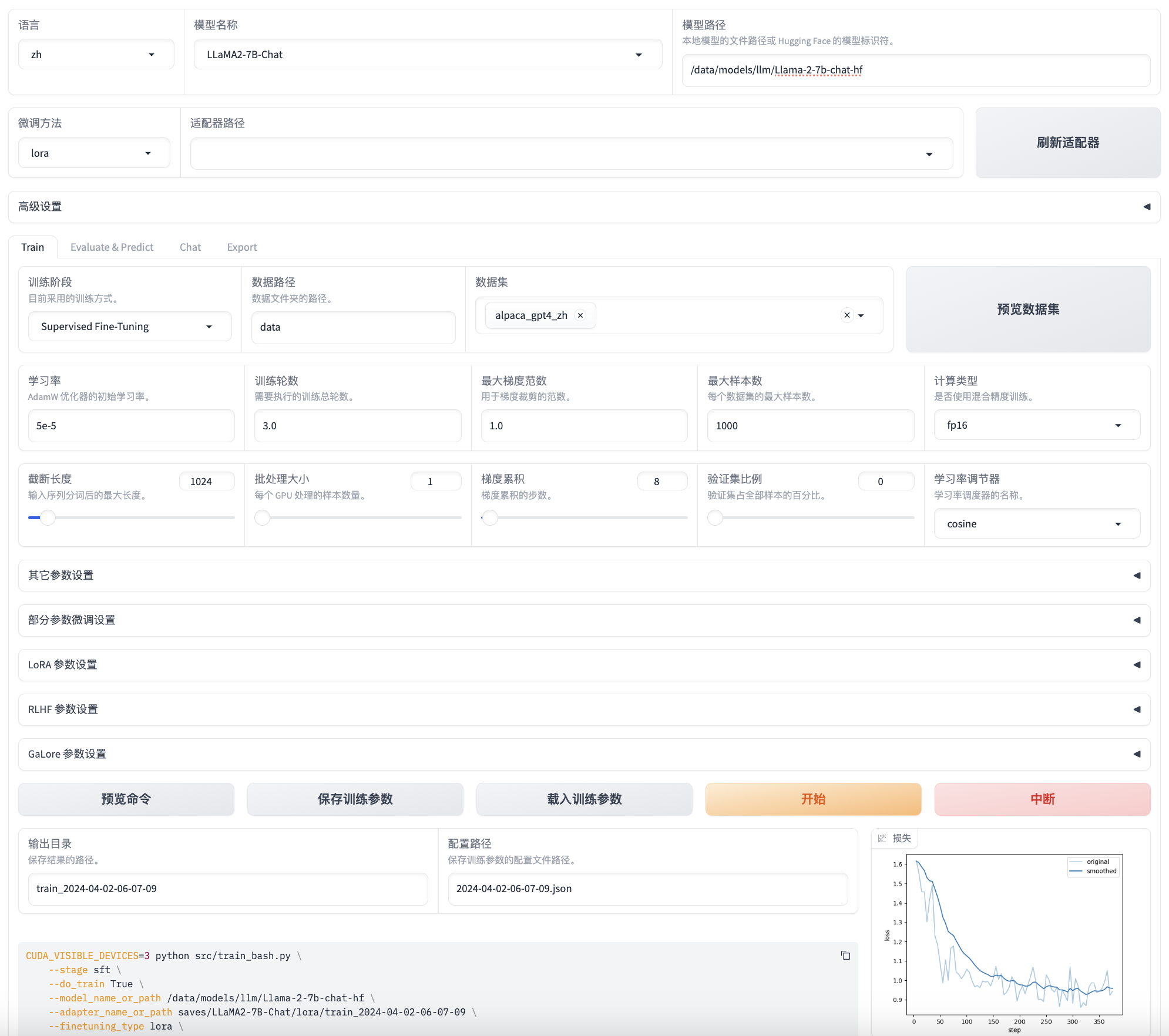
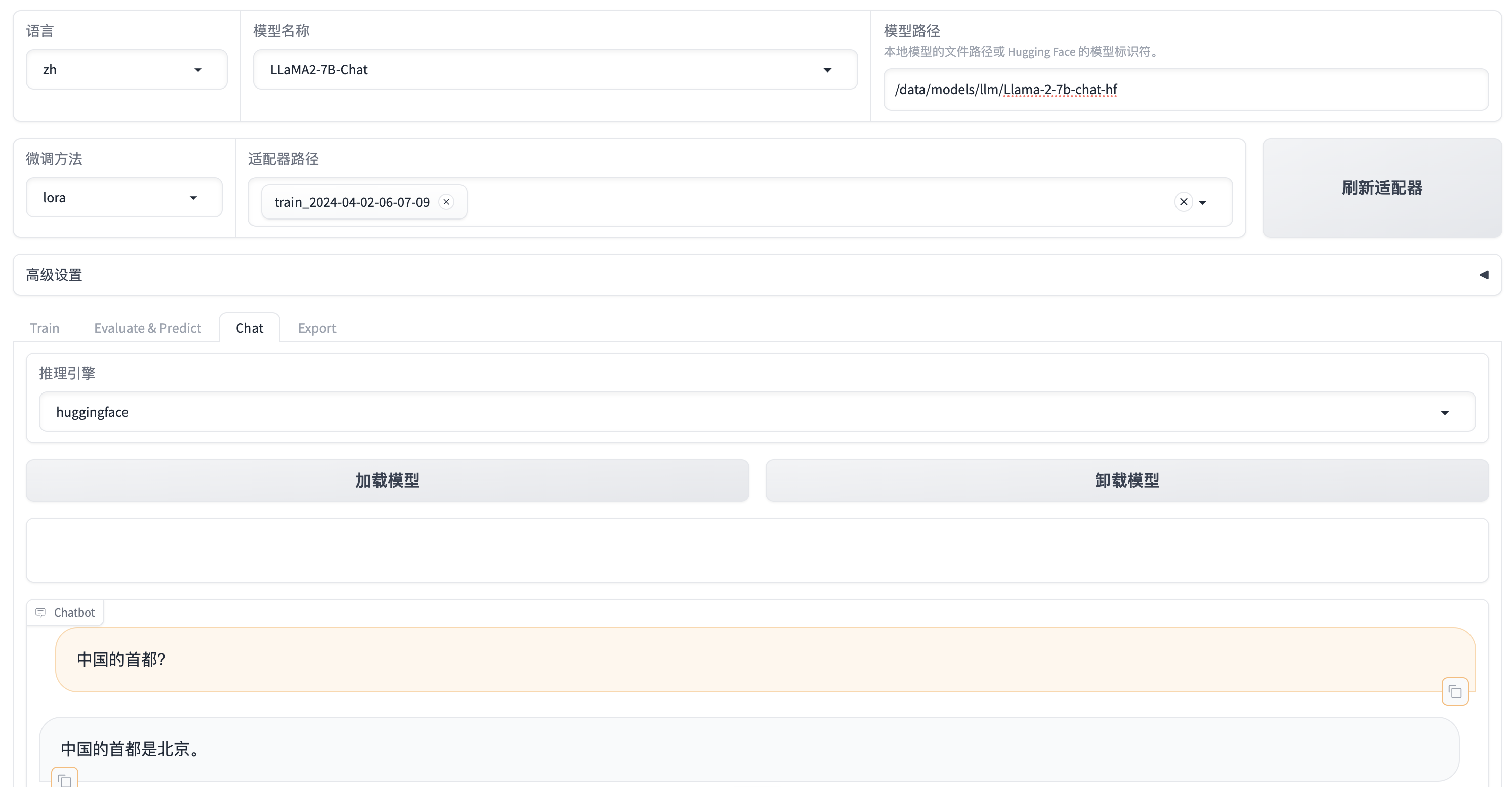
华为 Atlas A2 上使用 LLaMA-Factory 模型微调
- 云资源
- ModelArts
- 开发环境
- Notebook
- 开发环境
- ModelArts
- 自定义镜像:llama2
- 类型:ASCEND
- 规格:Ascend: 8*Ascend910 ARM: 192核 768GB
- 存储配置:云硬盘EVS
- 磁盘规格:200GB
工作目录:/home/ma-user/work
pip install --upgrade modelscope
编辑 download.py 文件
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-7B-Chat')
export MODELSCOPE_CACHE=/home/ma-user/work
python download.py
ll /home/ma-user/work/hub/Qwen/Qwen1___5-7B-Chat
修改配置文件:Qwen/Qwen1___5-7B-Chat/config.json
{
"torch_dtype": "float16",
}
NPU 不支持 bfloat16,模型配置文件需要修改为 float16。
git clone https://github.com/hiyouga/LLaMA-Factory
❌ 网络不稳定,多试几次。