硅谷 101:物理 AI

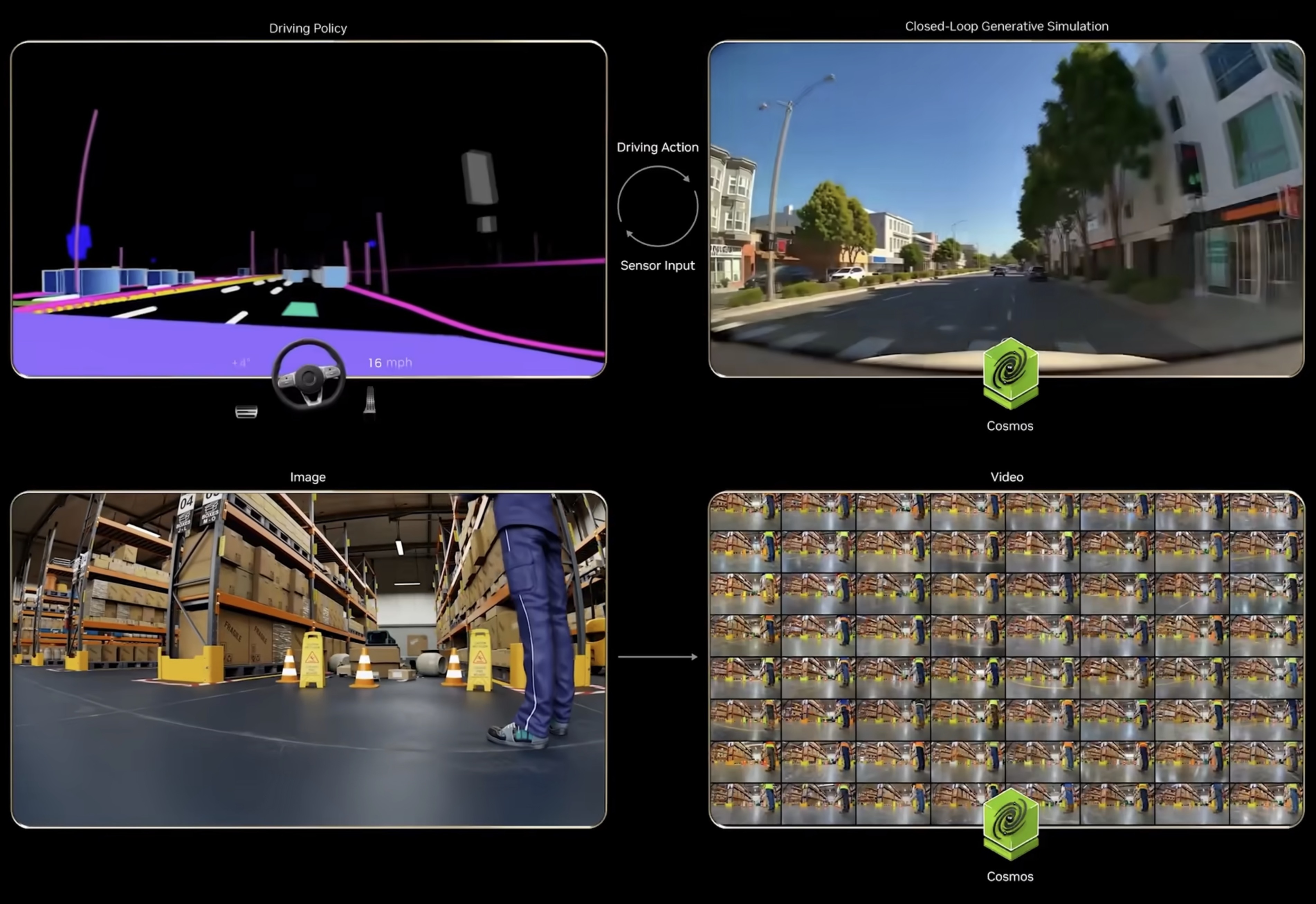



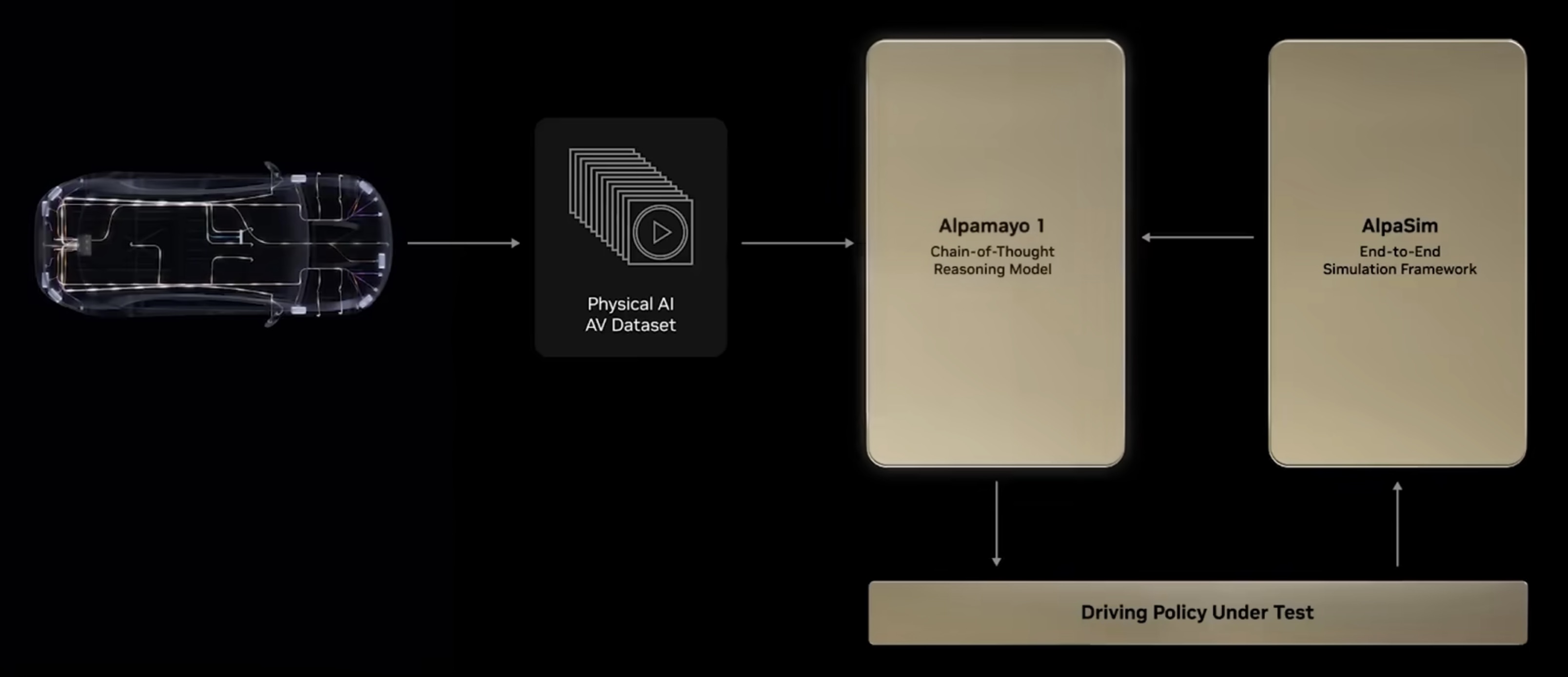
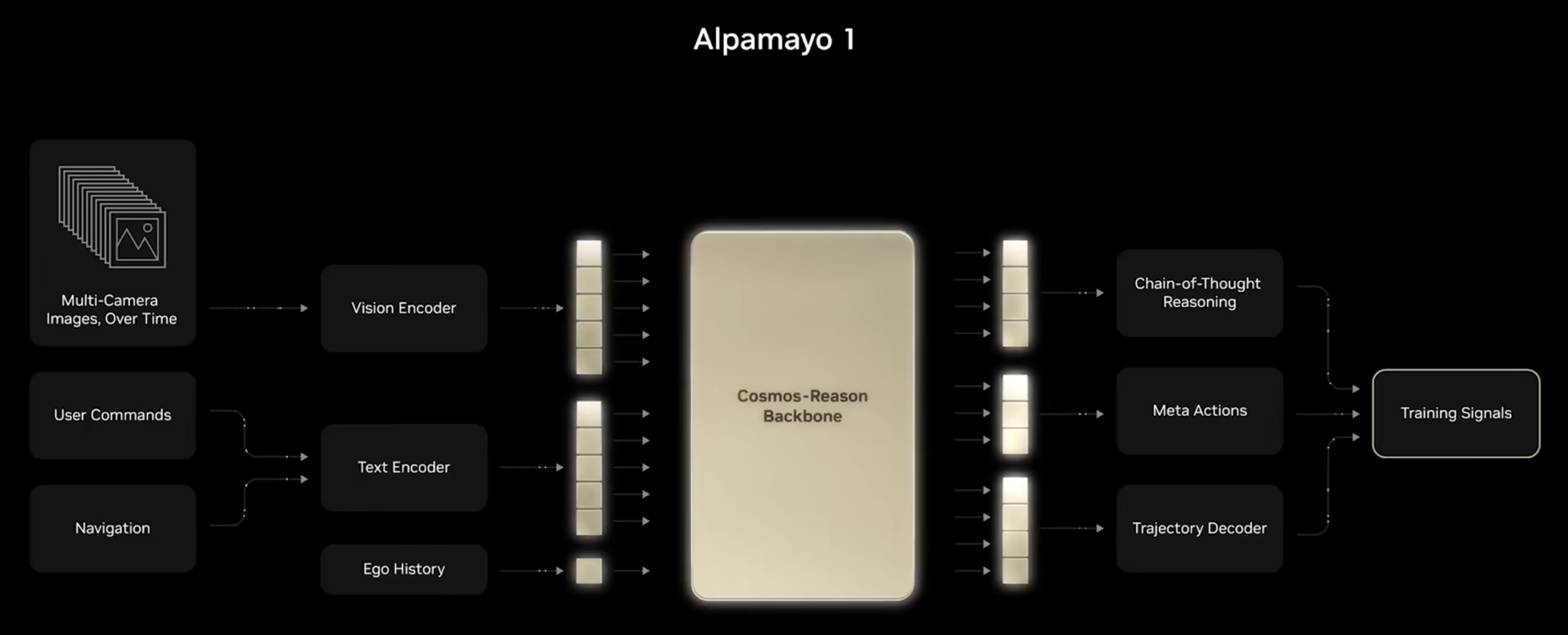








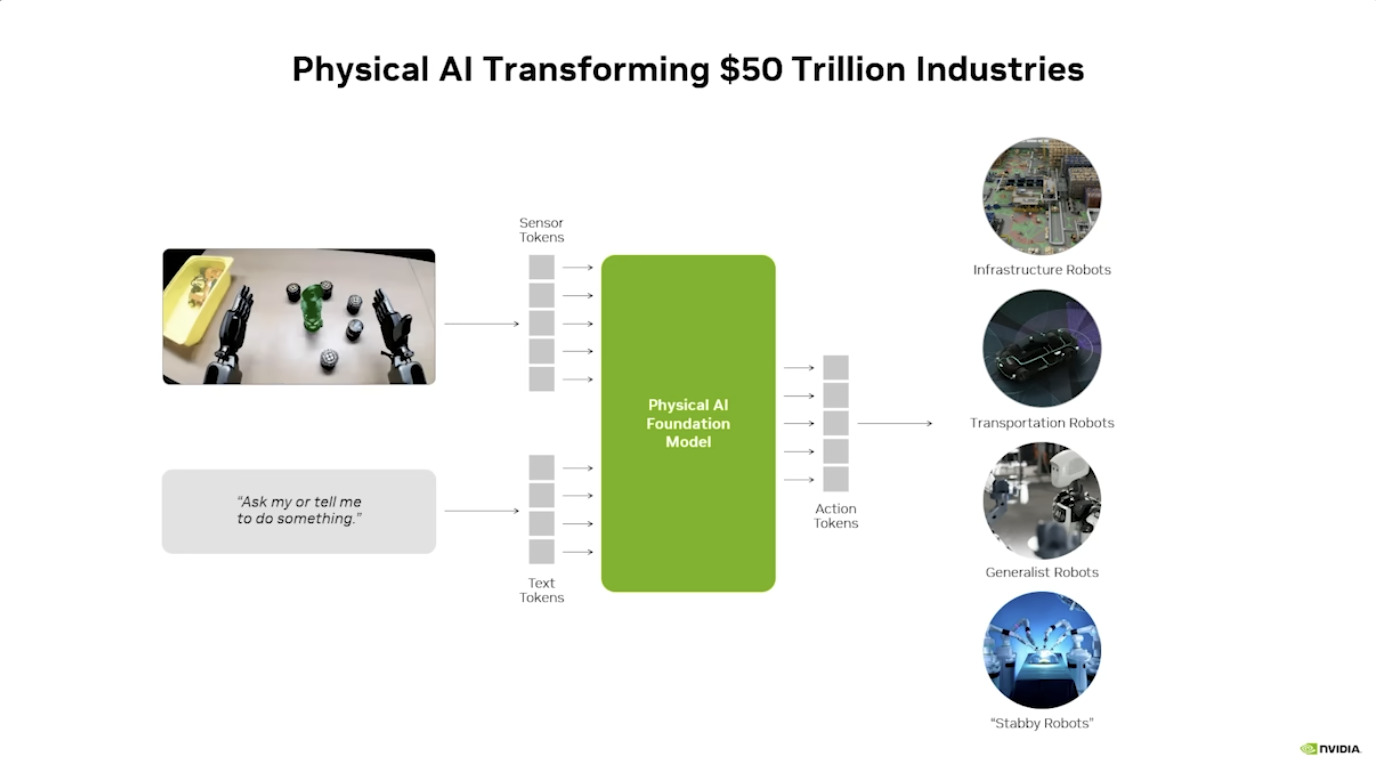
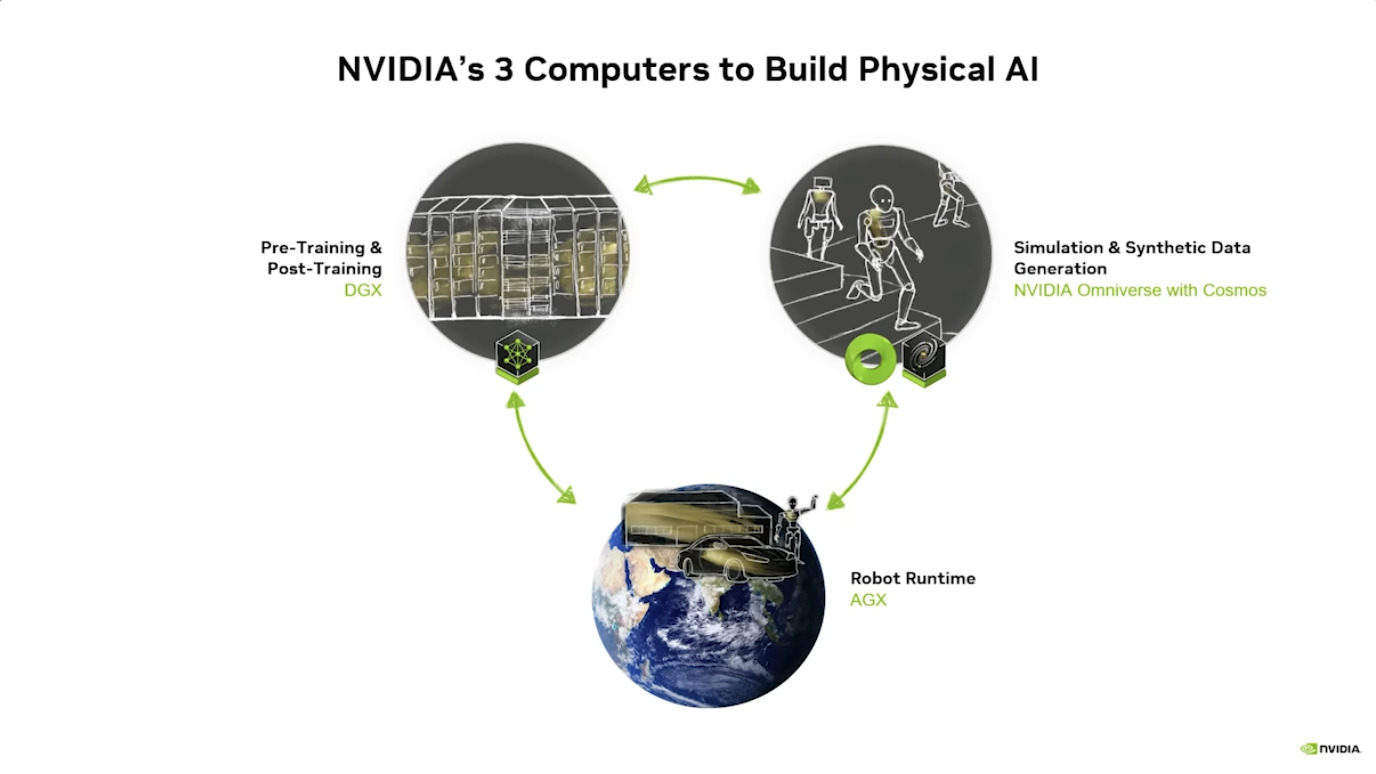
NVIDIA 正致力于打造全栈物理AI(Physical AI)平台,推动人工智能从数字领域向理解并交互物理世界跨越。该平台的核心由 Cosmos 世界模型、Omniverse 模拟环境以及针对机器人(GROOT)和自动驾驶(Alpamayo)的专属模型组成。
在硬件层面,NVIDIA 推出了突破性的 Vera Rubin 架构。其中,Rubin GPU 拥有 3360 亿个晶体管,其推理性能达到 Blackwell 的 5 倍;Vera CPU 则配备 88 个定制内核,显著提升了系统内存带宽。配合 BlueField-4 DPU 和 NVLink 6 技术,NVIDIA 构建了能够支持海量算力需求的 AI 基础设施。
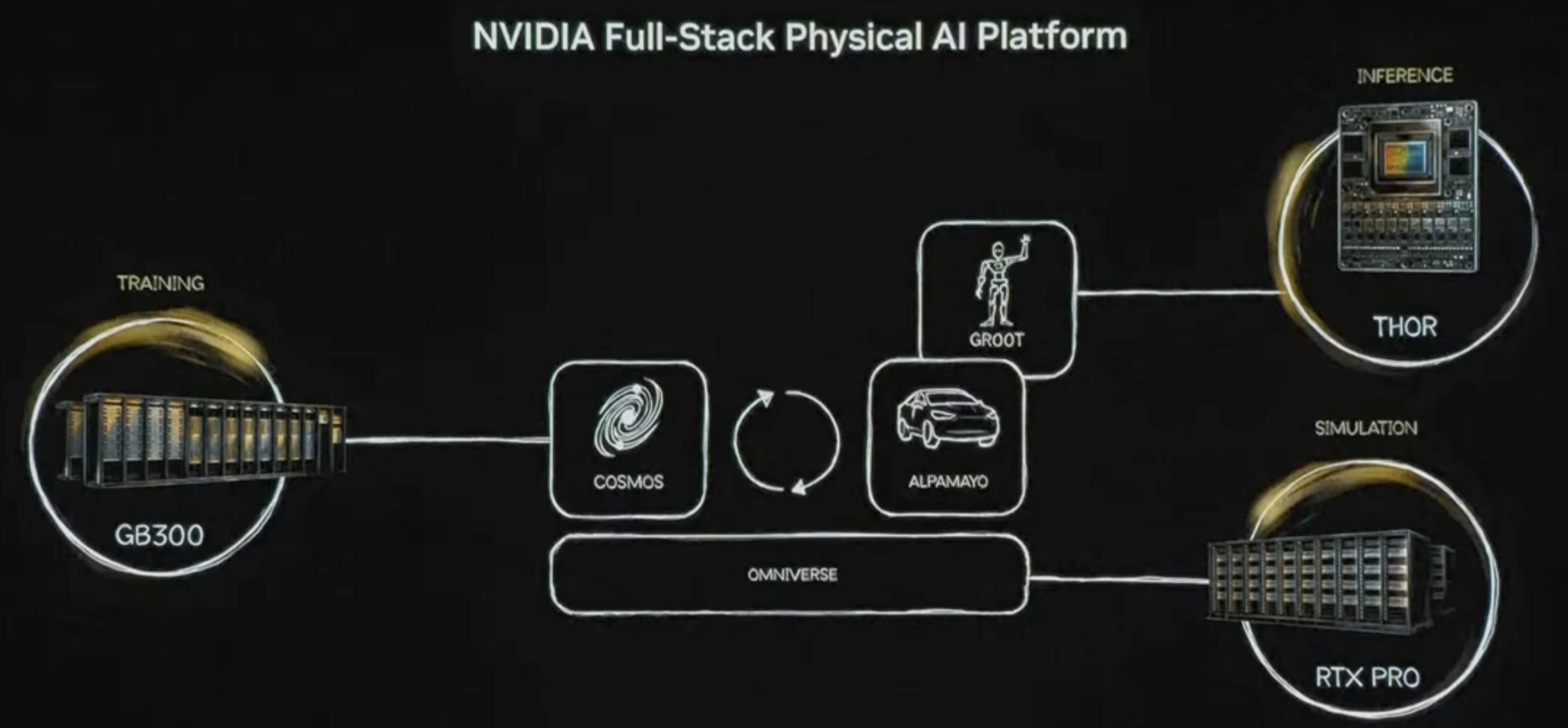
