LLaMA Factory: Easy and Efficient LLM Fine-Tuning
- pip
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
python -m venv env
source env/bin/activate
pip install -e .[metrics]
- conda
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt
使用 conda 第二次没有安装成功
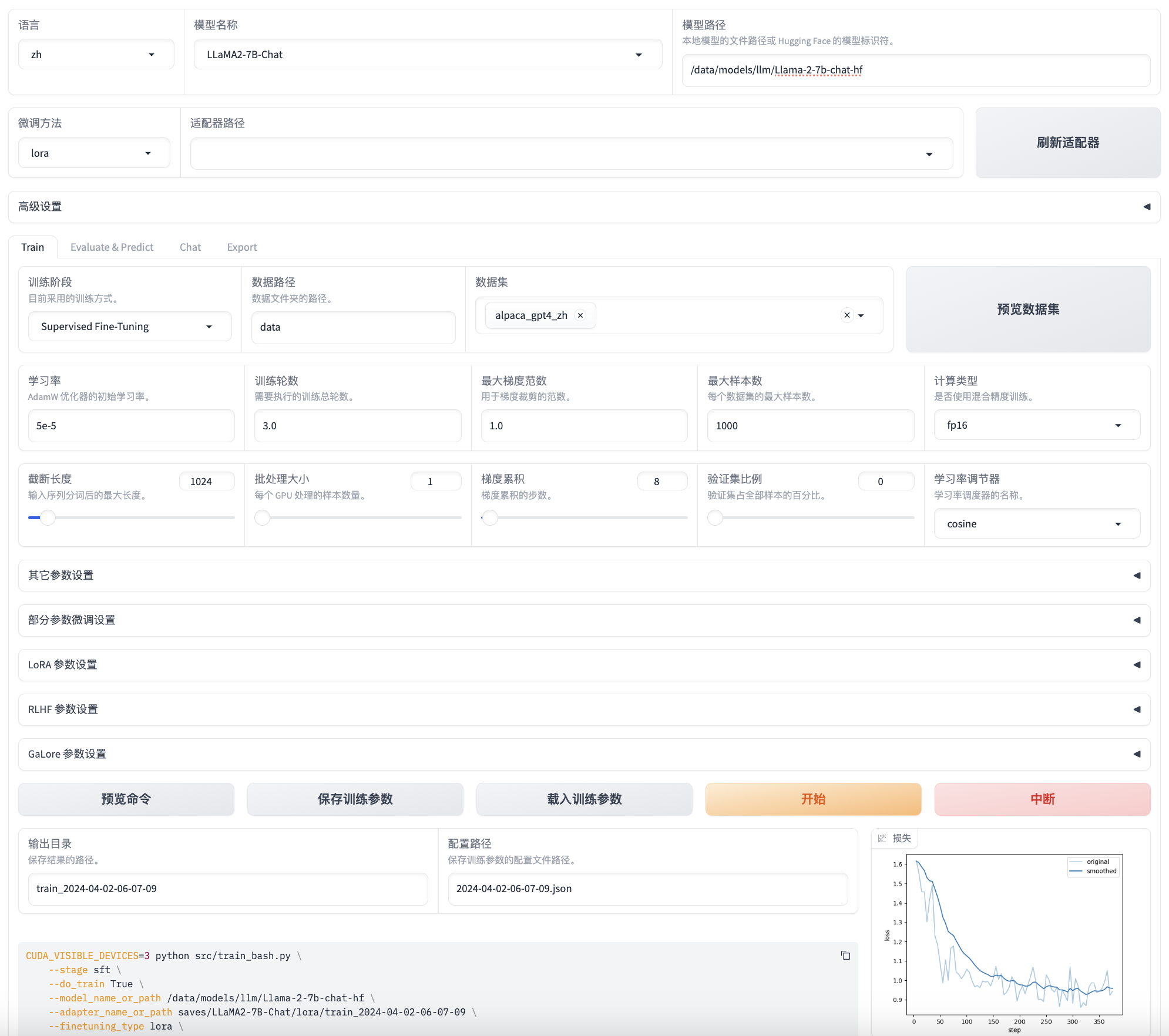
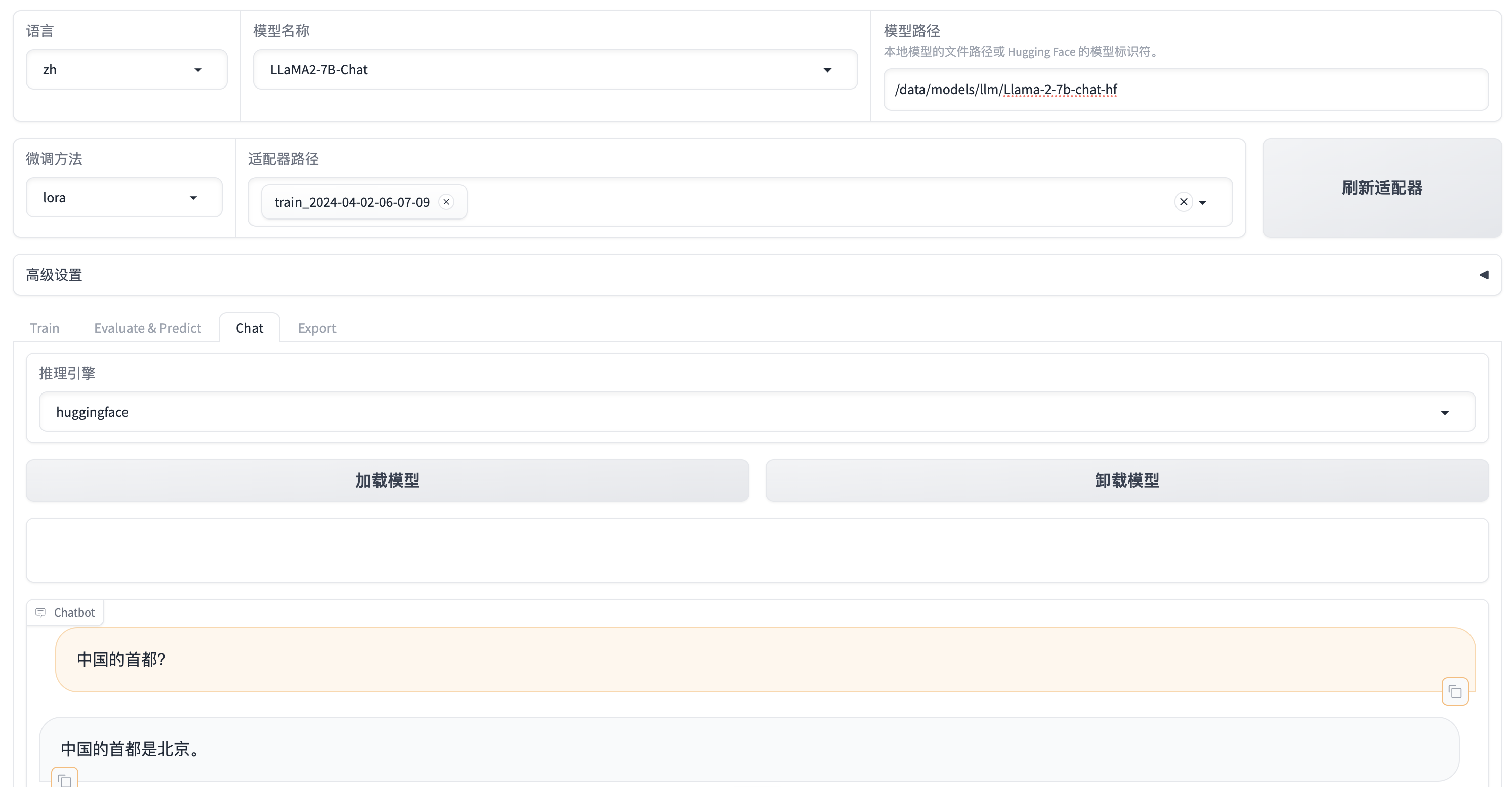
CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 python src/train_web.py
- CUDA_VISIBLE_DEVICES=0: 指定 GPU
- USE_MODELSCOPE_HUB=1: 使用魔搭社区的模型和数据集下载