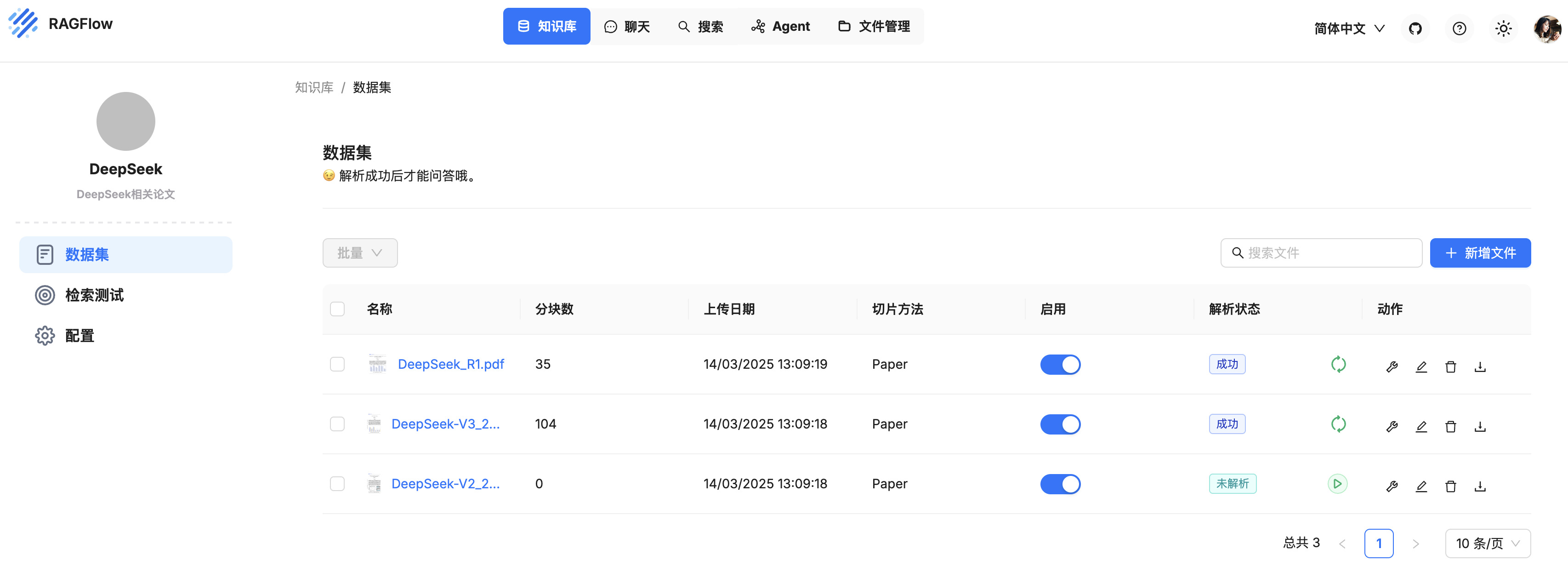
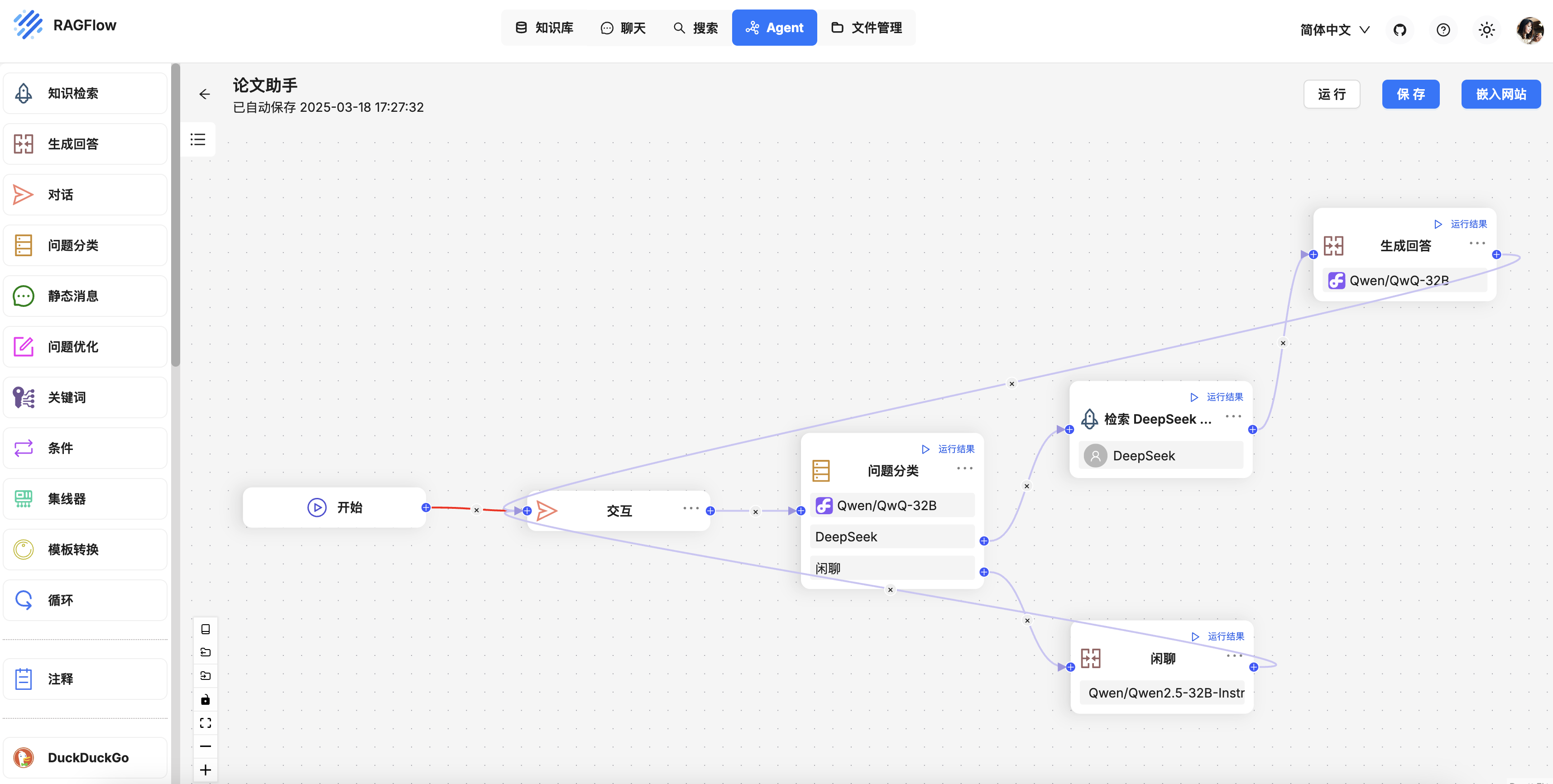
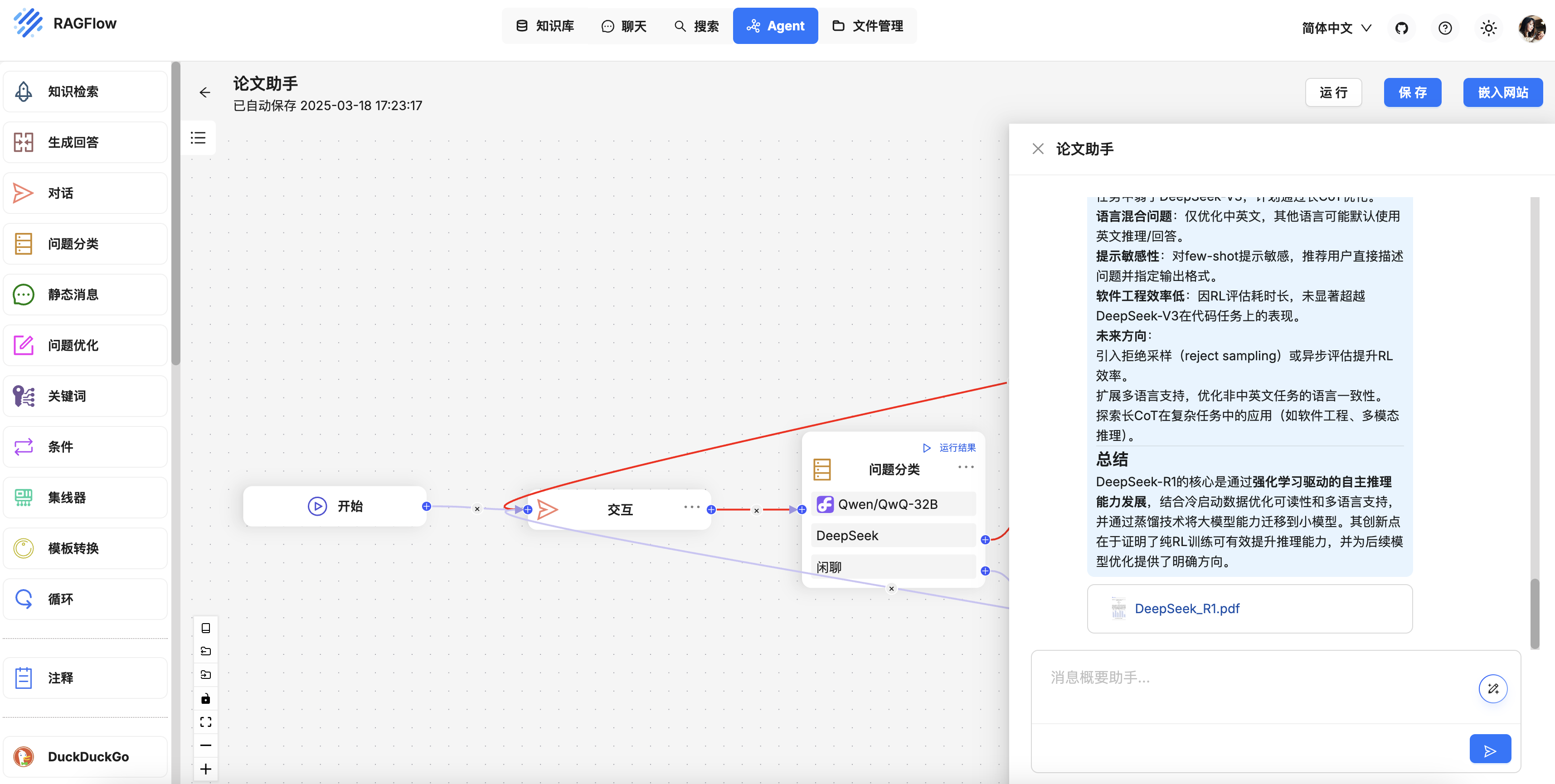
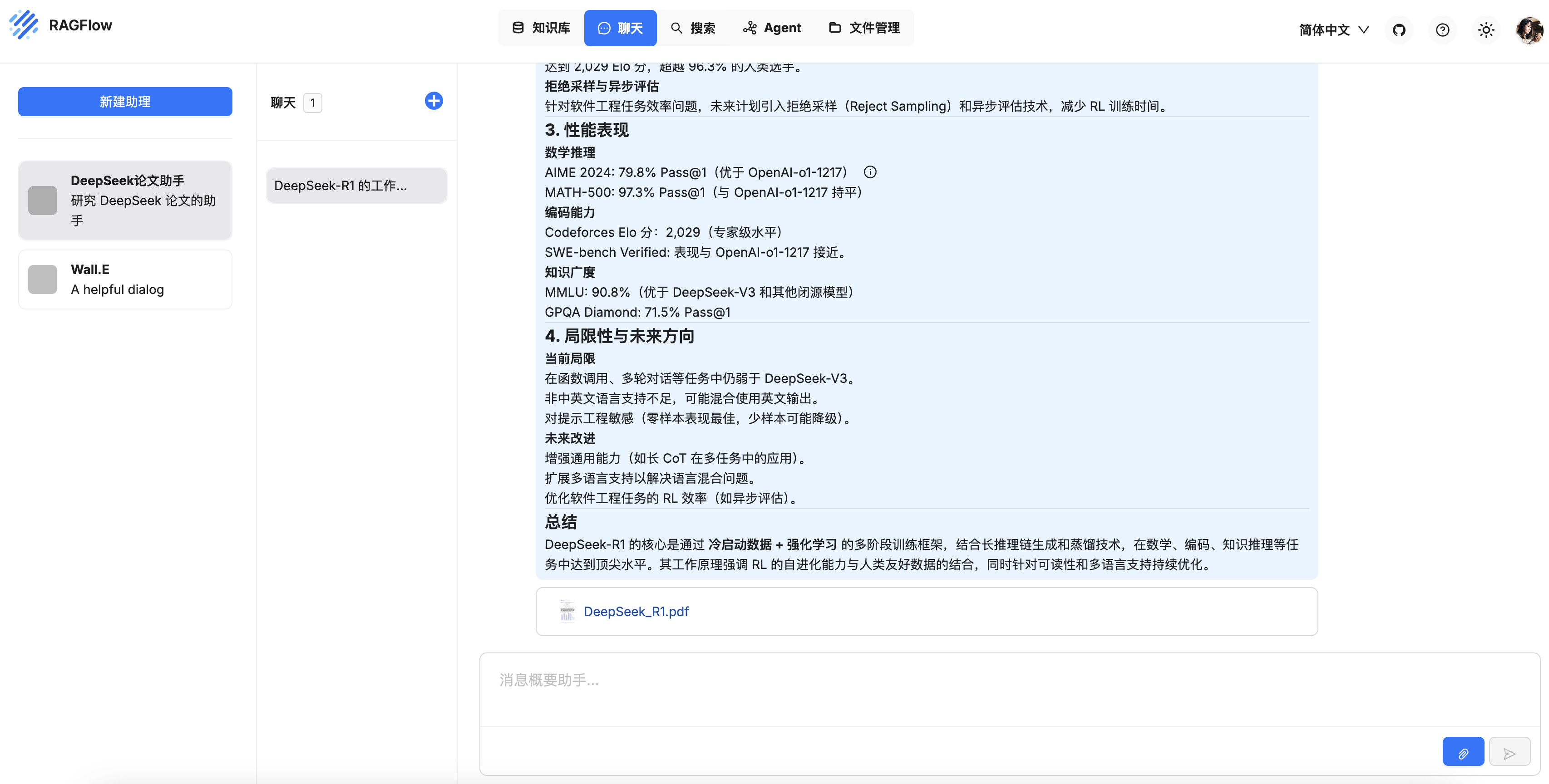
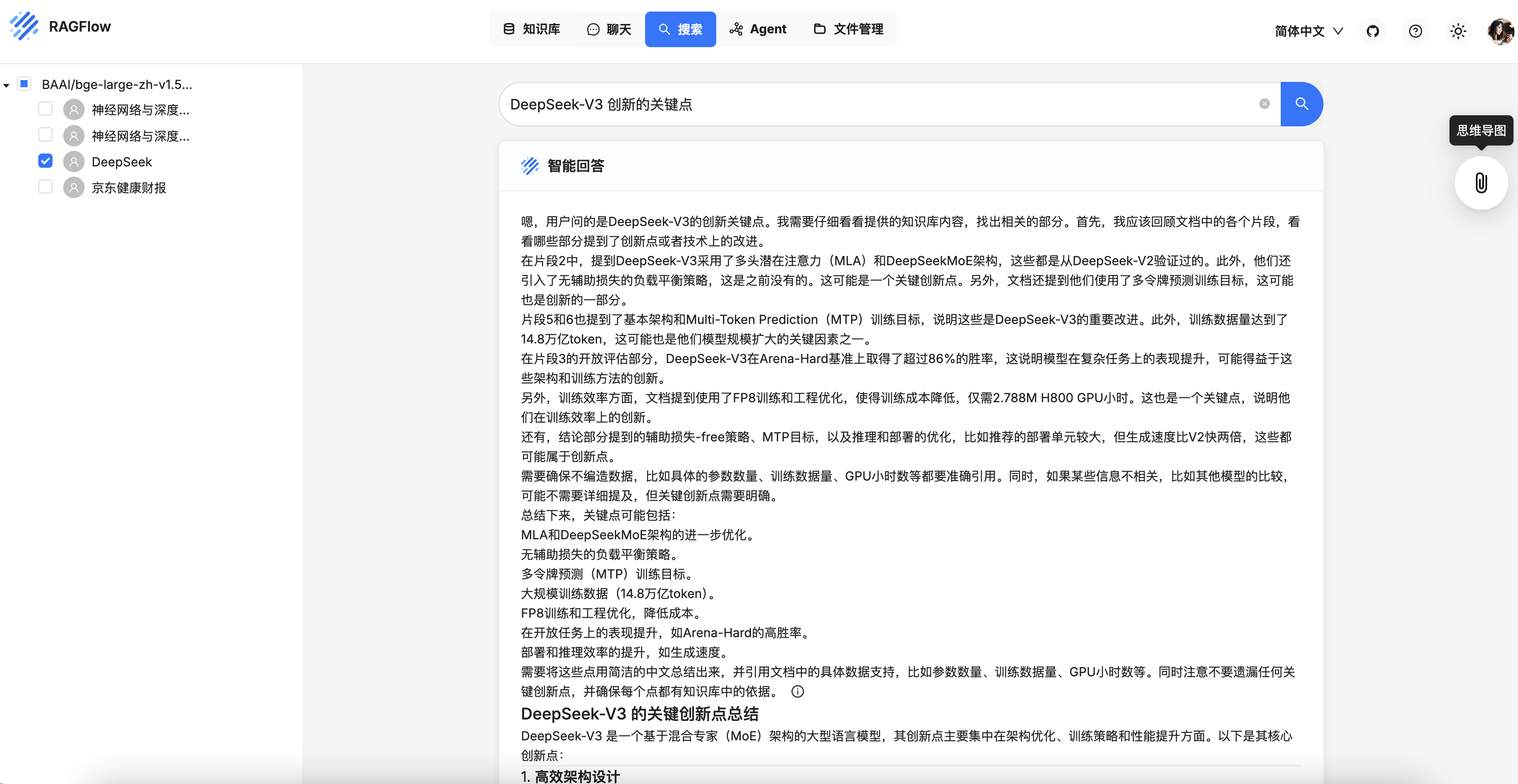
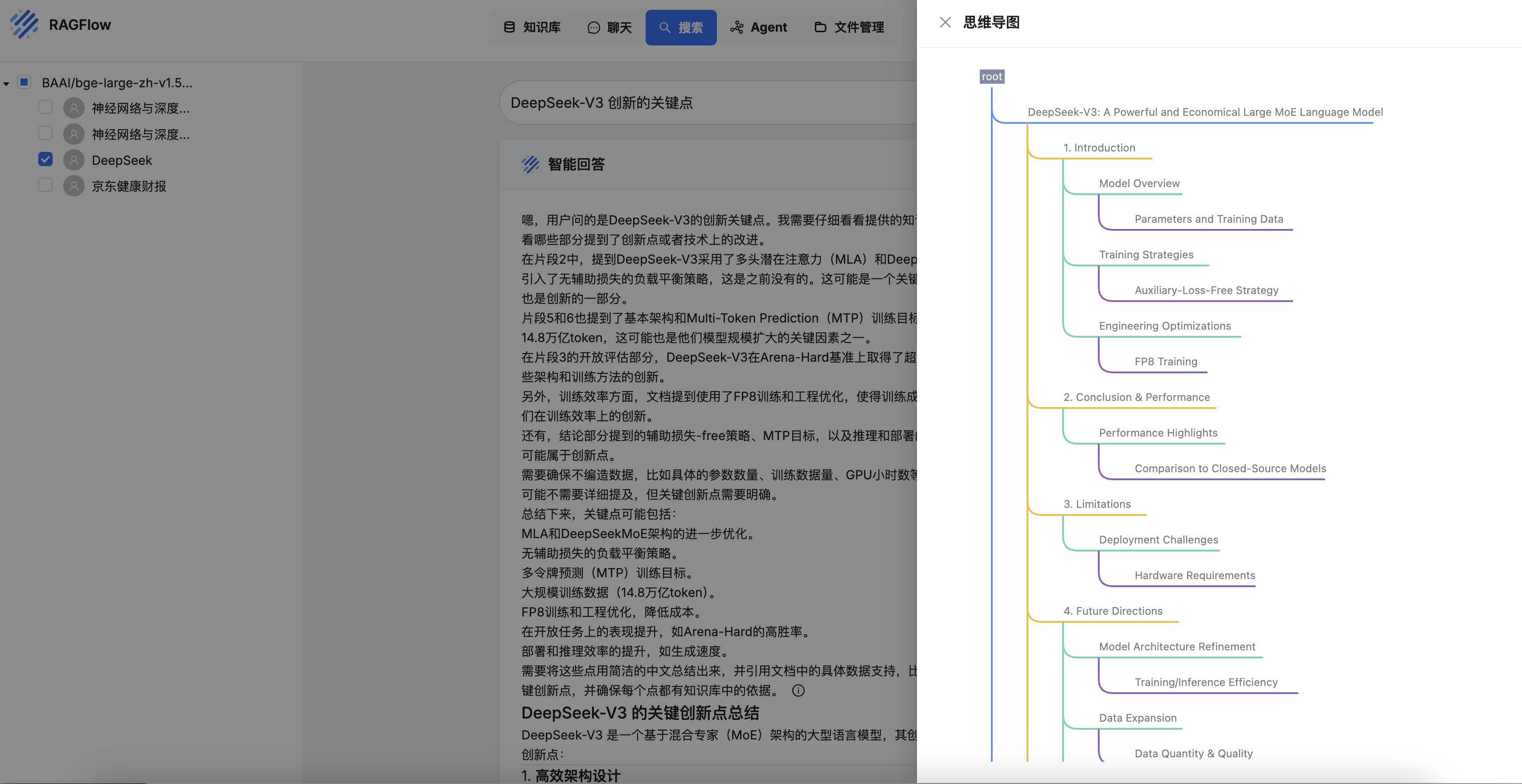
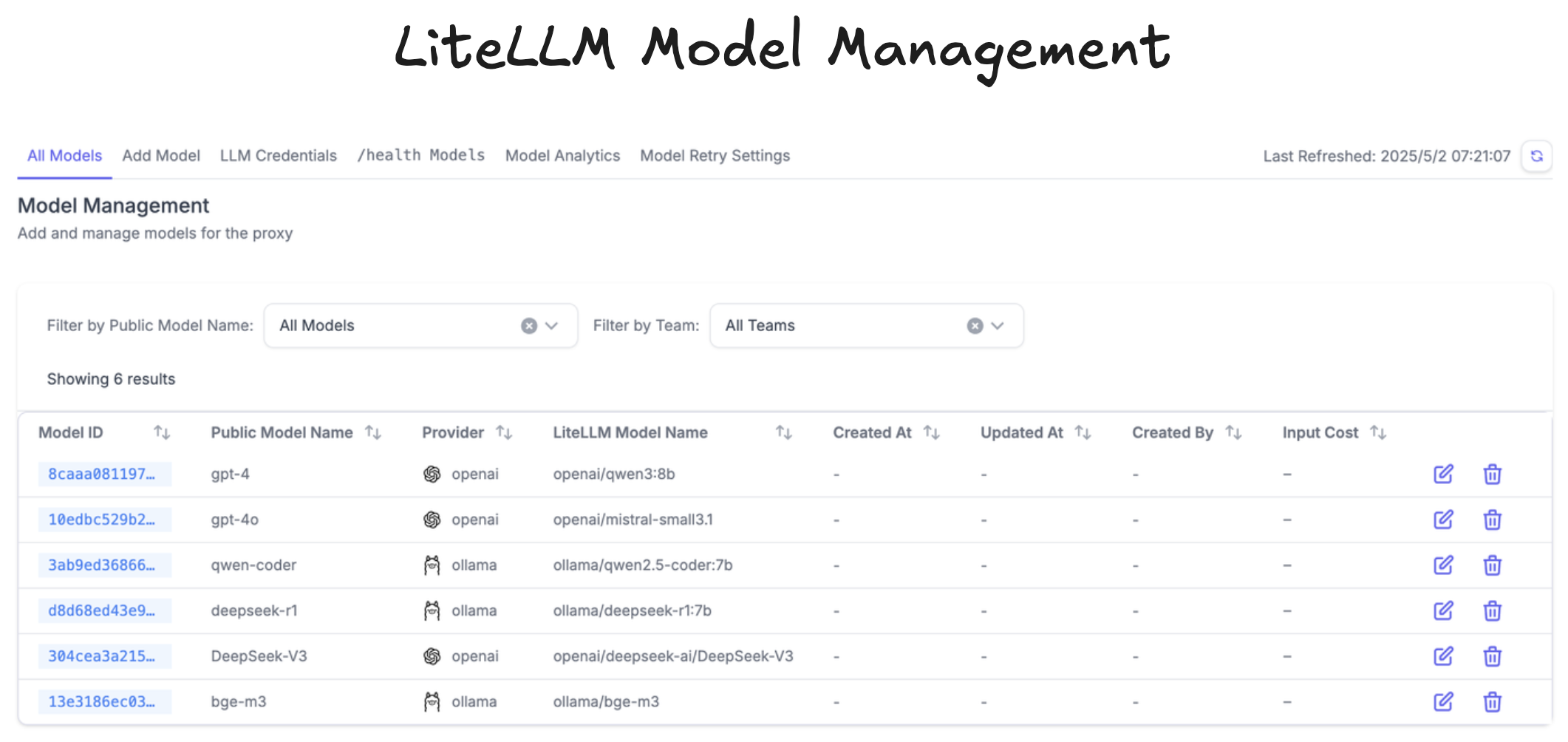
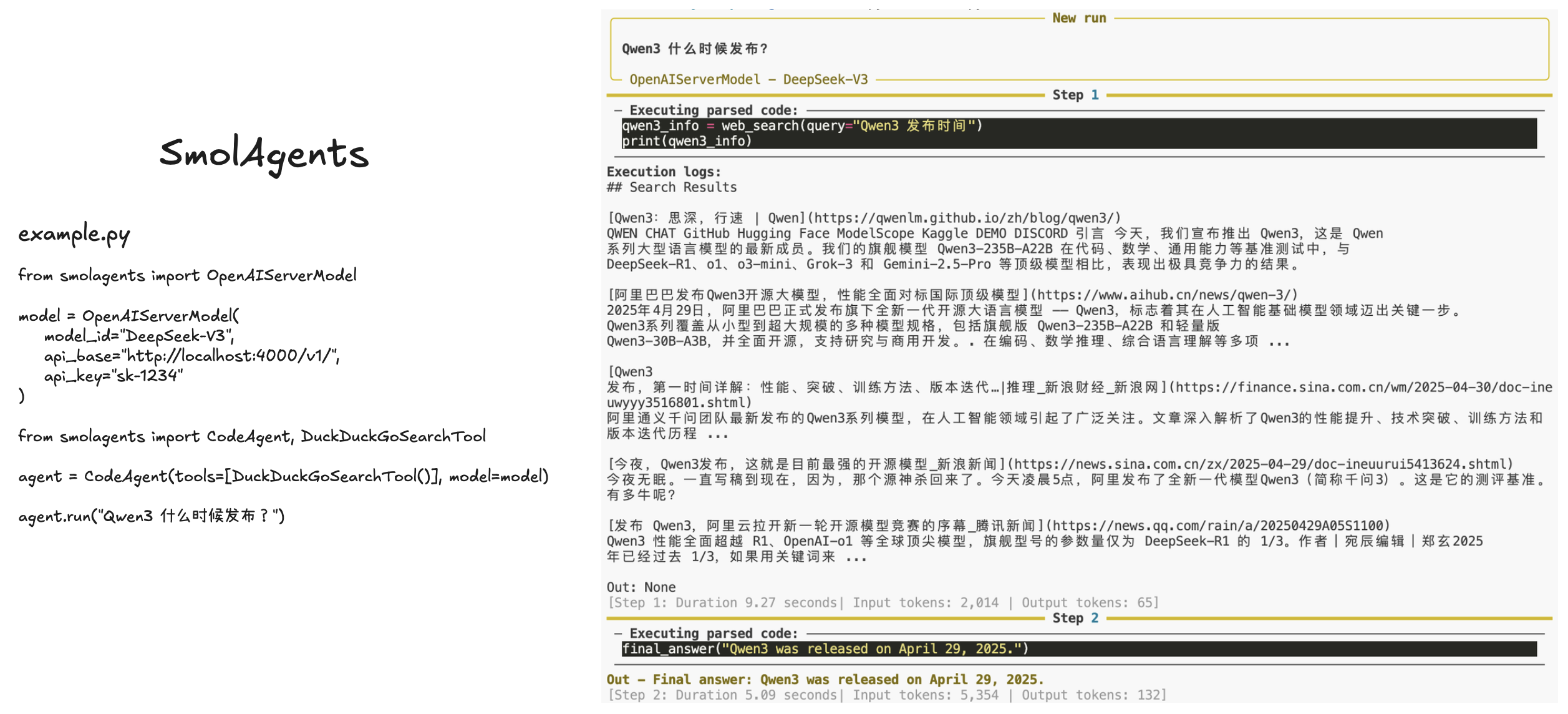
SmolAgents 技术栈: LangFuse & LiteLLM



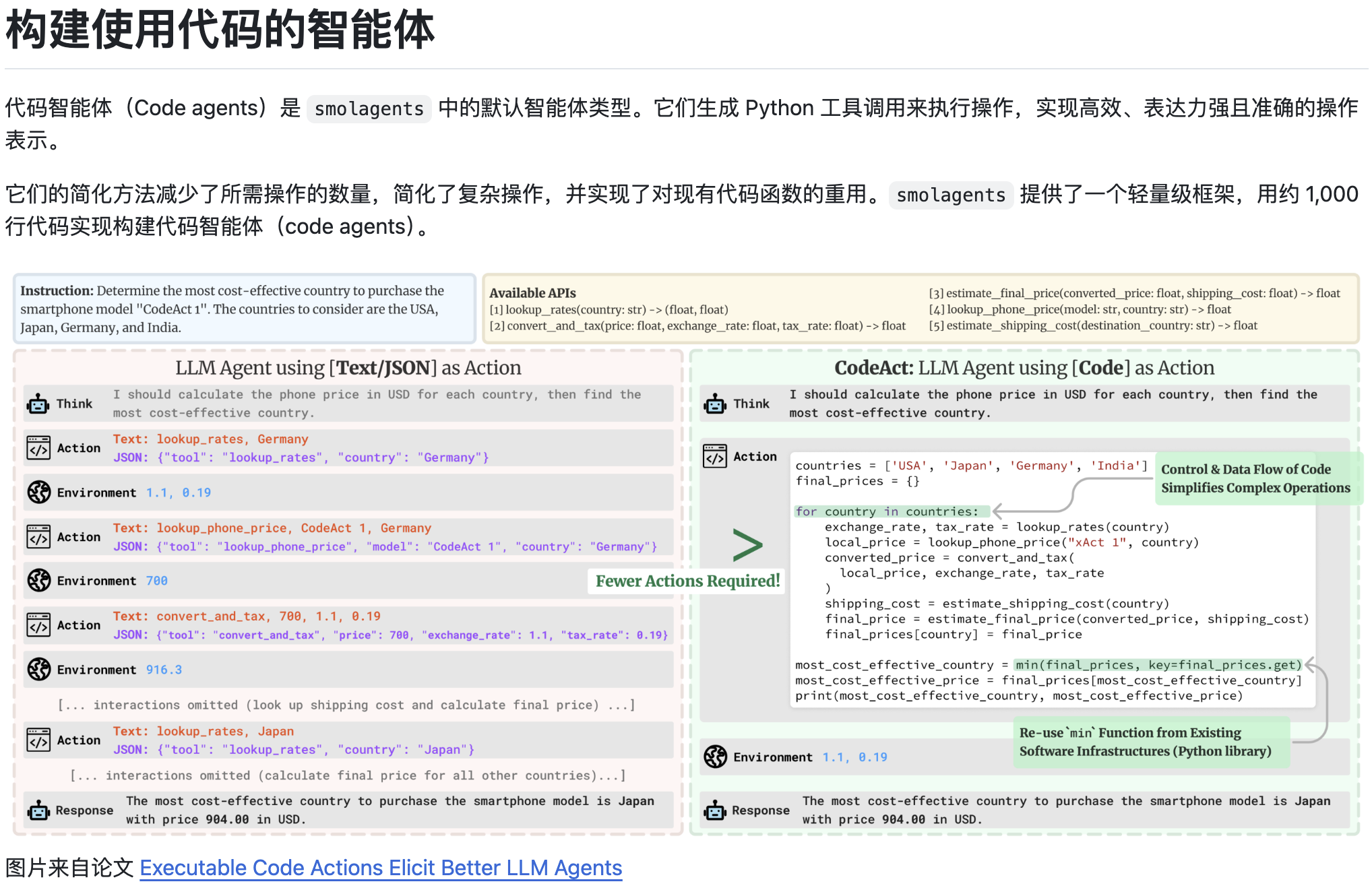
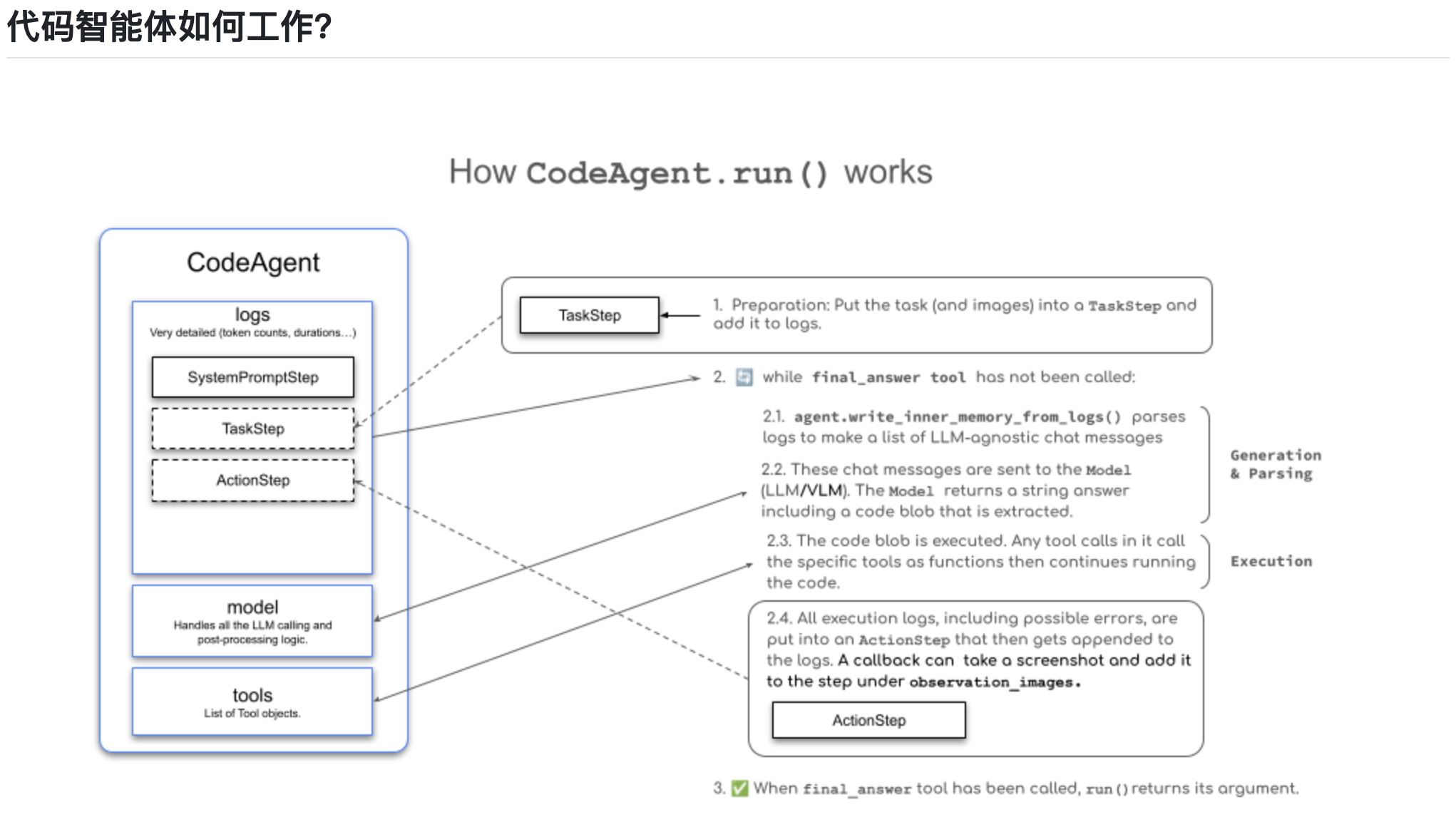

