随着可用的软件越来越像拧开水龙头一样唾手可得,我感到很多事情都在发生变化。杰文斯悖论开始显现,我对软件的需求也在大幅增长。你可以要求任何东西——解释器、可视化工具、仪表盘、定制的单次使用应用……你可以把测试套件扩大 10 倍,自动优化代码,运行大型研究项目并用自定义 HTML 展示结果,什么都可以!《黑客帝国》里说的「解放你的思想」。来源: Simon Willison 的网络日志
普通高中英语课程标准(2017年版2025年修订)附录2 词汇表

以下是完整的词汇表(共3100个单词,按字母顺序排列):
AI编码助手代码归因与贡献占比量化系统设计
这是一个非常实际的工业需求。MinHash 在这个场景中不是直接检测"是否 AI 生成",而是作为代码指纹匹配引擎,追踪"AI 原始输出 → 人修改后最终代码"的相似度与存活比例。
下面给出完整的AI 生成代码占比统计系统设计方案。
一、问题定义:什么是"AI 生成代码占比"
在智能体编码助手(GitHub Copilot、Kilo Code、Cursor 等)的工作流中,代码的生命周期通常是:
AI 生成建议 → 人接受/修改 → 进入代码库 → 后续迭代中被修改
我们需要统计的是最终代码库中,可追溯至 AI 原始生成的代码比例。这不是简单的"谁按了 Tab 键",而是:
| 统计维度 | 含义 | 计算方式 |
|---|---|---|
| AI 原始贡献率 | AI 生成的代码在最终代码中的存活比例 | 匹配上的代码行 / 总行数 |
| 人修改深度 | 人在 AI 代码基础上做了多大改动 | 1 - (AI 原始代码保留率) |
| 人效提升系数 | 有 AI 辅助时人均产出 vs 无 AI 辅助 | 对比实验或历史基线 |
二、为什么 MinHash 适合这个场景
核心挑战
- 人会修改:AI 生成的代码被人接受后,通常会修改变量名、加注释、调逻辑,文本相似度会下降
- 代码重构:函数拆分、类提取等操作会让纯文本匹配失效
- 规模问题:一个团队每天可能产生数千次 AI 交互,需要快速匹配
MinHash 的优势
深入浅出 k-Shingle:海量文本去重的防篡改利器
在文本挖掘和信息检索领域,-Shingle(通常也被称为 -gram)是一种将连续的文本切分成固定长度碎片的技术。它是海量文本去重(如 MinHash + LSH 架构)中极其关键的数据预处理阶段。
简单来说,它的核心任务是:把一篇文章(一维的字符串)转化成一个集合(Set),并且在这个集合中锁死文本的局部语序。
一、 核心概念:滑动窗口(Sliding Window)
-Shingle 的工作原理就像一把长度为 的滑动尺子。尺子从文本的开头开始,每次框住 个单位的内容作为一个 Shingle,然后向右平移一个单位,重复这个过程,直到文本结束。
根据具体需求,这里的“单位”可以是字符(Character),也可以是单词(Word):
- 基于字符的 -Shingle:通常用于拼写检查、DNA 序列分析或中文字符处理。
- 基于单词的 -Shingle:通常用于英文等有天然空格分隔的文本去重与防抄袭。
直观案例演练
我们以短语 abcde 为例,来看看在不同的 值下,基于字符切分出来的 -Shingle 集合是什么样的:
- 当 时(尺子长度为 1):每次只框一个字母。
- 集合结果:
{ "a", "b", "c", "d", "e" }
海量文本去重与相似度检索:从 Jaccard 到 MinHash 的完整技术指南
问题背景:为什么百亿级去重不可能暴力求解?
