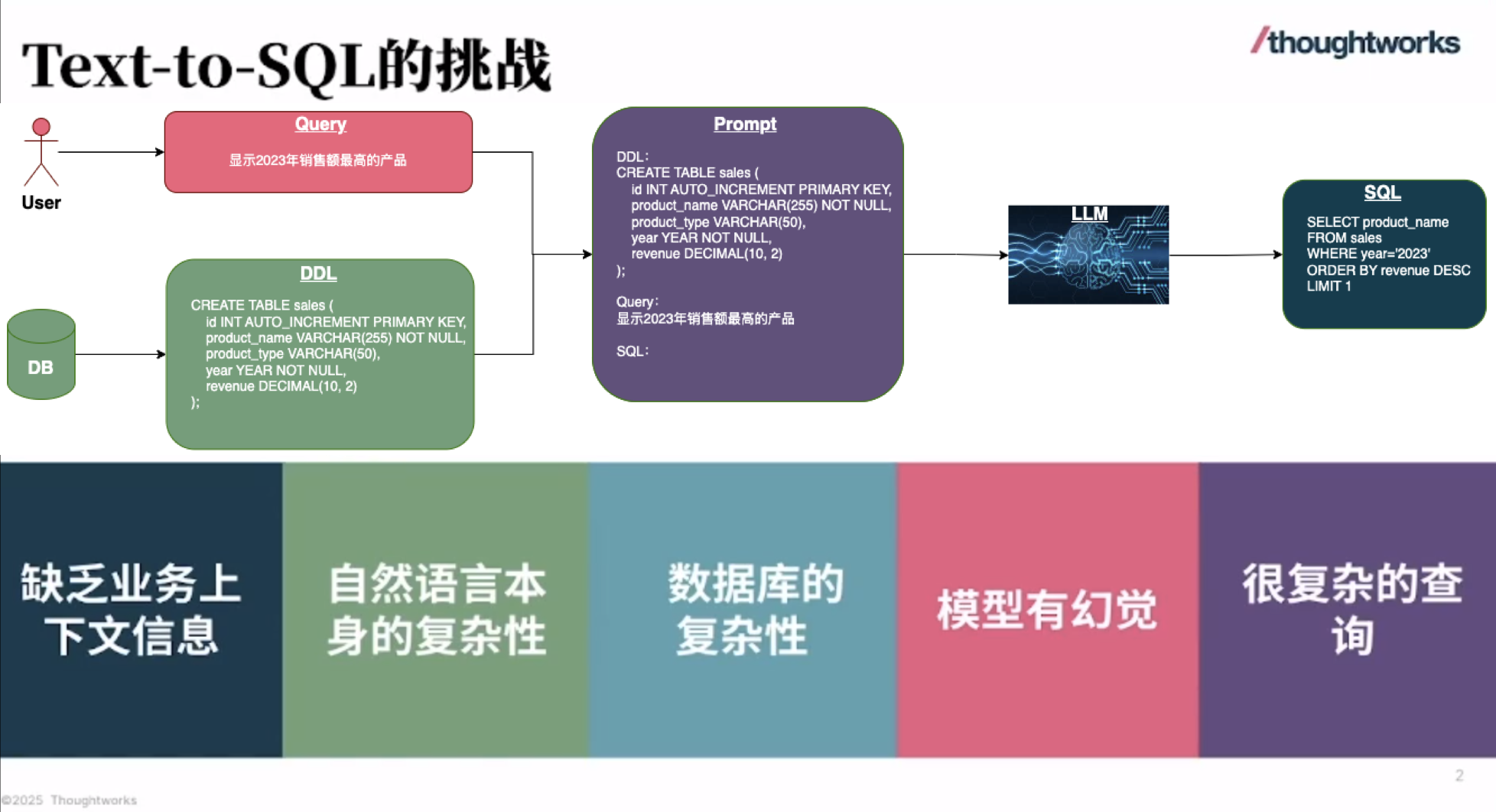
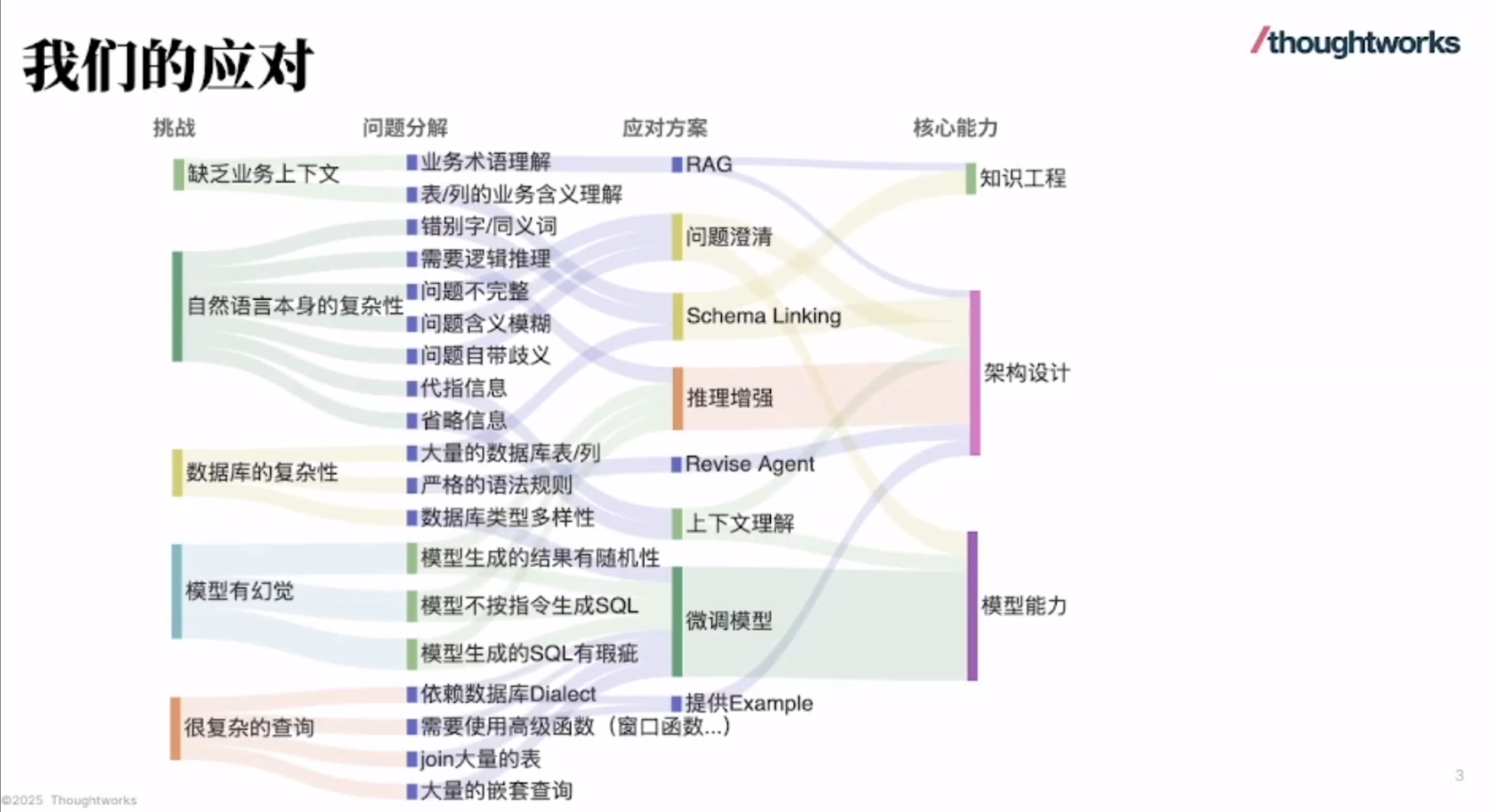
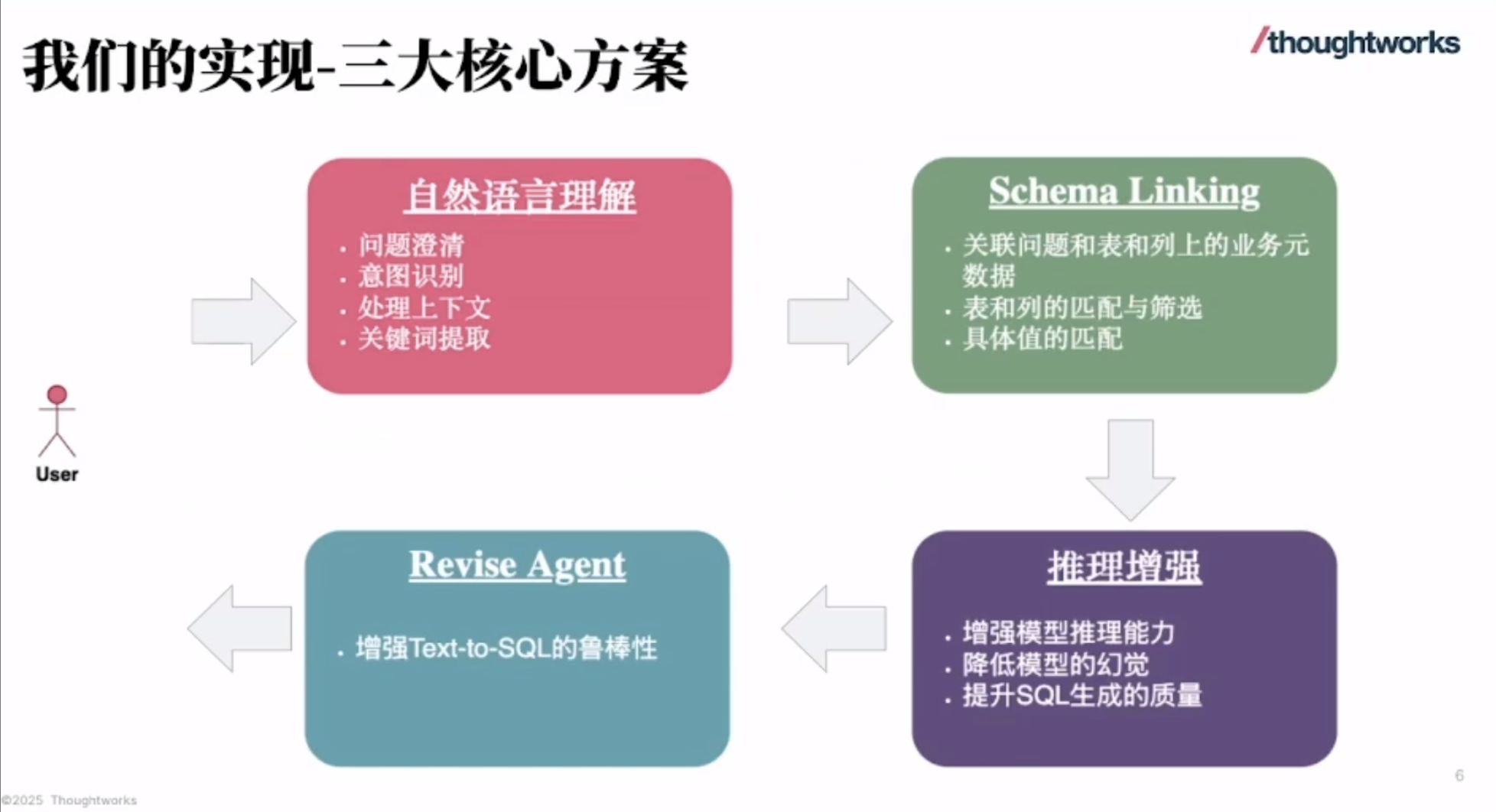
