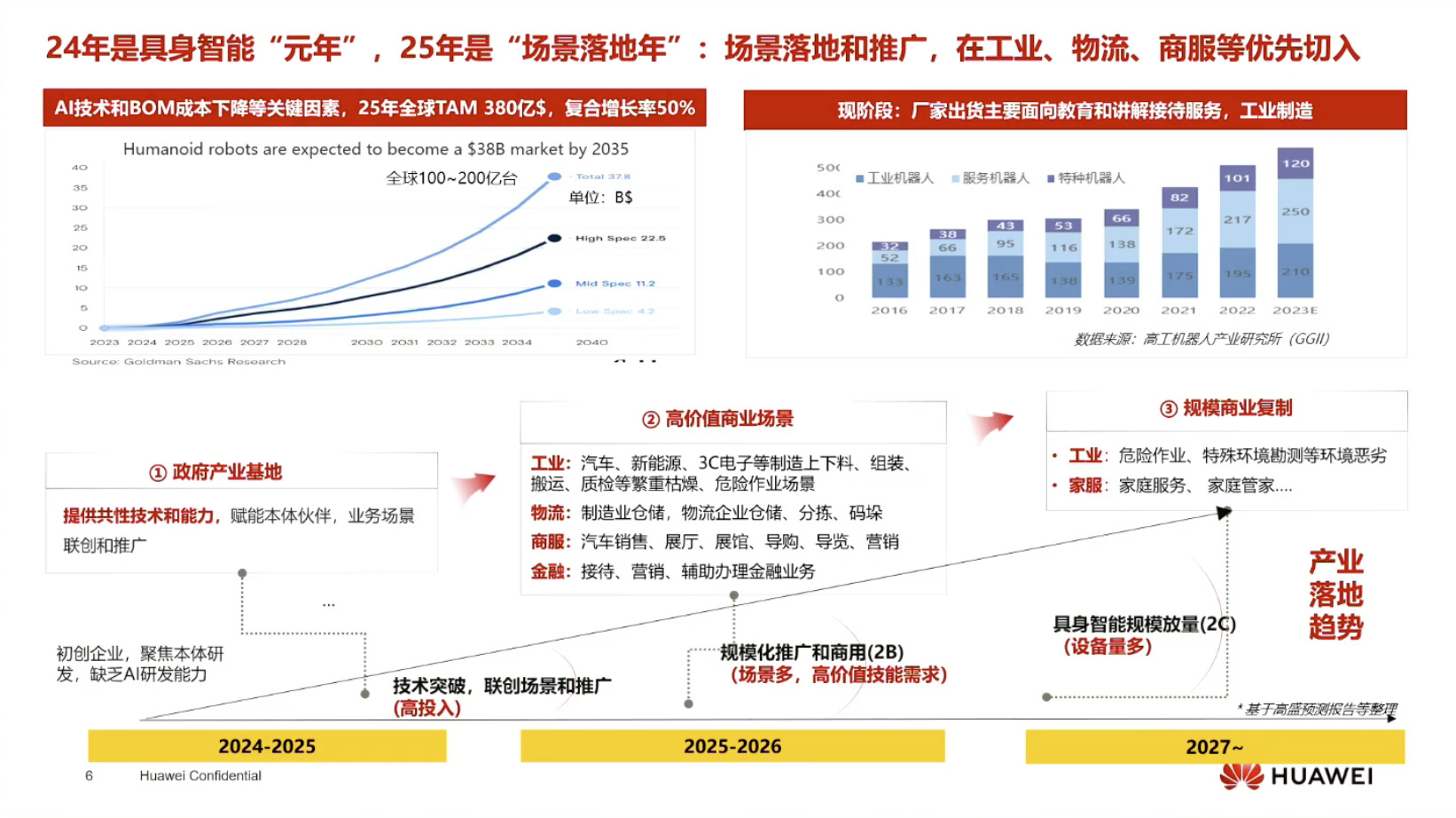
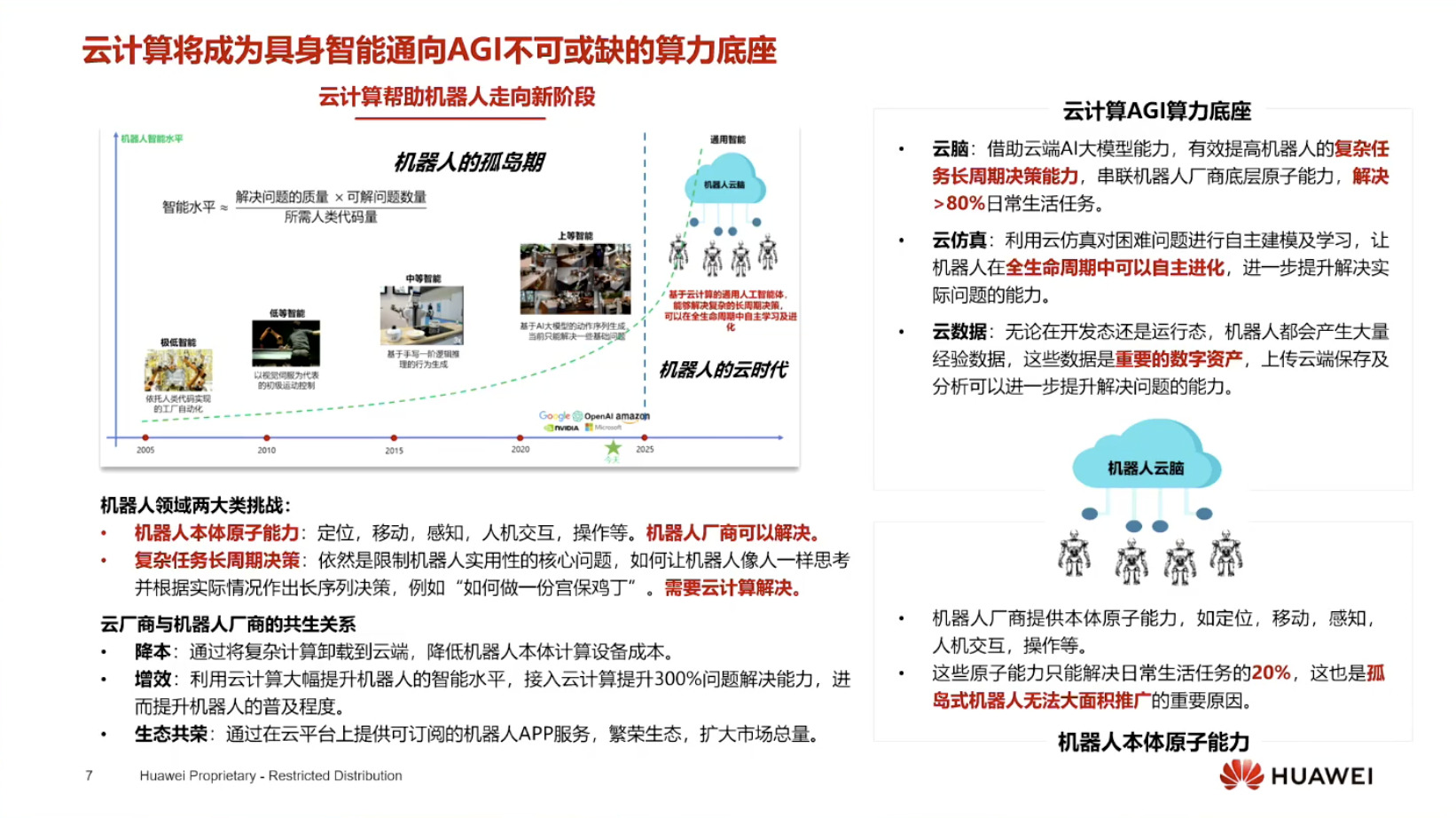
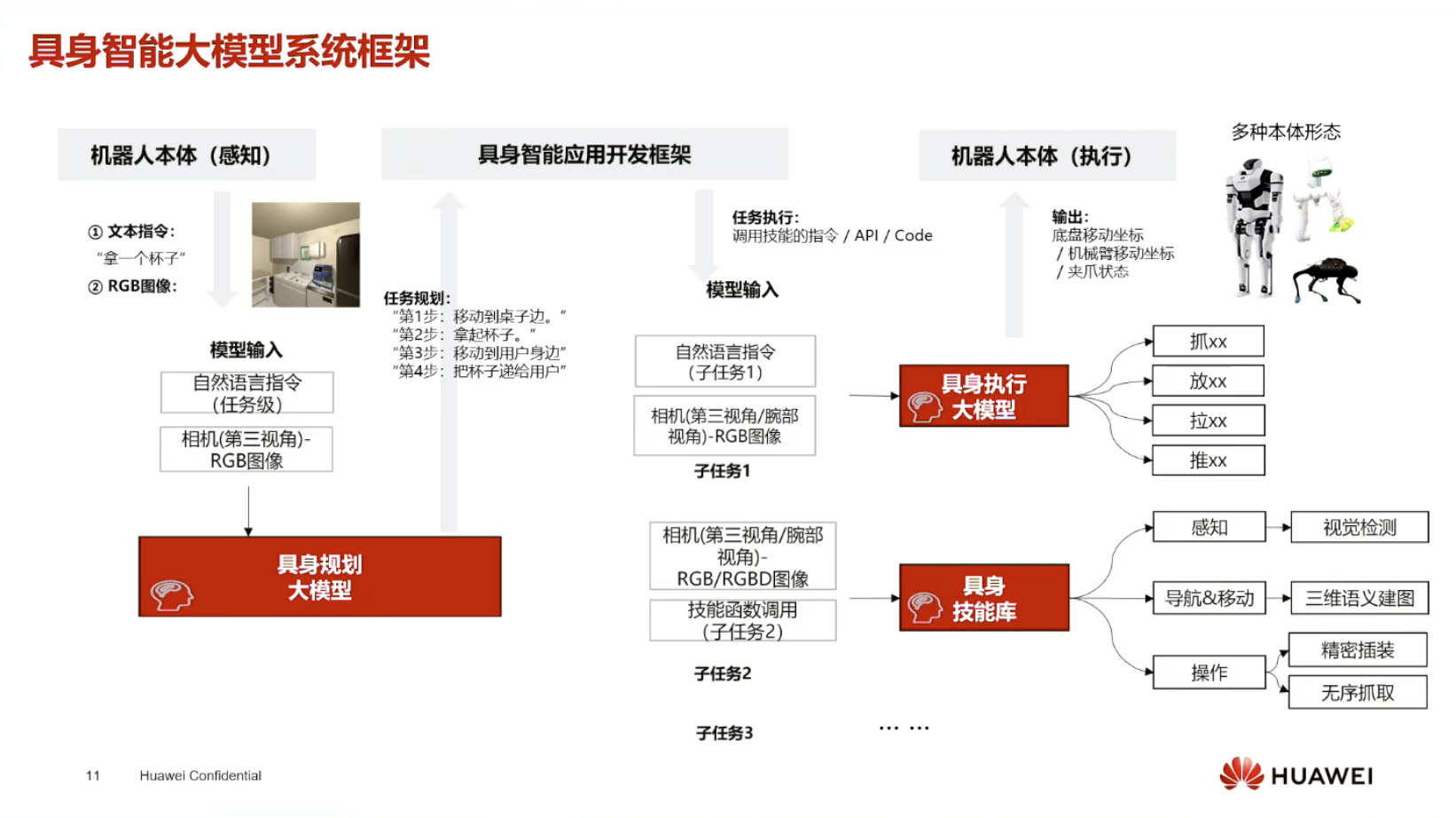
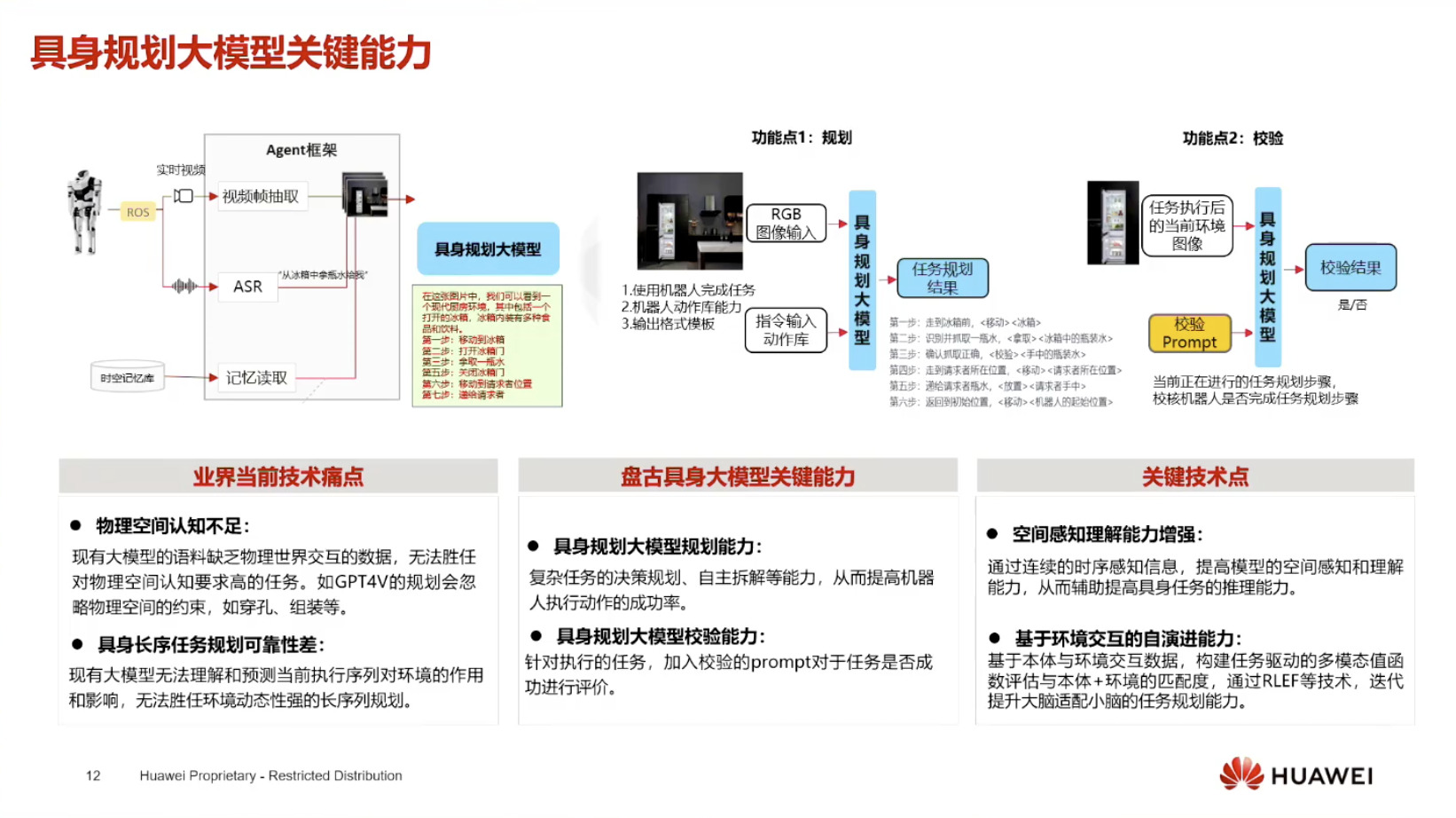
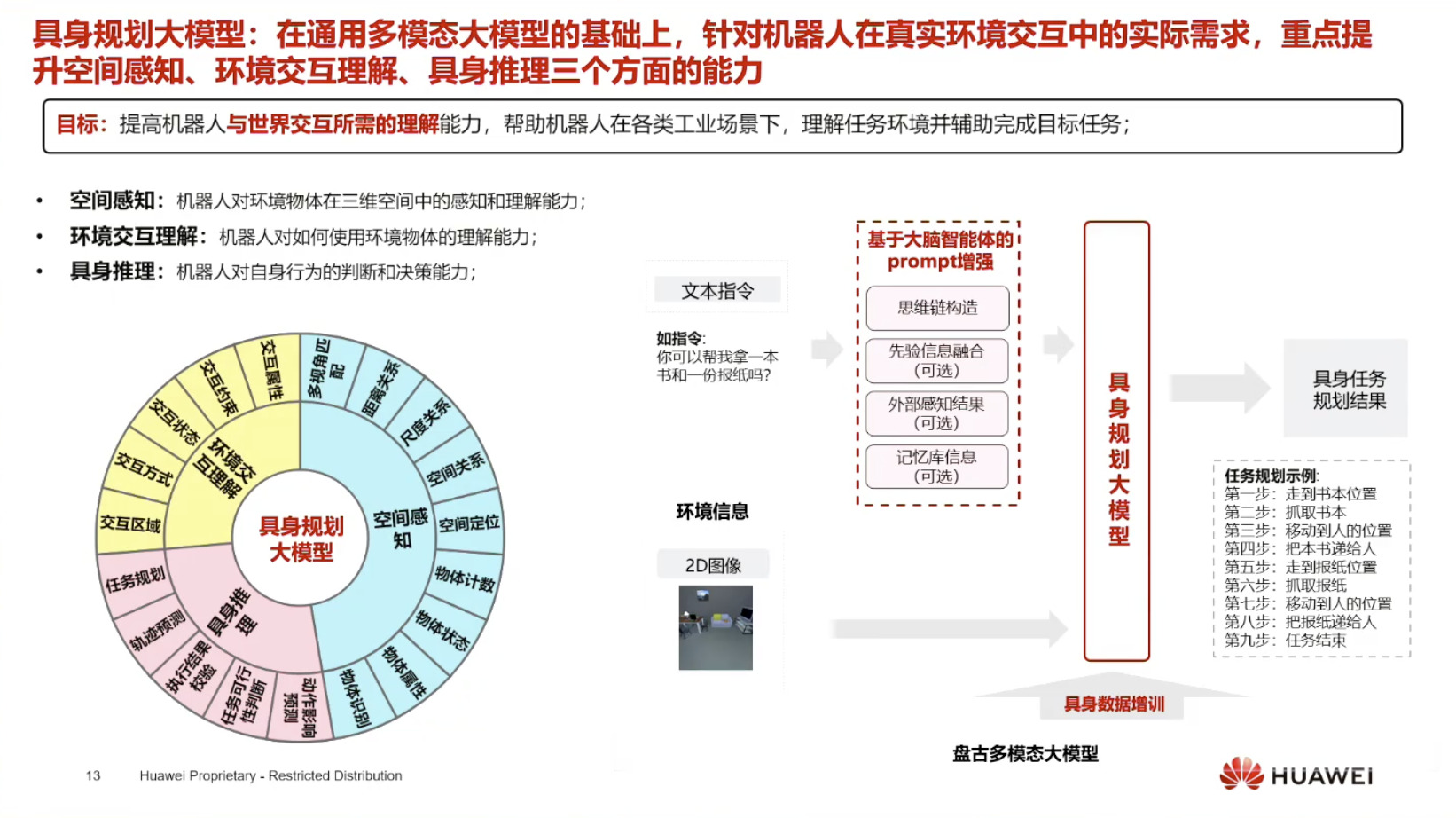
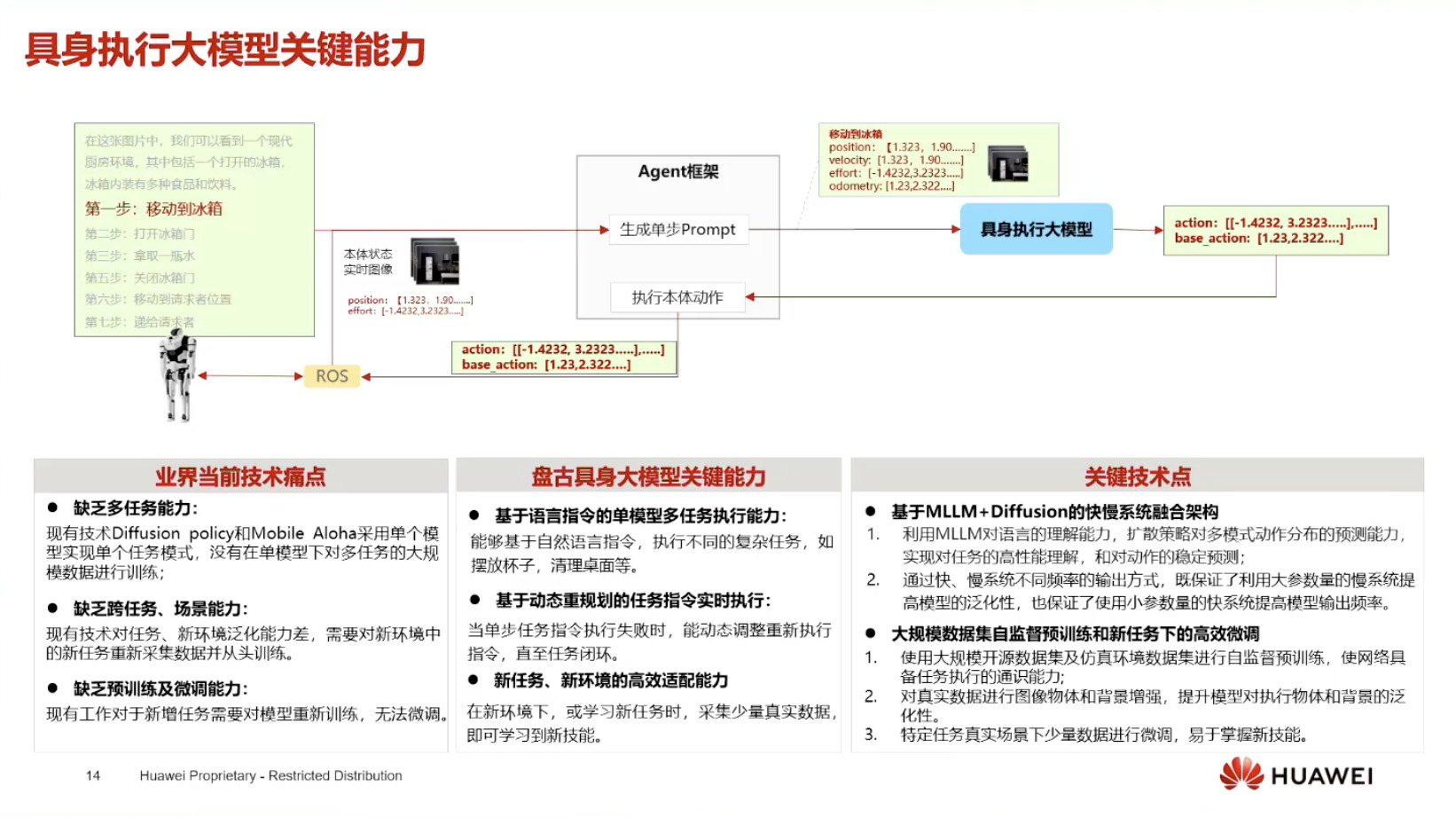
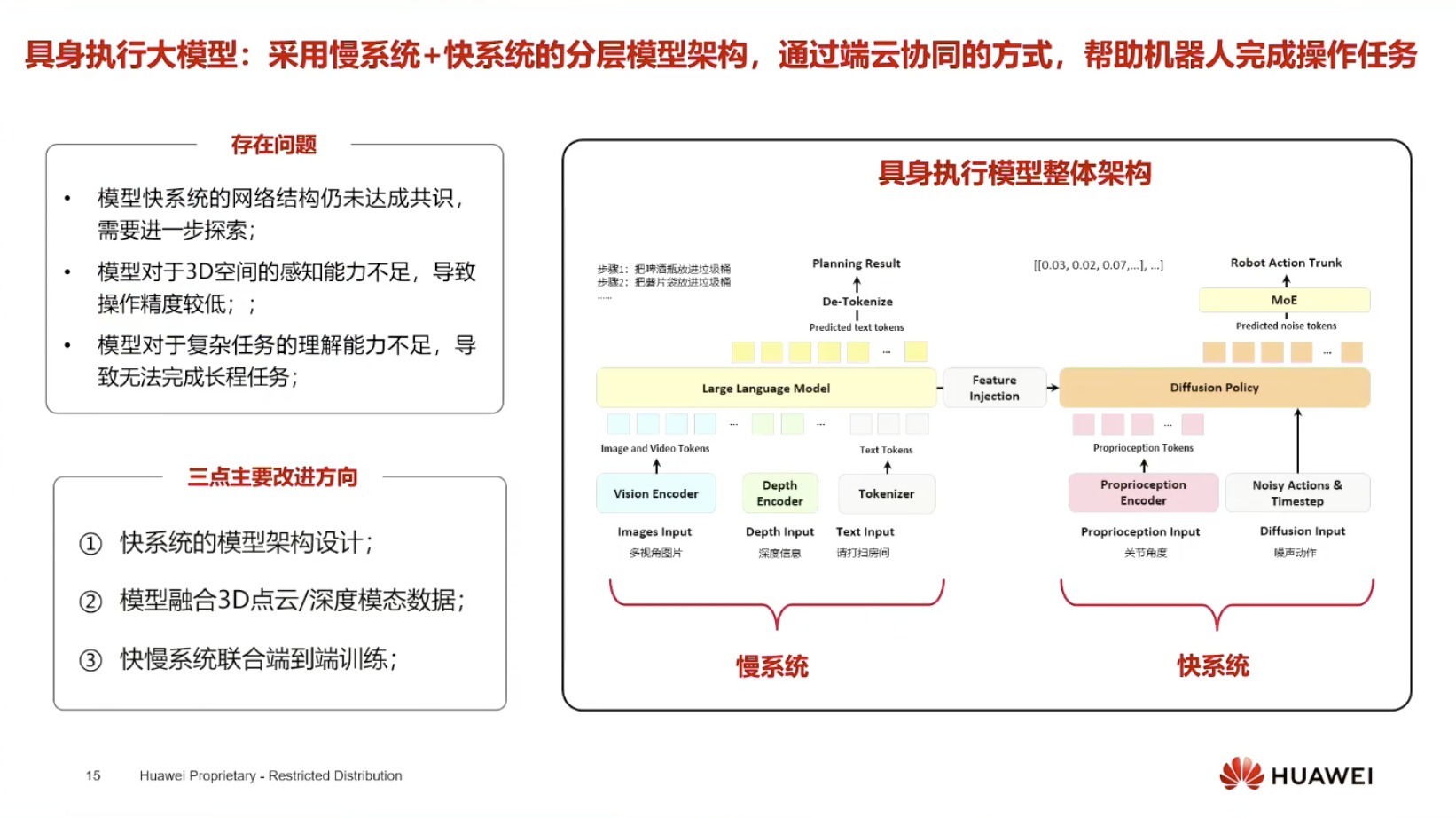
具身模型 NVIDIA Isaac GROOT N1 详解
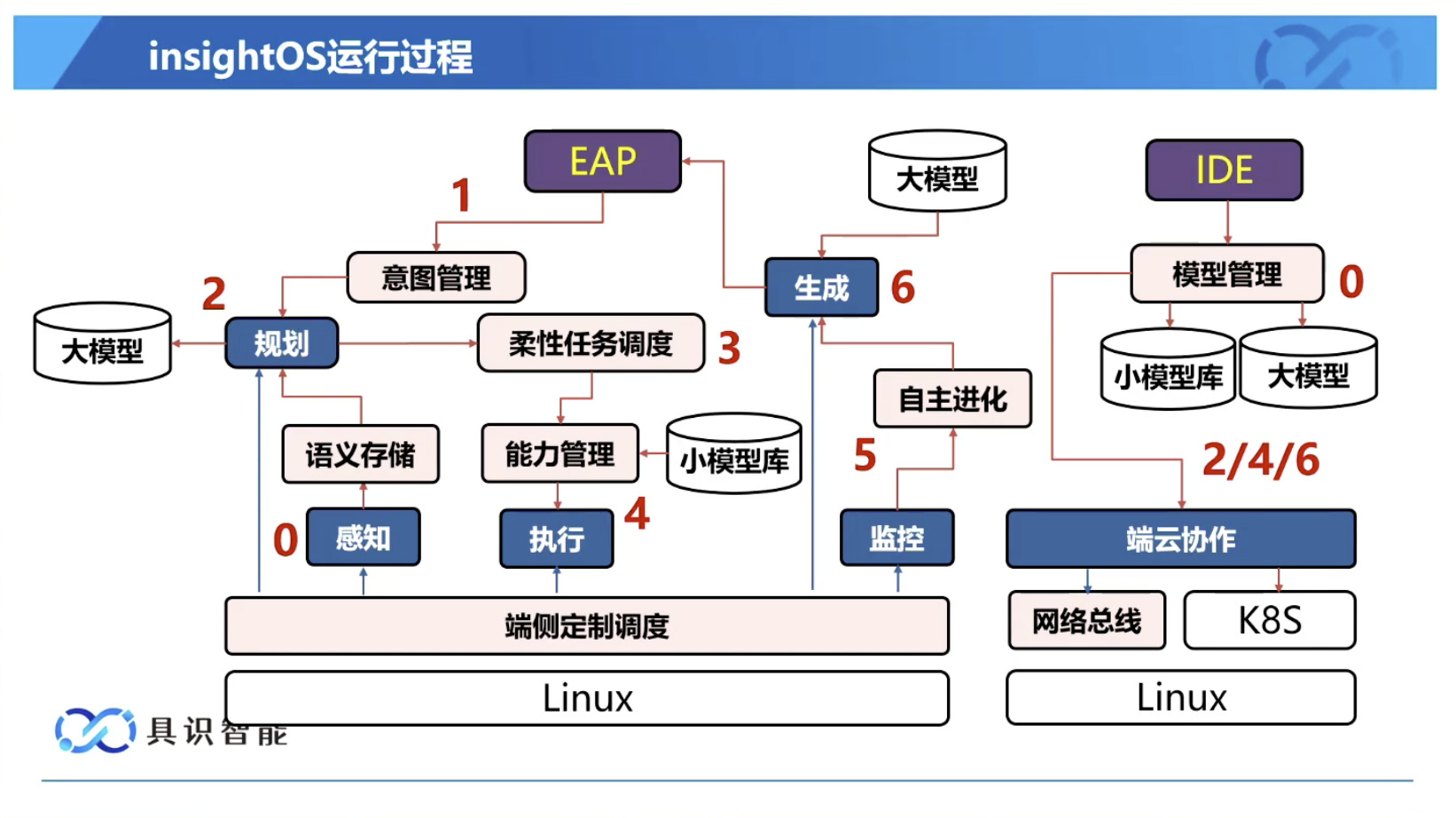
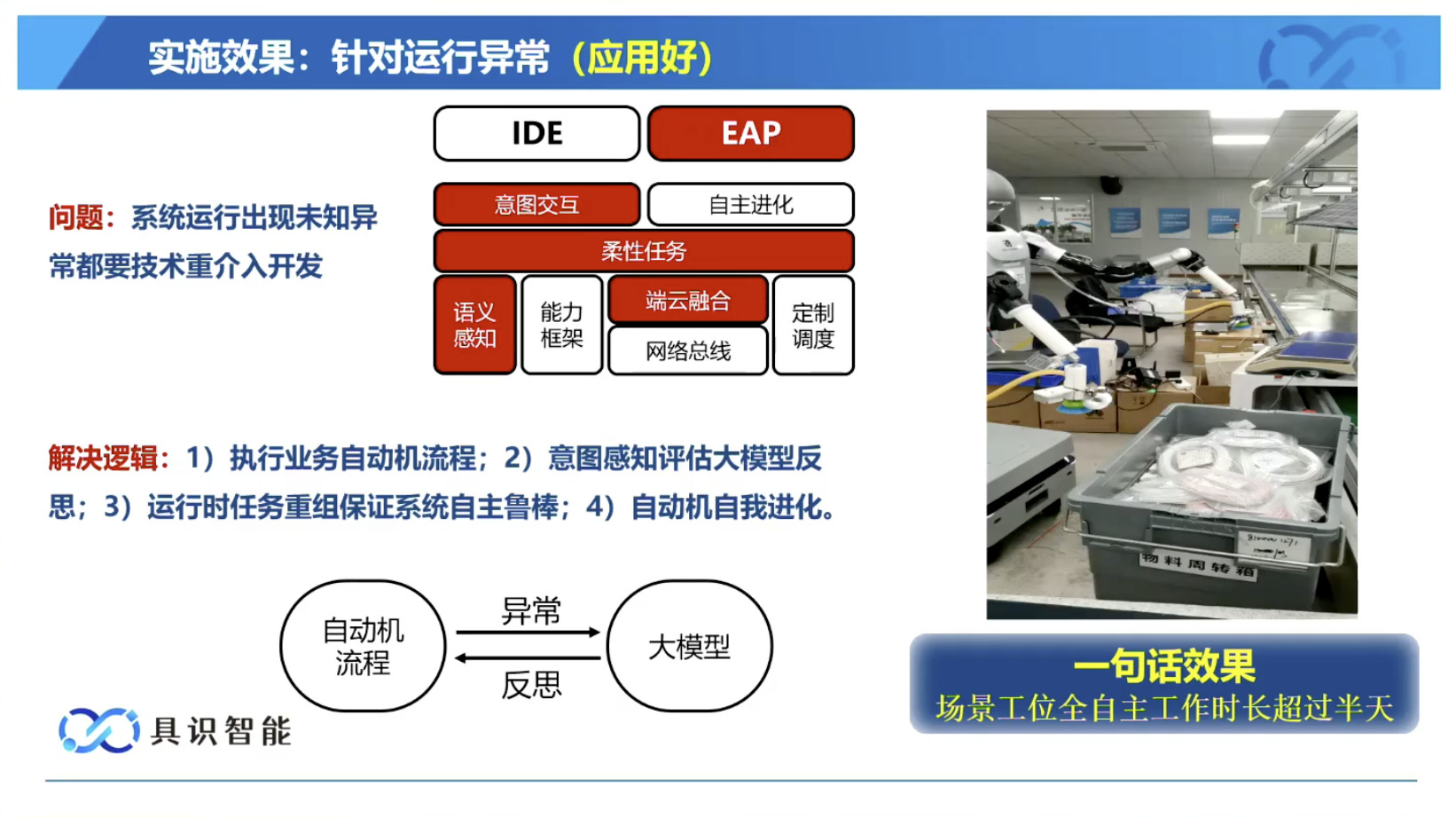
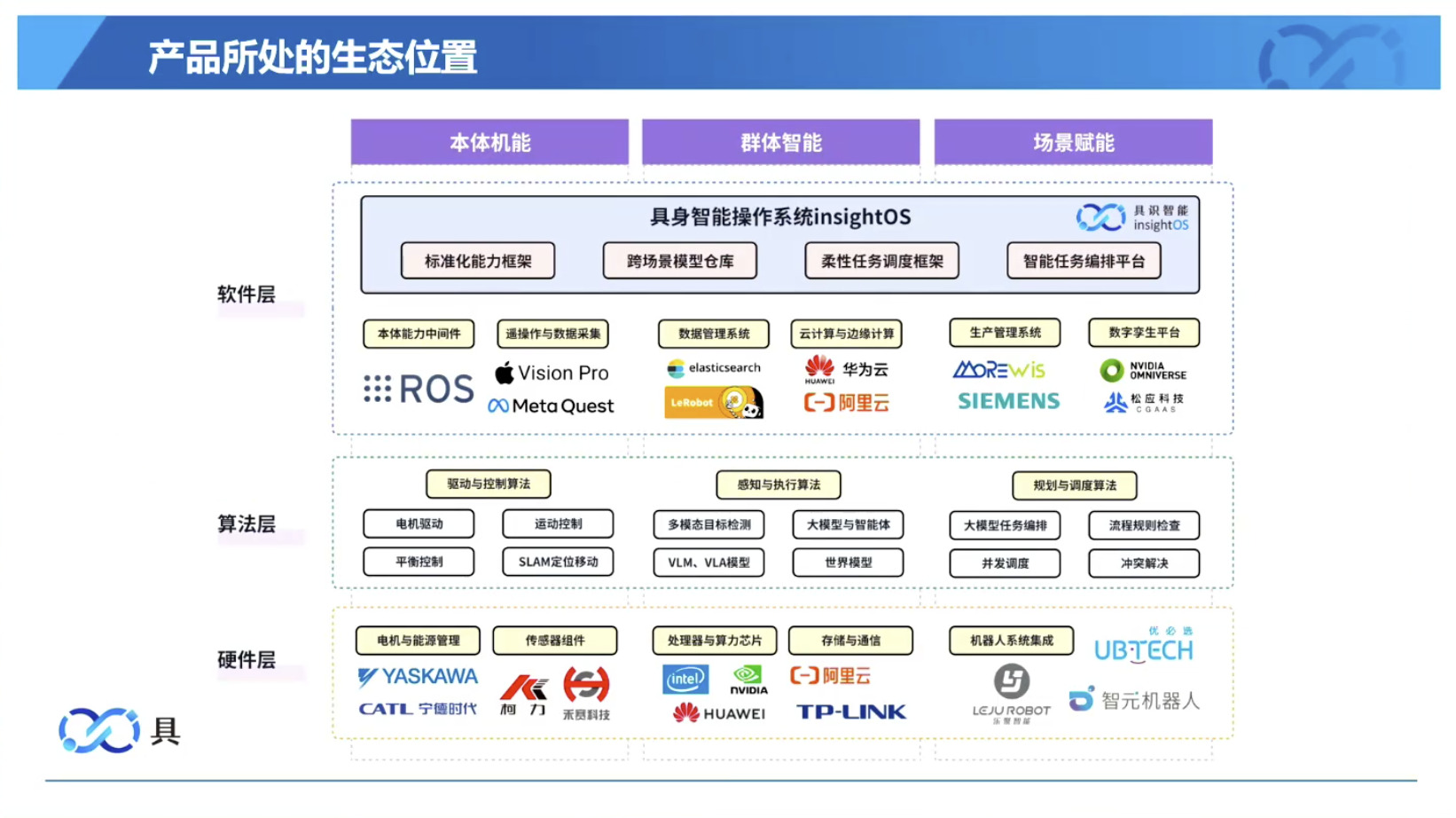
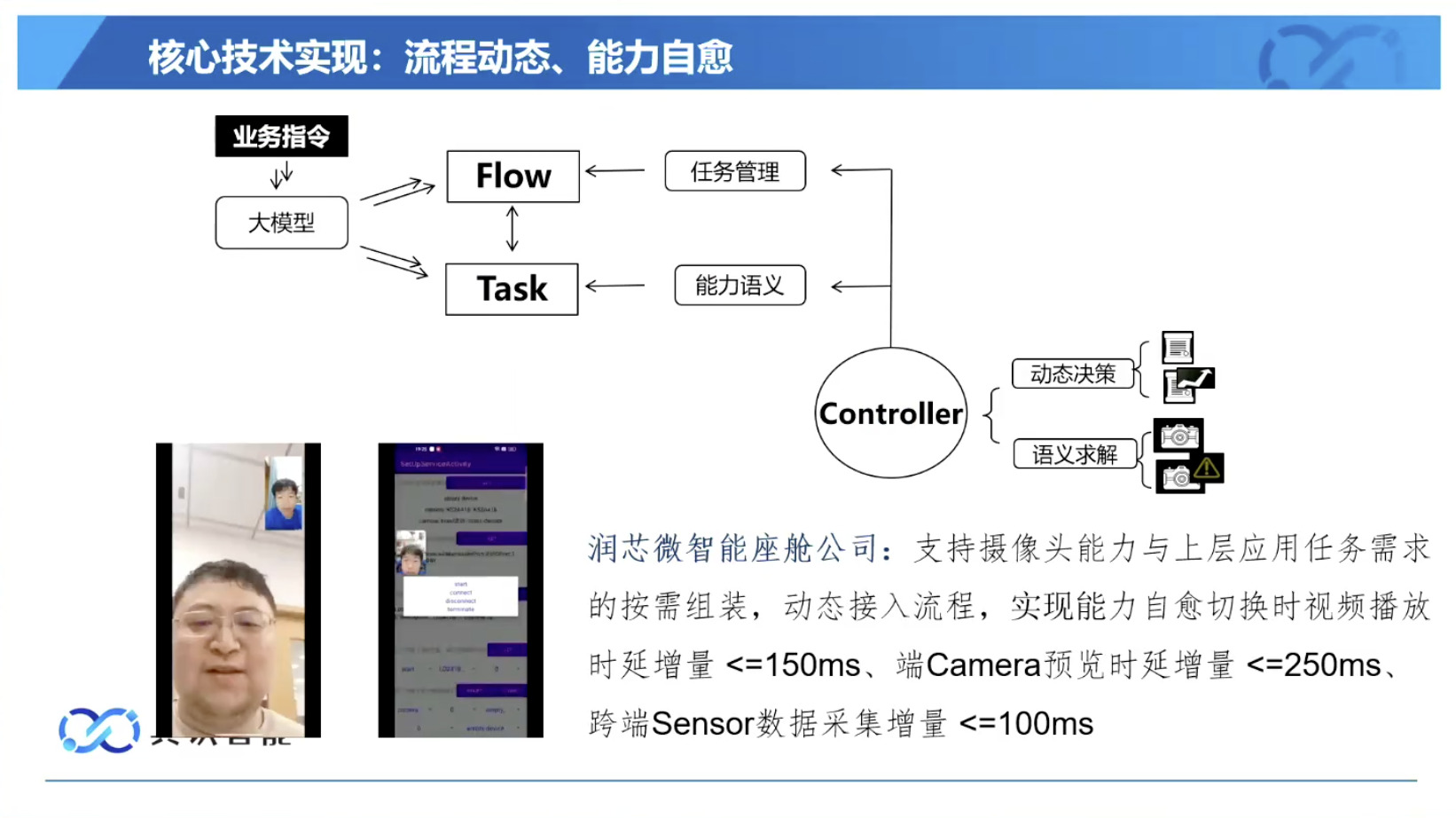
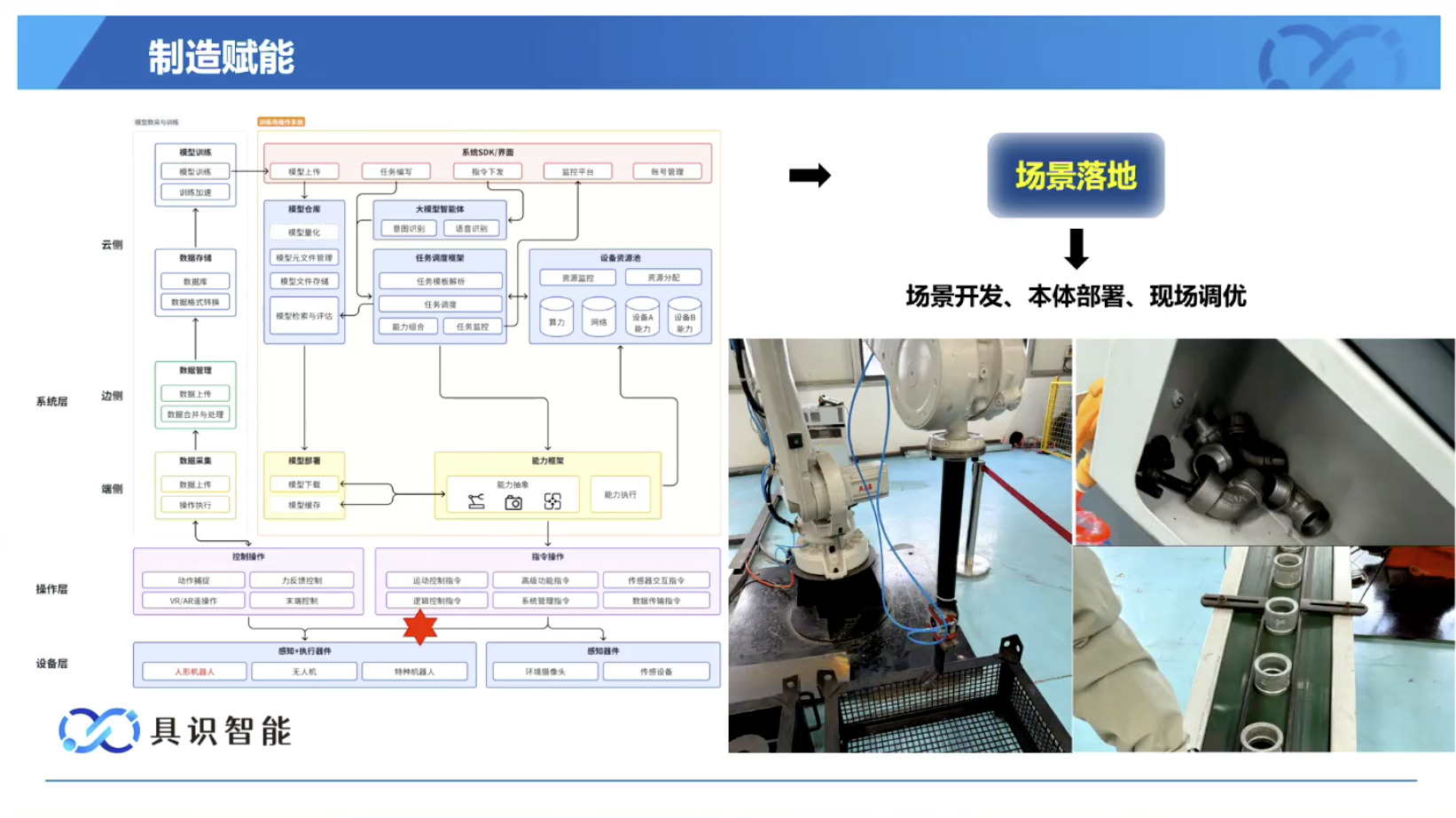
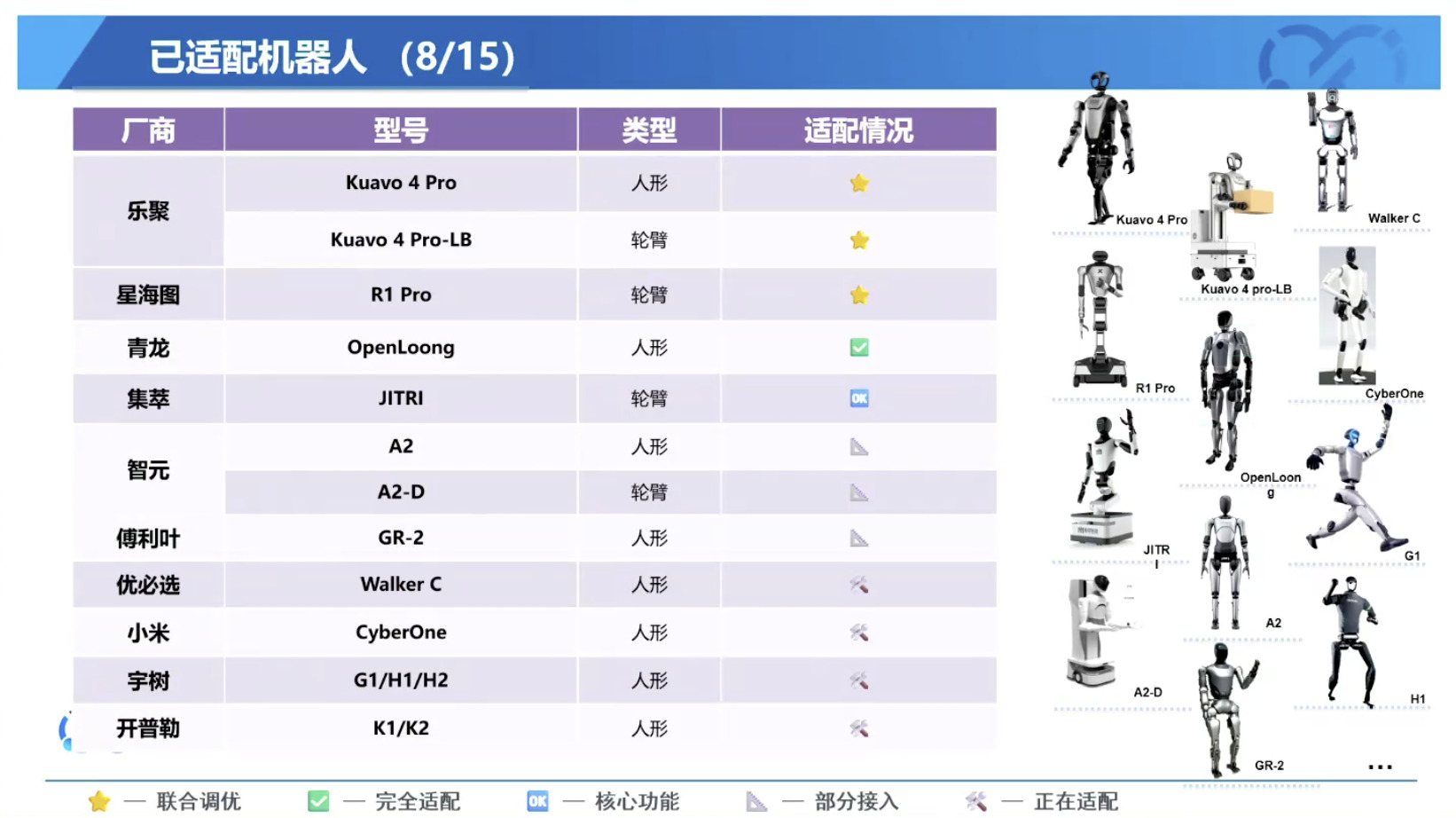
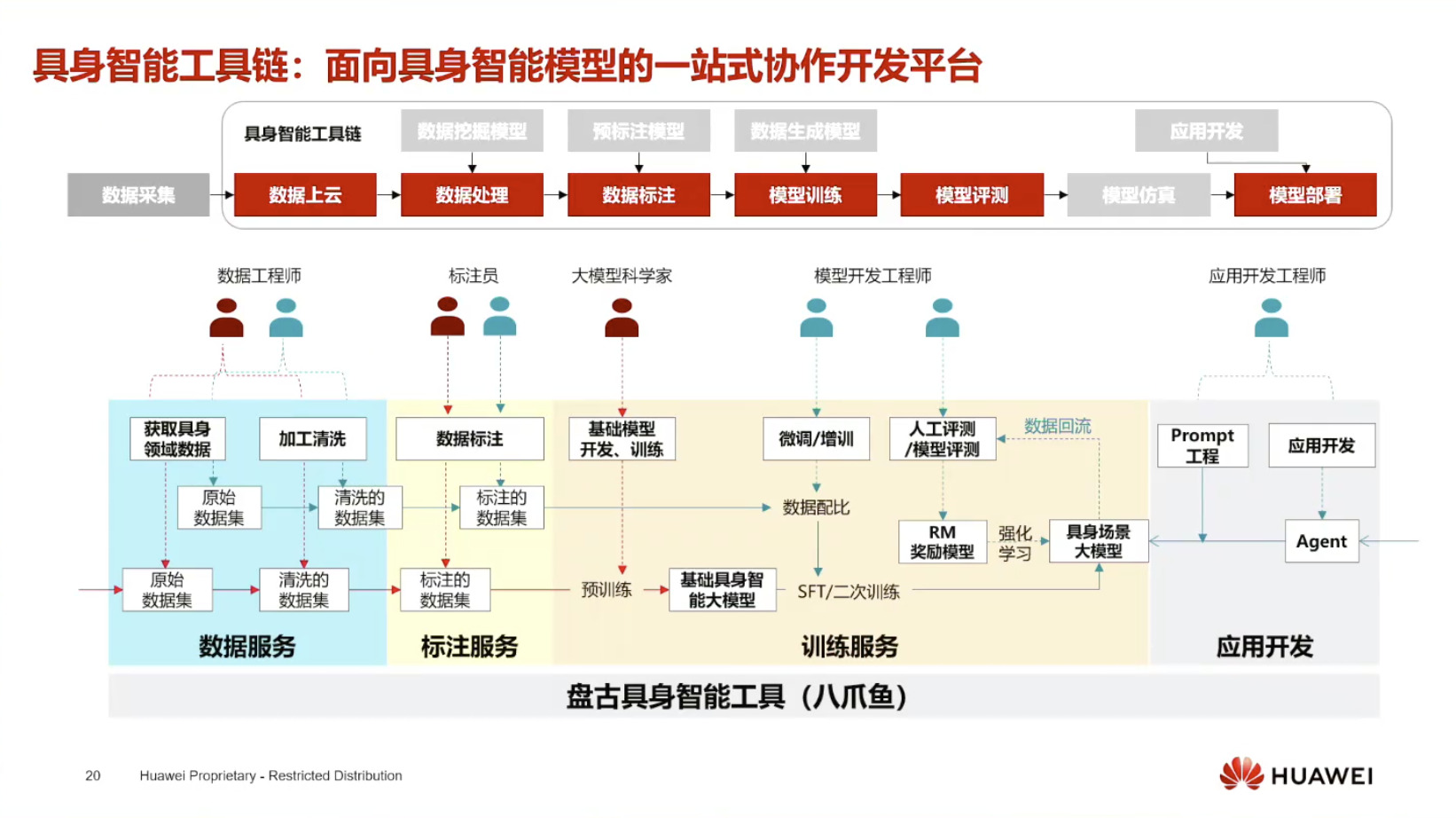
