探索多模态大模型 GLM-4.1V-Thinking
本文档介绍了多模态大模型GLM-4.1V-Thinking,这是一个基于 GLM-4-9B-0414 的开源视觉语言模型,通过强化学习显著提升了其性能。文档详细阐述了该模型在设计图转代码(Design2Code)任务上的卓越表现,能将设计图转换为高质量的HTML/CSS代码,并提供了与Qwen-2.5-VL-32B-Instruct的对比示例。此外,资源还展示了如何通过智谱API免费使用GLM-4.1V-Thinking进行图像识别,并给出了一个安全检测系统的代码示例,该系统能够识别图像中的火灾、烟雾以及人员安全帽佩戴情况,并进行坐标标注,强调了模型在实际应用中的潜力。
基于 GLM-4-9B-0414 基座模型,我们推出新版VLM开源模型 GLM-4.1V-9B-Thinking ,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力, 达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。
论文 GLM-4.1V-Thinking:通过可扩展强化学习实现通用多模态推理
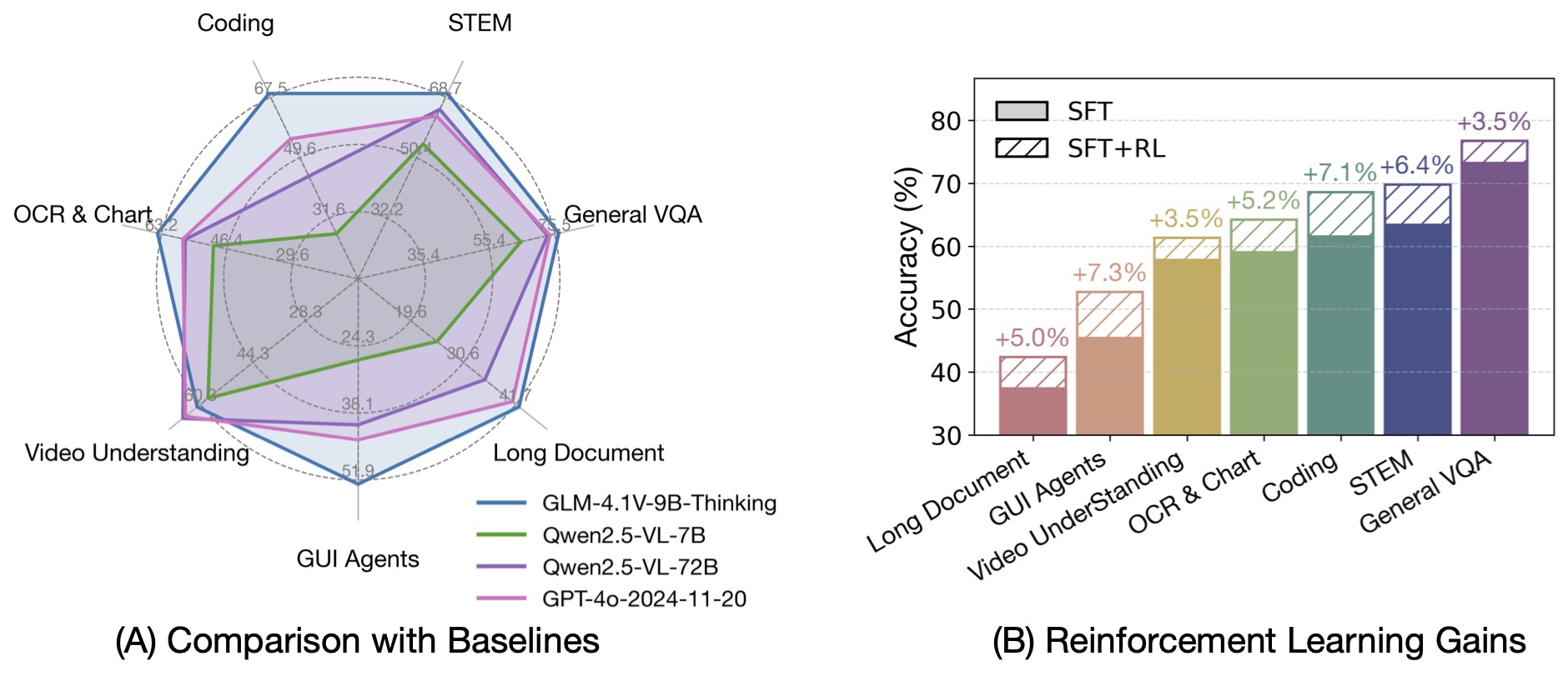
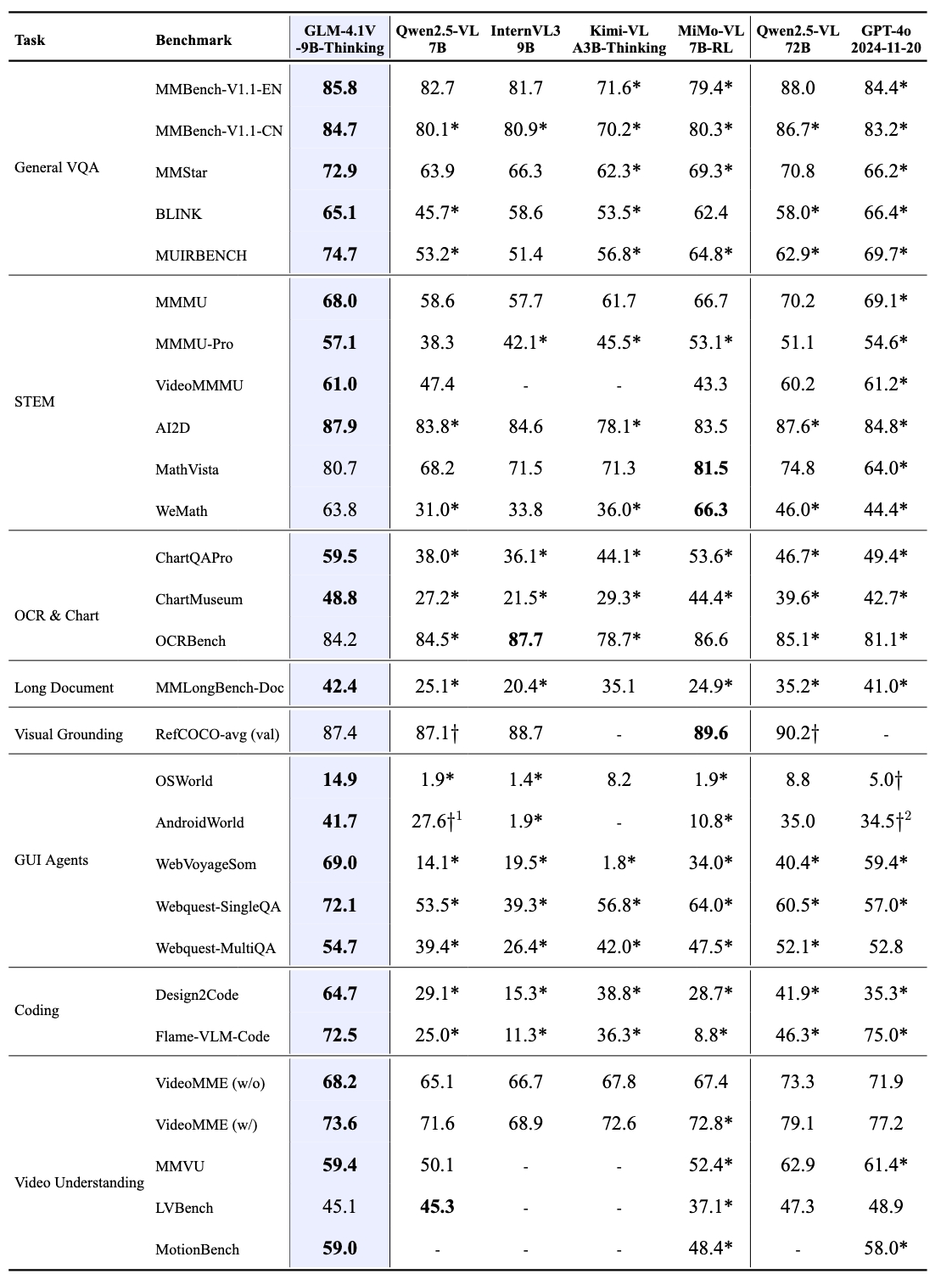

GLM-4.