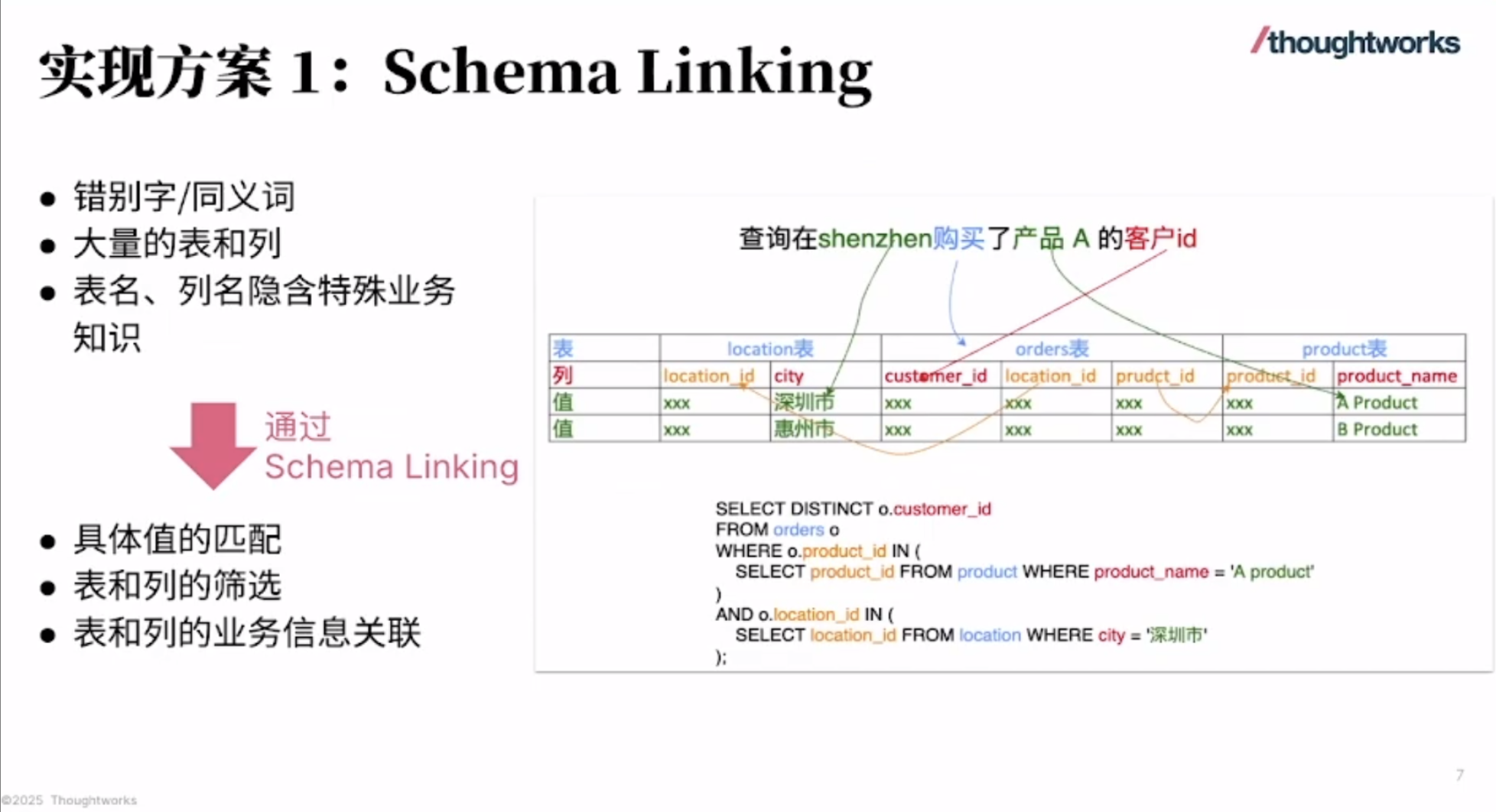
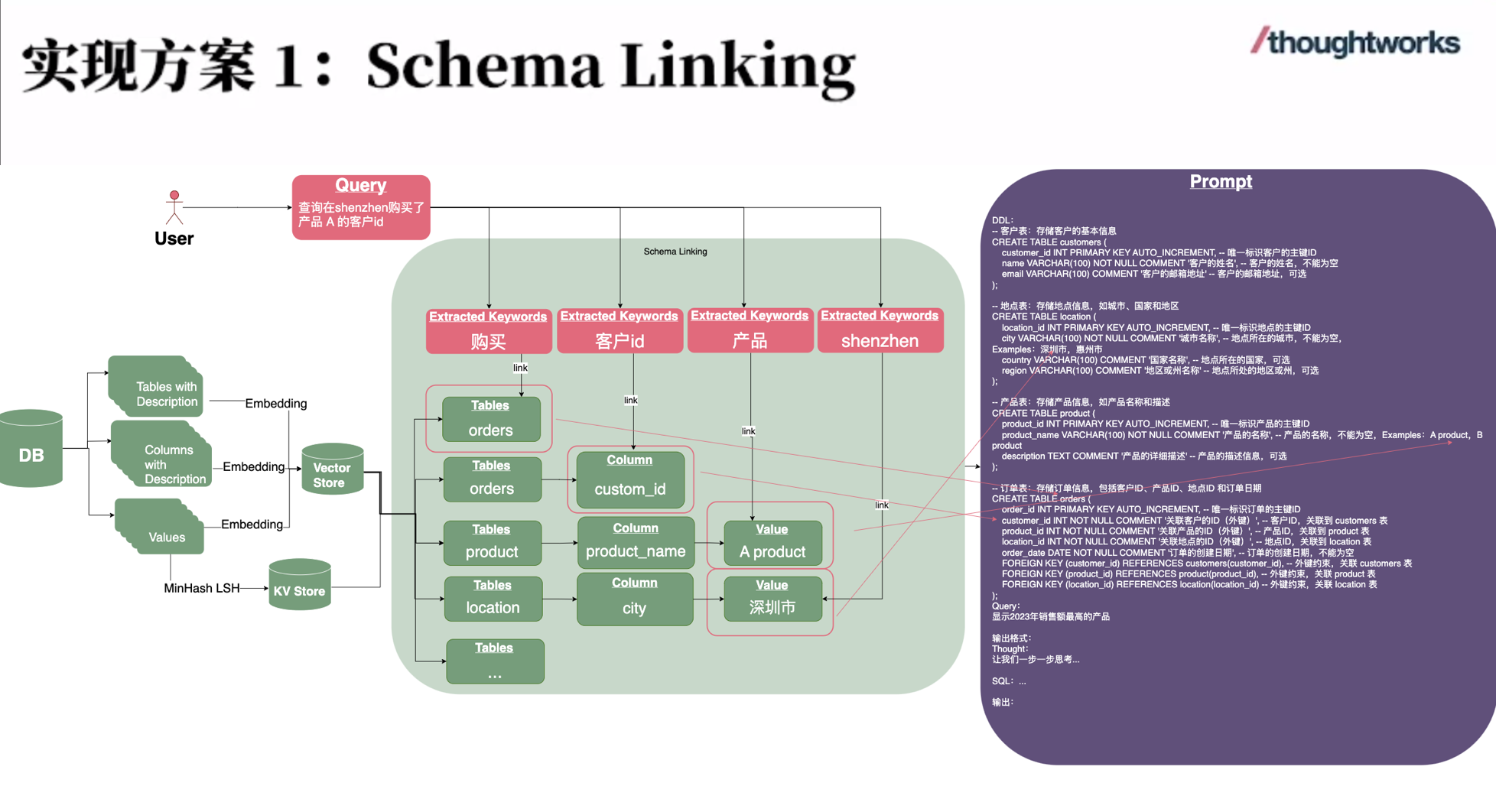
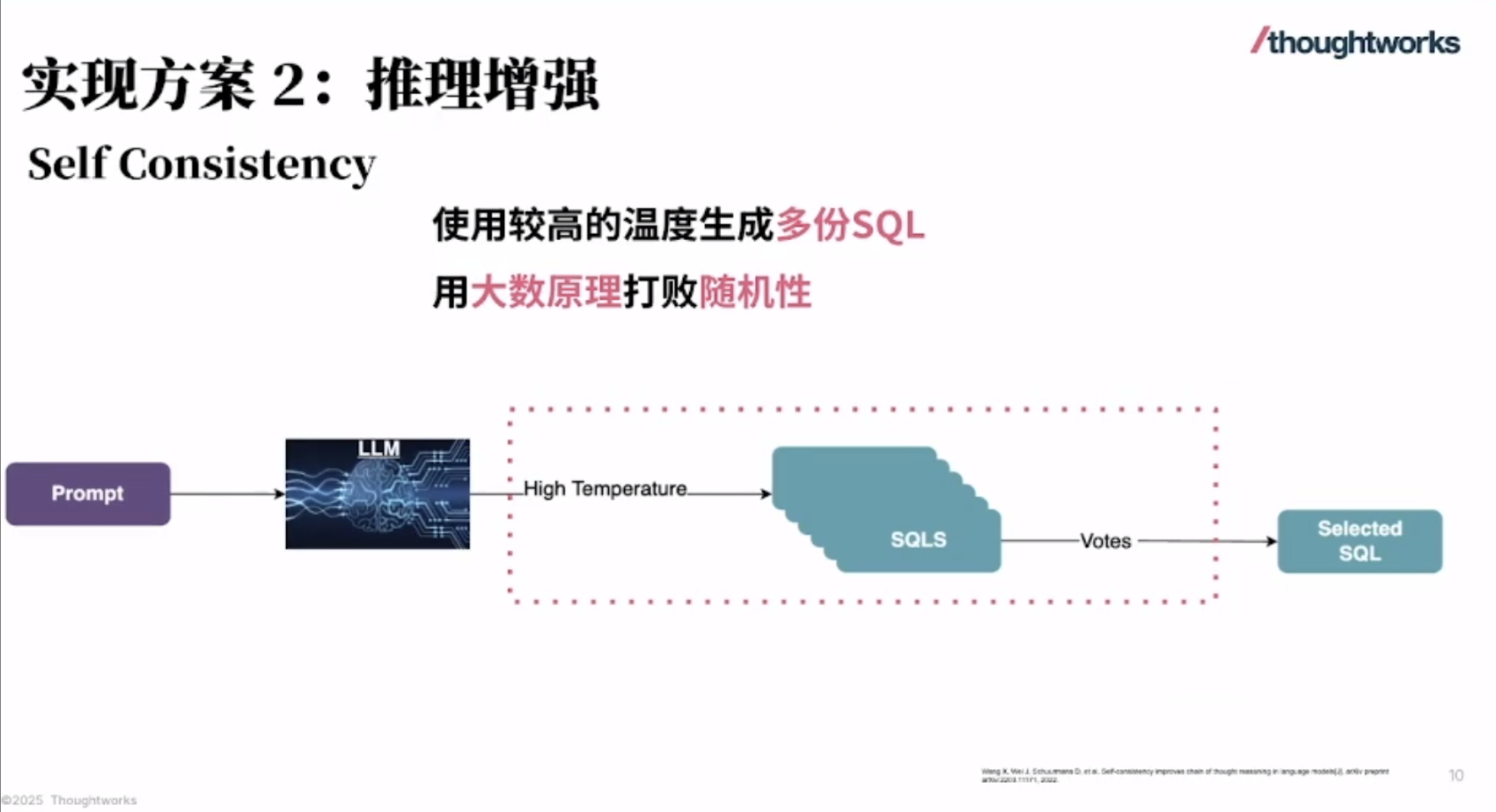
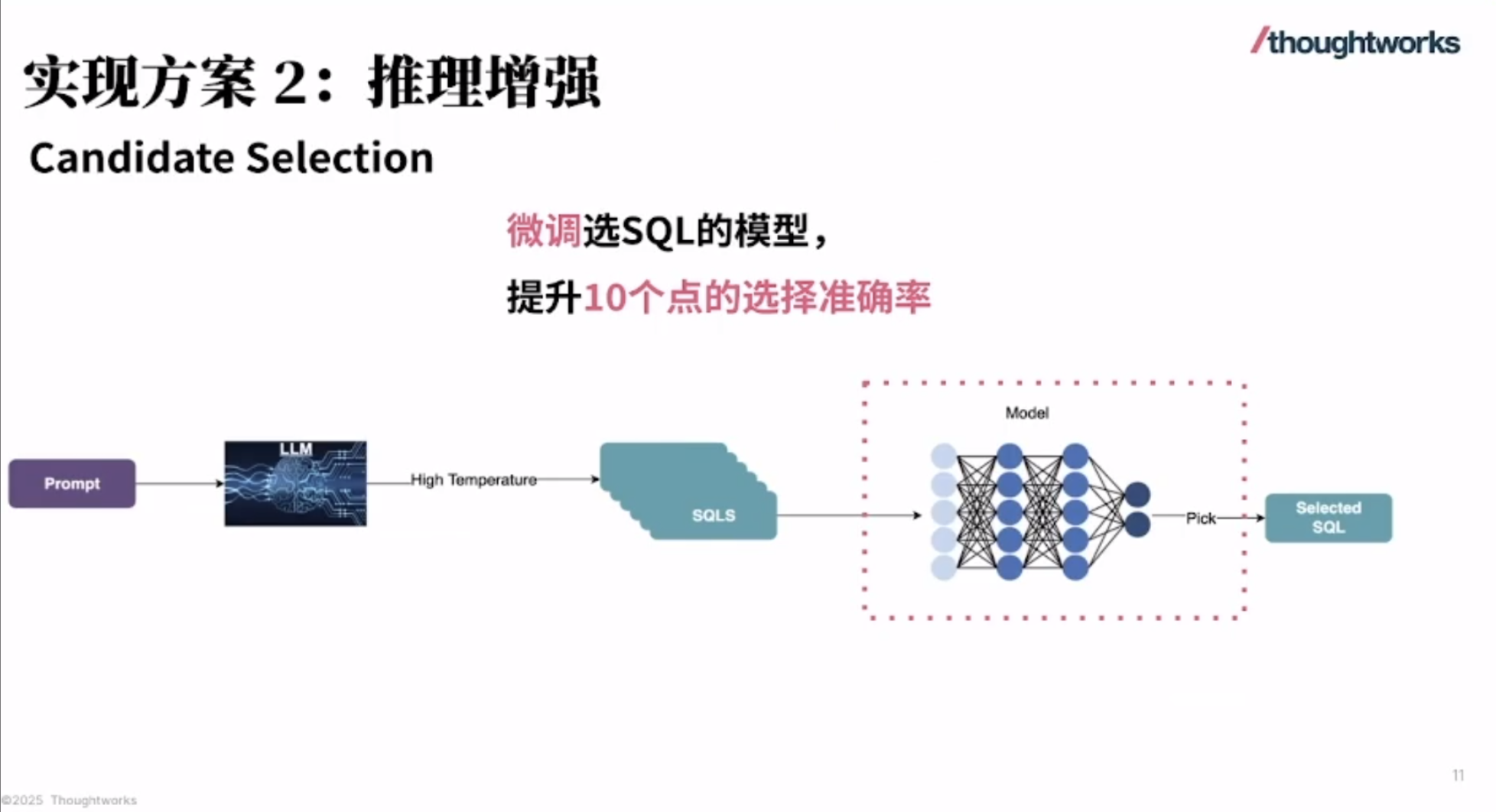
