Kimi K2.5:首个开源多模态智能体集群
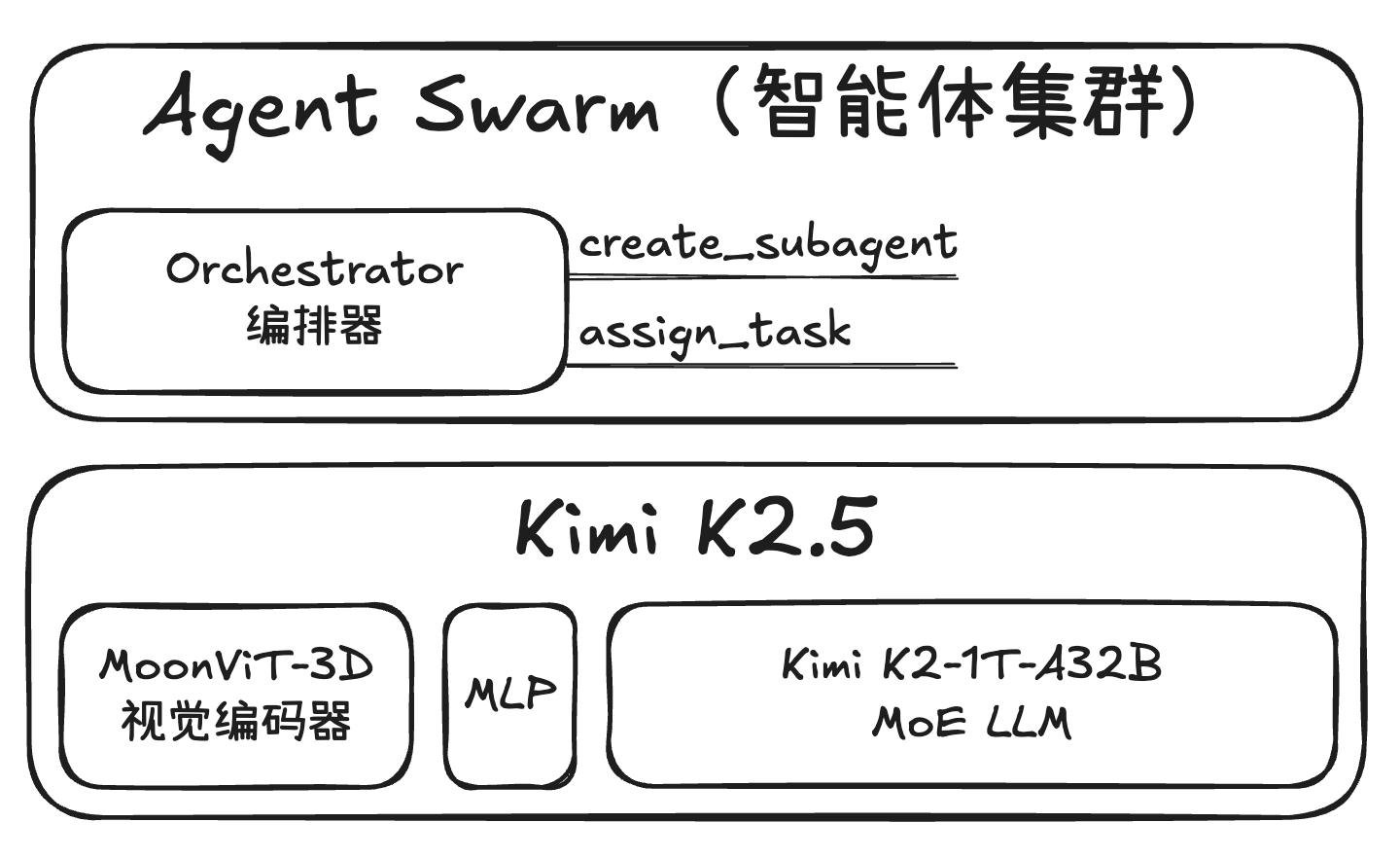
感觉 Kimi K2.5 在国内被低估了,让子弹飞一会儿 🚀🚀🚀
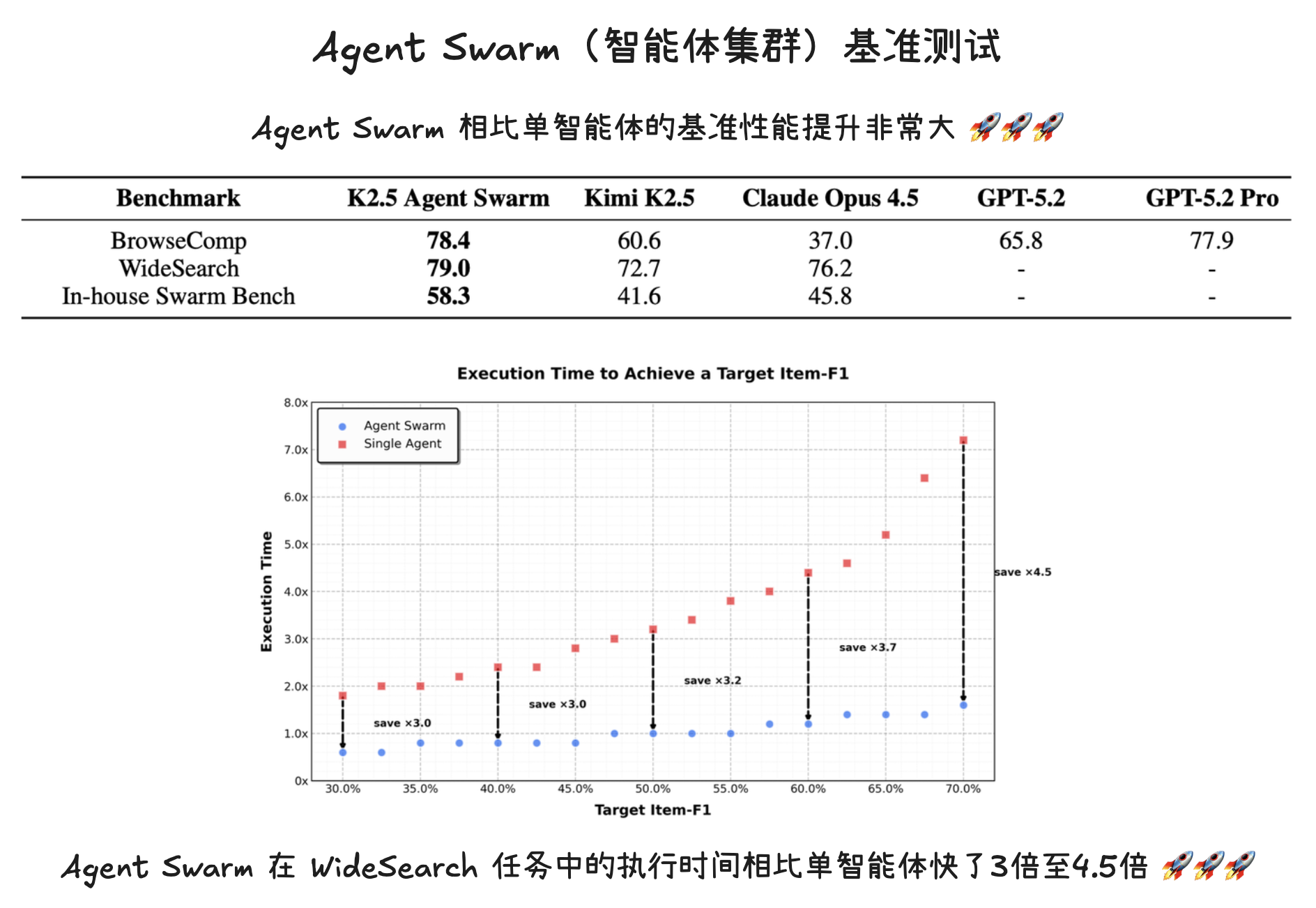
为了严格评估智能体集群(Agent