NVIDIA Omniverse:是 NVIDIA 推出的、基于 OpenUSD 的实时 3D 开发与协作平台,核心用于构建大规模 3D 应用、工业数字孪生及物理 AI 仿真,依托 RTX 渲染与 GPU 加速,实现跨工具互操作、实时协作与高保真模拟,支持云边端灵活部署。 NVIDIA Cosmos:这是一款为物理 AI 设计的世界基础模型(World Foundation Model)。它能理解物理定律(如重力、惯性、碰撞),并能将合成数据(Synthetic Data)转化为训练 AI 的高质量数据,解决物理世界数据稀缺的问题。
git clone https://github.com/ggml-org/whisper.cpp.git
cd whisper.cpp
cmake -B build -DGGML_CUDA=1 -DCMAKE_CUDA_ARCHITECTURES="110"
cmake --build build -j --config Release
sh ./models/download-ggml-model.sh small
sh ./models/download-ggml-model.sh large-v3-turbo
./build/bin/whisper-cli -f samples/jfk.wav
./build/bin/whisper-cli -m /models/whisper.cpp/models/ggml-large-v3-turbo.bin -f samples/jfk.wav
iw list | grep "AP"
Device supports AP-side u-APSD.
* AP
HE Iftypes: AP
Rx HE MU PPDU from Non-AP STA
HE Iftypes: AP
Rx HE MU PPDU from Non-AP STA
* AP: 0x00 0x10 0x20 0x30 0x40 0x50 0x60 0x70 0x80 0x90 0xa0 0xb0 0xc0 0xd0 0xe0 0xf0
* AP/VLAN: 0x00 0x10 0x20 0x30 0x40 0x50 0x60 0x70 0x80 0x90 0xa0 0xb0 0xc0 0xd0 0xe0 0xf0
* AP: 0x00 0x20 0x40 0xa0 0xb0 0xc0 0xd0
* AP/VLAN: 0x00 0x20 0x40 0xa0 0xb0 0xc0 0xd0
Maximum associated stations in AP mode: 32
AP 字样,则不支持 AP 模式。sudo nmtui 并选择“编辑一个连接”。nmtui 主菜单中,确保选中“Edit a connection”选项。<OK> 键。添加一个新的连接。
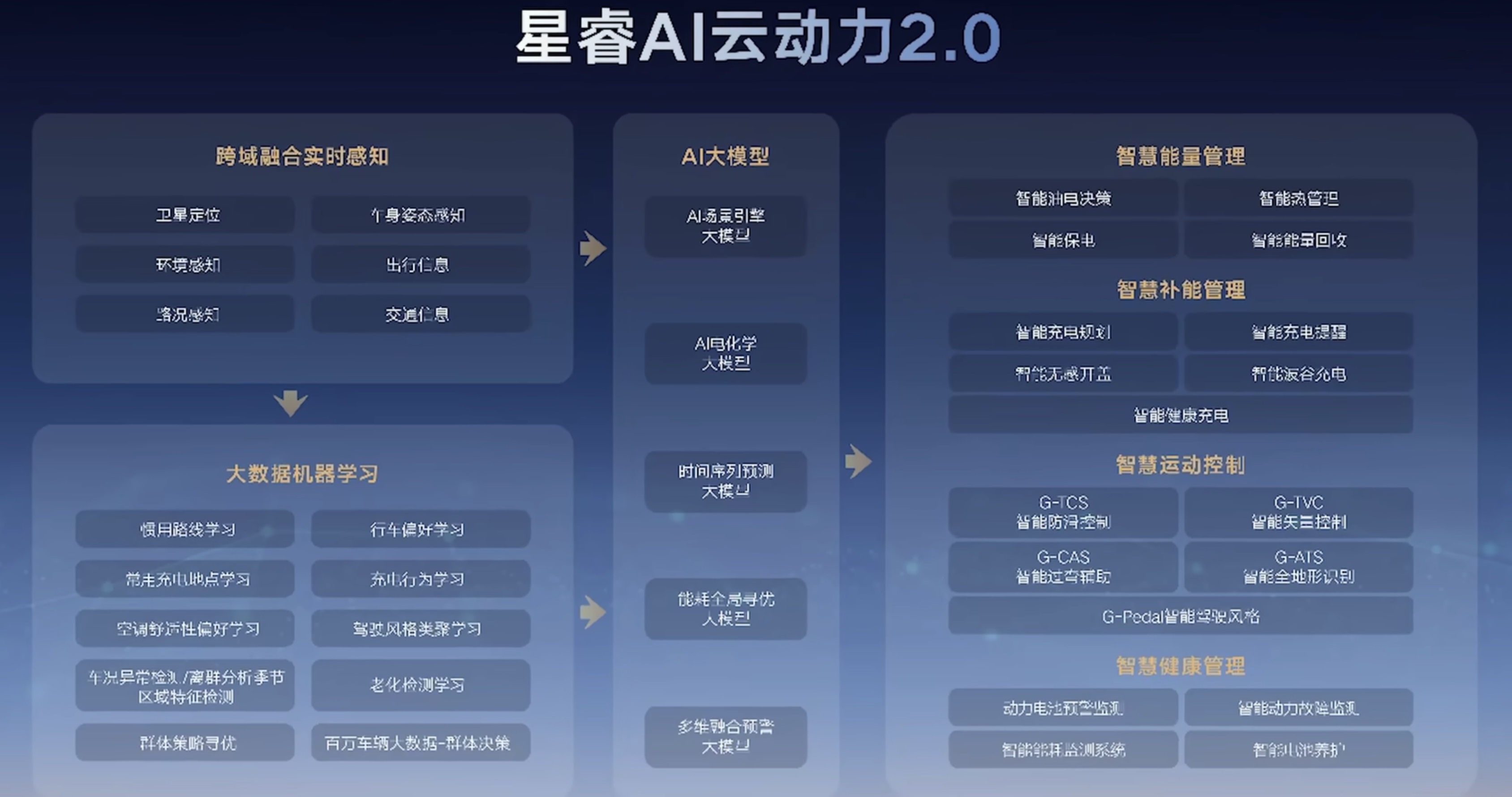
