基于 Pi Agent SDK 适配 OpenAI 兼容接口
通过两种方式,在 TypeScript 中使用 @earendil-works 的 Pi Agent 框架连接本地运行的 Ollama 模型(以 qwen3.5:9b 为例)。
首先,初始化项目并配置为 ES Modules (ESM) 模式,以支持顶层 await 语法。
npm init -y
在生成的 package.json 中,手动添加 "type": "module":
通过两种方式,在 TypeScript 中使用 @earendil-works 的 Pi Agent 框架连接本地运行的 Ollama 模型(以 qwen3.5:9b 为例)。
首先,初始化项目并配置为 ES Modules (ESM) 模式,以支持顶层 await 语法。
npm init -y
在生成的 package.json 中,手动添加 "type": "module":
git clone https://github.com/cline/cline.git
code cline
npm run install:all
如果构建项目时遇到问题,请安装 esbuild problem matchers 扩展。
Activating task providers npm
错误: problemMatcher 引用无效: $esbuild-watch
打开 运行和调试 侧边栏,运行 Run Extension,或者按 F5 键启动调试,打开一个新的 VSCode 窗口,加载扩展。
这里想探索使用多模态大模型答题的技术方案,包含单选题、多选题、判断题,最终构建自主答题的智能体。
工作流程:🏞️ -> MLM(多模态大模型)-> 答案
直接使用多模态大模型读题(转成文字),然后检索答案,把题和答案组合的提示词输入给语言大模型。
我使用了 Ollama 调用多模态大模型
minicpm-v:8b来生成文字。llava:7b的效果不好。
代码示例:
import ollama
response = ollama.chat(
model="minicpm-v:8b",
messages=[
{
'role': 'user',
'content': '读取图像中的题。',
'images': ['ti.png']
}
]
)
print(response['message']['content'])
docker pull ghcr.io/open-webui/open-webui:main
编写配置文件:docker-compose.yml
version: '3'
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main
extra_hosts:
- host.docker.internal:host-gateway
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
volumes:
open-webui:
docker compose up
docker run -d -p 3000:8080 --name open-webui --restart always \
-e USE_EMBEDDING_MODEL= \
-e OPENAI_API_BASE_URL=http://172.16.33.66:9997/v1 \
-e OPENAI_API_KEY=NONE \
-v open-webui:/app/backend/data \
ghcr.io/open-webui/open-webui:main
curl -s: -s 选项表示静默模式,不输出进度信息。jq -r: -r 选项表示以原始格式输出,去掉了引号。在 Bash 中,单引号和双引号的使用有一些重要的区别:
echo '$LITELLM_API_KEY' # 输出: $LITELLM_API_KEY
echo "$LITELLM_API_KEY" # 输出: 变量的实际值(例如: sk-1234)
