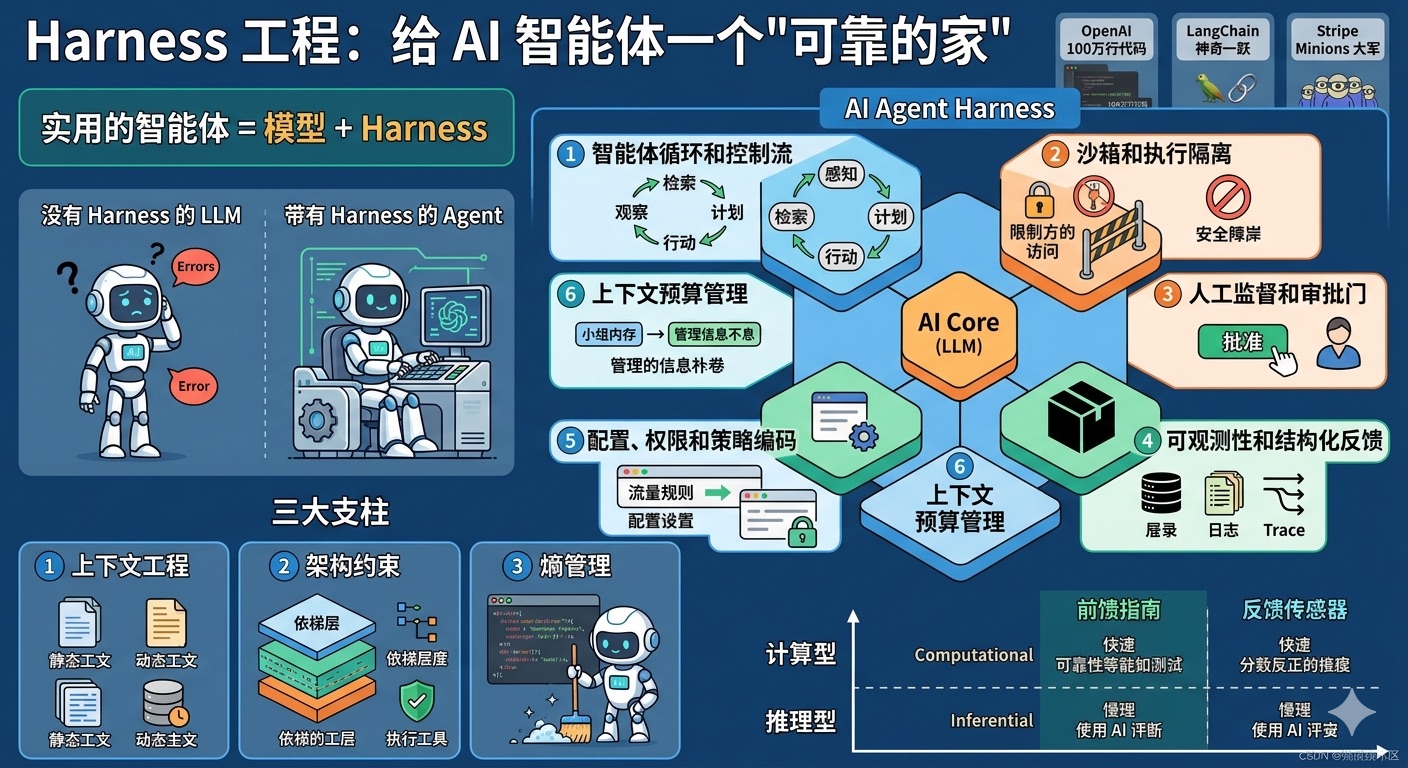
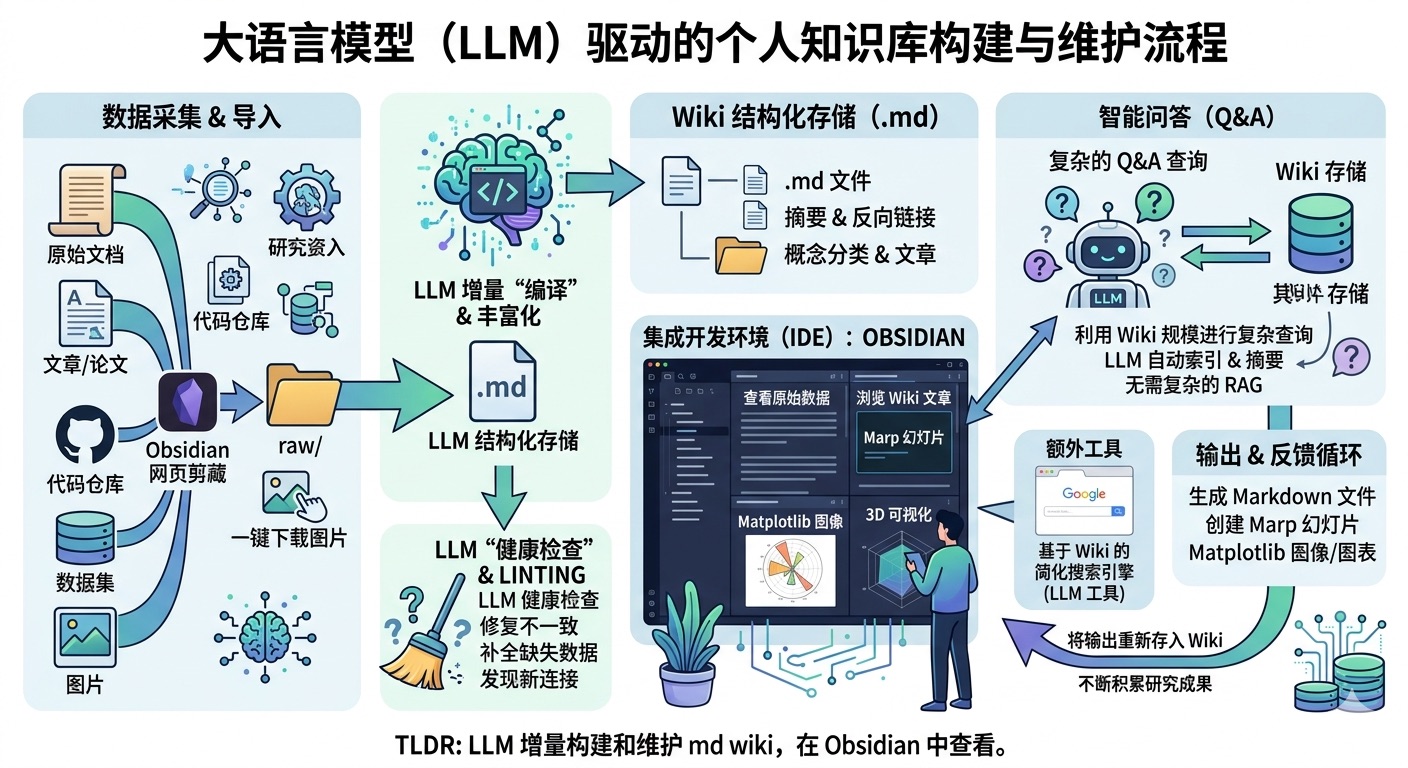
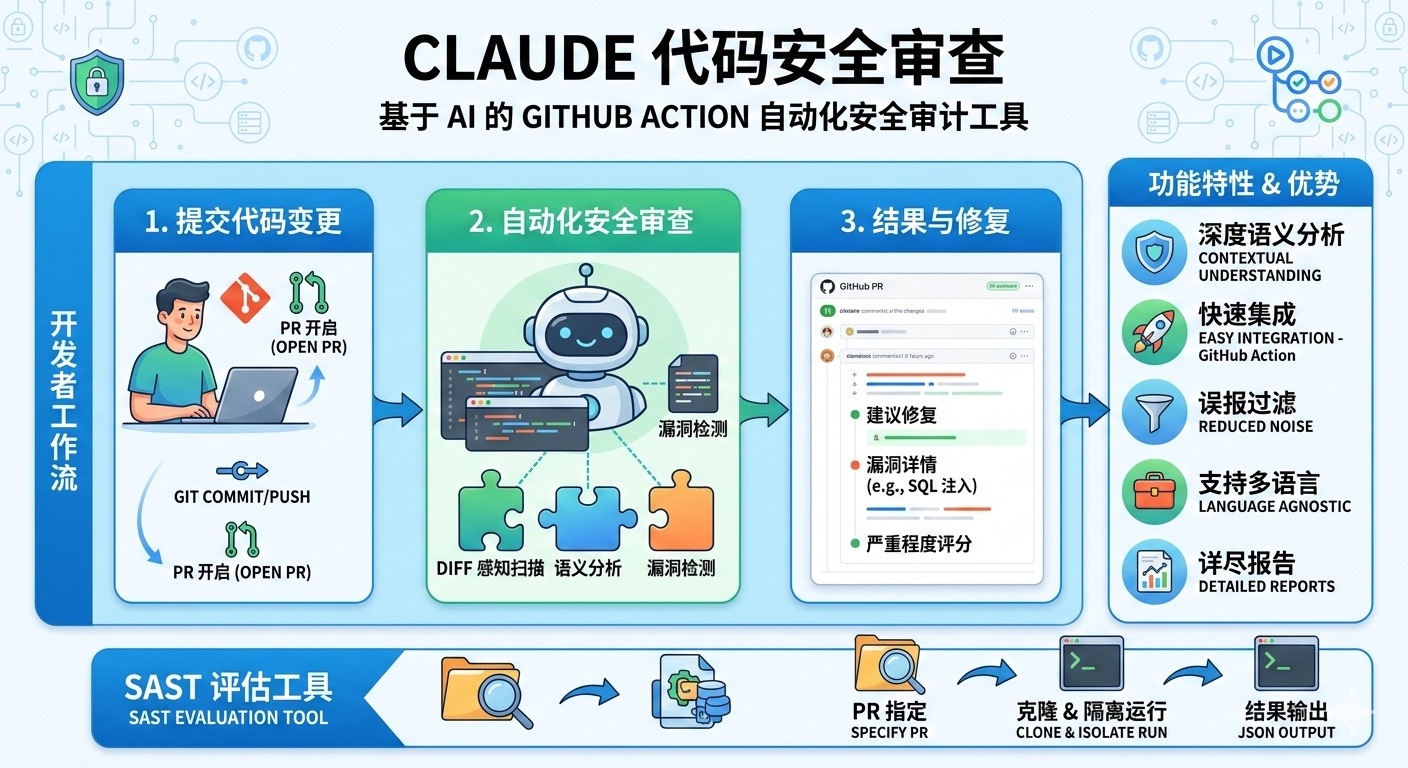
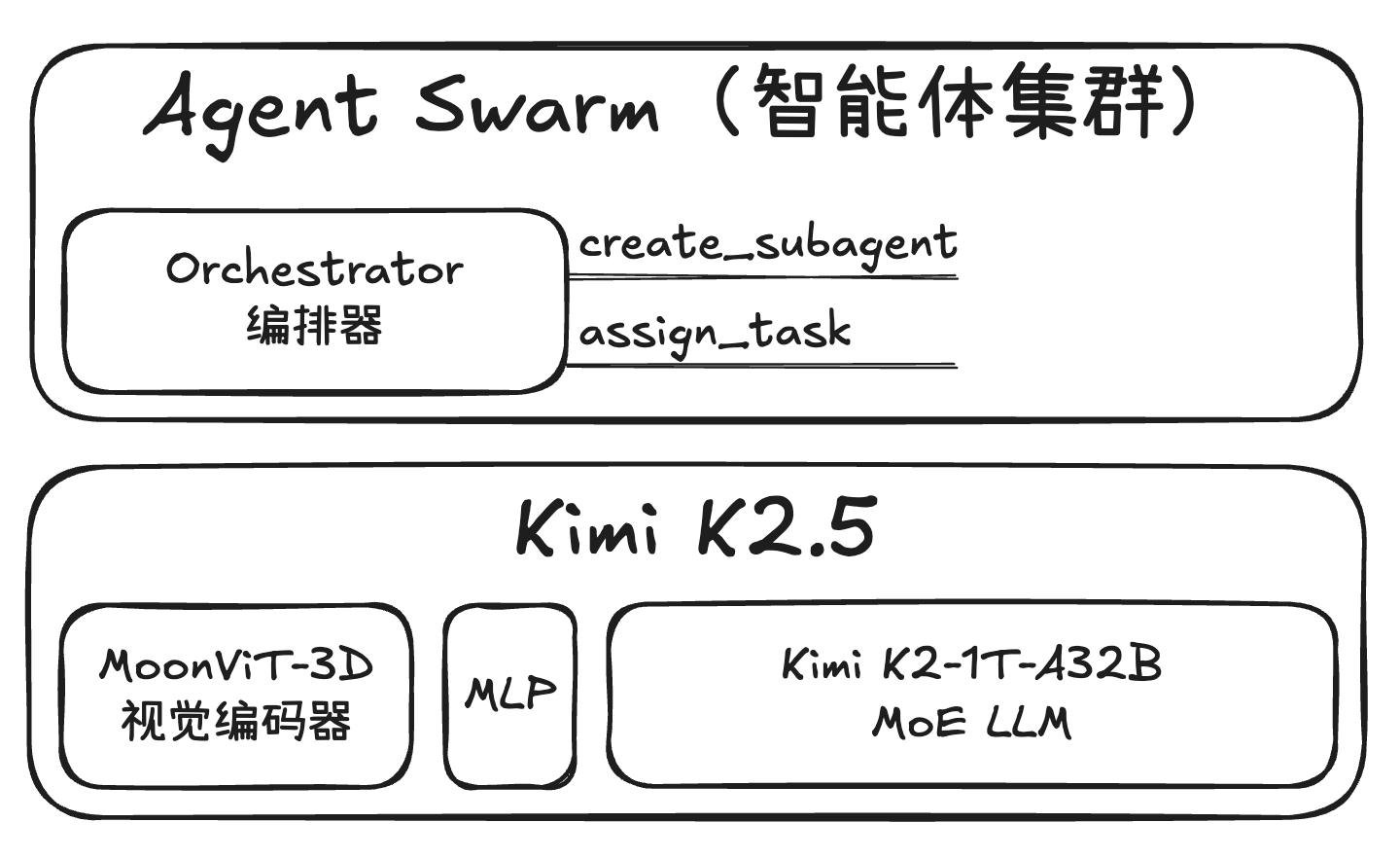
