使用 Claude Code:HTML 超乎寻常的妙用
Thariq: Using Claude Code: The Unreasonable Effectiveness of HTML
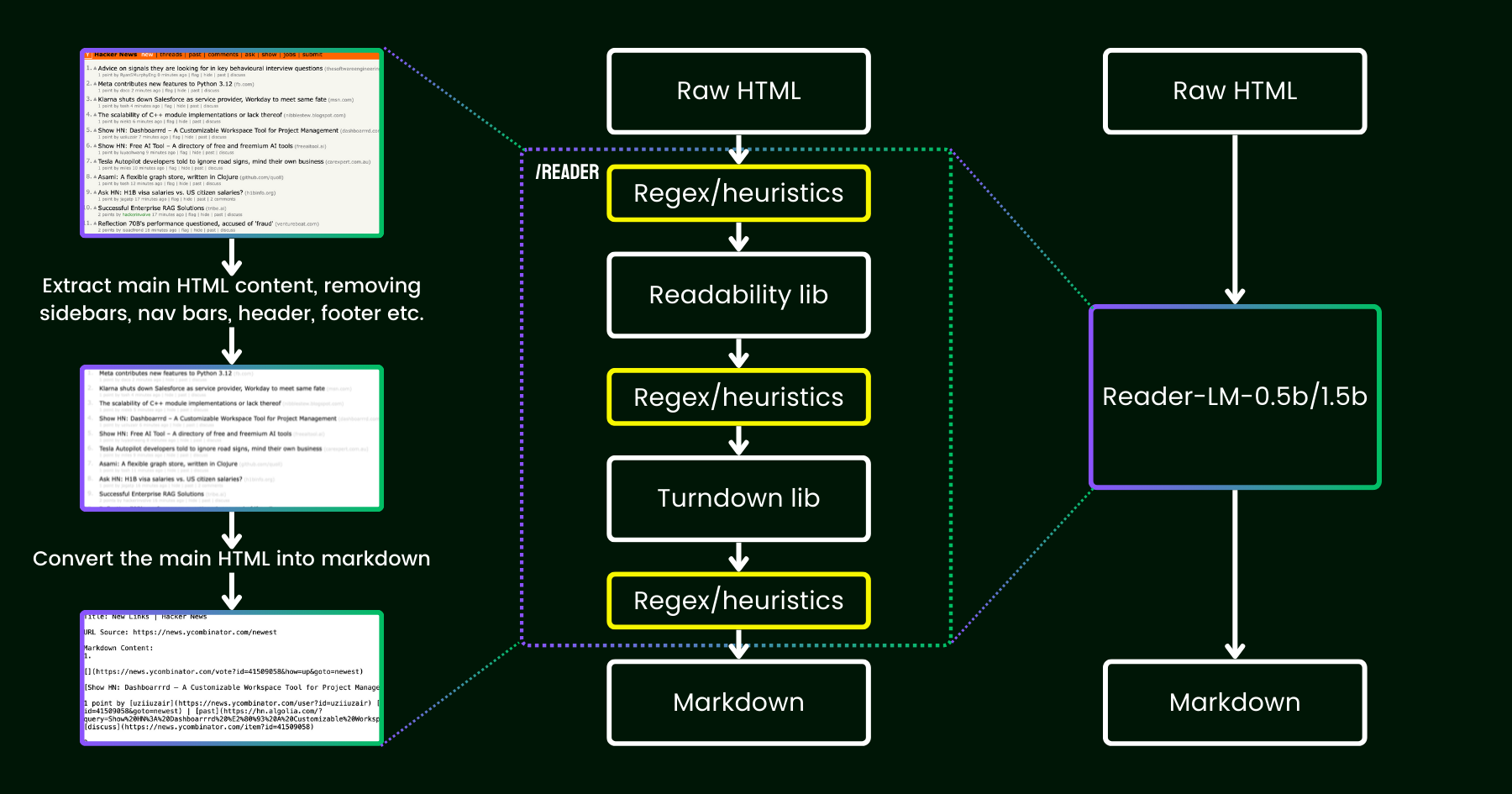
Markdown 已成为智能体(agent)与我们沟通时占主导地位的文件格式。它简单、可移植,具备一定的富文本能力,且易于编辑。Claude 甚至已经相当擅长在 Markdown 文件中使用 ASCII 绘制图表。
但随着智能体变得越来越强大,我感到 Markdown 已成为一种受限的格式。我发现自己很难阅读超过一百行的 Markdown 文件。我想要更丰富的可视化效果、色彩和图表,并且希望能轻松分享它们。