传统软件帮助用户简化和自动化工作流程,而智能体则能够以高度独立的方式代表用户执行这些工作流程。
智能体是能够独立代表您完成任务的一种系统。
工作流程是指为了实现用户目标而必须执行的一系列步骤,无论是解决客户服务问题、预订餐厅、提交代码变更,还是生成报告。
那些集成了大语言模型(LLM)但并未用其控制工作流程执行的应用程序(例如简单聊天机器人、单轮对话LLM或情感分类器)不属于智能体。
具体来说,智能体具备以下核心特征,使其能够可靠且一致地代表用户行动:
构建智能体需要重新思考系统如何决策和处理复杂性。与传统自动化不同,智能体特别适合那些传统确定性和基于规则的方法无法胜任的工作流程。
以支付欺诈分析为例:传统的规则引擎像一份检查清单,根据预设条件标记交易;而基于大语言模型的智能体则更像经验丰富的调查员,它能评估上下文、捕捉细微模式,即使没有明确违反规则也能识别可疑行为。这种精细的推理能力,正是智能体有效处理复杂模糊场景的关键所在。
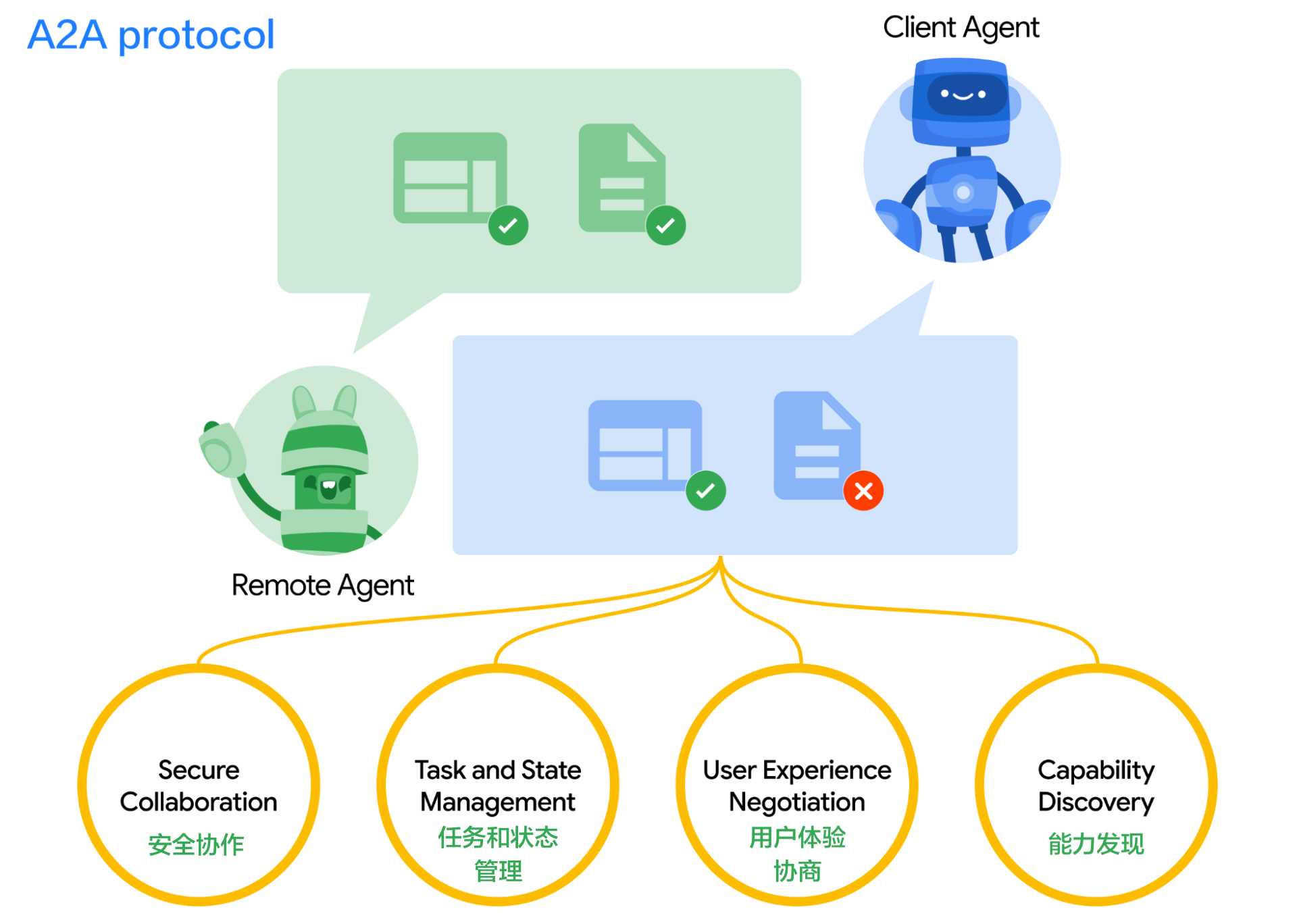
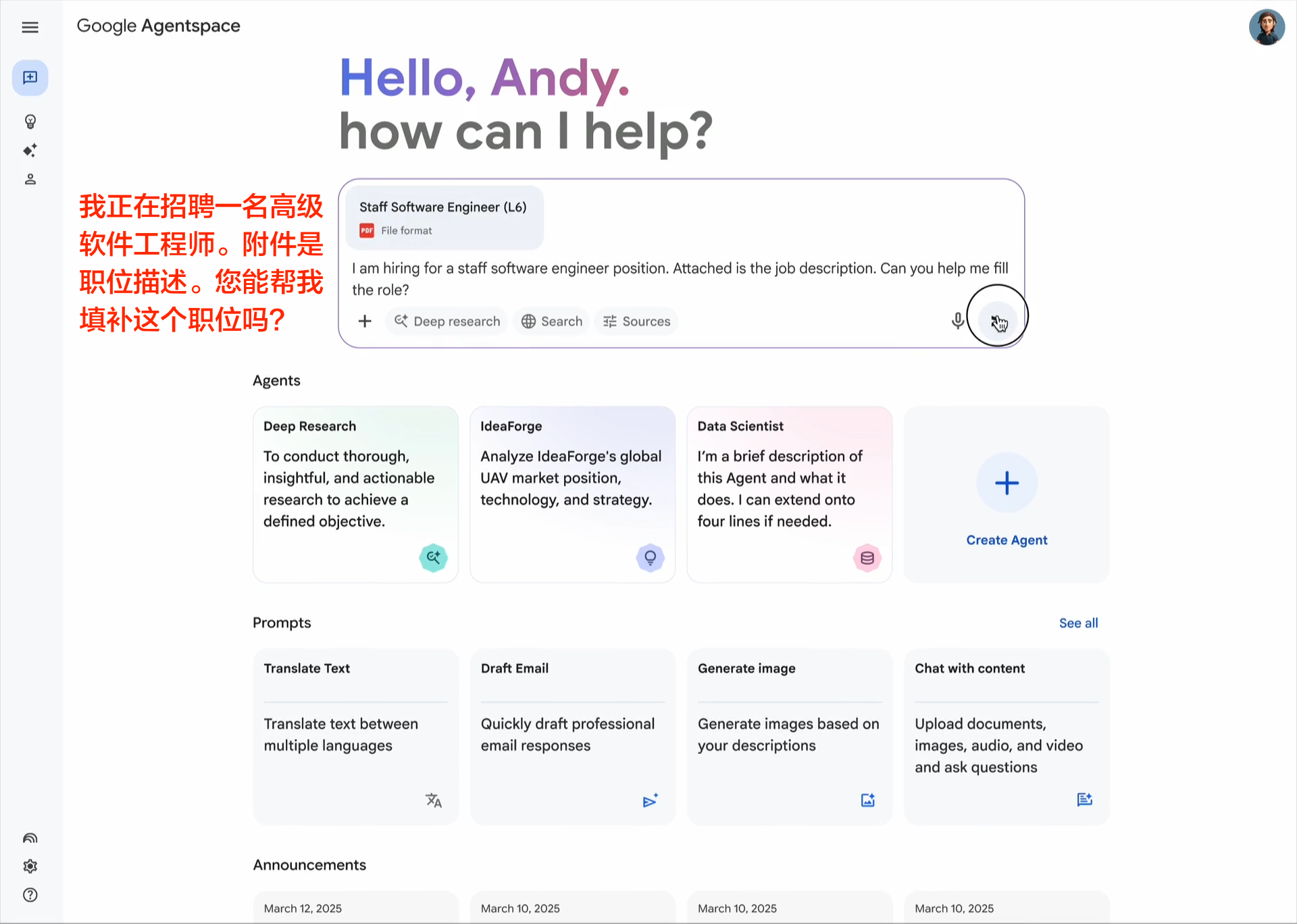
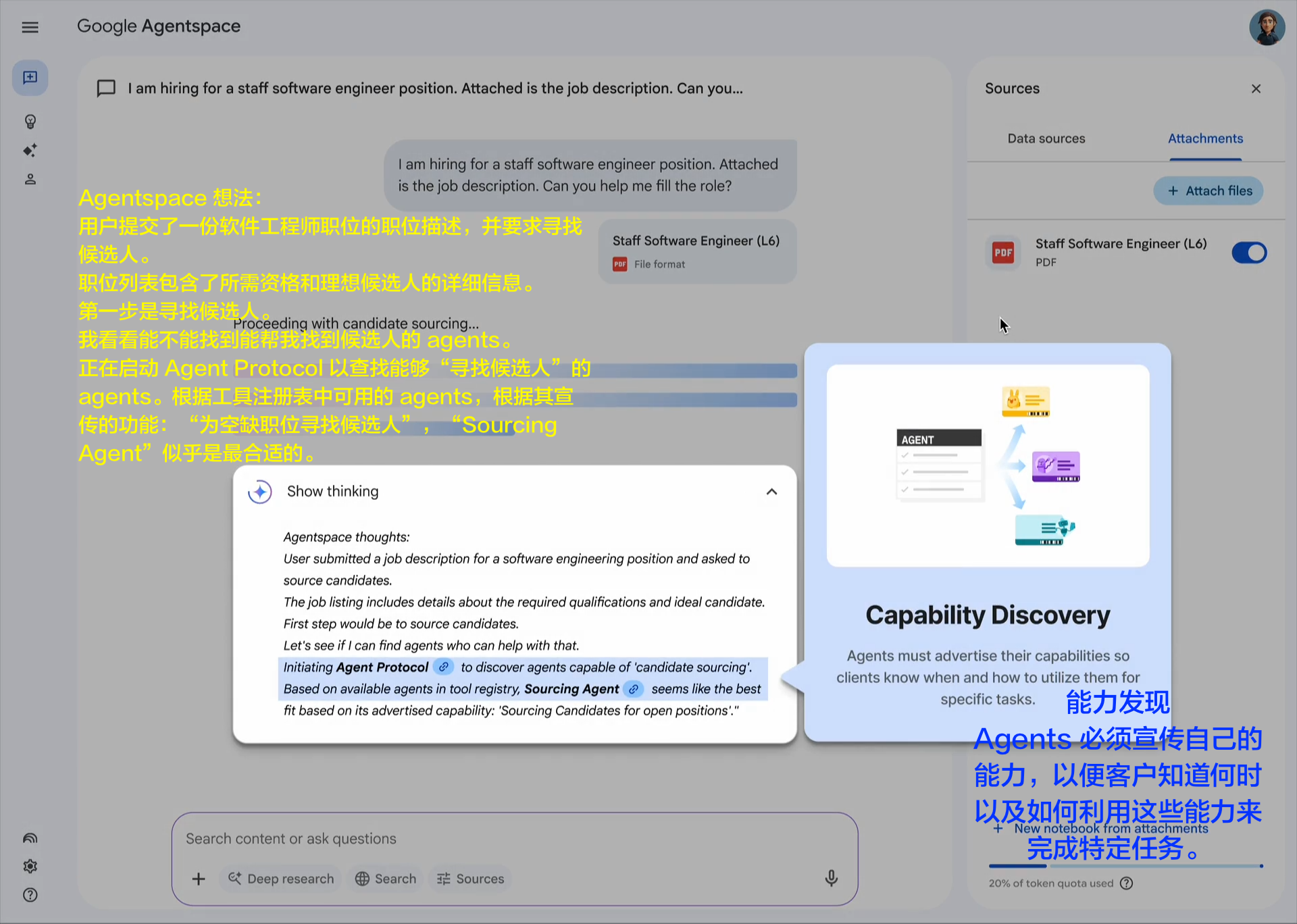
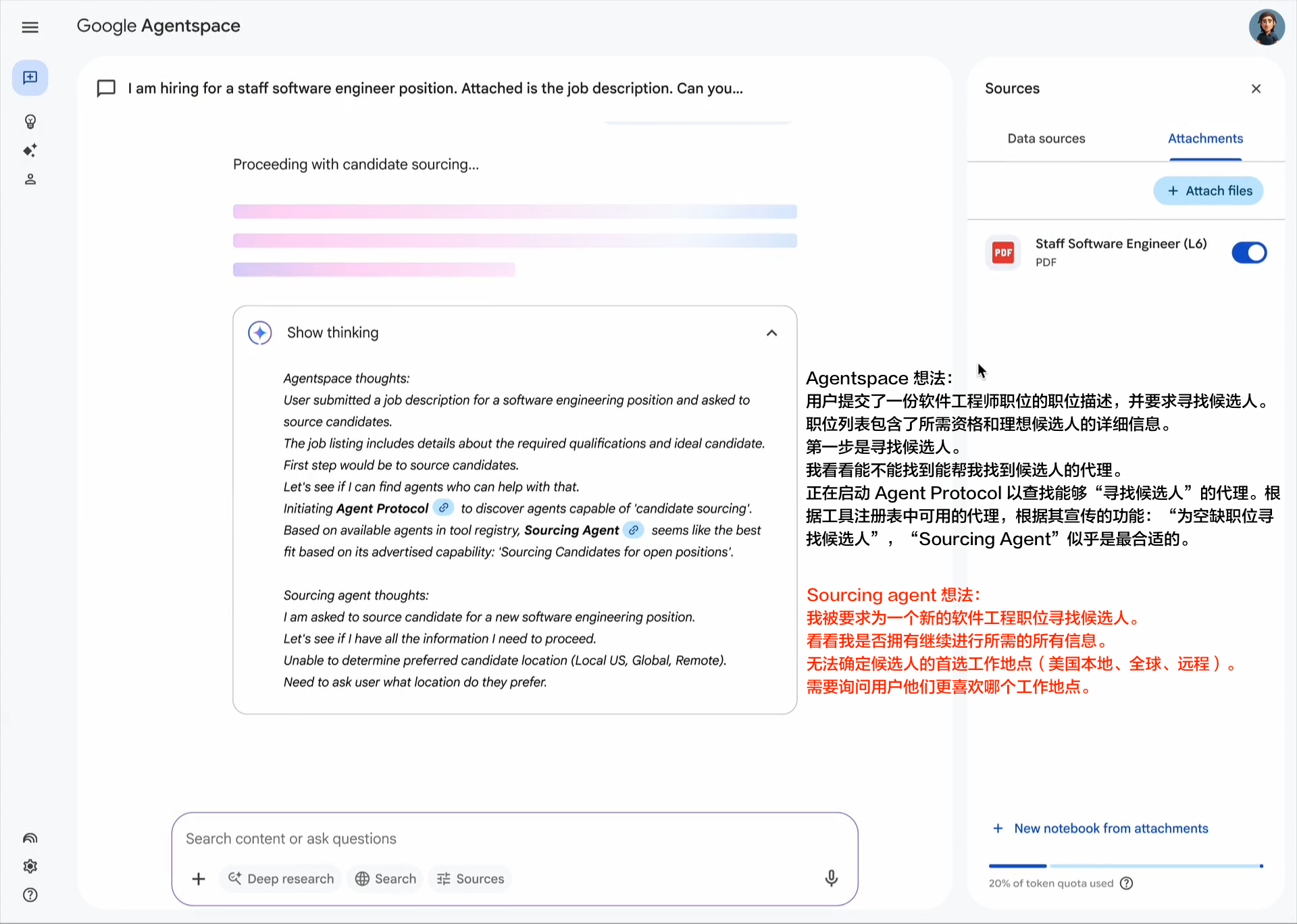
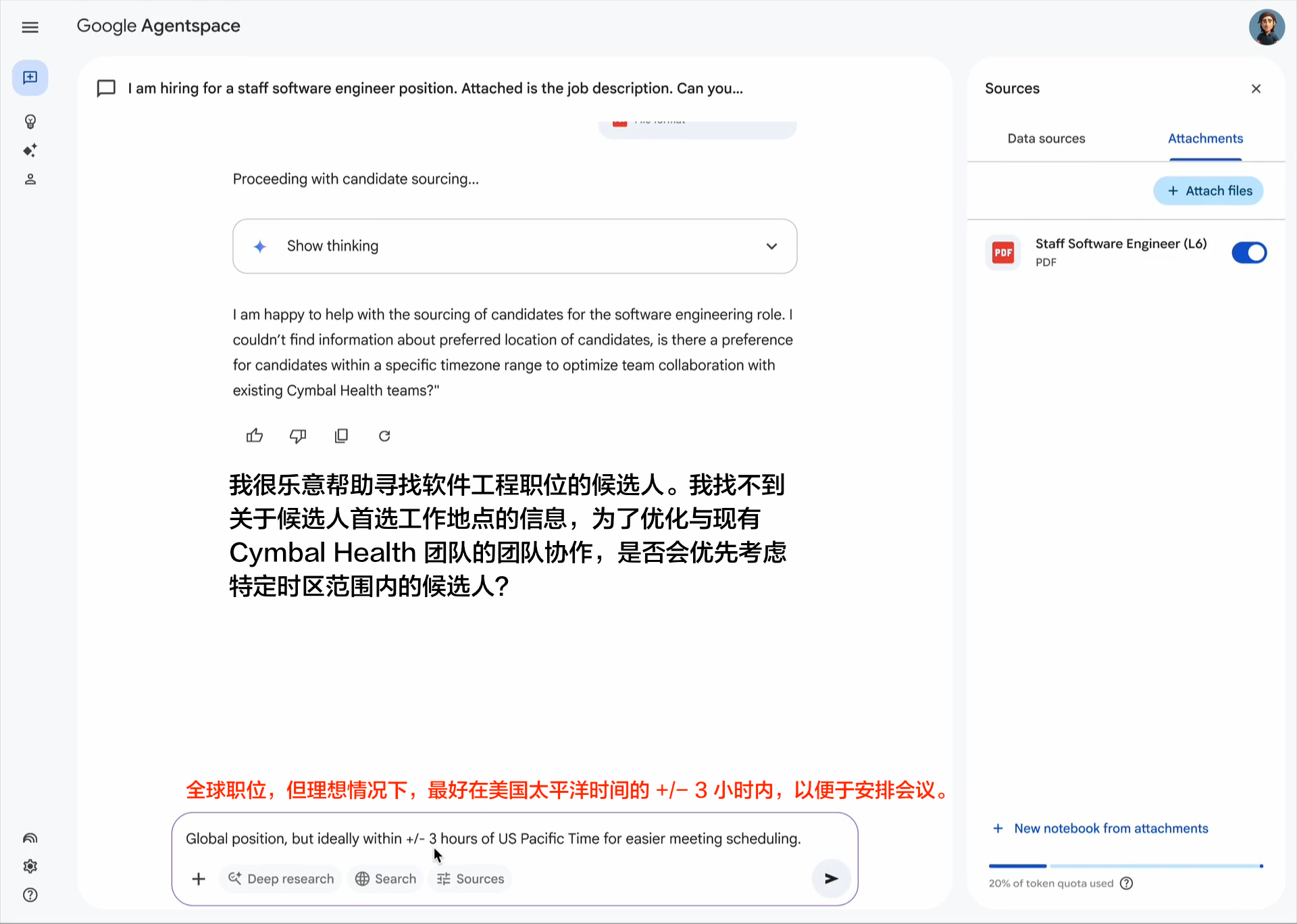
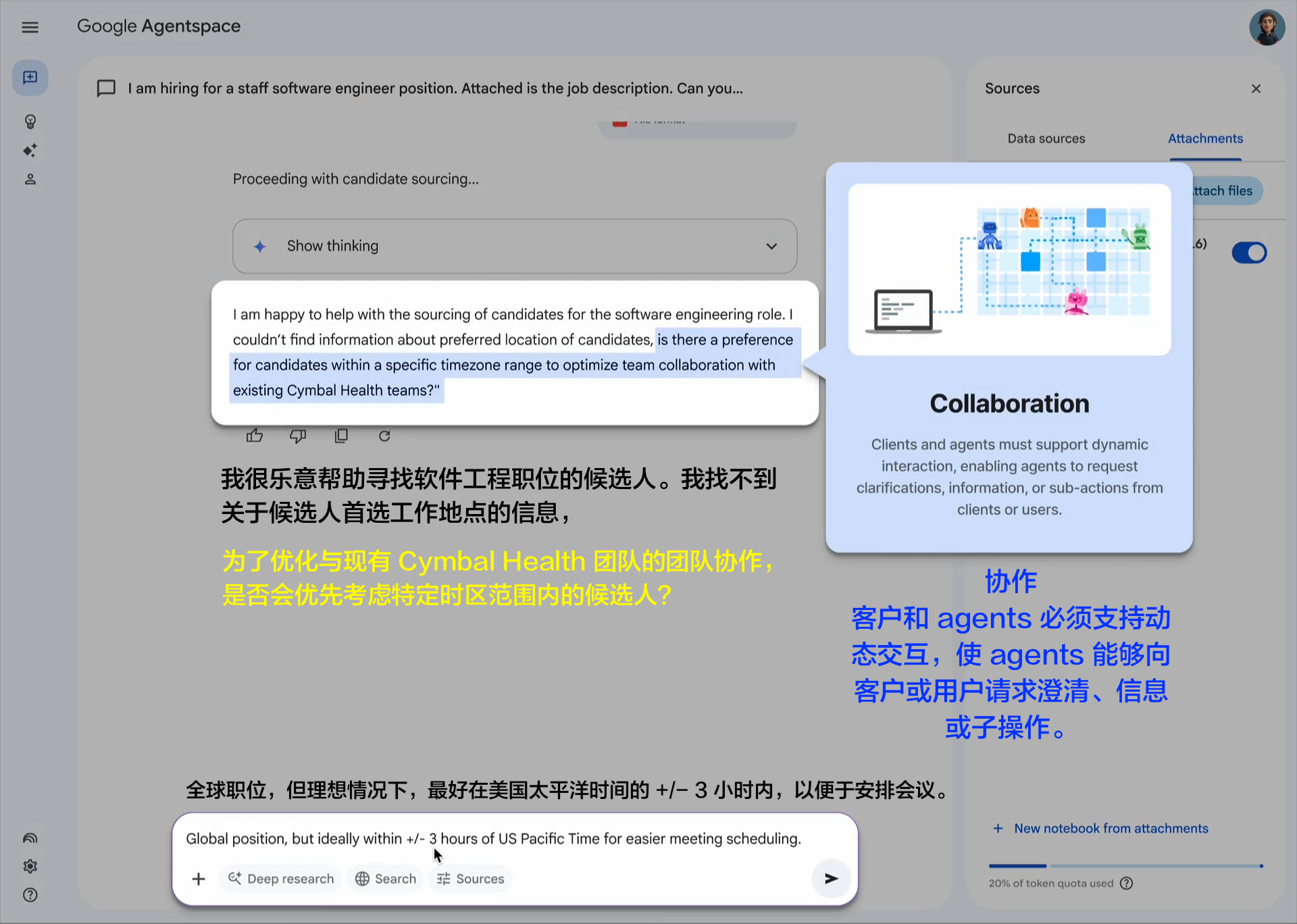
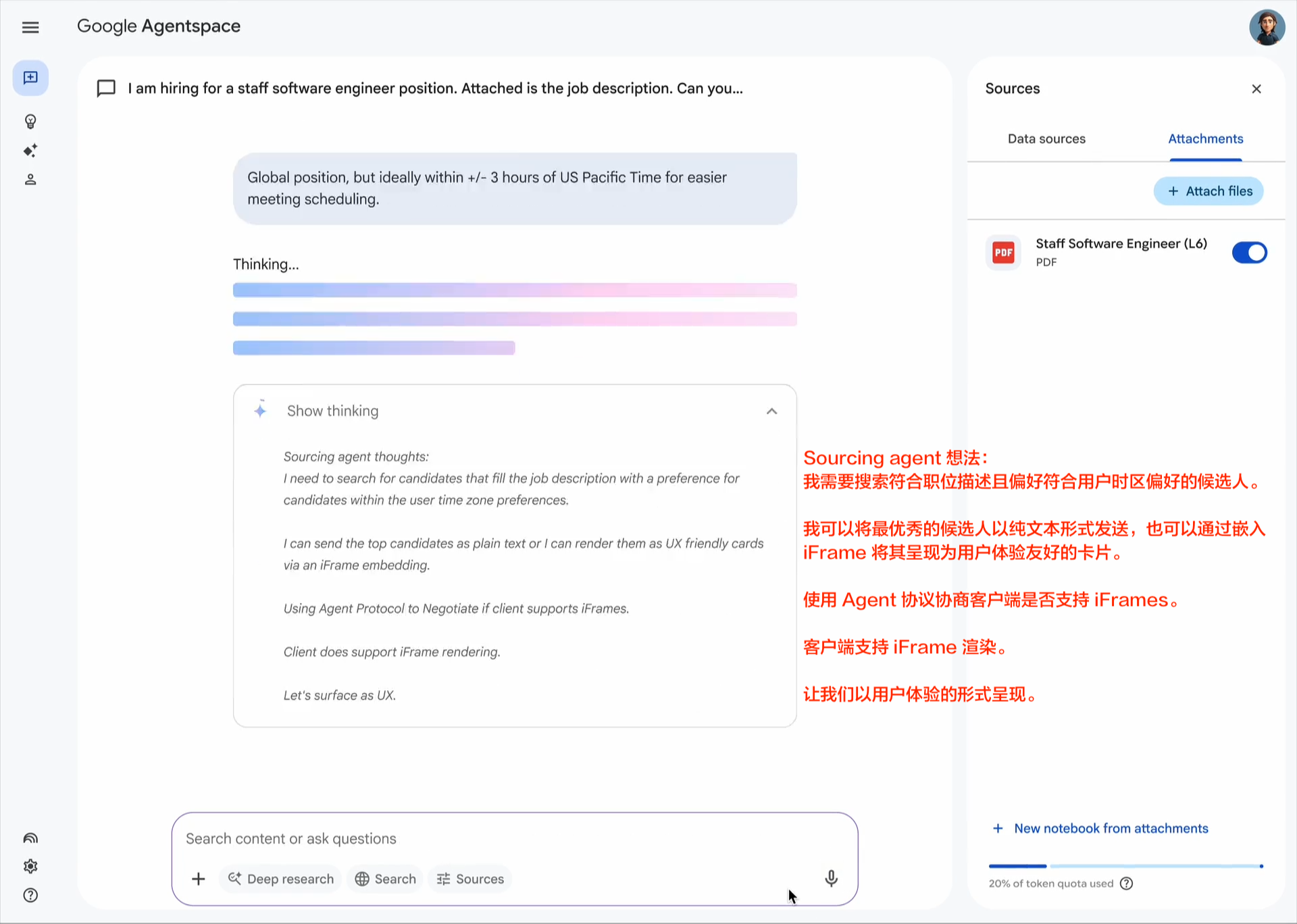
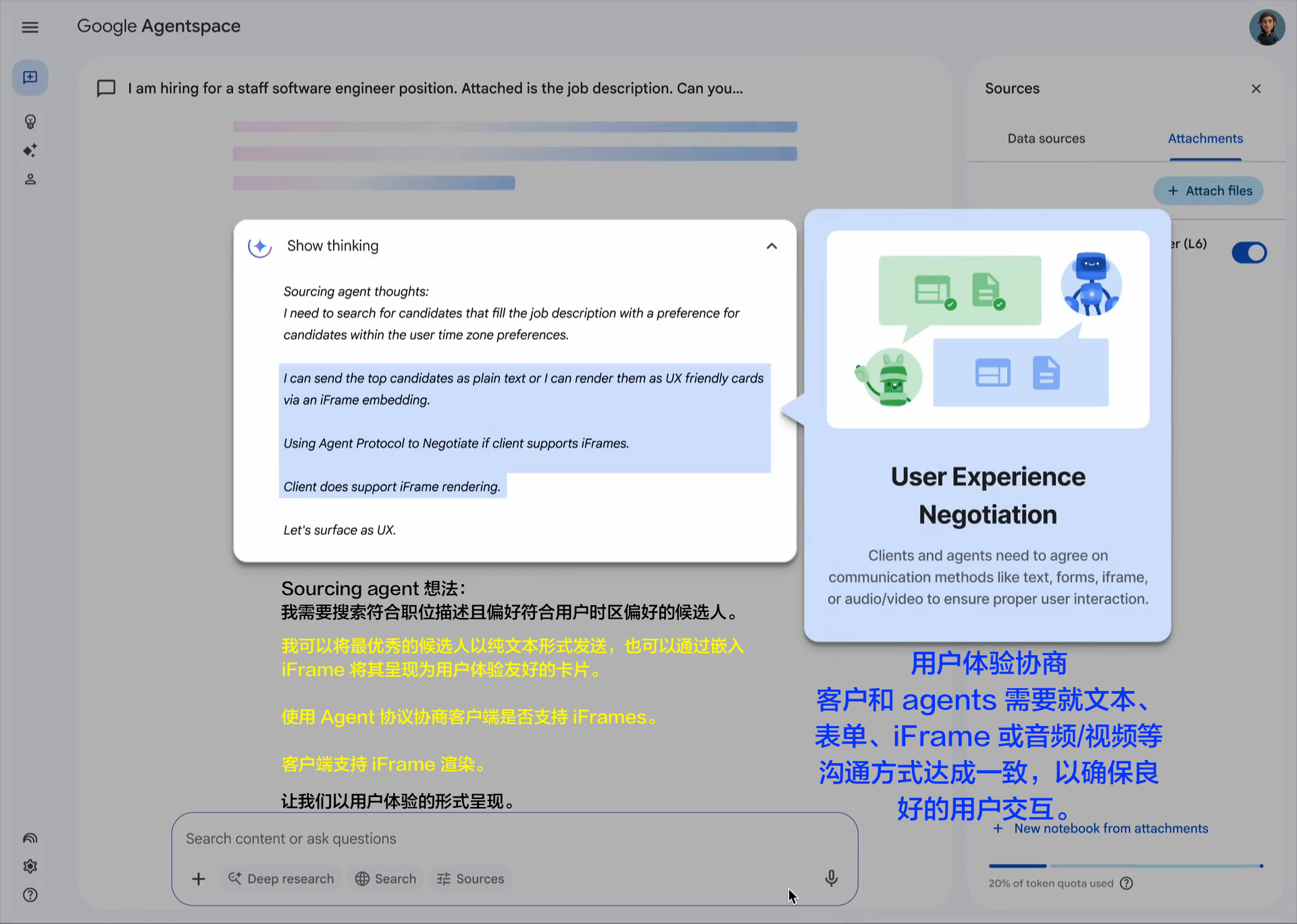
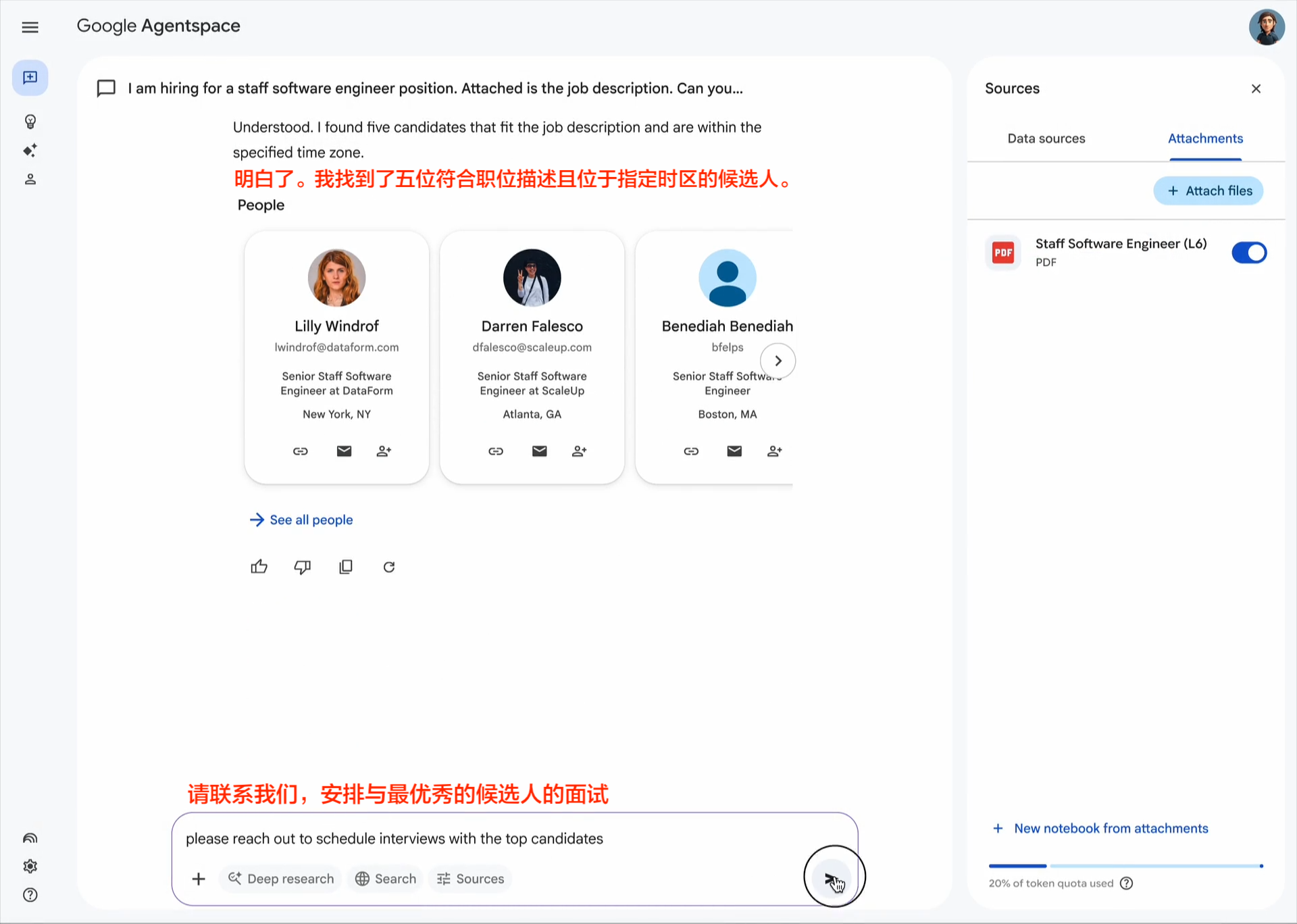

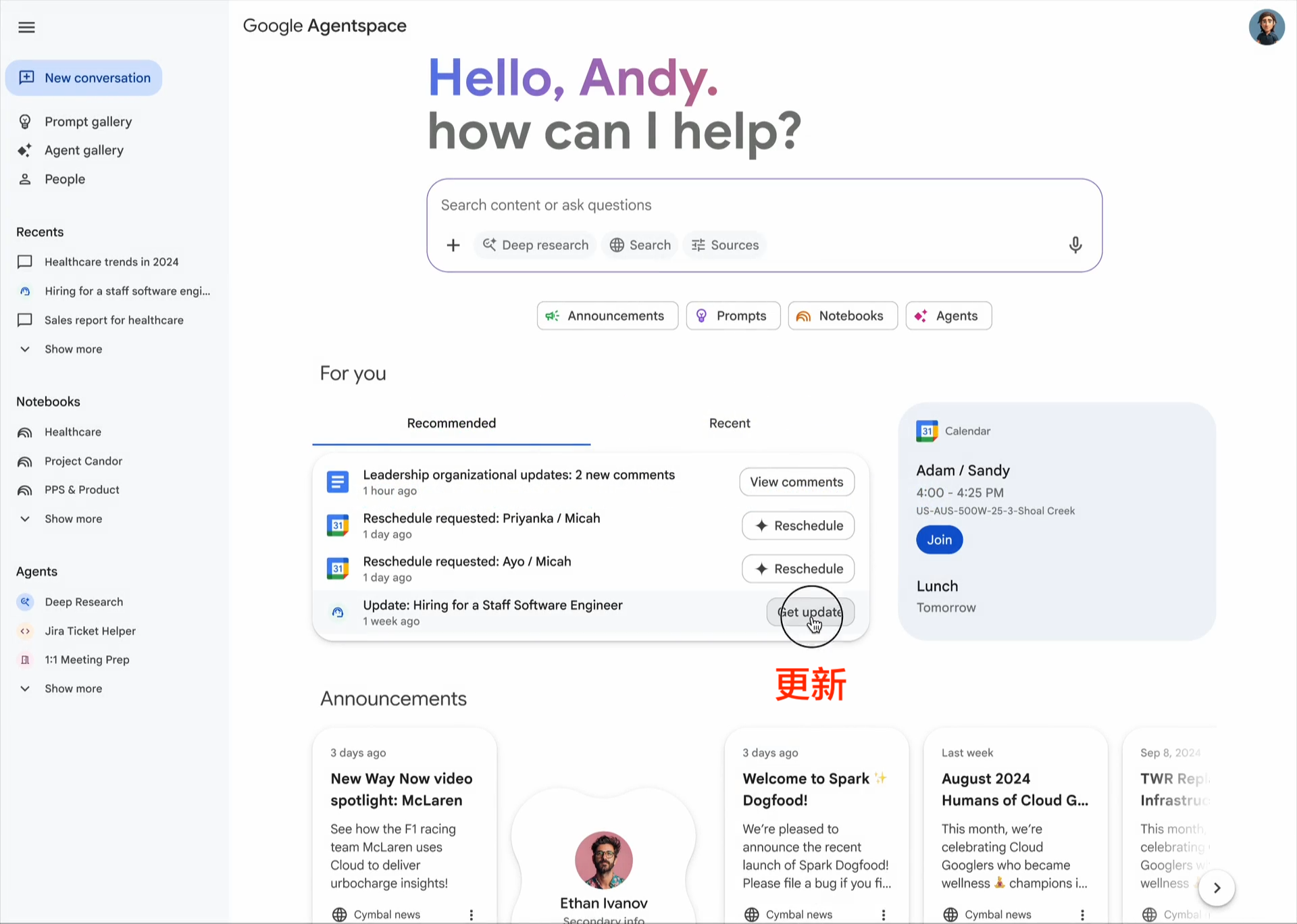
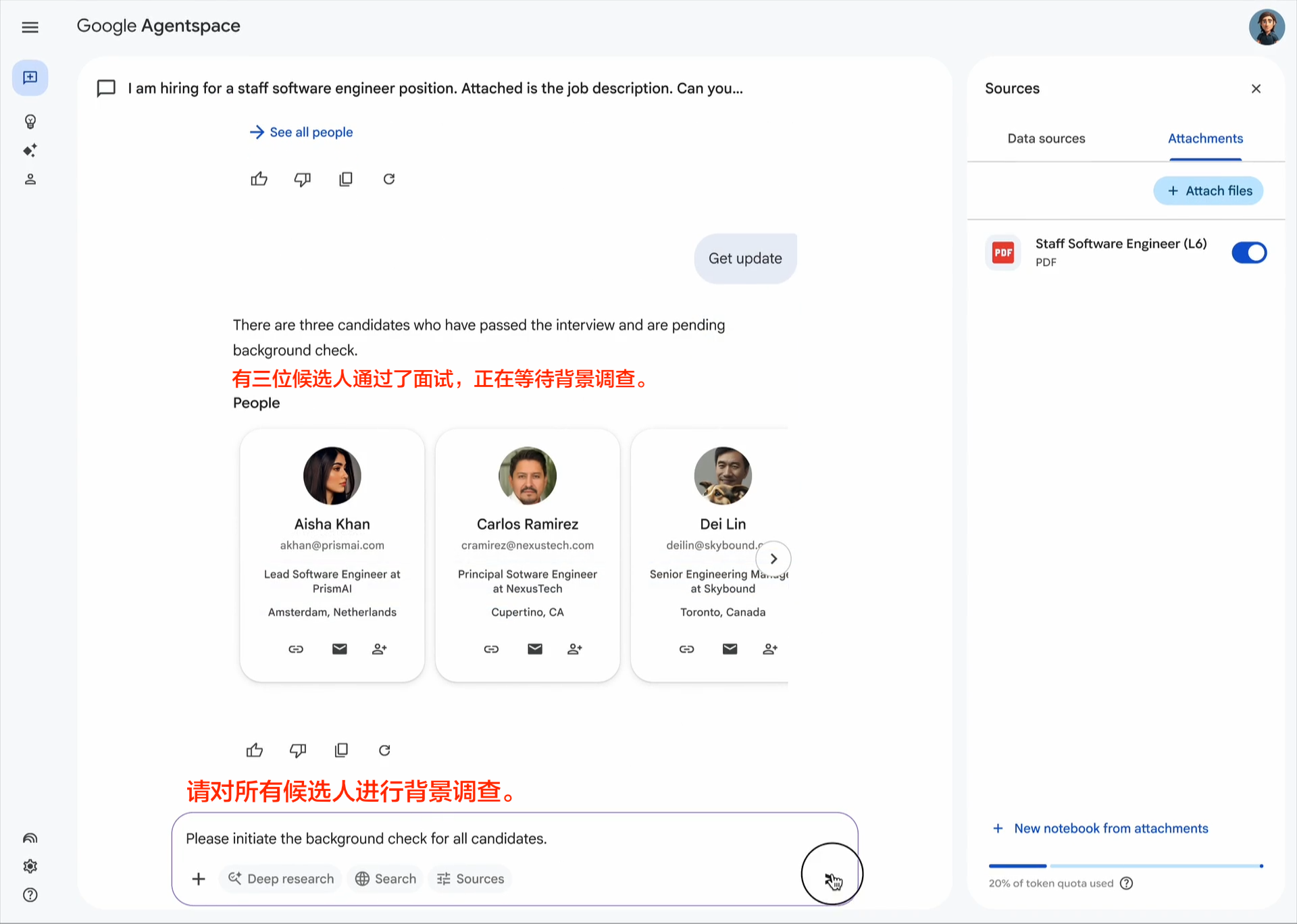