NVIDIA 提供 TensorRT-LLM、Triton Inference Server 和 NVIDIA Inference Microservice (NIM) 等工具来优化和加速 AI 模型的推理,使模型运行速度提升高达 5 倍。这意味着您可以高效地部署和运行 LLM 以生成内容。 同时,NVIDIA 还提供了用于 LLM 开发的工具和框架,如 NeMo,可以帮助开发者更轻松地创建和管理 LLM。
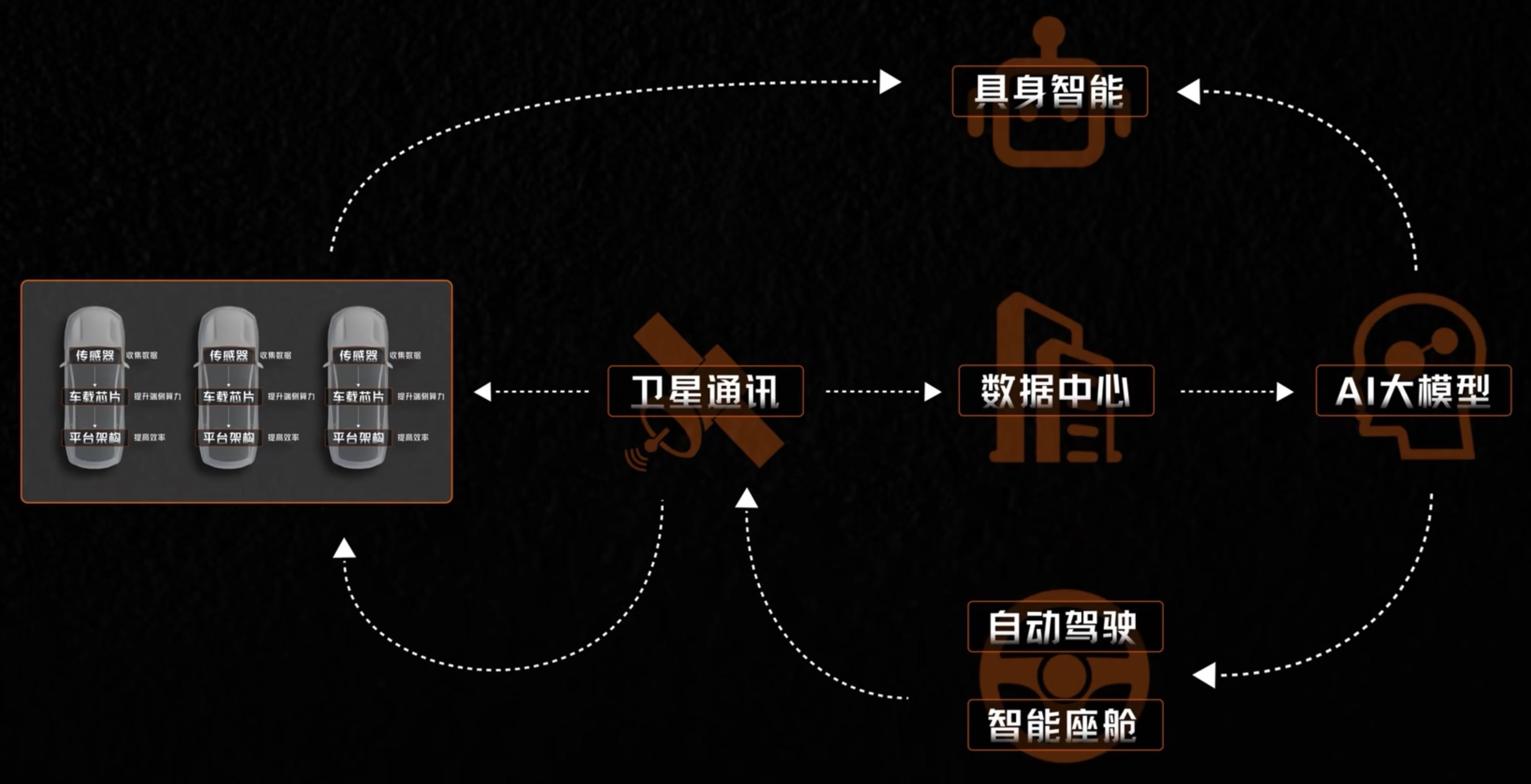
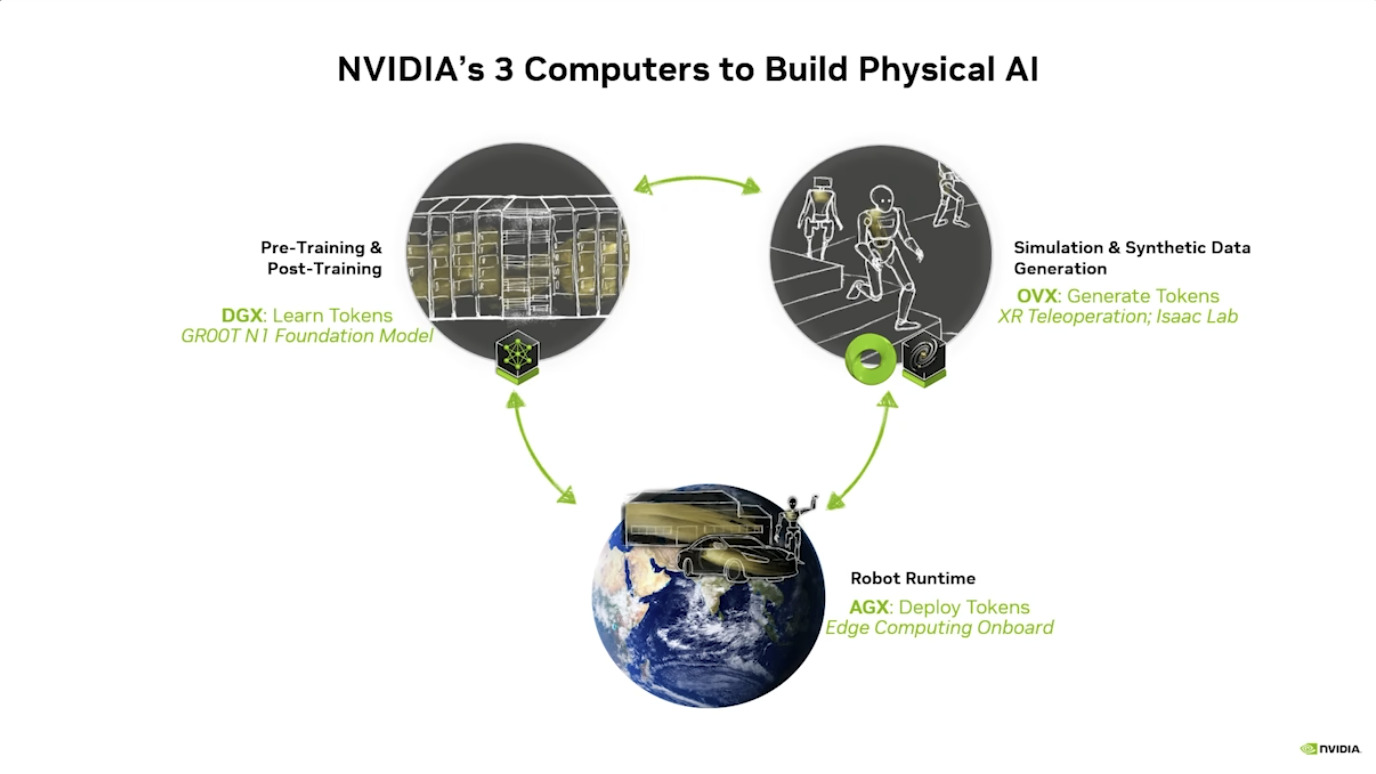
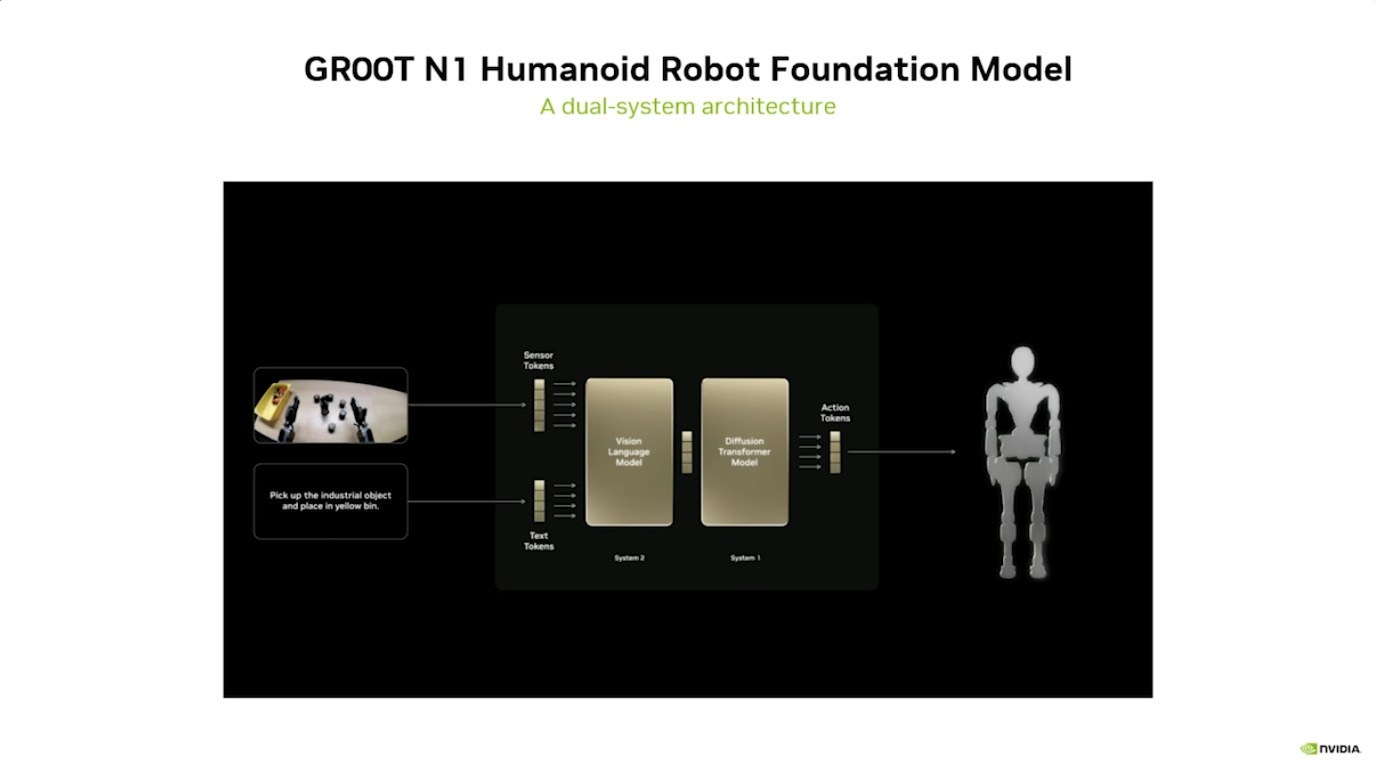
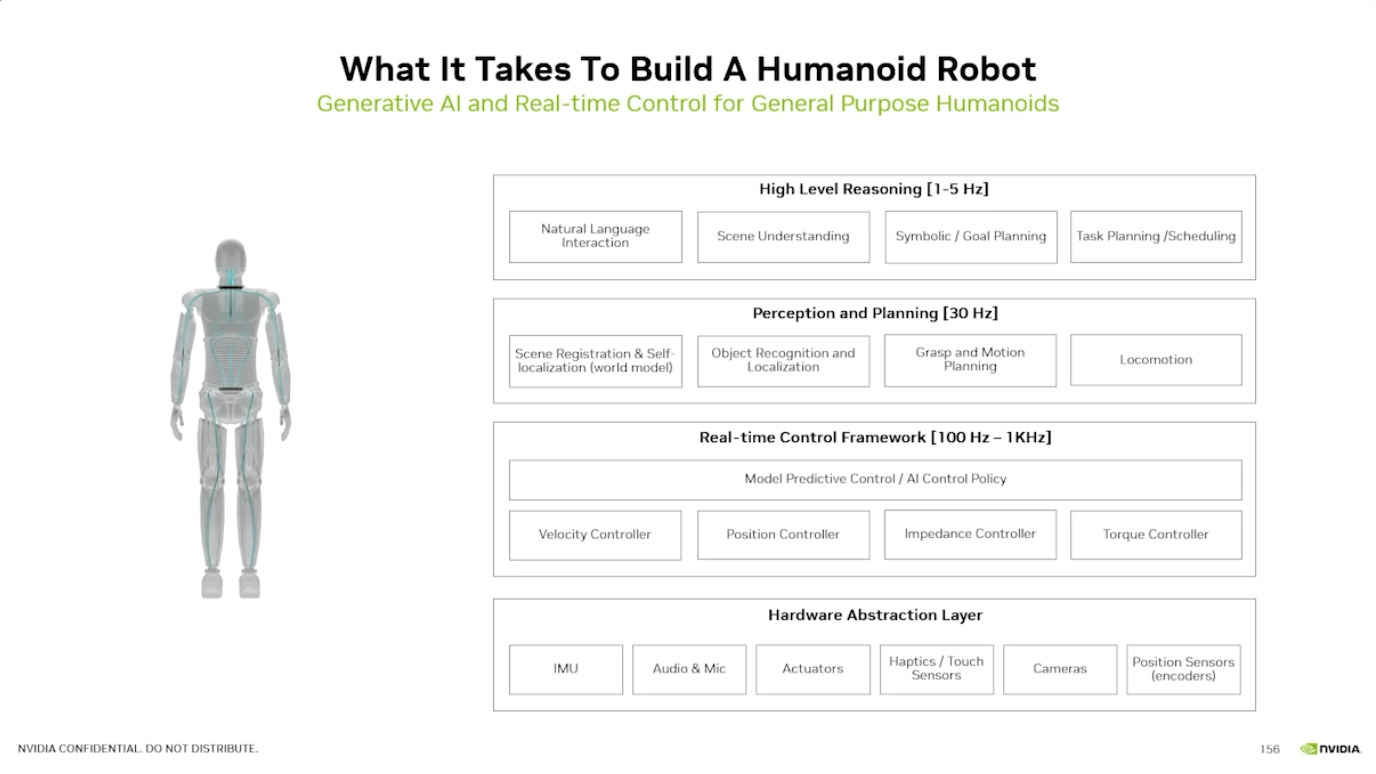
GROOT项目利用 合成运动生成 将人类演示转化为大量的训练数据,并通过 Isaac Lab 进行仿真训练,从而实现 机器人学习。整个系统建立在 Jetson Thor 架构之上,并整合了 NVIDIA Omniverse 等工具,支持机器人数据的处理与生成、仿真与学习,以及简化扩展,最终目标是推进 人形机器人技术 的发展。

















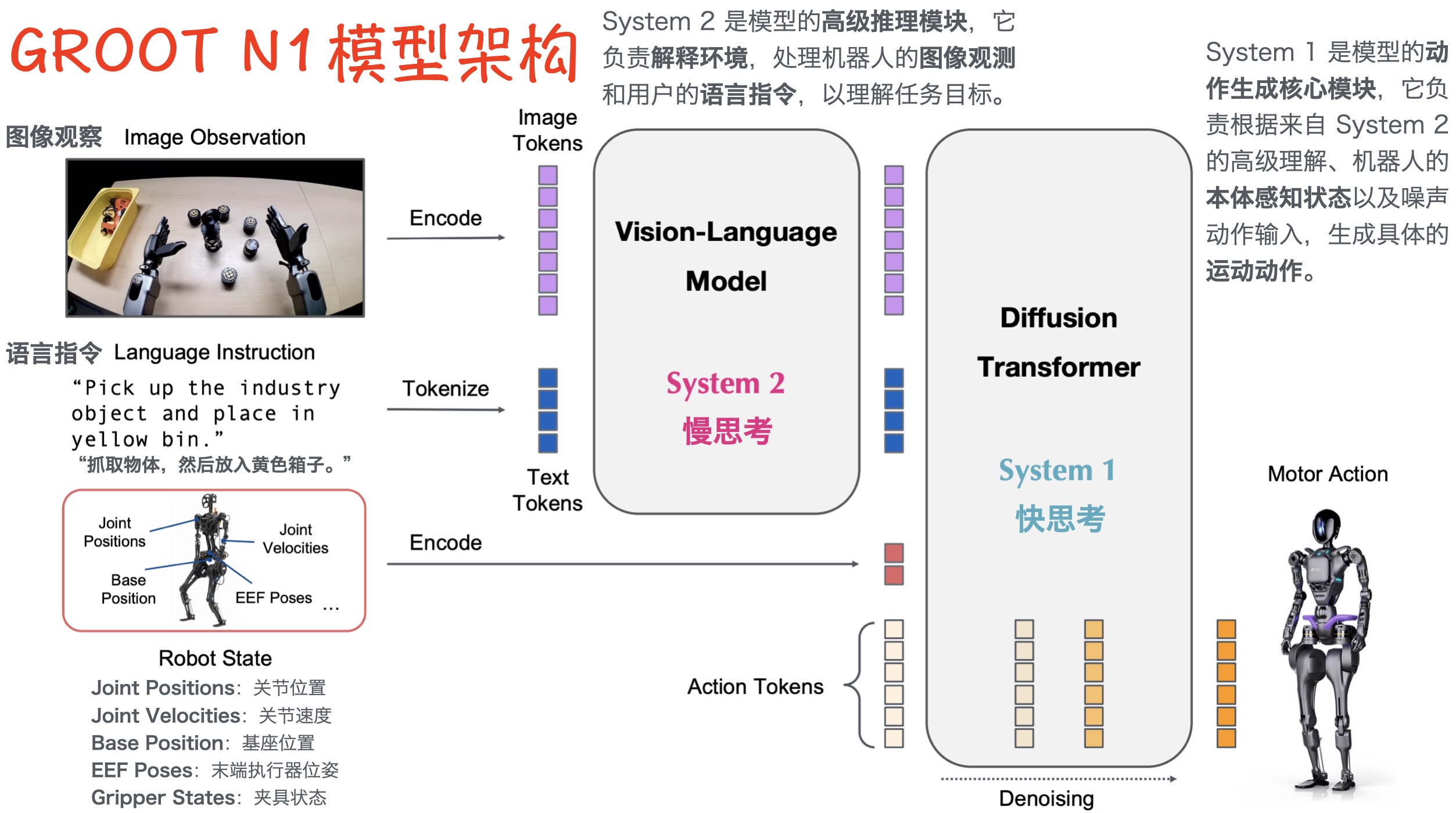
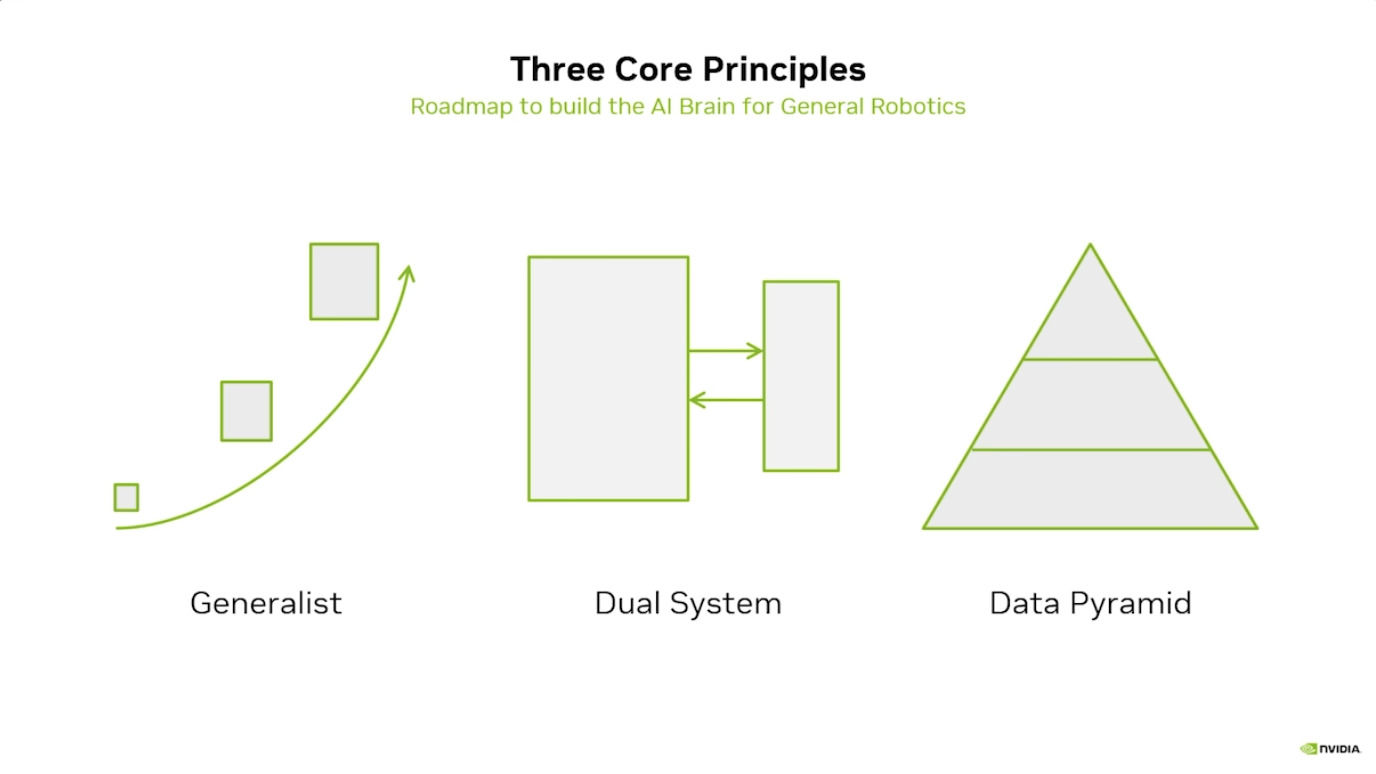
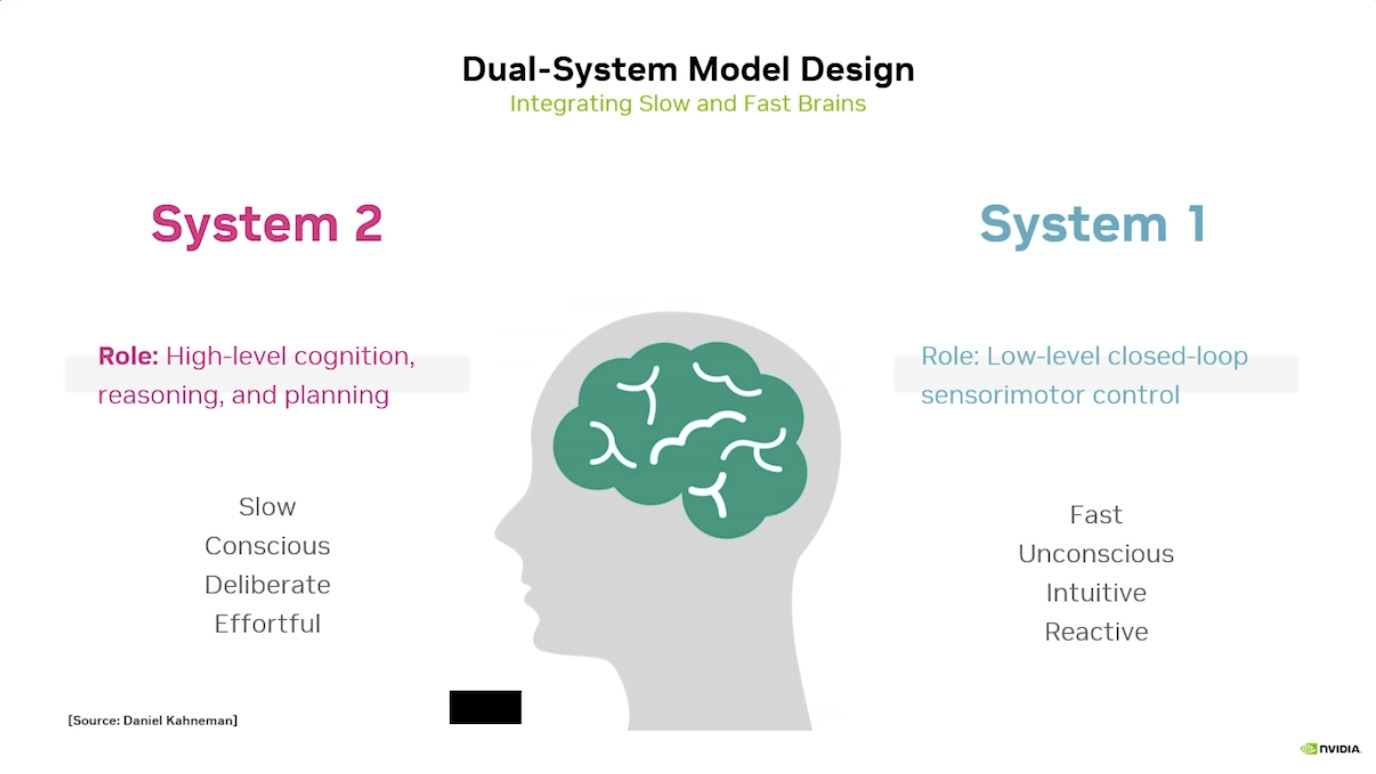