在互联网大数据场景中,如何从海量数据(如百亿网页、千万级商品描述、巨大的开源代码仓库)中快速找出重复或高度相似的内容?这是一个极其经典的工业界痛点。
最朴素的想法是:对文章进行分词,转成集合后两两比对。若有 篇文档,需要比较 次。当 (一千万)时,比较次数约为 50 万亿次。即便单次比较仅需 1 微秒,也需要 1.6 年 才能跑完。这种 复杂度的算法会导致服务器直接卡死崩溃。
本文将结合数学原理、算法推导与工程实战,深入拆解 Jaccard 相似度 的直觉陷阱,以及 MinHash(最小哈希) 算法如何对高维稀疏数据完成降维打击,最终给出可直接落地的工业级实现方案。
一、Jaccard 相似度:精准度量及其直觉陷阱
Jaccard 相似度(Jaccard Similarity) 是衡量两个集合重合度的标准数学方法。其核心思想非常直观:看两个集合的交集(共同拥有的元素)占它们并集(总共拥有的元素)的比例。
数学公式定义为:
1. 经典直觉陷阱:为什么你常常会算错?
端侧AI:Gemma 4 12B 创新架构与 LiteRT-LM 本地部署指南
- Introducing Gemma 4 12B: a unified, encoder-free multimodal model
- Gemma 4 12B: The Developer Guide
- Accelerating Gemma 4: faster inference with multi-token prediction drafters
- A Visual Guide to Gemma 4 12B
- Gemma 4: Byte for byte, the most capable open models
- Ollama Gemma 4
Gemma 4 12B 是谷歌最新推出的一款原生、无编码器(Encoder-free)的统一多模态大模型。它的核心定位是将高水平的“智能体(Agentic)”和多模态能力直接带到用户的笔记本电脑等日常消费级硬件上。
以下是对 Gemma 4 12B 大模型的详细介绍:
1. 创新的统一架构:无编码器设计(Encoder-free)
与传统的多模态模型(通常需要使用独立的、冻结的视觉或音频编码器将数据转化为文本格式)不同,Gemma 4 12B 采用了统一的、仅解码器(Decoder-only)的 Transformer 架构。
- 视觉嵌入器(Vision Embedder):仅有 35M 参数,取代了传统复杂的视觉 Transformer 层。它将 48x48 像素的原始图像块(Patches)通过单次矩阵乘法直接投影到大语言模型(LLM)的隐藏维度中,并利用 X 和 Y 矩阵的坐标查找技术,直接将空间位置信息附带在输入中。
- 音频波形投影(Audio Wave Projection):完全取消了独立的音频编码器。它直接将 16 kHz 的原始音频信号切片为 40ms 的帧(每帧包含 640 个浮点数),并通过线性投影无缝输入到 LLM 的空间中。
协同进化:寻找智能体时代效率与商业的平衡点(罗福莉)
罗福莉 2026年4月6日
两天前,Anthropic 切断了第三方客户端(Harnesses)使用 Claude 订阅的通道——这并不令人意外。三天前,MiMo 推出了其 Token 计划(Token Plan)——这是一个我投入了大量精力去设计的方案,也是我认为在实现合理的算力分配和智能体客户端开发方面一次严肃的尝试。将这两件事结合起来,我有以下几点思考:
- Claude Code 的订阅制是一个专为平衡算力分配而设计的精美系统。 我的猜测是——它并不赚钱,甚至可能在亏本,除非他们的 API 利润率高达 10-20 倍,但我对此深表怀疑。虽然我无法严密地计算出第三方客户端接入所带来的损失,但我近距离观察过 OpenClaw 的上下文管理——它真的很糟糕。在单个用户查询中,它会把一轮轮低价值的工具调用作为独立的 API 请求发送出去,每个请求都携带长达 100K 以上 Token 的长上下文窗口——即便有缓存命中,这也是极大的浪费,在极端情况下还会推高其他查询的缓存未命中率。其单次查询的实际请求次数最终比 Claude Code 自身框架高出数倍。折算成 API 定价的话,真实成本恐怕是订阅价格的几十倍。这不仅是一个差距,而是一个巨大的黑洞。
