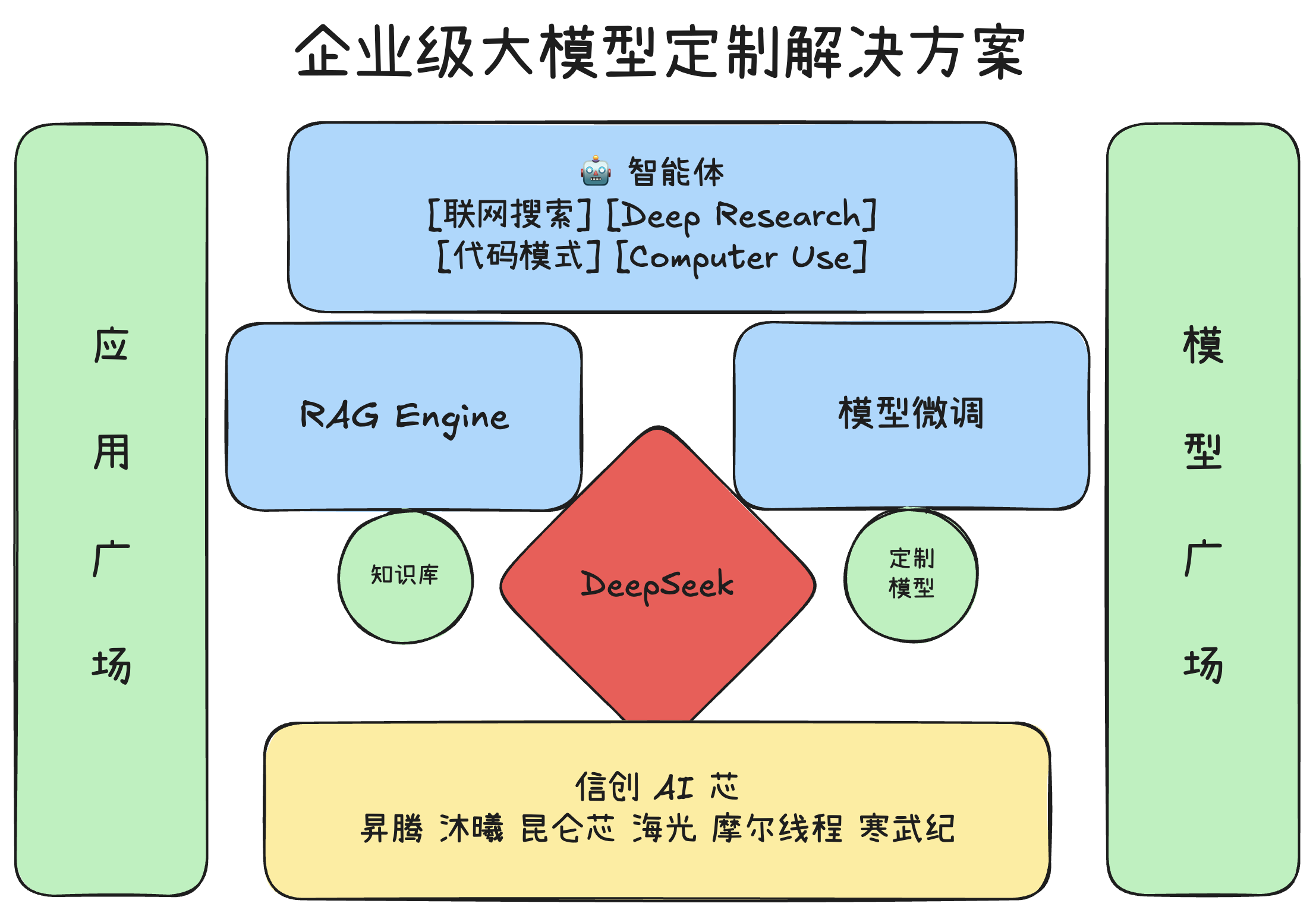
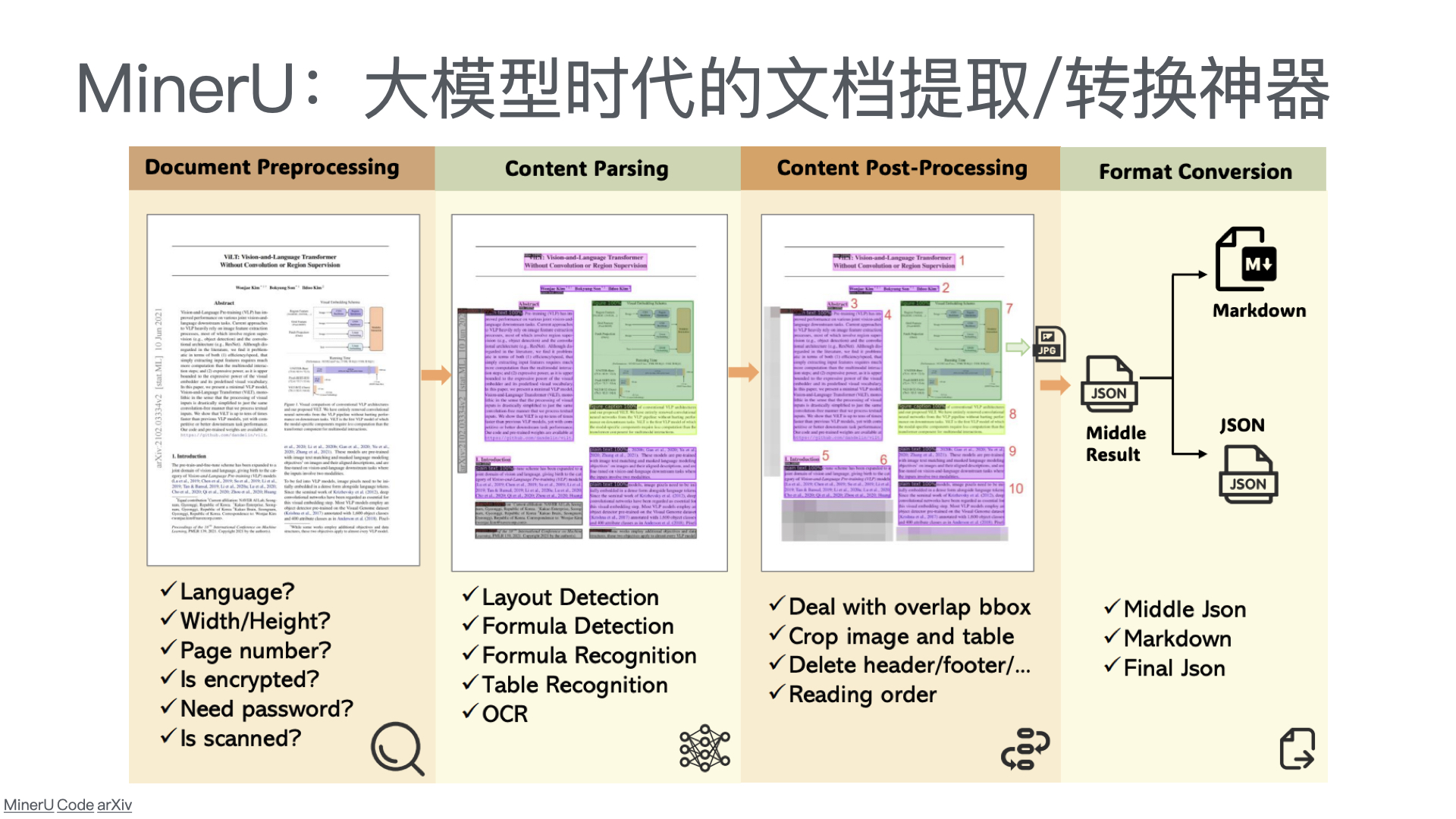
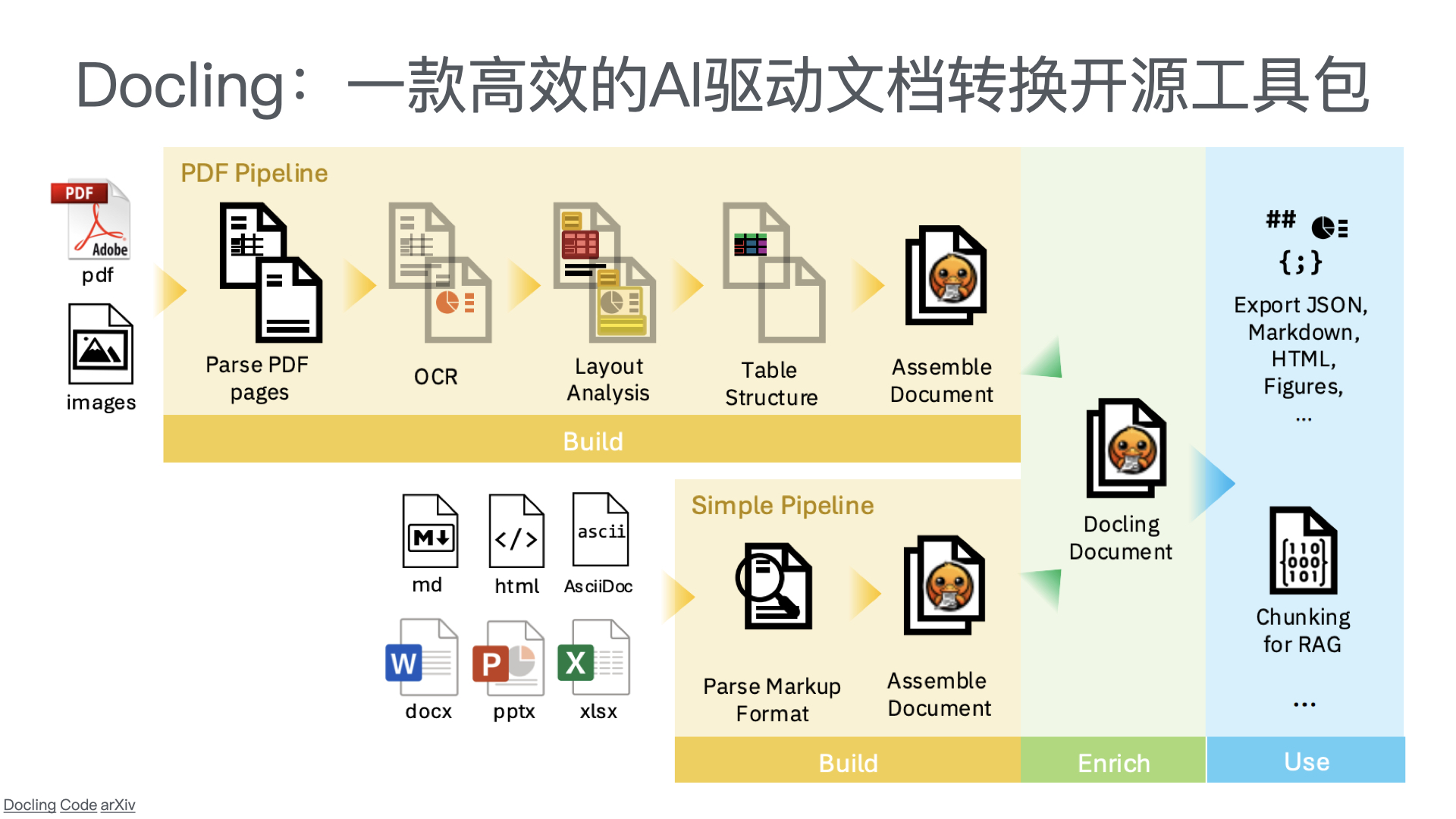
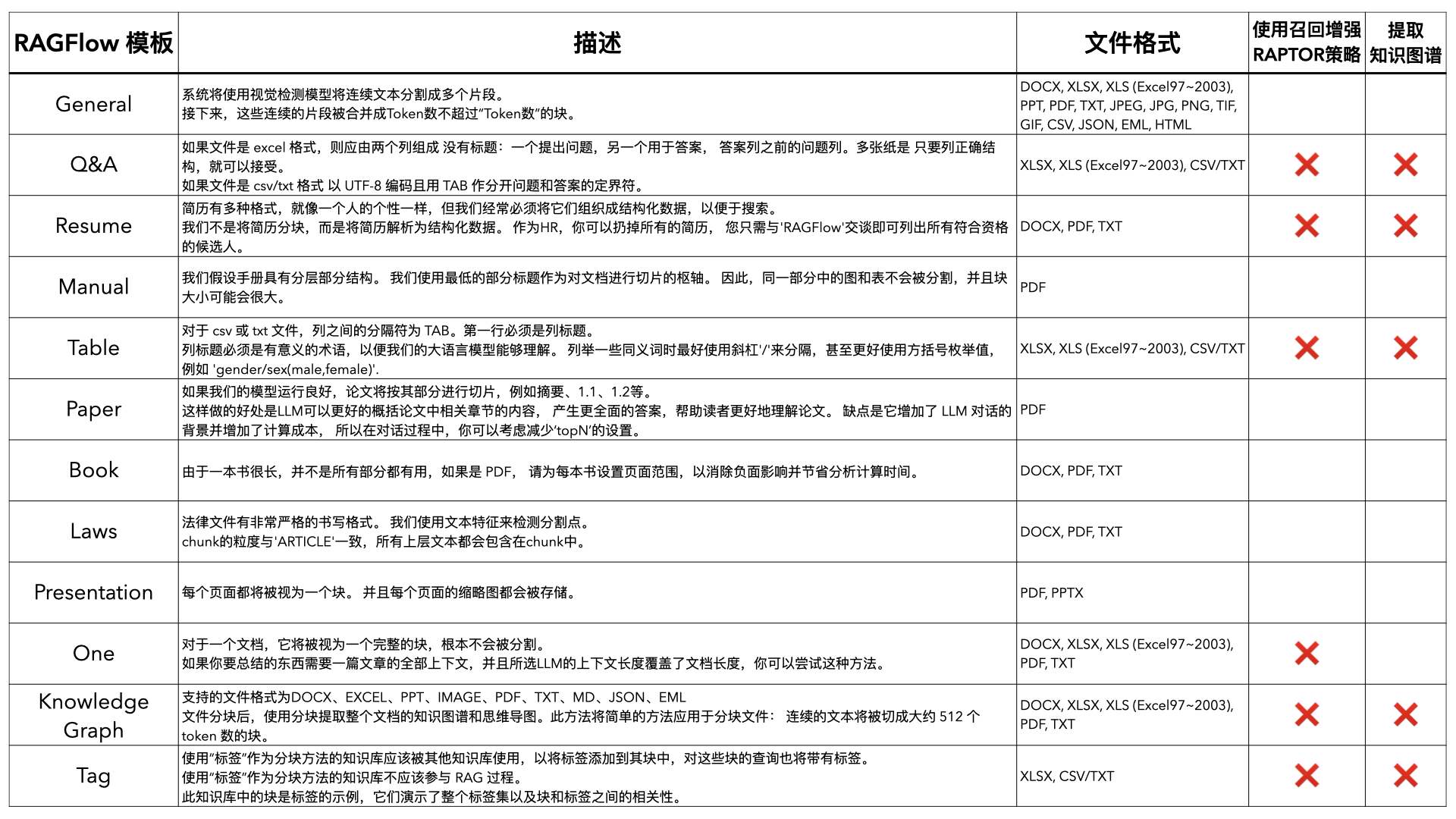
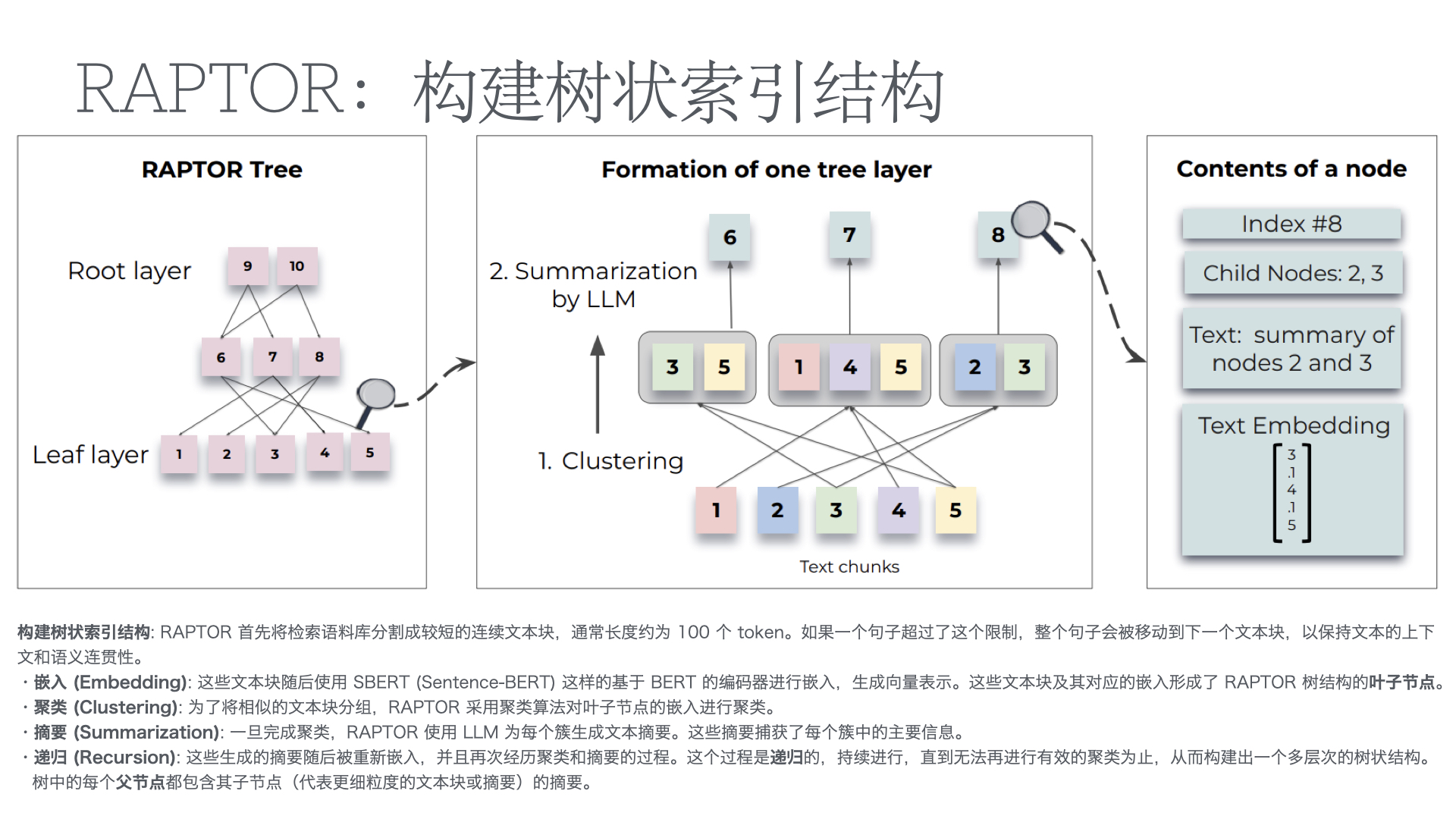
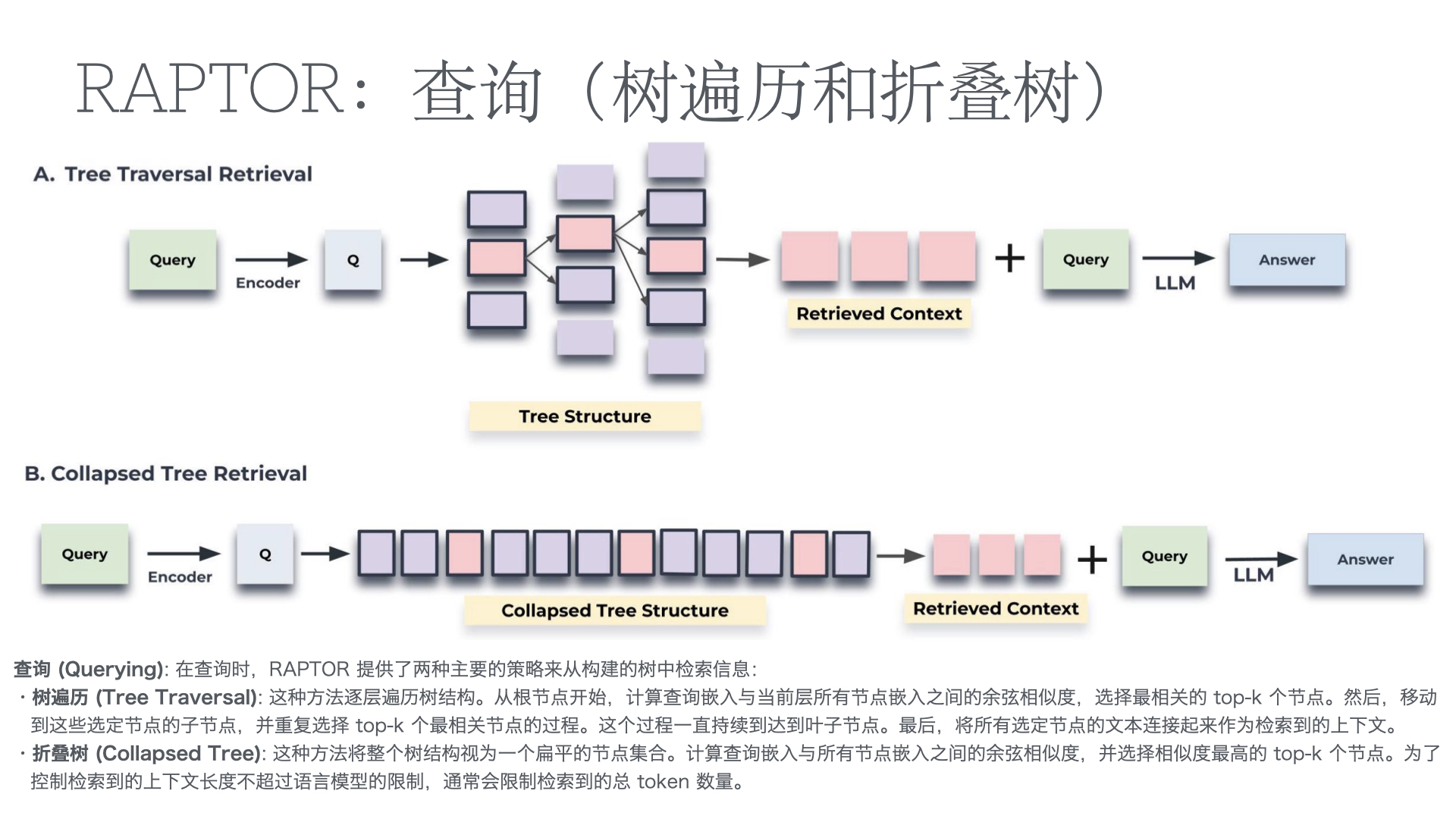
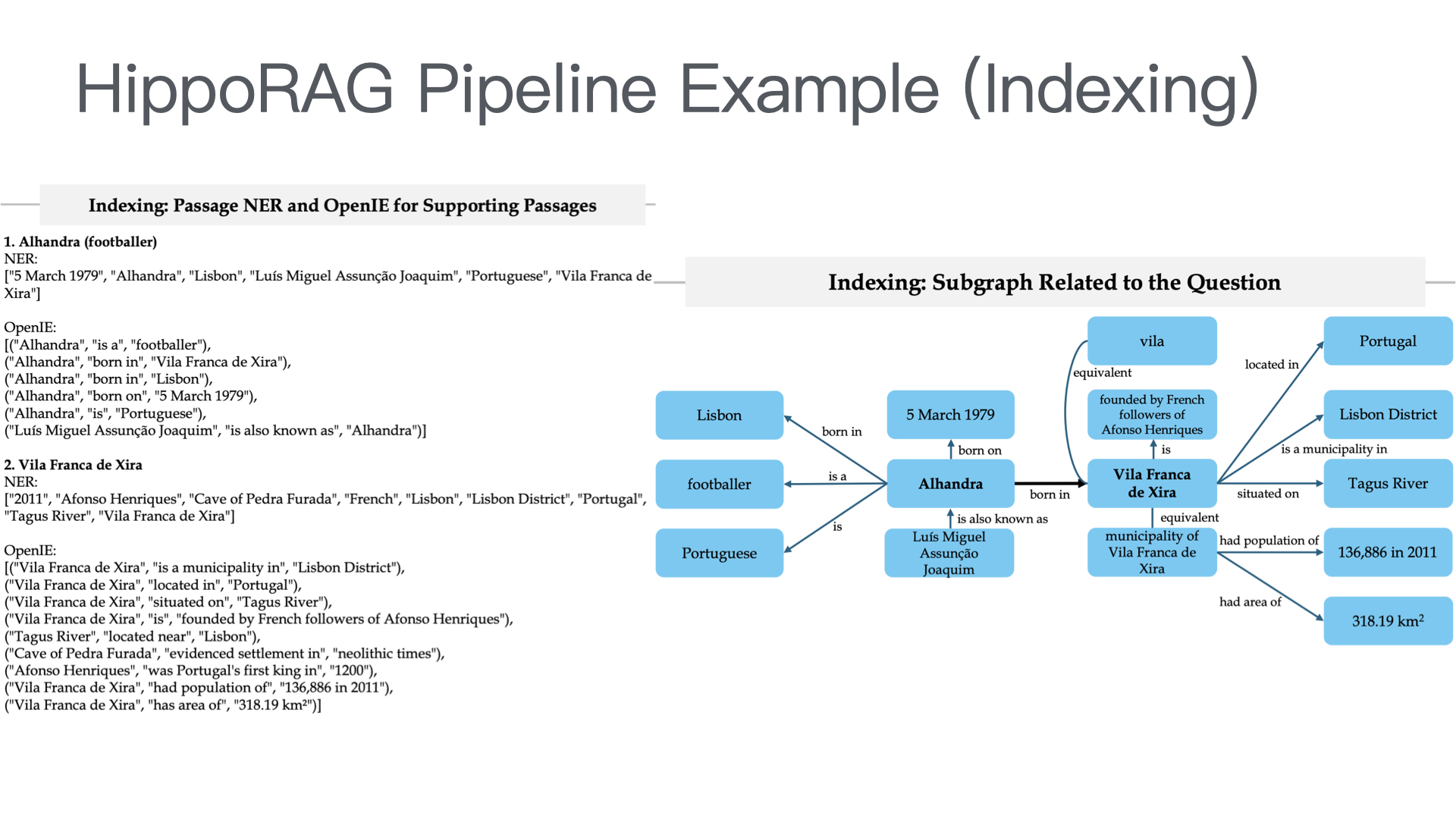
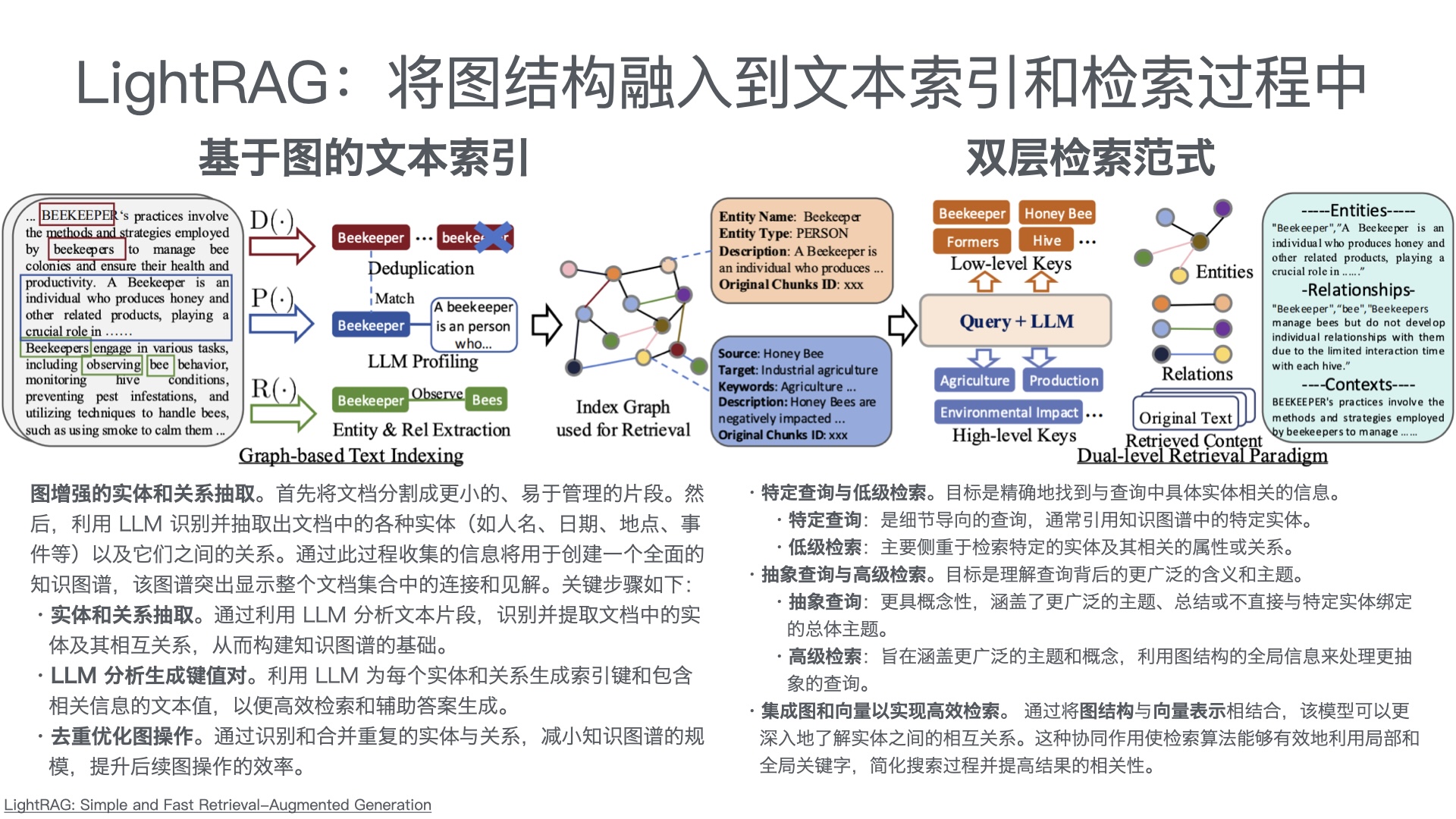
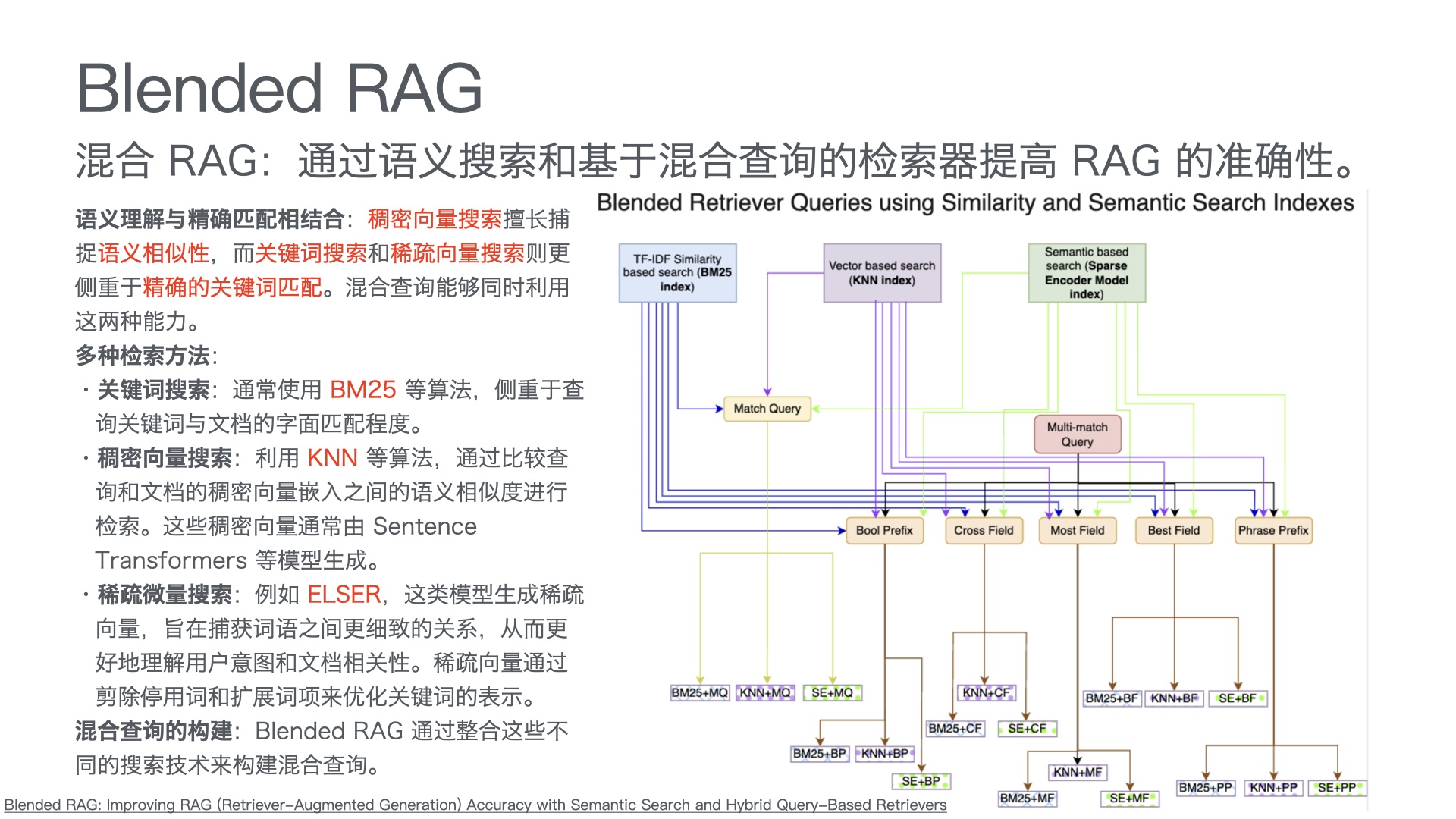
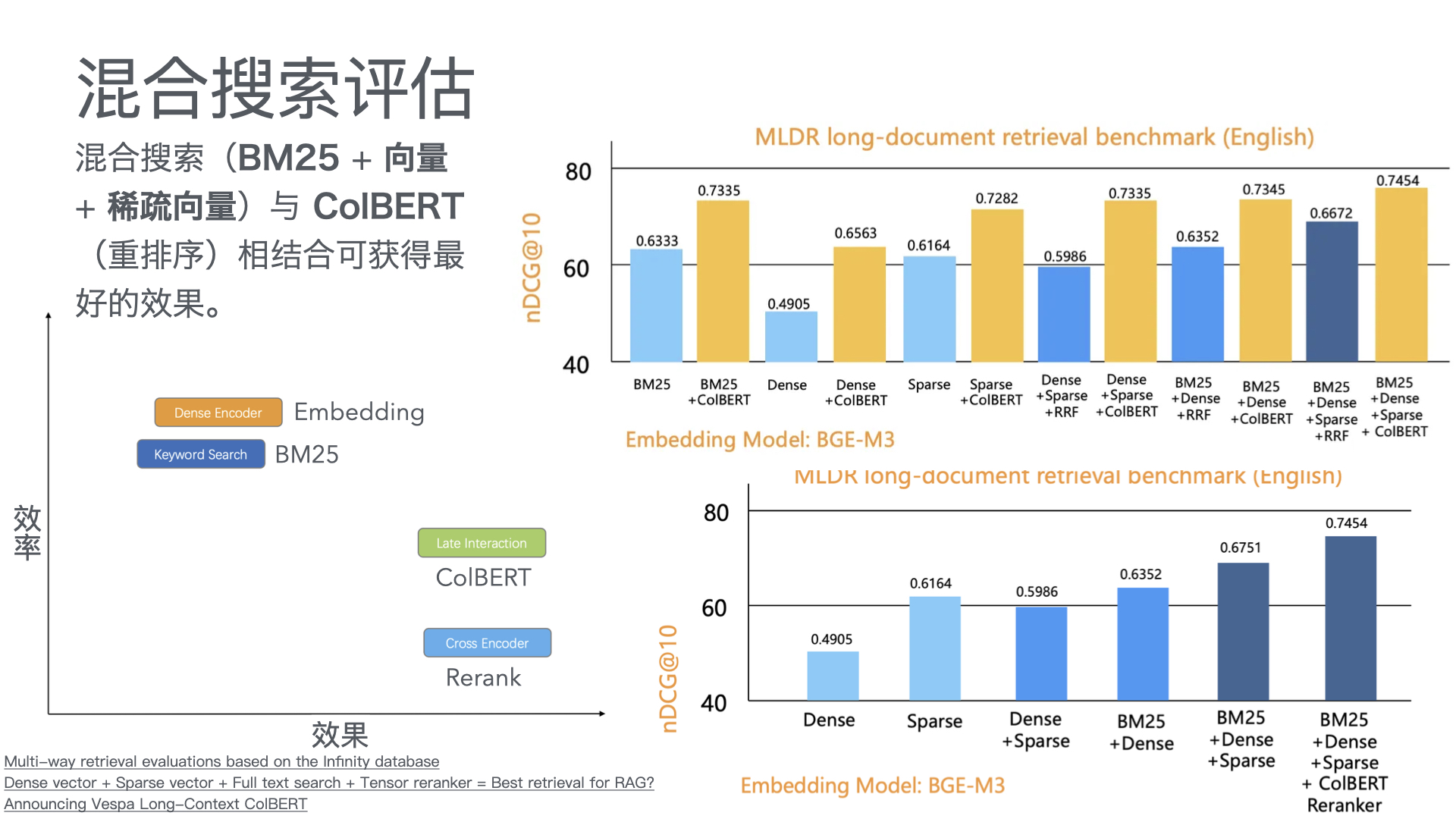
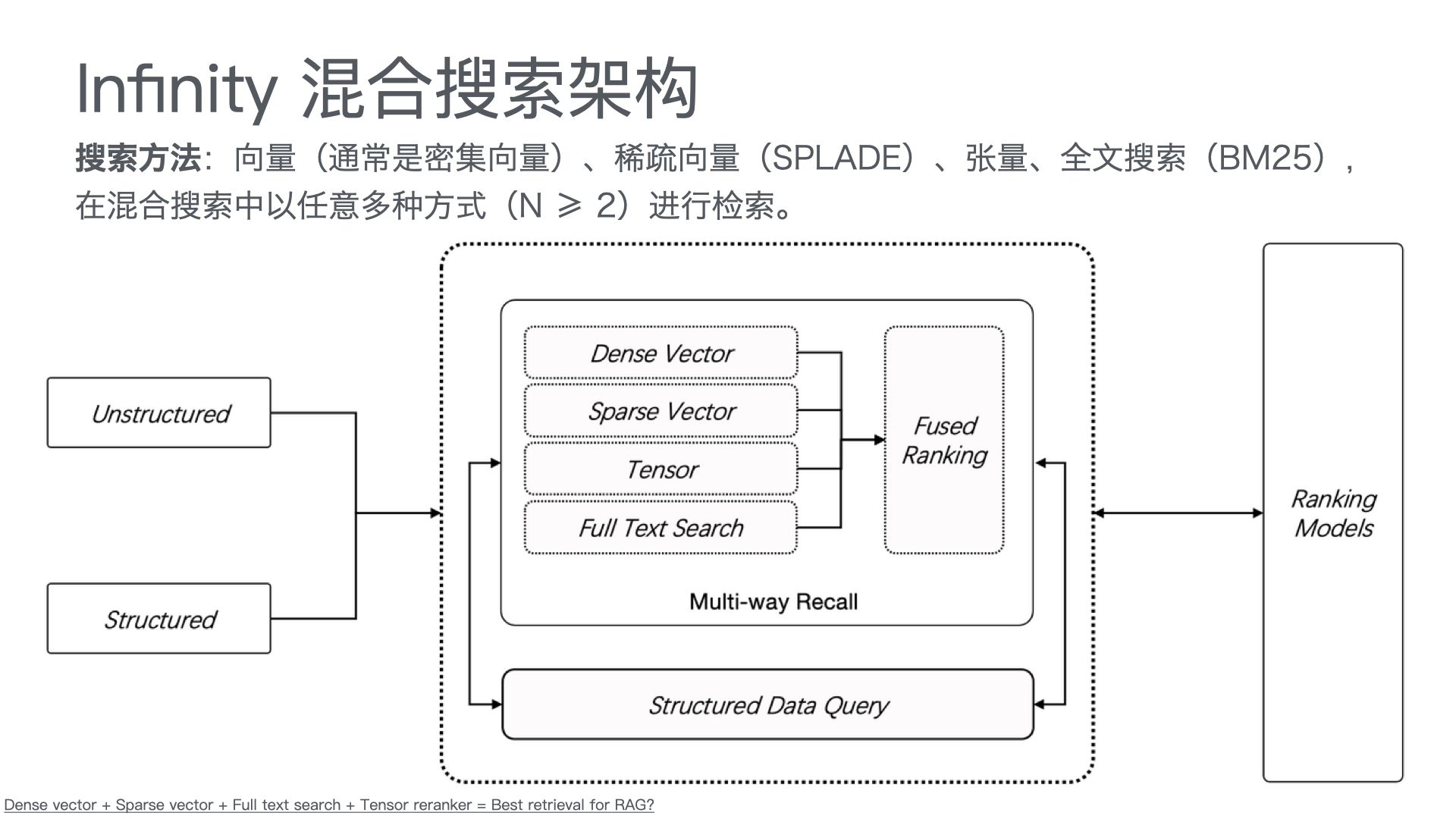
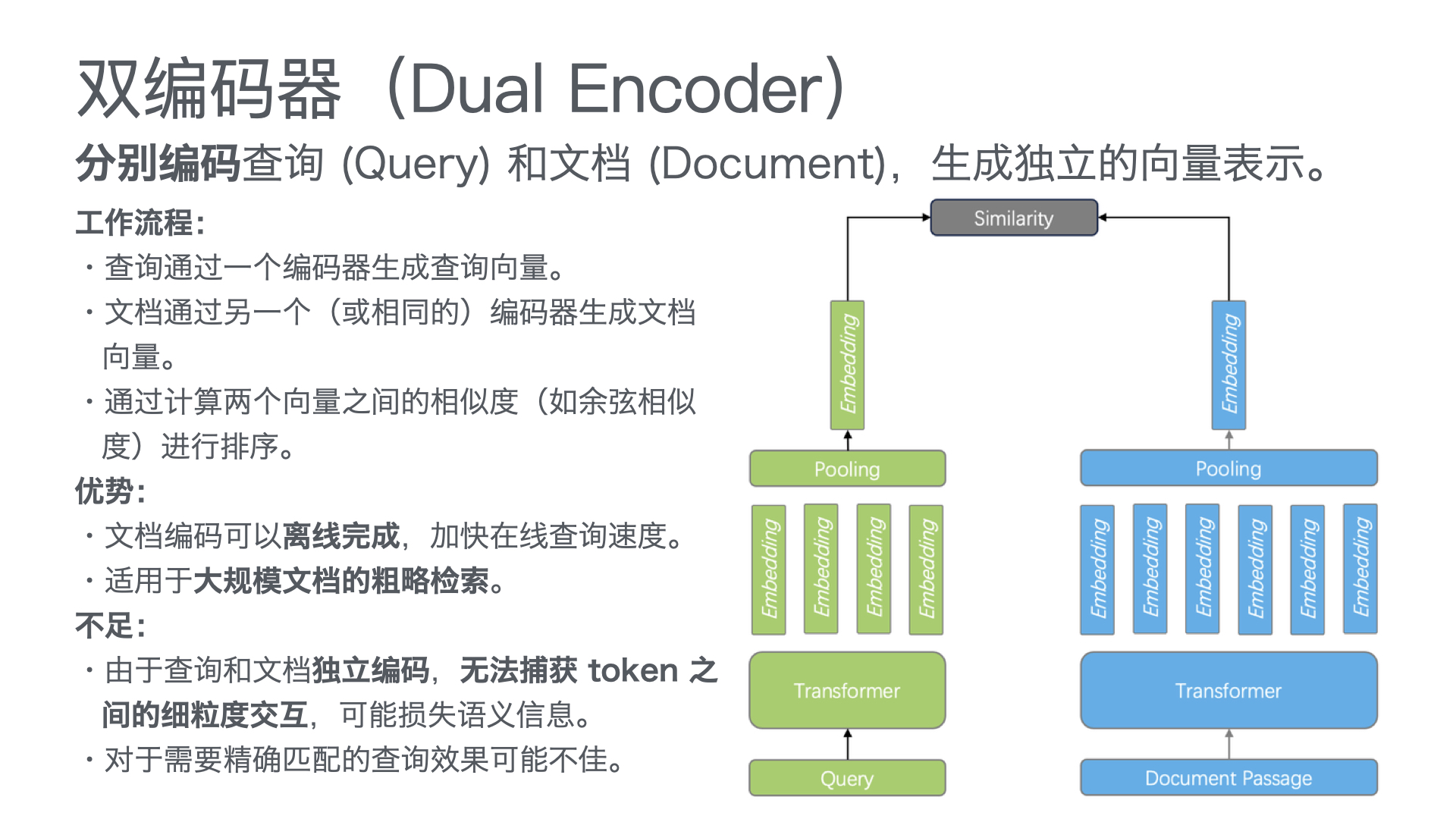
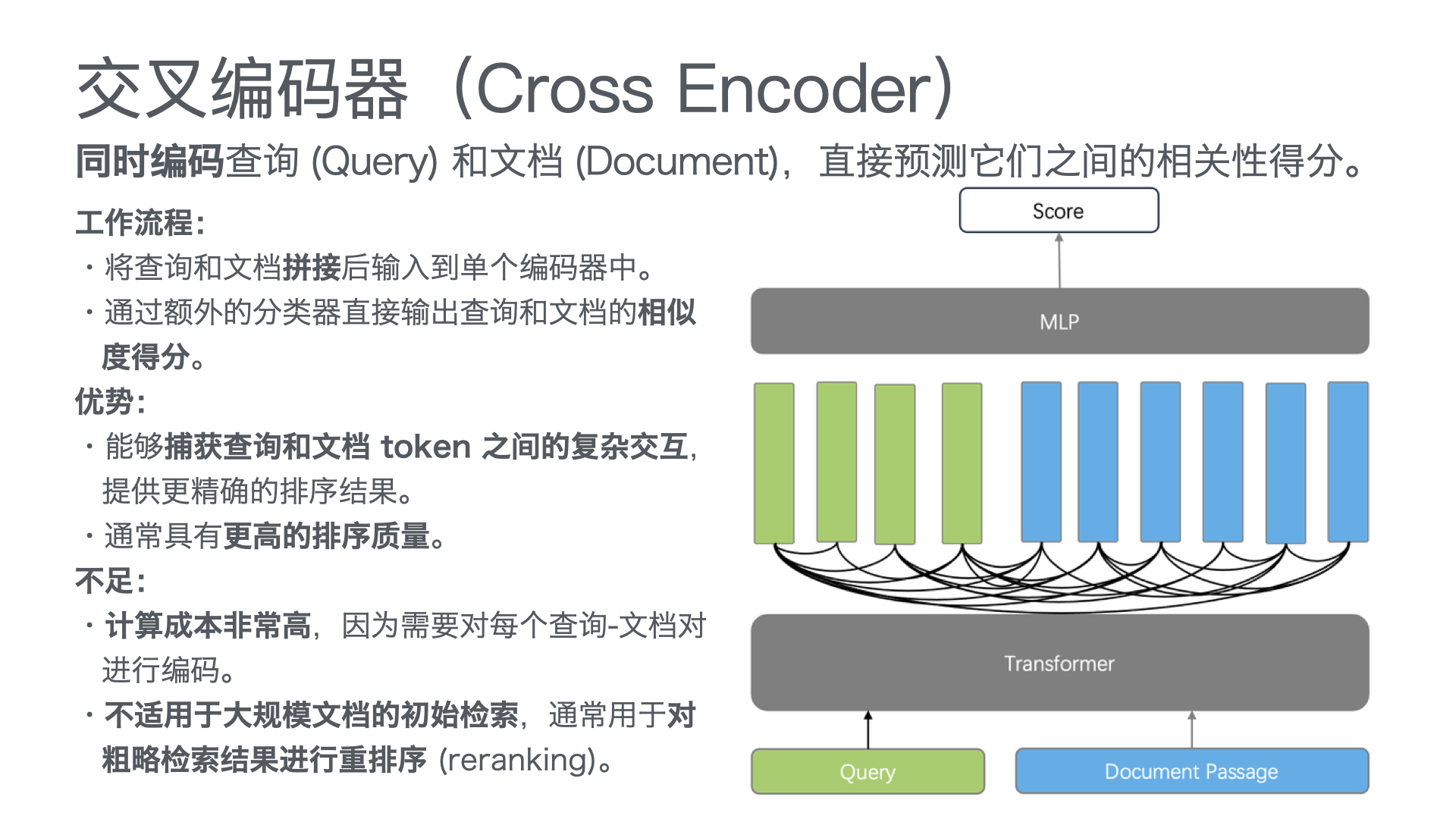
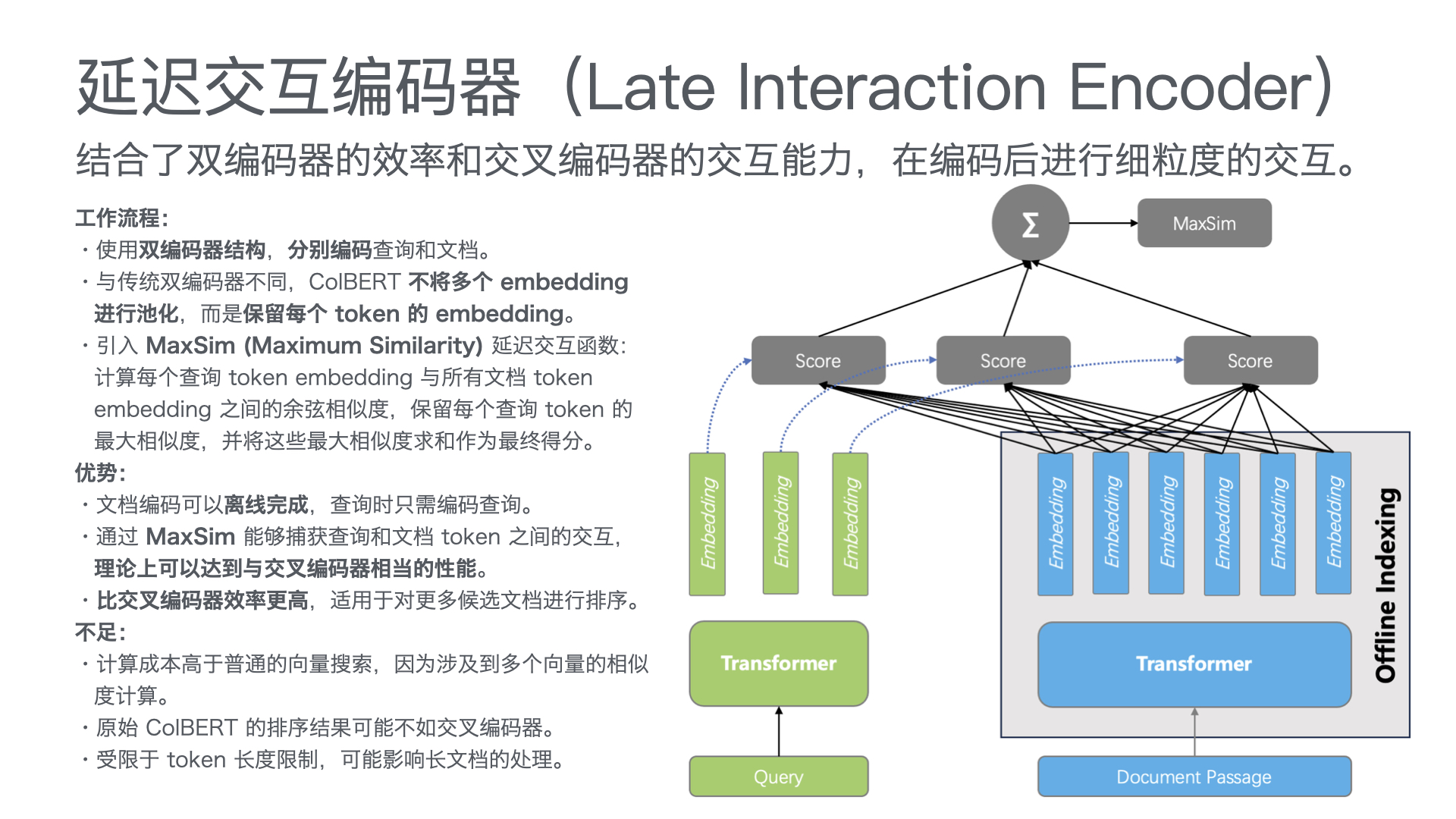
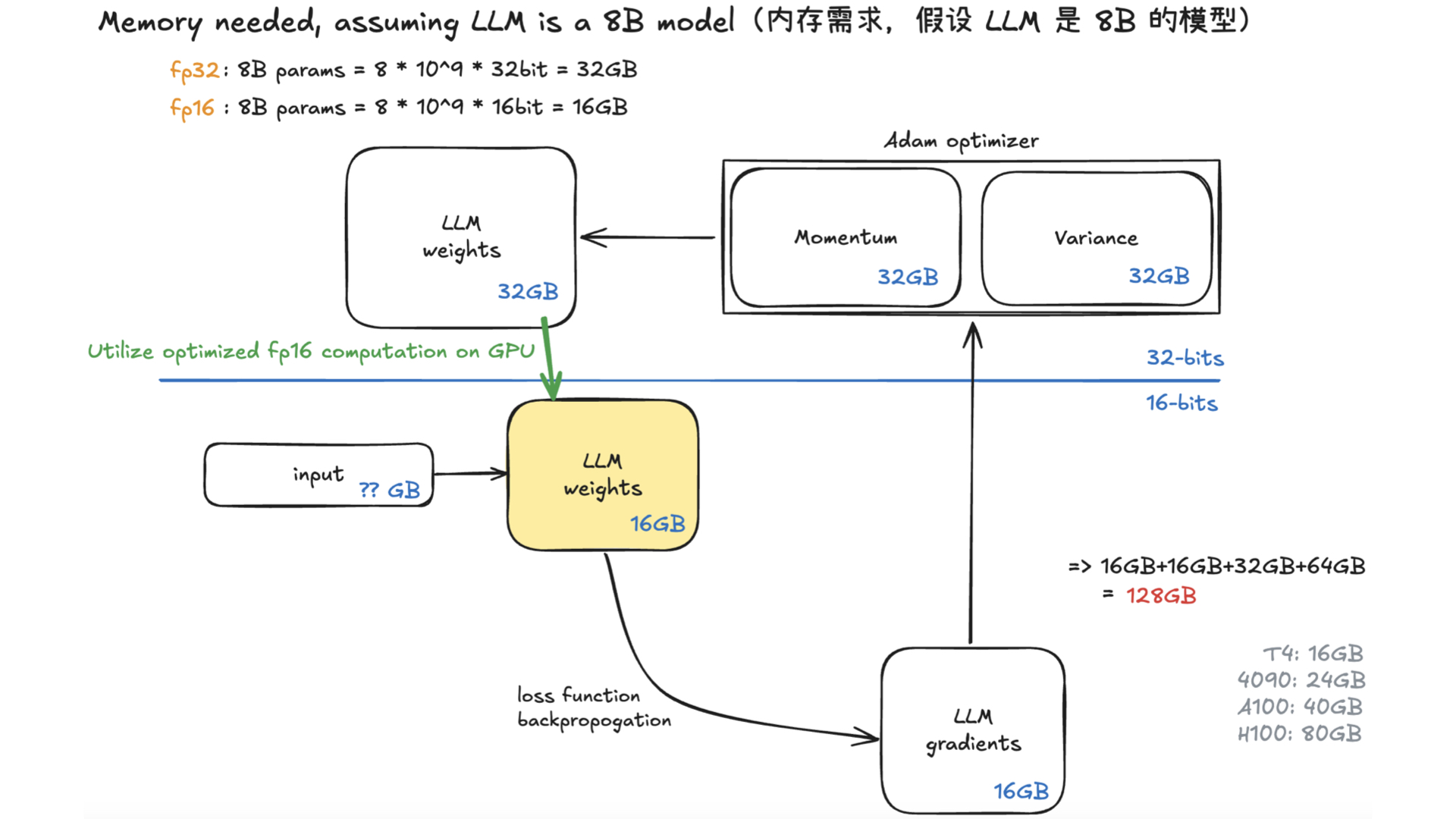
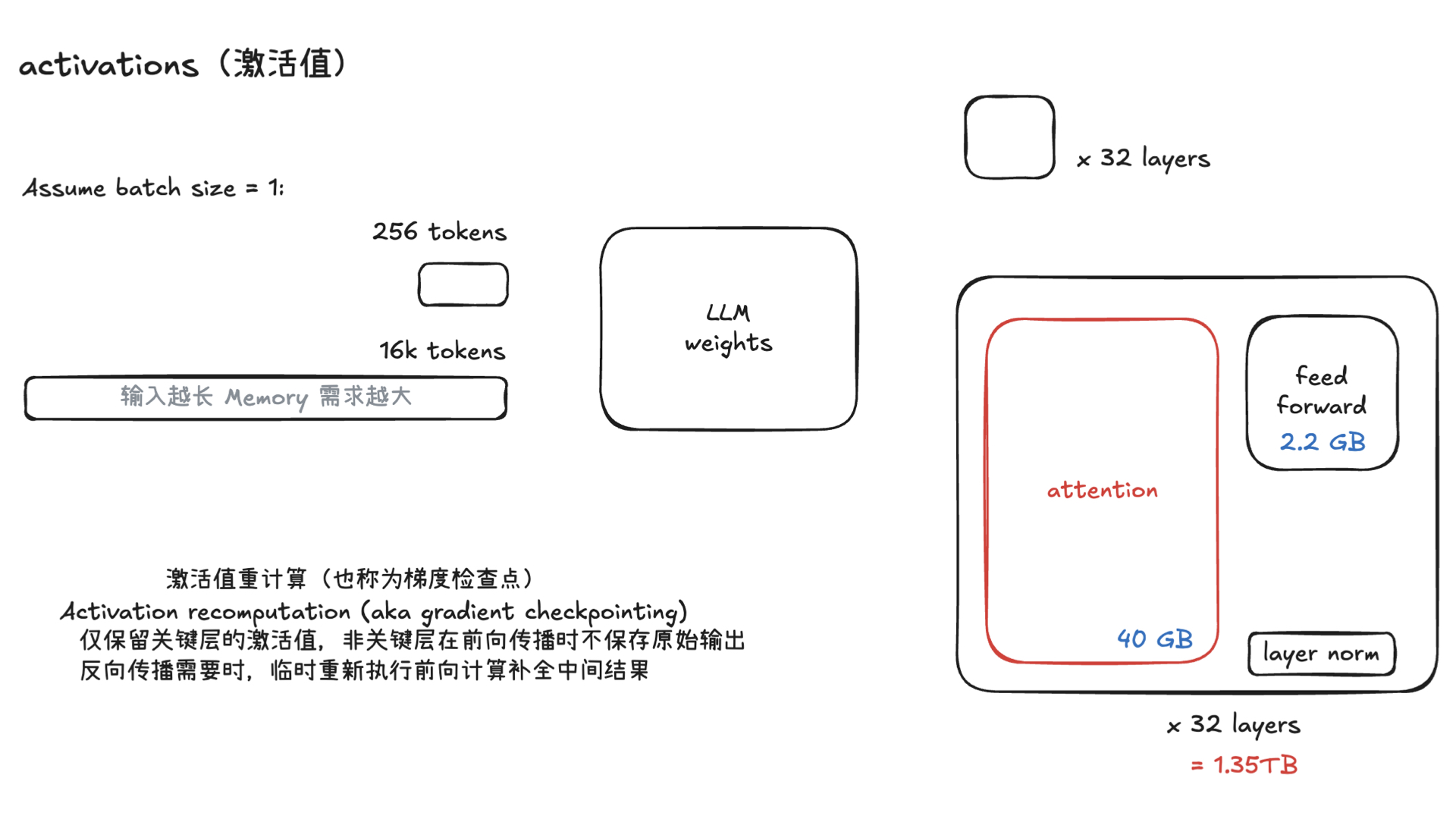
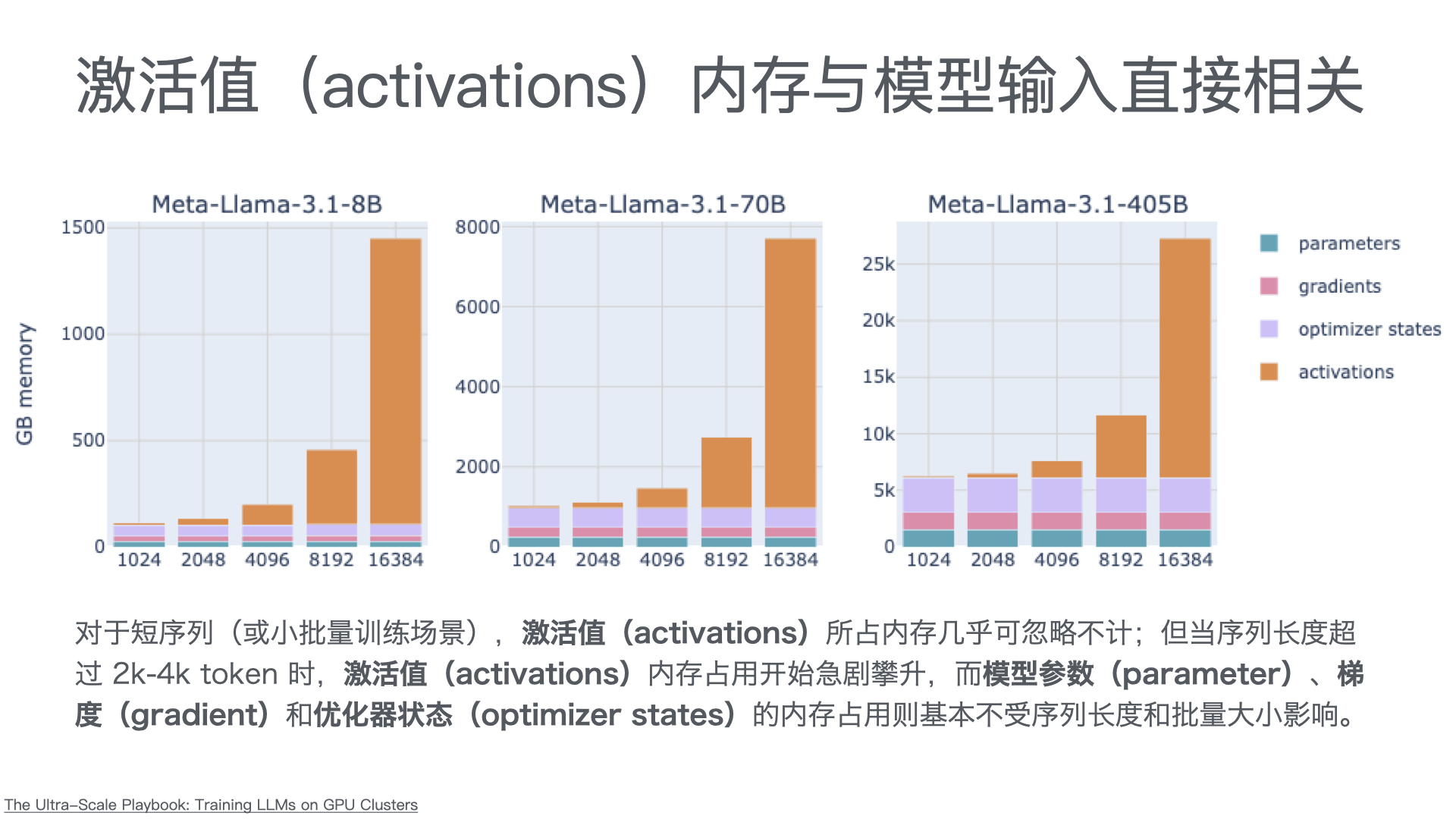
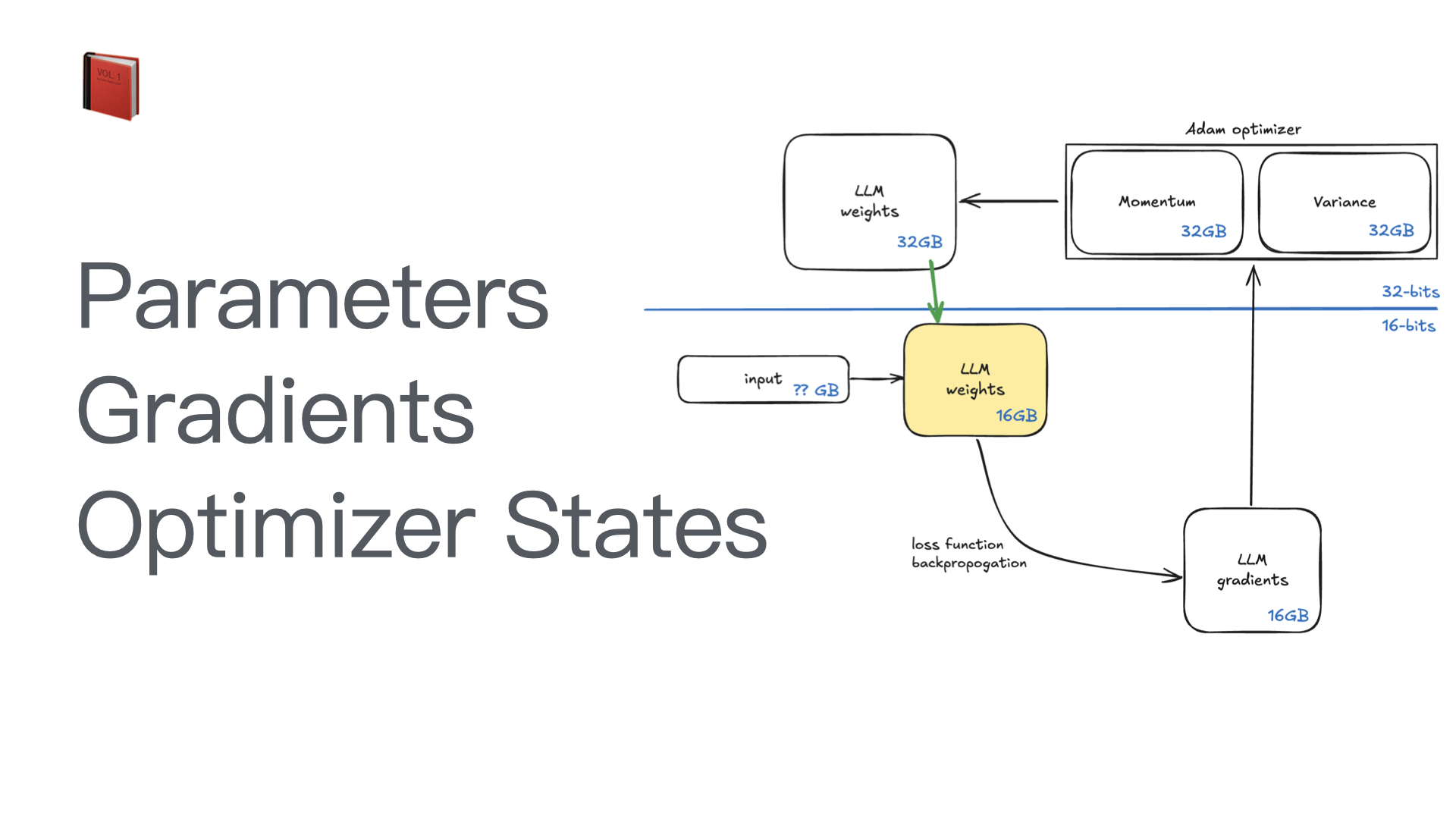
