学习【机器学习平台】建设的经验
快手技术 VP 王仲远对于 AI、大模型、深度学习的预测 2021-09-02
CV、Speech、NLP,背后主流的模型基本上都是基于 Transformer。在未来可能各方面的技术边界越来越模糊,事实上现在已经逐渐出现越来越多的多模态技术研究。技术融合变得门槛很低,但大家做的事越来越相像。
重要的研究方向
- 大模型
- 怎么让黑盒的深度学习跟知识能够进行融合变成可解释,然后增加常识。
近两年模型都已经到万亿级别了
- Google Switch Transformer
- OpenAI GPT-3
- 阿里 M6
搜索系统是先以内容分析为主,再结合了用户行为;而推荐系统则是以用户行为为主,再尝试结合内容理解。 内容理解可以帮助推荐系统为用户做更加个性化的内容分发和匹配,探索如何更好地利用内容理解为推荐系统进一步提升个性化推荐能力。
怎么去考虑 AI 技术布局?(任何新技术都是类似的) 如果我们都只关注于未来三个月或半年就能落地的技术,那么很显然它是不具备可持续发展的。反之,如果只关注中长期才能见效的研究方向和研究项目的话,那么不确定性又会非常大,毕竟业务对于 AI 技术的渴求是非常强烈的。所以技术布局本质上是一个短期项目与长期项目配比的问题。






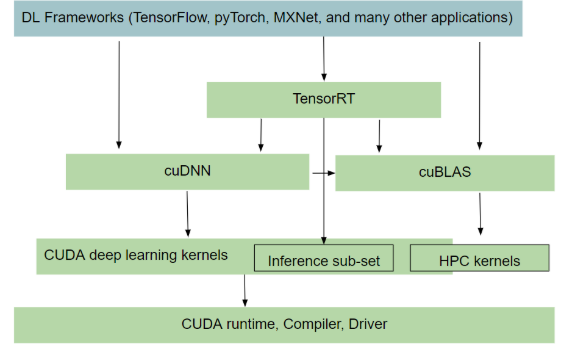
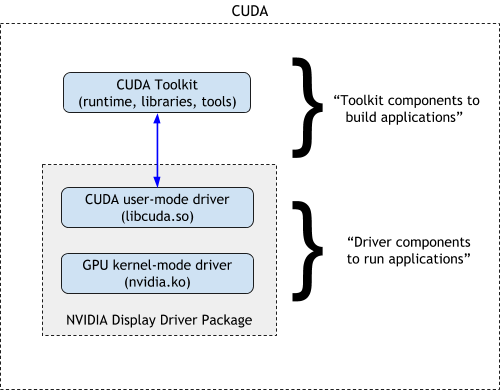
{kind=link}