- 像 OpenClaw/OpenCode 这样的第三方客户端依然可以通过 API 调用 Claude——它们只是不能再薅订阅制的羊毛了。 短期内,这些智能体用户会感到阵痛,成本极有可能飙升几十倍。但这种压力恰恰会倒逼这些客户端去优化上下文管理、最大化提升提示词缓存(Prompt Cache)的命中率以复用已处理的上下文,并减少无谓的 Token 消耗。痛苦最终会转化为工程上的严谨与克制。
- 我强烈呼吁大模型公司不要在搞清楚如何为编程套餐定价且不亏本之前,就盲目地进行价格战、卷到行业底层。 廉价销售 Token 却对第三方客户端敞开大门,看似对用户友好,实则是一个陷阱——正是 Anthropic 刚刚踩进去又退出来的那个陷阱。更深层次的问题在于:如果用户把精力浪费在低质的智能体客户端、极度不稳定且缓慢的推理服务,以及为了削减成本而降级的大模型上,结果却发现依然什么事也做不成——这对于用户体验或留存率来说,绝不是一个健康的循环。
- 关于 MiMo Token 计划——它支持第三方客户端,按 Token 配额计费,这与 Claude 最新推出的额外用量包逻辑一致。 因为我们追求的是长期、稳定地交付高质量的模型与服务——而不是吸引你冲动消费后便任由你弃船而去。
AGPL-3.0(GNU Affero 通用公共许可证 v3.0)
AGPL v3.0 许可证的开源豁免仅限于公司内部直签员工自用。由于公司混编了第三方外包人员,在法律主体上已被视作向外部第三方提供服务;一旦我们修改了该项目的核心代码,将直接触发强制开源机制,导致公司相关的商业源代码面临被迫向全社会彻底公开的重大合规风险。
GNU AFFERO通用公共许可证 第三版,2007年11月19日
版权所有 (C) 2007 Free Software Foundation, Inc. https://fsf.org/ 允许每个人复制和分发本许可证文档的完整副本,但不得修改它。
序言
GNU Affero通用公共许可证是一份自由的、著佐权性质的许可证,适用于软件及其他类型的作品,它专门设计用于确保在网络服务器软件的情况下与社区合作。
大多数软件的许可证旨在剥夺您分享和修改软件的自由。相反,我们的通用公共许可证旨在保证您分享和修改程序所有版本的自由——确保它对所有用户来说都是自由软件。
当我们谈论自由软件时,我们指的是自由,而非价格。我们的通用公共许可证旨在确保您拥有分发自由软件副本的自由(如果您愿意,也可以对此服务收费),确保您能够收到源代码或在需要时获取它,确保您可以更改软件或在新的自由程序中使用其部分内容,并且确保您知道您可以做这些事情。
使用我们的通用公共许可证的开发者通过两个步骤来保护您的权利:(1) 声明软件的版权,以及 (2) 向您提供本许
KiloCode AGENTS.md - OpenCode 智能体指南
构建/测试 (Build/Test)
- 运行 (Run):
bun run --conditions=browser ./src/index.ts - 测试 (Test):
bun test(运行所有测试)或bun test test/tool/tool.test.ts(运行单个测试) - 类型检查 (Typecheck):
bun run typecheck(运行tsgo --noEmit)
导入别名 (Import Aliases)
@/*映射到./src/*@tui/*映射到./src/cli/cmd/tui/*
核心模式 (Key Patterns)
命名空间模块 (Namespace modules) —— 代码以 TypeScript 命名空间(Namespace)的形式组织,而不是类(Class)。每个模块导出一个包含其 Zod schema、类型和函数的命名空间:
export namespace Session {
export const Info = z.object({ ... })
export type Info = z.infer<typeof Info>
export const create = fn(z.object({ ... }), async (input) => { ... })
}
Instance.
