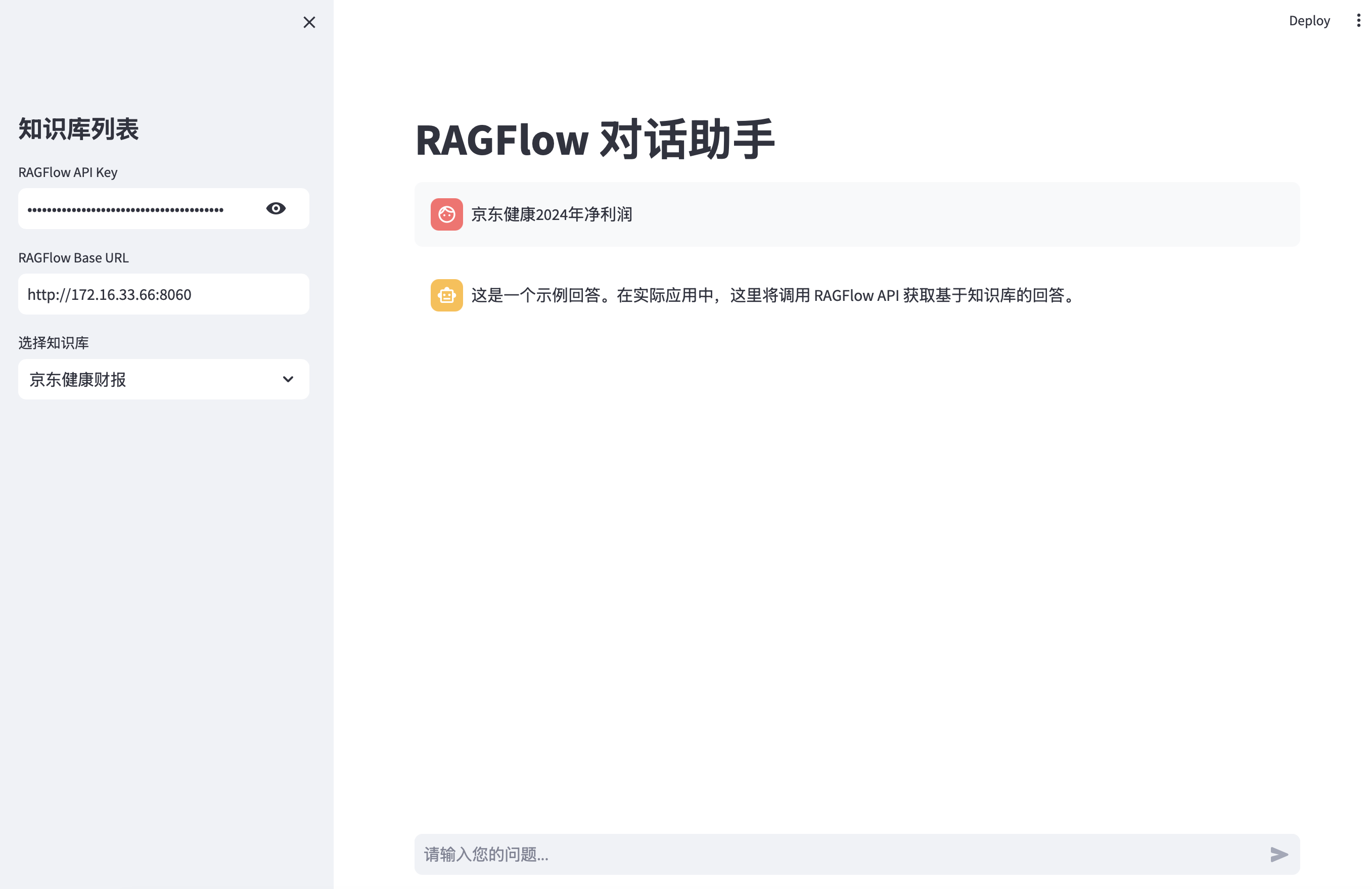
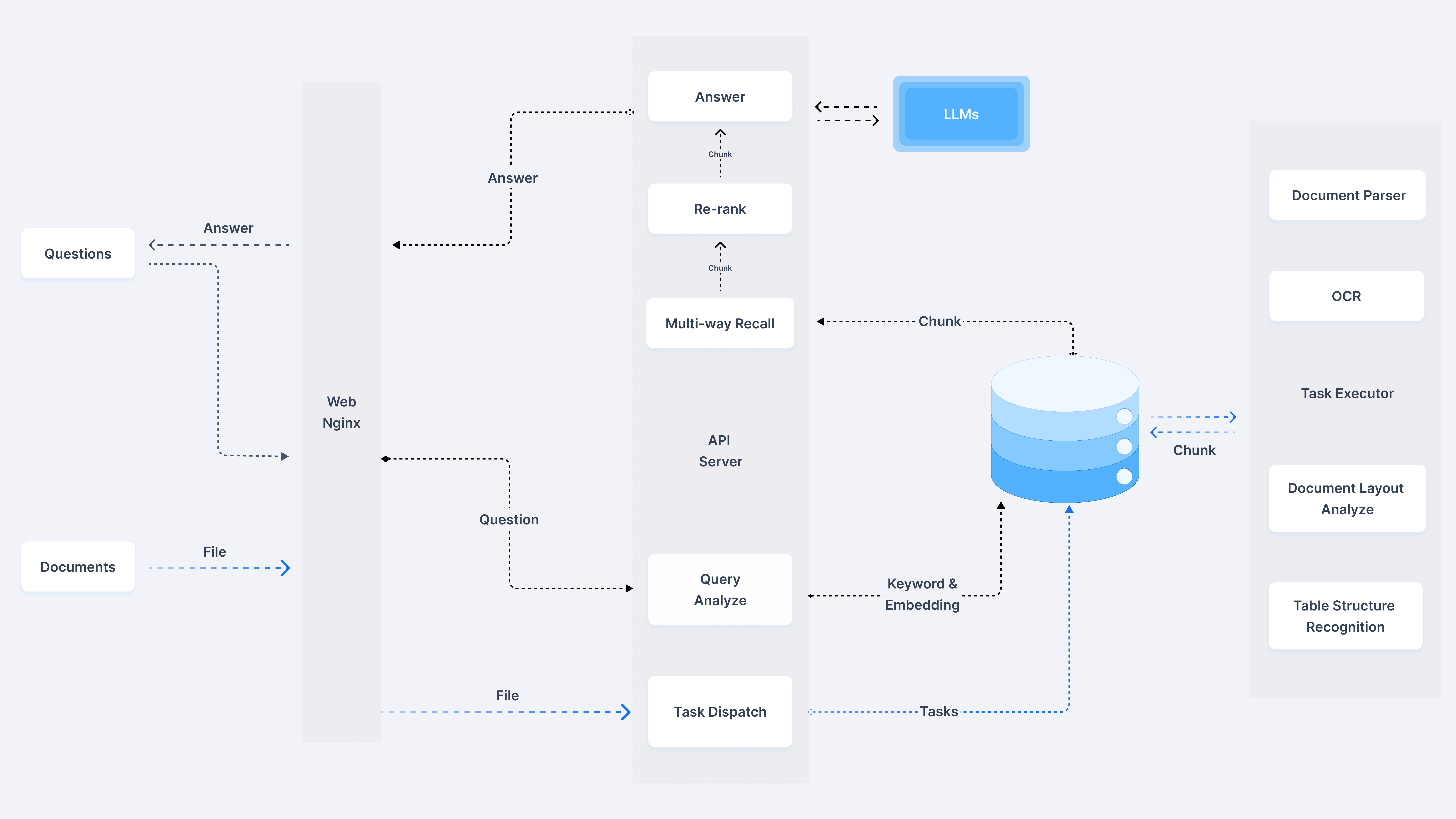
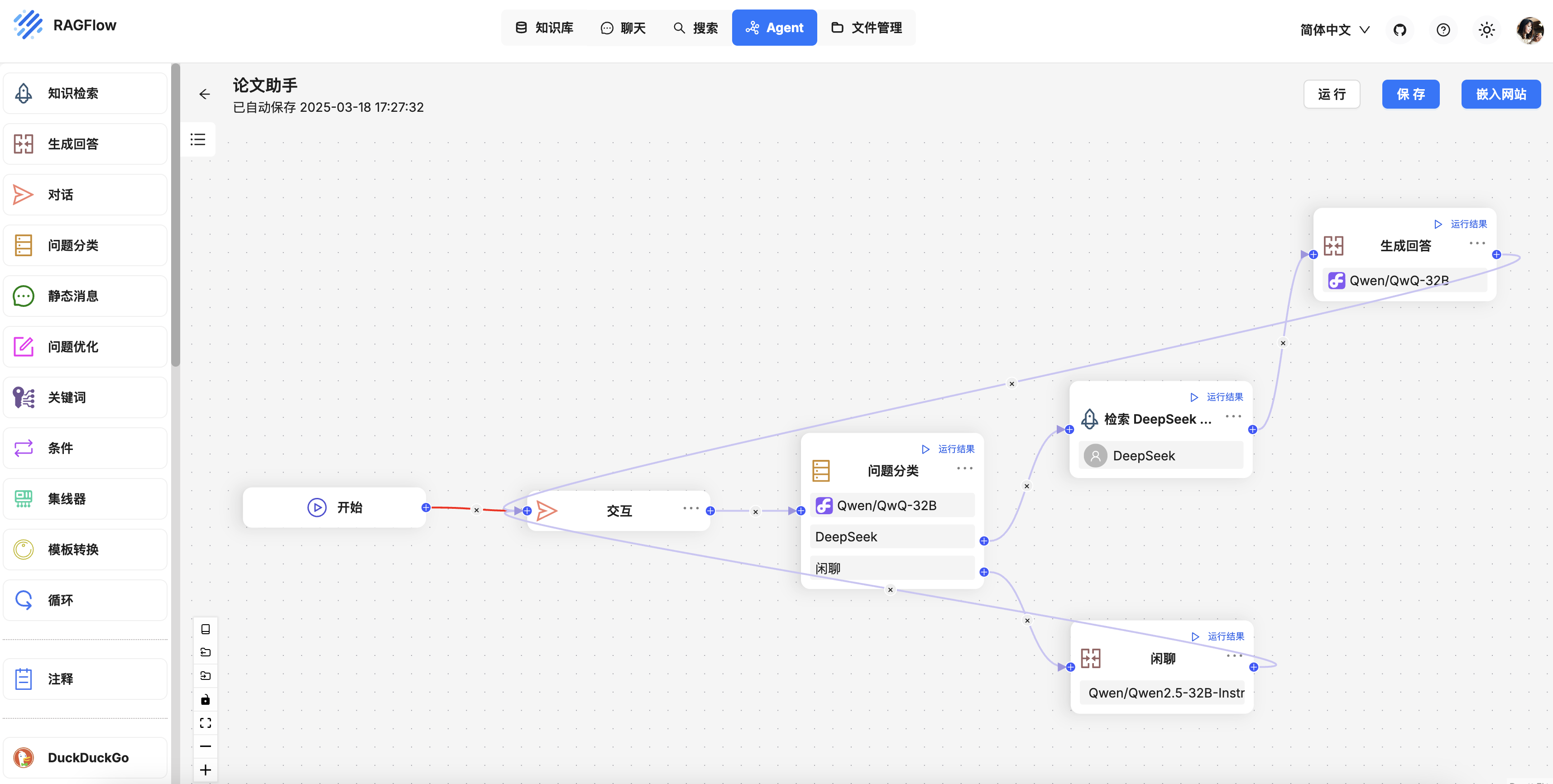
