“什么是代理?”
几乎每天都会有人问我这个问题。在 LangChain,我们构建工具来帮助开发者构建 LLM 应用程序,特别是那些充当推理引擎并与外部数据和计算源交互的应用程序。这包括通常被称为“代理”的系统。
每个人似乎对代理都有稍微不同的定义。我的定义可能比大多数人更技术性:
💡 代理是一个使用 LLM 来决定应用程序控制流的系统。
即使在这里,我也承认我的定义并不完美。人们通常认为代理是高级的、自主的、类人的——但如果是一个简单的系统,LLM 在两个不同路径之间进行路由呢?这符合我的技术定义,但不符合人们对代理应具备能力的普遍看法。很难准确定义什么是代理!
这就是为什么我非常喜欢 Andrew Ng 上周的推文。在推文中,他建议“与其争论哪些工作应被包括或排除为真正的代理,我们可以承认系统可以有不同程度的代理性。”就像自动驾驶汽车有不同的自动化级别一样,我们也可以将代理能力视为一个光谱。我非常同意这个观点,我认为 Andrew 表达得很好。将来,当有人问我什么是代理时,我会转而讨论什么是“代理性”。
去年我在 TED 演讲中谈到了 LLM 系统,并使用下面的幻灯片讨论了 LLM 应用程序中存在的不同自主级别。
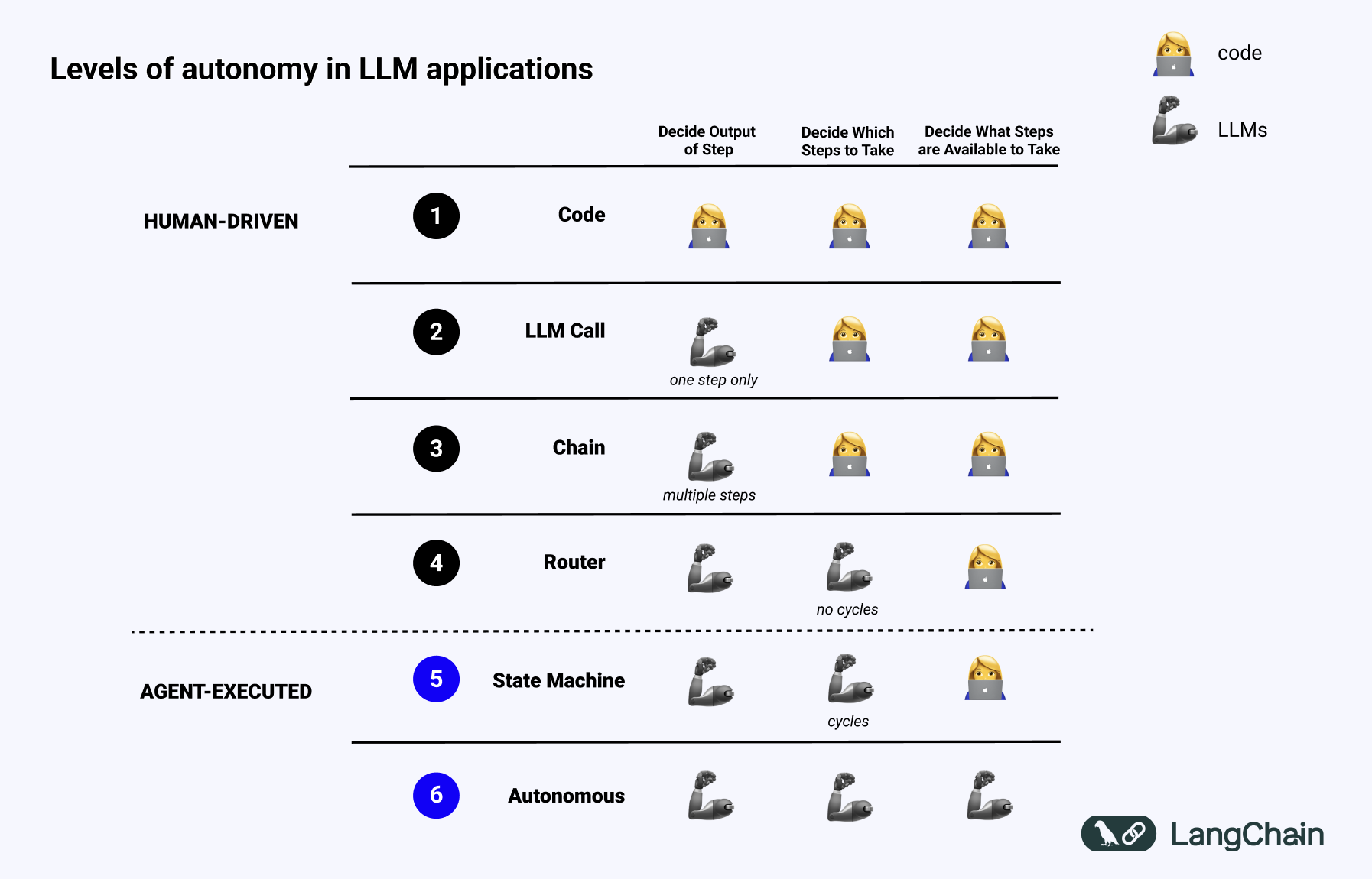
一个系统越“代理性”,LLM 决定系统行为的程度就越高。
使用 LLM 将输入路由到特定的下游工作流中具有一些小的“代理性”行为。这将属于上图中的路由器类别。