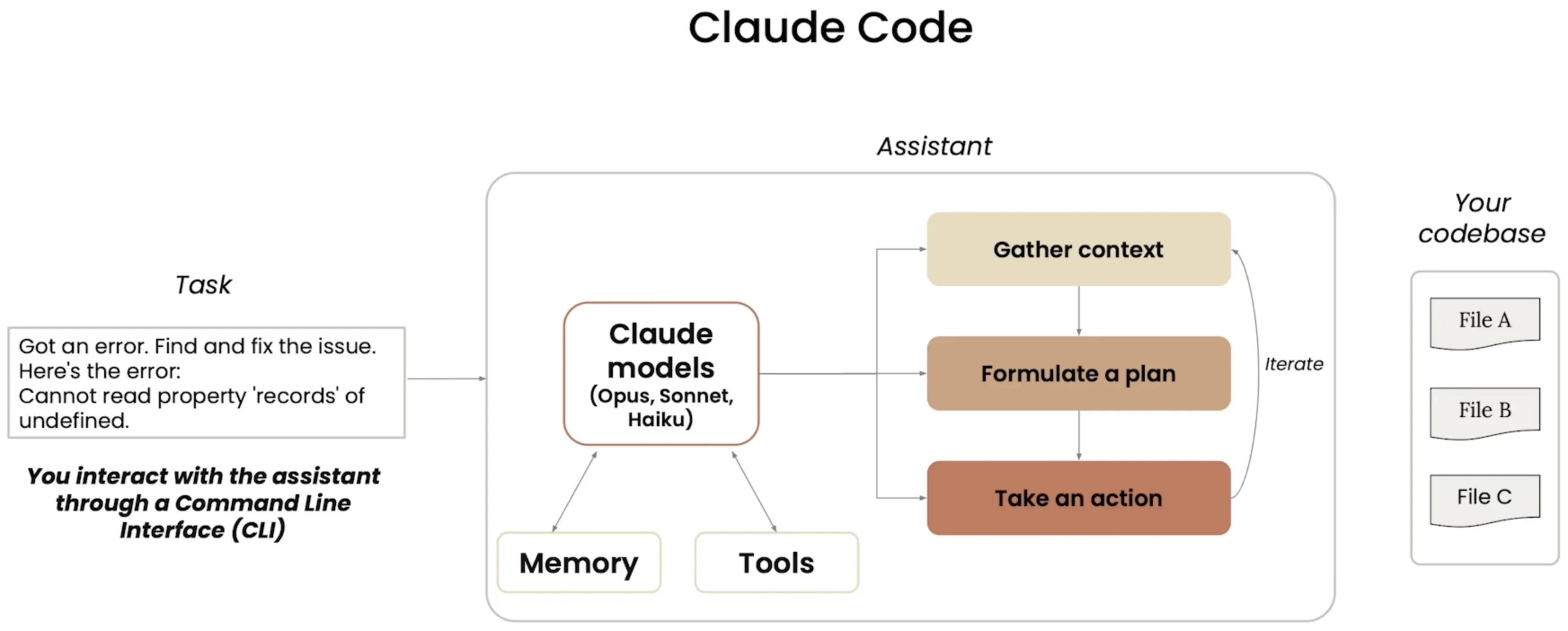
Claude Code 智能编程实战
什么是 Claude Code
应用于软件开发的各个阶段
| 1. 探索 (Discover) |
2. 设计 (Design) |
3. 构建 (Build) |
4. 部署 (Deploy) |
5. 维护与扩展 (Support & Scale) |
|---|---|---|---|---|
| 探索代码库与历史 (Explore codebase and history) |
规划项目 (Plan project) |
实现代码 (Implement code) |
自动化 CI/CD (Automate CI/CD) |
调试错误 (Debug errors) |
| 搜索文档 (Search documentation) |
制定技术规范 (Develop tech specs) |
编写并执行测试 (Write and execute tests) |
配置环境 (Configure environments) |
大规模重构 (Large-scale refactor) |
| 入职与环境配置 (Onboard & Setup) |
定义架构 (Define architecture) |
创建提交与 PR (Create commits and PRs) |