若要了解更多关于 GraphRAG 以及它如何用于增强您的大型语言模型(LLMs)对您的私有数据进行推理的能力,请访问 Microsoft Research Blog Post。
初始化您的工作区,运行 graphrag.index --init 命令
python -m graphrag.index --init --root ./ragtest
这将在 ./ragtest 目录中创建两个文件:.env 和 settings.yaml 。 .env 包含运行 GraphRAG pipeline 所需的环境变量。如果您检查该文件,您将看到定义了一个单一的环境变量,GRAPHRAG_API_KEY=<API_KEY> 。这是 OpenAI API 或 Azure OpenAI 端点的 API 密钥。您可以用您自己的 API 密钥替换它。
使用检索增强来帮助您使用 LLM 为数据库生成准确的 SQL 查询。
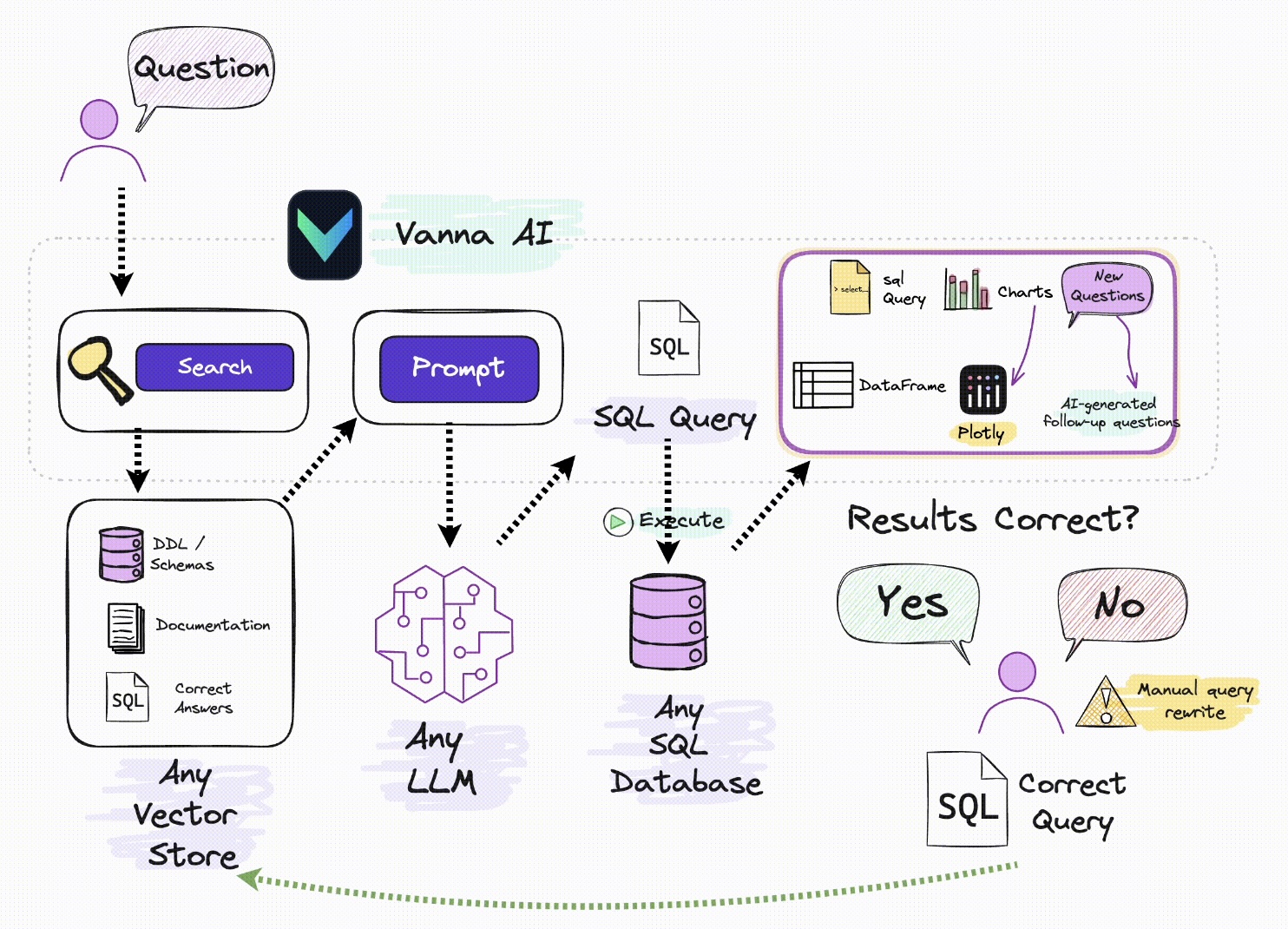
Vanna 的工作过程分为两个简单步骤 - 在您的数据上训练 RAG“模型”,然后提出问题,这些问题将返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。
在您的数据上训练 RAG“模型”。这些方法将添加到参考语料库。
问问题。这将使用参考语料库生成可以在您的数据库上运行的 SQL 查询。
启动 UI
Launch the User Interface
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Continue 使您能够在 IDE 中创建自己的 AI 代码助手。使用 VS Code 和 JetBrains 插件保持开发者的流畅体验,这些插件可以连接到任何模型、任何上下文以及任何其他你需要的东西。
Continue 使您能够使用适合工作的模型,无论是开源还是商业,本地运行还是远程运行,用于聊天、自动完成或嵌入。它提供了许多配置点,以便您可以自定义扩展以适应您现有的工作流程。
| 语言 | 占比 |
|---|---|
| TypeScript | 74.0% |
| Kotlin | 11.8% |
| Rust | 4.9% |
| CSS | 3.6% |
| Scheme | 2.5% |
| JavaScript | 2.4% |
| Other | 0.8% |
curl -fsSL https://ollama.com/install.sh | sh
systemctl edit ollama.service。这将打开一个编辑器。sudo systemctl edit ollama.service
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_NUM_PARALLEL=3"
Environment="OLLAMA_MAX_LOADED_MODELS=6"
Environment="OLLAMA_KEEP_ALIVE=4h"
sudo systemctl daemon-reload
sudo systemctl restart ollama
安装
pip install 'crewai[tools]'
版本1
每次执行结果都不一样
from dotenv import load_dotenv
load_dotenv()
from crewai import Agent, Task, Crew
from langchain_openai import ChatOpenAI
general_agent = Agent(
role = "数学教授",
goal = """为提问数学问题的学生提供解决方案并给出答案。""",
backstory = """您是一位优秀的数学教授,喜欢以每个人都能理解的方式解决数学问题。""",
allow_delegation = False,
verbose = True
)
// ...
