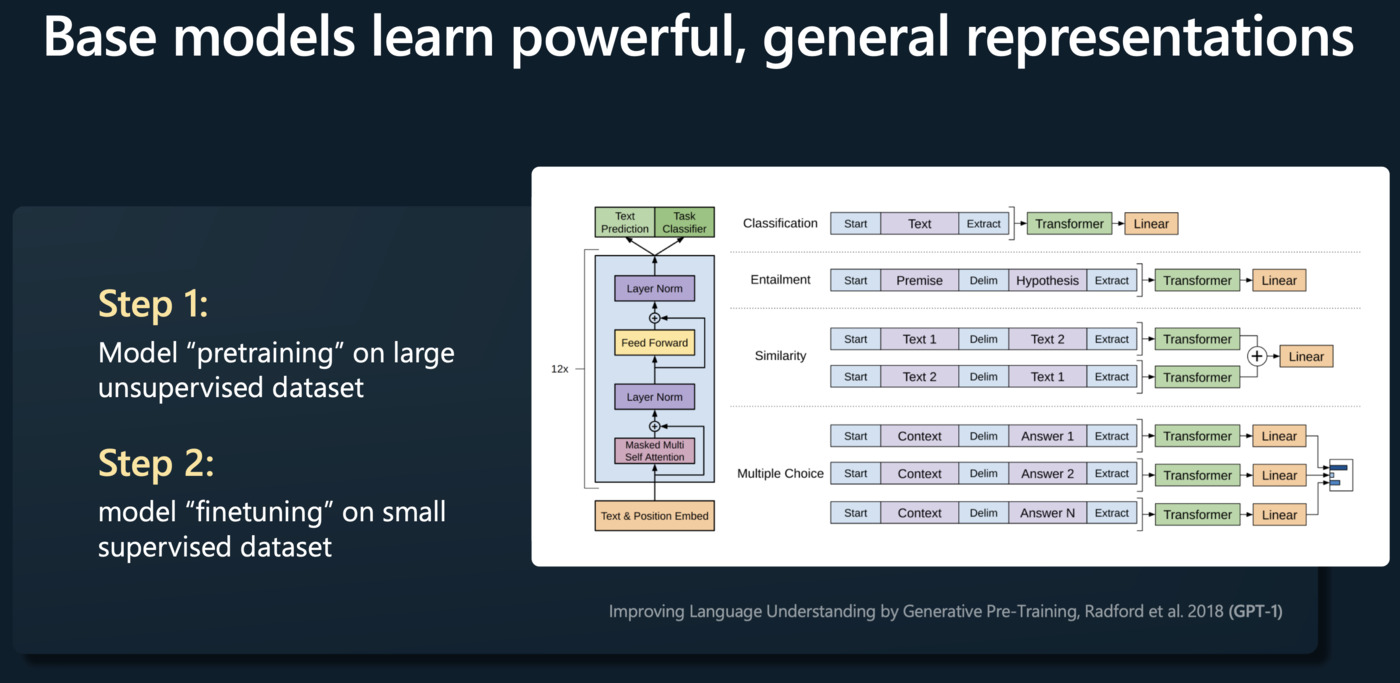
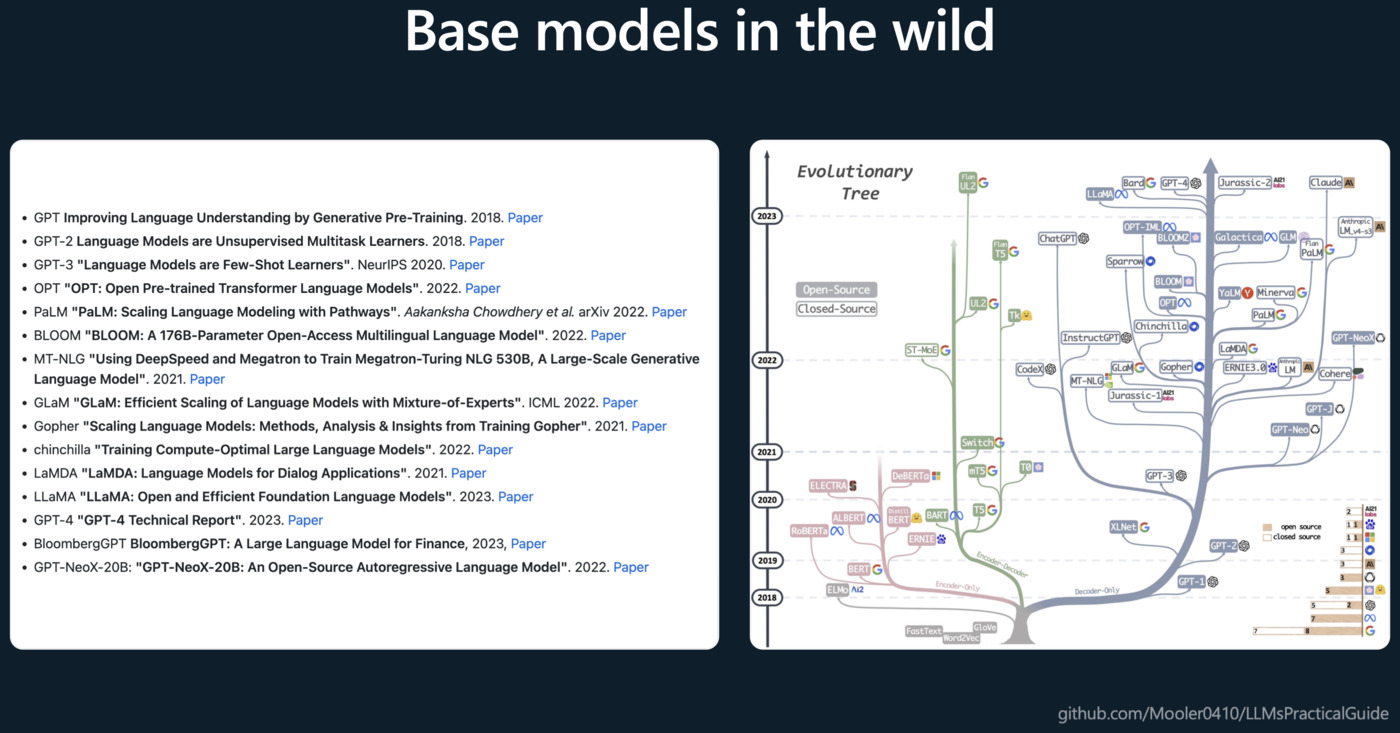
CodeGPT: 智能辅助编程
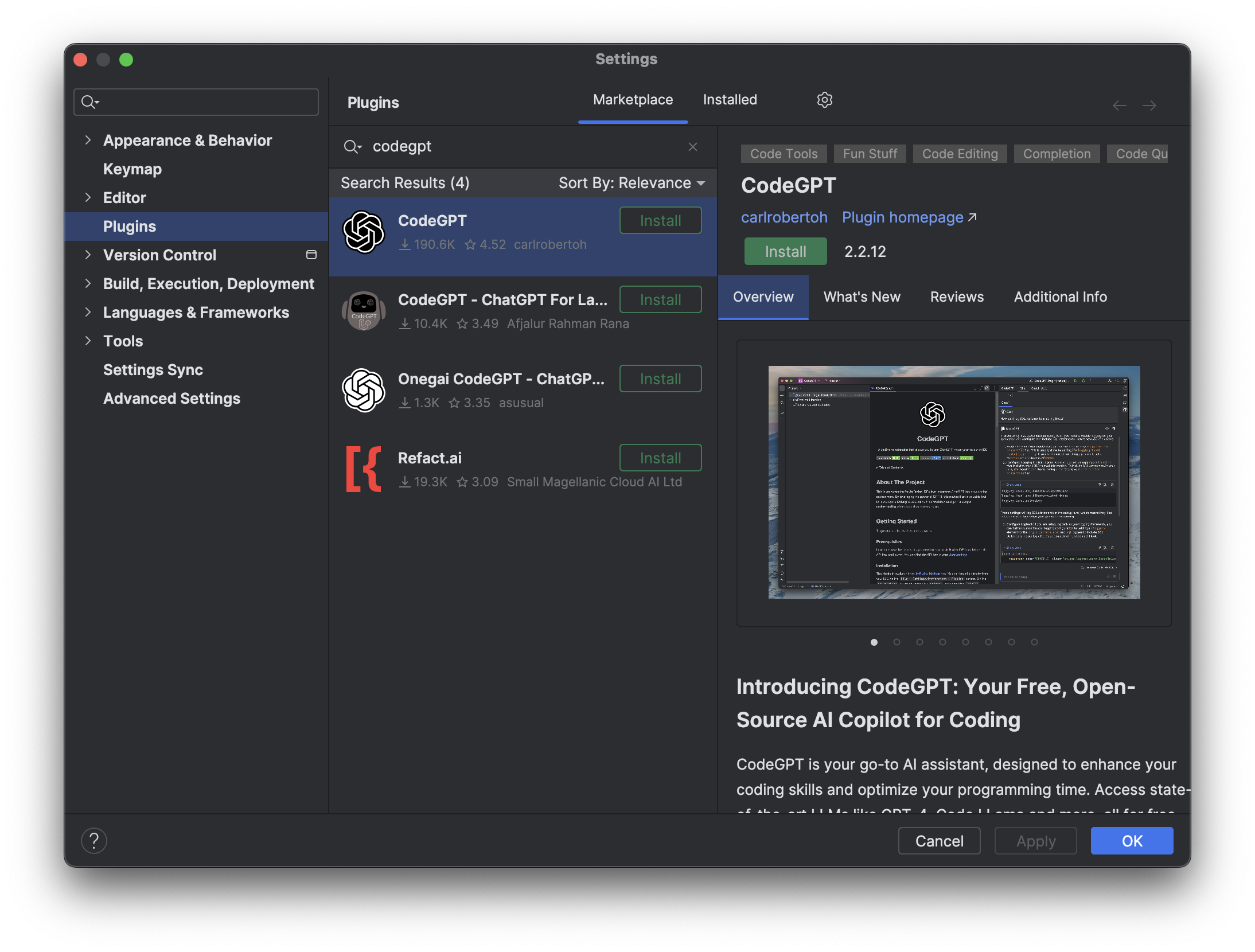