管理部署 (Manage deployments) |
监控使用情况与性能 (Monitor usage & performance) |
工具使用
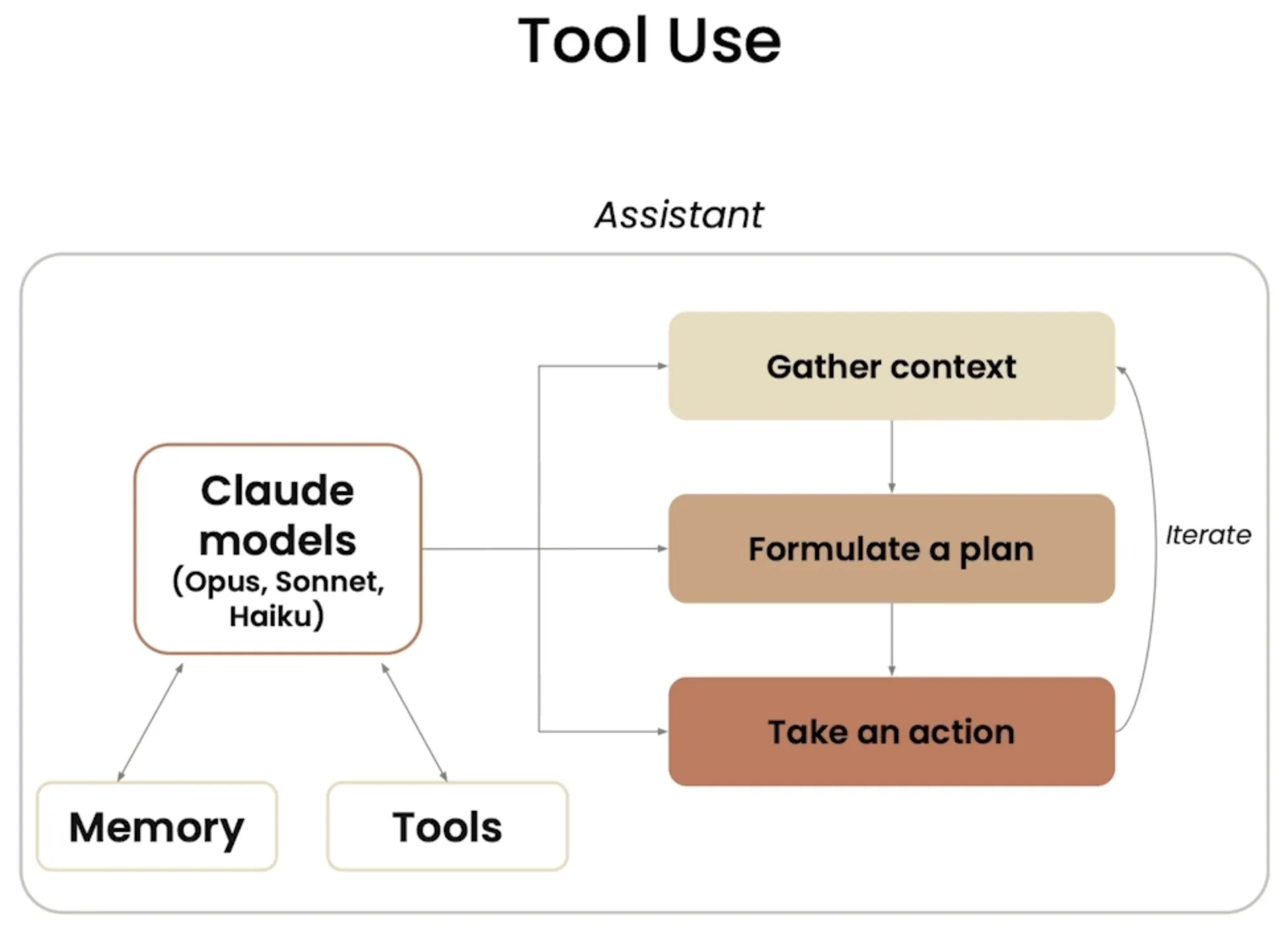
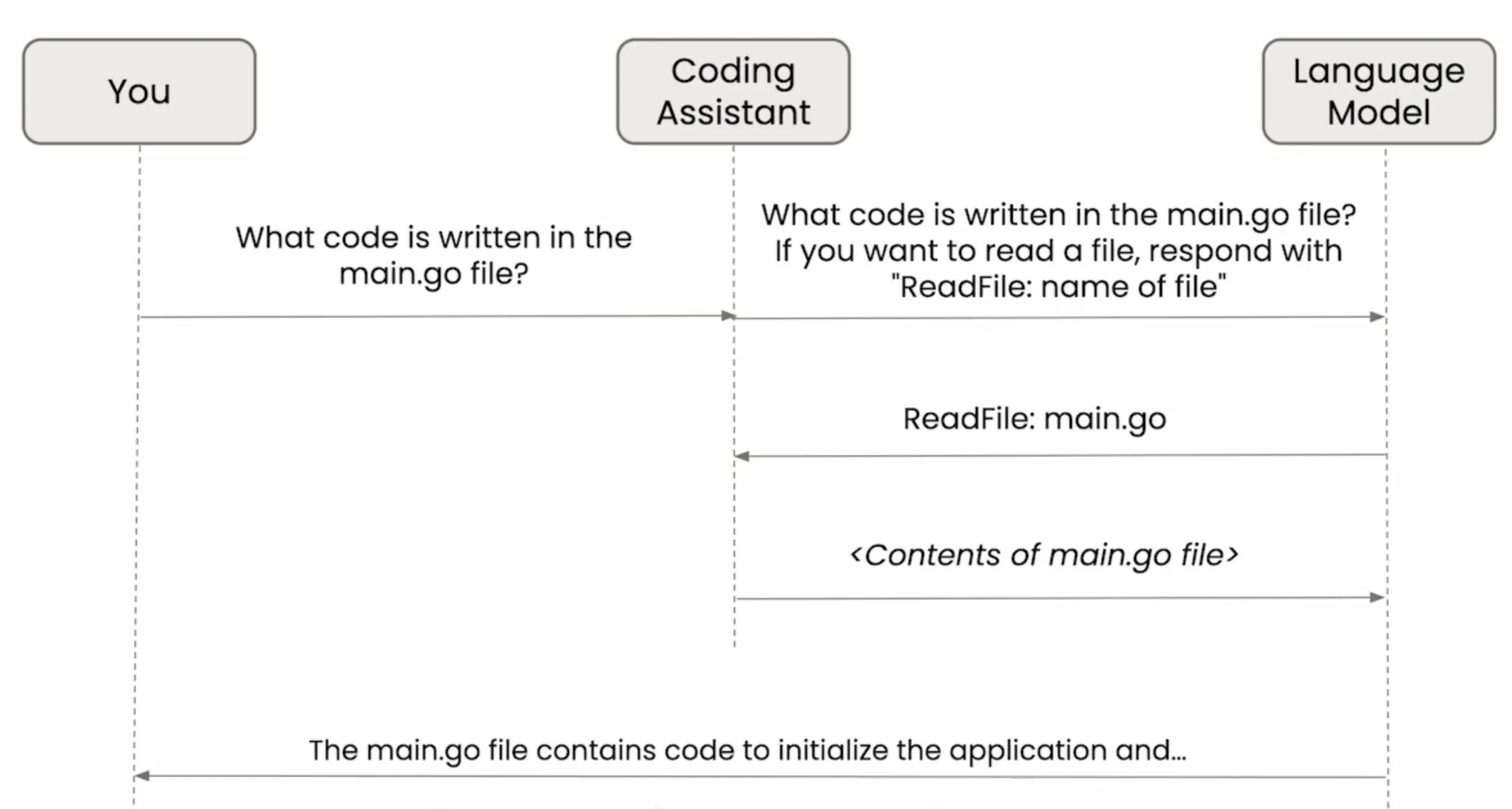
内置工具列表
Claude Code 安装、更新与卸载指南
安装 Claude Code
1. Native 安装(推荐)
⚠️ 国内用户会出现不能访问或卡住的问题。
curl -fsSL https://claude.ai/install.sh | bash
安装后的可执行文件路径:/Users/junjian/.local/bin/claude
下面是安装卡住,但是程序已经下载成功,我手动安装完成的过程:
下载的二进制文件会被保存在 ~/.claude/downloads 目录下:
ll ~/.claude/downloads
-rwxr-xr-x 1 junjian staff 205M 5月 29 22:56 claude-2.1.156-darwin-arm64
我们需要把它移动到 ~/.local/share/claude/versions 目录下,并创建一个软链接到 ~/.local/bin:
彻底搞懂 uv pip、uv add 和 uv tool 的核心区别
