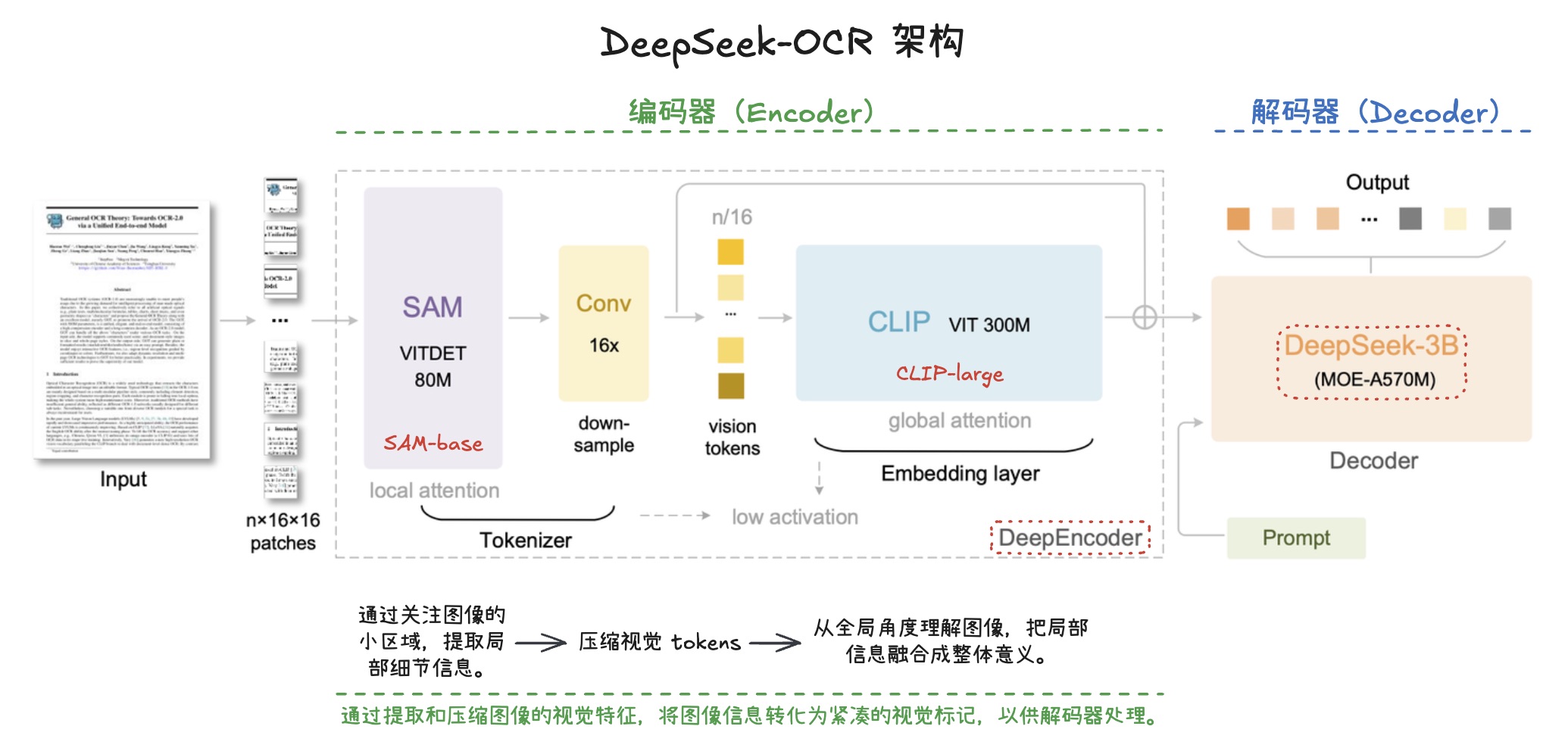
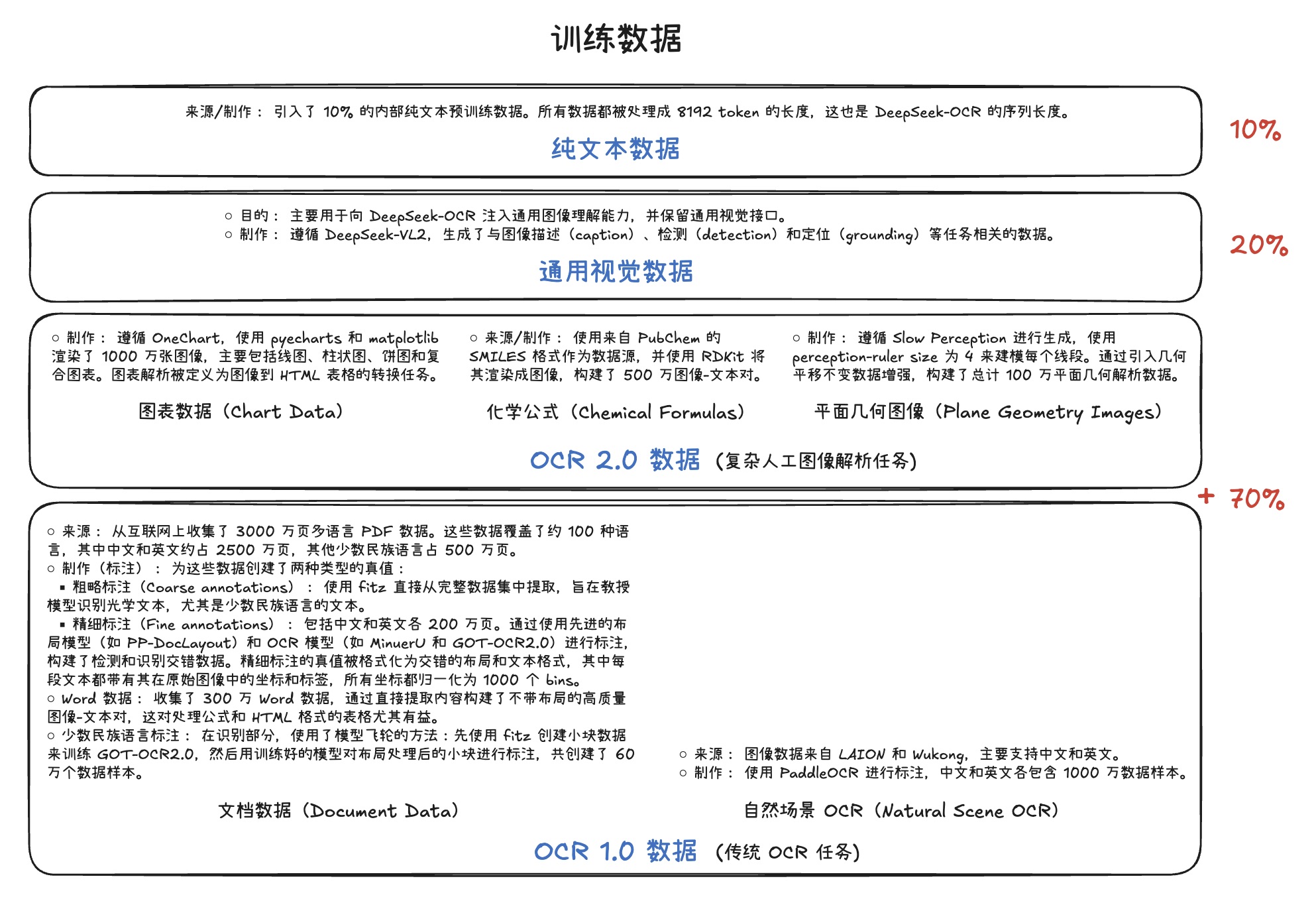
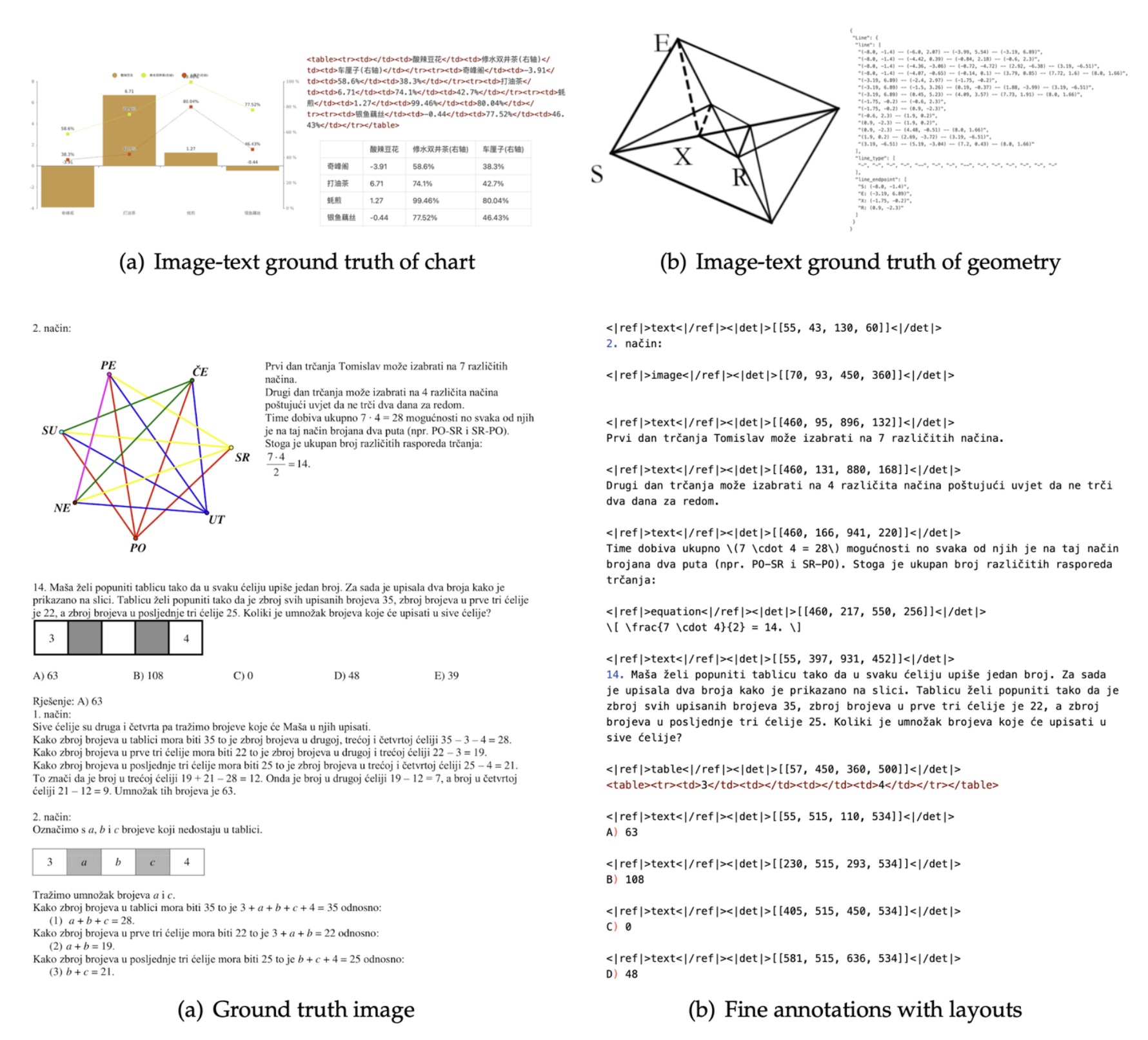
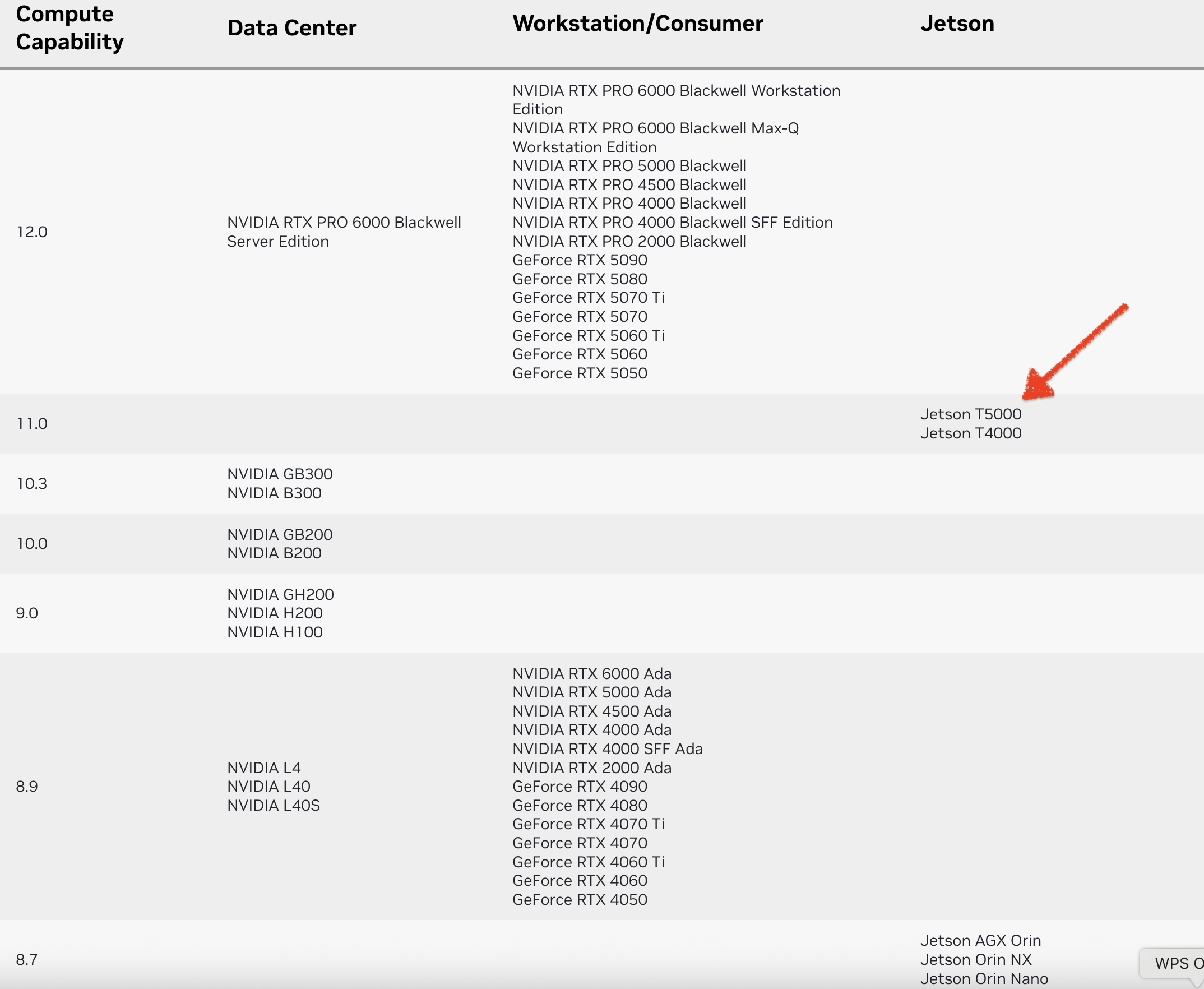