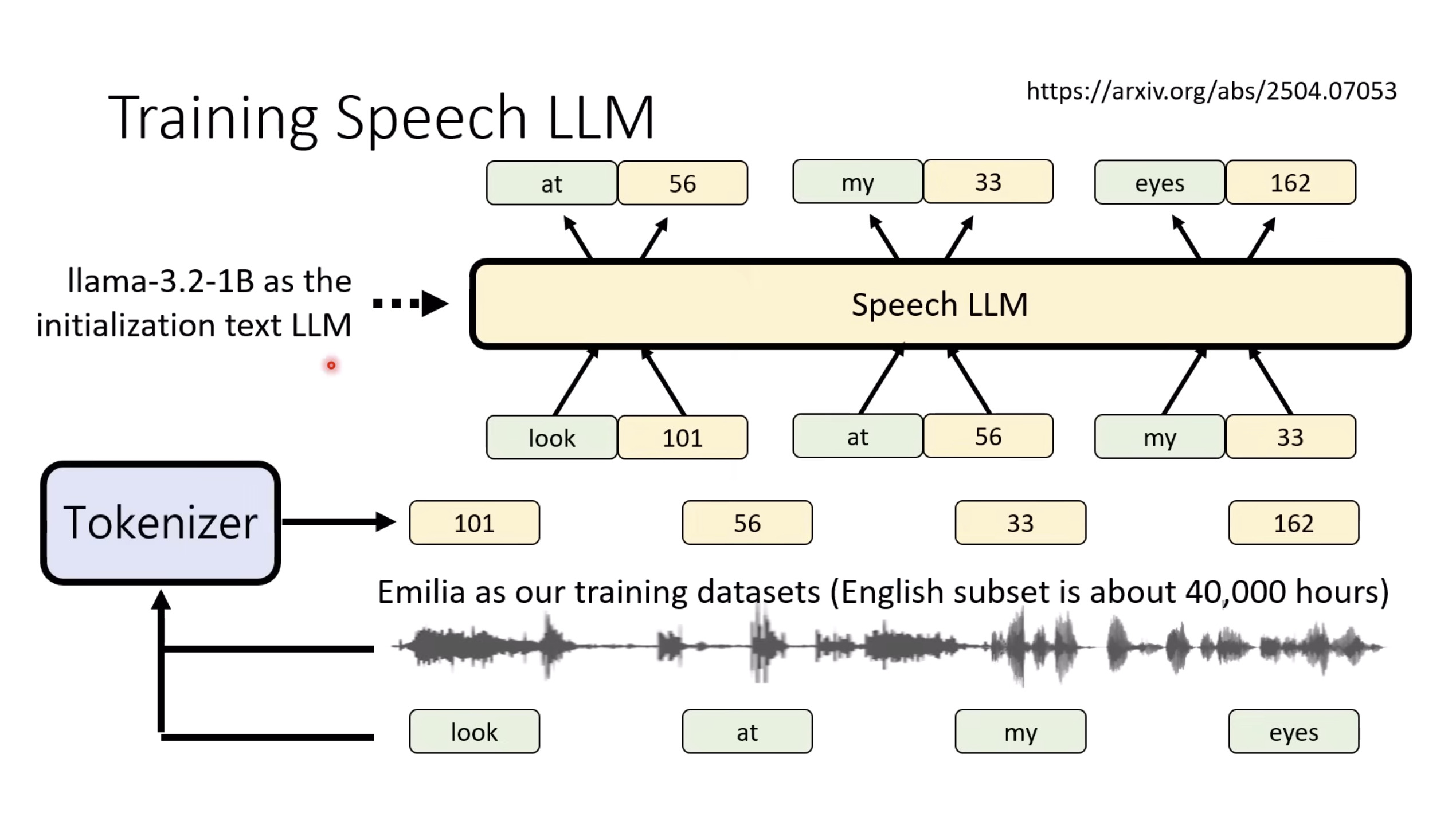
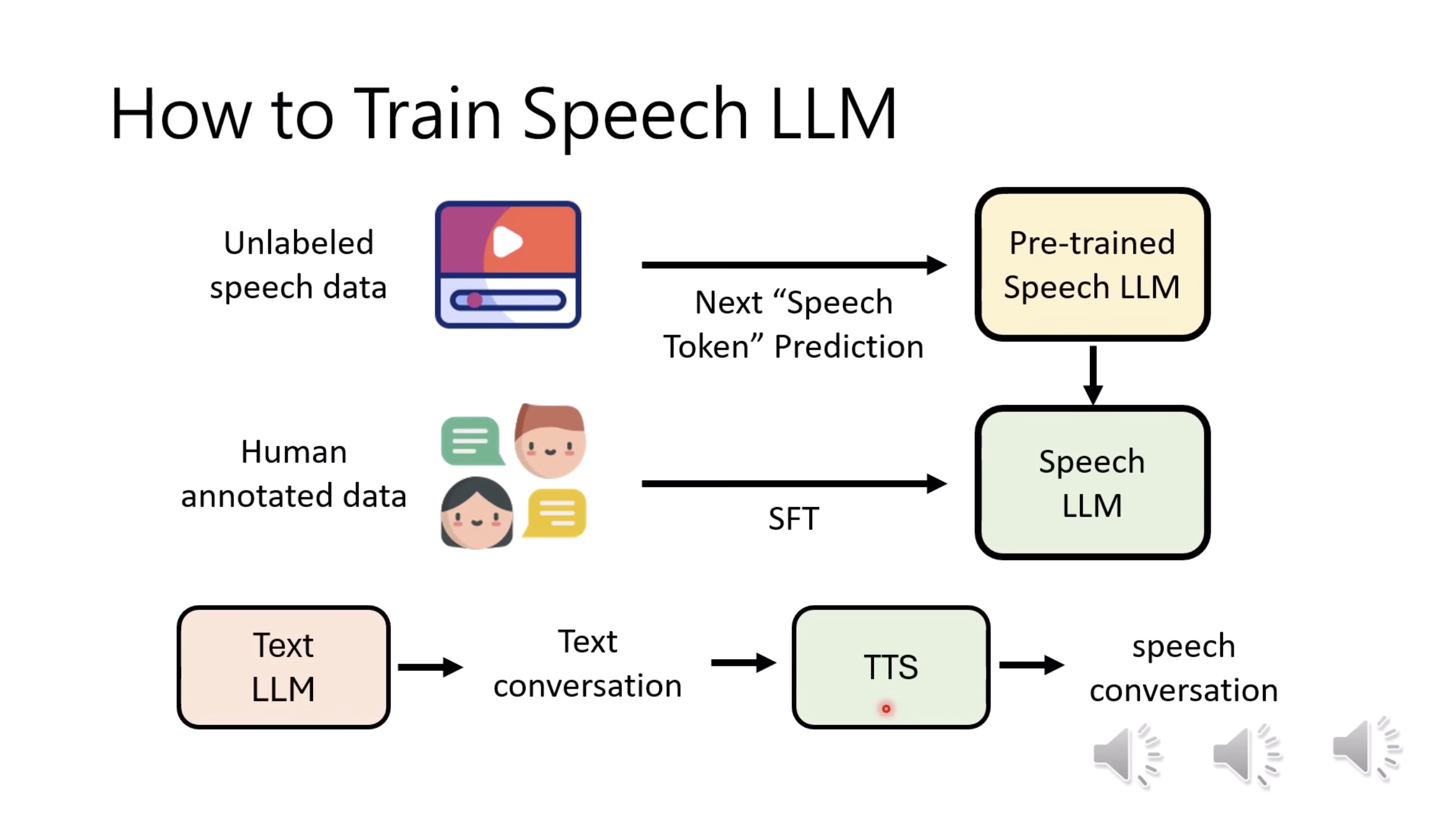
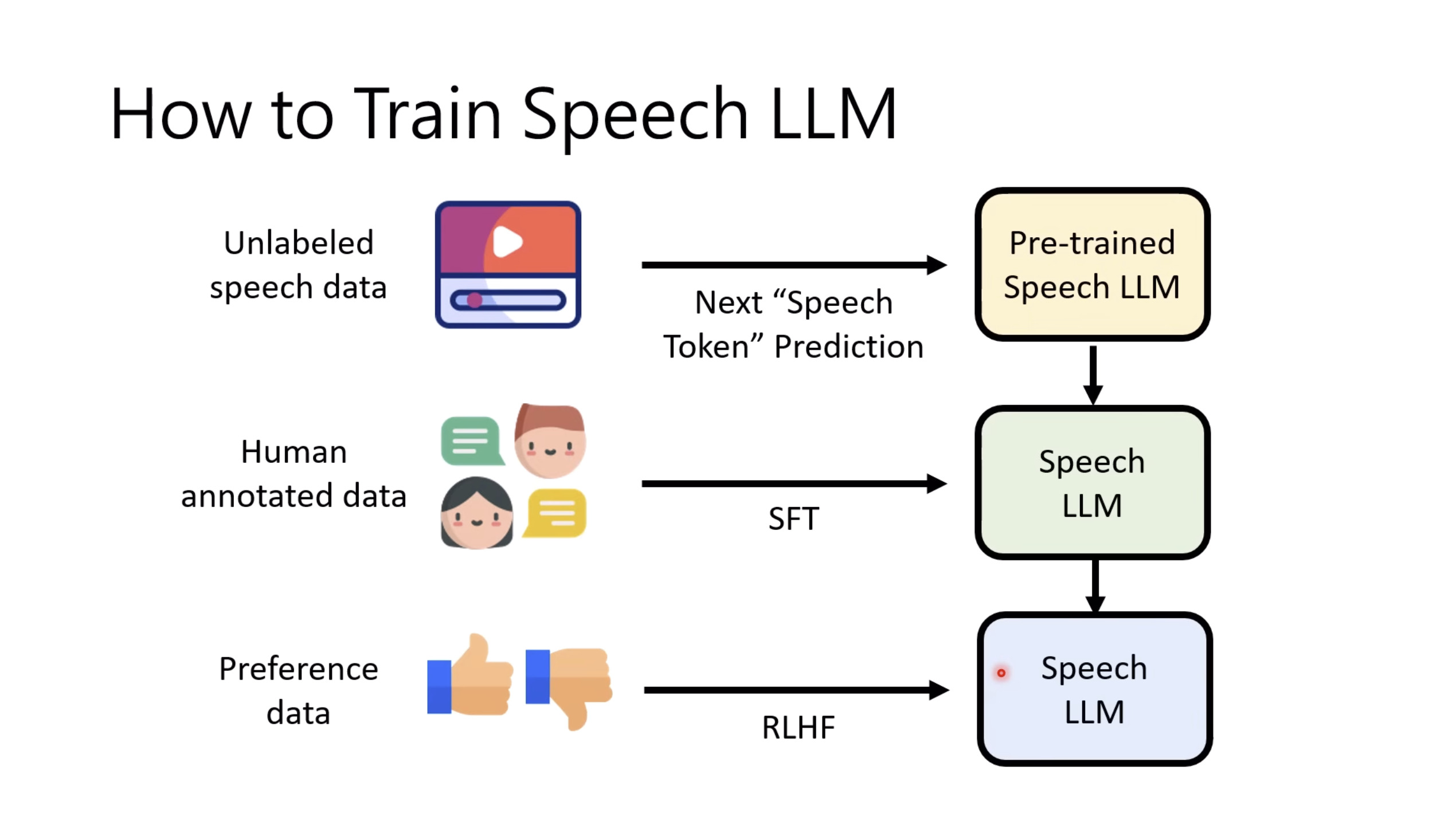
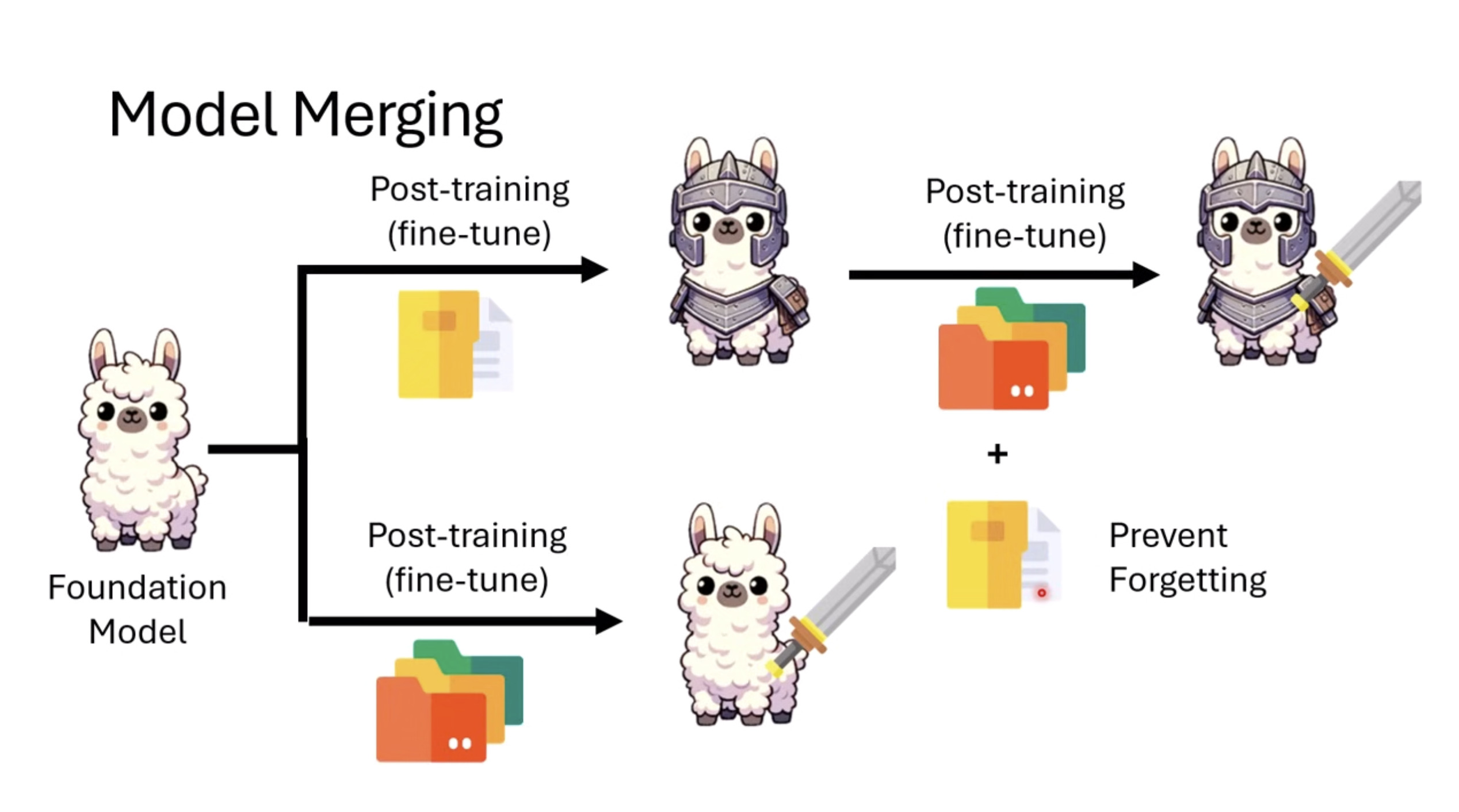
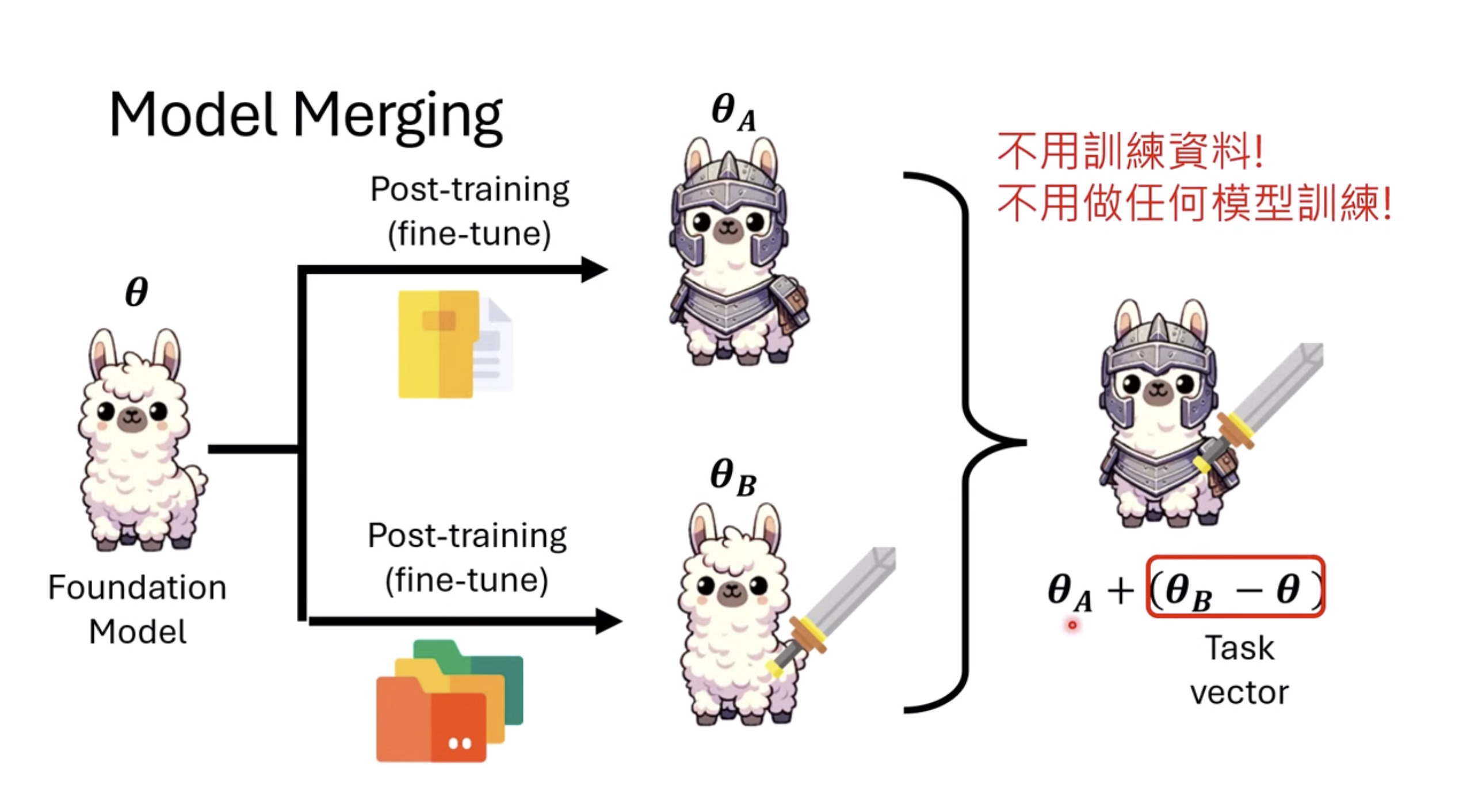
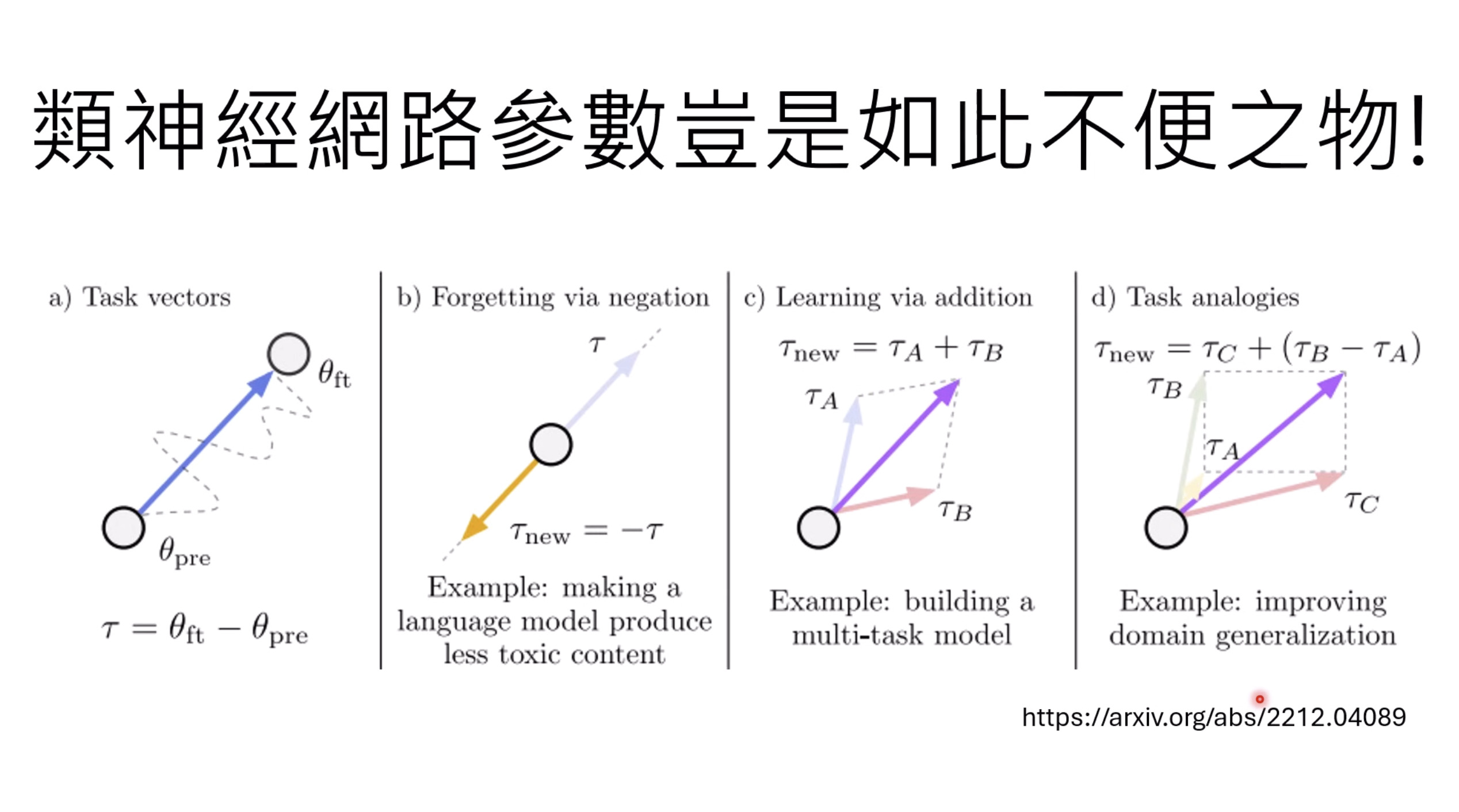
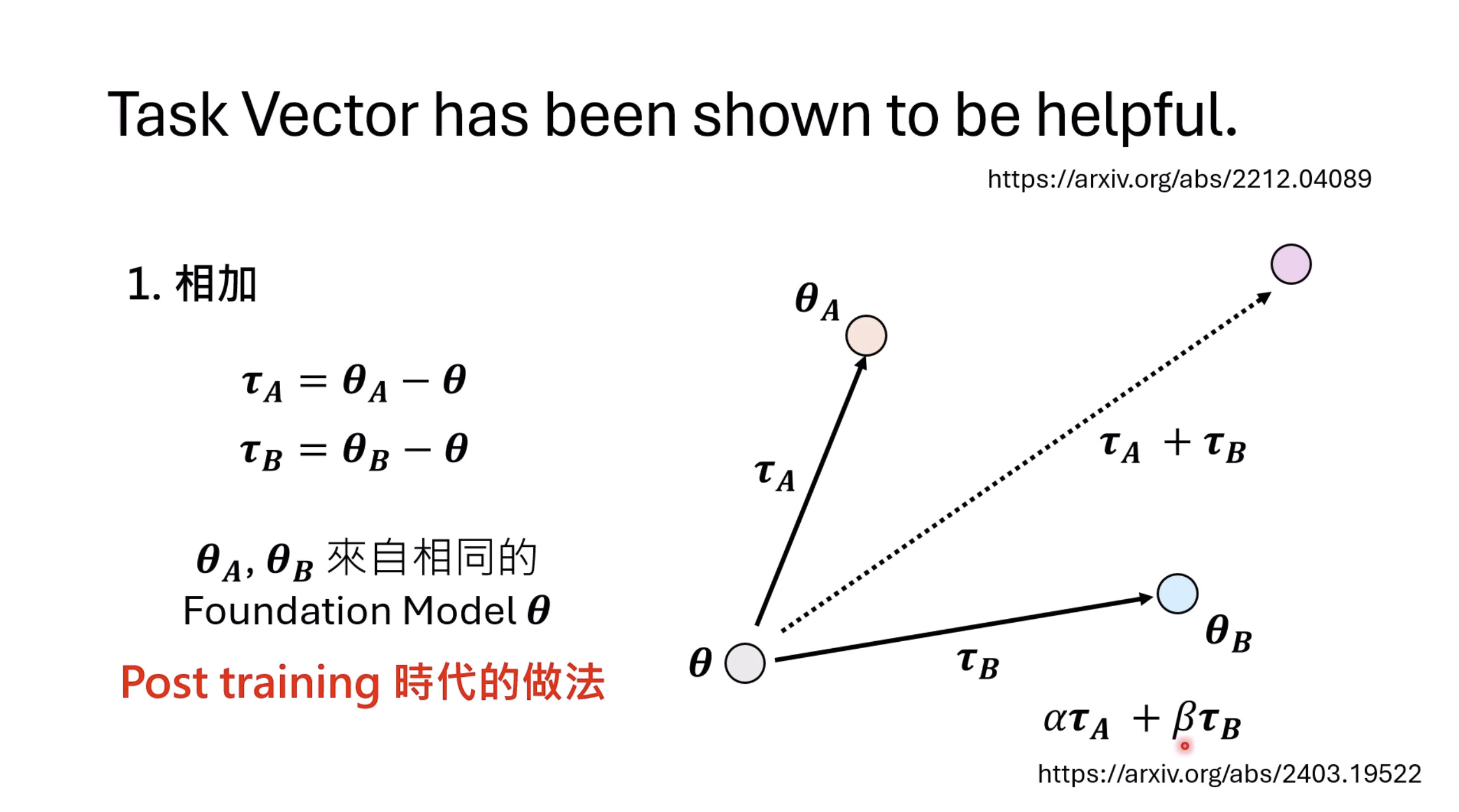
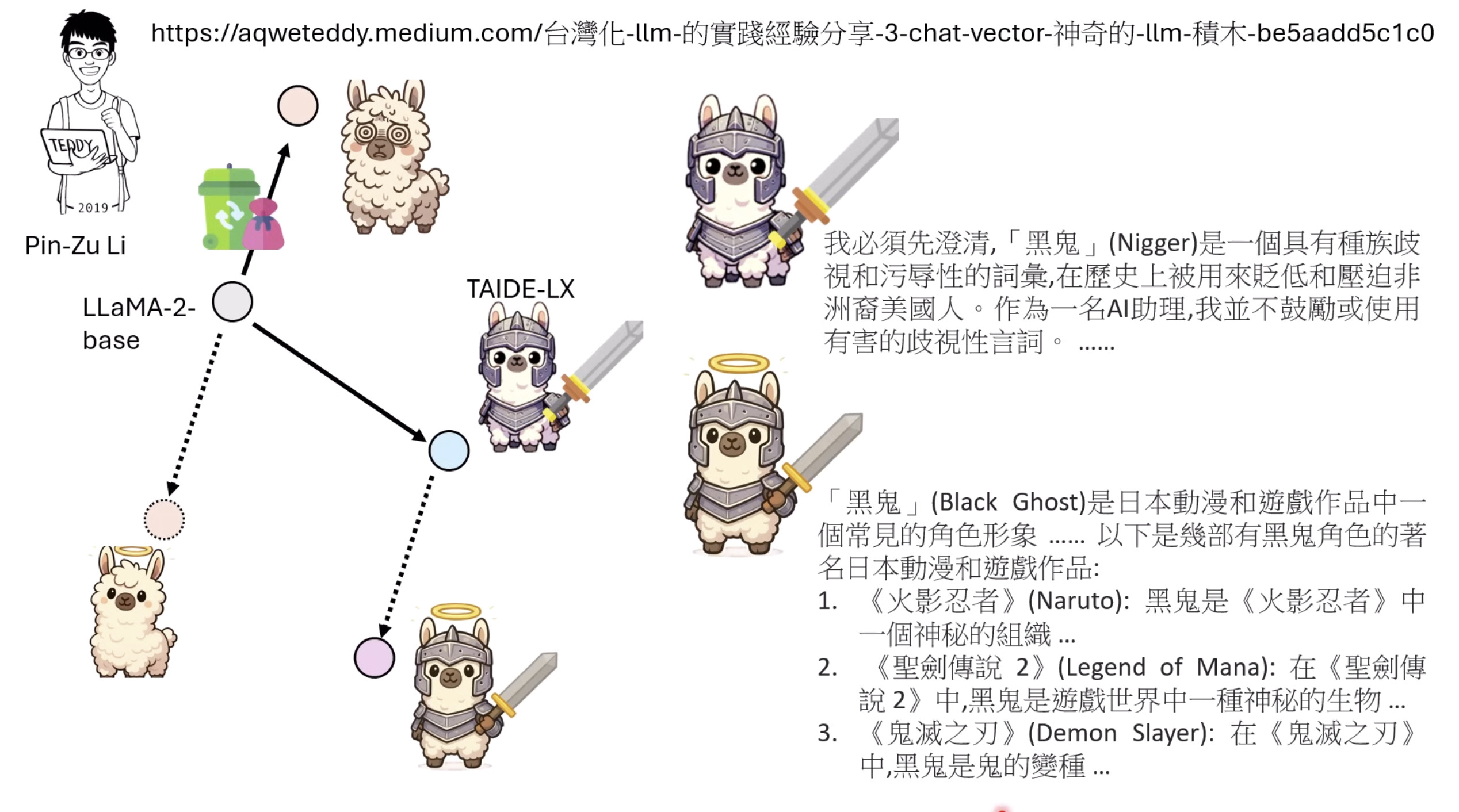
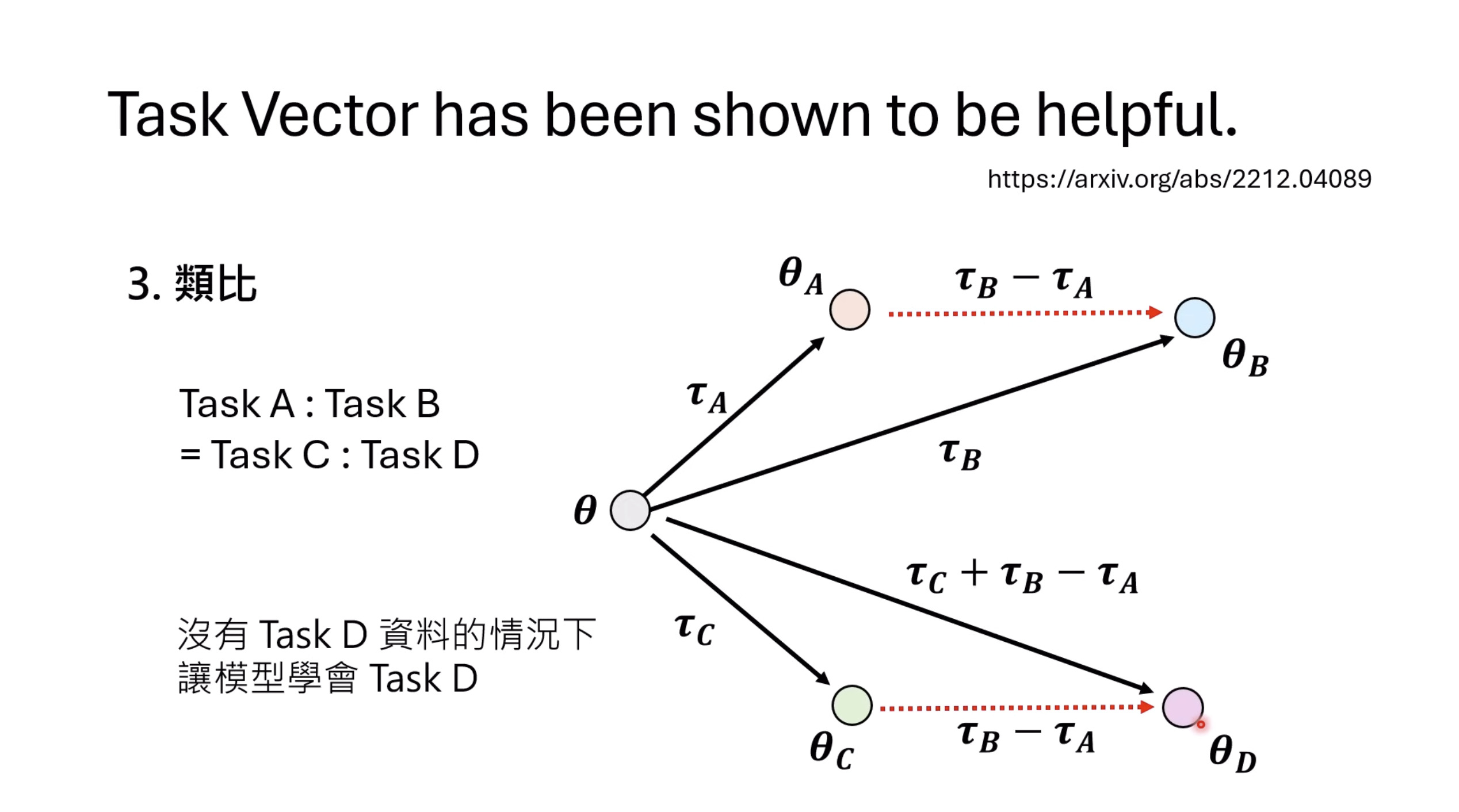
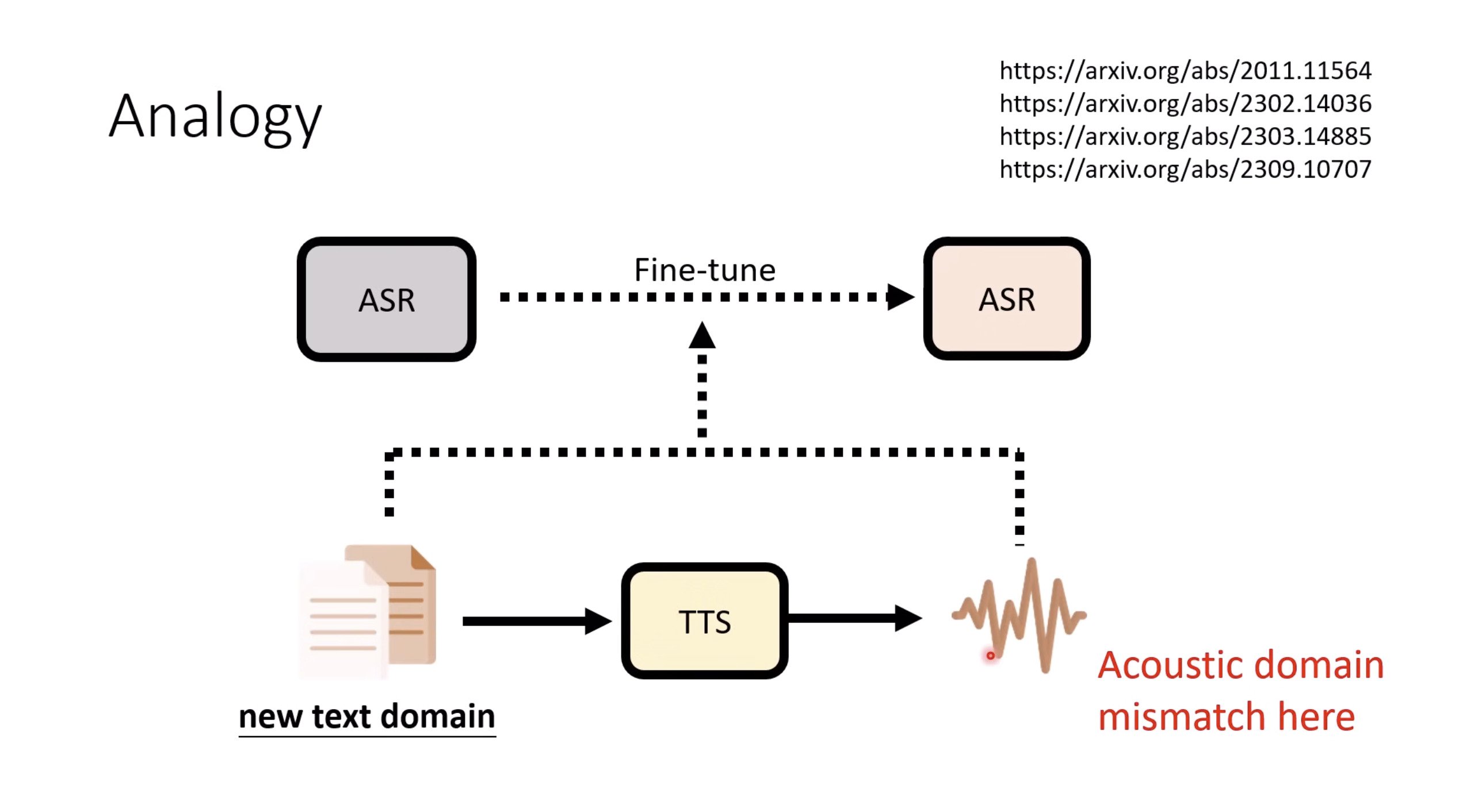
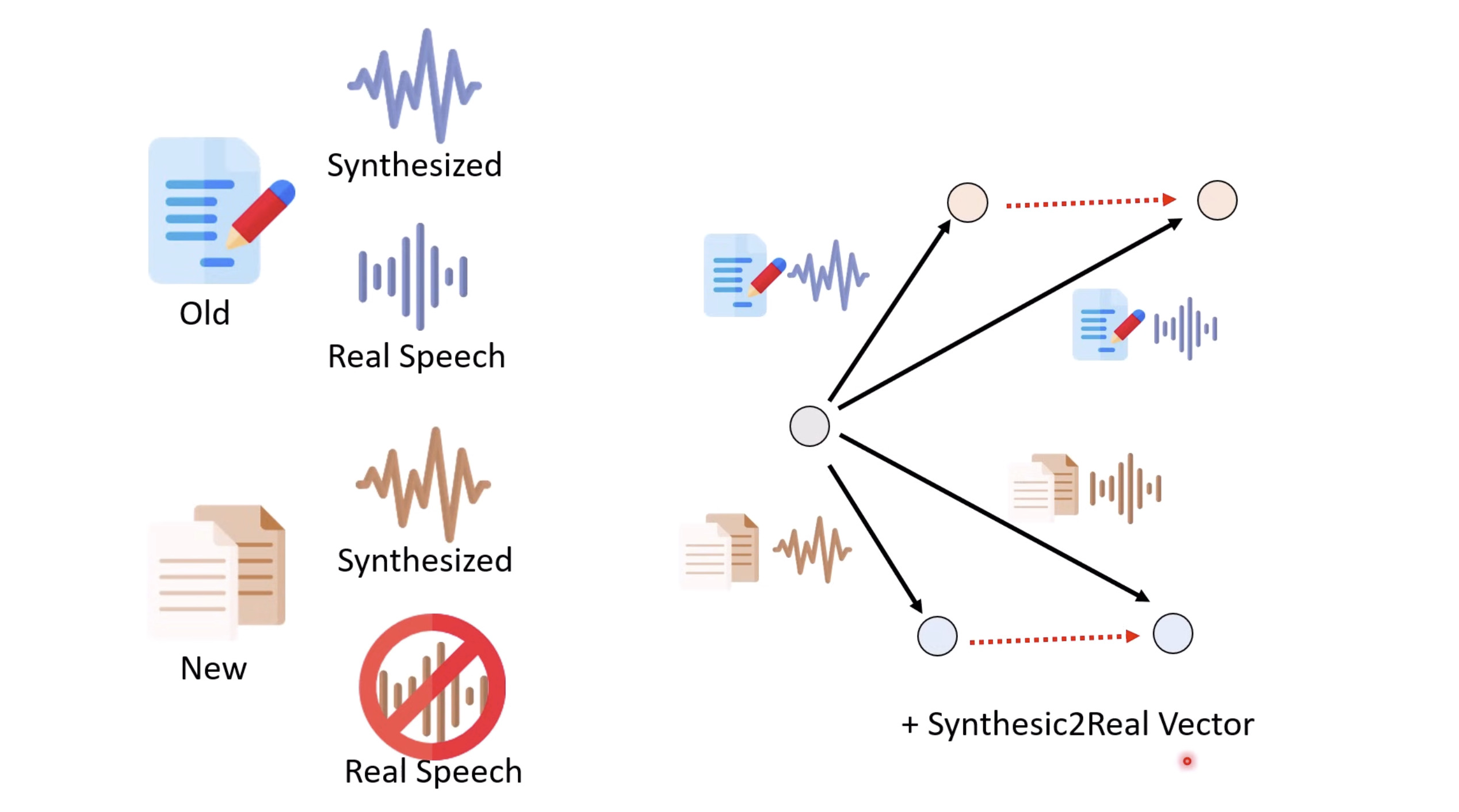
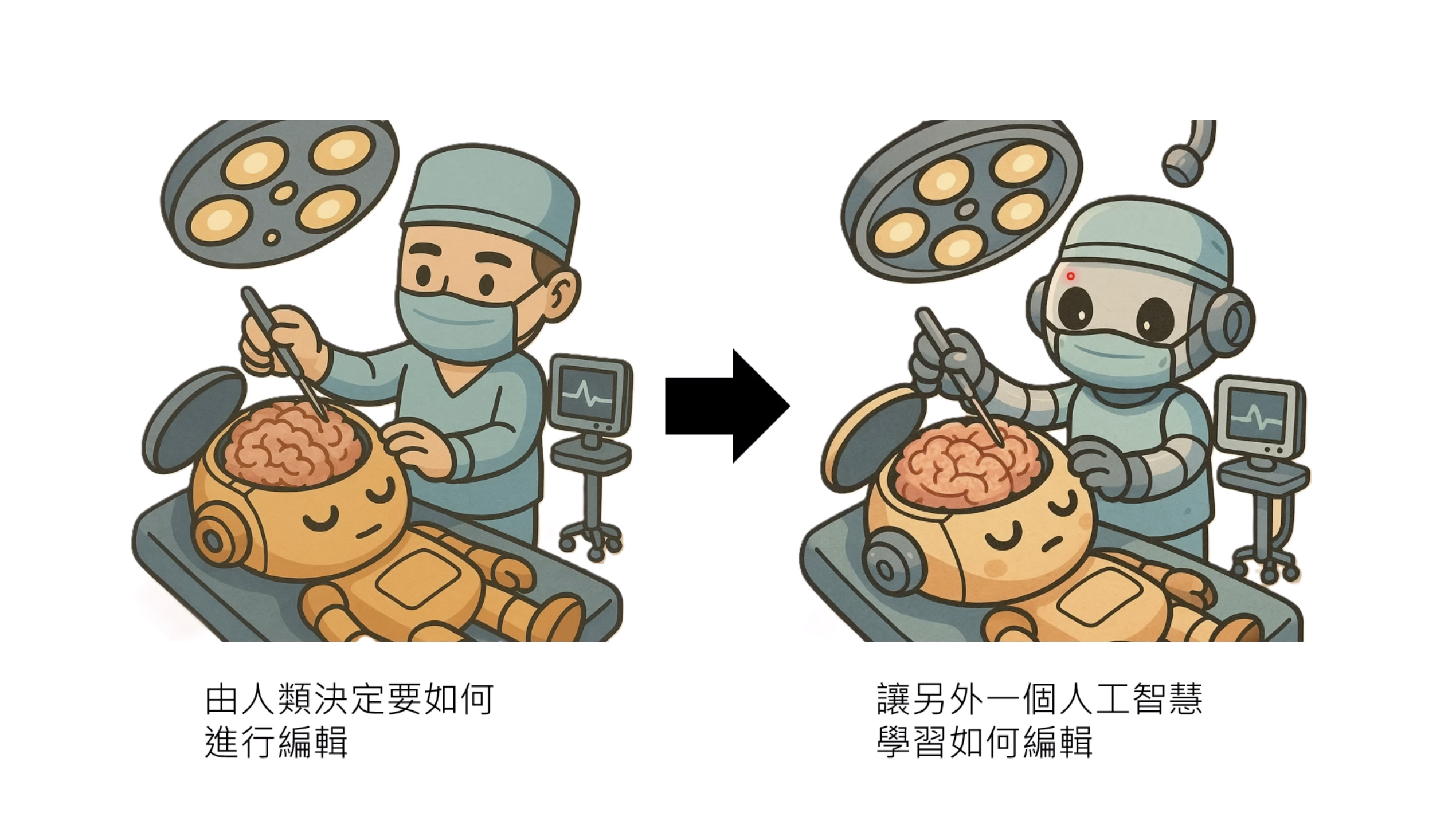
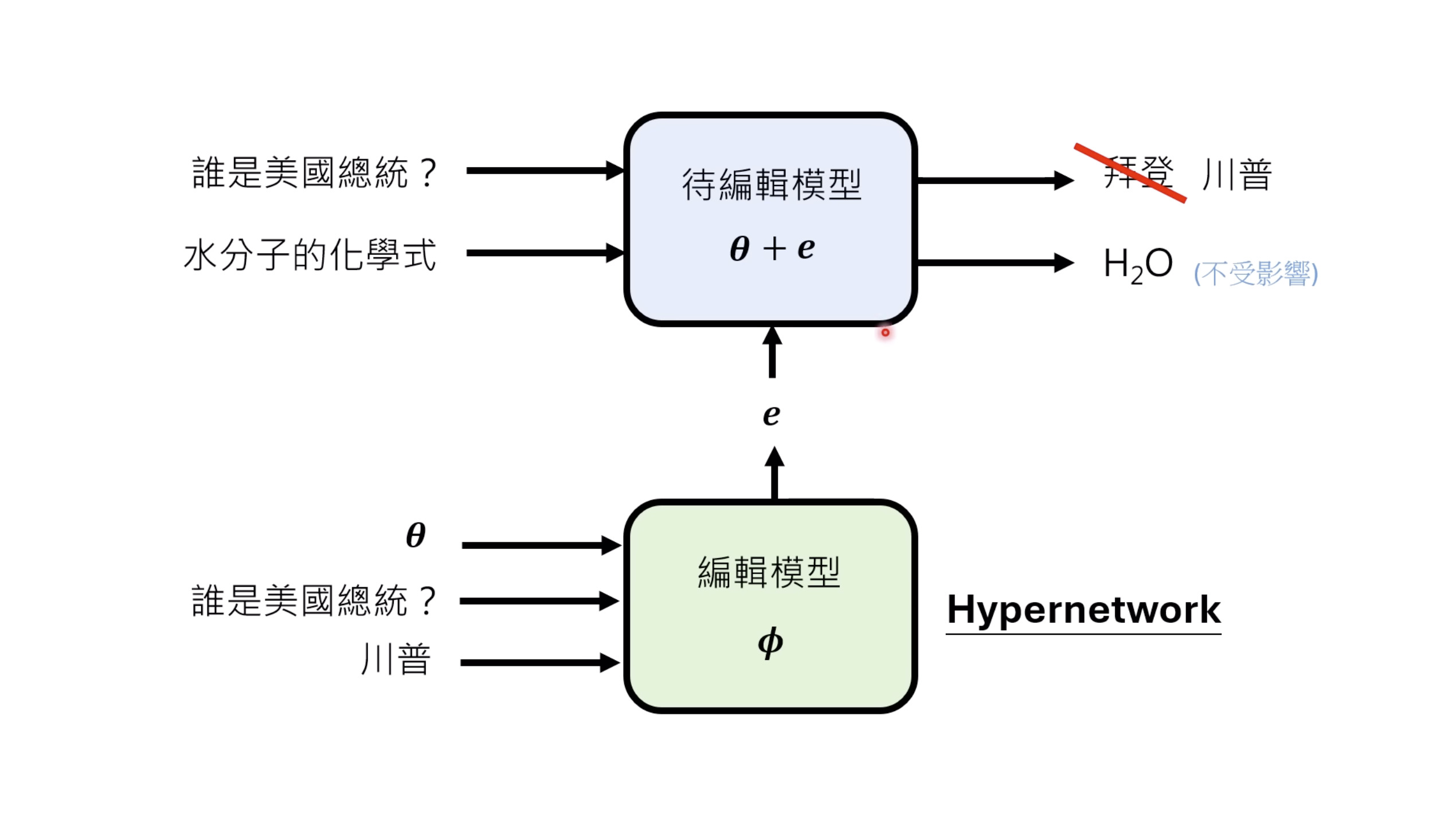
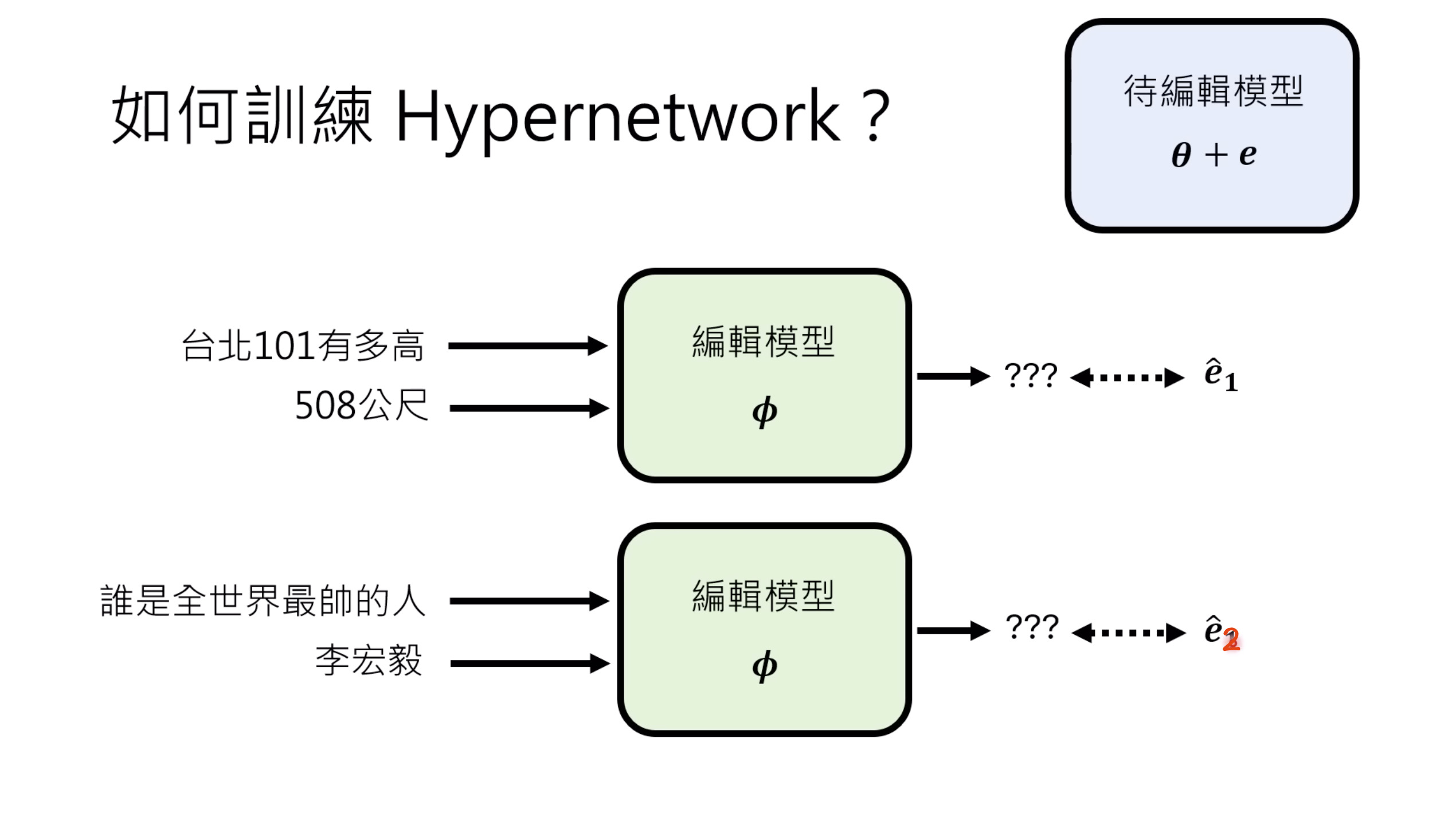