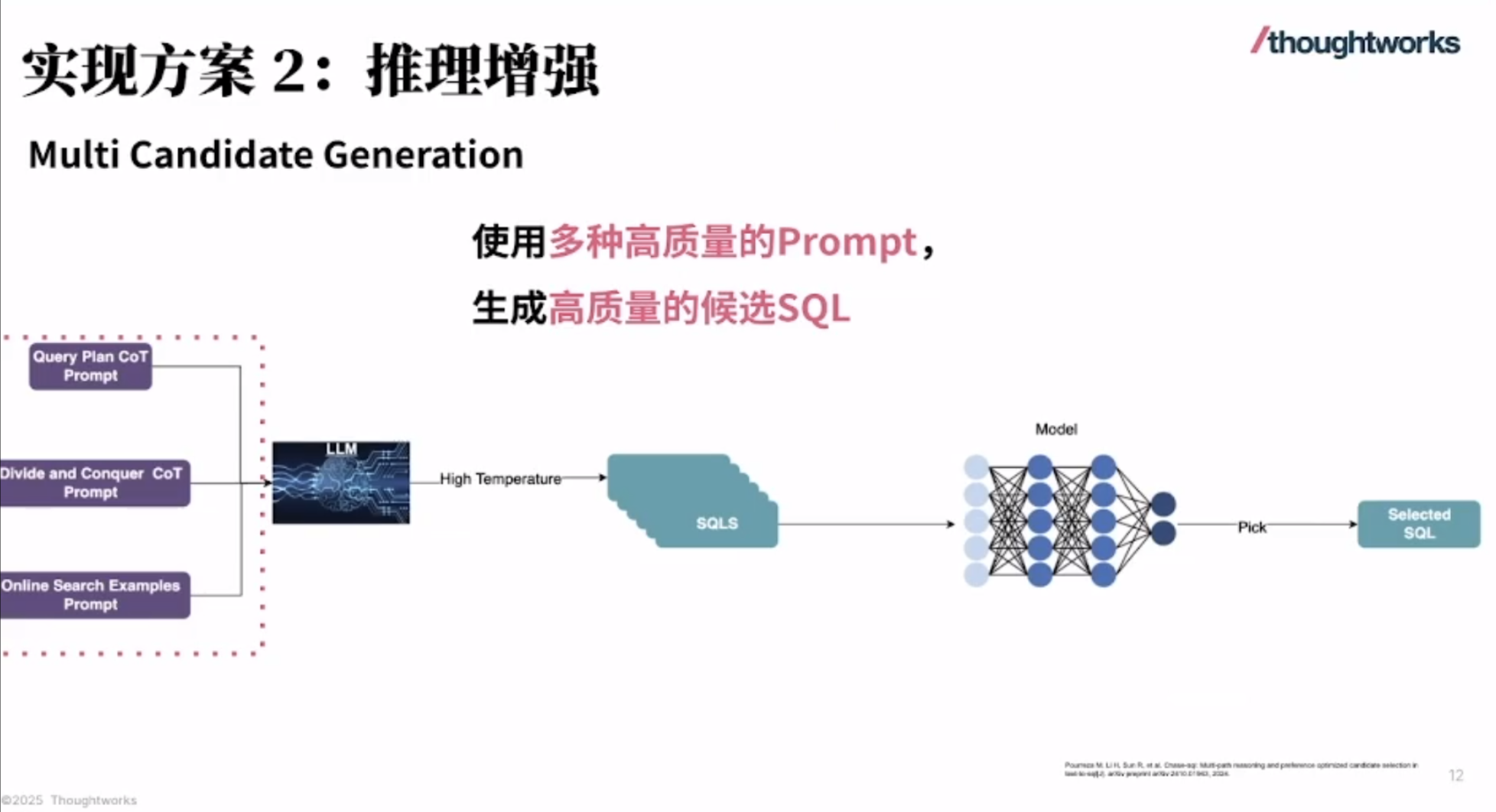
华为 Atlas 800I A2 大模型部署实战(七):完整的安装部署流程
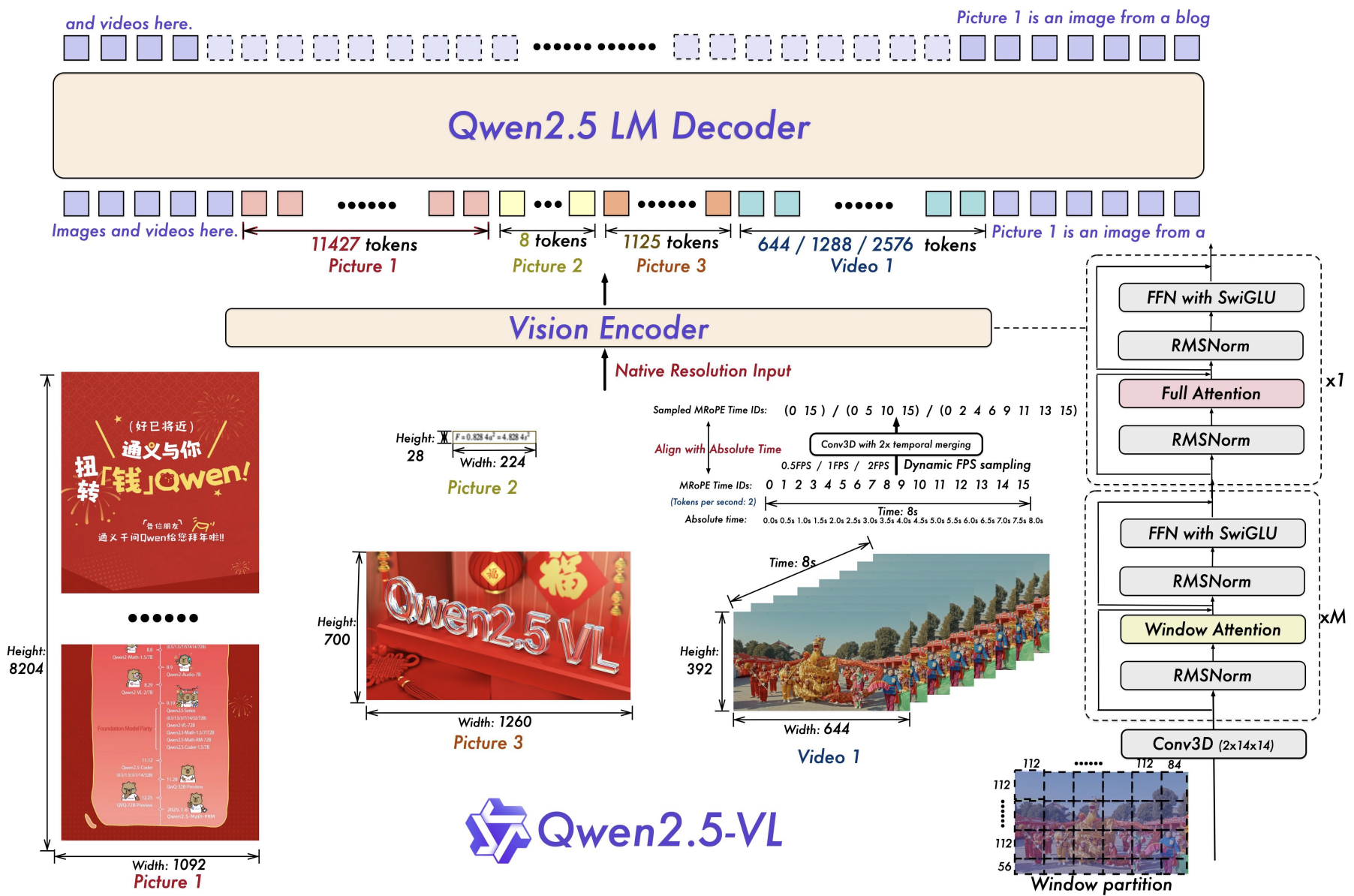