我也越来越不亲自编辑这些文件,而是将它们用作规格说明、参考文件、头脑风暴输出等。当我确实需要编辑时,我通常会让 Claude 来编辑,这就削弱了 Markdown 最大的一个优势。
我开始更偏爱 HTML 作为输出格式,而不是 Markdown,并且越来越多地看到 Claude Code 团队中的其他人也在使用它。以下就是原因。
(如果你想先看一些示例,可以在这里看到一大堆:https://thariqs.github.io/html-effectiveness ,不过记得回来看更多关于"为什么"的内容。)
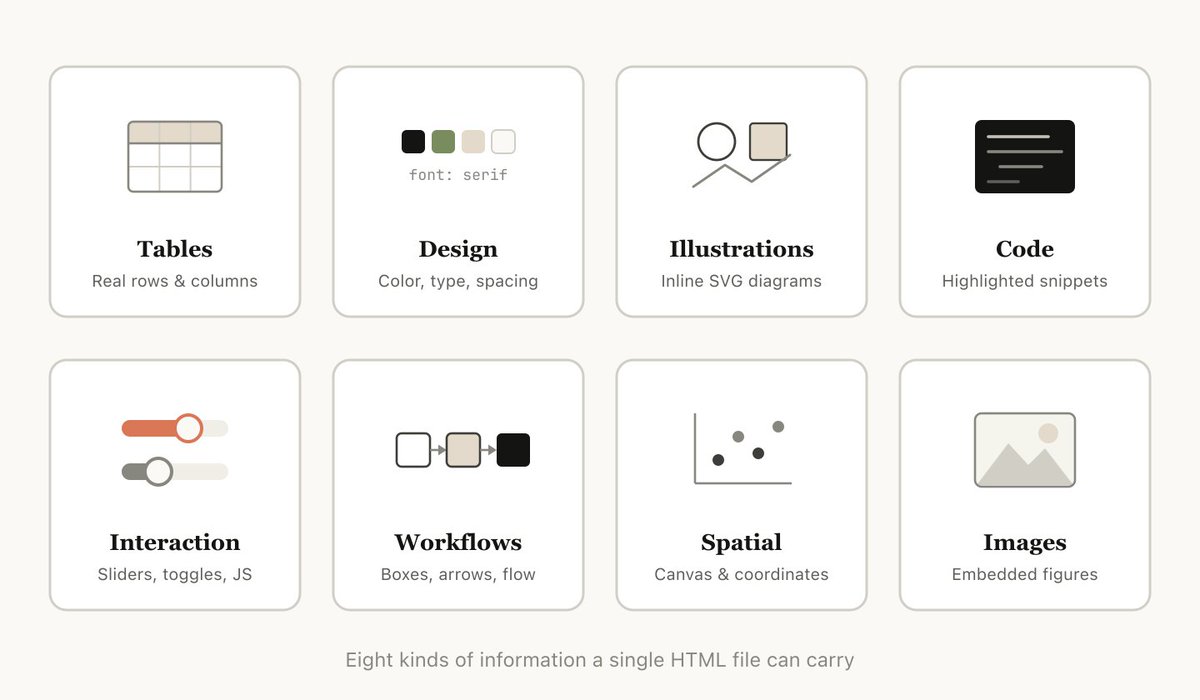
与 Markdown 相比,HTML 能够传达更丰富得多的信息。