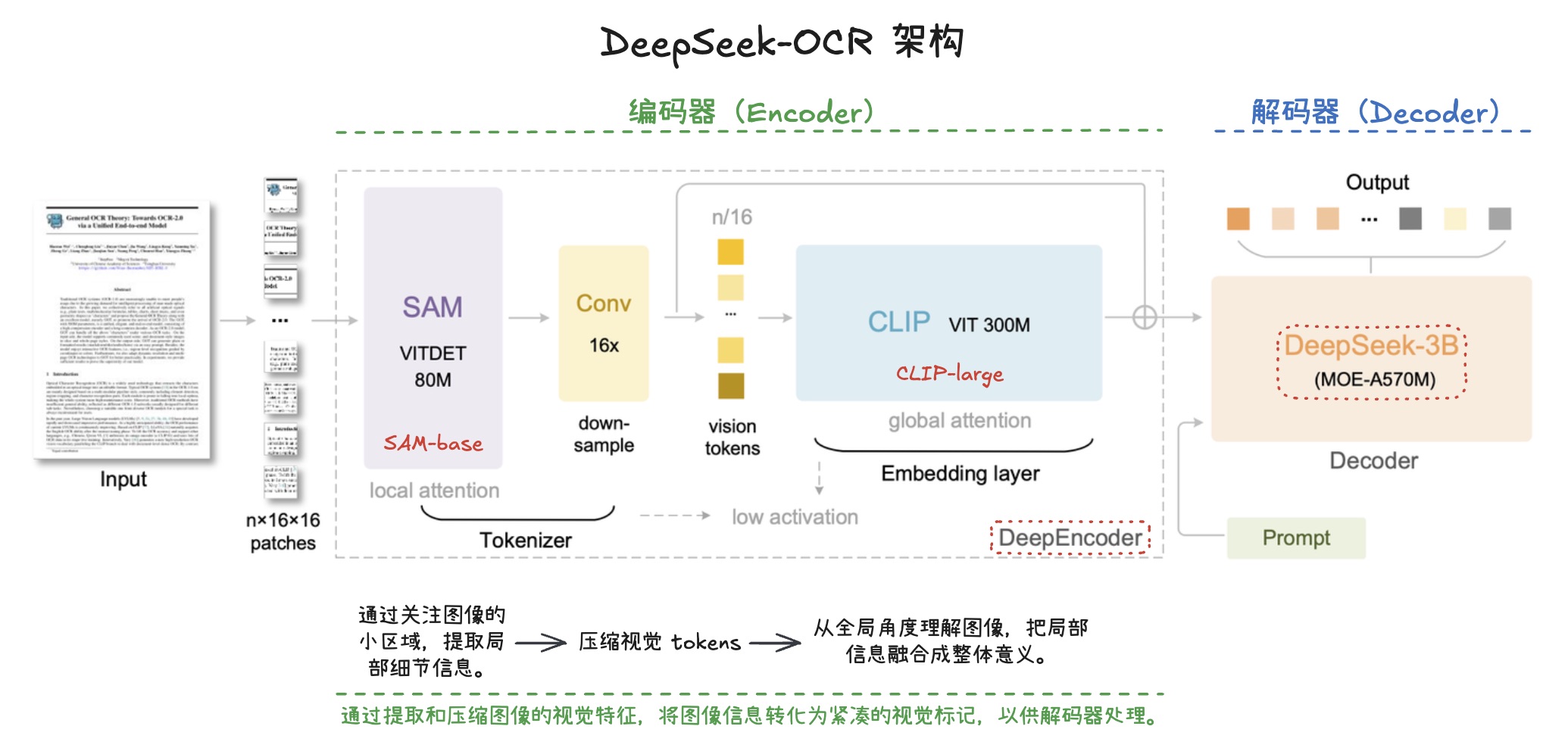
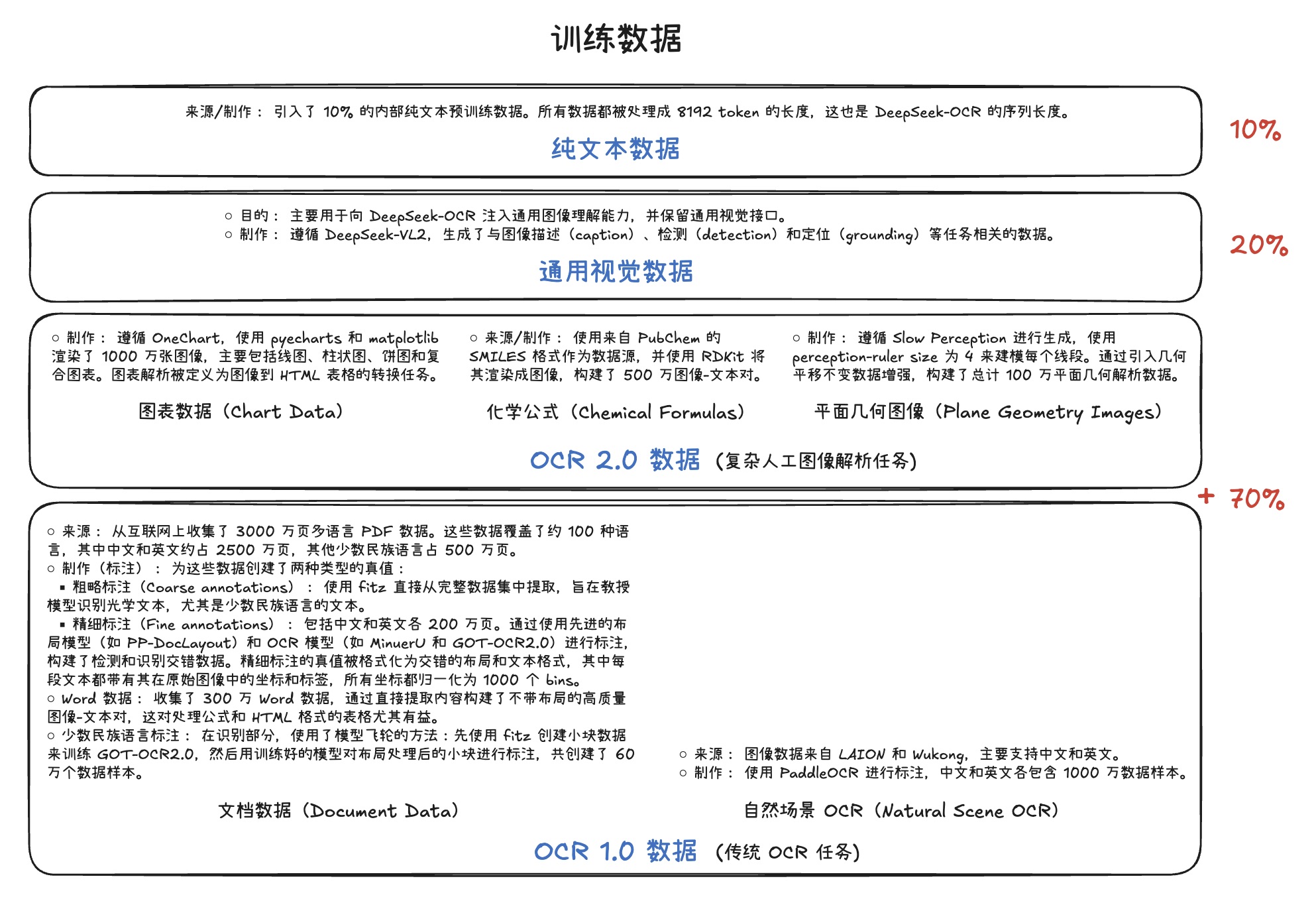
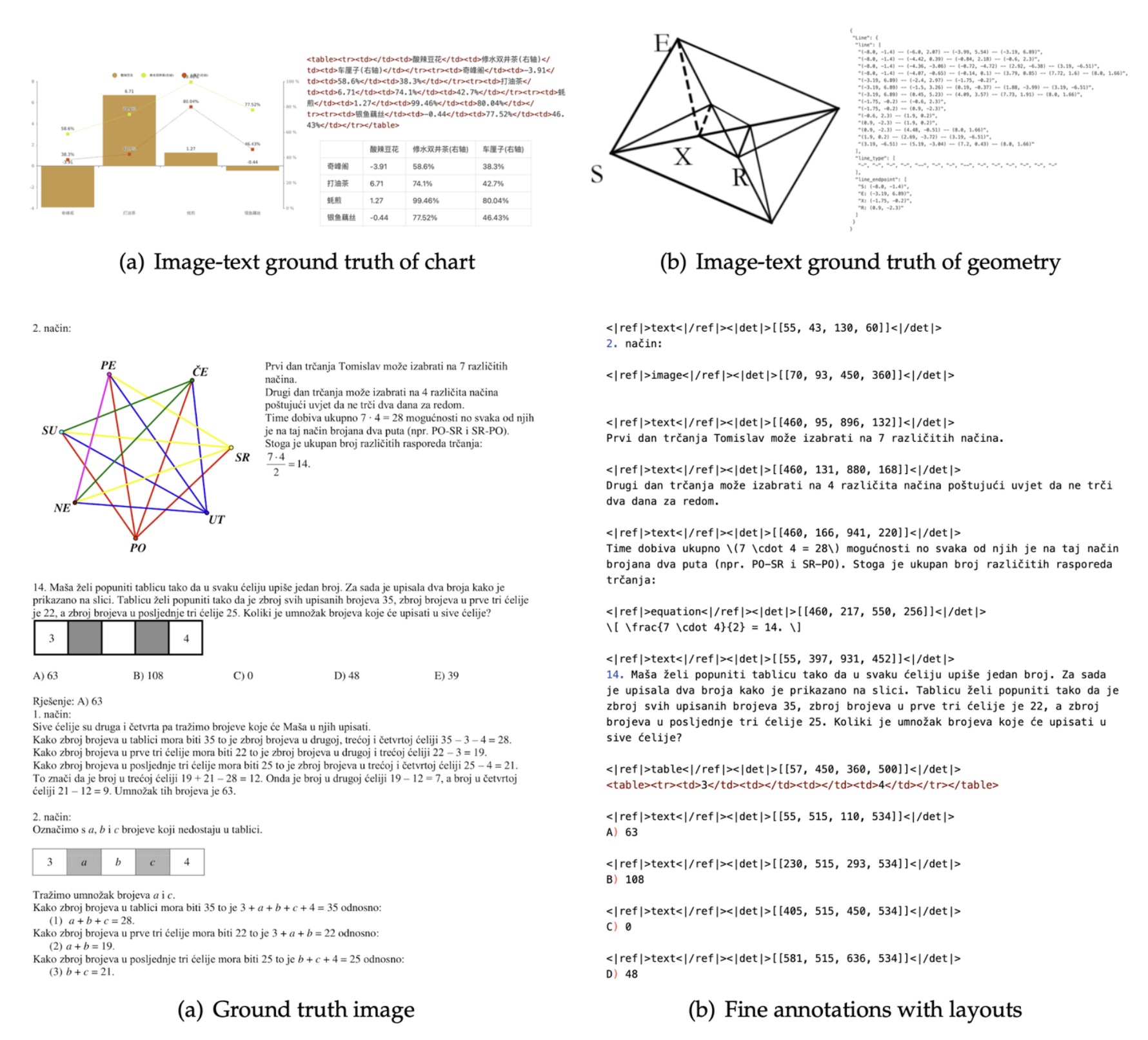
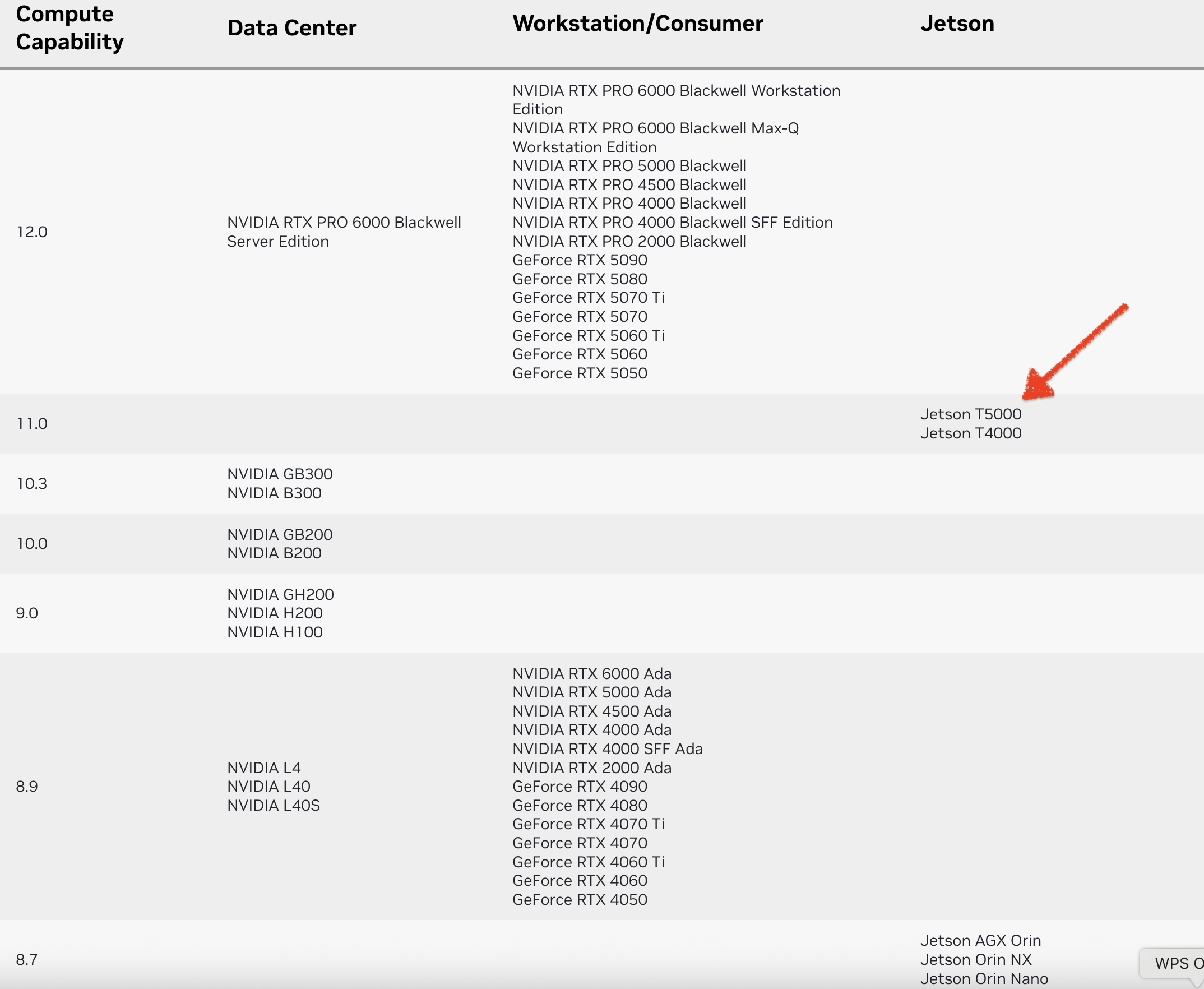
智能会议系统 Jetson Thor 上部署模型服务指南
内网IP:27.41.19.62
| 服务 | 说明 | 端口 | 模型 | 备注 |
|---|---|---|---|---|
| whisperlivekit | 实时语音识别服务 | 8000 | Whispersmall (默认)large-v3-turbo |
带说话人分离 |
| FunASR | 实时语音识别服务 | 8000 | 语音识别:paraformer-zh实时语音识别: paraformer-zh-streaming实时语音端点检测: fsmn-vad标点恢复: ct-punc文本逆规范化: fst_itn_zh |
实时与非实时一体化协同(2pass)服务模式 |
| llama-server | GGUF 模型推理服务 | 8080 | Qwen3Qwen3-8B-Q5_K_M.gguf |
模型名:qwen3 上下文长度:32K 不思考 |
sudo nvpmodel -m 0
sudo jetson_clocks
sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
tmux new -s wlk
docker run -it \
--ipc=host \
--net=host \
--runtime=nvidia \
-e MODEL=small \
-e PORT=8000 \
-e LANG=zh \
-e DIAR=true \
wangjunjian/whisperlivekit