打开 IntelliJ IDEA,选择 Settings 菜单,选择 Plugins,搜索 CodeGPT,点击 Install 安装。
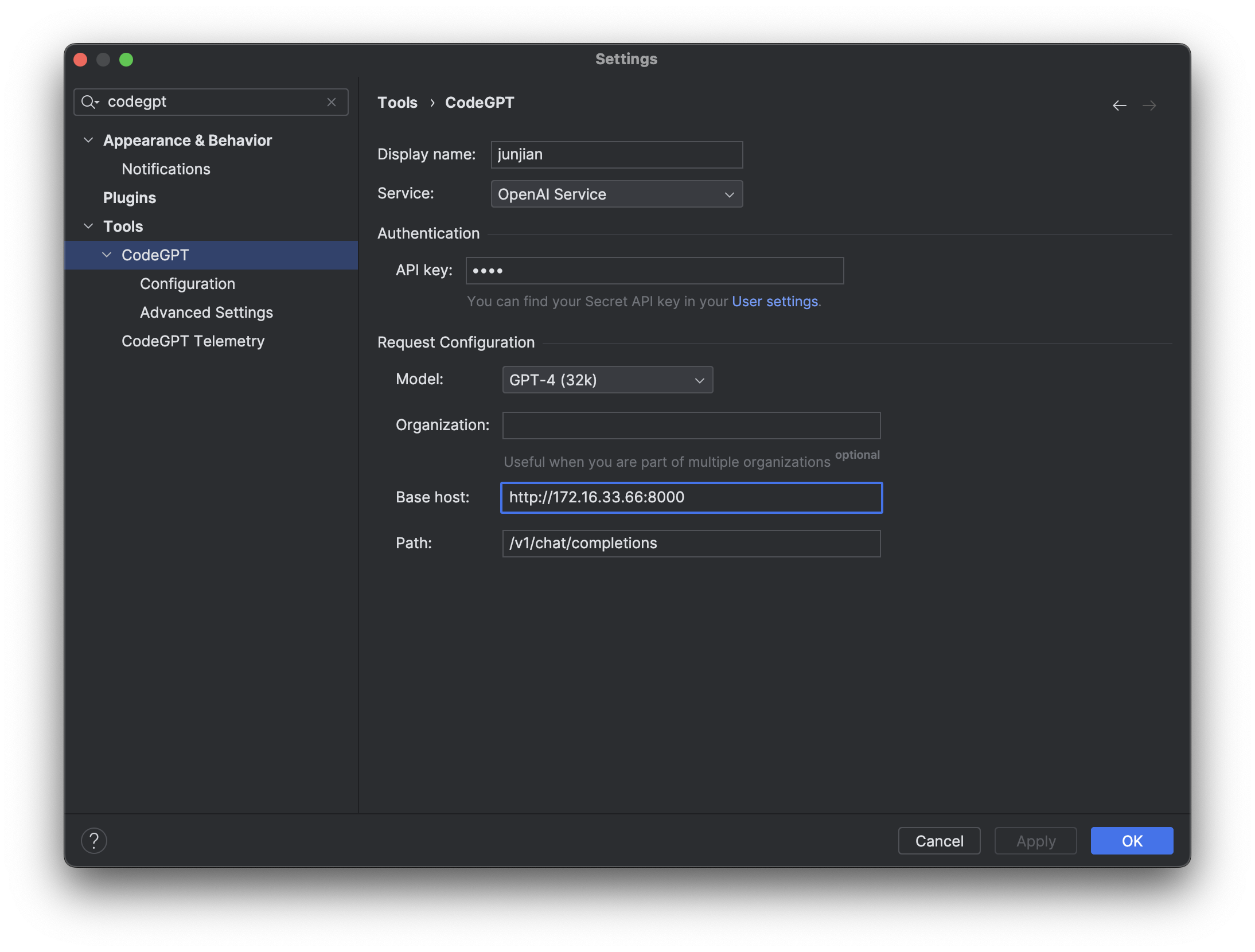
这里访问的 OpenAI 服务是我自己搭建的,使用的是 FastChat + ChatGLM3-6B。