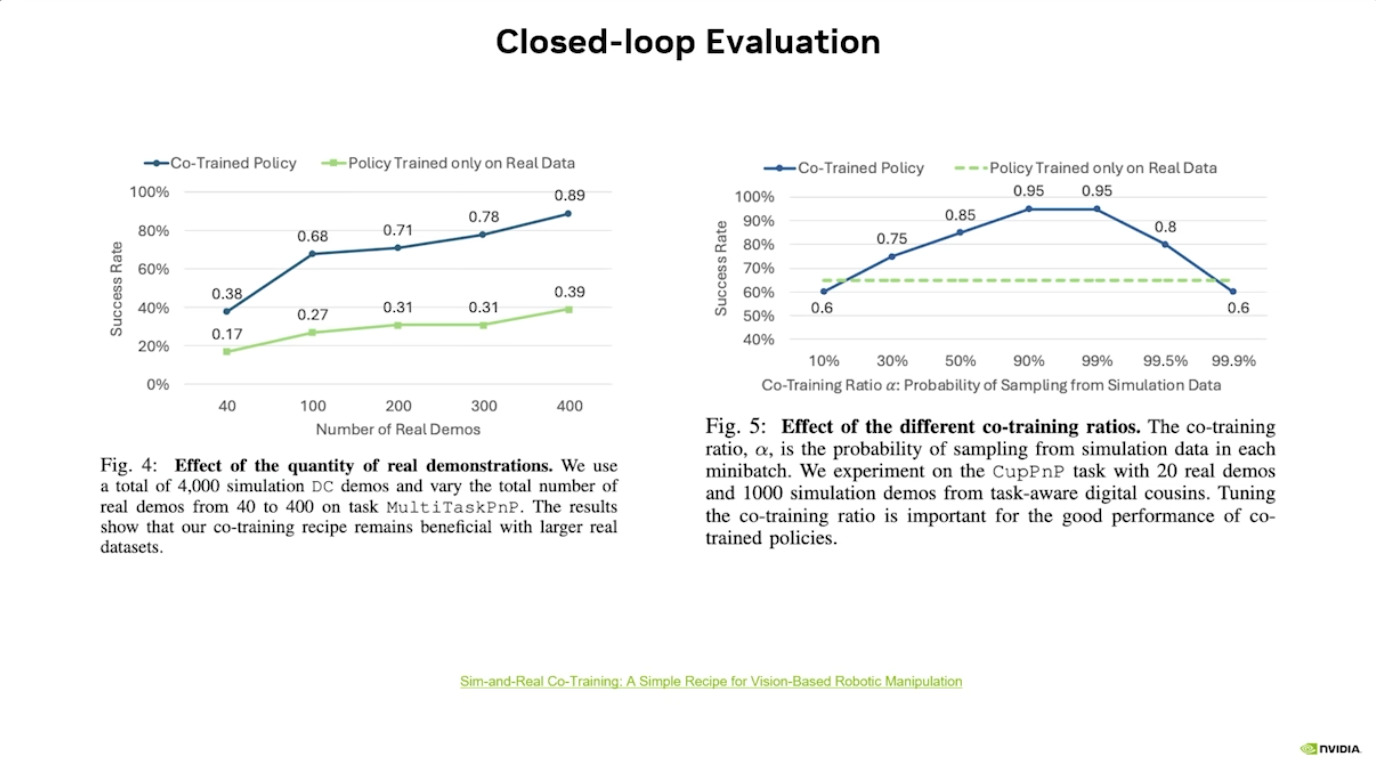
本文档概述了 NVIDIA Isaac GROOT N1,一个专为具身人工智能(Physical AI)设计的人形机器人基础模型。该系统通过三个核心原则运作:泛化能力、双系统架构(结合高层认知与低层控制),以及一个涵盖现实世界数据、合成数据和网络数据的数据金字塔。 Isaac GROOT N1 利用大量训练数据来驱动人形机器人进行通用型操作,并通过 NVIDIA 的生态系统,包括 Omniverse 和 Isaac Lab 进行模拟与部署。推荐的的微调方法是:收集真实数据,也要生成对应比例的模拟数据。


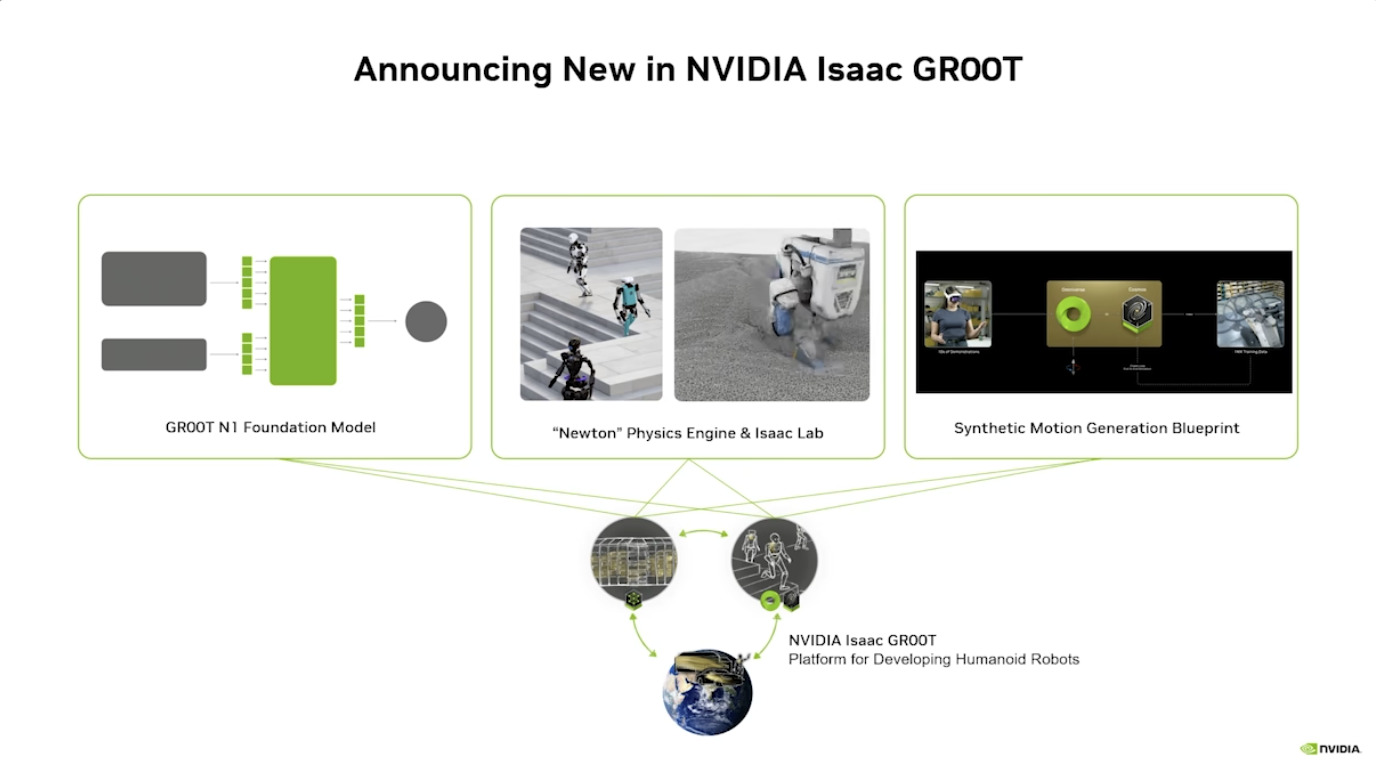




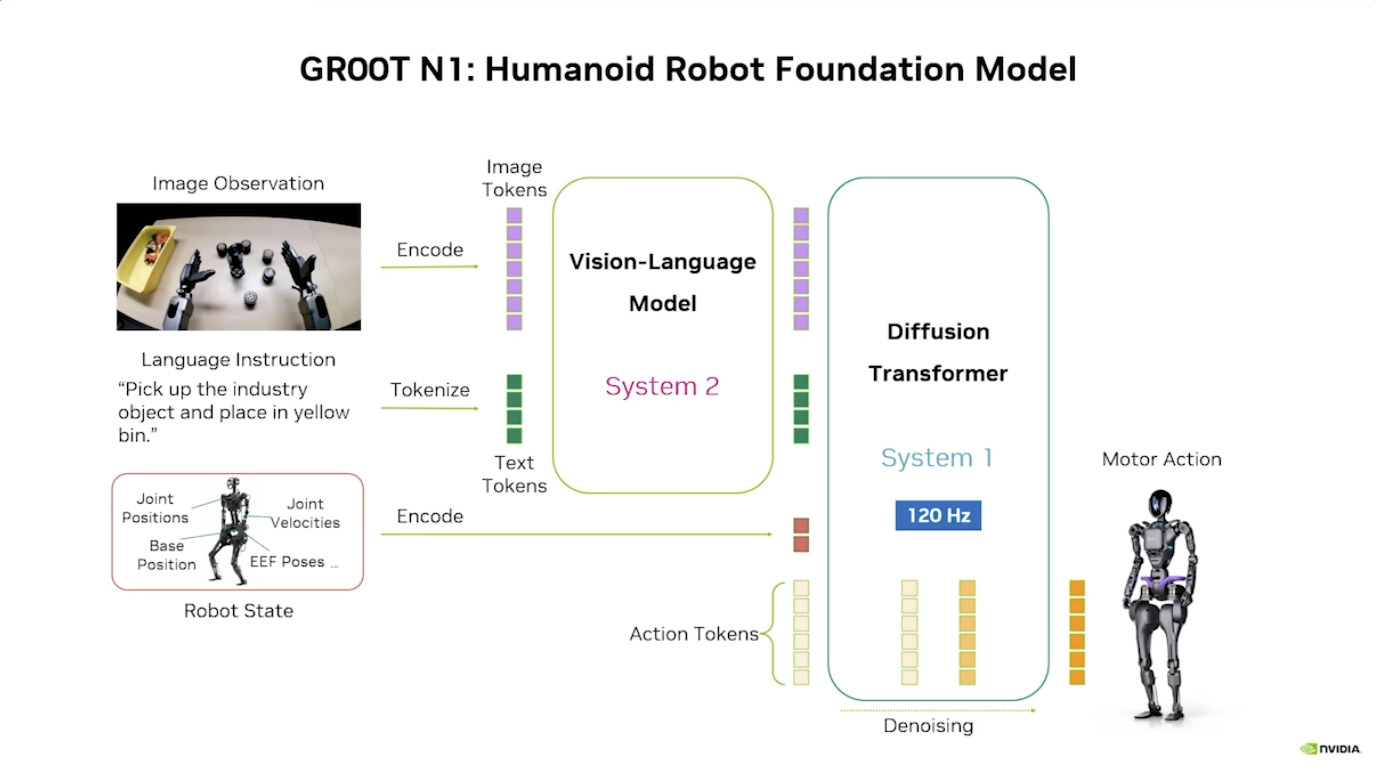
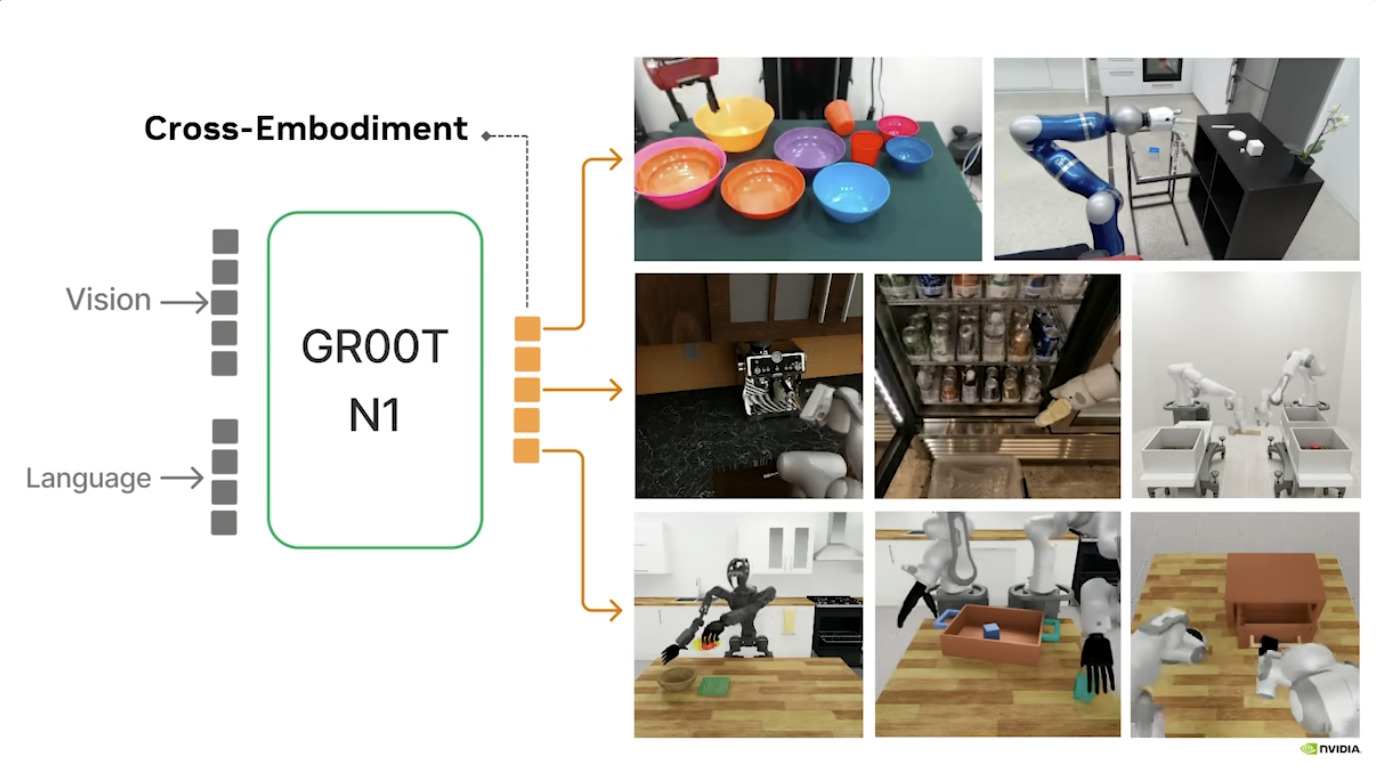
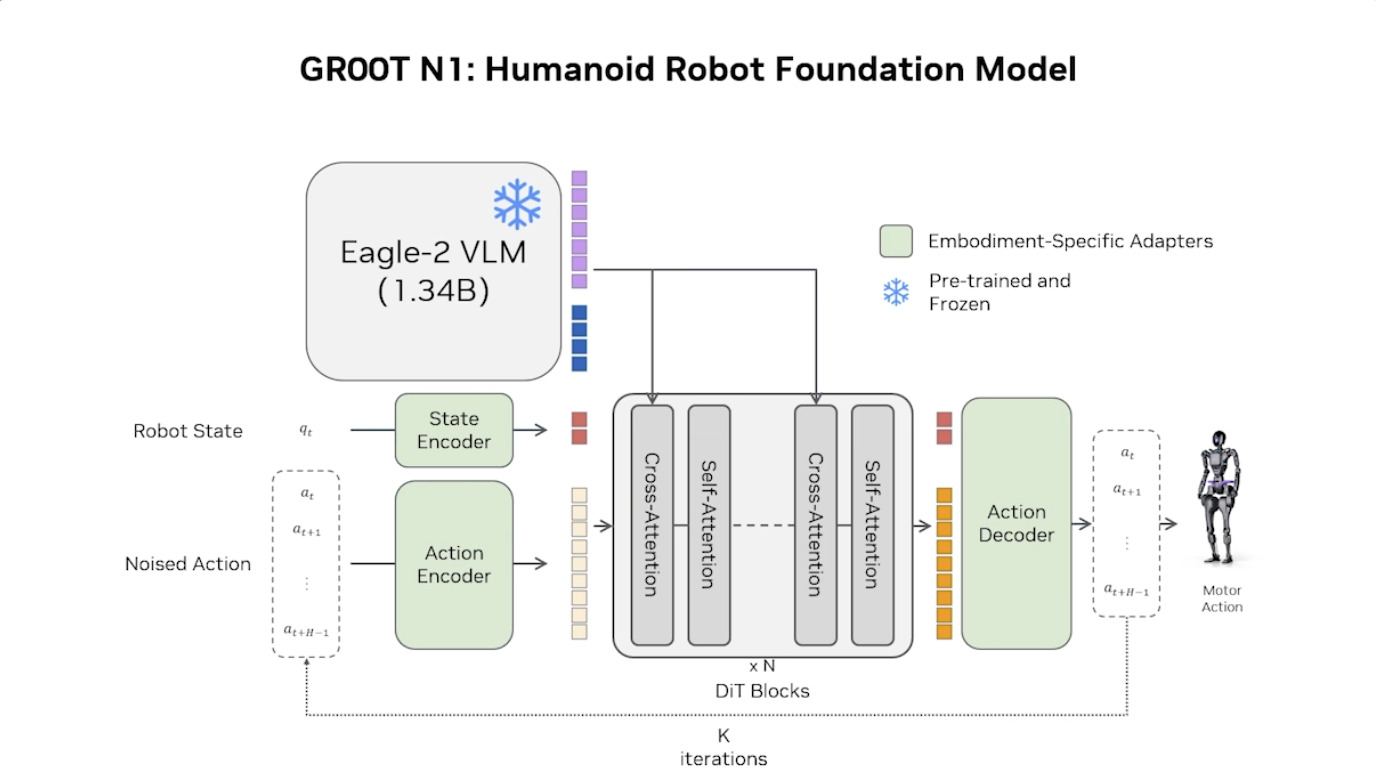

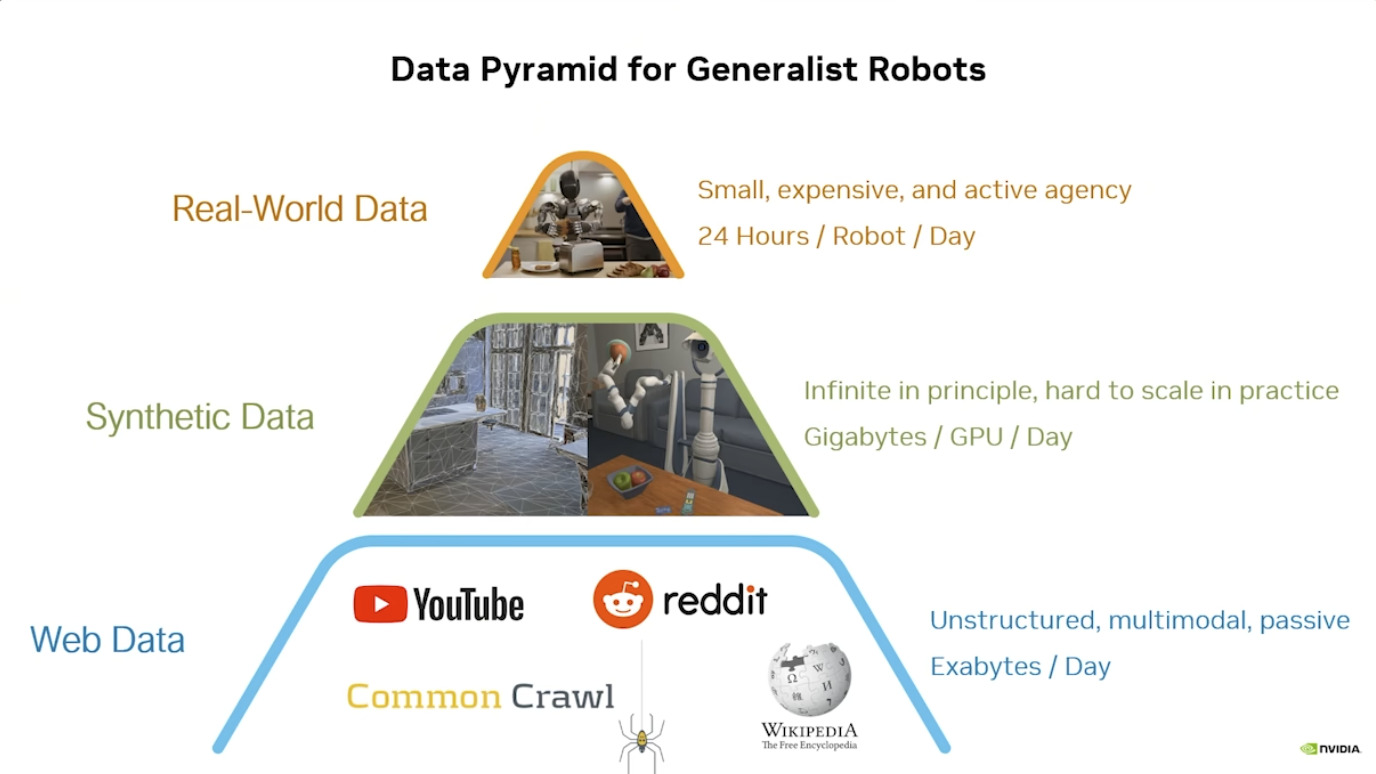
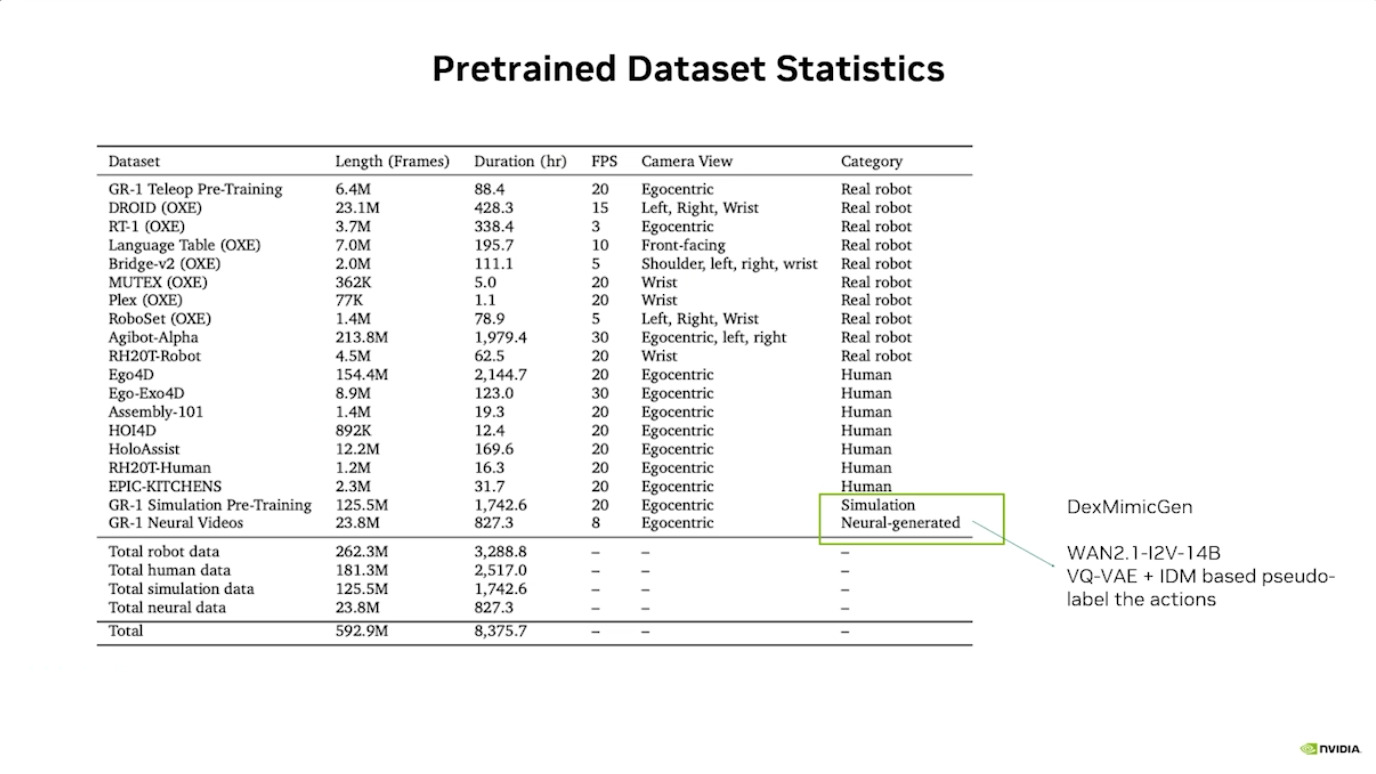

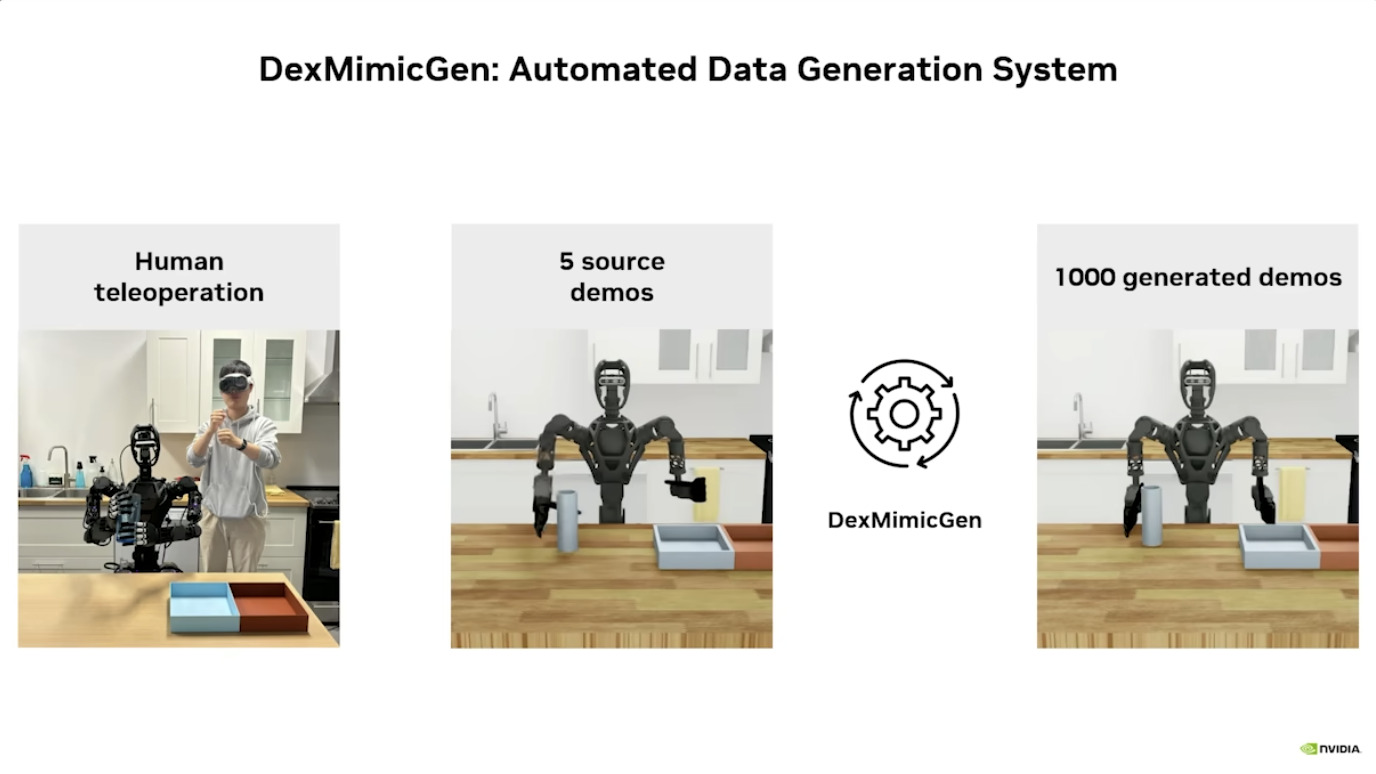




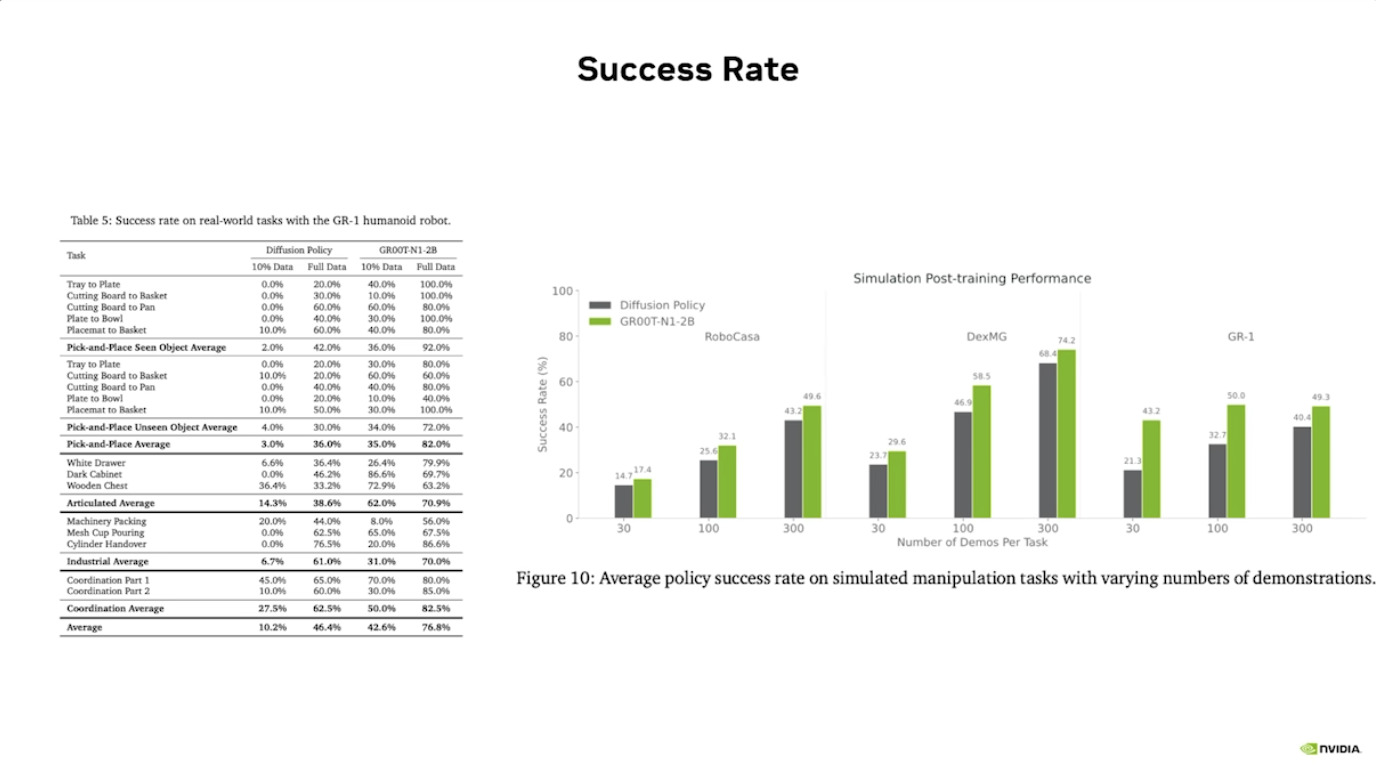