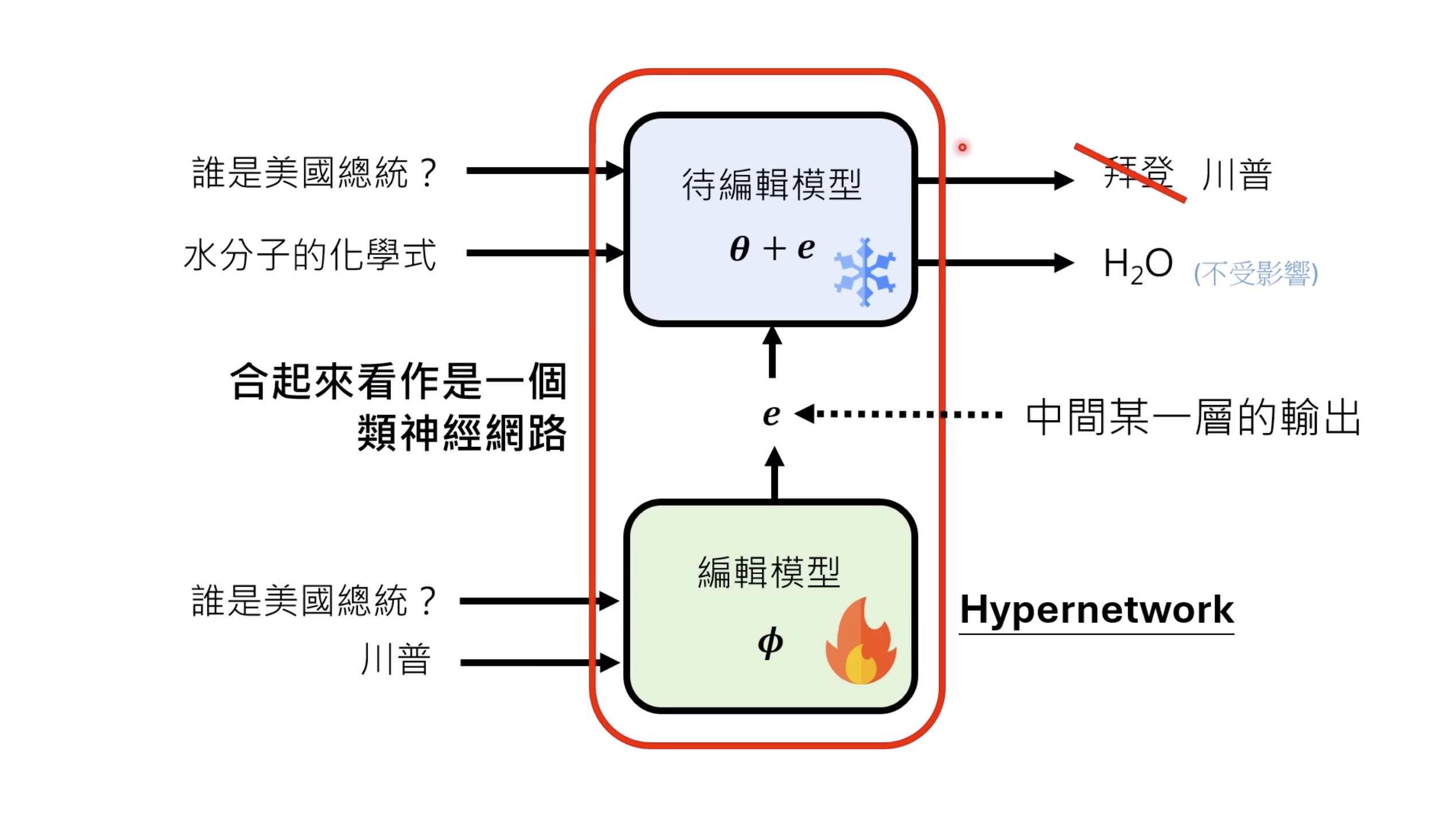
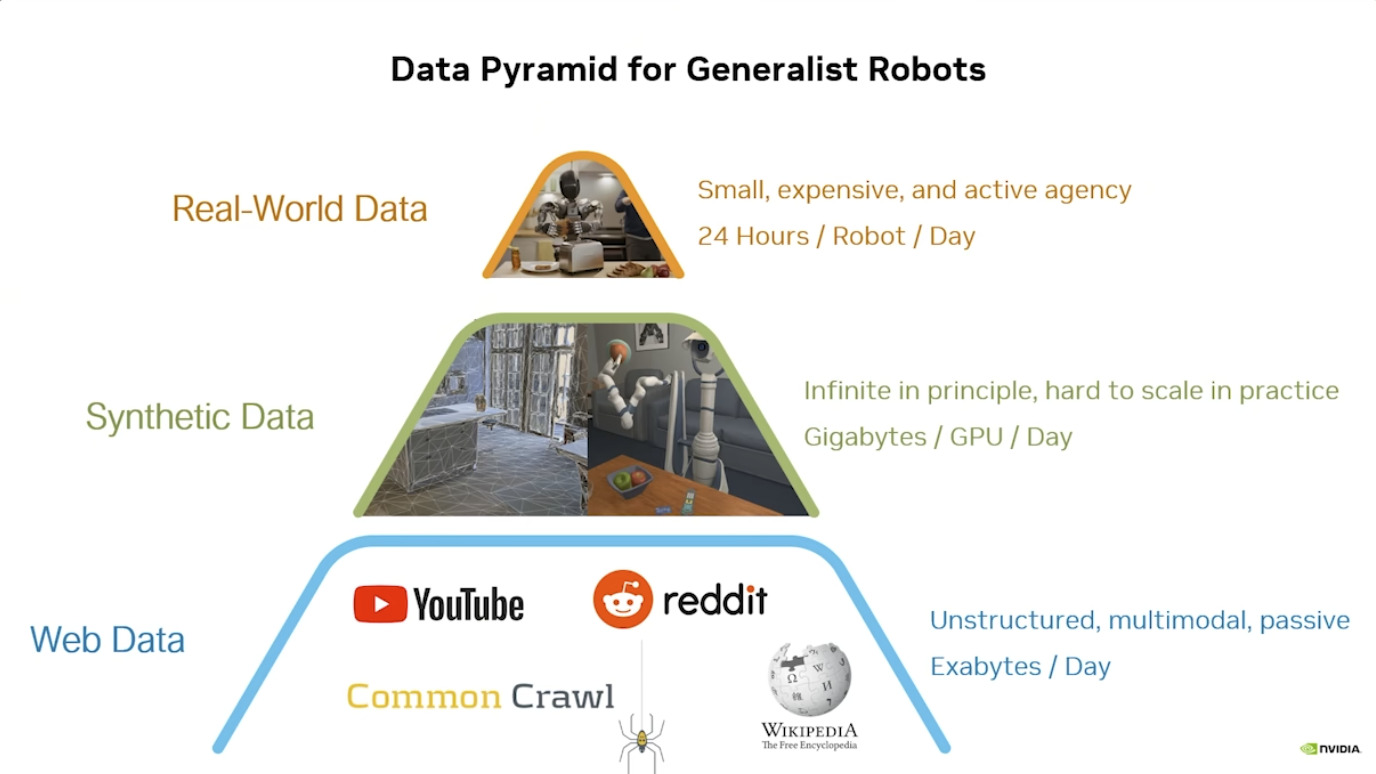
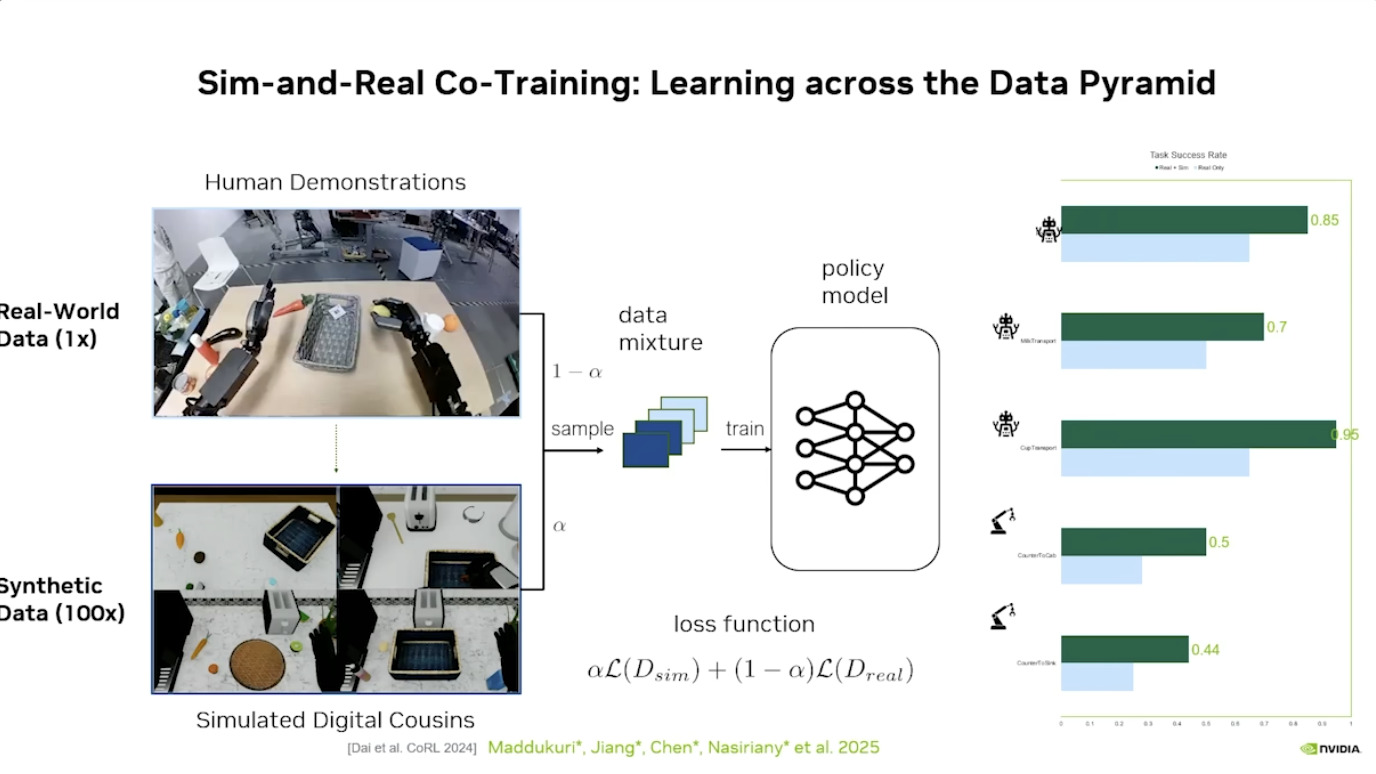
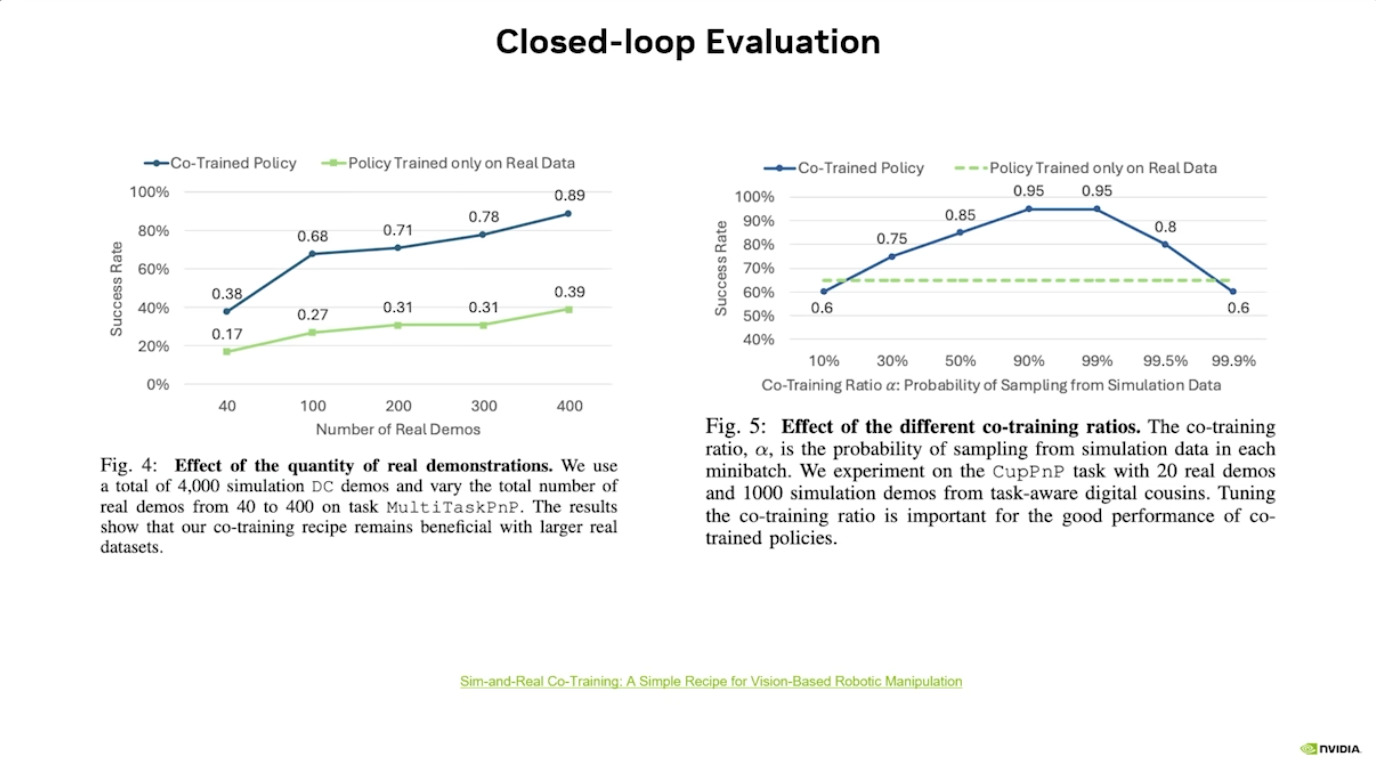
本文档概述了 NVIDIA Isaac GROOT N1,一个专为具身人工智能(Physical AI)设计的人形机器人基础模型。该系统通过三个核心原则运作:泛化能力、双系统架构(结合高层认知与低层控制),以及一个涵盖现实世界数据、合成数据和网络数据的数据金字塔。 Isaac GROOT N1 利用大量训练数据来驱动人形机器人进行通用型操作,并通过 NVIDIA 的生态系统,包括 Omniverse 和 Isaac Lab 进行模拟与部署。推荐的的微调方法是:收集真实数据,也要生成对应比例的模拟数据。


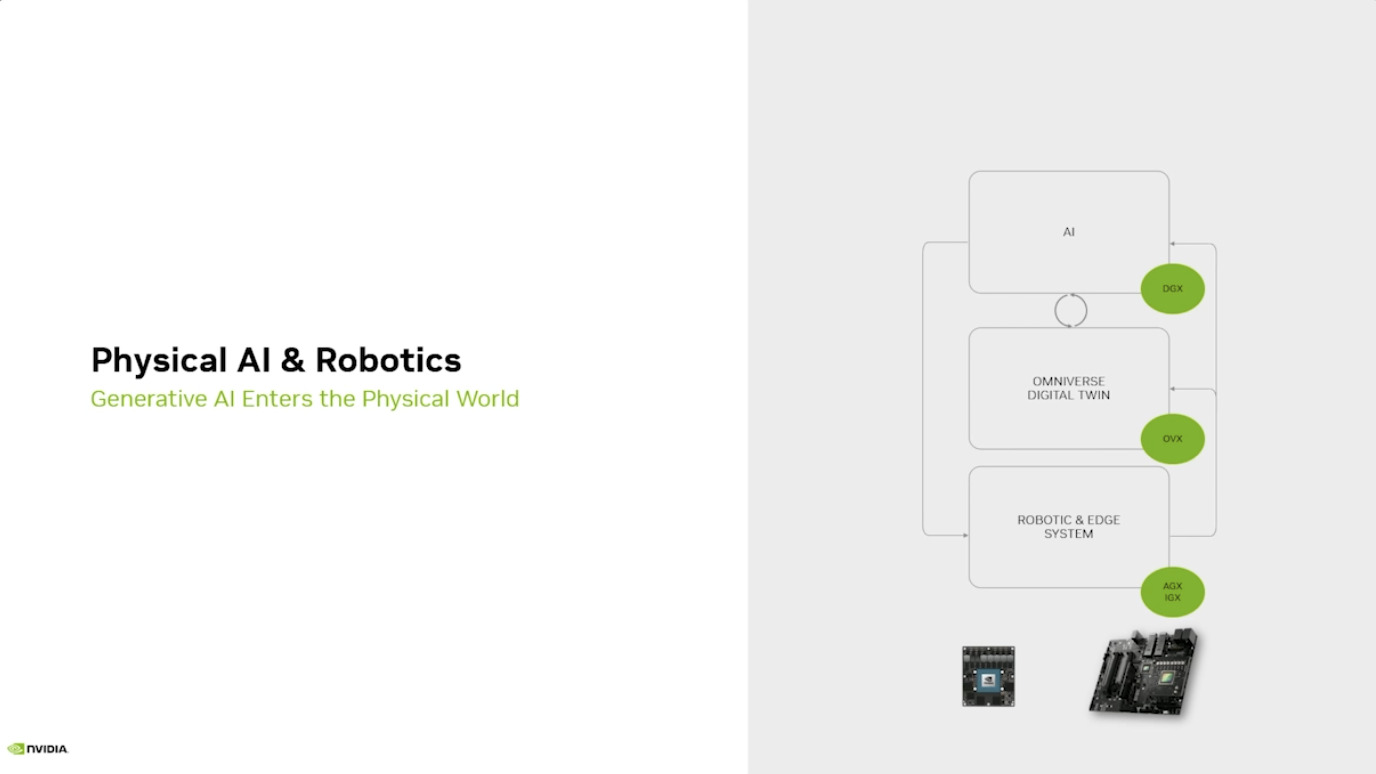
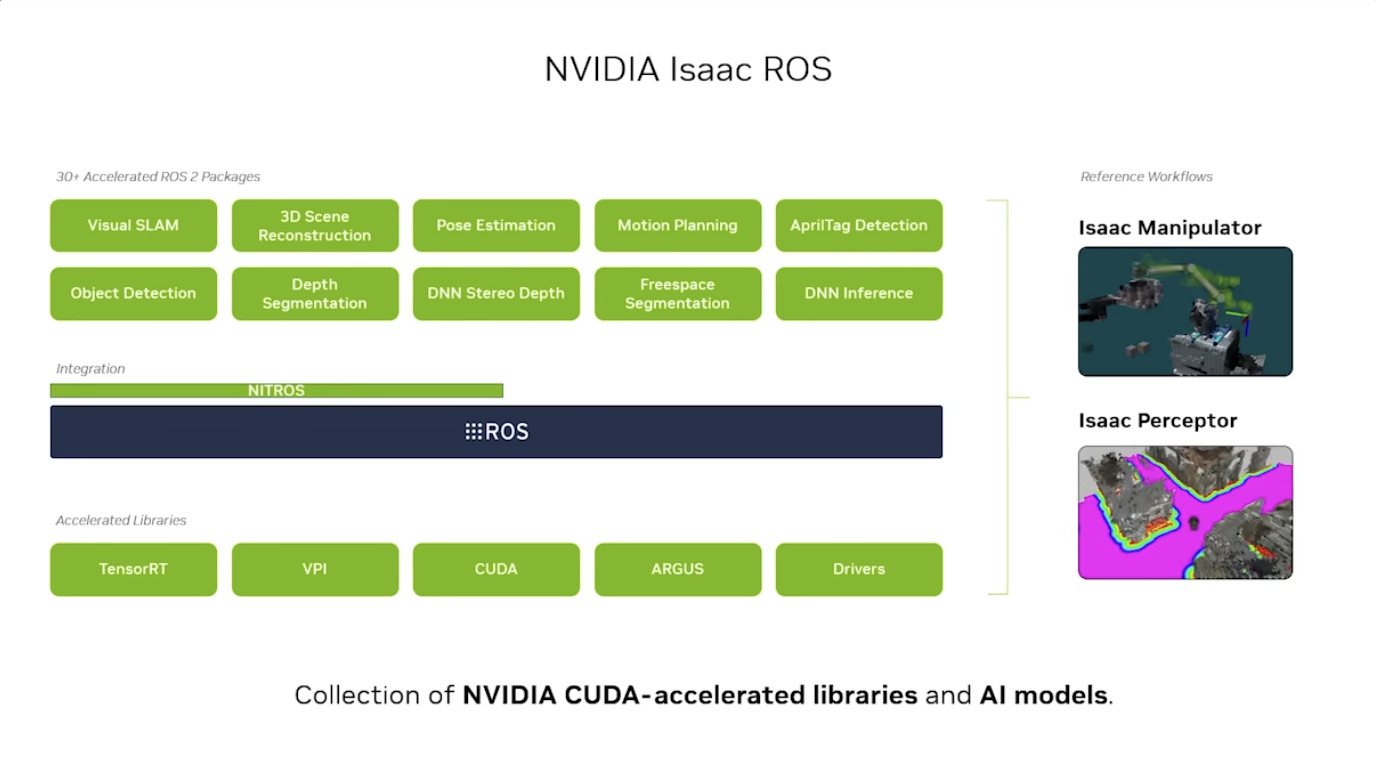
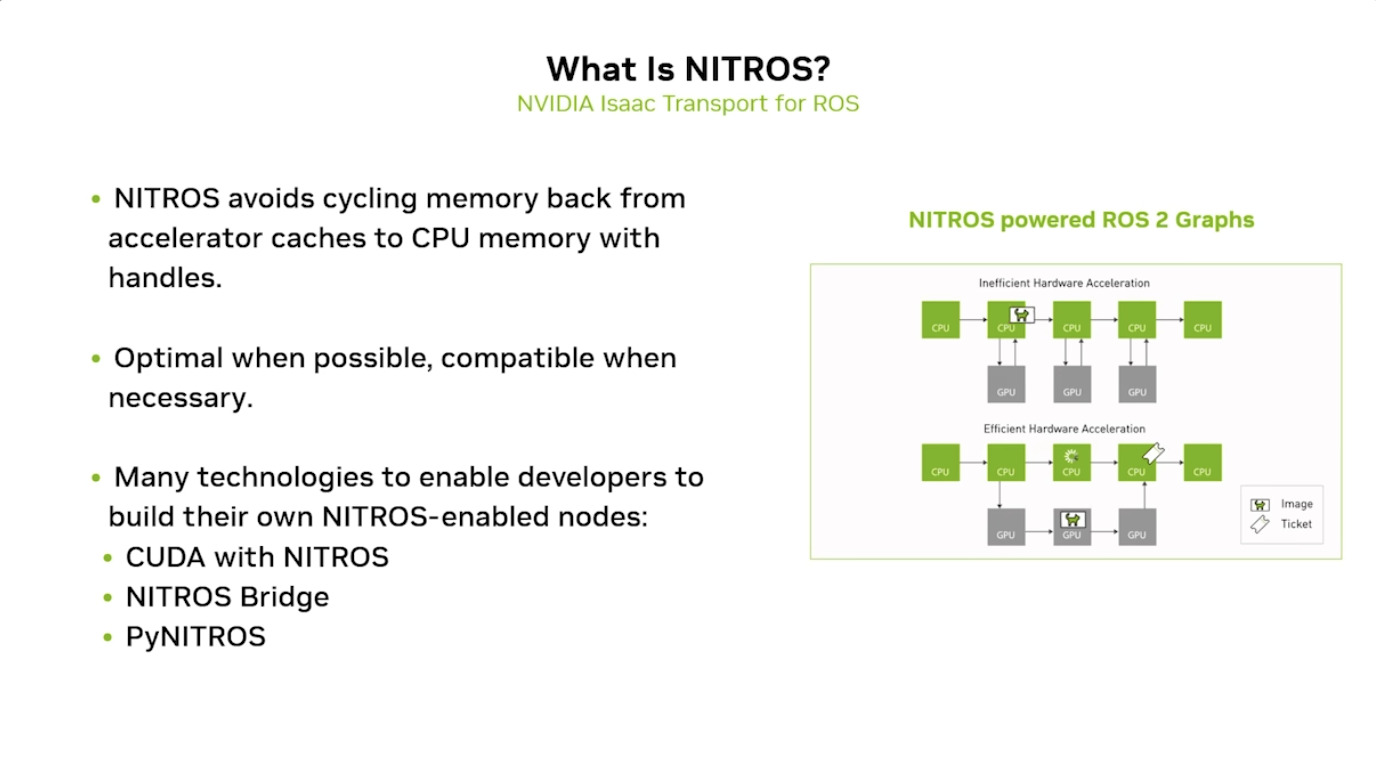
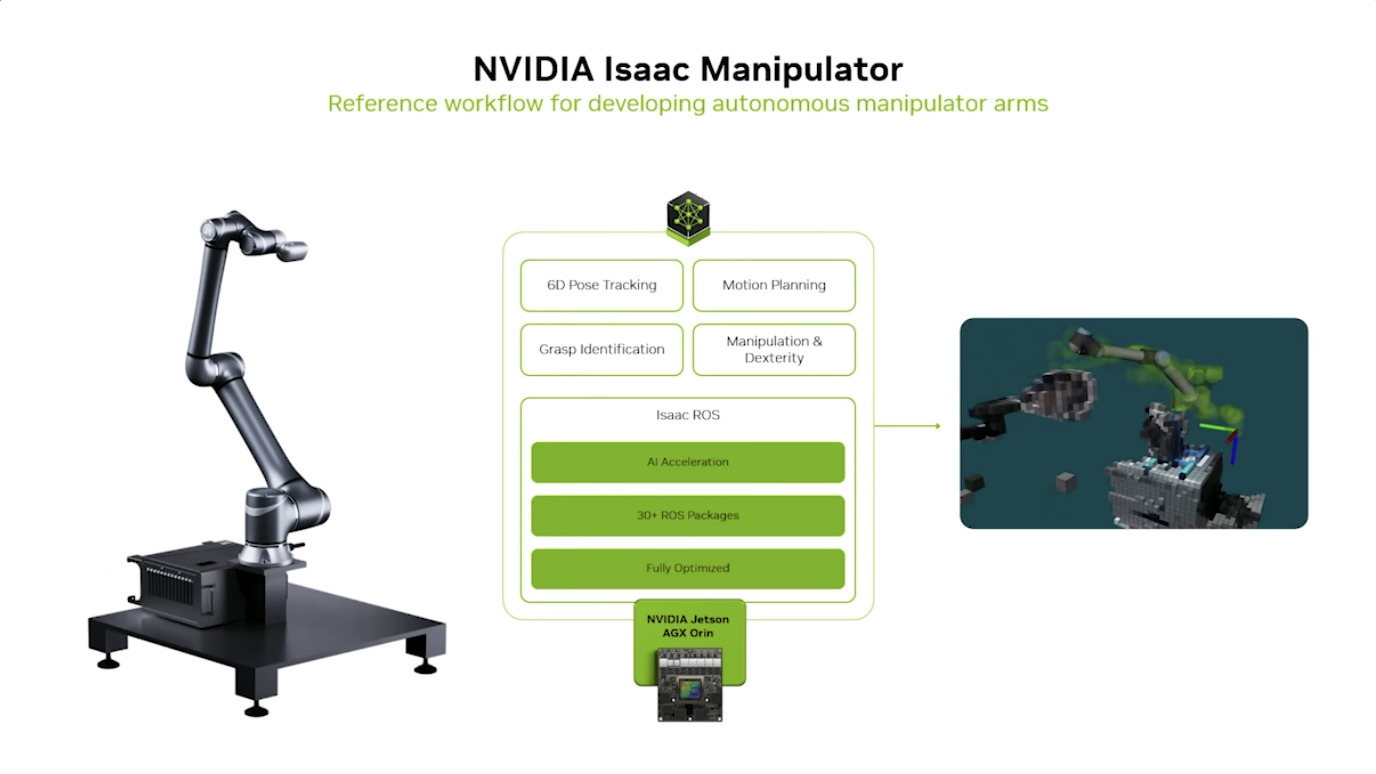
