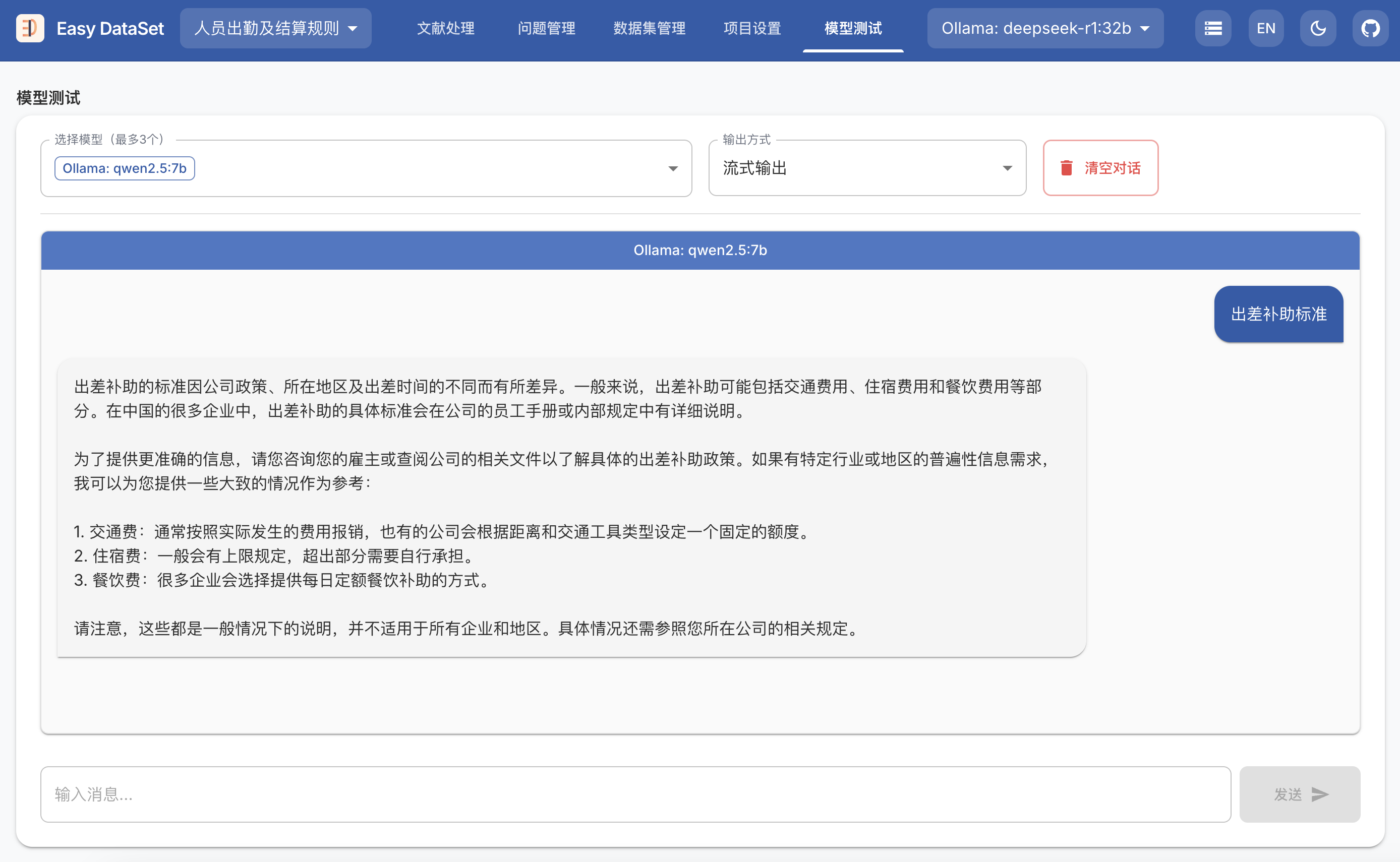
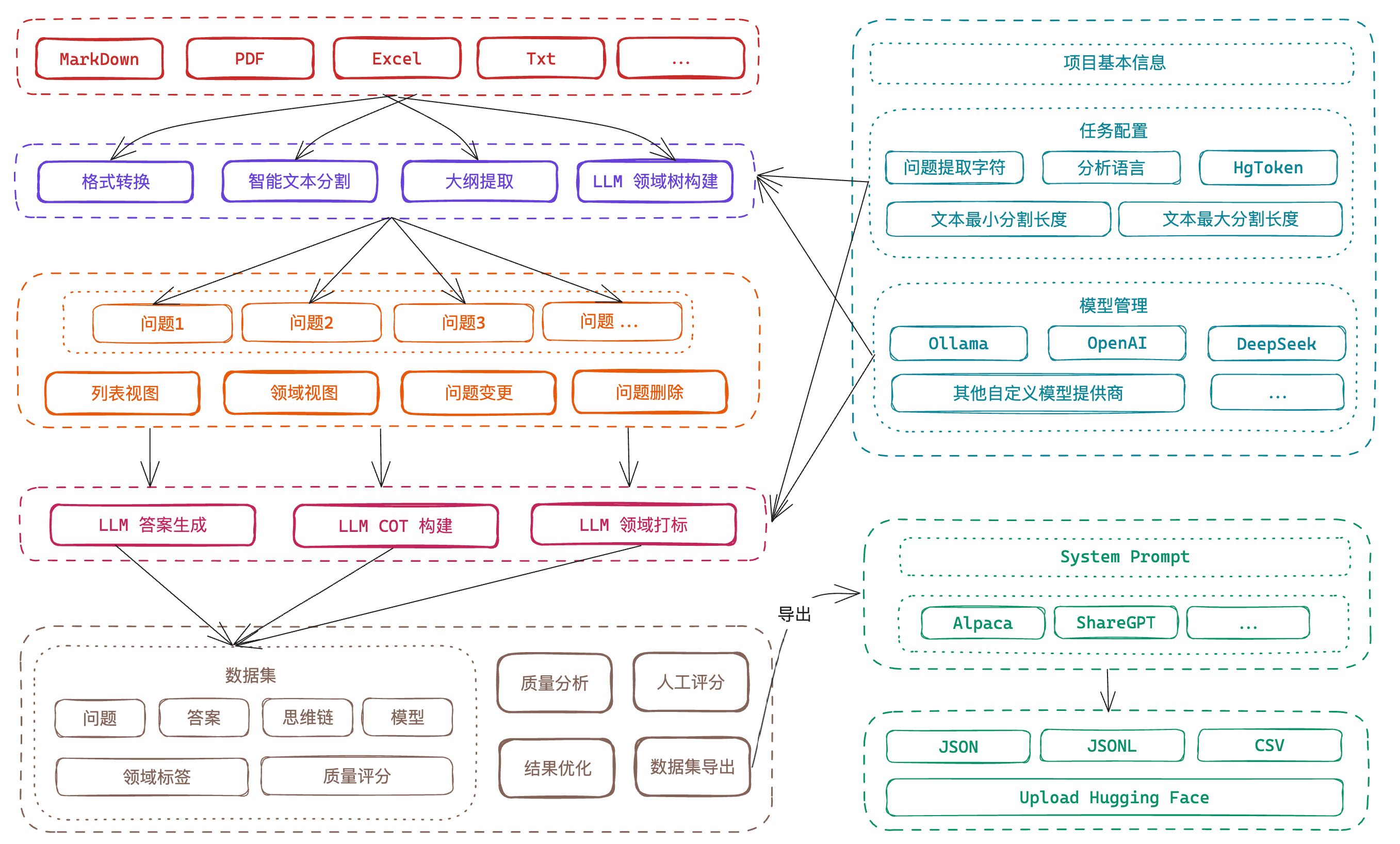
Easy Dataset:基于 LLM 微调数据集的工具
- 克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
- 安装依赖:
npm install
- 启动开发服务器:
npm run build
npm run start
- 打开浏览器并访问
http://localhost:1717
如果你想自行构建镜像,可以使用项目根目录中的 Dockerfile:
- 克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git cd easy-dataset - 构建 Docker 镜像:
docker build -t easy-dataset . - 运行容器:
注意: 请将docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset{YOUR_LOCAL_DB_PATH}替换为你希望存储本地数据库的实际路径。
- 打开浏览器,访问
http://localhost:1717