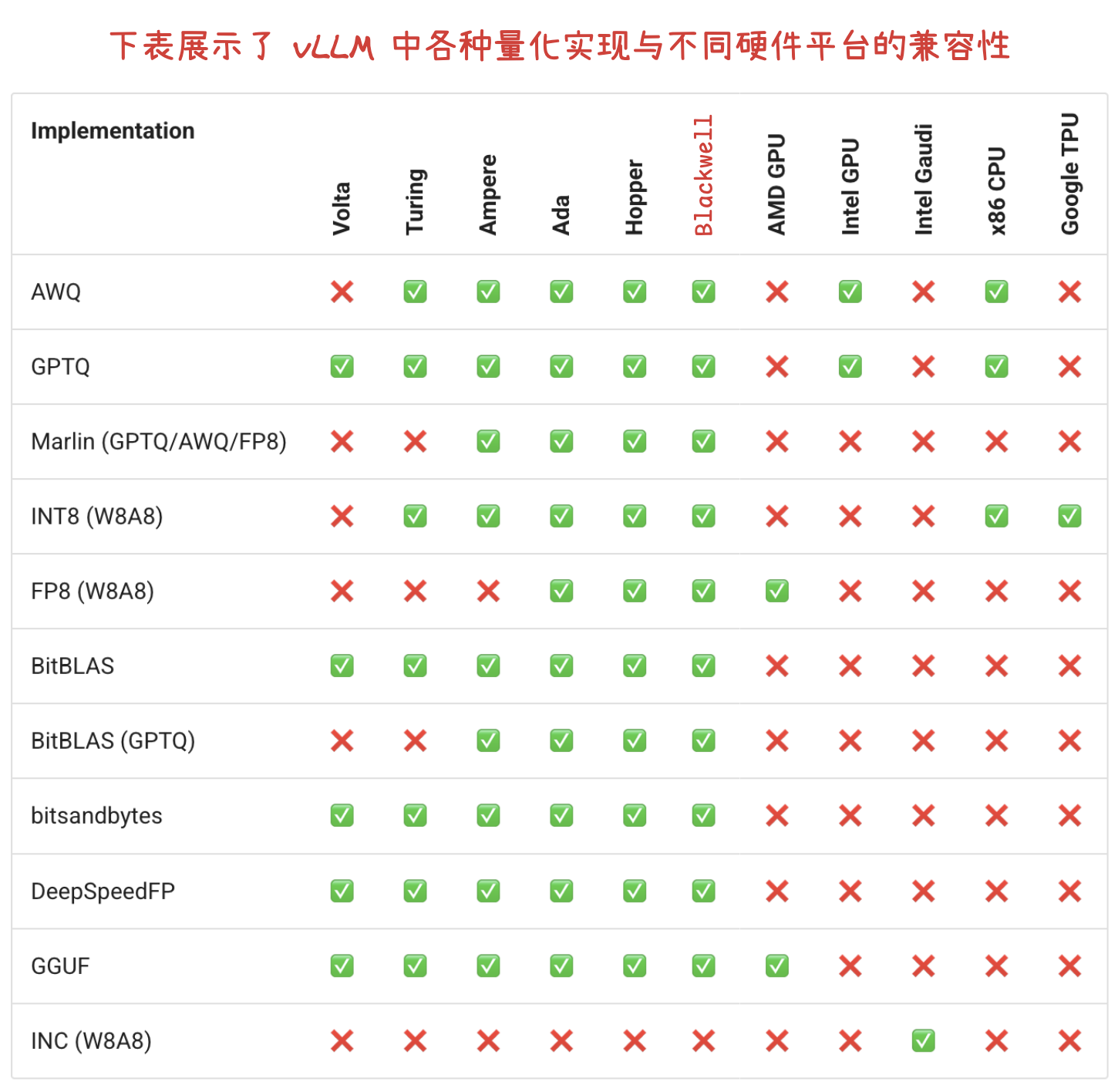
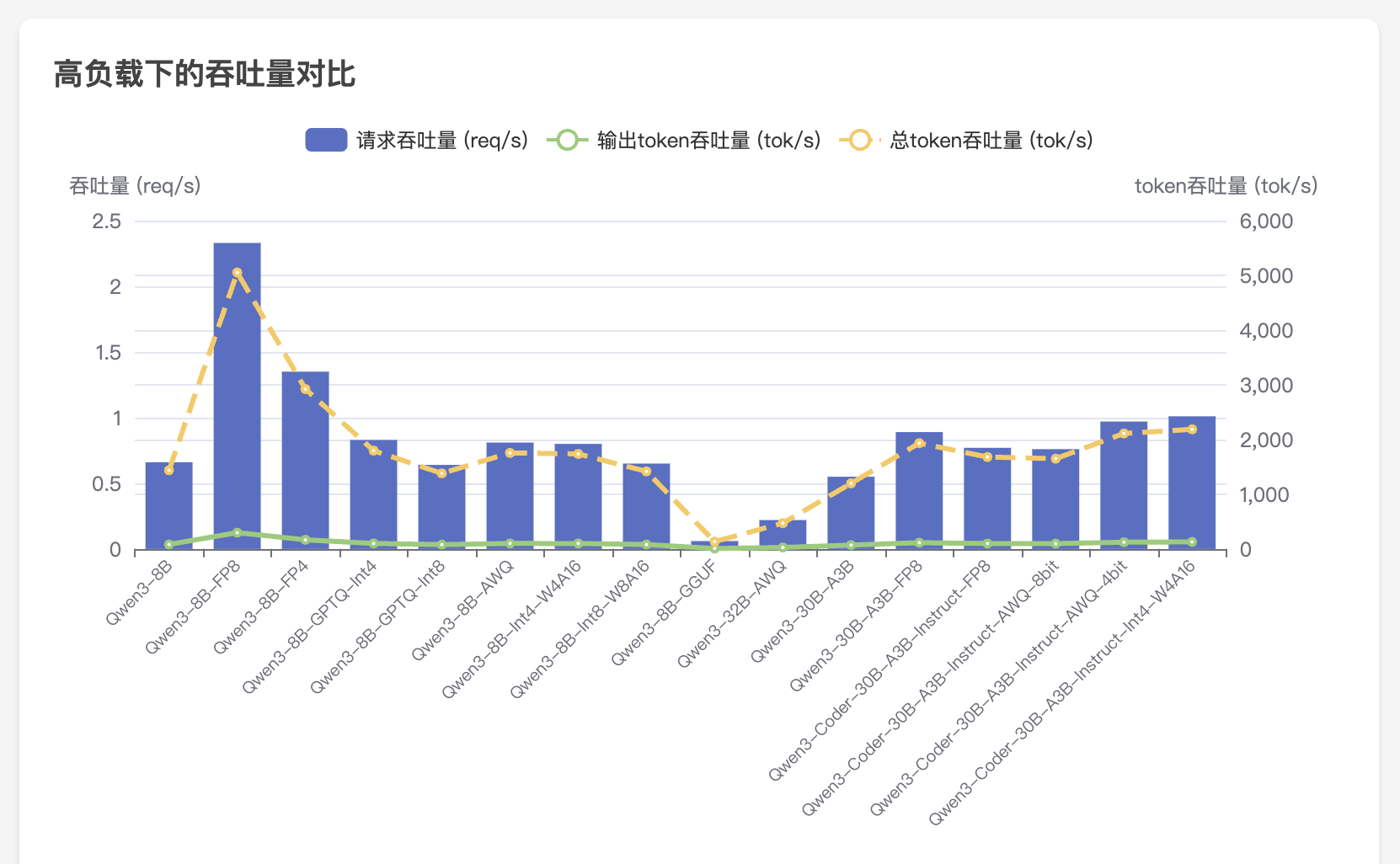
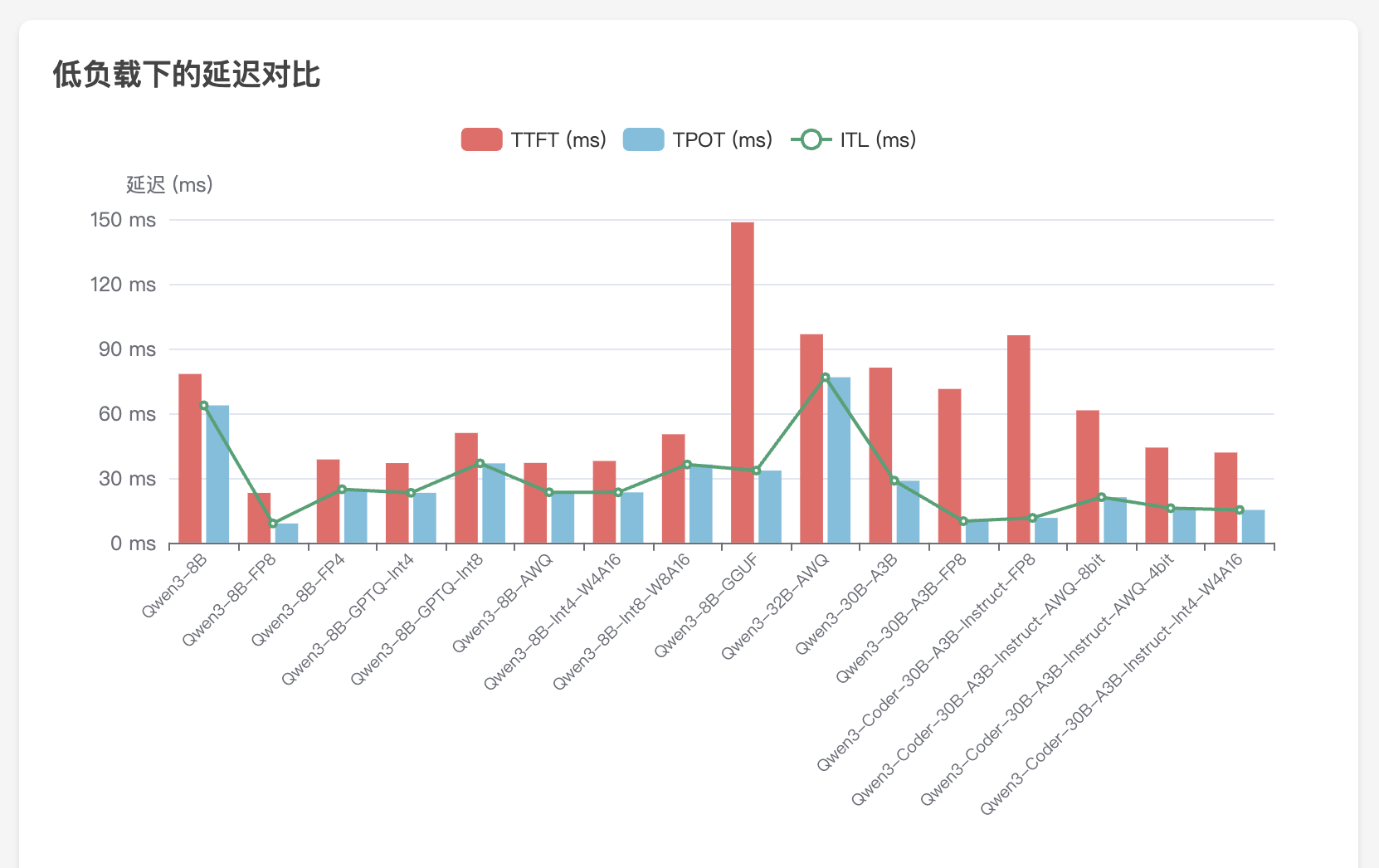