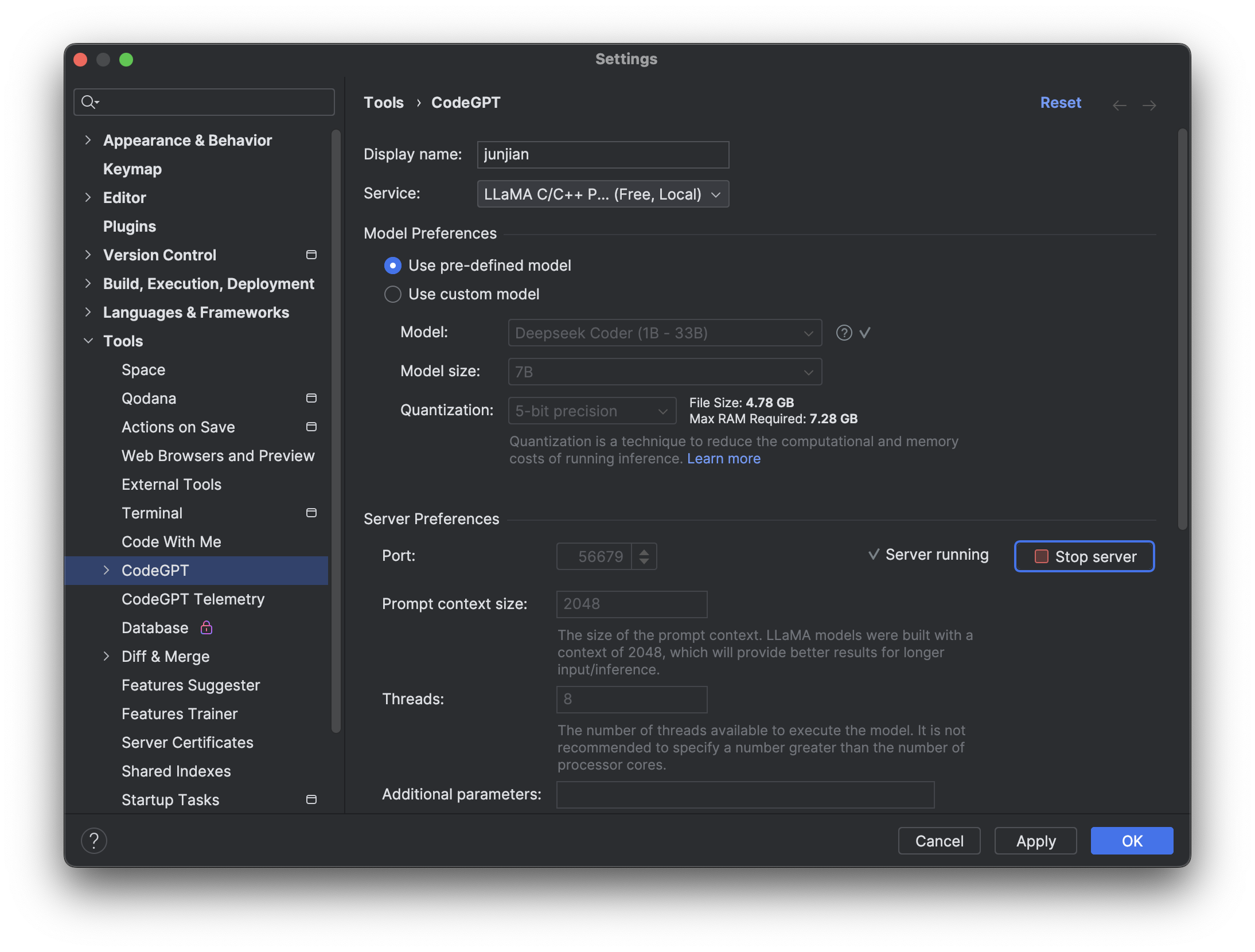
模型缓存到 ~/.codegpt/models/gguf 目录下,如果模型不存在,可以单击 Download Model 下载。
也可以自己到 HuggingFace 下载模型,然后放到 ~/.codegpt/models/gguf 目录下。
单击 Start server 启动服务。