Swarm)框架的有效性,选择了三个具有代表性的基准测试,它们共同涵盖了深度推理、大规模检索以及真实世界的复杂性:
- BrowseComp:一项具有挑战性的深度研究基准,需要多步推理和复杂的信息综合。
- WideSearch:旨在评估在不同来源中进行广泛、多步信息寻求和推理能力的基准。
- In-house Swarm Bench:一项内部开发的集群基准,旨在评估智能体集群在真实世界、高复杂度条件下的性能。 它涵盖了四个领域:
- WildSearch(开放网络上不受约束的真实世界信息检索);
- Batch Download(大规模获取多样化资源);
- WideRead(涉及 100 多个输入文档的大规模文档理解);
- Long-Form Writing(连贯生成超过 10 万字的海量内容)。 该基准整合了极端规模的场景,旨在压力测试基于智能体系统的编排(Orchestration)、可扩展性(Scalability)和协作能力。

Kimi K2.5 评估涵盖了多个领域的基准测试,下面是按能力维度分类的各基准测试说明:
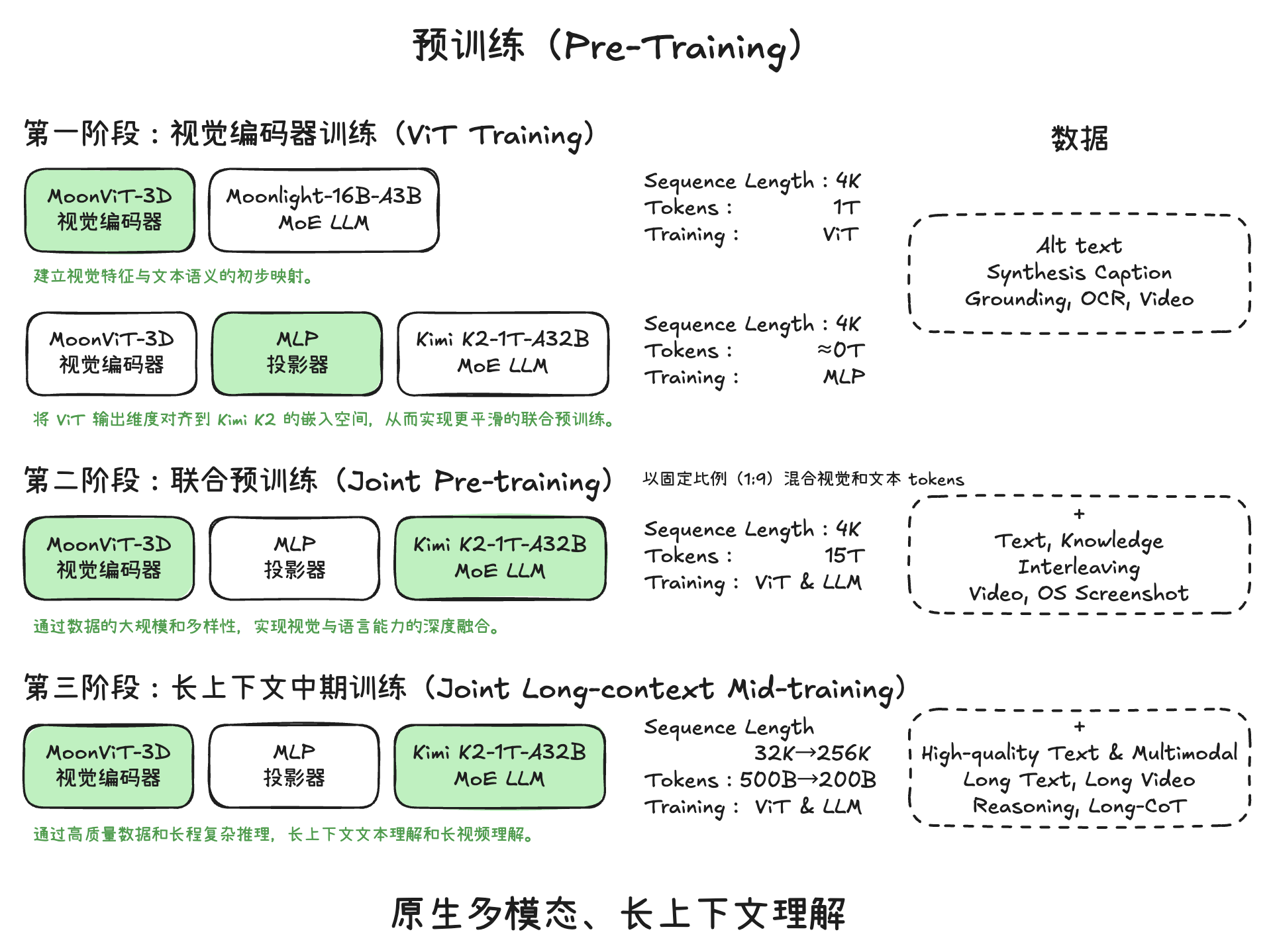