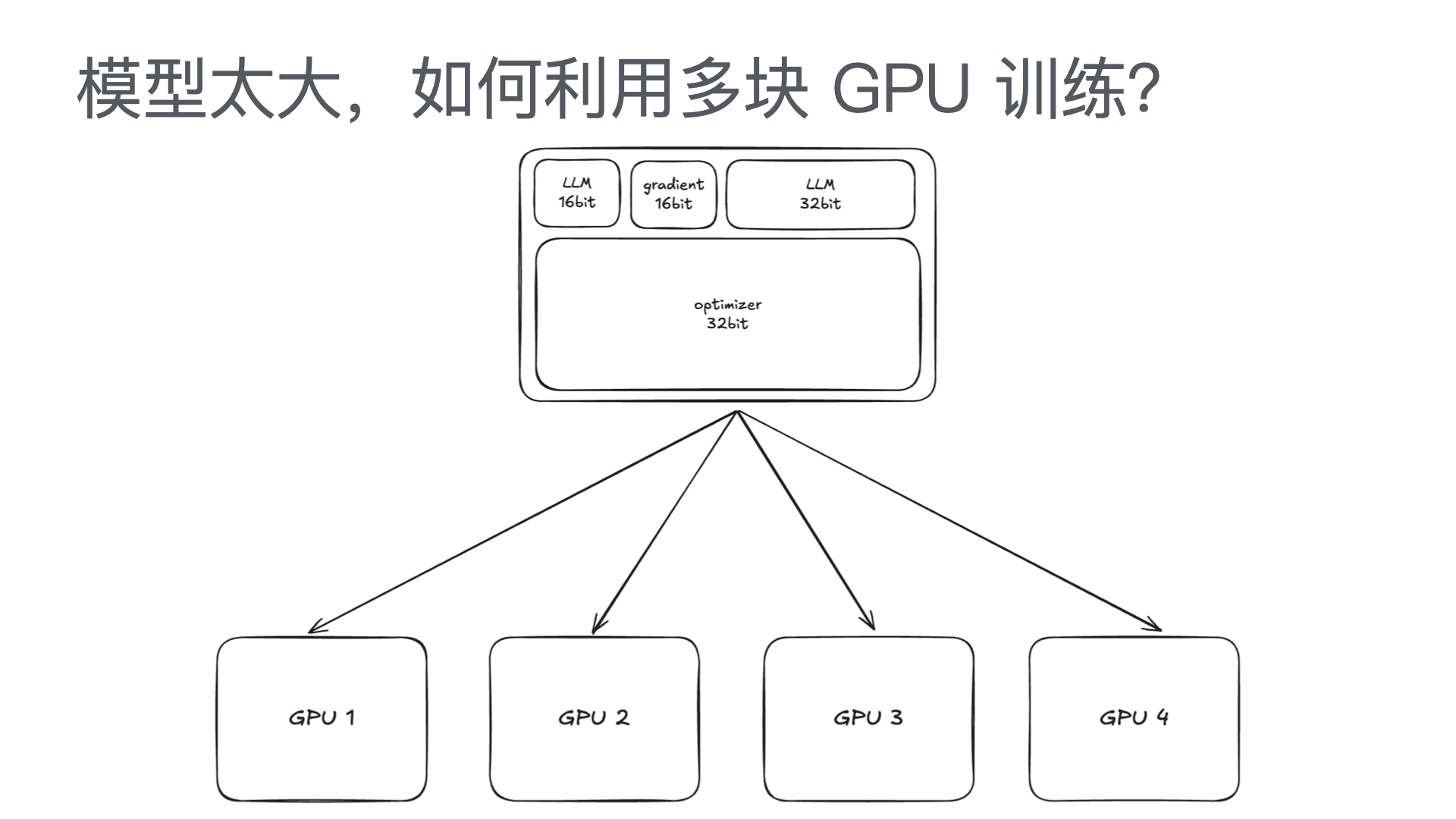
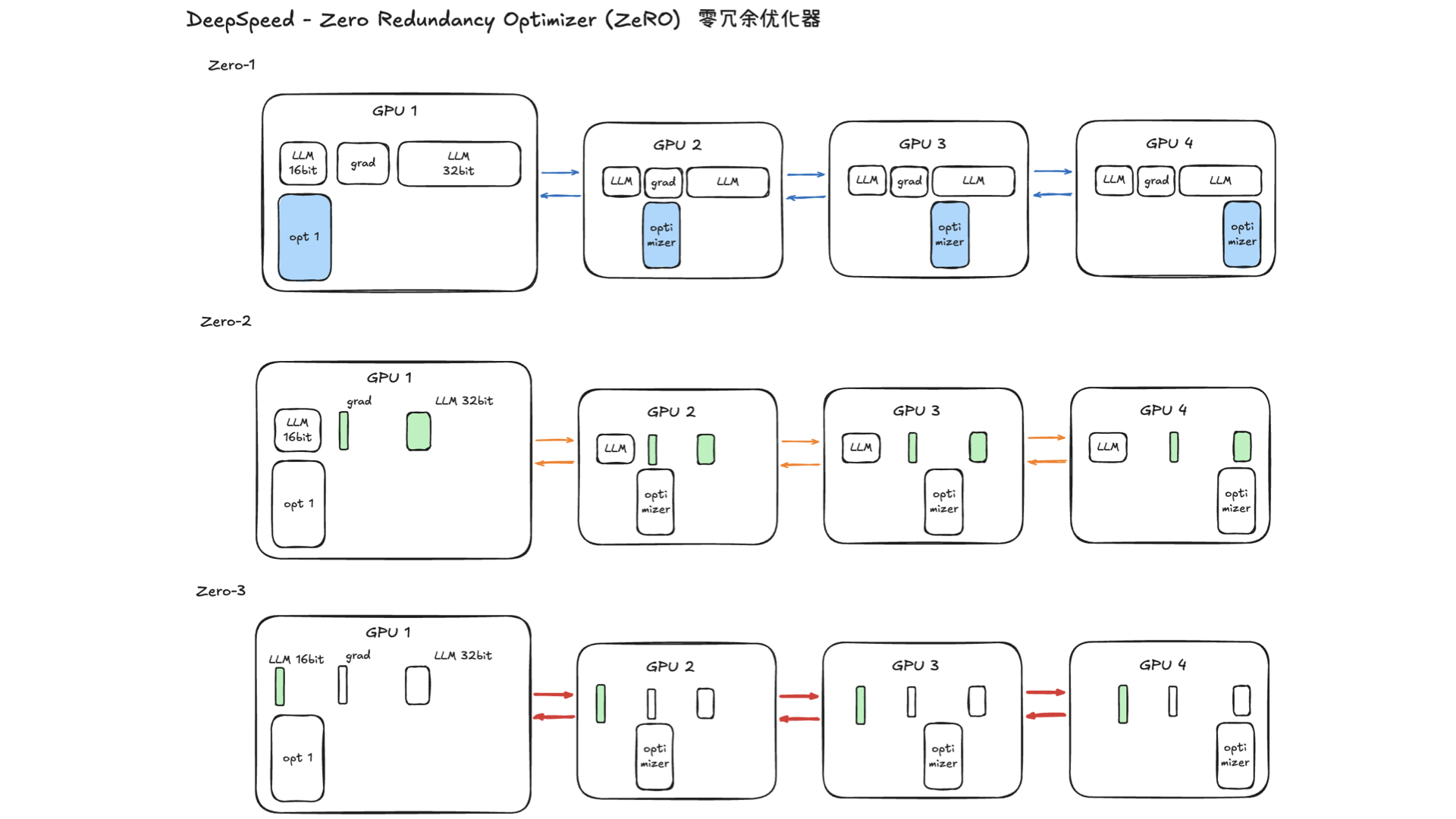
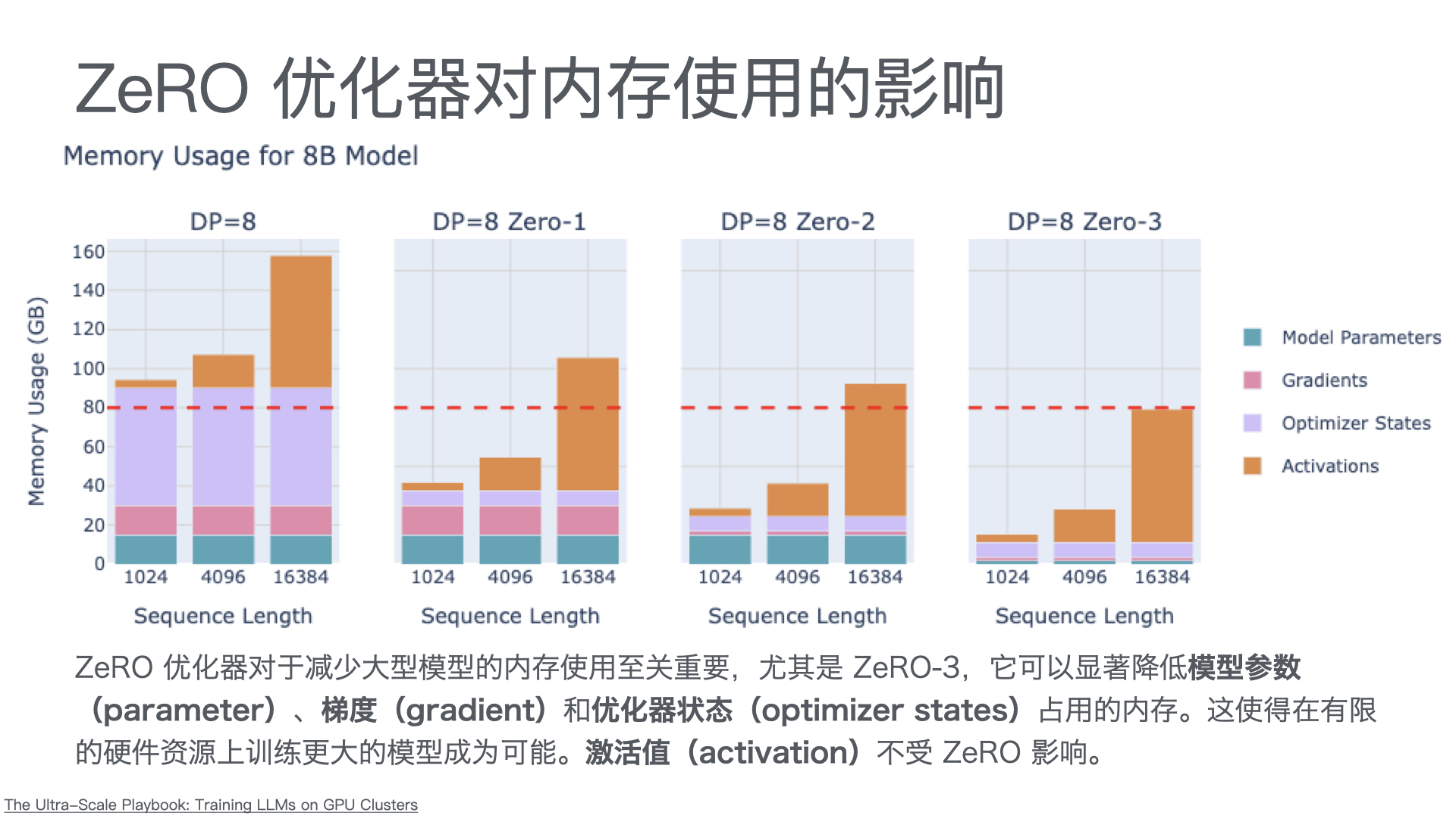
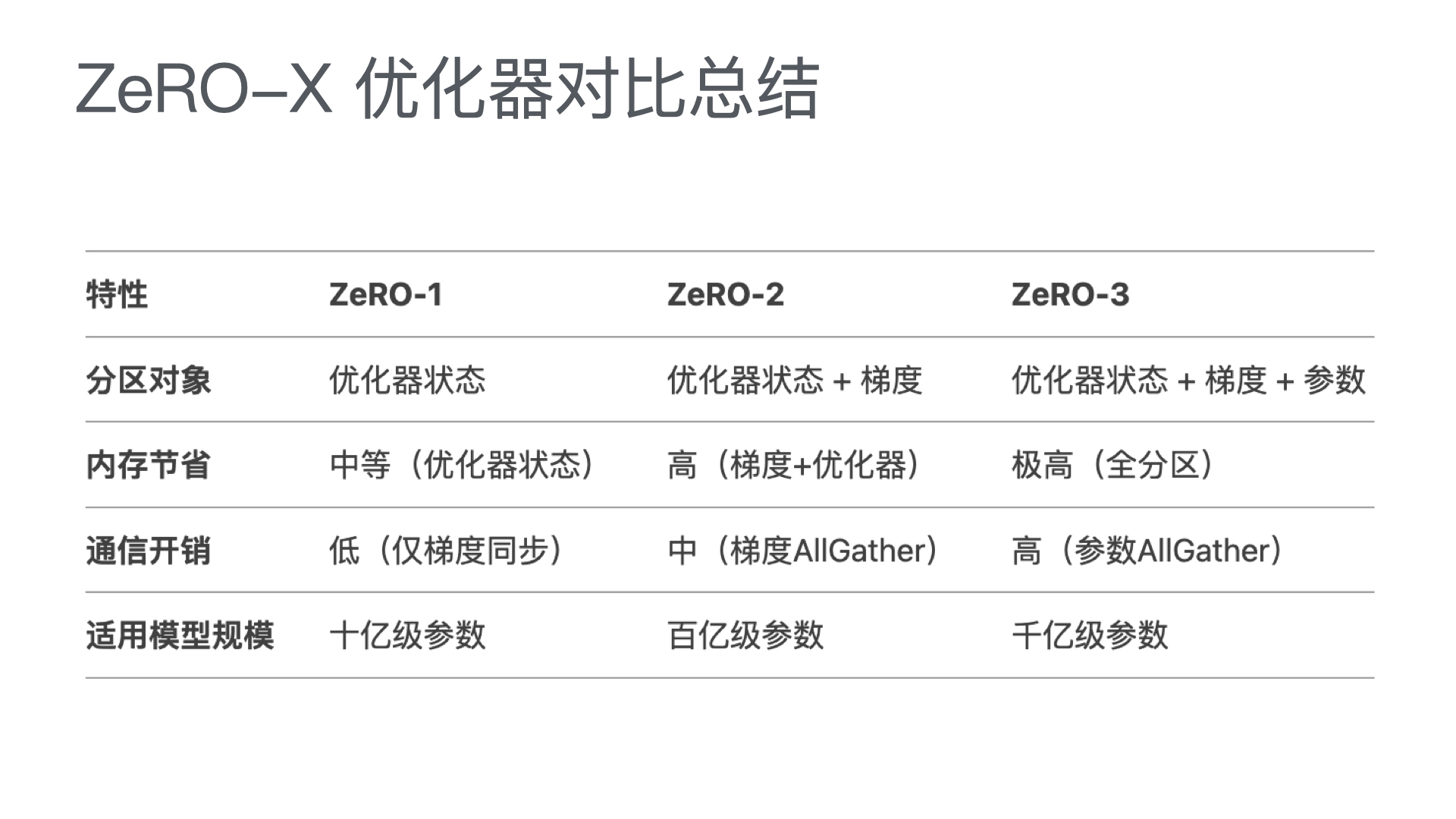
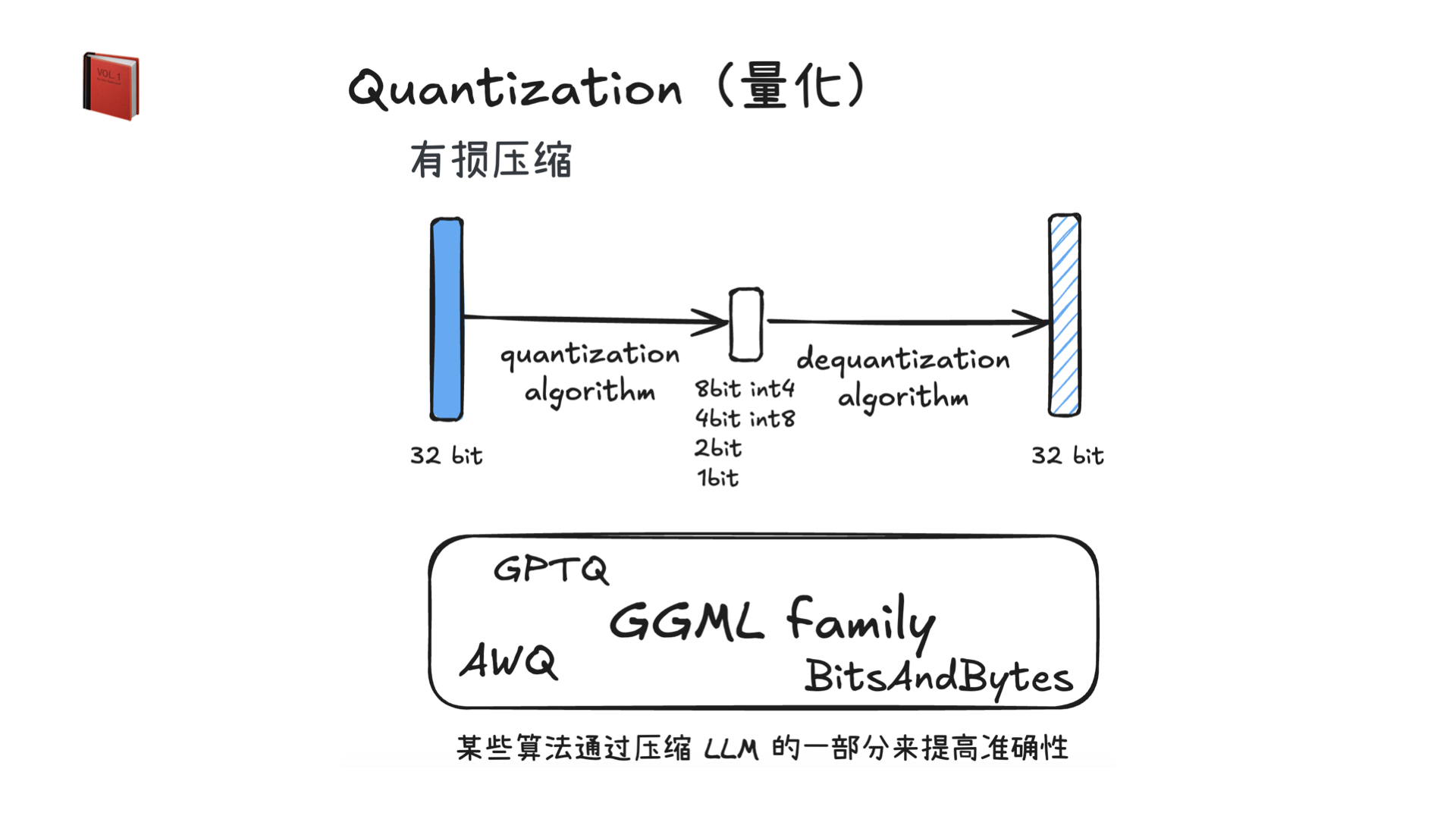
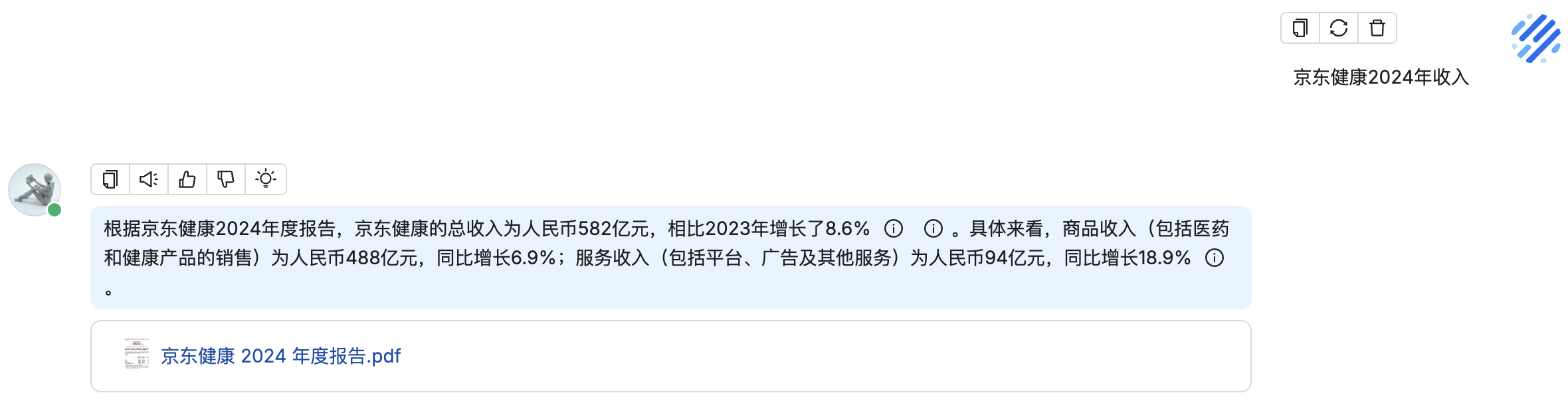
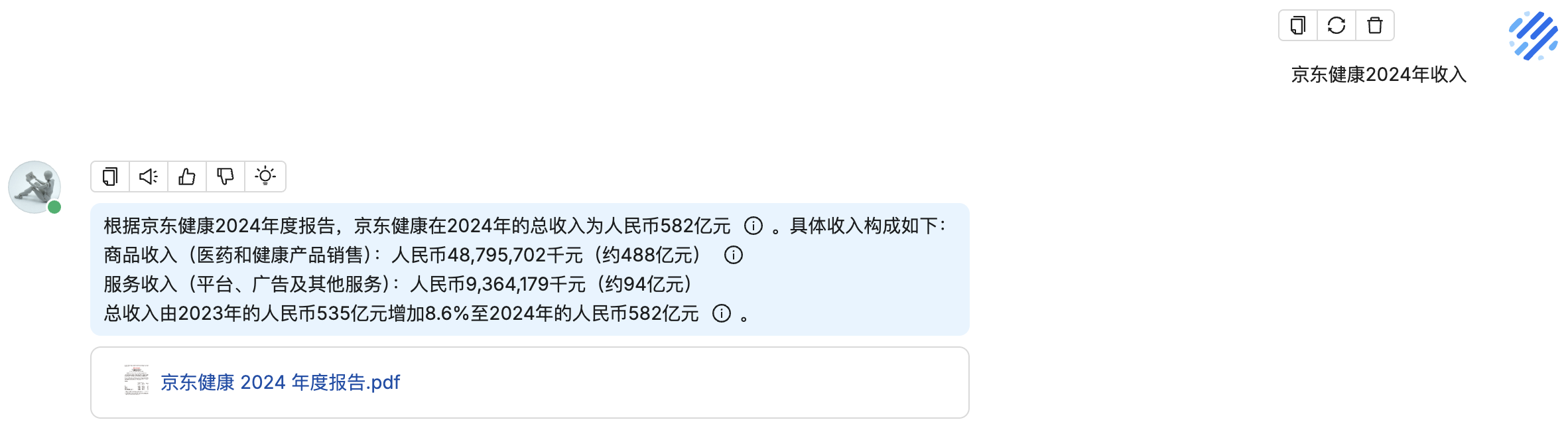
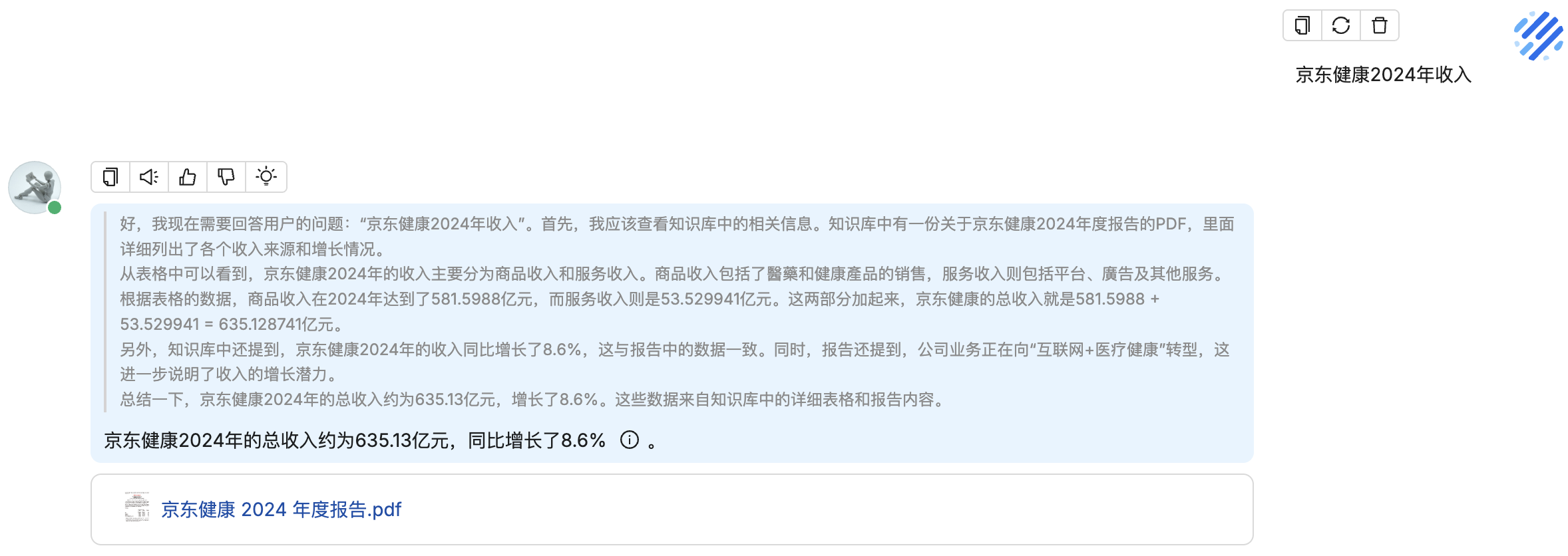
利用多张 GPU 训练大语言模型


本页概述了支持模型上下文协议(Model Context Protocol, MCP)的应用程序。每个客户端可能支持不同的MCP功能,从而实现与MCP服务器的不同级别的集成。
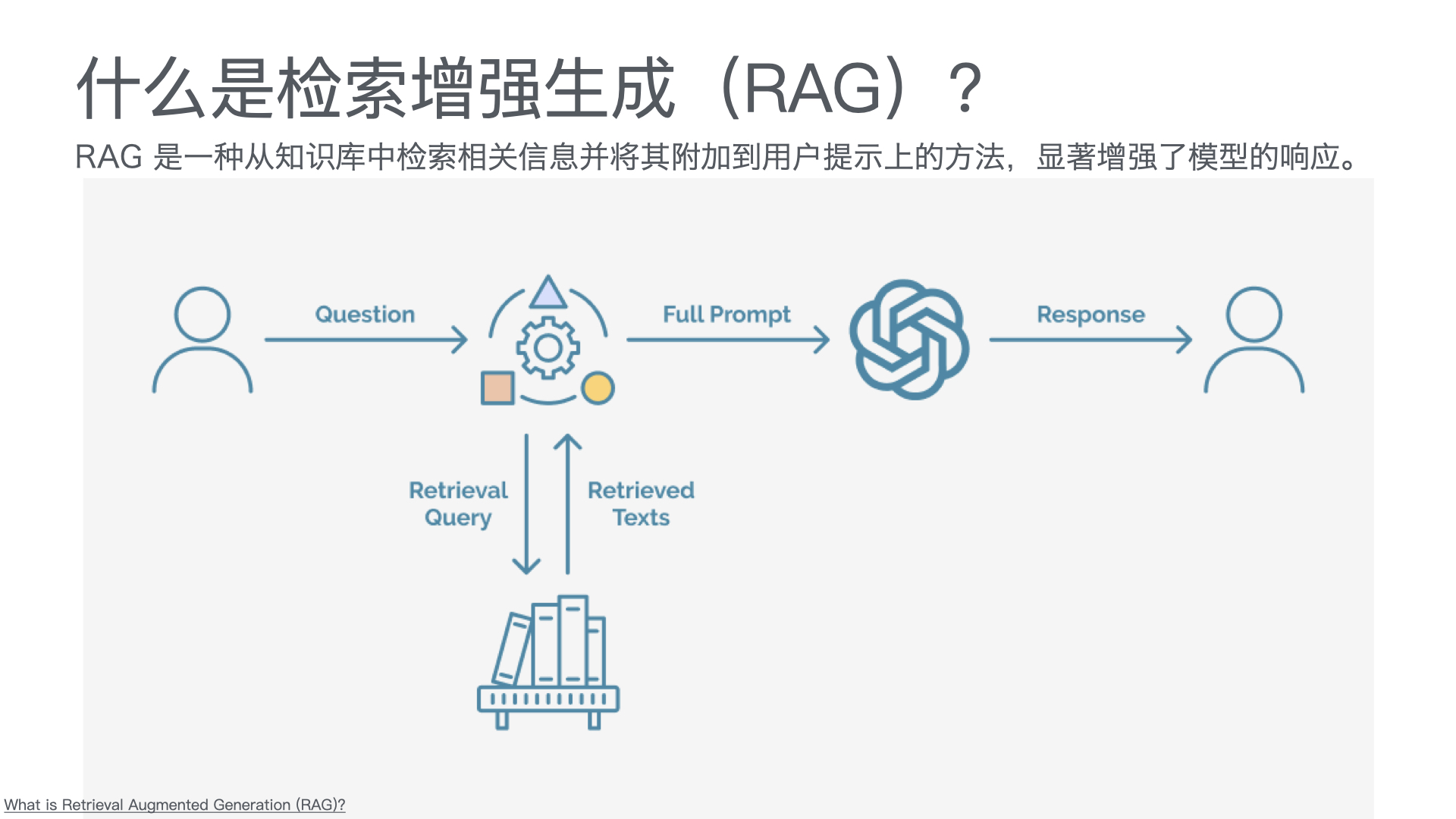
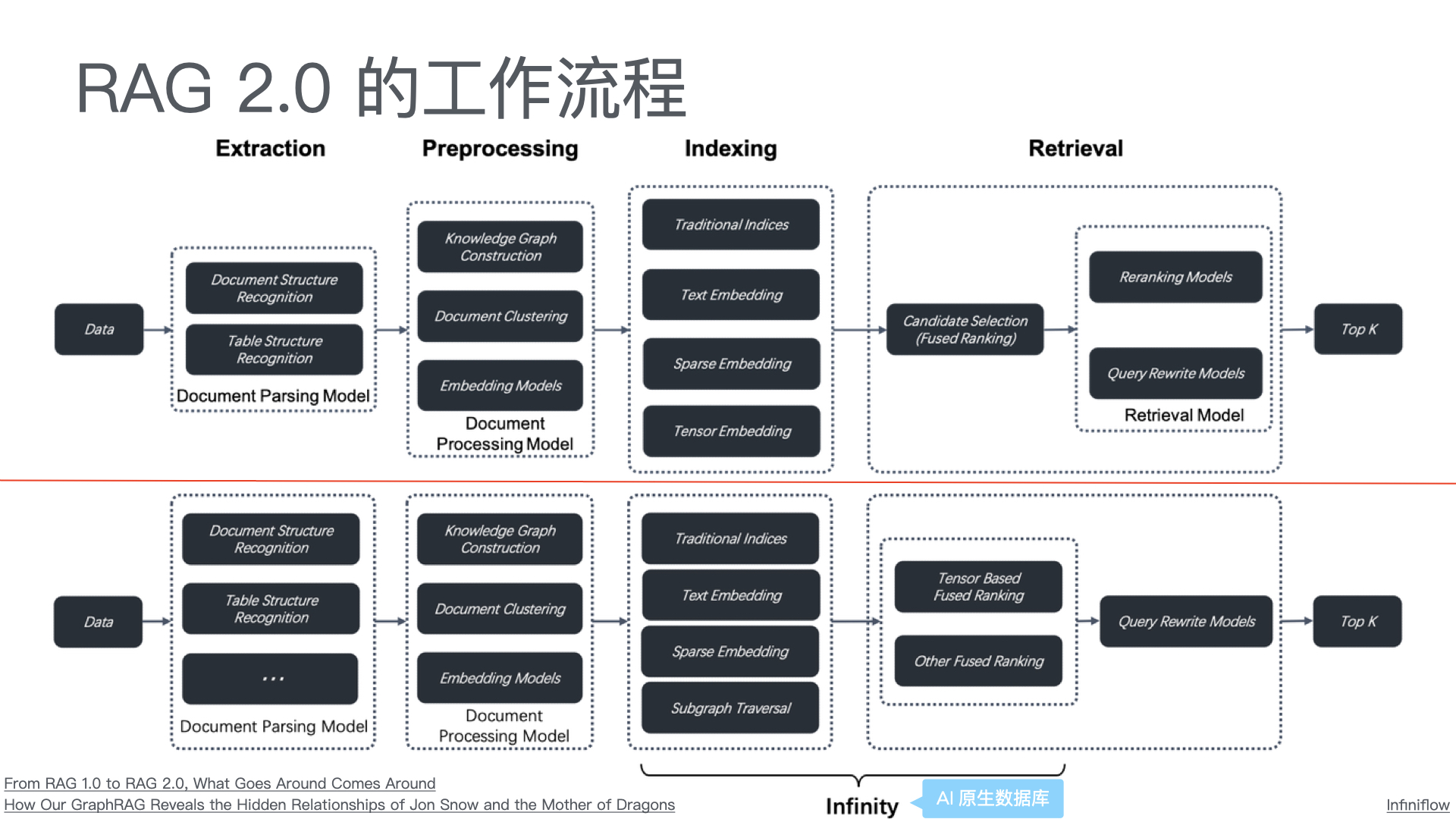
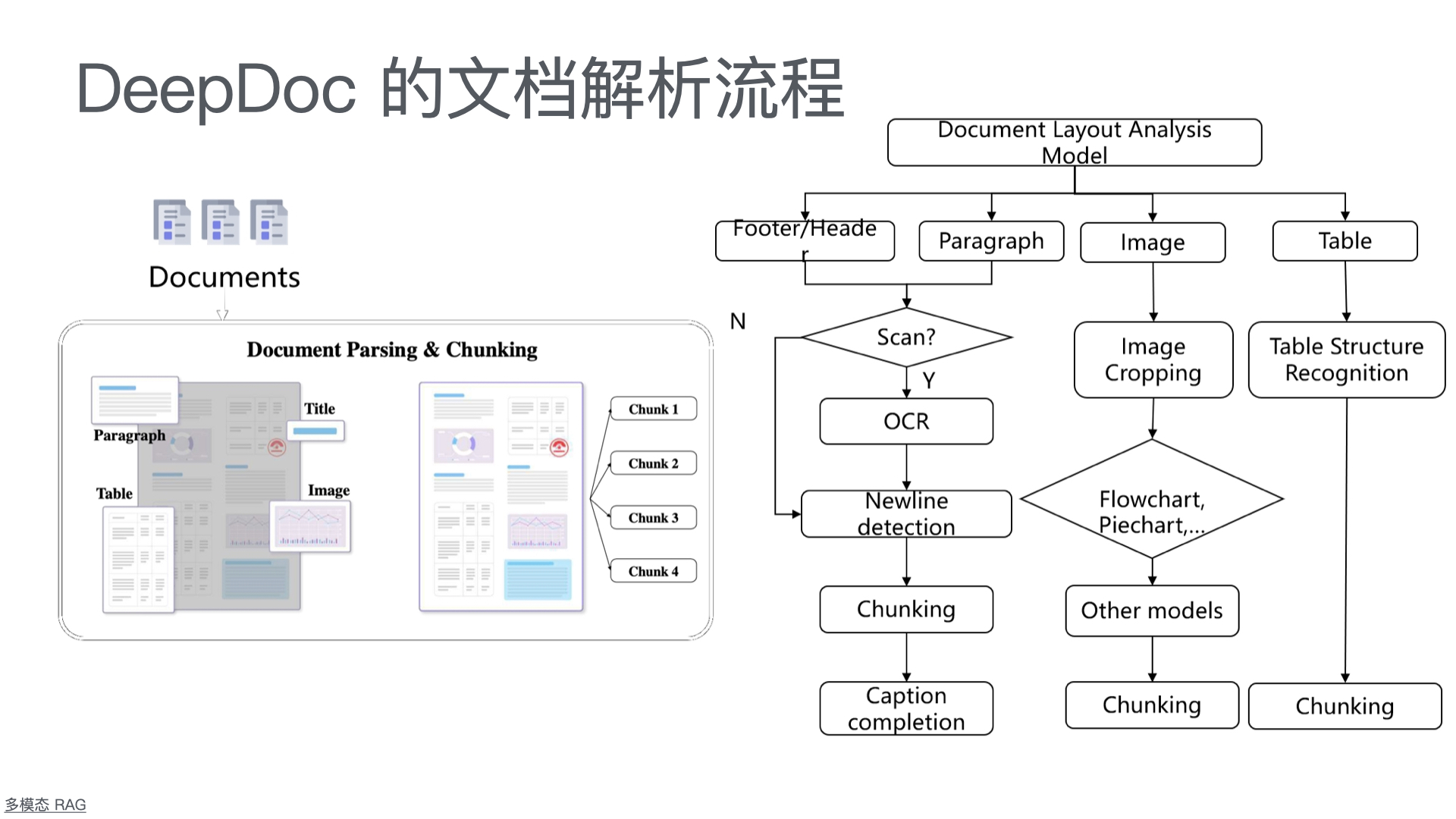
本页展示了各种模型上下文协议(MCP)服务器,这些服务器展示了该协议的功能和多样性。这些服务器使大型语言模型(LLM)能够安全地访问工具和数据源。
这些官方参考服务器展示了核心 MCP 功能和 SDK 用法:
这些 MCP 服务器由公司为其平台维护:
不断增长的社区开发服务器生态系统扩展了 MCP 的功能:
Docker - 管理容器、镜像、卷和网络 Kubernetes - 管理 pod
