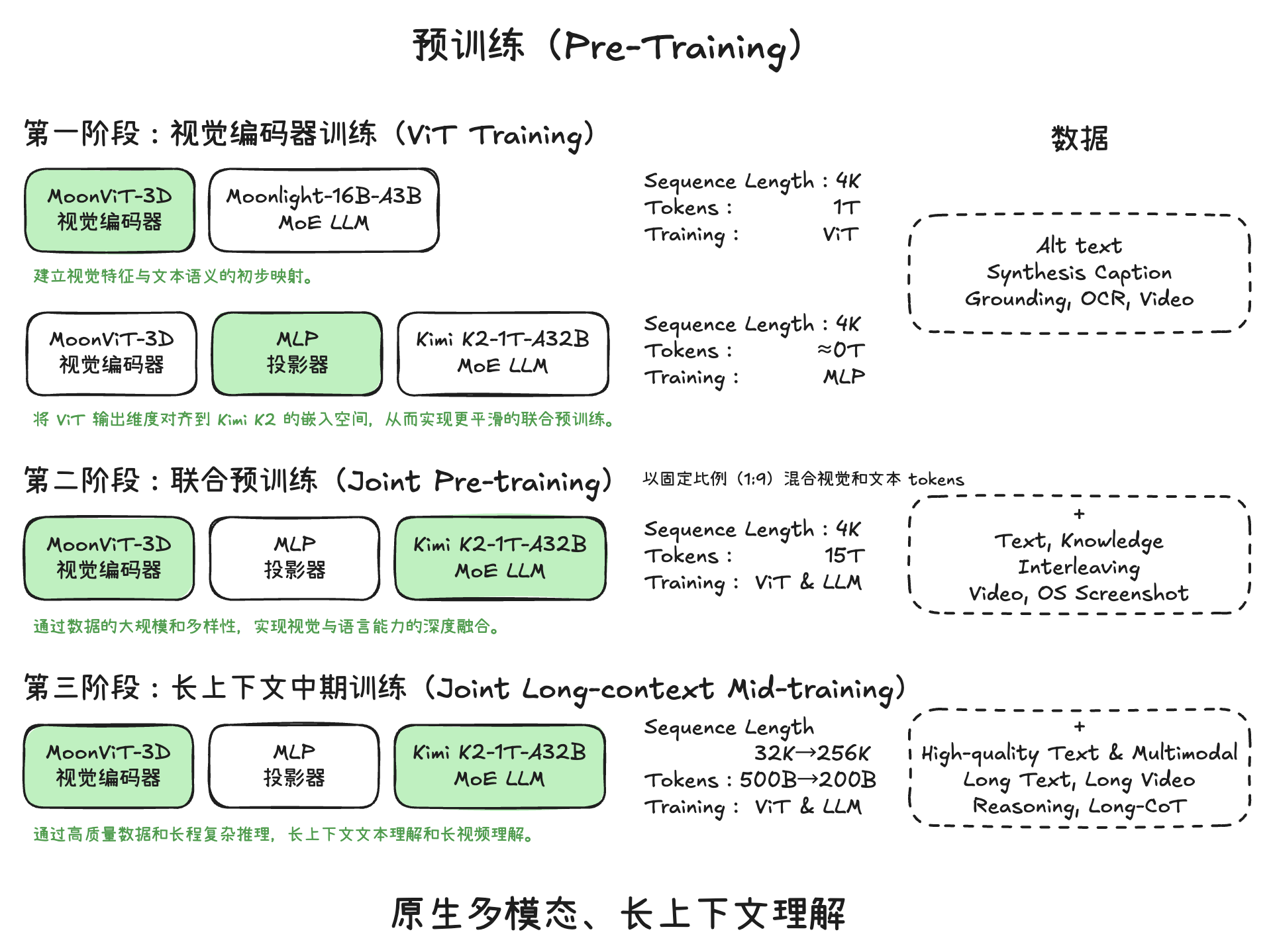
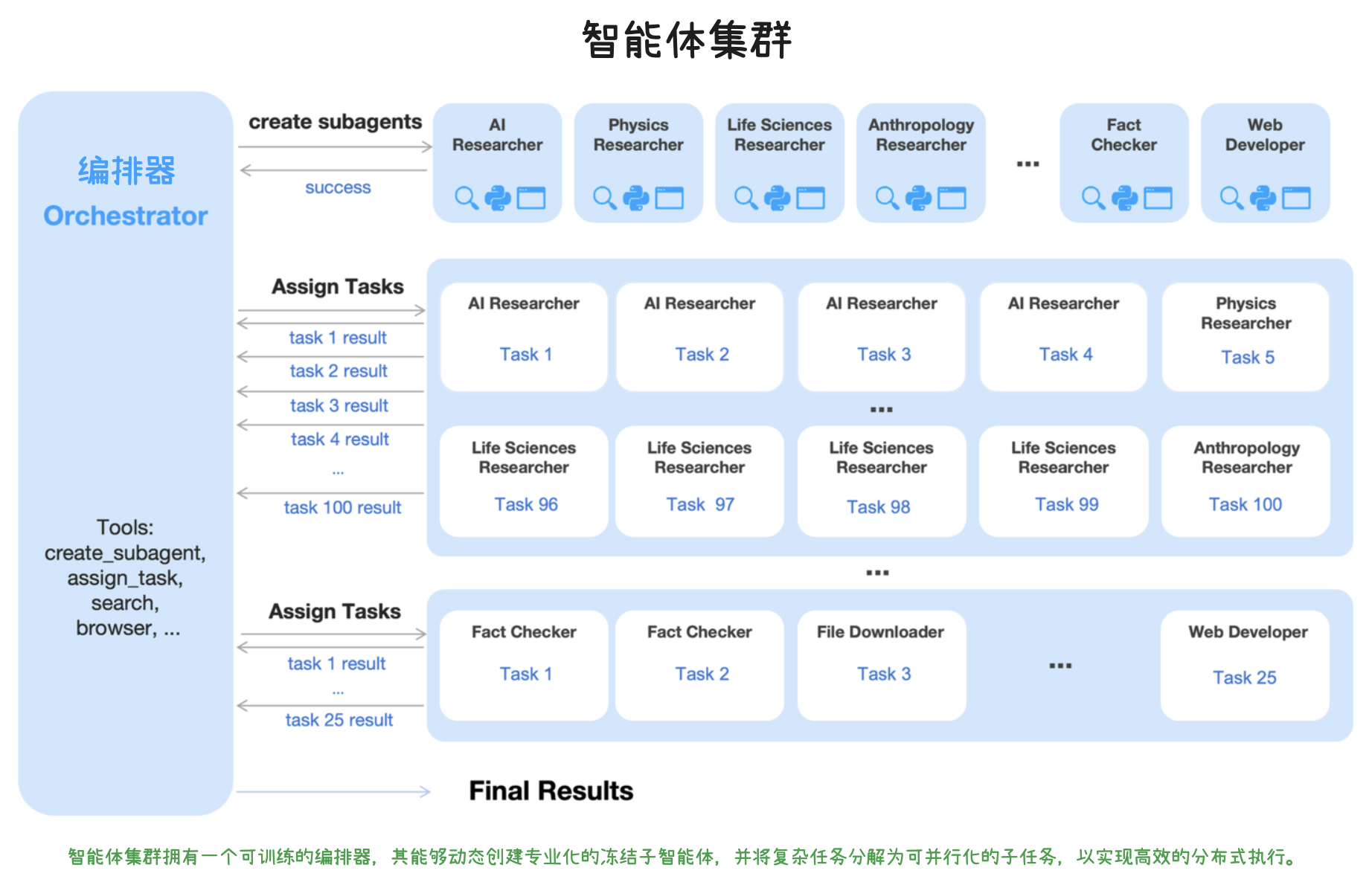
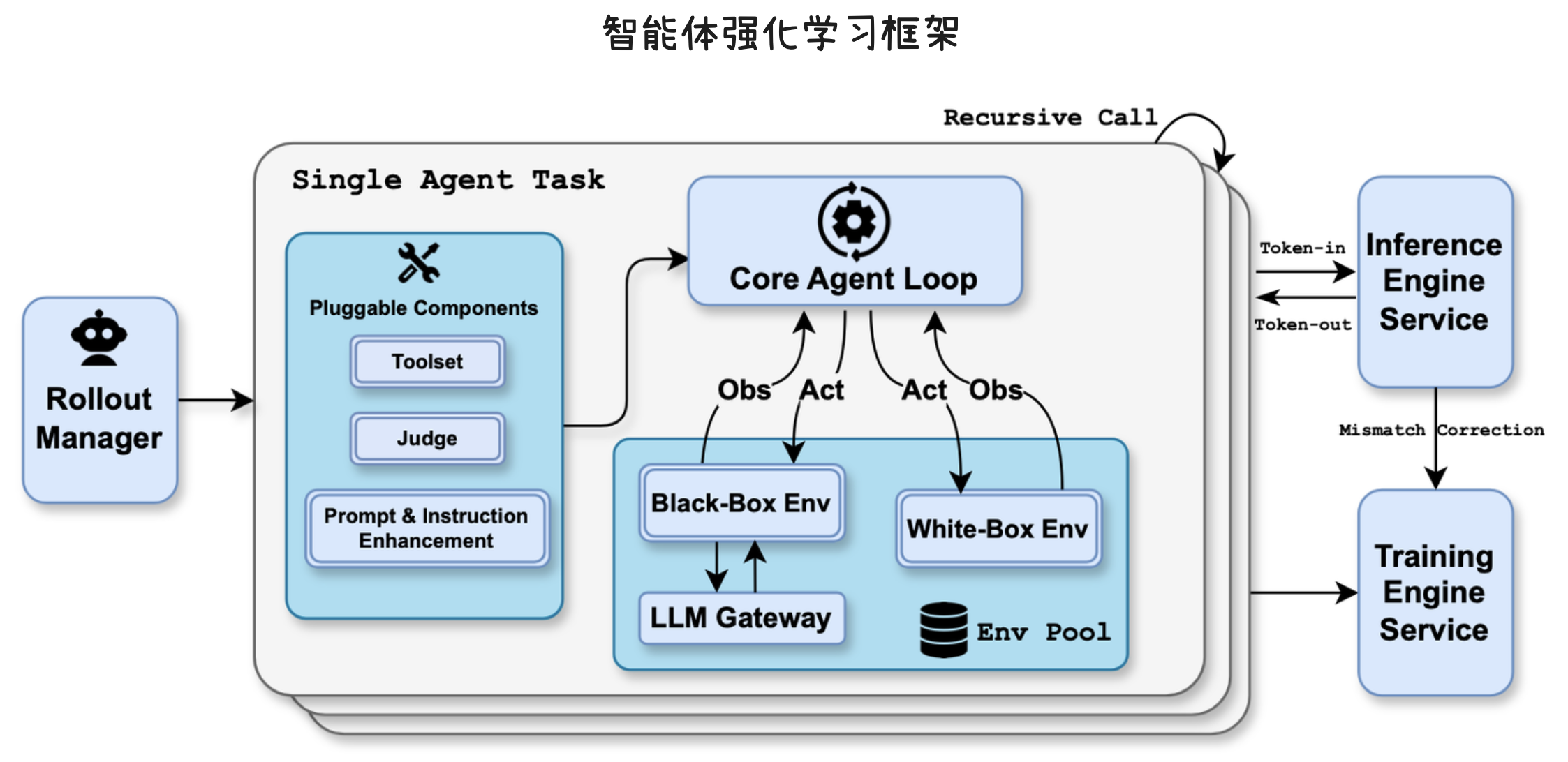
