英伟达全栈方案:LLM开发、推理与具身智能
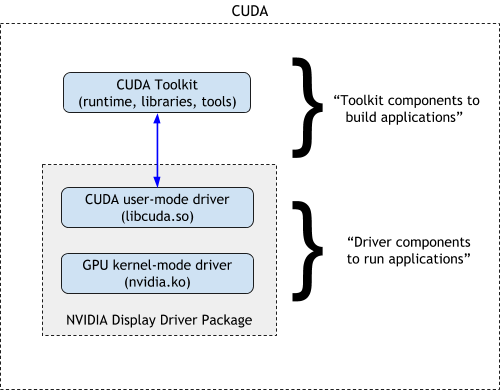
NVIDIA 提供 TensorRT-LLM、Triton Inference Server 和 NVIDIA Inference Microservice (NIM) 等工具来优化和加速 AI 模型的推理,使模型运行速度提升高达 5 倍。这意味着您可以高效地部署和运行 LLM 以生成内容。 同时,NVIDIA 还提供了用于 LLM 开发的工具和框架,如 NeMo,可以帮助开发者更轻松地创建和管理 LLM。
GROOT项目利用 合成运动生成 将人类演示转化为大量的训练数据,并通过 Isaac Lab 进行仿真训练,从而实现 机器人学习。整个系统建立在 Jetson Thor 架构之上,并整合了 NVIDIA Omniverse 等工具,支持机器人数据的处理与生成、仿真与学习,以及简化扩展,最终目标是推进 人形机器人技术 的发展。