PyTorch 神经网络实战:从训练到推理的完整指南
该文本提供了一个关于PyTorch二分类神经网络的实现与性能分析的全面概述。首先,它通过具体代码示例展示了如何构建、训练、评估和保存一个基础的神经网络模型,并演示了如何加载模型进行推理。其次,文章深入探讨了不同模型参数规模下,Apple的MPS(Metal Performance Shaders)框架与CPU在训练时间上的性能对比,通过表格数据清晰地呈现了MPS在处理大型模型时相较于CPU的显著优势,并指出了性能的“转折点”。
我的电脑是 Apple MacBook Pro M2 Max 16寸 64G内存
这不是好的实践,因为训练和数据加载在同一个 for 循环中顺序进行。每次我们加载下一个小批量时,模型和 GPU 都处于空闲状态。
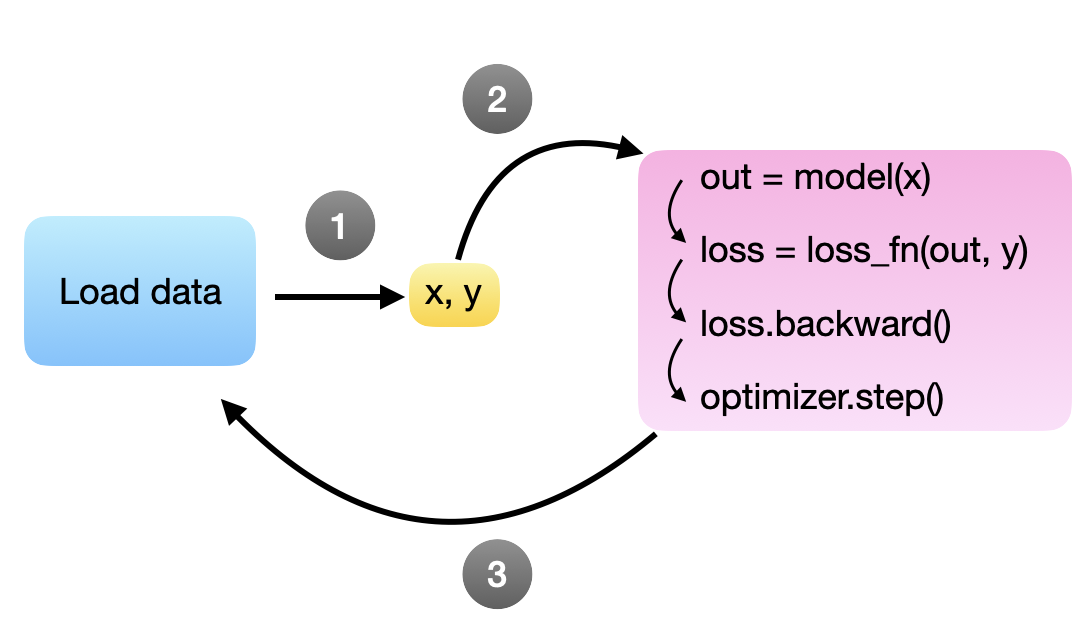
理想情况下,我们希望模型在后向调用和参数更新(通过.step())后立即处理下一个小批量。换句话说,目标是在模型准备就绪后立即准备好下一个小批量,因此我们希望在模型训练期间持续在后台加载小批量。遗憾的是,由于 Python 有一个全局解释器锁 (GIL),默认情况下只允许它运行单个进程,因此我们必须编写一个复杂的解决方法。
值得庆幸的是,我们可以使用 PyTorch 的 DataLoader 来实现这一点。