OpenClaw 架构设计
- 概览
- 核心组件
- 控制平面
- 网关协议
- 消息路由
- 消息流程
- 启动流程
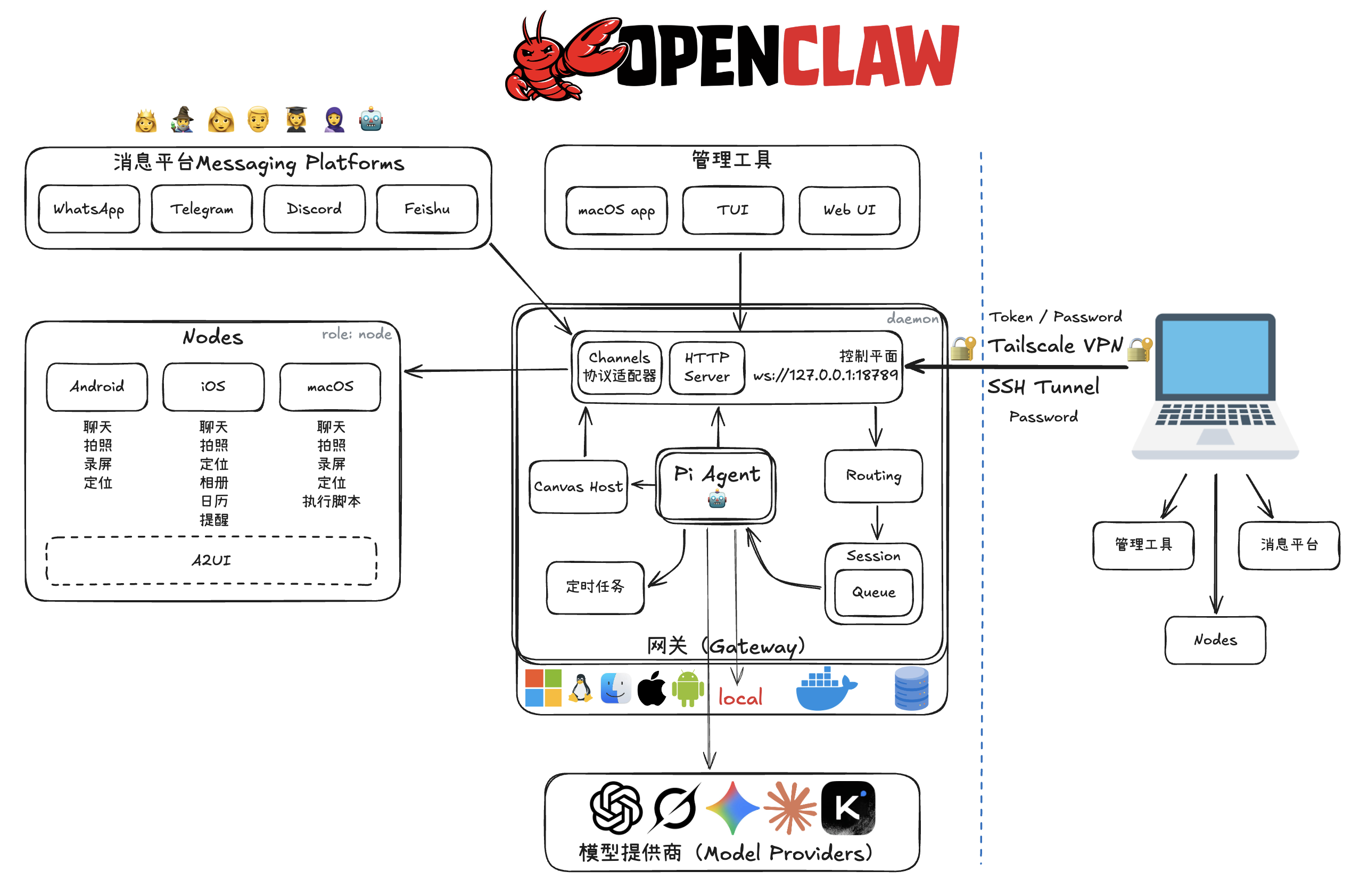