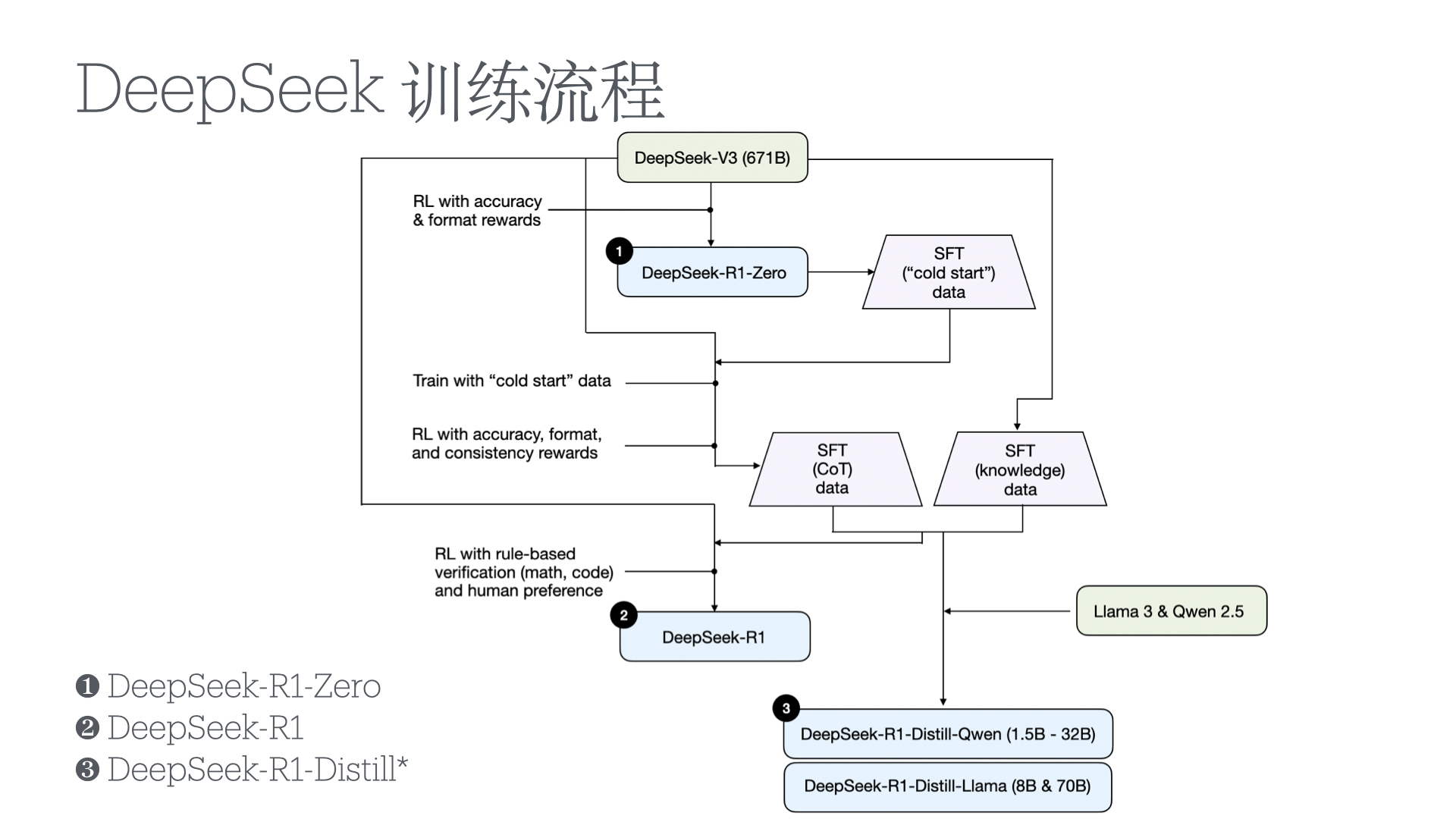
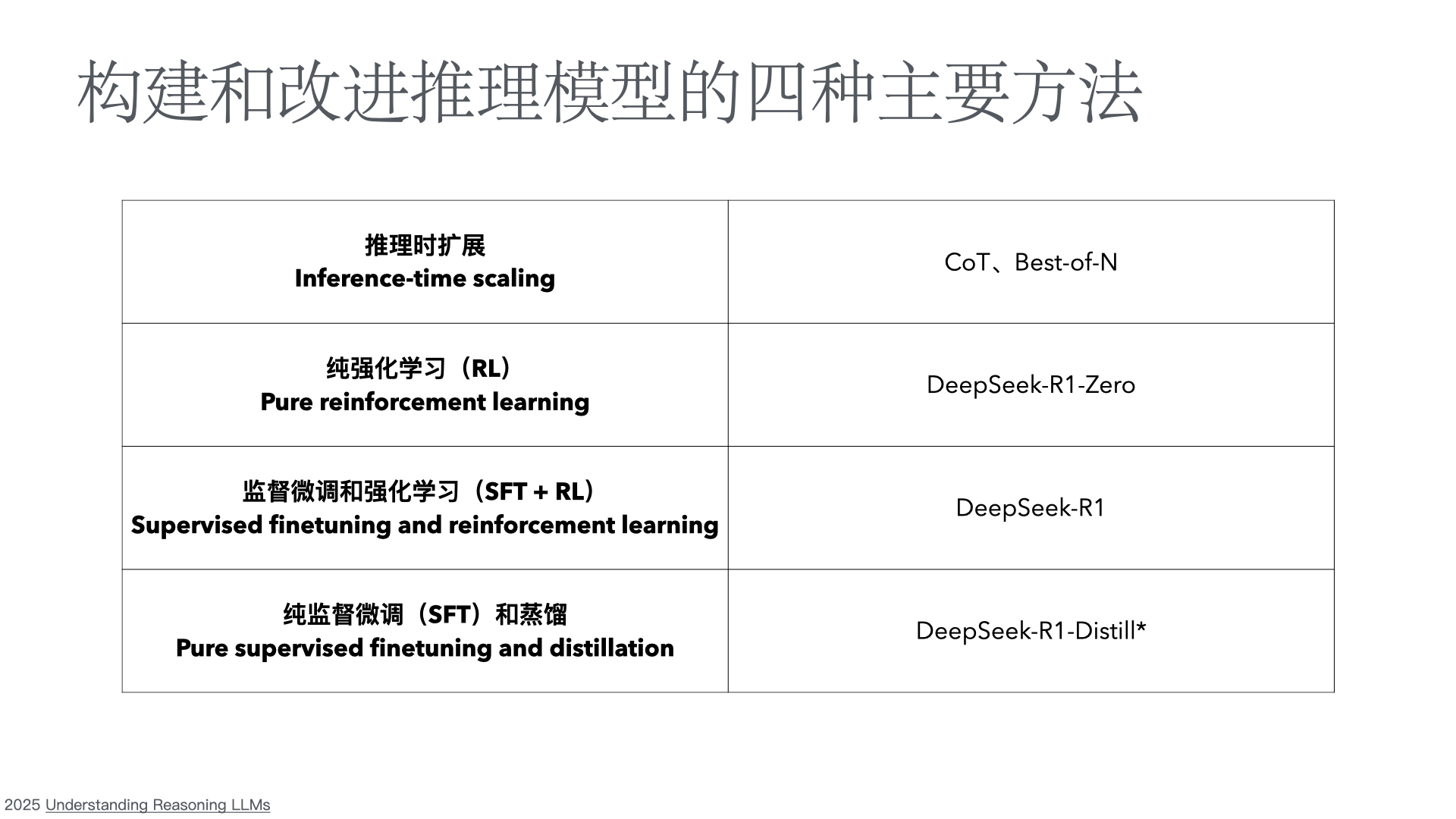
大型语言模型(LLM)的工作原理根植于模式匹配和对下一个词元的统计预测("随机鹦鹉")。从这种方法中产生的一个有些出人意料的能力是它们也能在一定程度上"推理"解决问题。有些模型的推理能力比其他模型更强,OpenAI的"o1"和"o3"模型是两个突出的推理模型,而DeepSeek的"R1"最近引起了很大轰动。但是当我们在编码任务中使用AI时,这种能力发挥什么作用呢?
剧透提醒:我还没有答案!但我有问题和想法。
我将从两个方面开始讨论,这两个方面在我的理解中是推理能力的限制,而且这些限制在编码环境中是相关的。然后我将分享我的想法,即推理在哪些编码任务中可能有用,在哪些任务中可能没用。
他们发现:
首先,这是一个很好的例子,说明为什么我们应该对LLM基准测试持保留态度。
在编码环境中,我发现最后一个发现特别有趣。
生成式人工智能和特别是大型语言模型(LLM)已迅速进入公众意识。像许多软件开发人员一样,我对其可能性感到好奇,但不确定它最终对我们的职业意味着什么。我现在在Thoughtworks担任一个角色,协调我们关于这项技术将如何影响软件交付实践的工作。我将在这里发布各种备忘录,描述我和同事们正在学习和思考的内容。
随着智能代理编码助手变得越来越强大,反应各不相同。有些人从最近的进步推断并声称,"一年后,我们将不再需要开发人员。"其他人则对AI生成代码的质量以及为初级开发人员准备应对这一变化的挑战表示担忧。