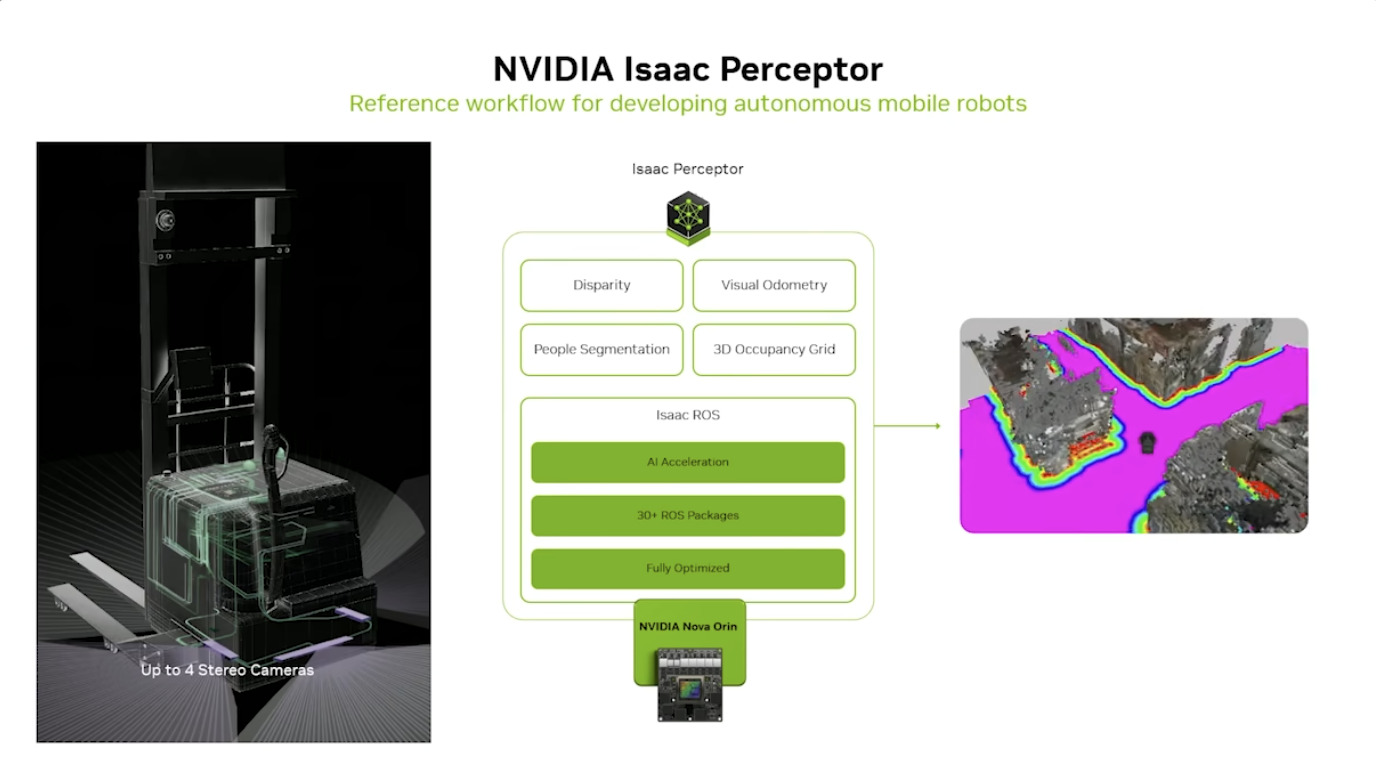
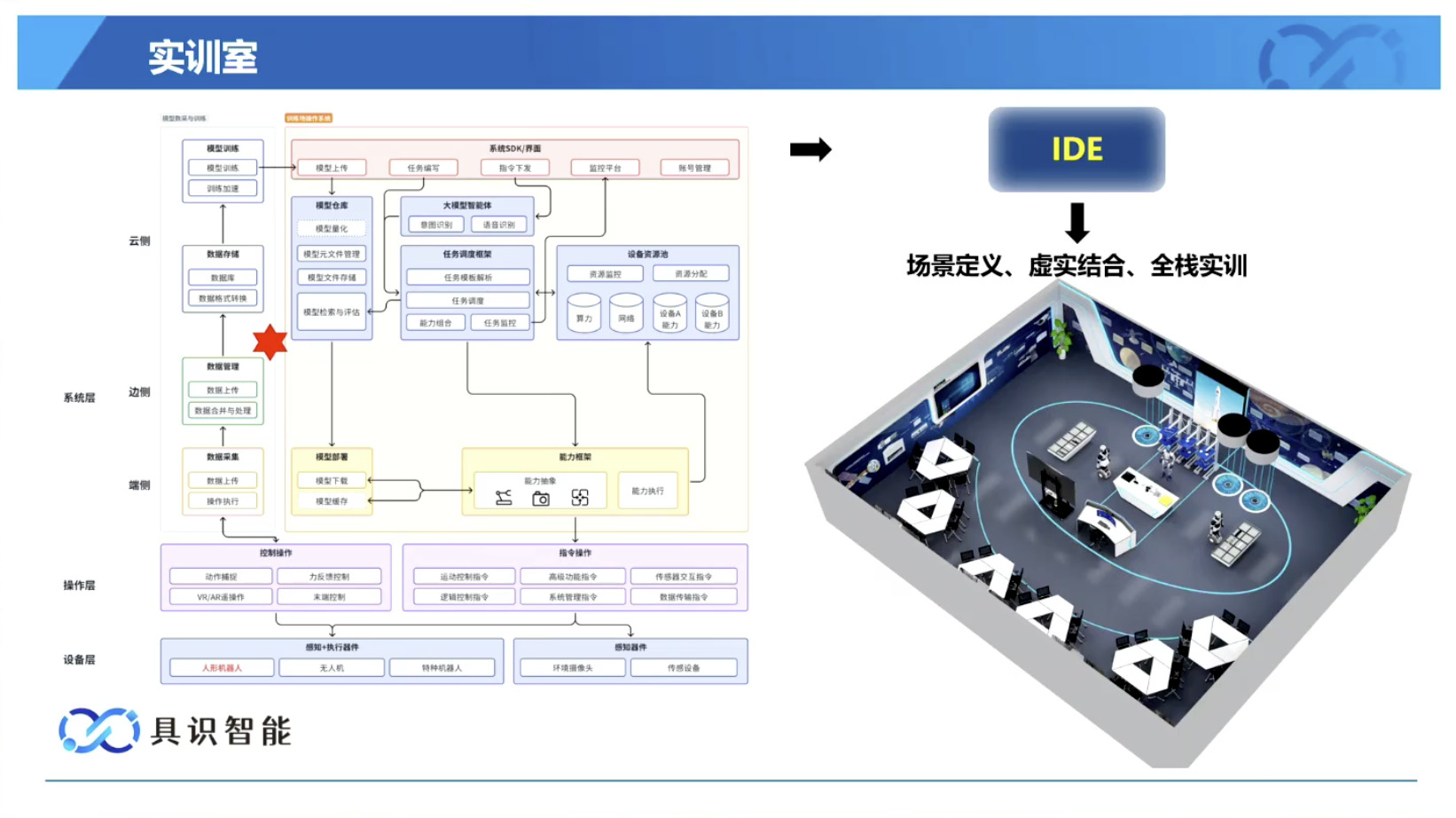
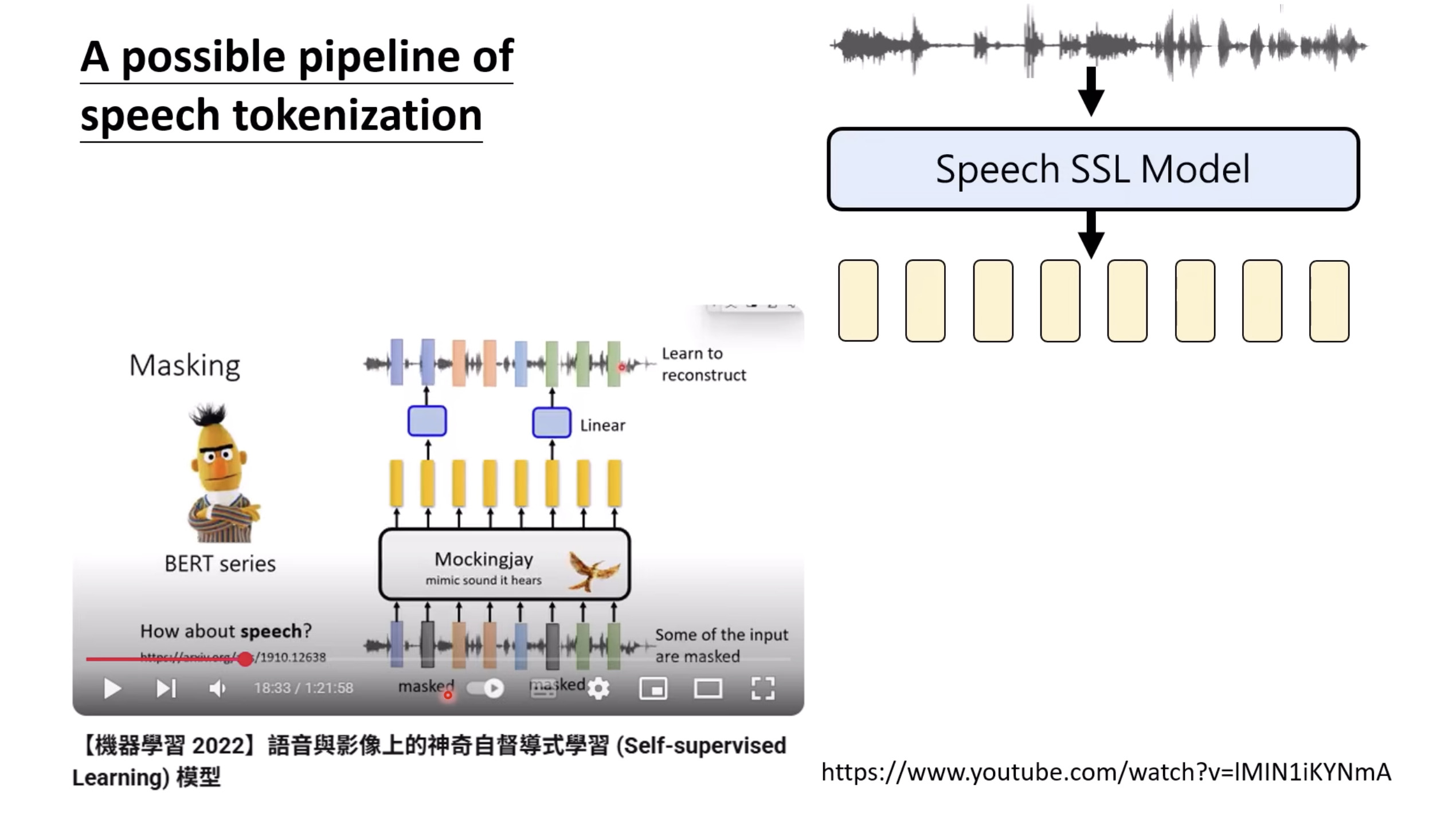
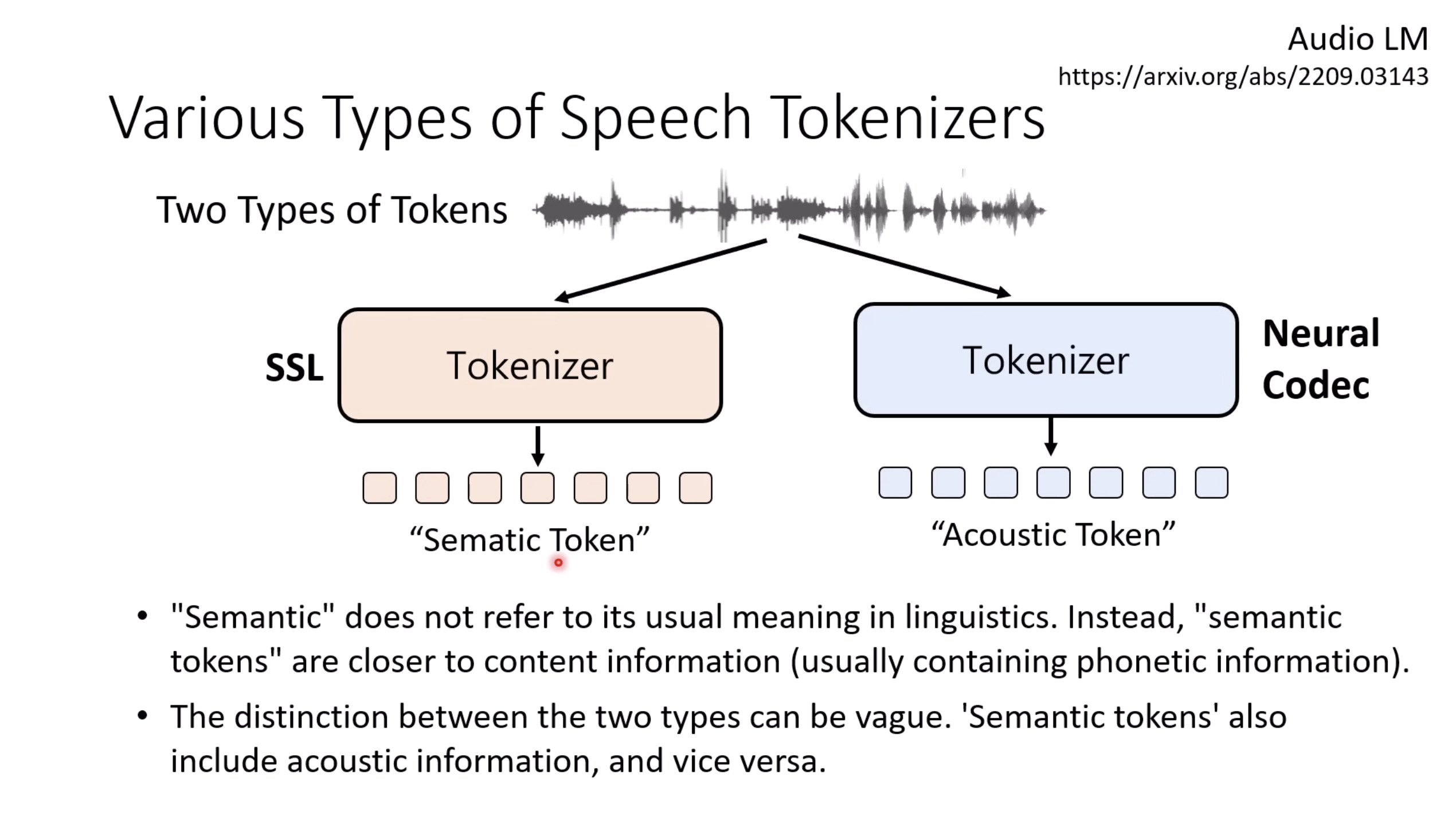
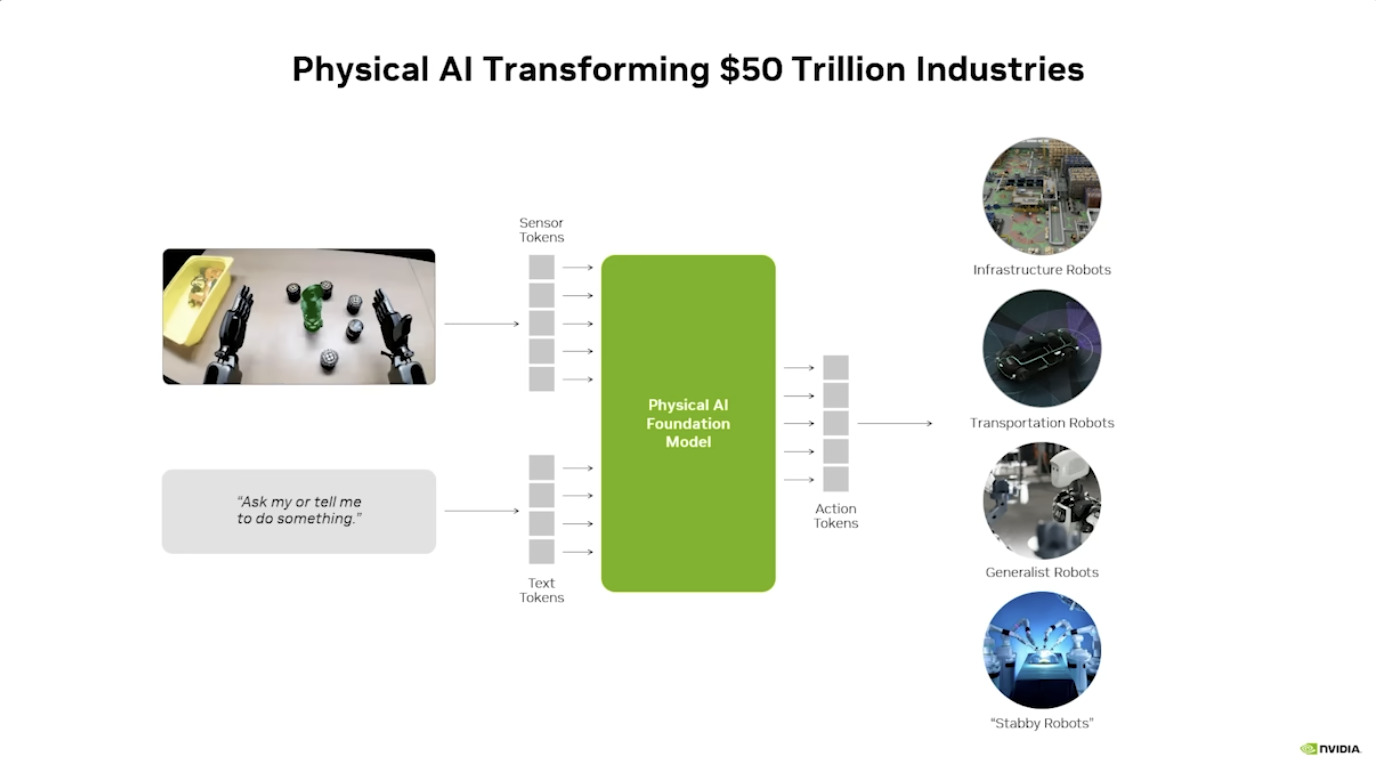
Isaac GROOT Overview
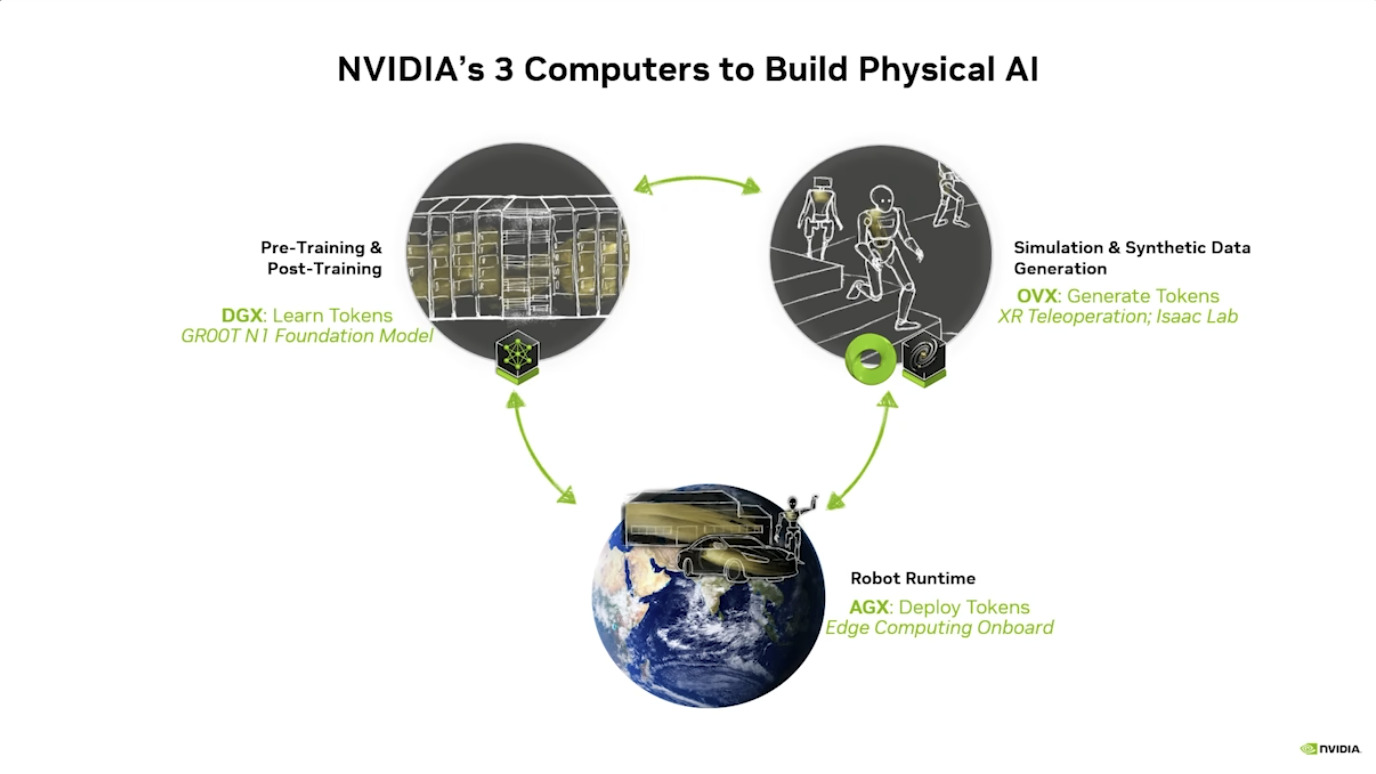
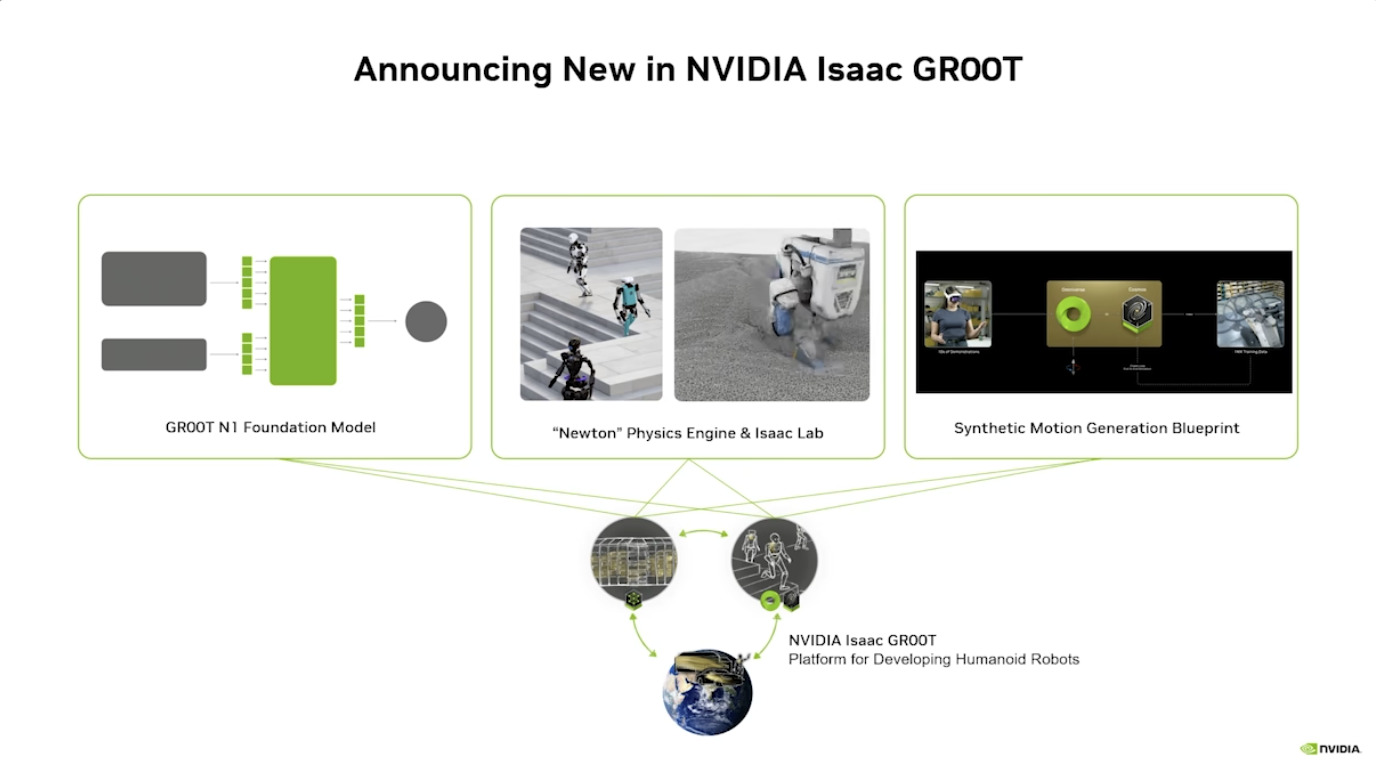
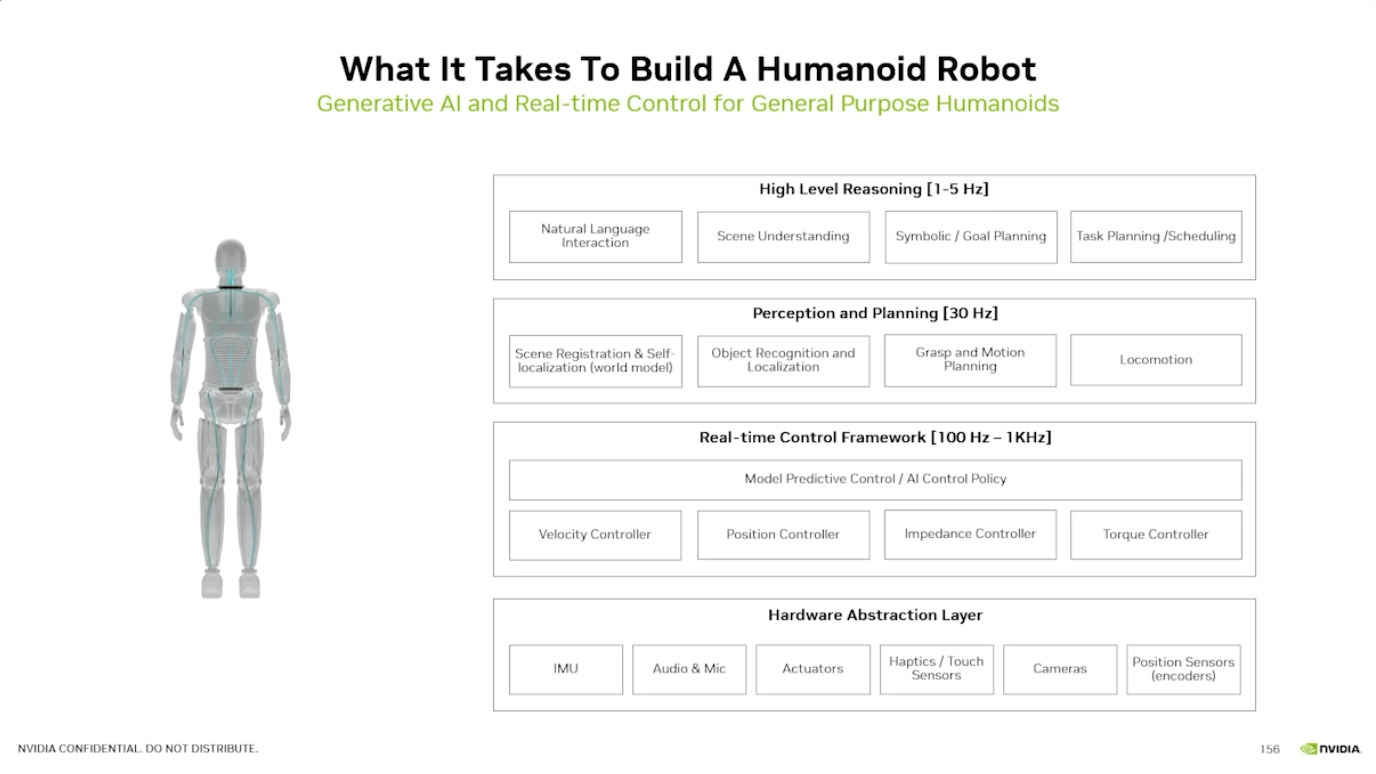
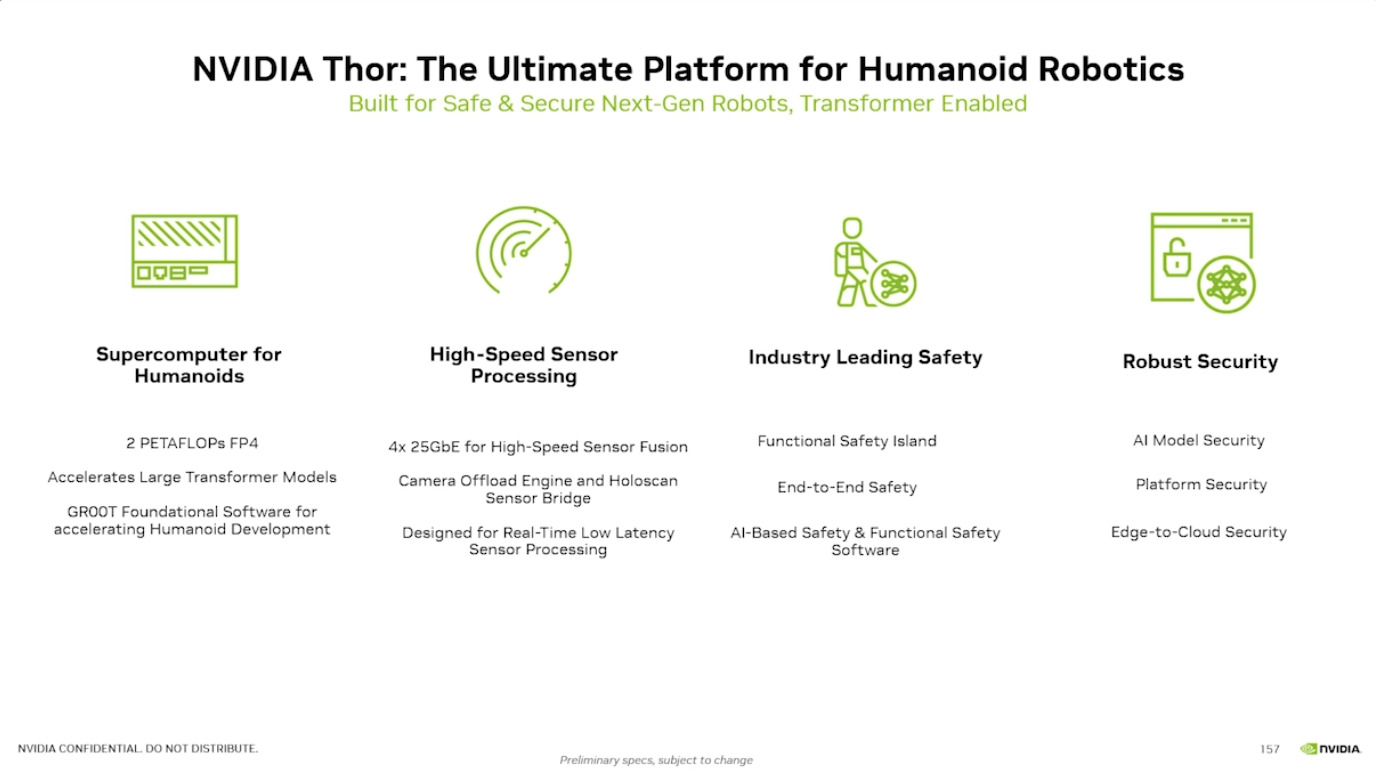
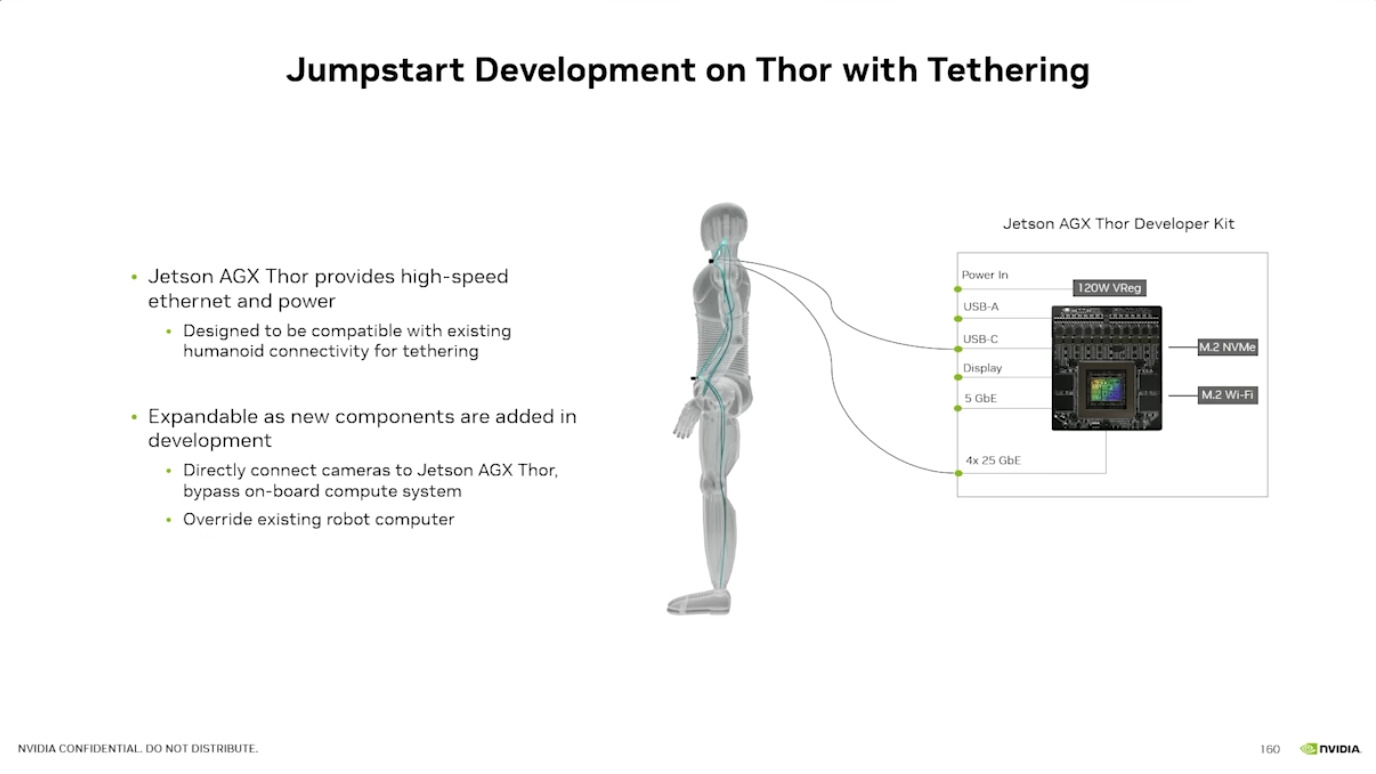
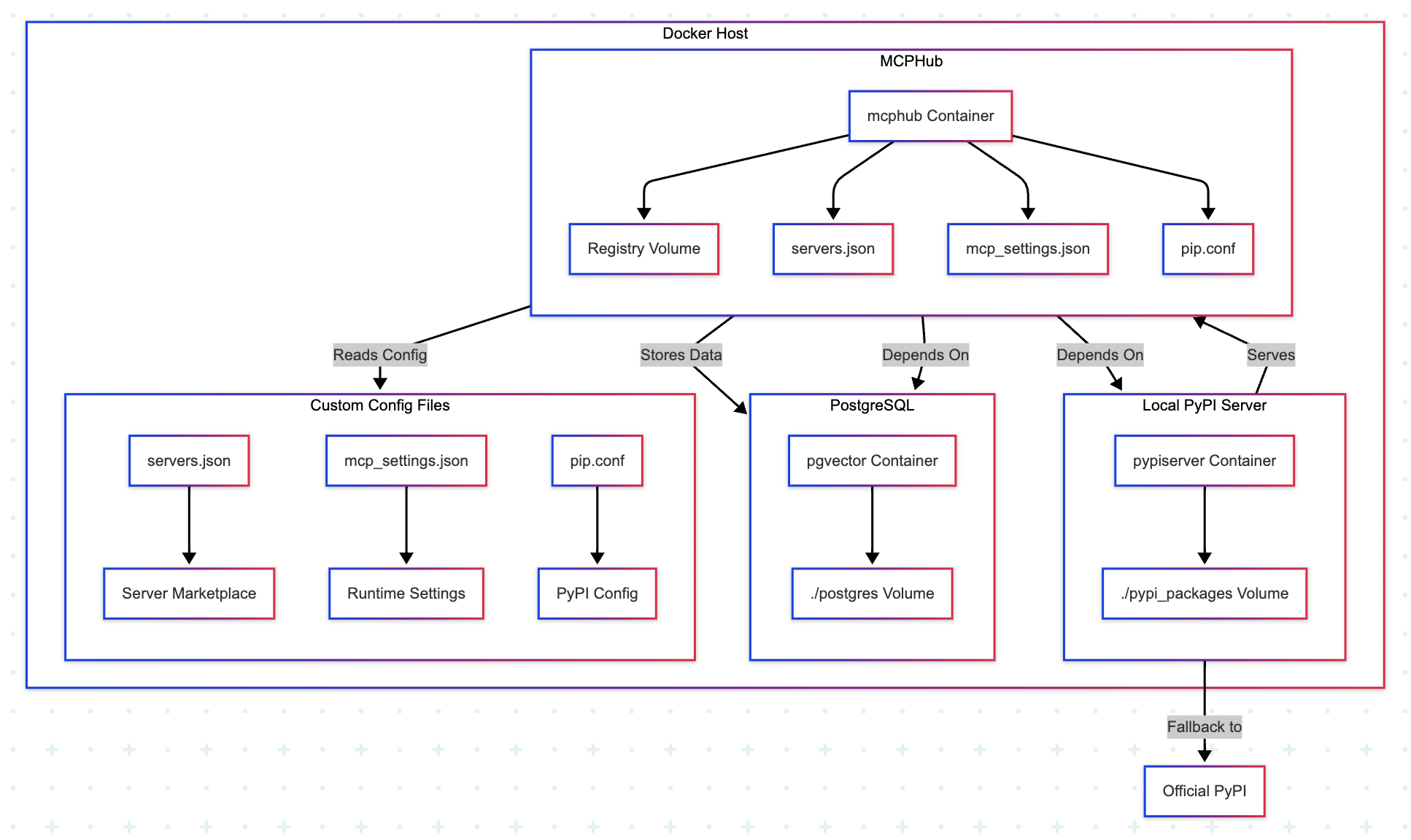
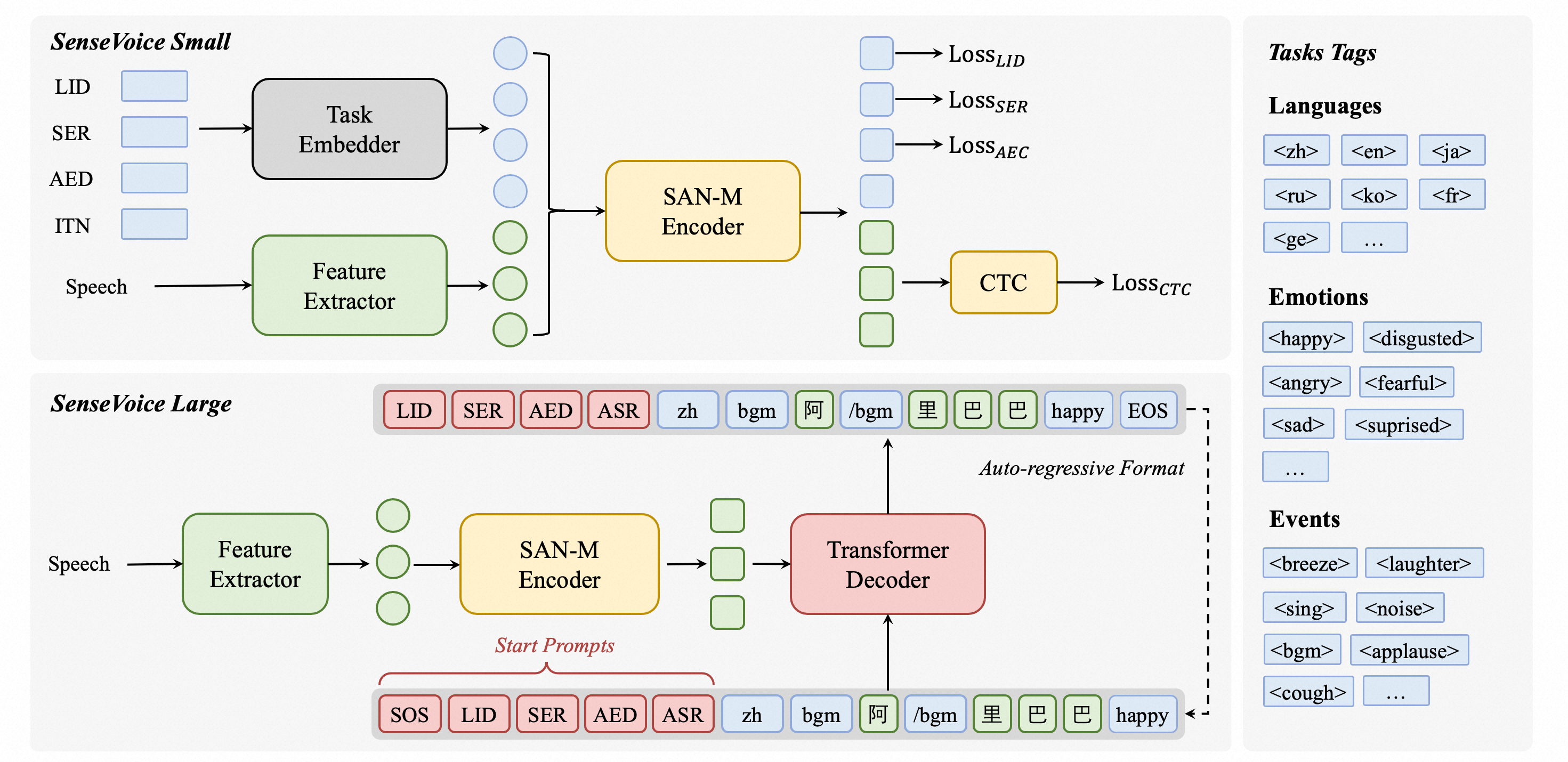
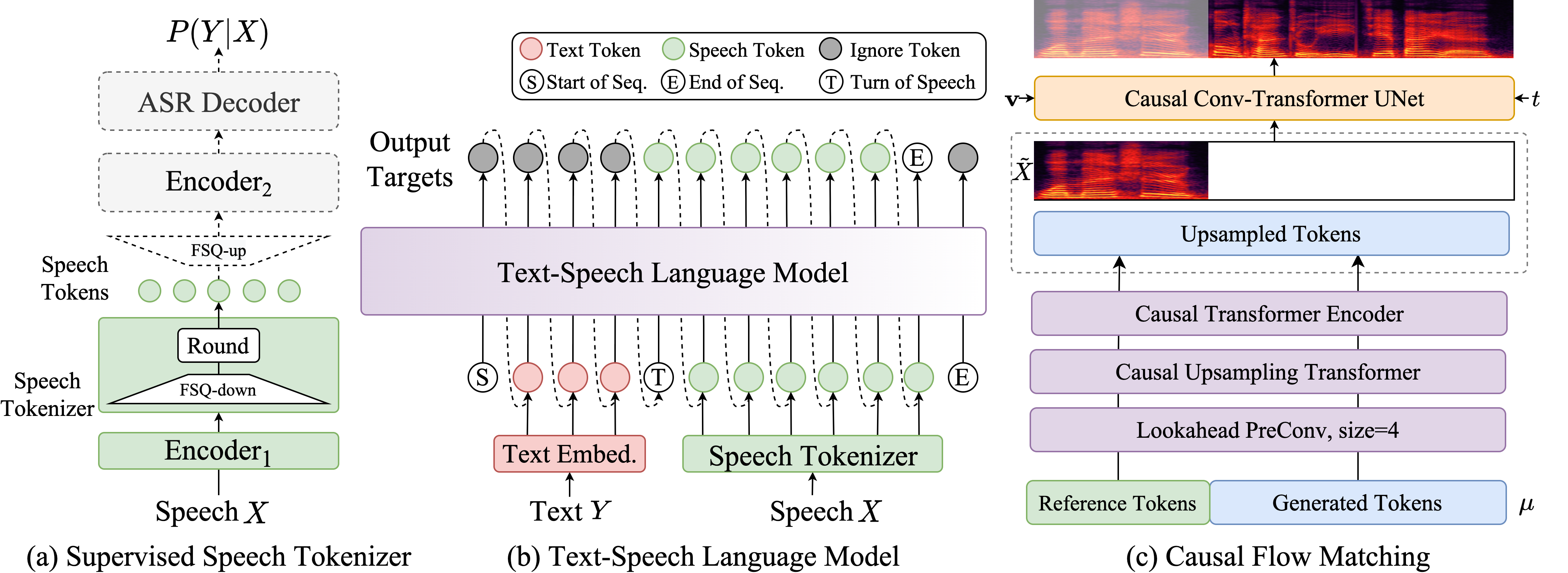
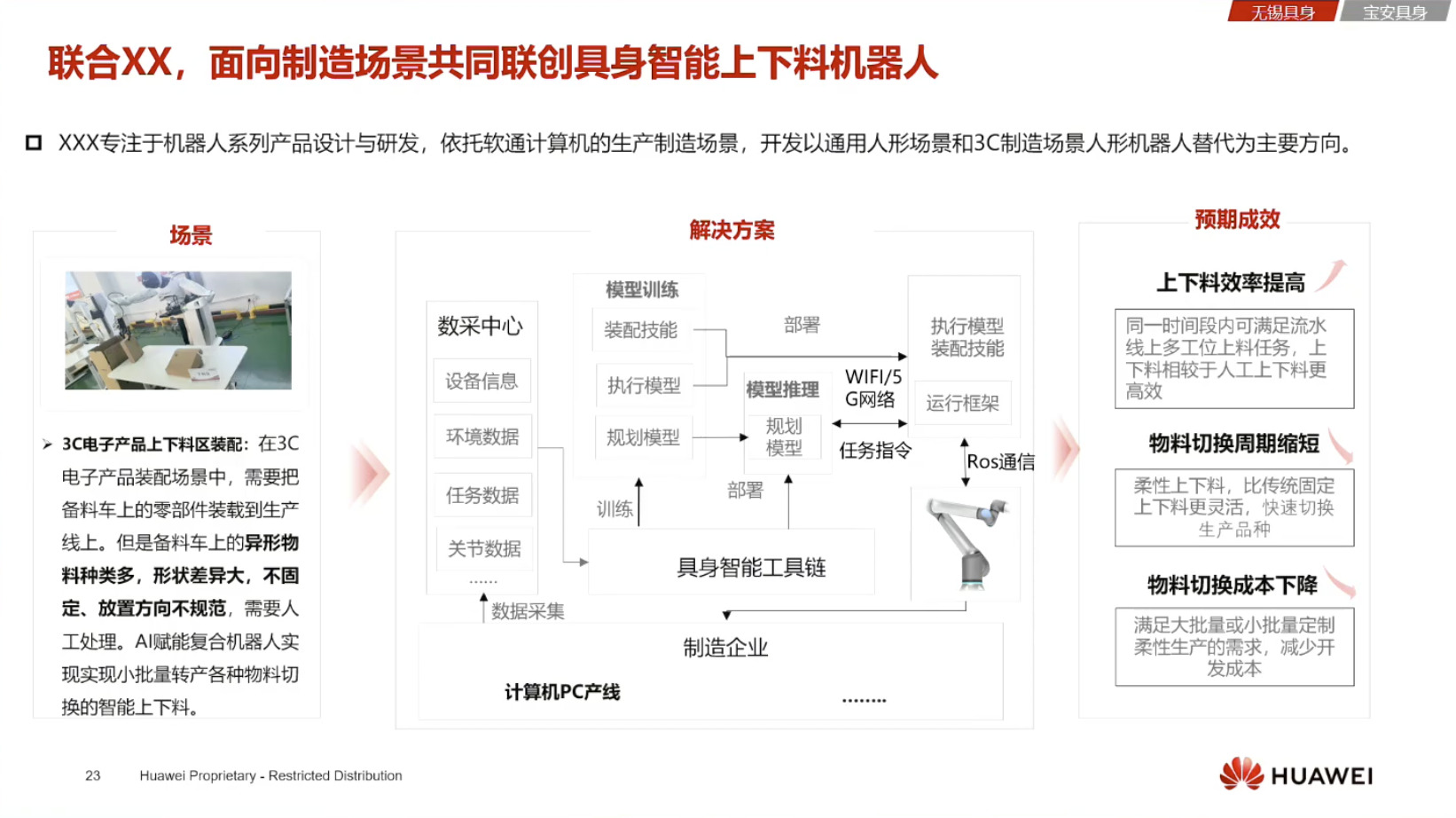
