Jetson Thor 平台上 Qwen3 系列大模型性能基准测试分析
NVIDIA Jetson Thor 采用了 Blackwell 架构的 GPU。
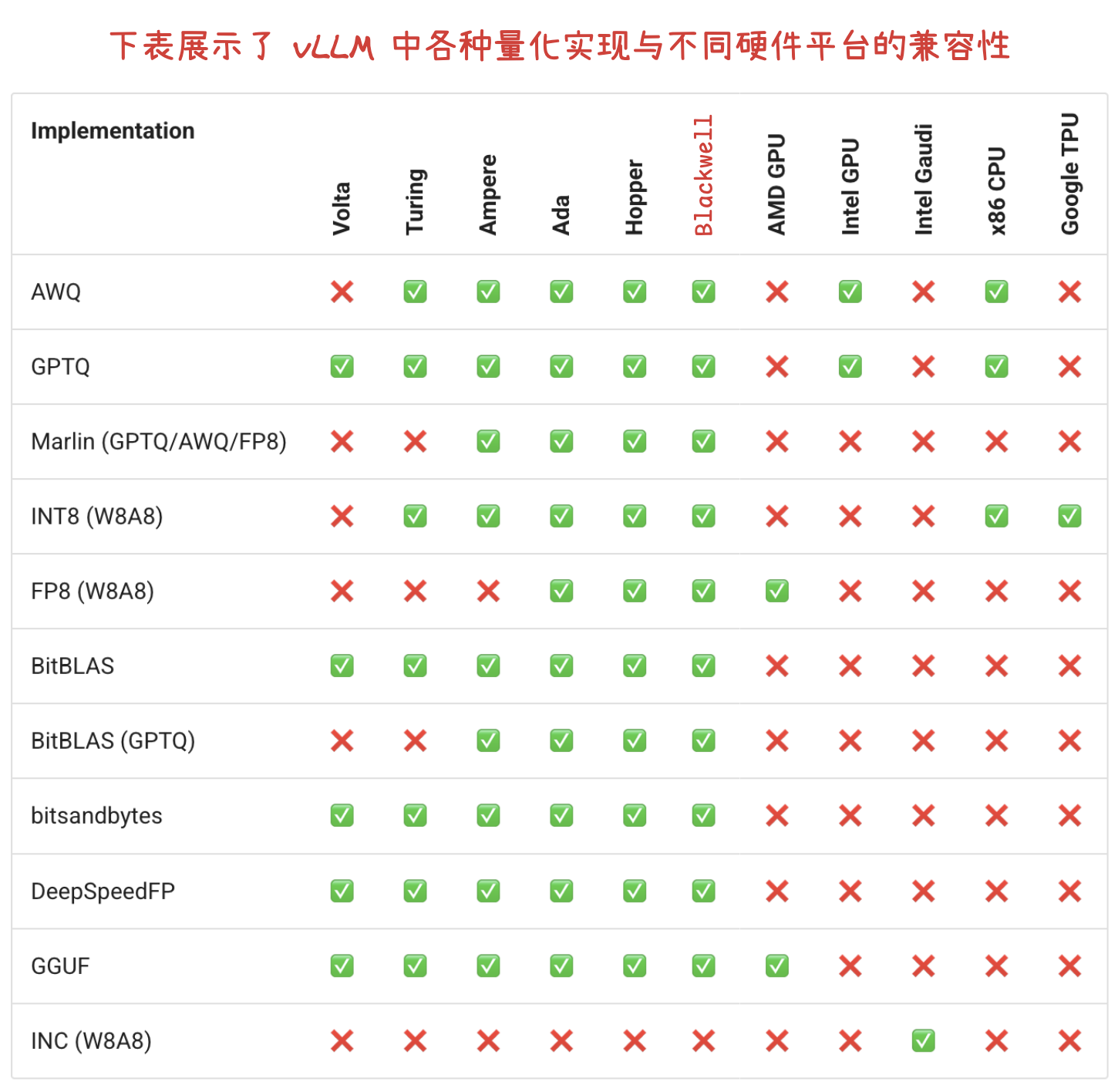

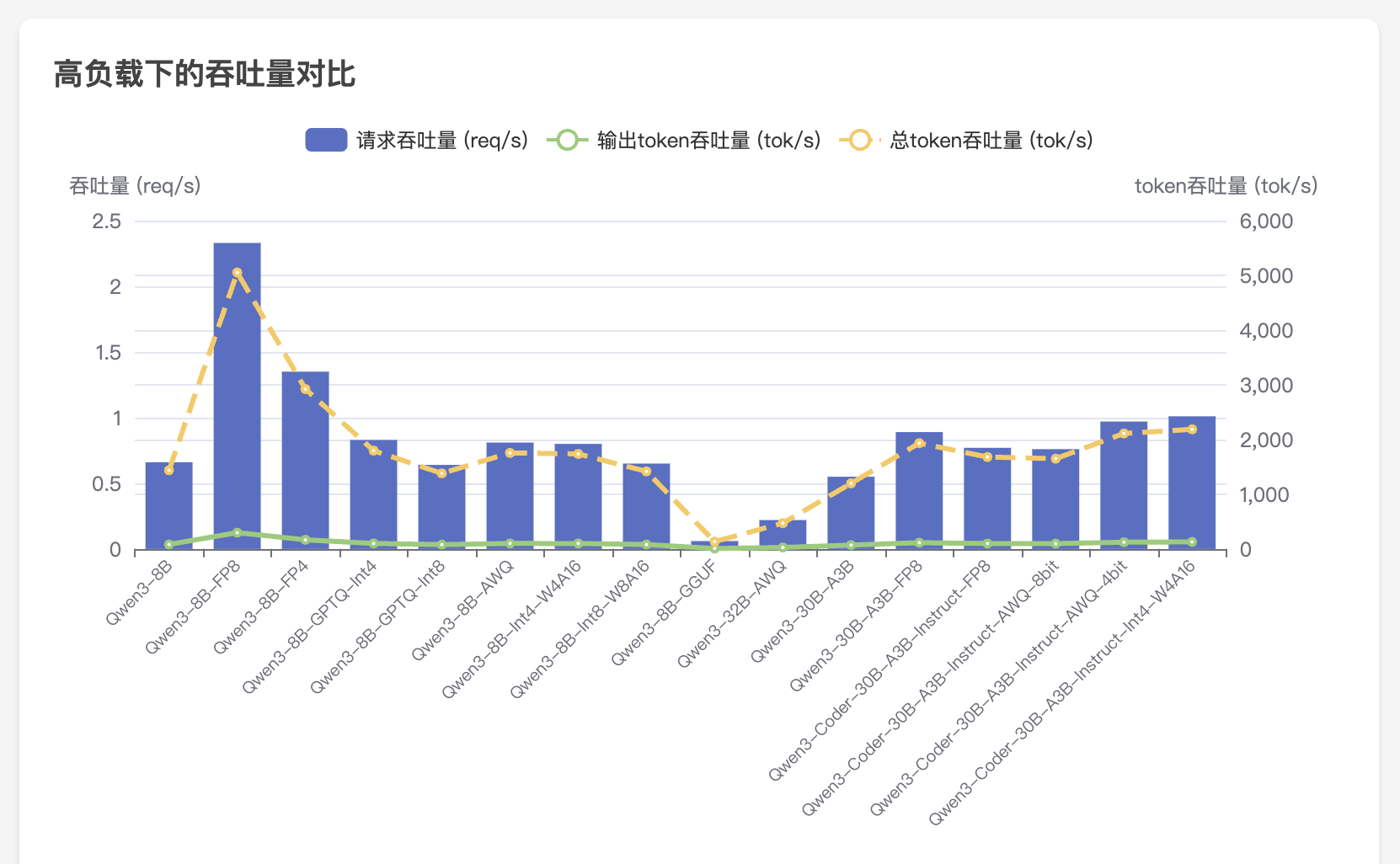