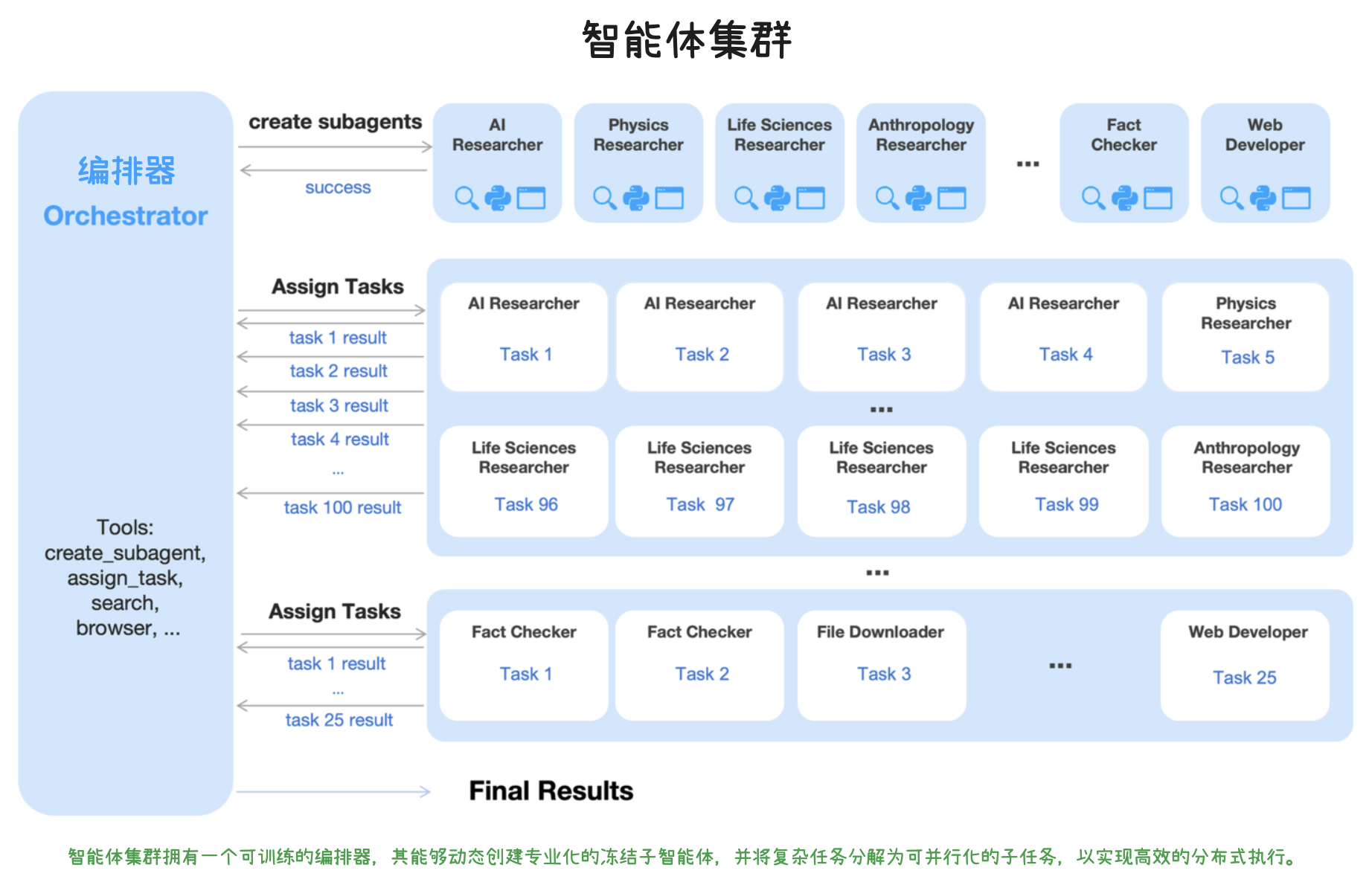
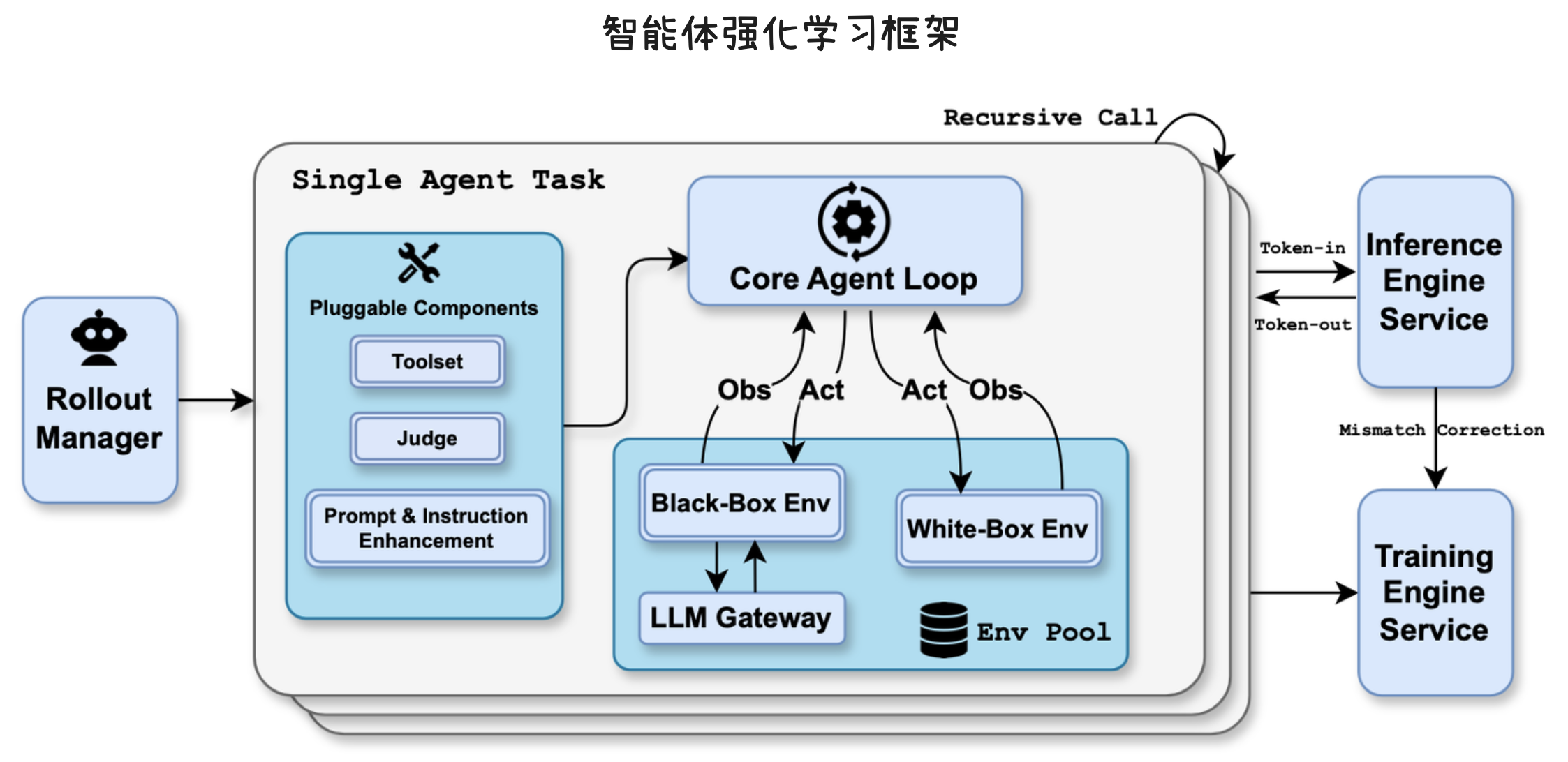
Unified Agentic Reinforcement Learning Environment(统一智能体强化学习环境)是 Kimi K2.