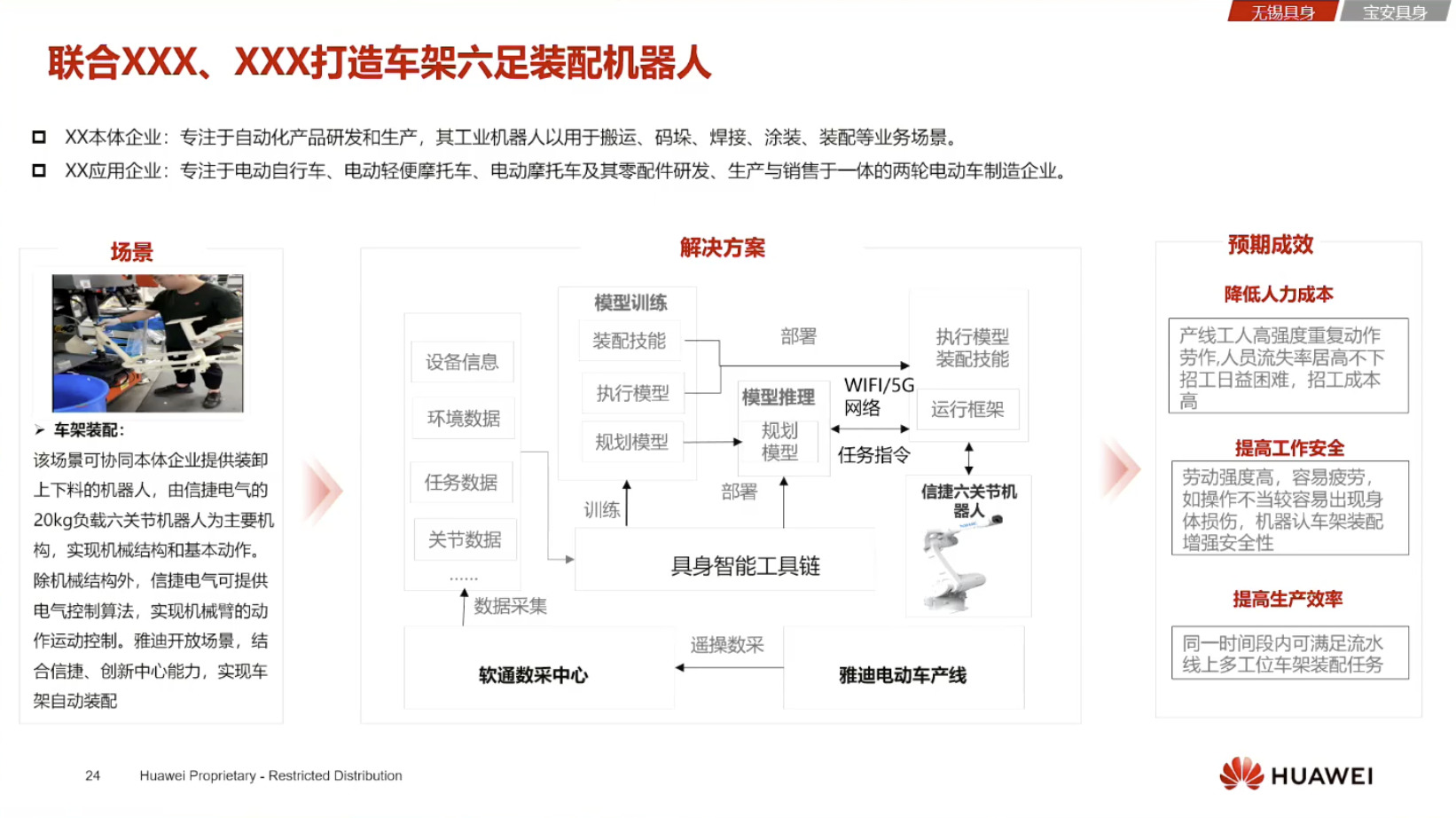
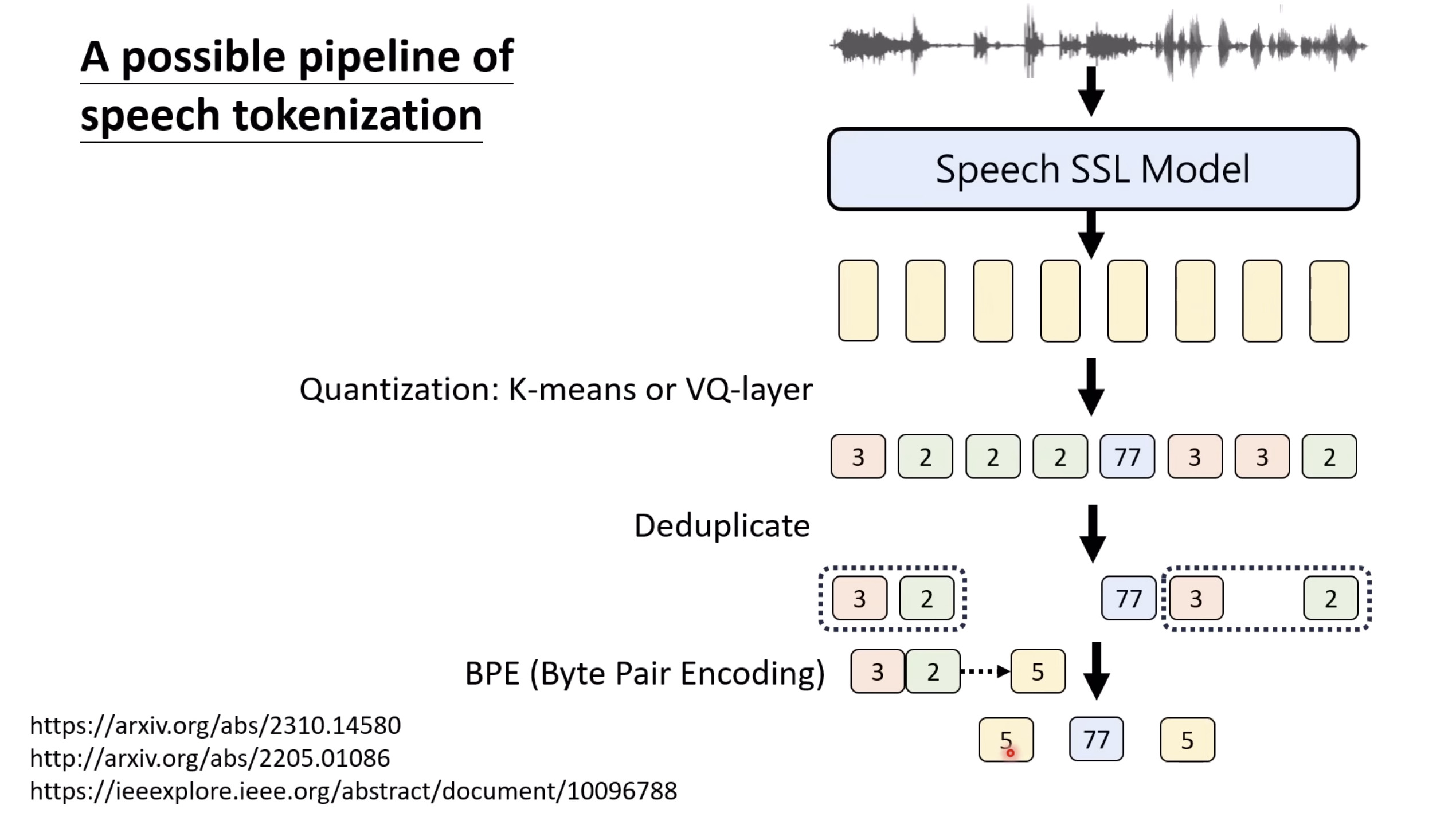
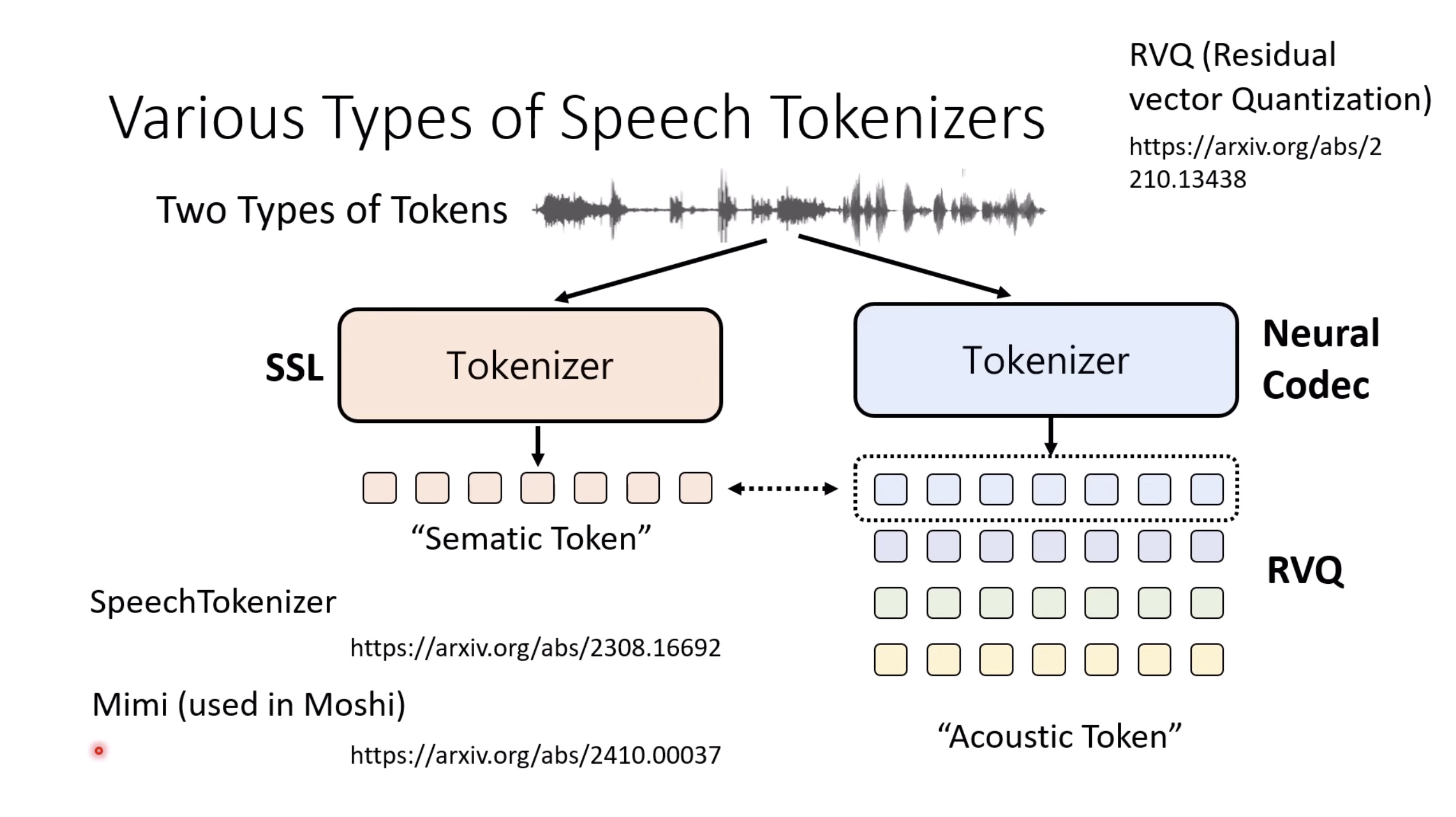
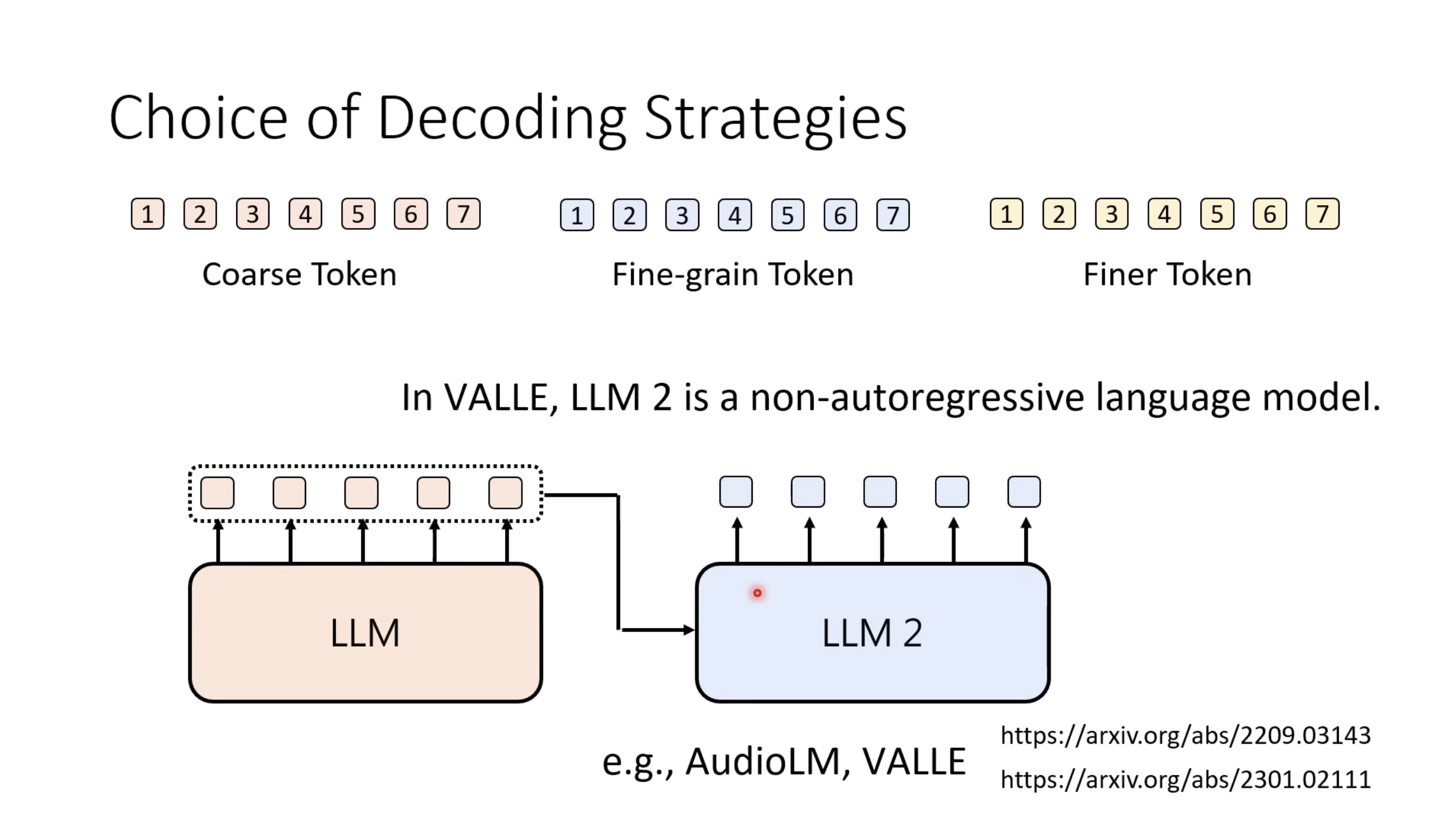
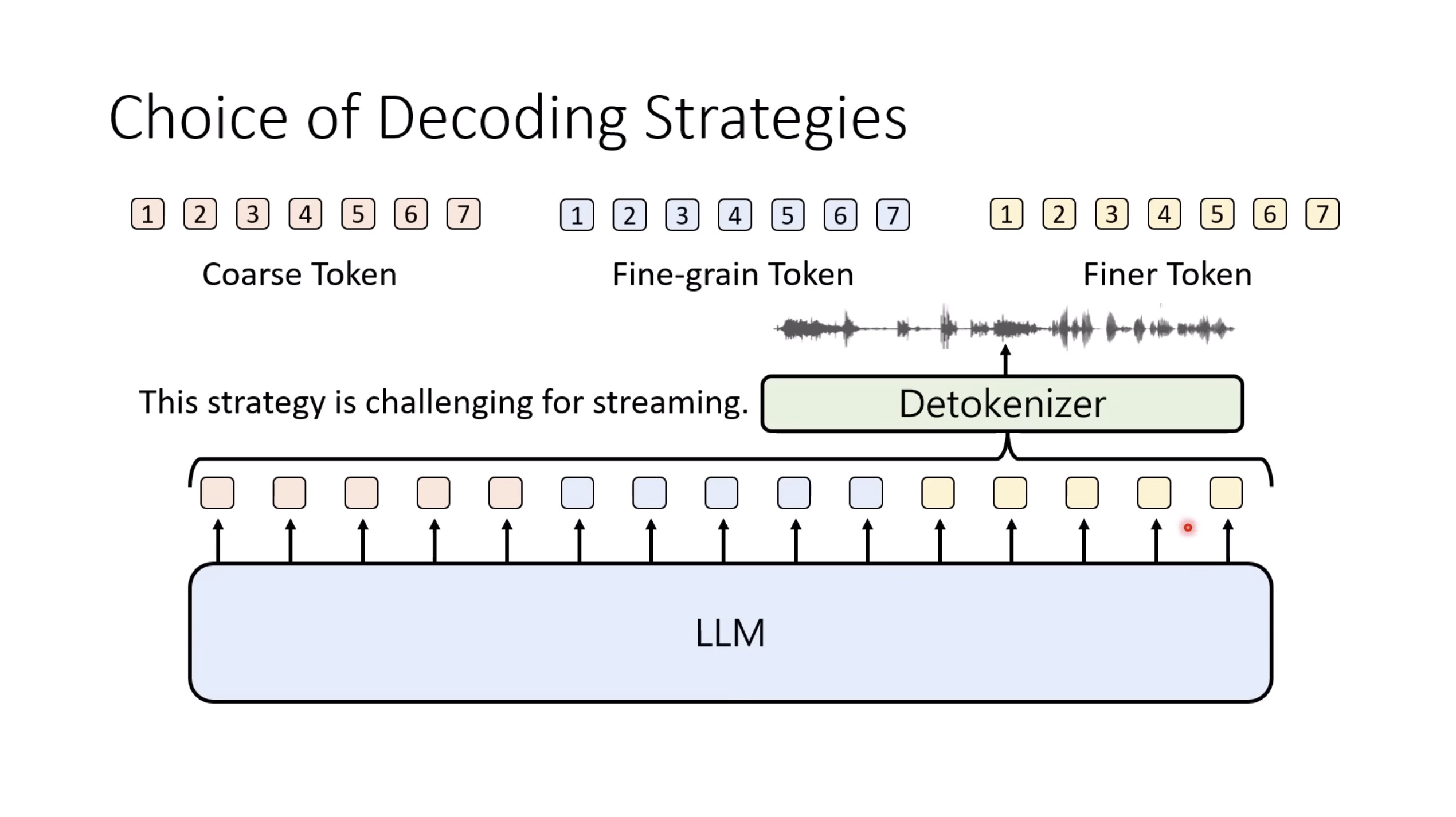
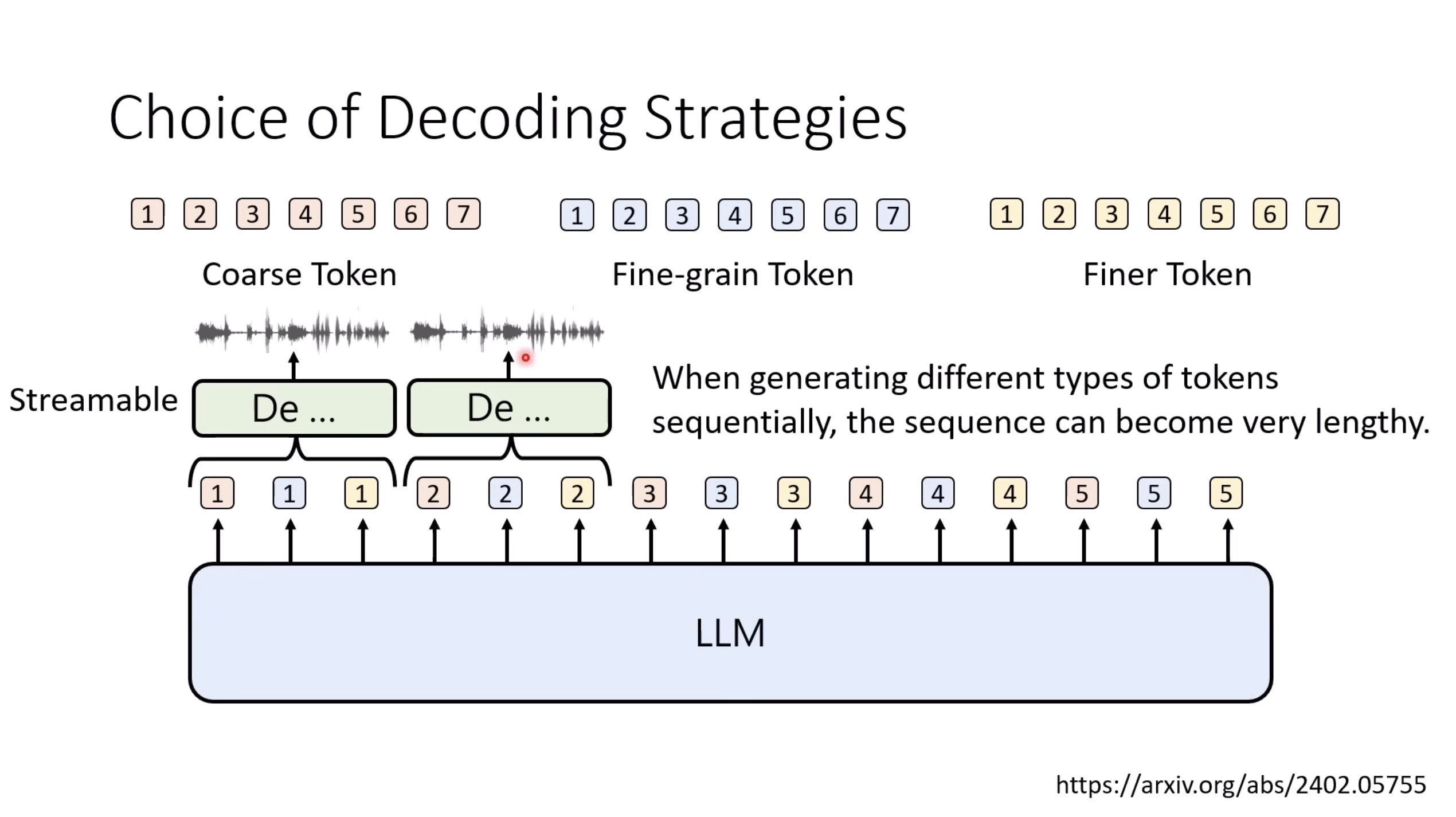
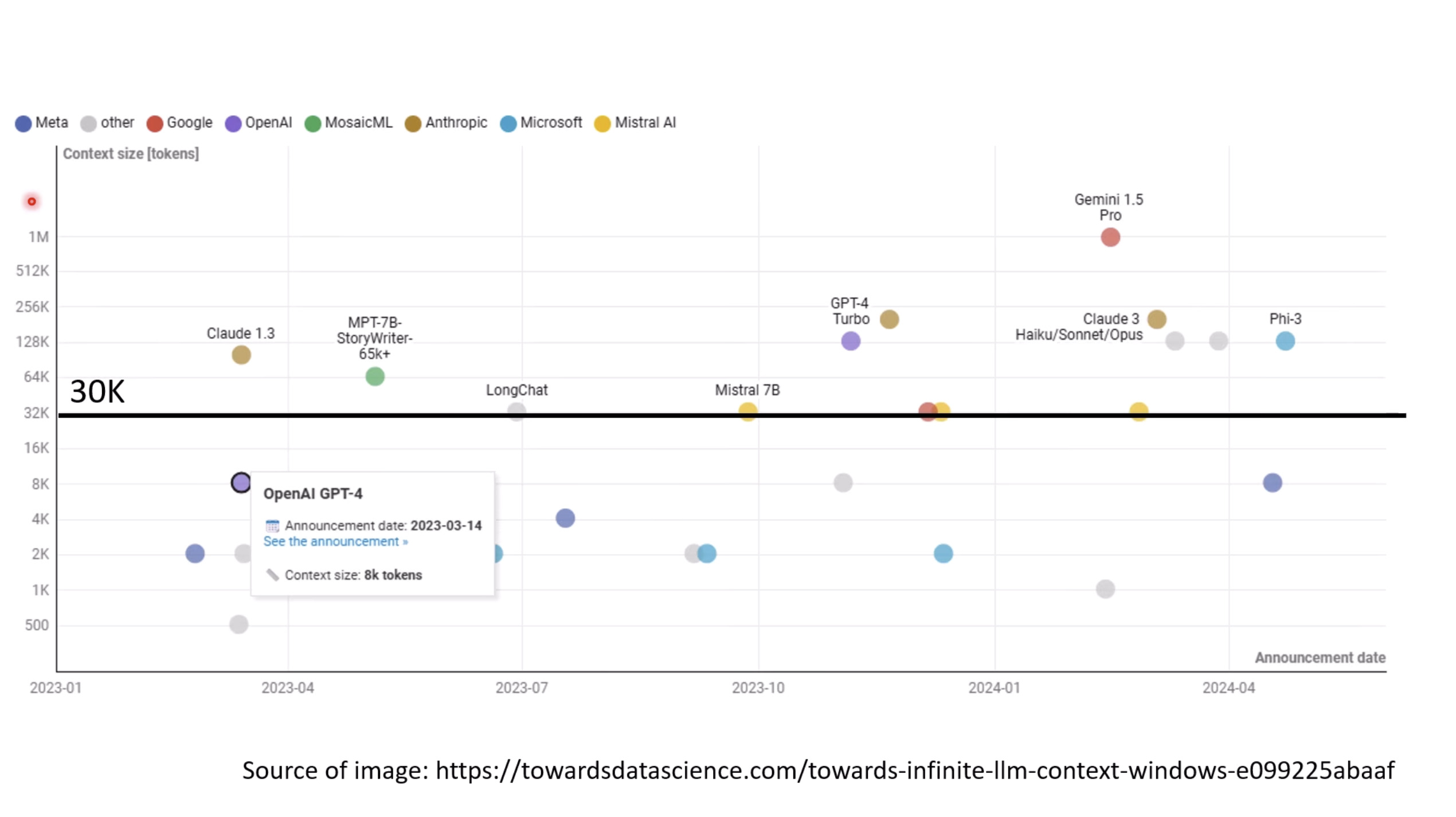
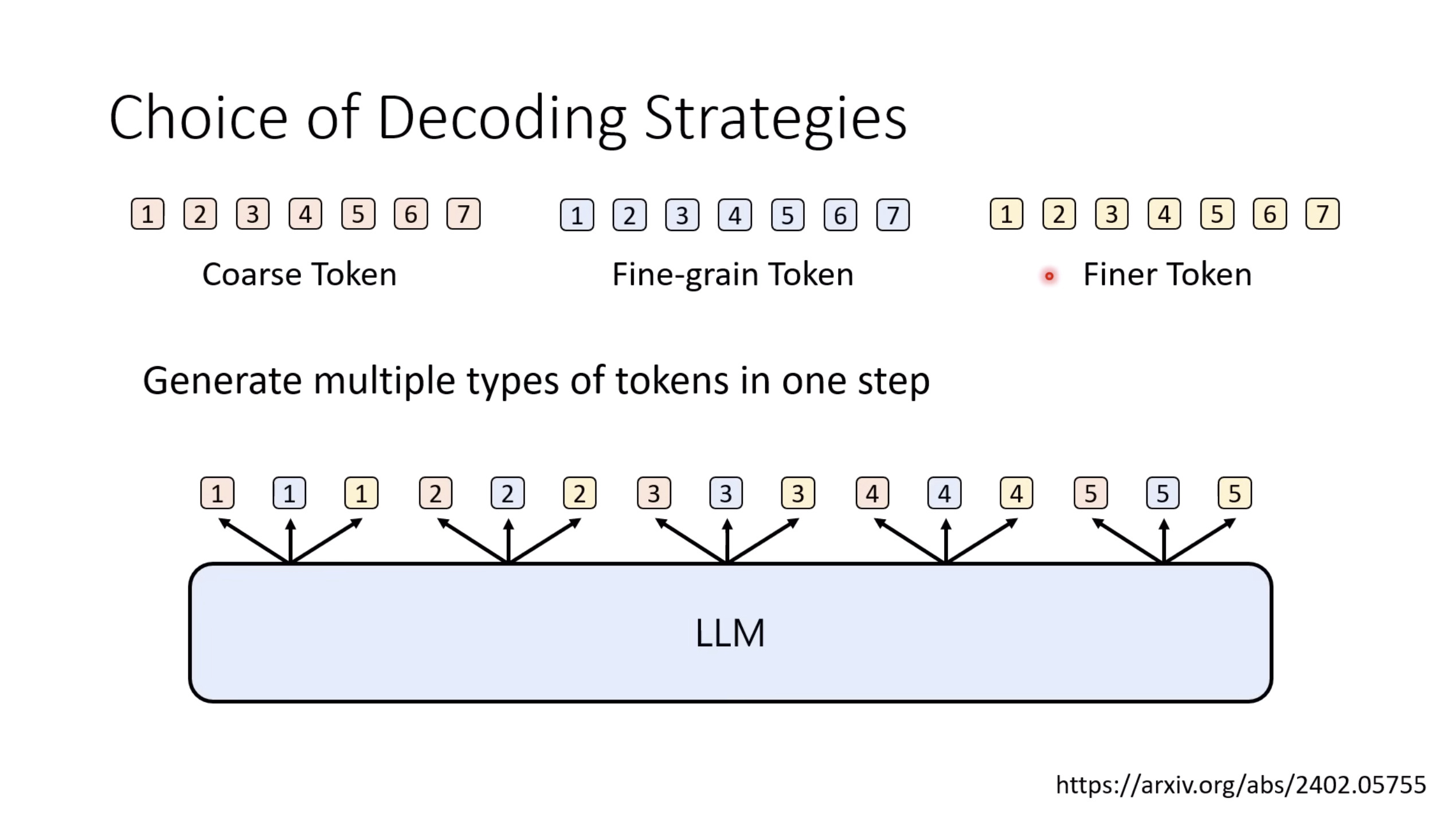
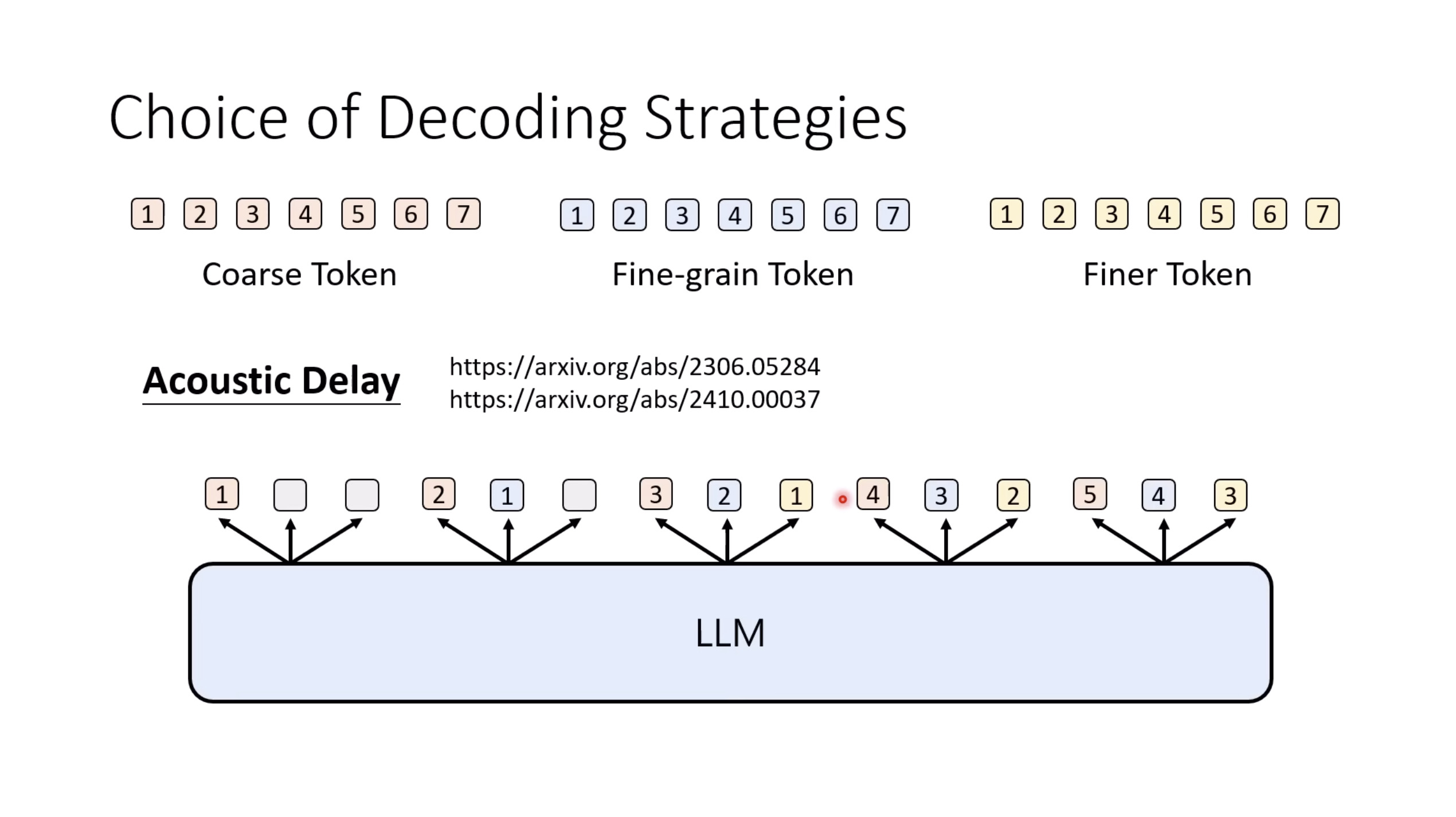
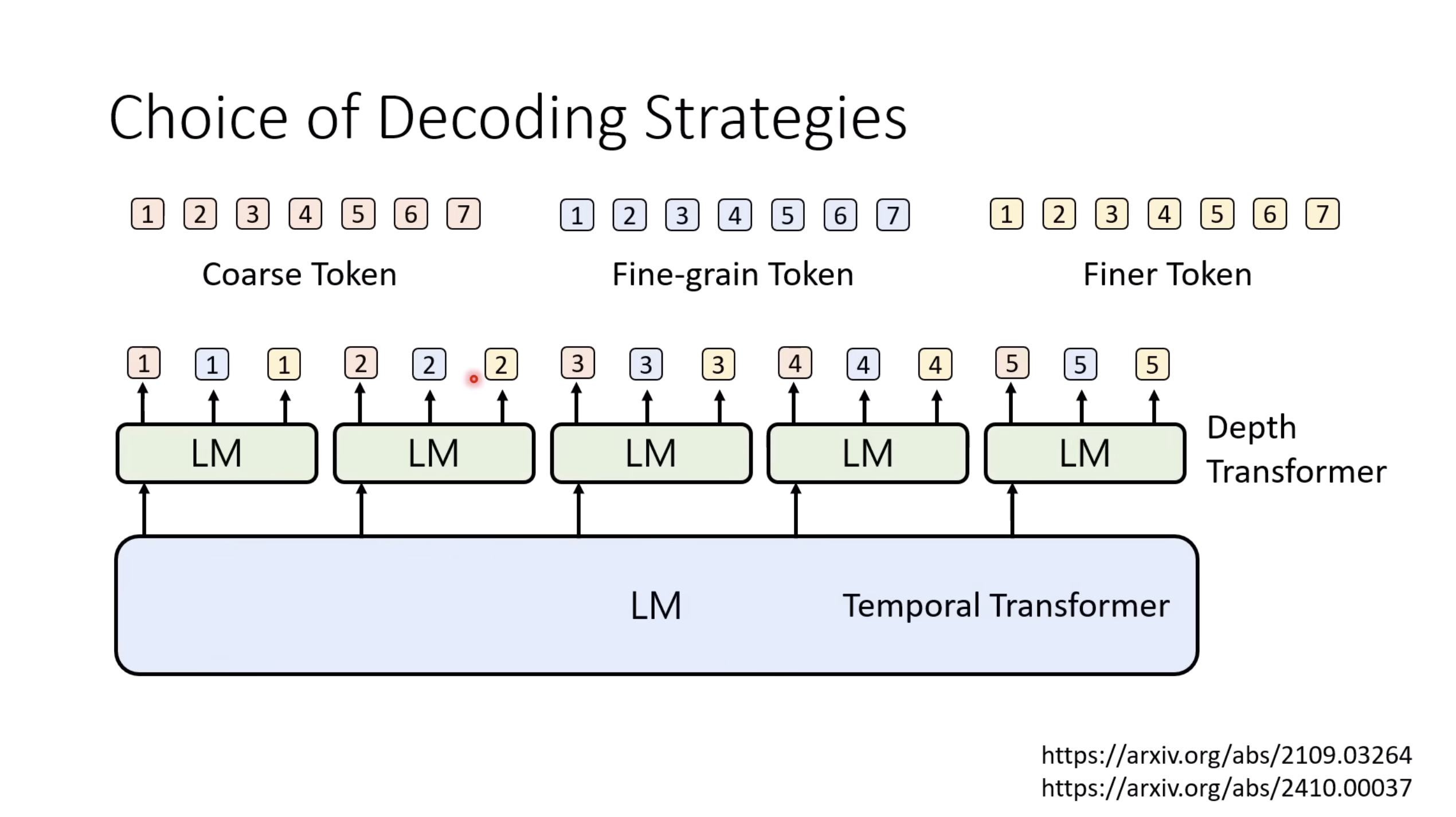
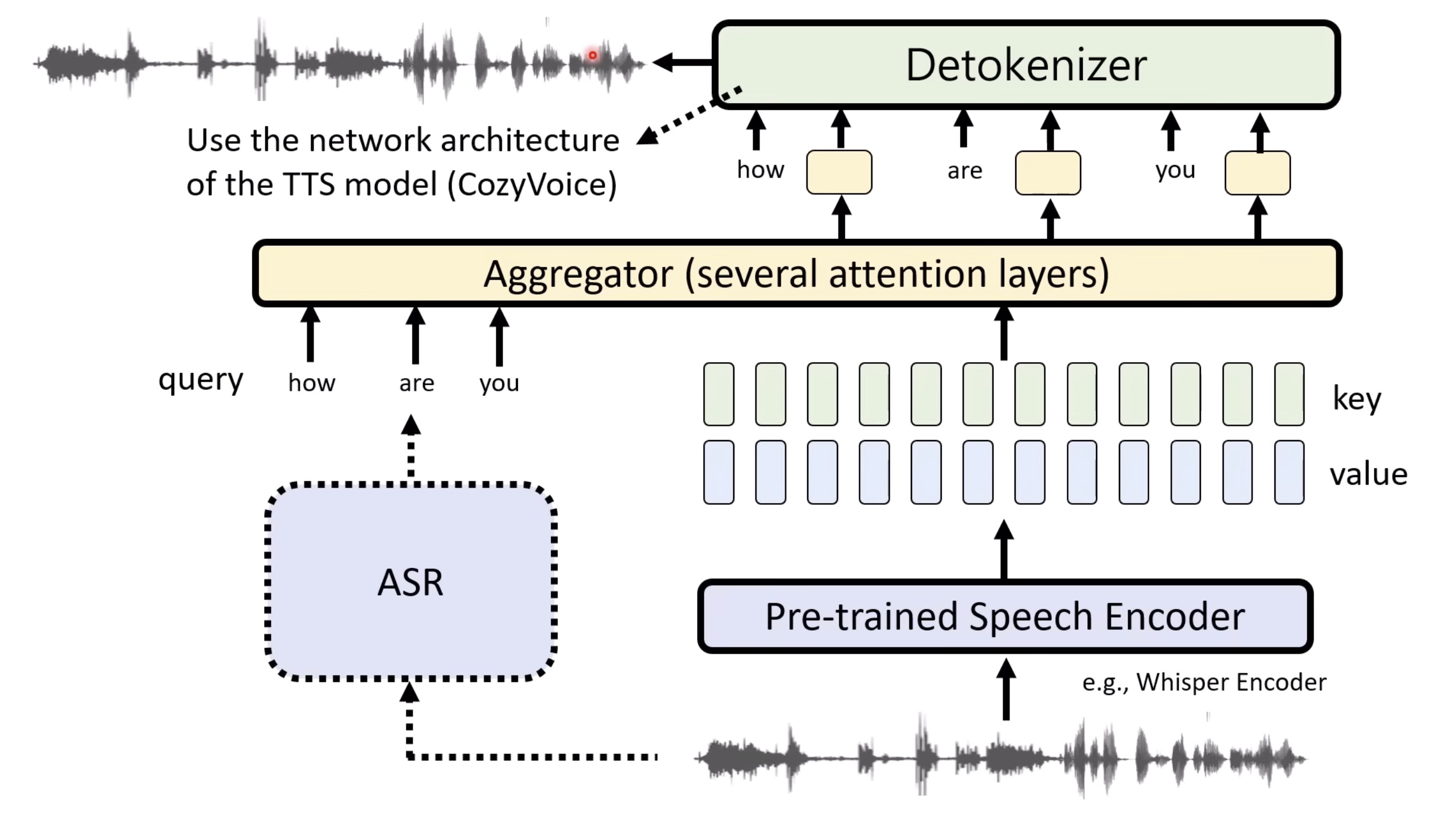
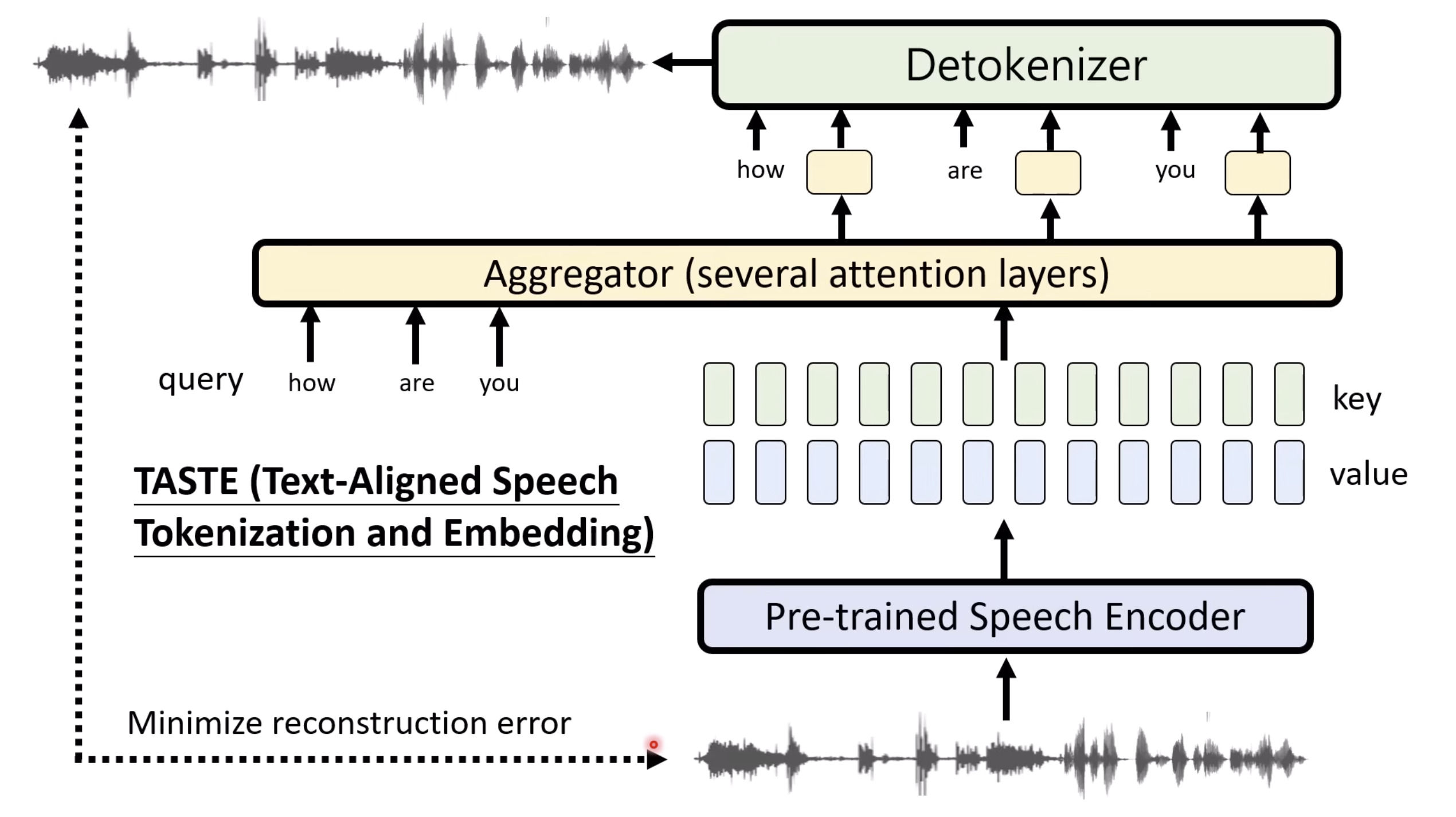
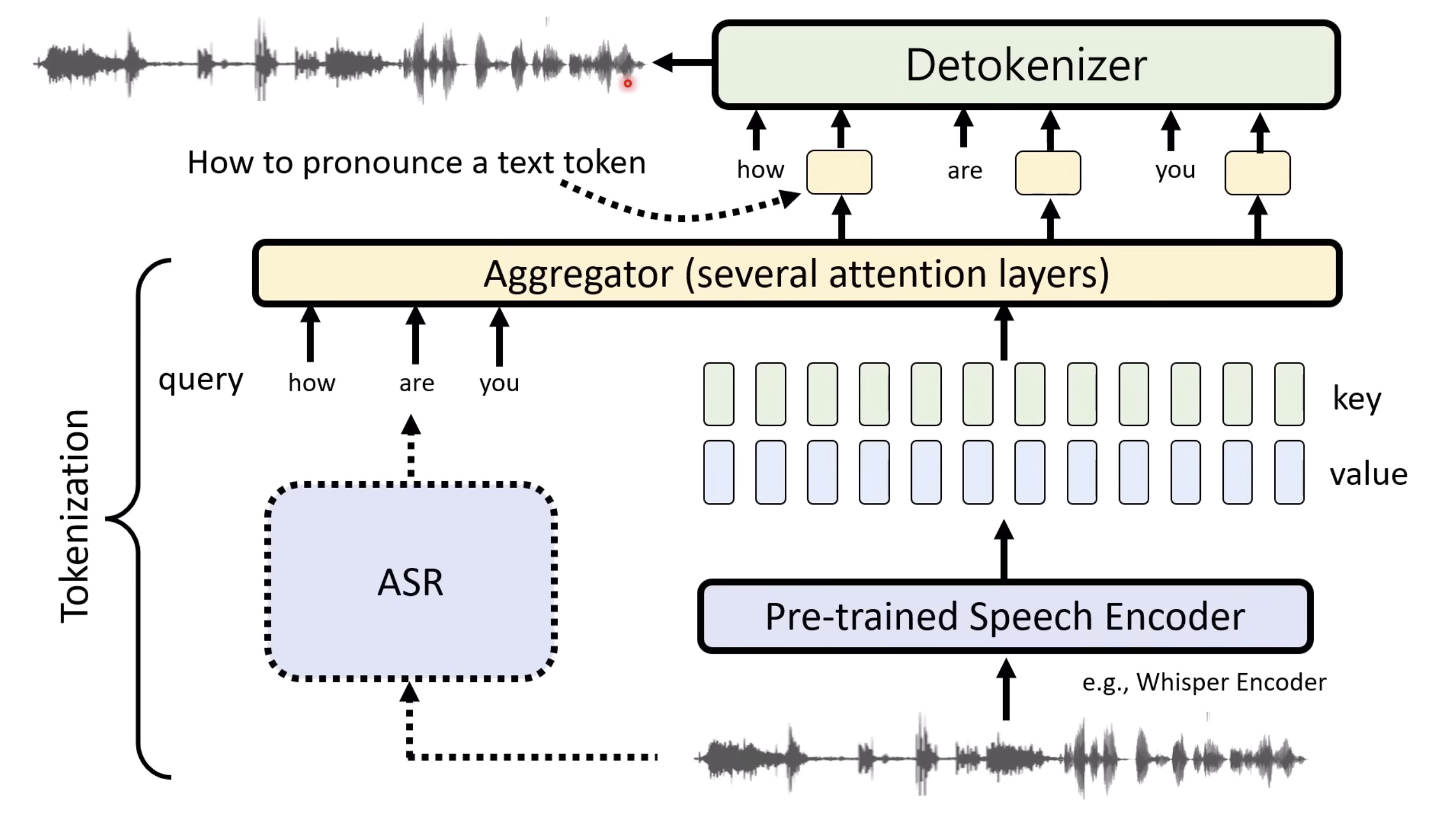
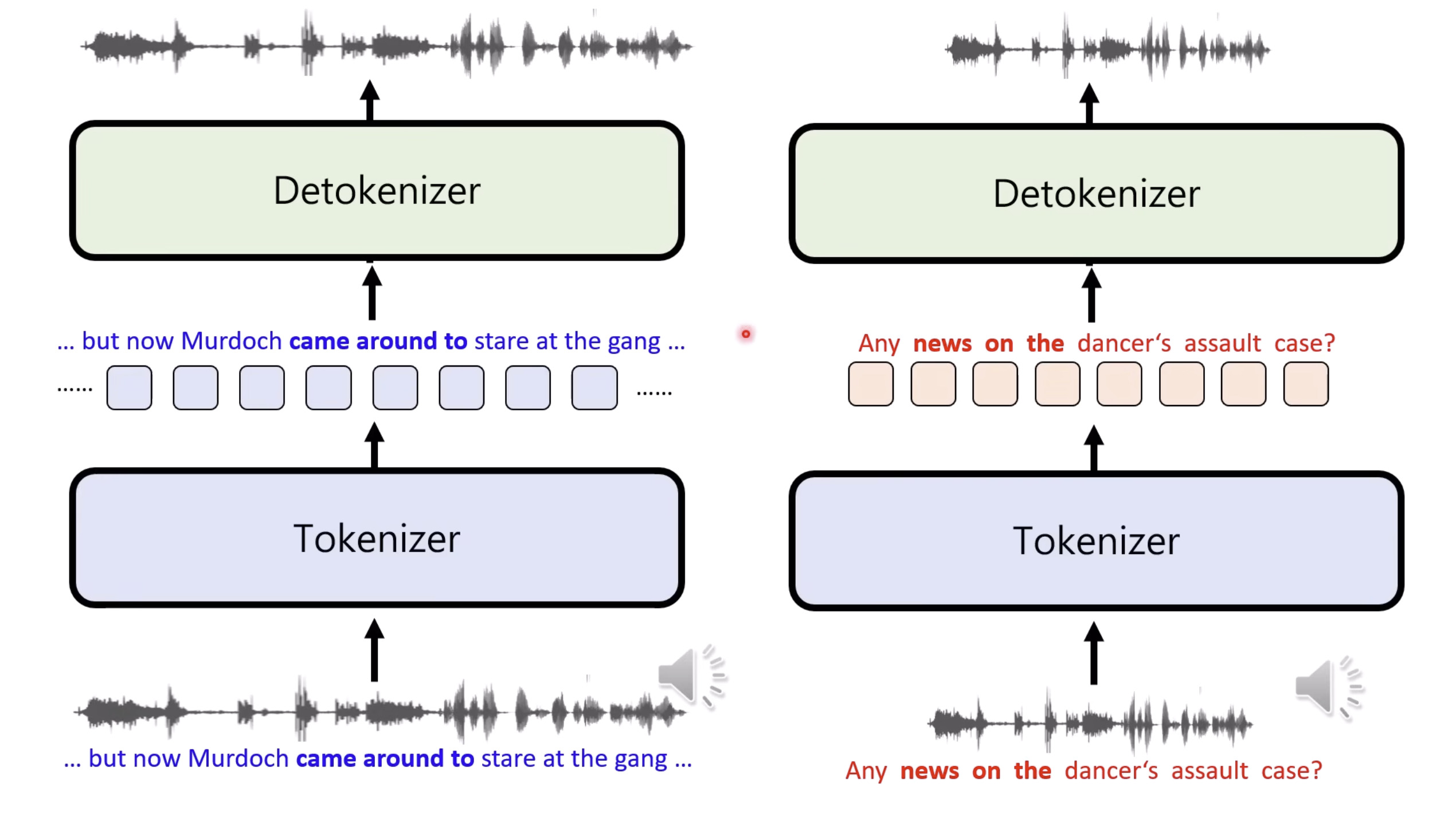