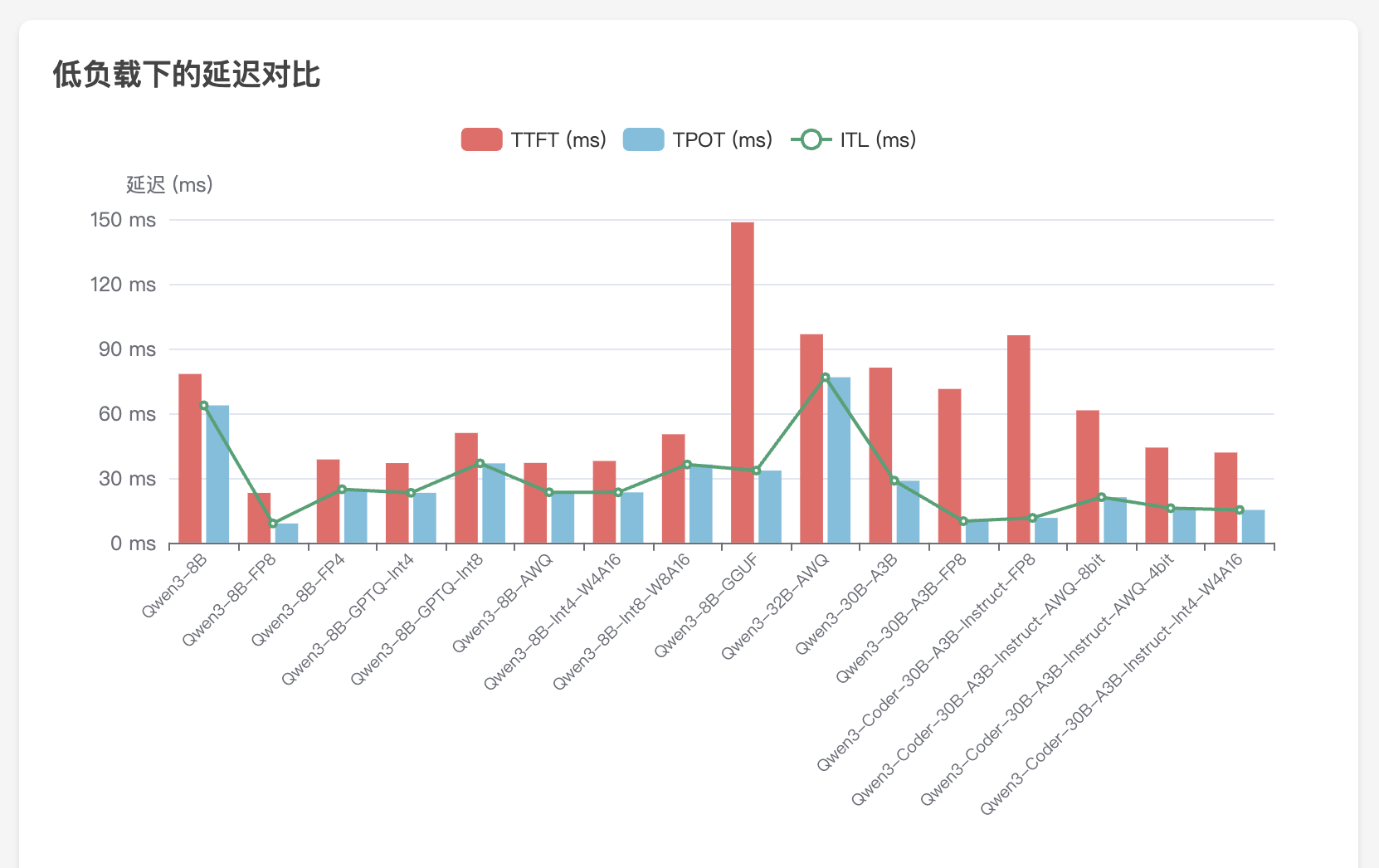
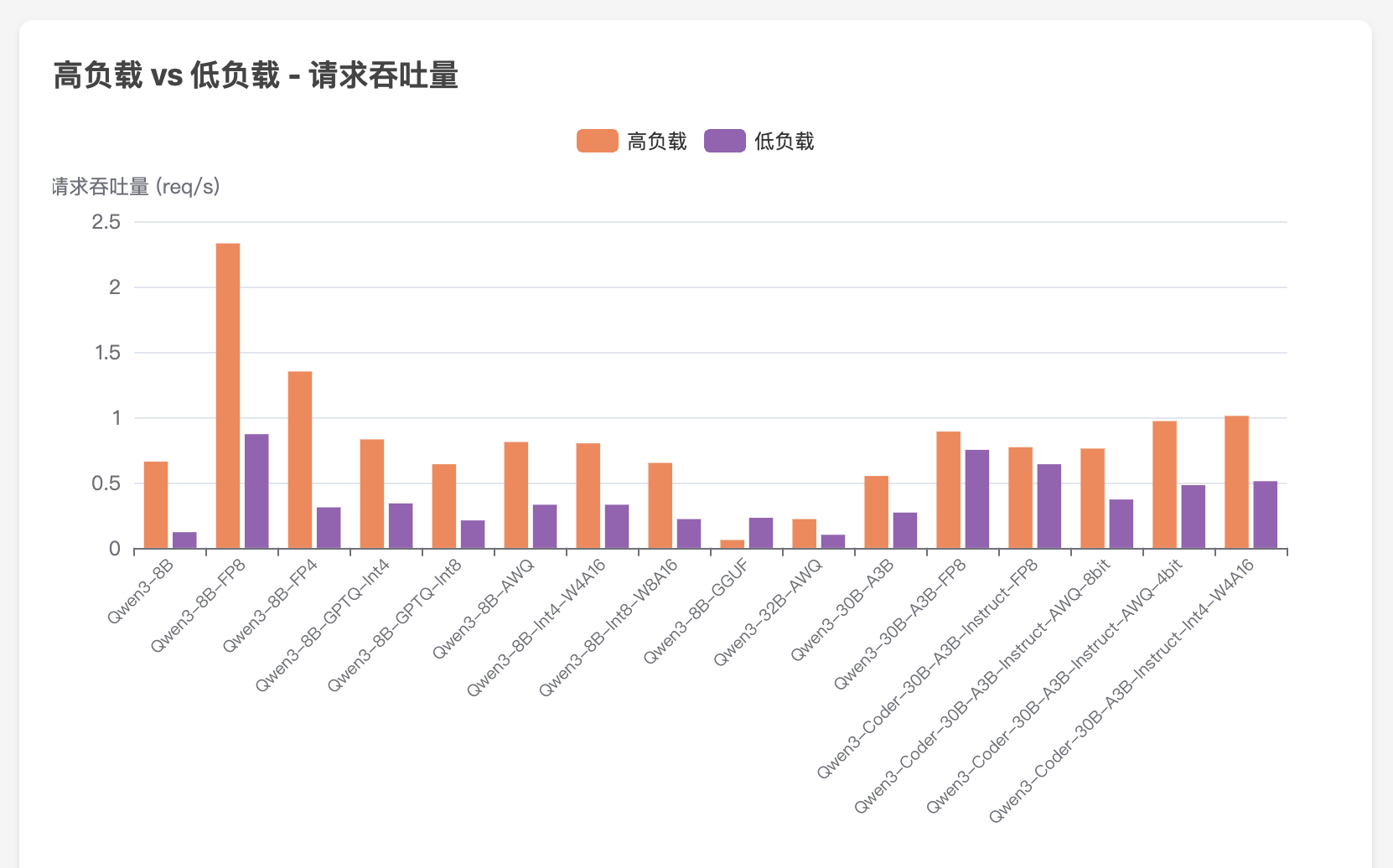
