Qdrant
用于下一代人工智能应用的向量搜索引擎
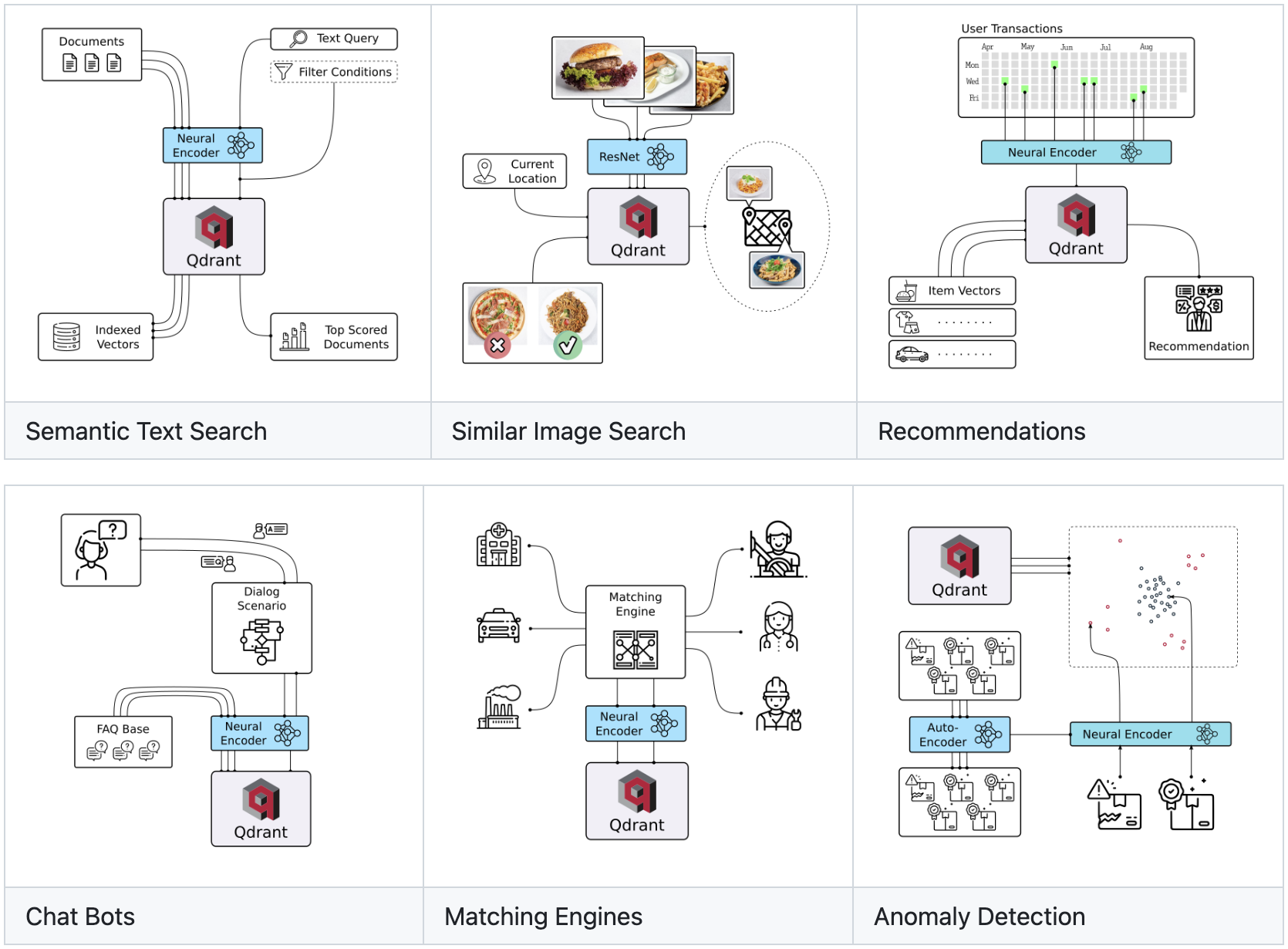
Qdrant(读作:quadrant)是一个向量相似性搜索引擎和向量数据库。它提供了一个生产就绪的服务,具有方便的 API 来存储、搜索和管理点 - 具有附加有效载荷的向量。Qdrant 专为扩展的过滤支持量身定制。它对所有类型的神经网络或基于语义的匹配、分面搜索和其他应用非常有用。
解决方案
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
Qdrant 现在可访问:
- REST API: localhost:6333
- Web UI: localhost:6333/dashboard
- GRPC API: localhost:6334
pip install qdrant-client