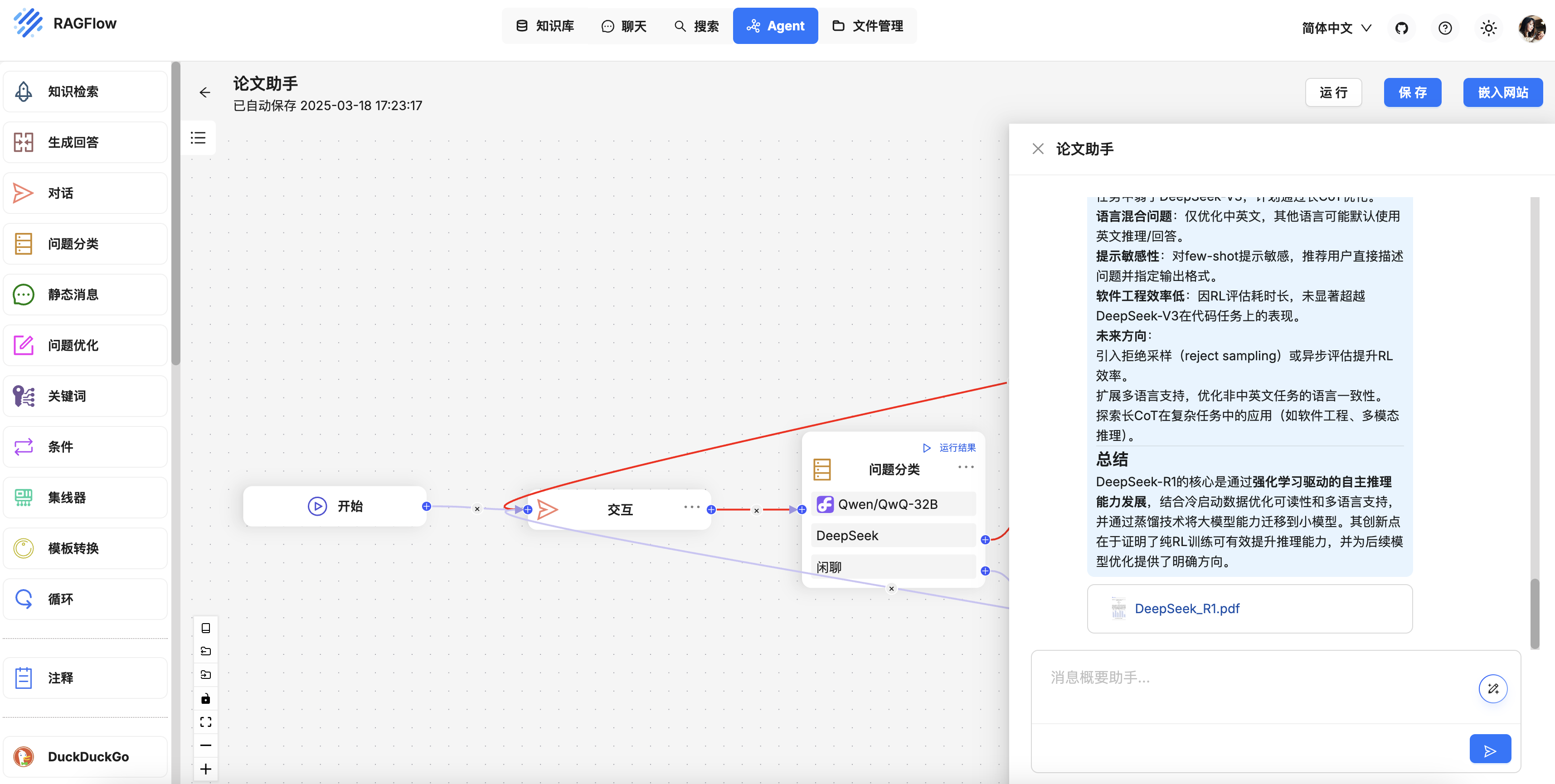
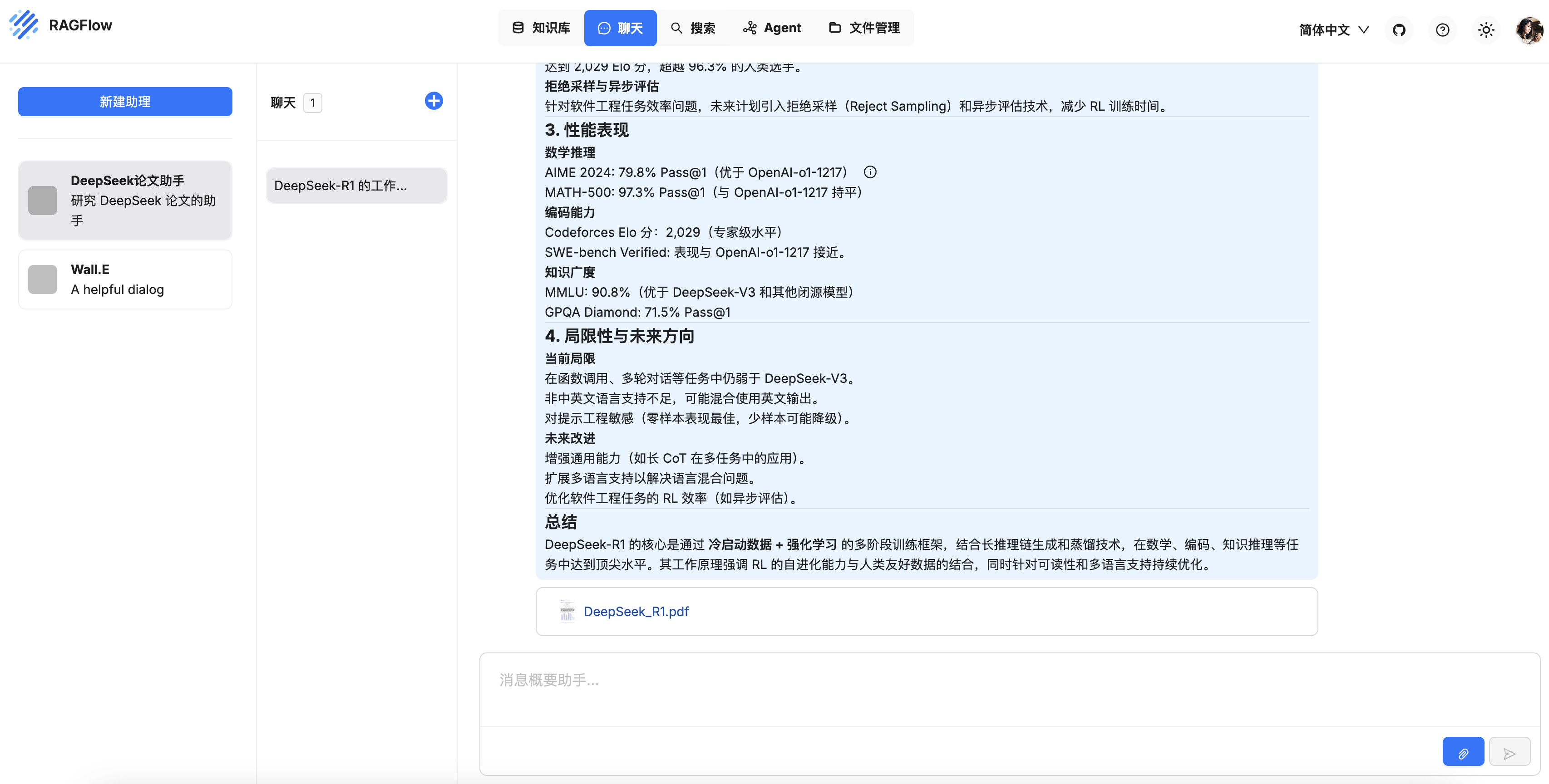