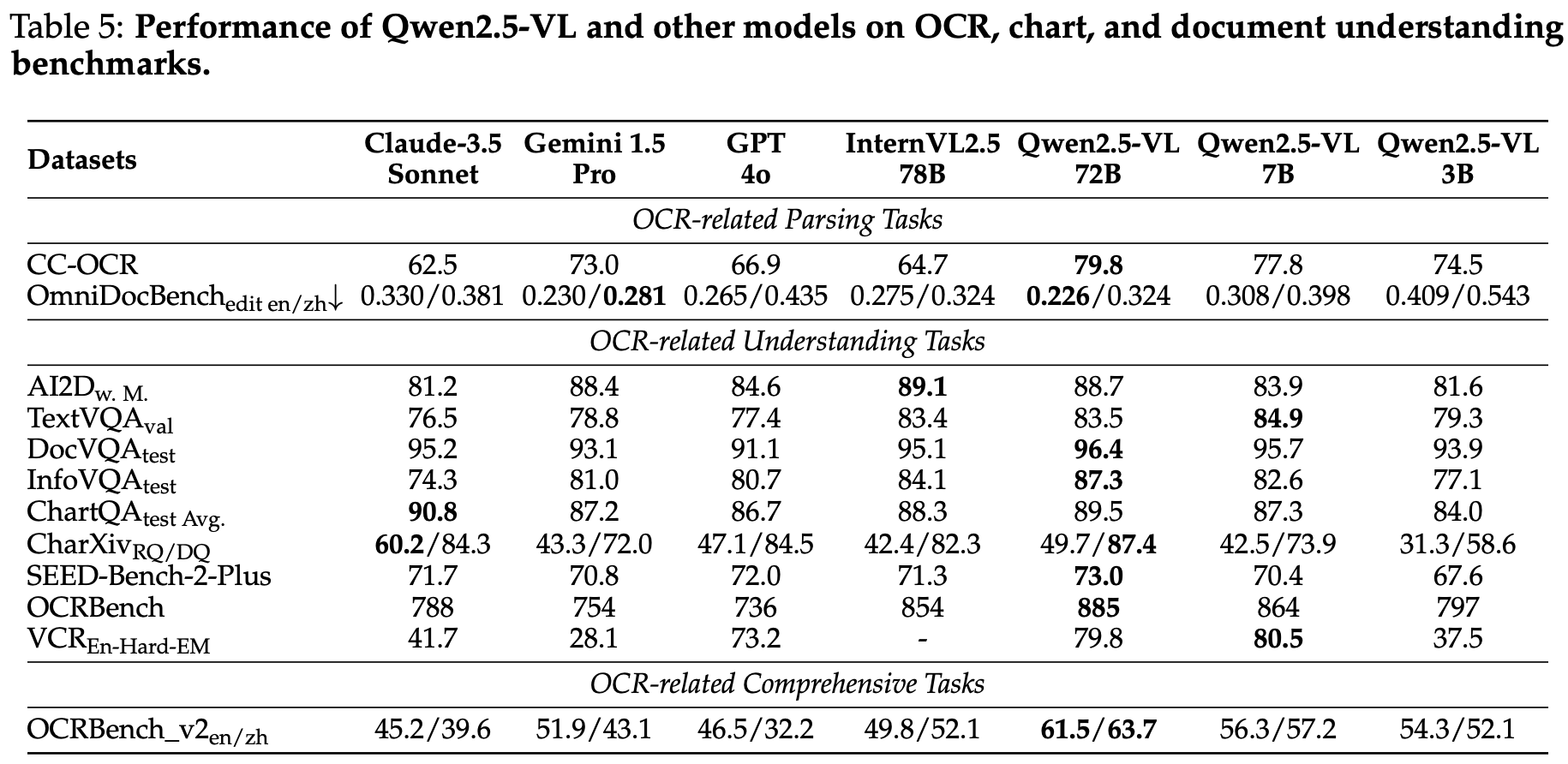
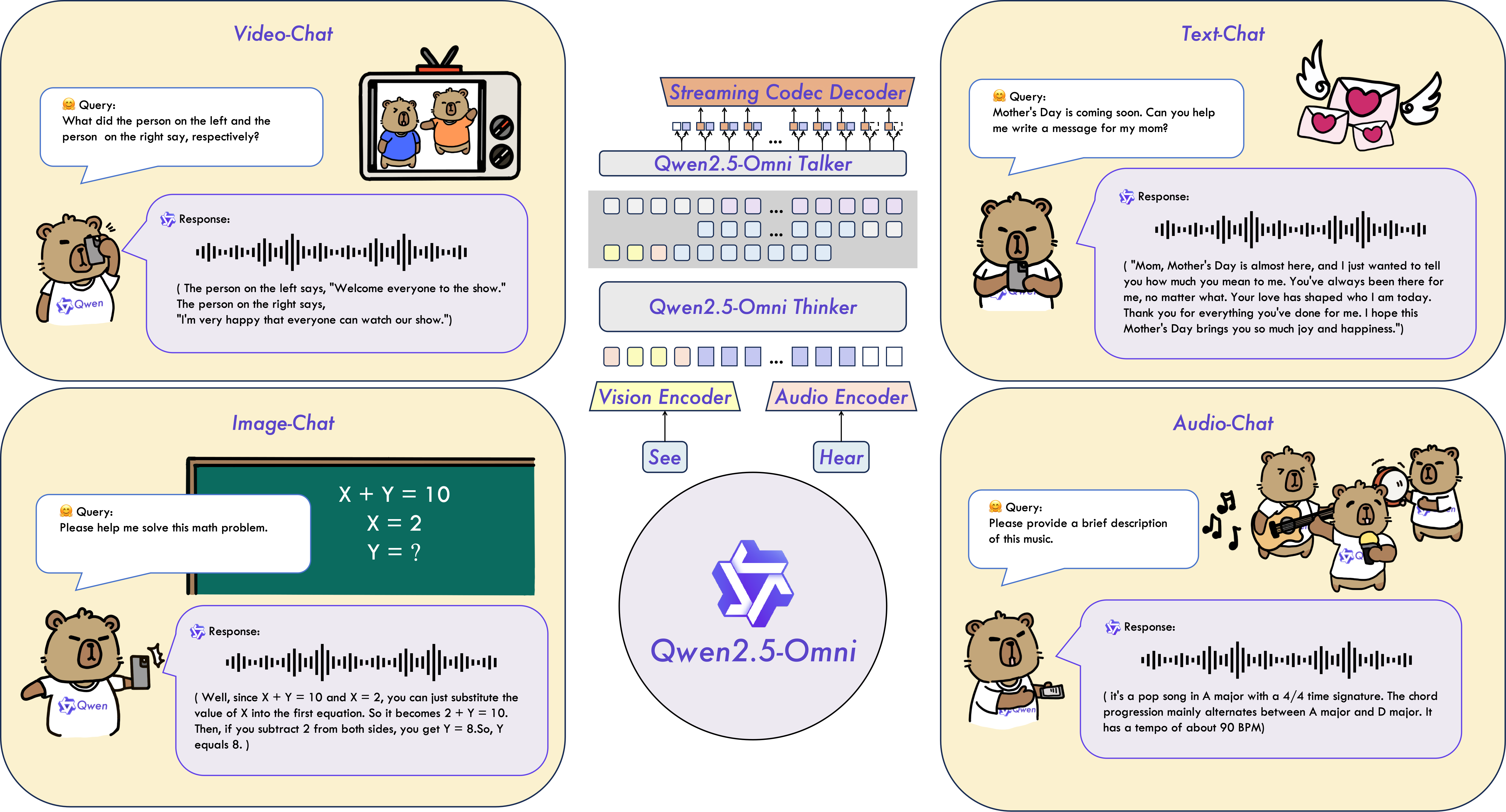
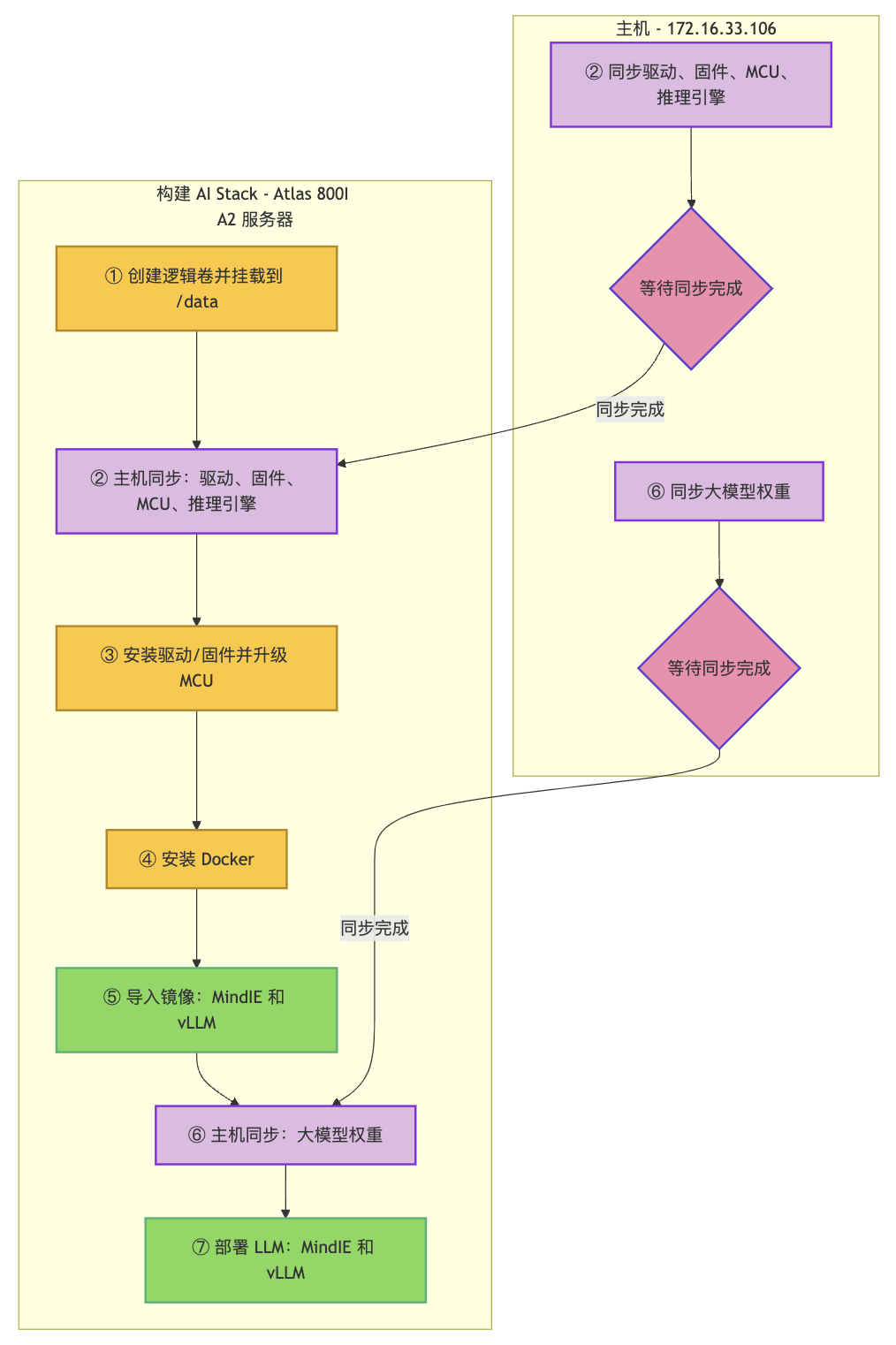
这份指南详细阐述了华为Atlas 800I A2推理服务器上大型模型的部署流程,旨在提供一个全面的安装与配置实践,用于扩展部署到其它服务器。随后,文章通过流程图和具体命令脚本,逐步指导用户如何创建和挂载逻辑卷、同步并安装驱动固件、部署Docker环境以及导入所需的MindIE和vLLM镜像。最后,指南还涵盖了同步大型模型权重文件的关键步骤,并指示用户通过Docker Compose启动模型服务,确保MindIE和vLLM能够顺利运行,以实现AI推理功能。
AI 服务器:华为 Atlas 800I A2 推理服务器
| 组件 | 规格 |
|---|---|
| CPU | 鲲鹏 920(5250) |
| NPU | 昇腾 910B4(8X32G) |
| 内存 | 1024GB |
| 硬盘 | 系统盘:450GB SSDX2 RAID1 数据盘:3.5TB NVME SSDX4 |
| 操作系统 | openEuler 22.03 LTS |



















/01.jpg)
/02.jpg)
/03.jpg)
/04.jpg)
/05.jpg)
/06.jpg)
/07.jpg)
/08.jpg)
/09.jpg)
/10.jpg)
/11.jpg)
/12.jpg)
/13.jpg)