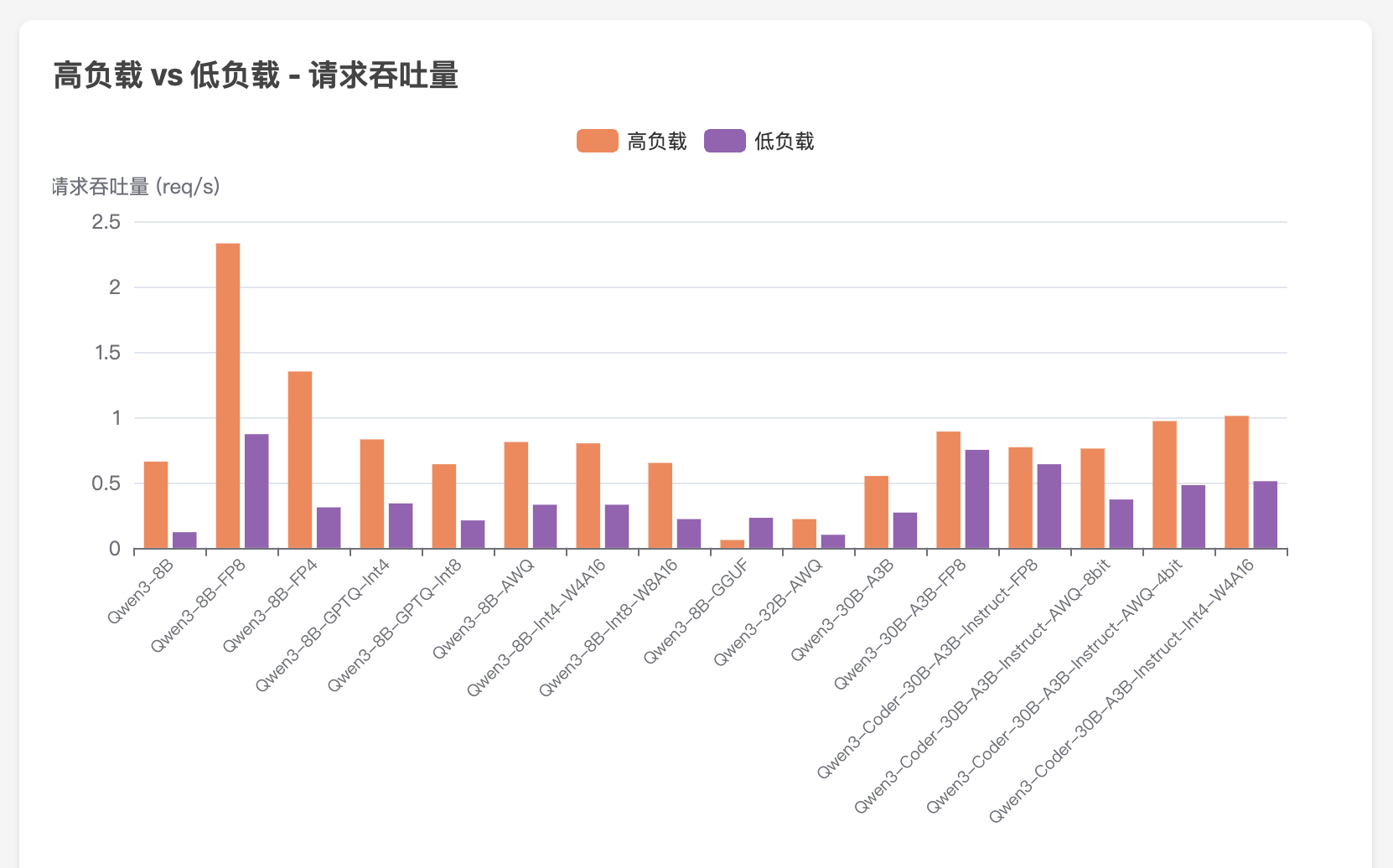
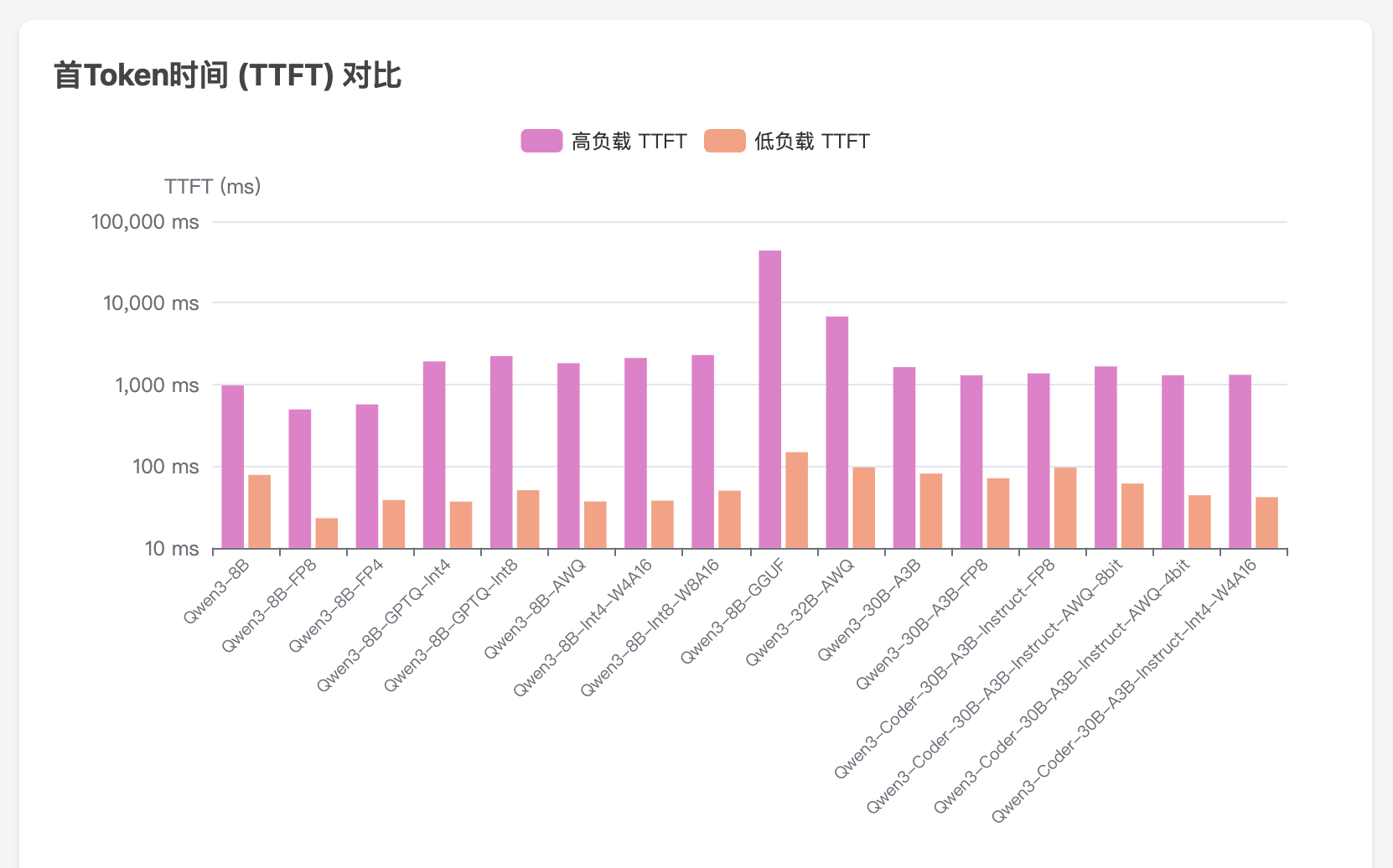
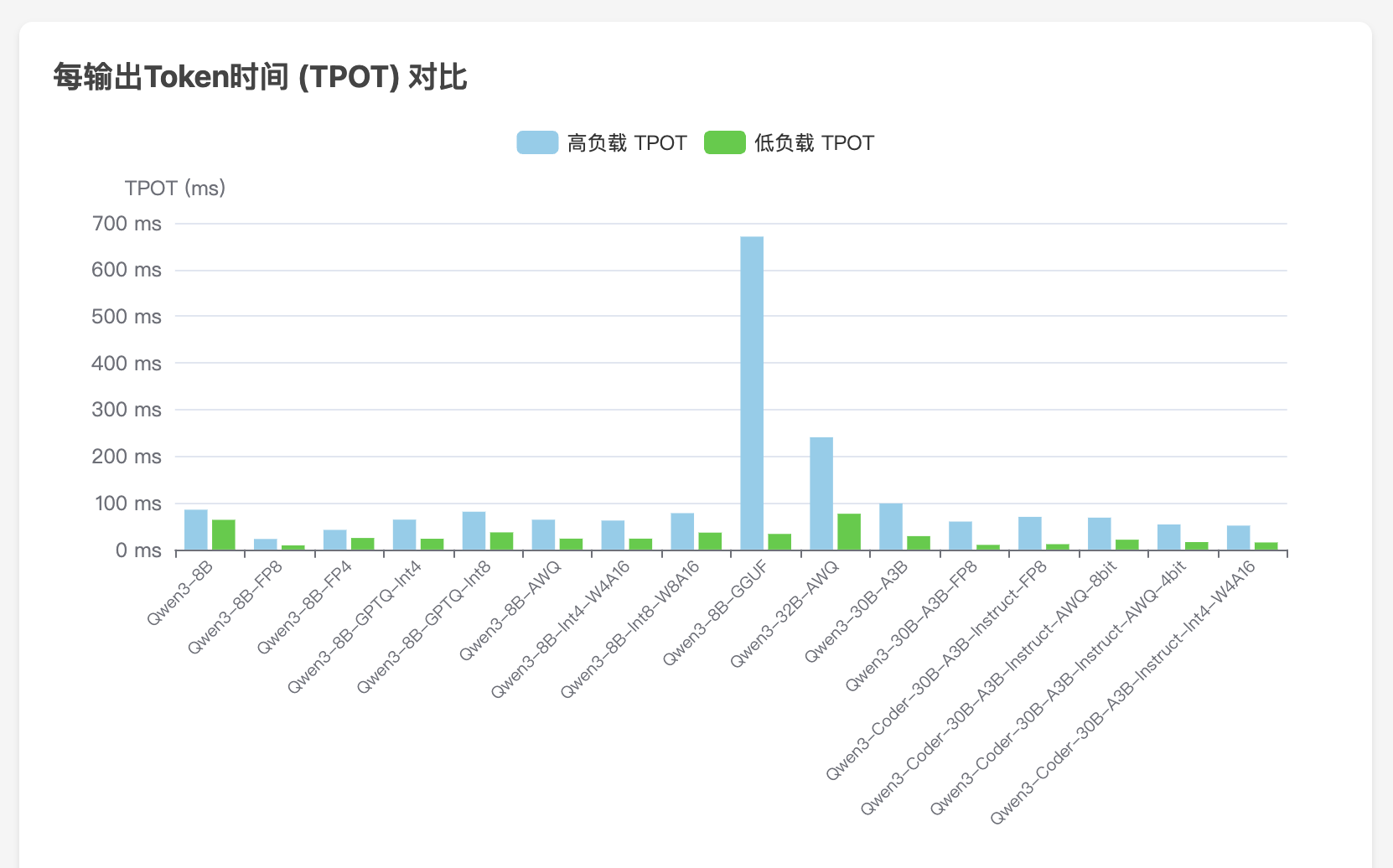
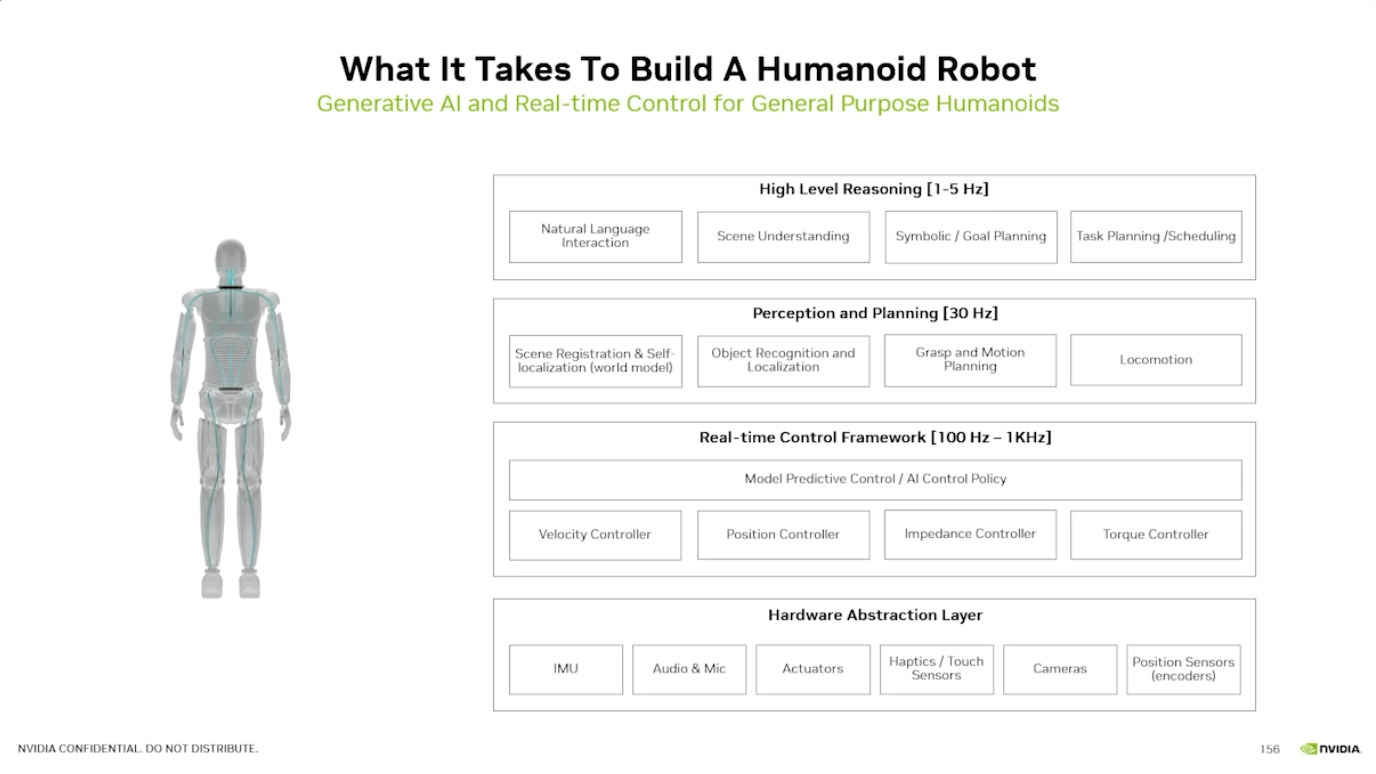