LLM Wiki:基于大语言模型的个人知识库构建模式
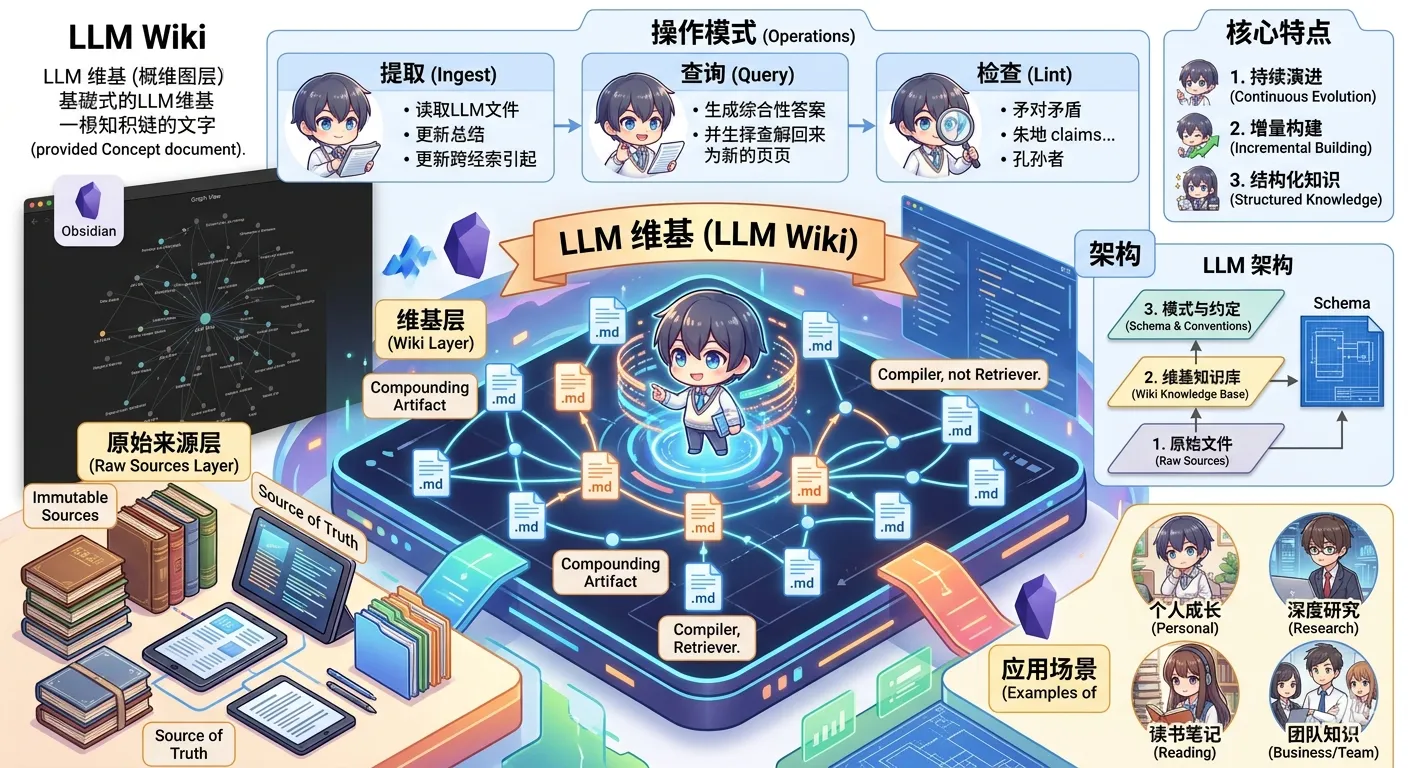
使用大语言模型(LLM)构建个人知识库的模式。
这是一份概念文件,设计用于复制粘贴到你自己的 LLM 智能体中(例如 OpenAI Codex、Claude Code、OpenCode / Pi 等)。它的目标是传达高层级的理念,而具体细节将由你的智能体与你协作构建。
大多数人与 LLM 和文档打交道的体验看起来像是 RAG:你上传一批文件,LLM 在查询时检索相关片段,然后生成答案。这确实有效,但 LLM 每次都要从零开始重新发现知识,没有任何积累。当你问一个需要综合五份文档的微妙问题时,LLM 必须每次都找到并拼凑相关片段,没有任何东西被沉淀下来。NotebookLM、ChatGPT 文件上传以及大多数 RAG 系统都是这样工作的。
这里的理念不同。与其仅在查询时从原始文档中检索,LLM 增量式地构建并维护一个持久的维基 —— 一个结构化的、相互关联的 Markdown 文件集合,位于你和原始来源之间。当你添加新来源时,LLM 不只是将其索引以备后用。它会阅读来源,提取关键信息,并将其整合到现有维基中 —— 更新实体页面、修订主题摘要、标注新数据与旧主张的矛盾之处、强化或挑战不断演进的综合结论。知识被编译一次,然后保持最新,而不是每次查询都重新推导。
这就是关键区别:维基是一个持久的、复合增长的产物。