SWIFT: Scalable lightWeight Infrastructure for Fine-Tuning
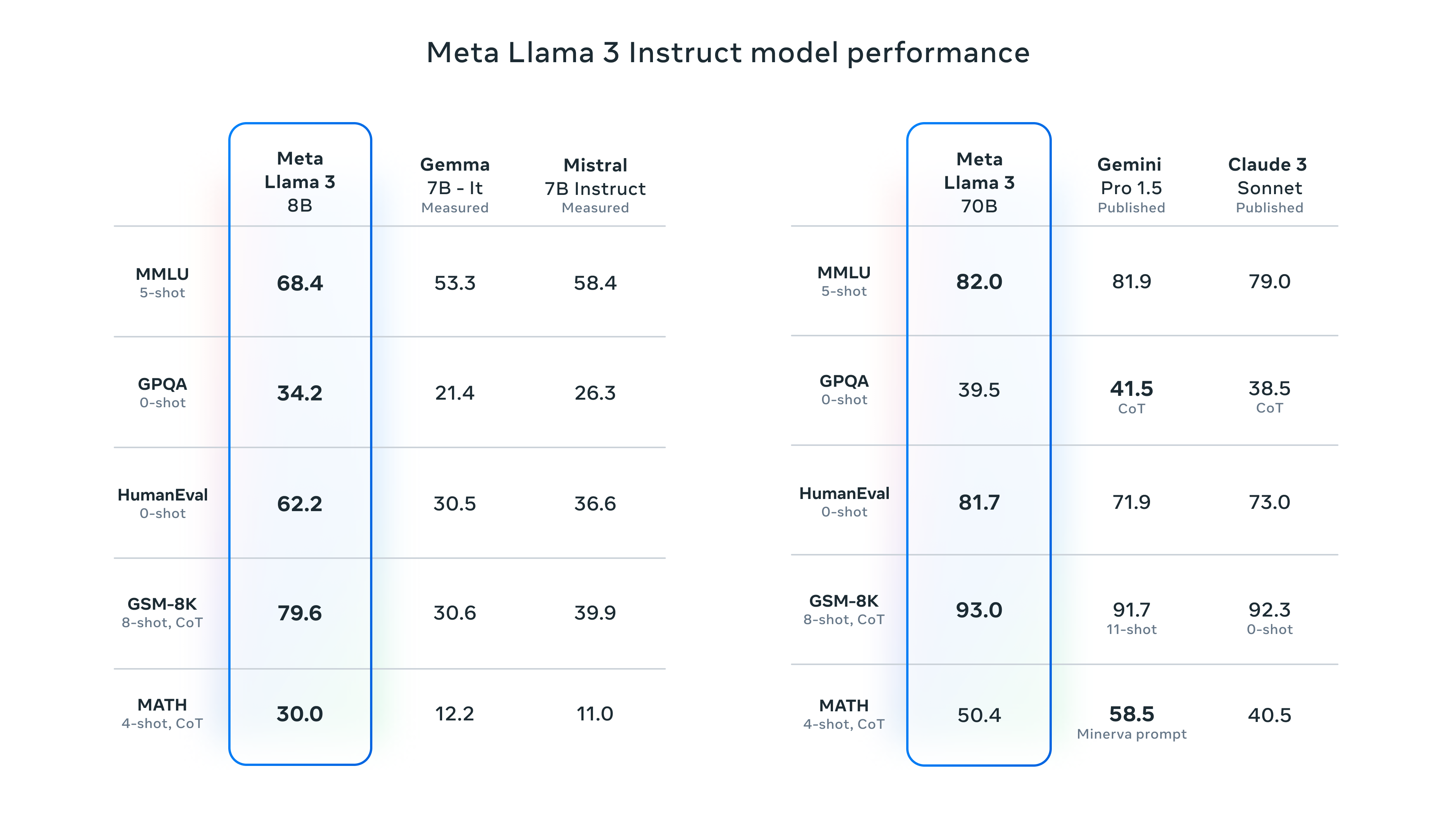
SWIFT 支持近200种LLM和MLLM(多模态大模型)的训练、推理、评测和部署。开发者可以直接将我们的框架应用到自己的Research和生产环境中,实现模型训练评测到应用的完整链路。我们除支持了PEFT提供的轻量训练方案外,也提供了一个完整的Adapters库以支持最新的训练技术,如NEFTune、LoRA+、LLaMA-PRO等,这个适配器库可以脱离训练脚本直接使用在自己的自定流程中。
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
['chinese-alpaca-2-13b-16k', 'chinese-alpaca-2-13b', 'chinese-alpaca-2-7b-64k', 'chinese-alpaca-2-7b-16k', 'chinese-alpaca-2-7b', 'chinese-alpaca-2-1_3b', 'chinese-llama-2-13b-16k', 'chinese-llama-2-13b', 'chinese-llama-2-7b-64k