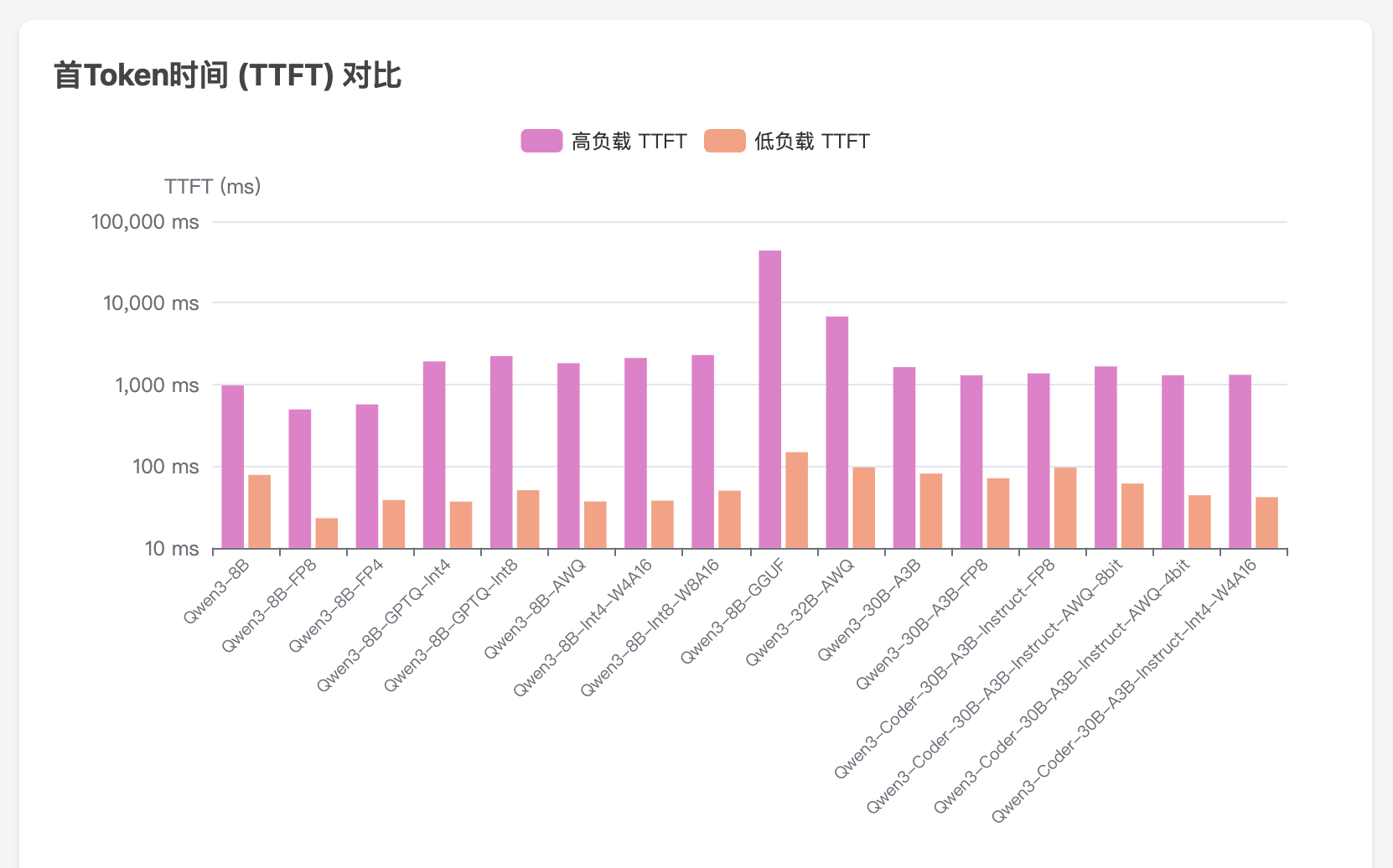
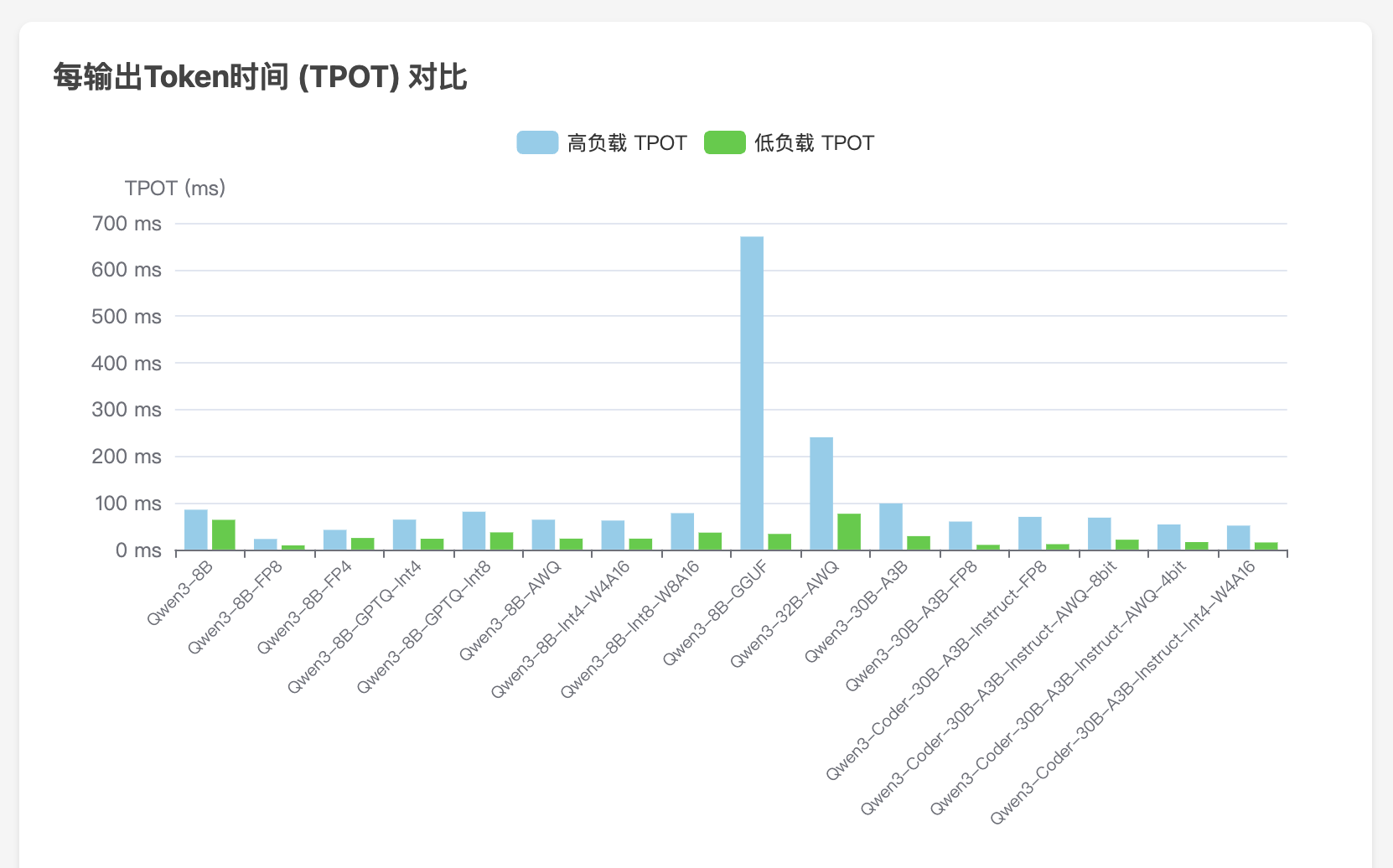
vllm serve /models/Qwen/Qwen3-8B --served-model-name qwen3
- 高负载
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 2048 \
--random-output-len 128 \
--num-prompts 100 \
--max-concurrency 8
- 低负载