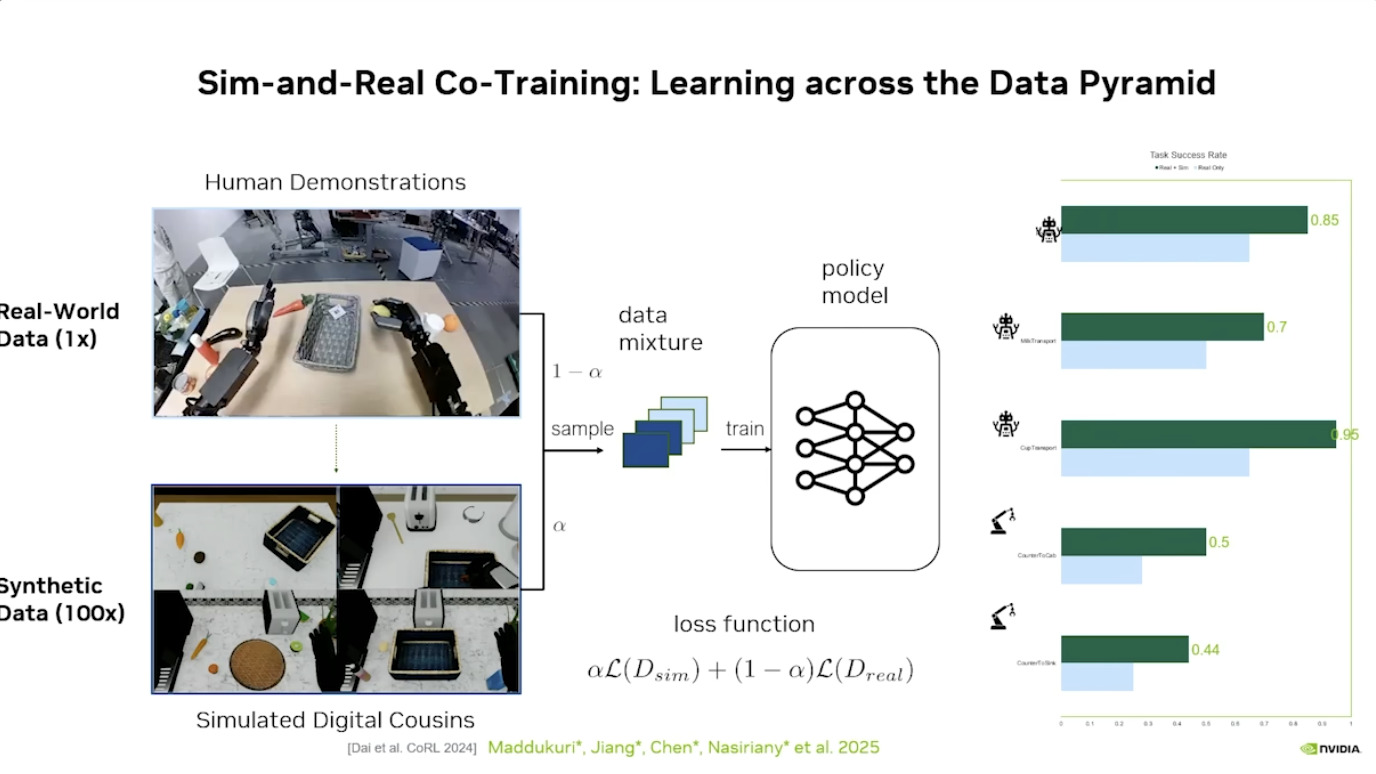






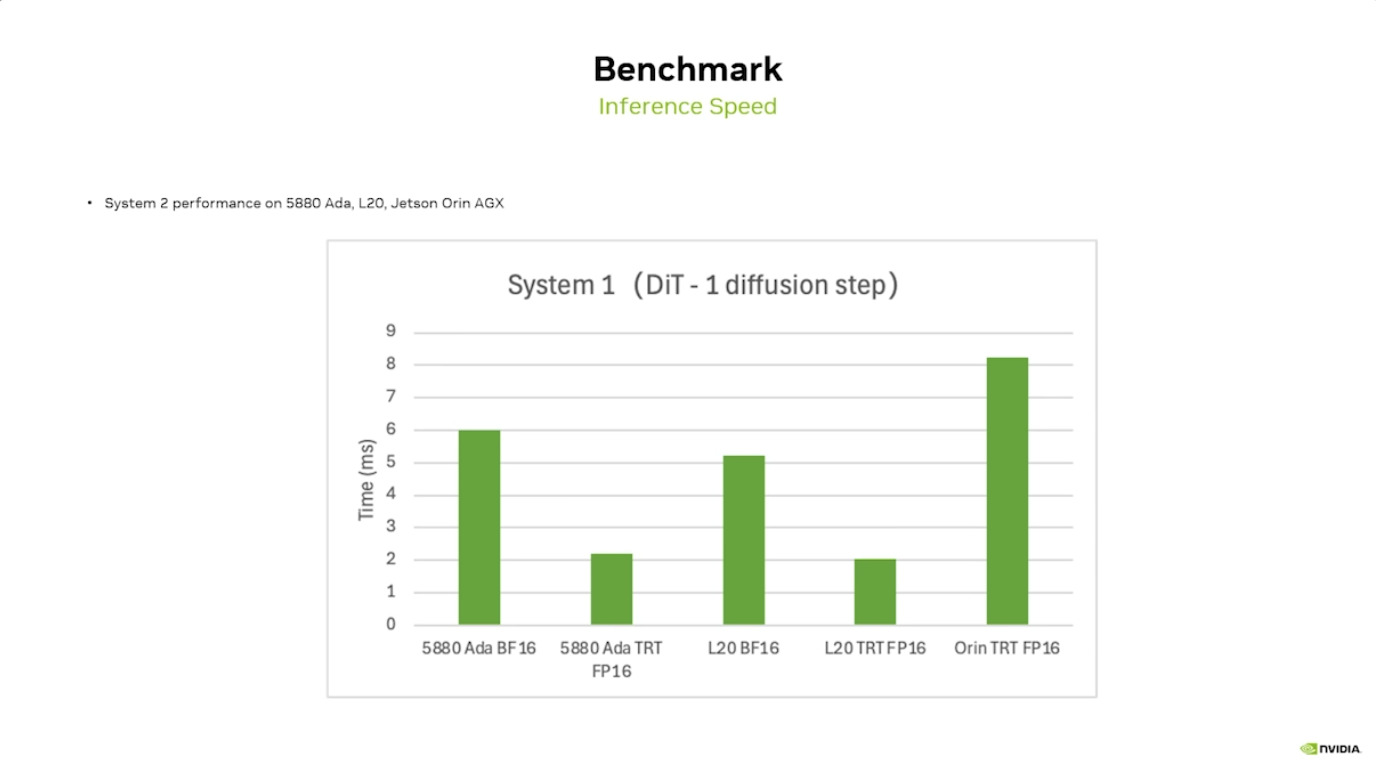

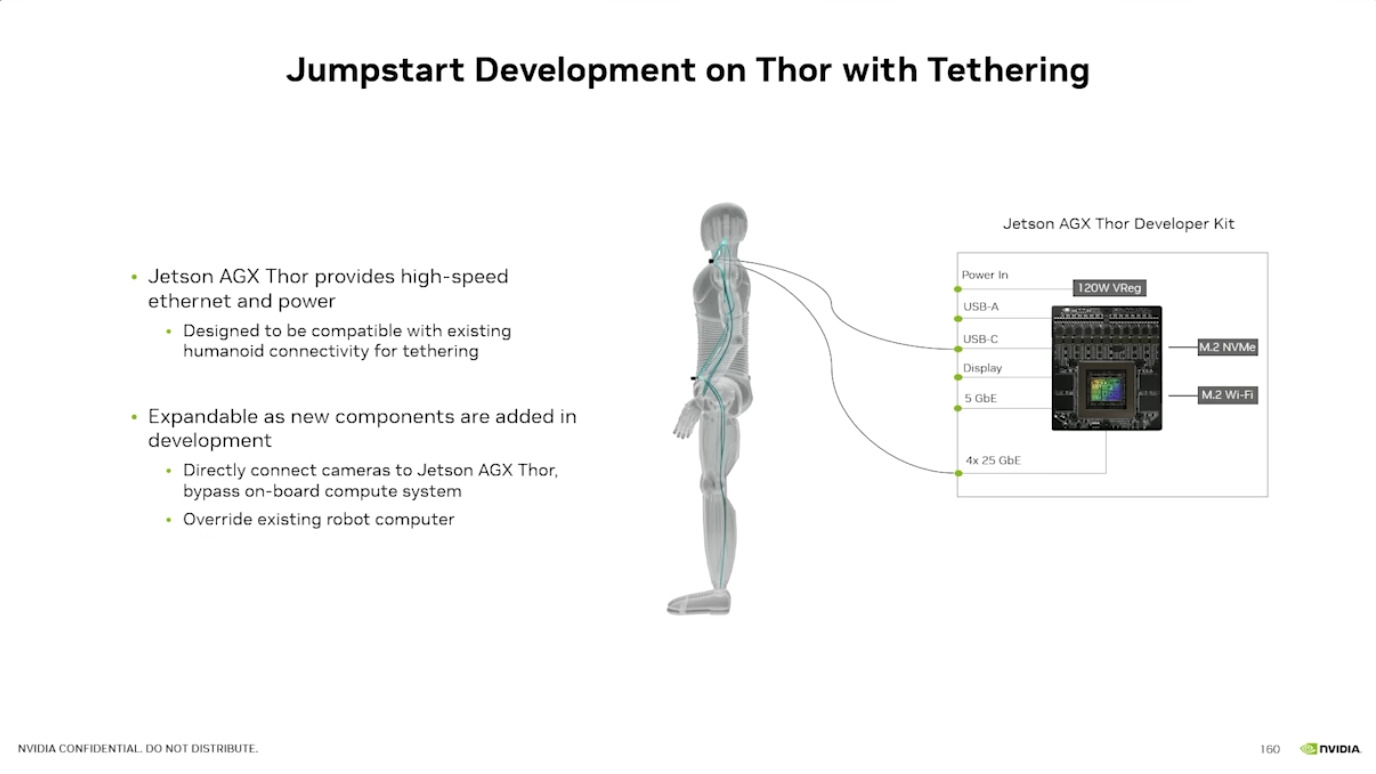
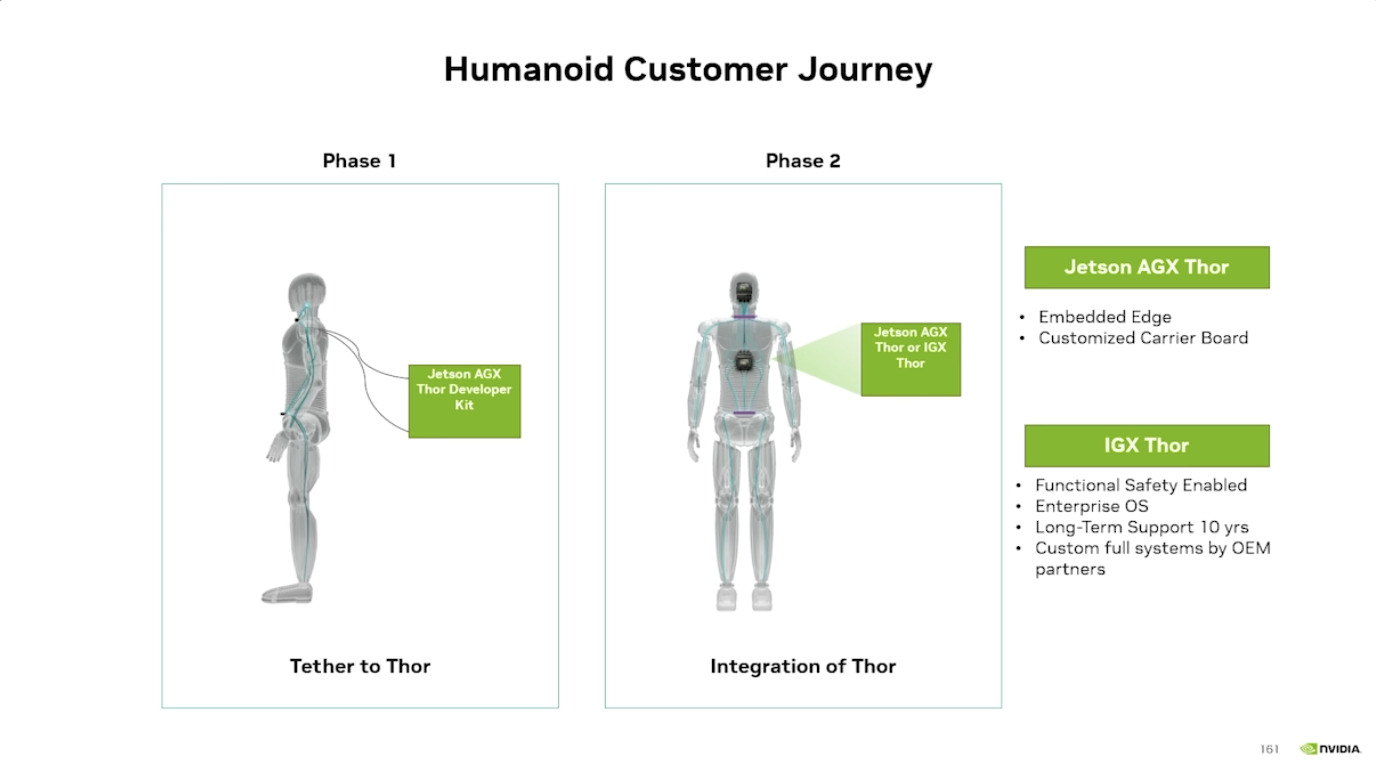
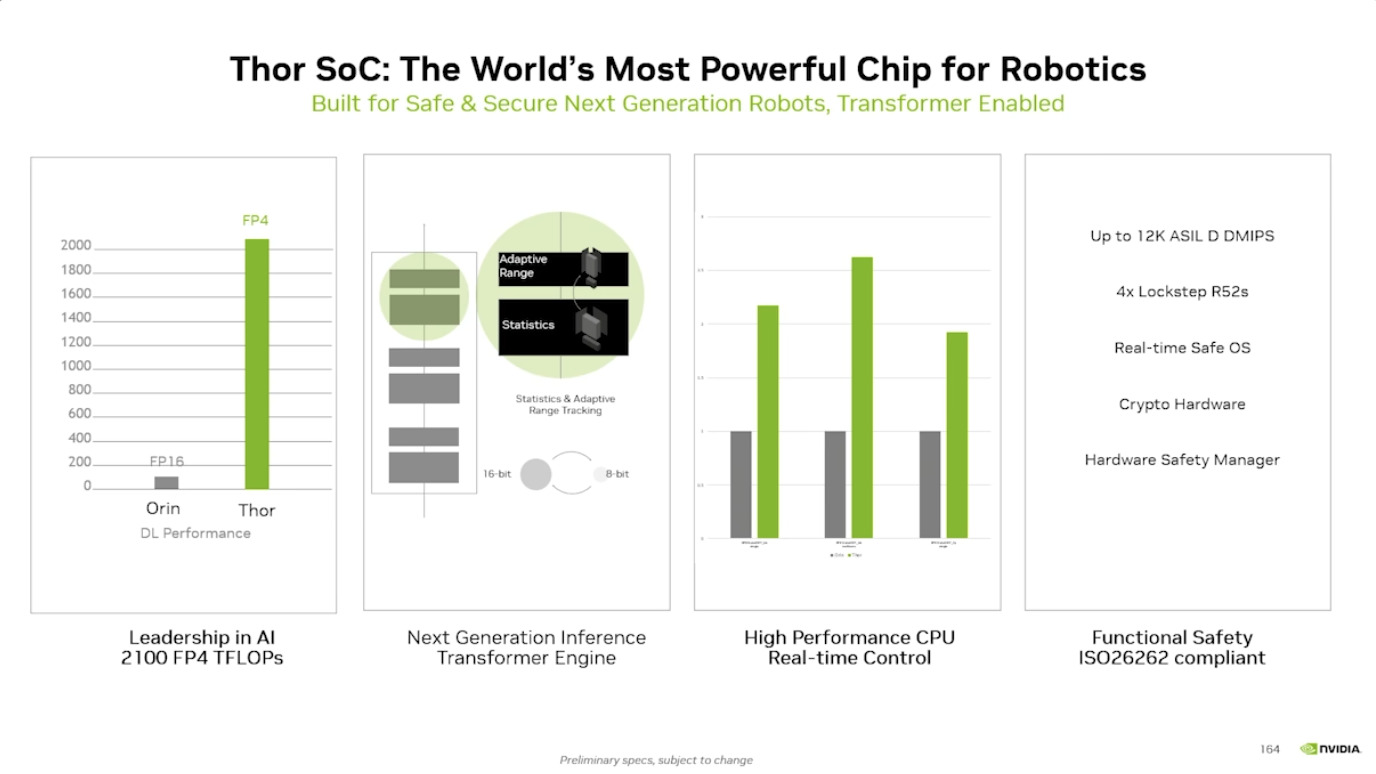
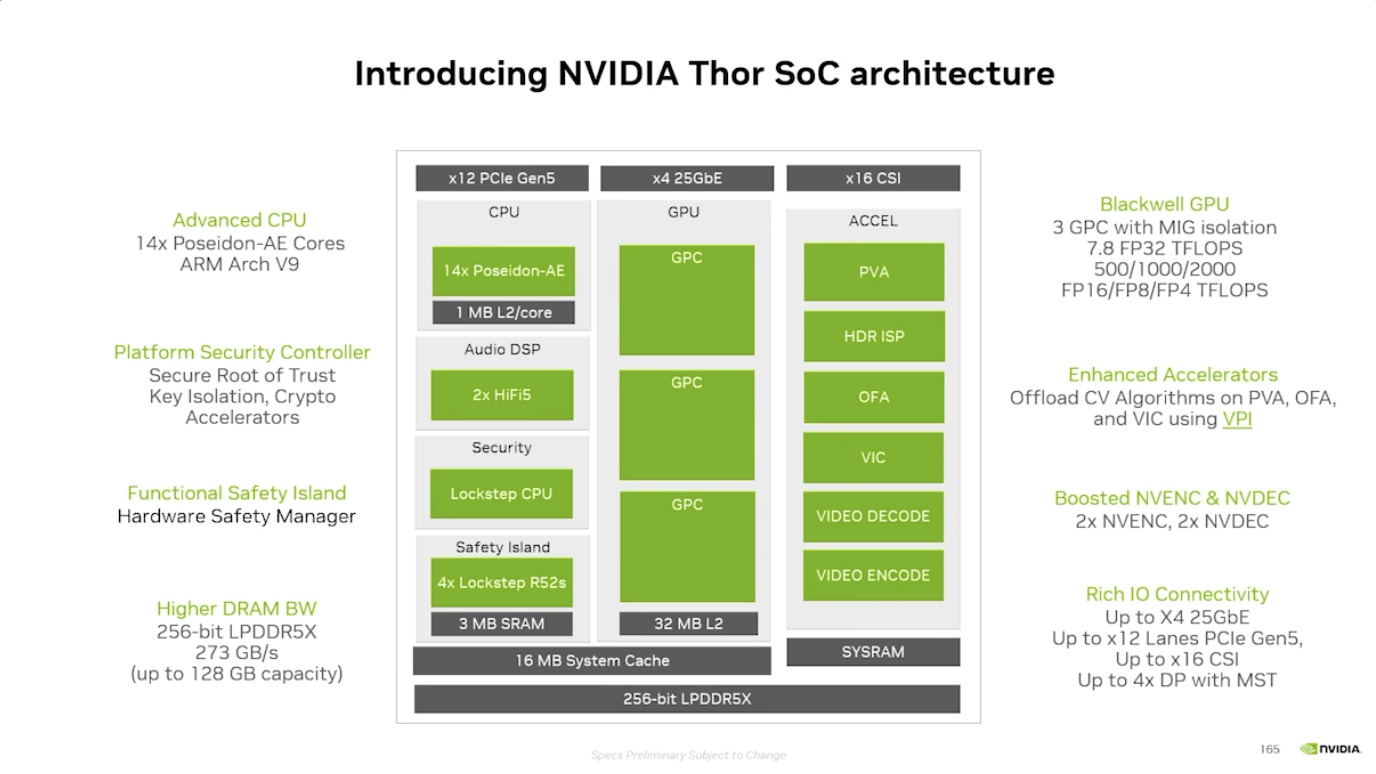
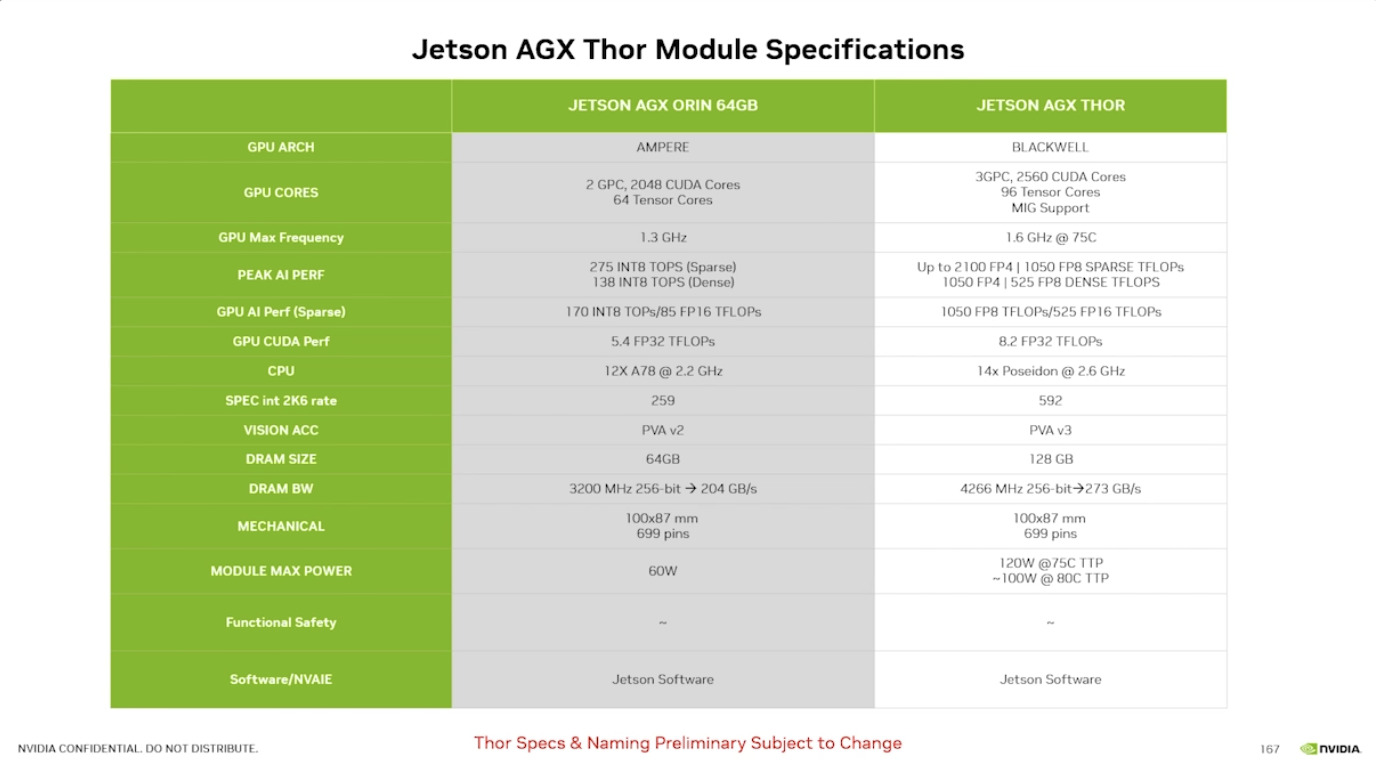
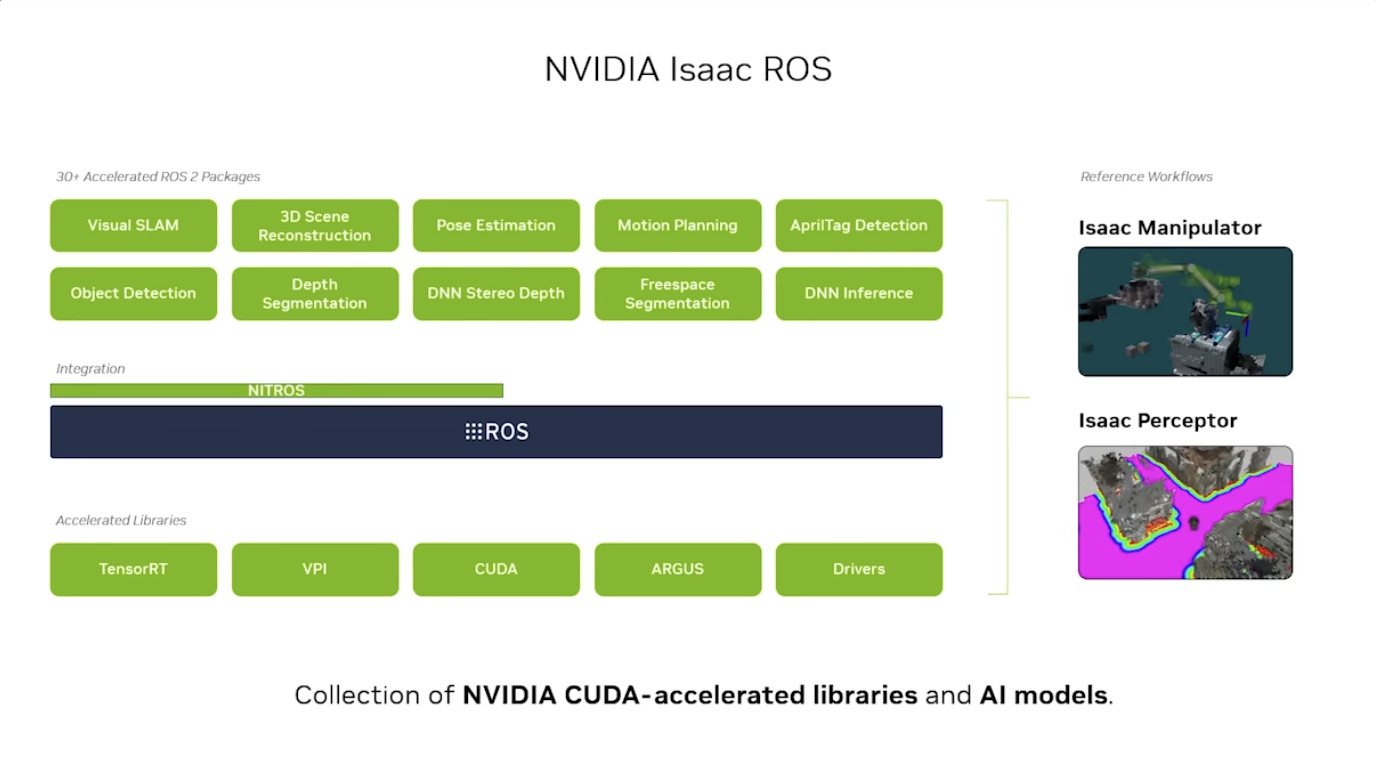
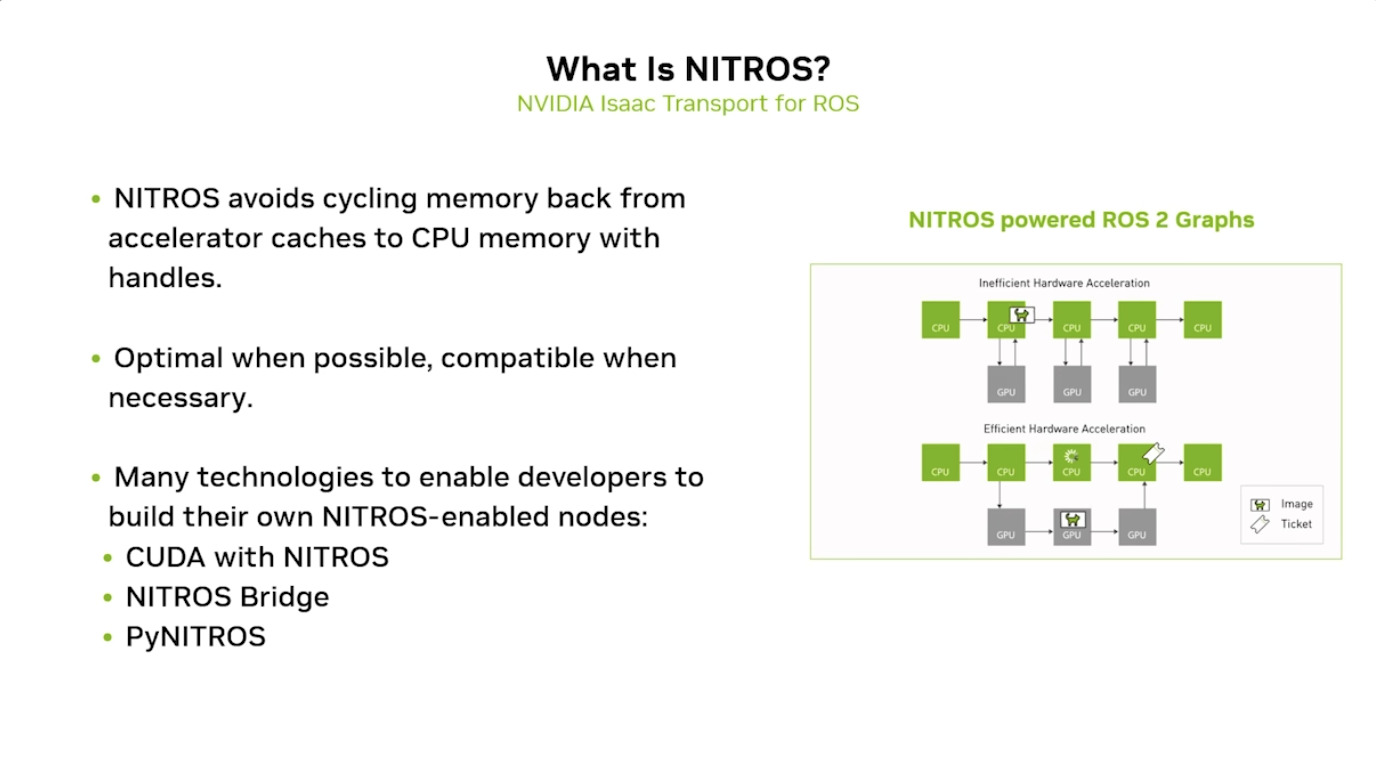
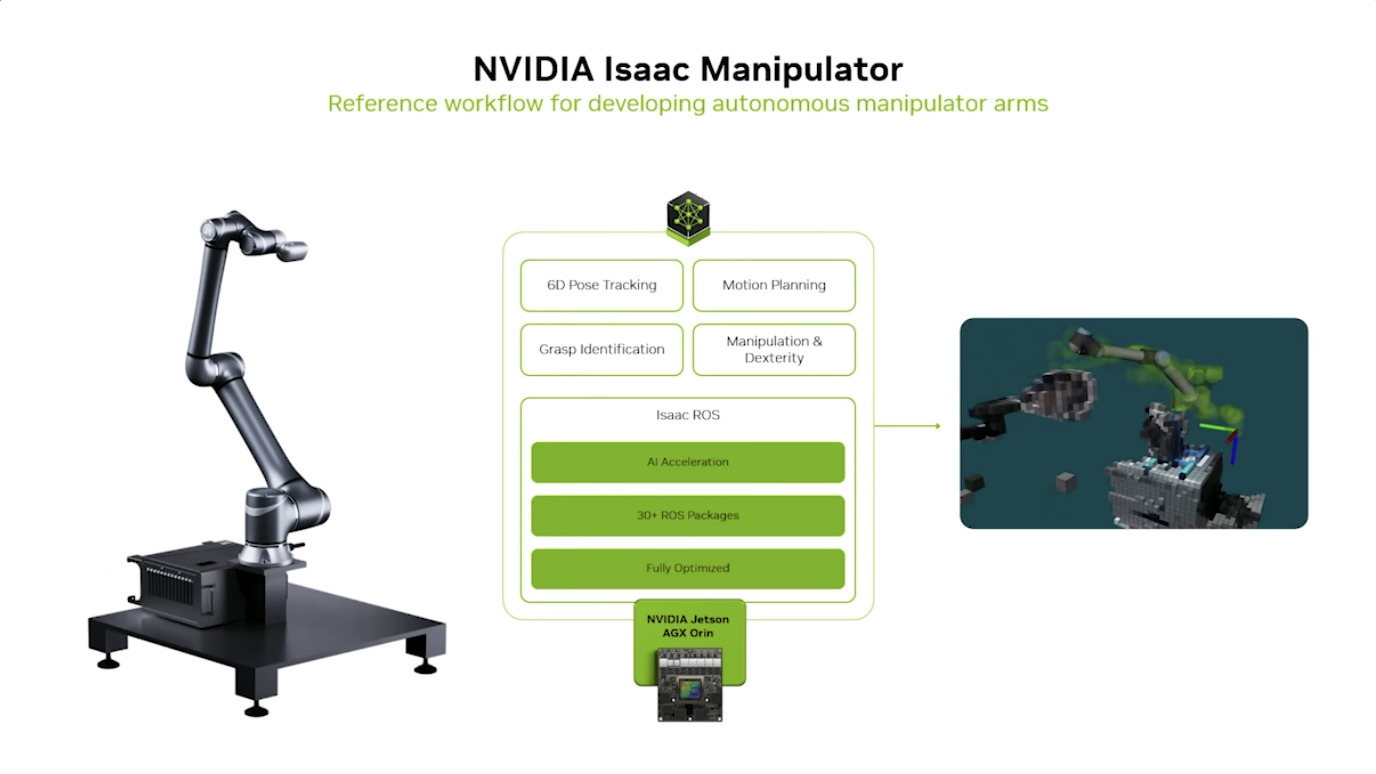
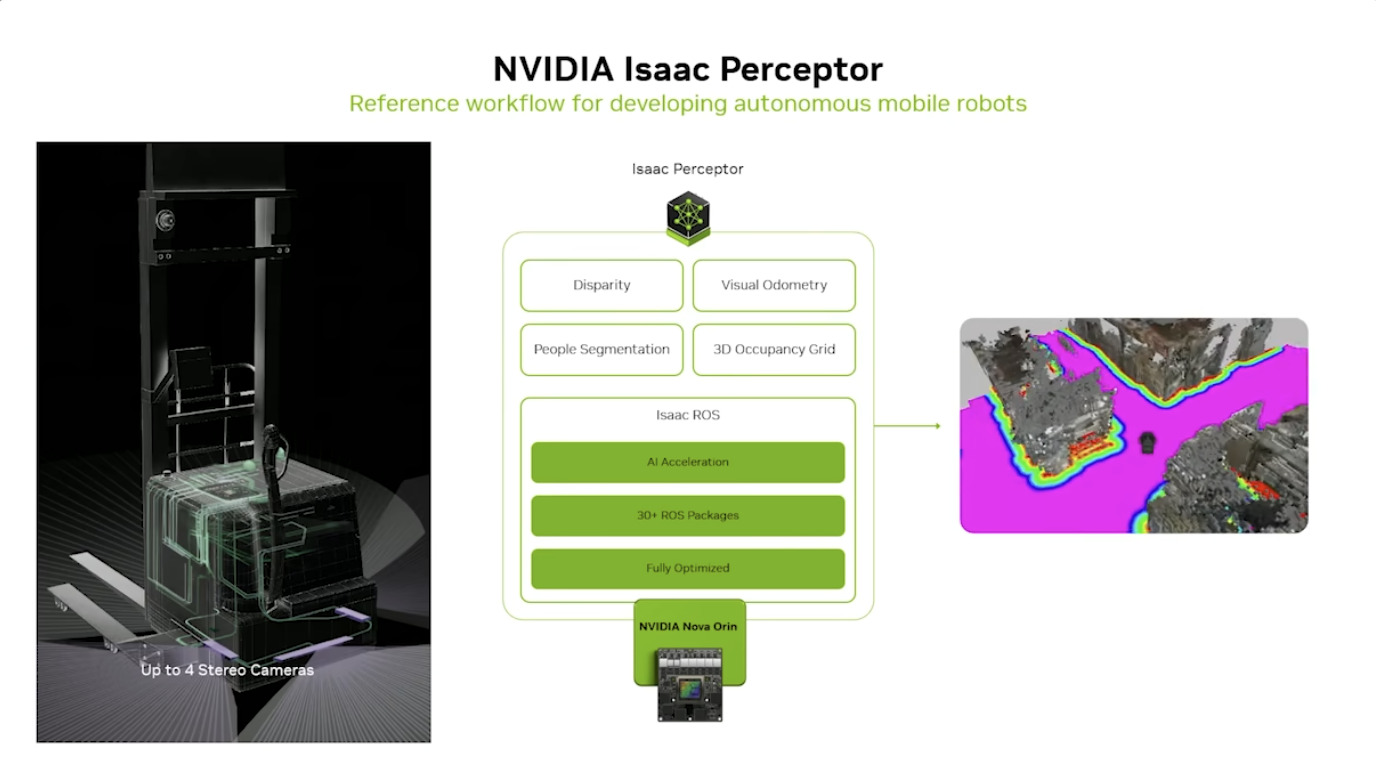
本文档详细介绍了NVIDIA Jetson Thor,这是一款为下一代人形机器人设计的强大计算平台,其特点包括卓越的AI性能、高速传感器处理、行业领先的安全性和强大的安全性。此外,文档还介绍了NVIDIA Isaac ROS,一个利用CUDA加速库和AI模型加速机器人开发的软件框架,并提及了NITROS以优化ROS 2的硬件加速。最后,还展示了Jetson AGX Thor开发套件和未来产品路线图,强调了该技术在复杂机器人应用中的应用,例如自主机械臂和移动机器人。