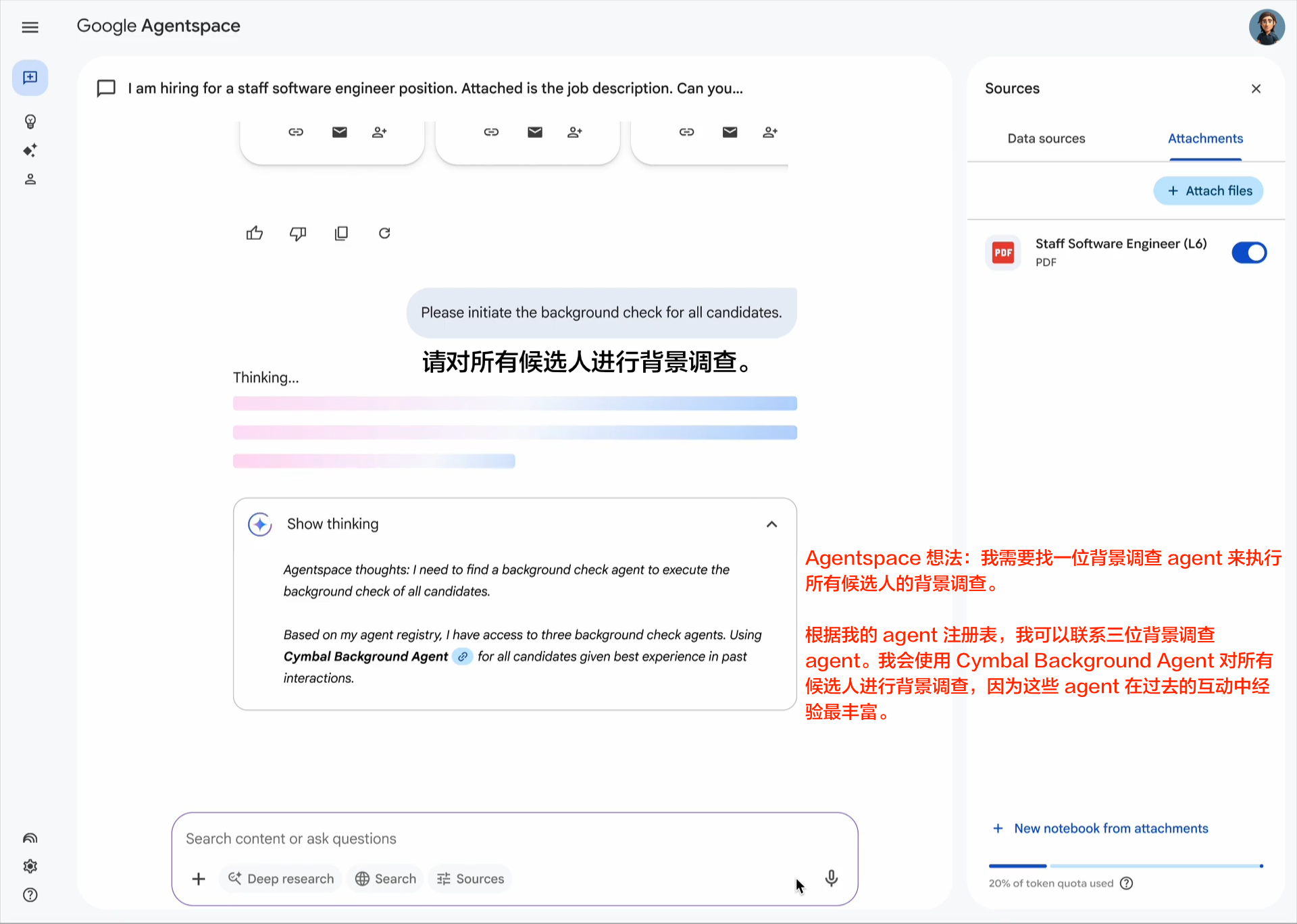
企业采用人工智能的最大挑战之一是如何让基于不同框架和供应商构建的代理协同工作。这就是我们创建开放的 Agent2Agent (A2A) 协议的原因,这是一种协作方式,旨在帮助不同生态系统中的代理相互通信。Google 正在推动这项行业开放协议倡议,因为我们相信这个协议对于支持多代理通信至关重要,它将为您的代理提供一种通用语言——无论它们构建于哪个框架或供应商之上。借助 A2A,代理可以相互展示它们的功能并协商如何与用户交互(通过文本、表单或双向音频/视频)——所有这些都在安全地协同工作的同时进行。
观看此演示视频,了解 A2A 如何实现不同代理框架之间的无缝通信。
Agent2Agent (A2A) 协议促进了独立 AI 代理之间的通信。以下是核心概念:
代理卡片 (Agent Card): 一个公开的元数据文件(通常位于 /.well-known/agent.json),描述了代理的功能、技能、端点 URL 和身份验证要求。客户端使用它进行发现。 A2A 服务器 (A2A Server): 一个公开 HTTP 端点并实现 A2A 协议方法(定义在 json 规范 中)的代理。它接收请求并管理任务执行。 A2A 客户端 (A2A Client): 一个消费 A2A 服务的应用程序或另一个代理。
构建AI代理的新手指南,帮助您克服挑战。
AI代理正变得越来越复杂,能够自动化工作流程、做出决策并与外部工具集成。然而,在现实世界中部署AI代理面临着很多挑战,这些挑战会影响其可靠性、性能和准确性。现在优先建立AI代理设计的强大基础,将为未来可靠、安全的自主系统奠定基础。
👉 本指南探讨了开发人员在创建AI代理时面临的五个最常见障碍,以及克服这些障碍的实用解决方案。 无论您是刚刚入门的新手还是正在改进方法的资深开发人员,这些最佳实践都将帮助您设计出在复杂环境中更可靠、更具扩展性和更有效的AI代理。
让我们开始构建代理式AI吧!