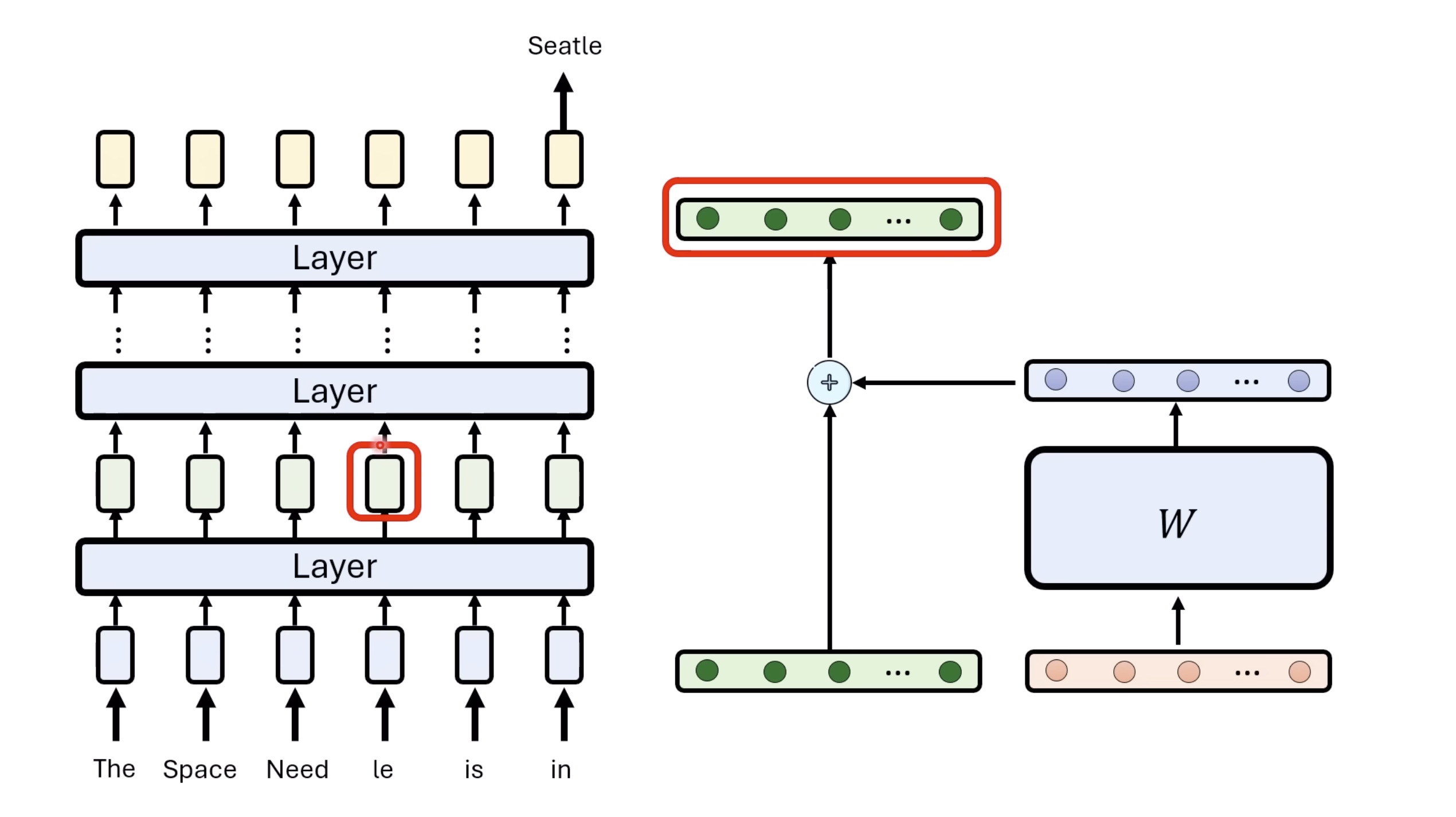
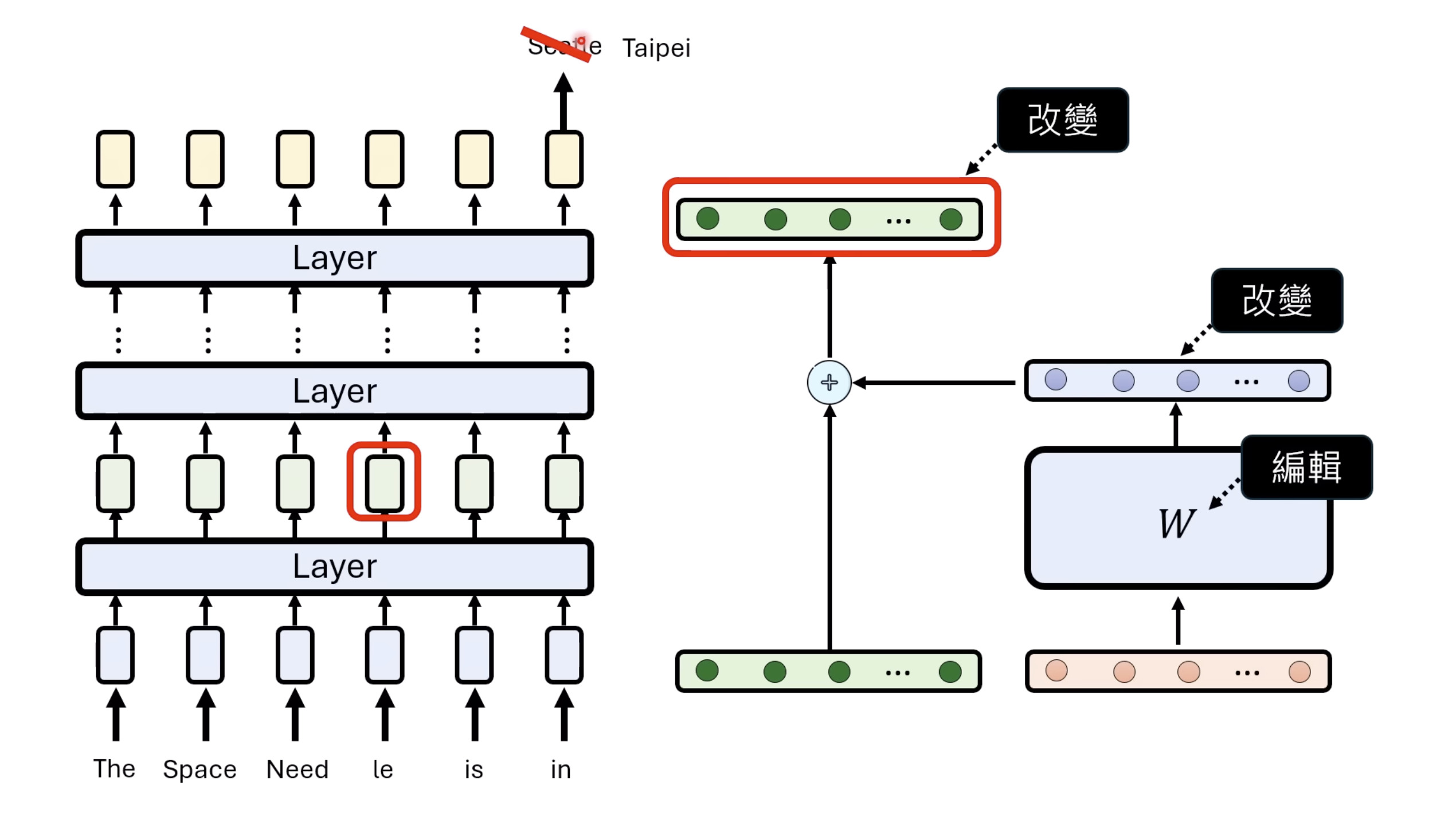
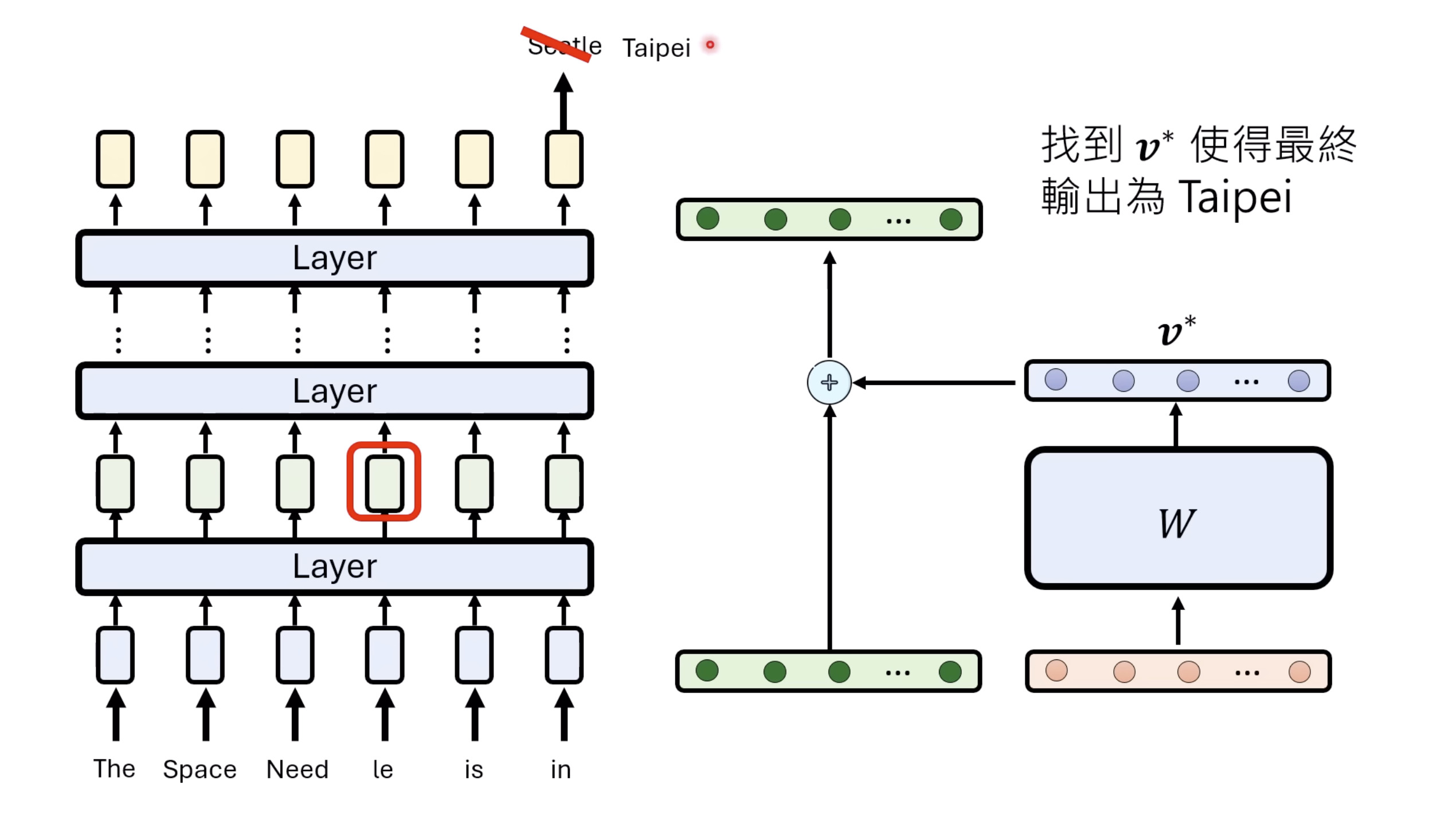
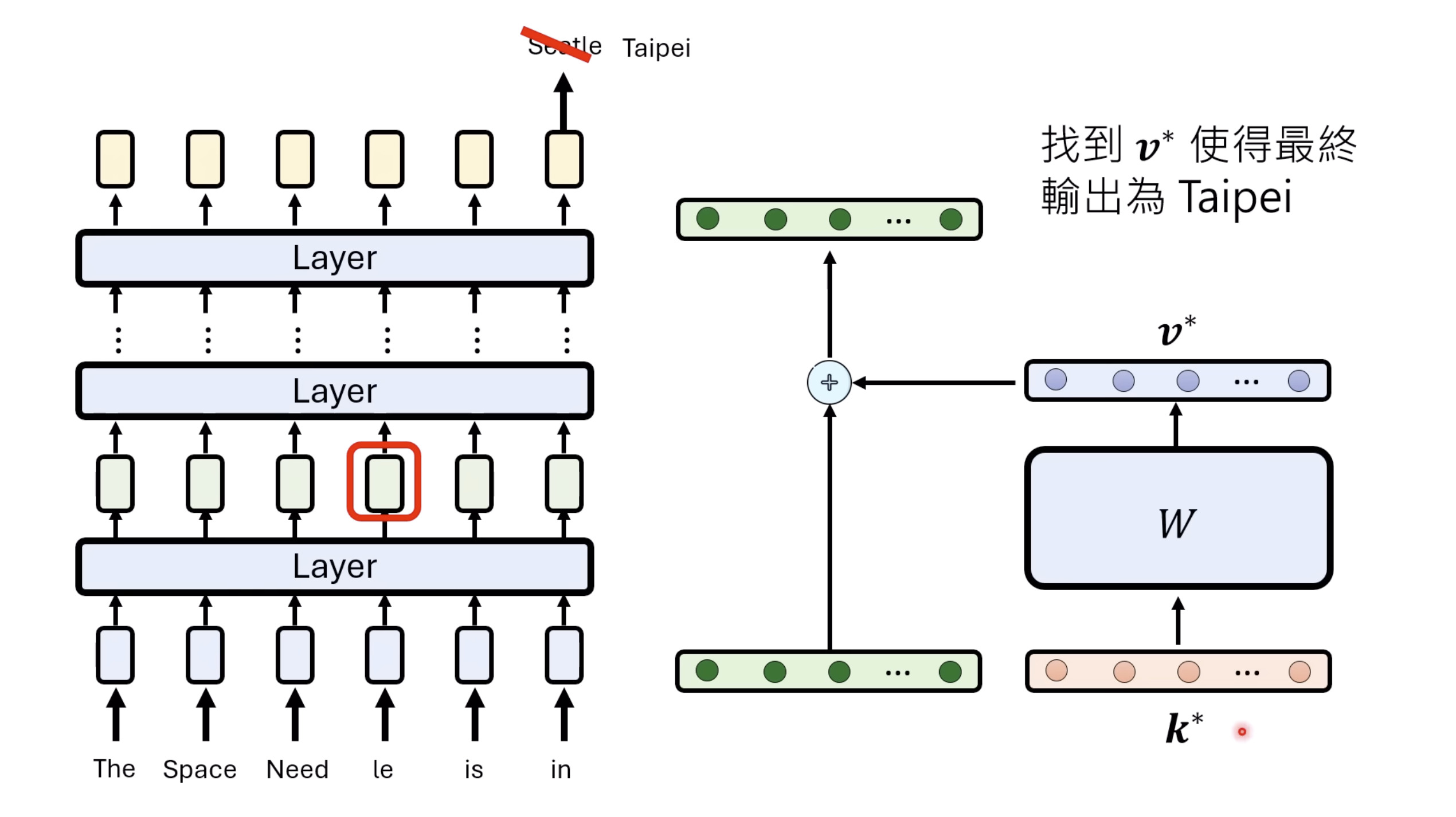
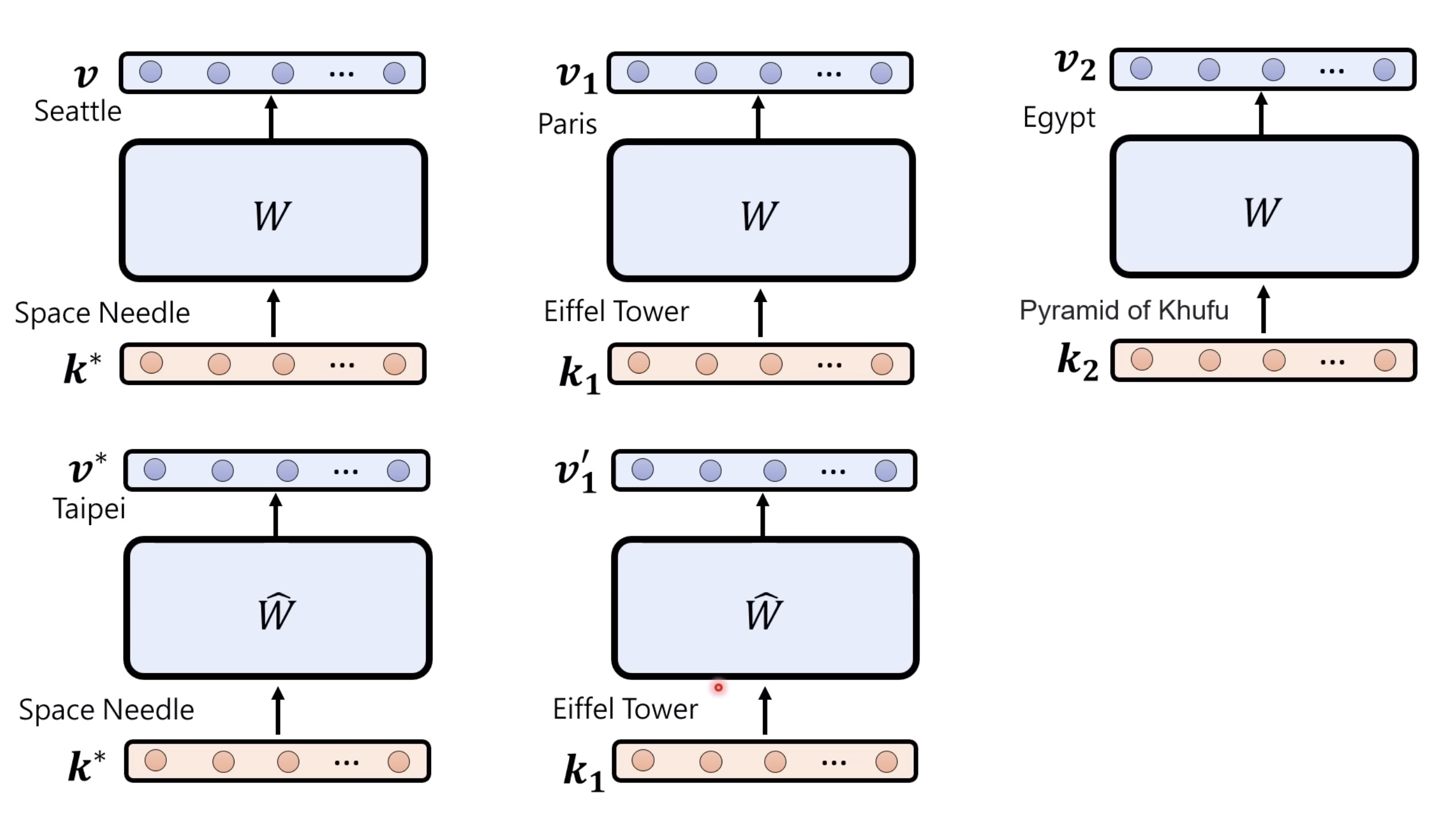
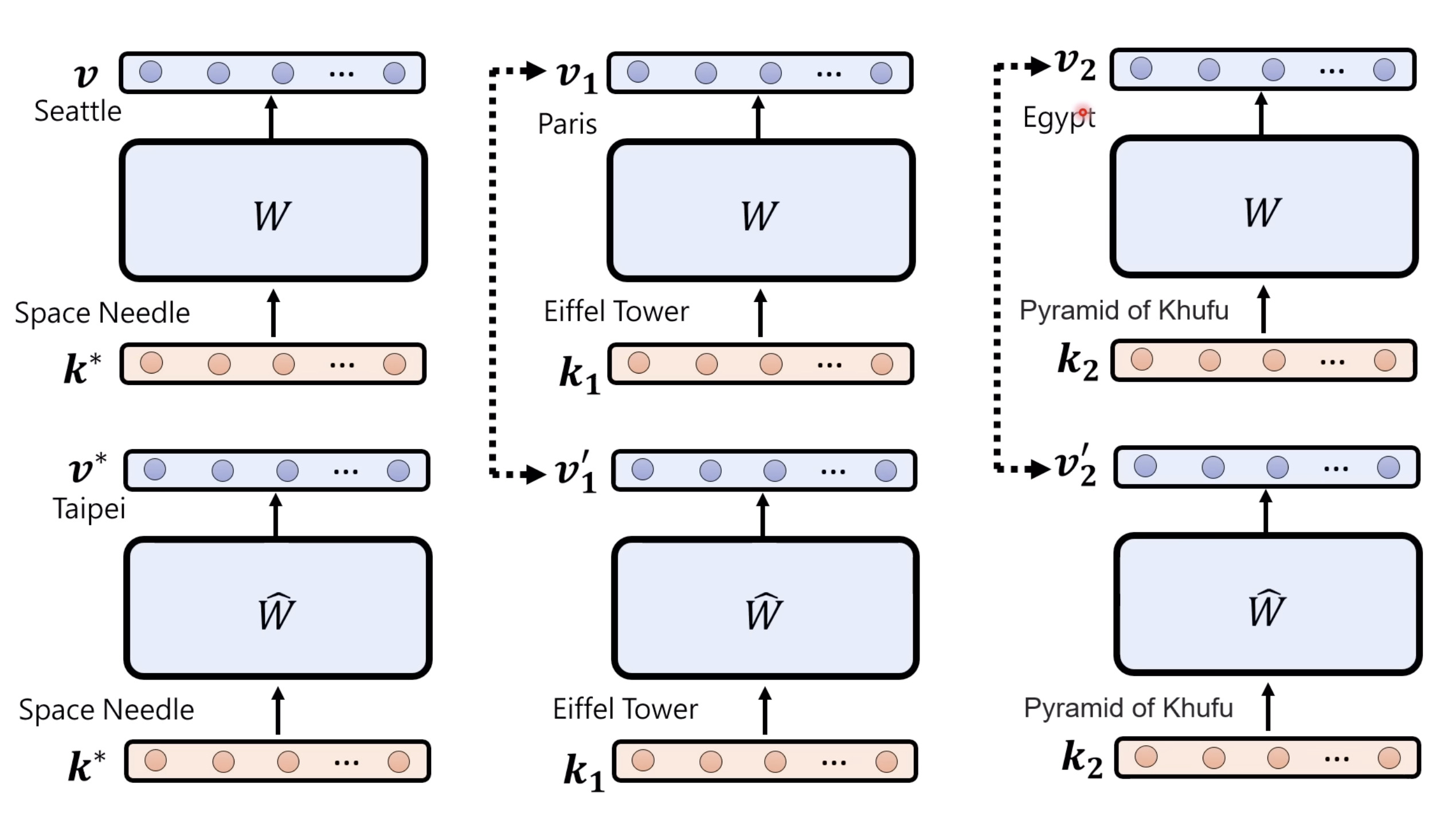
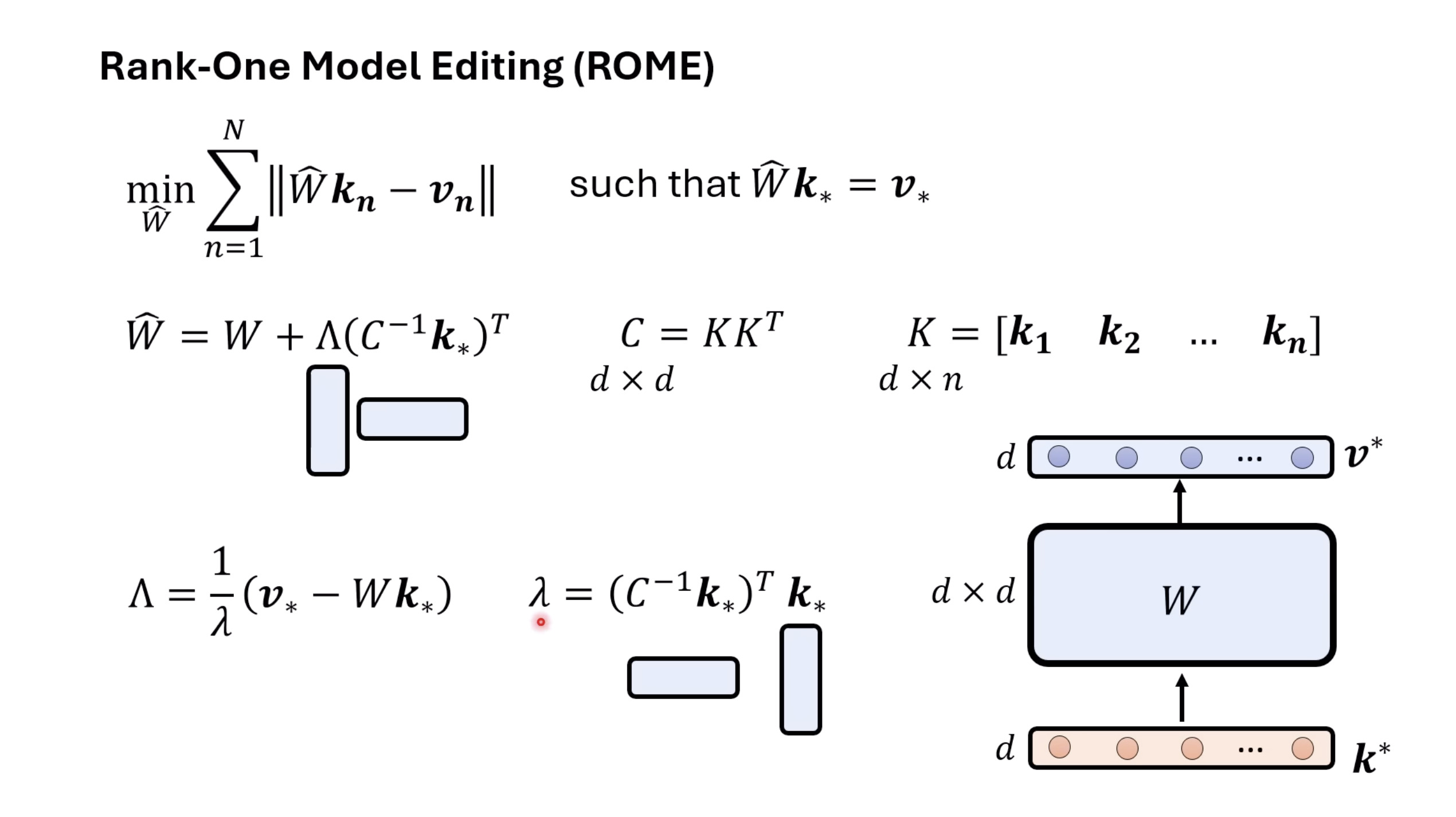
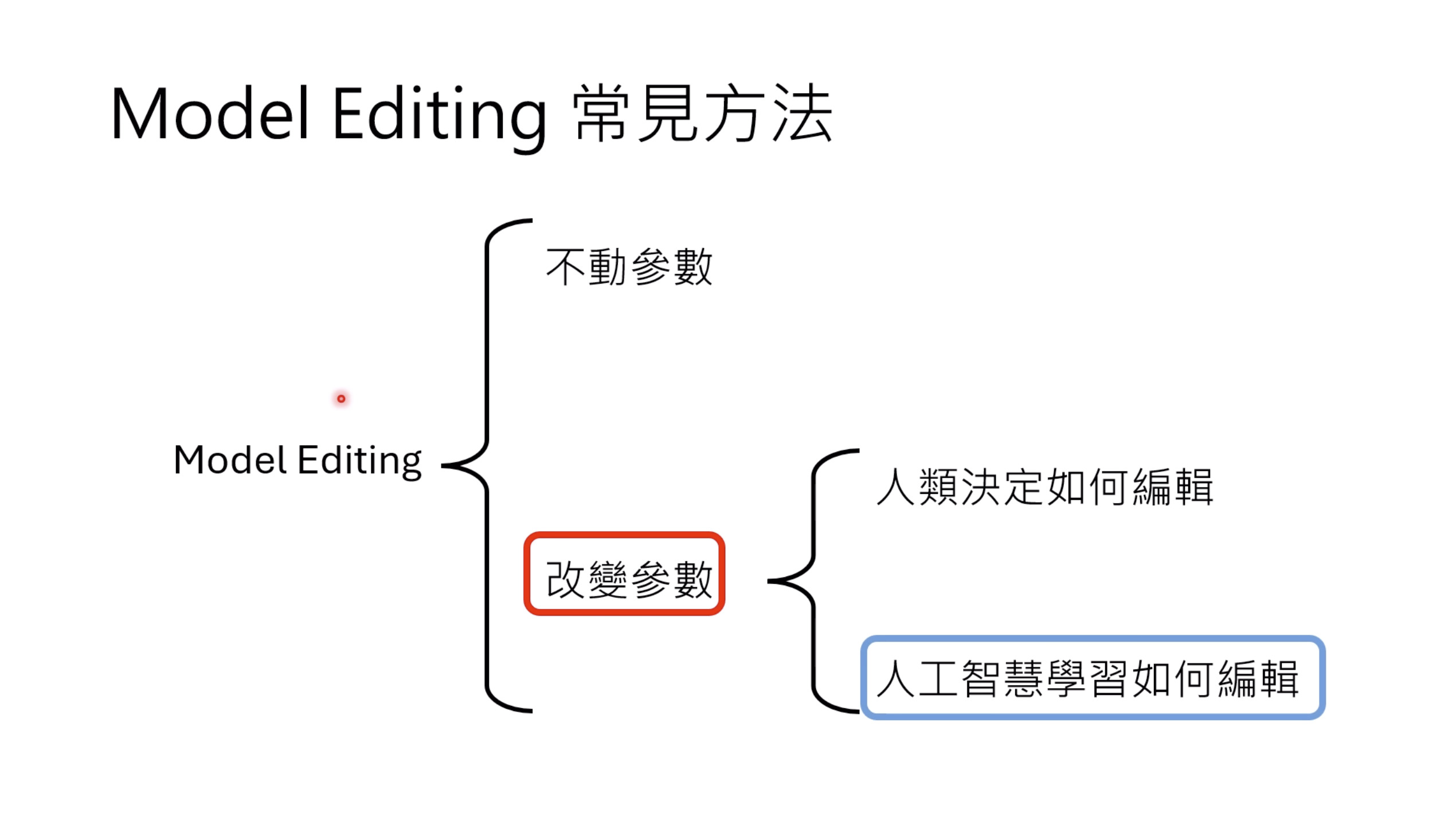
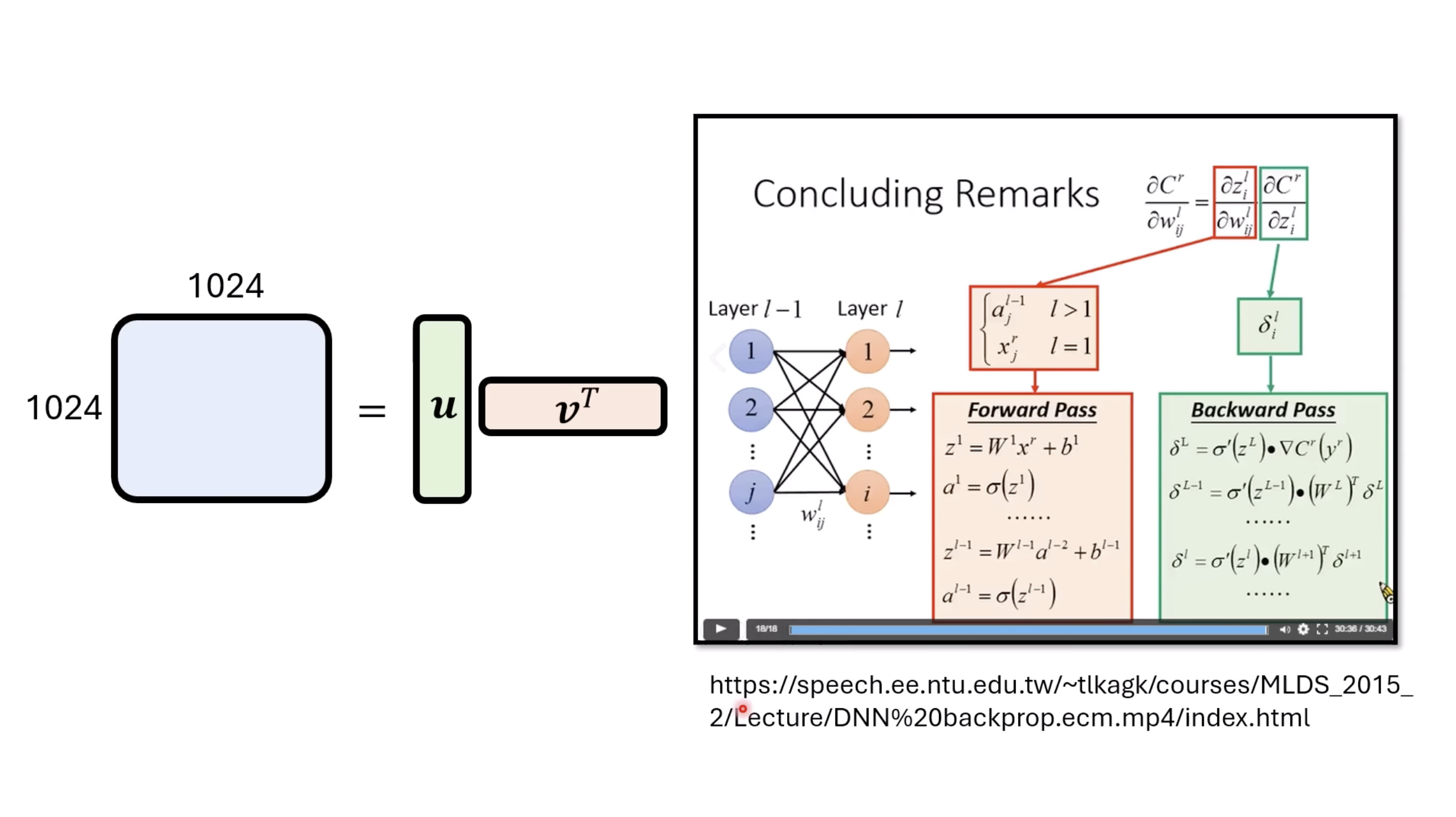
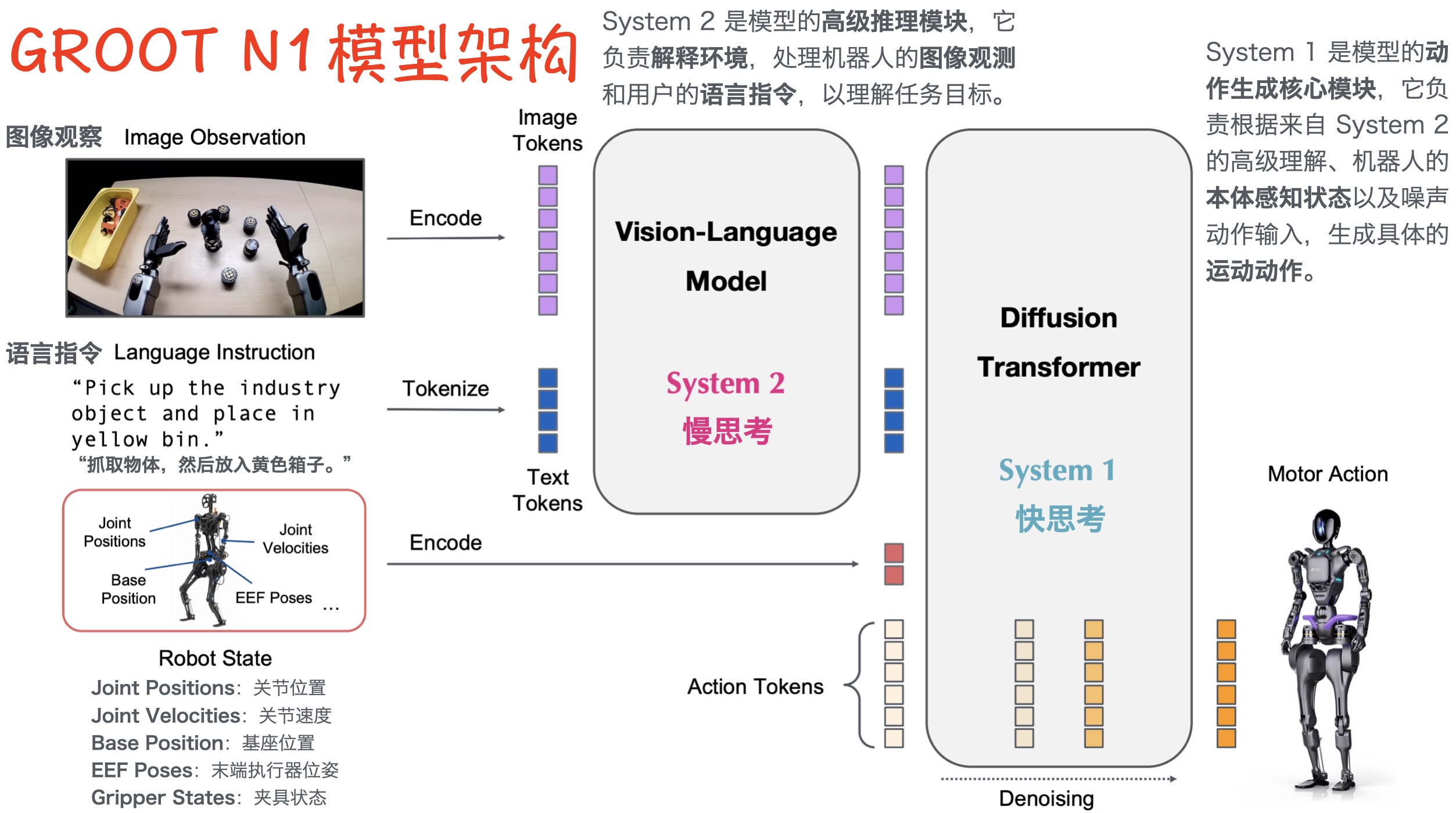
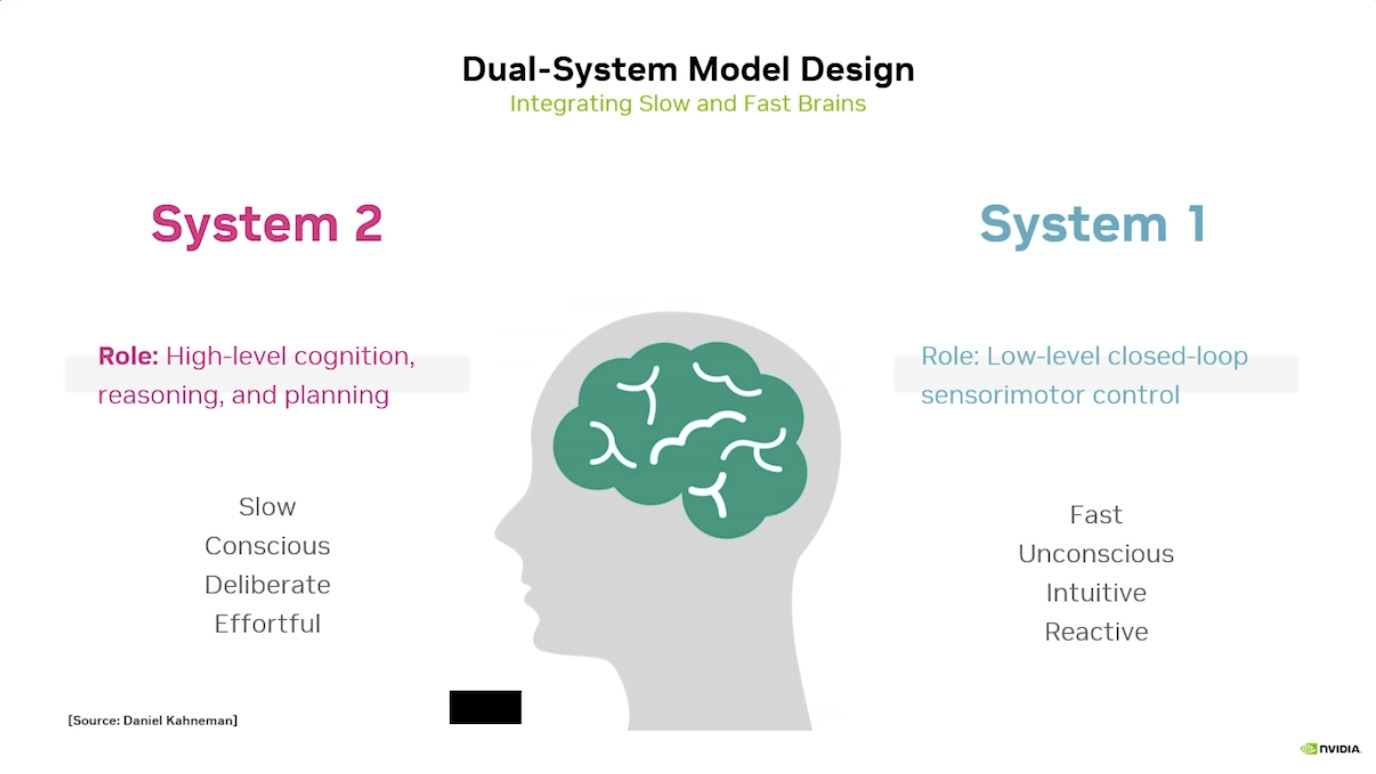
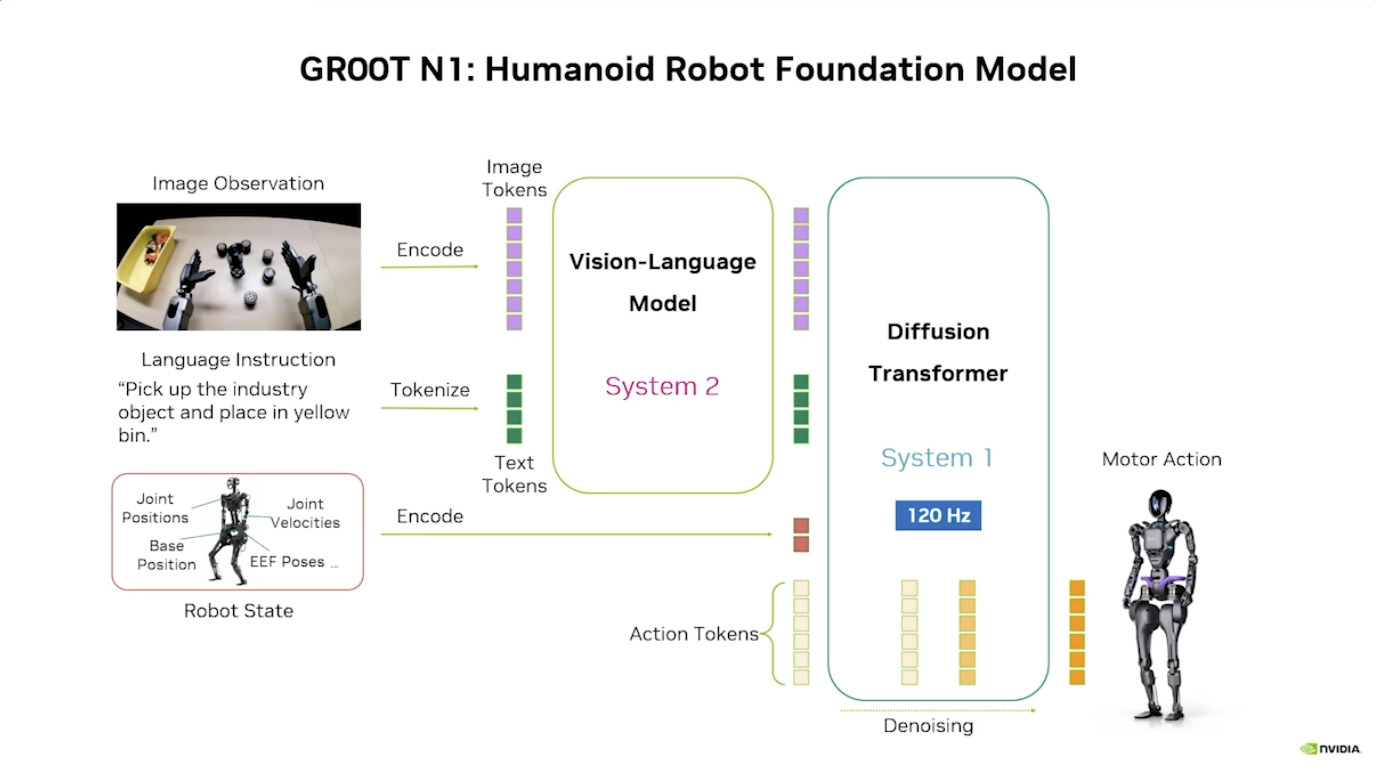
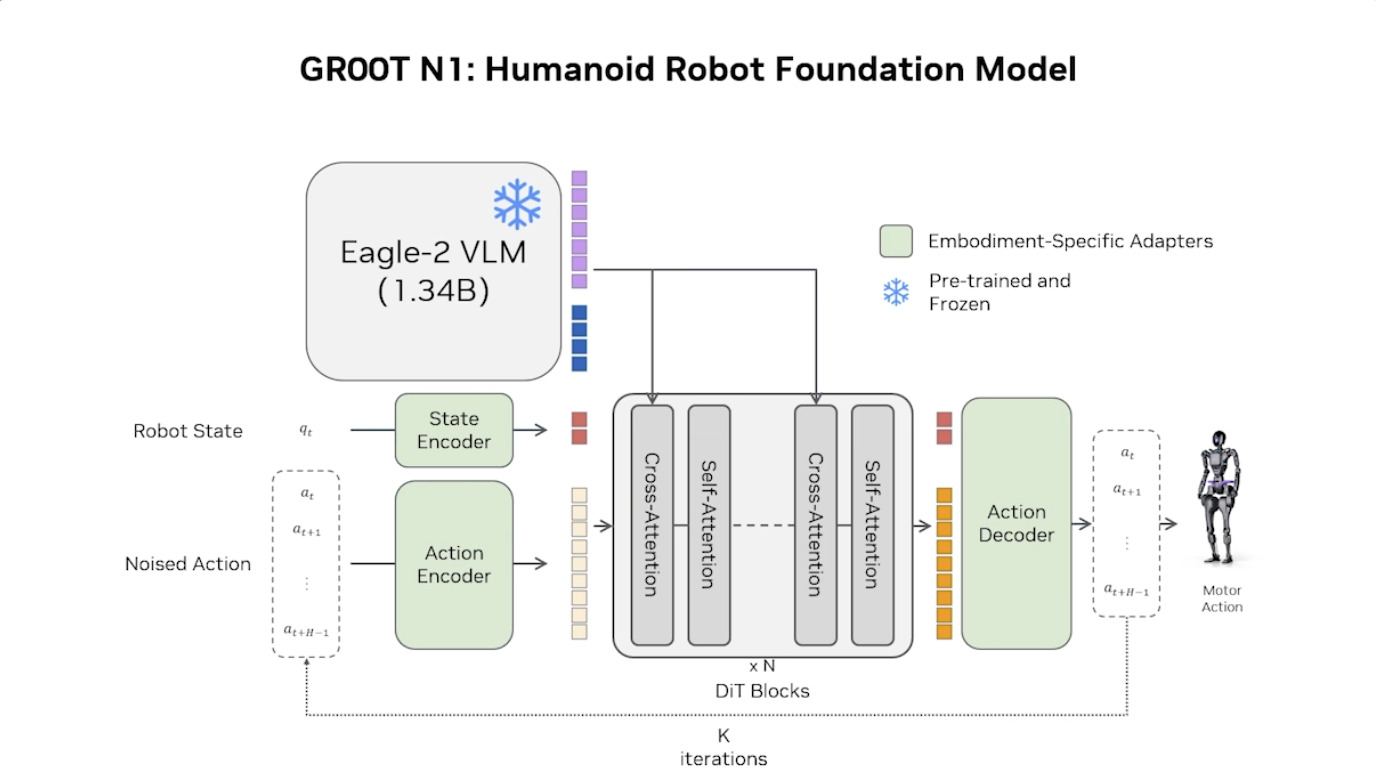
Isaac GROOT N1 - Architecture


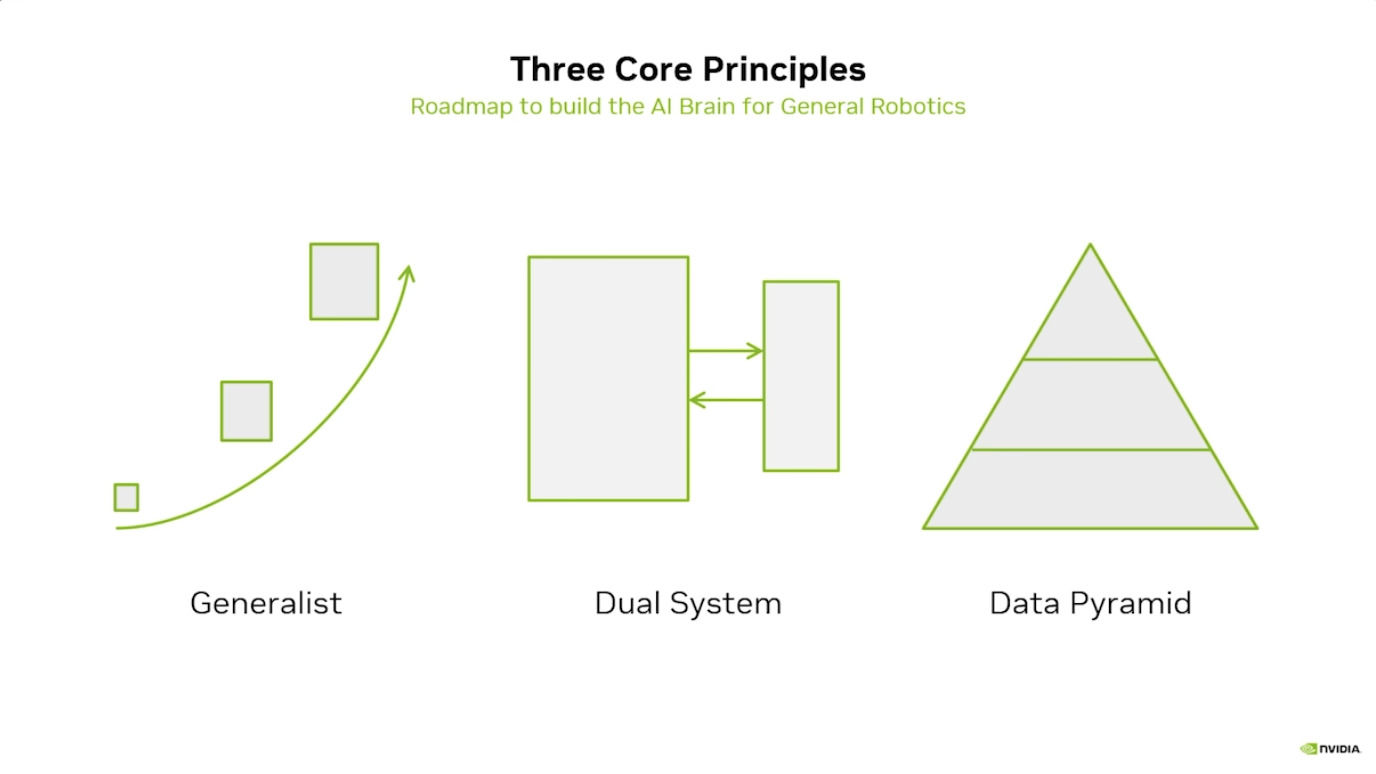