在过去几个月中,我定期使用Cursor、Windsurf和Cline中的智能代理模式,几乎完全用于更改现有代码库(而不是从头创建井字游戏)。总体而言,我对IDE集成的最新进展以及这些集成如何极大地提升工具辅助我的方式印象深刻。它们
所有这些都带来了与AI令人印象深刻的协作会话,有时帮助我在创纪录的时间内构建功能和解决问题。
然而。
即使在那些成功的会话中,我也一直在干预、纠正和引导。而且我经常决定不提交更改。
服务器通过MCP提供了为语言模型添加上下文的基本构建块。这些原语支持客户端、服务器和语言模型之间的丰富交互:
每个原语可以在以下控制层次结构中概括:
| 原语 | 控制方 | 描述 | 示例 |
|---|---|---|---|
| 提示 | 用户控制 | 由用户选择调用的交互式模板 | 斜杠命令、菜单选项 |
| 资源 | 应用程序控制 | 由客户端附加和管理的上下文数据 | 文件内容、Git历史 |
| 工具 | 模型控制 | 向LLM公开以执行操作的函数 | API POST请求、文件写入 |
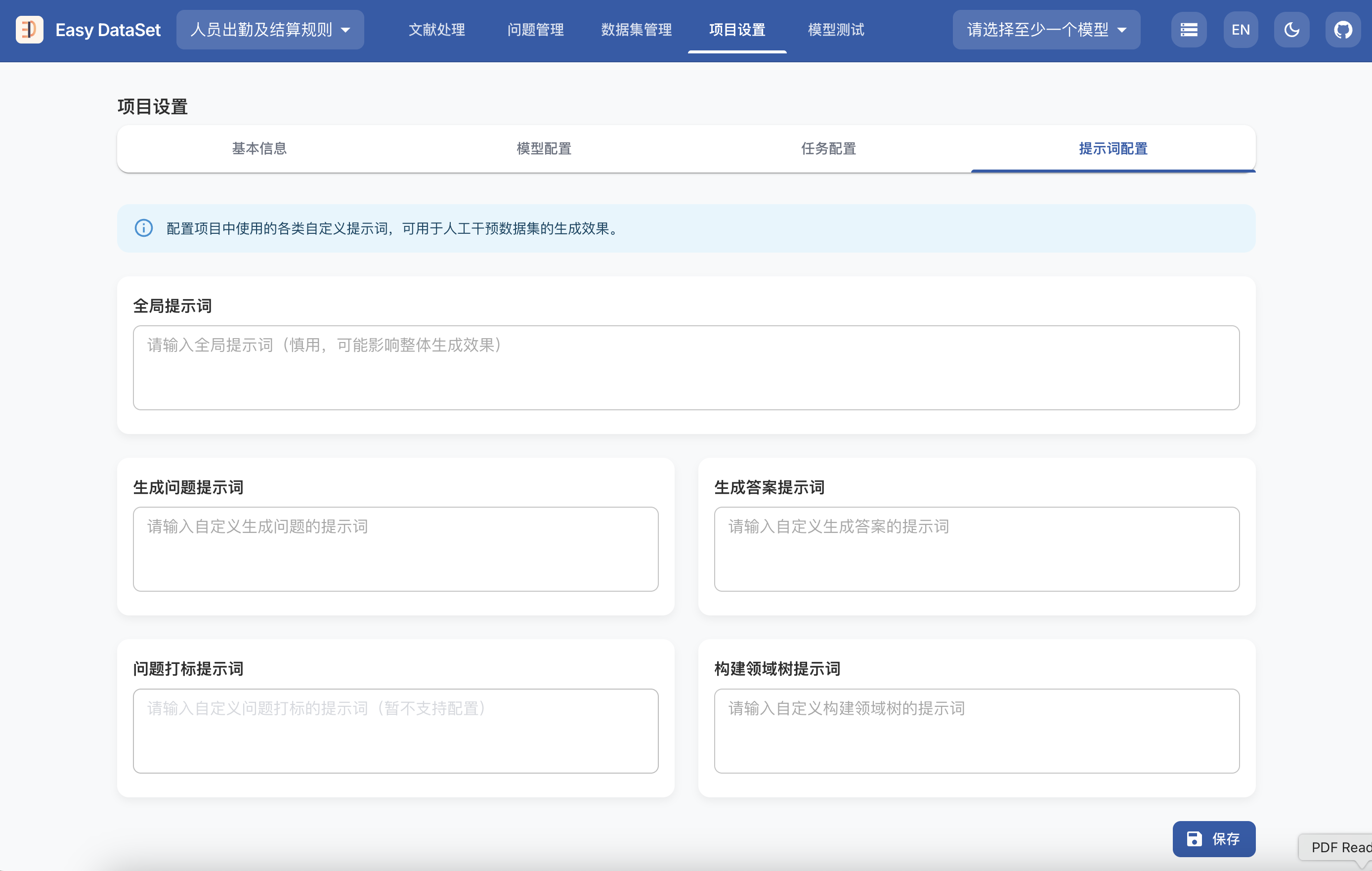
模型上下文协议(MCP)提供了一种标准化方式,使服务器能够向客户端公开提示词模板。提示词允许服务器提供结构化消息和与语言模型交互的指令。客户端可以发现可用的提示词,获取其内容,并提供参数来自定义它们。
提示词设计为用户控制的,这意味着它们从服务器暴露给客户端,目的是让用户能够明确选择使用它们。
通常,提示词会通过用户界面中的用户发起命令触发,这允许用户自然地发现和调用可用的提示词。
例如,作为斜杠命令:
然而,实现者可以自由地通过任何适合其需求的界面模式来公开提示词——协议本身不强制要求任何特定的用户交互模型。
支持提示词的服务器必须在初始化期间声明prompts能力:
