利用多张 GPU 训练大语言模型


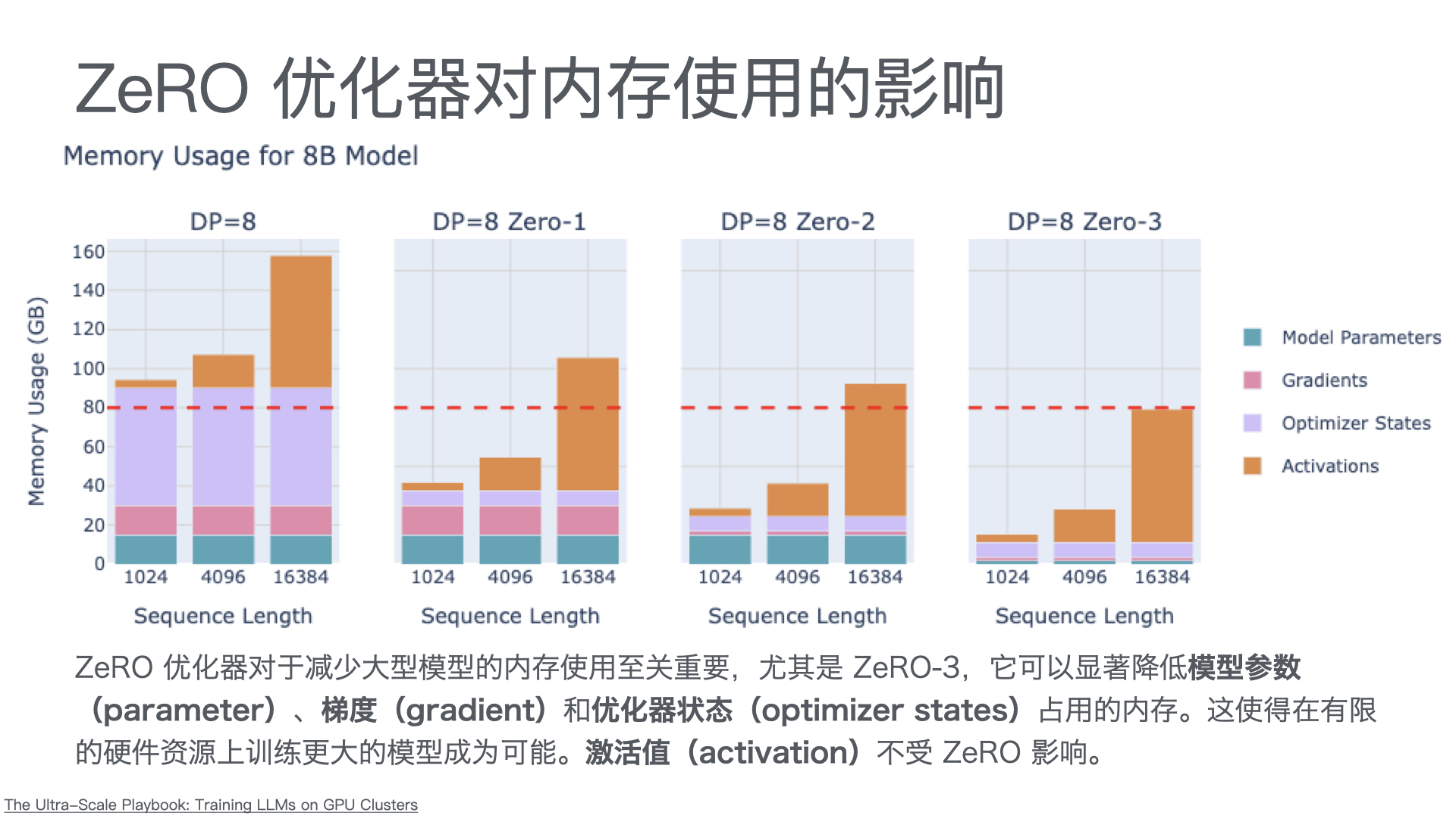
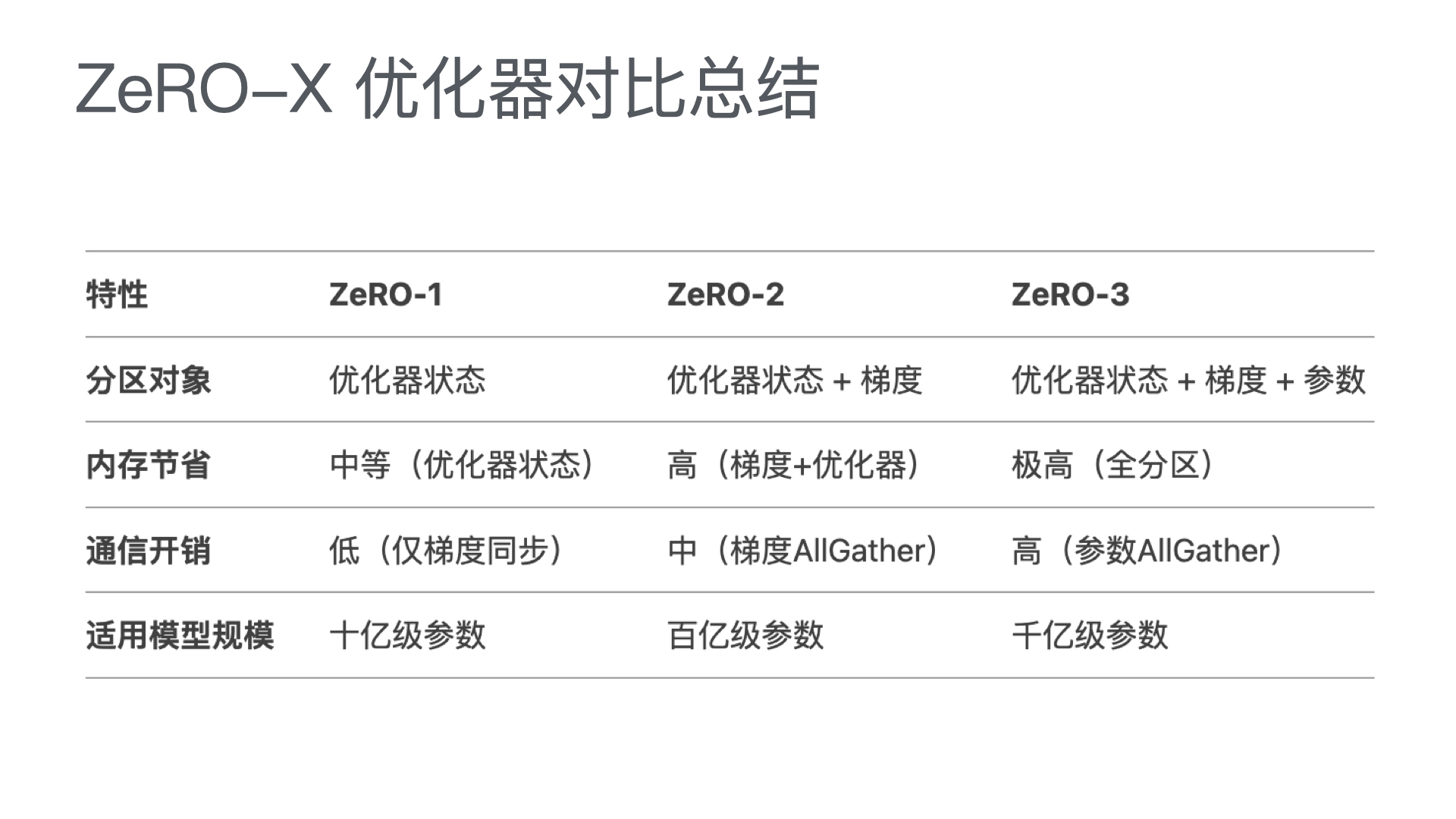
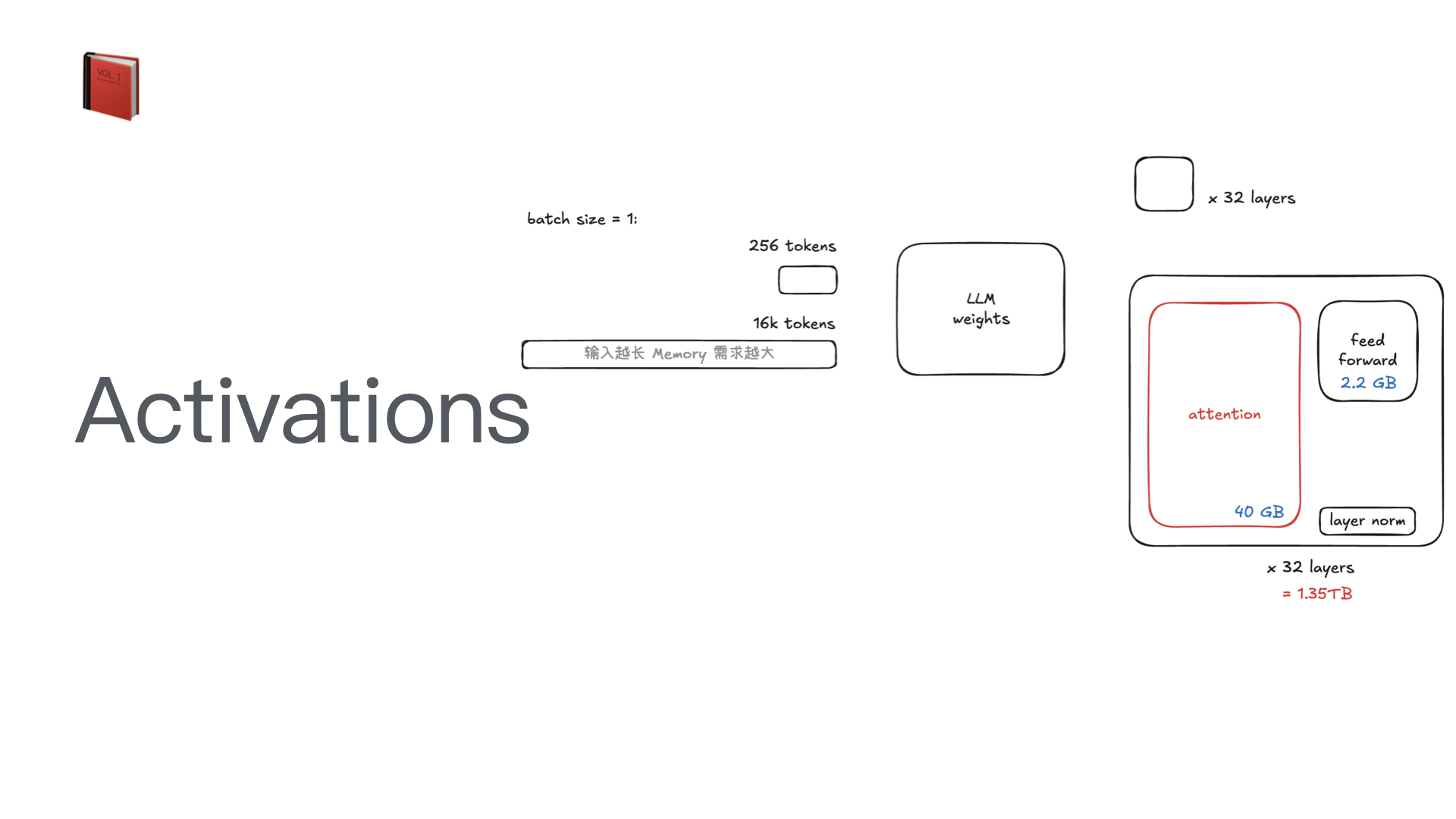
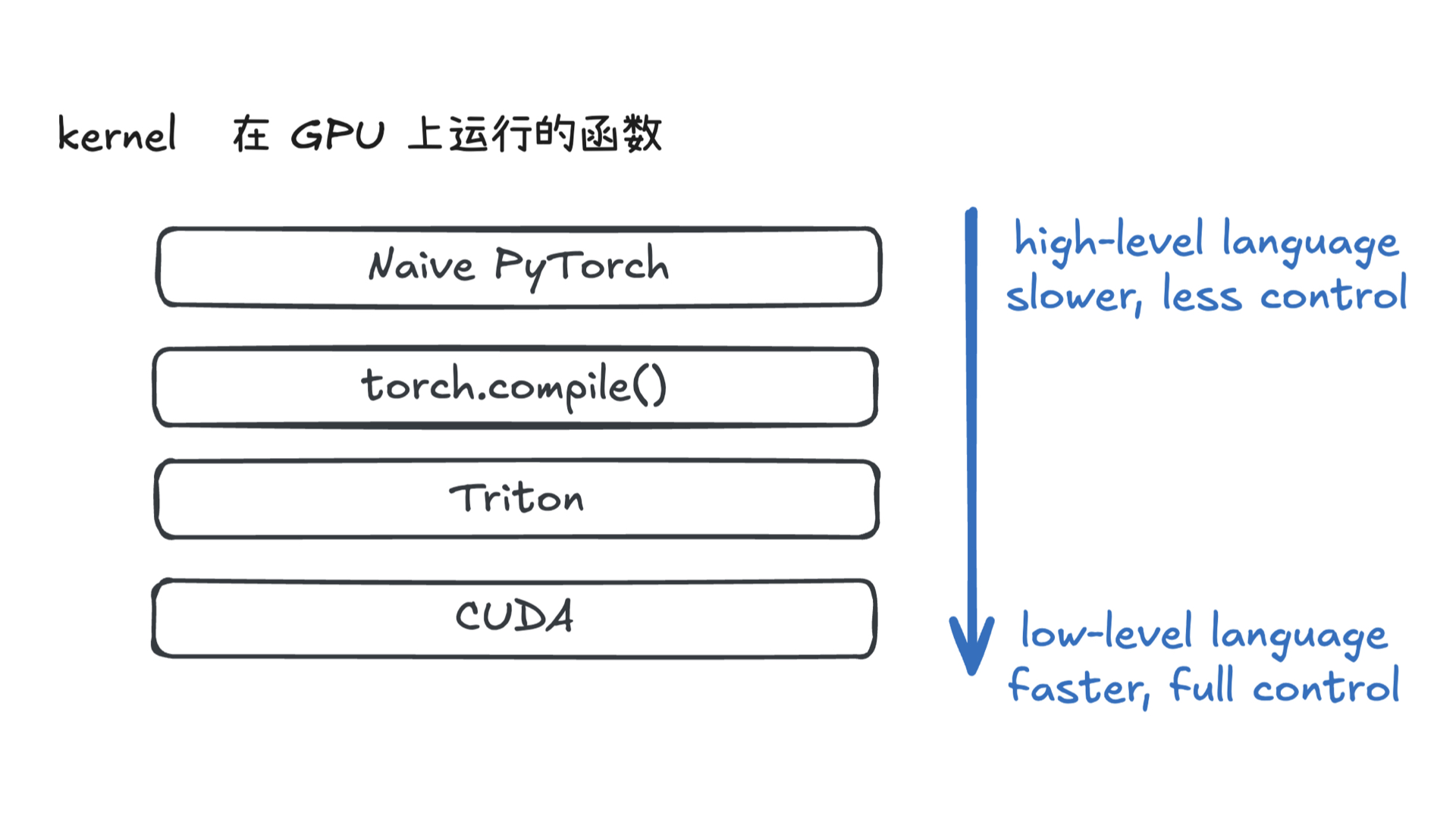
困惑度基于模型对测试集数据的概率,它的值越小,说明模型的性能越好。具体来说,如果一个模型的困惑度为 P,那么当这个模型预测下一个词的时候,它的不确定性(或者说“困惑度”)就相当于在 P 个词中随机选择一个词。
例如,如果一个模型的困惑度为 10,那么这个模型预测下一个词的不确定性就相当于在 10 个词中随机选择一个词。如果另一个模型的困惑度为 5,那么这个模型预测下一个词的不确定性就相当于在 5 个词中随机选择一个词。因此,困惑度越小,模型的性能就越好。
克隆代码
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make LLAMA_CUBLAS=1
--n-gpu-layers 设置 -1 没有效果,设置大一点的数字即可,如:15000
可以从 TheBloke 下载更多不同量化的 GGUF 模型。
python convert-hf-to-gguf.py \
--outtype f32 \
--outfile ~/HuggingFace/wangjunjian/gguf/qwen-7b-chat-f32.gguf \
~/HuggingFace/Qwen/Qwen-7B-Chat
量化 Q5_K_M .