困难重重 😭
服务器是 NVIDIA Tesla T4,系统是 Ubuntu 20.04,从 Kubernetes 集群中分离出来的,因 Tabby 请求 CUDA >= 11.7,需要重新安装新版本的驱动。
就两步就完成了,简单吧 😄
安装驱动
sudo sh NVIDIA-Linux-x86_64-535.129.03.run
日志查看错误信息
IGD(Integrated Graphics Device)
操作系统:Ubuntu 18.04,主机有一张 NVIDIA 的独立显卡 GP106 [GeForce GTX 1060 6GB],还有 Intel 酷睿处理器 i5 8500 自带的集成显卡(Intel UHD Graphics 630)。为了更充分的使用独立显卡用于深度学习计算,需要把集成显卡用于显示。在这个过程中遇到了各种各样的问题:
选择 IGD,保存退出。
-pix_fmt(像素格式) -s(设置帧大小WxH)ffmpeg -y -i input.mp4 -pix_fmt rgb8 -r 10 -s 320x240 output.gif
ffmpeg -y -i input.mp4 -pix_fmt rgb8 -r 10 -vf 'scale=320:-1' output.gif
-ss(开始时间偏移) -t(持续时间)ffmpeg -i input.mp4 -vf "fps=10,scale=320:-1:flags=lanczos,split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" -loop 0 output.gif
ffmpeg -y -ss 5 -t 5 -i input.mp4 -vf "fps=10,scale=320:-1:flags=lanczos,split[s0][s1];[s0]palettegen[p];[s1][p]paletteuse" -loop 0 output.gif
-r(设置帧速率)ffmpeg -i input.mp4 -r 1 -s 1024x768 -f image2 input-%03d.jpeg
在一台新安装的 Ubuntu20.04 系统上安装 NVIDIA GPU 驱动。
$ sudo update-initramfs -u
$ sudo reboot
$ lsmod | grep nouveau

$ wget https://cn.download.nvidia.com/tesla/450.80.02/NVIDIA-Linux-x86_64-450.80.02.run
$ sudo sh NVIDIA-Linux-x86_64-450.80.02.run