模型上下文协议(Model Context Protocol)由几个协同工作的关键组件组成:
所有实现必须支持基础协议和生命周期管理组件。其他组件可以根据应用程序的特定需求来实现。
这些协议层在实现客户端和服务器之间丰富交互的同时,建立了明确的关注点分离。模块化设计允许实现精确支持所需的功能。
MCP 客户端和服务器之间的所有消息必须遵循 JSON-RPC 2.0 规范。协议定义了以下类型的消息:
请求从客户端发送到服务器,或者从服务器发送到客户端,用于启动操作。
{
jsonrpc: "2.0";
id: string | number;
method: string;
params?: {
[key: string]: unknown;
};
}
null。响应是对请求的回复,包含操作的结果或错误。
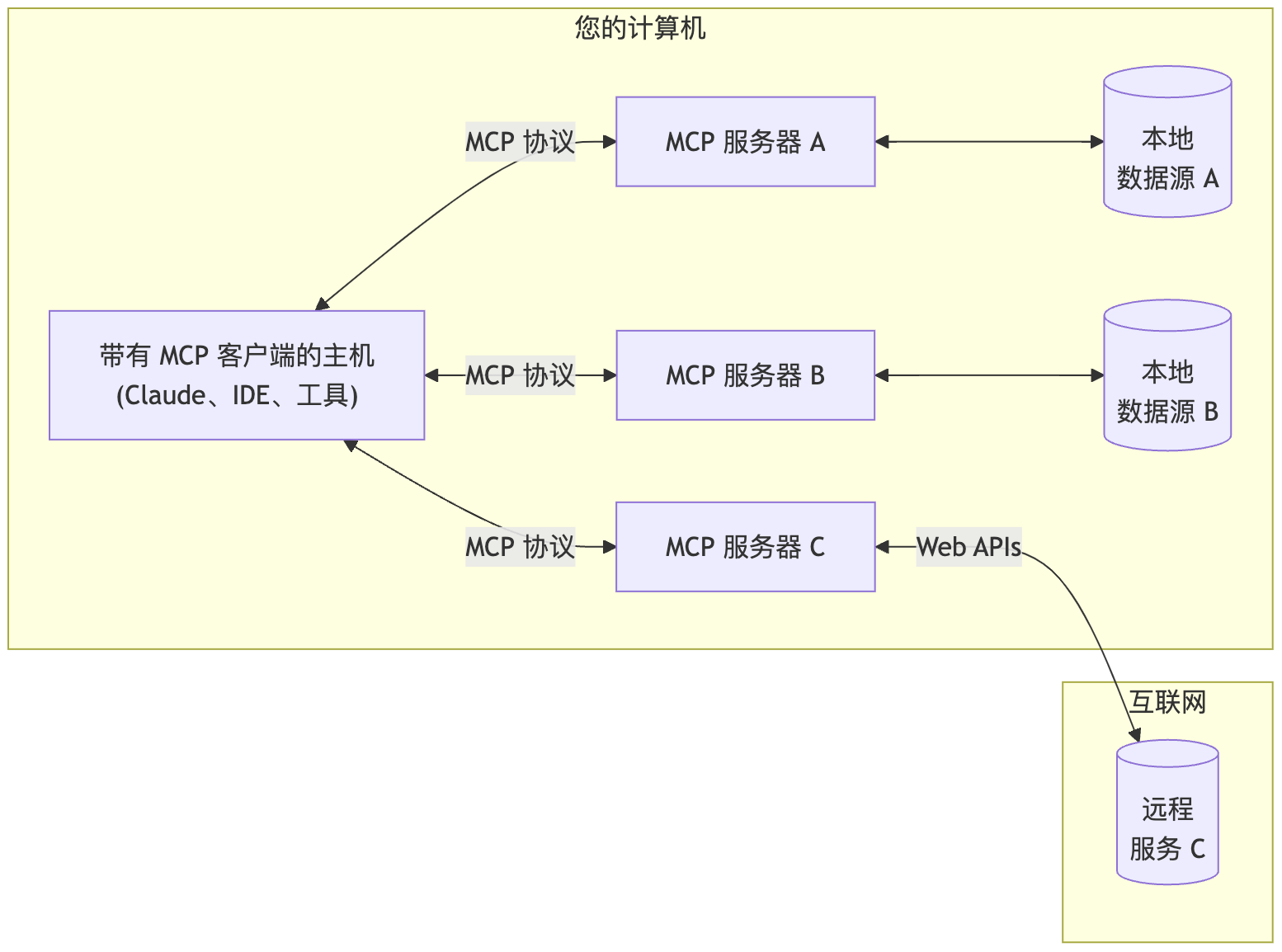
模型上下文协议(MCP)采用客户端-主机-服务器架构,每个主机可以运行多个客户端实例。这种架构使用户能够跨应用程序集成AI功能,同时保持明确的安全边界和关注点隔离。MCP基于JSON-RPC构建,提供专注于客户端和服务器之间上下文交换和采样协调的有状态会话协议。
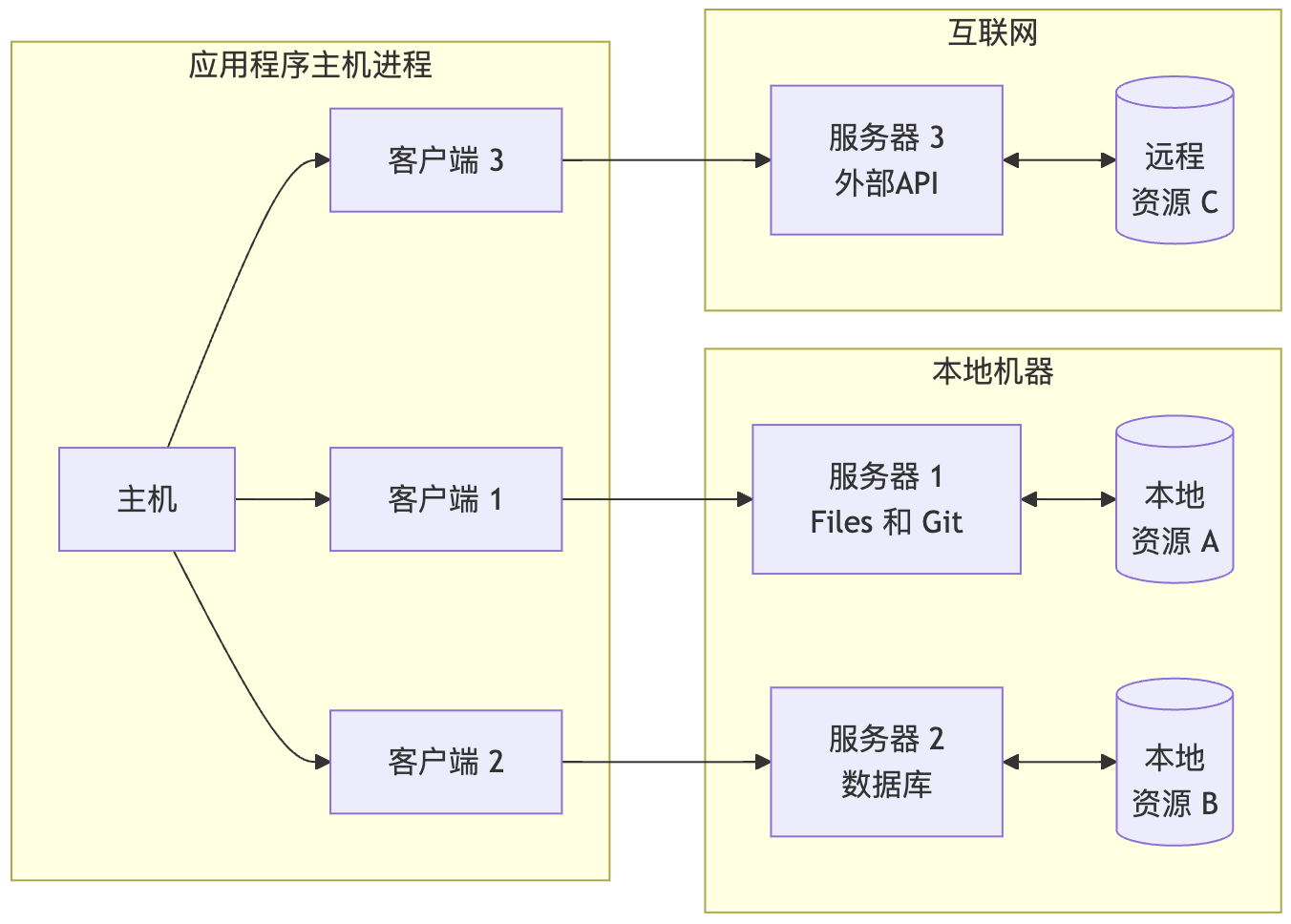
graph LR
subgraph "应用程序主机进程"
H[主机]
C1[客户端 1]
C2[客户端 2]
C3[客户端 3]
H --> C1
H --> C2
H --> C3
end
subgraph "本地机器"
S1[服务器 1<br>Files 和 Git]
S2[服务器 2<br>数据库]
R1[("本地<br>资源 A")]
// ...
