DeepSeek-Coder 论文解读
- GitHub数据抓取
- 规则过滤
- 依存分析
- 仓库级重复数据删除
- 质量筛选
下表中列出保留的87种编程语言统计摘要(磁盘大小、文件数量和百分比),总数据量为798 GB,包含603百万个文件。
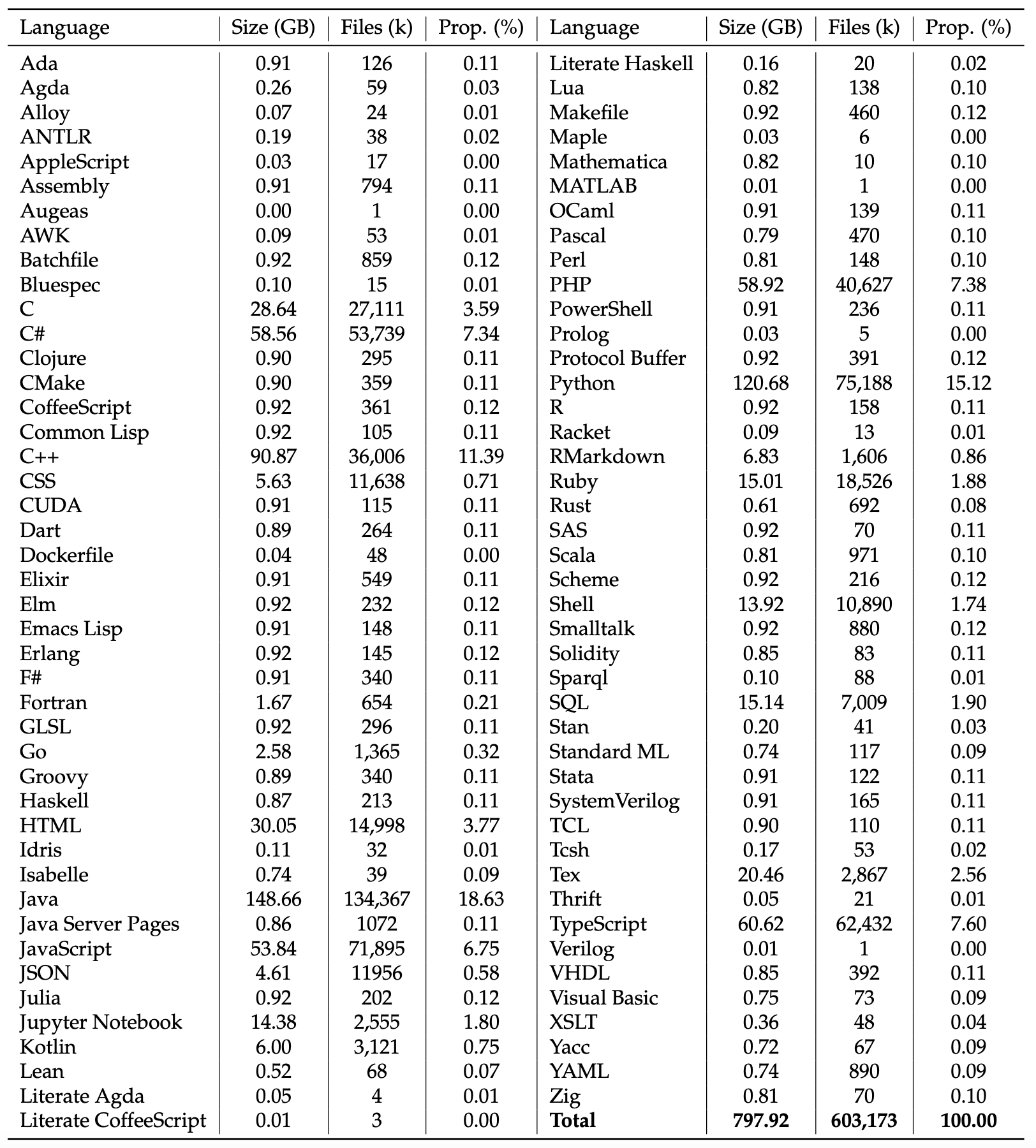
下表中列出保留的87种编程语言统计摘要(磁盘大小、文件数量和百分比),总数据量为798 GB,包含603百万个文件。
Introducing the Coding LLM Leaderboard

更新日期:2023-11-13
在代码补全中,模型预测的是跨越多行的代码块。一种朴素的方法是直接将预测的代码块与实际提交的代码进行比较。虽然这种方法看起来理想,但它通常被认为是一个“过于稀疏”的度量标准。另一方面,下一行准确度可以作为整体代码块匹配准确度的可靠代理。
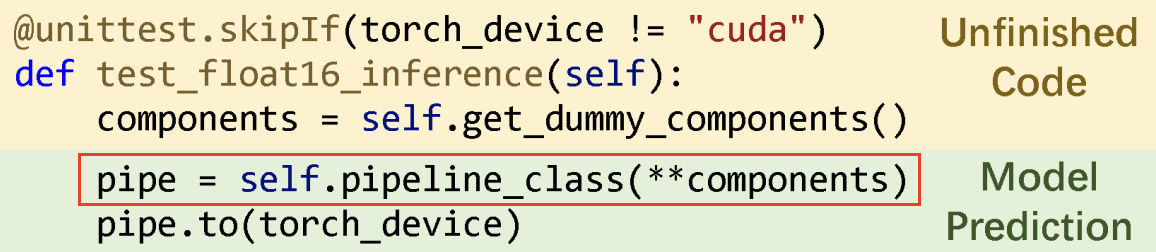
只有红色框内的内容被用于与真实值进行比较,以计算准确度指标。
brew cleanup tabby 命令的意思是清理所有旧版本的 tabby 包和缓存的 tabby 下载。选择了两个通用基准来评估:
下面显示了 OctoCoder vs Base HumanEval prompt 的示例,在这里可以找到它。




如果您不想使用提供的 API apply_chat_template 加载模板 tokenizer_config.json,您可以使用以下模板与我们的模型聊天。将替换 ['content'] 为您的指令和模型之前(如果有)的响应,然后模型将生成对当前给定指令的响应。 You are an AI programming assistant, utilizing the DeepSeek Coder model, developed by DeepSeek Company, and you only answer questions related to computer science.