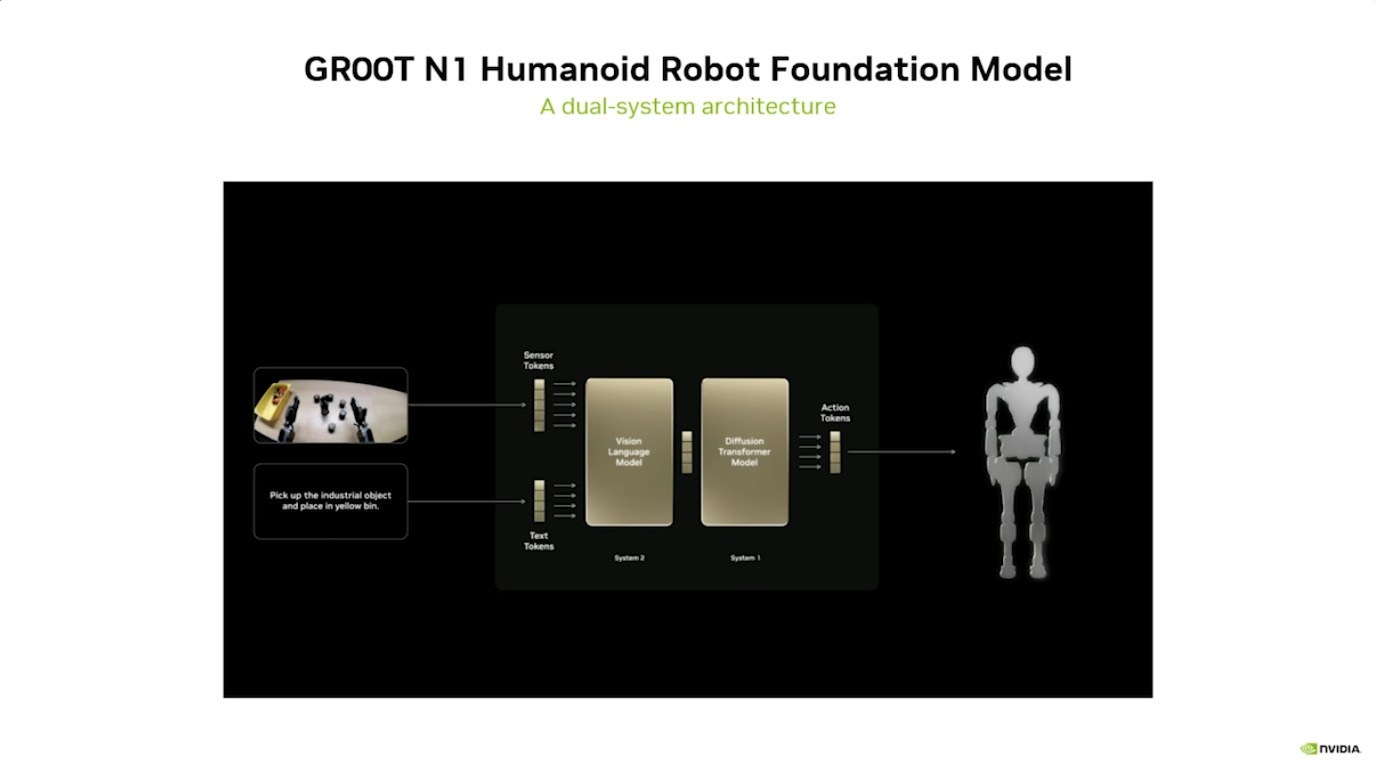


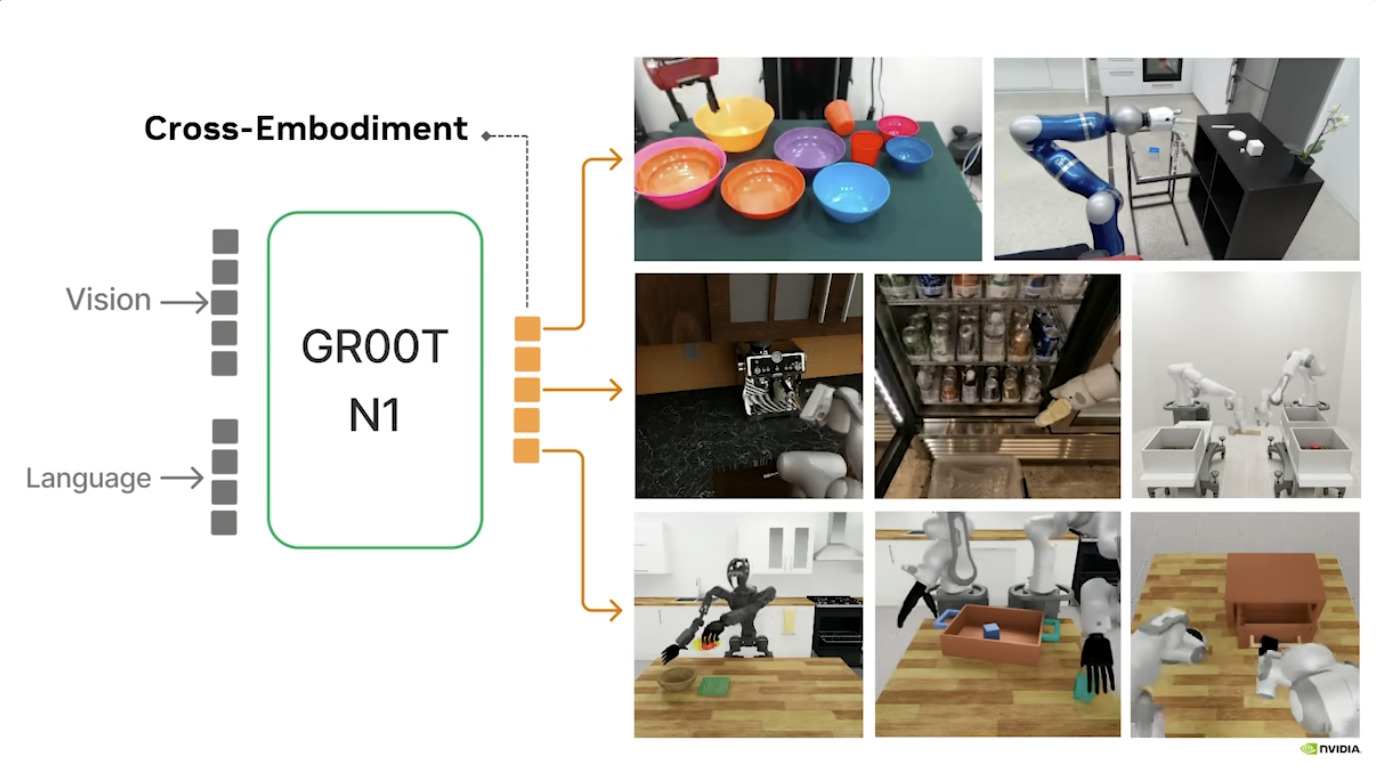
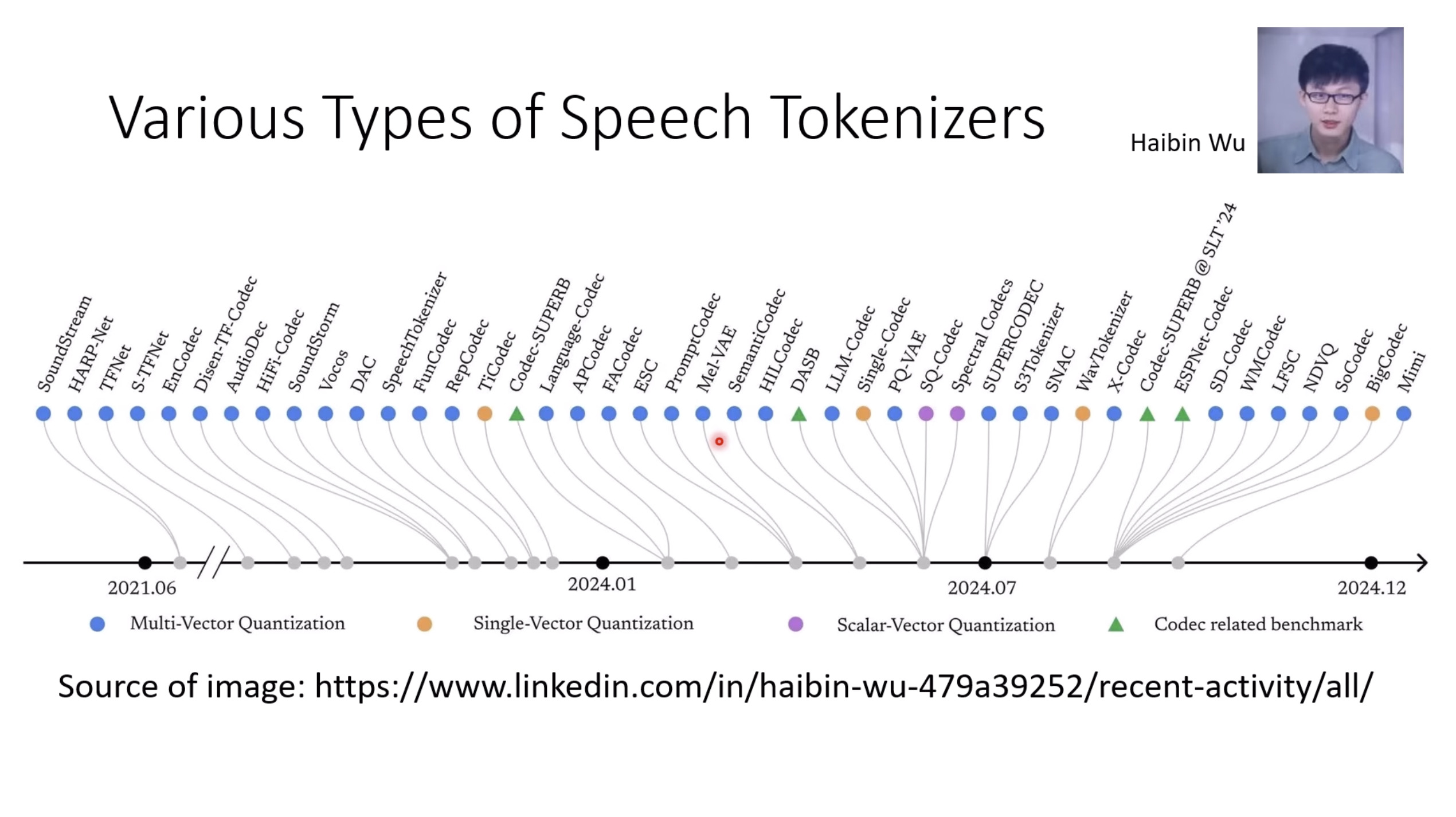
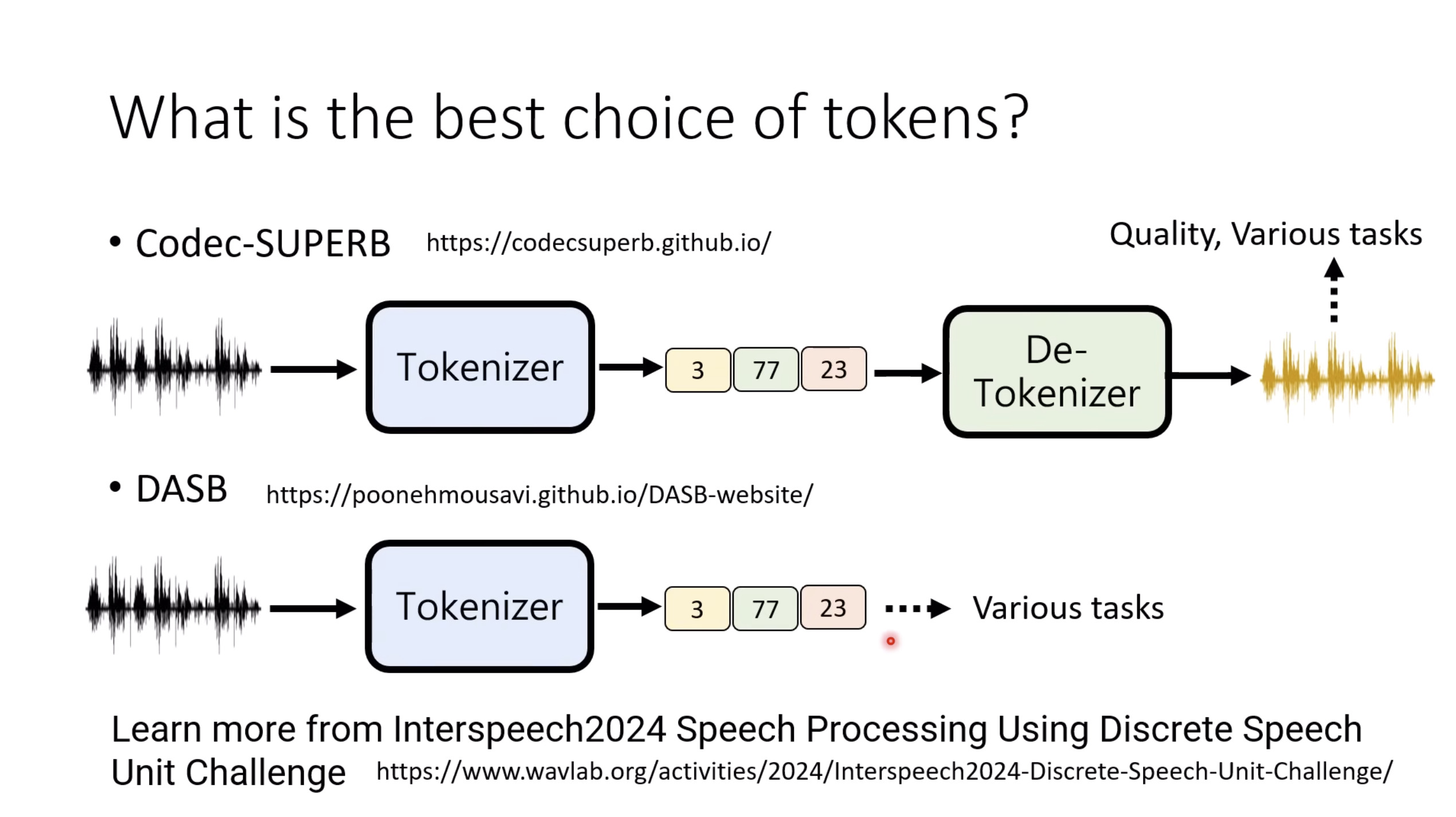
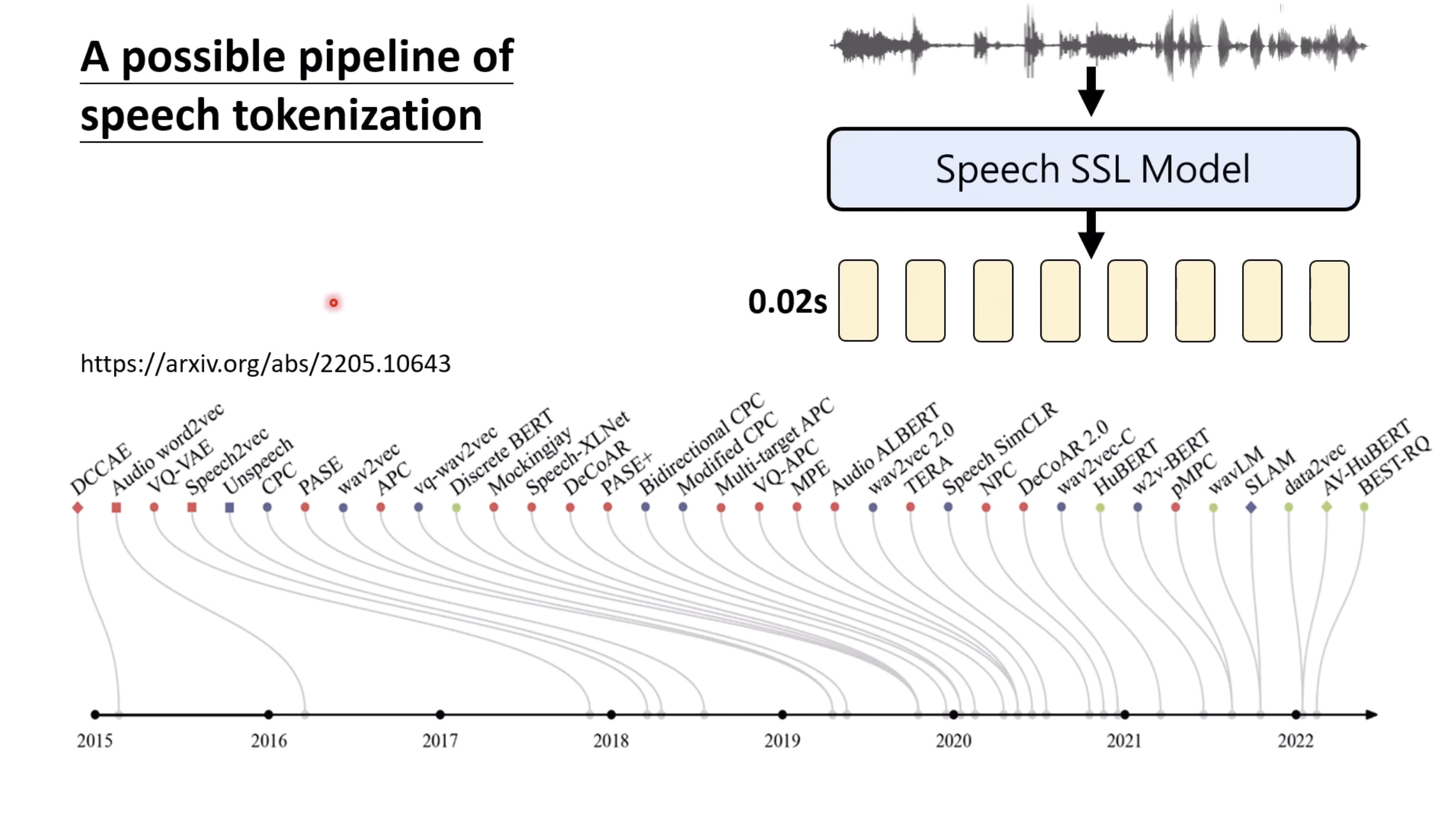
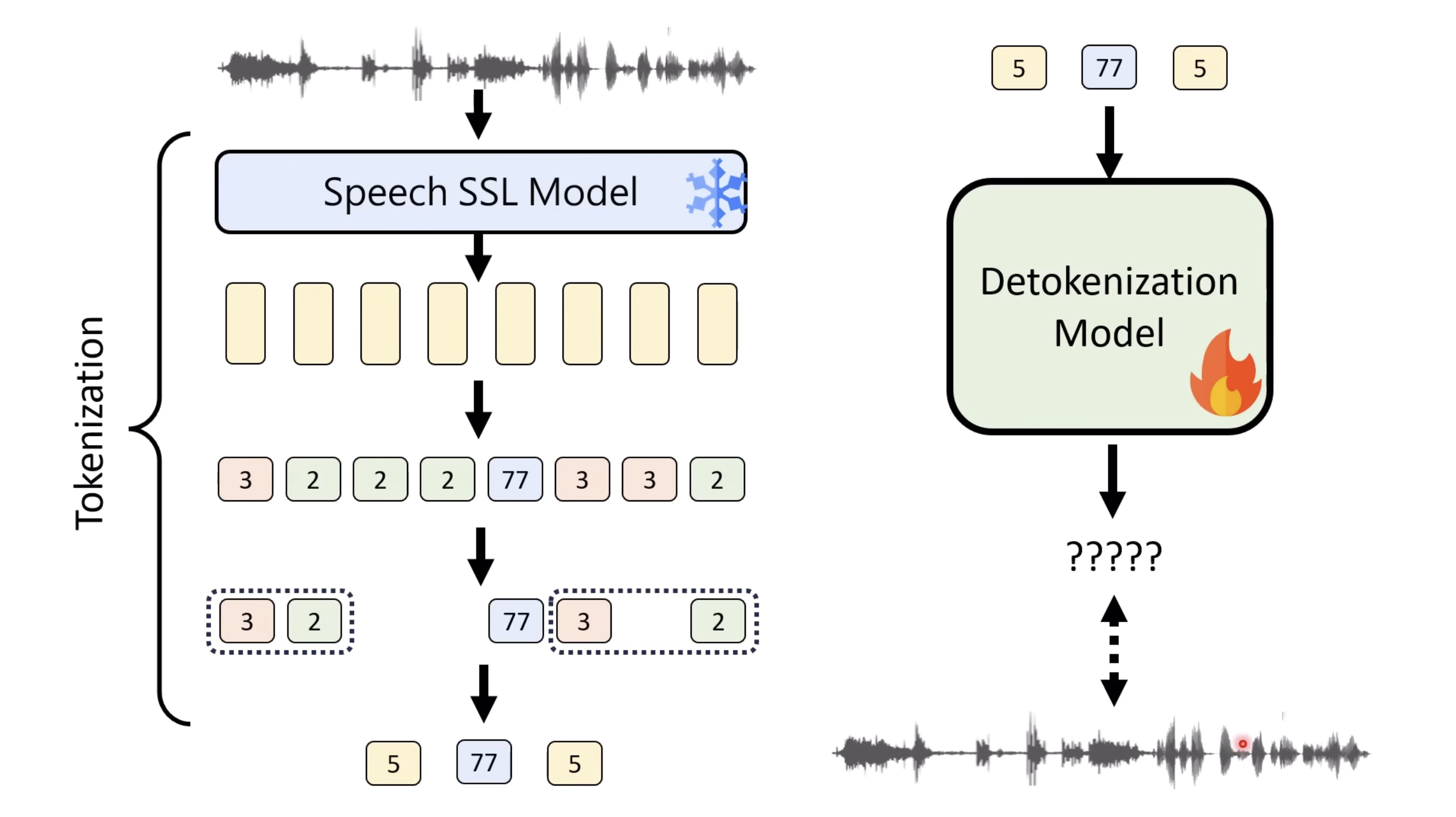
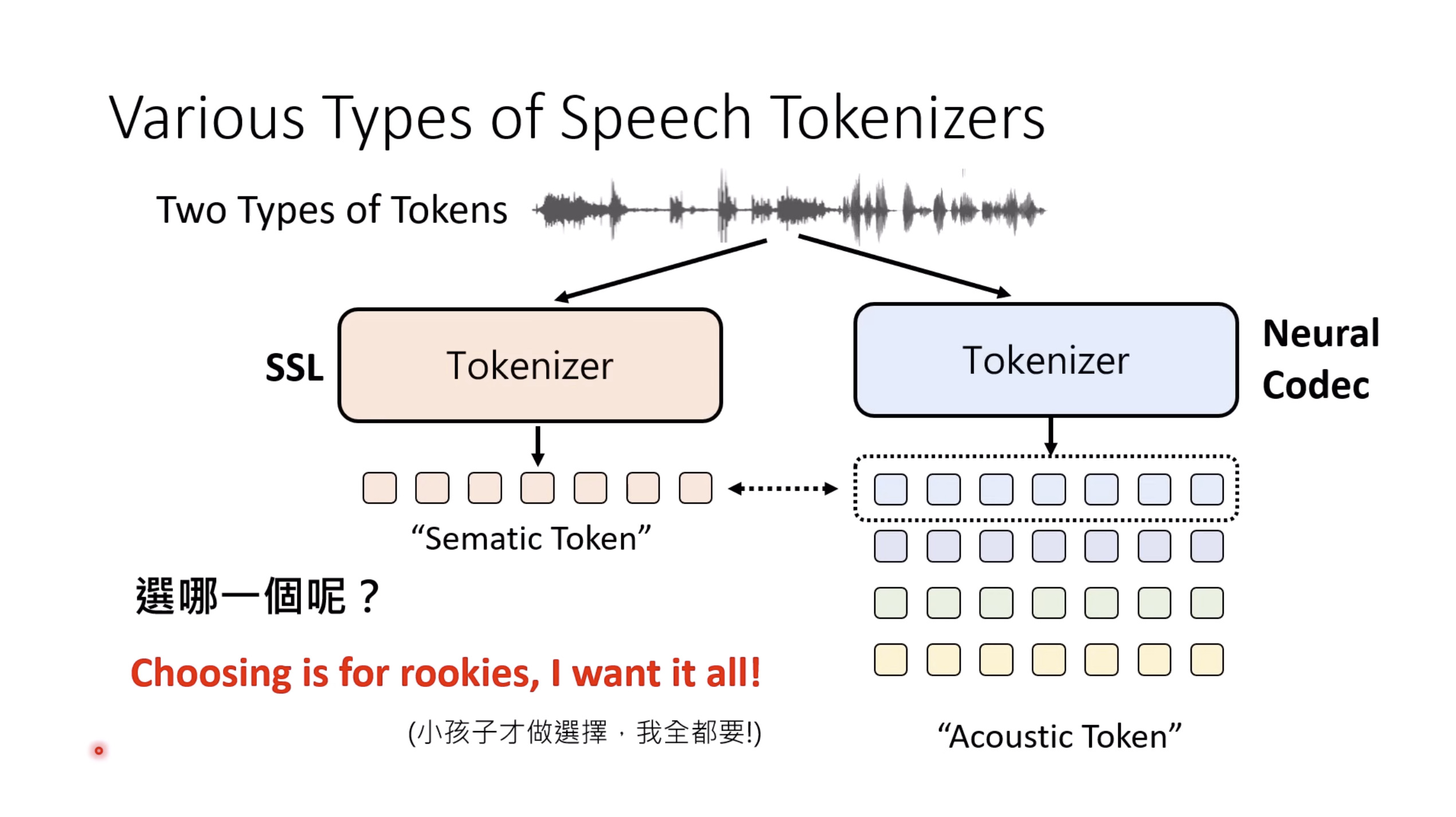
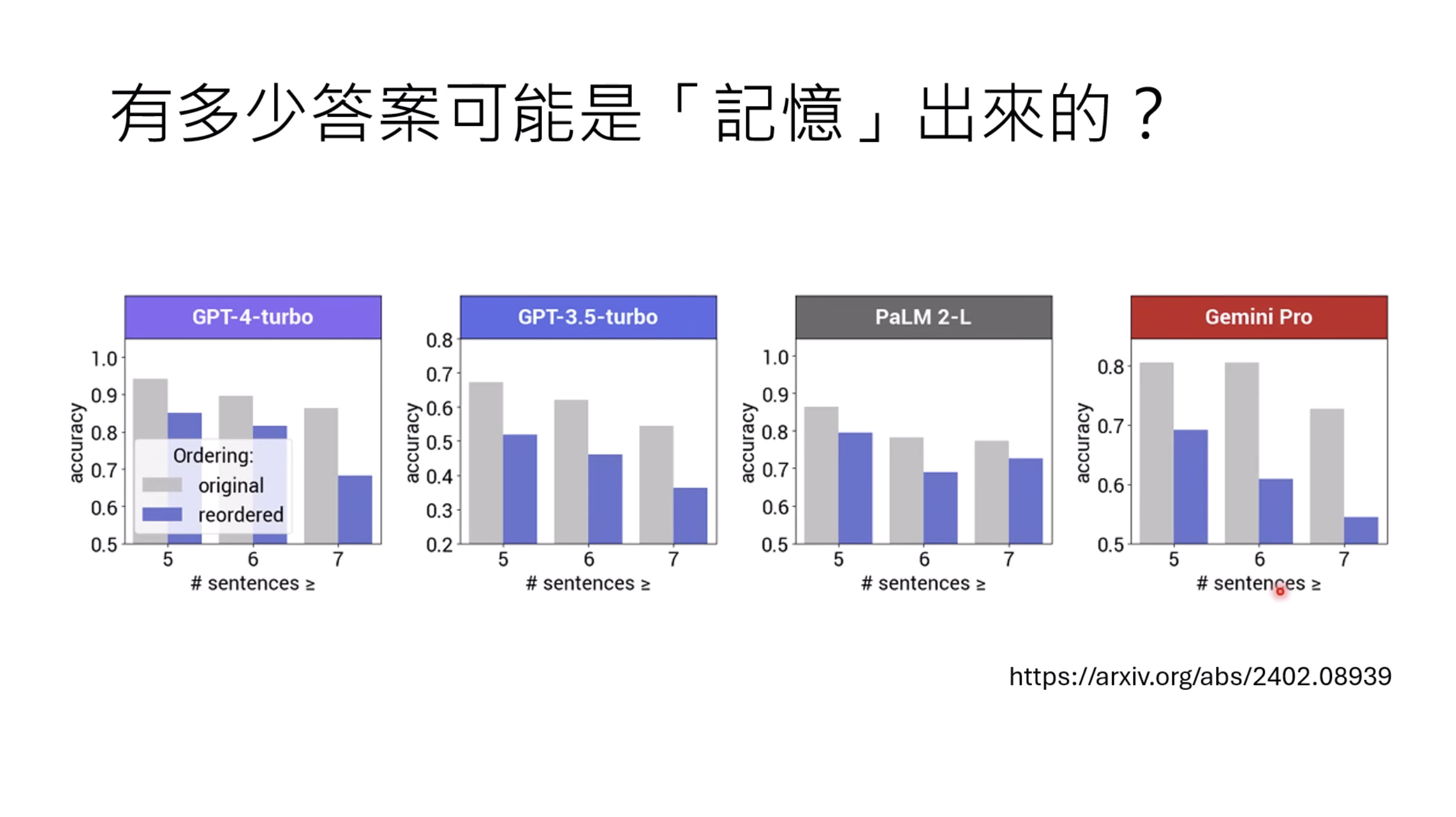
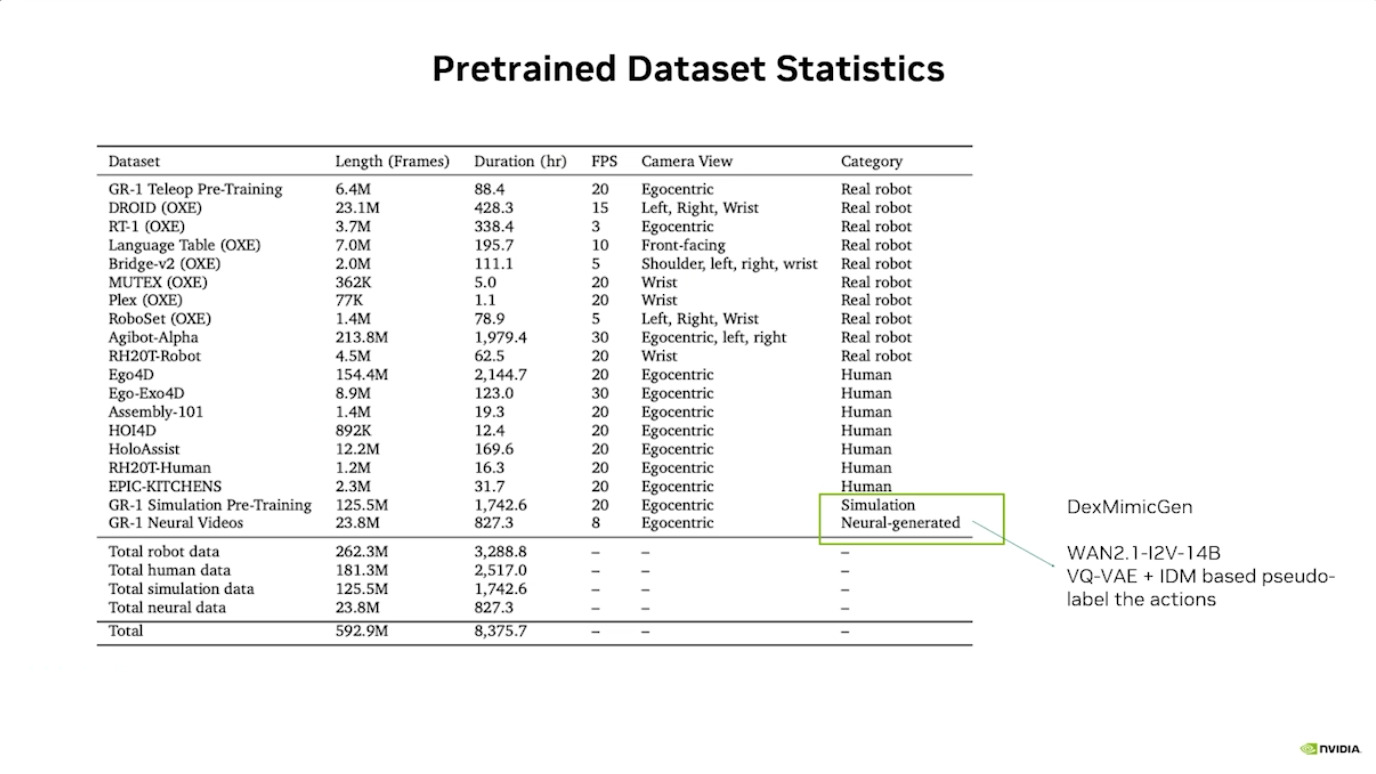
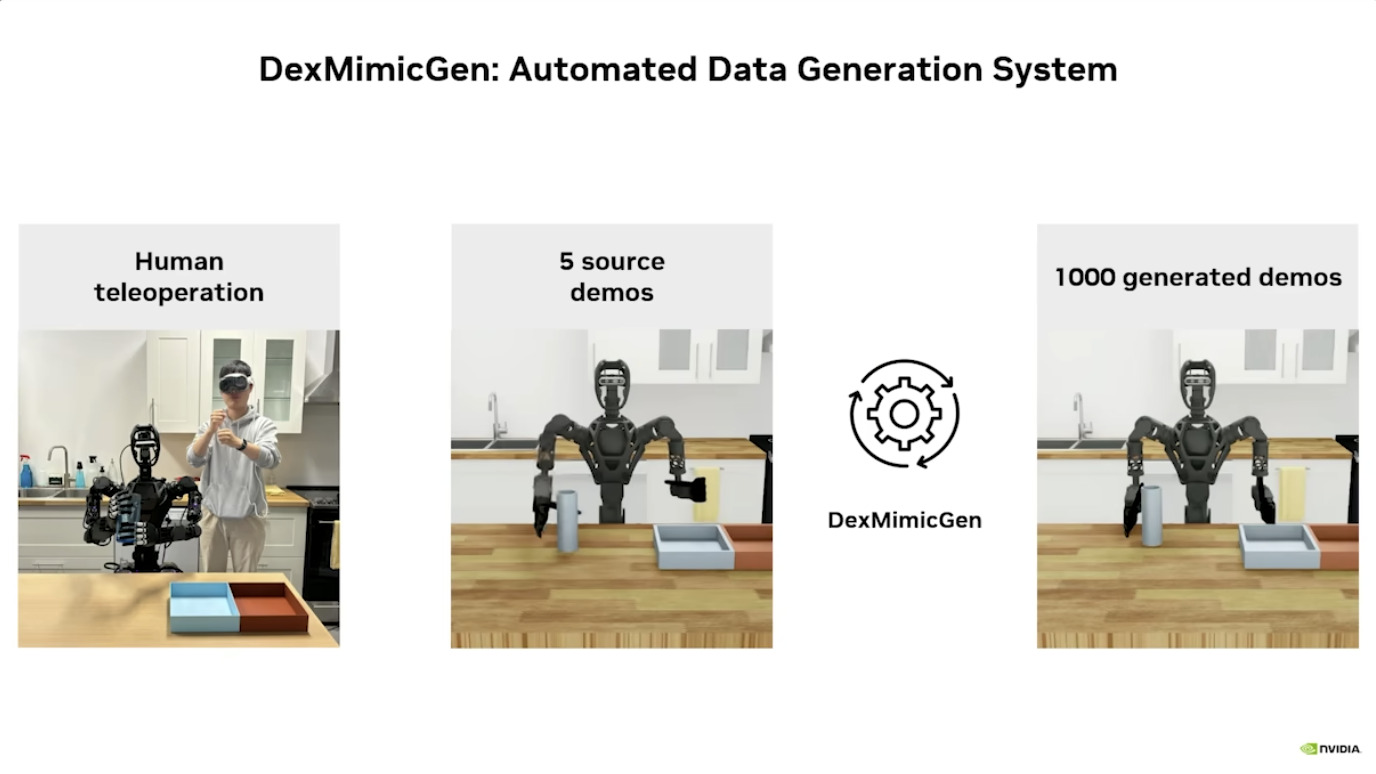
Isaac GROOT N1 - Data





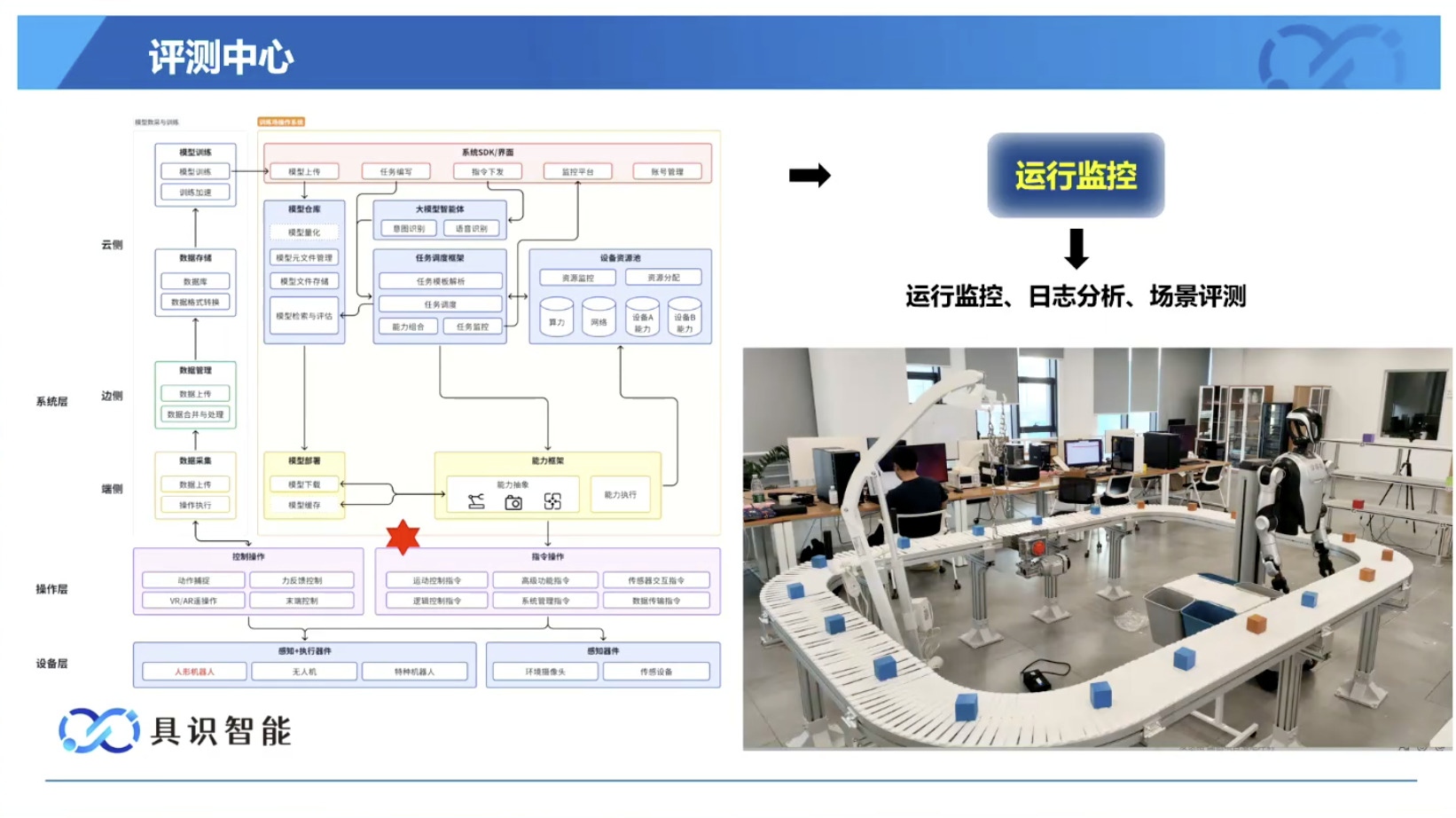
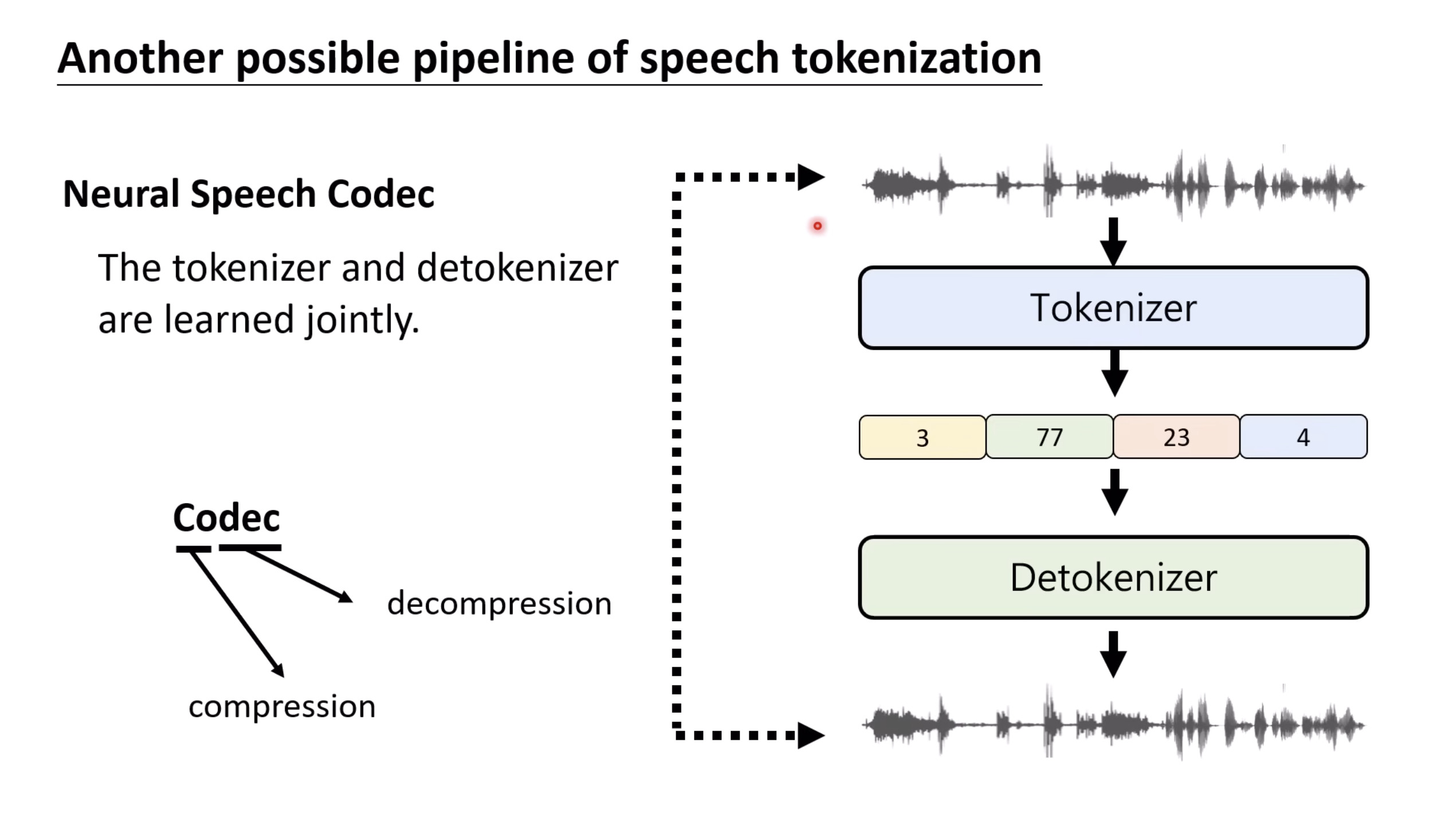
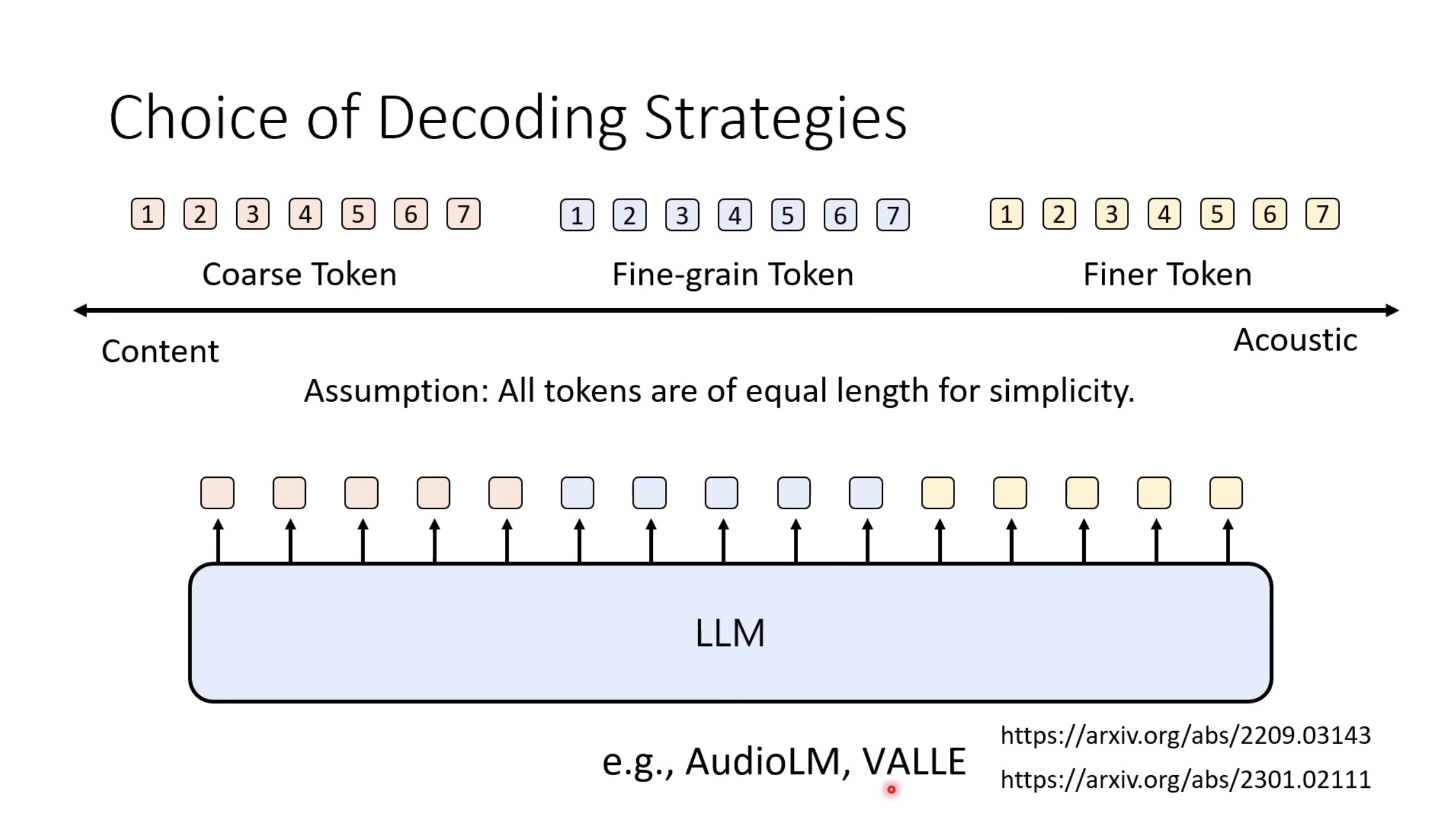