主机进程作为容器和协调器:
每个客户端由主机创建,并维护独立的服务器连接:
主机应用程序创建和管理多个客户端,每个客户端与特定服务器保持1:1关系。
服务器提供专门的上下文和功能:
Model Context Protocol(MCP)是一个开放协议,它使 LLM 应用程序与外部数据源和工具之间能够无缝集成。无论您是构建 AI 驱动的 IDE、增强聊天界面,还是创建自定义 AI 工作流,MCP 都提供了一种标准化的方式来连接 LLM 与它们所需的上下文。
本规范基于 schema.ts 中的 TypeScript 模式,定义了权威的协议要求。
有关实现指南和示例,请访问 modelcontextprotocol.io。
MCP 为应用程序提供了标准化的方式来:
该协议使用 JSON-RPC 2.0 消息在以下组件之间建立通信:
MCP 部分受到 Language Server Protocol 的启发,后者标准化了如何在整个开发工具生态系统中添加对编程语言的支持。类似地,MCP 标准化了如何将额外的上下文和工具集成到 AI 应用程序的生态系统中。
服务器向客户端提供以下任何功能:
资源(Resources):供用户或 AI 模型使用的上下文和数据 提示(Prompts):为用户提供的模板化
Model Context Protocol 允许应用程序以标准化的方式为 LLM 提供上下文,将提供上下文的关注点与实际的 LLM 交互分离开来。这个 Python SDK 实现了完整的 MCP 规范,使您能够轻松地:
我们推荐使用 uv 来管理您的 Python 项目。在由 uv 管理的 Python 项目中,通过以下方式将 mcp 添加到依赖项:
uv add "mcp[cli]"
或者,对于使用 pip 管理依赖的项目:
pip install mcp
要使用 uv 运行 mcp 命令:
