vLLM 推理性能优化实验与分析
该文章详细探讨了如何通过优化vLLM框架来提升Qwen3-4B大型语言模型在Tesla T4 GPU上的推理性能。实验中,我评估了不同配置对关键性能指标的影响,包括首次生成Token时间(TTFT)、端到端延迟(E2EL)和请求吞吐量。结果表明,结合前缀缓存(prefix caching)、分块预填充(chunked prefill)以及调整批处理Token数量(max-num-batched-tokens=8192)能显著改善模型性能。尤其在模拟Agent场景下的自定义数据集测试中,这些优化措施成功将TTFT大幅降低约64%,同时提升了请求和输出Token的吞吐量。最终,文章提供了一套推荐的最佳vLLM部署配置,旨在最大化长上下文模型的推理效率和用户体验。
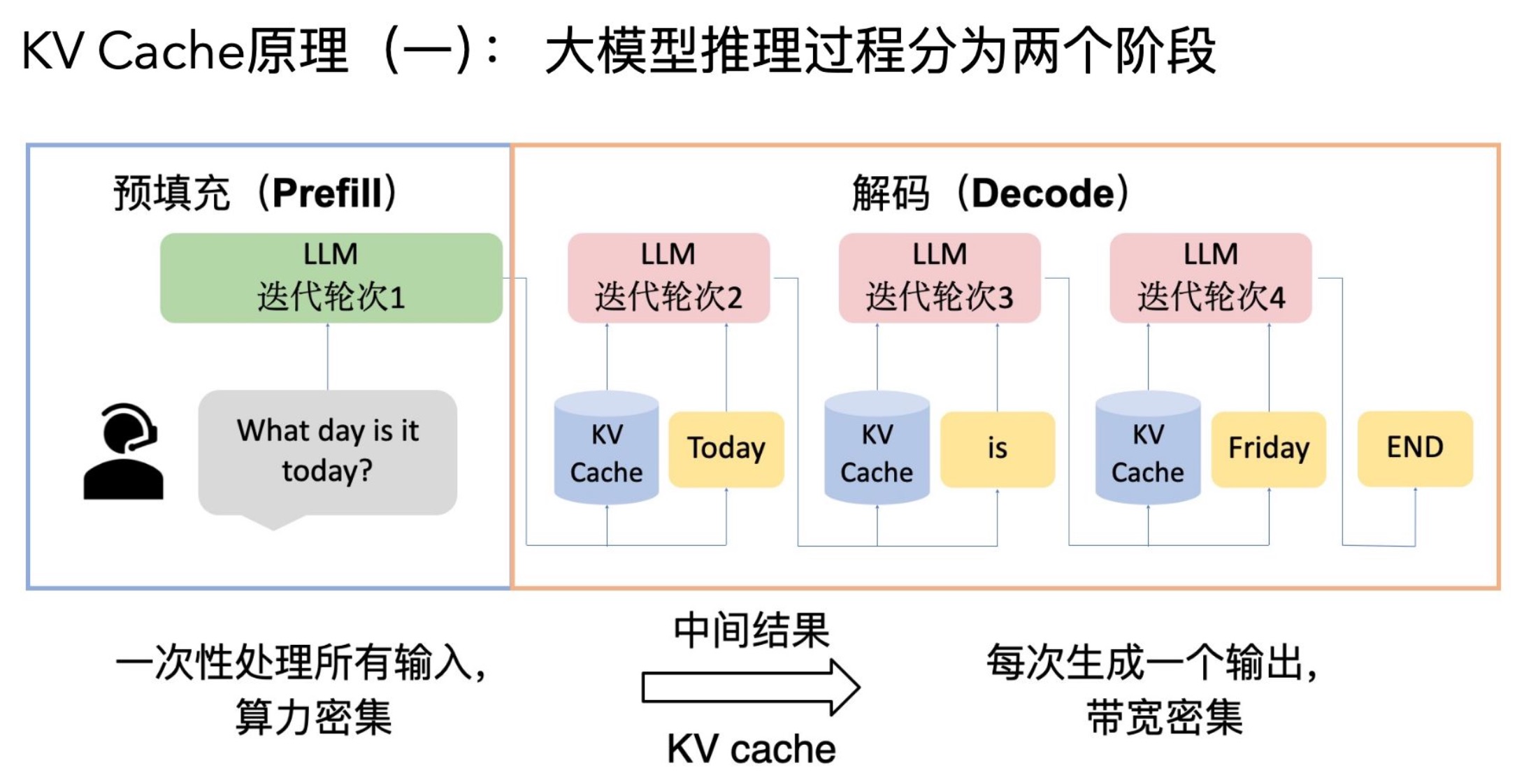
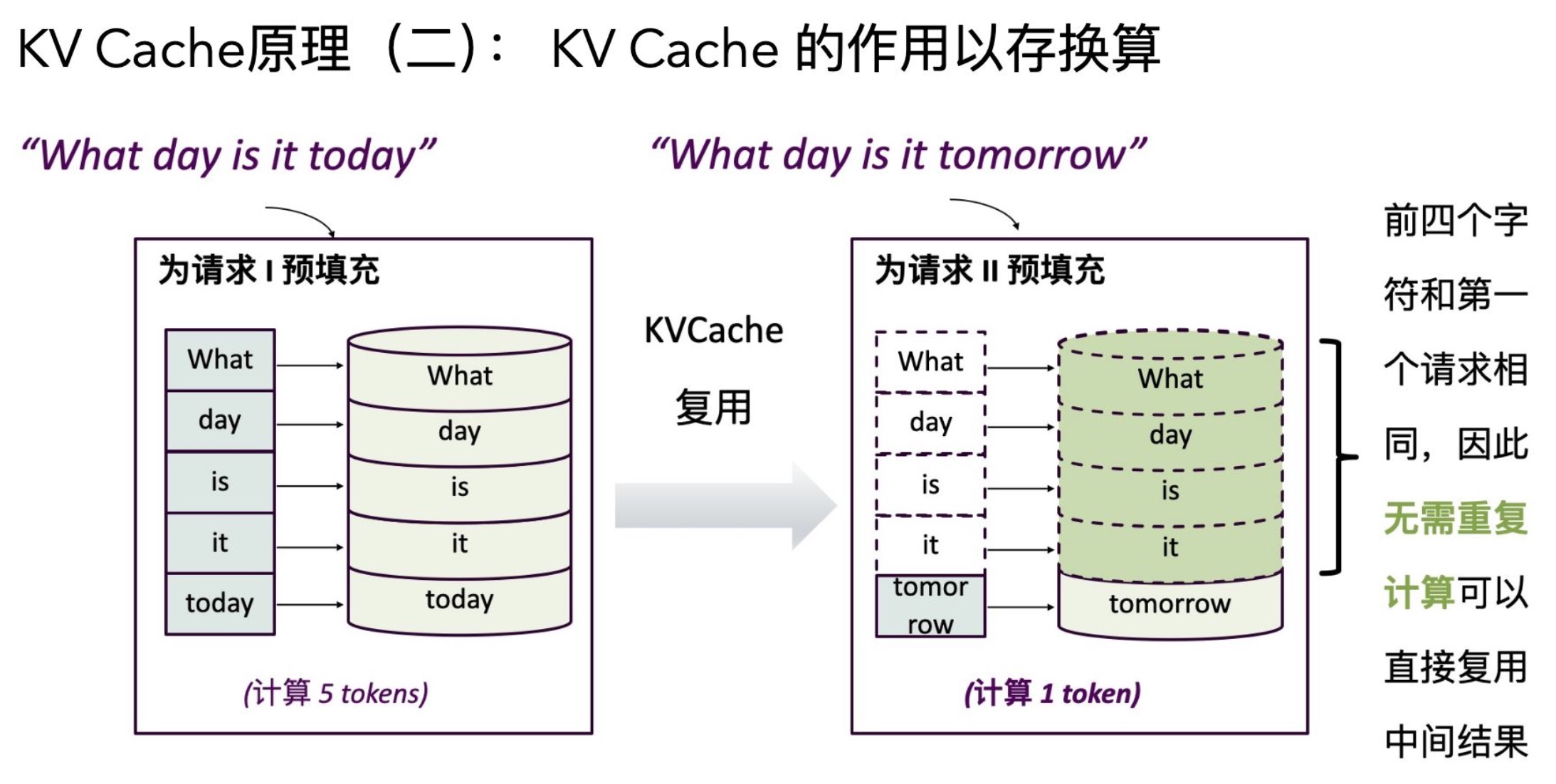
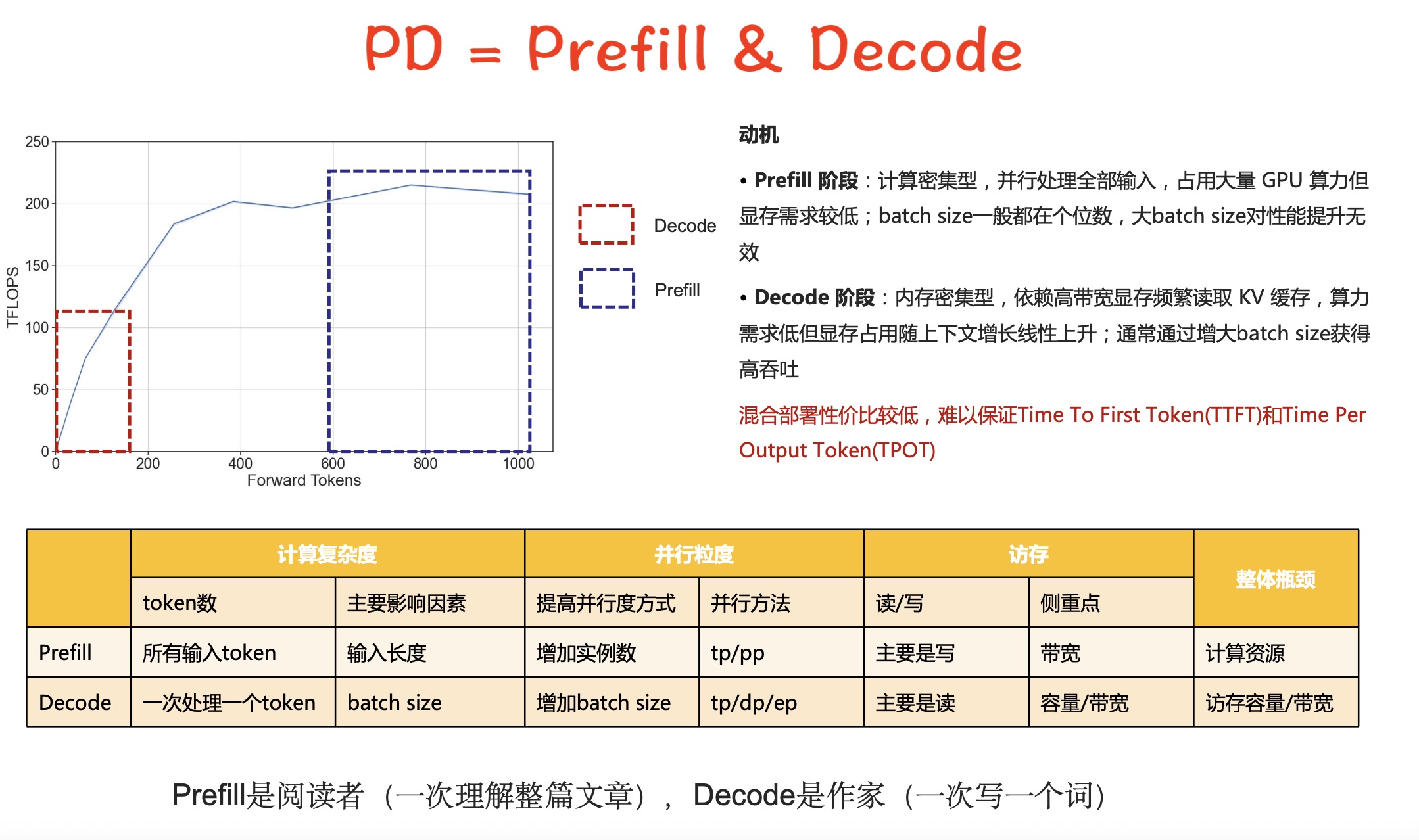
Prefill 阶段是指模型在生成任务开始时,将输入 prompt(提示词)全部送入模型,并填充(prefill)KV Cache(键值缓存)。这个阶段通常只在生成的第一个 token 前进行。
主要作用:将所有 prompt token 送入模型,建立好 KV Cache,为后续高效 decode 做准备。 在 vLLM 里,prefill 可以独立出来(Disaggregated Prefill),甚至由独立的实例来执行,prefill 完成后把 KV Cache 通过网络/进程传给 decode 节点。