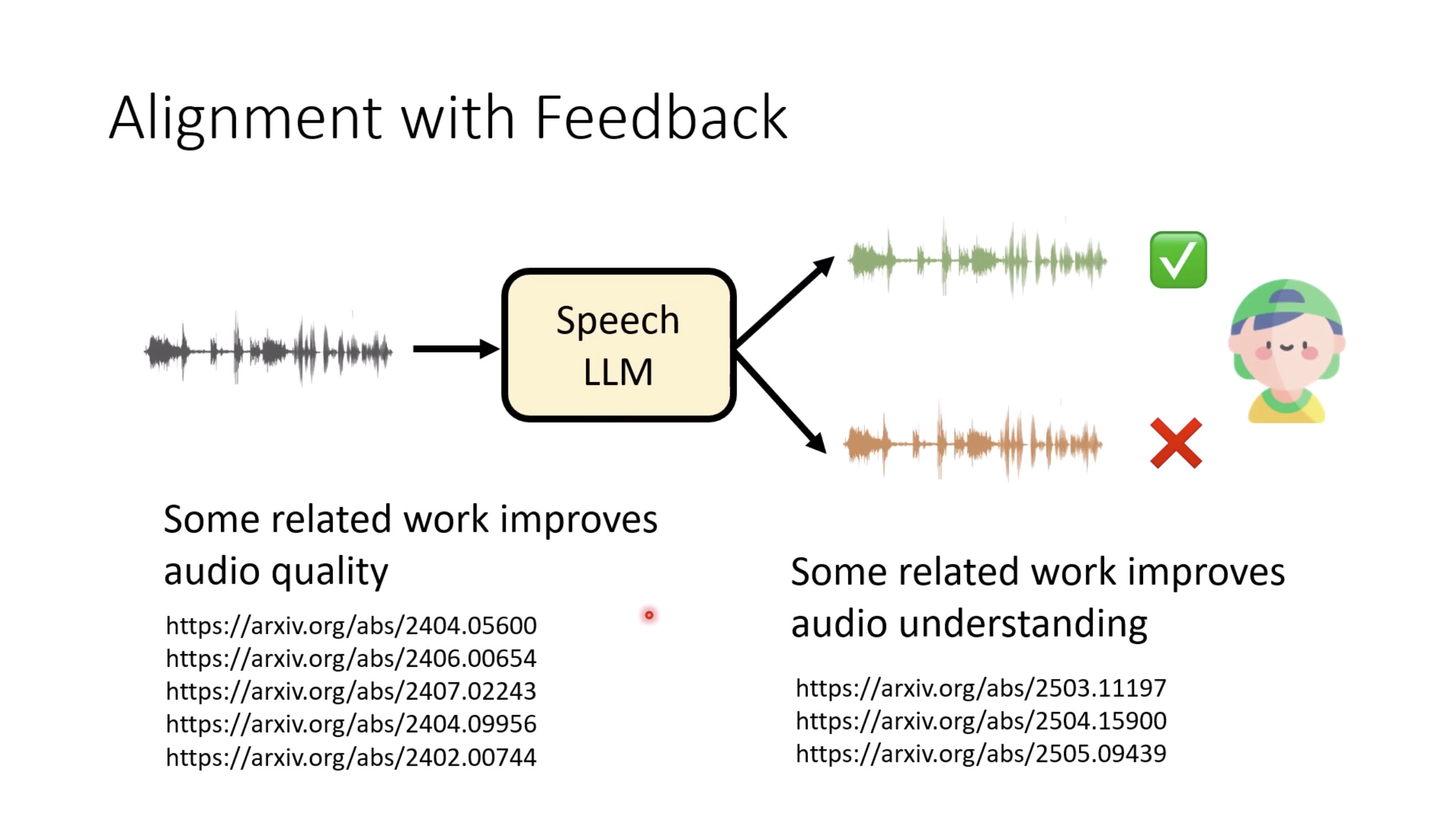
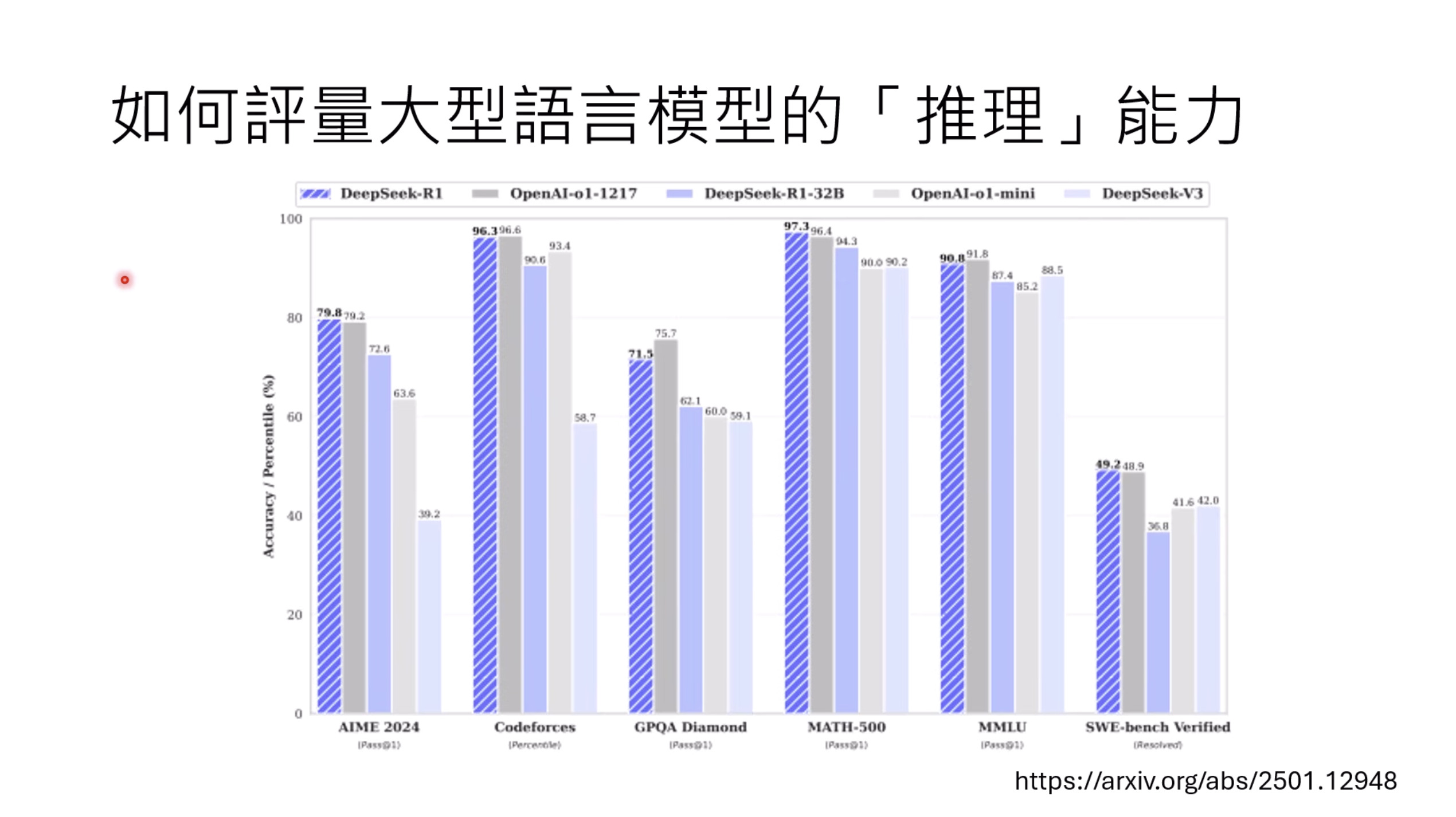
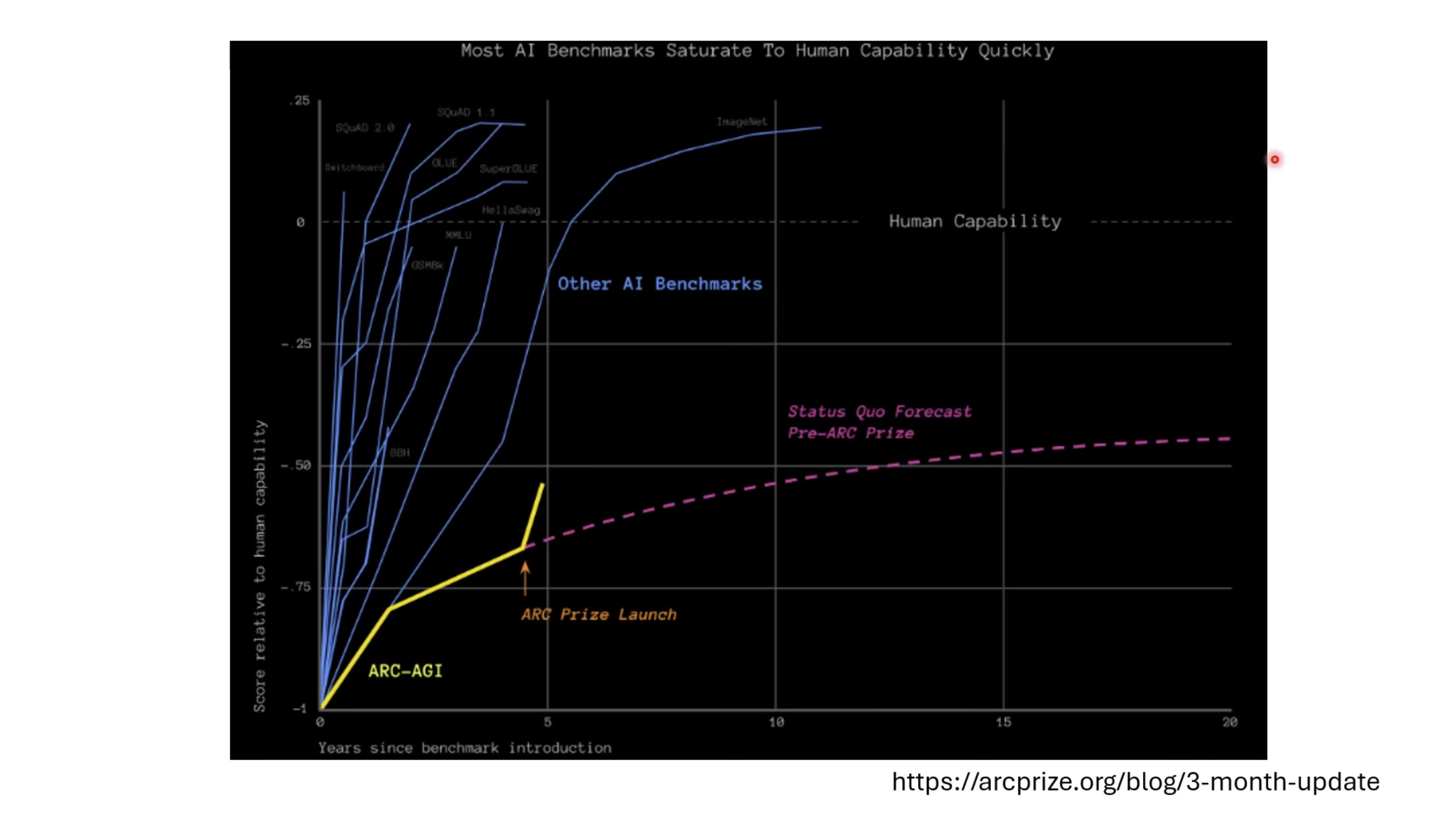
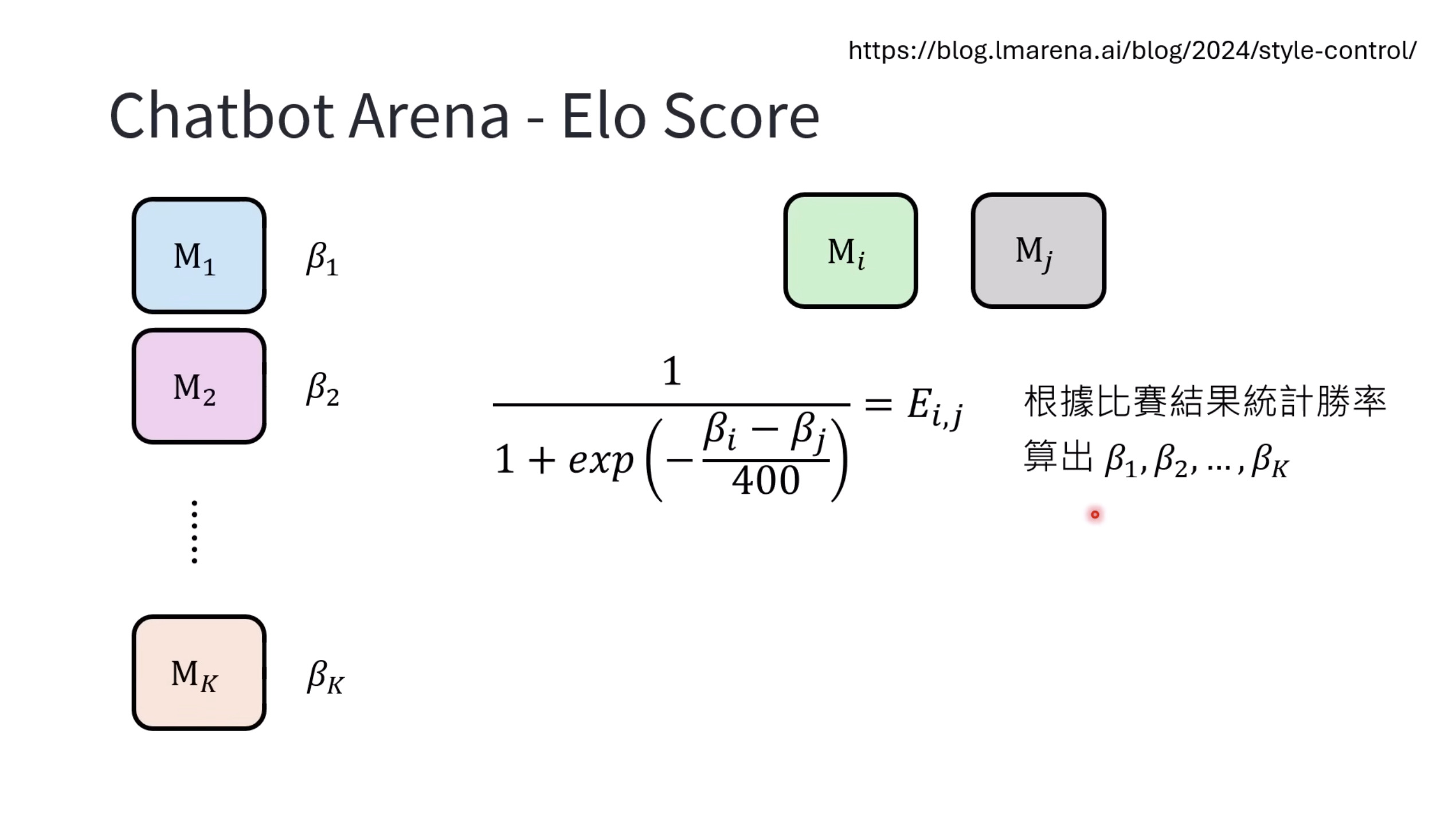
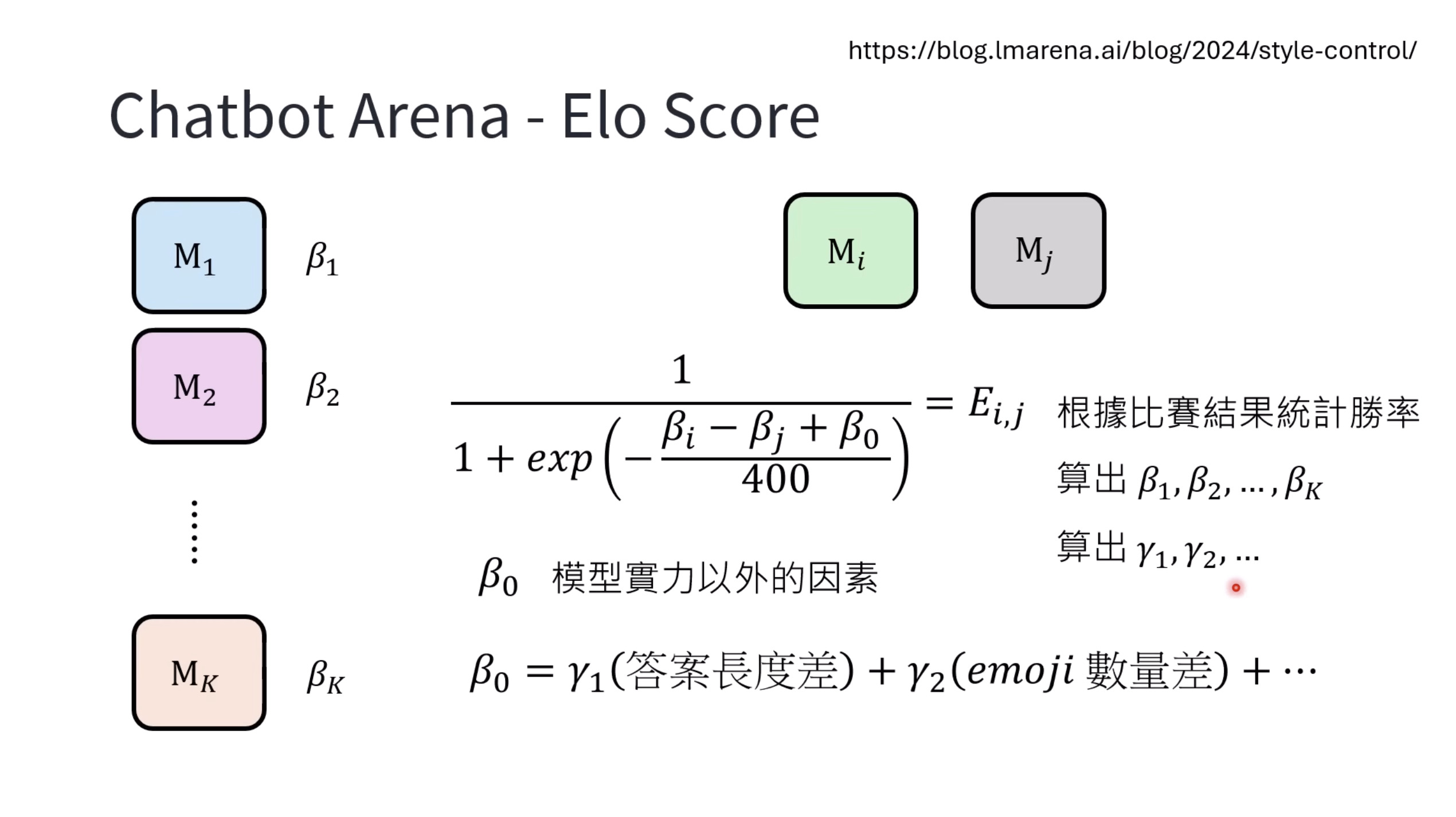
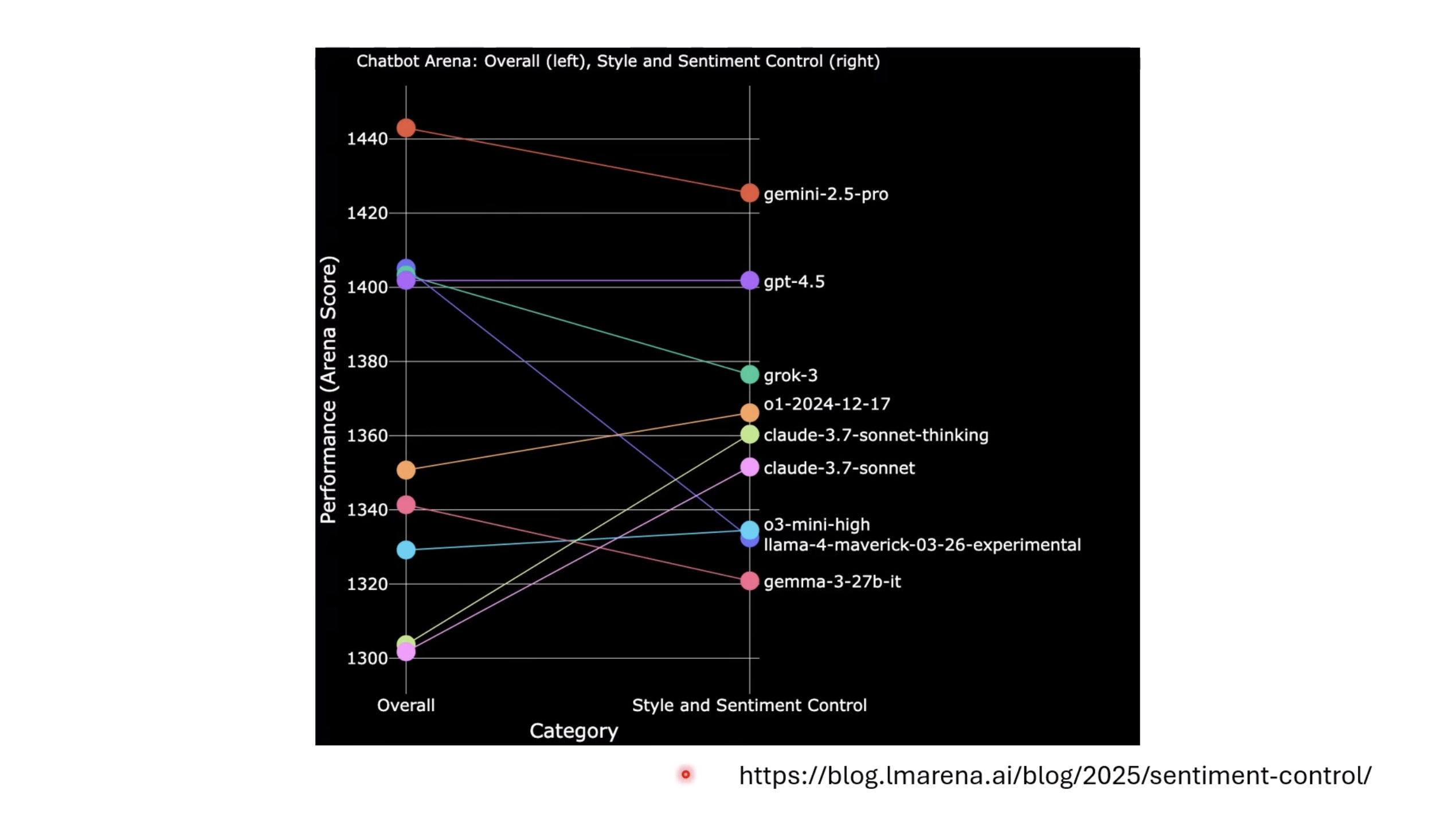
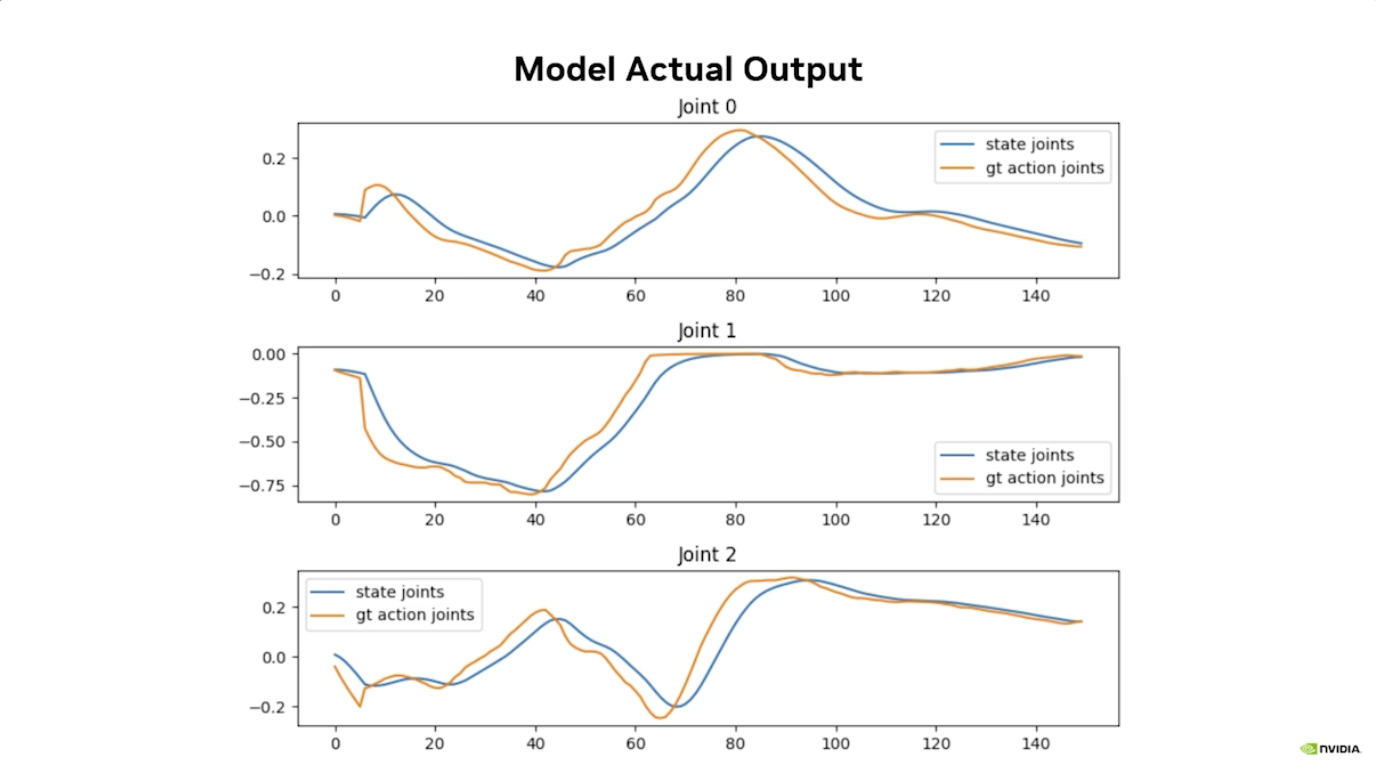
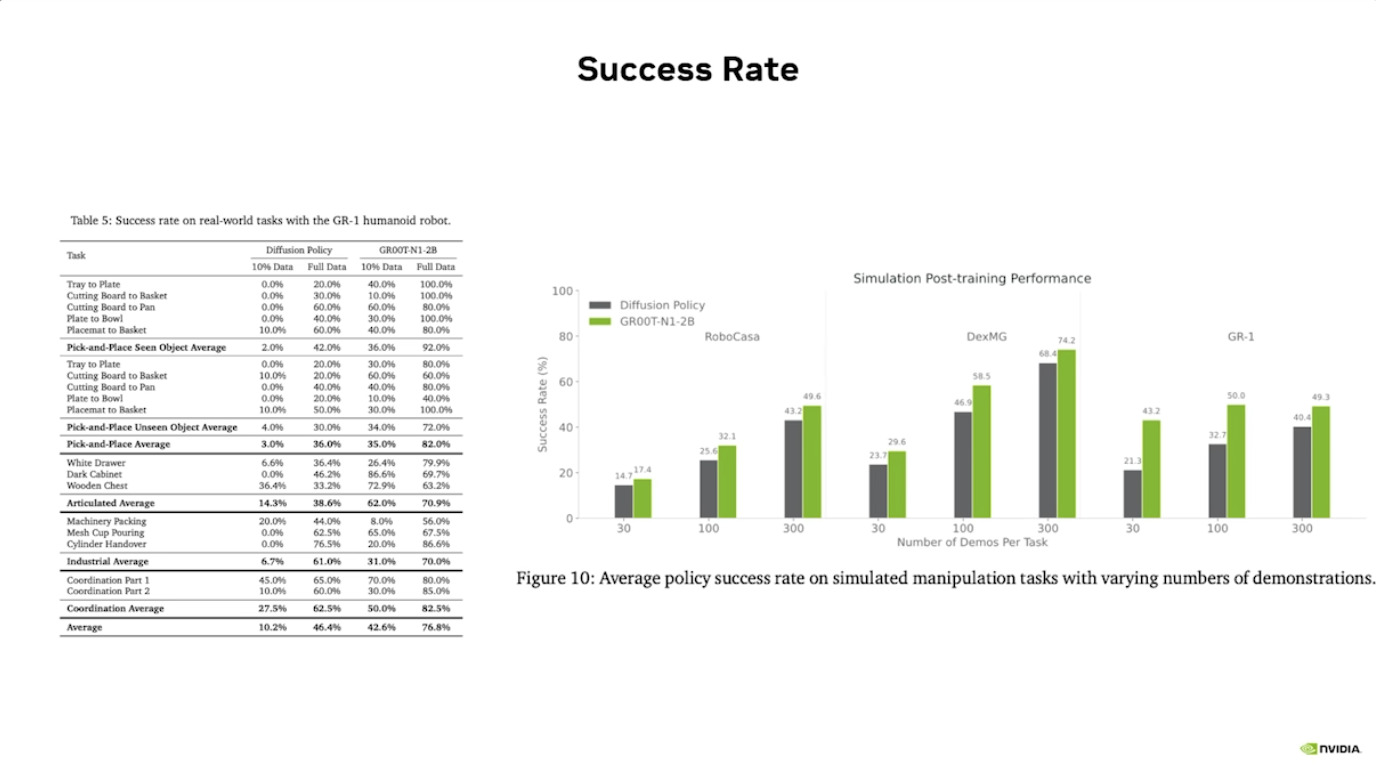
Isaac GROOT N1 - Evaluation





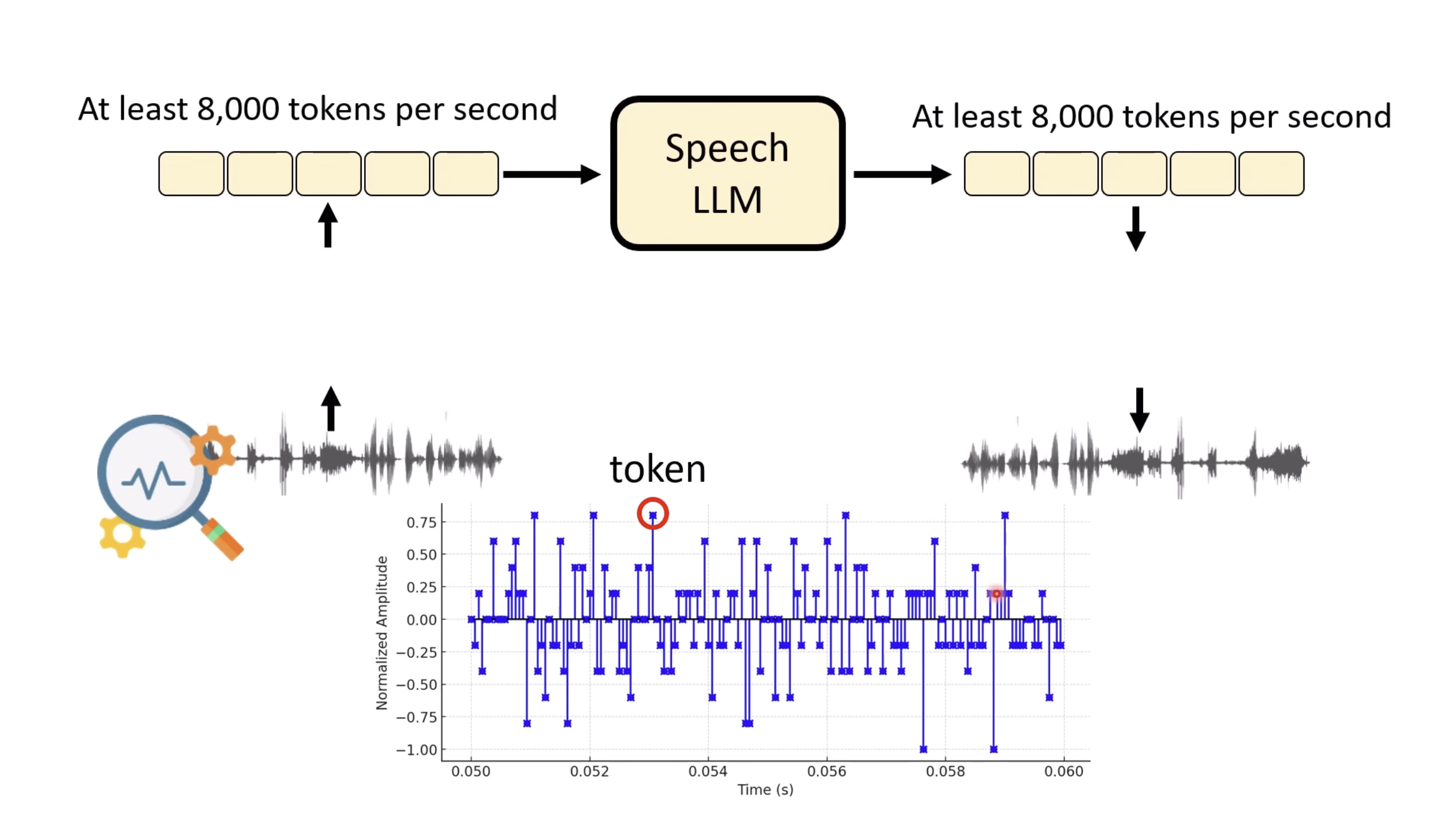
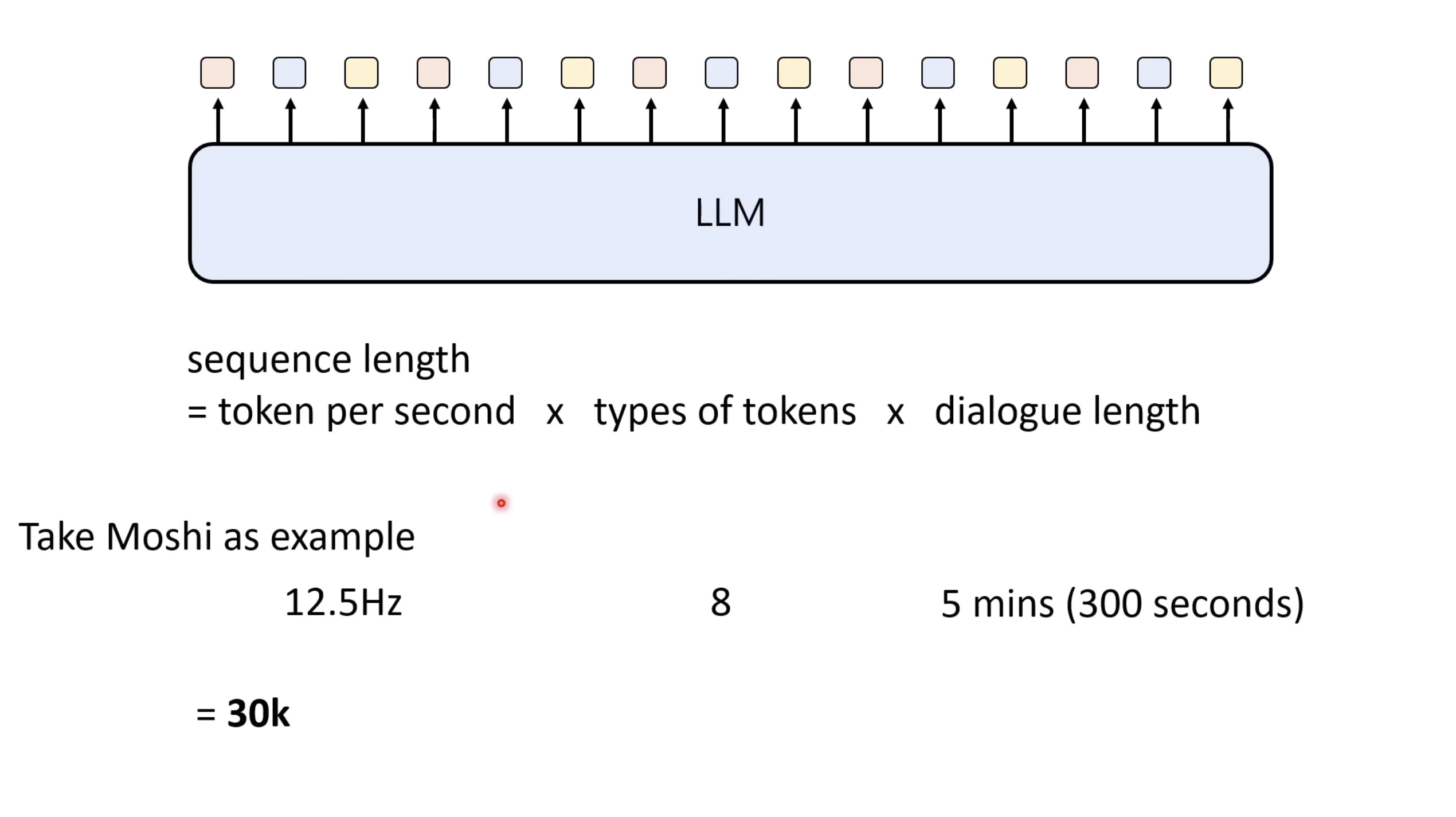
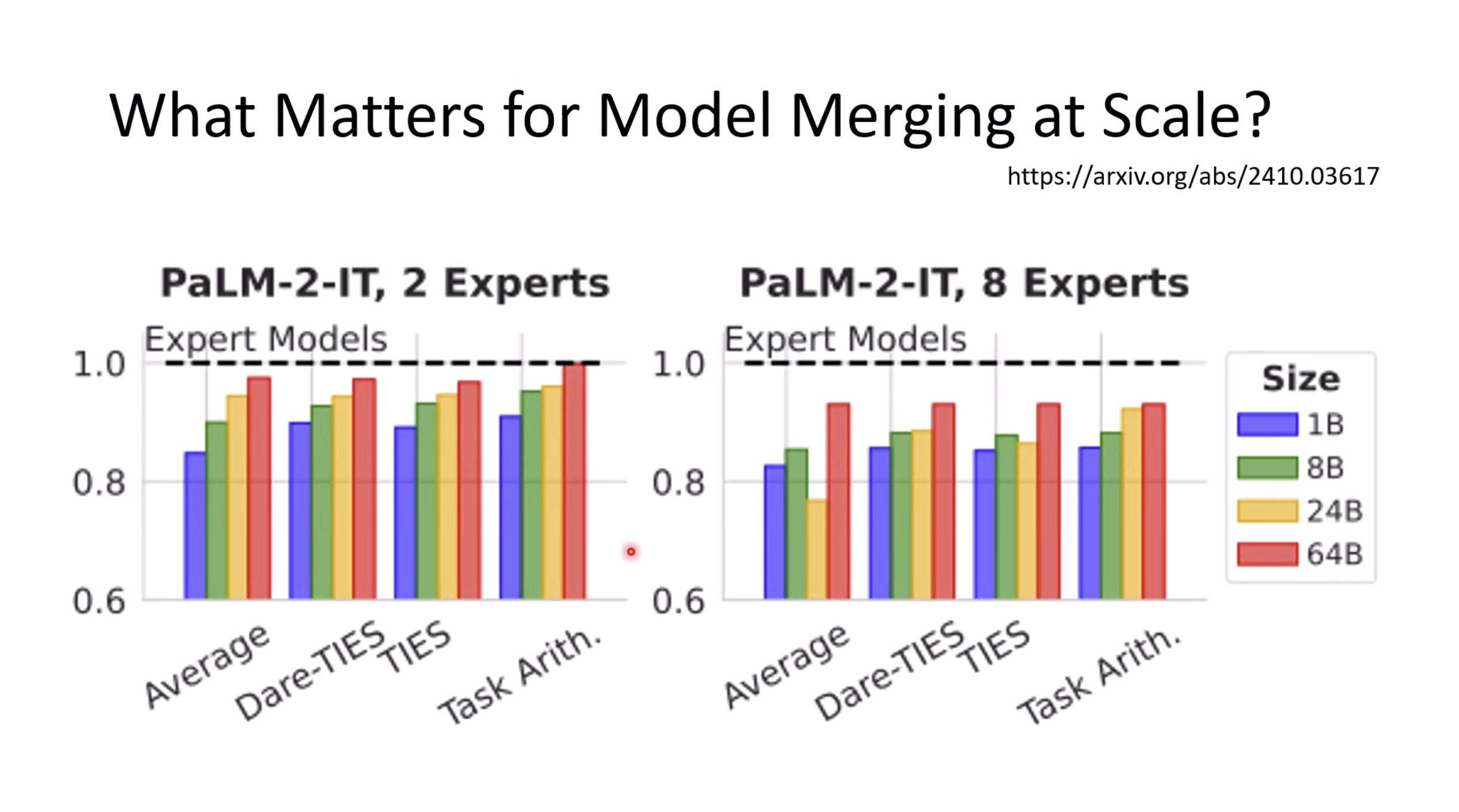
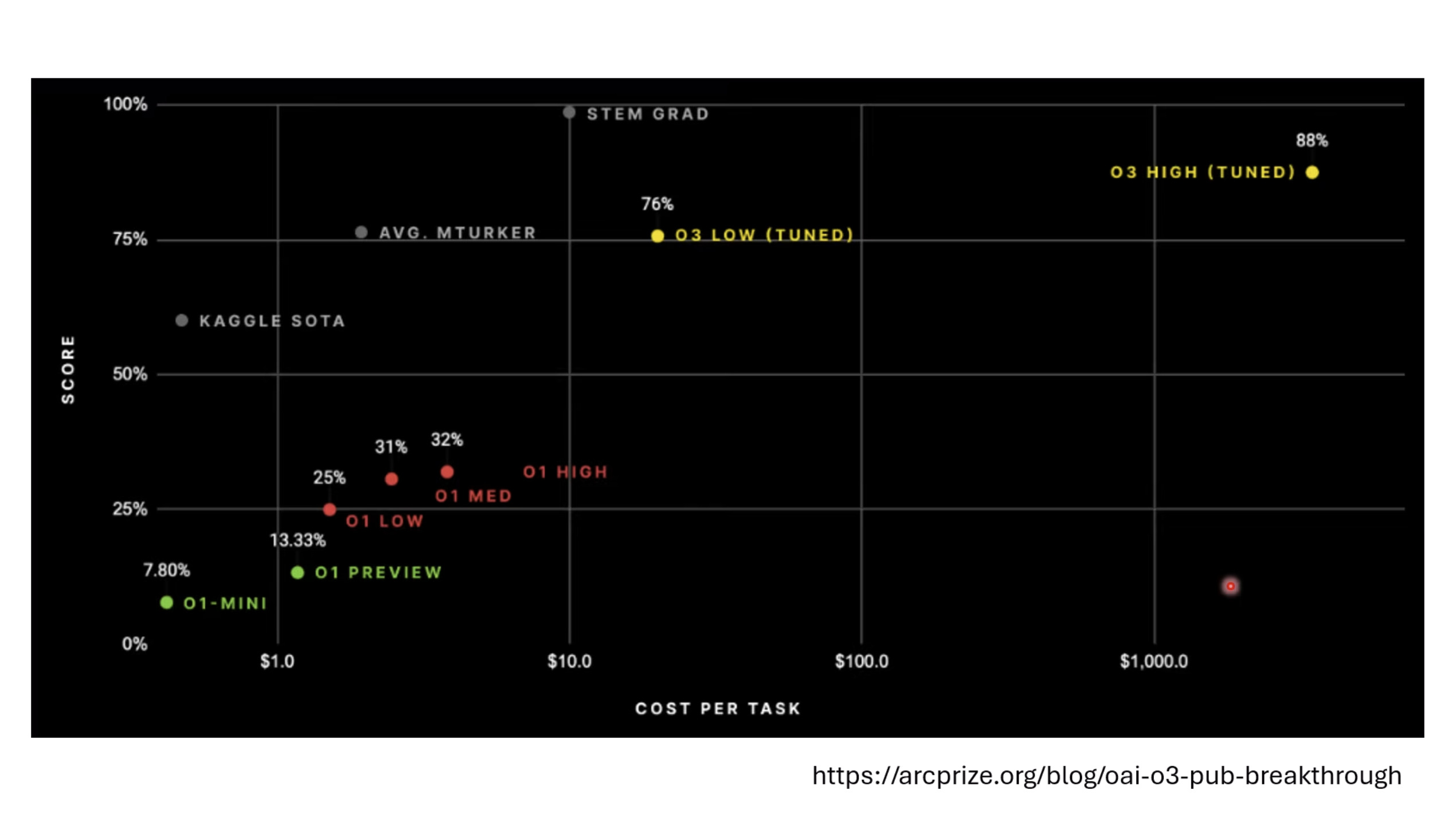
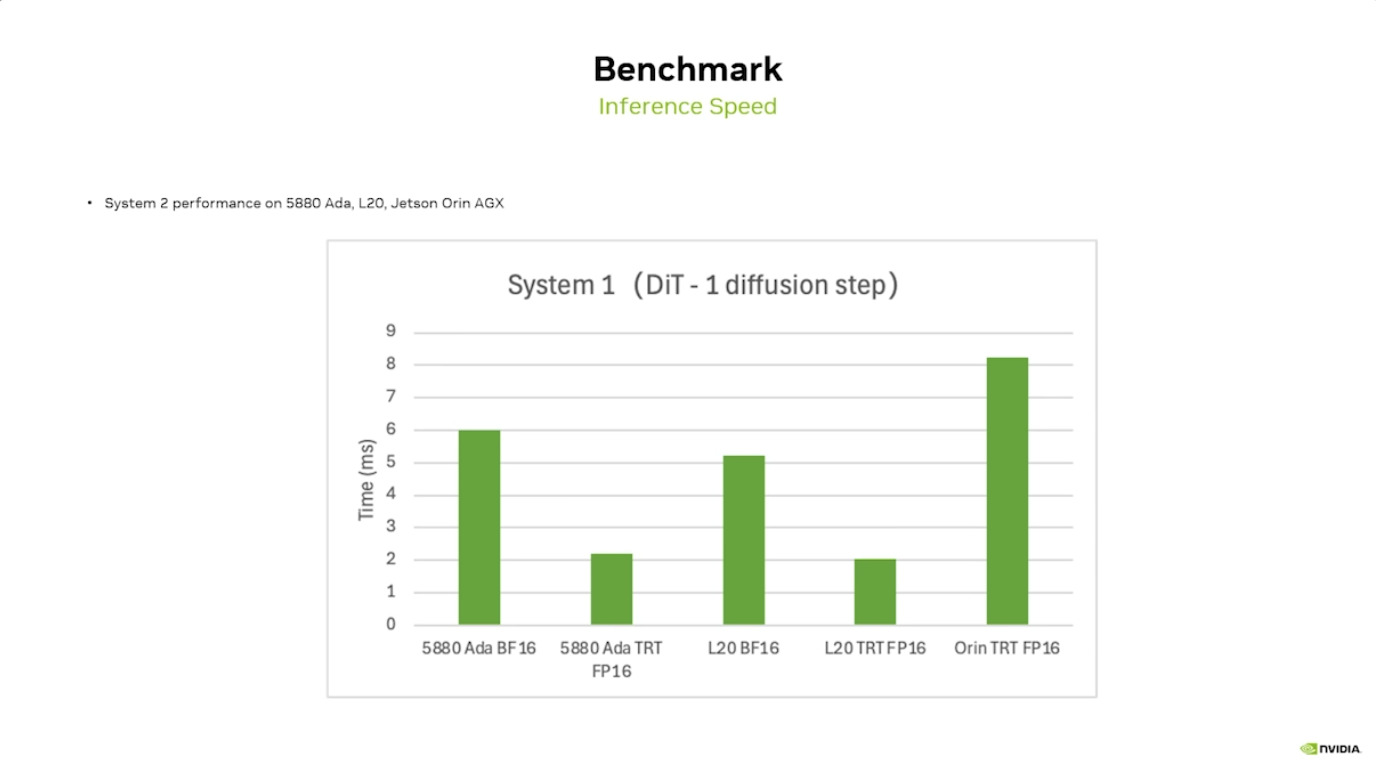
Inference Benchmark



参考资料