DeepSeek-OCR 研究与实测
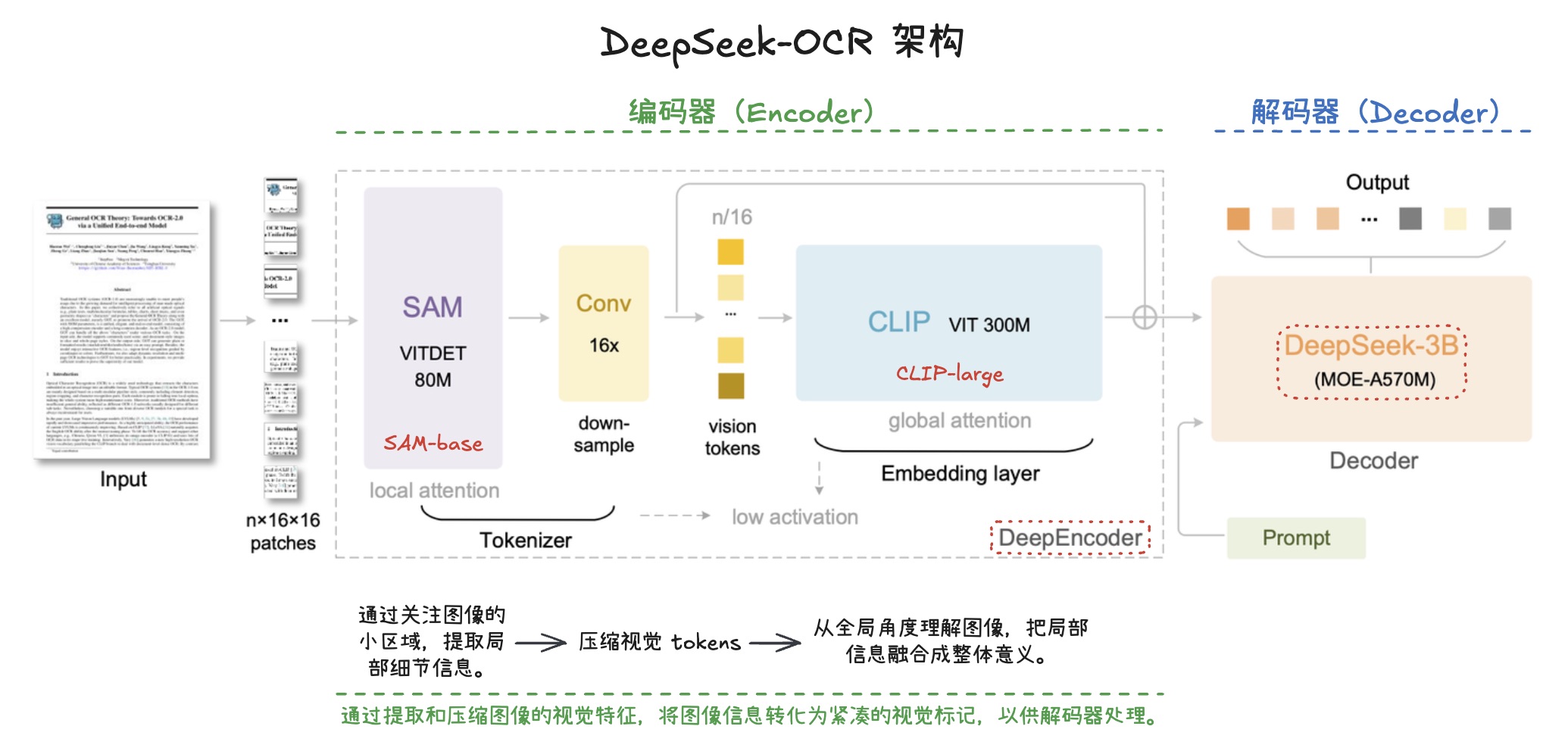

- 方法: 遵循
Vary,使用紧凑语言模型和下一词元预测(next token prediction)框架进行训练。 - 数据: 使用所有
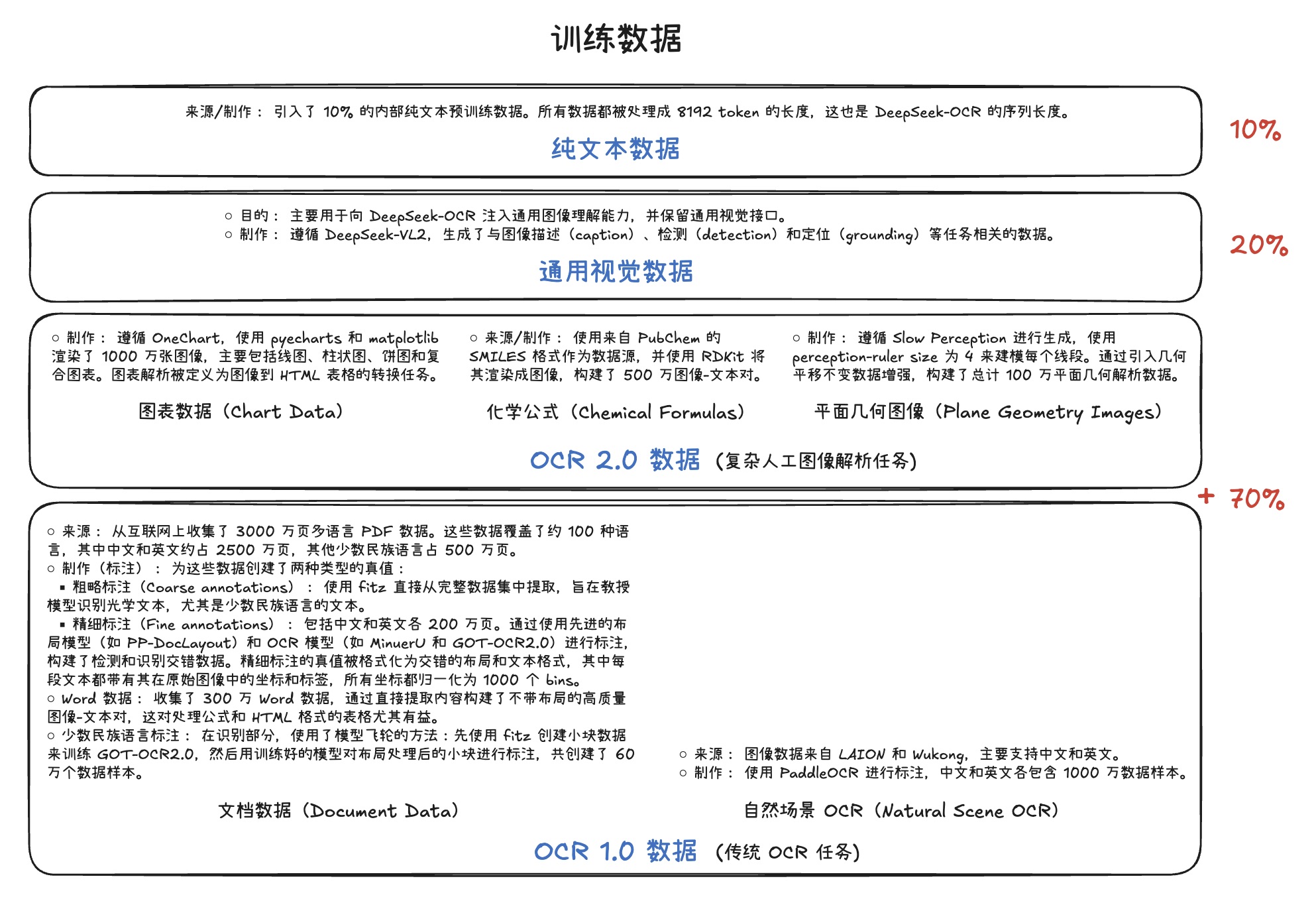
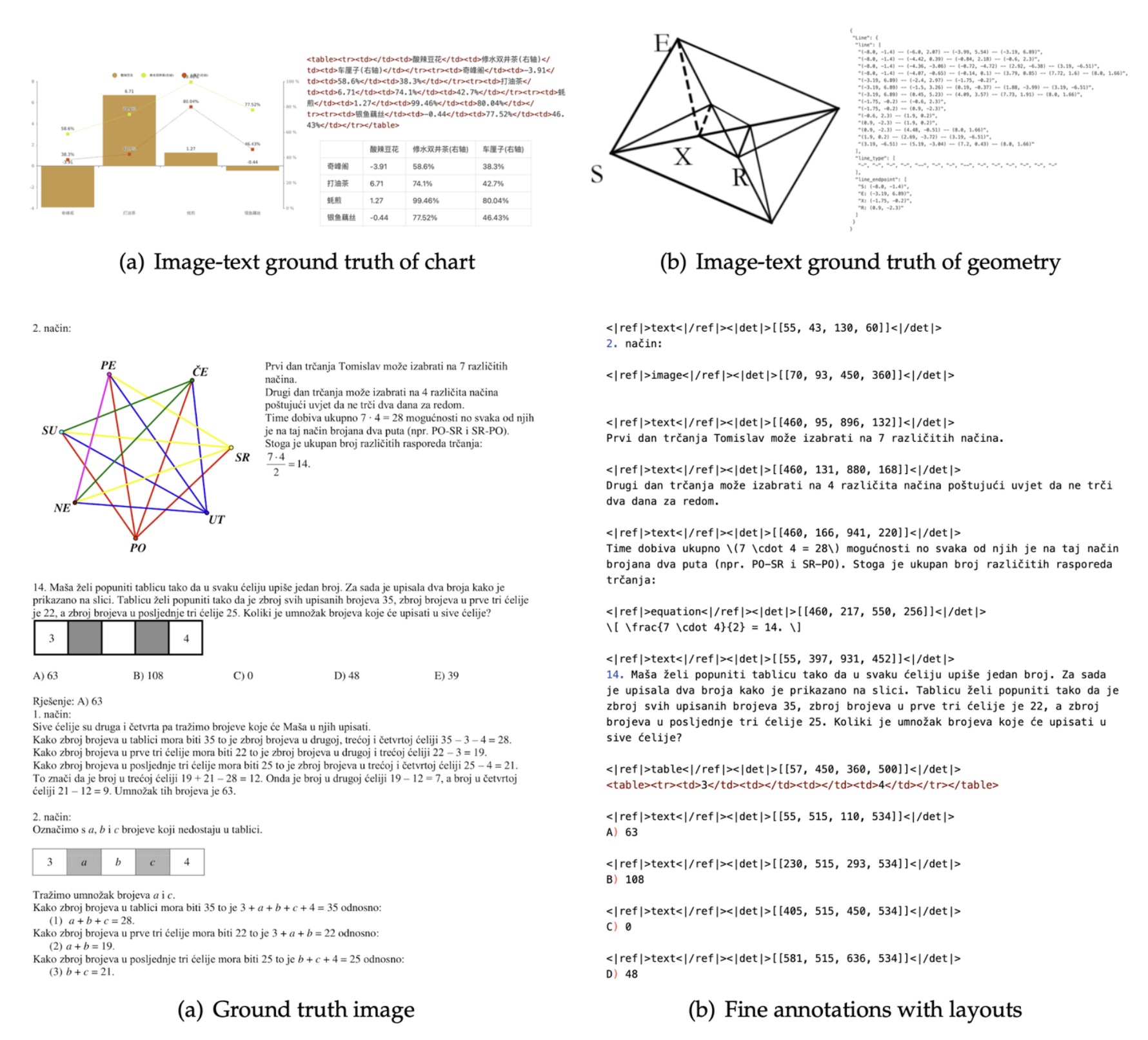
OCR 1.0和OCR 2.0数据,以及从LAION数据集中采样的1 亿(100M)通用数据。 - 训练细节: 训练
2个 epoch,批次大小为1280,使用AdamW 优化器,配合余弦退火(cosine annealing)调度器,学习率为5e-5。训练序列长度为4096。
时机: DeepEncoder 准备好后进行。 数据: 使用训练数据。 并行策略: 采用流水线并行(PP),模型被分为 4 部分: DeepEncoder (PP0, PP1): PP0: 包含 SAM 和压缩器(作为视觉词元分析器),参数冻结。 PP1: 包含 CLIP 部分(作为输入嵌入层),权重不冻结,参与训练。 语言模型 (PP2, PP3): DeepSeek3B-MoE 共有 12 层,PP2 和 PP3 各放置 6 层。 硬件与批次: 使用 20 个节点(每个节点配备 8 块 A100-40G GPU)进行训练,数据并行(DP)为 40,全局批次大小为 640。 优化器: 使用 AdamW 优化器,配合基于步数的调度器(step-based scheduler),初始学习率为 3e-5。