uv run mcp
让我们创建一个简单的 MCP 服务器,它暴露一个计算器工具和一些数据:
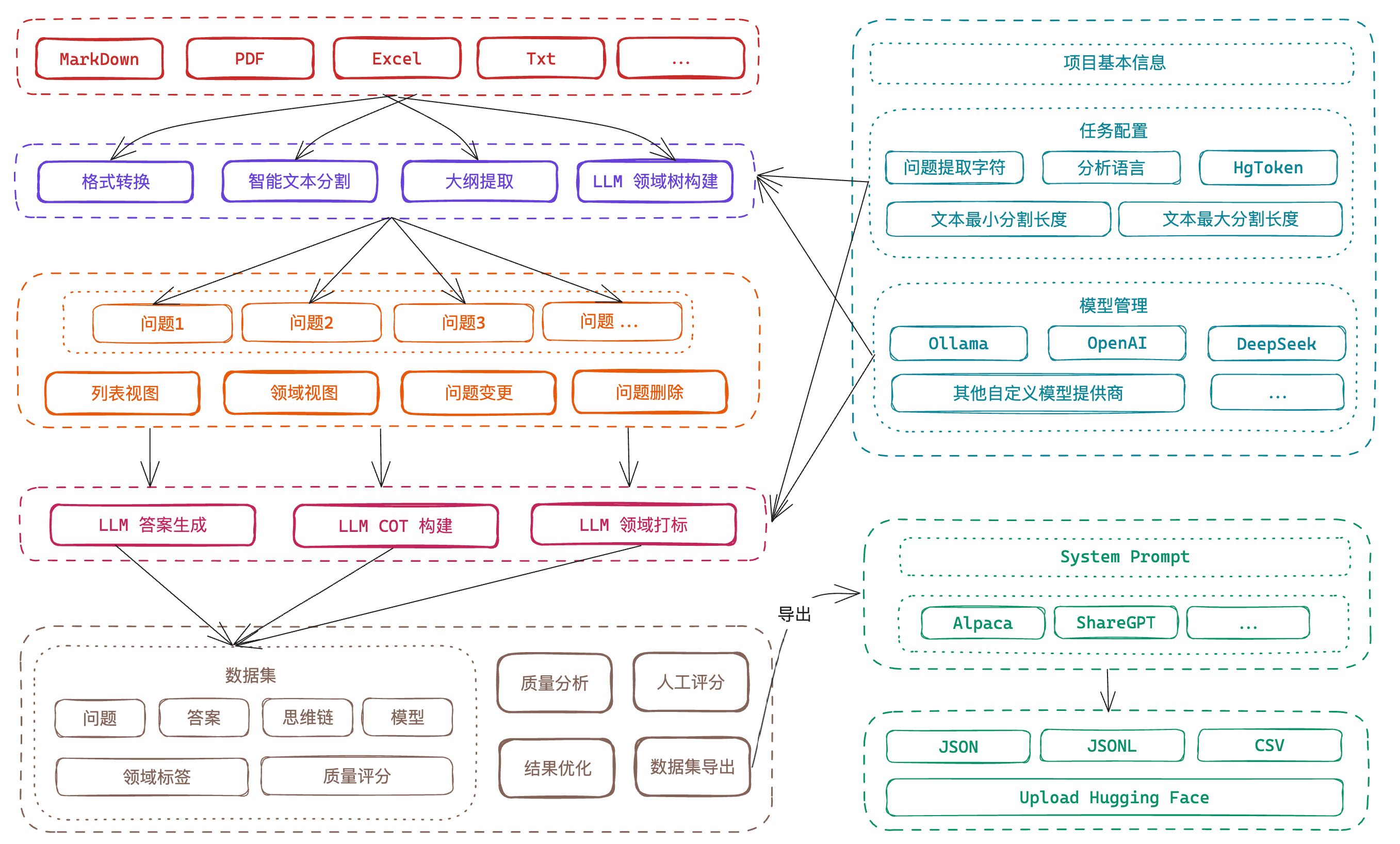
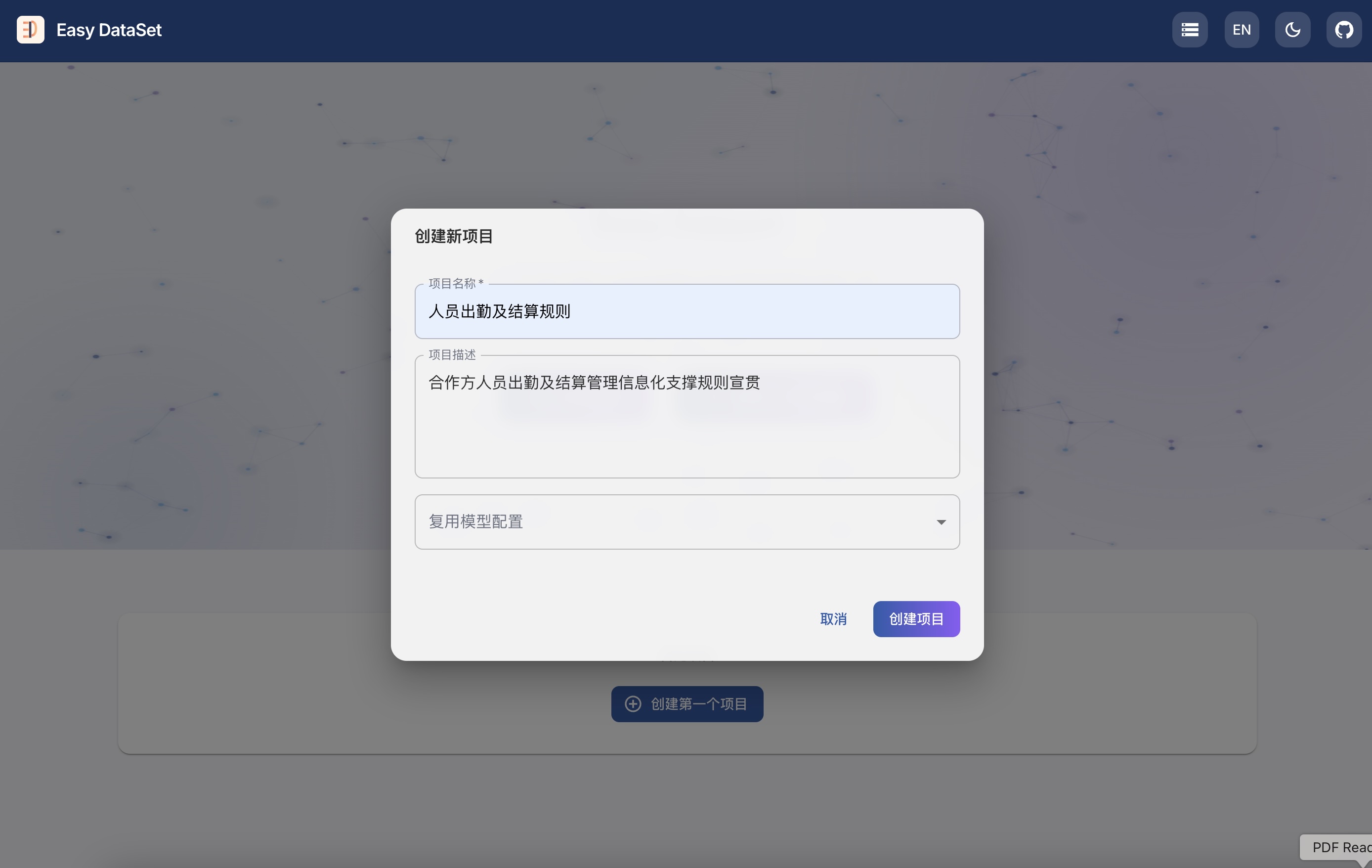
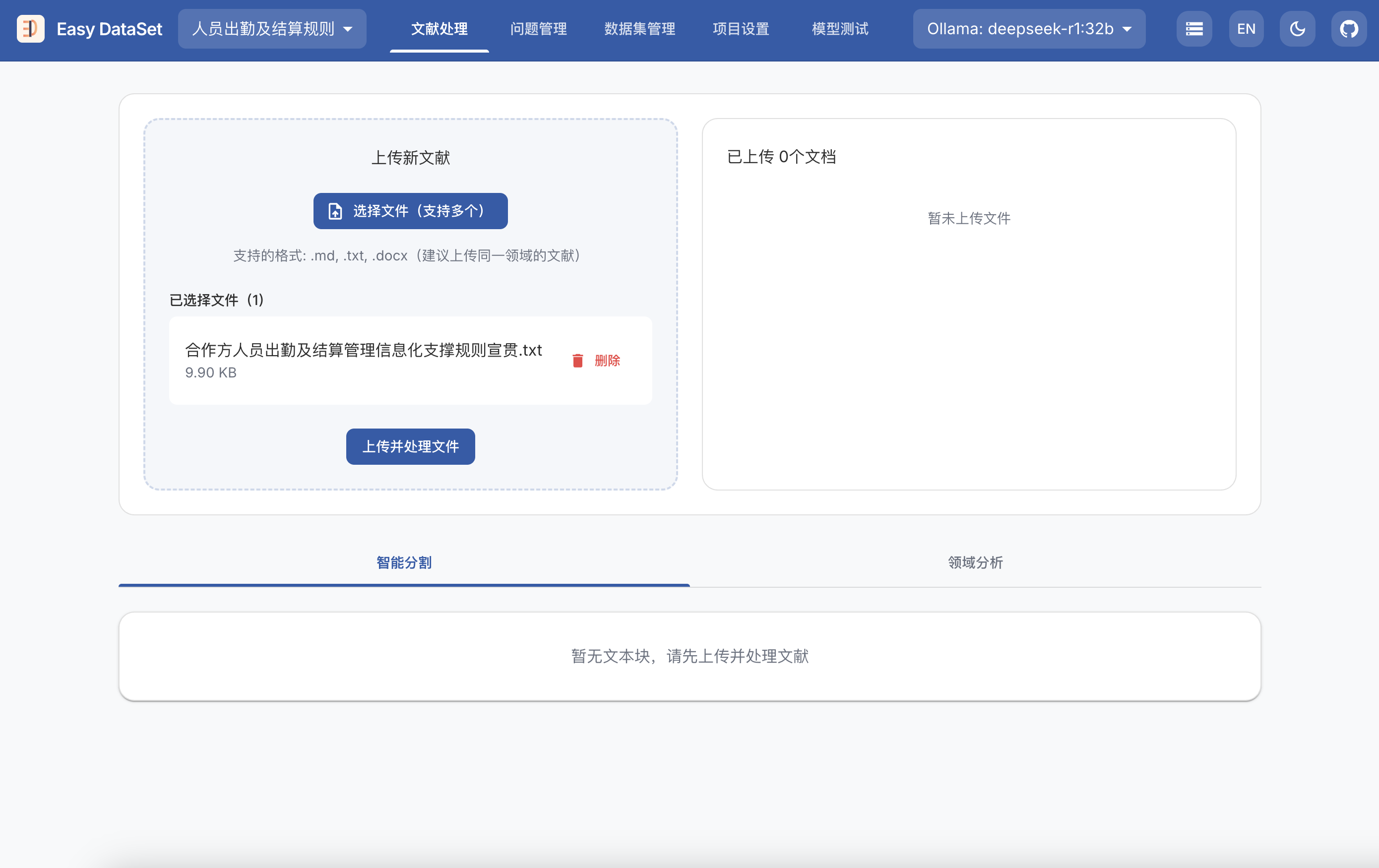
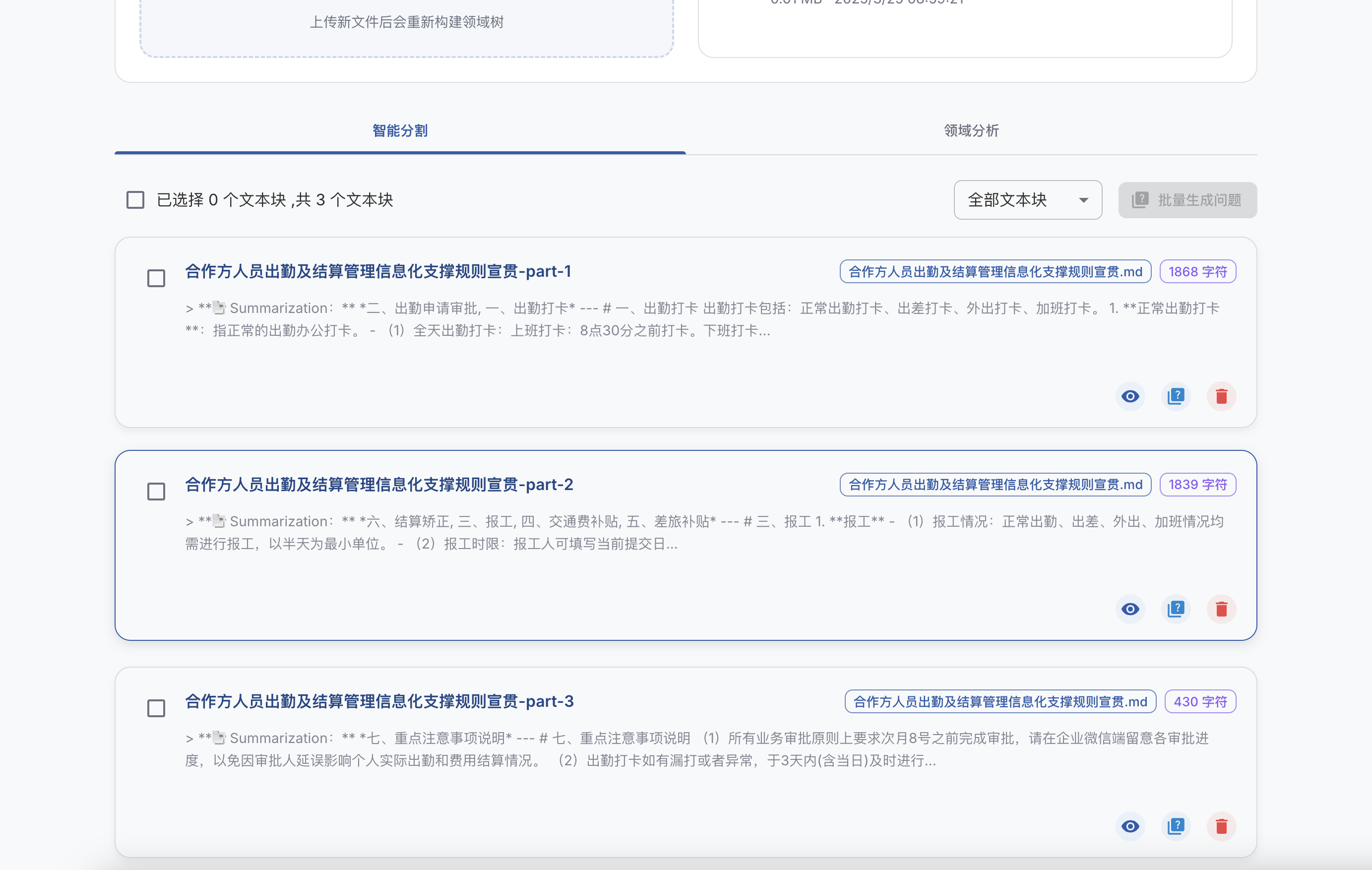
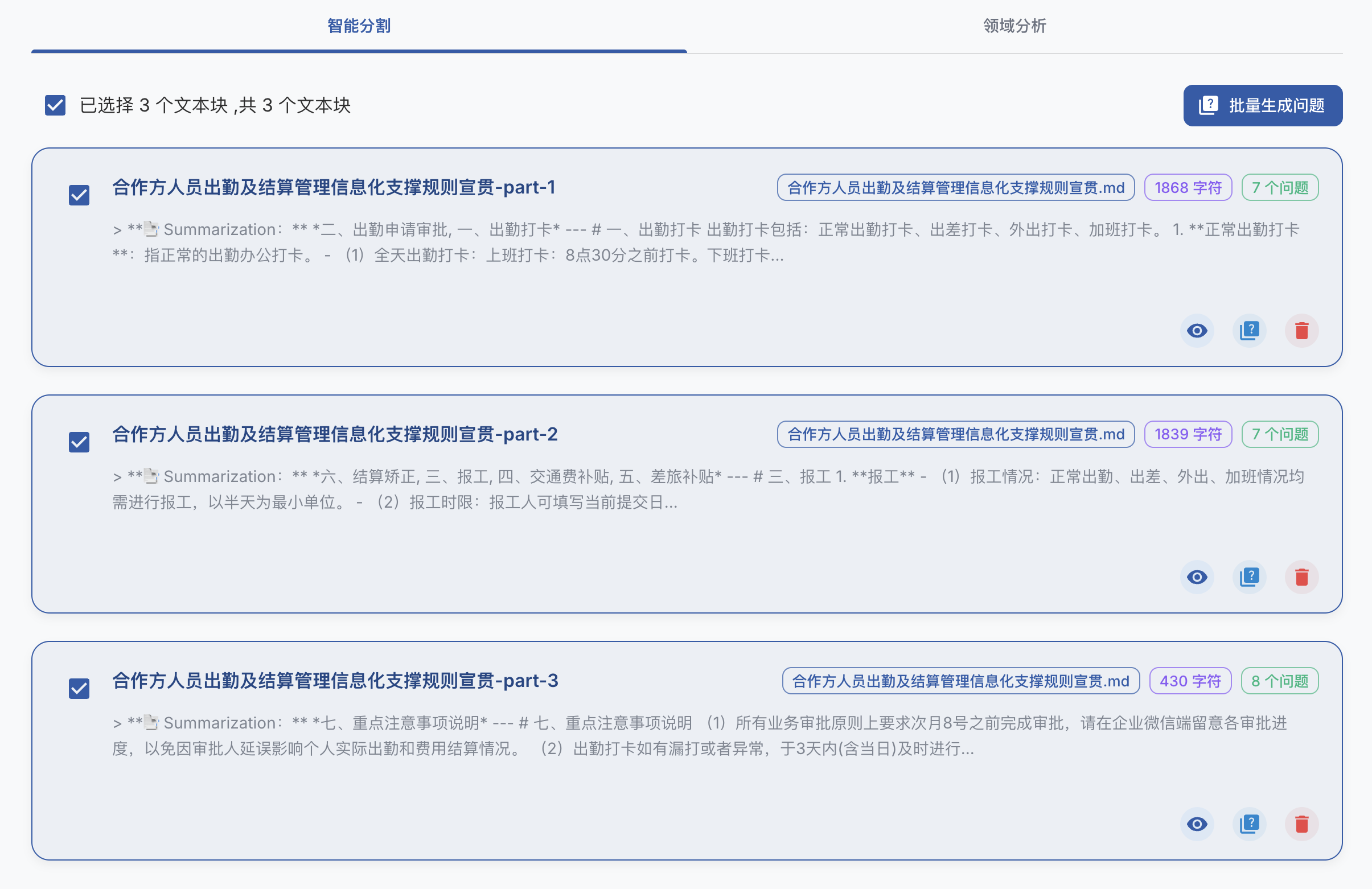
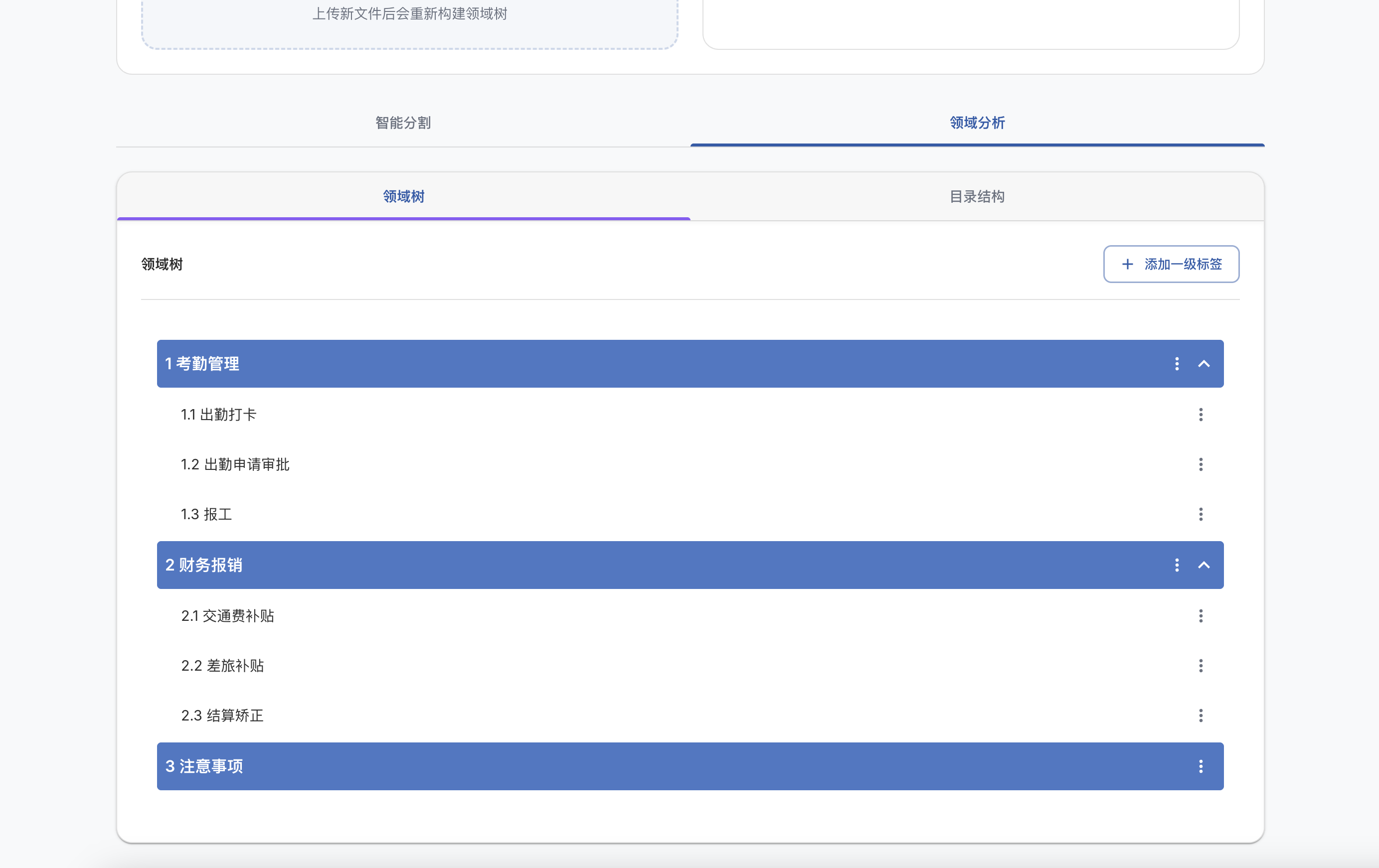
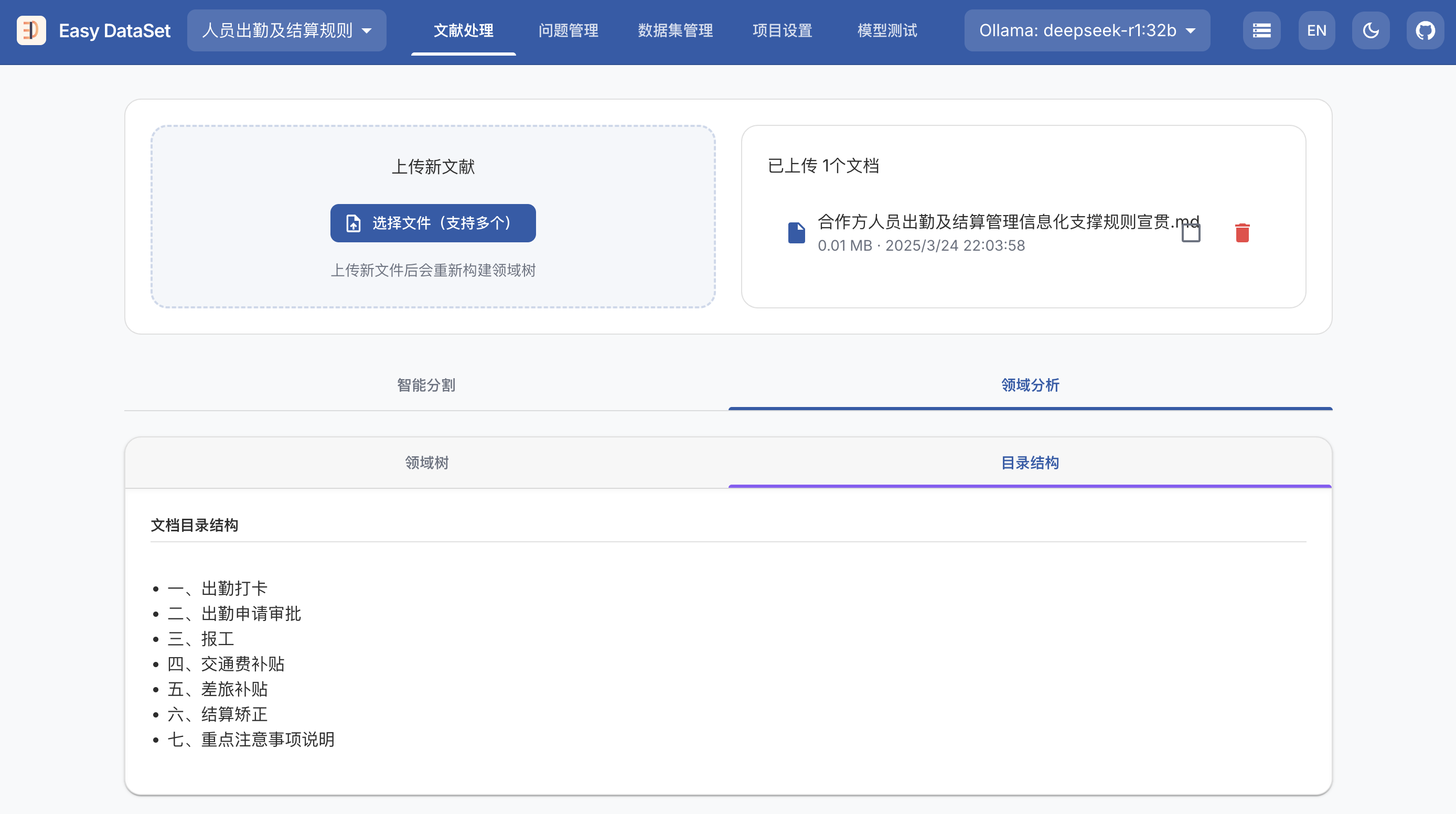
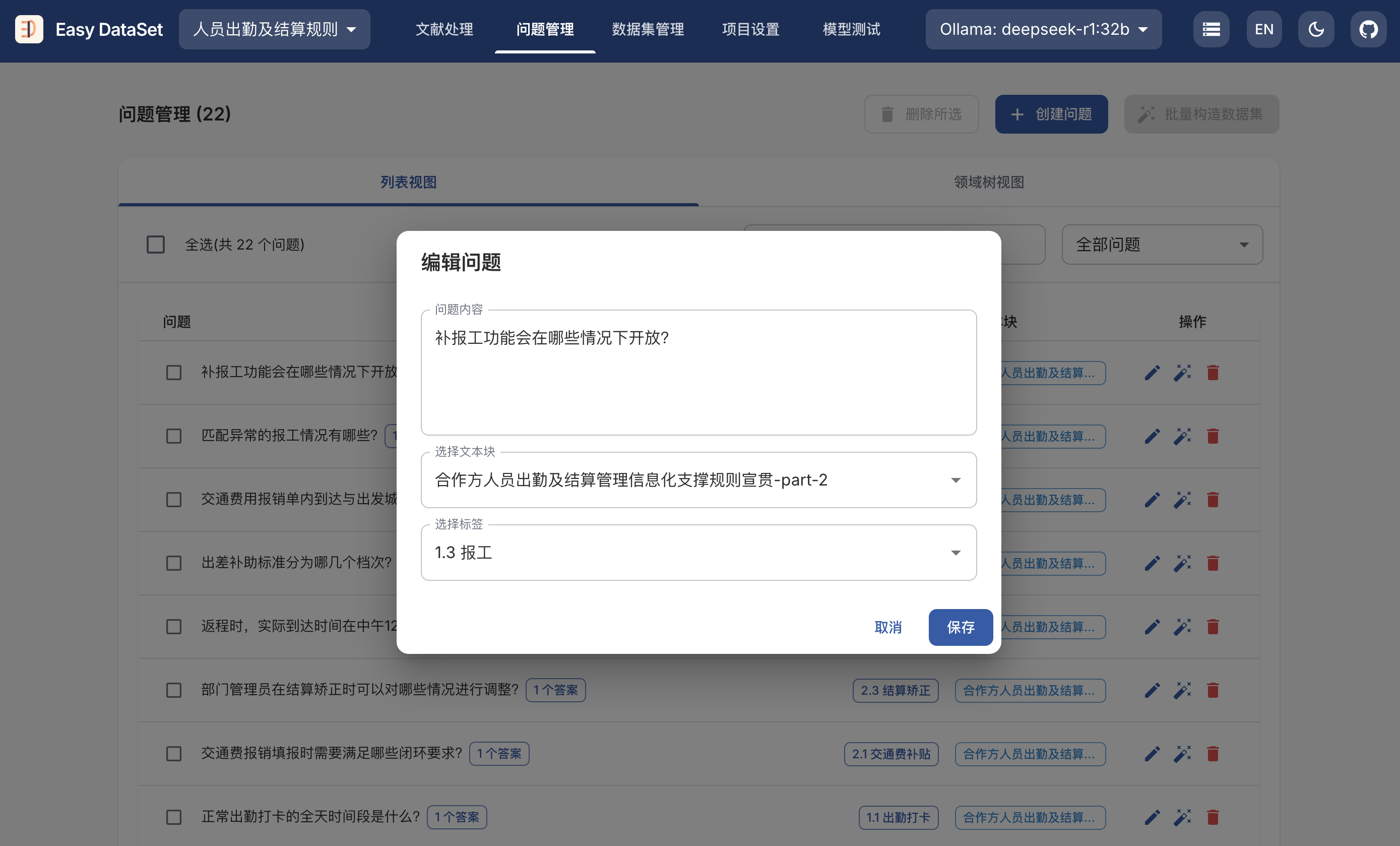
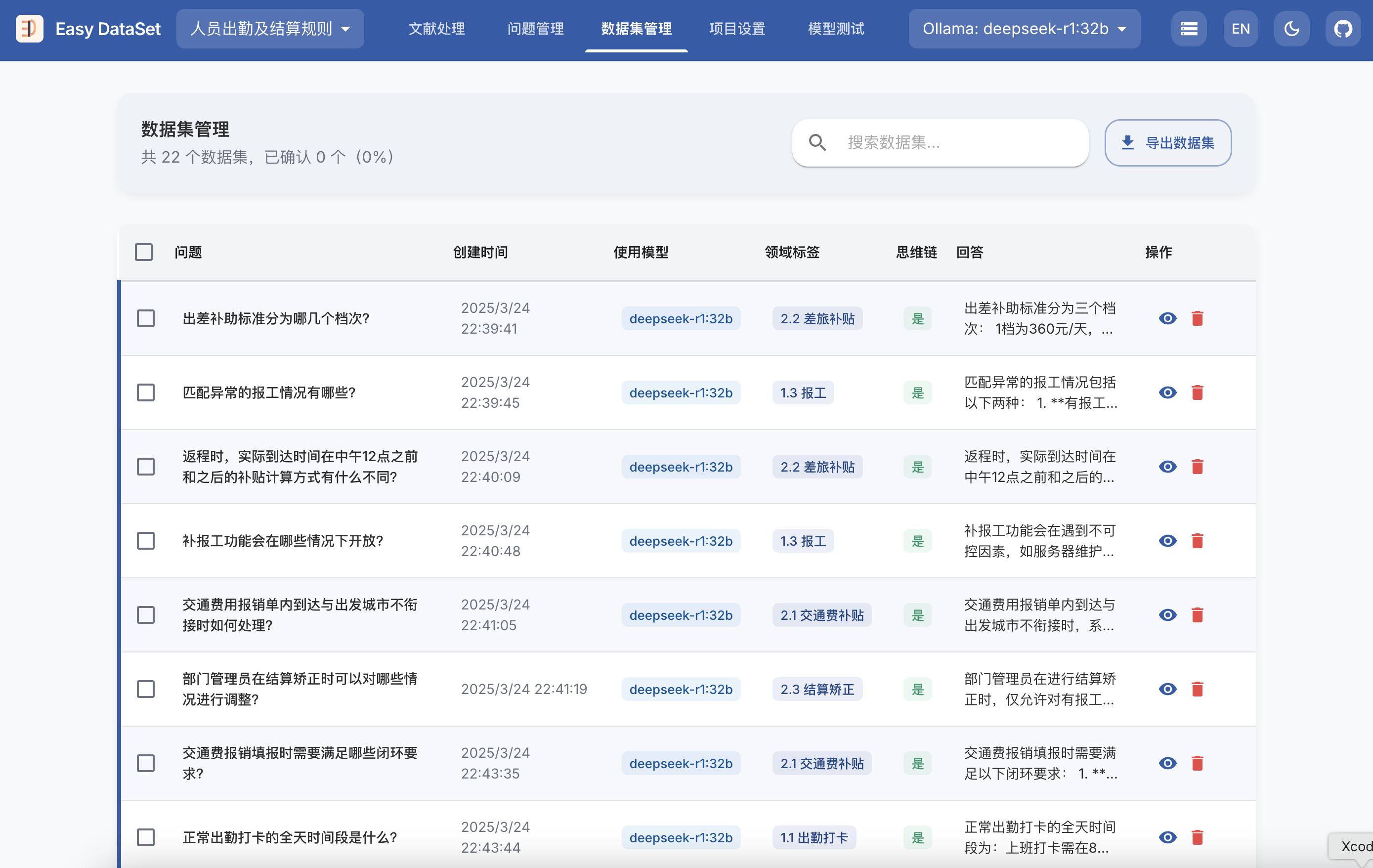
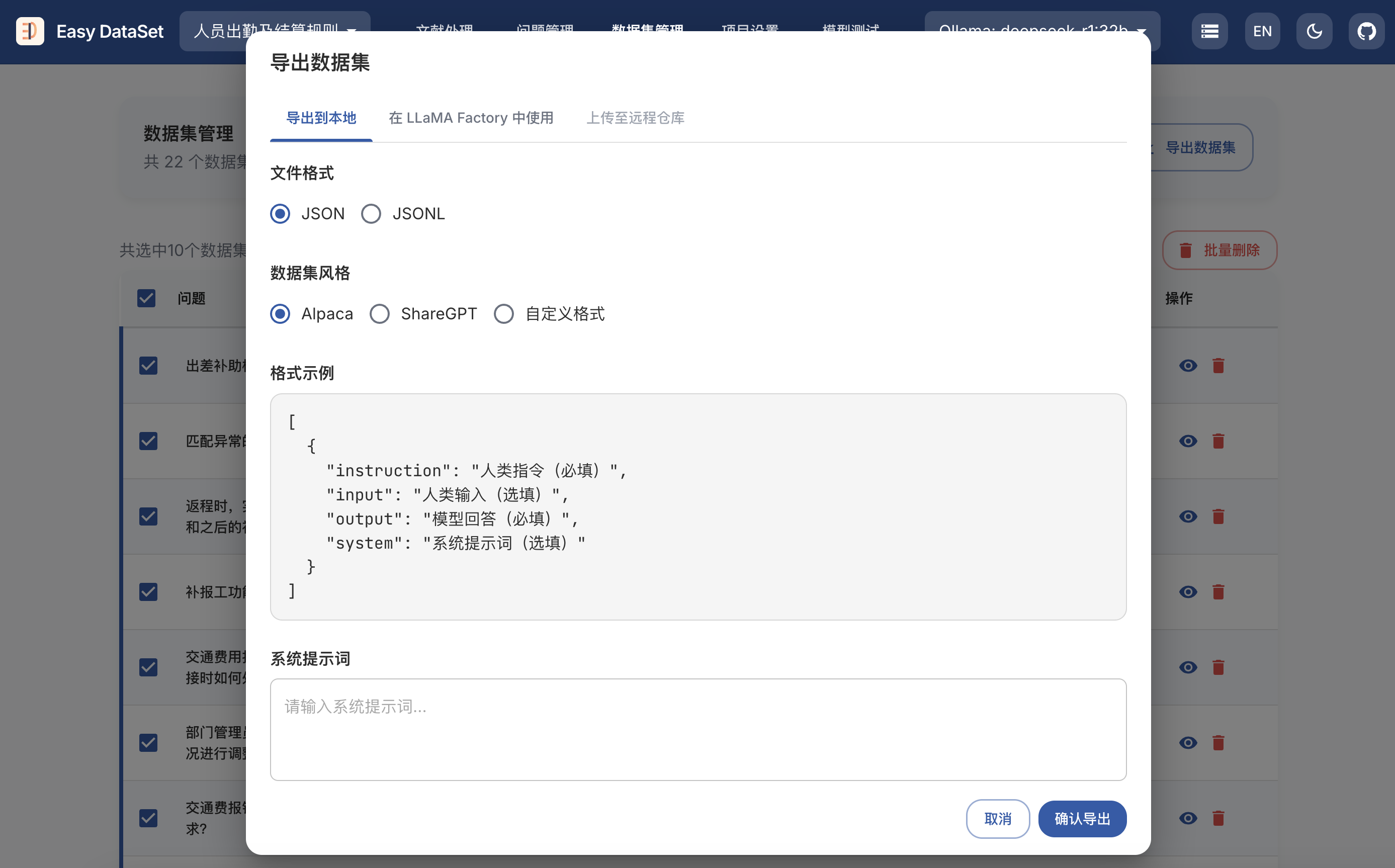
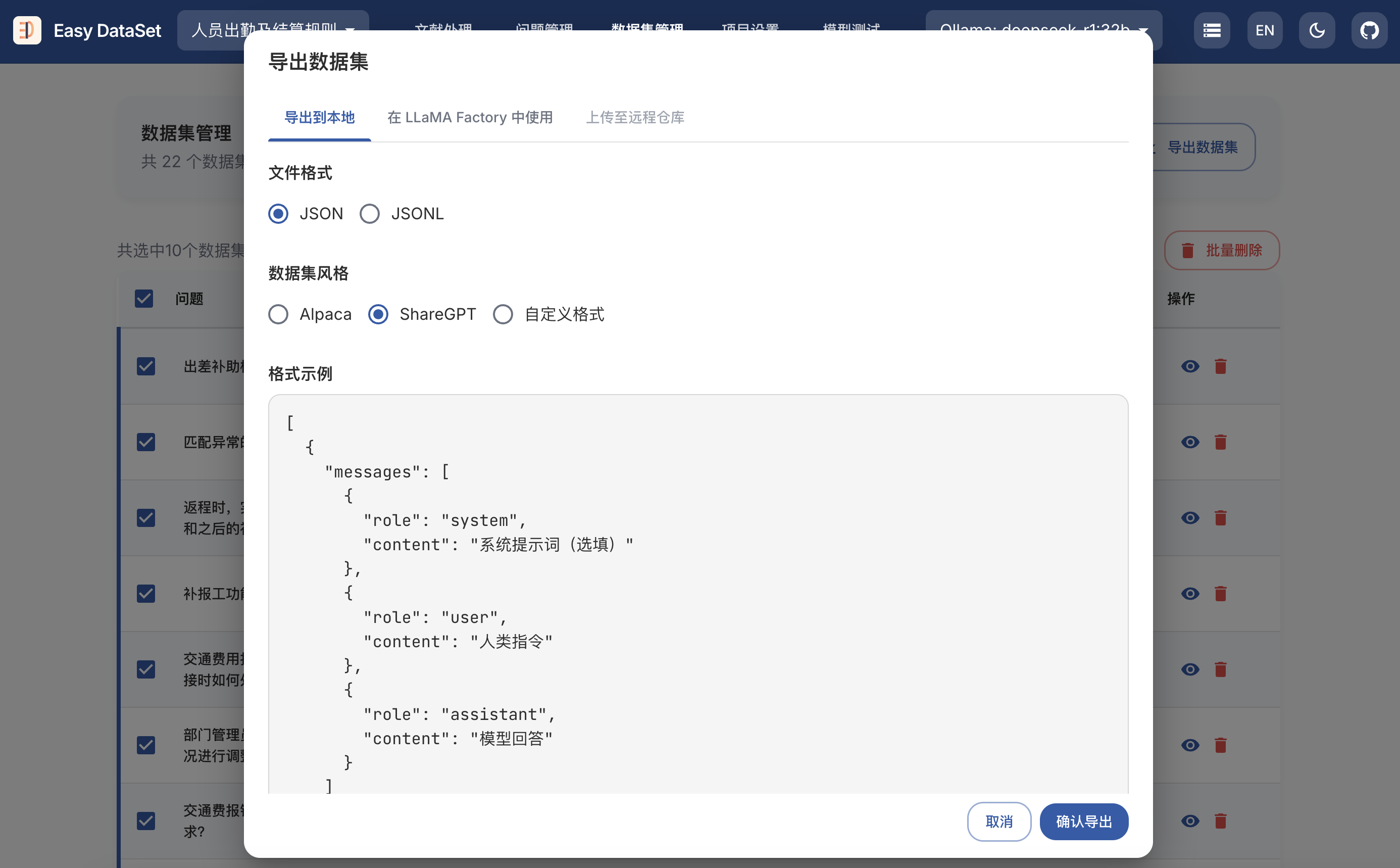
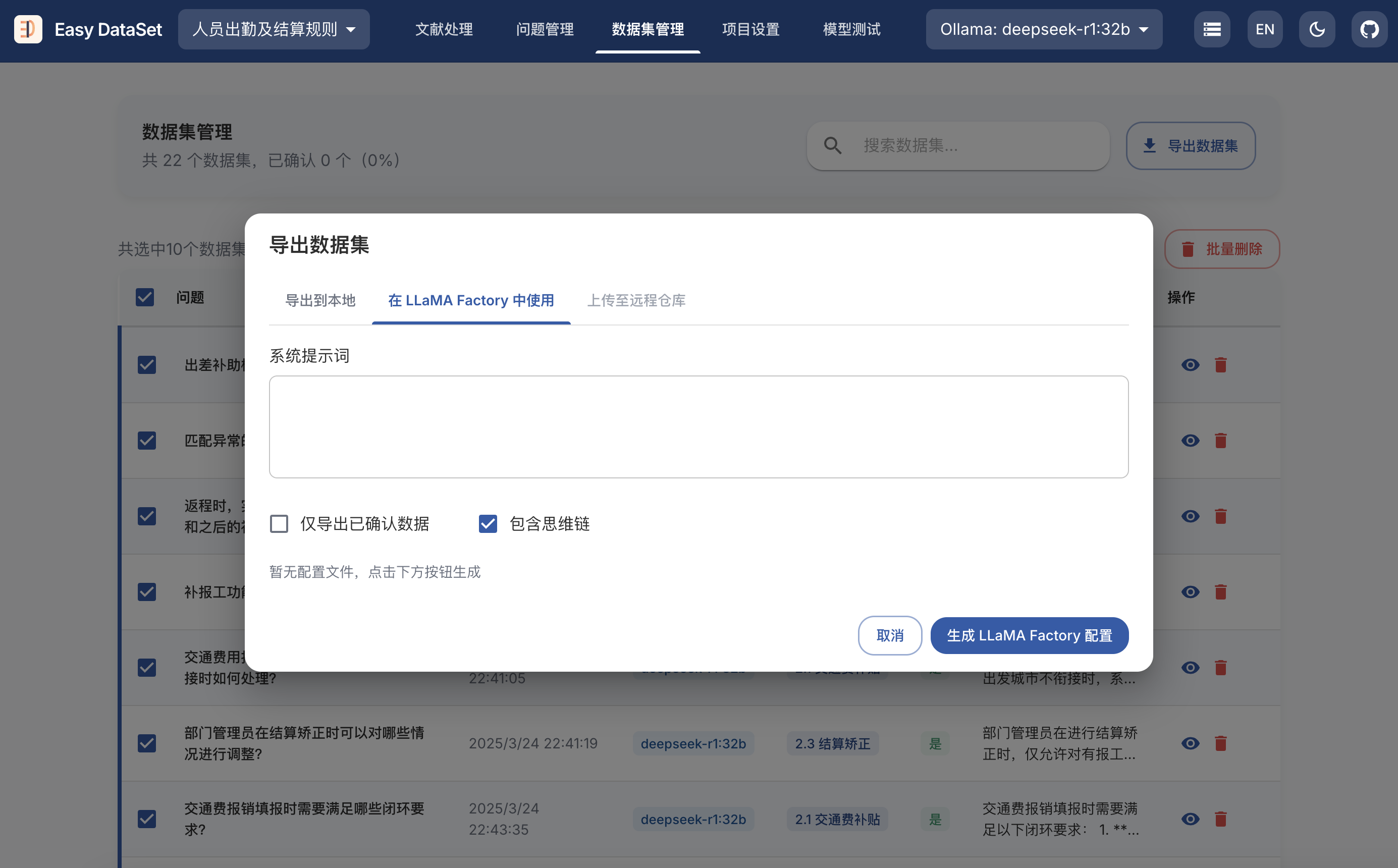
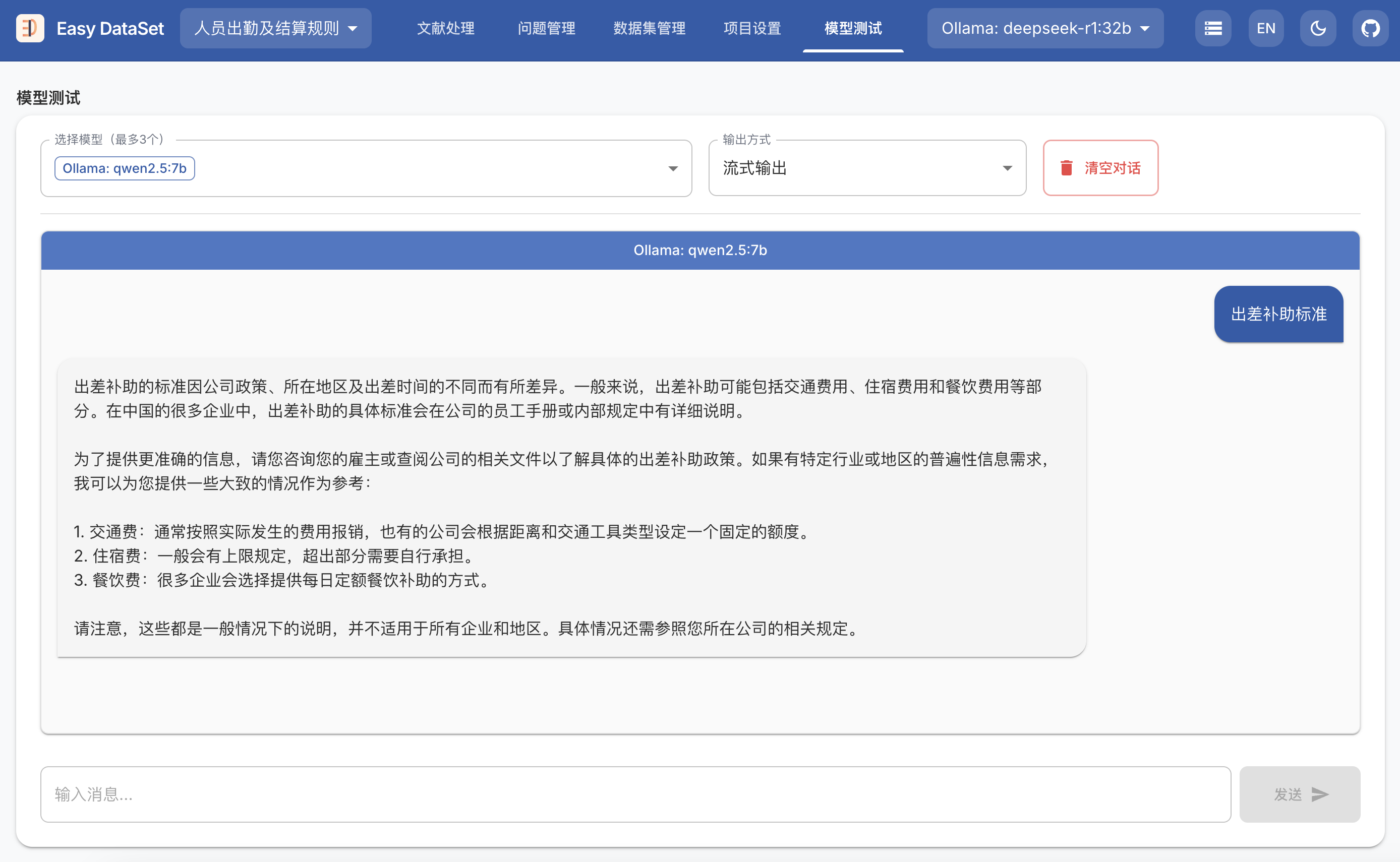
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
npm install
npm run build
npm run start
http://localhost:1717如果你想自行构建镜像,可以使用项目根目录中的 Dockerfile:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
docker build -t easy-dataset .