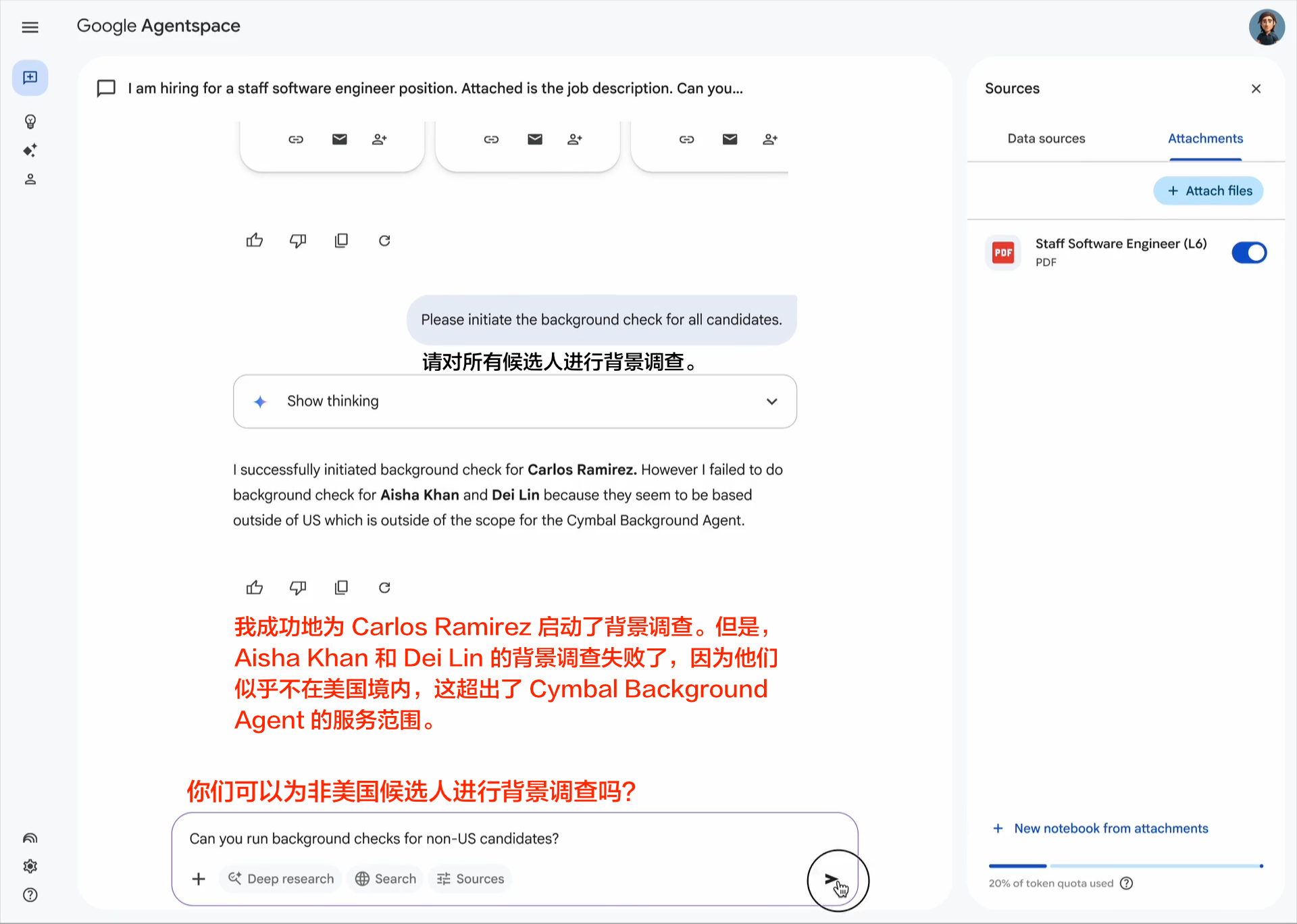
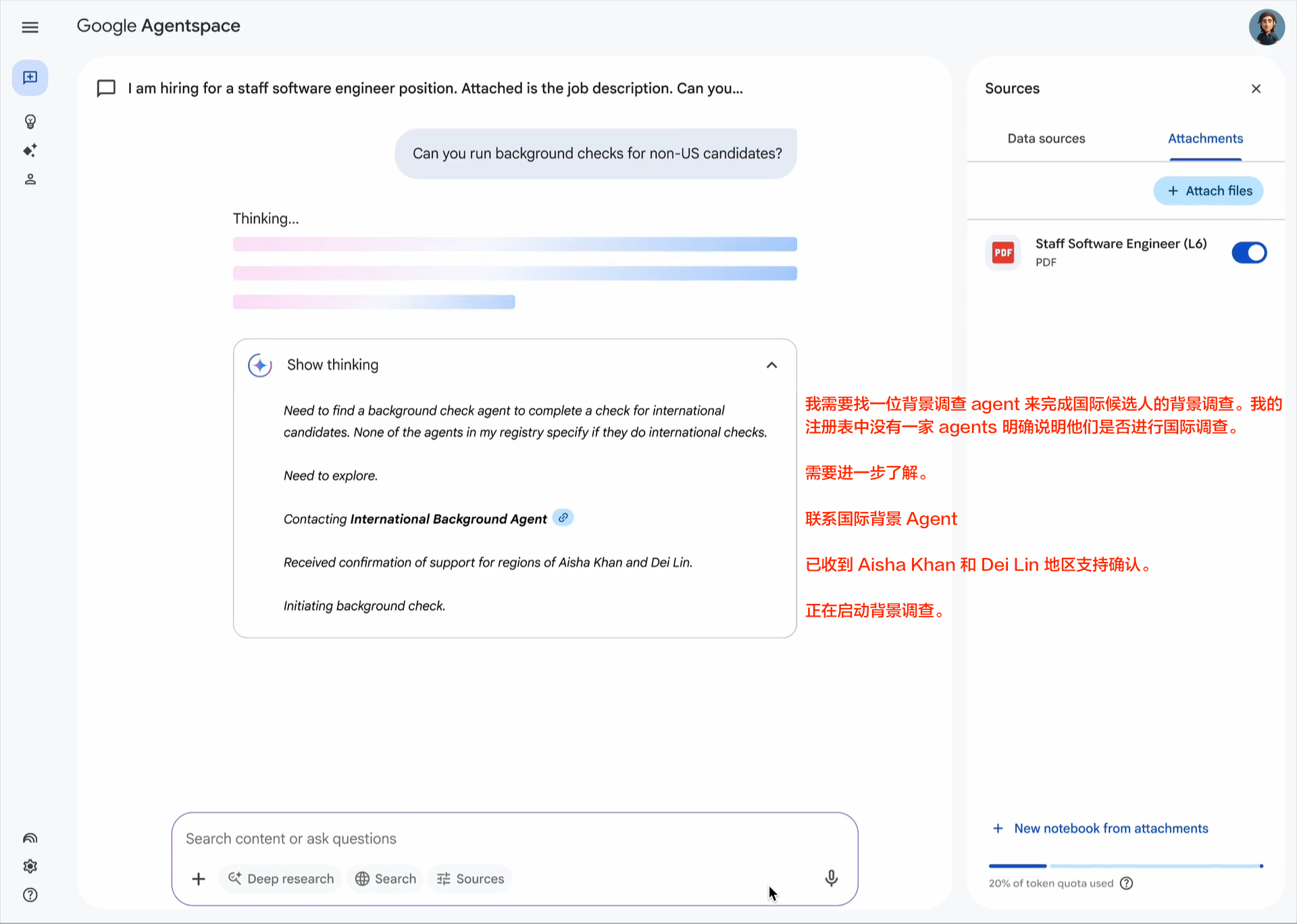
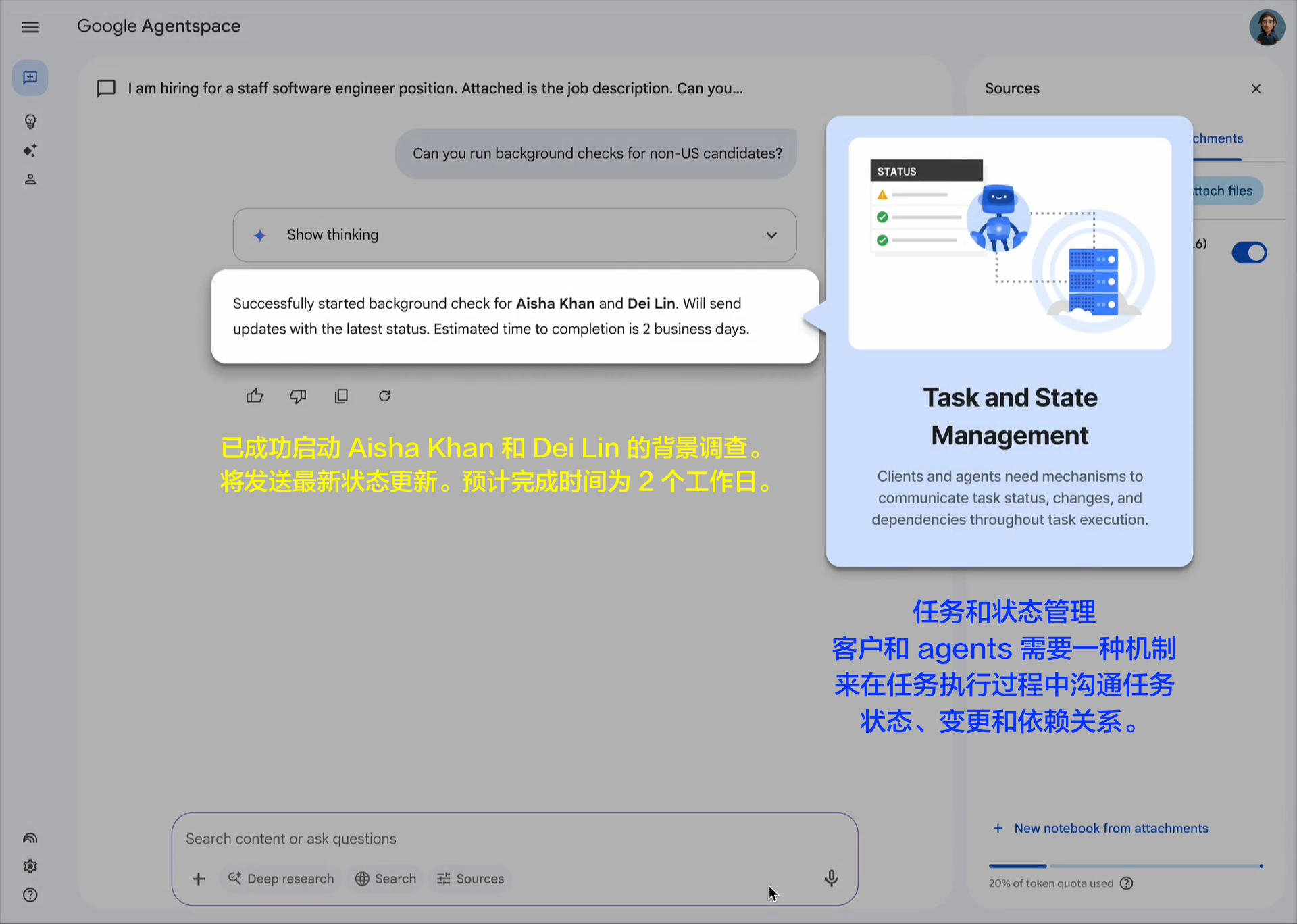
随着AI代理变得越来越复杂,管理它们对各种工具的访问和使用变得越来越具有挑战性。每增加一个工具都会引入新的潜在故障点、安全考虑因素和性能影响。确保代理适当地使用工具并优雅地处理工具故障对于可靠运行至关重要。
要解决这一挑战,请为代理工具箱中的每个工具创建精确的定义。包括何时使用该工具的明确示例、有效参数范围和预期输出。构建能够强制执行这些规范的验证逻辑,并从一小组定义明确的工具开始,而不是许多定义松散的工具。定期监控将帮助您识别哪些工具最有效,以及哪些定义需要完善。
构建AI代理的一个基本挑战是确保一致可靠的决策。与遵循明确规则的传统软件系统不同,AI代理必须解释用户意图,对复杂问题进行推理,并最终基于概率分布做出决策。
这篇文章是使用 Google Gemini Deep Research 生成的。提示词:
研究 Model Context Protocol
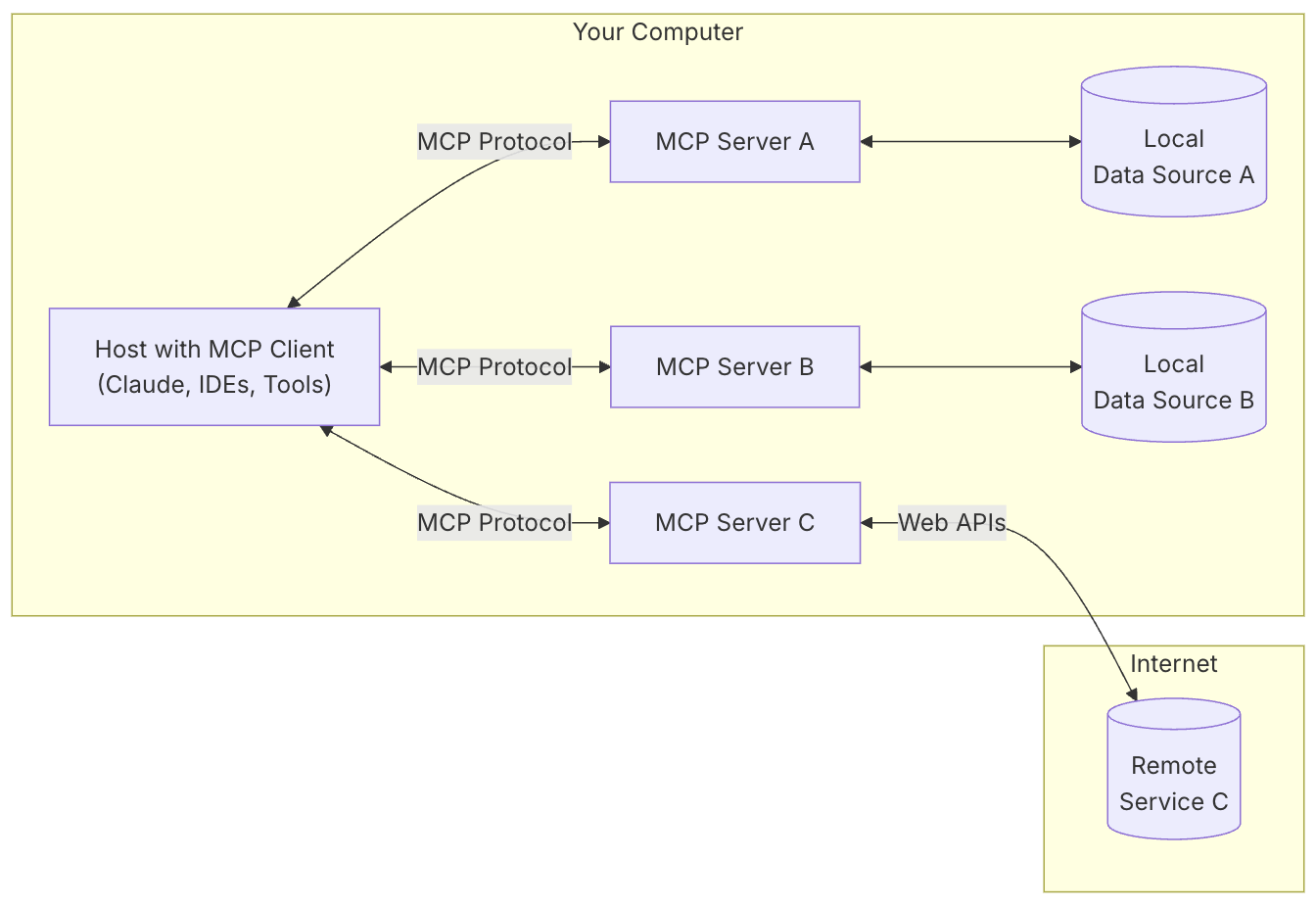
大型语言模型 (LLMs) 在理解和生成人类语言方面取得了显著的进步。然而,这些模型本质上是孤立的,它们的知识仅限于训练数据,并且缺乏与外部世界交互的能力 1。为了克服这些限制,将 LLMs 与外部数据源和工具集成变得至关重要 1。传统上,这种集成是通过为每个新的数据源或工具开发定制的连接器来实现的 1。这种方法导致了集成工作的重复,难以扩展,并且维护成本高昂,阻碍了上下文感知 AI 的广泛采用 1。
为了应对这一挑战,模型上下文协议 (MCP) 应运而生 1。MCP 是一种开放标准,旨在规范应用程序如何向 LLMs 提供上下文和工具 6。可以将 MCP 视为 AI 应用程序的通用连接器,类似于 USB-C 标准化了设备和外设之间的连接 6。通过提供一种标准化的方式将 AI 模型连接到各种数据源和工具,MCP 简化了集成,增强了互操作性,并促进了可扩展性 6。
本报告旨在对模型上下文协议 (MCP) 进行全面的解析,涵盖其基本原理、核心架构、通信机制、广泛的应用场景以及客户端和服务器端的创建方法。通过深入理解 MCP,开发者和组织可以更好地利用这一新兴标准,构建更智能、更具上下文感知能力的 AI 应用。
MCP 的设计基于若干核心原则,这些原则共同塑造
快速链接:
本文档解释了模型上下文协议 (MCP) 服务器的功能以及 Cline 如何帮助构建和使用它们。
MCP 服务器充当大型语言模型 (LLM)(如 Claude)与外部工具或数据源之间的中介。它们是向 LLM 提供功能的小程序,使其能够通过 MCP 与外部世界交互。MCP 服务器本质上就像 LLM 可以使用的 API。
MCP 服务器定义了一组"工具",即 LLM 可以执行的函数。这些工具提供了广泛的功能。
MCP 的工作原理:
MCP 服务器的潜力非常广阔。它们可以用于多种用途。
以下是 MCP 服务器的一些具体使用示例:
项目和任务管理: 基于代码提交自动创建 Jira 工单 生成每周进度报告 根据项
git clone https://github.com/cline/cline.git
code cline
npm run install:all
如果构建项目时遇到问题,请安装 esbuild problem matchers 扩展。
Activating task providers npm
错误: problemMatcher 引用无效: $esbuild-watch
打开 运行和调试 侧边栏,运行 Run Extension,或者按 F5 键启动调试,打开一个新的 VSCode 窗口,加载扩展。
这里想探索使用多模态大模型答题的技术方案,包含单选题、多选题、判断题,最终构建自主答题的智能体。
工作流程:🏞️ -> MLM(多模态大模型)-> 答案
直接使用多模态大模型读题(转成文字),然后检索答案,把题和答案组合的提示词输入给语言大模型。
我使用了 Ollama 调用多模态大模型
minicpm-v:8b来生成文字。llava:7b的效果不好。
代码示例:
import ollama
response = ollama.chat(
model="minicpm-v:8b",
messages=[
{
'role': 'user',
'content': '读取图像中的题。',
'images': ['ti.png']
}
]
)
print(response['message']['content'])
Yesterday, OpenAI released Deep Research, a system that browses the web to summarize content and answer questions based on the summary. The system is impressive and blew our minds when we tried it for the first time.