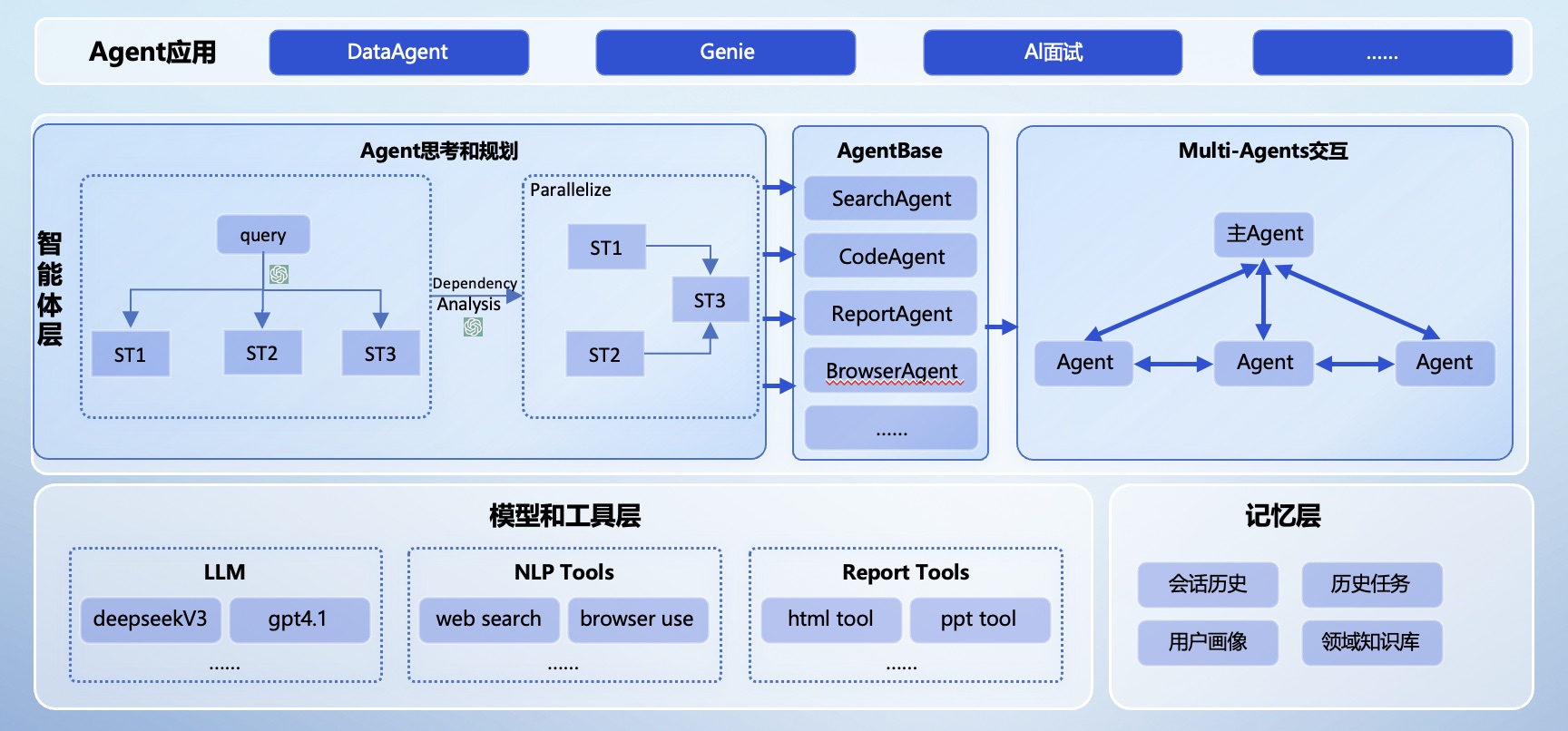
OpenClaw 是一个多渠道 AI 助手网关,设计用于在用户自己的设备上运行。它采用单一网关 + 多客户端/节点模型,支持 WhatsApp、Telegram、Slack、Discord、Google Chat、Signal、iMessage 等多种通信渠道。
| 组件 | 描述 |
|---|---|
| 🌐 Gateway(网关) | 长期运行的守护进程,管理所有消息平台连接和智能体通信 |
| 💻 Clients(客户端) | 控制平面应用(macOS 应用、CLI、Web 界面) |
| 📱 Nodes(节点) | 设备节点,提供硬件能力(macOS/iOS/Android/无头设备) |