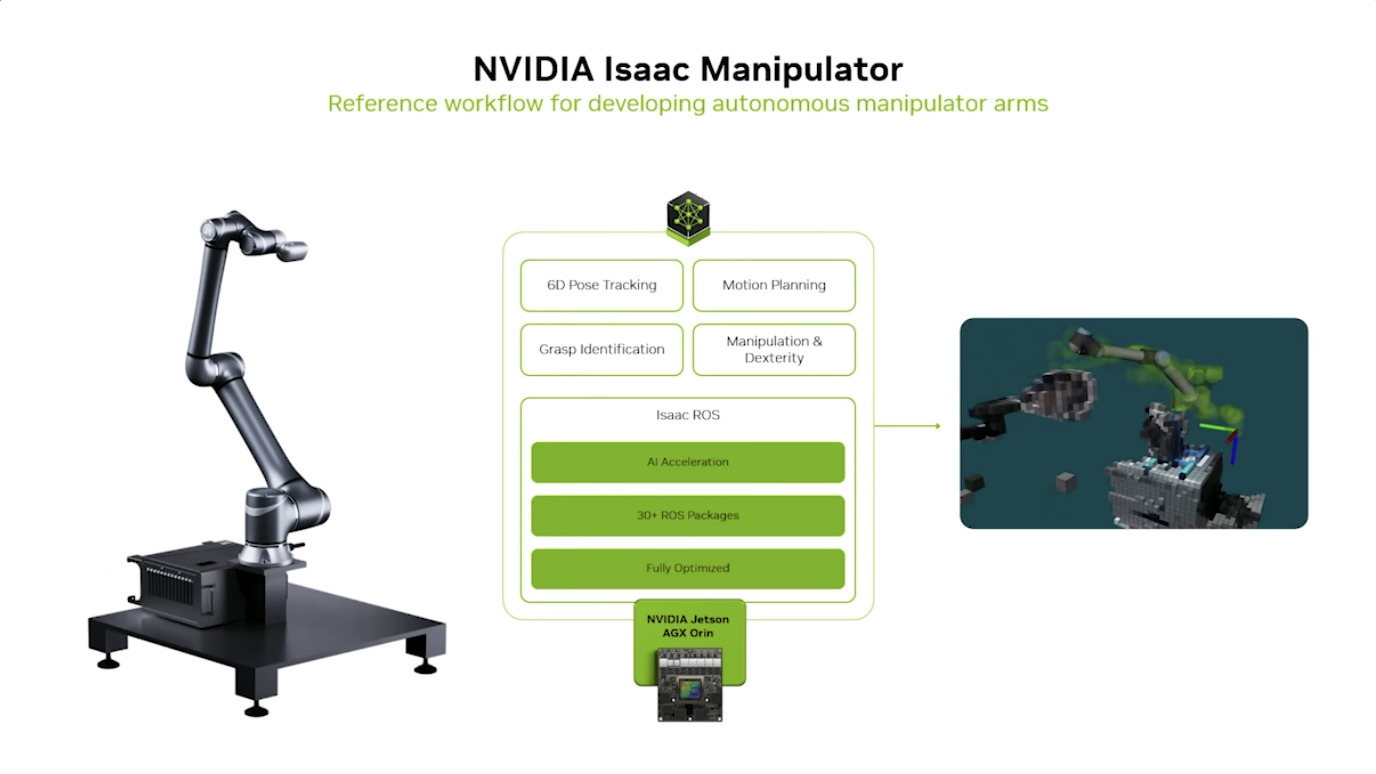
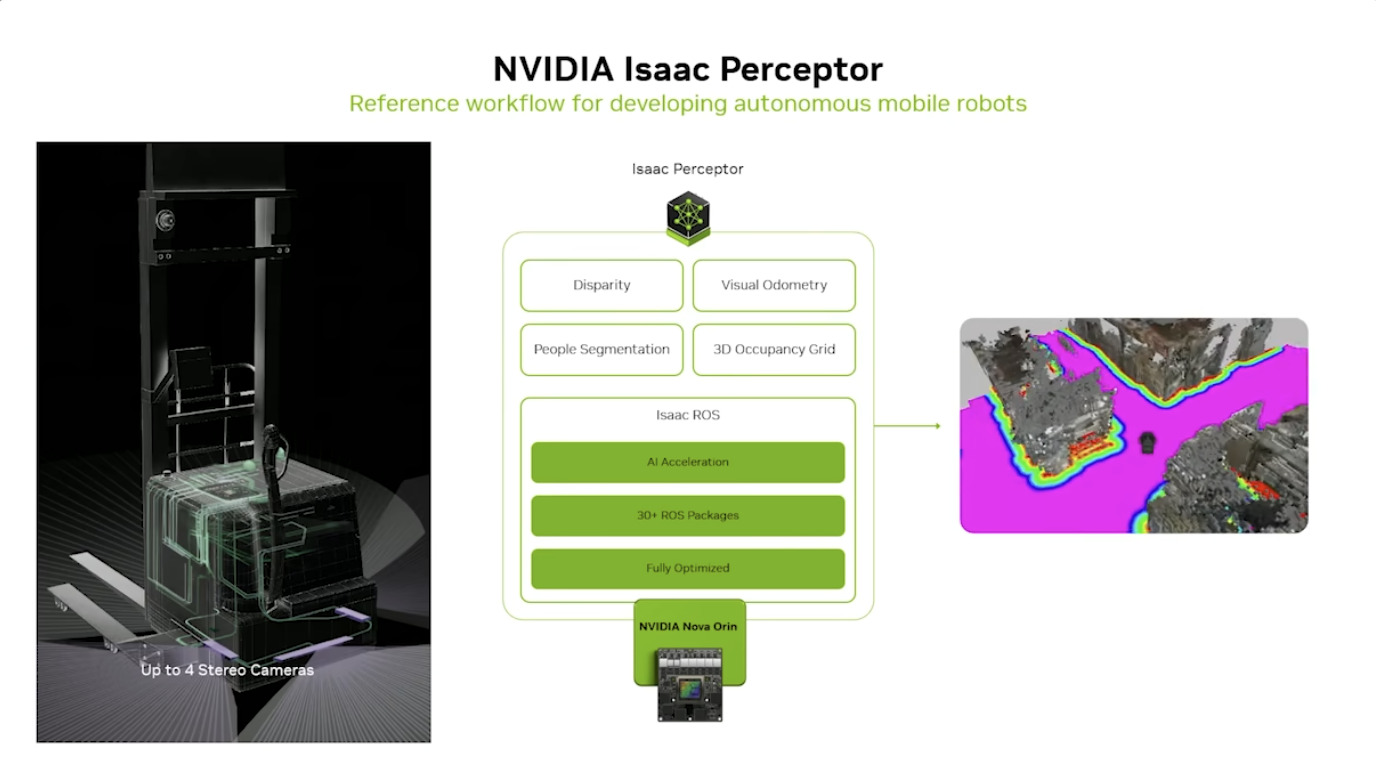
WhisperLiveKit - 实时语音识别
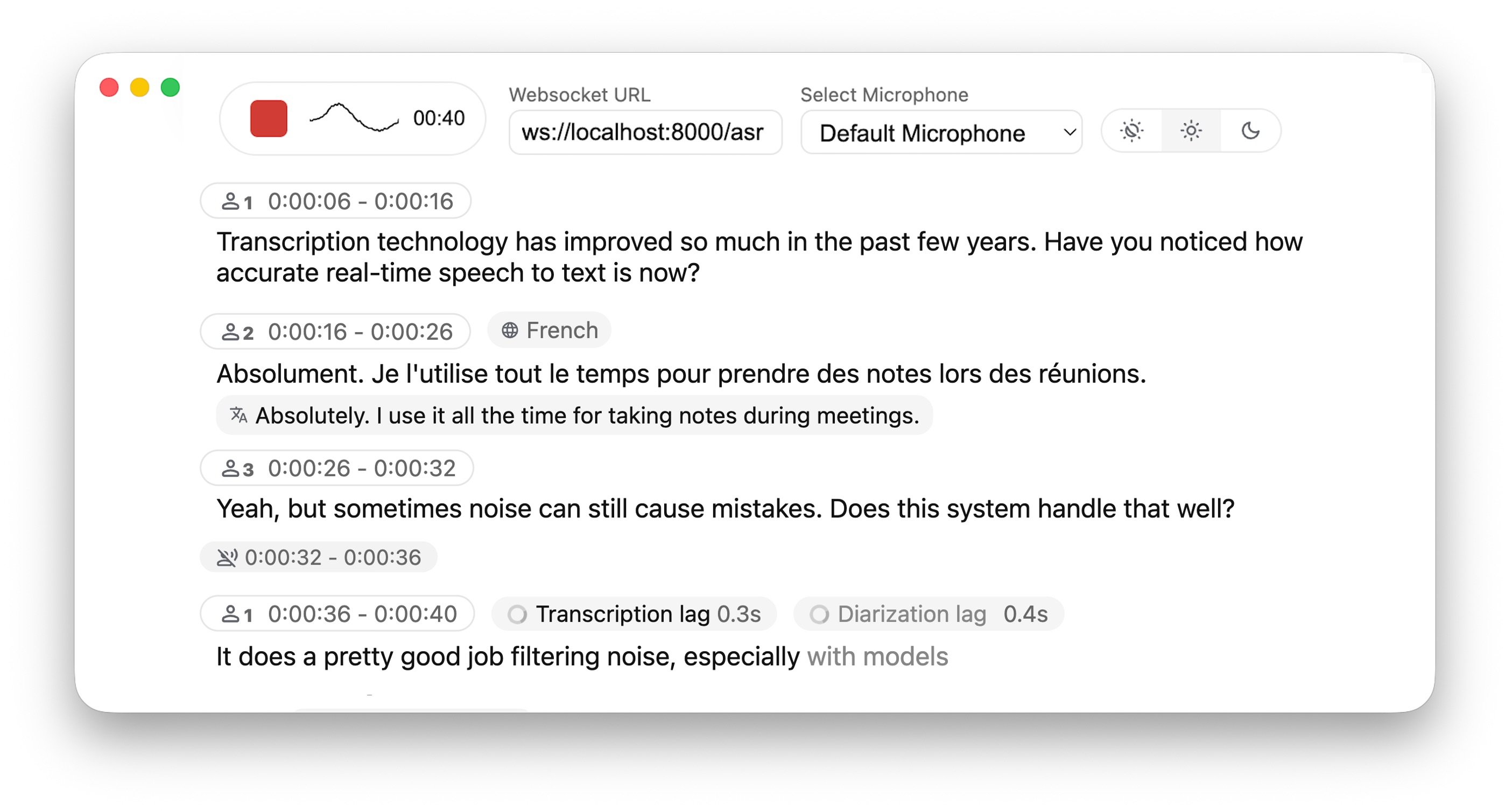