昨天,OpenAI 发布了 Deep Research,这是一个浏览网页以总结内容并根据总结回答问题的系统。当我们第一次尝试时,这个系统给我们留下了深刻的印象。
One of the main results in the blog post is a strong improvement of performances on the General AI Assistants benchmark (GAIA), a benchmark we’ve been playing with recently as well, where they successfully reached near 67% correct answers on 1-shot on average, and 47.
An agent that uses reasoning to synthesize large amounts of online information and complete multi-step research tasks for you.
一个代理,使用推理来综合大量在线信息,并为您完成多步研究任务。
Today we’re launching deep research in ChatGPT, a new agentic capability that conducts multi-step research on the internet for complex tasks. It accomplishes in tens of minutes what would take a human many hours.
今天我们在 ChatGPT 中推出了 deep research,这是一种新的代理能力,可以在互联网上进行复杂任务的多步研究。 它可以在几十分钟内完成人类需要花费数小时才能完成的任务。
Deep research is OpenAI's ne
Get started quickly with our computer use reference implementation that includes a web interface, Docker container, example tool implementations, and an agent loop.
快速开始使用我们的计算机使用参考实现,其中包括Web界面、Docker容器、示例工具实现和代理循环。
Here’s an example of how to provide computer use tools to Claude using the Messages API:
以下是如何使用消息API为Claude提供计算机使用工具的示例:
Claude can now use computers. The latest version of Claude 3.5 Sonnet can, when run through the appropriate software setup, follow a user’s commands to move a cursor around their computer’s screen, click on relevant locations, and input information via a virtual keyboard, emulating the way people interact with their own computer.
Claude现在可以使用计算机了。最新版本的Claude 3.5 Sonnet可以在通过适当的软件设置后,按照用户的命令在计算机屏幕上移动光标,单击相关位置,并通过虚拟键盘输入信息,模拟人们与自己的计算机交互的方式。
We think this skill—which is currently in public beta—represents a significant breakthrough in AI progress.
Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWORLD, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWORLD can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWORLD, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWORLD reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWORLD provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents(与本地代理进行自动化 GUI 交互的先驱)