版本2
稳定地生成结果
No Robots 是由熟练的人类注释者创建的包含 10,000 条指令和演示的高质量数据集。该数据可用于监督微调(SFT),使语言模型更好地遵循指令。 No Robots 是根据 OpenAI 的 InstructGPT 论文中描述的指令数据集进行建模的。
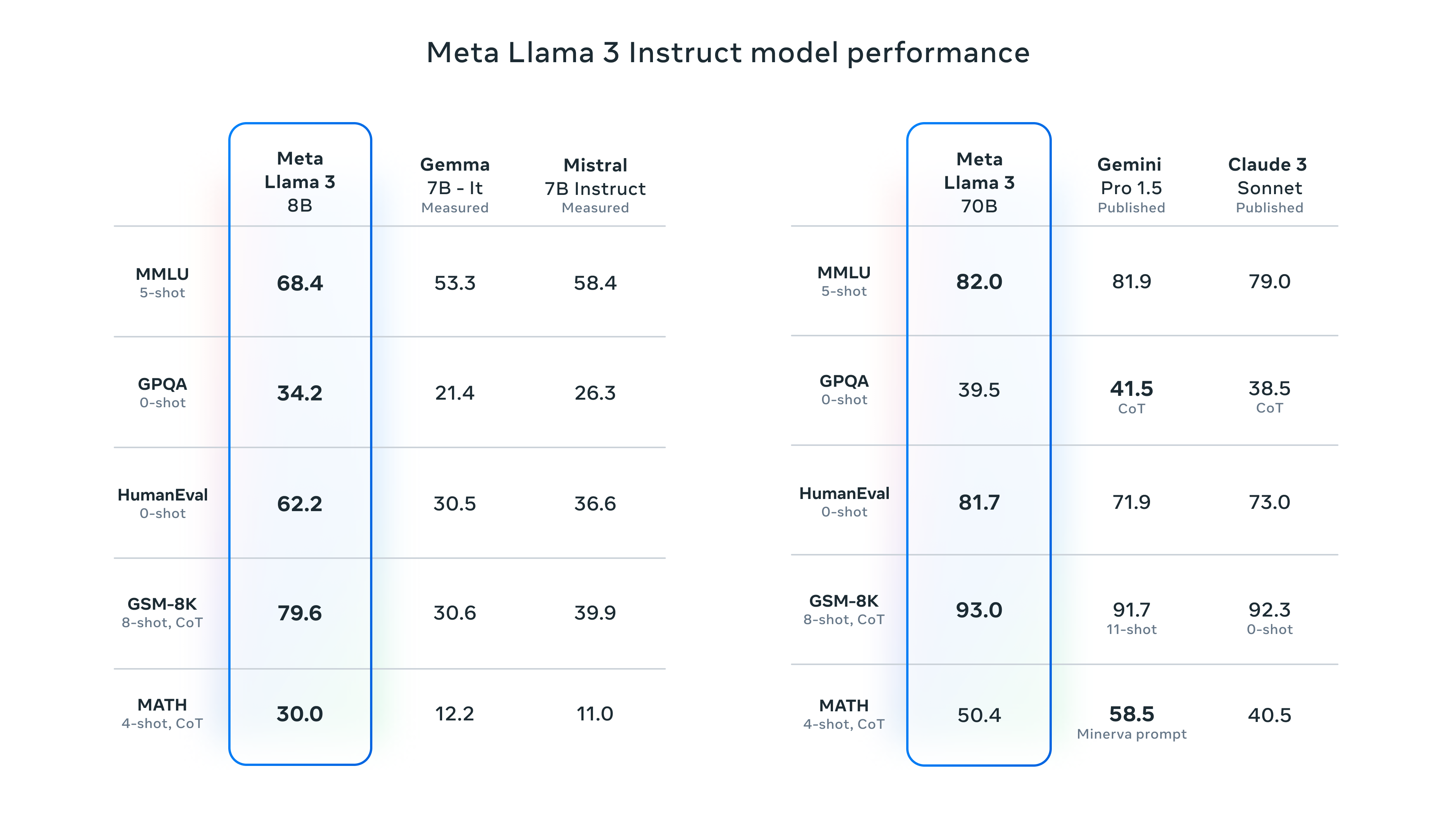
Llama 3 模型在两个拥有 24,000 GPU 的集群上进行了训练,使用的是超过 15 万亿 Token 的新公共在线数据。我们无法得知训练数据具体细节,但可以推测,更大规模且更细致的数据策划是性能提升的重要因素。Llama 3 Instruct 针对对话应用进行了优化,结合了超过 1000 万的人工标注数据,通过监督式微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)进行训练。
负责任使用指南 MLCommons AI Safety AI Safety Benchmarks Announcing MLCommons AI Safety v0.
ollama pull llama2
ollama pull llava


模型版本化

这里我使用了本地的 GGUF 模型进行构建。
编辑 Modelfile 文件 From /Users/junjian/.cache/lm-studio/models/TheBloke/Llama-2-7B-chat-GGUF/llama-2-7b-chat.Q4_K_M.