Sky-T1-7B:通过强化学习提升推理模型的潜力
我们很高兴发布 Sky-T1-7B,这是一个在数学推理任务上达到 SOTA 水平的开源 7B 模型,它通过对 Qwen2.5-Math-7B 基础模型进行 SFT->RL->SFT->RL 四步训练而成。我们同时还发布了 Sky-T1-mini,这个模型是在 DeepSeek-R1-Distill-Qwen-7B 模型基础上使用简单的强化学习(RL)训练得到的,在流行的数学基准测试上接近 OpenAI o1-mini 的性能水平。我们进行了一系列消融实验,研究了 SFT 数据规模、RL 规模以及模型在 SFT 和 RL 后的 pass@k 性能。我们观察到,长链条 CoT SFT 通常可以提升模型的 pass@k 性能,而 RL 则提高了模型在较低生成预算下(即 pass@1)的性能,但有时会以牺牲解决方案的熵为代价。
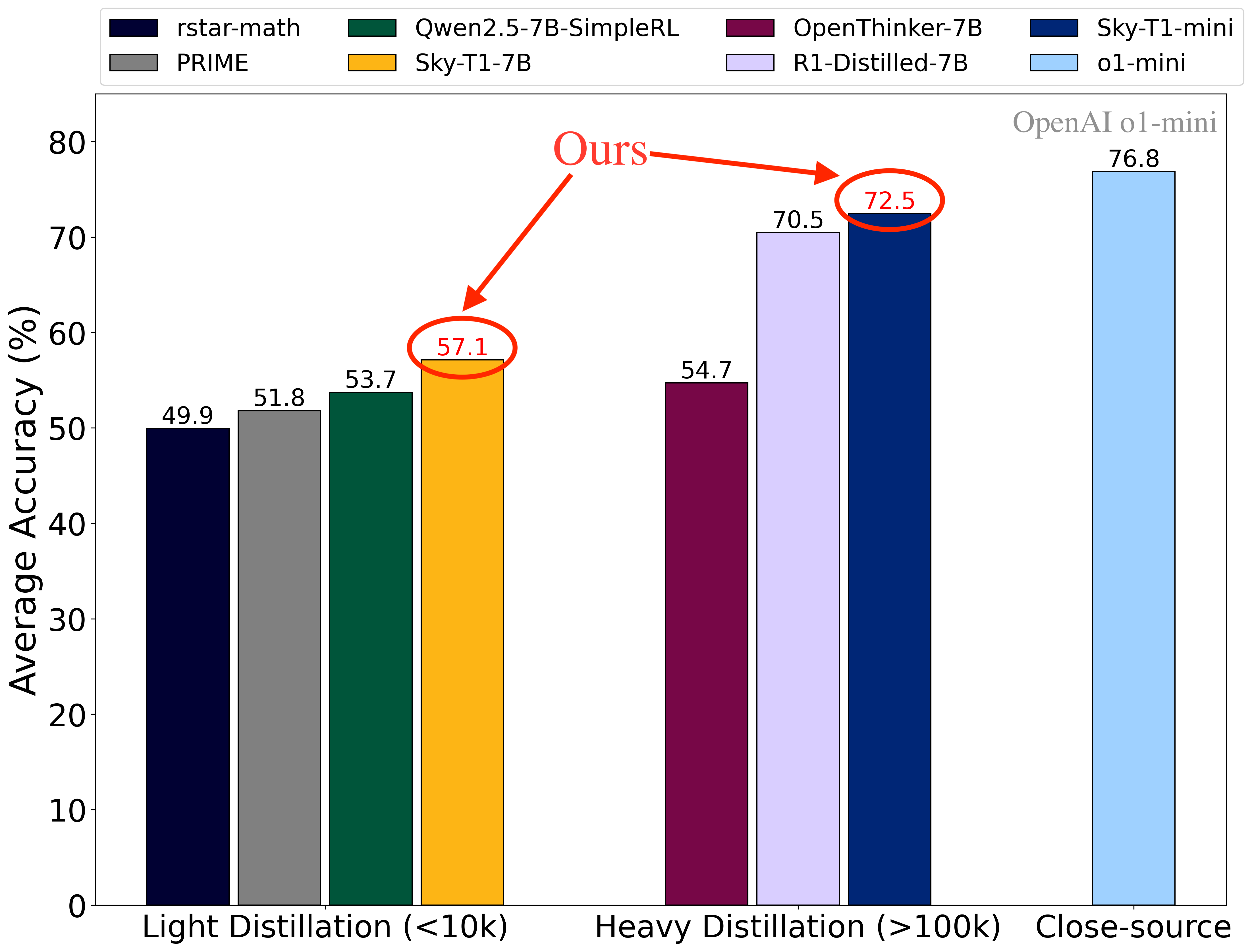
图 1: 不同模型在四个流行数学推理任务(AIME24, AMC23, MATH500 和 OlympiadBench)上的平均准确率。