Continue 源码分析 - RerankerRetrievalPipeline

源代码:core/context/retrieval/pipelines/RerankerRetrievalPipeline.ts
源代码:core/context/retrieval/pipelines/RerankerRetrievalPipeline.ts
三元组分词的优势在于,它可以将文本中的单词分解为更小的片段,这样就可以更容易的匹配到包含拼写错误的单词,或者匹配到相似的单词。
tag_catalog
---
id PK int
dir string
branch string
artifactId string
path string
cacheKey string
lastUpdated int
sqlite_sequence
---
name
seq
// ...
使用检索增强来帮助您使用 LLM 为数据库生成准确的 SQL 查询。
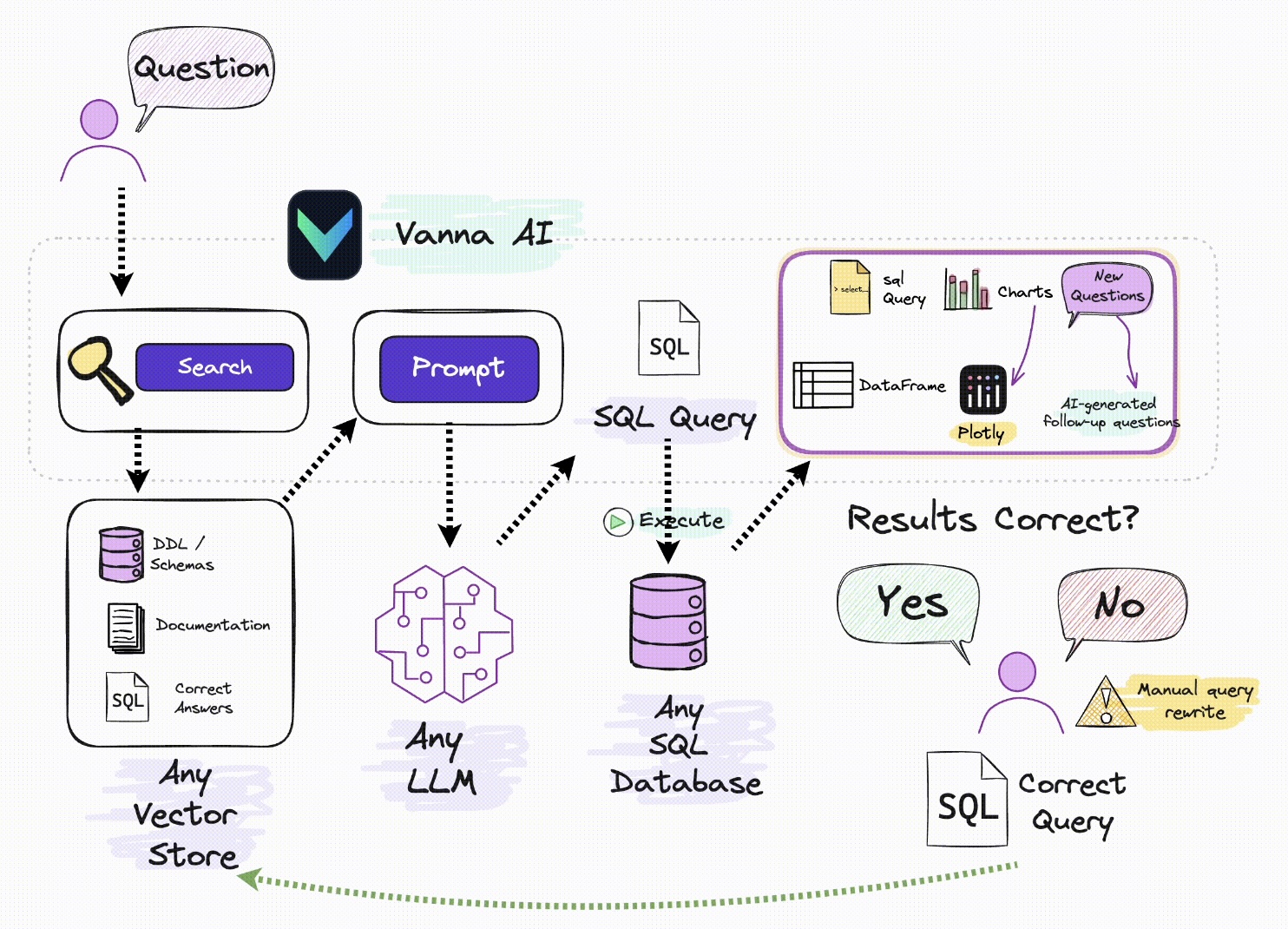
Vanna 的工作过程分为两个简单步骤 - 在您的数据上训练 RAG“模型”,然后提出问题,这些问题将返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。
在您的数据上训练 RAG“模型”。这些方法将添加到参考语料库。
问问题。这将使用参考语料库生成可以在您的数据库上运行的 SQL 查询。
启动 UI
Launch the User Interface
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()