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset
{YOUR_LOCAL_DB_PATH} 替换为你希望存储本地数据库的实际路径。http://localhost:1717
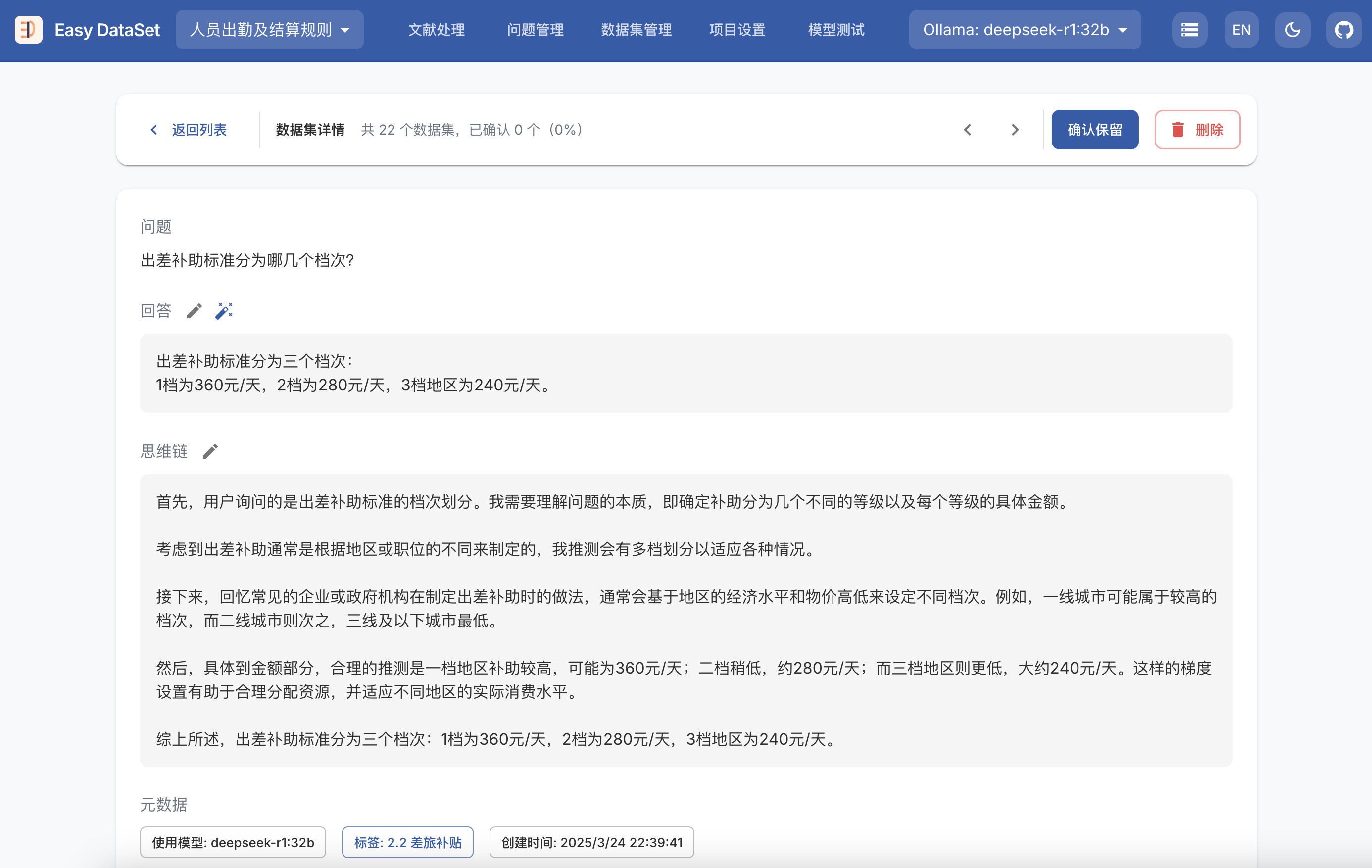
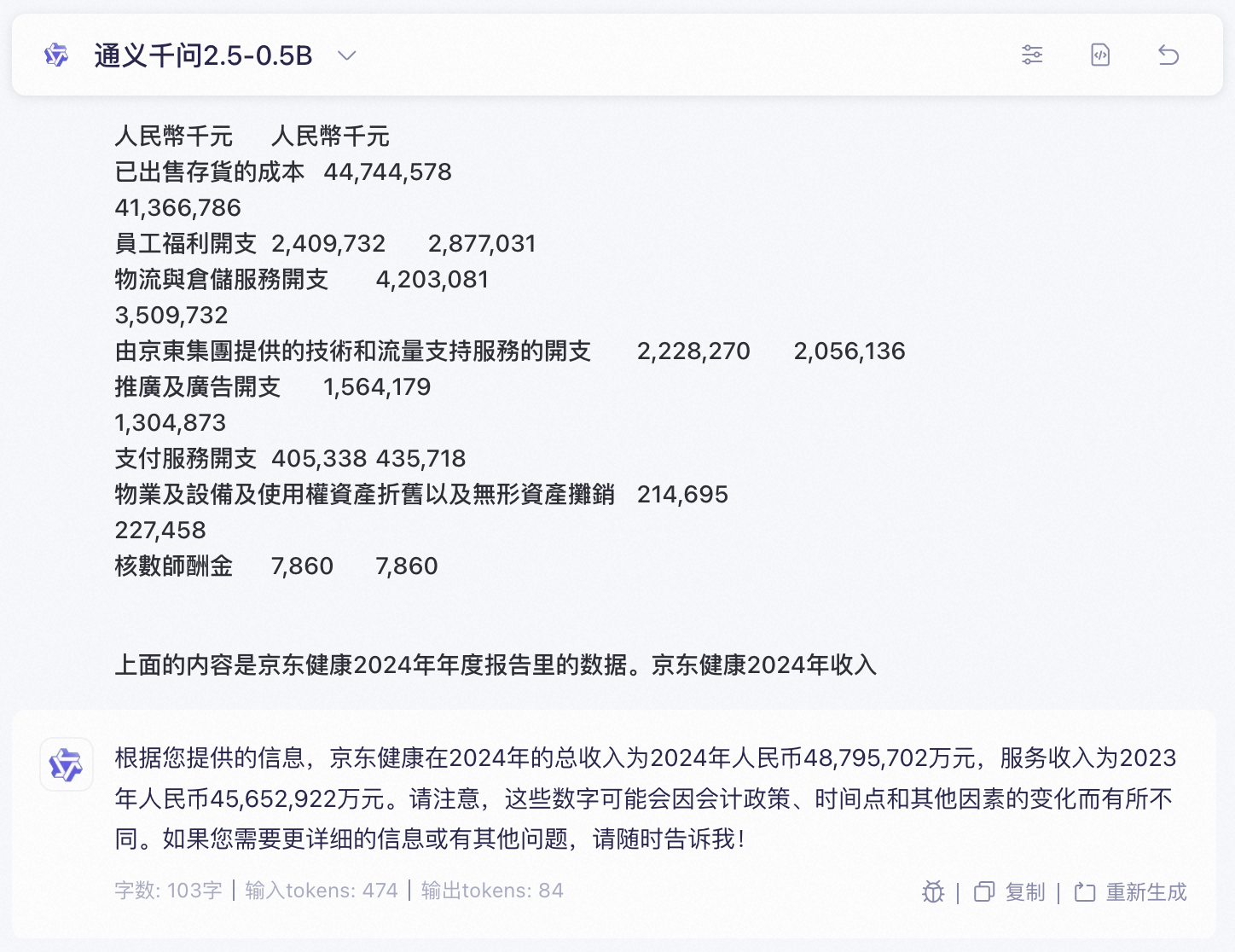
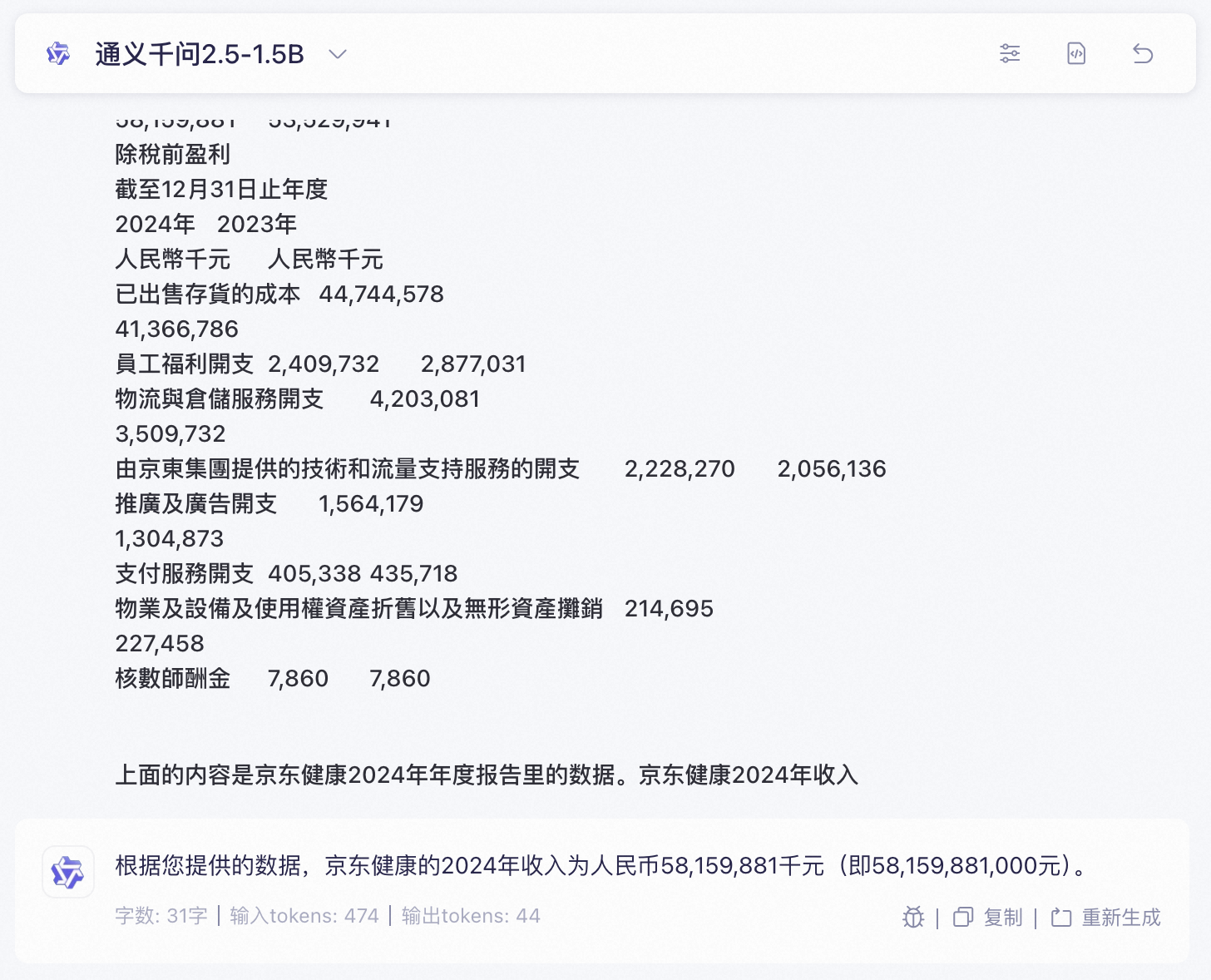
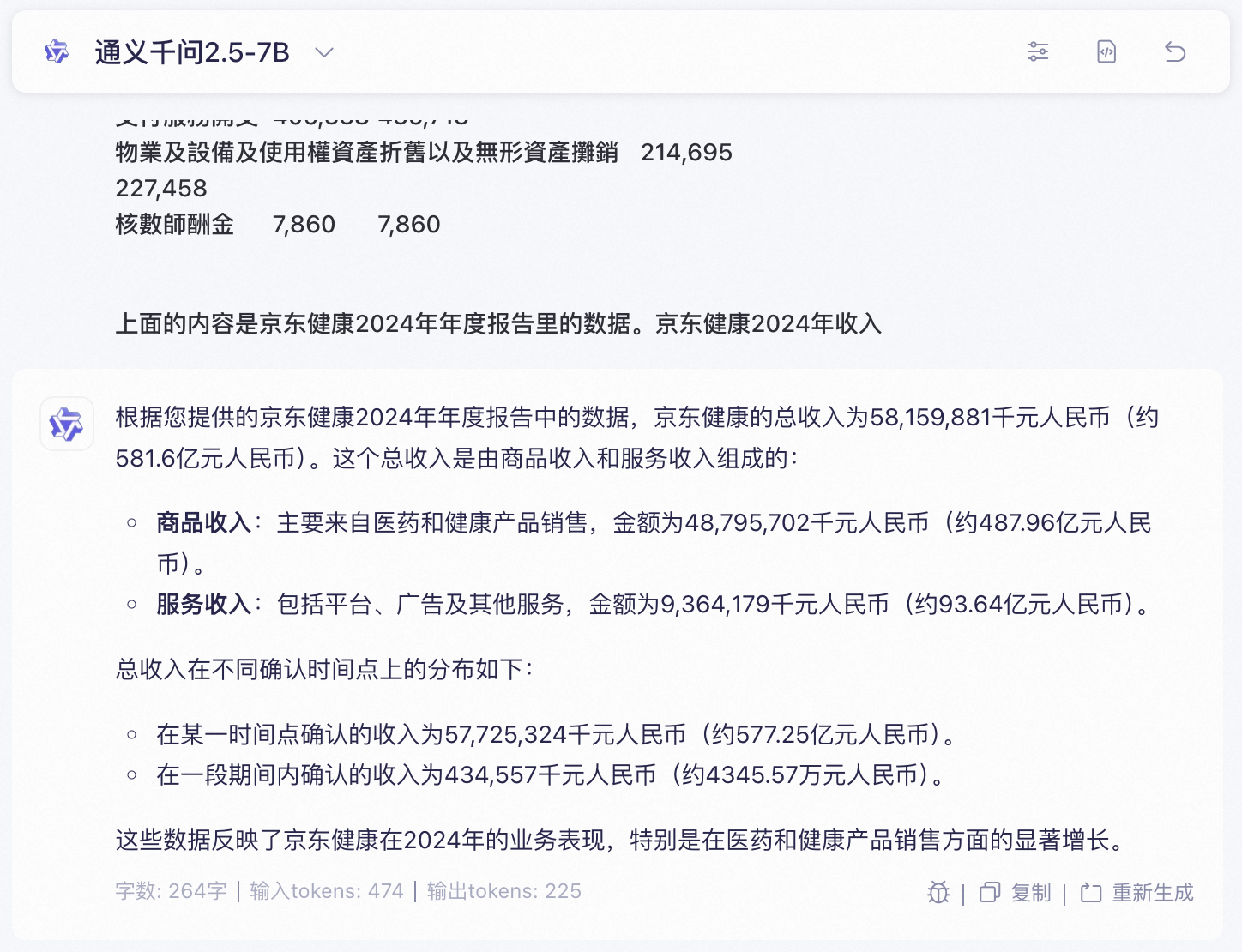
| 模型类型 | 模型 | 评估结果 |
|---|---|---|
| 语言模型 | Qwen2.5-0.5B | ❌ |
| Qwen2.5-1.5B | ✅ | |
| Qwen2.5-7B | ✅ | |
| Qwen2.5-14B-Instruct | ✅ | |
| Qwen2.5-32B-Instruct | ✅ | |
| 推理模型 | DeepSeek-R1-Distill-Qwen2.5-1.5B | ❌ |
| DeepSeek-R1-Distill-Qwen2.5-7B | ❌ | |
| DeepSeek-R1-Distill-Qwen2.5-14B | ✅ | |
| DeepSeek-R1-Distill-Qwen2.5-32B | ✅ | |
| Qwen/QwQ-32B | ✅ | |
| Qwen/QwQ-32B-Preview | ✅ | |
| Qwen/QwQ-32B-AWQ | ❌ | |
| 代码模型 | Qwen2.5-Coder-0.5B | ❌ |
| Qwen2.5-Coder-1.5B | ✅ | |
| Qwen2.5-Coder-3B | ✅ |
对于这样的阅读理解任务,推理模型的表现要反而不如语言模型和代码模型,通过分析发现在思考的过程可能会出错而导致答案错误。对于大参数模型,进行了量化会导致模型性能下降,如:Qwen/QwQ-32B-AWQ。
Model Context Protocol (MCP) 入门
MCP 是一个开放协议,用于标准化应用程序向 LLM 提供上下文的方式。可以将 MCP 视为 AI 应用程序的 USB-C 端口。正如 USB-C 提供了一种将设备连接到各种外围设备和配件的标准化方式一样,MCP 提供了一种将 AI 模型连接到不同数据源和工具的标准化方式。
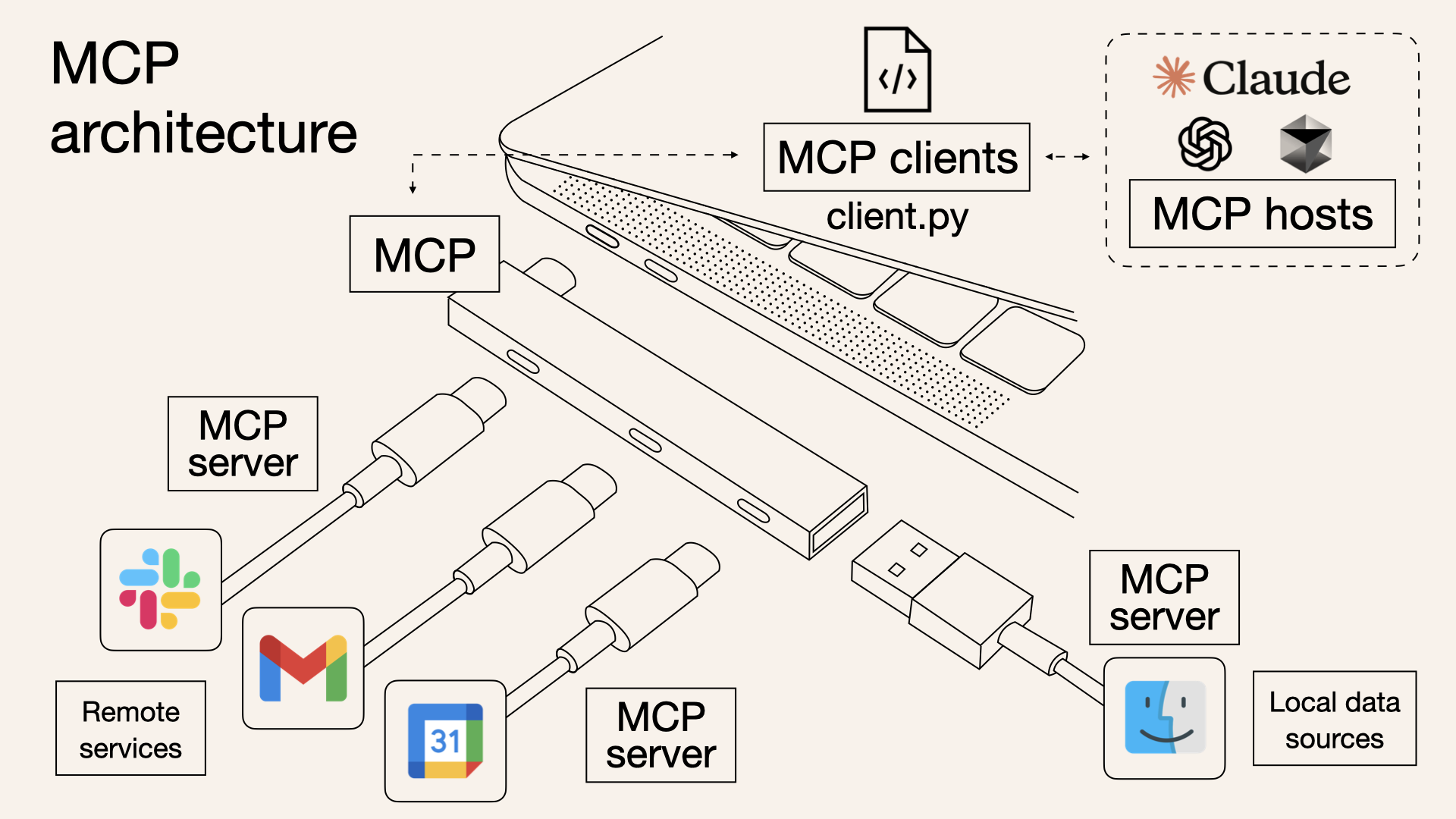
MCP 帮助您在 LLM 之上构建代理和复杂的工作流程。LLM 经常需要与数据和工具集成,而 MCP 提供了:
MCP 的核心遵循客户端-服务器架构,其中主机应用程序可以连接到多个服务器:
这篇文章是使用 Google Gemini Deep Research 生成的。提示词:
研究 Model Context Protocol
大型语言模型 (LLMs) 在理解和生成人类语言方面取得了显著的进步。然而,这些模型本质上是孤立的,它们的知识仅限于训练数据,并且缺乏与外部世界交互的能力 1。为了克服这些限制,将 LLMs 与外部数据源和工具集成变得至关重要 1。传统上,这种集成是通过为每个新的数据源或工具开发定制的连接器来实现的 1。这种方法导致了集成工作的重复,难以扩展,并且维护成本高昂,阻碍了上下文感知 AI 的广泛采用 1。
为了应对这一挑战,模型上下文协议 (MCP) 应运而生 1。MCP 是一种开放标准,旨在规范应用程序如何向 LLMs 提供上下文和工具 6。可以将 MCP 视为 AI 应用程序的通用连接器,类似于 USB-C 标准化了设备和外设之间的连接 6。通过提供一种标准化的方式将 AI 模型连接到各种数据源和工具,MCP 简化了集成,增强了互操作性,并促进了可扩展性 6。
本报告旨在对模型上下文协议 (MCP) 进行全面的解析,涵盖其基本原理、核心架构、通信机制、广泛的应用场景以及客户端和服务器端的创建方法。通过深入理解 MCP,开发者和组织可以更好地利用这一新兴标准,构建更智能、更具上下文感知能力的 AI 应用。
MCP 的设计基于若干核心原则,这些原则共同塑造







CPU: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz(64核)GPU: NVIDIA T4(16GB)X 4内存: 256GBconda create -n eval-llm python==3.12 -y
conda activate eval-llm
cd /data/wjj
mkdir eval-llm
cd eval-llm
pip install vllm==0.7.3 pandas
git clone https://github.com/vllm-project/vllm
docker pull lmsysorg/sglang:latest
pip install evalscope-perf==1.0.0
通过设置环境变量没有生效。
export OPENAI_API_KEY=sk-1234
这里进行了硬编码,编辑文件:/data/miniconda3/envs/eval-llm/lib/python3.12/site-packages/evalscope_perf/main.py
conda create -n litellm python==3.12.9 -y
conda activate litellm
pip install "litellm[proxy]" langfuse openai
git clone https://github.com/langfuse/langfuse.git
cd langfuse
docker compose up
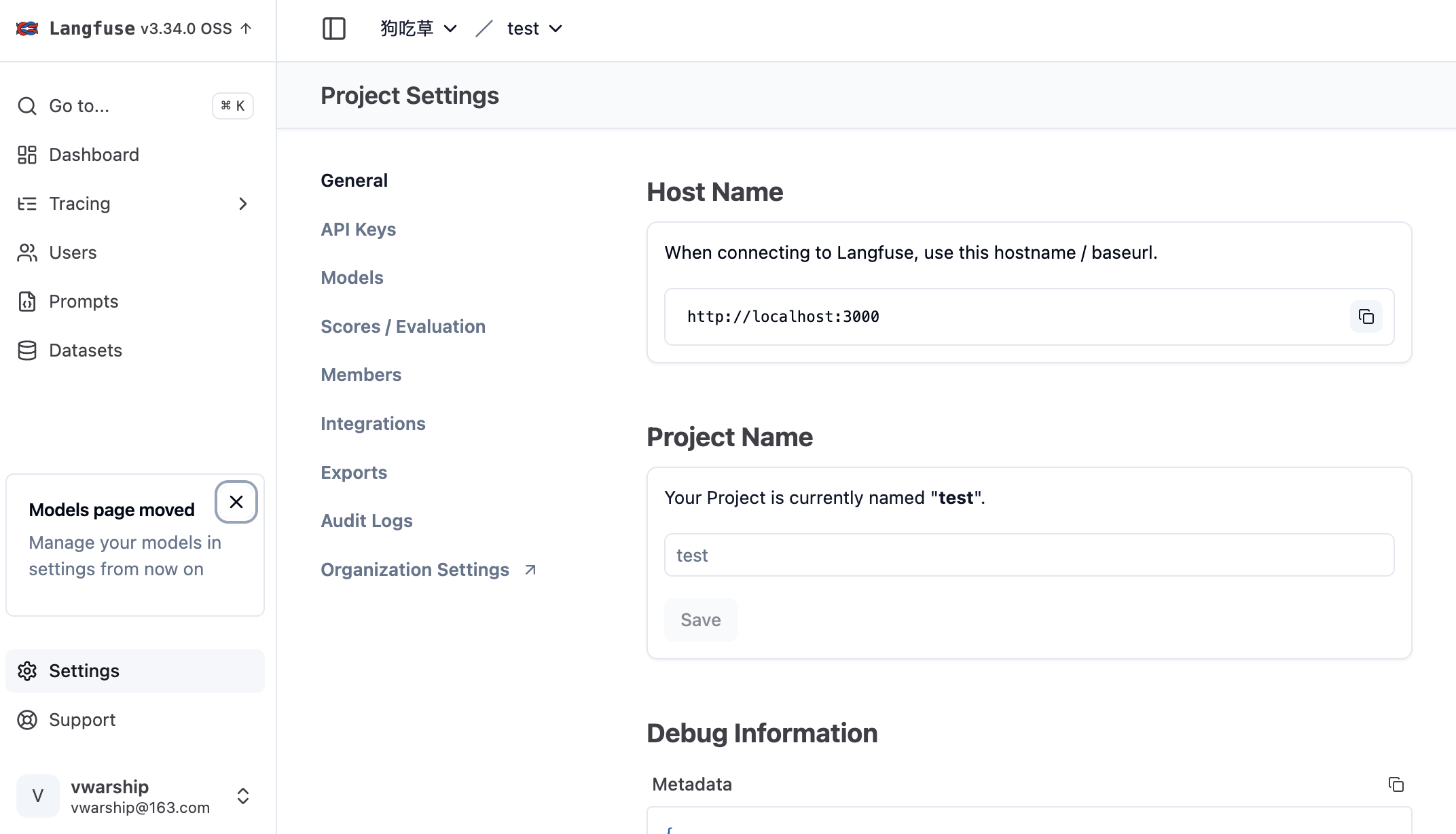
注册用户
浏览器访问 http://localhost:3000/,单击 Sign up 注册一个新账户。
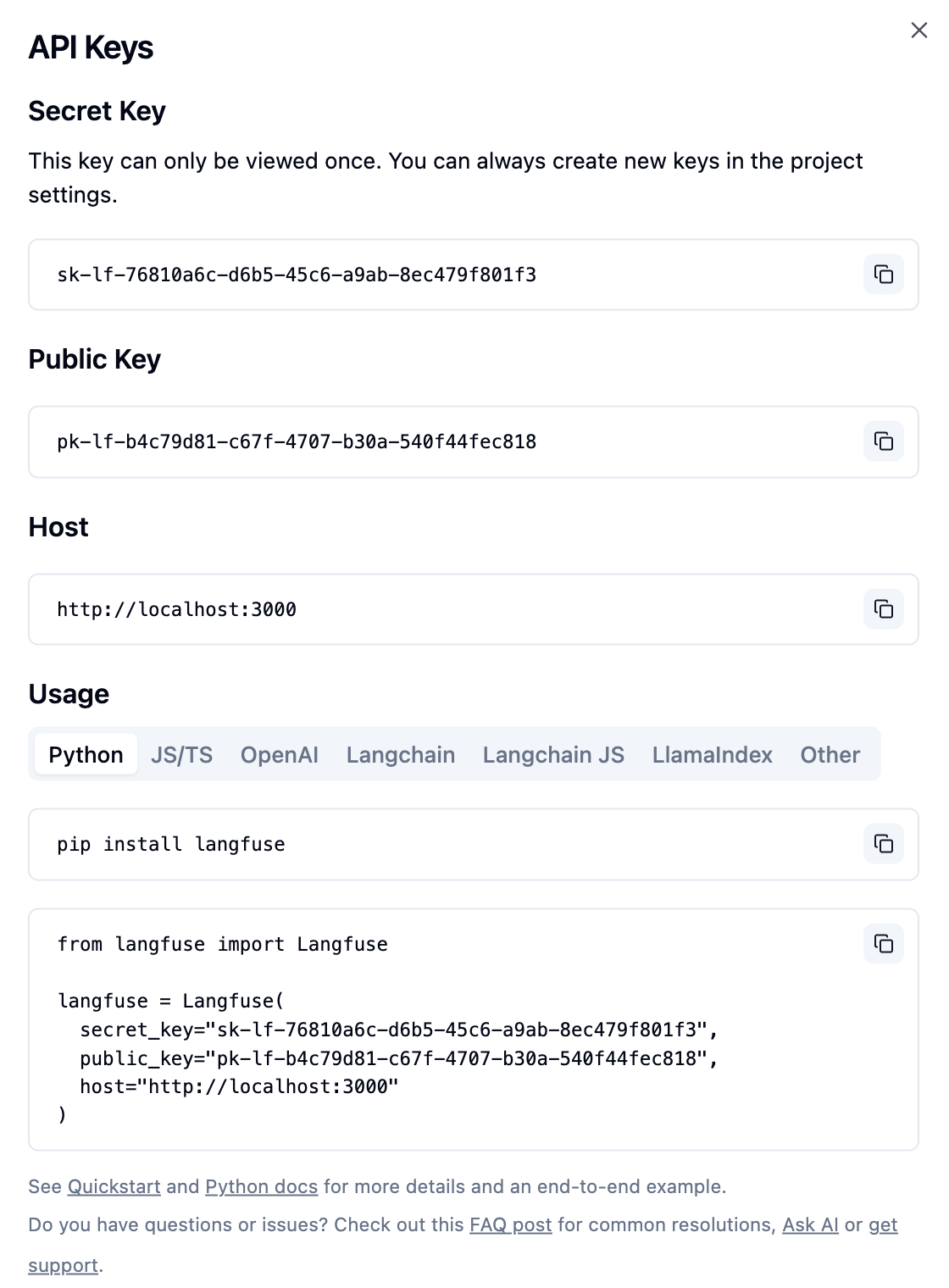
# 模型列表
model_list:
## 语言模型
- model_name: gpt-4
litellm_params:
model: openai/qwen2.5:7b
api_base: http://localhost:11434/v1
api_key: NONE
## 视觉模型
- model_name: gpt-4o
litellm_params:
model: openai/llama3.2-vision
api_base: http://localhost:11434/v1
api_key: NONE
## 代码模型
// ...
lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU: 256
在线 CPU 列表: 0-254
离线 CPU 列表: 255
每个核的线程数: 1
每个座的核数: 64
座: 2
NUMA 节点: 8
厂商 ID: HygonGenuine
BIOS Vendor ID: Chengdu Hygon
CPU 系列: 24
型号: 4
// ...
DCU:Hygon K100_AI 64G X 8
lspci -v | grep -A22 'Co-processor'