Harness Engineering(驾驭工程):2026 AI 软件工程新范式
Harness Engineering 是 AI 时代的全新软件工程学科 —— 设计和实现系统来约束、引导、验证和修正 AI 智能体的行为,让强大但不可预测的 AI 模型能够可靠地完成复杂任务。
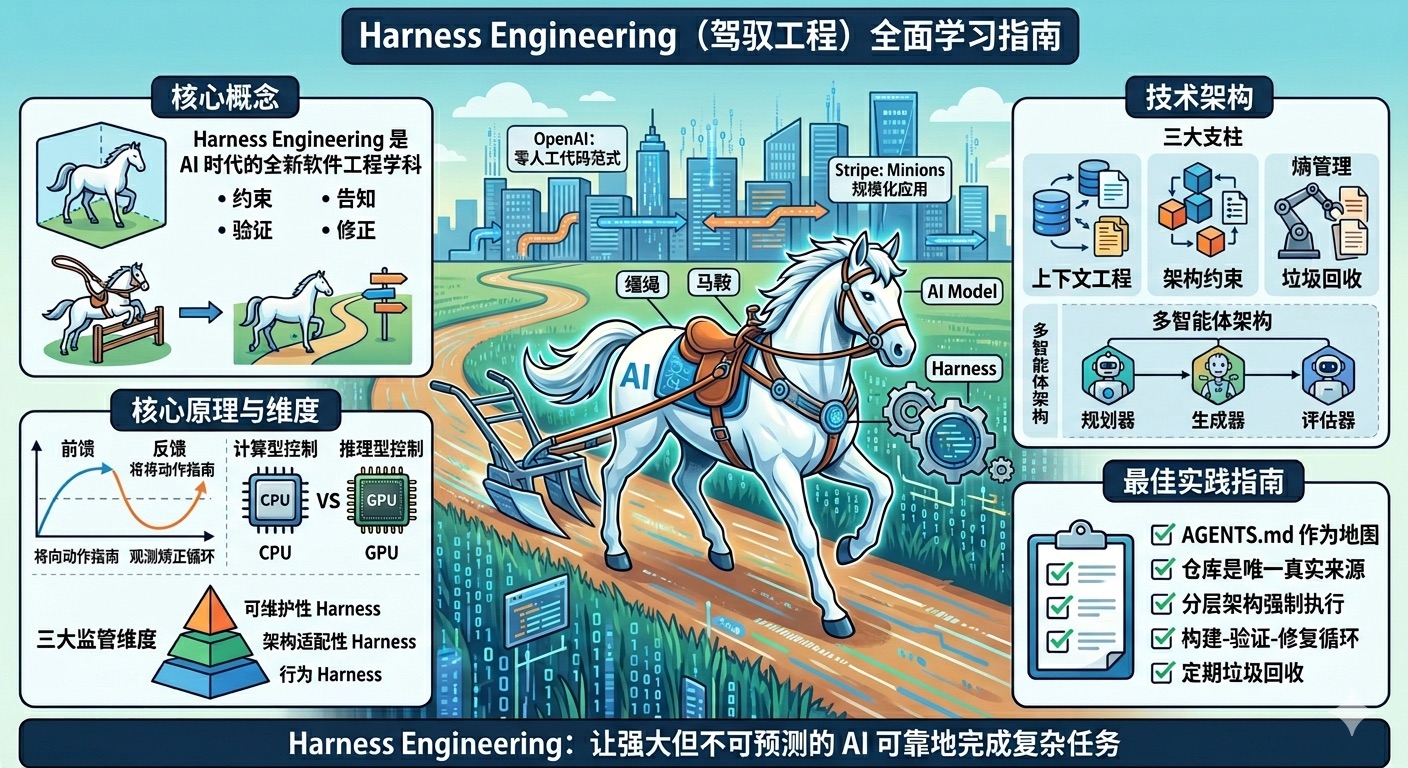
Harness Engineering 是设计和实现系统的学科,这些系统能够:
- 约束:定义 AI 智能体可以做什么(架构边界、依赖规则)
- 告知:告诉智能体应该做什么(上下文工程、文档体系)
- 验证:检查智能体是否正确完成任务(测试、 linting、CI 验证)
- 修正:当智能体出错时引导其自我修复(反馈循环、自我修正机制)
类比:AI 模型是一匹强大但无方向的骏马,Harness 是缰绳、马鞍和全套马具,人类工程师是骑手。没有 Harness 的 AI 是开阔场地里的纯种马——速度快、令人印象深刻,但完全无法用来完成任何实际工作。
AI 行业正在达成一个共识:底层模型的重要性远低于围绕它的系统。LangChain 的实验最能证明这一点:他们的编码智能体在 Terminal Bench 2.0 上的得分从 52.8% 提升到 66.5%,从排名前 30 跃升至前 5 —— 完全没有改动模型,只是优化了 Harness。