This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks.
Operator is a research preview of our Computer-Using Agent (CUA) model, which combines GPT-4o’s vision capabilities with advanced reasoning through reinforcement learning. It interprets screenshots and interacts with graphical user interfaces (GUIs) — the buttons, menus, and text fields people see on a computer screen — just as people do. Operator’s ability to use a computer enables it to interact with the same tools and interfaces that people rely on daily, unlocking the potential to assist with an unparalleled range of tasks.
Operator 是我们计算机使用代理(CUA)模型的研究预览,它将 GPT-4o 的视觉能力
下面的截图显示了示例扩展中 Visual Studio Code 聊天体验中的不同聊天概念。
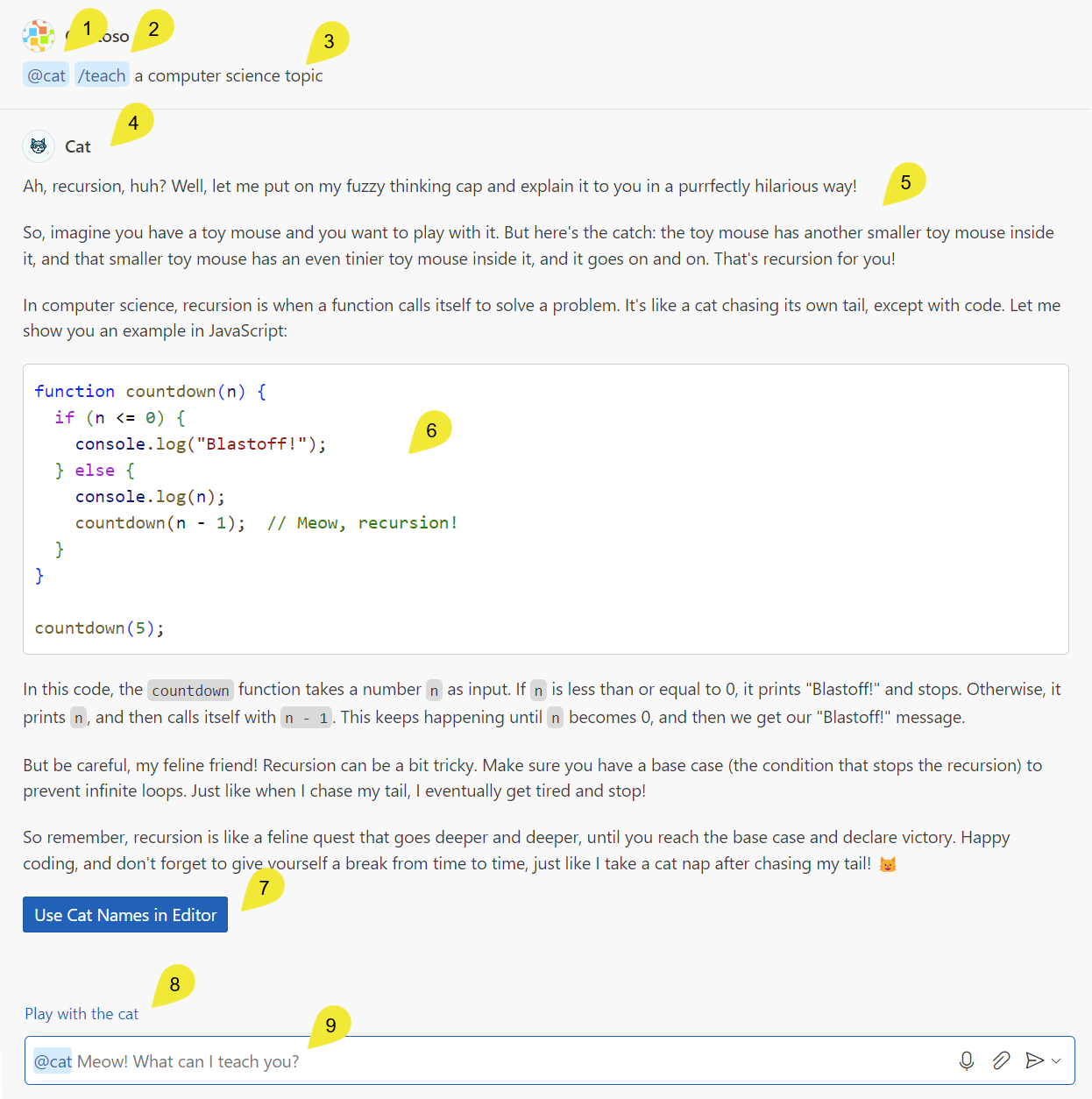
@ 语法调用 @cat 聊天参与者/ 语法调用 /teach 命令fullName,表示 Copilot 正在使用 @cat 聊天参与者@cat 提供的 Markdown 响应@cat 响应中的按钮,按钮调用 VS Code 命令后续问题description 属性提供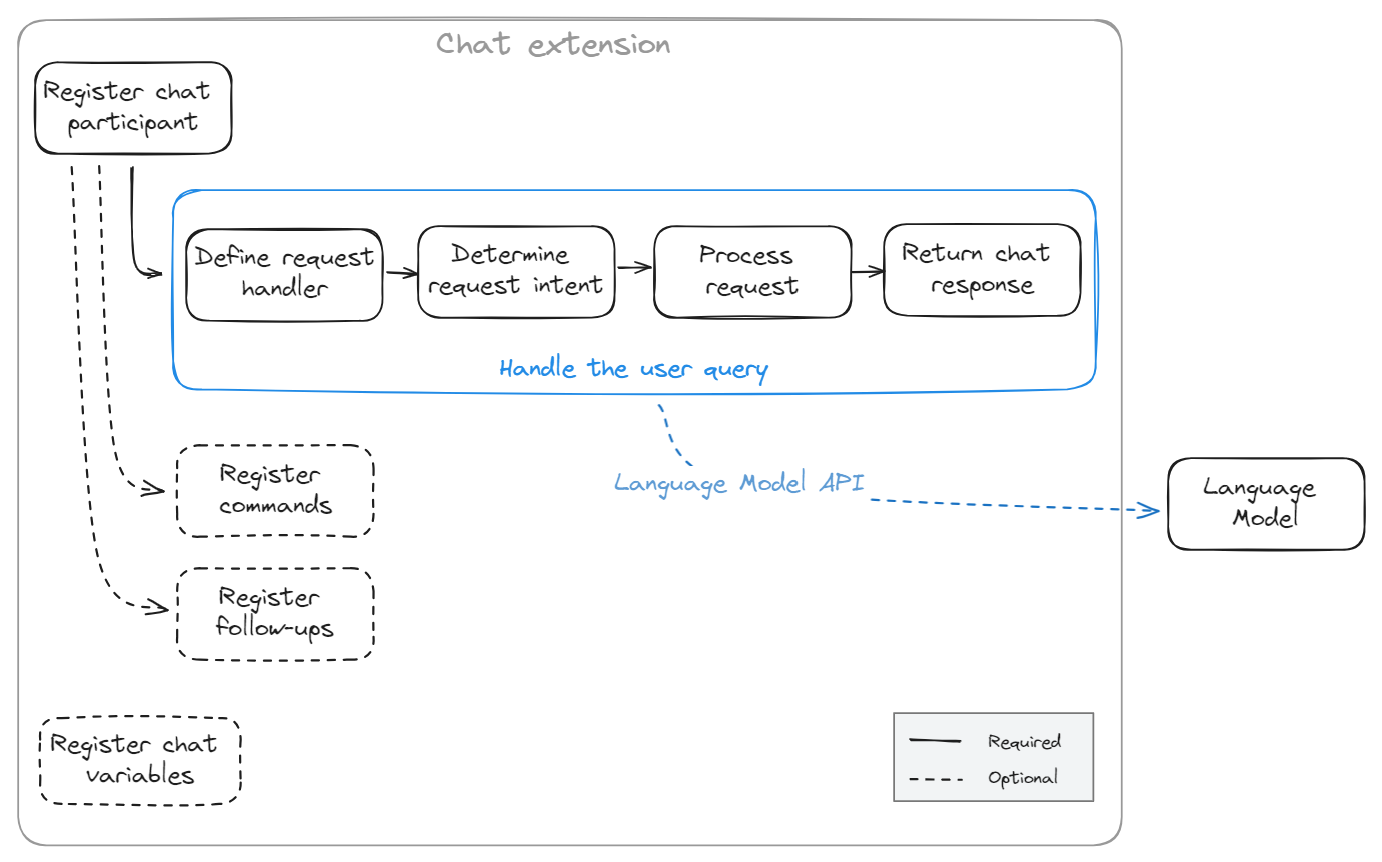
聊天扩展是一种扩展,它向 Chat 视图提供了一个聊天参与者。
实现聊天扩展所需的最小功能是:
@ 符号调用它。您可以使用以下可选功能进一步扩展聊天扩展的功能:
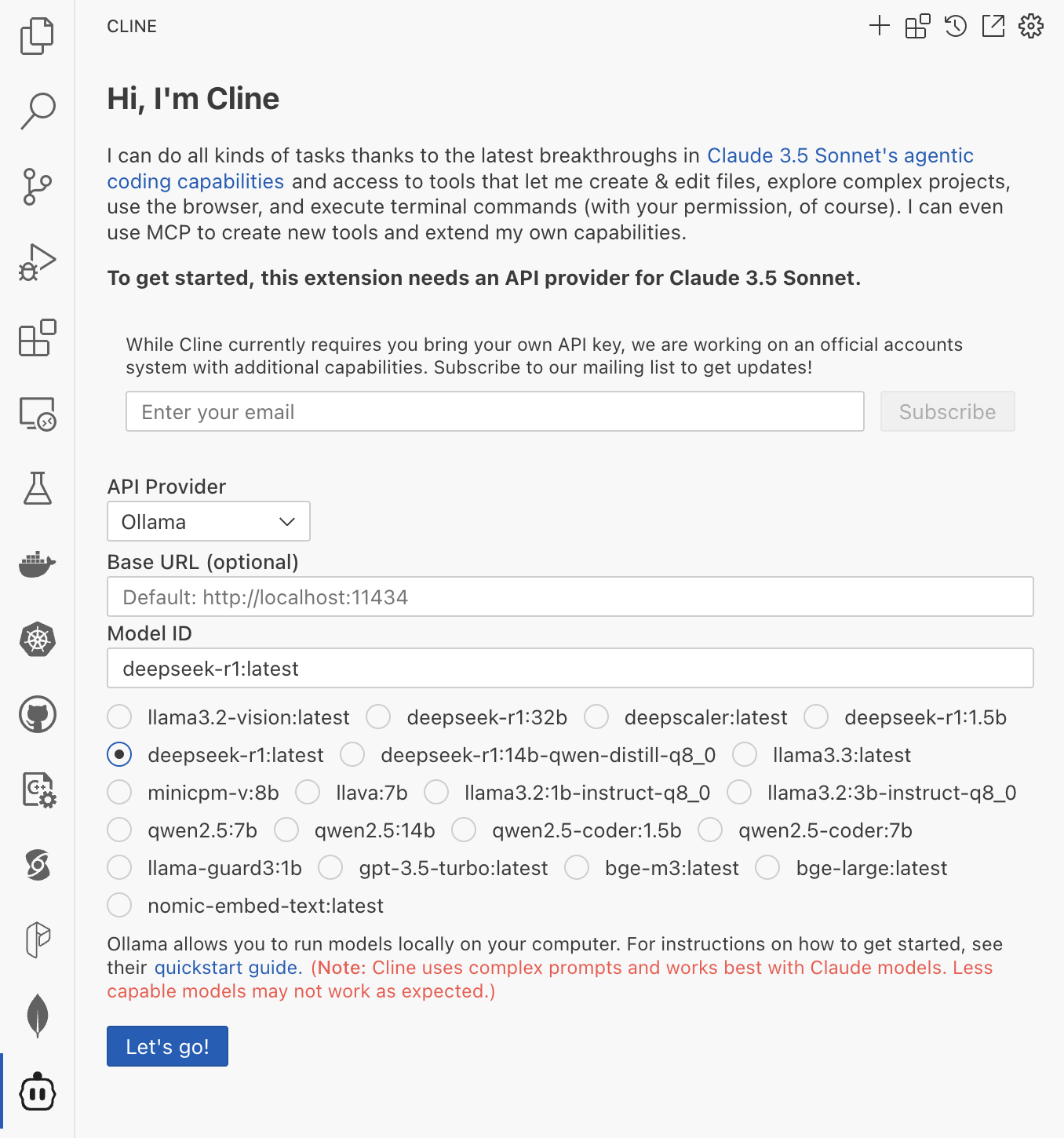
作为开发聊天扩展的起点,您可以参考我们的 chat extension sample。此示例实现了一个简单的猫导师,可以使用猫隐喻解释计算机科学主题。
创建聊天扩展的第一步是在 package.
“什么是代理?”
几乎每天都会有人问我这个问题。在 LangChain,我们构建工具来帮助开发者构建 LLM 应用程序,特别是那些充当推理引擎并与外部数据和计算源交互的应用程序。这包括通常被称为“代理”的系统。
每个人似乎对代理都有稍微不同的定义。我的定义可能比大多数人更技术性:
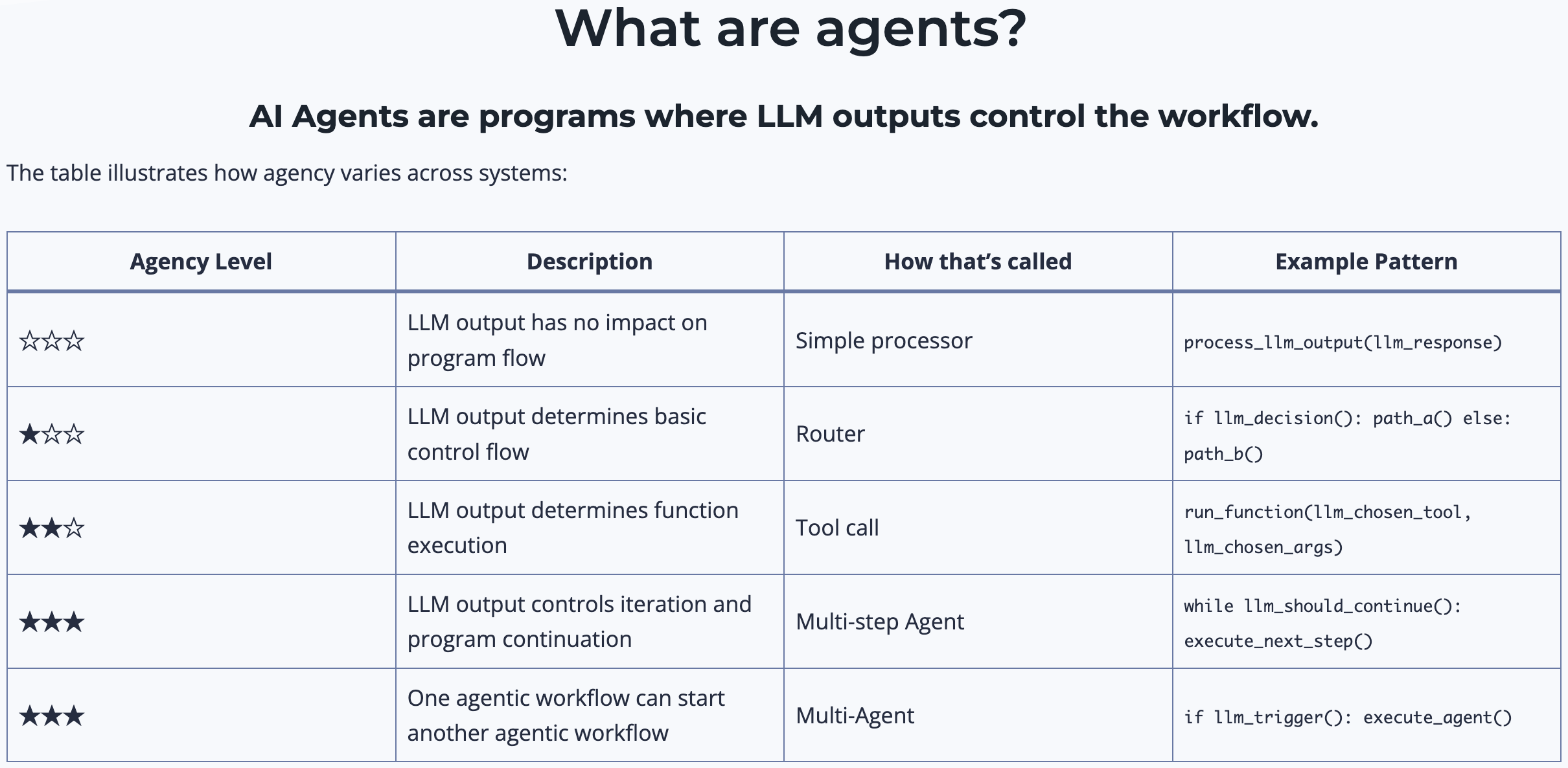
💡 代理是一个使用 LLM 来决定应用程序控制流的系统。
即使在这里,我也承认我的定义并不完美。人们通常认为代理是高级的、自主的、类人的——但如果是一个简单的系统,LLM 在两个不同路径之间进行路由呢?这符合我的技术定义,但不符合人们对代理应具备能力的普遍看法。很难准确定义什么是代理!
这就是为什么我非常喜欢 Andrew Ng 上周的推文。在推文中,他建议“与其争论哪些工作应被包括或排除为真正的代理,我们可以承认系统可以有不同程度的代理性。”就像自动驾驶汽车有不同的自动化级别一样,我们也可以将代理能力视为一个光谱。我非常同意这个观点,我认为 Andrew 表达得很好。将来,当有人问我什么是代理时,我会转而讨论什么是“代理性”。
去年我在 TED 演讲中谈到了 LLM 系统,并使用下面的幻灯片讨论了 LLM 应用程序中存在的不同自主级别。
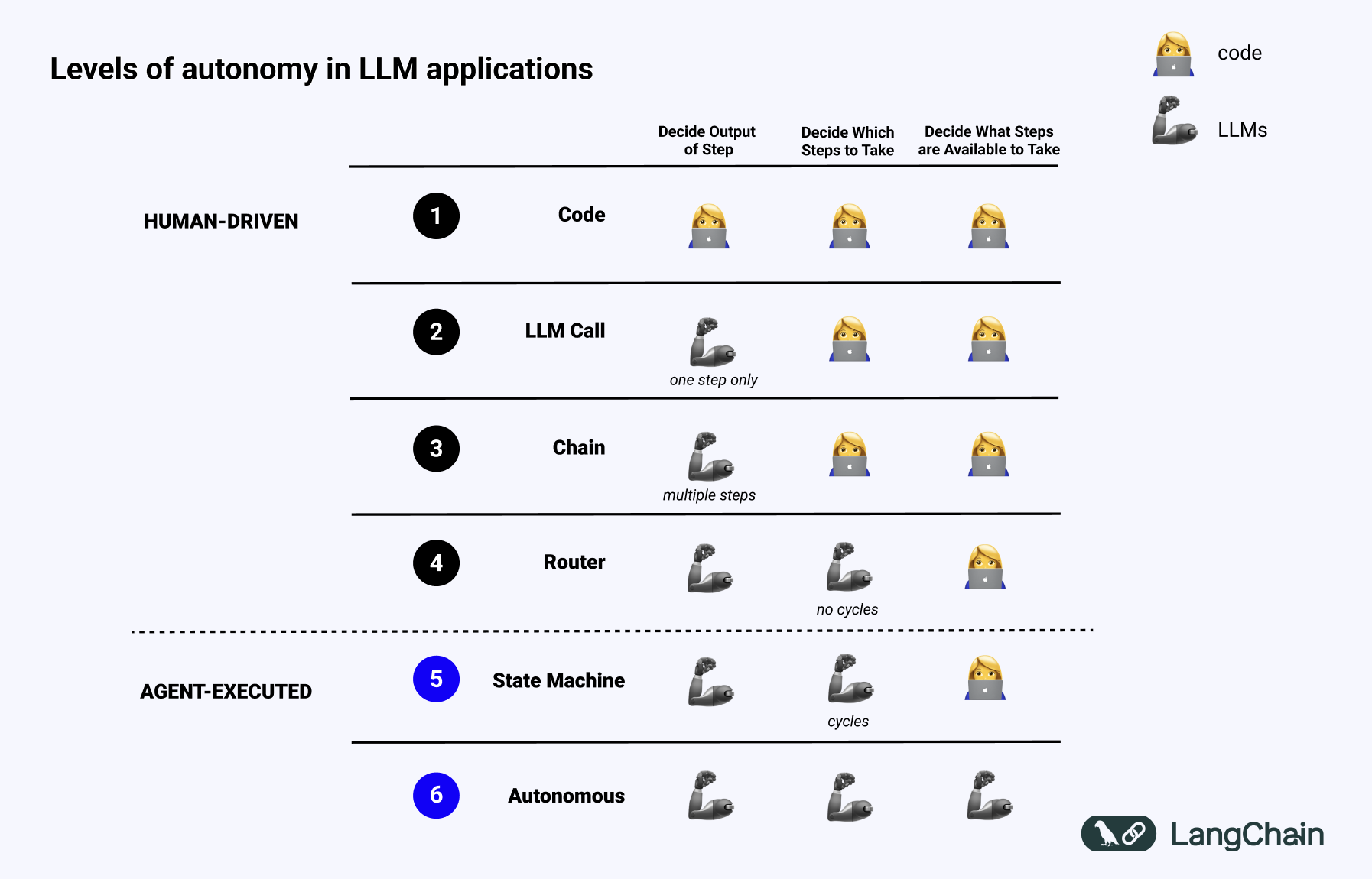
一个系统越“代理性”,LLM 决定系统行为的程度就越高。
使用 LLM 将输入路由到特定的下游工作流中具有一些小的“代理性”行为。这将属于上图中的路由器类别。
from autogen import ConversableAgent
llm_config = {"model": "gpt-3.5-turbo"}
agent = ConversableAgent(
name="chatbot",
llm_config=llm_config,
human_input_mode="NEVER",
)
reply = agent.generate_reply(
messages=[{"content": "给我讲个笑话。", "role": "user"}]
)
print(reply)
// ...
为什么八卦杂志最爱讲床上故事?因为上面都有新闻!哈哈哈~
为什么兔子喜欢吃胡萝卜?因为胡萝卜有好处,营养丰富!