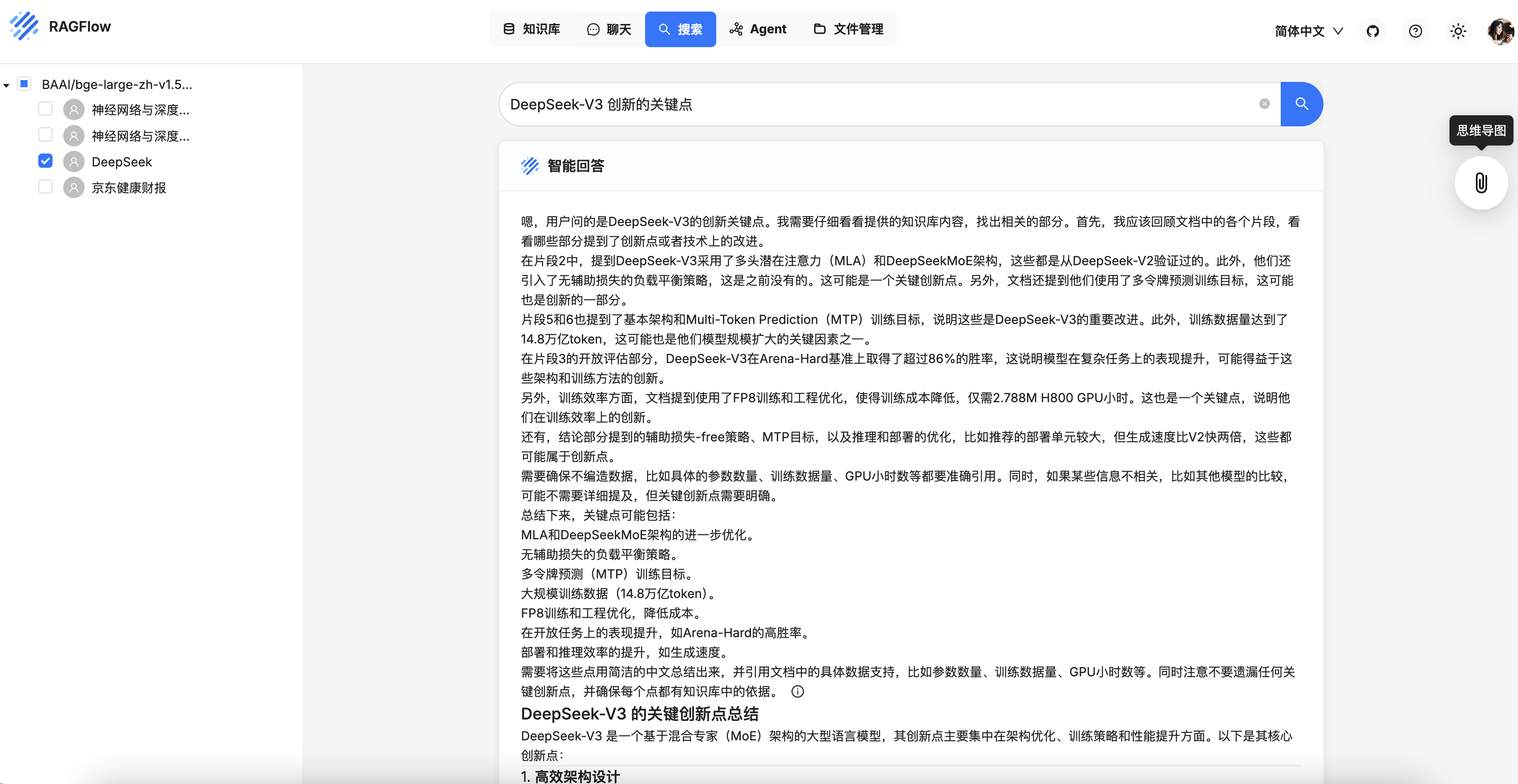
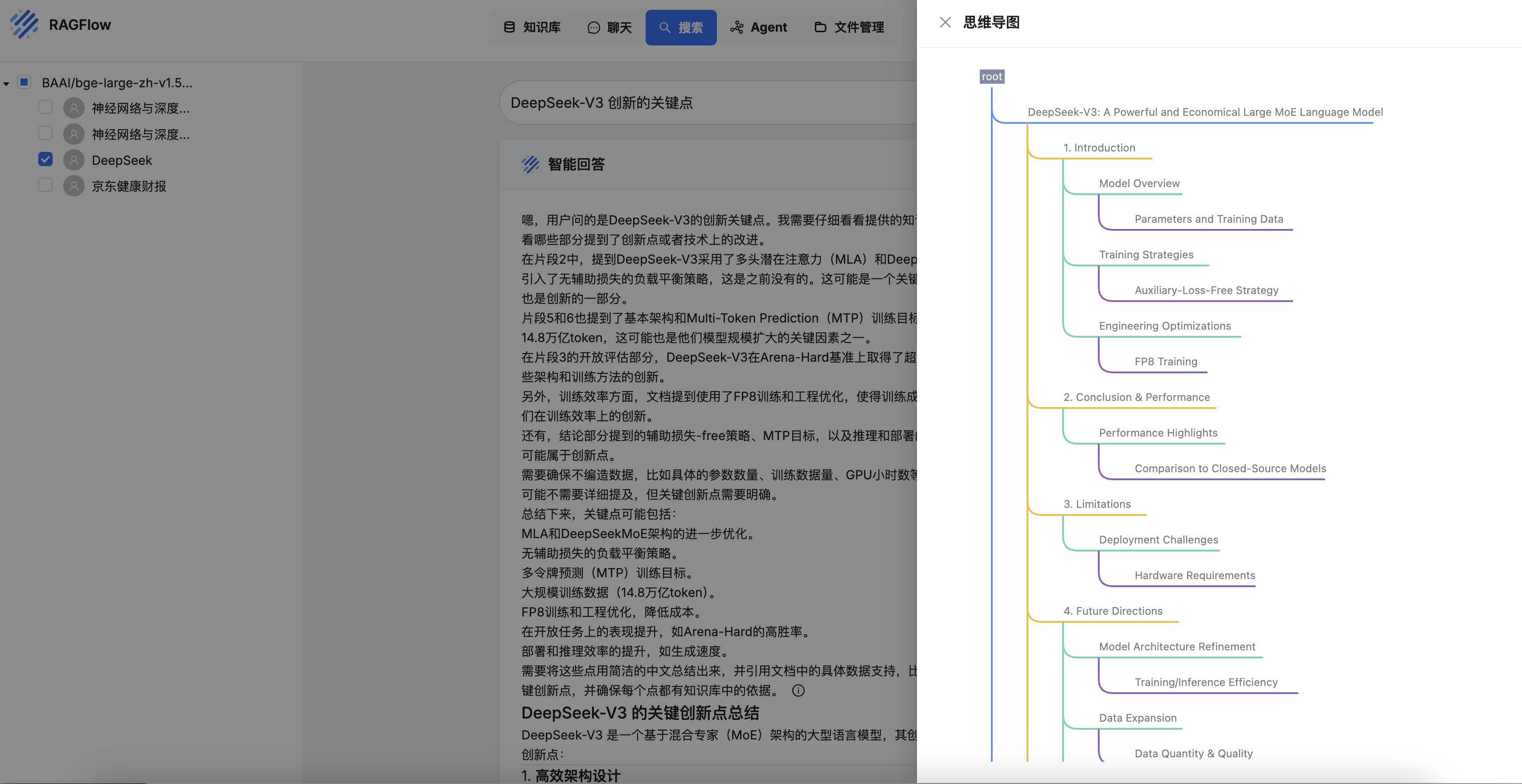
开发 RAGFlow MCP Server