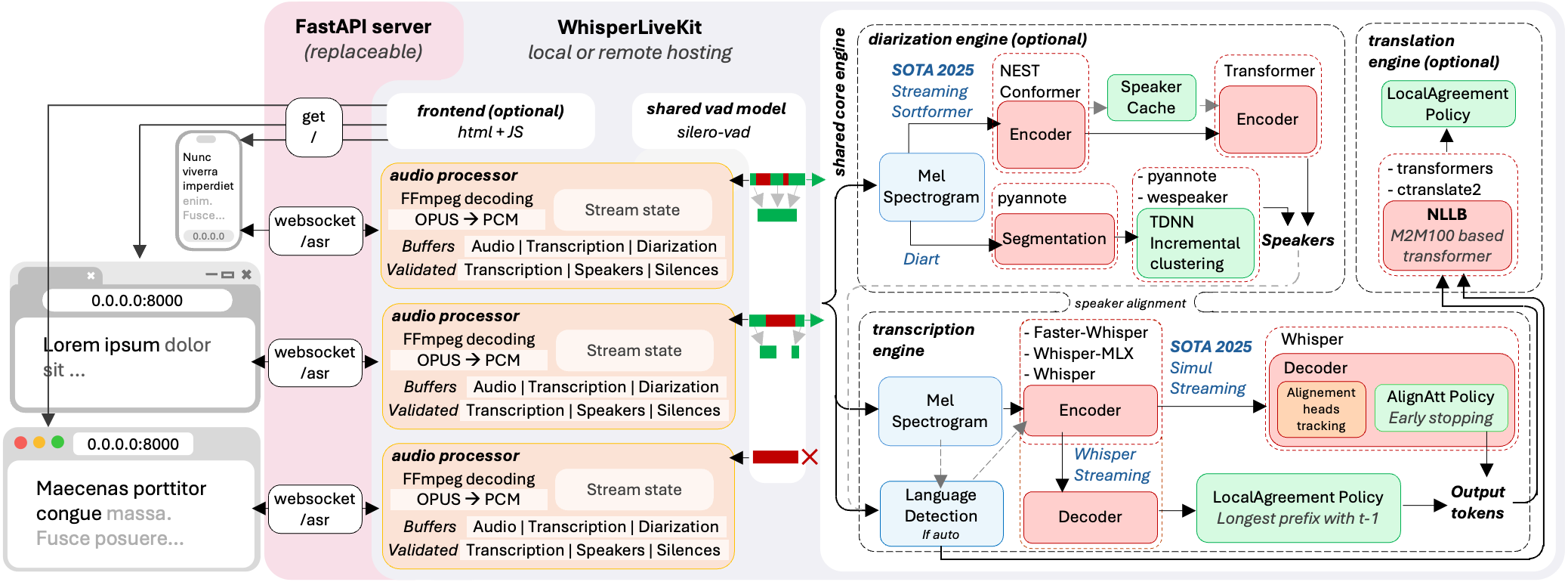
实时、完全本地化的语音转文本,带说话人识别功能
docker run -it \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=whisperlivekit \
-v ~/.cache:/root/.cache \
-v /models:/models \
nvcr.io/nvidia/pytorch:25.10-py3 \
bash
mkdir -p .cert && cd .cert
openssl req -x509 -newkey rsa:4096 \
-keyout key.pem \
-out cert.pem \
-days 365 \
-nodes \
-subj "/C=CN/ST=ShanDong/L=JiNan/O=LNSoft/OU=LNSoft/CN=localhost/emailAddress=wjj@163.com"
-x509:生成自签名证书-newkey rsa:4096:新建 4096 位 RSA 密钥-keyout key.pem:输出私钥文件-out cert.pem:输出证书文件-days 365:证书有效期 365 天-nodes:不加密私钥(即无需输入密码)-subj:直接指定证书主题,跳过交互式输入