在 Python 工具链大洗牌的今天,Astral 团队推出的 uv 已经成为了无可争议的“速度之王”。它不仅能用 Rust 带来百倍的速度提升,还展现出了统一 Python 生态的野心。
然而,很多刚从 pip 或 poetry 迁移过来的开发者,在看到 uv pip、uv add 和 uv tool 这三个都在“装包”的命令时,难免会产生疑问:它们难道不是重合的吗?为什么装个包还要分三种命令?
我们就来彻底拆解这三者的设计哲学和应用场景,帮你建立起最清晰的 uv 工作流。
💡 一分钟核心速览
其实,这是 uv 为了彻底解决 Python 长期以来“全局环境污染”、“虚拟环境混乱”以及“工具与项目依赖混淆”等痛点,而设计的三套完全独立的工作流。
| 命令 | 对应传统工具 | 管理的目标对象 | 核心作用 |
|---|---|---|---|
uv pip |
pip / pip-tools |
底层虚拟环境中的包 | 作为原生 pip 的超快替代品,直接向当前激活的环境中塞入依赖。 |
uv add |
poetry add / pdm add |
当前声明式项目的依赖 | 现代项目管理工作流。自动管理 pyproject.toml 和 uv.lock。 |
uv tool |
pipx |
全局可执行工具(如 ruff, black) |
在完全隔离的专用环境中安装 CLI 工具,并自动暴露到全局,绝不污染项目。 |
🔍 深度对比:为什么它们不能互相替代?
LiteLLM 代理实践:安装、配置与测试

安装
uv tool install 'litellm[proxy]'
配置
编写配置文件:config.yaml
model_list:
- model_name: gpt-5
litellm_params:
model: openai/LongCat-2.0-Preview
api_base: https://api.longcat.chat/openai/
api_key: sk-xxx
- model_name: gpt-5-nano
litellm_params:
model: openai/qwen3.5:9b
api_base: http://localhost:11434/v1
api_key: none
运行
litellm --config config.yaml
测试
⚠️ 通过测试说明 LiteLLM 代理只支持中转,上游没有提供对应的API支持(LongCat 只支持 Chat Completions),LiteLLM 也不支持。
我现在收到的很多创始人邮件都写成了一种强硬的新闻体风格。我知道它们是 AI 写的,因为以前从来没有创始人这样写过。一旦你意识到某件事是 AI 写的,就很难不去忽略它。
我从未 knowingly 读完过一封由人署名但由 AI 写的邮件。这感觉像被欺骗,谁会忍受呢?