查看缓存的模型
ls ~/.codegpt/models/gguf
deepseek-coder-6.7b-instruct.Q5_K_M.gguf
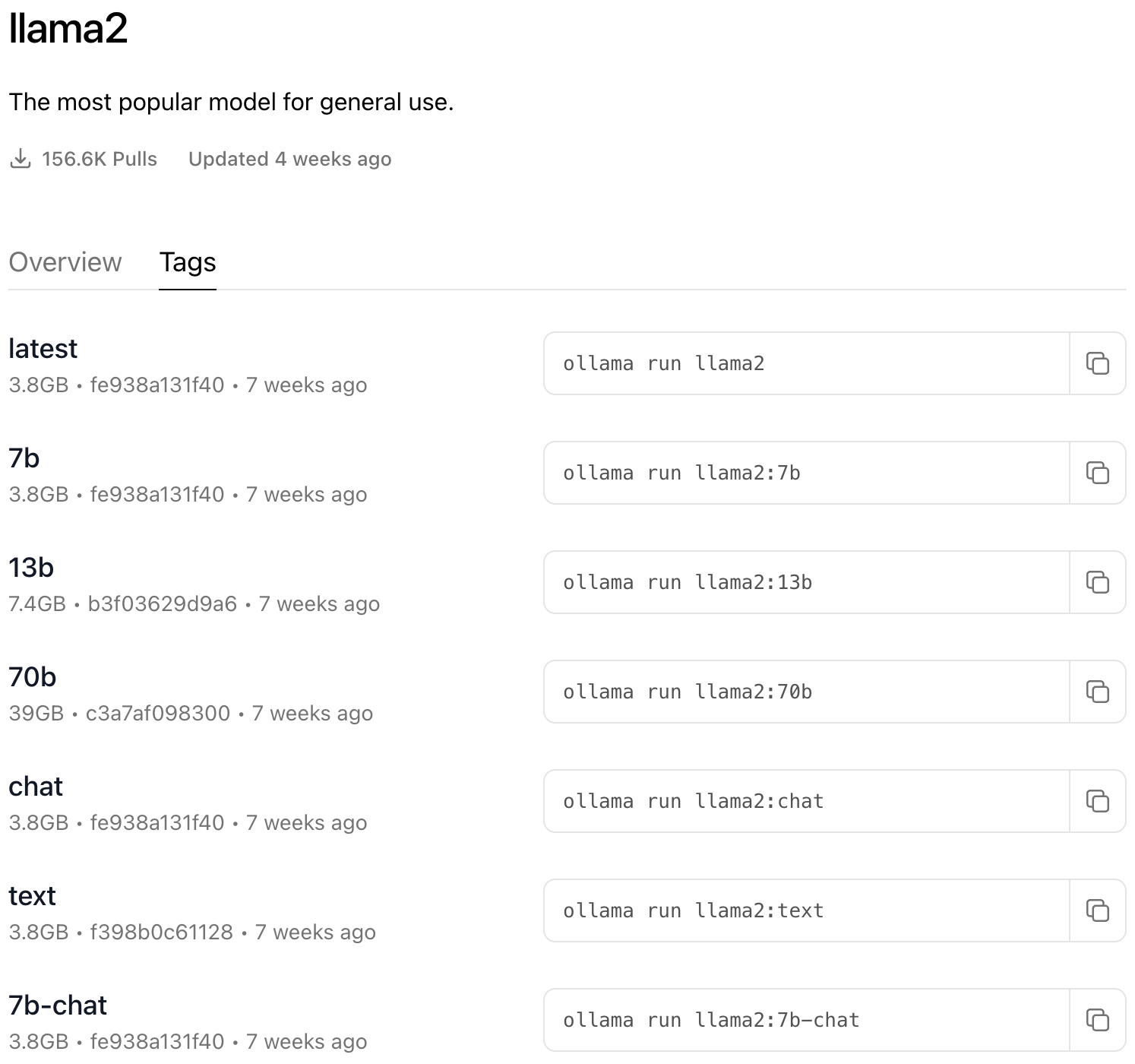
可以到 HuggingFace 下载 LLaMA 2-7B-Chat 模型的 GGUF格式。
- Service: LLaMA C/C++ Port (Free, Local)
- Use custom model
- Model path: 您下载的 LLaMA 2-7B-Chat 模型的路径
- Prompt template: Llama
单击 Start server 启动服务。