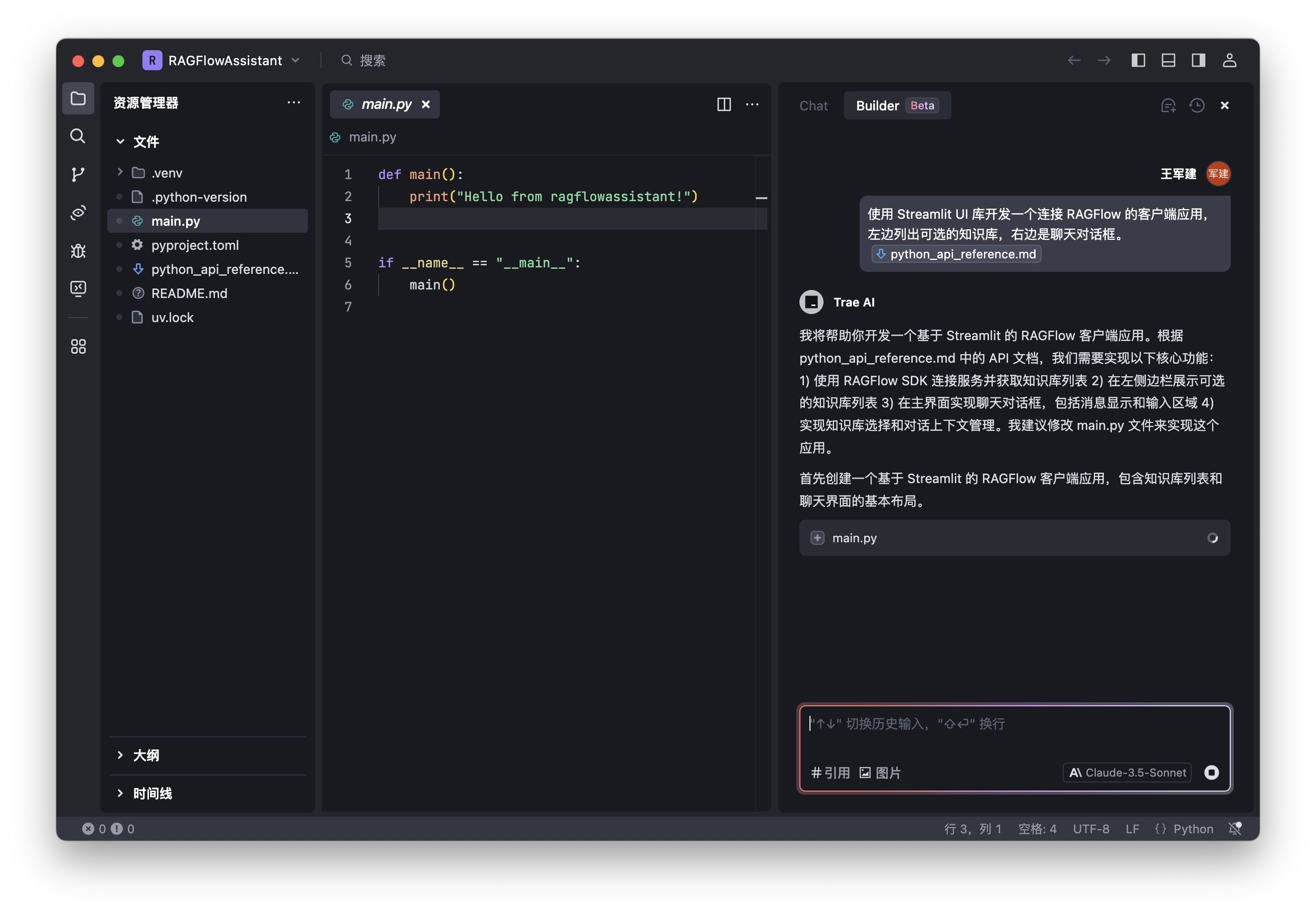
这是第一次开发 MCP Server,想着使用智能编码工具(GitHub Copilot、Cursor、Trae)进行氛围编程,发现真不容易,Claude 3.7 sonnet 效果不错,在 GitHub Copilot 没用多长时间超限制了;Cursor 没有达到之前那种随心的效果;Trae 要排长队,太有挫败感了。于是,开始了以人编码为主,大模型辅助的开发过程。
- 初始化:加载环境变量,初始化 RAGFlow 客户端。
- 工具注册:定义工具列表,描述工具的输入/输出。
- 工具逻辑:实现工具的具体调用逻辑。
- 服务器启动:通过 stdio 启动 MCP Server 并监听请求。
uvx create-mcp-server \
--path ragflow-mcp-server \
--name ragflow-mcp-server \
--version 0.1.0 \
--description "RAGFlow MCP Server" \
--no-claudeapp
cd ragflow-mcp-server
uv sync --dev --all-extras
uv add ragflow-sdk