这让我对作者评价降低。这意味着他们无法独立写好(或者觉得自己写不好),而且他们试图欺骗我。
用 AI 帮你写东西并不令人印象深刻;任何青少年都能做到。
Mac 屏幕素材处理指南:从多图合成 GIF 到 FFmpeg 视频智能去重压缩
多张图片合成 GIF / 视频
使用 ImageMagick 的 magick 命令将一系列按时间顺序命名的 PNG 截屏图片合成为一个无限循环播放的动态 GIF 动图。
合成 GIF
Pi Agent Event Examples
事件流
事件类型
| 事件 | 描述 |
|---|---|
agent_start |
智能体开始处理 |
agent_end |
运行的最终事件。为此事件等待的订阅者仍会计入结算 |
turn_start |
新轮次开始(一次 LLM 调用 + 工具执行) |
turn_end |
轮次完成,包含助手消息和工具结果 |
message_start |
任何消息开始(user、assistant、toolResult) |
message_update |
仅限助手。 包含带有增量的 assistantMessageEvent |
message_end |
消息完成 |
tool_execution_start |
工具开始执行 |
tool_execution_update |
工具流式传输进度 |
tool_execution_end |
工具执行完成 |
prompt() 事件序列
当你调用 prompt("Hello") 时:
Pi Agent Core 开发指南
基于 @earendil-works/pi-ai 构建的有状态智能体,支持工具执行和事件流。
安装
npm install @earendil-works/pi-agent-core
快速开始
Pi Agent SDK 参考文档
本 SDK 提供对 Pi 智能体能力的程序化访问。可用于将 Pi 嵌入其他应用、构建自定义界面,或集成到自动化工作流中。
典型使用场景:
- 构建自定义界面(网页、桌面、移动端)
- 将智能体能力集成到现有应用
- 用智能体推理创建自动化流程
- 构建可生成子智能体的自定义工具
- 以编程方式测试智能体行为
参见 examples/sdk/,获取从极简到全量控制的可运行示例。
快速上手 import { AuthStorage, createAgentSession, ModelRegistry, SessionManager } from "@earendil-works/pi-coding-agent"; // 设置凭证存储与模型注册器 const authStorage = AuthStorage.create(); const modelRegistry = ModelRegistry.create(authStorage); const { session } = await createAgentSession({ sessionManager: SessionManager.inMemory(), authStorage, modelRegistry, }); // 订阅事件流 session.subscribe((event) => { if (event.
基于 Pi Agent SDK 适配 OpenAI 兼容接口
通过两种方式,在 TypeScript 中使用 @earendil-works 的 Pi Agent 框架连接本地运行的 Ollama 模型(以 qwen3.5:9b 为例)。
环境初始化
首先,初始化项目并配置为 ES Modules (ESM) 模式,以支持顶层 await 语法。
npm init -y
在生成的 package.json 中,手动添加 "type": "module":
惨痛的教训(The Bitter Lesson)
AI 的未来不在于将人类现有的经验硬塞给机器,而在于设计出能够利用无限算力进行搜索与学习的“元方法”。
- The Bitter Lesson
- 里奇·萨顿(Rich Sutton)
- 2019年3月13日
回顾70年人工智能研究历程,最深刻的一条教训是:依托算力的通用方法,最终效果远超其他路径,且优势极其显著。究其根本,源于摩尔定律——或者更广义地说,单位计算成本持续呈指数级下降。绝大多数人工智能研究开展时,都默认智能体可使用的算力是恒定的(这种情况下,借助人类知识就成了提升性能为数不多的手段之一)。但只要研究周期稍长于普通科研项目,海量算力必然会成为现实。
研究者为追求短期见效的性能提升,往往试图融入自身对领域的人类认知;但从长远来看,真正起决定性作用的,只有对算力的充分利用。这两条路径本不必相互对立,现实中却常常冲突:投入在一方的时间,就无法用于另一方。研究者会在心理上执着于某一种研究思路;而依赖人类知识的方法,往往会让模型变得复杂,反而难以适配依托算力的通用优化路径。
人工智能研究者们屡屡迟来地领悟到这一惨痛教训,回顾其中几个典型案例,颇具启发意义。
在国际象棋领域,1997年击败世界冠军卡斯帕罗夫的算法,依靠的是大规模深度搜索。彼时,多数国际象棋计算机研究者对此倍感沮丧——他们此前一直钻研的,是融入人类对国际象棋特有棋局结构理解的方法。
没有找到匹配的文章