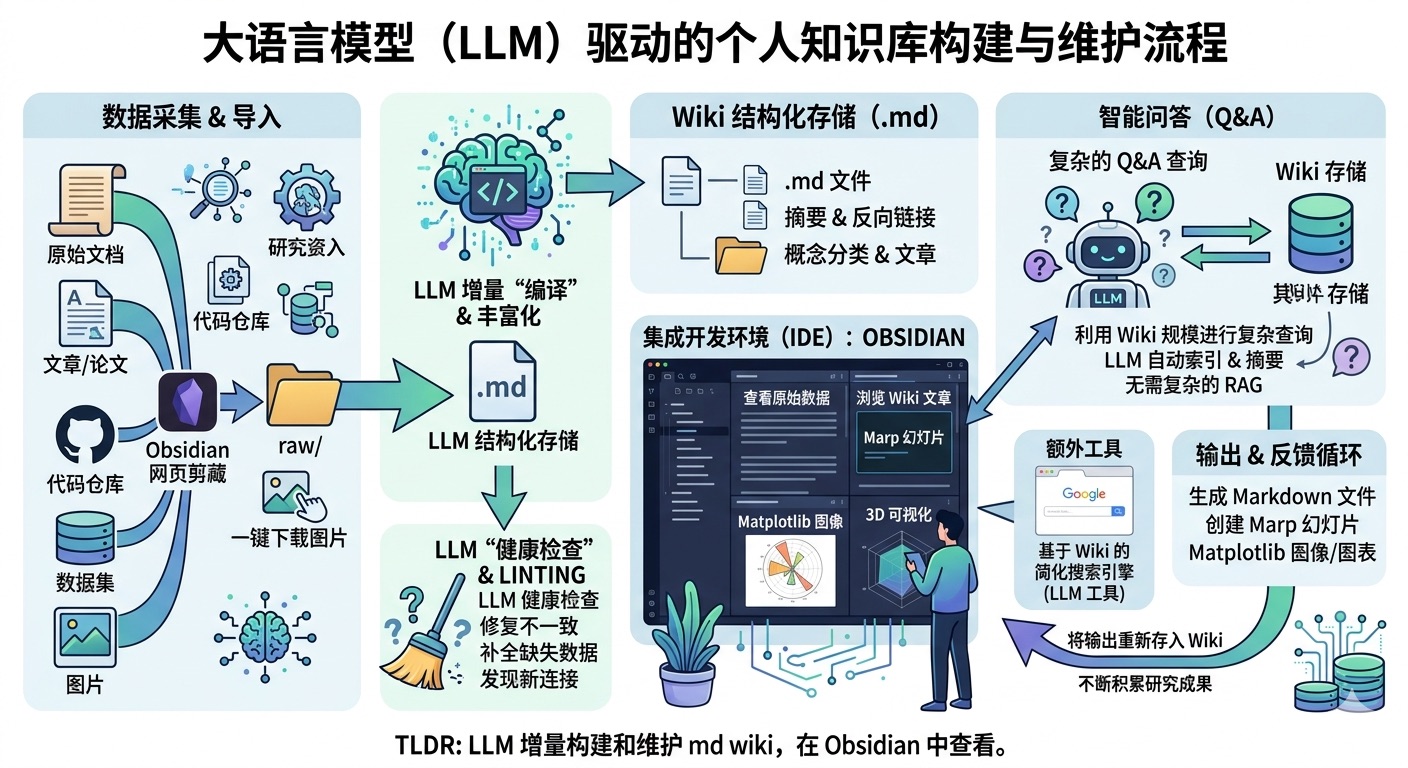
WikiLLM:基于 LLM 驱动的个人知识库
利用 LLM 构建个人知识库的系统。WikiLLM 将原始素材"编译"成结构化、交叉链接的高质量中文 Wiki,可在 Obsidian 中查看。
本项目基于 Andrej Karpathy 提出的理念构建。详见:LLM Knowledge Bases

WikiLLM 的工作流包括:
- 数据摄入:源文档(文章、论文、代码库、数据集、图像)被索引到
raw/目录 - Wiki 编译:LLM 增量地"编译"原始数据成 markdown 文件的 wiki,包含摘要、反向链接、分类概念和相互链接的文章
- IDE:Obsidian 用作前端查看原始数据、编译后的 wiki 和可视化
- 问答:LLM 可以通过研究相关数据来回答针对 wiki 的复杂问题
- 输出:结果渲染为 markdown 文件、Marp 幻灯片或 matplotlib 图像,可在 Obsidian 中查看
- Linting:LLM"健康检查"发现不一致、填补缺失数据、建议新文章候选
- 额外工具:诸如 wiki 上的朴素搜索引擎等额外工具
- LLM 编写和维护所有 wiki 数据;手动编辑很少见
- 用户探索和查询被归档回 wiki 以增强它
- 系统专注于 markdown 文件和 Obsidian 兼容格式
- 图像被下载到本地 以便 LLM 轻松引用